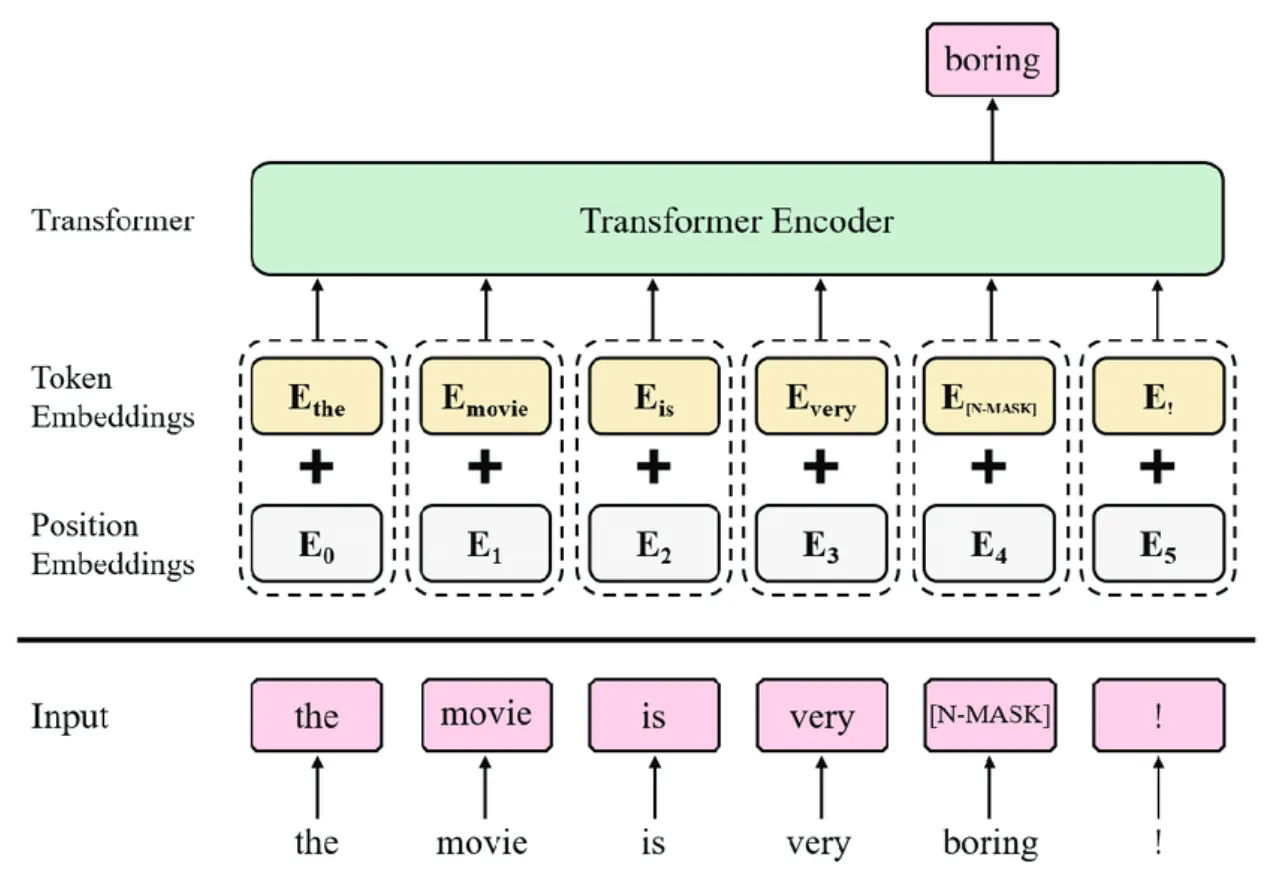
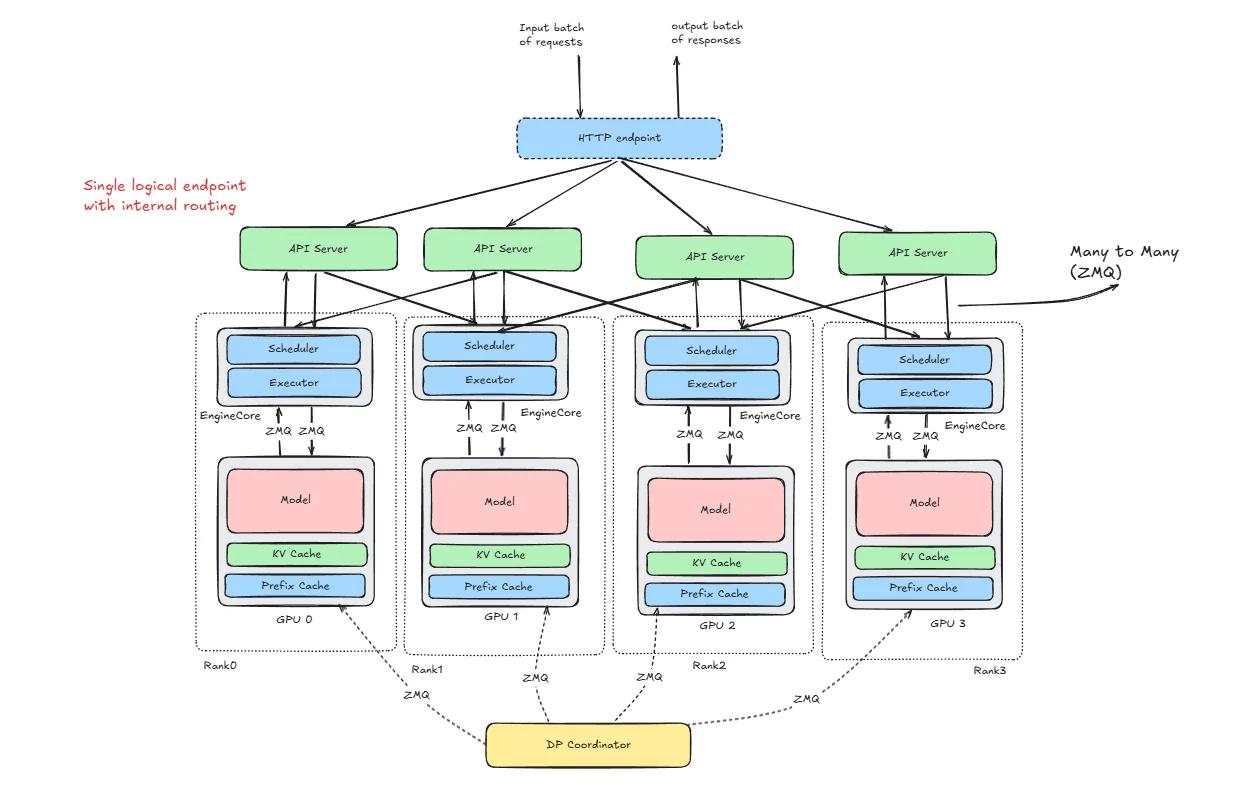
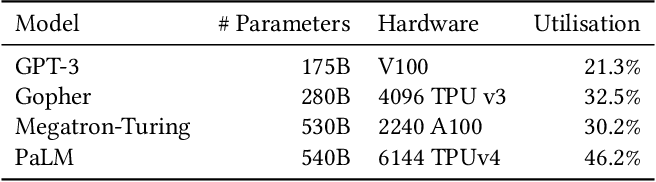
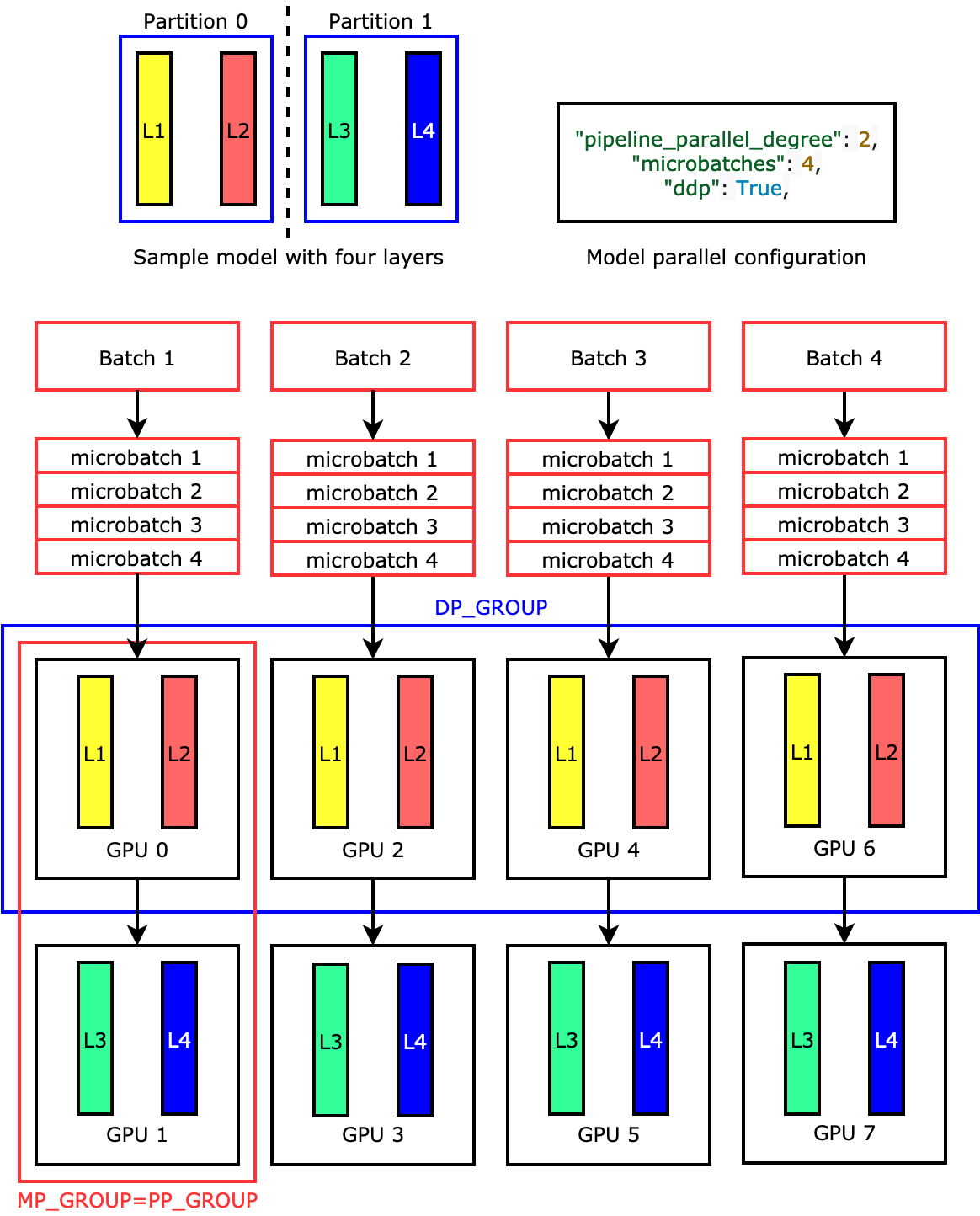
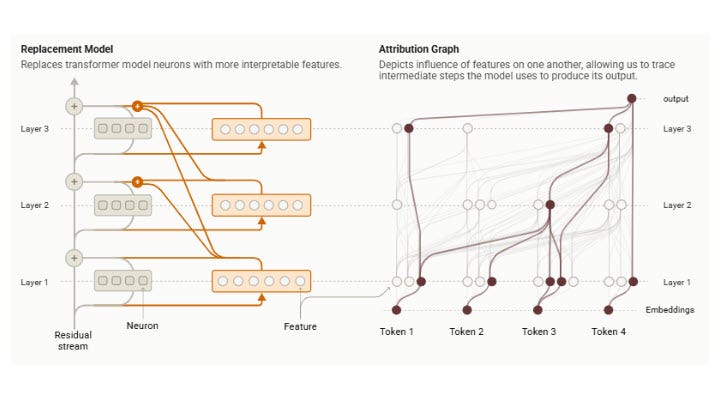
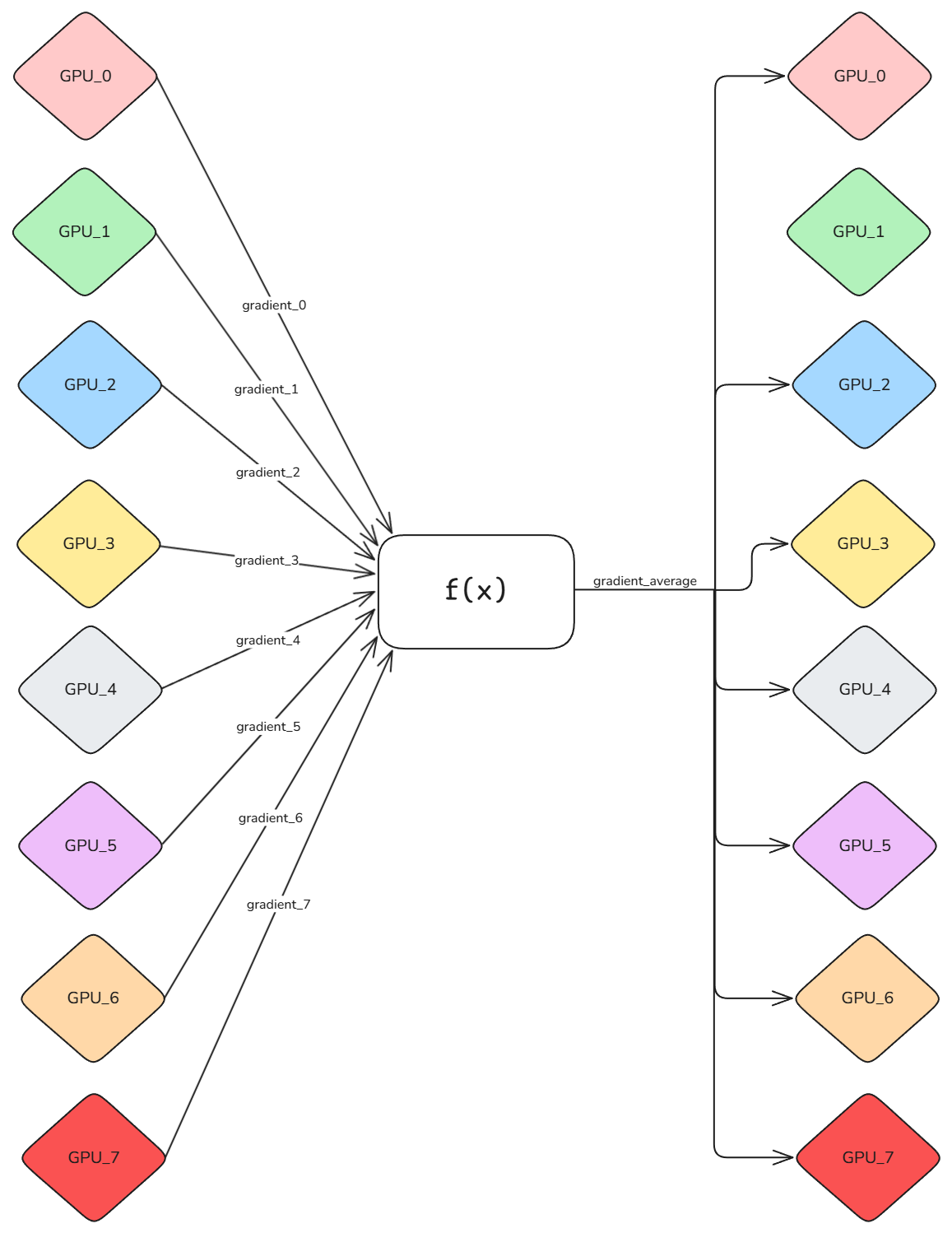
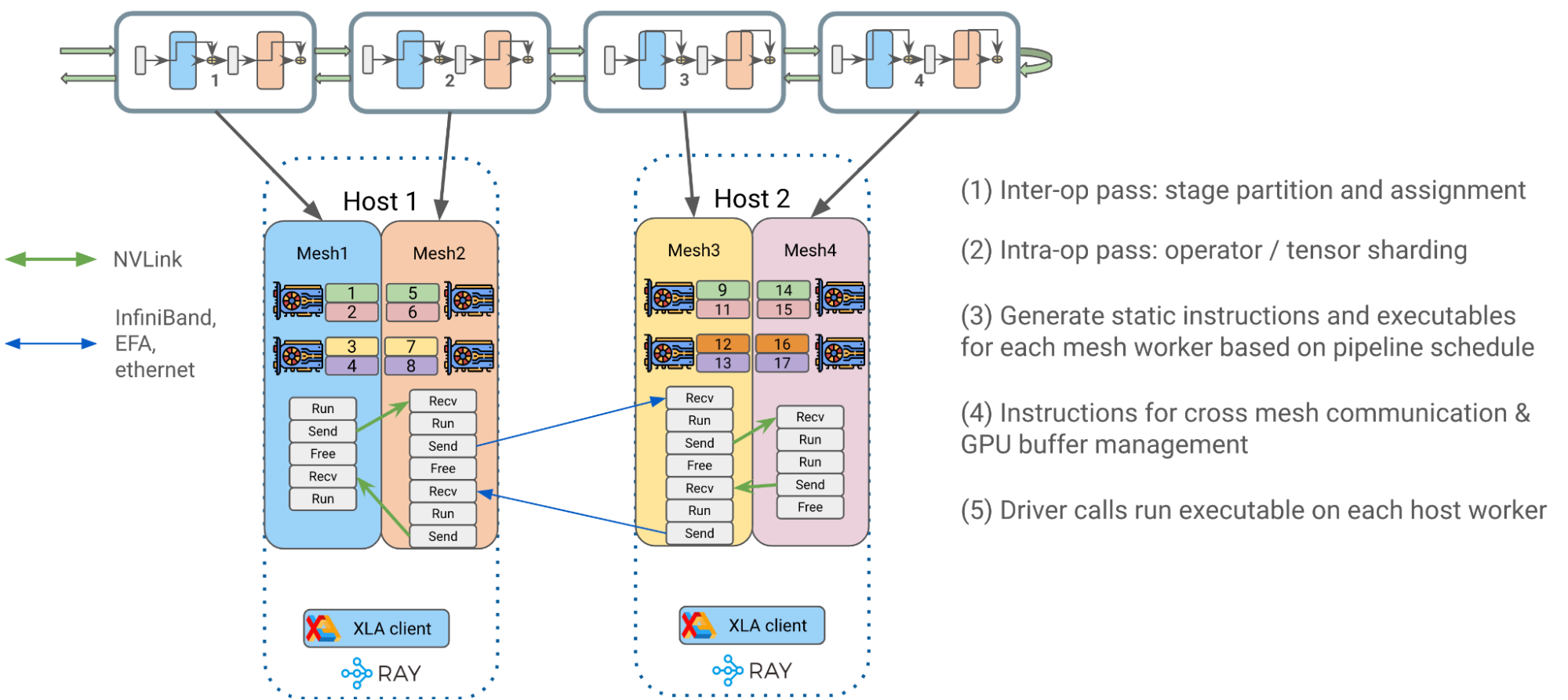
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
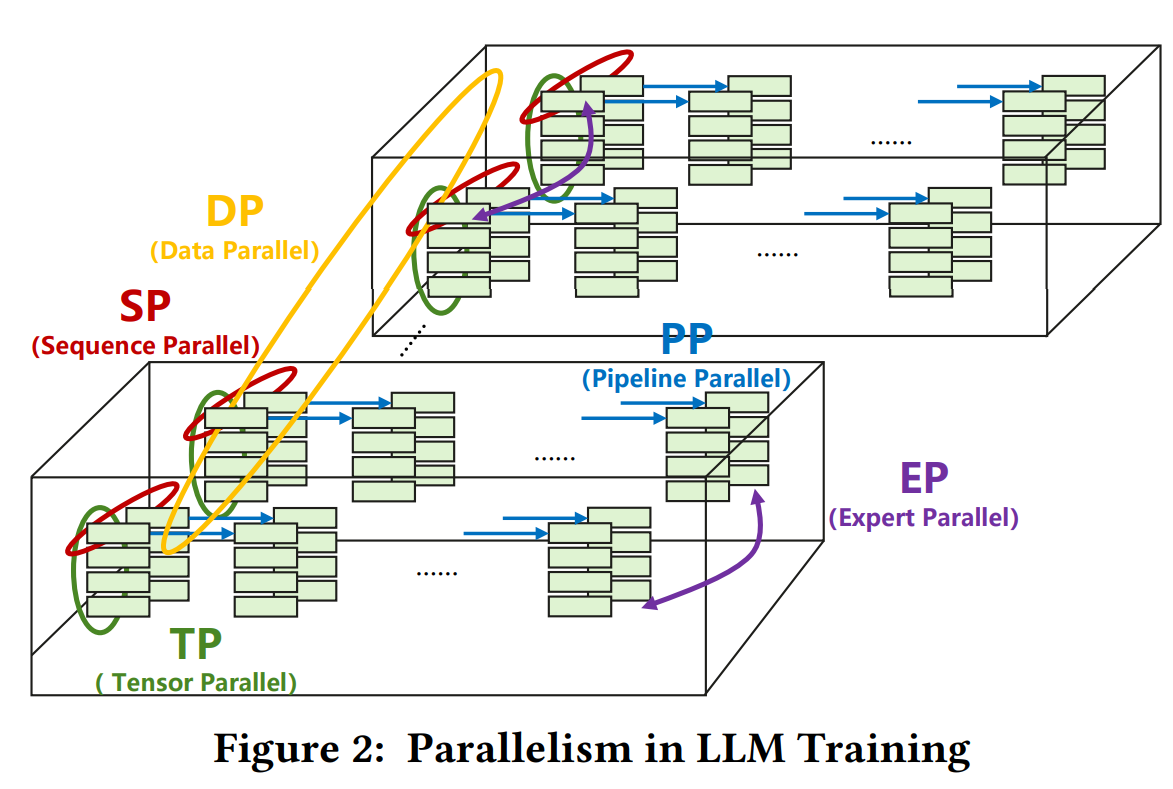
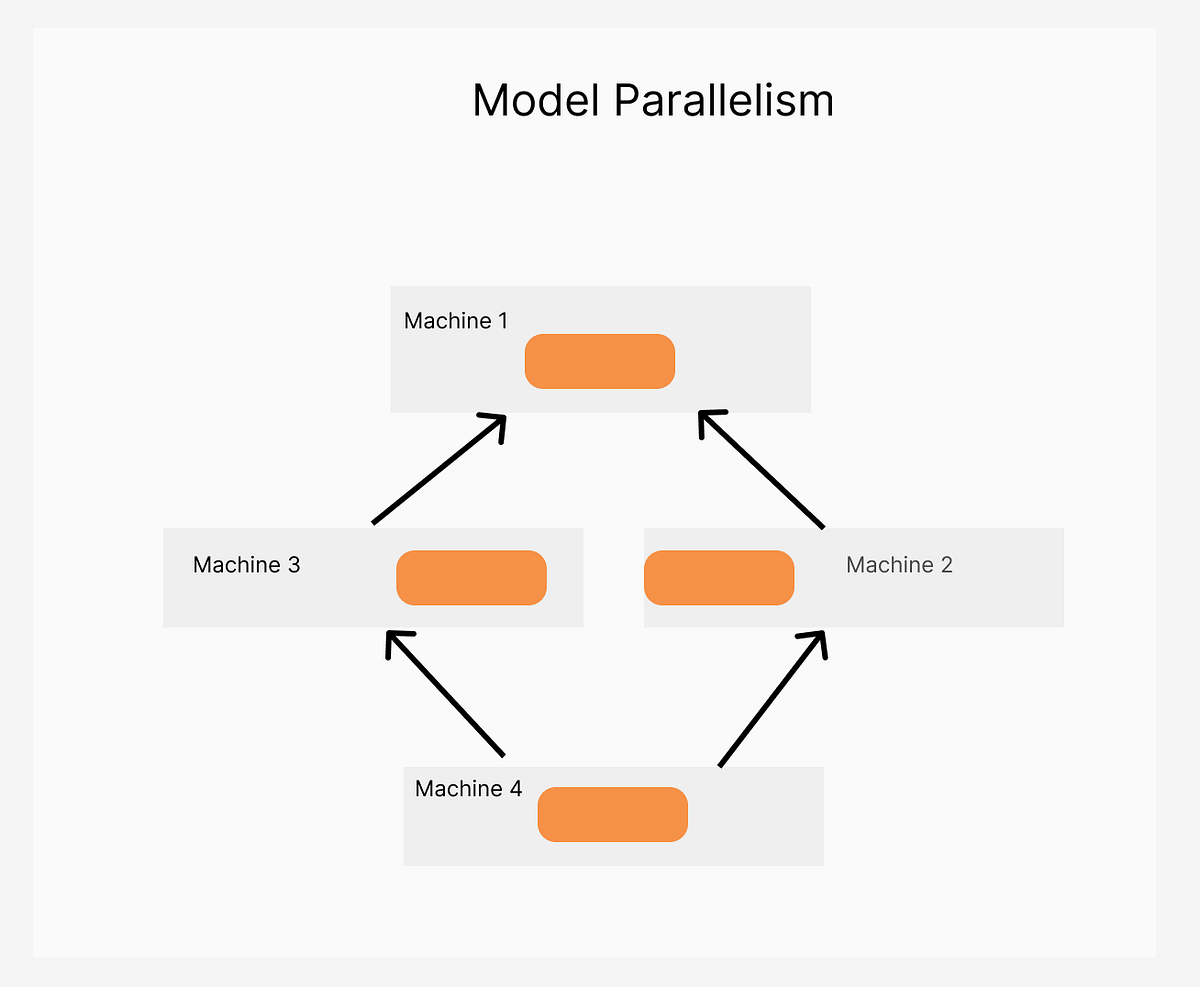
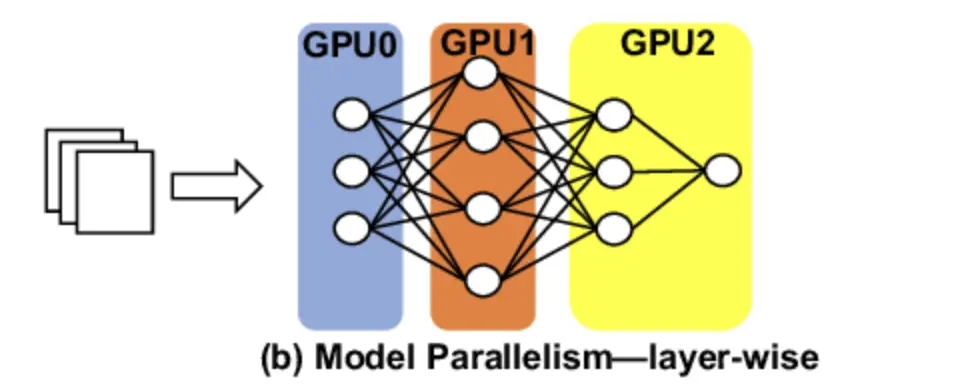
Model Parallelism - LLM Workshop
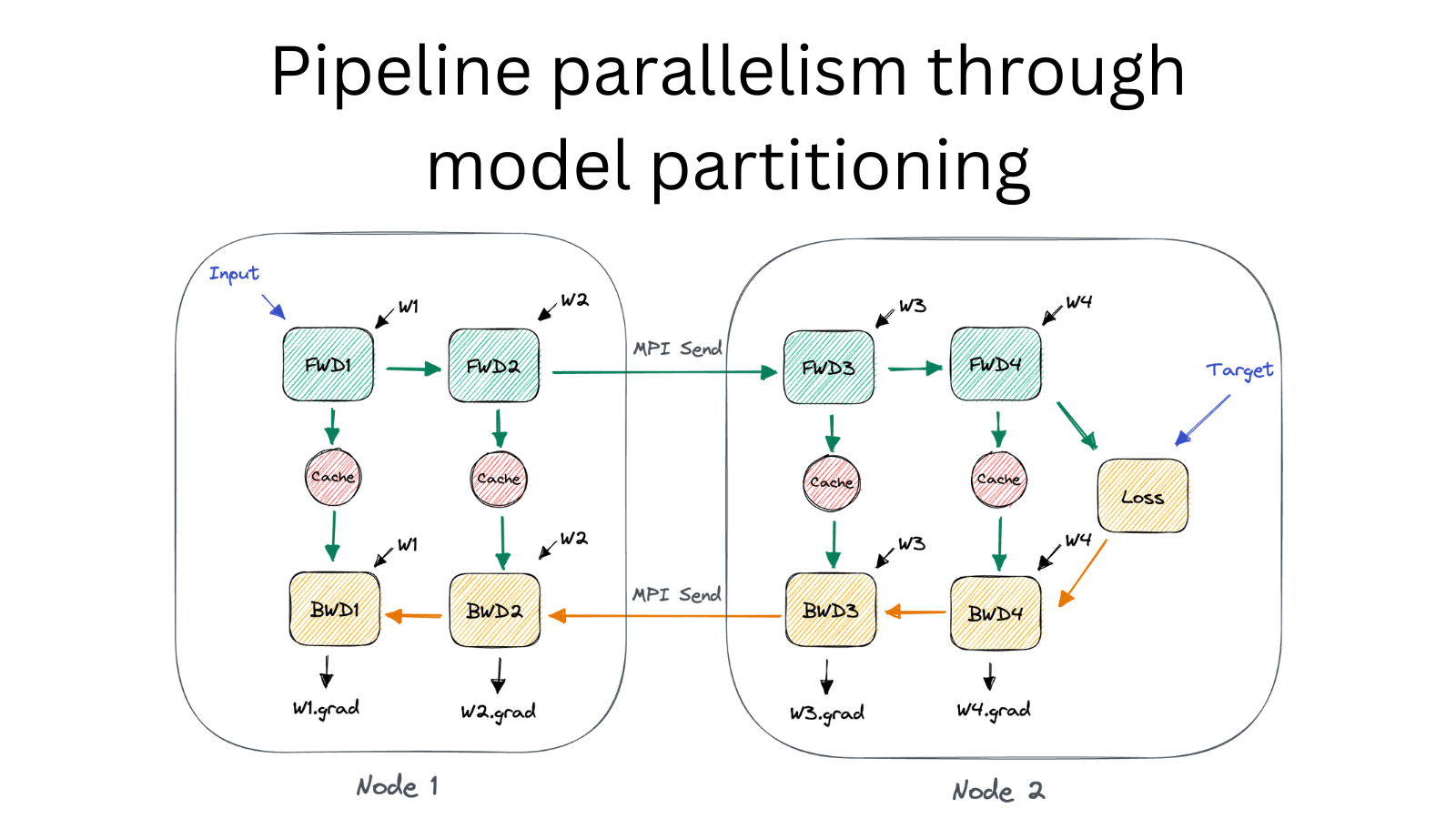
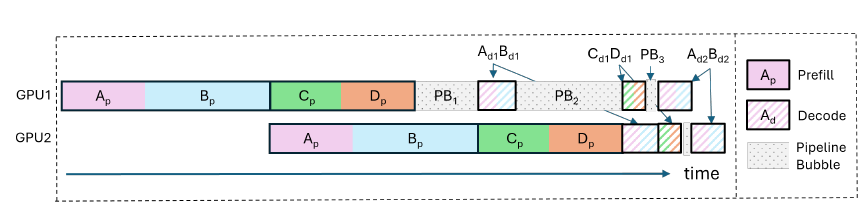
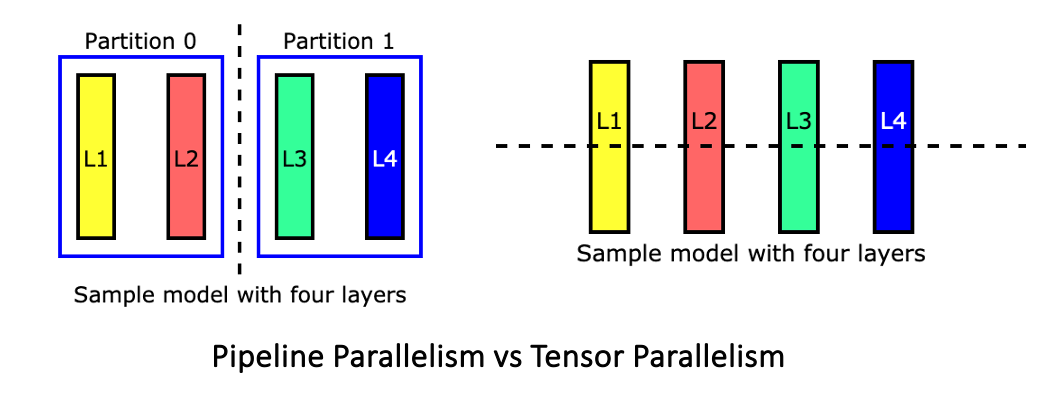
Pipeline Model Parallelism in LLM Pretraining | HE Tao
Megatron LM — How Model Parallelism Is Pushing Language Models to New ...
gLLM: Global Balanced Pipeline Parallelism System for Distributed LLM ...
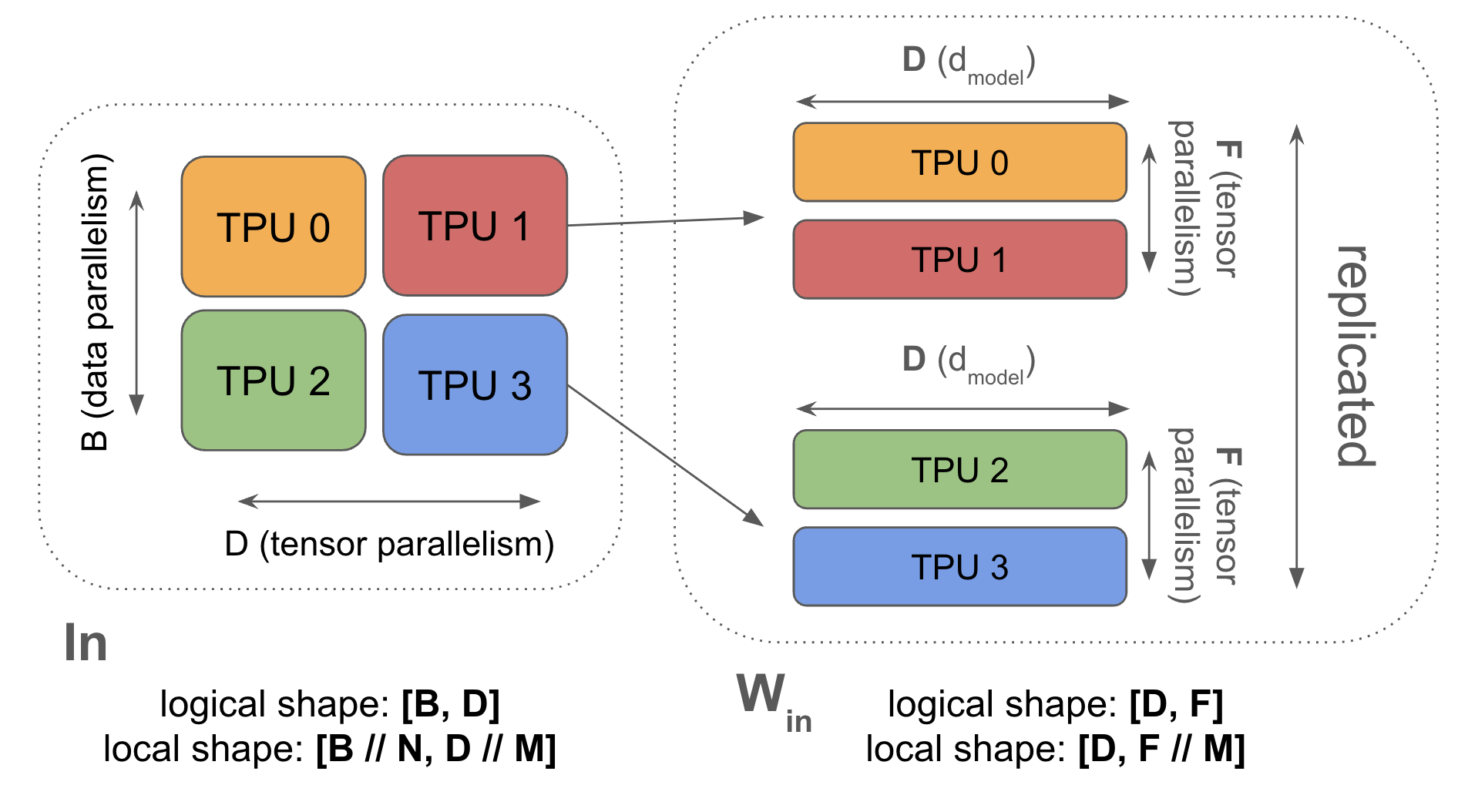
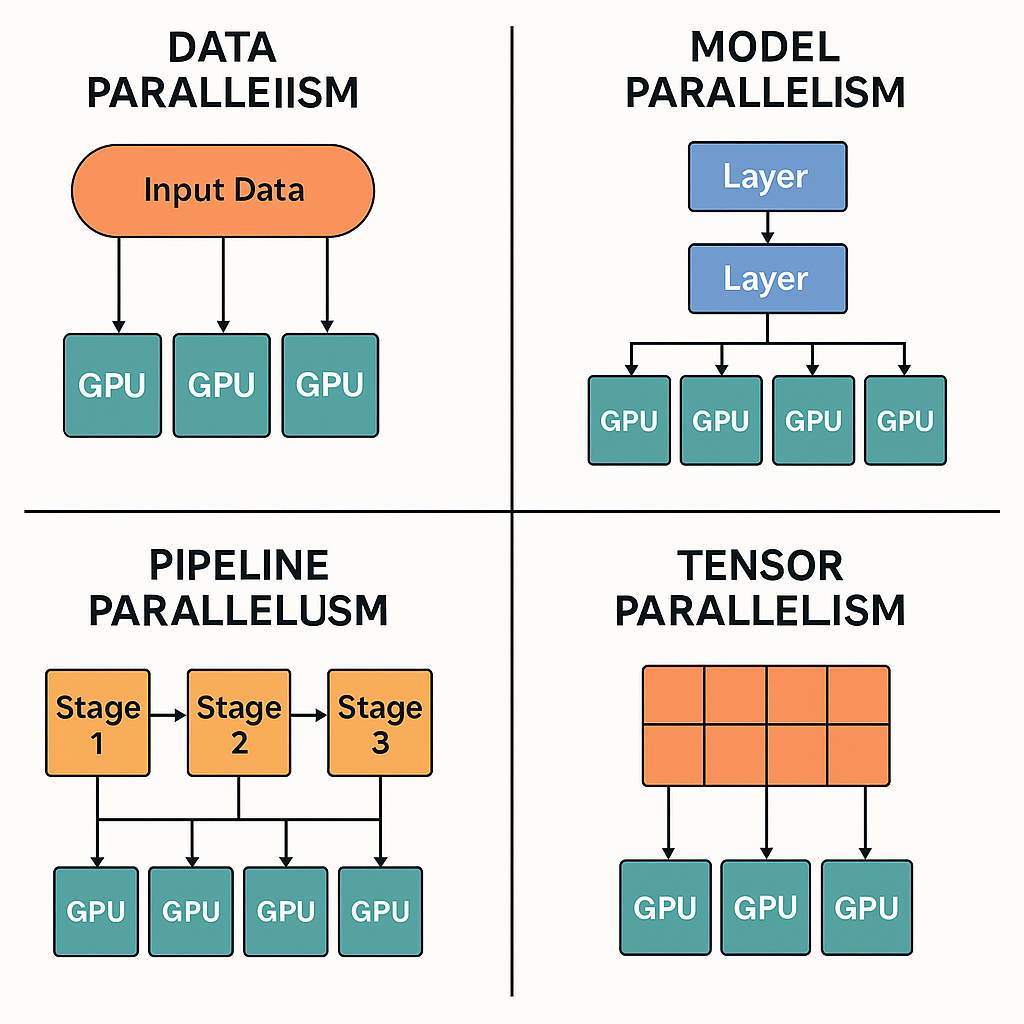
3.1 Parallelism Concepts - LLM Study
Breaking Down Parallelism Techniques in Modern LLM Inference | by Hao C ...
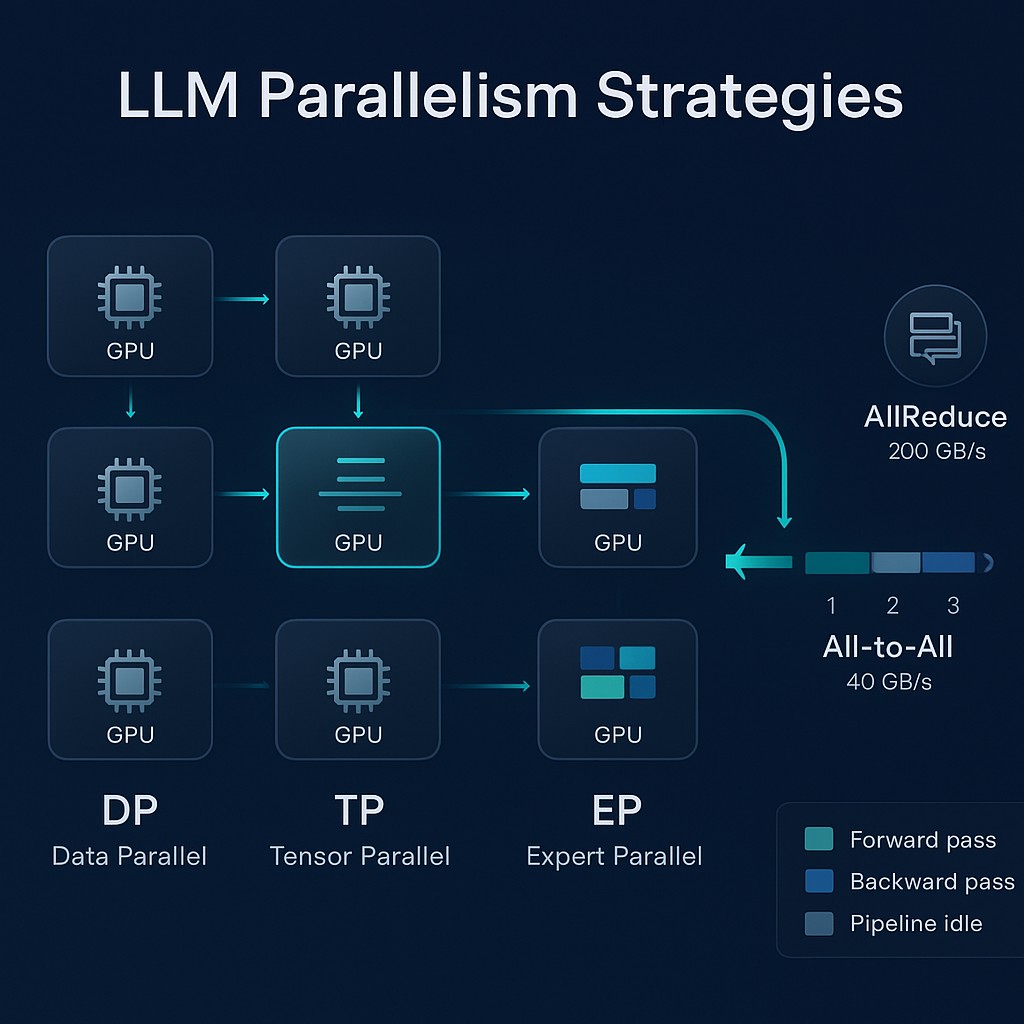
LLM Parallelism Strategies Explained | Simulations4All
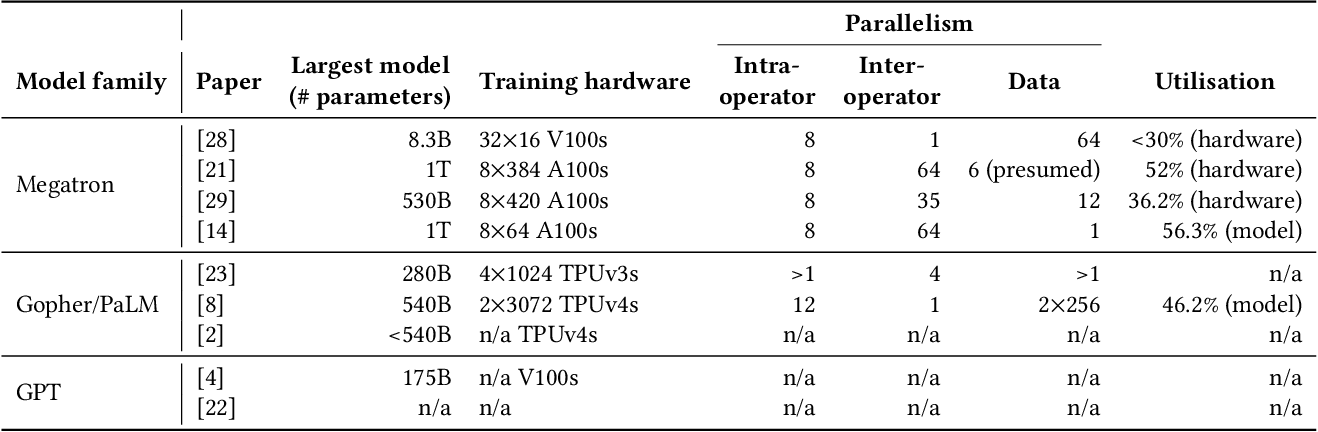
Table 2 from Model Parallelism on Distributed Infrastructure: A ...
Model Parallelism Techniques and Optimizations for Deep Learning Models ...
[LLM] Model Parallelism and Data Parallelism – THE NEWTH
Meta Details GEM Ads Model Using LLM-Scale Training, Hybrid Parallelism ...
Model Parallelism | huggingface/llm_training_handbook | DeepWiki
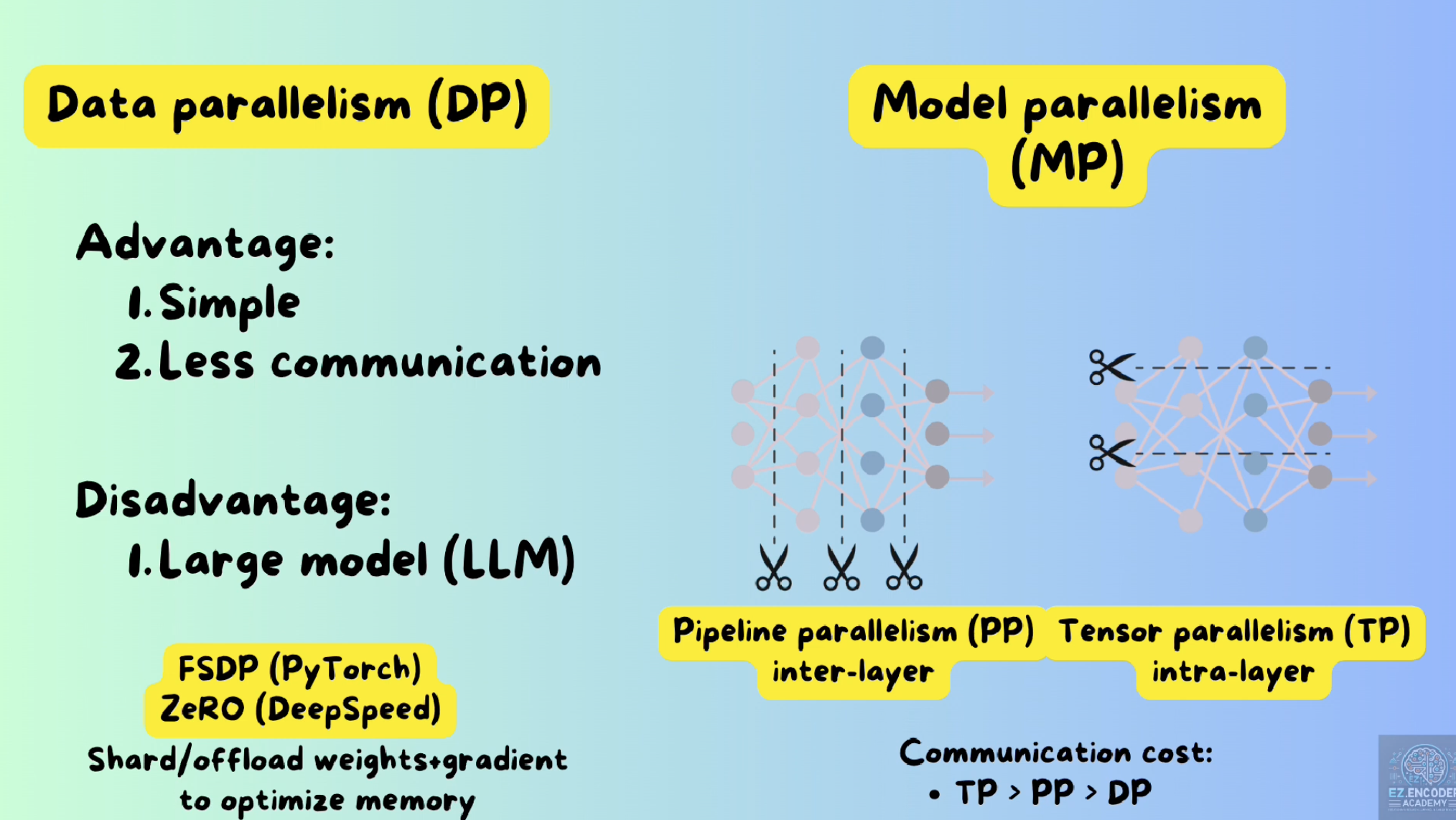
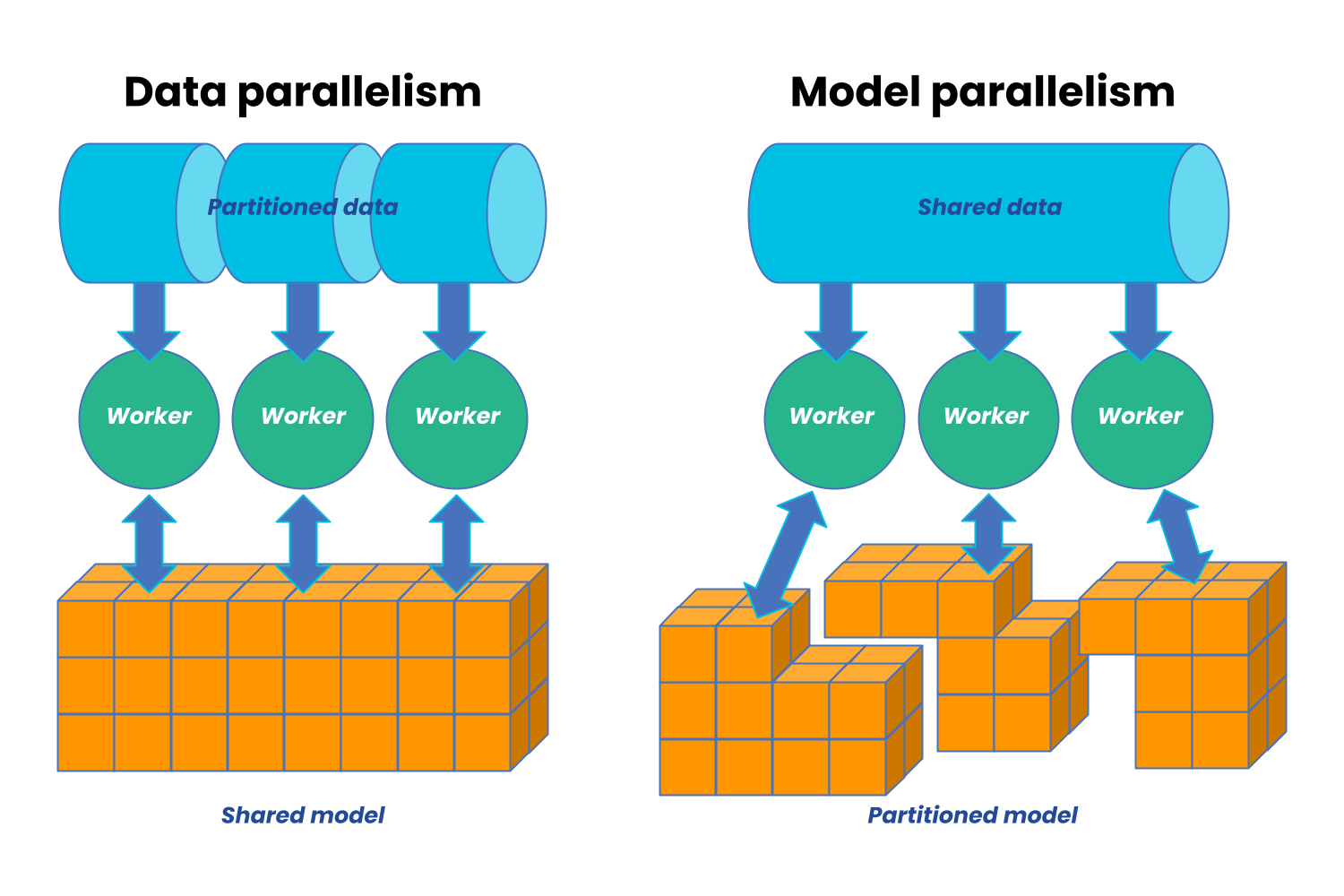
Distributed Parallel Training: Data Parallelism and Model Parallelism ...
LLM training and GPU parallelism - Ref - 1. Megatron-LM: Training Multi ...
[2403.03699] Model Parallelism on Distributed Infrastructure: A ...
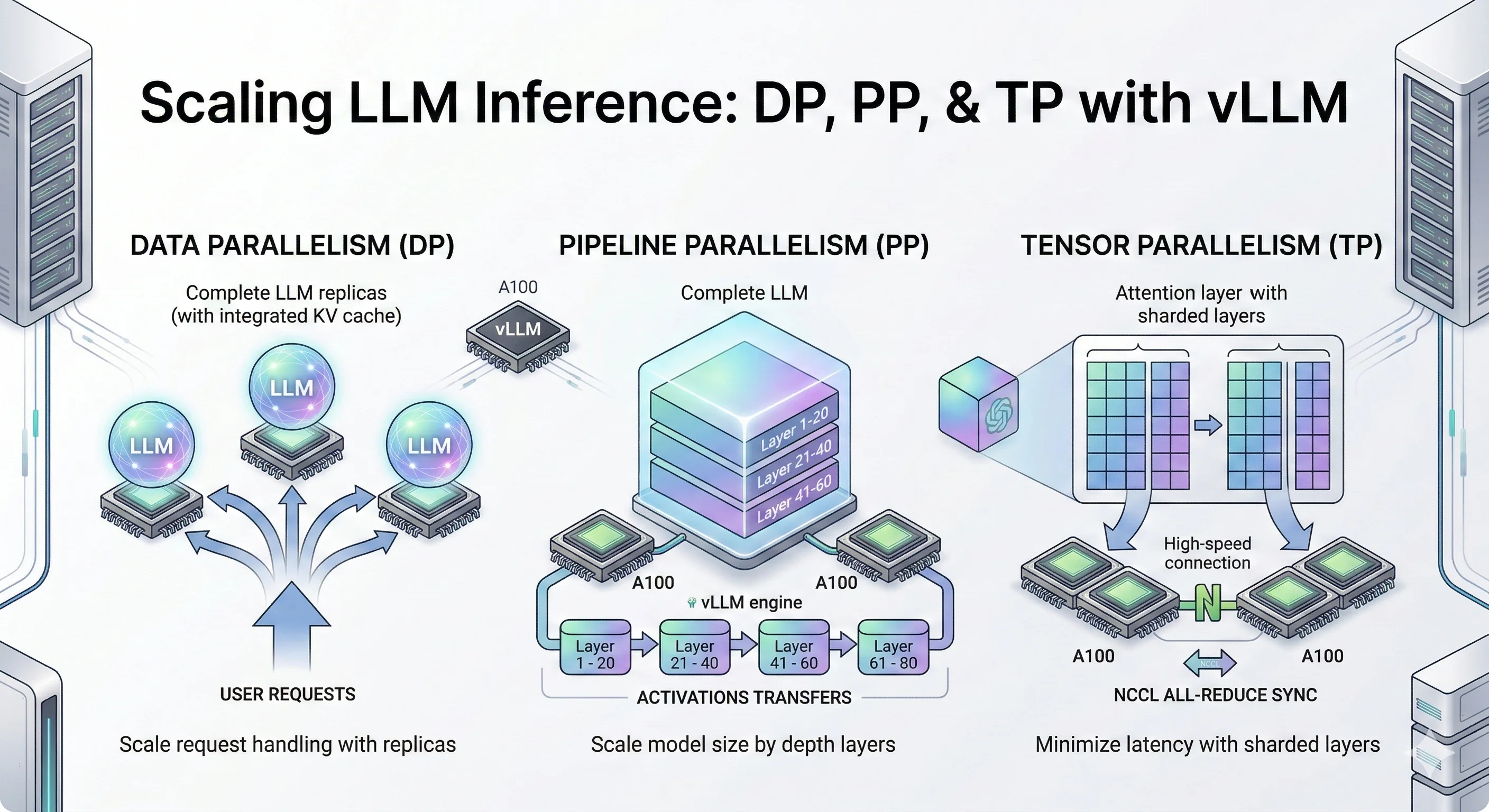
Scaling LLM Inference: Data, Pipeline & Tensor Parallelism in vLLM ...
Table 1 from Model Parallelism on Distributed Infrastructure: A ...
Introduction to Model Parallelism - Amazon SageMaker AI
Comprehensive Analysis of LLM Inference Parallelism Strategies: TP / DP ...
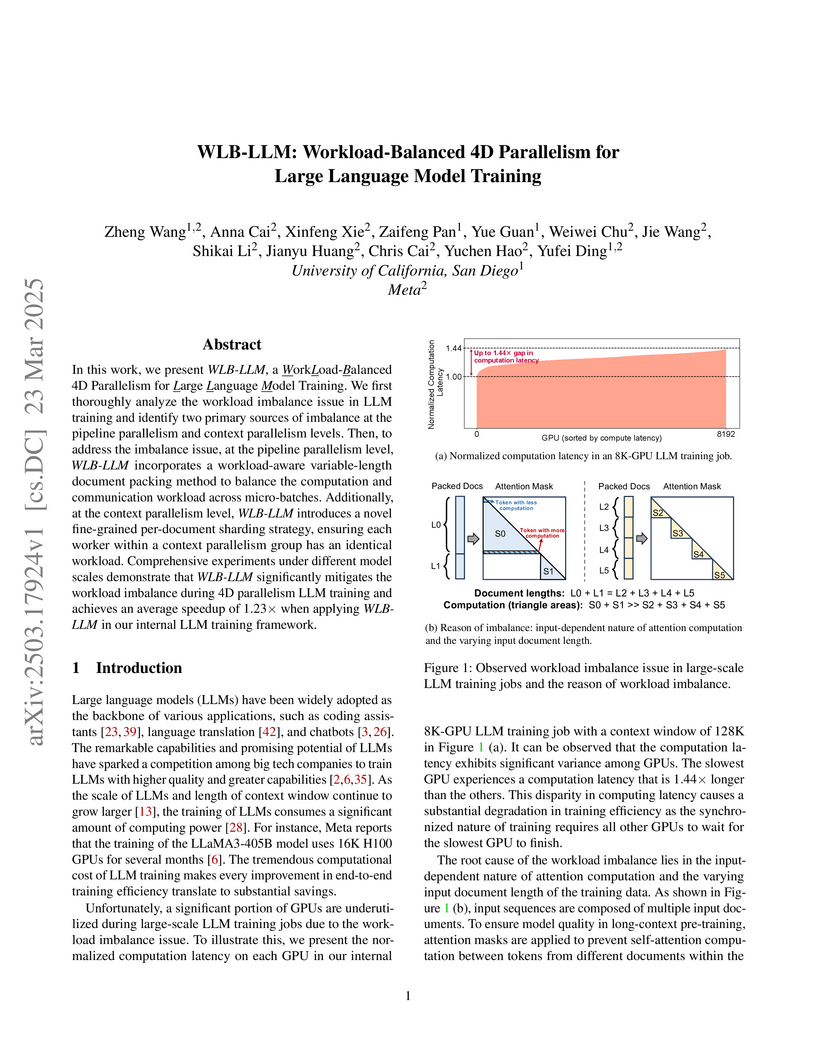
WLB-LLM: Workload-Balanced 4D Parallelism for Large Language Model ...
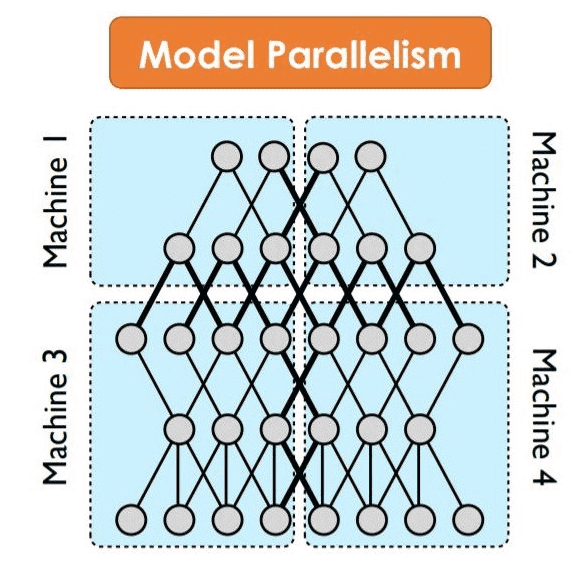
Model Parallelism
Model And Data Parallelism at Esteban Roder blog
The LLM Scaling Hierarchy: Mastering Every Dimension of Parallelism ...
Illustration of data parallelism and model parallelism. | Download ...
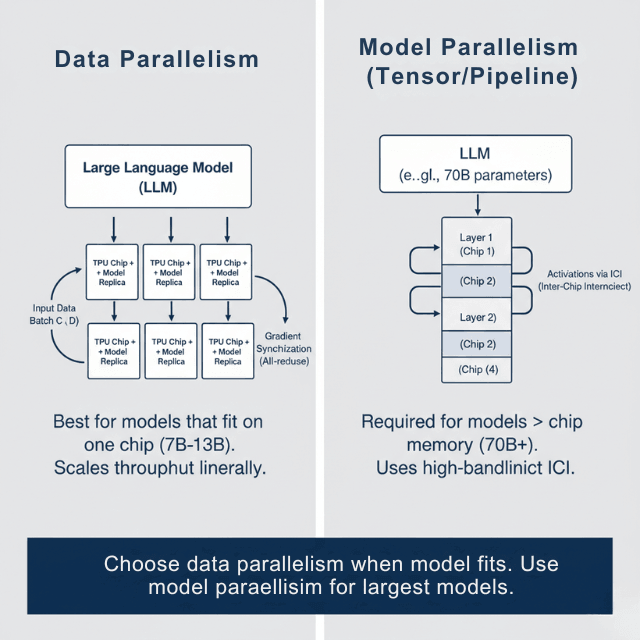
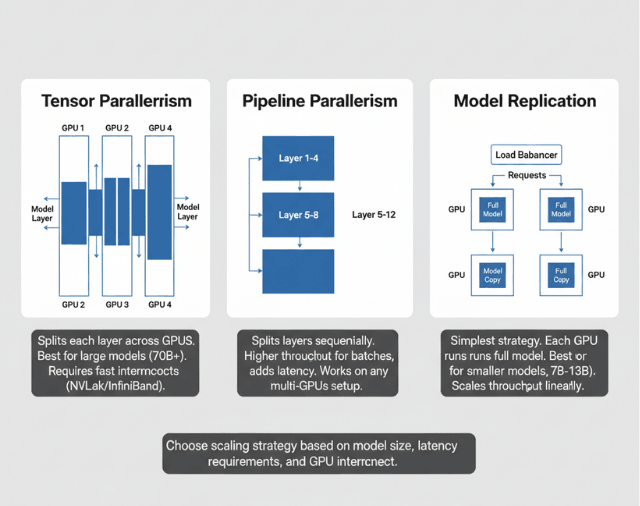
Model Parallelism vs Data Parallelism vs Tensor Parallelism | # ...
Analyzing the Impact of Tensor Parallelism Configurations on LLM ...
Data Parallelism vs. Model Parallelism: Optimizing ML Runtime with ...
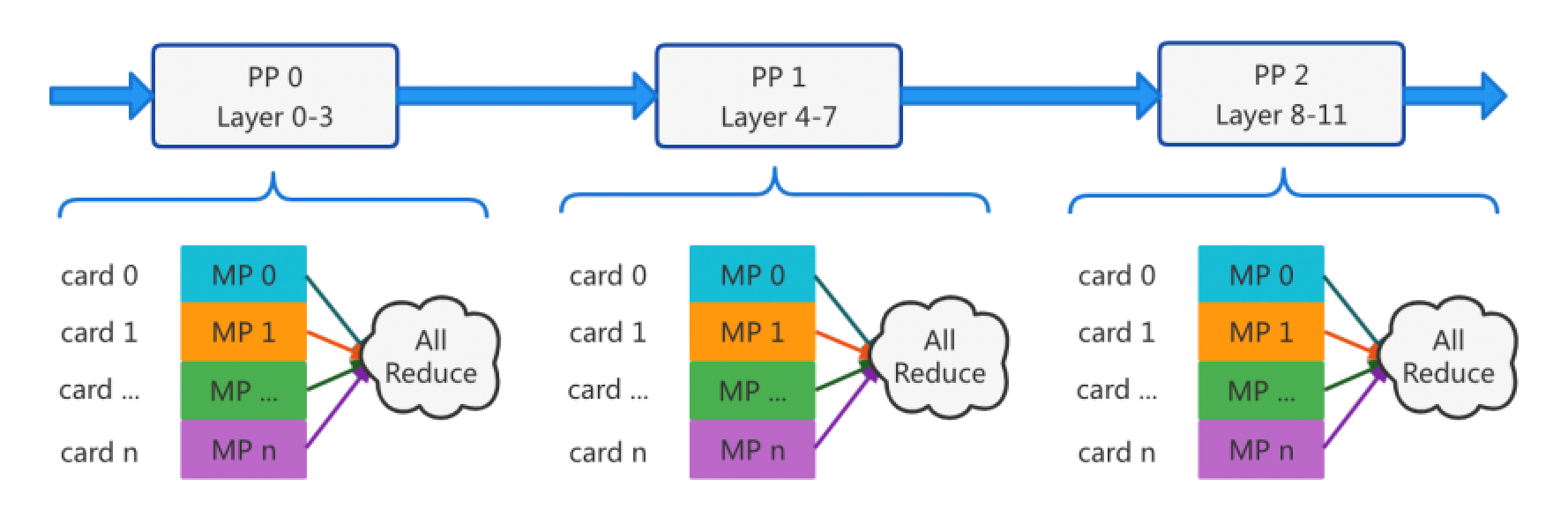
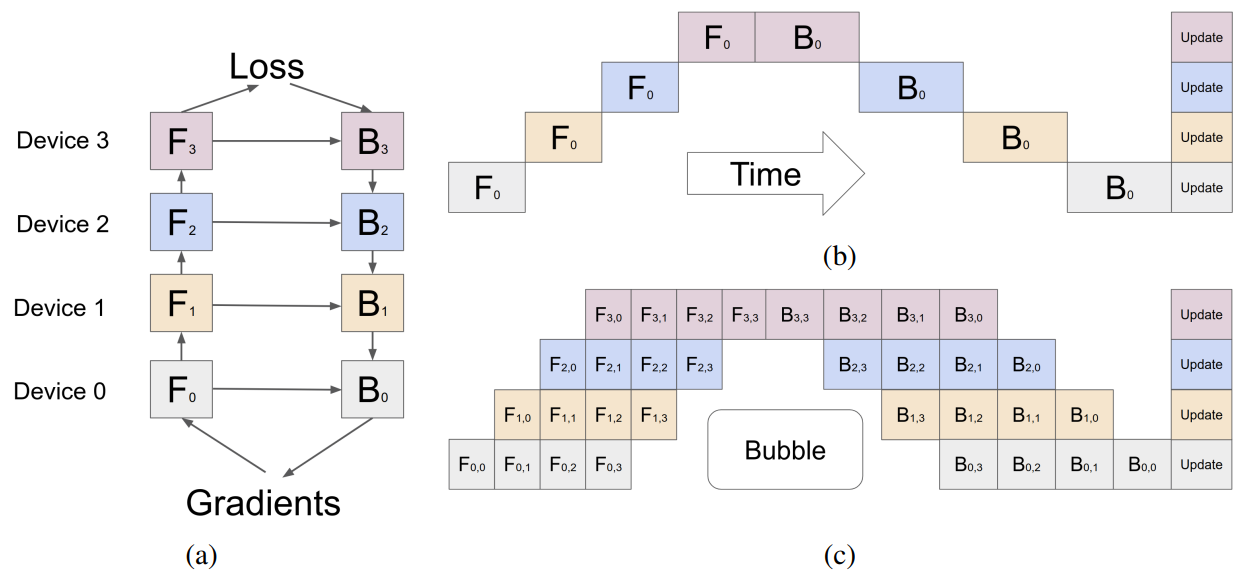
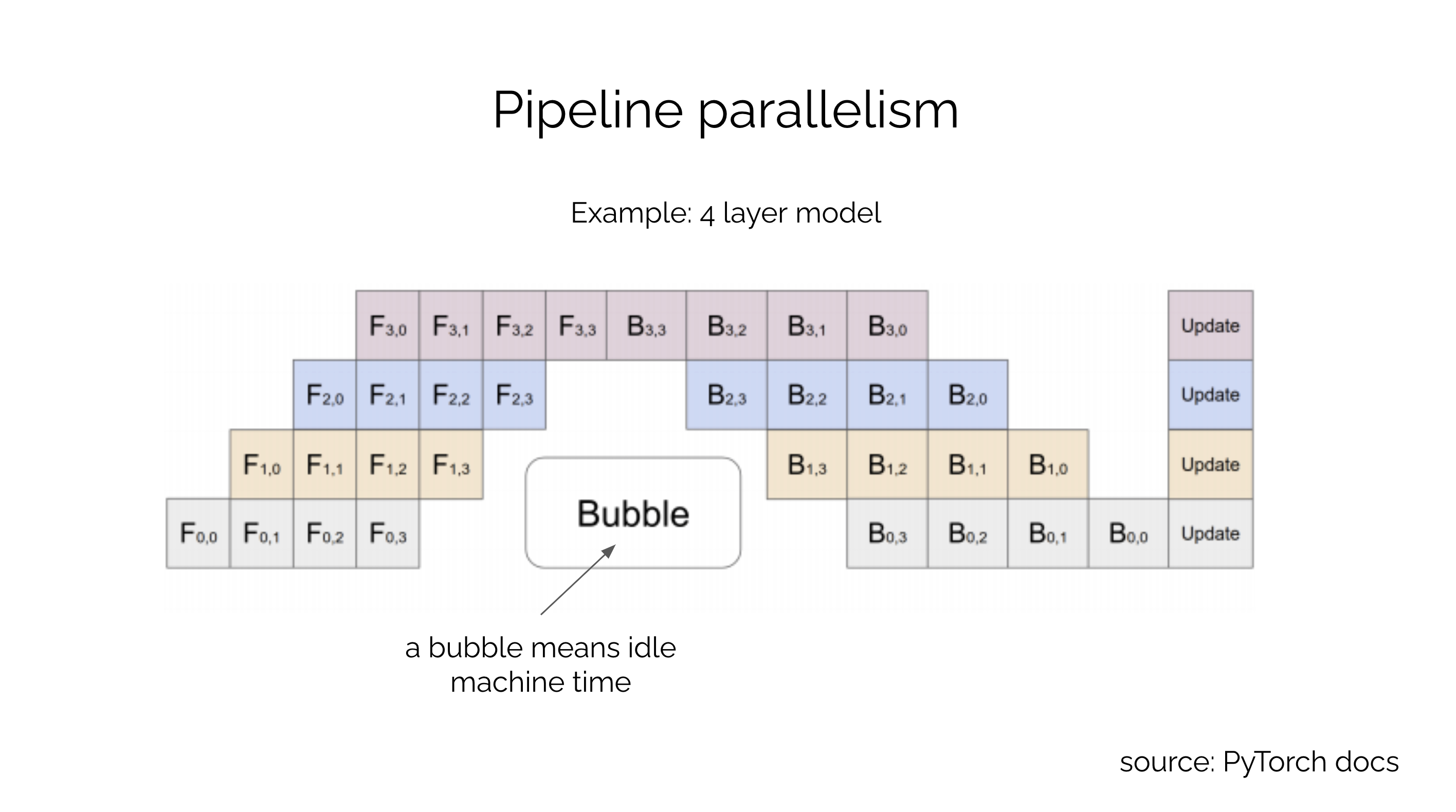
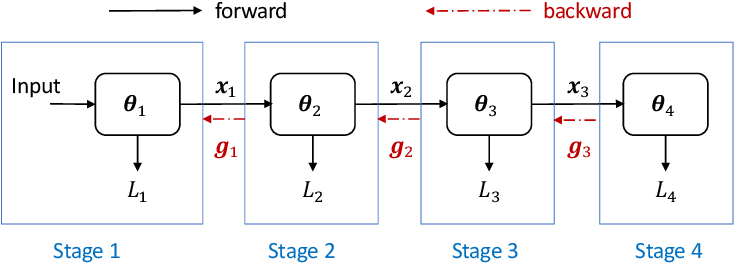
LLM Training — Fundamentals of Pipeline Parallelism | by Don Moon ...
Google Cloud TPU v5p - Specs, Pricing and LLM Benchmarks (2026)
Parallelism and Memory Optimization Techniques for Training Large ...
GPU Guide for LLM Deployment - RTX 4090 to A100 Benchmarks (2026)
Uncensored LLM Models: A Complete Guide to Unfiltered AI Language ...
LLM in the Parallel Learning Framework. | Download Scientific Diagram
Mastering LLM Techniques: Inference Optimization – GIXtools
What is Inference Parallelism and How it Works
GitHub - nbeeeel/LLM-Model-Level-Parallelism-For-HPC: 4-node model ...
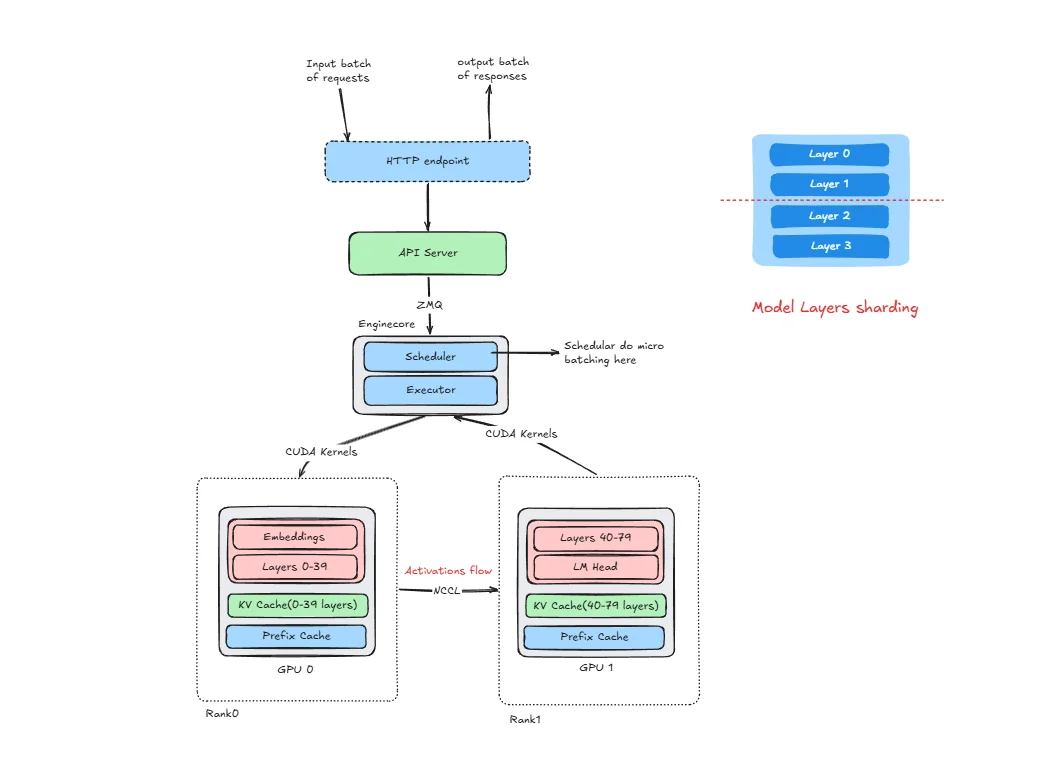
[vLLM vs TensorRT-LLM] #9. Parallelism Strategies - The official ...
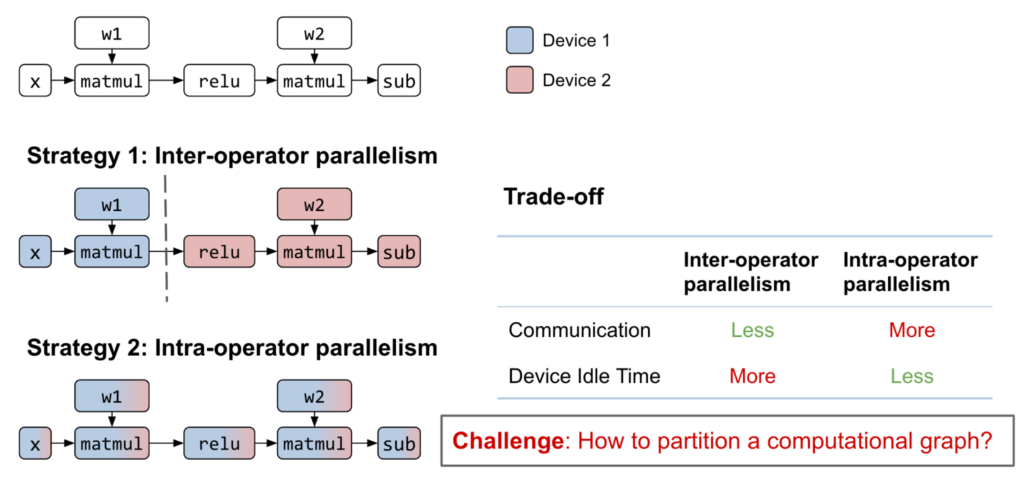
Efficiently Scale LLM Training Across a Large GPU Cluster with Alpa and ...
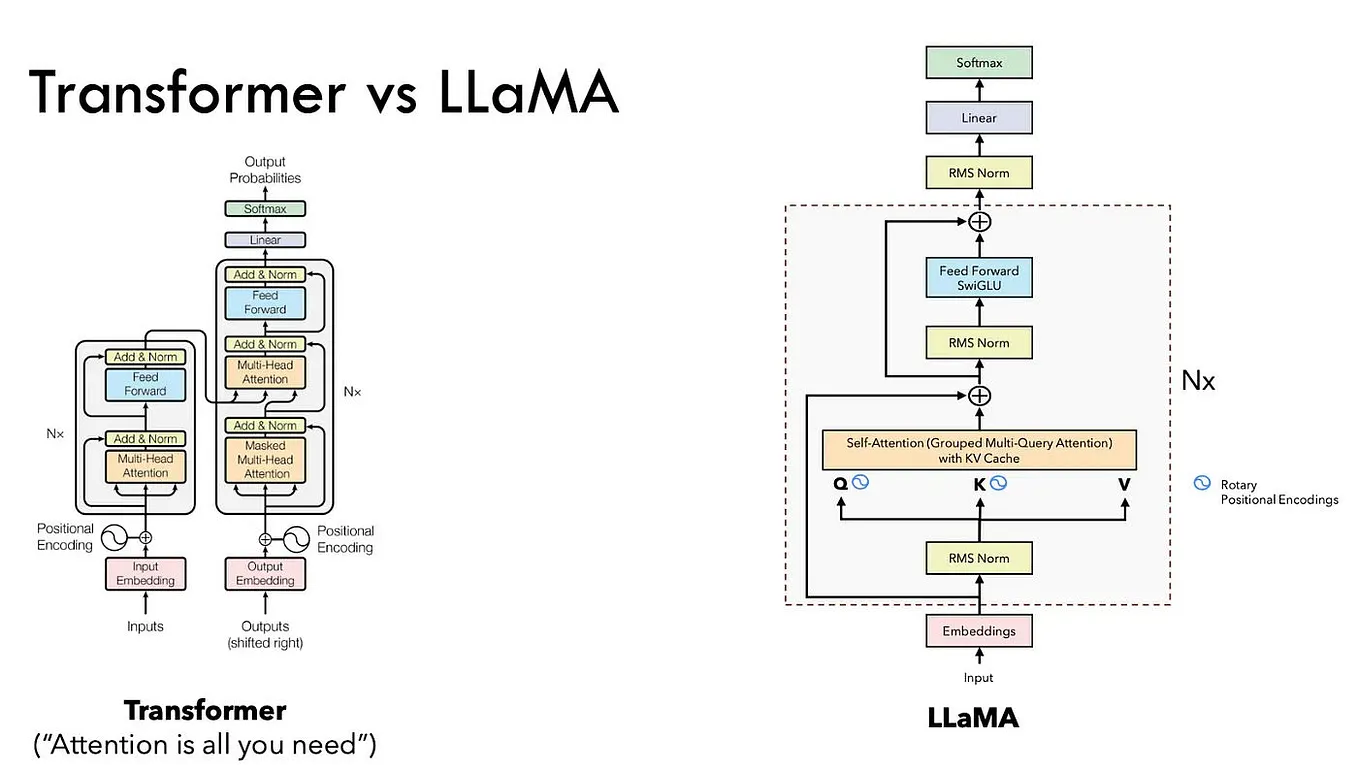
How to Parallelize a Transformer for Training | How To Scale Your Model
LLM Training Parallelism: A Practical Guide to Choosing the Right Strategy
Tensor Parallelism and Pipeline Parallelism - Kyle’s Tech Blog
Understanding Model Sharding and Model Parallelism: Scaling Large ...
Free Video: WLB-LLM - Workload-Balanced 4D Parallelism for Large ...
[vLLM vs TensorRT-LLM] #9. Parallelism Strategies - SqueezeBits
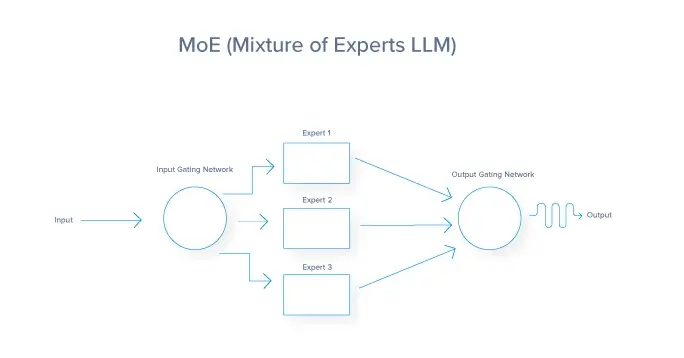
Exploring parallelism in Large Language Models (LLMs) - DEV Community
Data Parallelism Implementation for LLMs
Building a Parallel LLM Network | MindSpore master Tutorials | MindSpore
Optimizing Long-context LLM Serving via Fine-grained Sequence ...
Tensor Parallel LLM Inferencing. As models increase in size, it becomes ...
LLM (In)Consistency: The Hidden Pitfall of Parallel Inference
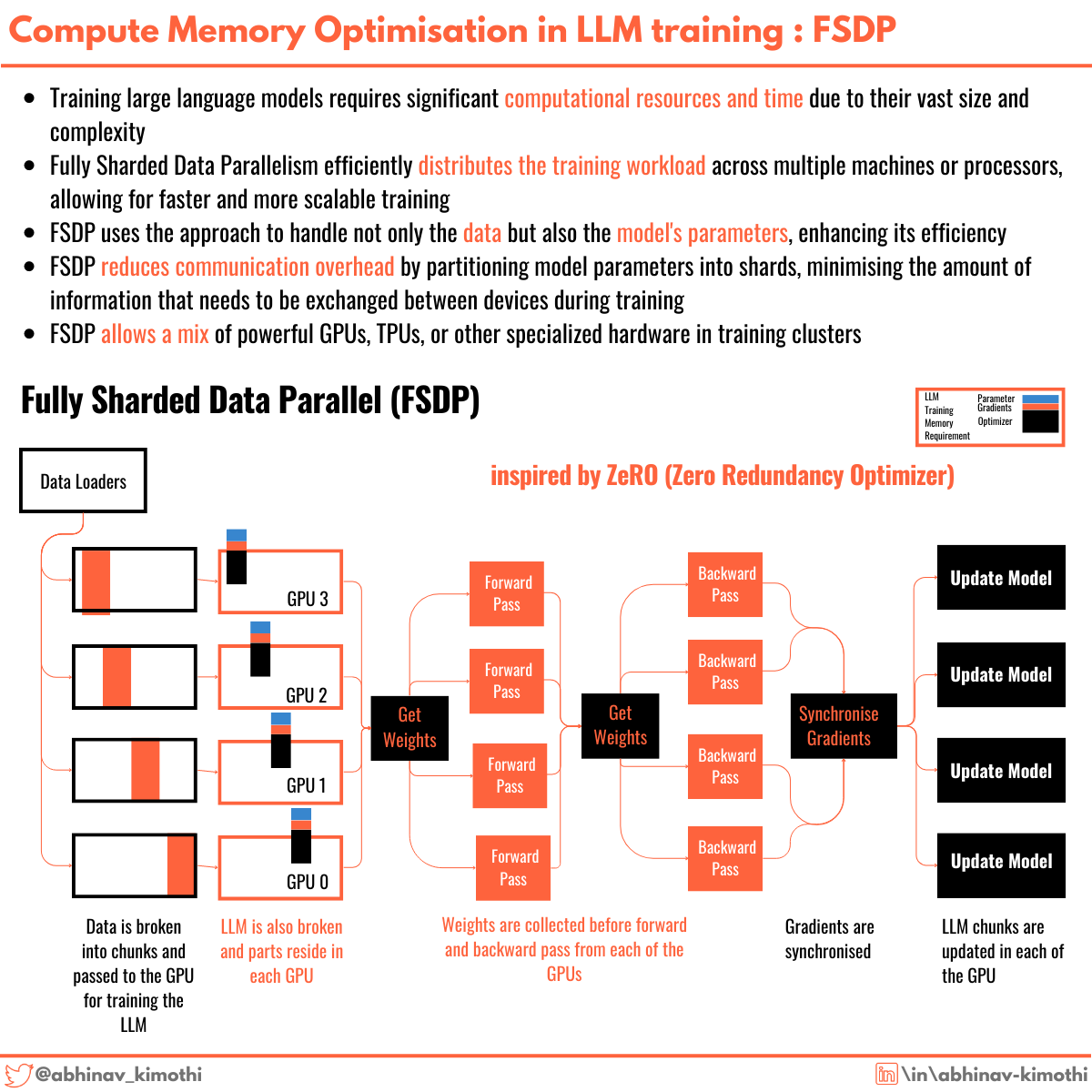
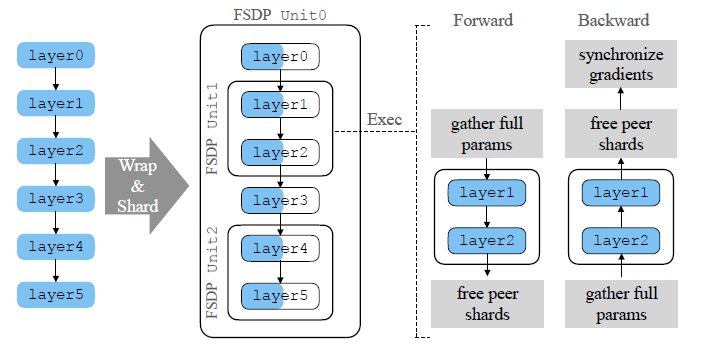
LLM Training — Fully Sharded Data Parallel (FSDP): An Efficient ...
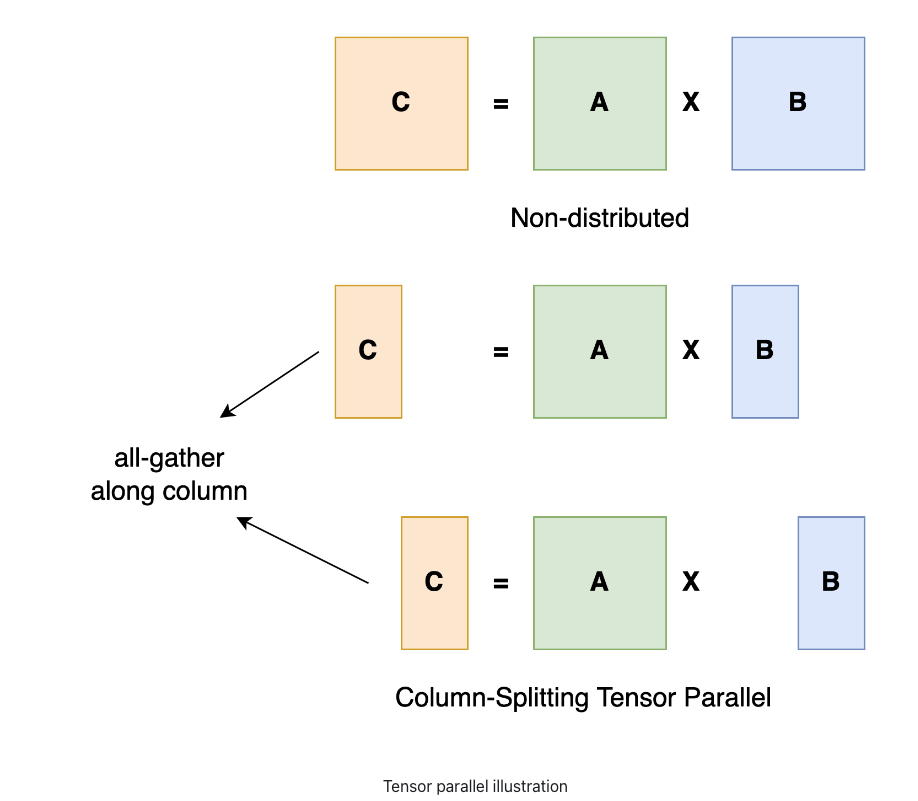
Sharding Large Models with Tensor Parallelism
AiDOOS Blog : Parallelism in Large Language Models (LLMs) to Boost ...
Essential Practices for Building Robust LLM Pipelines
Context Parallelism for Scalable Million-Token Inference | AI Research ...
[논문 리뷰] WLB-LLM: Workload-Balanced 4D Parallelism for Large Language ...
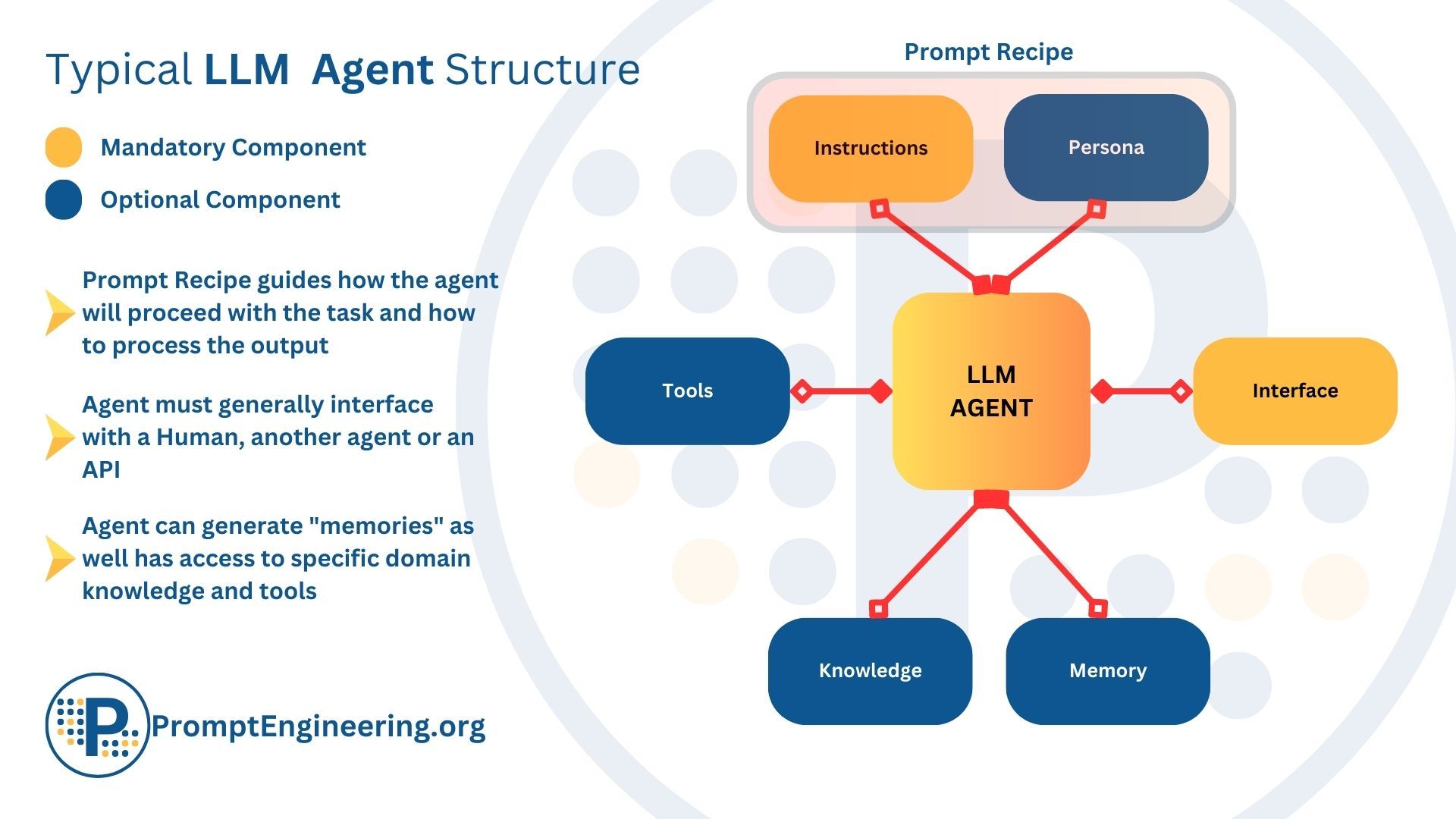
What Are Large Language Model (LLM) Agents and Autonomous Agents
Train Large Language Models Faster - Parallelism Deep Dive | Coursera
Deploying a Large Language Model (LLM) with TensorRT-LLM on Triton ...
Figure 3 from TokenRing: An Efficient Parallelism Framework for ...
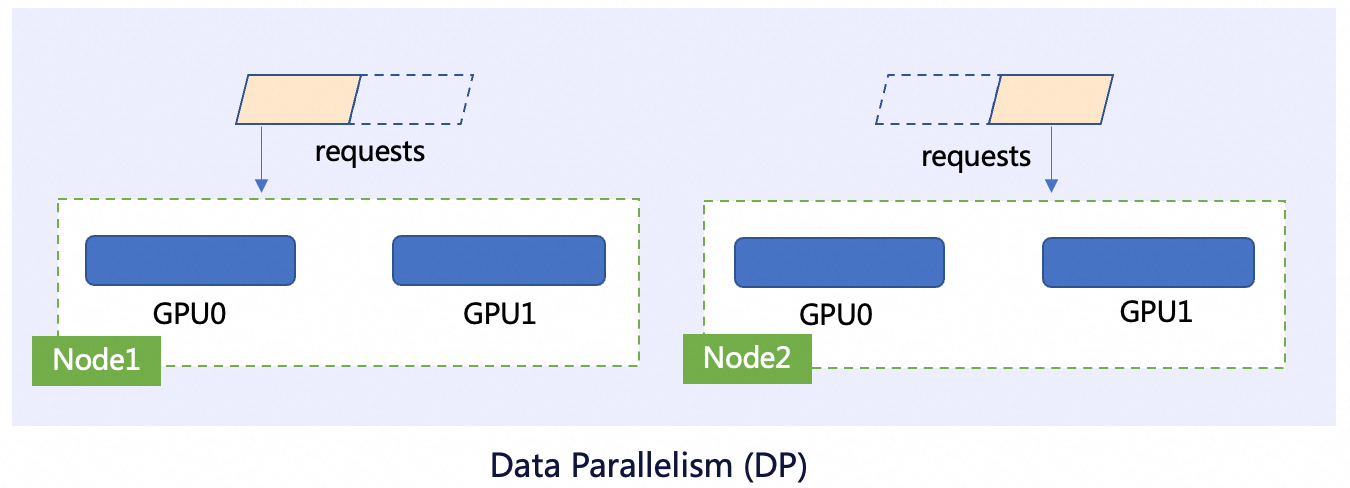
Data Parallelism: Scaling LLM Training Through Parallel Processing
Parallel LLM Calls from Scratch — Tutorial For Dummies (Using PocketFlow!)
Multi-GPU and Parallelism | intel/llm-scaler | DeepWiki
EcoServe: Enabling Cost-effective LLM Serving with Proactive Intra- and ...
High-Performance LLM Training at 1000 GPU Scale With Alpa & Ray
Synergistic Tensor and Pipeline Parallelism | AI Research Paper Details
Sharding Large models for parallel inference | by shashank Jain | Medium
🚀 Beyond Data Parallelism: A Beginner-Friendly Tour of Model, Pipeline ...
What Is Distributed Training?
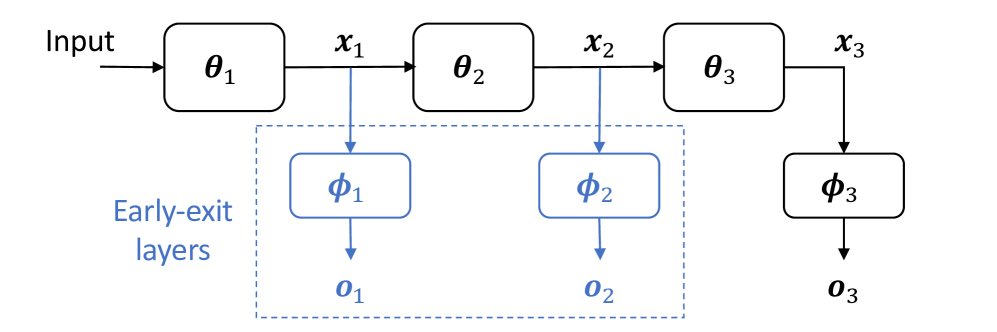
EE-LLM: Large-Scale Training and Inference of Early-Exit Large Language ...
GitHub - furqan-y-khan/parallel-llm: A Framework to Parallelly Train ...
GitHub - hundredblocks/large-model-parallelism: Functional local ...
Paper page - EE-LLM: Large-Scale Training and Inference of Early-Exit ...
Nonuniform-Tensor-Parallelism: Mitigating GPU failure impact for Scaled ...
Parallel and Distributed Systems in Machine Learning Haichuan
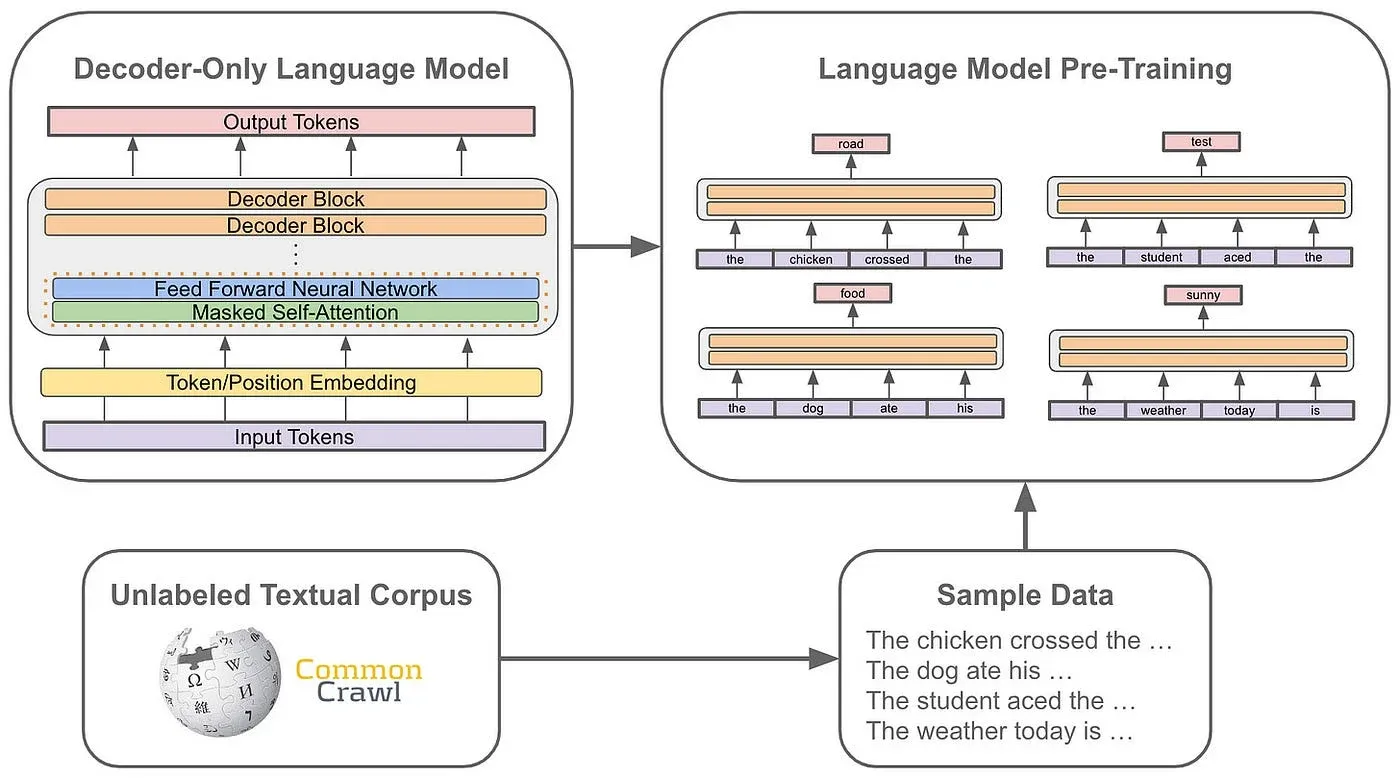
How Large Language Models are Trained? A Complete Guide
Helix Parallelism: Rethinking Sharding Strategies for Interactive Multi ...
Parallelisms Guide — Megatron Bridge
Scaling LLMs: GPT-3 and Beyond | AI Tutorial | Next Electronics
模型并行 - TKDO的个人网站
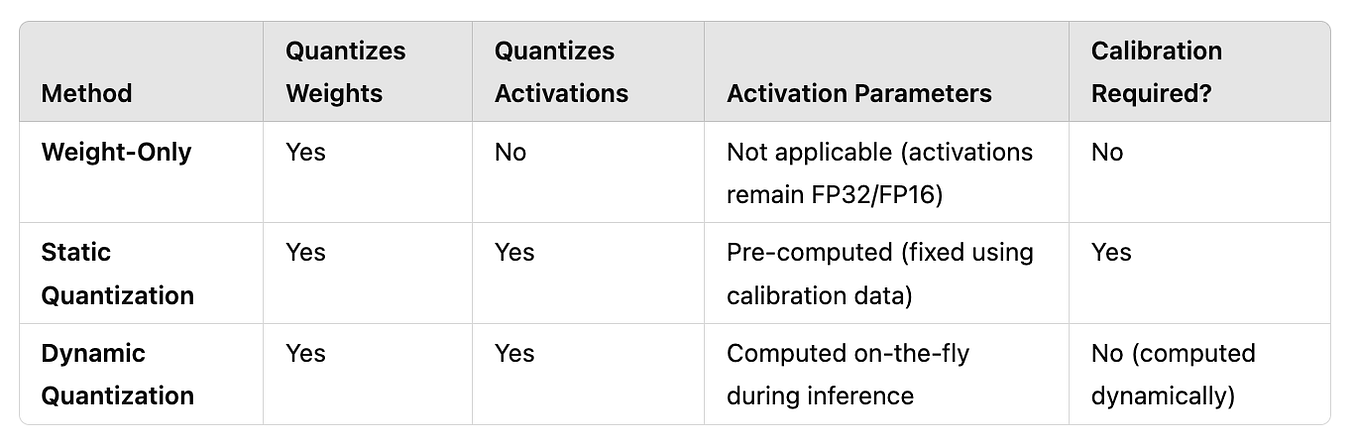
Running LLMs in low-resource settings | Pablo Miralles
PPT - Parallel and Distributed Systems in Machine Learning PowerPoint ...
模型并行(Model Parallelism)原理详解-CSDN博客
Systems & Machine Learning
LoopAnimate、LLM-Seg、DreamScape、LoopGaussian、TransformerFAM_adaptive n ...
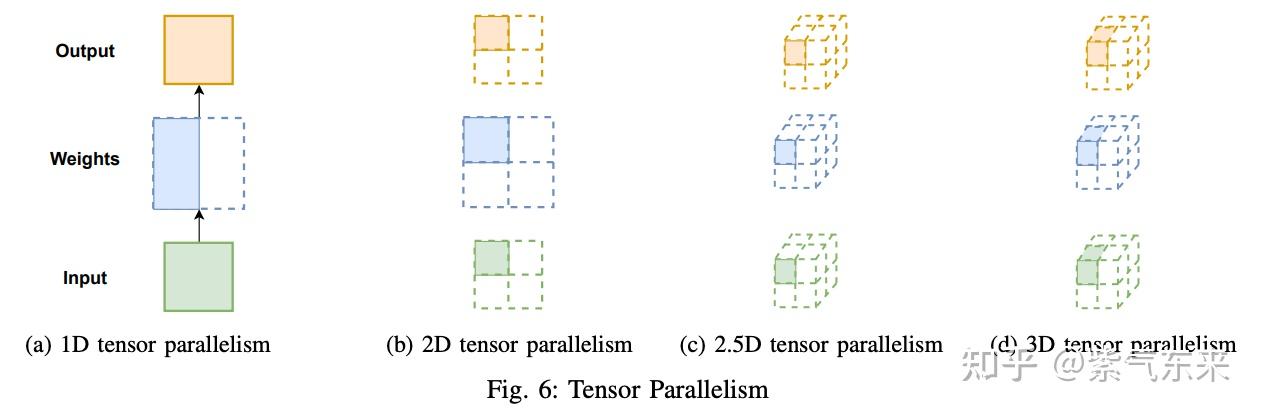
LLM(6):GPT 的张量并行化(tensor parallelism)方案 - 知乎
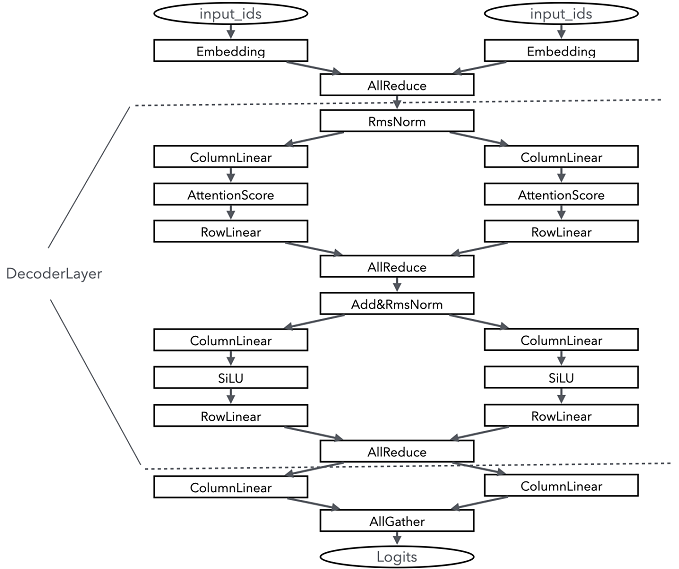
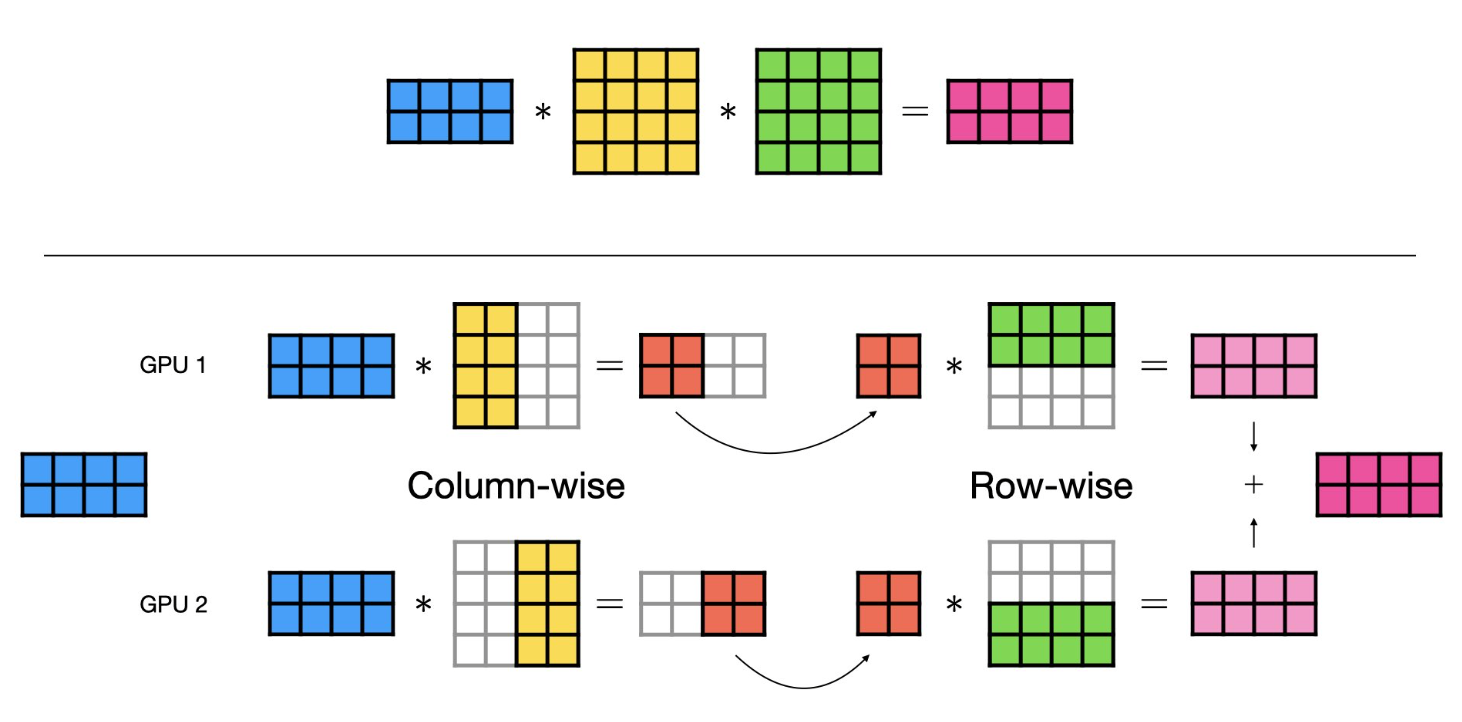
Combined Column- and Row-wise Parallelism:
LLM分布式训练 --- Megatron-LM-CSDN博客
Figure 2 from EE-LLM: Large-Scale Training and Inference of Early-Exit ...