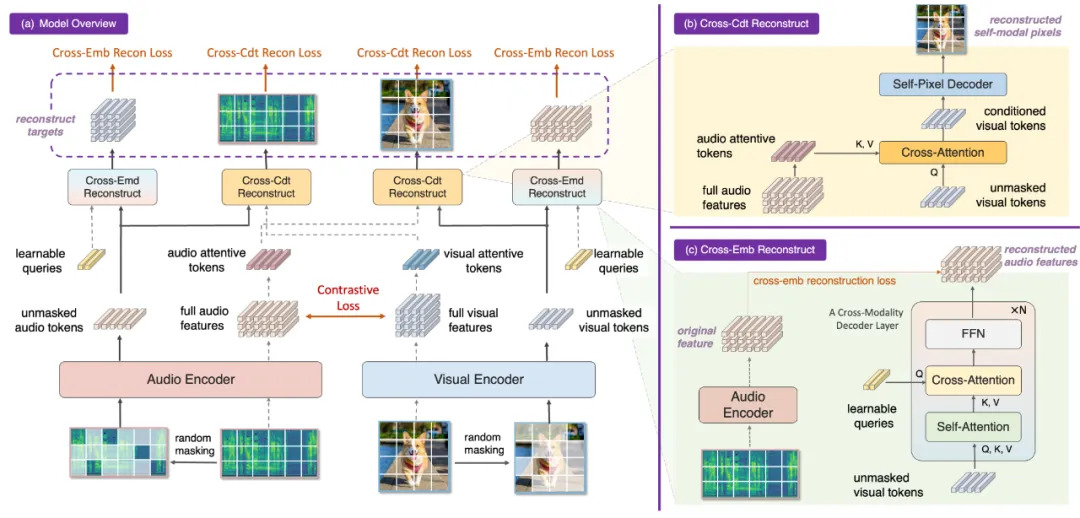
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
【CVPR2024】Sparse Semi-DETR: Sparse Learnable Queries for Semi ...
(PDF) Image Aesthetics Assessment via Learnable Queries
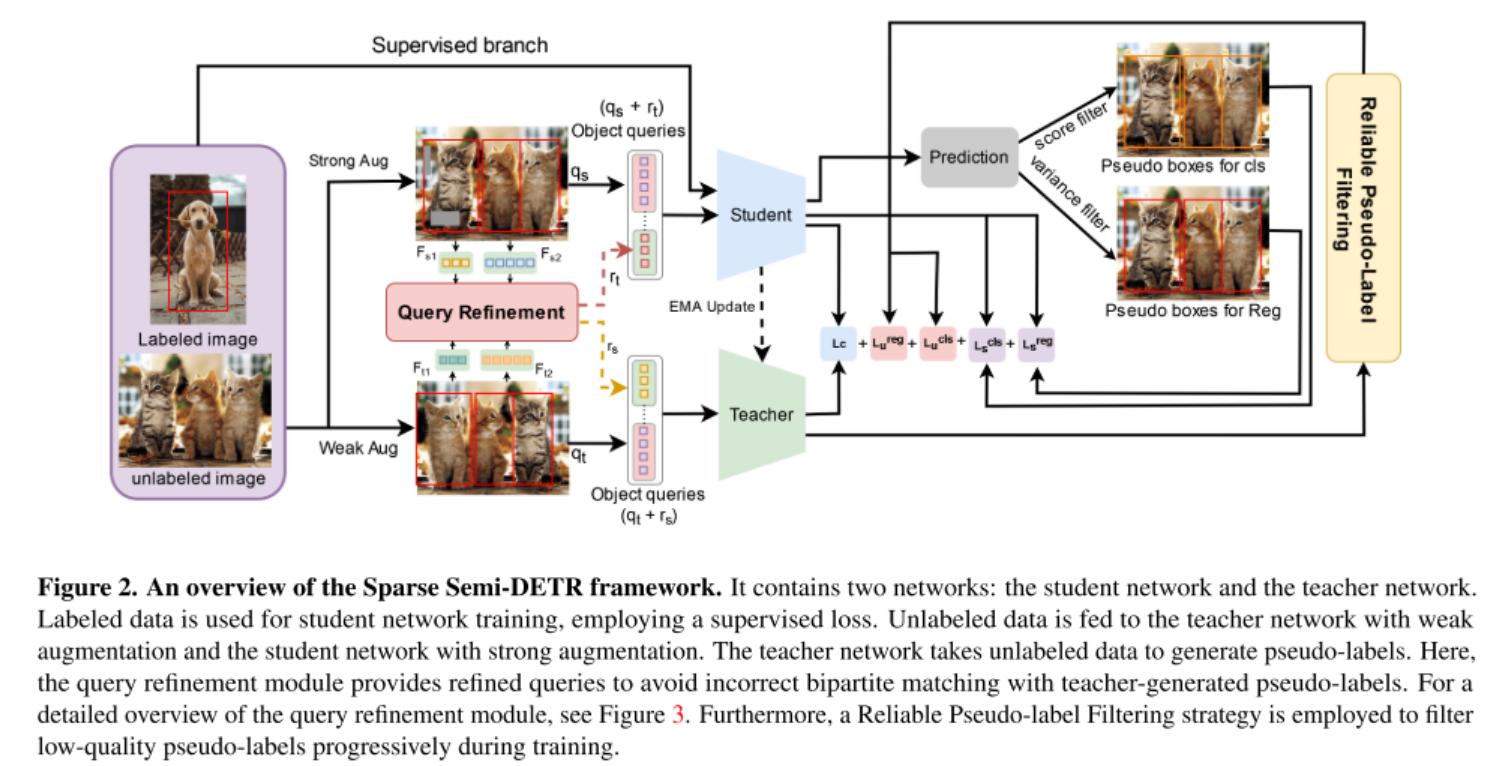
(PDF) Sparse Semi-DETR: Sparse Learnable Queries for Semi-Supervised ...
[论文评述] Sparse Semi-DETR: Sparse Learnable Queries for Semi-Supervised ...
BoQ: A Place is Worth a Bag of Learnable Queries | AI Research Paper ...
Multi-modal Learnable Queries for Image Aesthetics Assessment - YouTube
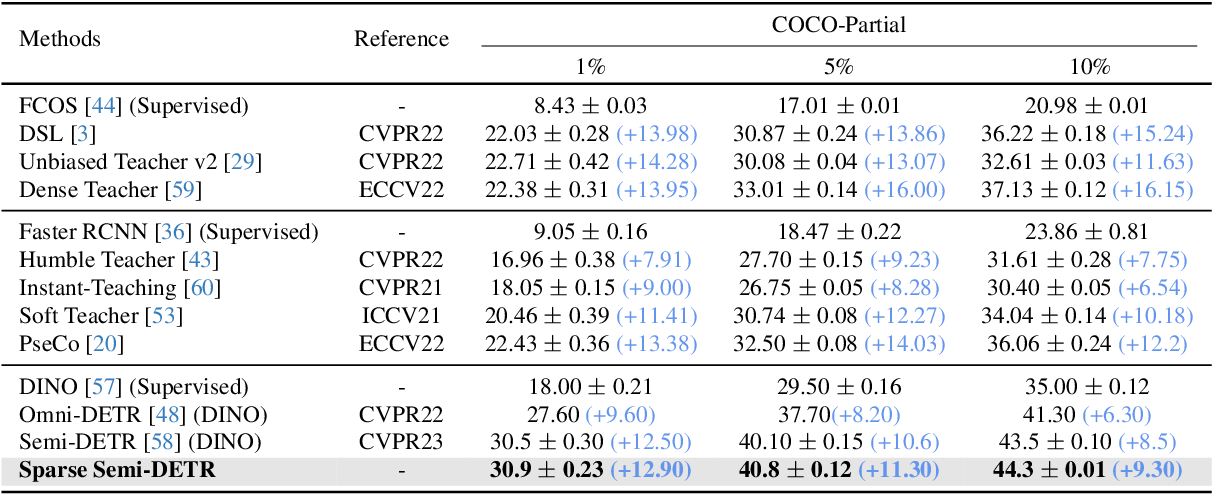
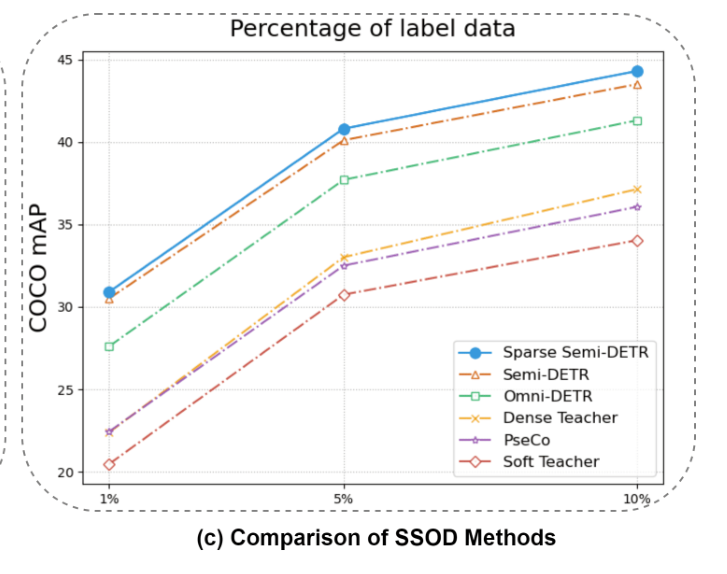
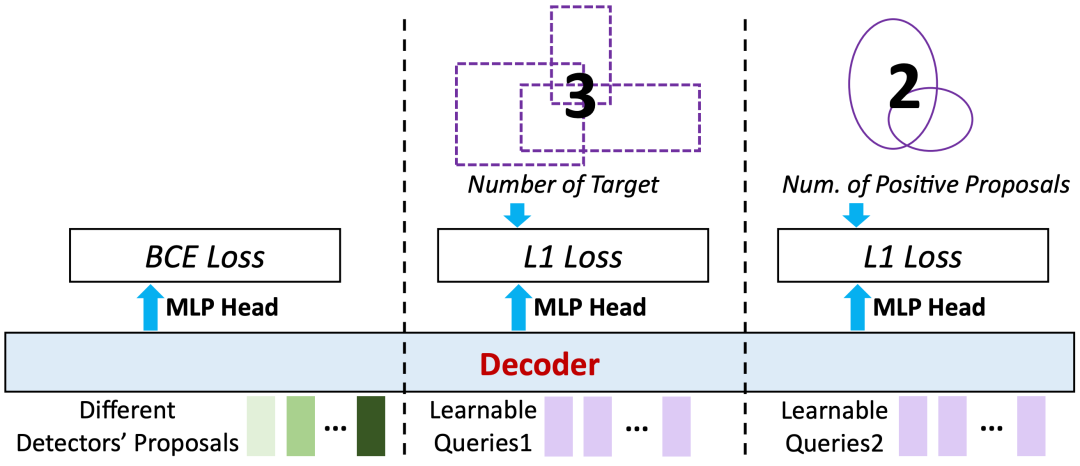
Table 1 from Sparse Semi-DETR: Sparse Learnable Queries for Semi ...
Image Aesthetics Assessment via Learnable Queries | DeepAI
(PDF) LQ-Adapter: ViT-Adapter with Learnable Queries for Gallbladder ...
Figure 1 from Multi-modal Learnable Queries for Image Aesthetics ...
Mask proposals from some learnable queries showing "thing" instances ...
Performance comparison using different num- bers of learnable queries ...
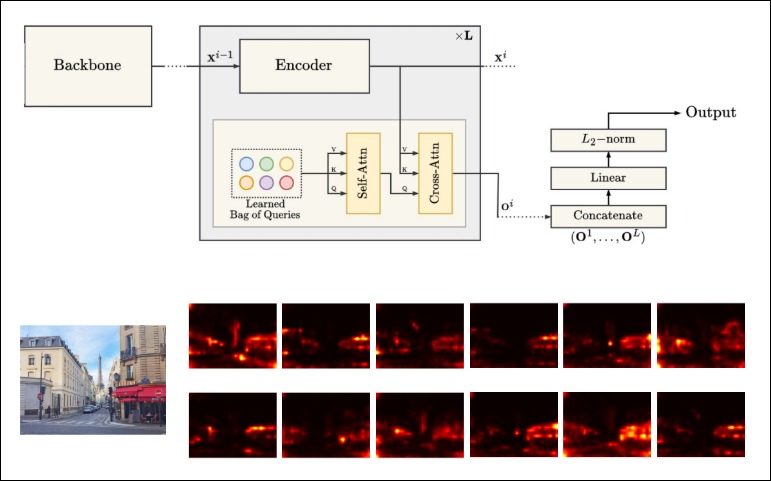
BoQ: A Place is Worth a Bag of Learnable Queries - 智源社区论文
Figure 6 from Multi-modal Learnable Queries for Image Aesthetics ...
Multi-modal Learnable Queries for Image Aesthetics Assessment | AI ...
CVPR 2024 Paper: Sparse Semi-DETR: Sparse Learnable Queries for Semi ...
2024 CVPR Sparse Semi-DETR: Sparse Learnable Queries for Semi ...
Figure 2 from Learnable Query Guided Representation Learning for ...
Underwater object detection method based on learnable query recall ...
Figure 1 from Conditional-Based Transformer Network With Learnable ...
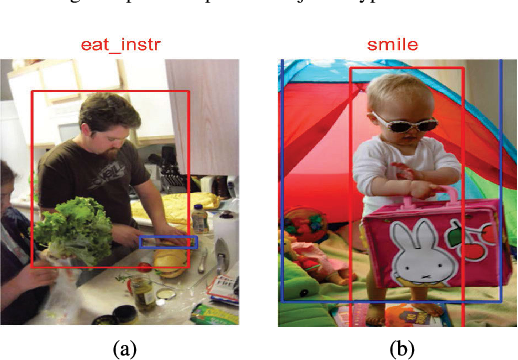
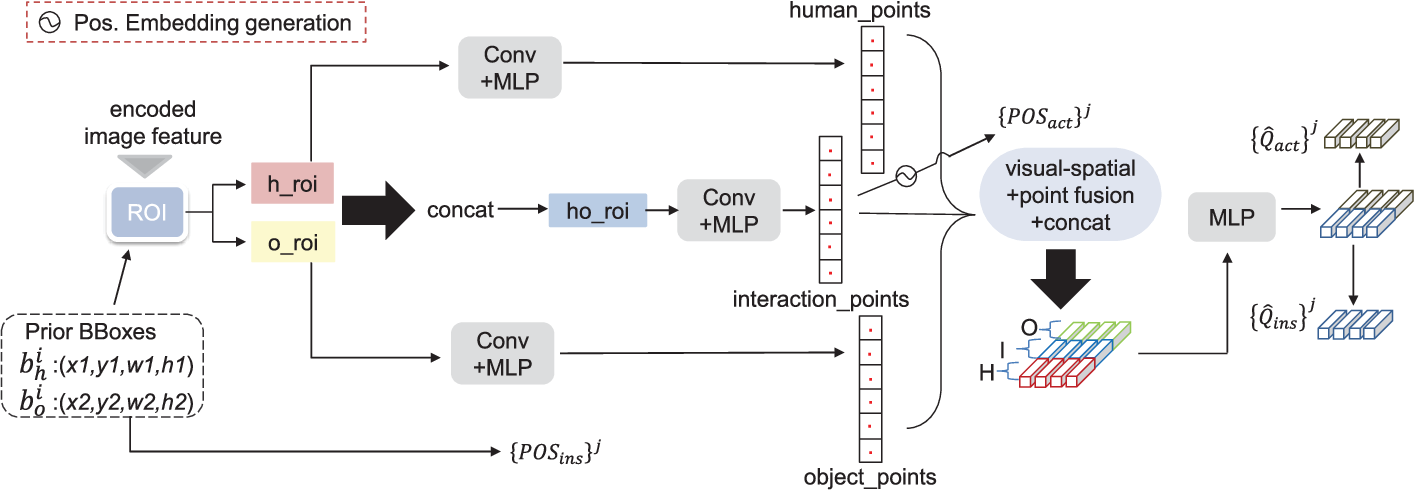
Figure 1 from Point-Based Learnable Query Generator for Human–Object ...
PointTAD: Multi-Label Temporal Action Detection with Learnable Query ...
Process of applying consecutive decoder layers. The learnable J ...
Dual-Path Dynamic Fusion with Learnable Query for Multimodal Sentiment ...
Micro-gesture Online Recognition using Learnable Query Points | AI ...
Learnable Query Aggregation with KV Routing for Cross-view Geo ...
The Learnable Query (LQ) guides the model to pay attention (Attn) to ...
Figure 7 from Point-Based Learnable Query Generator for Human–Object ...
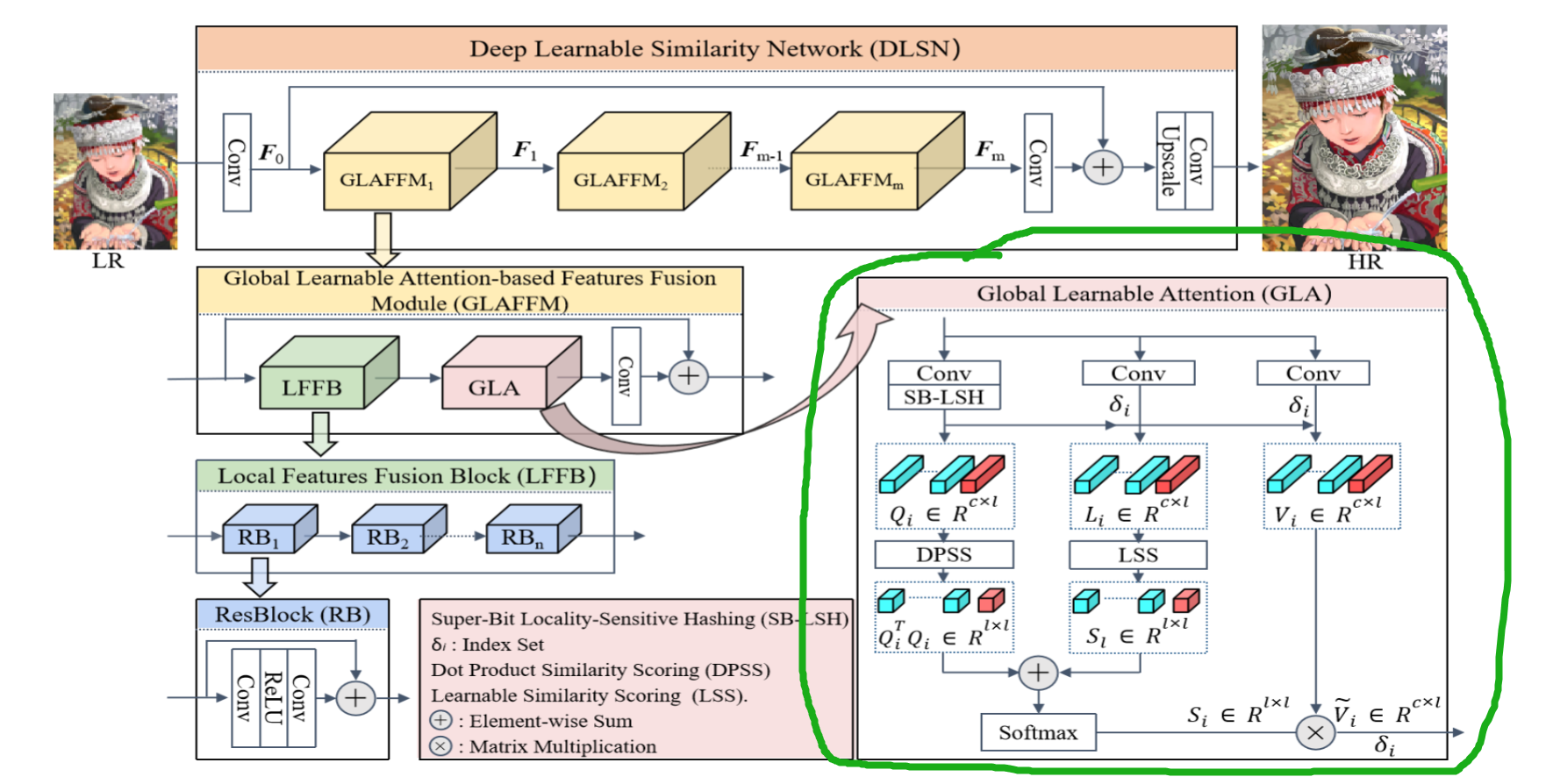
【TPAMI2023】Global Learnable Attention for Single Image Super-Resolution ...
Performance of IAA-LQ with different numbers of learnable queries. M ...
Hybrid Spectral Denoising Transformer with Learnable Query | DeepAI
(PDF) Micro-gesture Online Recognition using Learnable Query Points
Figure 8 from Point-Based Learnable Query Generator for Human–Object ...
Learnable query features are directly supervised before being used in ...
Figure 3 from Learnable Query Guided Representation Learning for ...
Figure 3 from Point-Based Learnable Query Generator for Human–Object ...
论文阅读CVPR2022 《Language As Queries for Referring Video Object ...
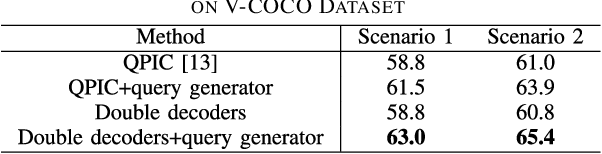
Table VII from Point-Based Learnable Query Generator for Human–Object ...
(PDF) Hybrid Spectral Denoising Transformer with Learnable Query
Figure 5 from Point-Based Learnable Query Generator for Human–Object ...
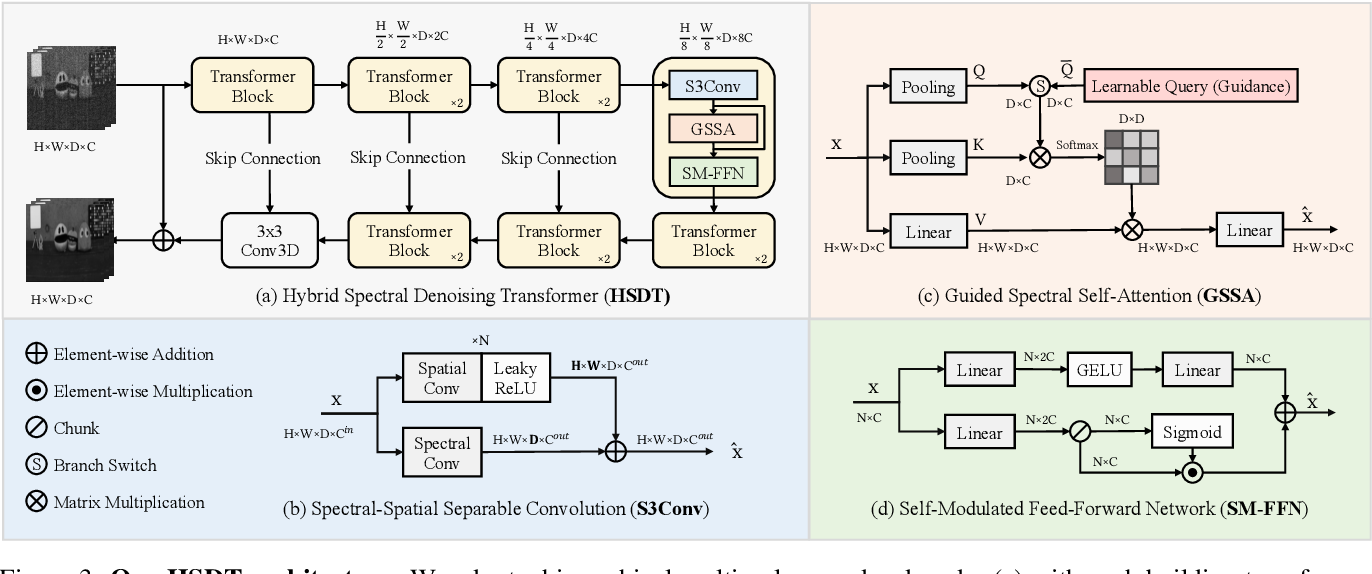
Figure 1 from Hybrid Spectral Denoising Transformer with Learnable ...
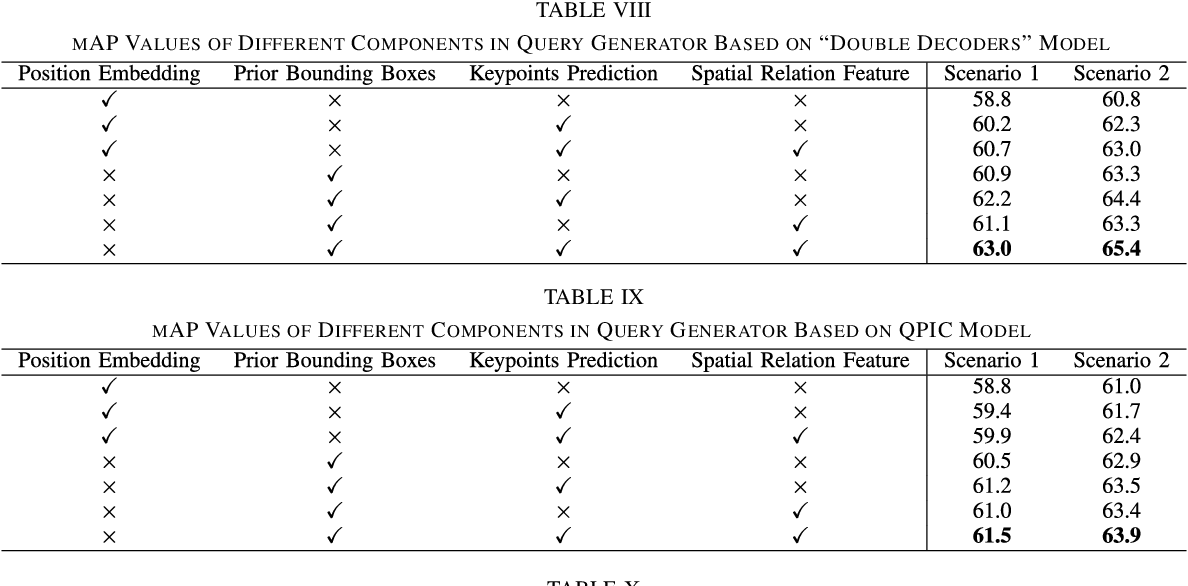
Table IX from Point-Based Learnable Query Generator for Human–Object ...
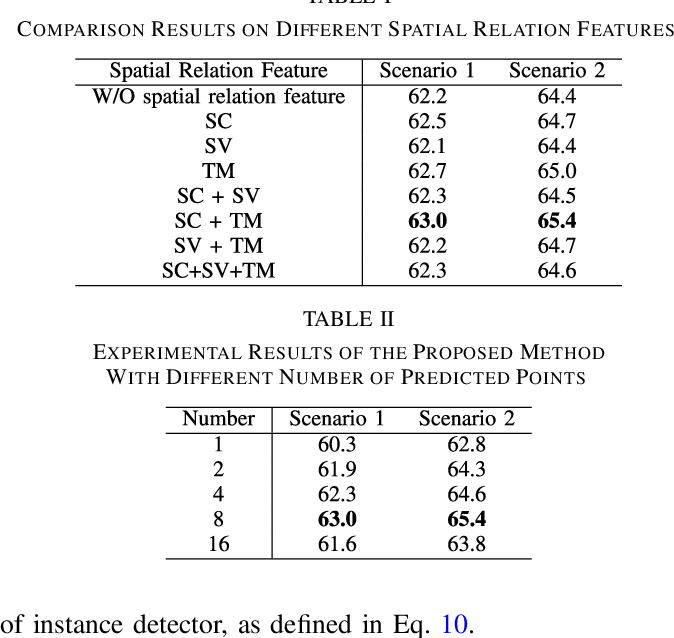
Table II from Point-Based Learnable Query Generator for Human–Object ...
Figure 1 from Micro-gesture Online Recognition using Learnable Query ...
Figure 1 from NavTr: Object-Goal Navigation With Learnable Transformer ...
The structure of transform decoders [10]. Given learnable object ...
[论文评述] Query-Aware Learnable Graph Pooling Tokens as Prompt for Large ...
(PDF) PointTAD: Multi-Label Temporal Action Detection with Learnable ...
Learnable Query Initialization for Surgical Instrument Instance ...
Hybrid Spectral Denoising Transformer with Learnable Query: Paper and Code
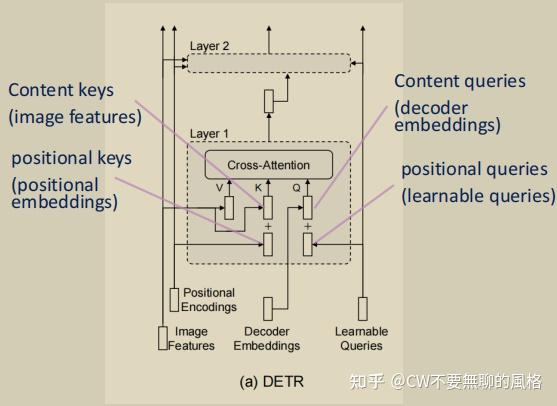
DAB-DETR:Dynamic Anchor Boxes Are Better Queries for DETR阅读笔记_dab-detr ...
Vol. 22 No. 10 (2024): Ordinary Issue | IEEE Latin America Transactions
Schematic architecture diagram of the proposed LQ-Adapter. The ...
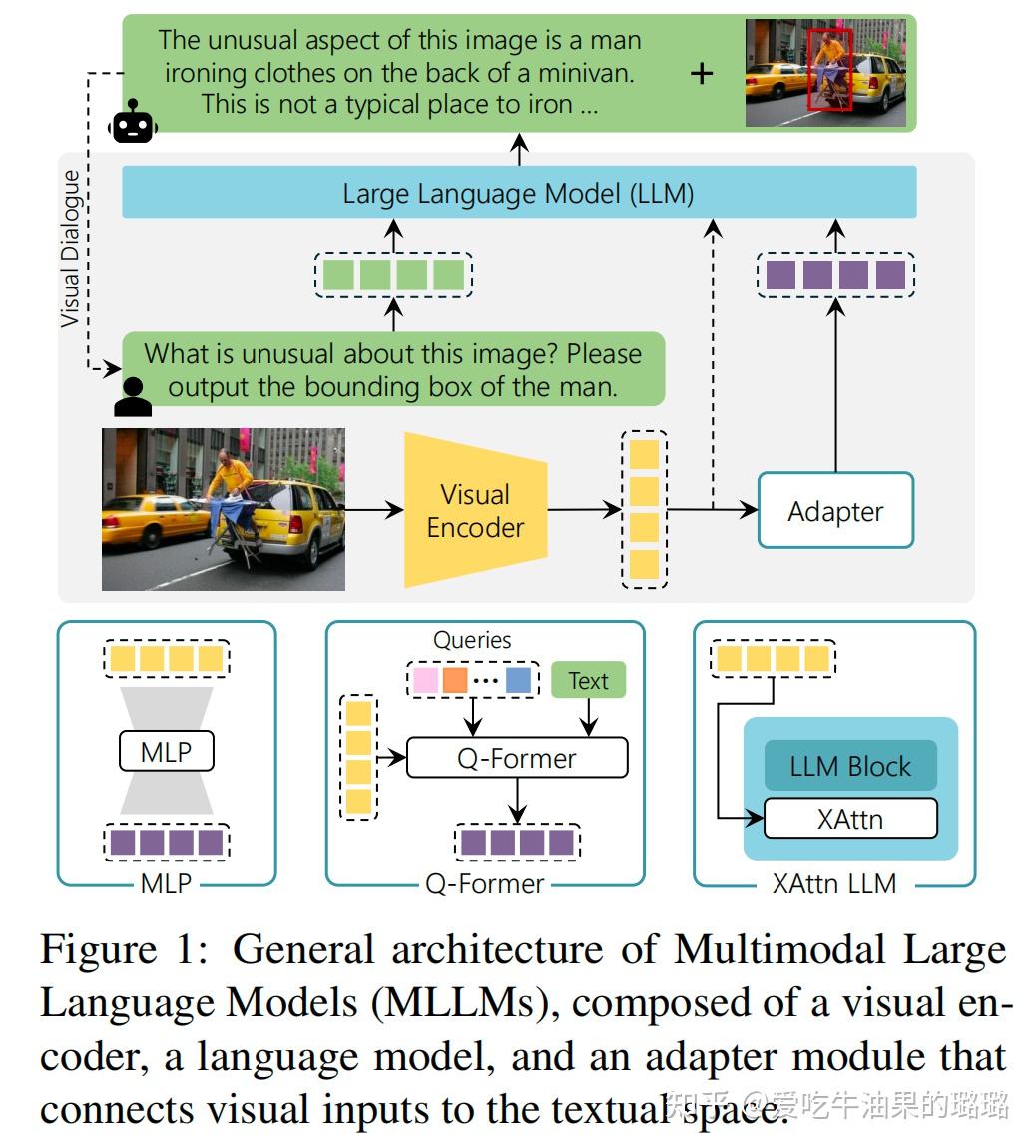
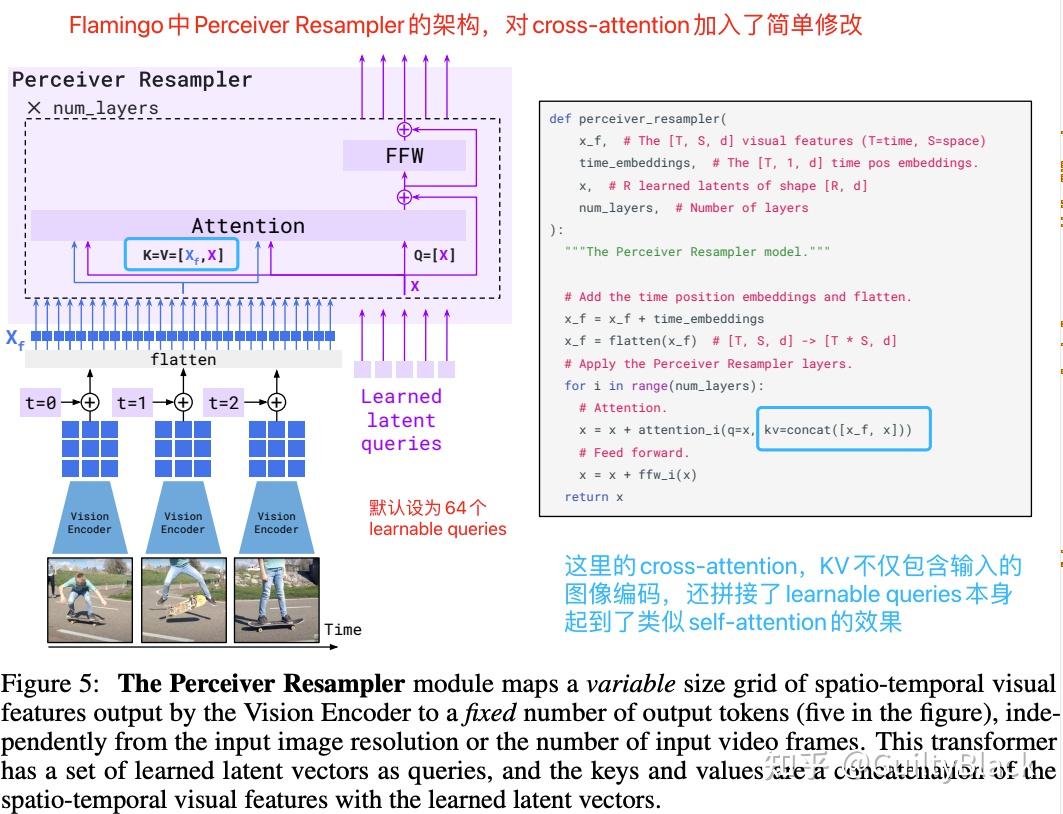
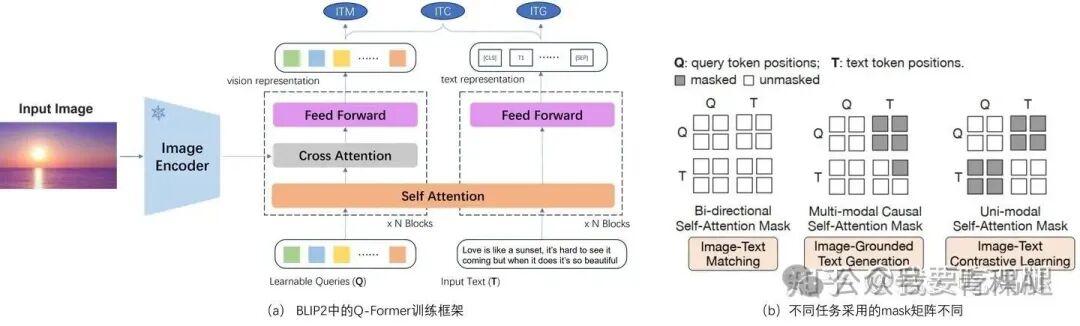
多模态大模型基础 - 知乎
F1暴涨20分,推理速度恒定!新架构VGent:多目标定位又快又准-腾讯云开发者社区-腾讯云
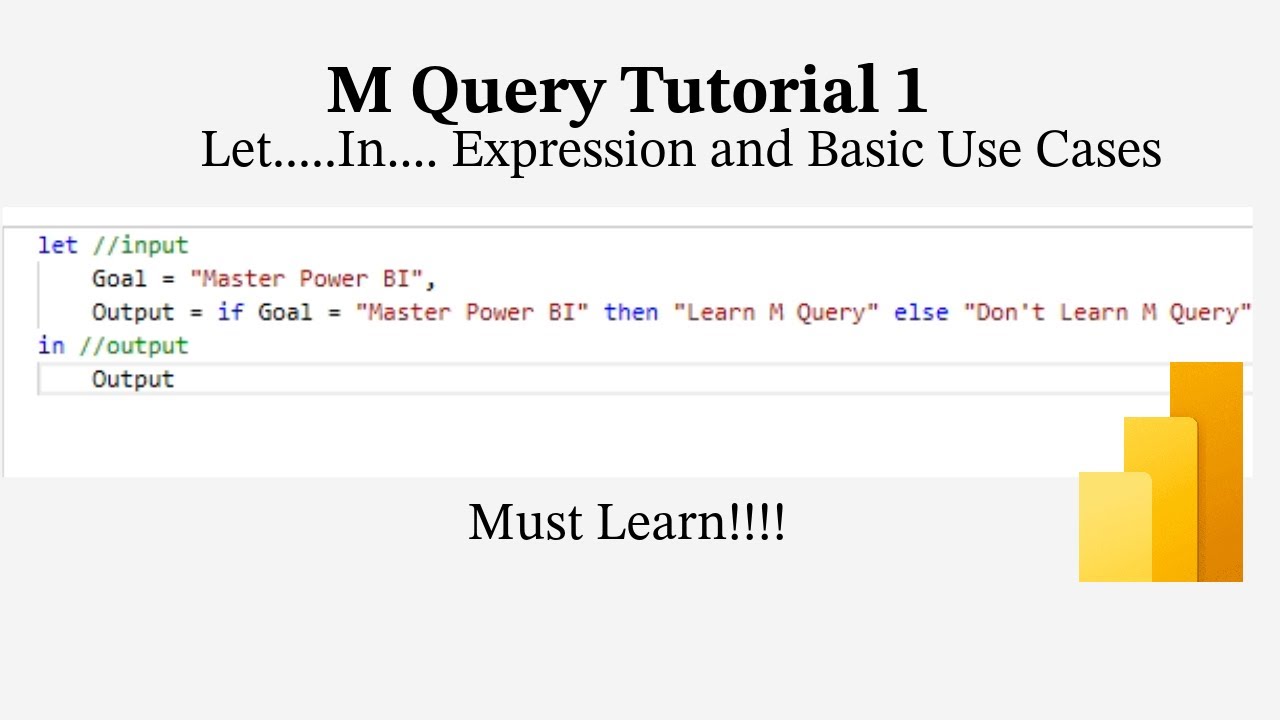
M Query Tutorial 1 - Let In Expression - Why Do You Need To Learn M ...
ICLR 2022 | 将Anchor box重新引入DETR,提供query可解释性并加速收敛 - 智源社区
多模态大模型(理解)入门看这一篇就好了_learnablemkvmr queries)从视觉编码器(-CSDN博客
极市开发者平台-计算机视觉算法开发落地平台-极市科技
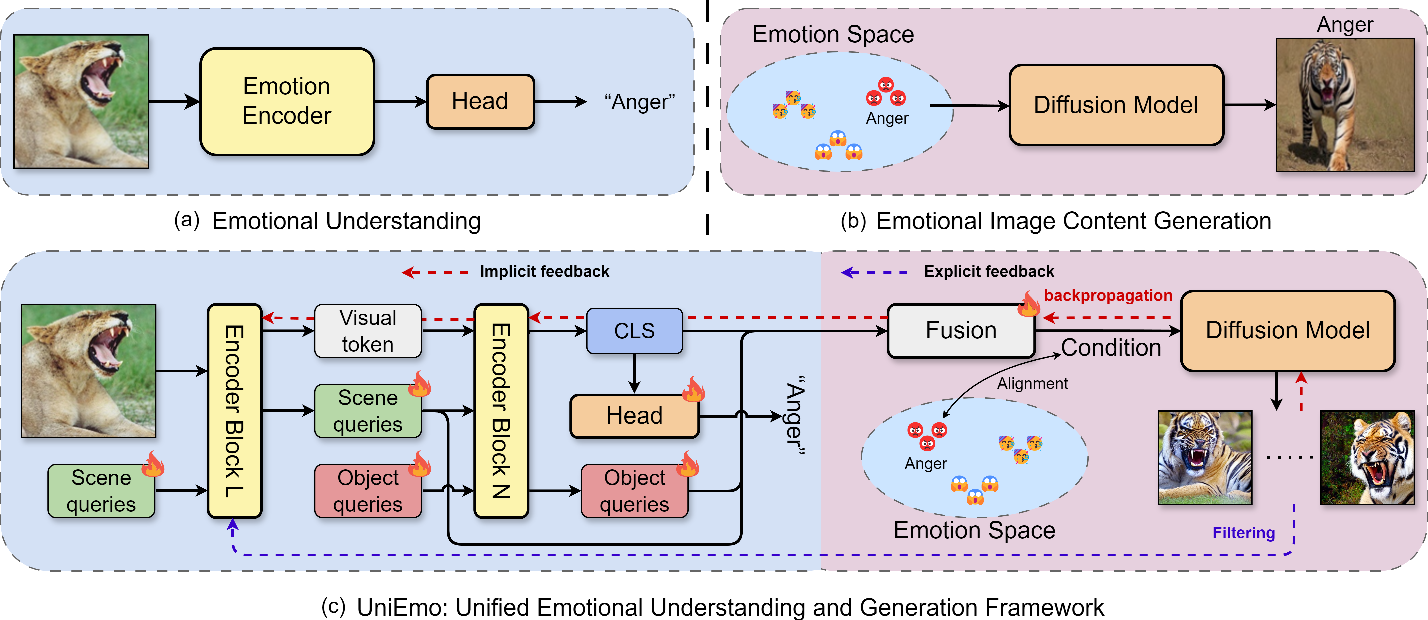
Figure 1 from UniEmo: Unifying Emotional Understanding and Generation ...
Comparisons of different object detection paradigms. (a) Detection from ...
[论文评述] BREEN: Bridge Data-Efficient Encoder-Free Multimodal Learning ...
[PDF] UniEmo: Unifying Emotional Understanding and Generation With ...
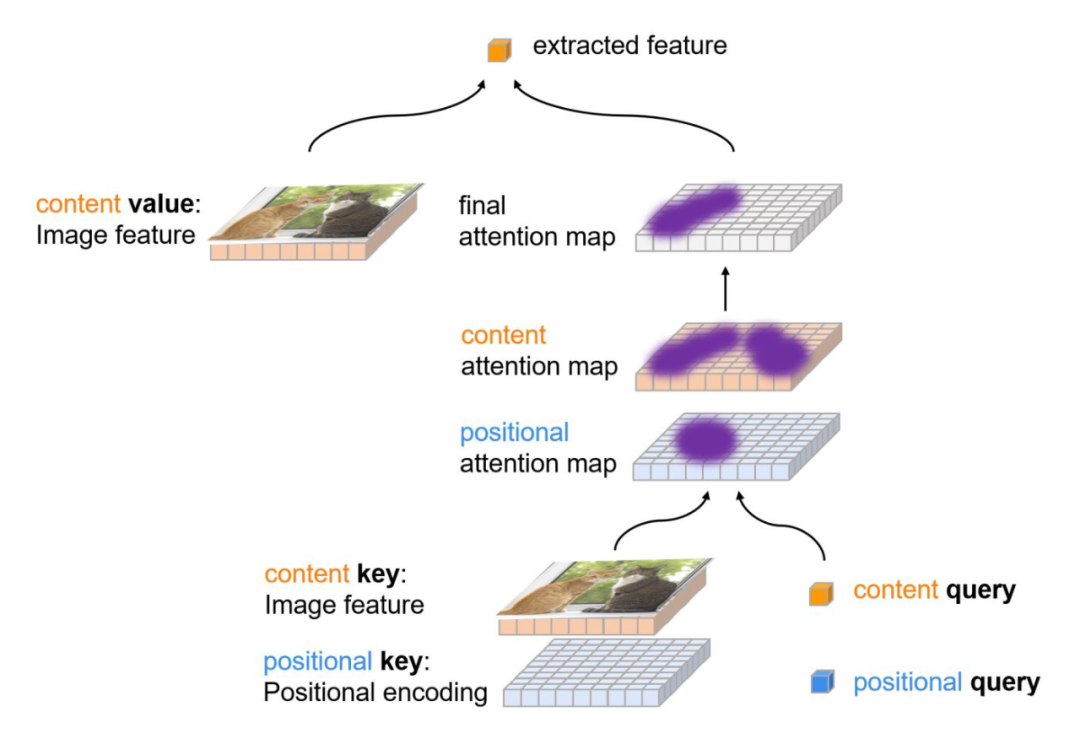
找到 DETR 慢收敛的罪魁祸首了!DAB-DETR 利用迭代更新的 Anchor Box 作为位置先验,将 DETR 演绎成为 Soft ...
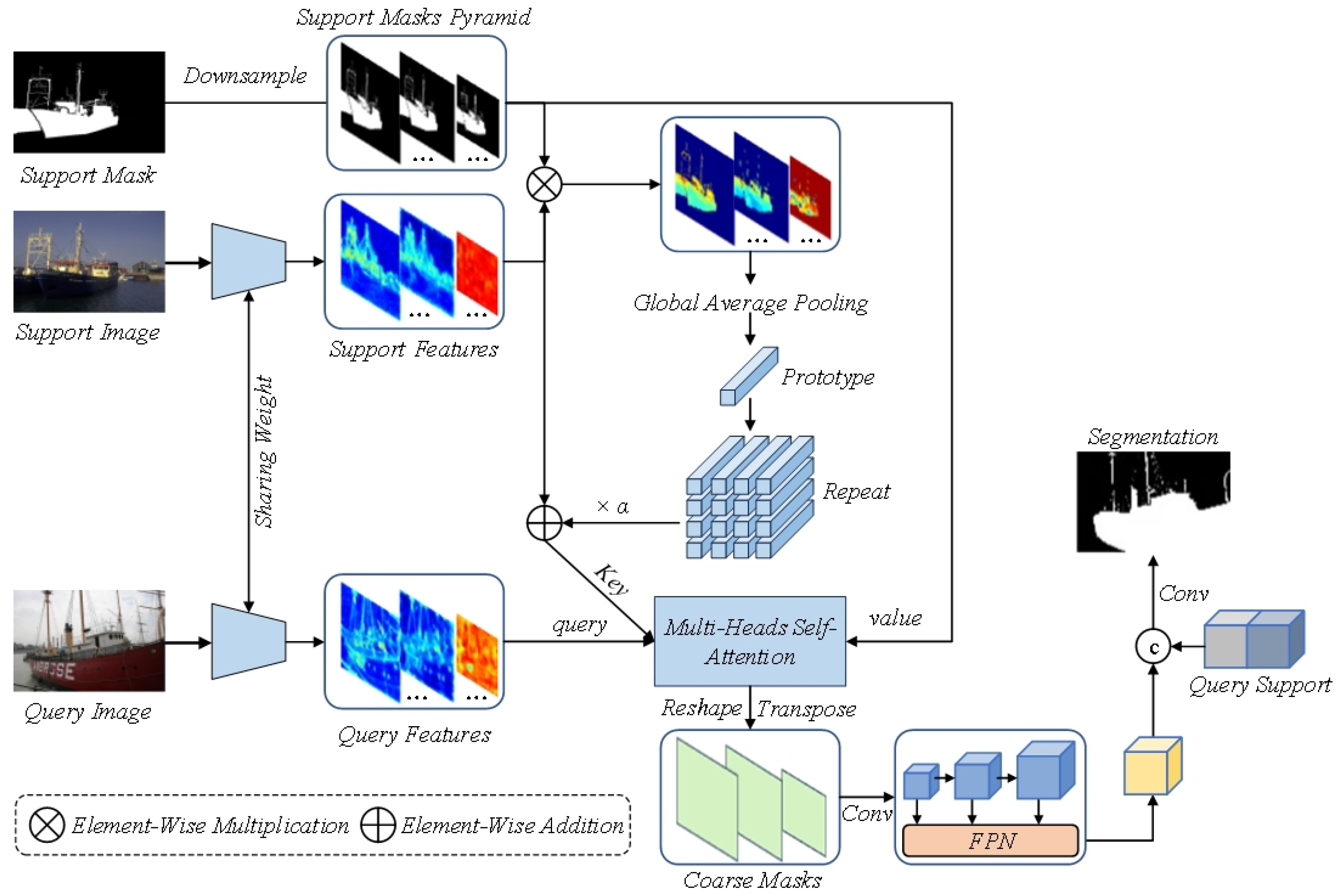
Global–Local Query-Support Cross-Attention for Few-Shot Semantic ...
GitHub - amaralibey/Bag-of-Queries: BoQ: A Place is Worth a Bag of ...
Architecture of the proposed model based on a non-autoregressive ...
【多模态大模型】盘点part3: Gemini系列 - 知乎
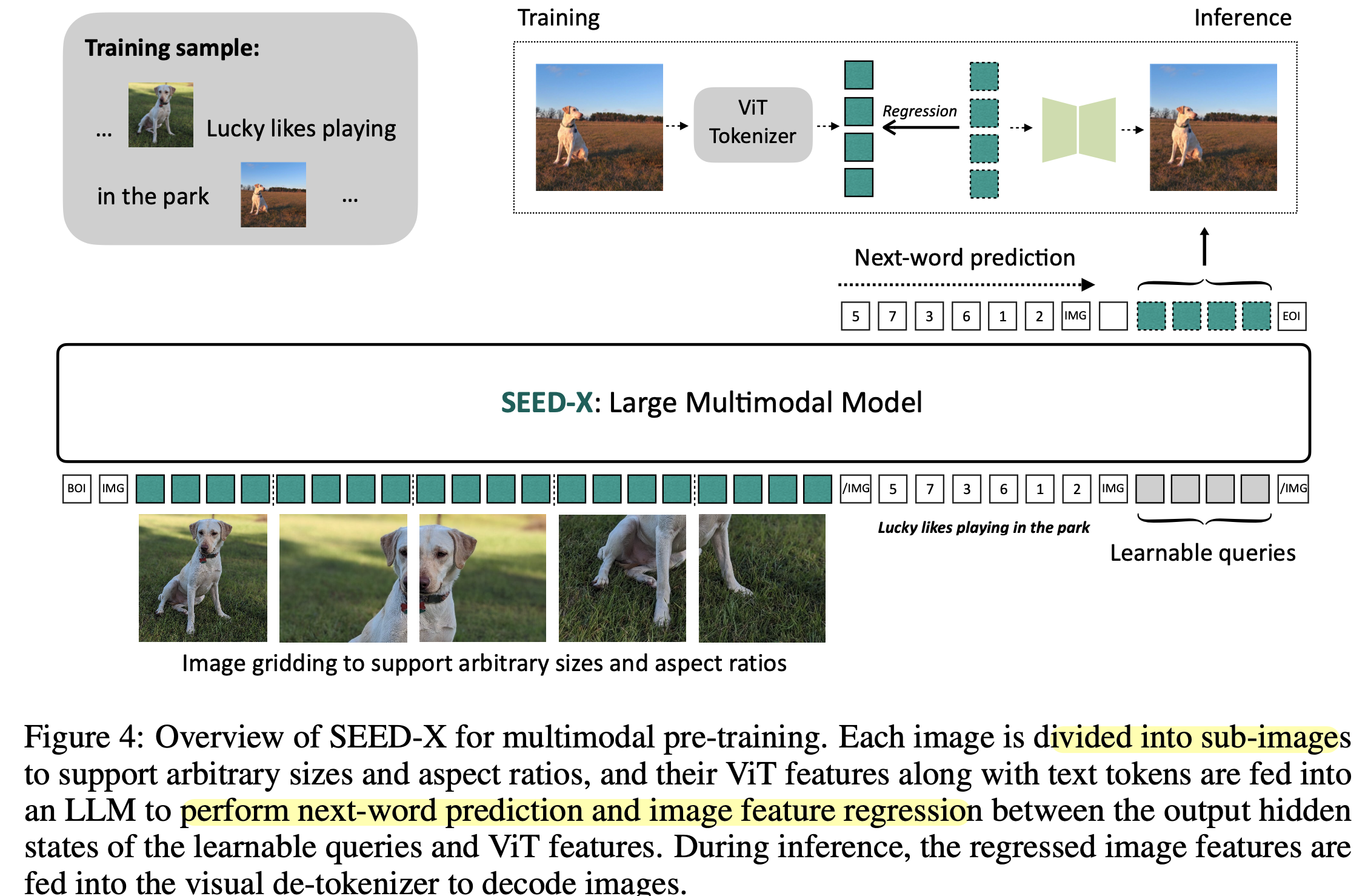
[MM] SEED-X: Multimodal Models with Unified Multi-granularity ...
Lecture 15:元学习Meta Learning_meta-learning framework-CSDN博客
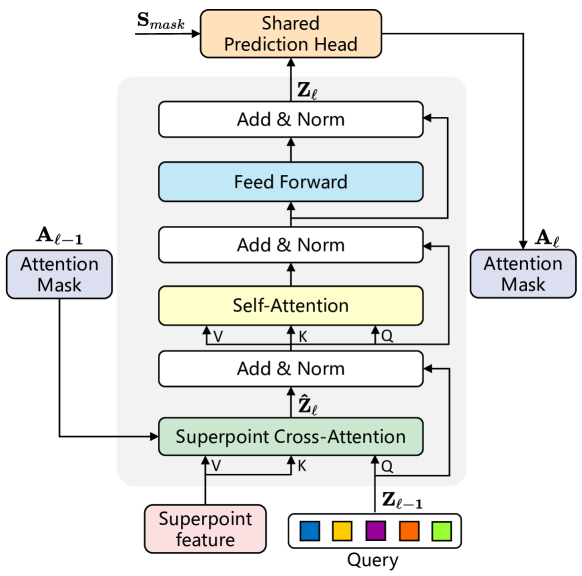
Neural Networks in Trading: Superpoint Transformer (SPFormer) - MQL5 ...
TBAC-UniImage: Unified Understanding and Generation by Ladder-Side ...
[2508.01852] Context Guided Transformer Entropy Modeling for Video ...
Figure 1 from PointTAD: Multi-Label Temporal Action Detection with ...
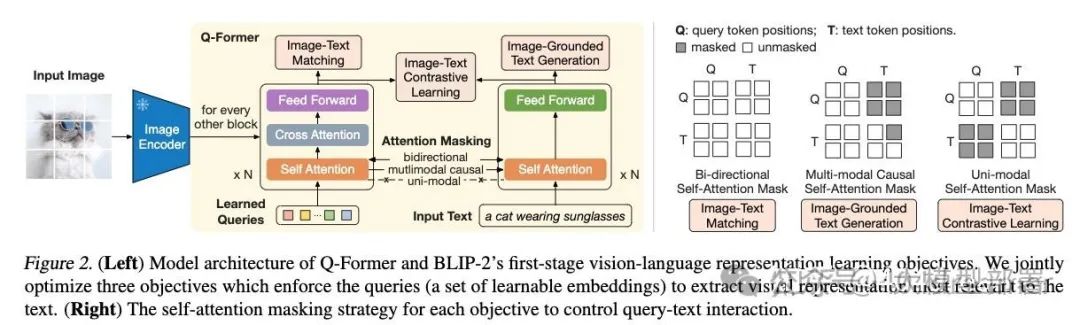
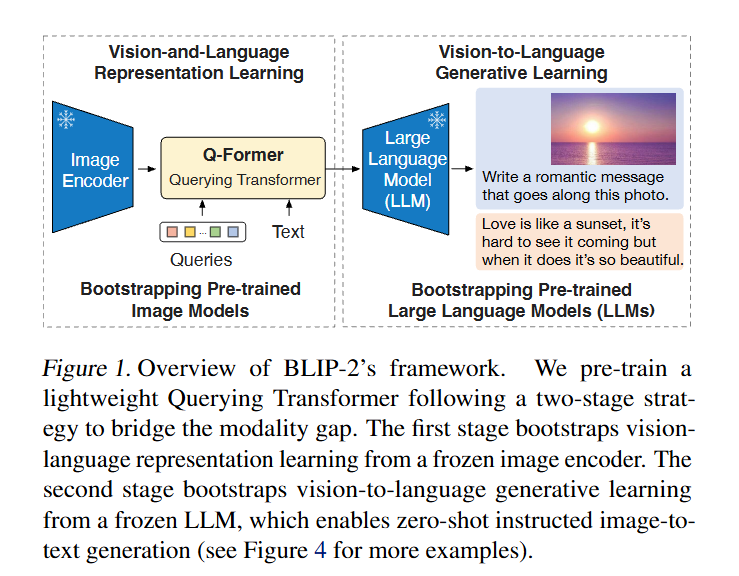
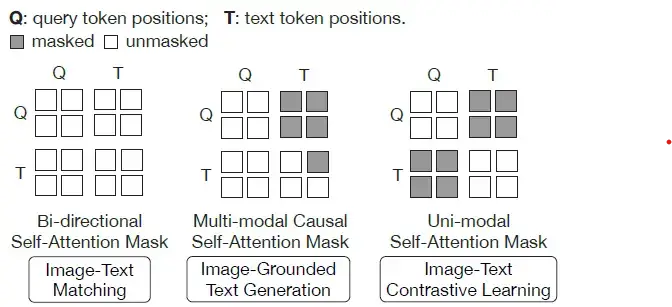
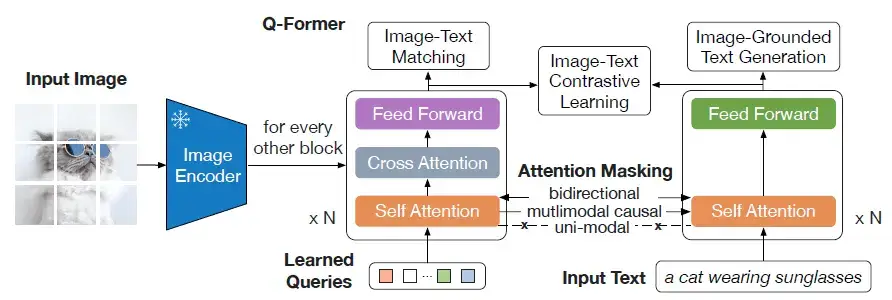
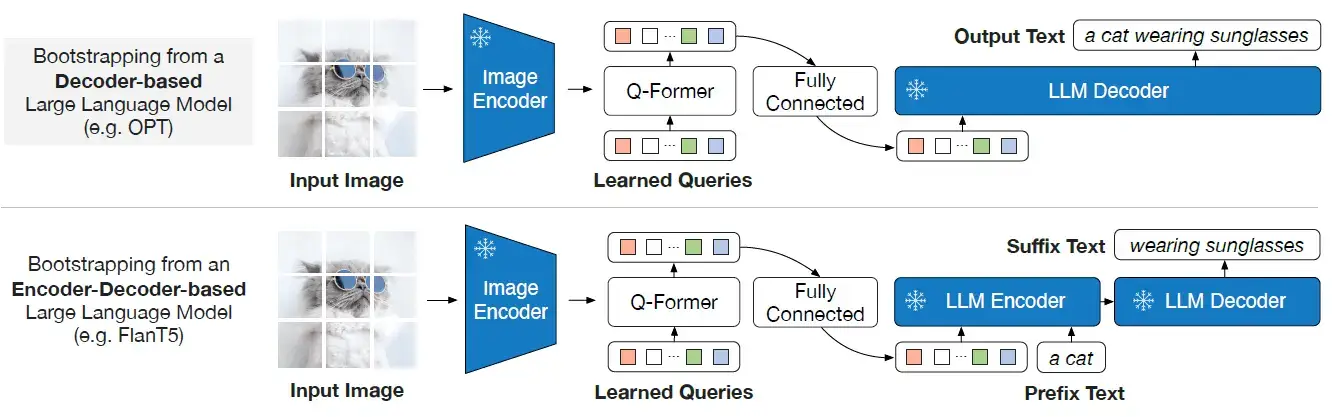
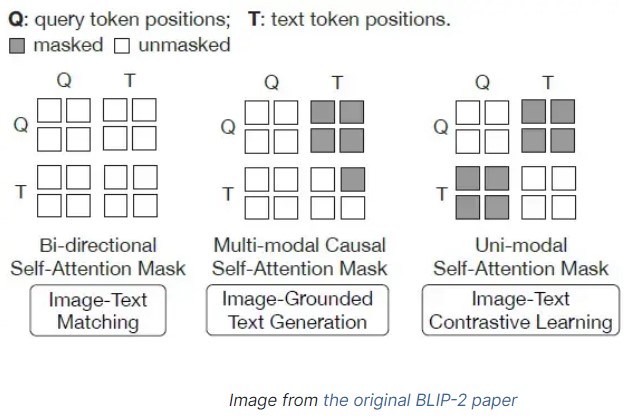
(Left) Model architecture of Q-Former and BLIP-2's first-stage ...
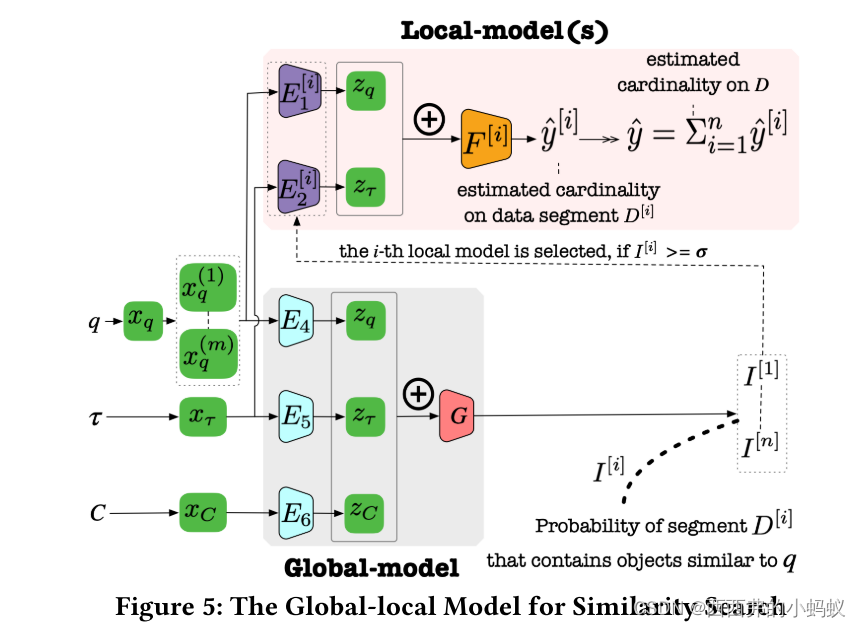
Learned Cardinality Estimation for Similarity Queries-CSDN博客
Paper page - Visual Query Tuning: Towards Effective Usage of ...
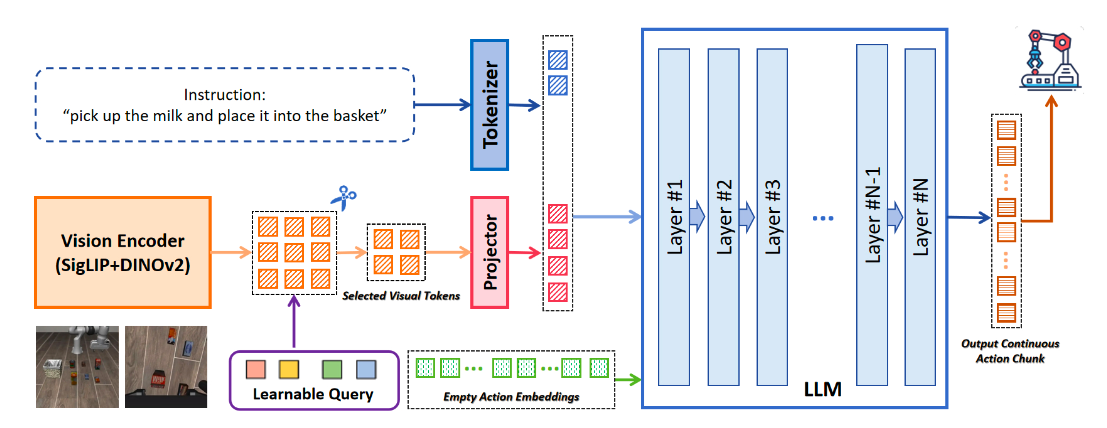
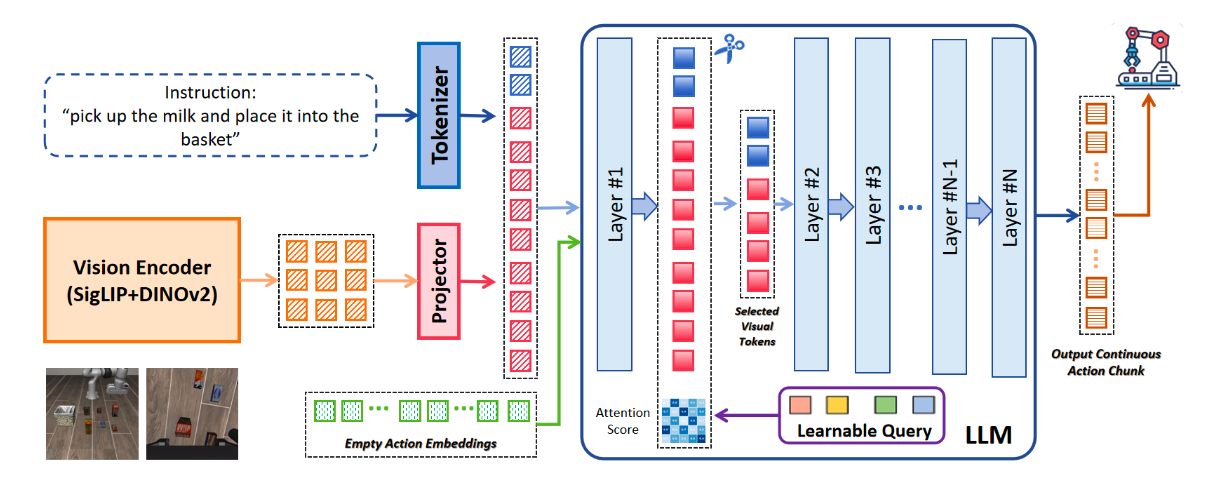
聊聊LightVLA:越学越会“抠”视觉 Token 的 VLA 加速框架 - 知乎
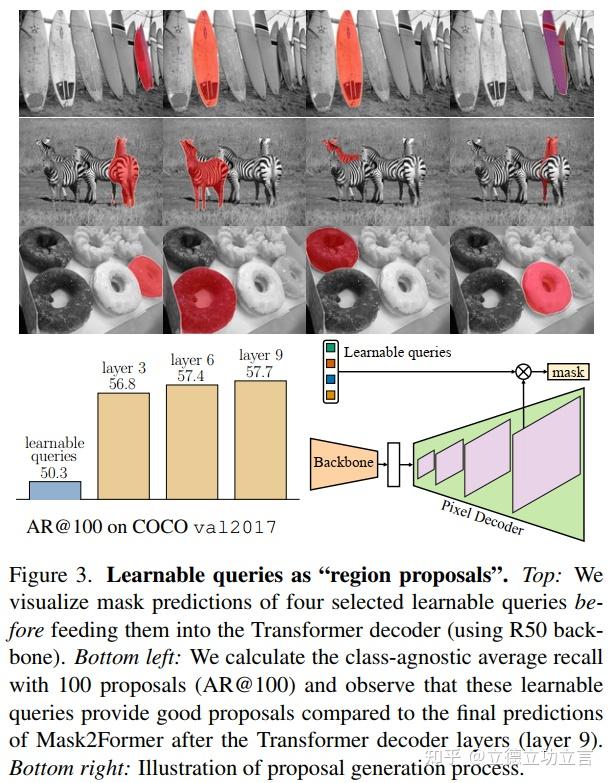
Vision Transformer系列5 - 全景分割MaskFormer系列 - 知乎
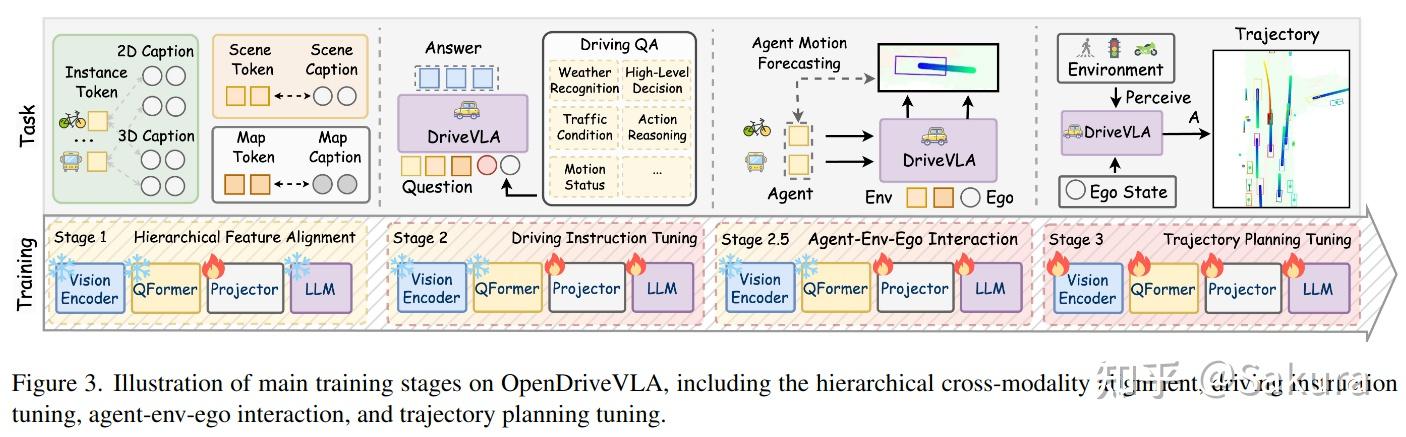
自动驾驶VLA简单调研--Part1 Vision Encoder - 知乎
Transformer-Based Multiple-Object Tracking via Anchor-Based-Query and ...
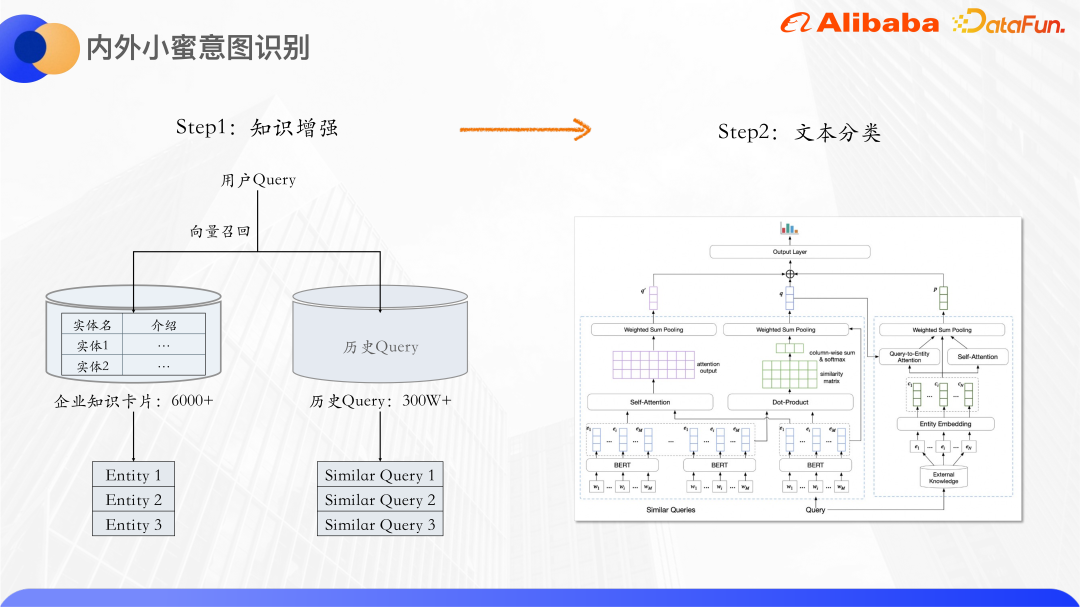
基于知识增强和预训练大模型的 Query 意图识别 - 知乎
Rethinking Query-based Transformer for Continual Image Segmentation ...
基于知识增强和预训练大模型的 Query 意图识别-51CTO.COM
LFTD: Transformer-Enhanced Diffusion Model for RealisticFinancial Time ...
深度解构!多模态大模型架构:从 LLaVA 到 Qwen3-VL! - 知乎
(PDF) Query-Informed Multi-Agent Motion Prediction
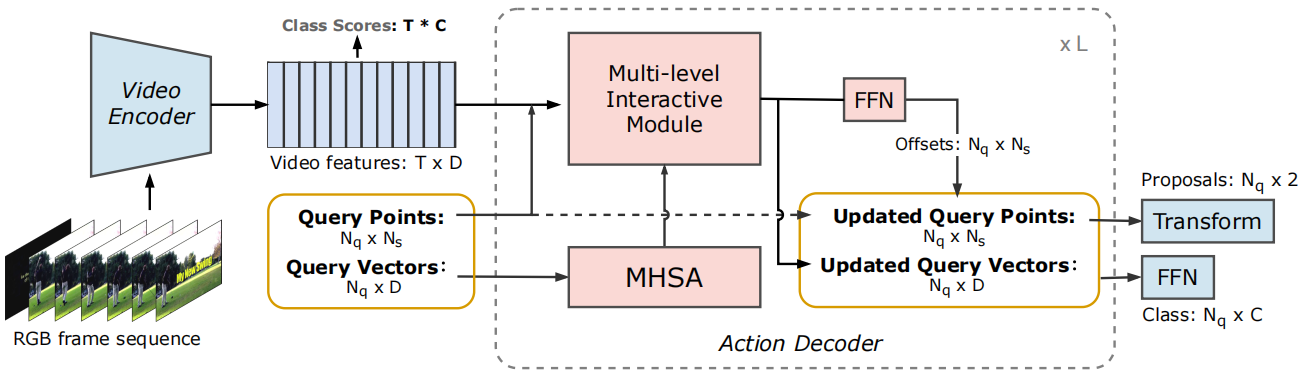
The architecture of TadTR. It takes the video features extracted with a ...
[2208.12398] Few-Shot Learning Meets Transformer: Unified Query-Support ...
Unified Multimodal Understanding and Generation Models: Advances ...
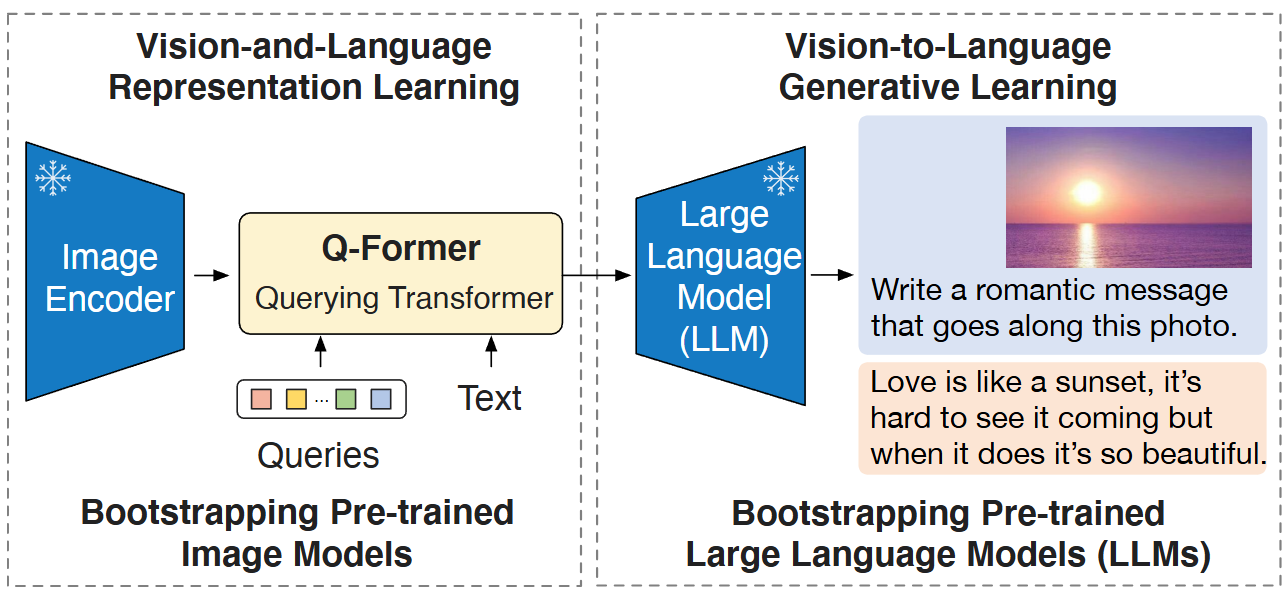
[논문 번역] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen ...
Amar Ali-bey
26. Vision Language Pretraining — LLM Foundations
[ICLR22] DAB-DETR: 将Anchor box重新引入DETR,提供query可解释性并加速收敛 - 知乎
[PDF] ReMem-VLA: Empowering Vision-Language-Action Model with Memory ...
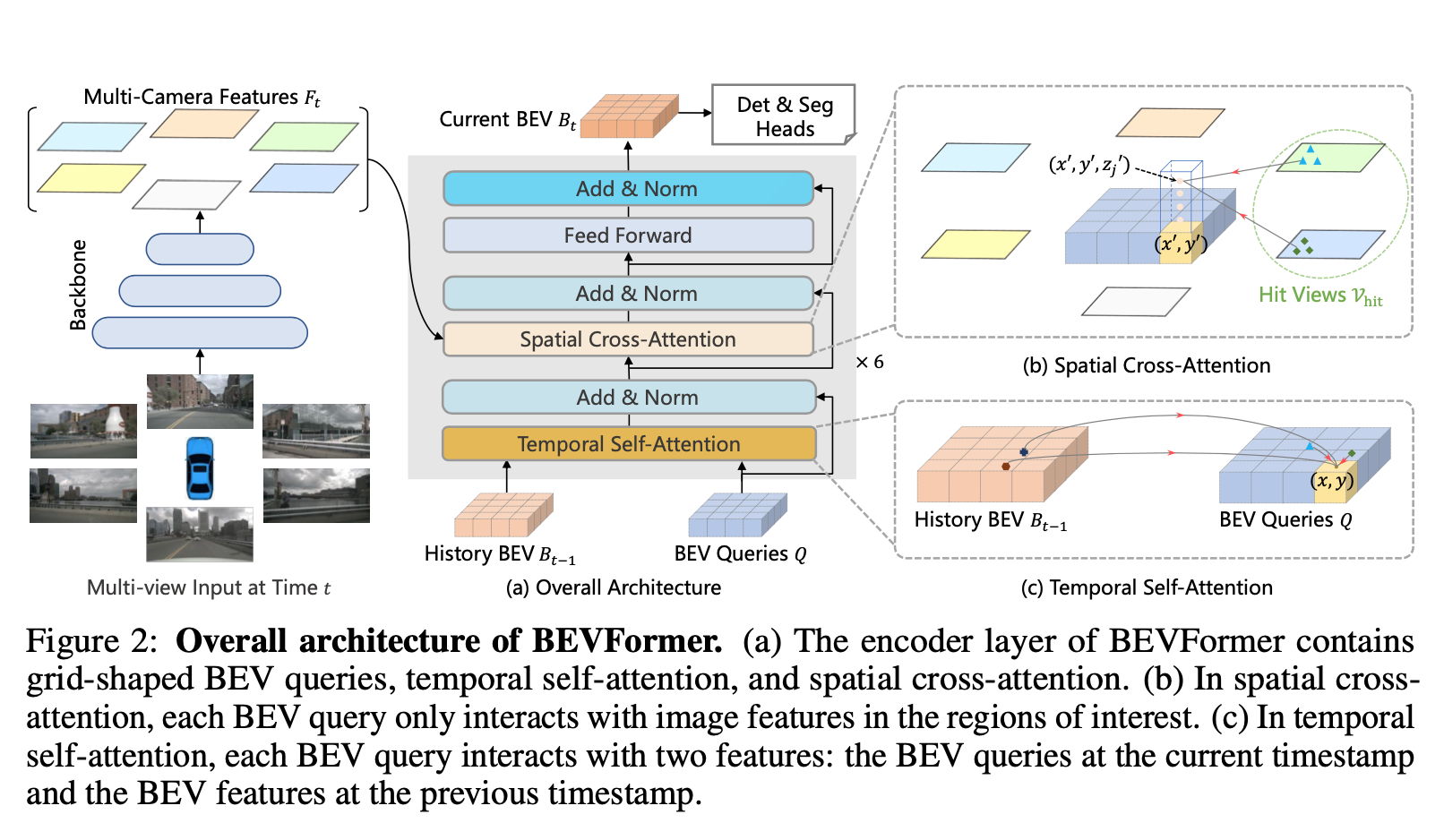
BEV | Less is More
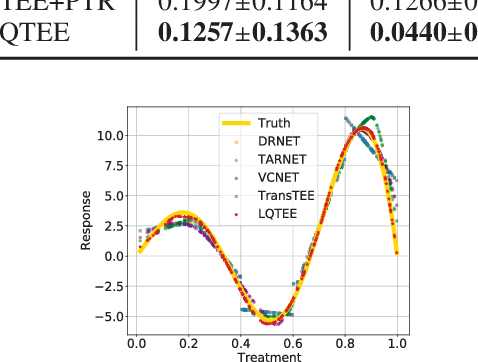
GitHub - ZhouMiaoGX/DPDF-LQ: Code and supplementary material for our ...
自注意力机制与transform_自注意力机制query的作用-CSDN博客
E-InMeMo: Enhanced Prompting for Visual In-Context Learning | AI ...
Visual Question Answering using GEMINI LLM
Daily AI Papers on Twitter: "StepFormer: Self-supervised Step Discovery ...
NeurIPS 2022 | PointTAD: 基于稀疏点表示的多类别时序动作检测框架 - 智源社区
多模态大模型调研 - 知乎
(PDF) Visual Query Tuning: Towards Effective Usage of Intermediate ...
GitHub - ZEBAAFROZ/Visual_Question_Answer: VQA Explorer: An AI project ...