Showing 118 of 118on this page. Filters & sort apply to loaded results; URL updates for sharing.118 of 118 on this page
Deploy Nvidia Triton Inference Server with MinIO as Model Store - The ...
Serving ML Model Pipelines on NVIDIA Triton Inference Server with ...
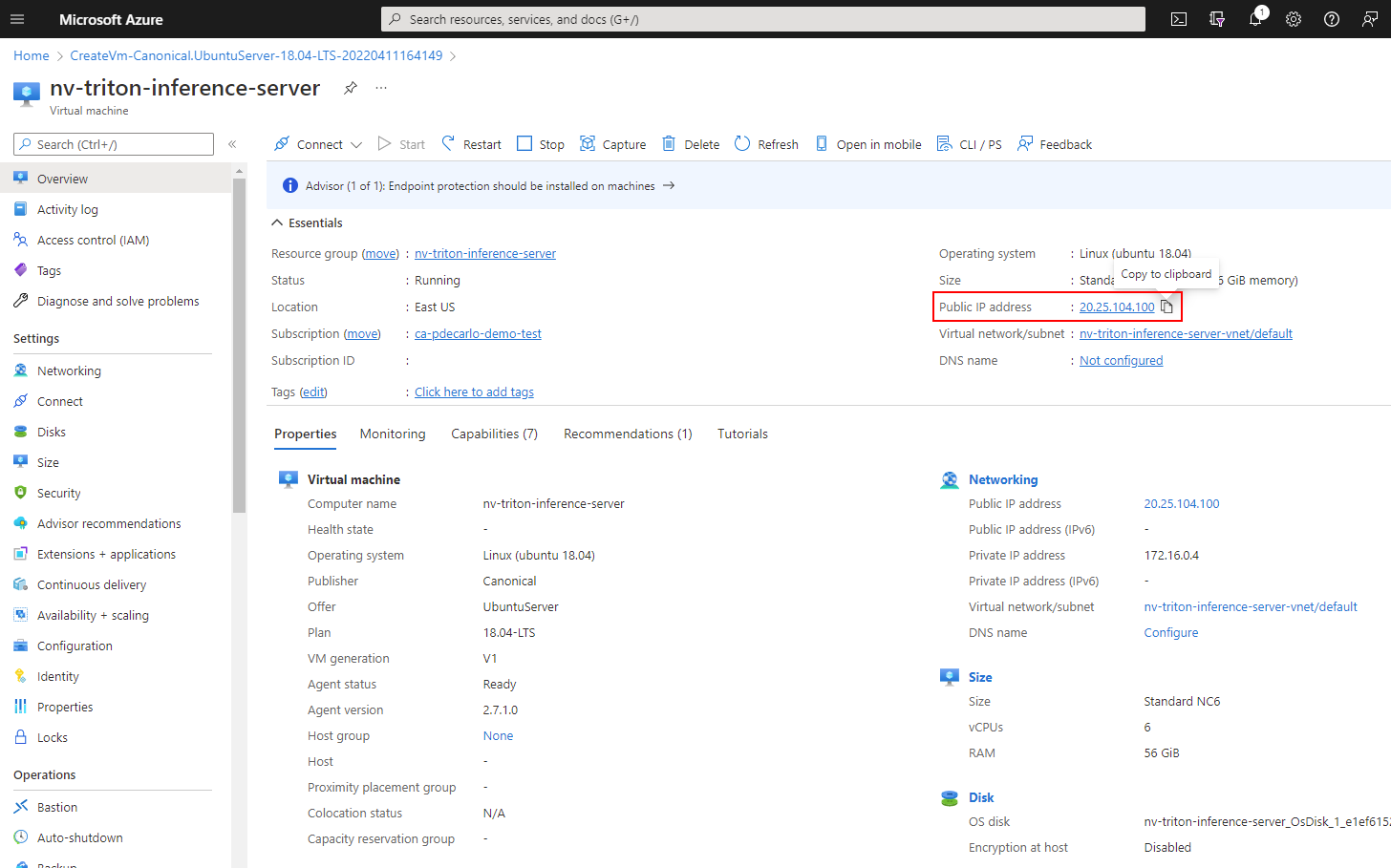
Triton Inference Server in Azure ML Speeds Up Model Serving | # ...
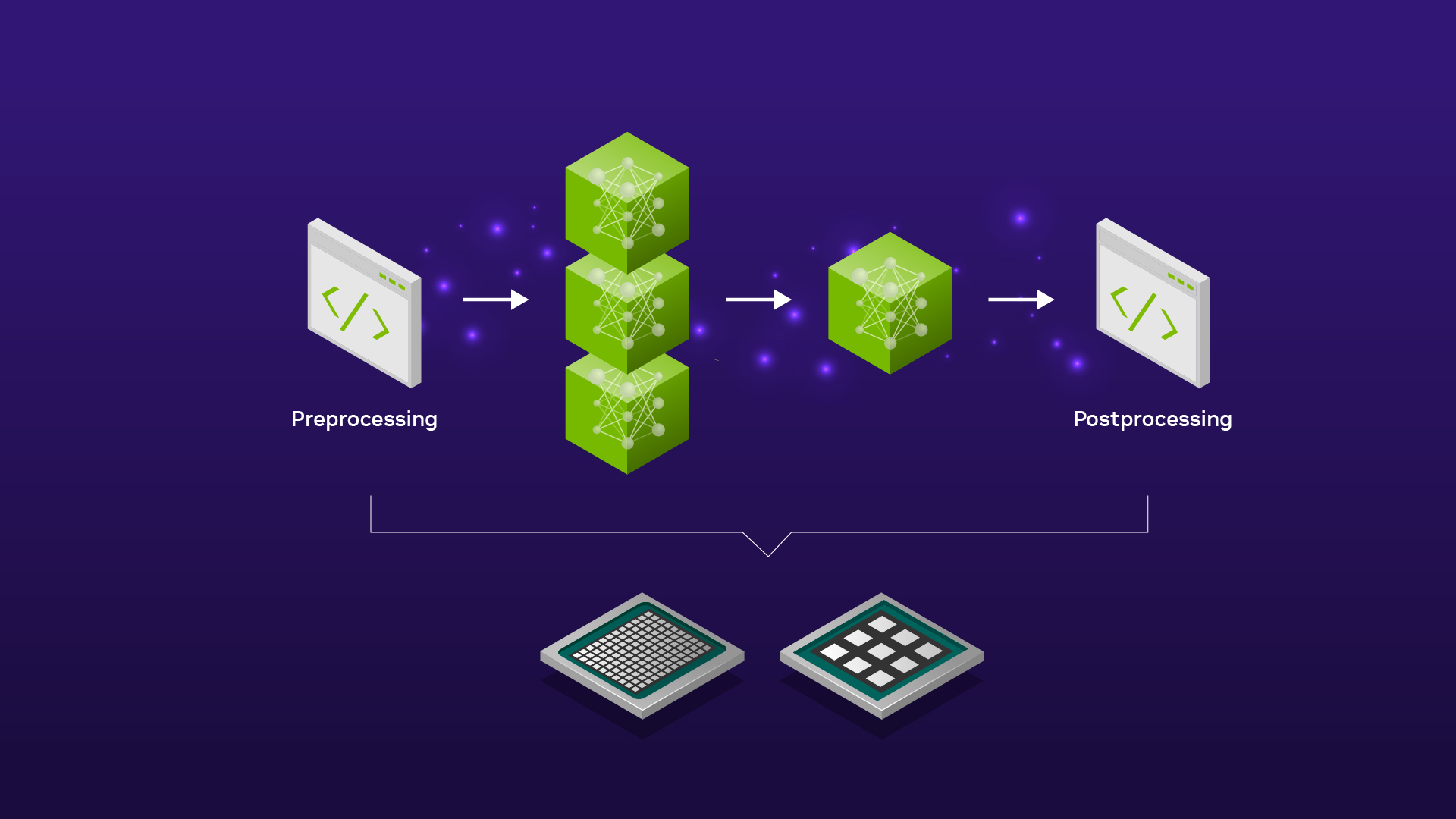
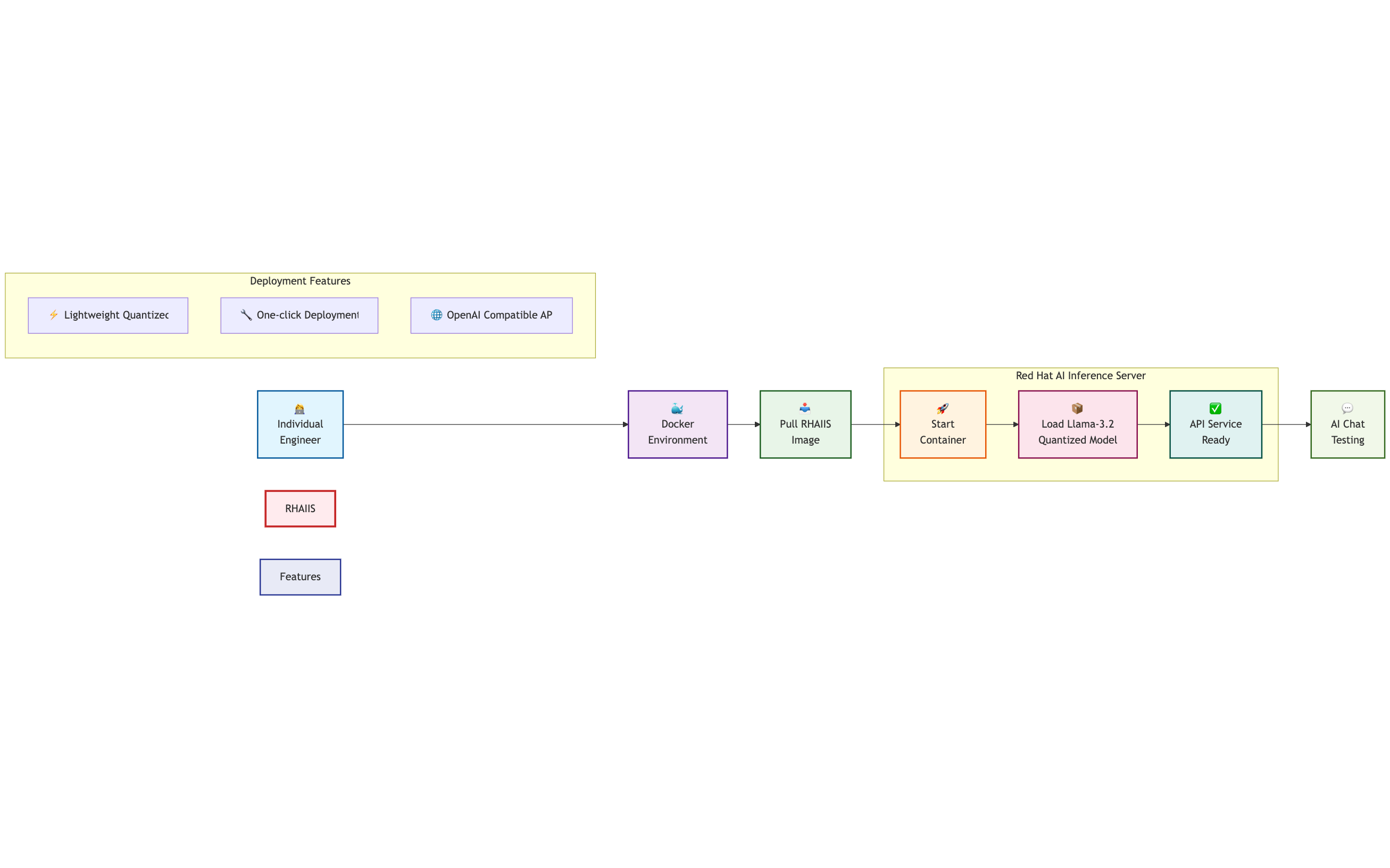
Deploy a lightweight AI model with AI Inference Server containerization ...
Triton Inference Server – Scalable AI Model Serving | PickYourTech
Red Hat AI Inference Server ปลดล็อกนำ Generative AI ใช้กับ Model และ ...
Module 14: Deploy model to NVIDIA Triton Inference Server | Machine ...
Triton Model Inference Server is a recommnded option when putting ...
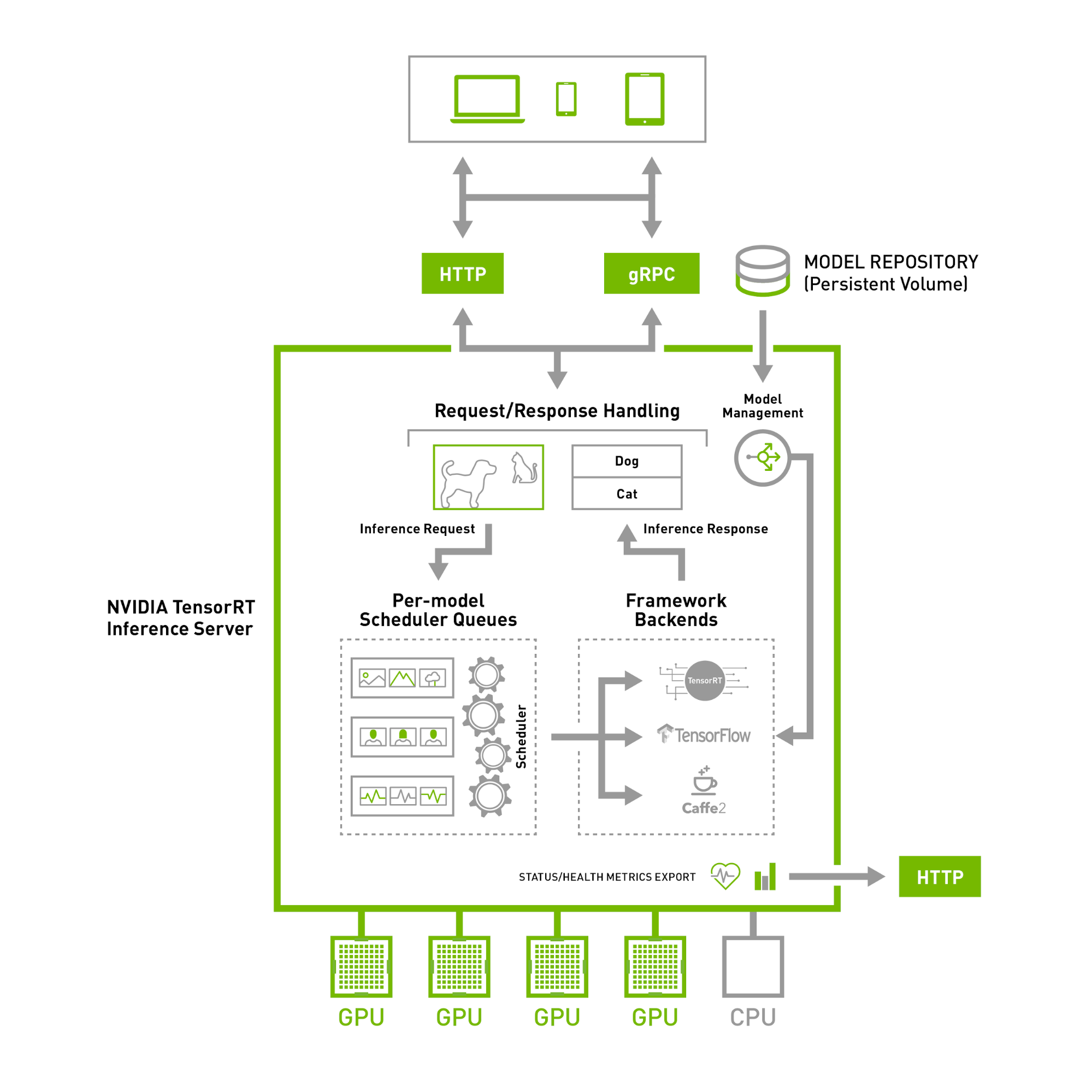
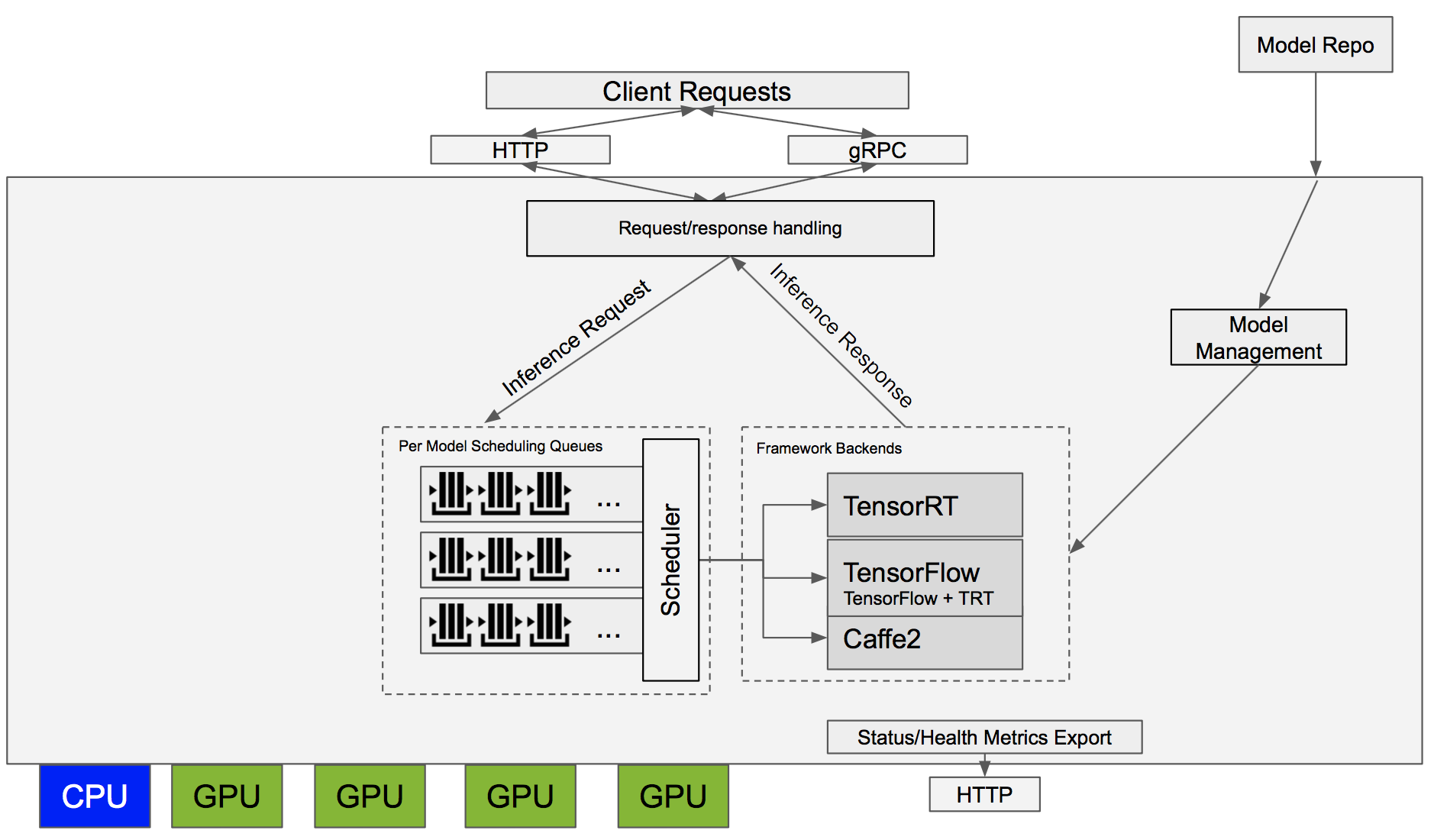
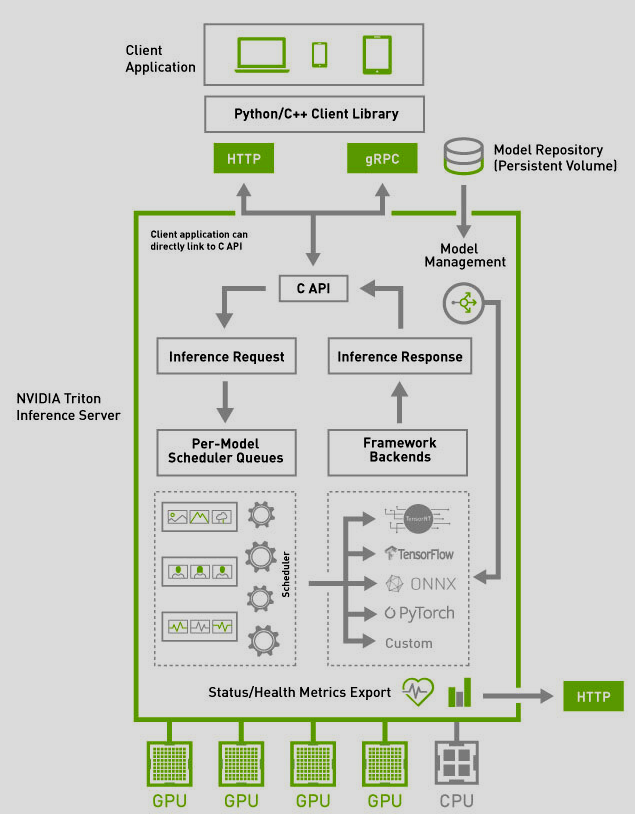
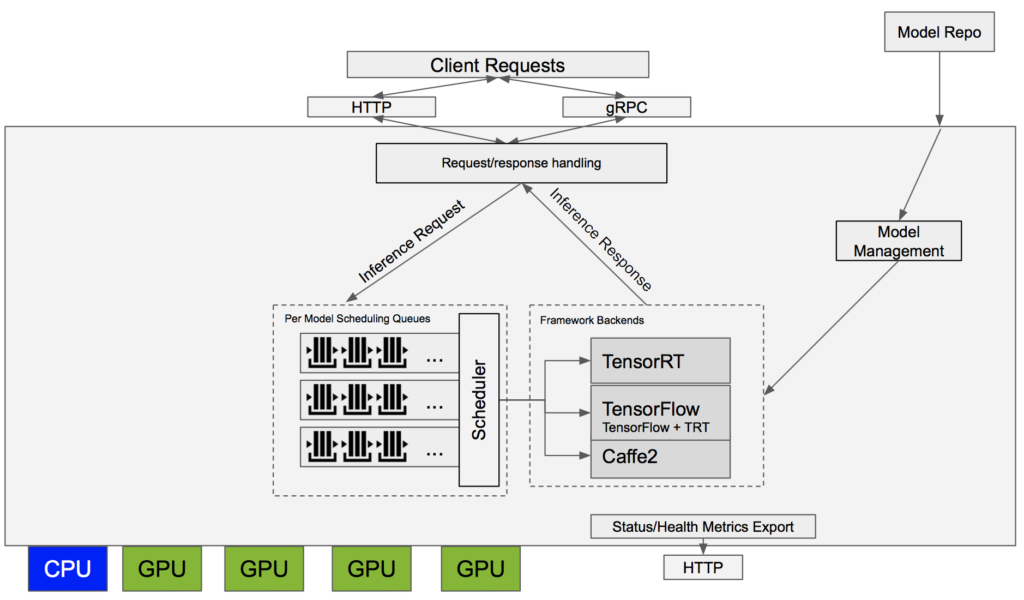
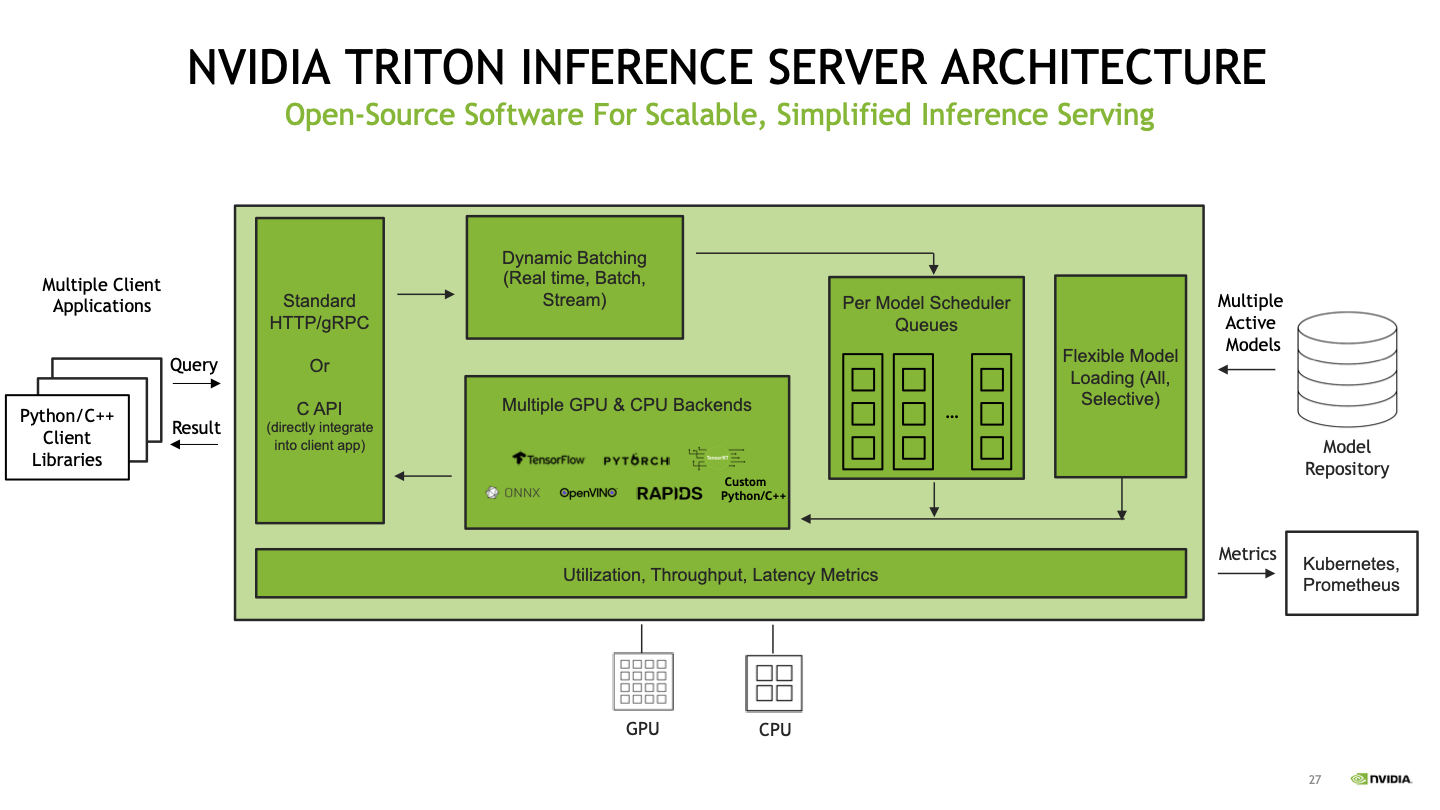
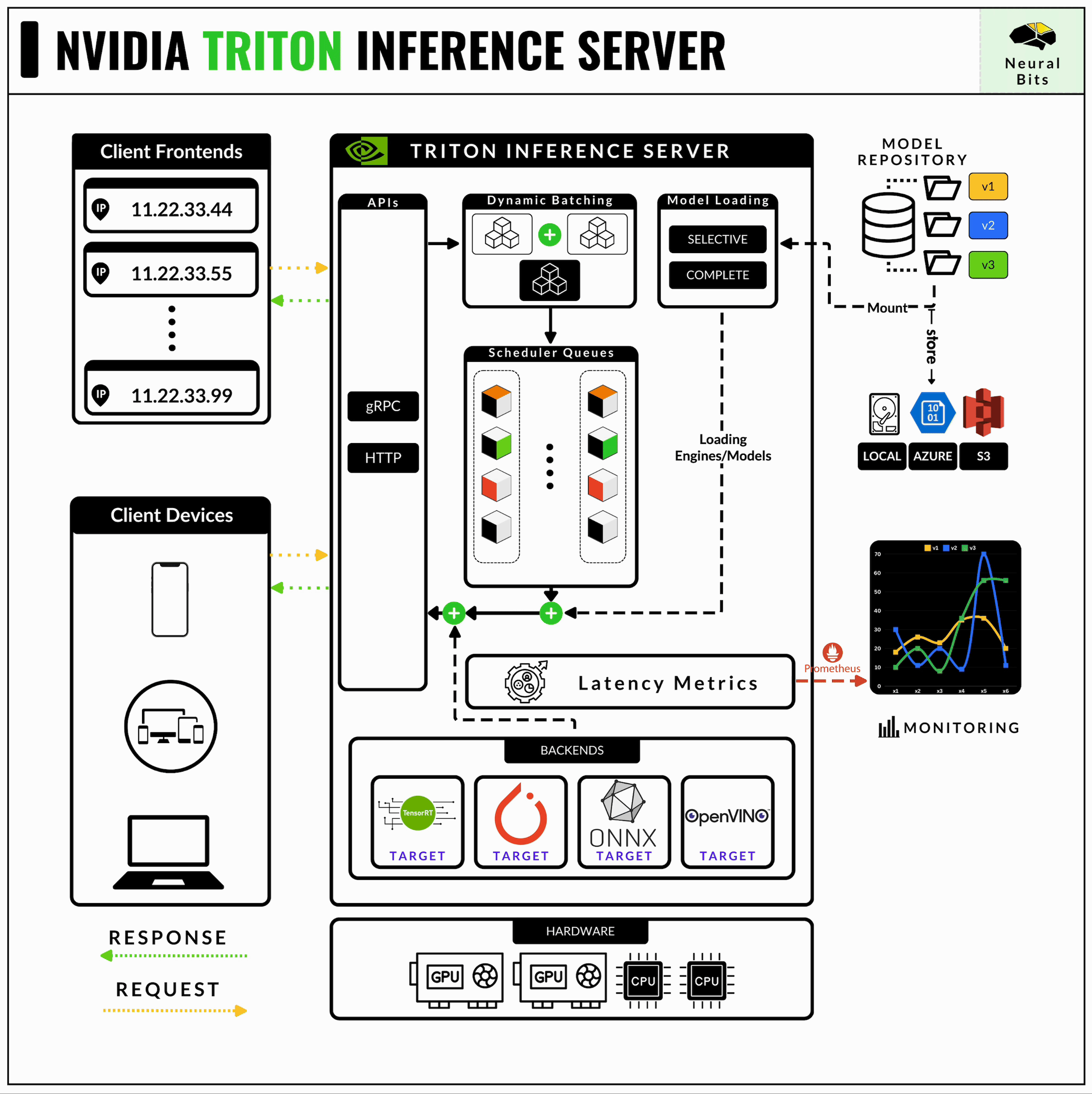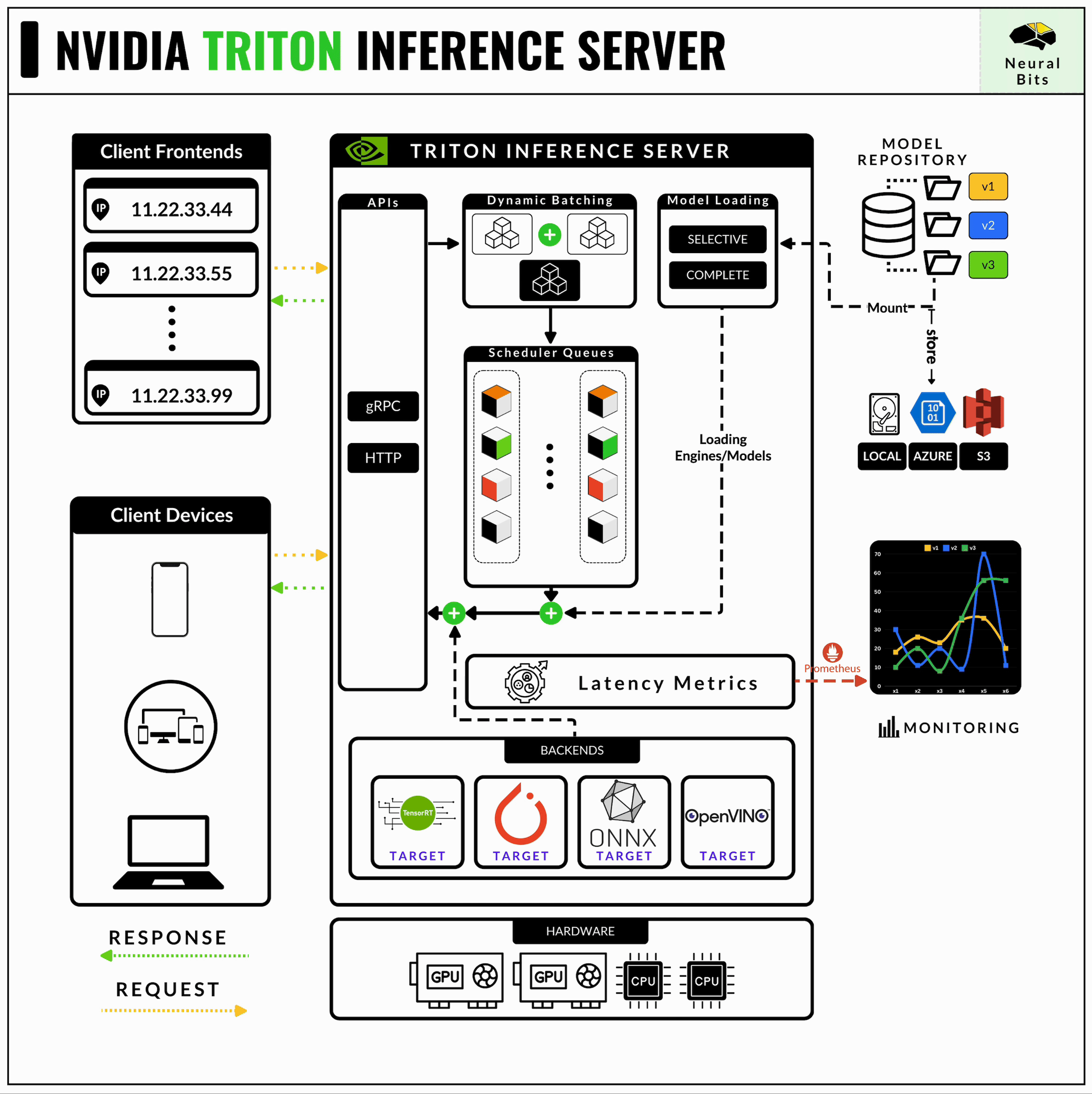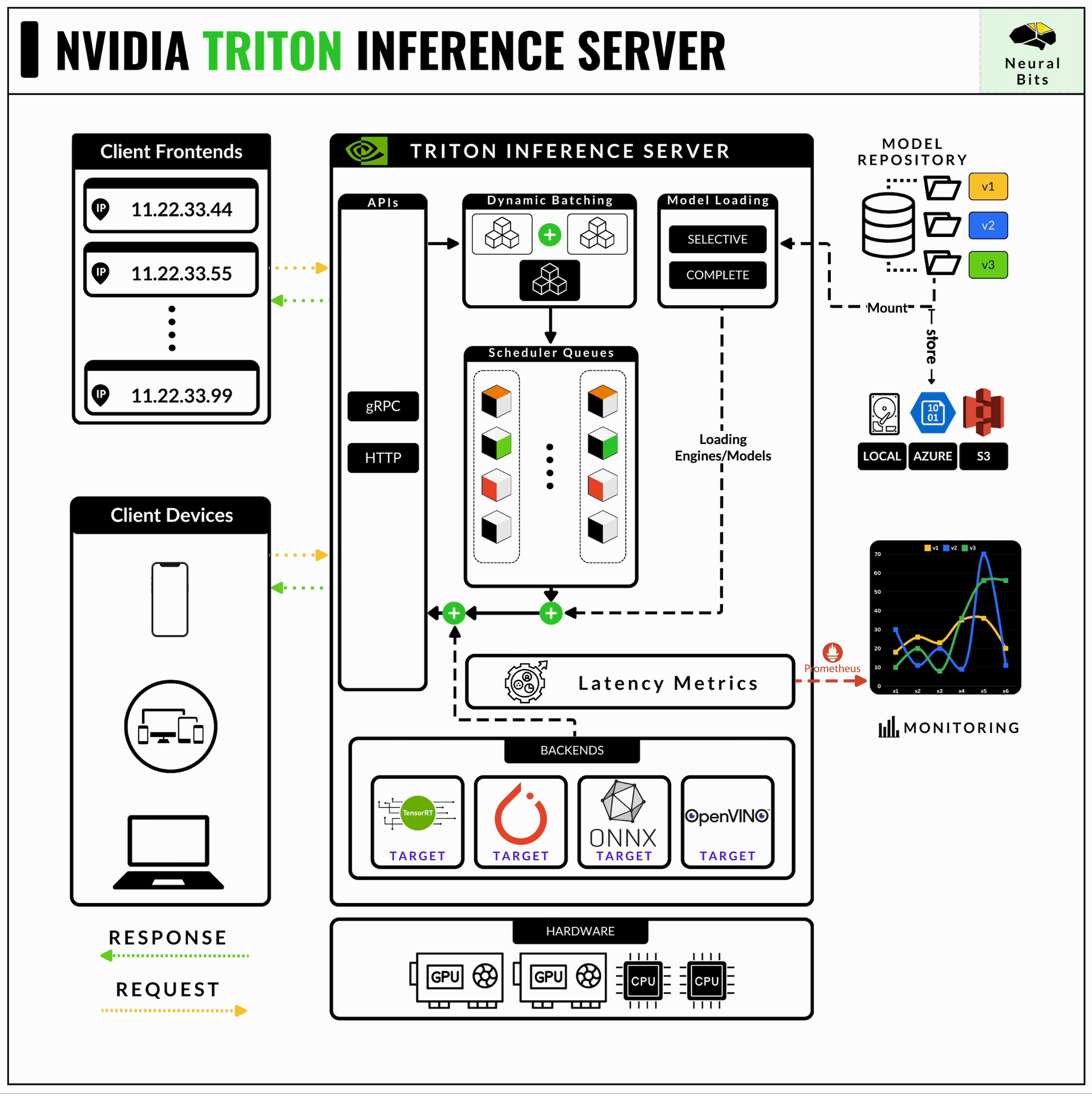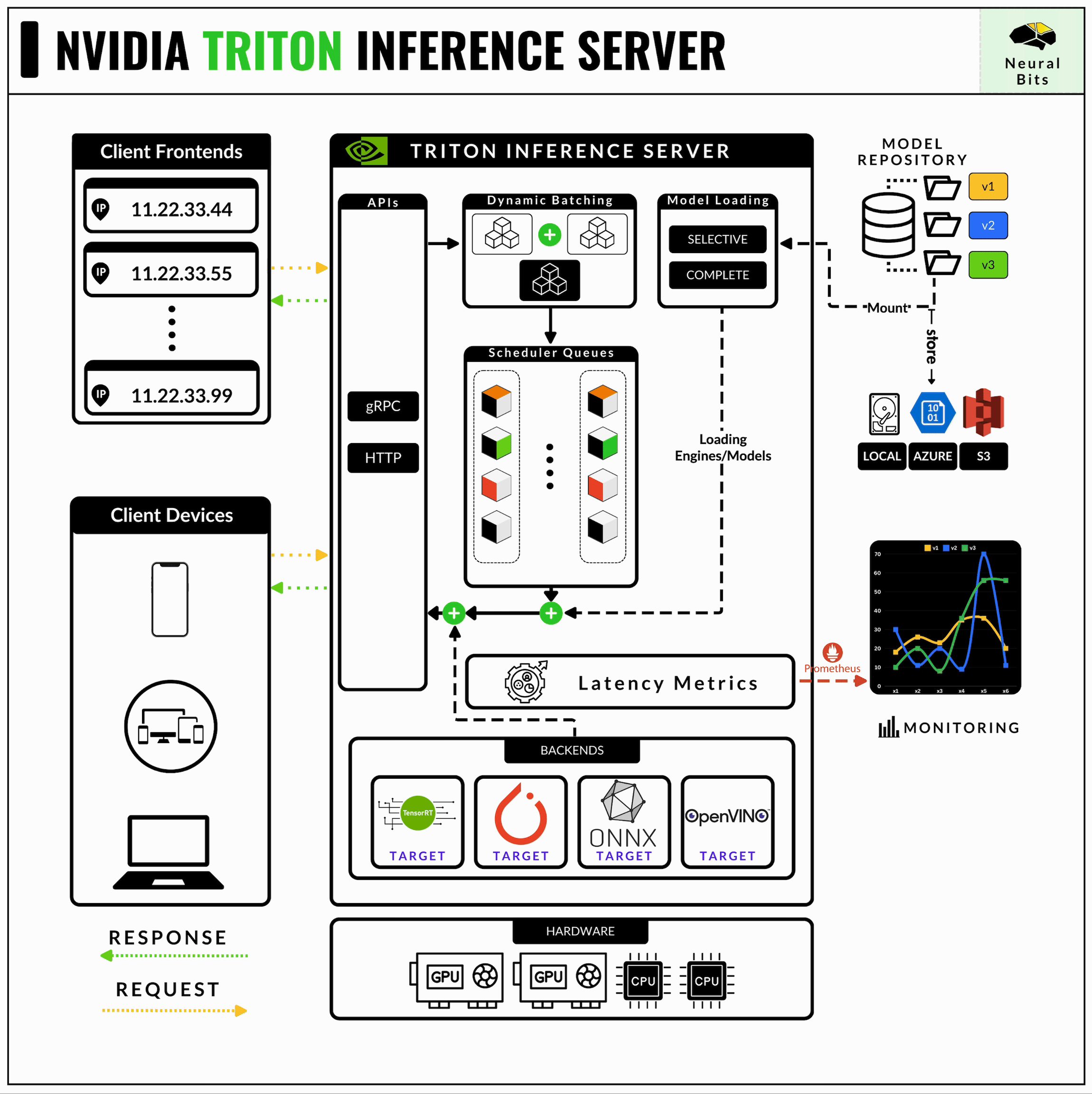
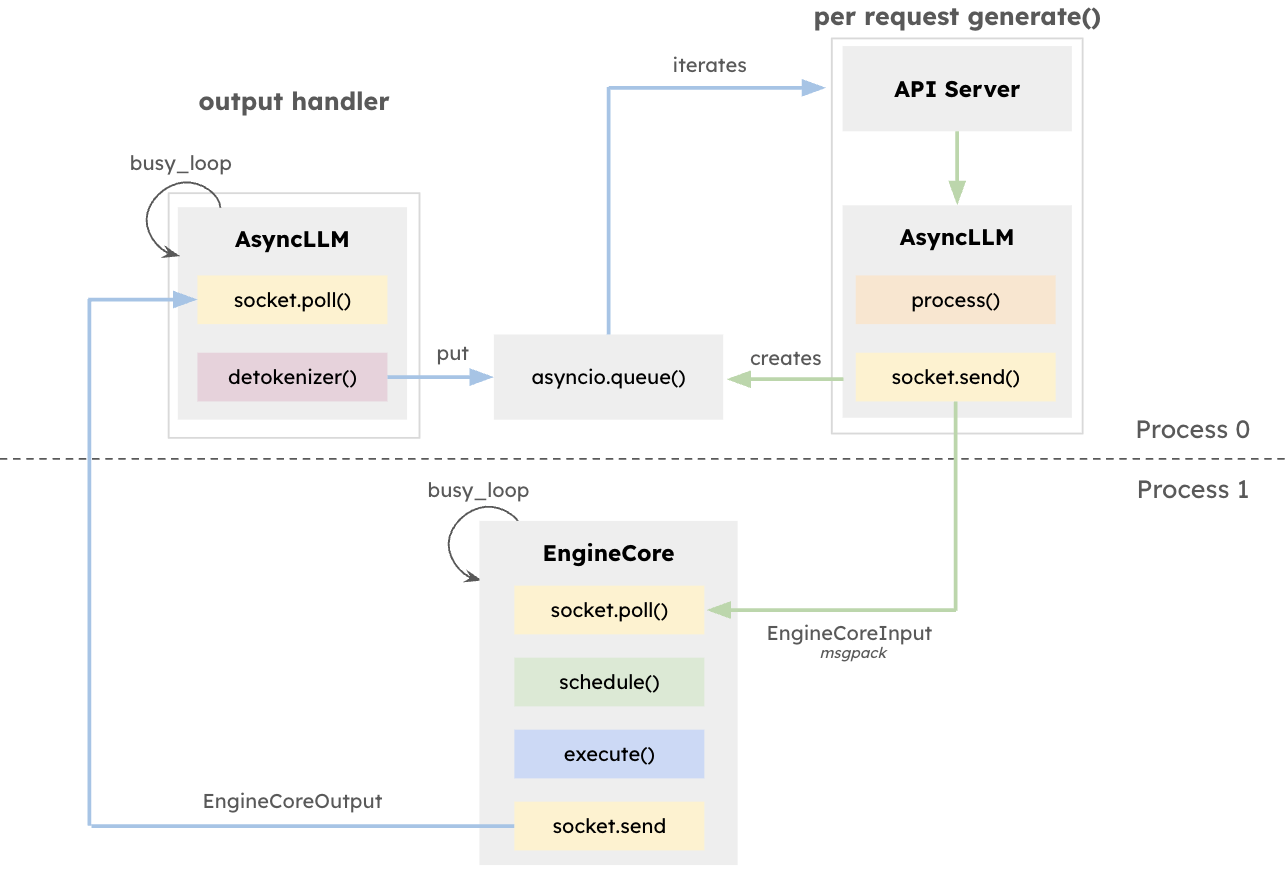
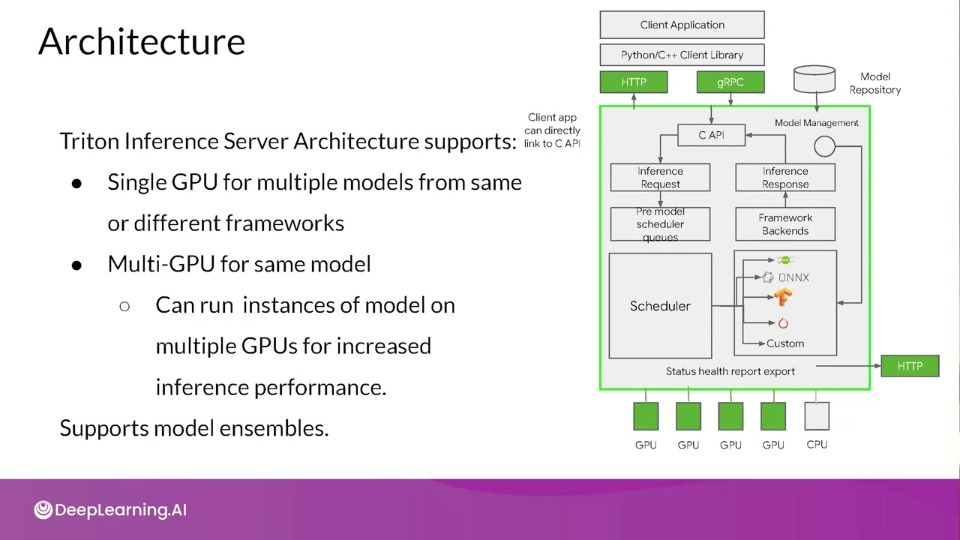
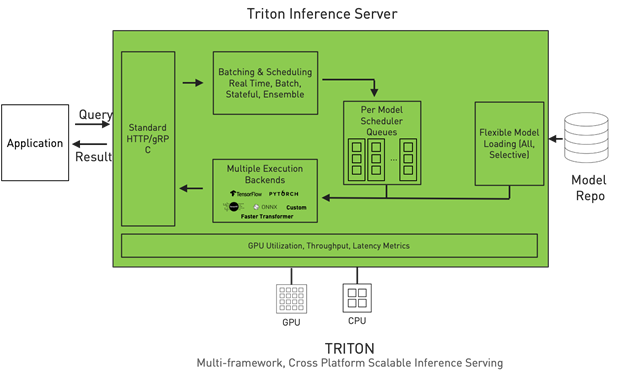
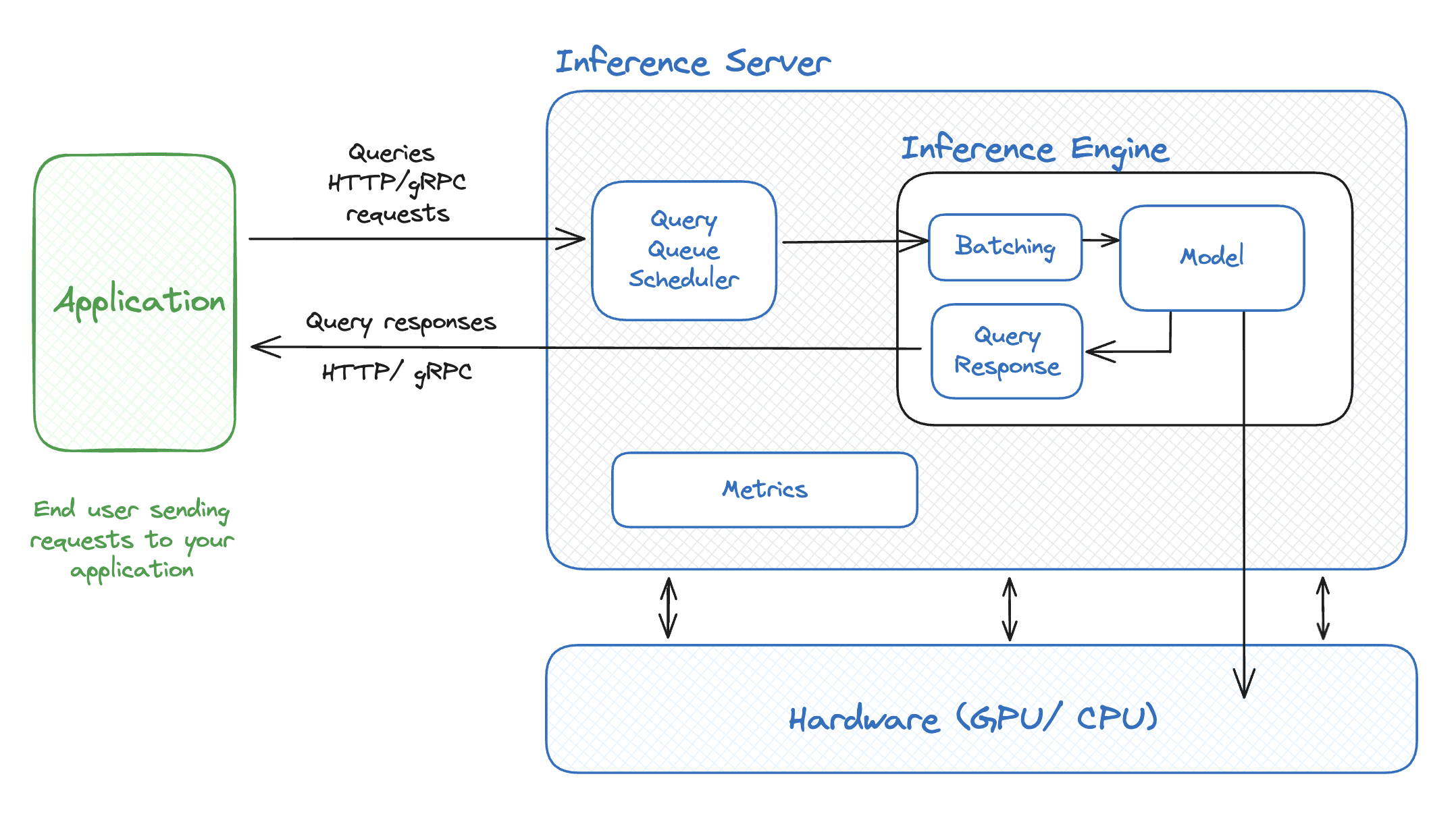
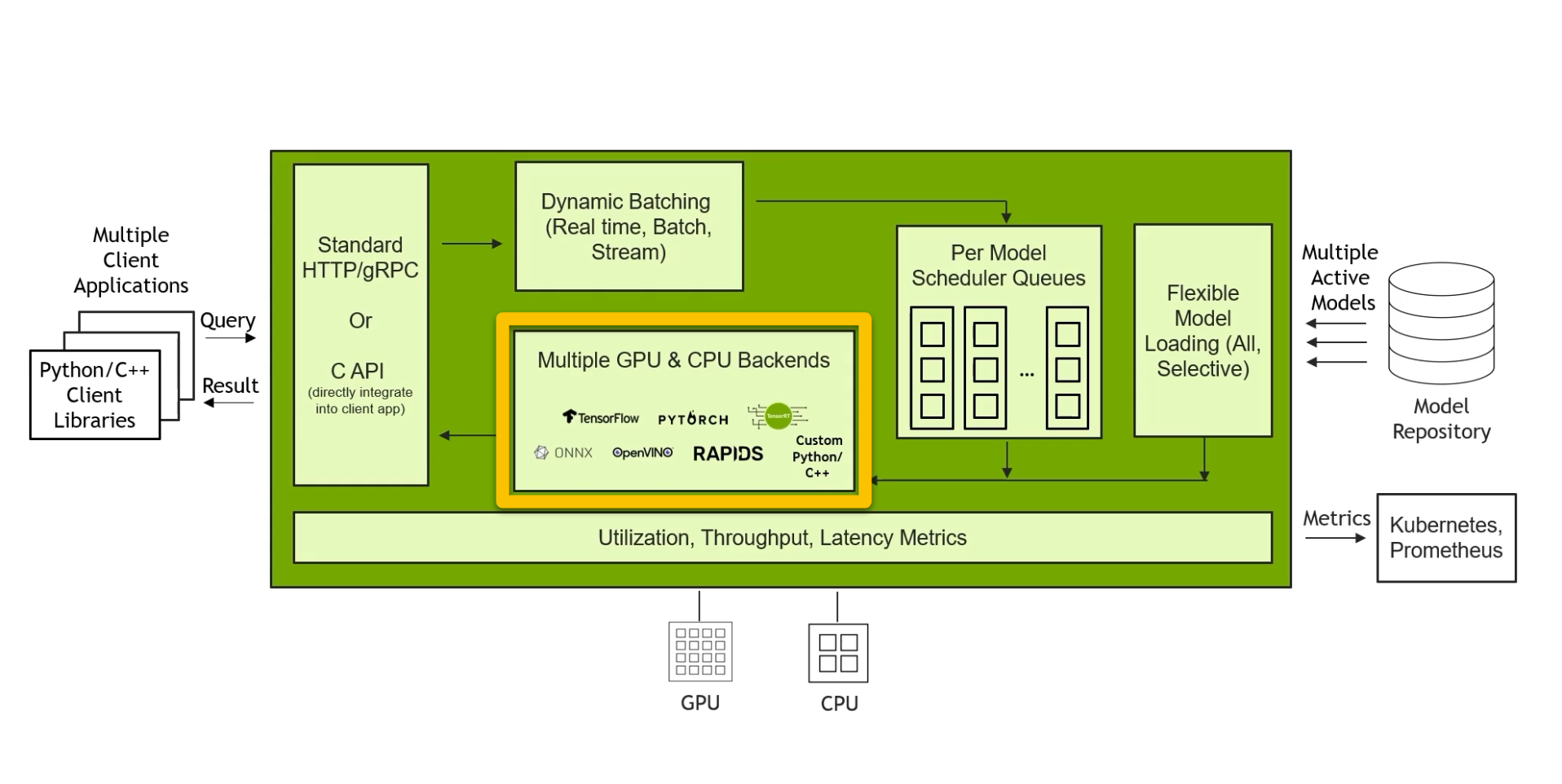
Architecture — NVIDIA Triton Inference Server 1.12.0 documentation
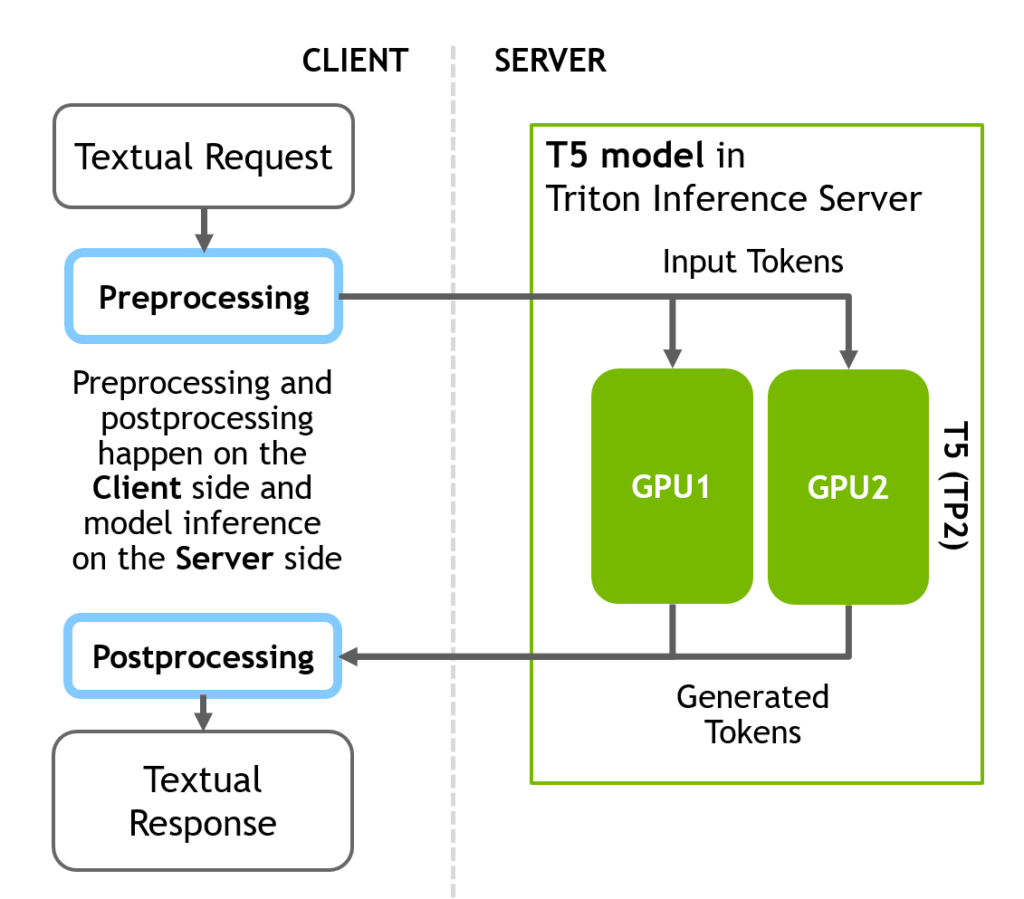
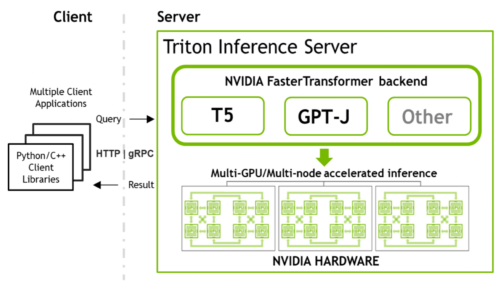
Deploying GPT-J and T5 with NVIDIA Triton Inference Server | NVIDIA ...
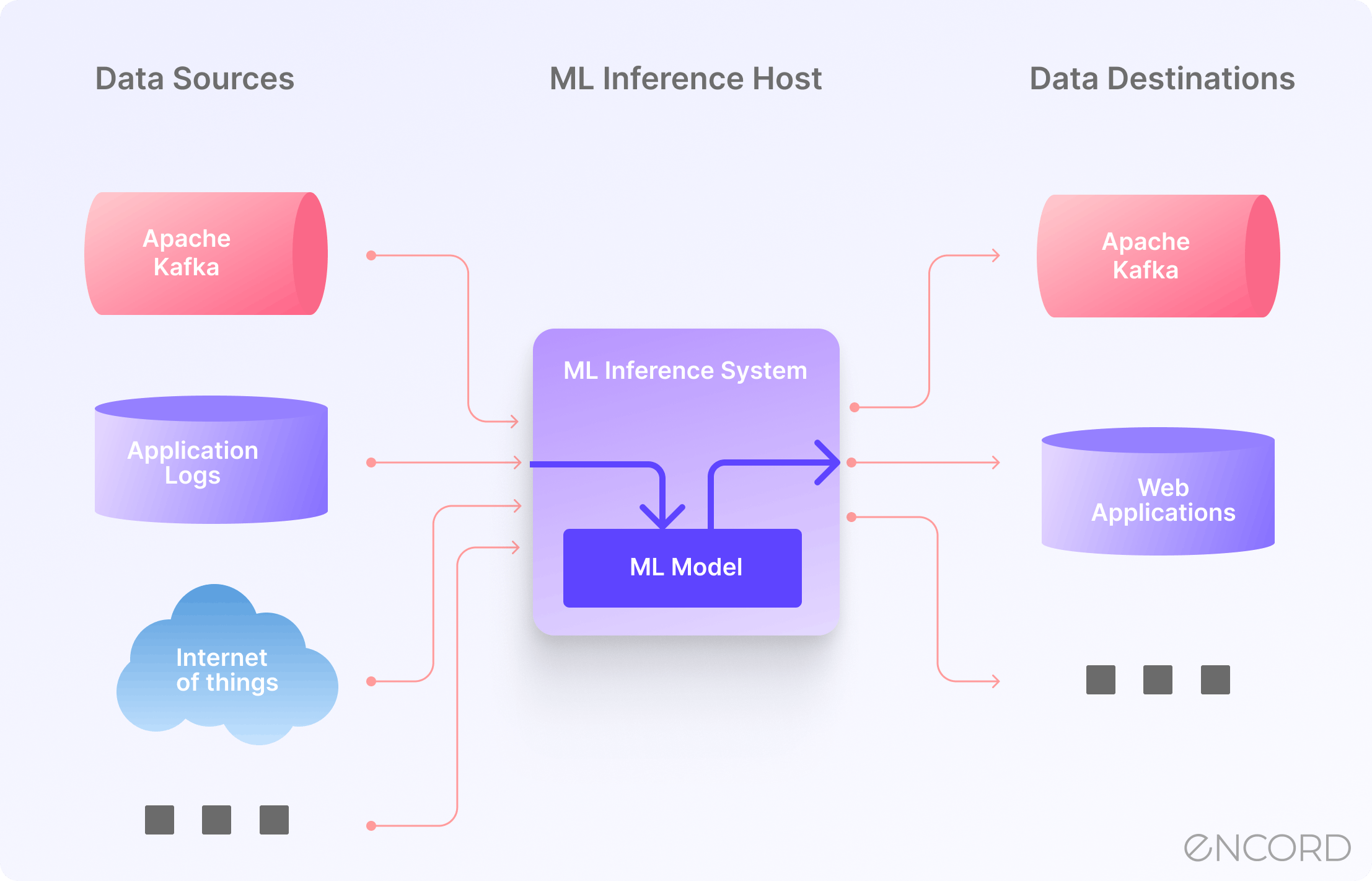
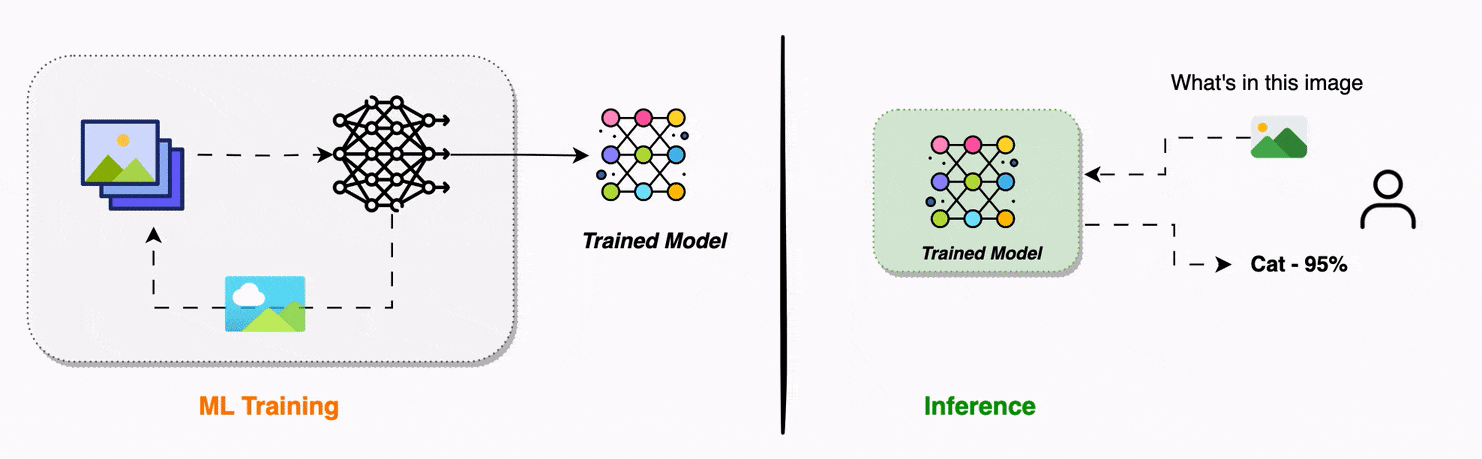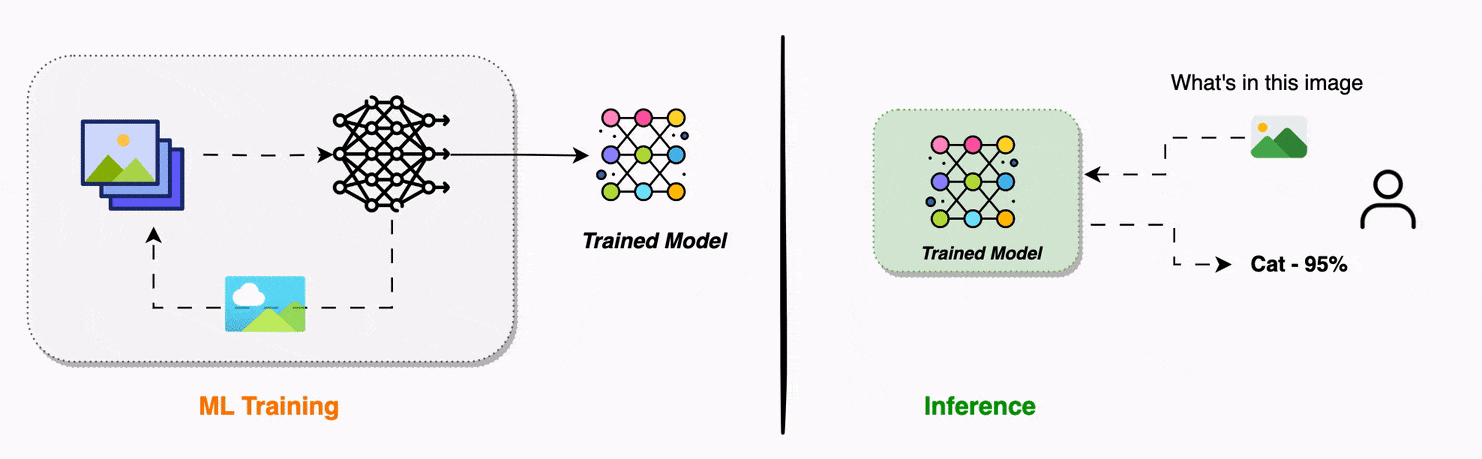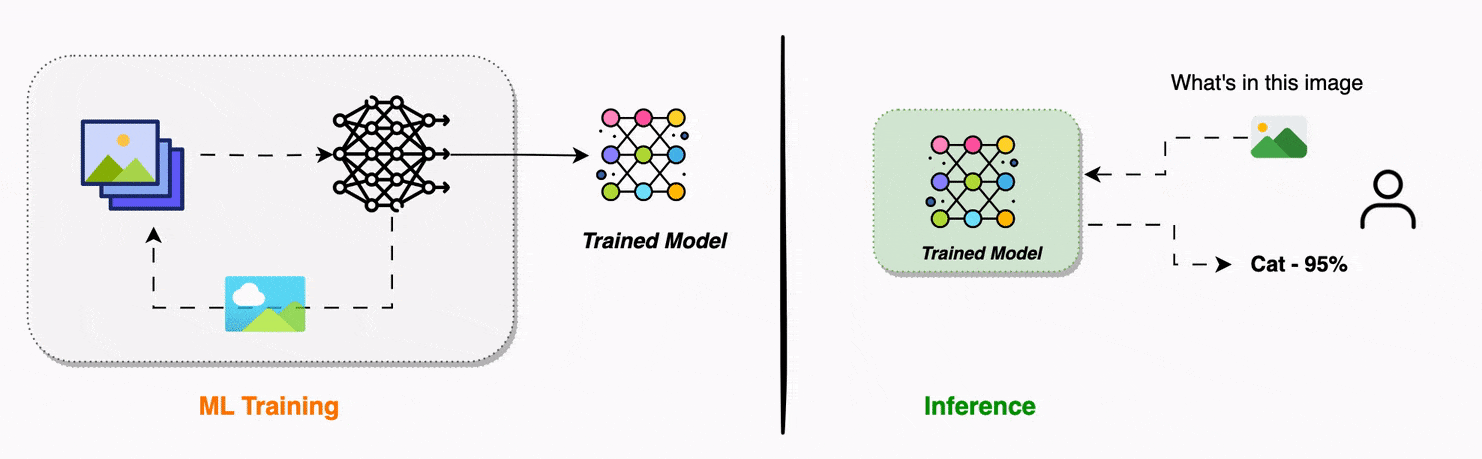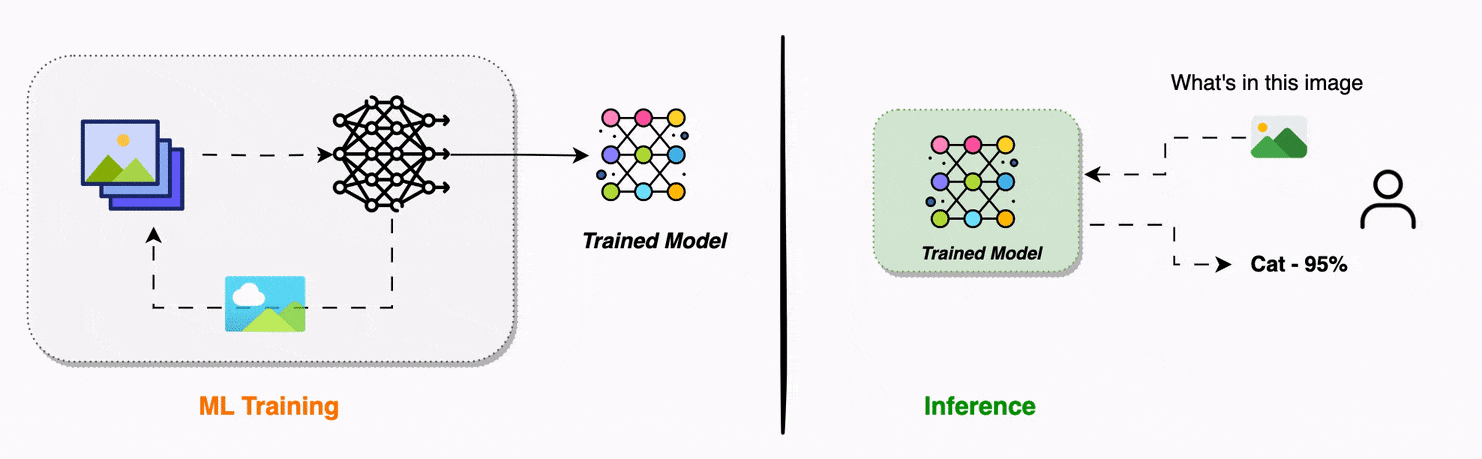
Model Inference in Machine Learning | Encord
Deploying Deep Learning Models at Scale — Triton Inference Server 0 to ...
One-click Deployment of NVIDIA Triton Inference Server to Simplify AI ...
NVIDIA Triton Inference Server Boosts Deep Learning Inference | NVIDIA ...
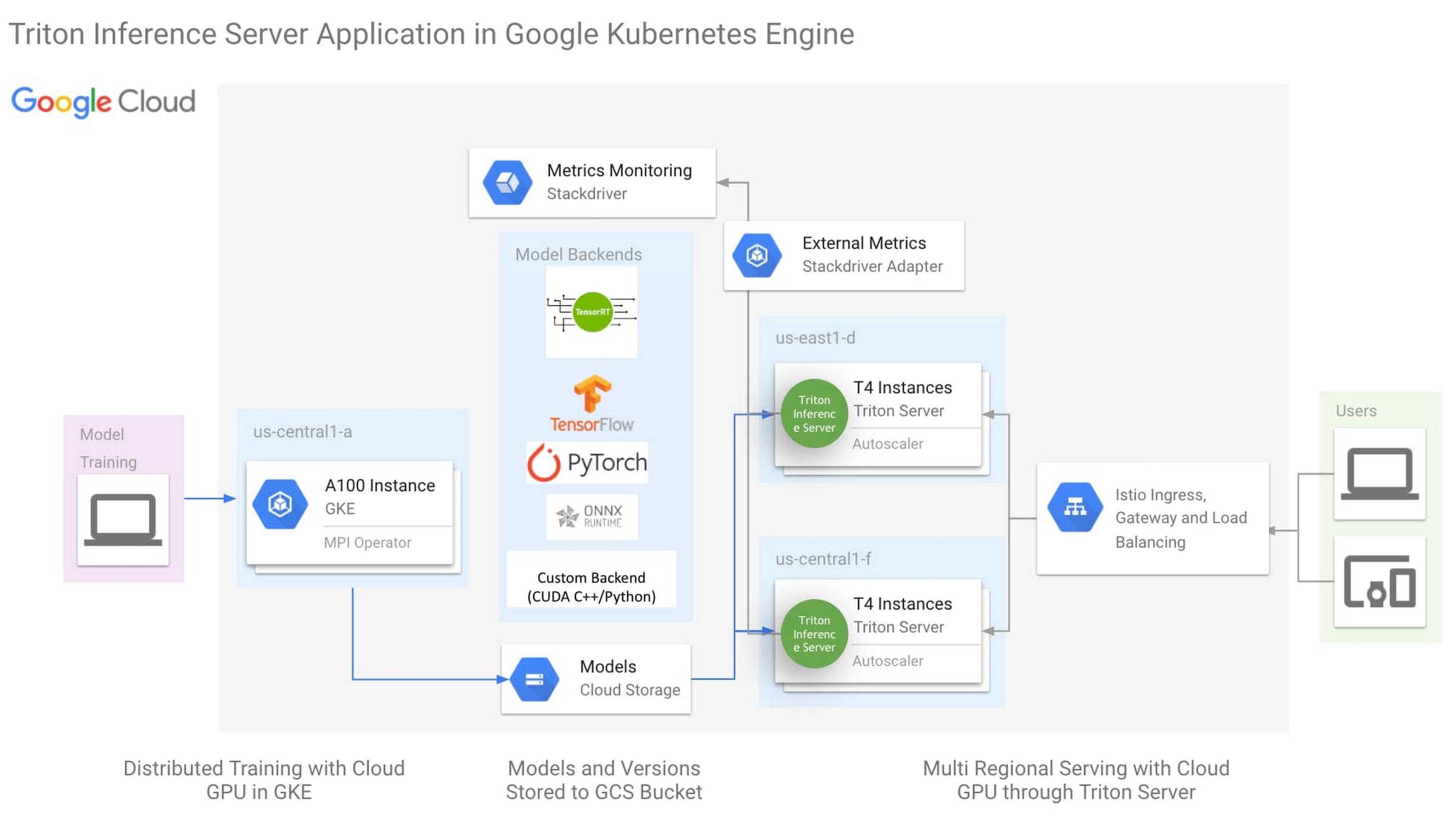
Triton Inference Server in GKE - NVIDIA - Google Kubernetes | Google ...
Boosting AI Model Inference Performance on Azure Machine Learning ...
Fast and Scalable AI Model Deployment with NVIDIA Triton Inference ...
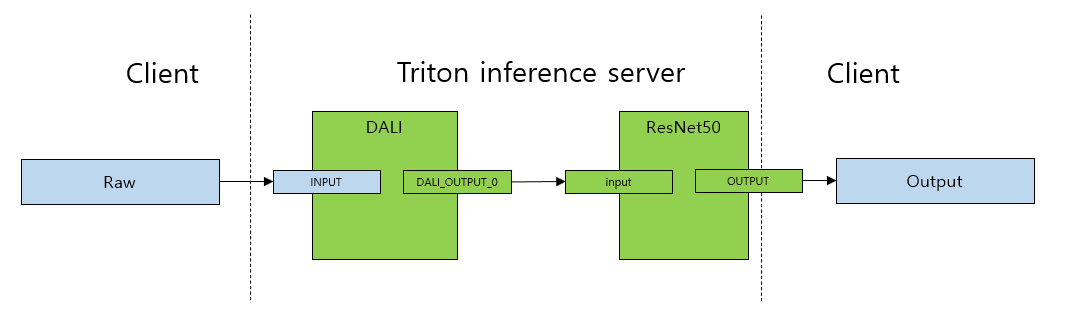
Triton Inference Server with DALI backend — NVIDIA Triton Inference Server
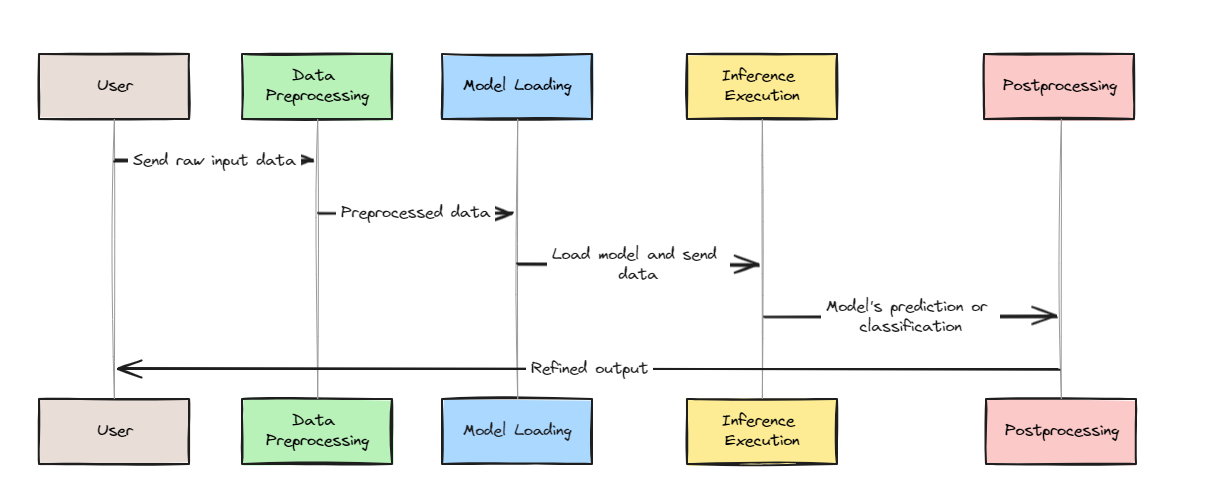
Model Inference Explained: Turning AI Models into Real-World Solutions ...
Triton Inference Server for Multi-Model Inference | E2E Cloud posted on ...
How to Implement Multi-Model Servers with Triton Inference Server on ...
Deploy models using Triton — NVIDIA Triton Inference Server
Triton inference server фото - Euroalarm.ru
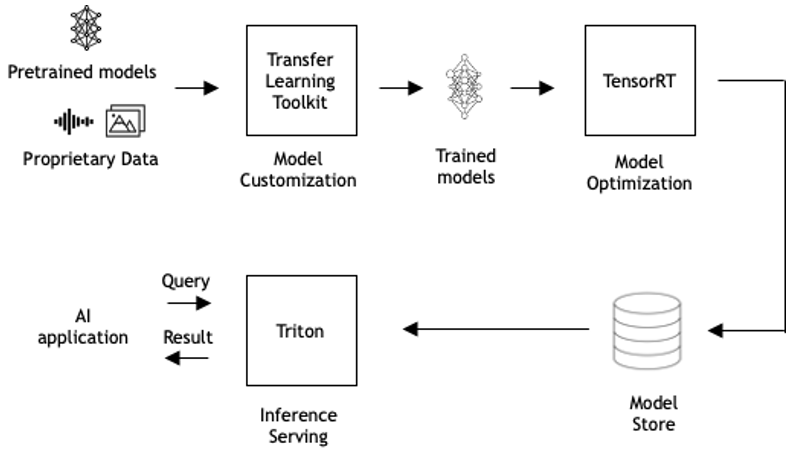
Deploying AI Deep Learning Models with NVIDIA Triton Inference Server ...
Deploying Your Trained Model Using Triton — Nvidia Triton Inference ...
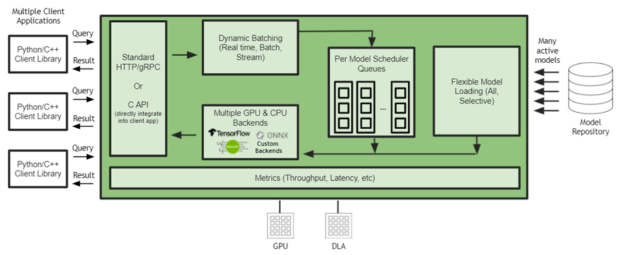
Serving Models with NVIDIA Triton Inference Server
Triton Inference Server
NVIDIA Triton Inference Server: Optimize AI Model Deployment
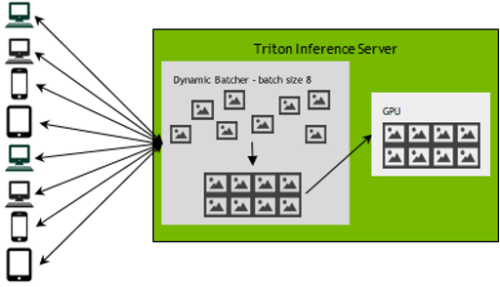
Triton Inference Server Tips & Tricks
Master TRITON INFERENCE SERVER TUTORIAL - Get Started NOW!
Local Model Inference Framework | AgentOpera AI
LLM Deployment: A Guide to NVIDIA Triton Inference Server and TensorRT ...
Model Deployment for Computer Vision: Scalable Inference
Tổng quan về Triton Inference Server
ML inference workloads on the Triton Inference Server | Palo Alto Networks
Accelerating Inference with NVIDIA Triton Inference Server and NVIDIA ...
AI Server Products - Inference Server
Defending Against Model Weight Exfiltration Through Inference ...
Deploying ML Models using Nvidia Triton Inference Server | by ...
Model Inference in Machine Learning | Encord - Worksheets Library
How to build high performance model serving with AWS Sagemaker & Nvidia ...
The AI Engineer's Guide to Inference Engines and Frameworks
Introducing Red Hat AI Inference Server: High-performance, optimized ...
Week 2 — Model Serving Architecture, Scaling Infrastructure and More ...
Deploying Diverse AI Model Categories from Public Model Zoo Using ...
Simplifying AI Inference in Production with NVIDIA Triton | NVIDIA ...
Accelerated Inference for Large Transformer Models Using NVIDIA Triton ...
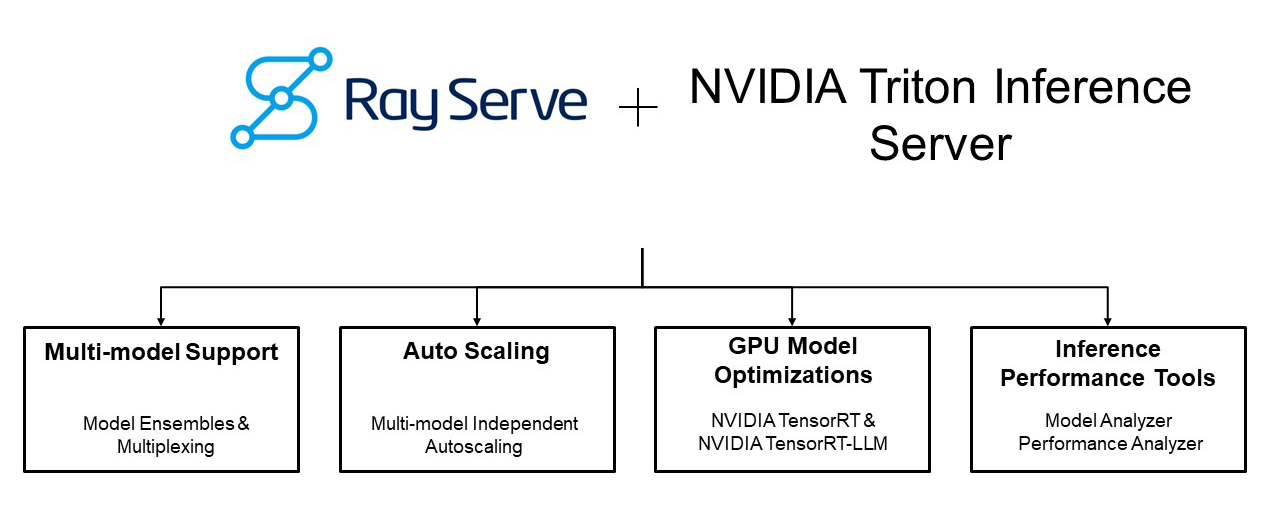
Low-latency Generative AI Model Serving with Ray, NVIDIA Triton ...
Exploring AI Model Inference: Servers, Frameworks, and Optimization ...
Simplifying and Scaling Inference Serving with NVIDIA Triton 2.3 ...
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
Simplifying AI Model Deployment at the Edge with NVIDIA Triton ...
AI Model Serving | aptone
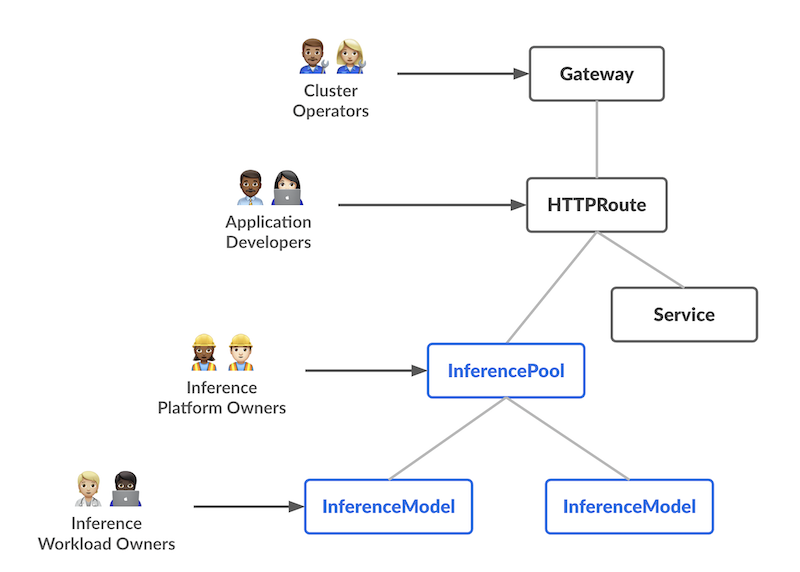
Introducing Gateway API Inference Extension | Kubernetes
GitHub - niyazed/triton-mnist-example: MNIST inference example on ...
Introduction to Inference and Inference Servers · Praveen's Blog
Inference Server: - GreenCloud - Affordable KVM and Windows VPS
From Research to Production I: Efficient Model Deployment with Triton ...
[논문 리뷰] Optimizing Distributed Deployment of Mixture-of-Experts Model ...
The Future of Serverless Inference for Large Language Models – Unite.AI
Accelerating Inference for Deep Learning Models — NVIDIA Triton ...
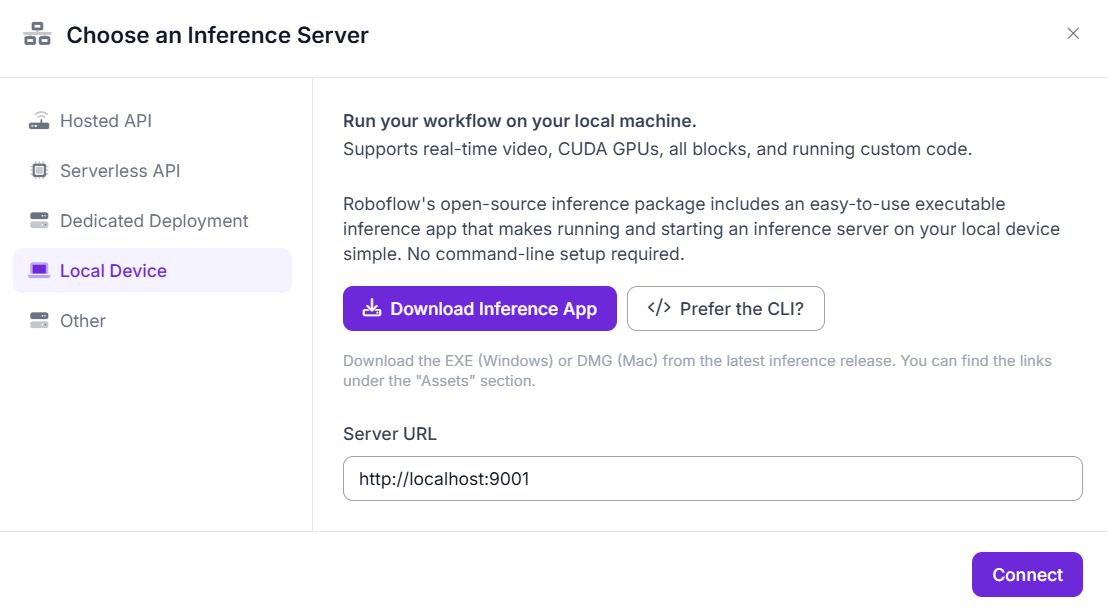
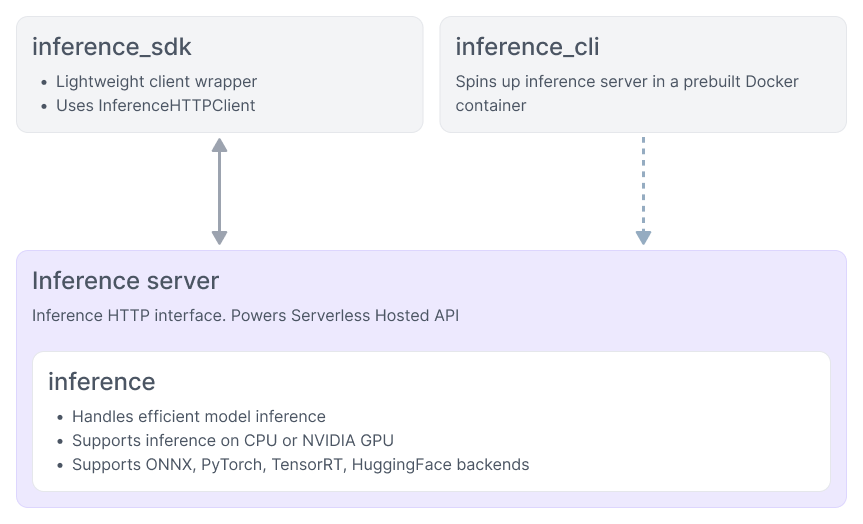
Inference - Roboflow Inference
NVIDIA Triton Inference Server, a game-changing platform for deploying ...
Deploying a Large Language Model (LLM) with TensorRT-LLM on Triton ...
Achieve hyperscale performance for model serving using NVIDIA Triton ...
Accelerate Deep Learning and LLM Inference with Apache Spark in the ...
Deploy and Serve AI Models (Part-1) | by Rahul Thai Valappil | CodeX ...
Generate Stunning Images with Stable Diffusion XL on the NVIDIA AI ...
Achieve low-latency hosting for decision tree-based ML models on NVIDIA ...
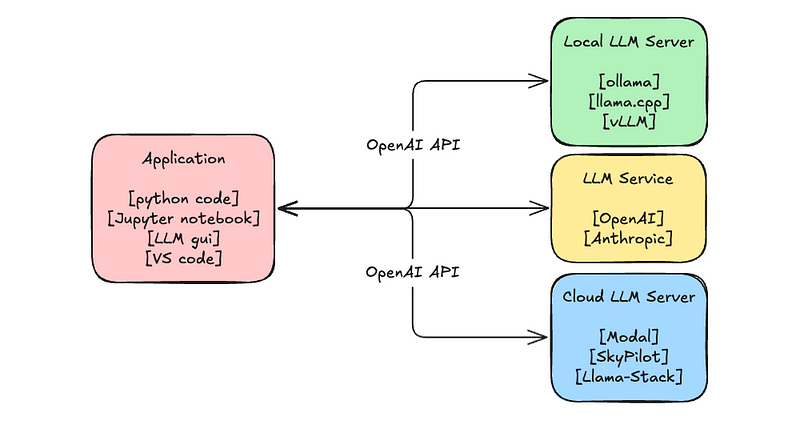
The Emerging LLM Stack: A Comprehensive Guide for Developers - Helicone
NVIDIA-Triton-Inference-Server-Scalable-AI-Model-Serving.pptx
model_analyzer by triton-inference-server - SourcePulse
Driving Hyper-automation In Manufacturing - FutureIoT
Author: BoYang Hsueh | NVIDIA Technical Blog
部署必备—triton-inference-server的backend(一)——关于推理框架的一些讨论 - 智源社区
Red_Hat_AI_Inference_Server-3.2-Validated_models-en-US.pdf
triton-inference-server/docs/user_guide/model_configuration.md at main ...
使用NVIDIA Triton简化生产中的人工智能推理




























































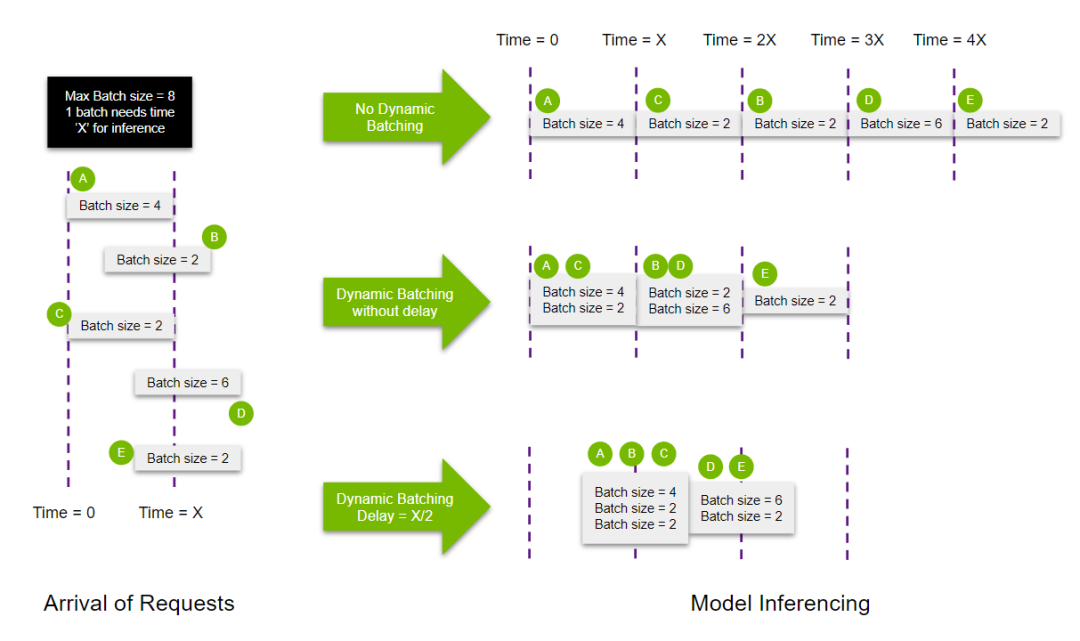

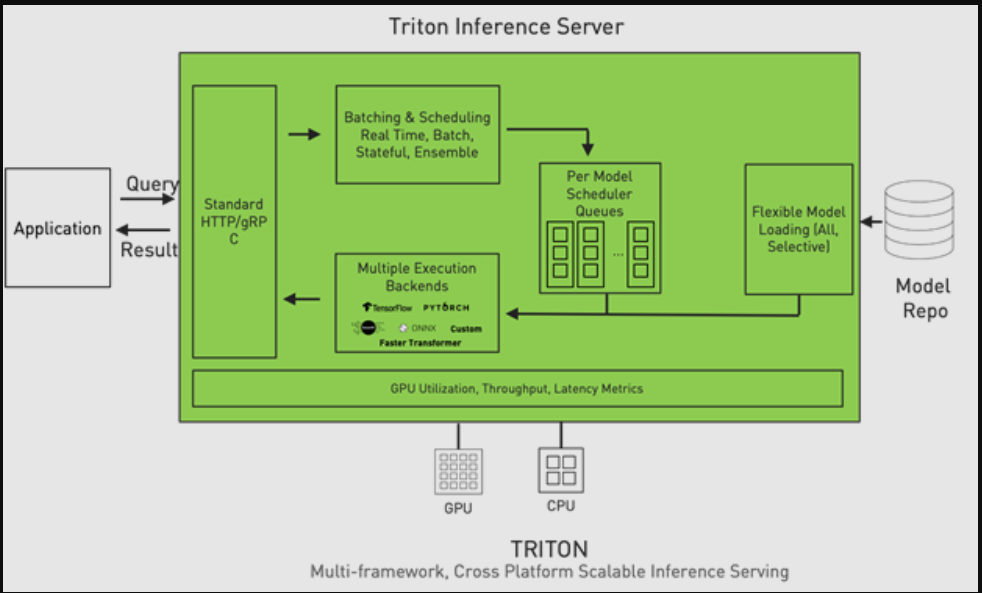
{kind=link}