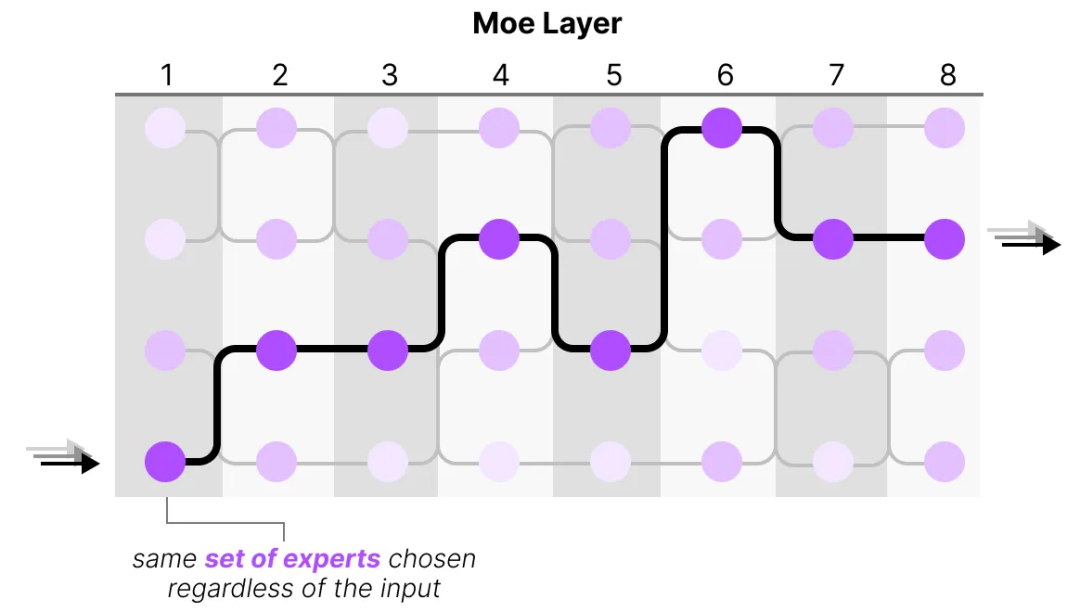
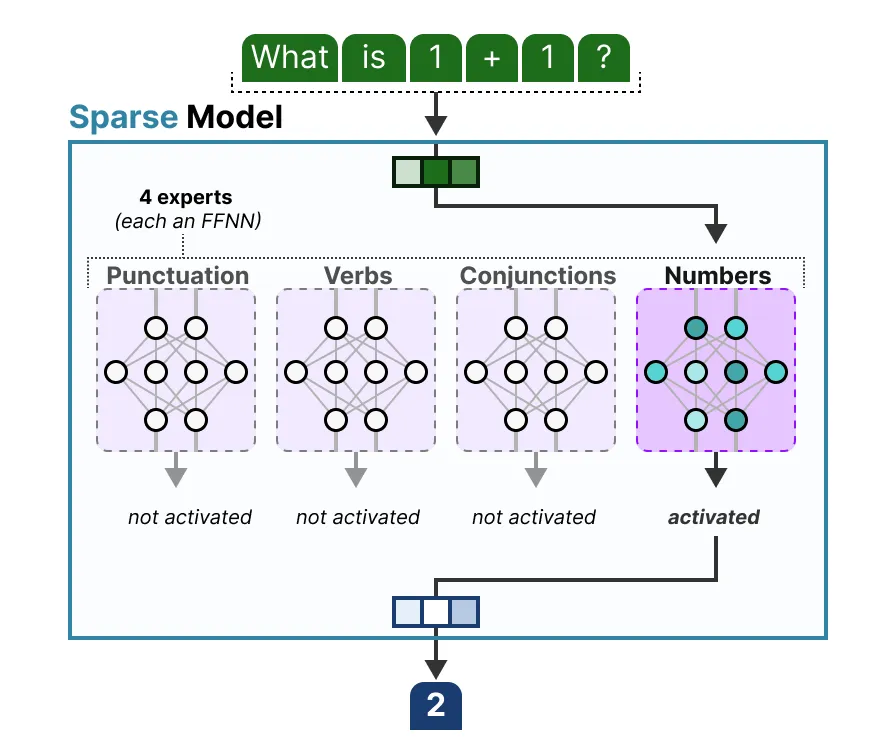
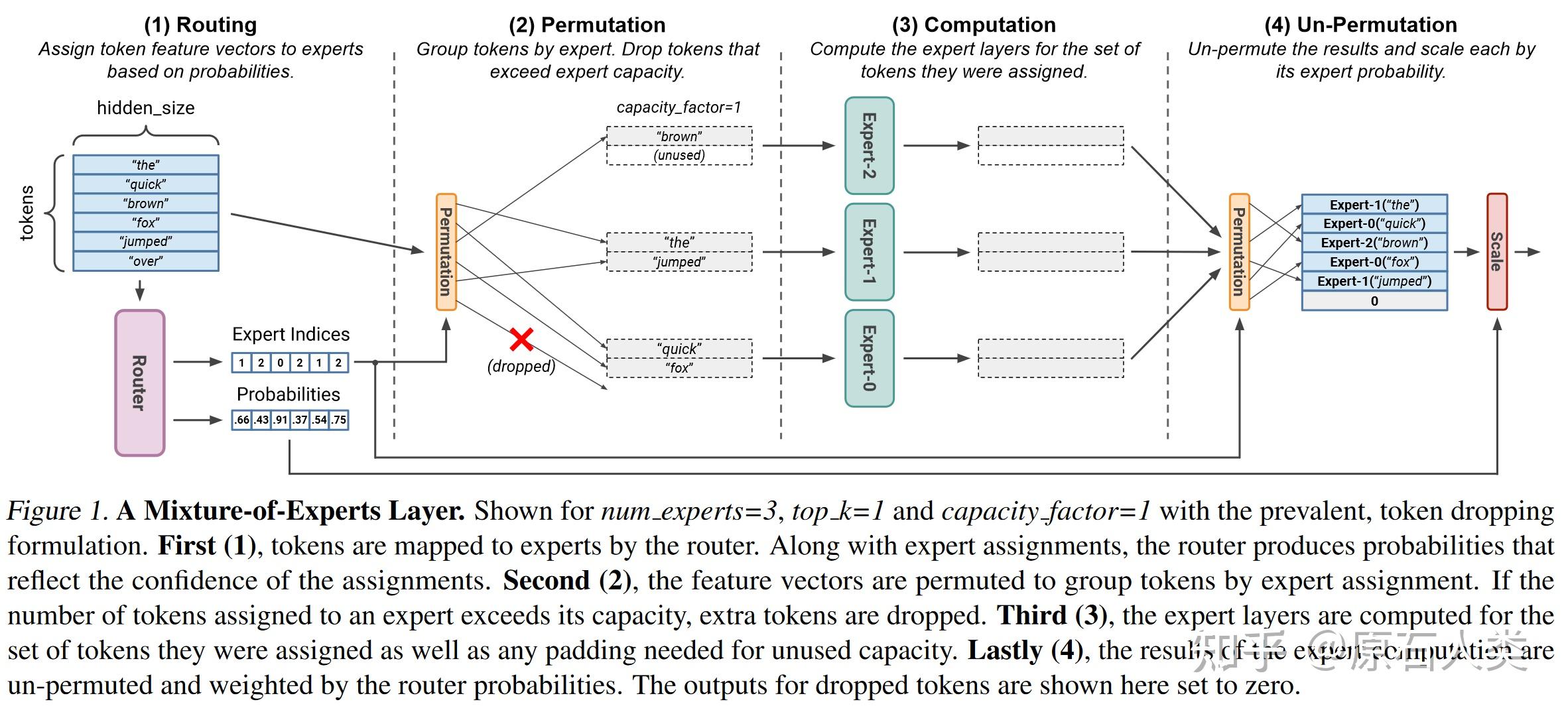
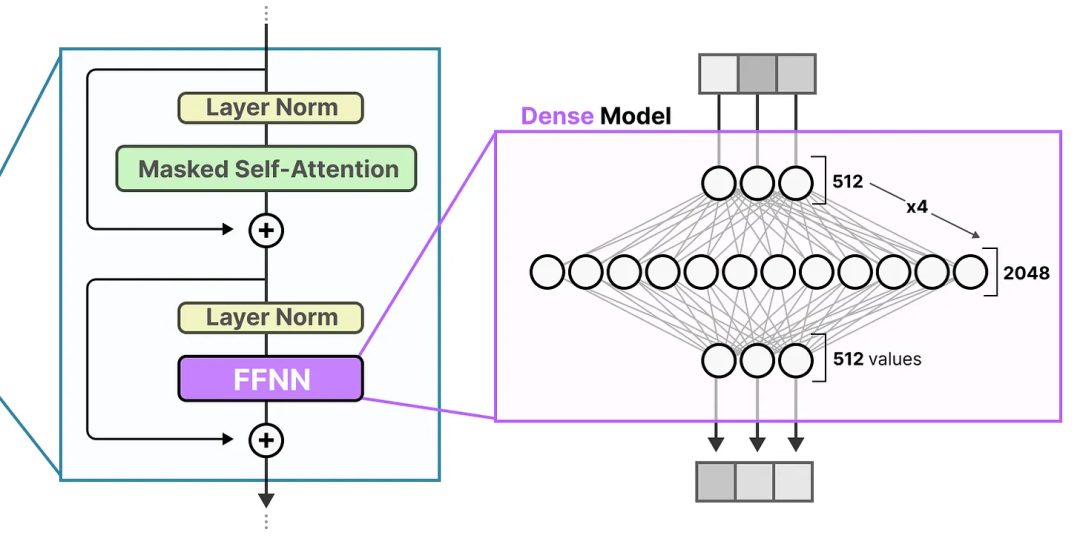
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Organizational Model of MoE Application Stages (adapted from ...
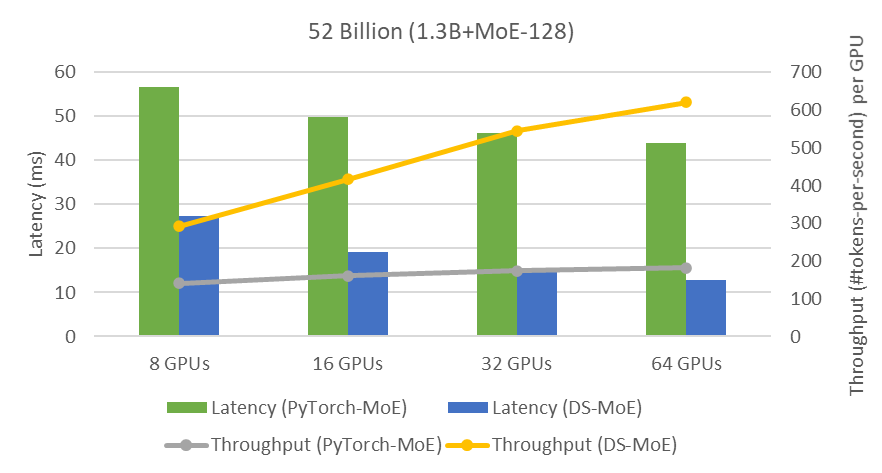
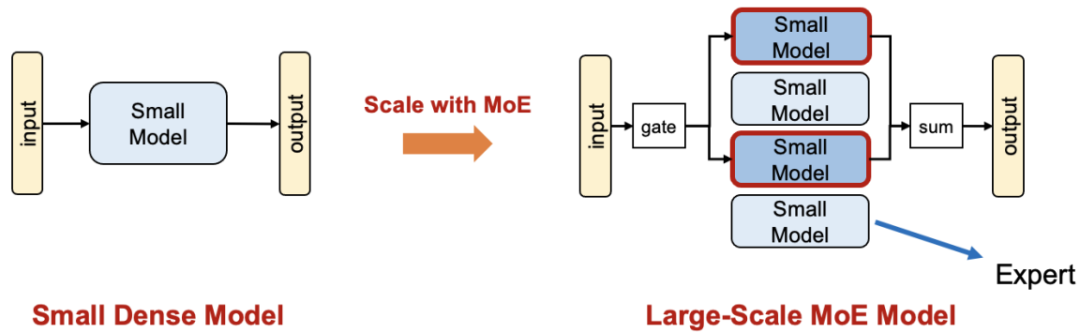
DeepSpeed powers 8x larger MoE model training with high performance ...
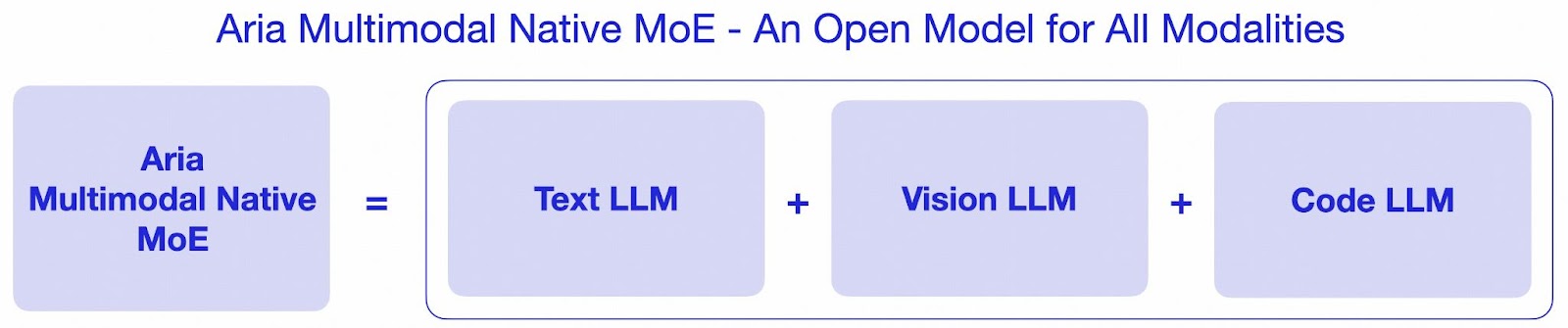
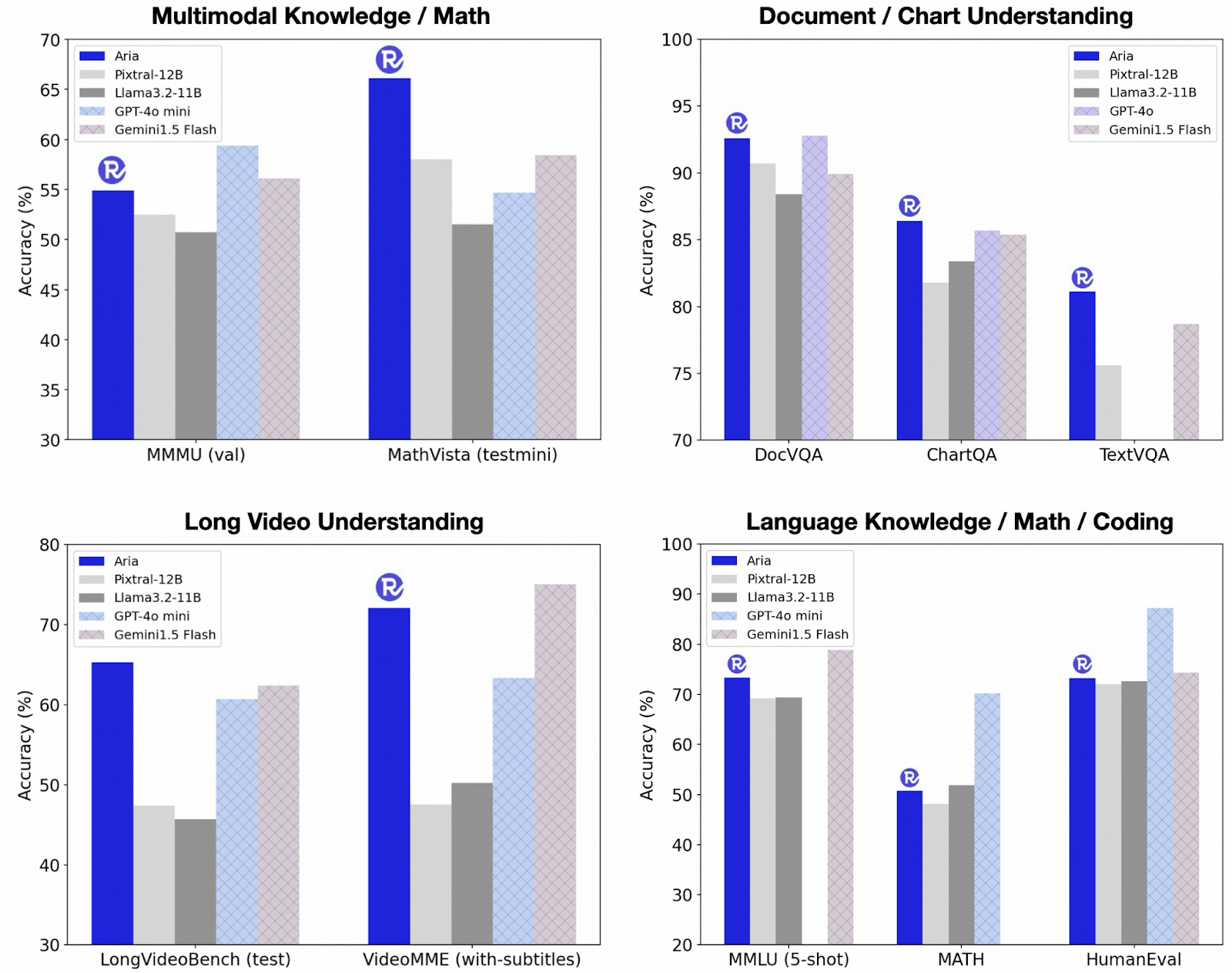
Rhymes AI Released Aria: An Open Multimodal Native MoE Model Offering ...
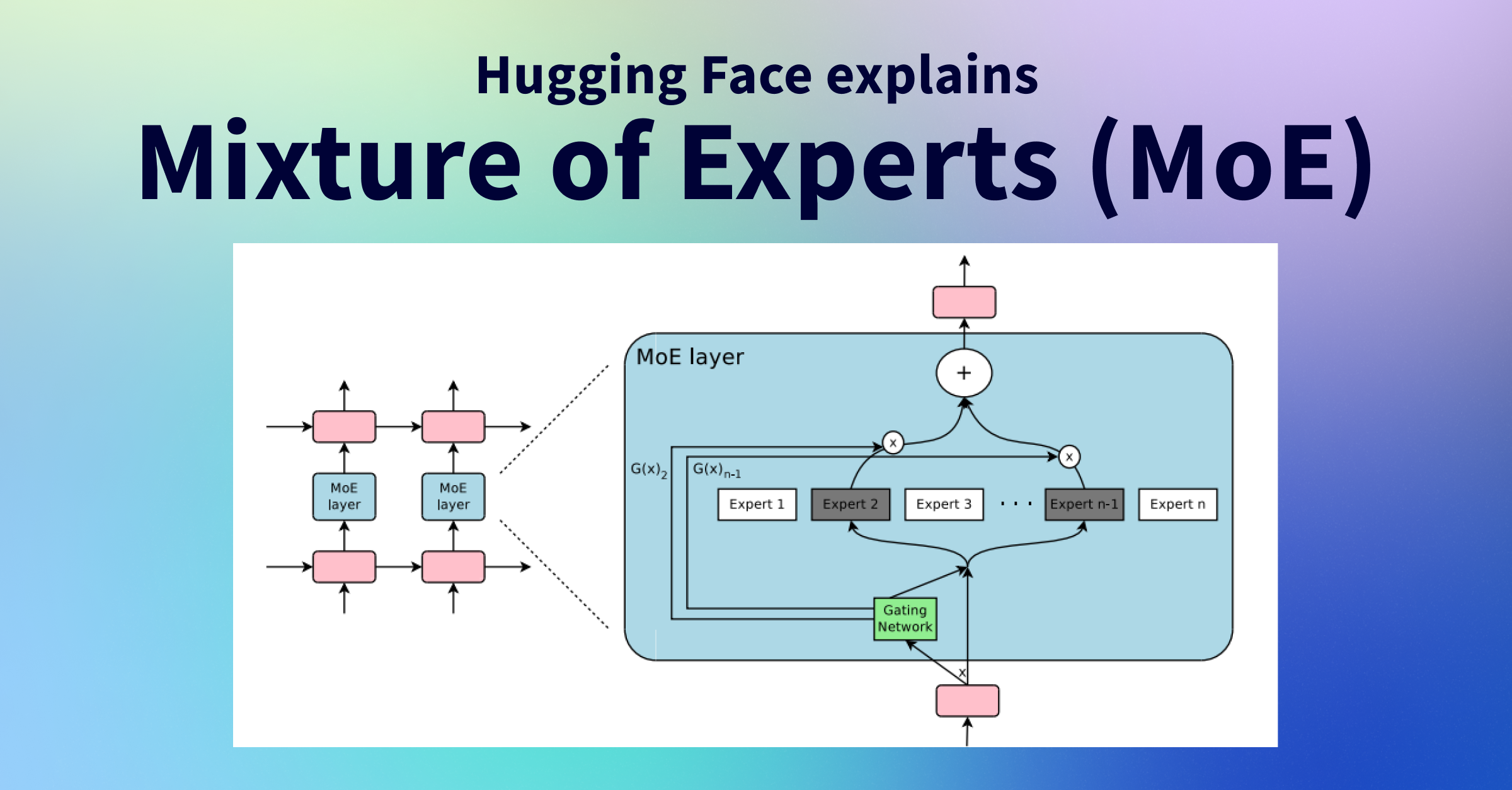
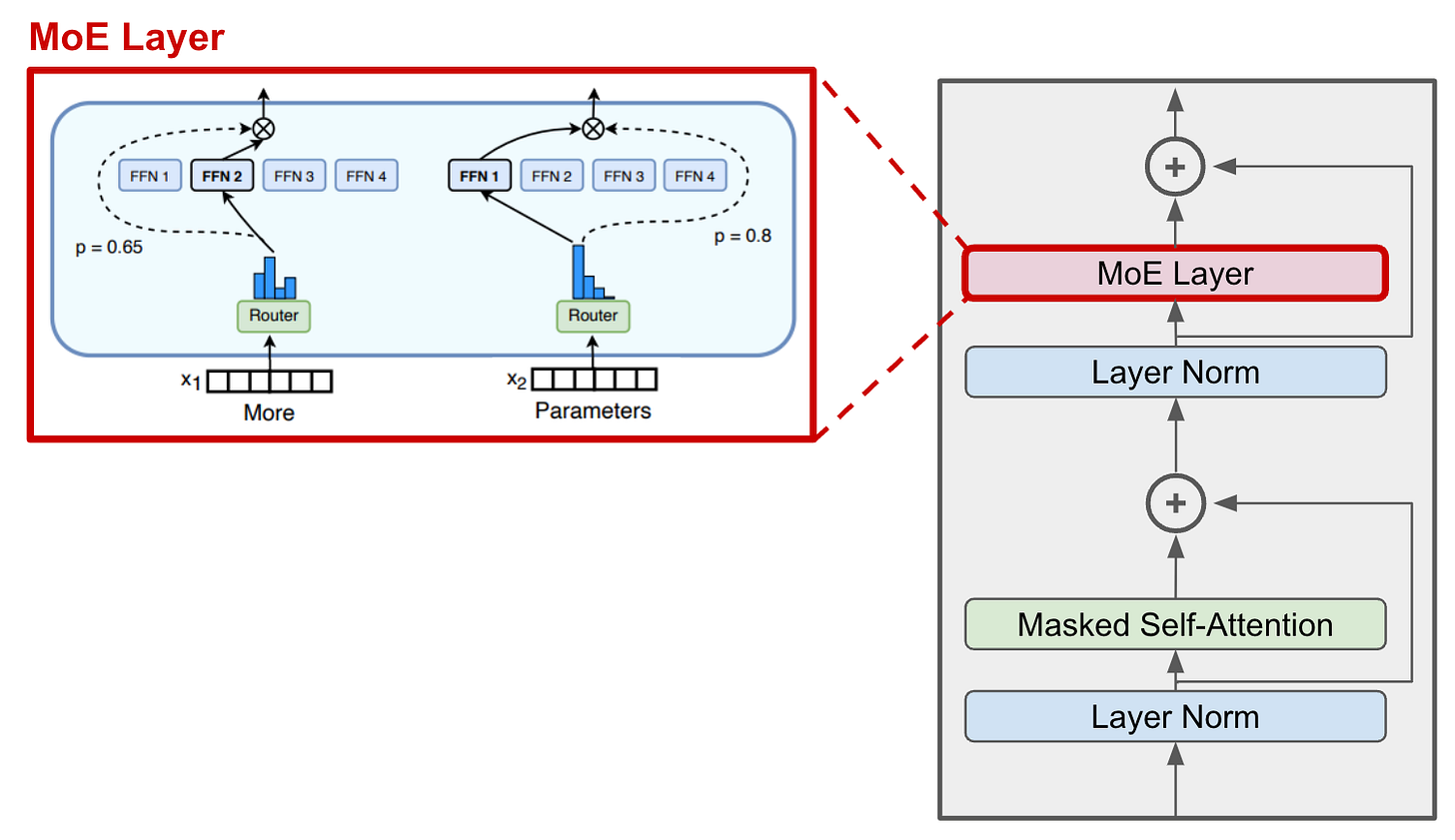
The all-to-all communication illustration of an MoE model with two ...
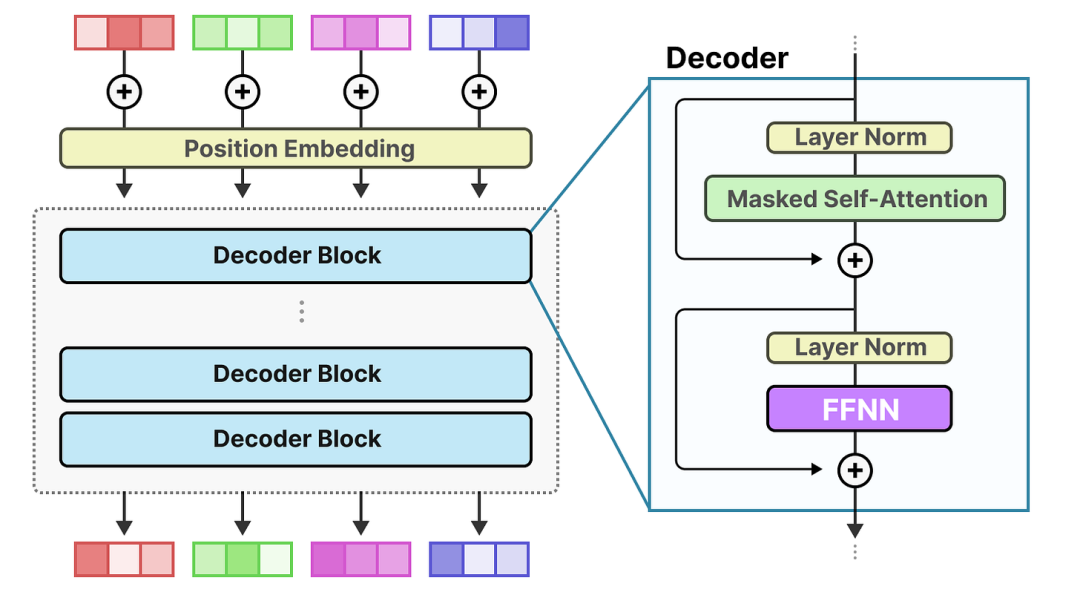
Build a Llama-Style MoE Model From Scratch (Part 1) | LLM Practical ...
Upcycled and Merged MoE Reward Model for Mitigating Reward Hacking | AI ...
MoE-Infinity - Offloading-Efficient MoE Model Serving | PDF | Cache ...
MoE model fits to behavior in Hierarchical and Flat conditions. Graph ...
Unlocking Mixture-of-Experts (MoE) LLM : Your MoE model can be ...
MoE Model Exam for Hotel Management 2023 | PDF | Hotel | Marketing
Accelerating MoE model inference with Locality-Aware Kernel Design 🔥 ...
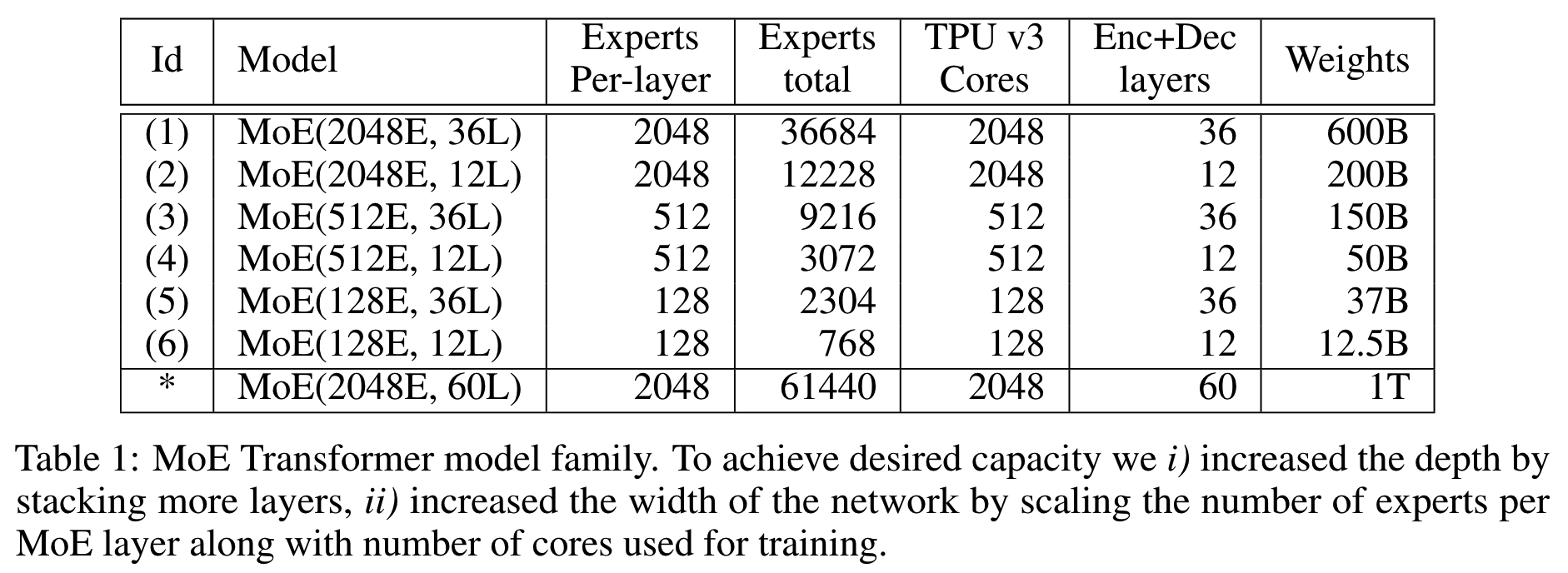
Enhanced MoE Parallelism, Open-source MoE Model Training Can Be 9 Times ...
MOE Model | PDF
How to Use the DeepSeek MoE Model fxis.ai
Architecture of an MoE prediction model for a single data point x i ...
Understanding Mixture of Experts: Building a MoE Model with PyTorch ...
2025 MOE Model Paper - II | PDF
Redefining AI with Mixture-of-Experts (MOE) Model
图解 MoE 模型_moe模型-CSDN博客
从零手写MOE大模型,复现 DeepSeek MOE 算法_sparsemoe (大模型训练使用)-CSDN博客
Introduction to Mixture-of-Experts | Original MoE Paper Explained
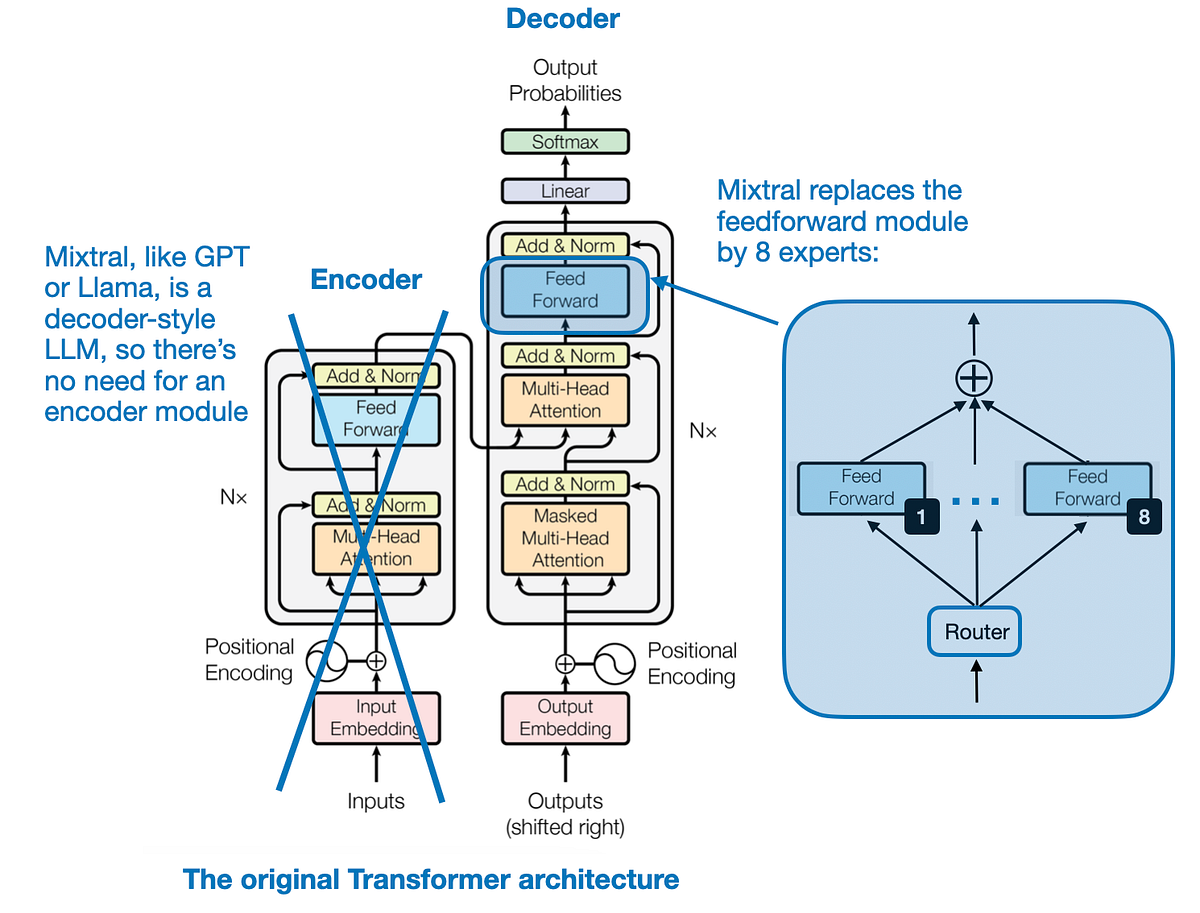
Mistral AI’s Latest Mixture of Experts (MoE) 8x7B Model – Unite.AI
MoE 入门介绍 核心工作回顾 模型篇 - 知乎
SlimMoE: Structured Compression of Large MoE Models via Expert Slimming ...
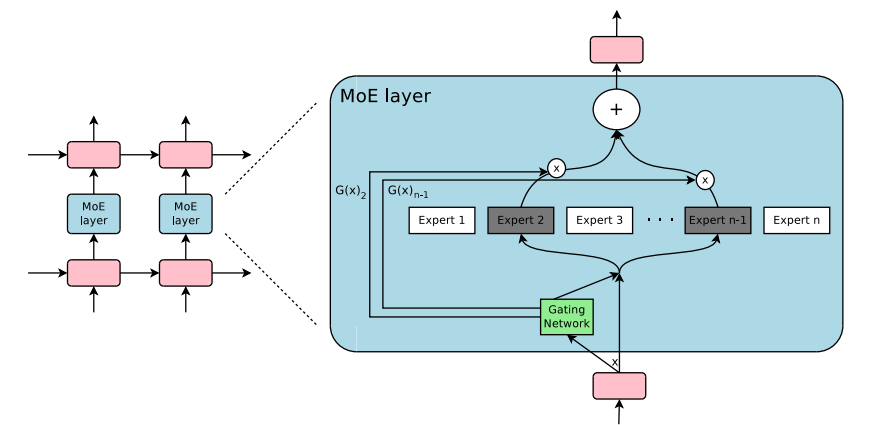
(a): An example of a MoE that can be used as a standalone learner or ...
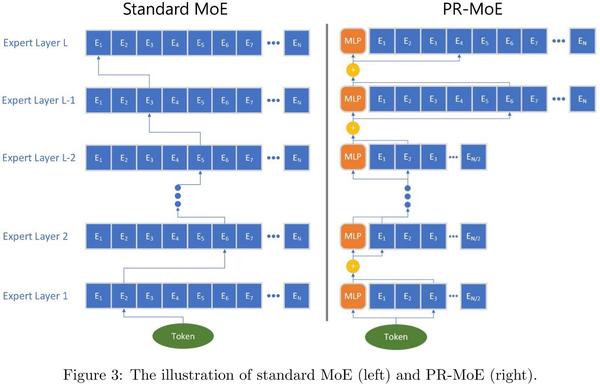
Getting Started with DeepSpeed-MoE for Inferencing Large-Scale MoE ...
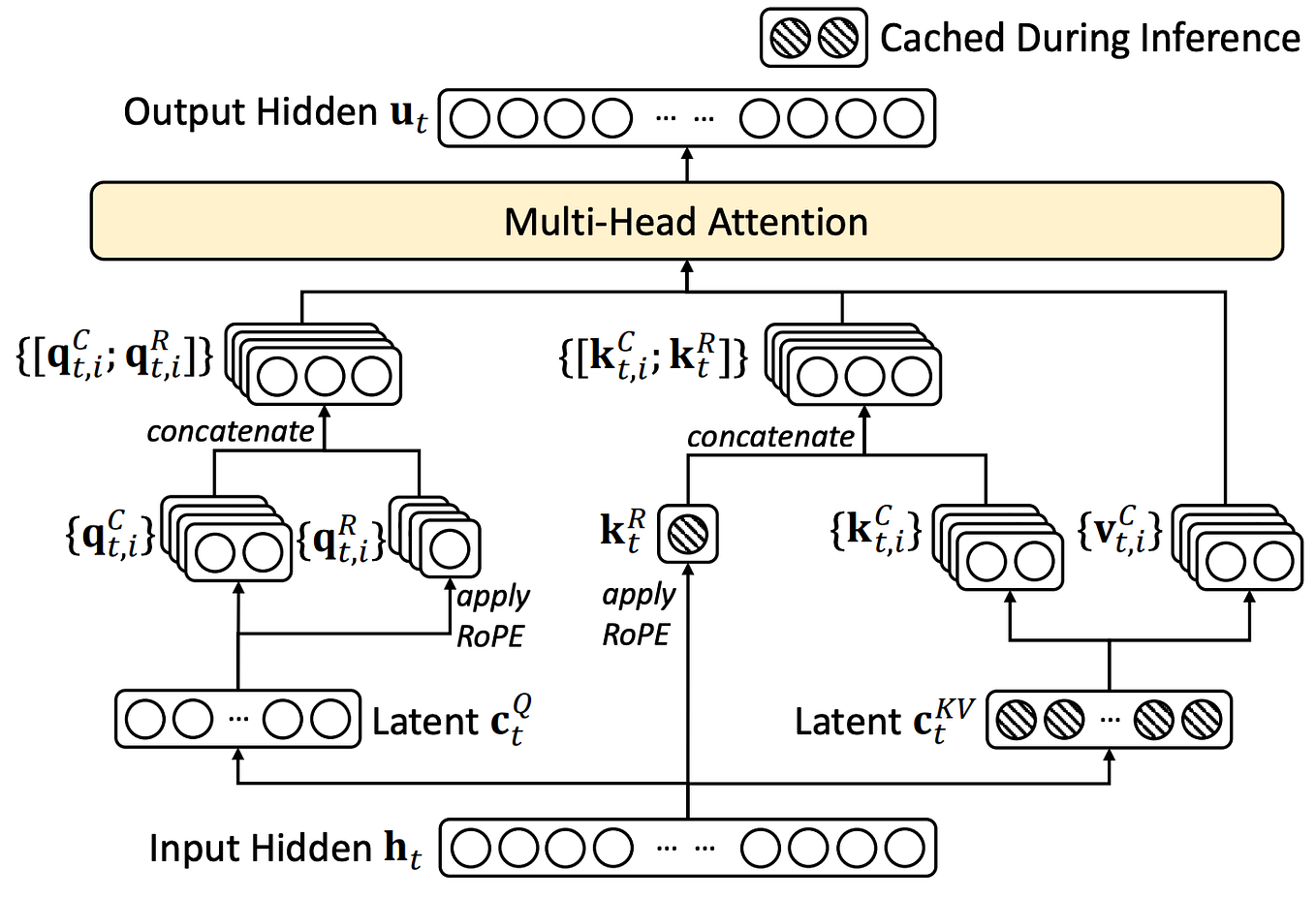
Illustration of an MoE model. A re-built version of Figure 3 from ...
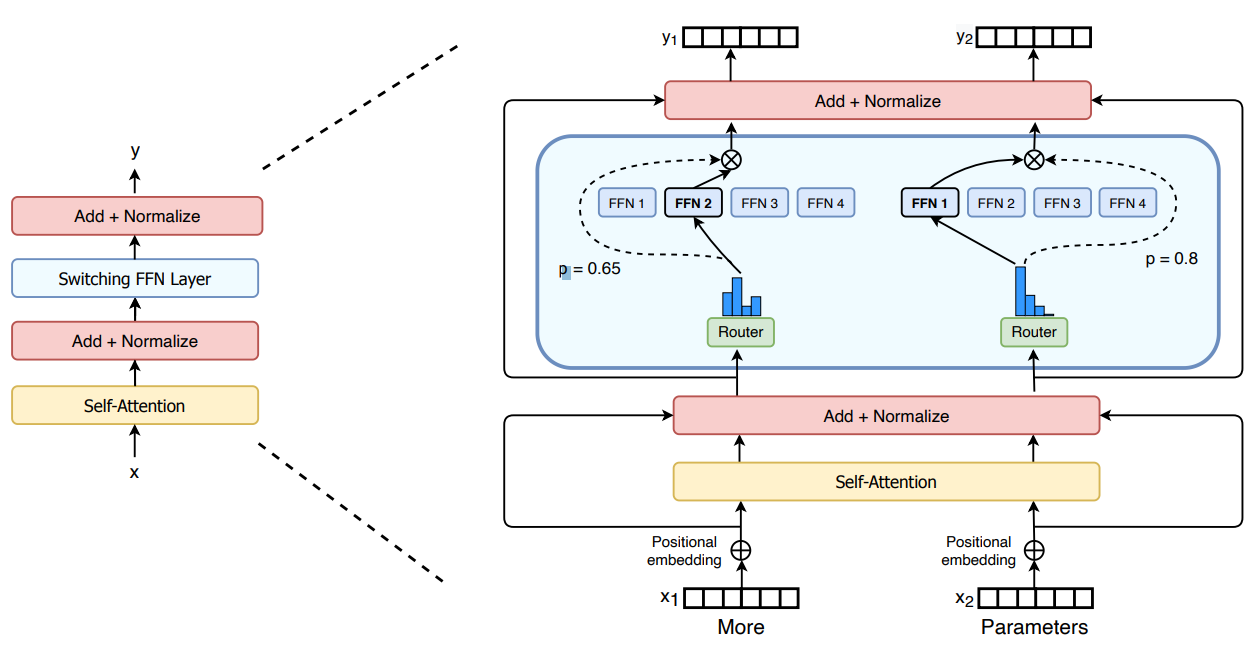
The standard MoE architecture. The outputs (classifications) from the ...
MoE Models & Cloud GPUs: The Perfect Match for AI Innovation - Novita
DS-MoE: Making MoE Models More Efficient and Less Memory-Intensive
For the baseline MoE model, we plot the steps corresponding to the best ...
Scaling Large MoE Models with Wide Expert Parallelism on NVL72 Rack ...
Scaling MoE Models with Distributed Training
All the Transformer Math You Need to Know | How To Scale Your Model
MoE models - a zh-ai-community Collection
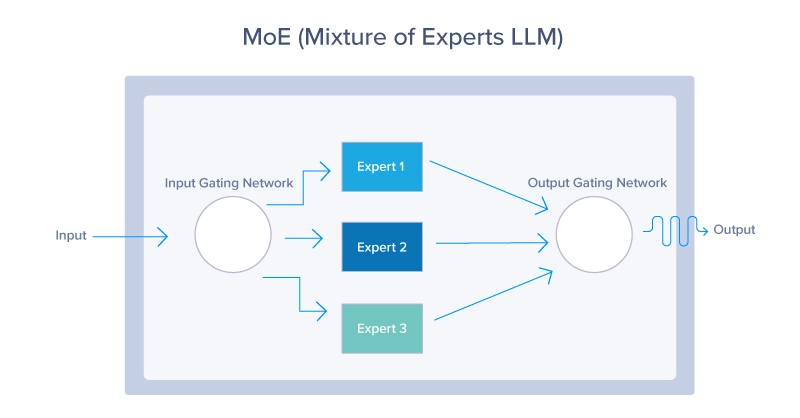
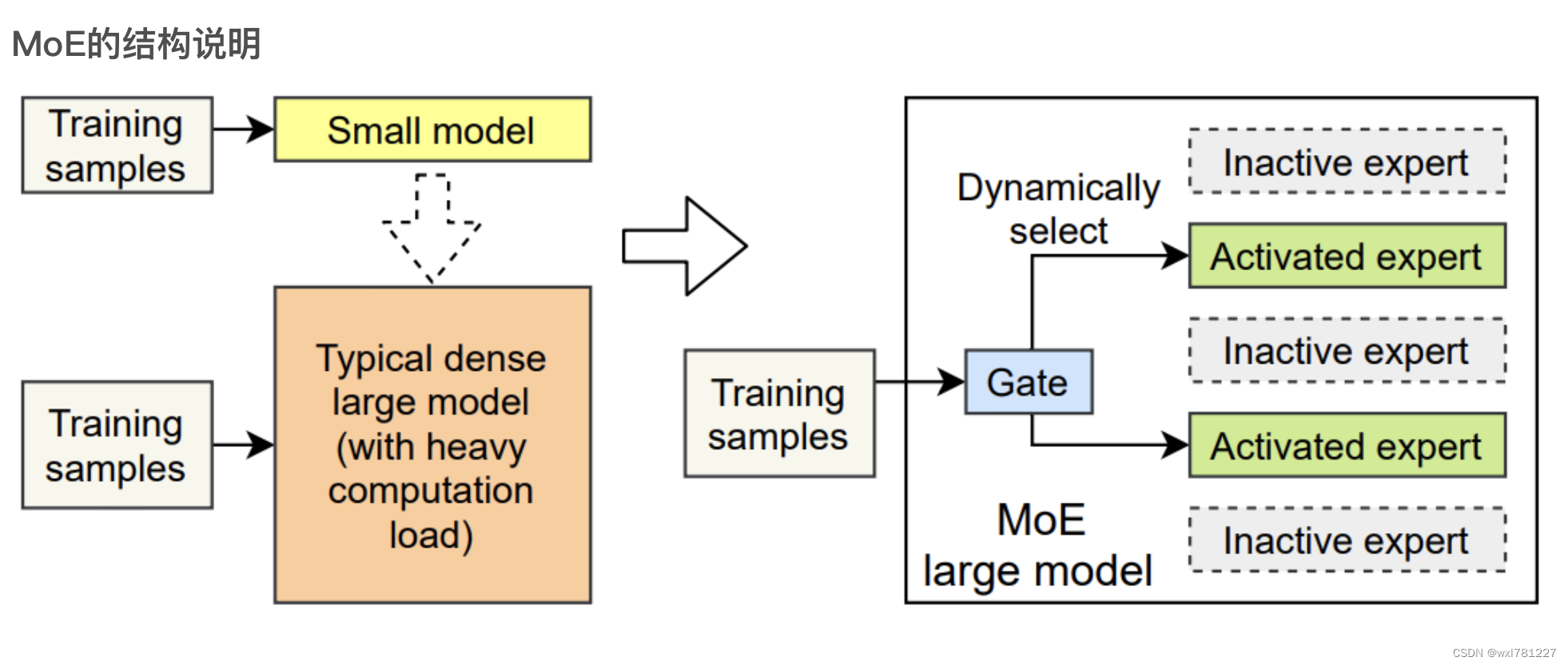
What is Mixture of Experts- MoE Architecture- Mixture of Experts in AI ...
Paper page - SlimMoE: Structured Compression of Large MoE Models via ...
Why large MoE models break latency budgets and what speculative ...
Paper page - AquilaMoE: Efficient Training for MoE Models with Scale-Up ...
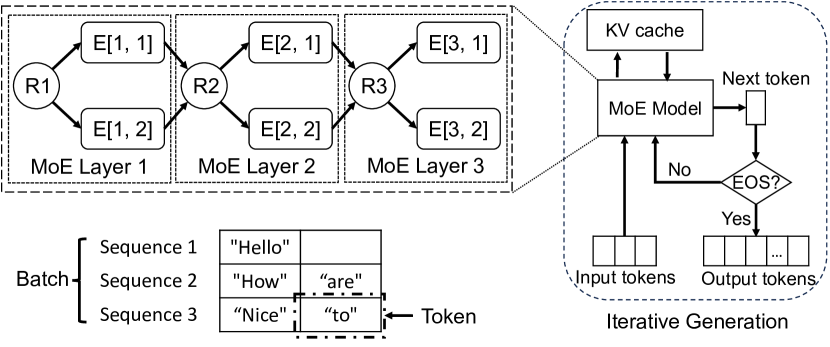
MoE models over a distributed setup with Expert Parallelism. | Download ...
Dynamic Expert Selection in MoE Models | PDF | Algorithms | Learning
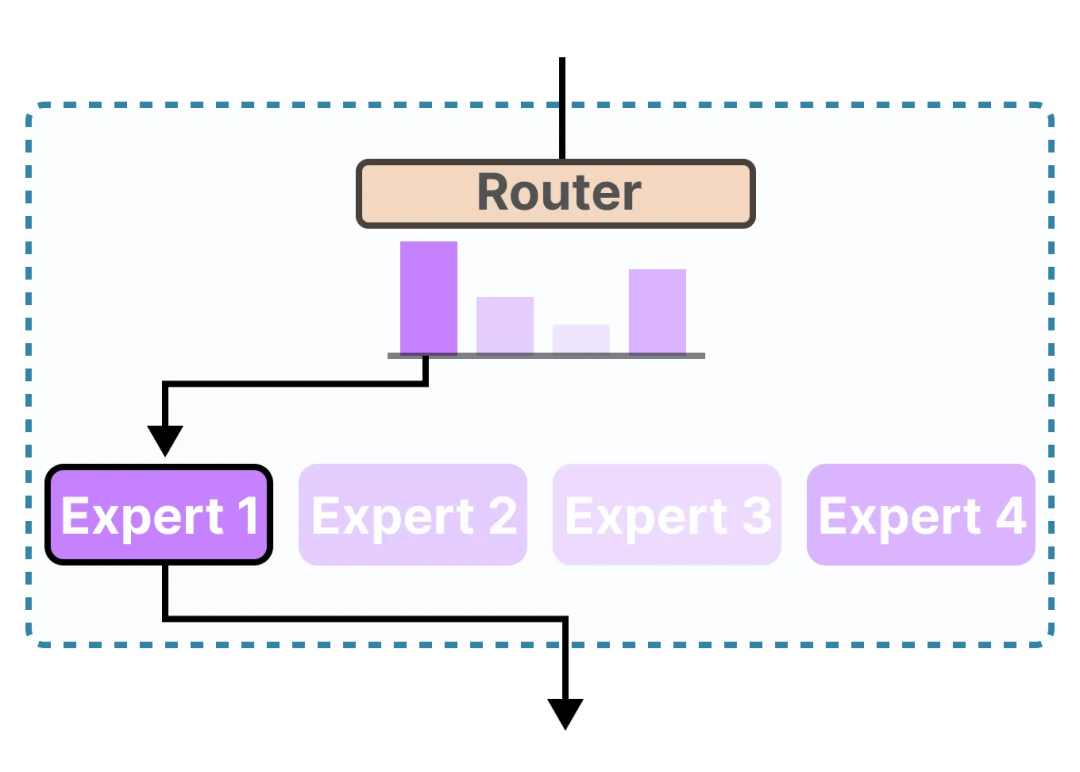
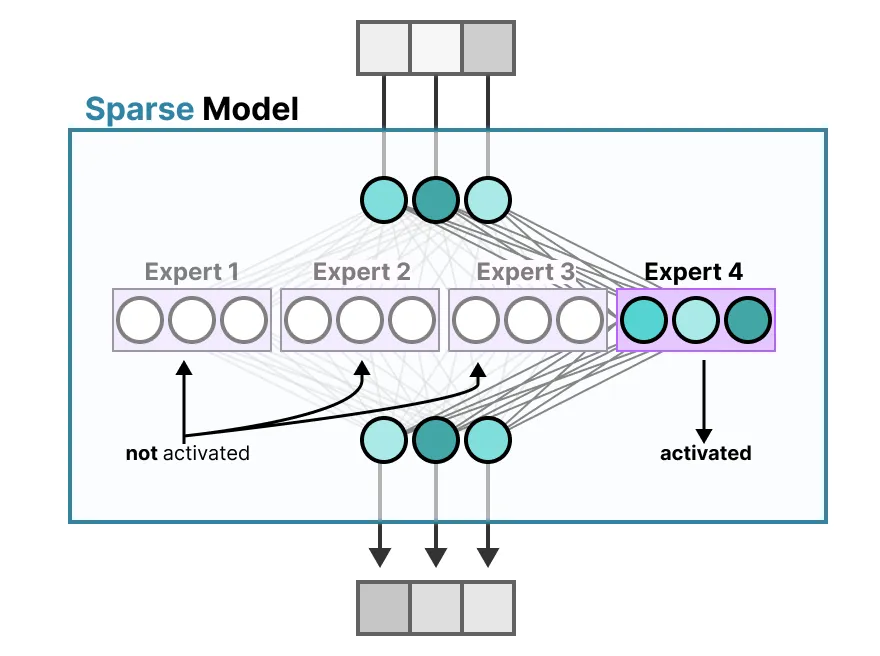
MoE (Mixture of Expert) Explained: How Sparse Models Are Changing Deep ...
MoE 模型原理:架构与理论
Fine-tuning Pre-trained MoE Models
Rethinking MoE Architectures: A Measured Look at the Chain-of-Experts ...
The validation curves of different MoE models based on 350M+MoE ...
Performance of MoE models with mlp as expert network | Download ...
Implementing a Mixture of Experts (MoE) Model Using PyTorch | by ...
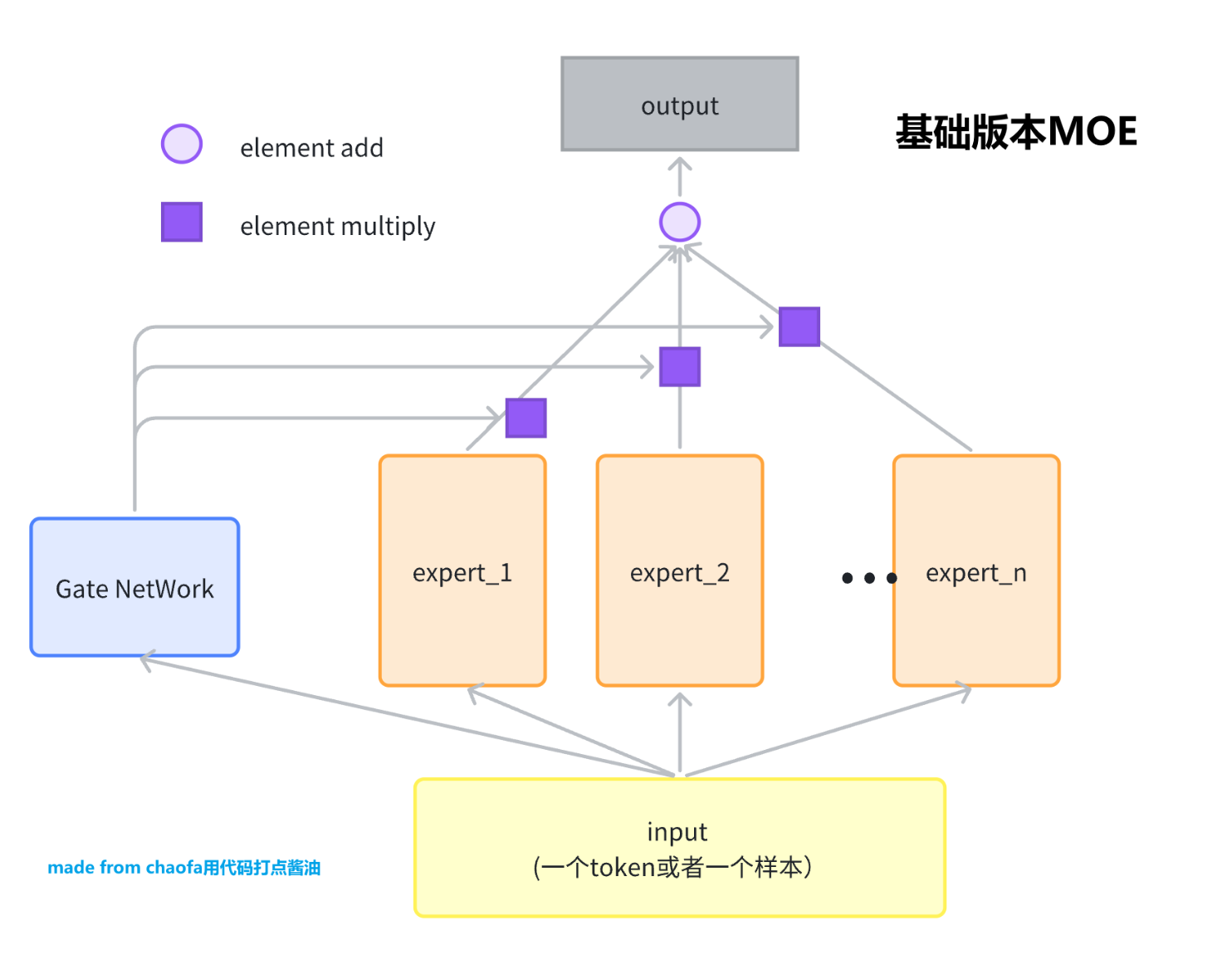
Mixture of experts (MoE) a, The MoE network models the forward ...
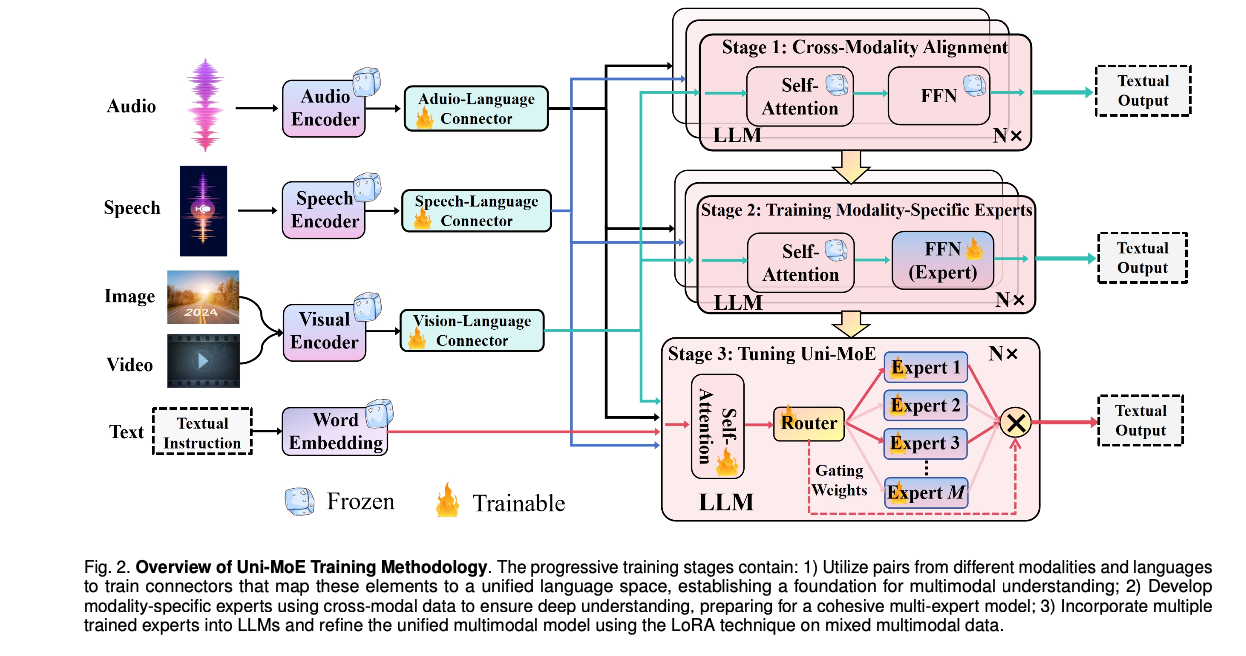
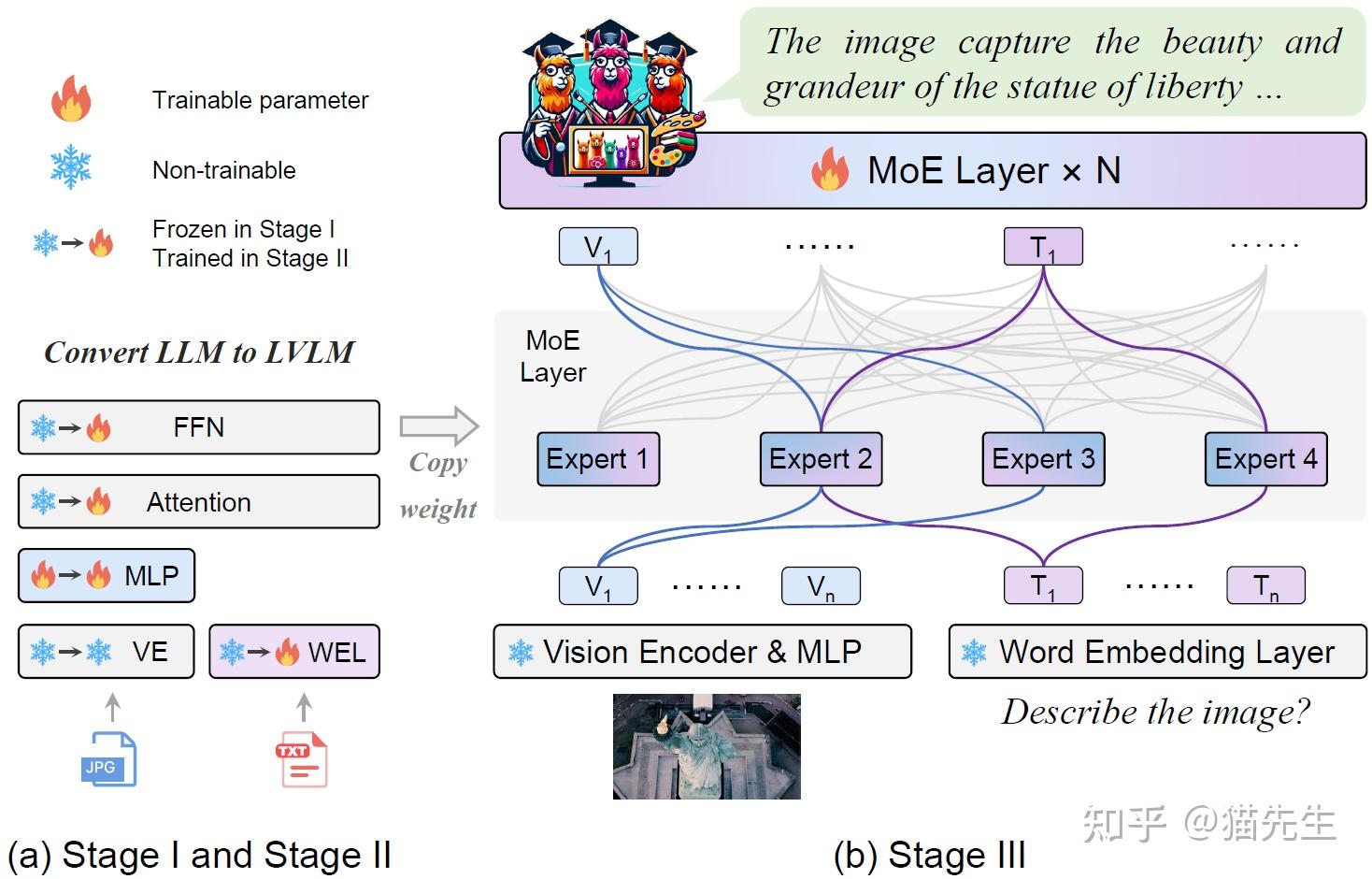
Uni-MoE: A Unified Multimodal LLM based on Sparse MoE Architecture ...
(Left): An example of a MoE that can be used as a standalone learner or ...
Next steps in your MoE journey - Scaling AI Models with Mixture of ...
Salesforce AI Research Introduces Moirai-MoE: A MoE Time Series ...
Carlos E. Perez on LinkedIn: 32 expert Mixture of Expert (Moe) model ...
Why the Newest LLMs use a MoE (Mixture of Experts) Architecture - KDnuggets
The illustration of various gating functions employed in MoE models ...
Mixture of Experts DeepSeek: How MoE Models Work | CodeForGeek
An image retrieval example by the model without experts and MoE-hash on ...
The configuration of different MoE models used for the performance ...
MoE 模型全解析:从架构原理到训练优化,一文掌握稀疏大模型核心技术_moe 训练-CSDN博客
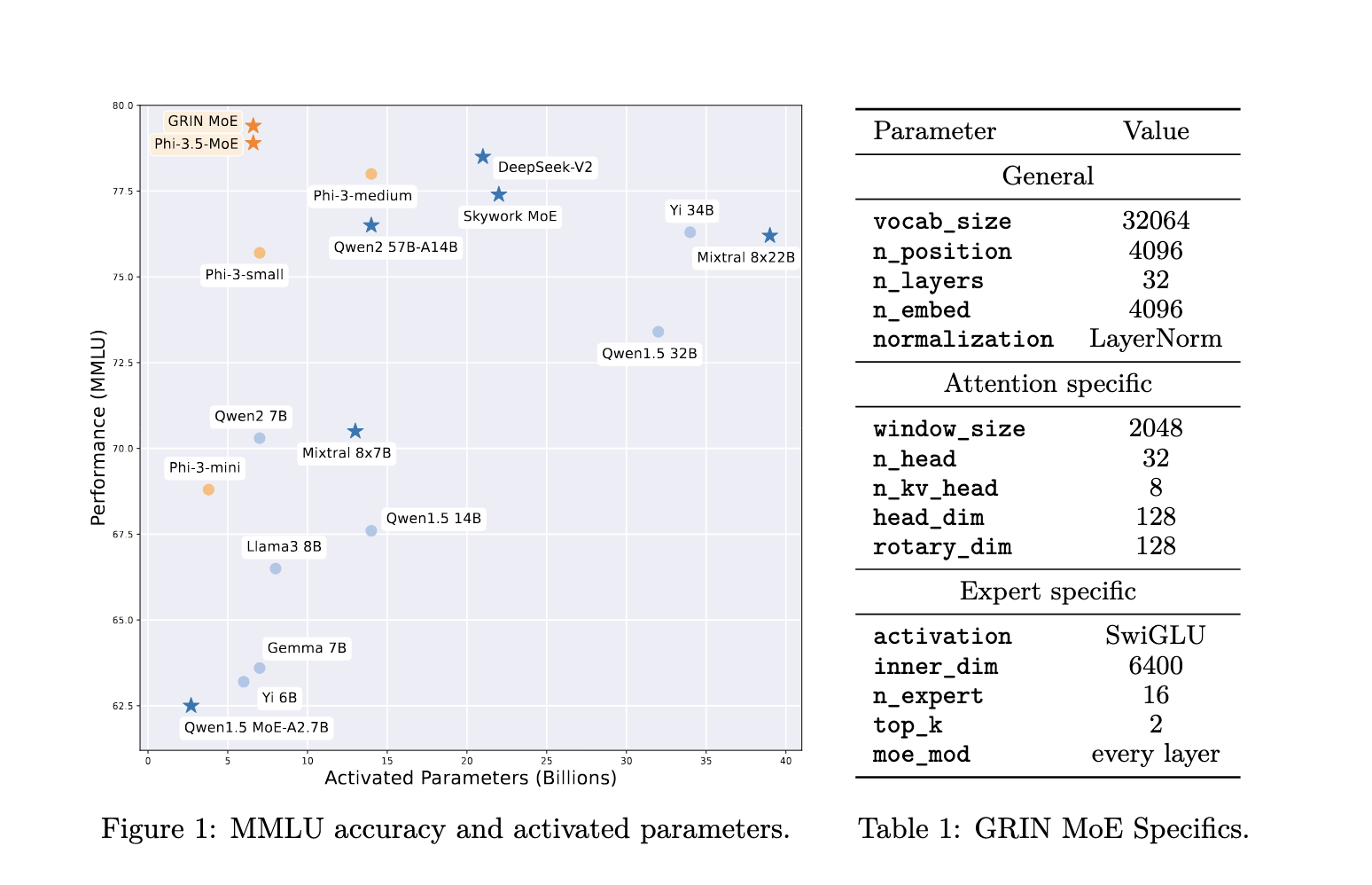
Microsoft Releases GRIN MoE: A Gradient-Informed Mixture of Experts MoE ...
Mixture-of-Experts (MoE) Models: Structure and Trade-offs
What Is Mixture of Experts (MoE) in Machine Learning
PPT - Carolyn Holcroft , Foothill College Craig Rutan, Santiago Canyon ...
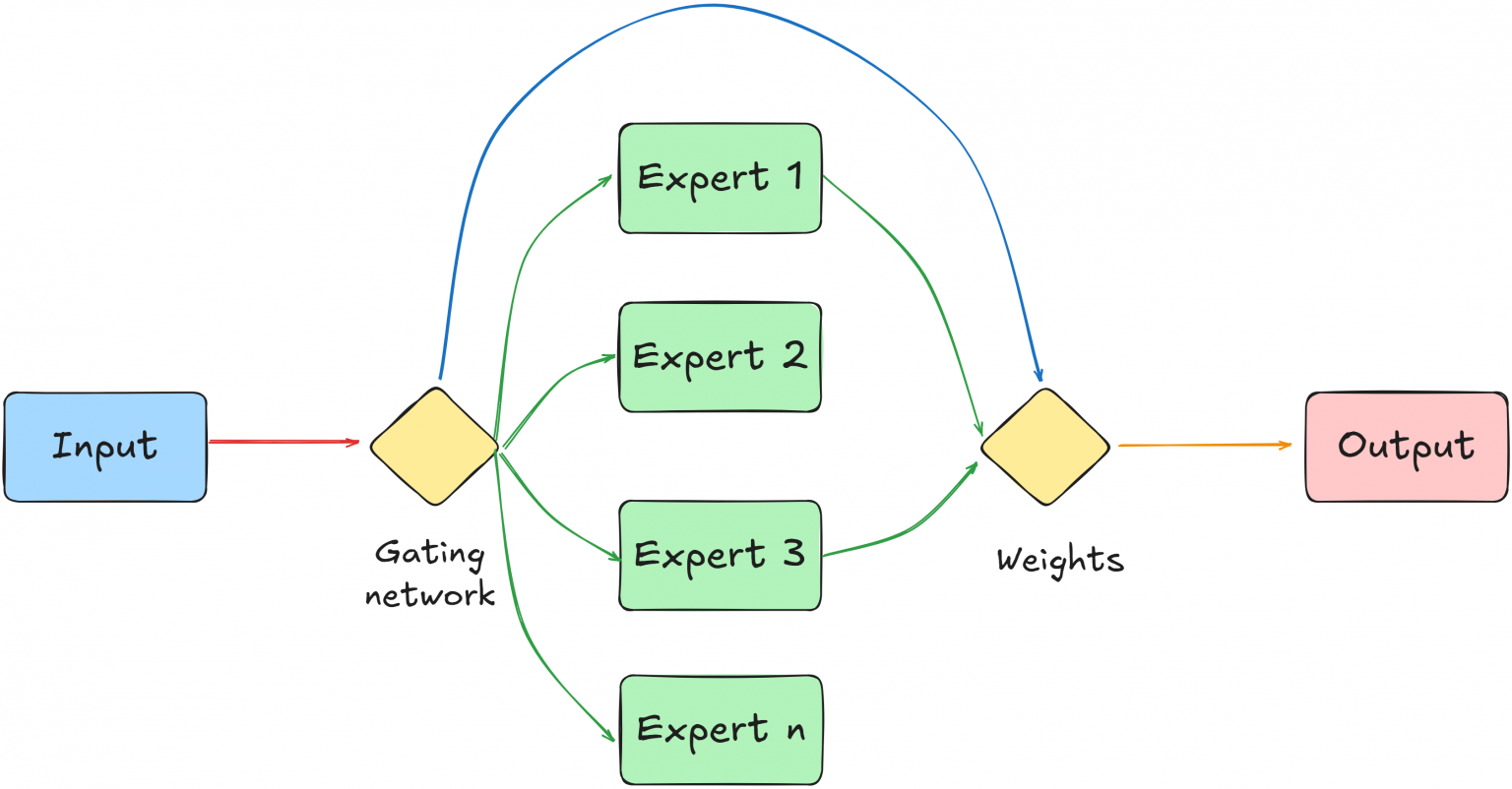
What is Mixture of Experts (MoE)? - GeeksforGeeks
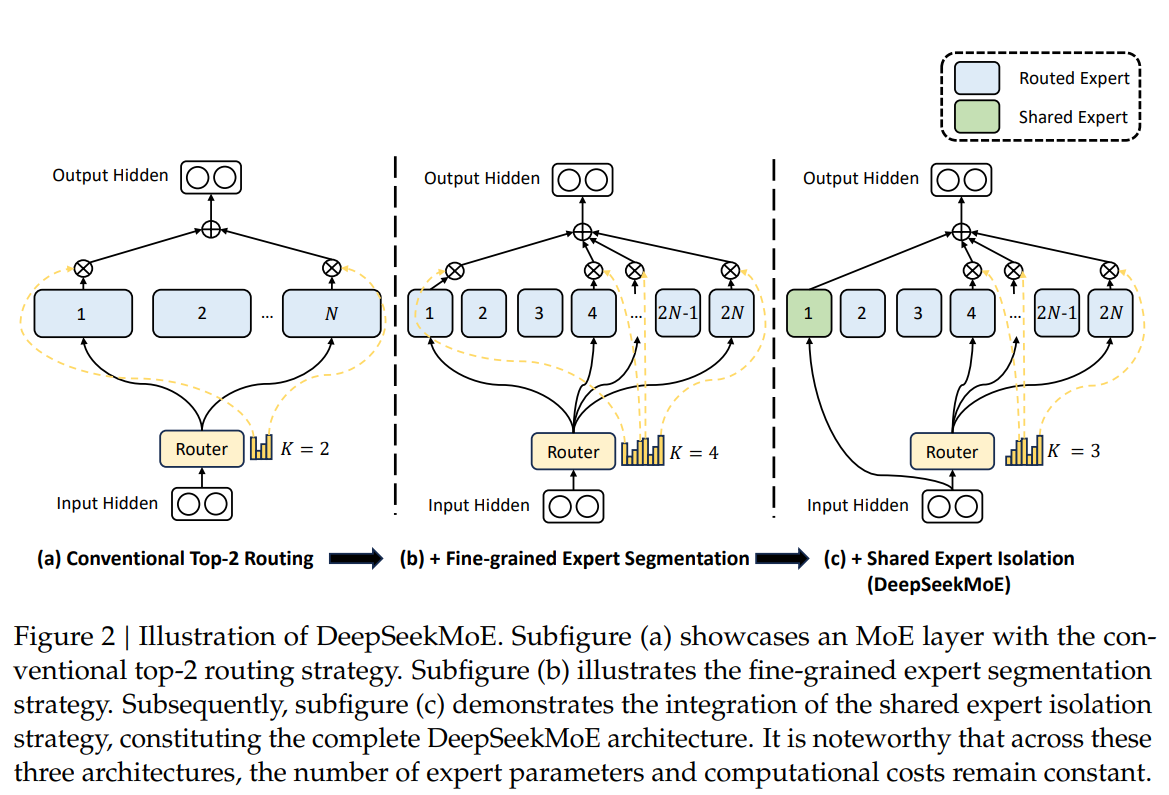
DeepSeek-AI Proposes DeepSeekMoE: An Innovative Mixture-of-Experts (MoE ...
DeepSpeed-MoE - 知乎
Researchers from Princeton and Meta AI Introduce 'Lory': A Fully ...
Mixture-of-Experts (MoE): The Birth and Rise of Conditional Computation
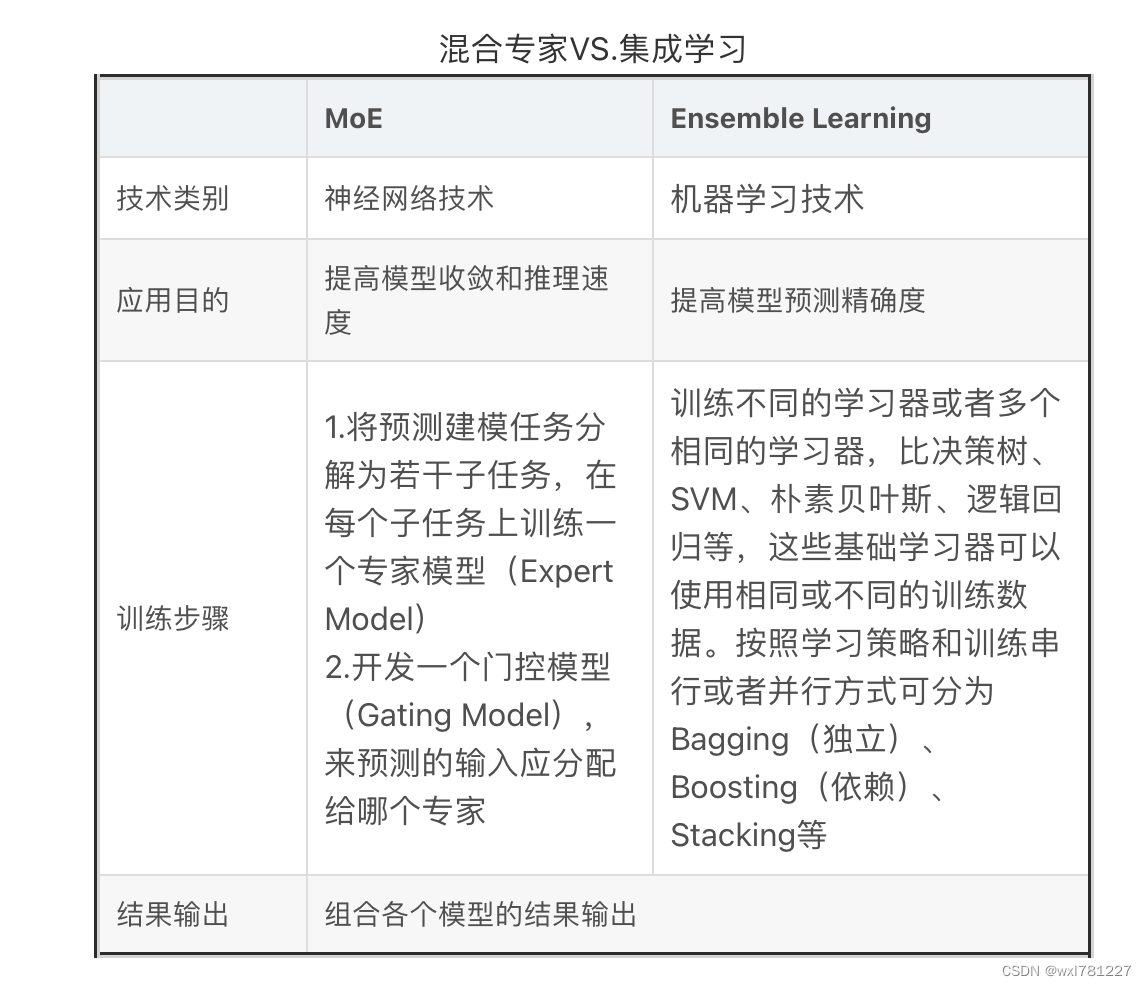
混合专家模型 (MoE) 详解 - 知乎
Demystifying Mixture-of-Experts (MoE) Layers | by Dipankar | Medium
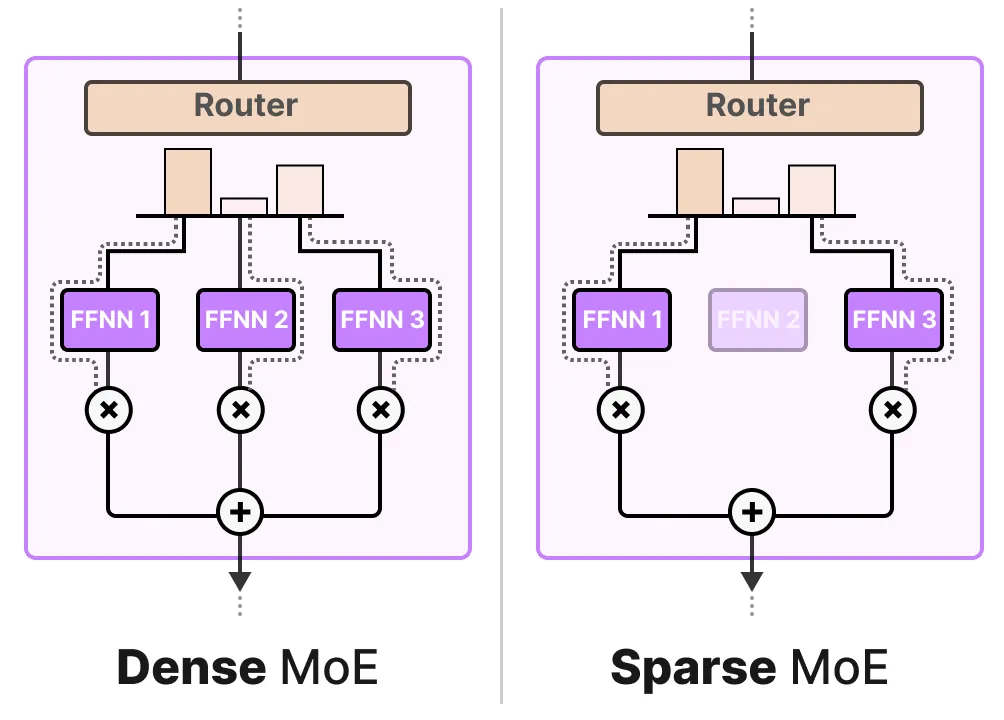
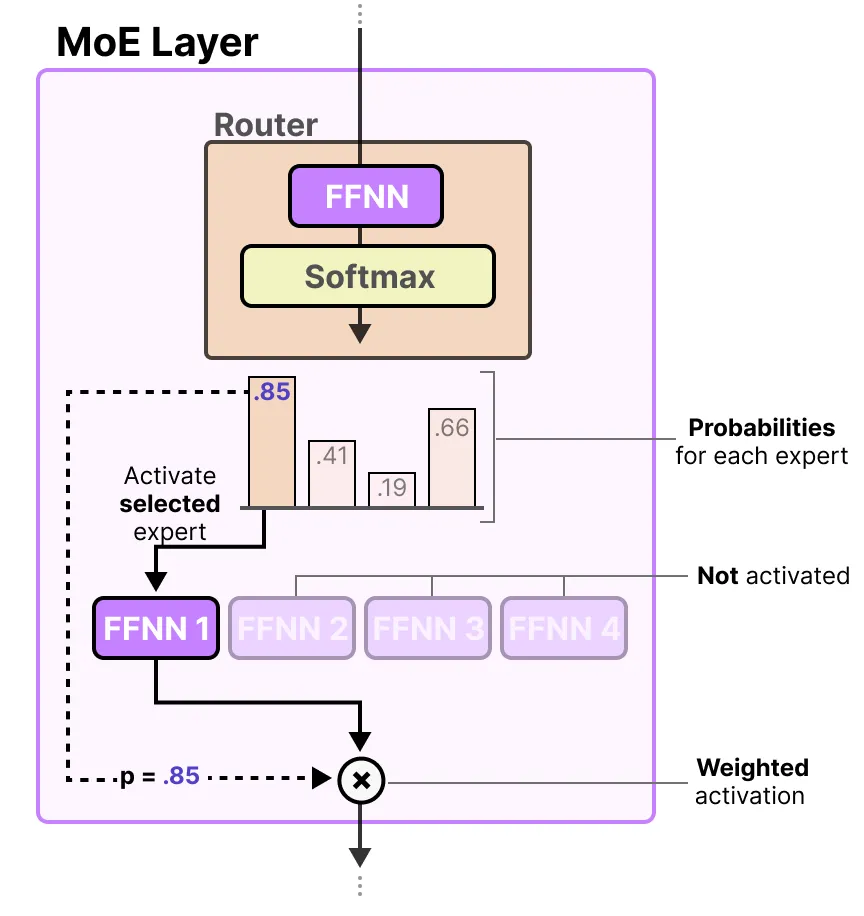
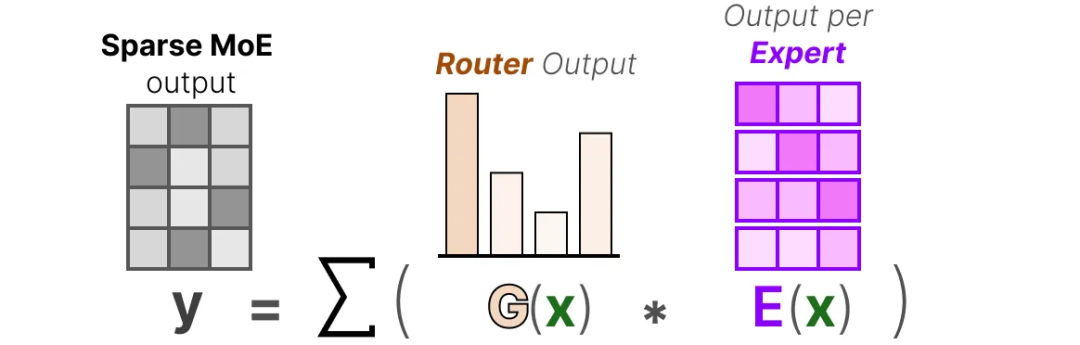
50张图,直观理解混合专家(MoE)大模型_maarten grootendorst-CSDN博客
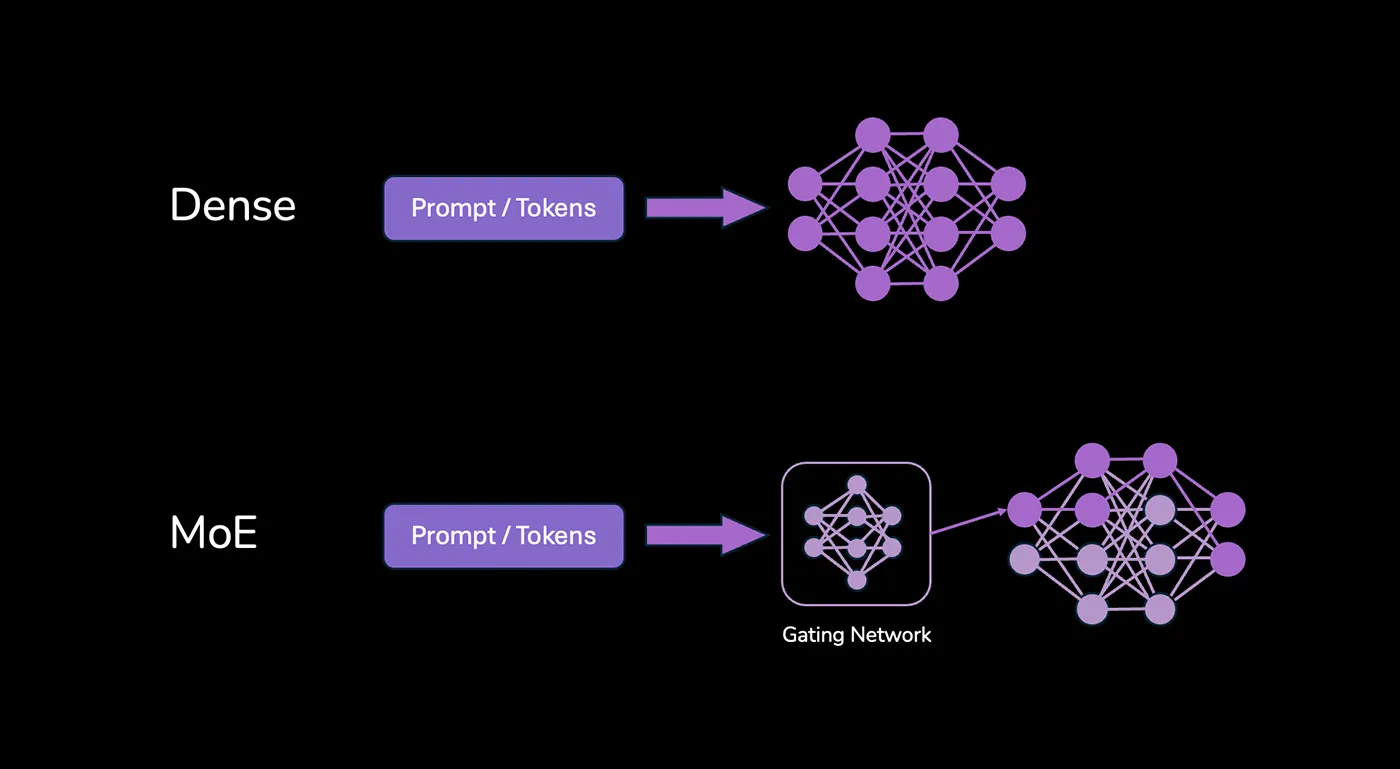
Mixture of Experts (MoE) vs Dense LLMs
小白必看:MoE 架构详解(大模型入门指南),一篇搞定!_moe框架-CSDN博客
[2401.14361] MoE-Infinity: Activation-Aware Expert Offloading for ...
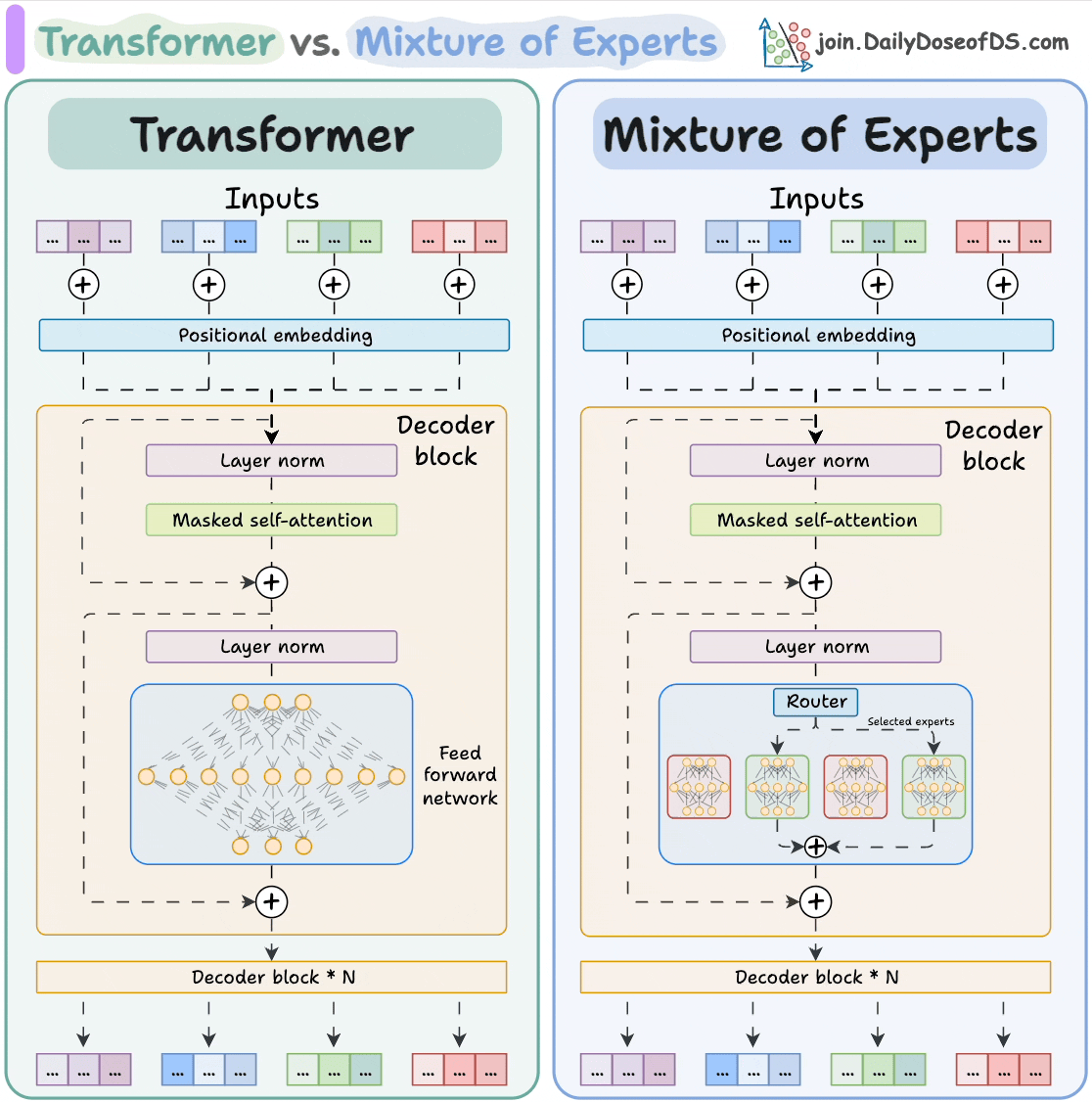
Let's talk about dense models and Mixture of Experts (MoE) models But ...
快速理解MoE模型-CSDN博客
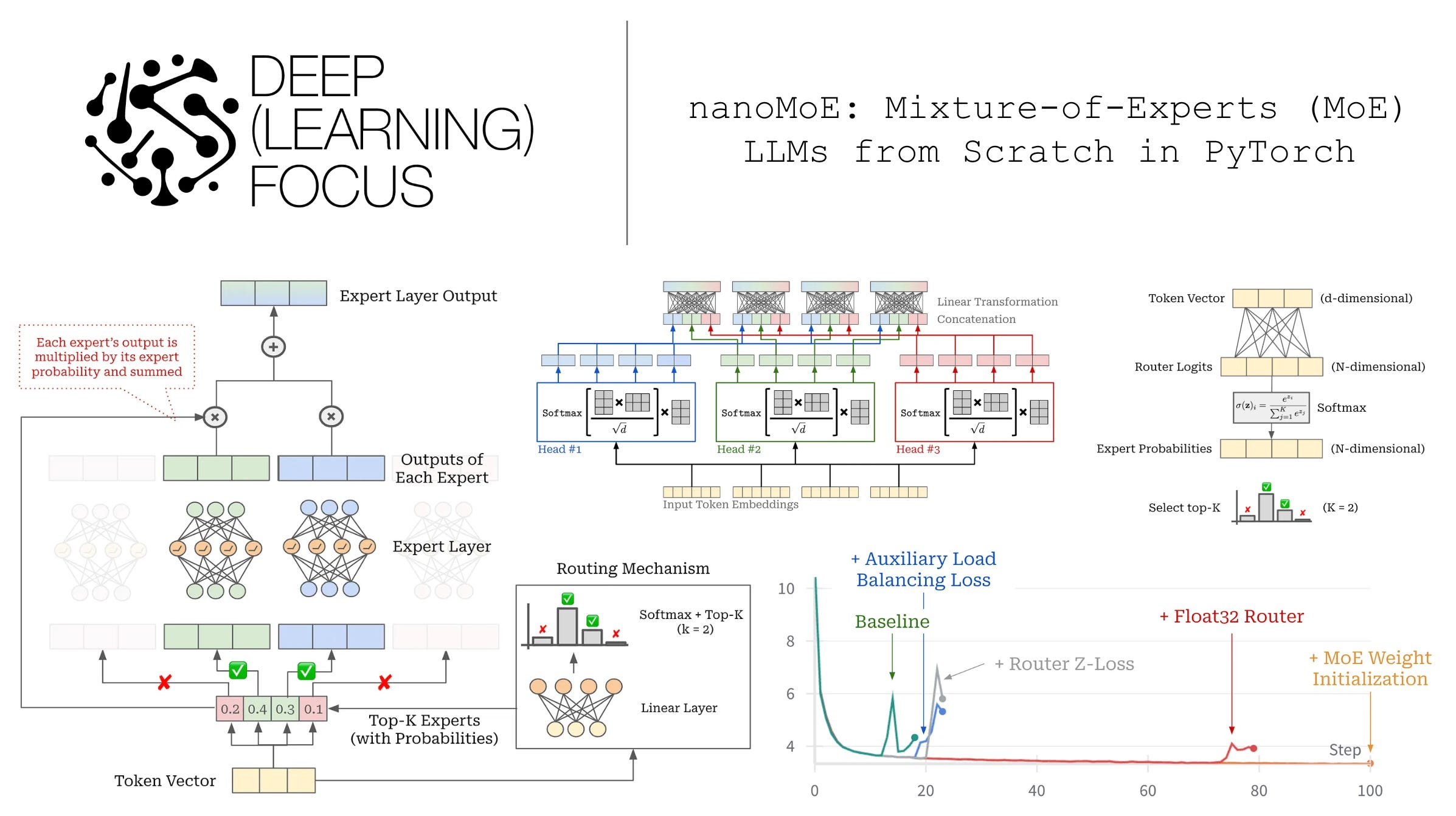
nanoMoE: Mixture-of-Experts (MoE) LLMs from Scratch in PyTorch
大模型Transformer的MOE架构介绍及方案整理-CSDN博客
大模型从0到1|第四讲:详解MoE架构 - WuJing's Blog
GitHub - ckhinvasara/MoE-Model-for-Bias-Detection
Mixture of Experts (MoE) in AI Models Explained | by Marko Vidrih | GoPenAI
Understanding Mixture of Experts (MoE) Neural Networks | IntuitionLabs
一文搞懂什么是MoE模型!DeepSeek为什么采用与主流大模型不一样的MoE架构?_deepseek模型里门控网络输出是8个概率还是256个 ...
清华发布SmartMoE:一键实现高性能MoE稀疏大模型分布式训练-腾讯云开发者社区-腾讯云
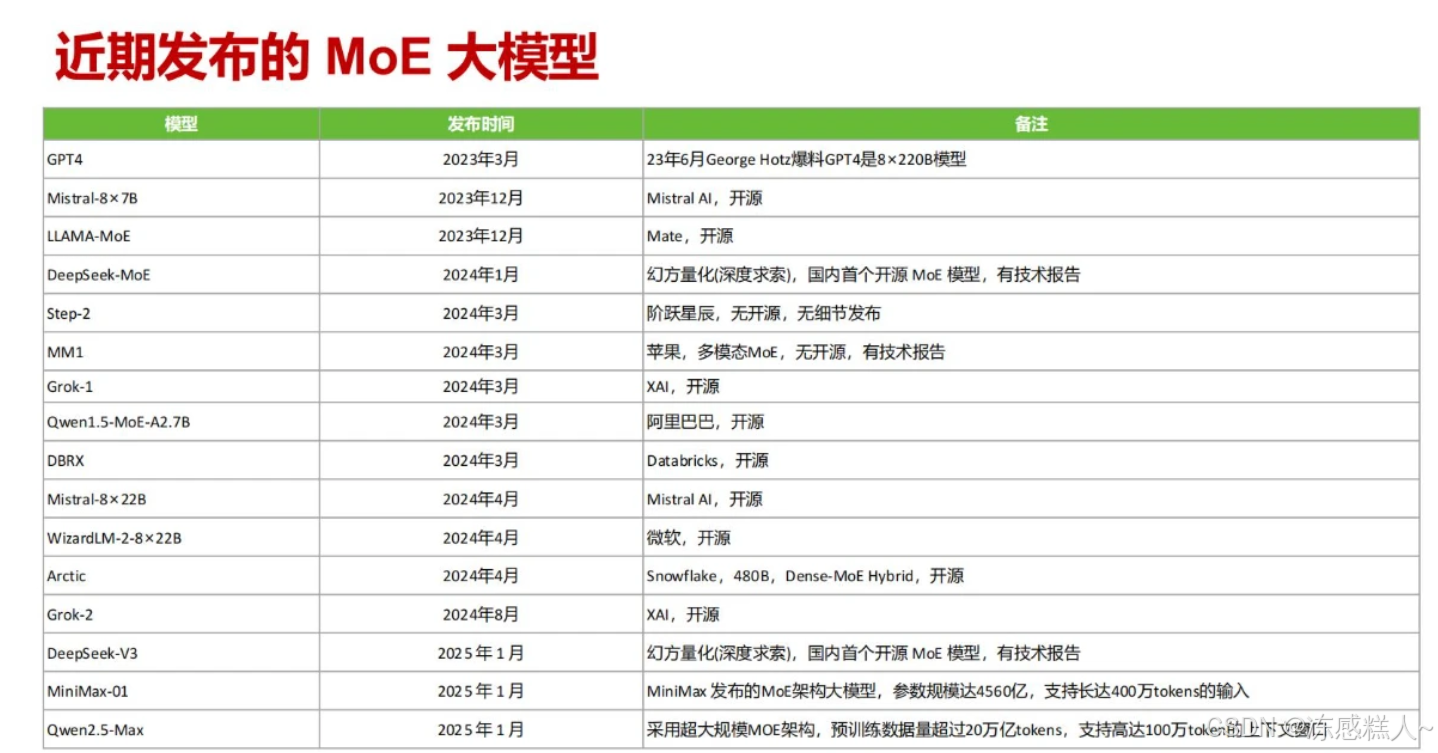
The Rise of MoE: Comparing 2025’s Leading Mixture-of-Experts AI Models
[2201.05596] DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and ...
MoE模型的前世今生 - 知乎
MOIRAI-MOE: Upgrading MOIRAI with Mixture-of-Experts for Enhanced ...
Mixture of Experts (MoE) Models: The Future of AI
Advancing Accuracy in Energy Forecasting using Mixture-of-Experts and ...
一周前被MoE刷屏?来看看LoRAMoE吧!通过类MoE架构来缓解大模型世界知识遗忘-CSDN博客
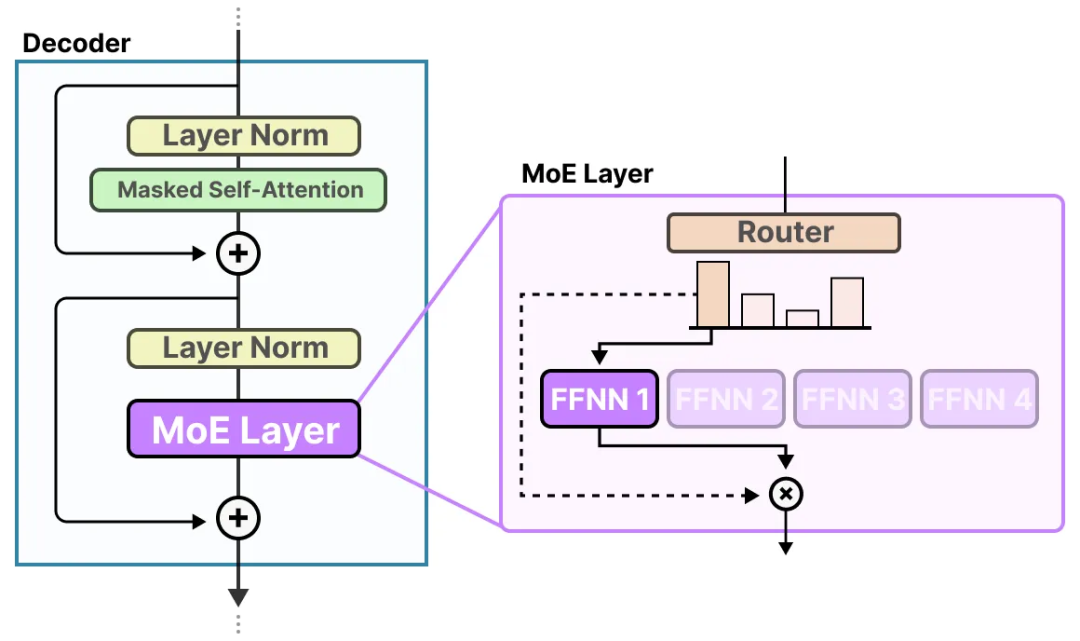
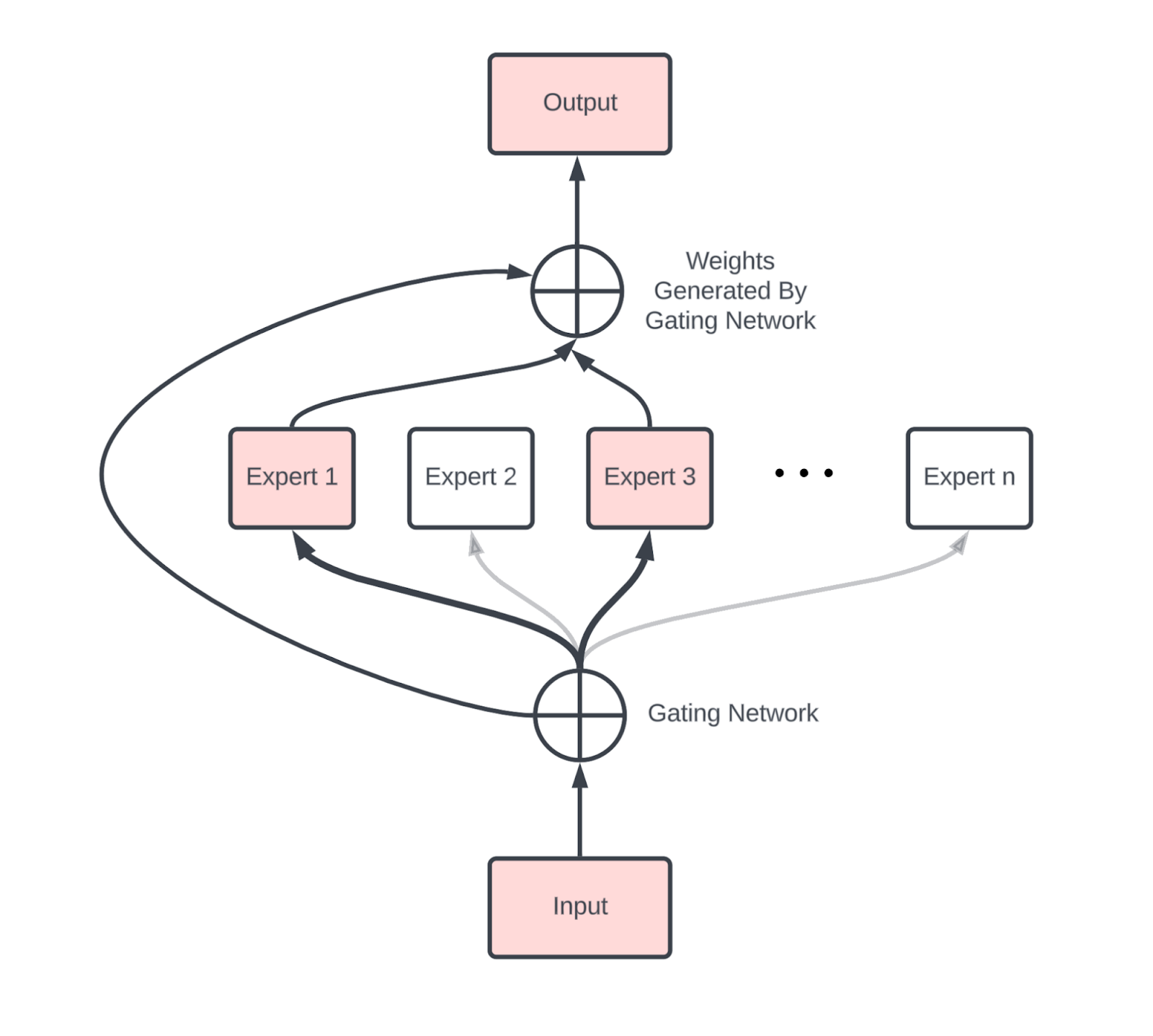
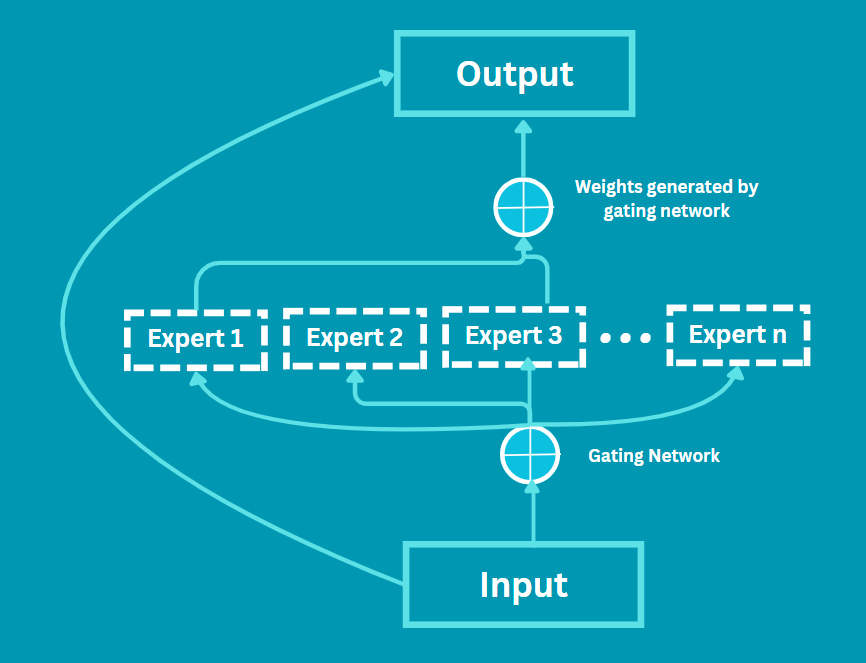
Original Mixture of Experts (MoE) architecture with 3 experts and 1 ...
Mixtures of Expert (MoE) models have rapidly become one of the most ...
Cerebras
一文详解MoE模型(超全面) - 知乎
MoE(Mixture-of-Experts)架构的大模型具体怎么训练? - 知乎
Mixture-of-Experts (MoE) Models: Scaling Efficiently Beyond 1T Parameters
MOE-Model For Exit - 2015 NO ANS | PDF
详解专家混合:MoE模型 - 知乎