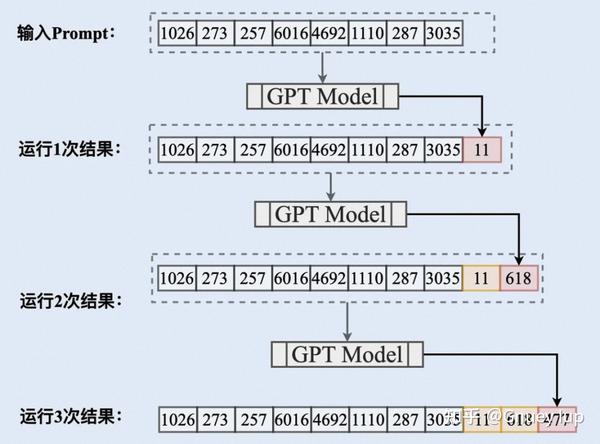
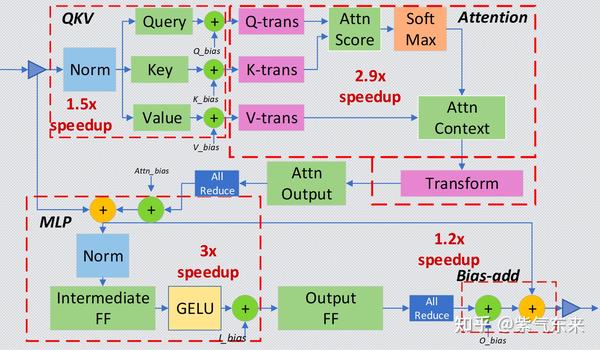
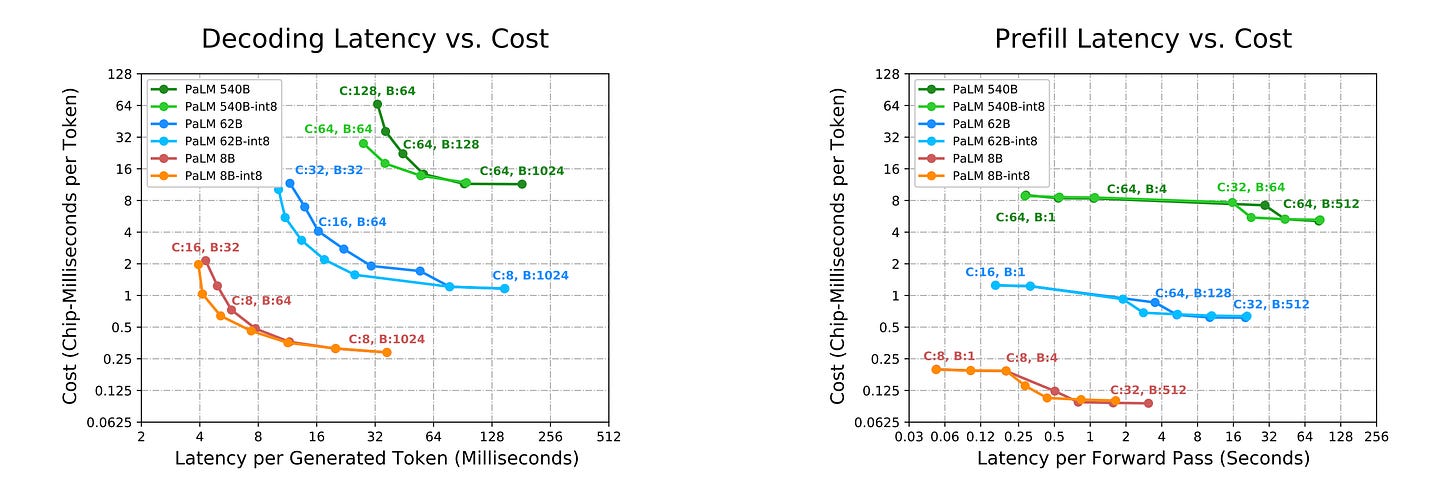
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Framework of the proposed method for the inference phase | Download ...
Overview of the inference phase of the proposed architecture ...
Independence illustration of inference phase with Bayesian network ...
Visual representation of the results of the inference phase within the ...
Figure 1 from An Iteratively Parallel Generation Method with the Pre ...
Method Overview: Phase II -Inference. In the inference phase, the ...
Posterior inference and prior generation in Experiment 1. Interaction ...
Text Generation Inference | Grafana Labs
PriMed inference phase methodology | Download Scientific Diagram
Machine Learning Model Training/Building and Inference Phase Overview ...
Demystifying AI Inference Deployments for Trillion Parameter Large ...
Streamlining AI Inference Performance and Deployment with NVIDIA ...
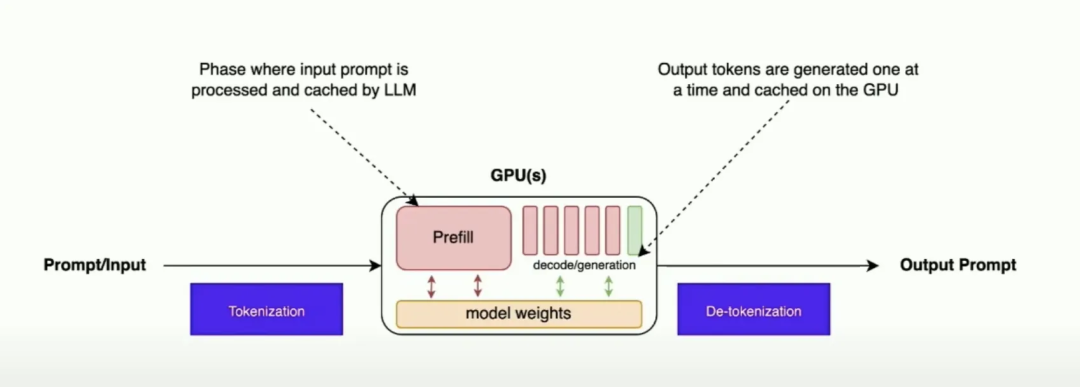
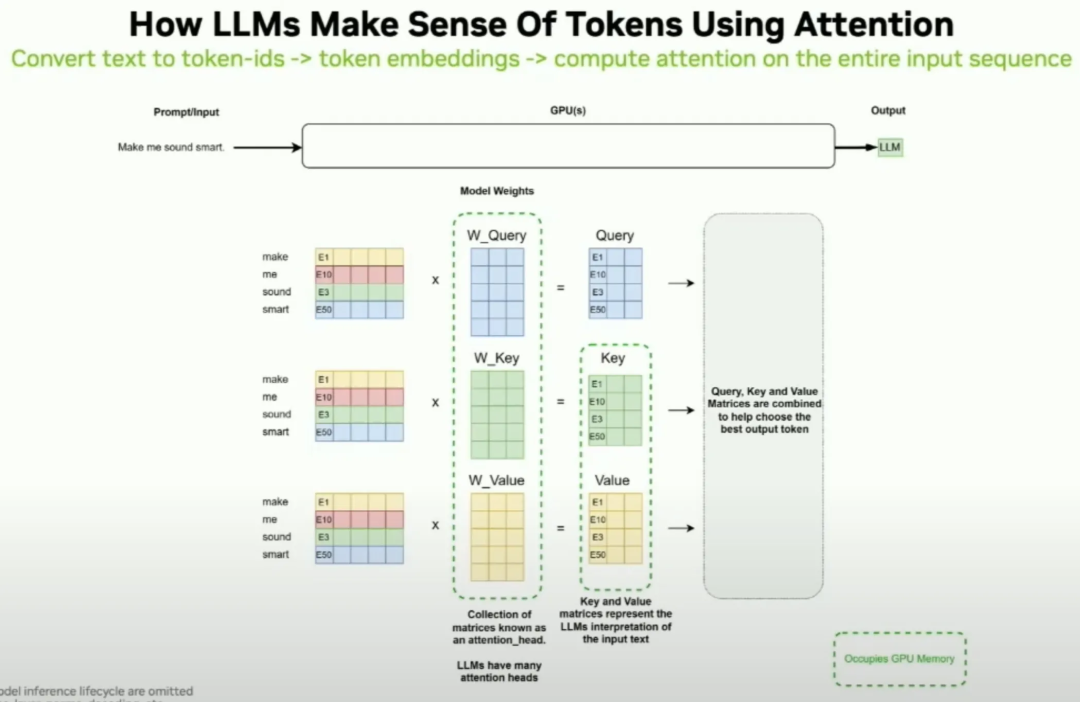
How does LLM inference work? | LLM Inference Handbook
A Survey of LLM Inference Systems | alphaXiv
Accelerating LLM and VLM Inference for Automotive and Robotics with ...
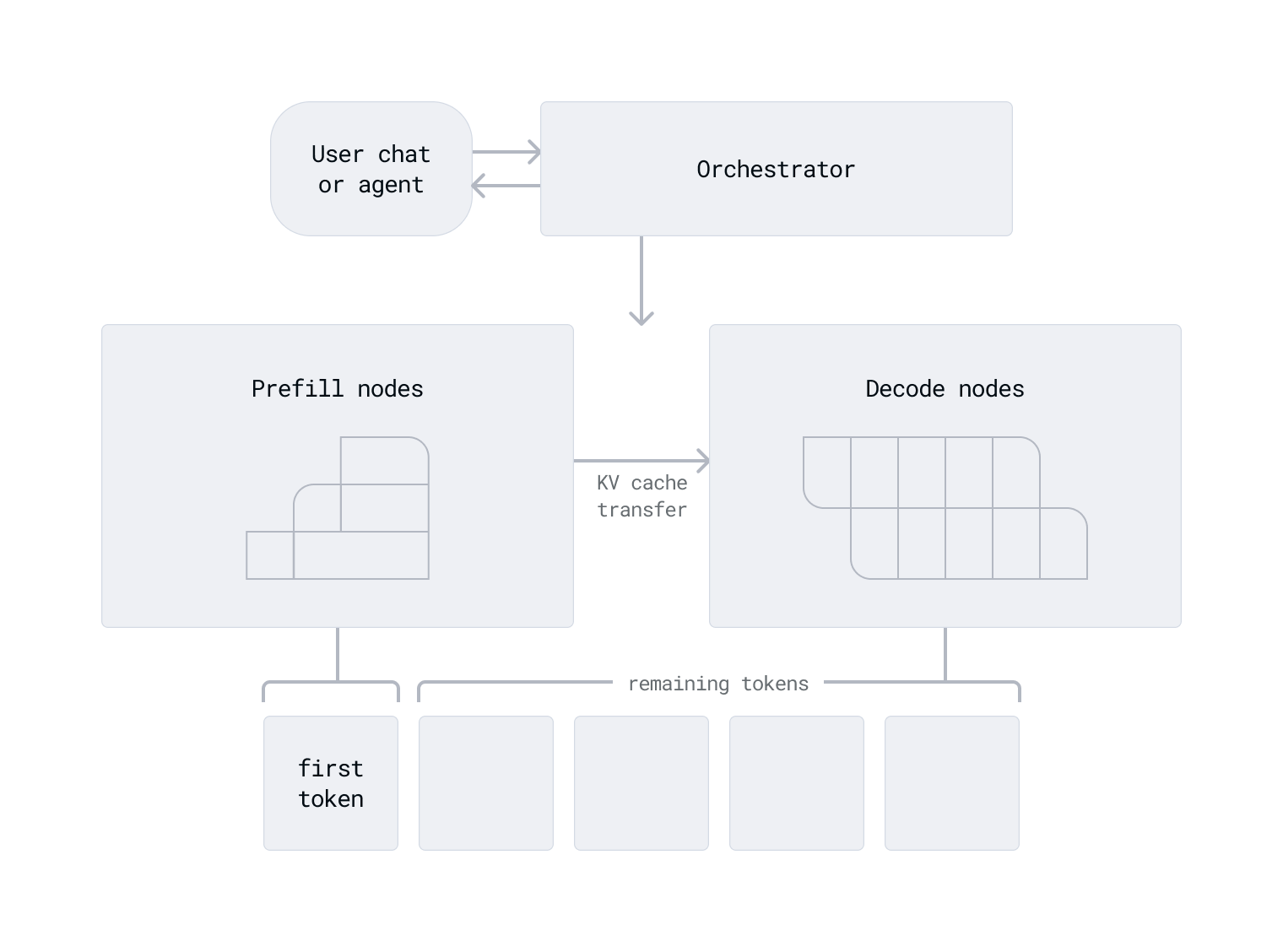
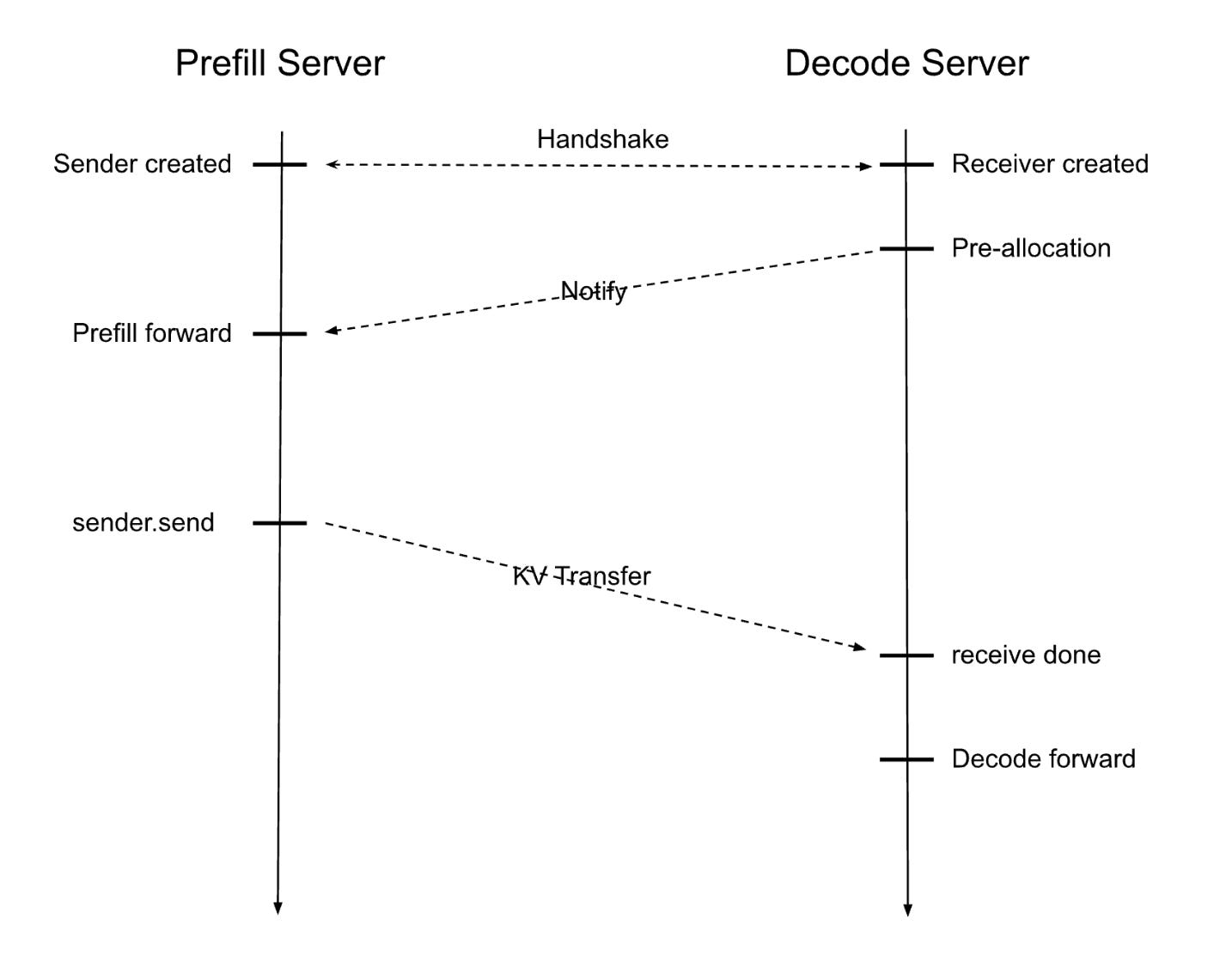
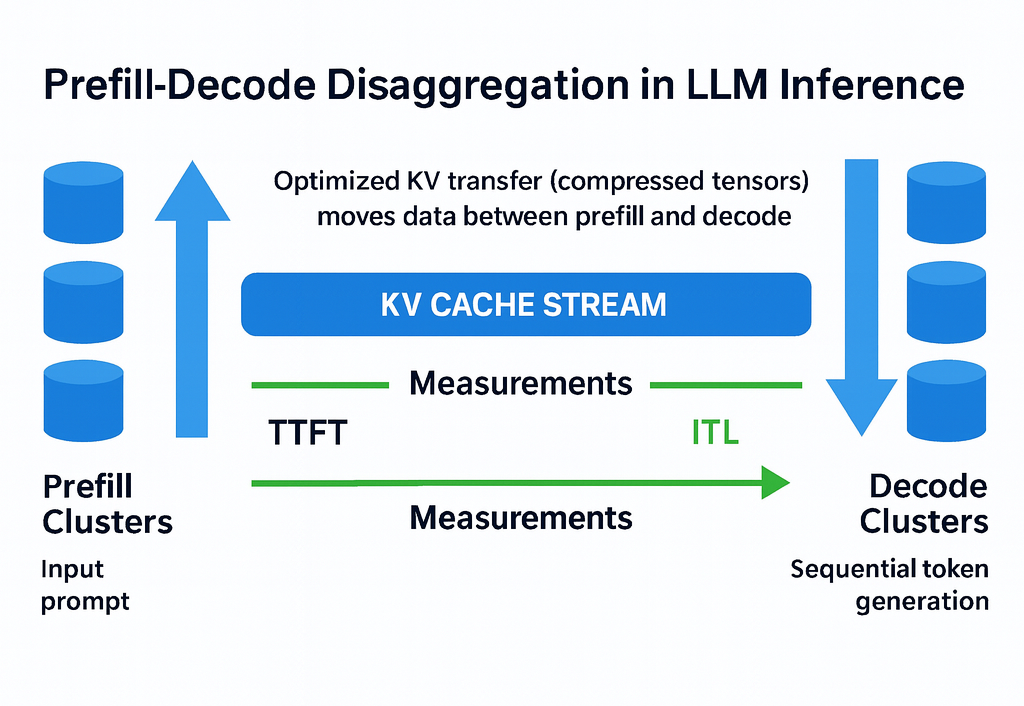
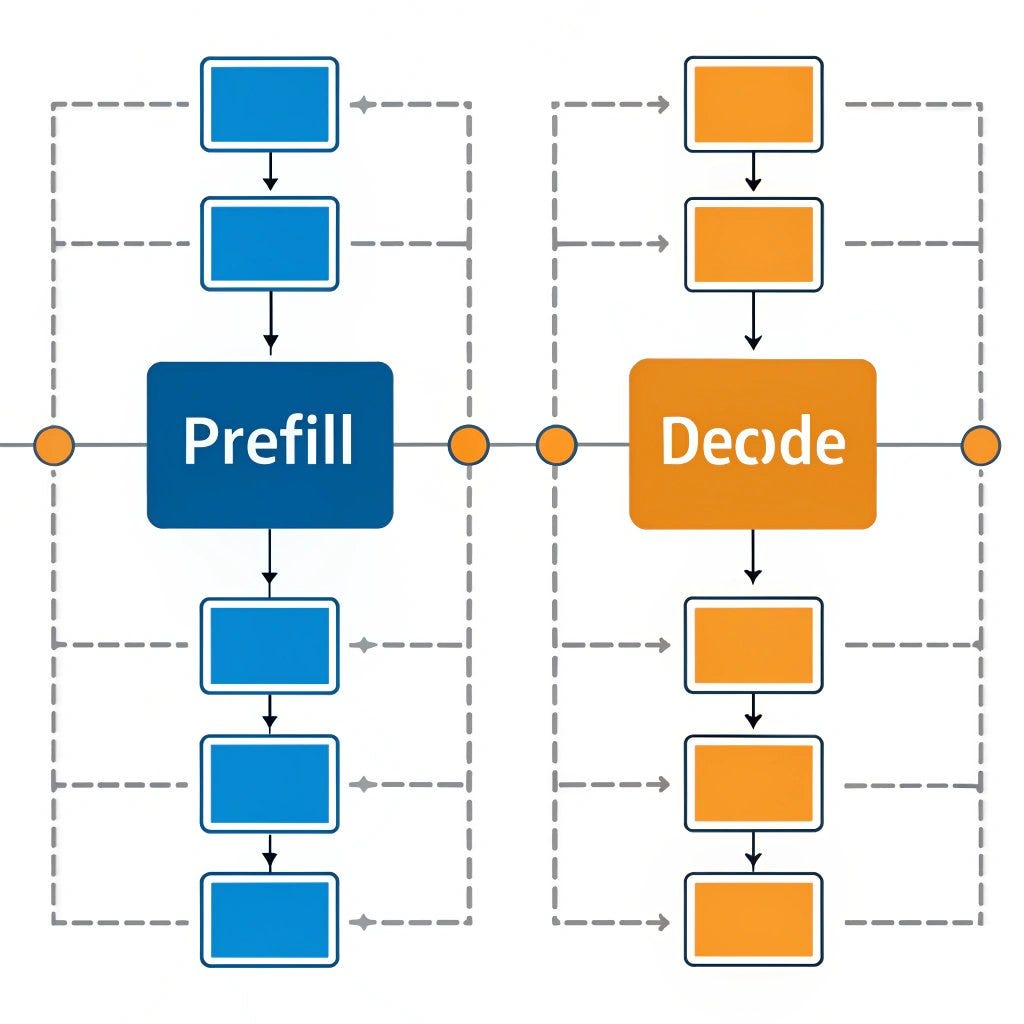
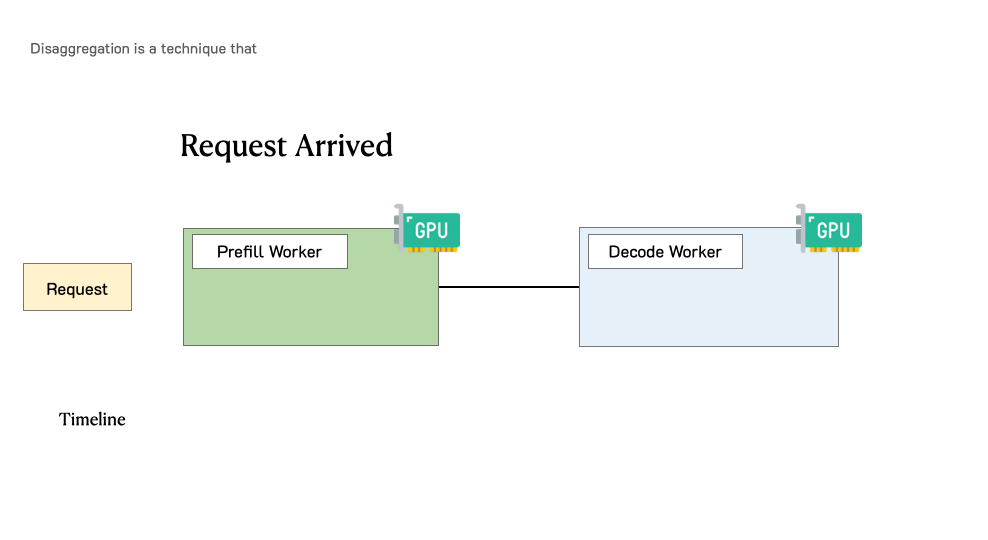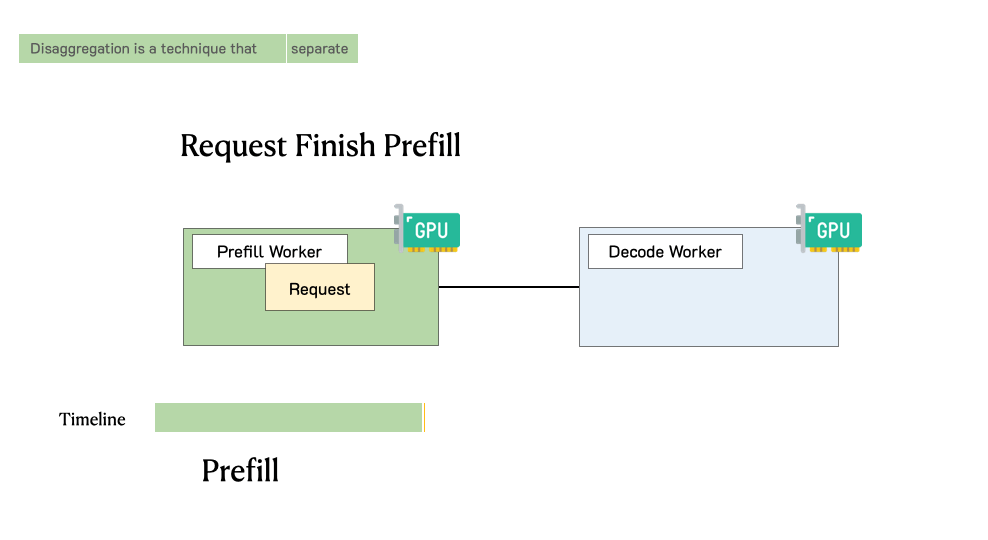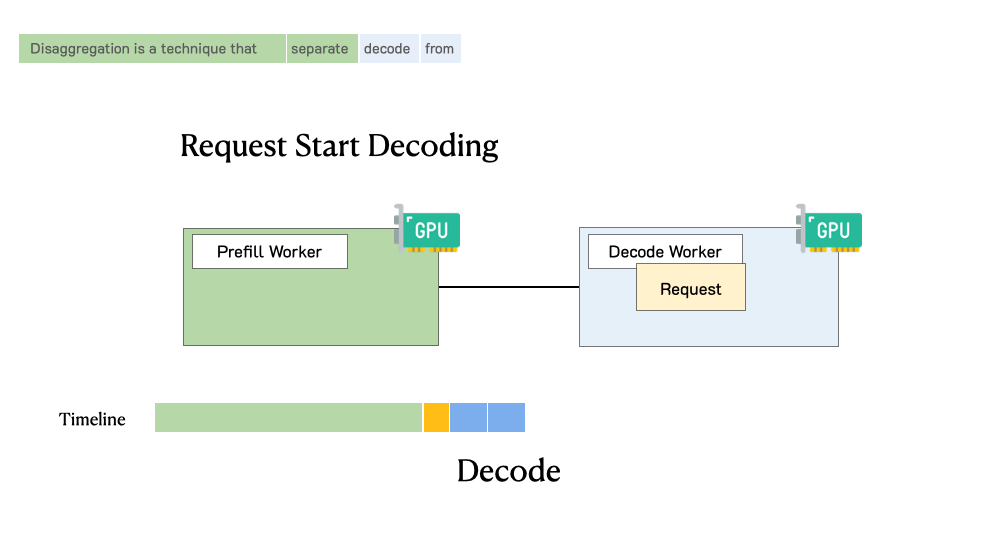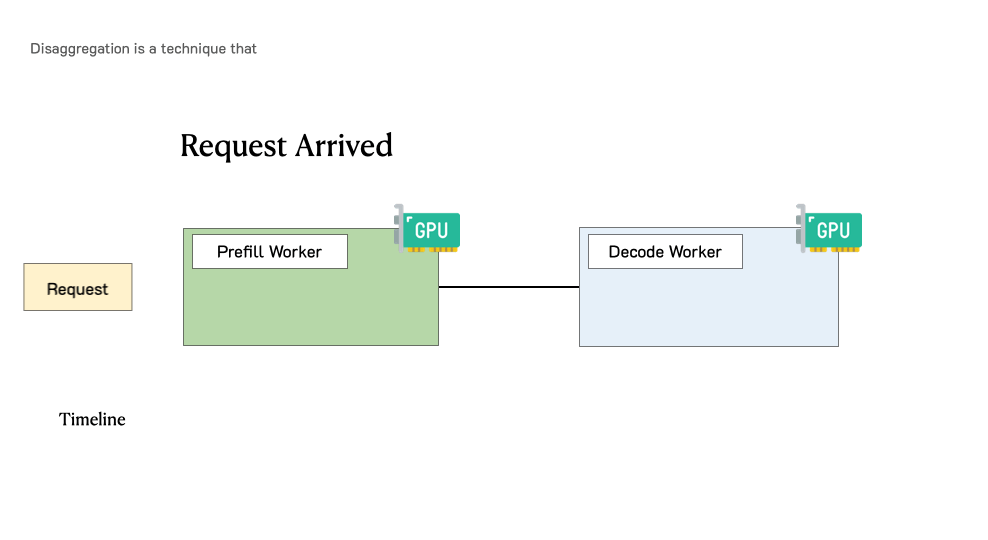
Prefill-decode disaggregation | LLM Inference Handbook
LLM Inference - Hw-Sw Optimizations
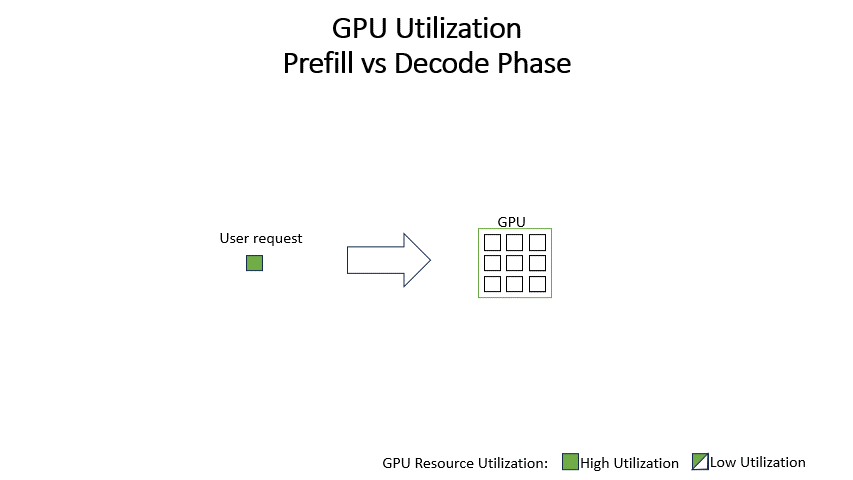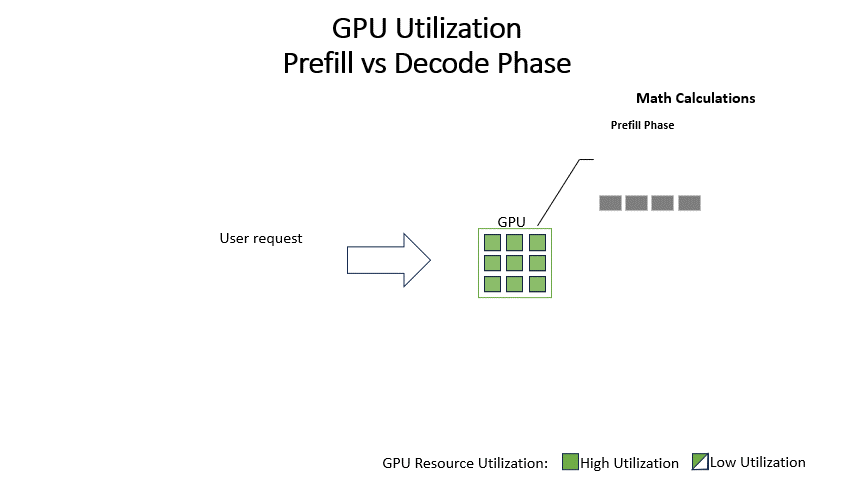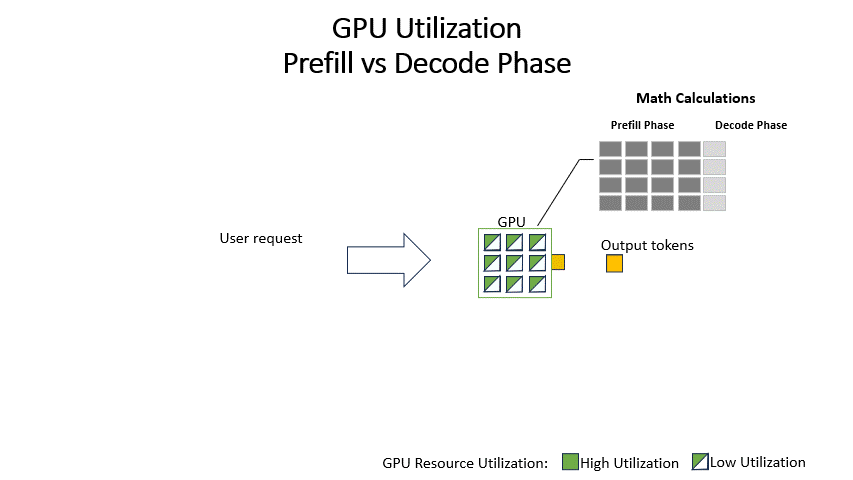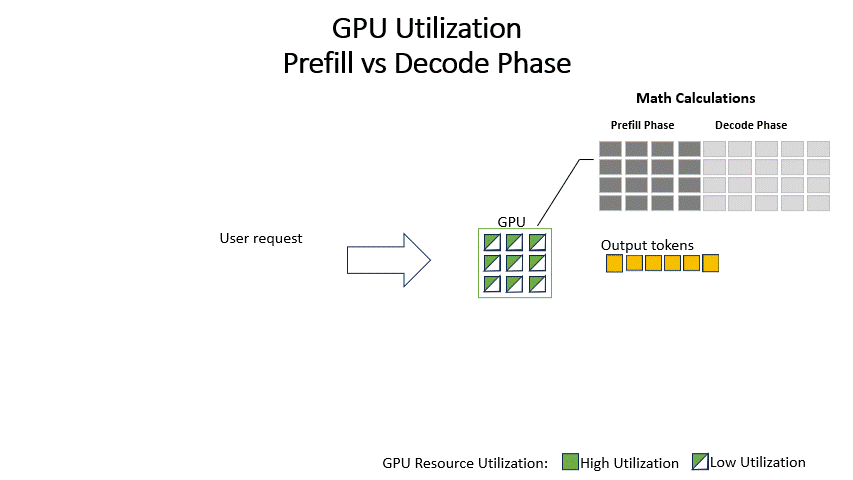
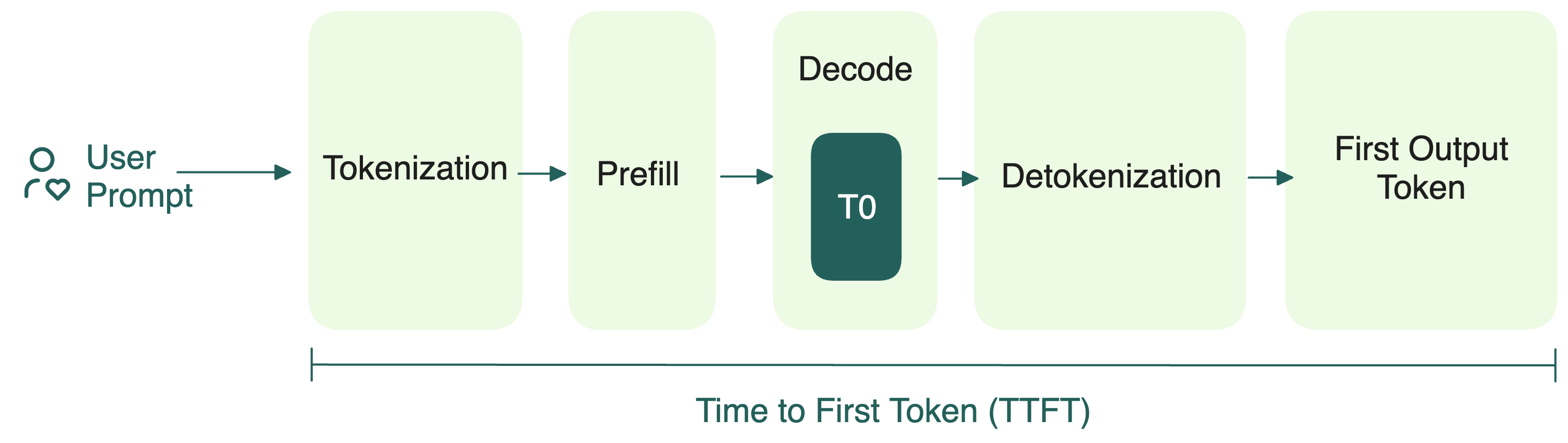
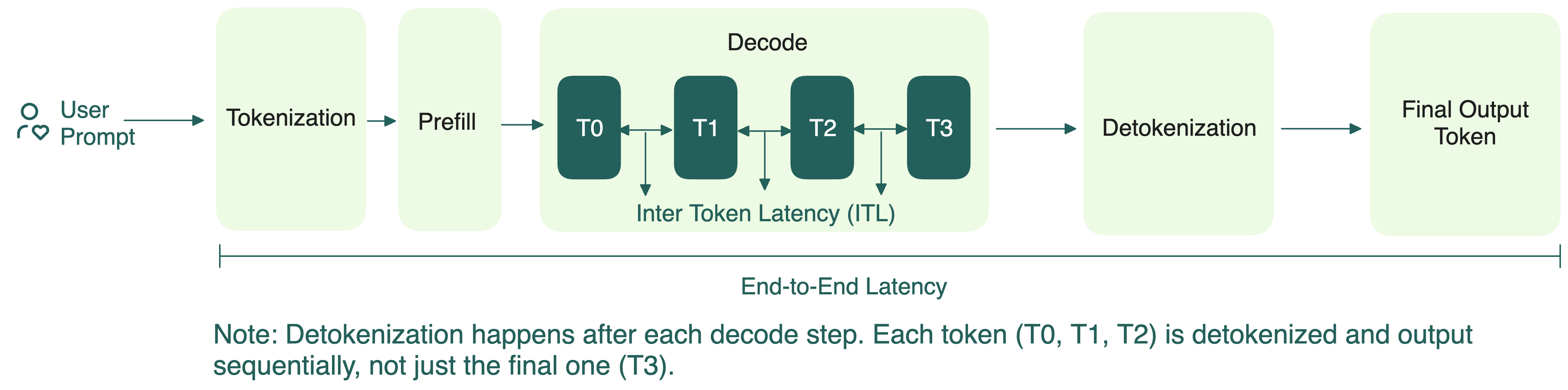
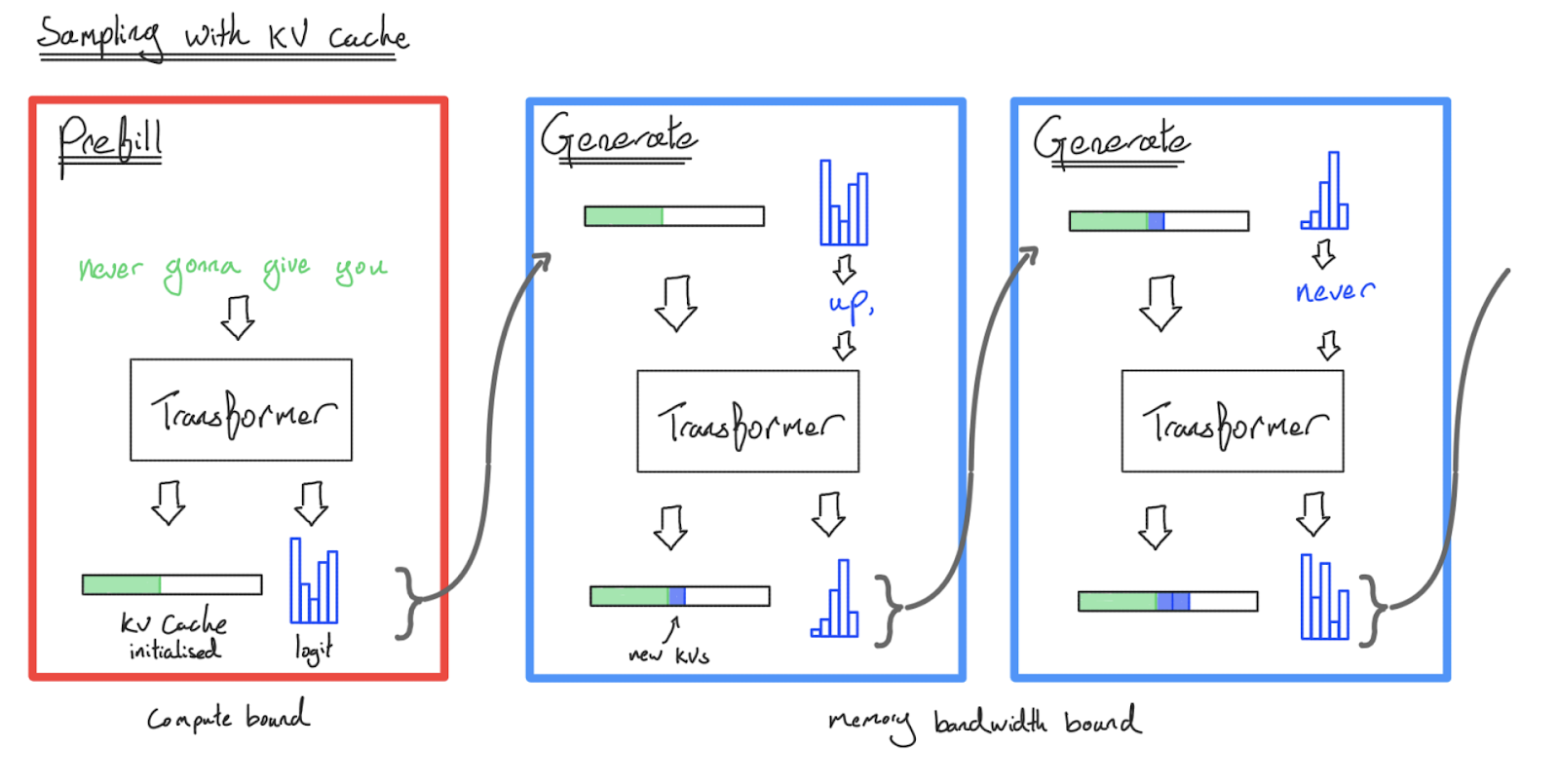
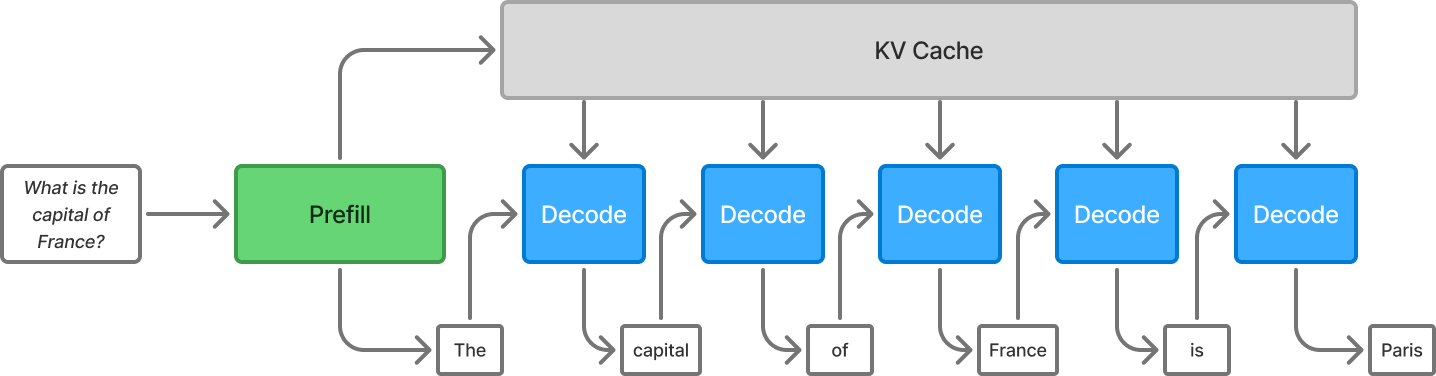
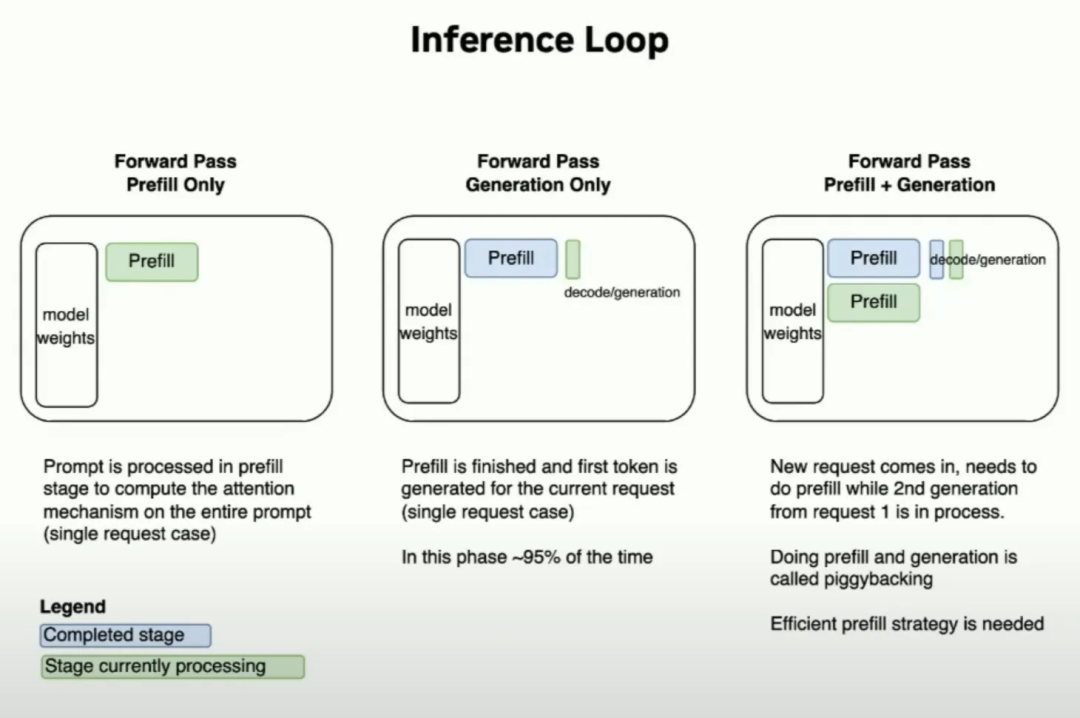
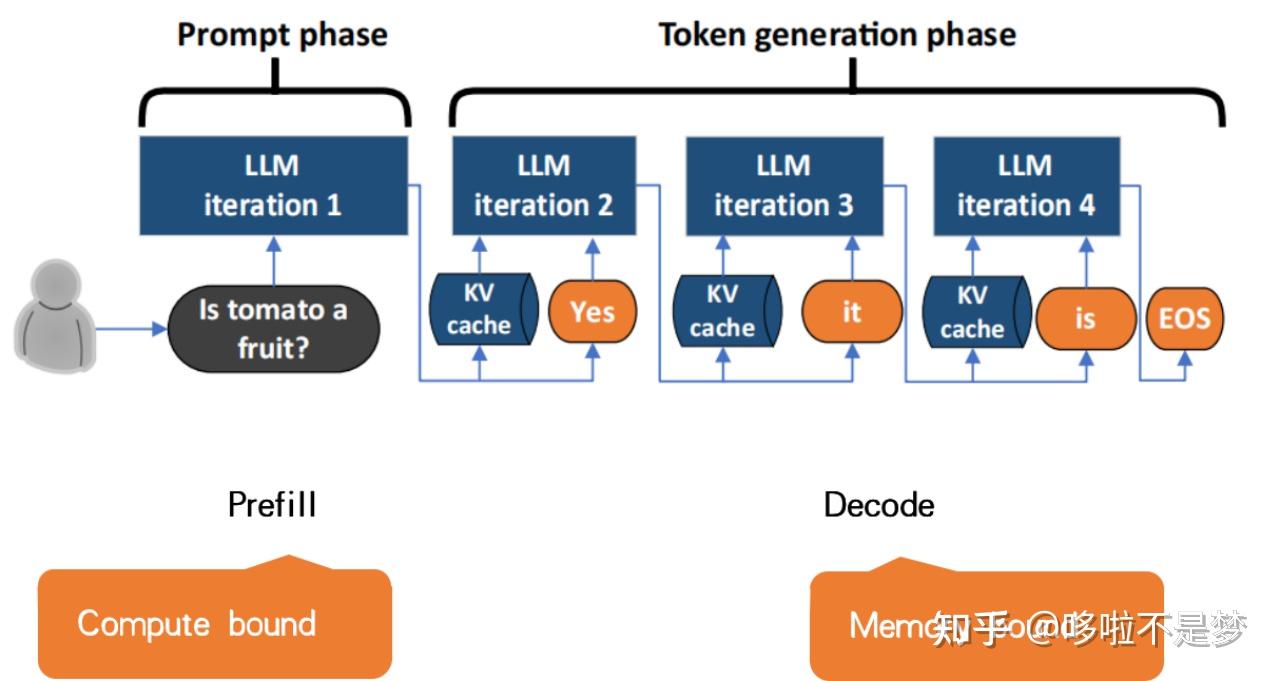
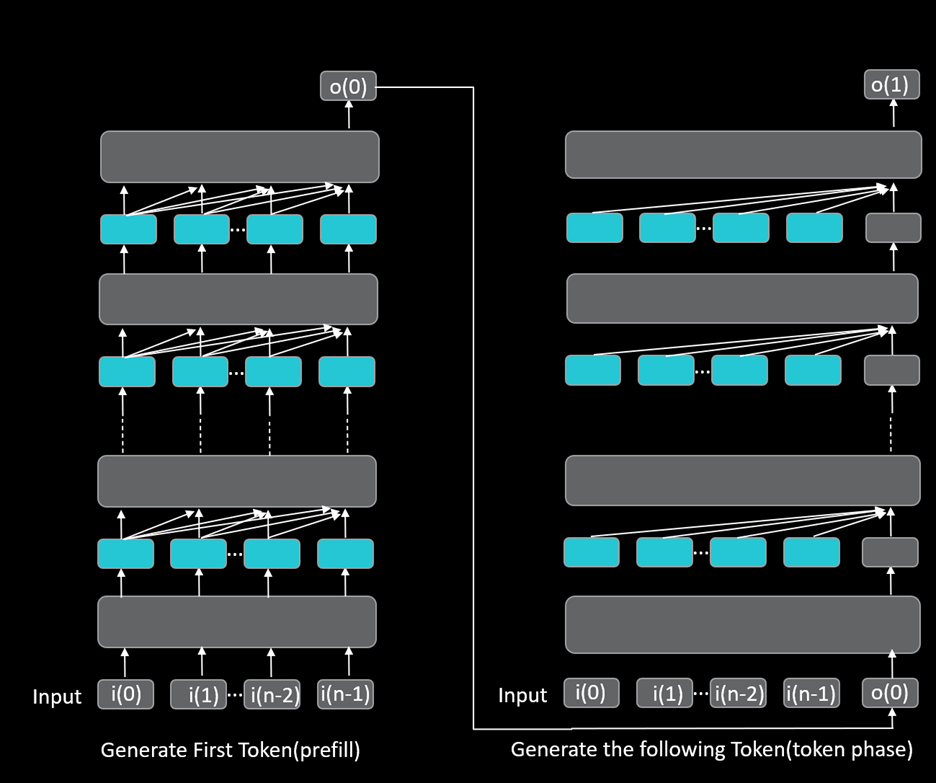
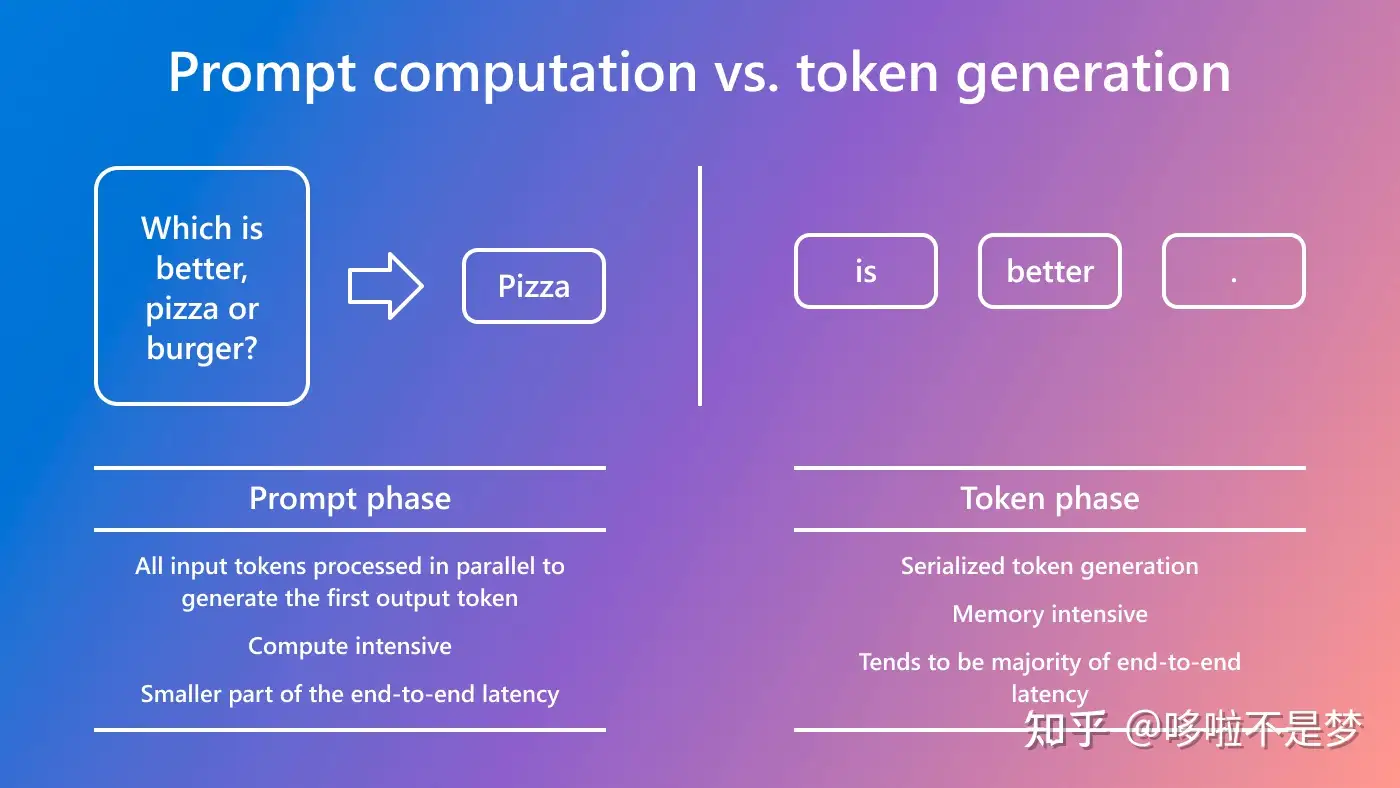
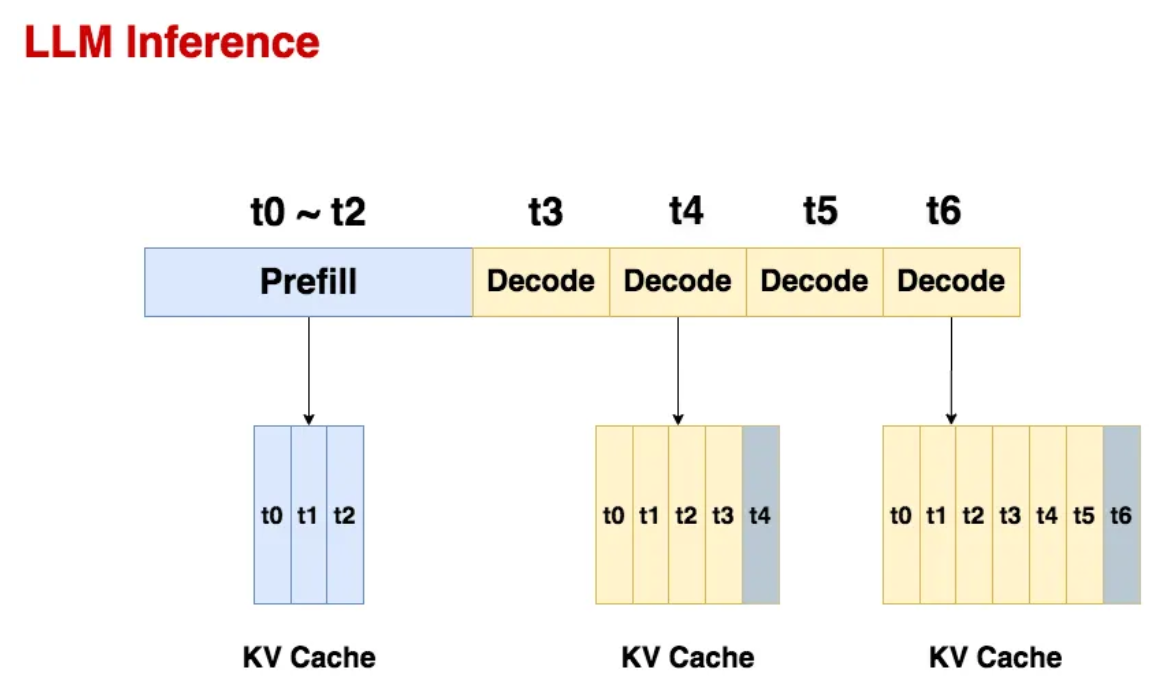
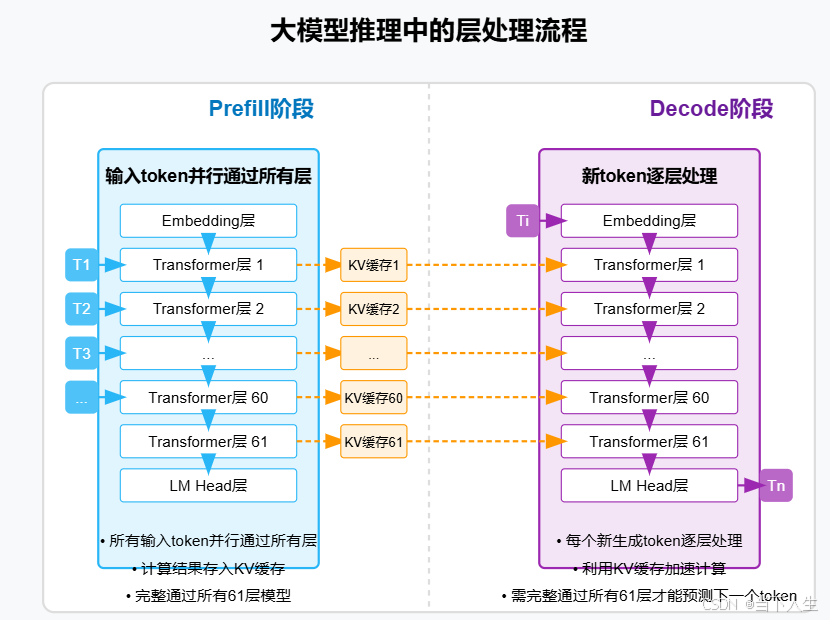
Understanding LLM Inference Basics: Prefill and Decode, TTFT, and ITL ...
[PDF] SARATHI: Efficient LLM Inference by Piggybacking Decodes with ...
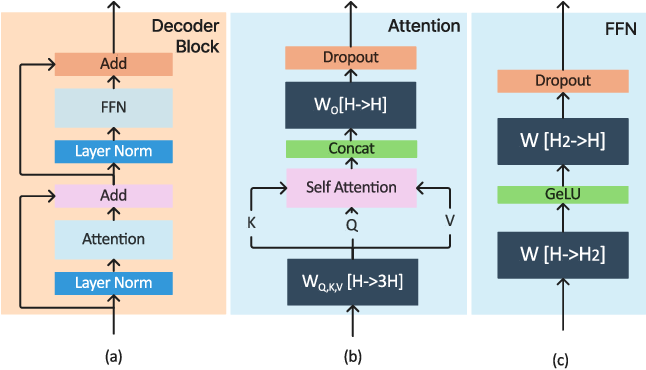
All About Transformer Inference | How To Scale Your Model
Disaggregated inference | Modular
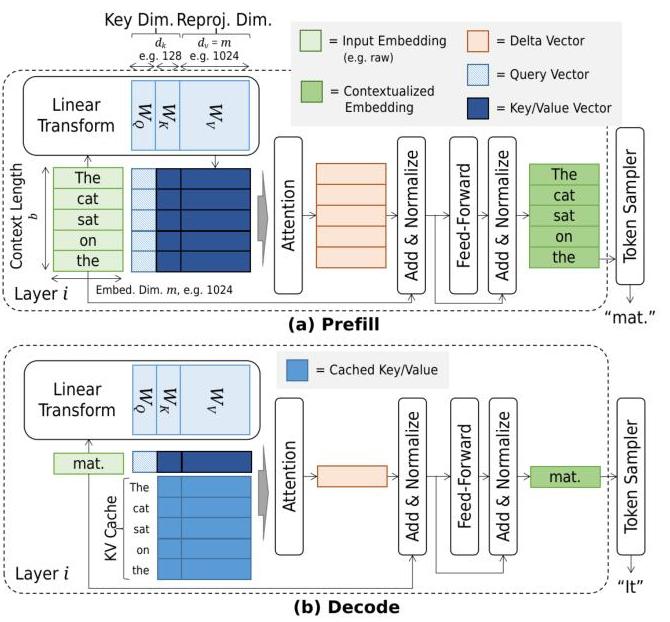
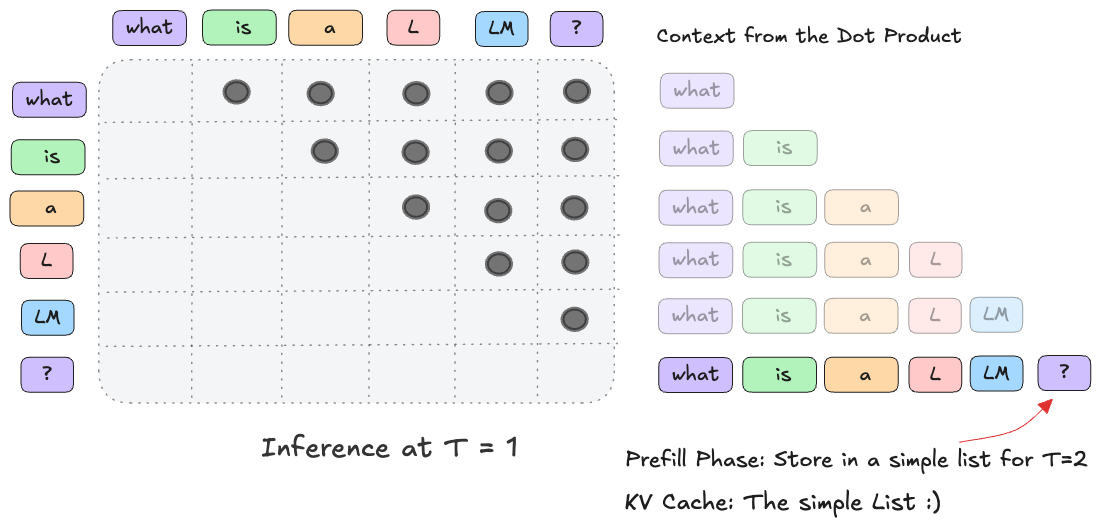
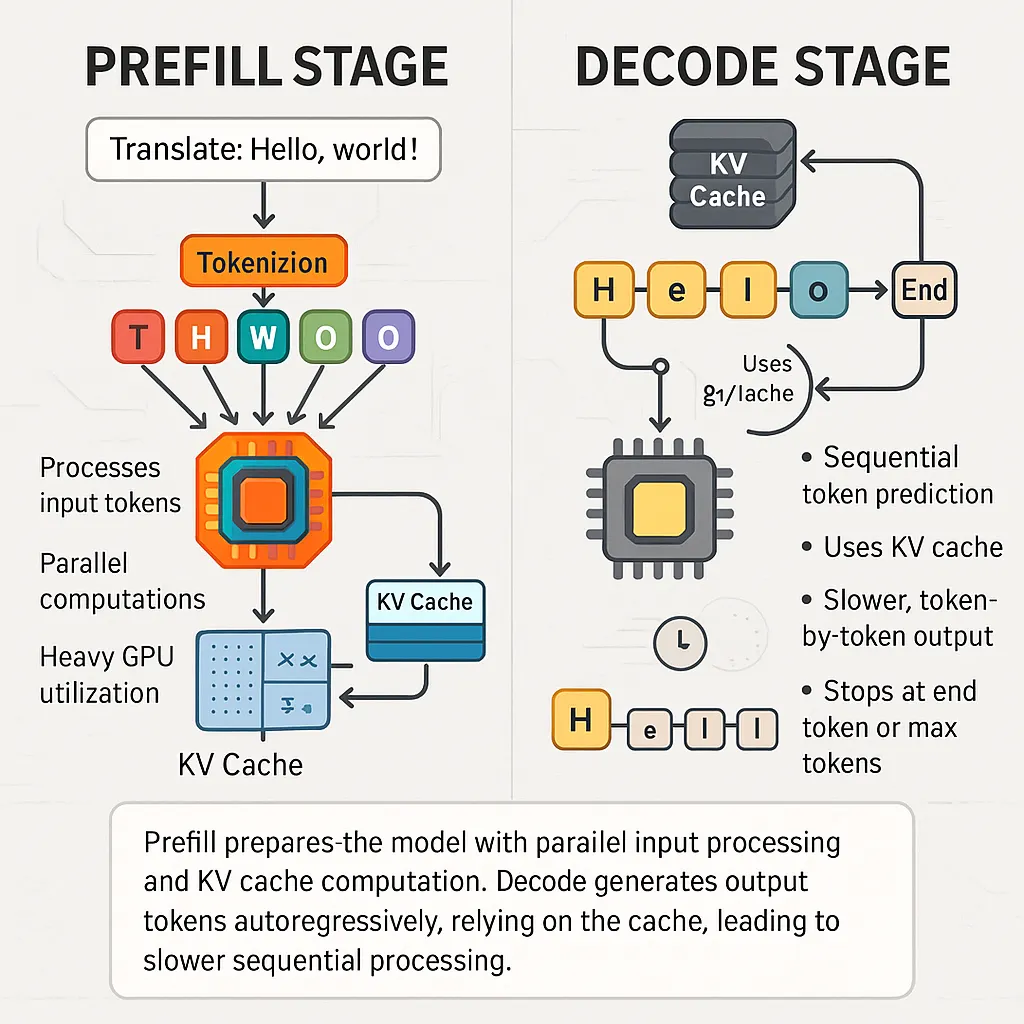
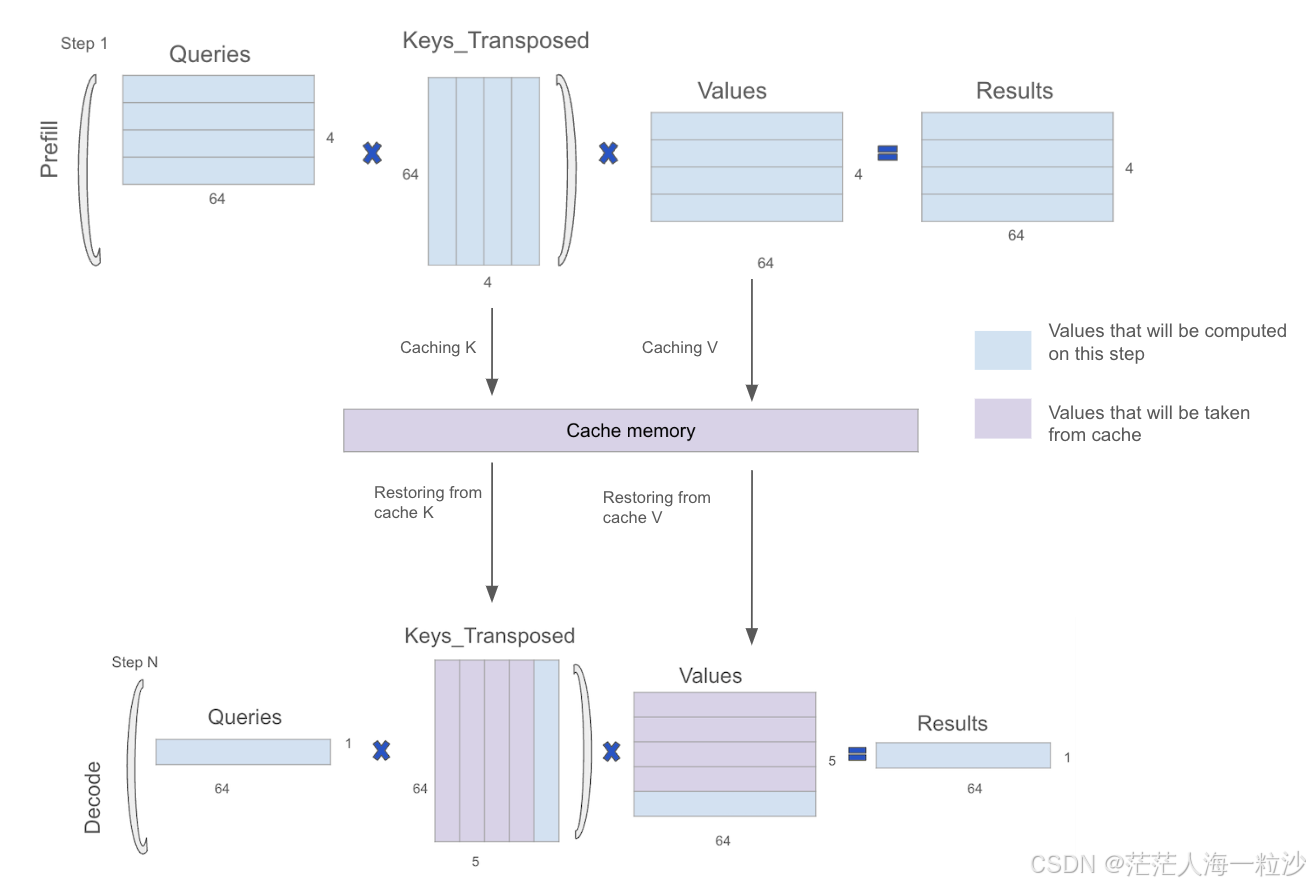
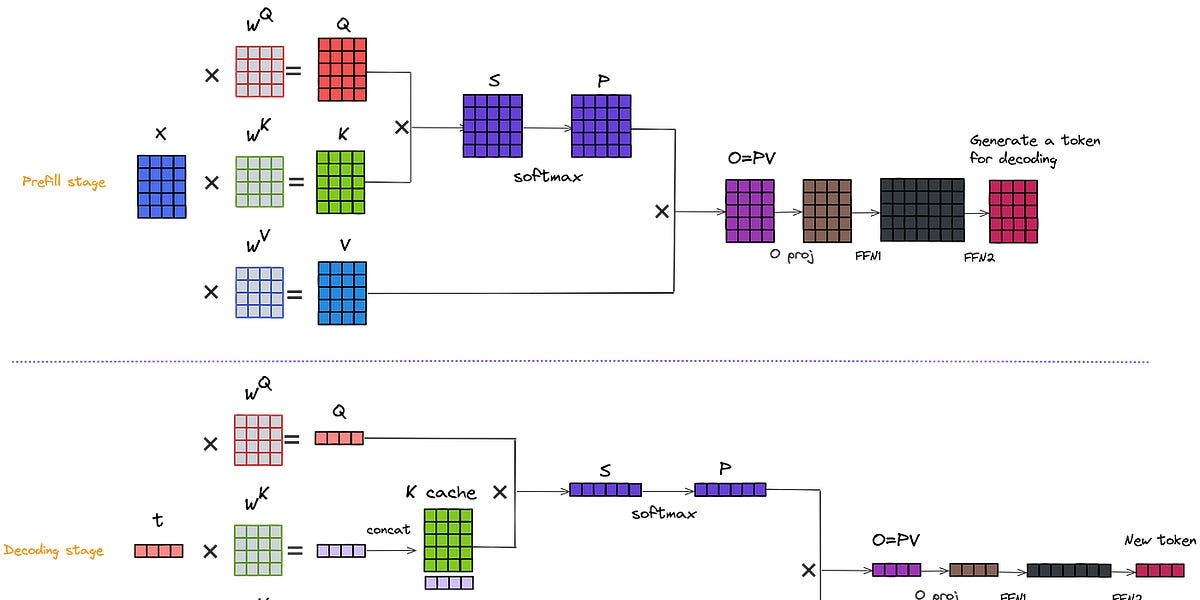
KVCache and Prefill phase in LLMs - James Melvin’s Homepage
Prefill and Decode in 2 Minutes: AI Inference Explained in Simple Words ...
Diagram of inference phase. We start from a radio component catalogue ...
Prefill Phase | vllm-project/vllm-metal | DeepWiki
Inference phase: two images are processed concurrently for the purpose ...
NVIDIA Rubin CPX Accelerates Inference Performance and Efficiency for ...
KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache ...
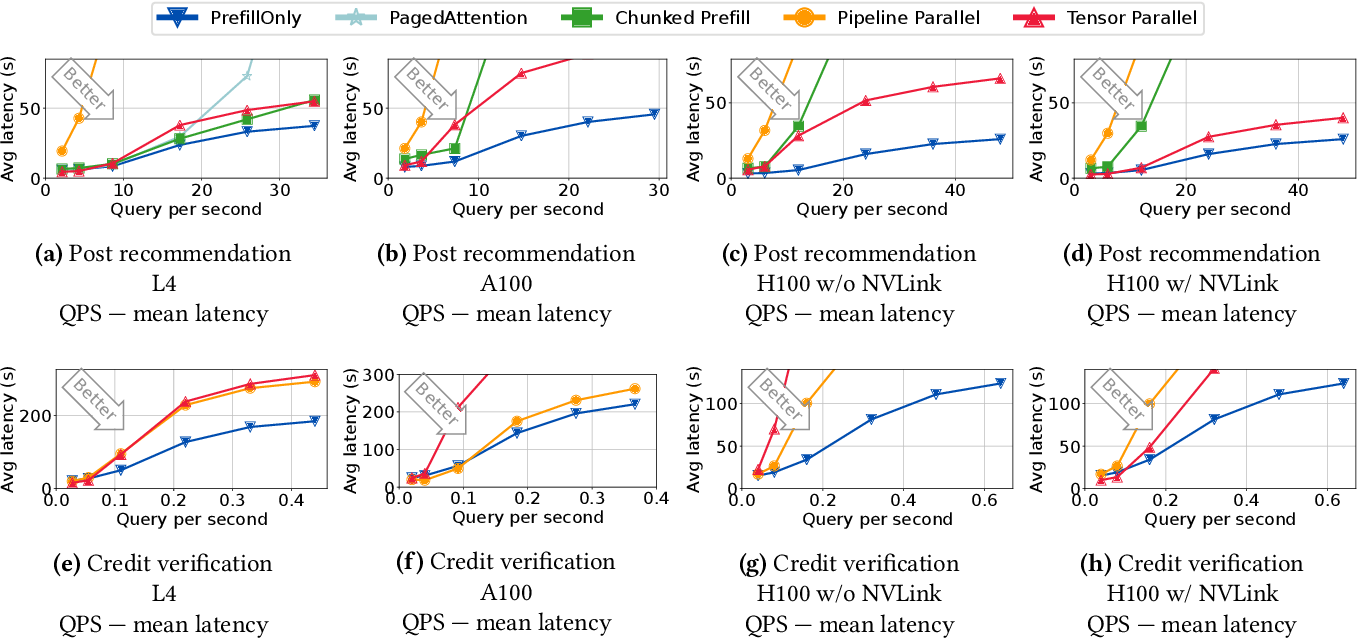
[论文评述] PrefillOnly: An Inference Engine for Prefill-only Workloads in ...
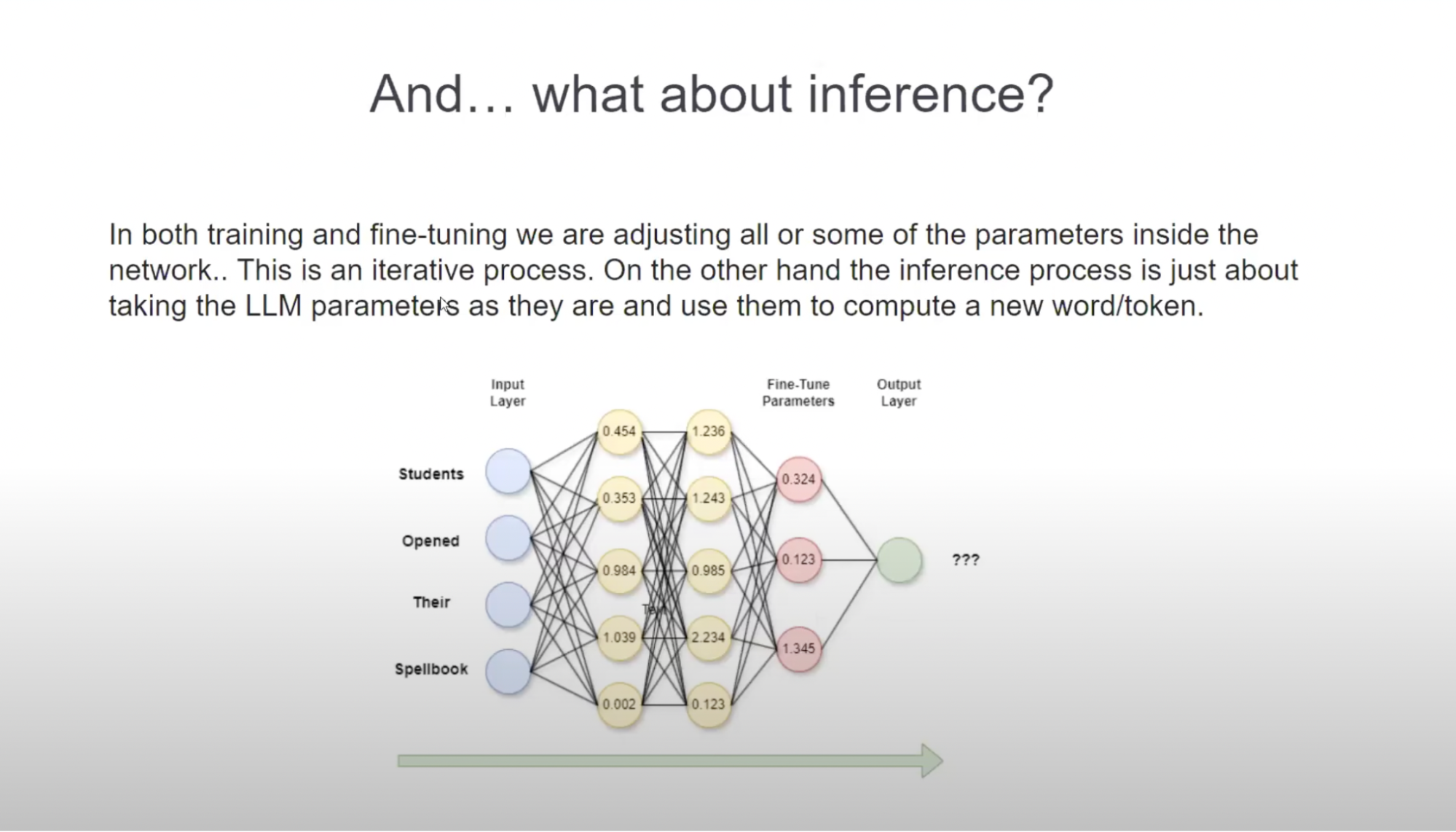
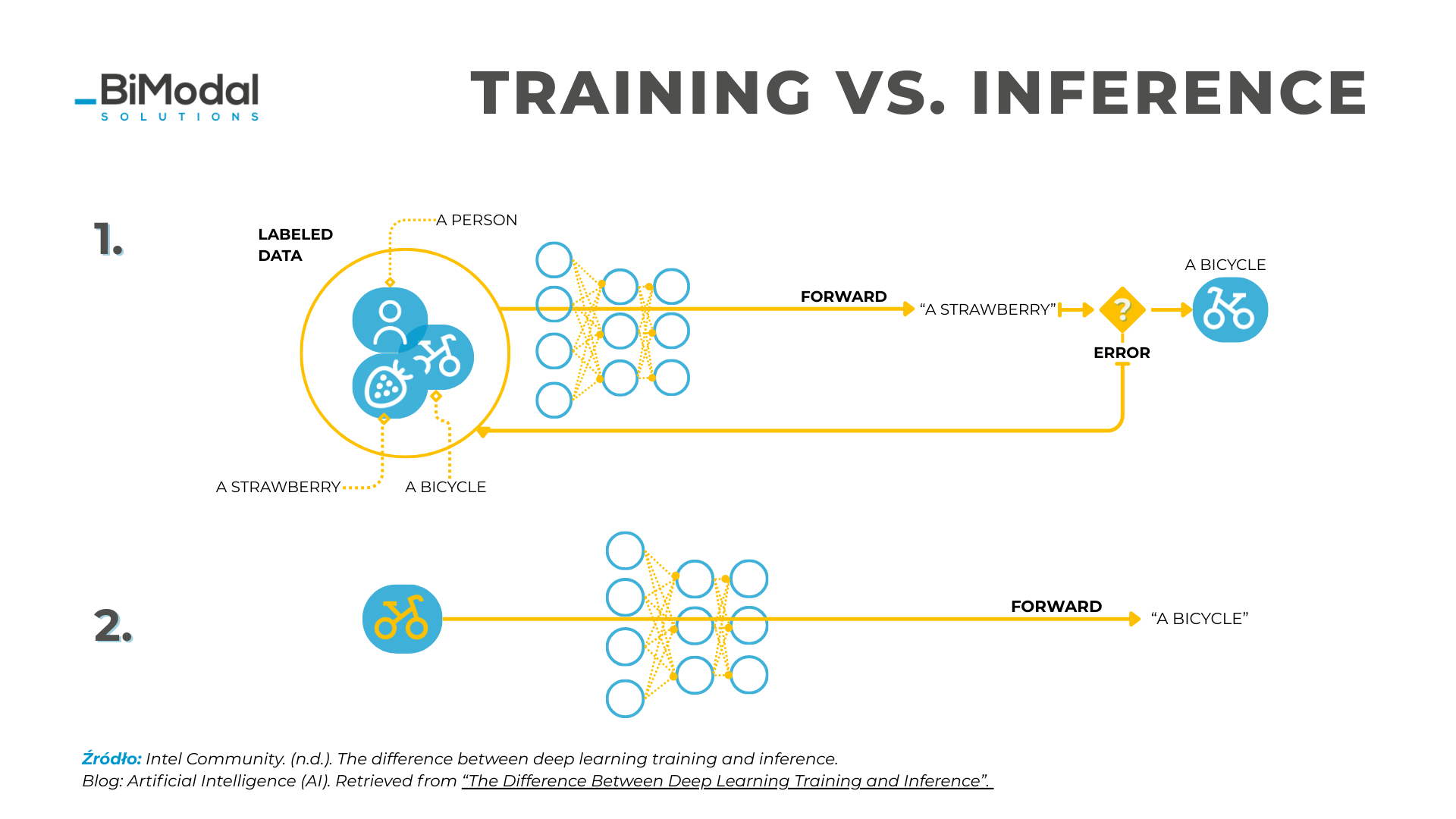
AI Inference vs Training vs Fine Tuning | What’s the Difference ...
(PDF) SwiftKV: Fast Prefill-Optimized Inference with Knowledge ...
MoE Inference Economics from First Principles
Inference Procedure In figure 6, we have five phases and these phases ...
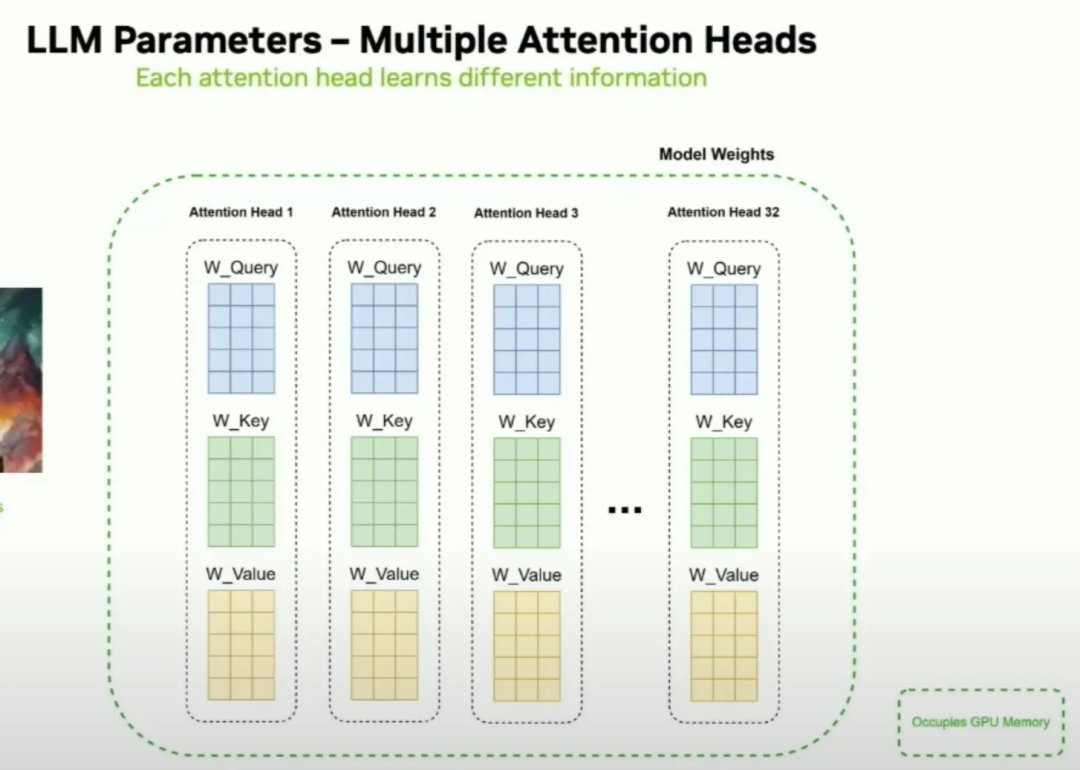
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
Dataset generation and pre-processing phase: (a) six different ...
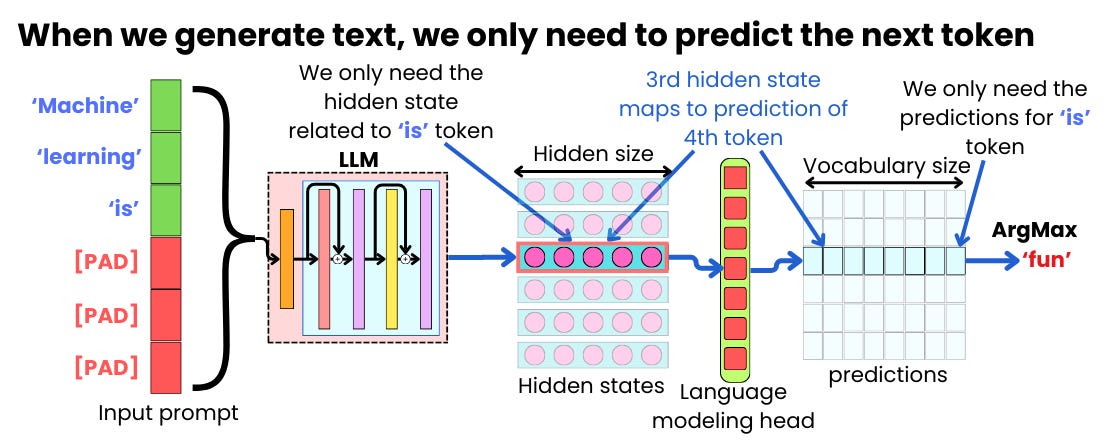
Understanding Prefill in Large Language Model (LLM) Inference
深入解析Hugging Face的Text Generation Inference工具包:为大型语言模型赋能 - 懂AI
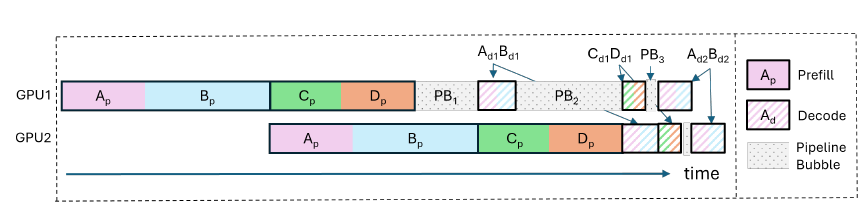
Figure 6 from PrefillOnly: An Inference Engine for Prefill-only ...
Flowchart of the inference phase. | Download Scientific Diagram
An Iteratively Parallel Generation Method with the Pre-Filling Strategy ...
Splitting LLM inference across different hardware platforms | Gimlet Blog
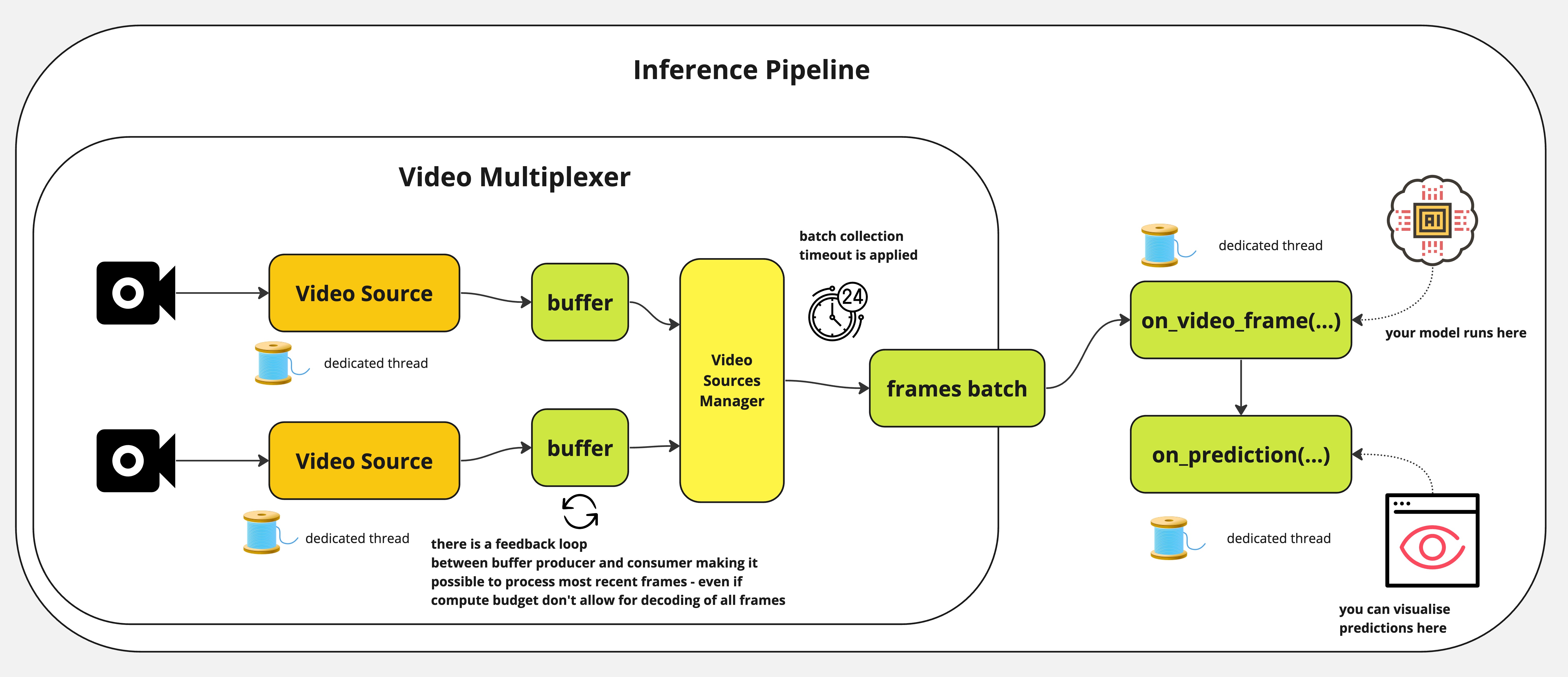
Inference pipeline - Roboflow Inference
How to Scale LLM Inference - by Damien Benveniste
Model overview. In the inference phase, the input volume (left) is ...
Text Generation Inference源码解读(一):架构设计与业务逻辑 - 知乎
LLM(十二):DeepSpeed Inference 在 LLM 推理上的优化探究 - 知乎
Illustration of different inference processes: (a) the regular ...
Using teacher knowledge at inference time to enhance student model ...
The AI Engineer's Guide to Inference Engines and Frameworks
Aikipedia: Prefill–Decode Disaggregation – Champaign Magazine
深入浅出,一文理解LLM的推理流程_chunked prefill-CSDN博客
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率 _ 同行 ...
Hybrid NPU/iGPU Optimized Agent on AMD Ryzen AI Powered PC
Prefill and Decode for Concurrent Requests - Optimizing LLM Performance
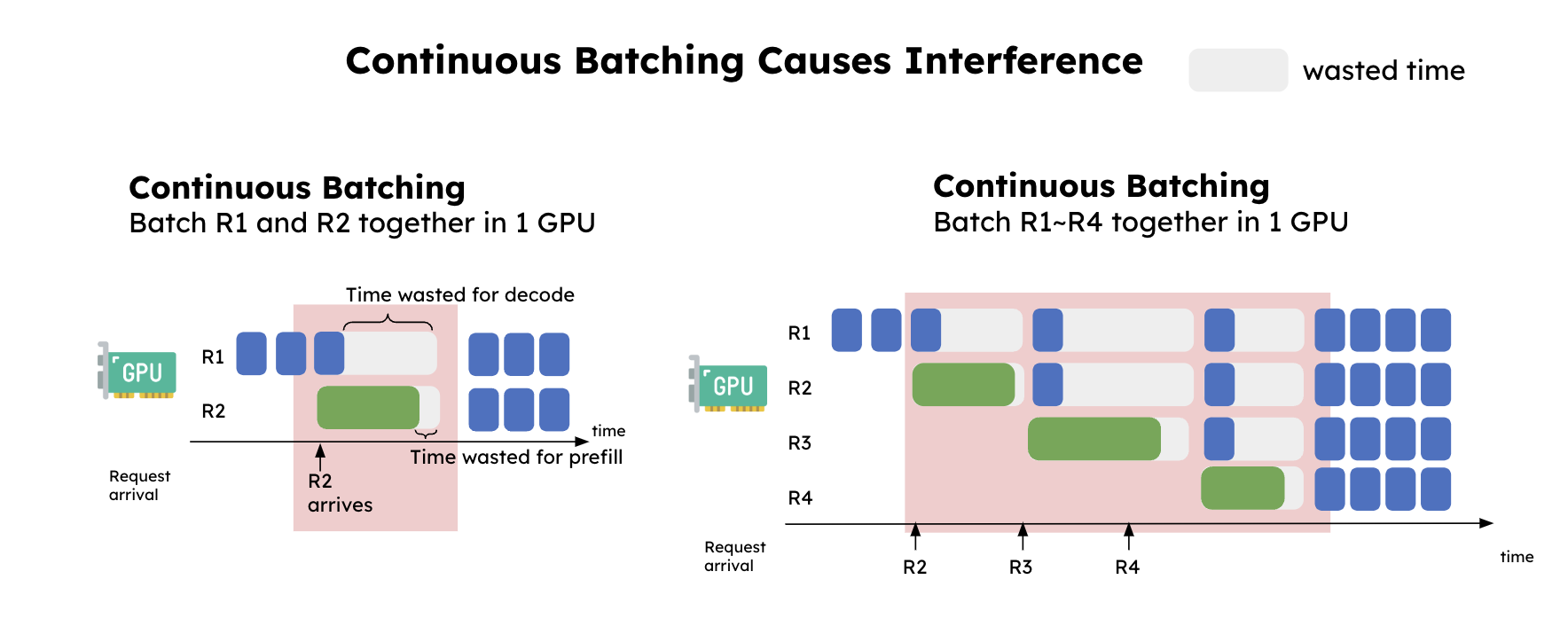
为什么大语言模型推理要分成 Prefill 和 Decode?深入理解这两个阶段的真正意义_prefill和decode-CSDN博客
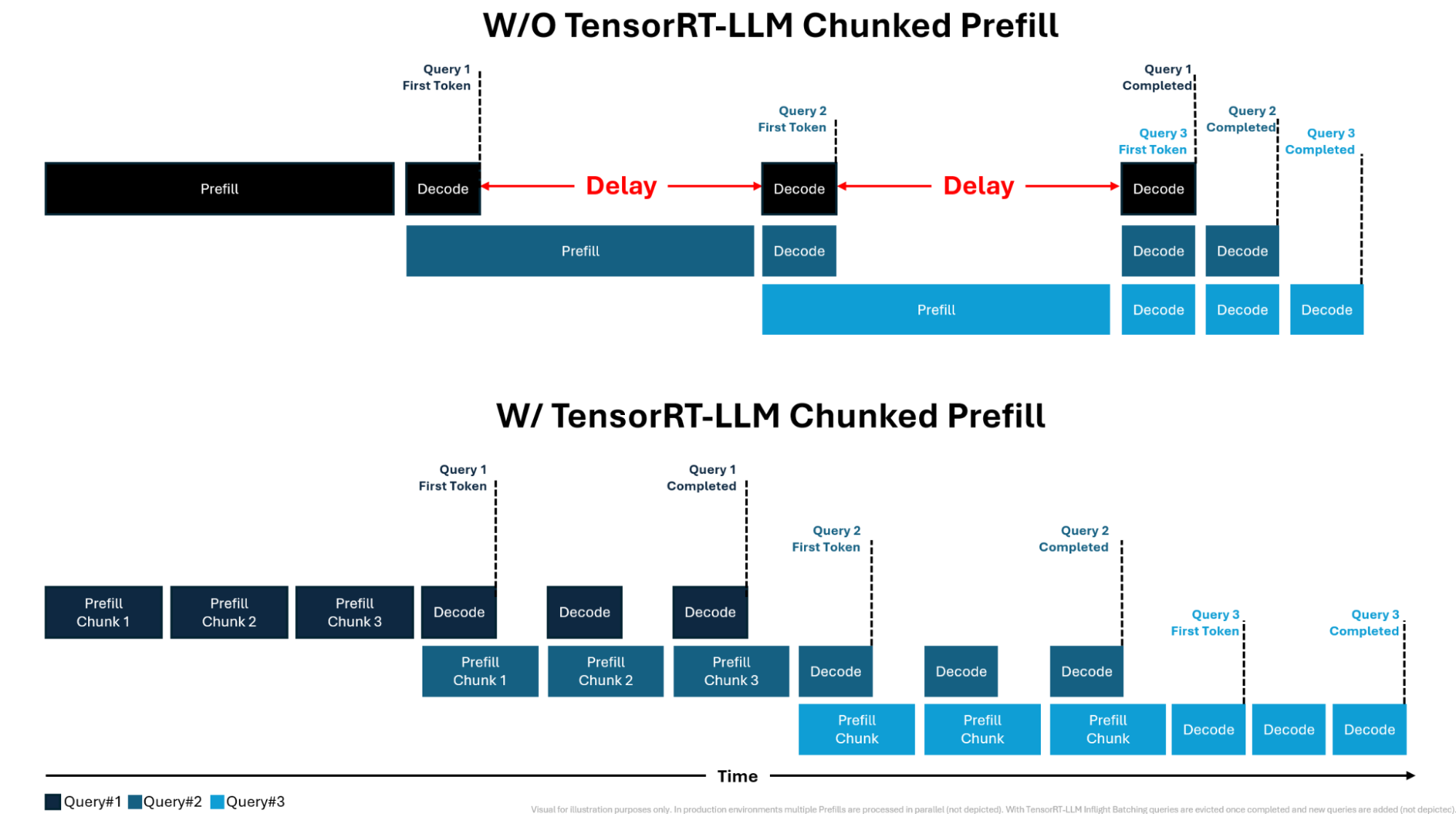
Chunked-Prefills 分块预填充机制详解_chunk prefill-CSDN博客
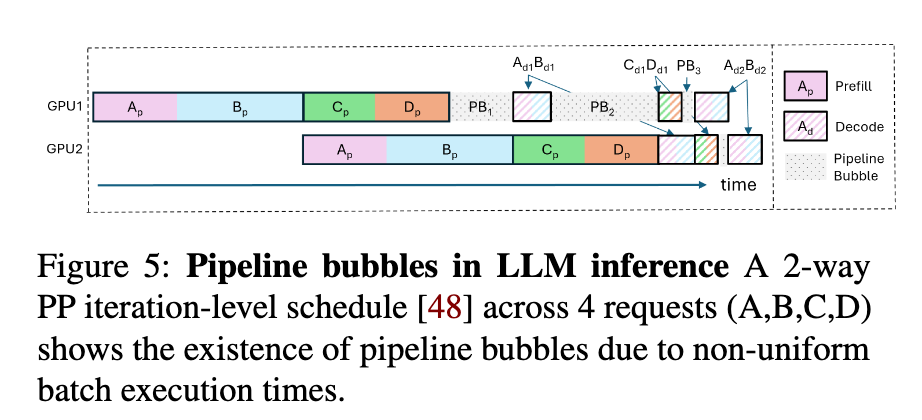
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using ...
LLM大模型系列(十):深度解析 Prefill-Decode 分离式部署架构_prefill和decode-CSDN博客
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率哆啦不是梦 ...
LoongServe 论文解读:prefill/decode 分离、弹性并行、零 KV Cache 迁移开销 - 知乎
Evaluation of vAttention for LLM Inference: Prefill and Decode ...
MInference (Milliontokens Inference): A Training-Free Efficient Method ...
To Harness Generative AI, You Must Learn About “Training” & “Inference ...
Projects | MLsys@UCSD
deepseek大模型推理prefill/decode阶段研究分析_php_新兴ICT项目支撑-MCP技术社区
Optimizing LLM Inference: Prefill vs Decode on Multi-GPU NVIDIA Systems ...
Optimizing LLM Inference: Prefill vs Decode, Latency vs Throughput | by ...
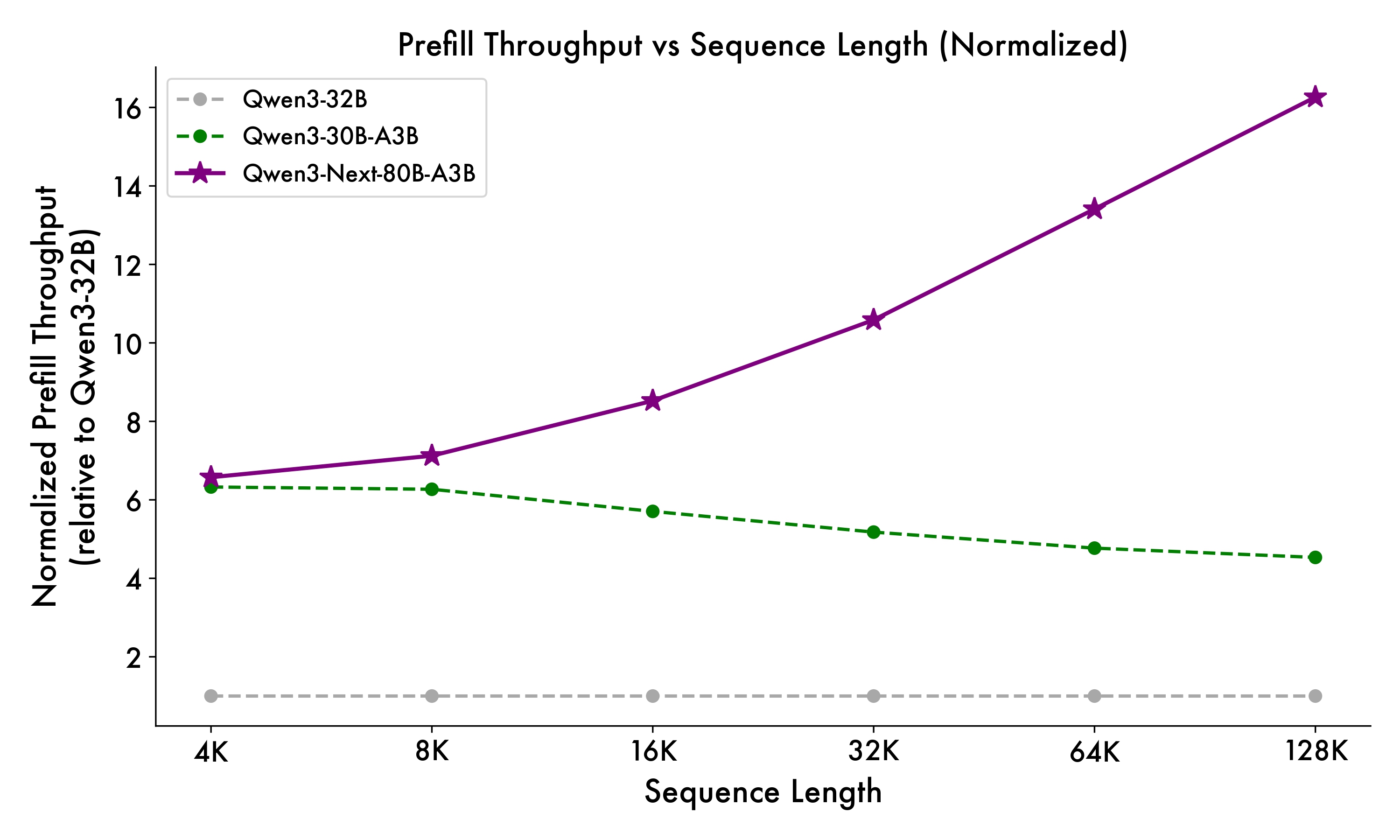
Qwen3-Next: Revolutionary 80B Model with Only 3B Active Parameters ...
DistServe: disaggregating prefill and decoding for goodput-optimized ...
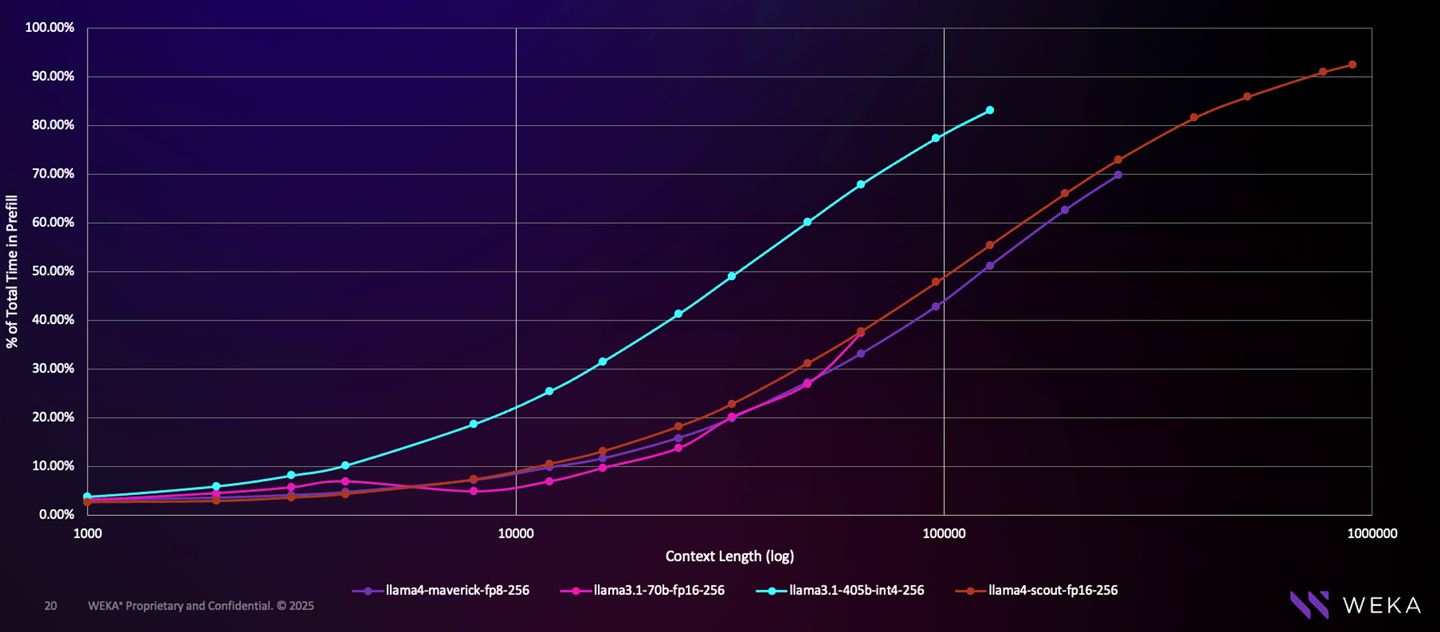
Why Prefill has Become the Bottleneck in Inference—and How Augmented ...
What Is LLM Inference? Process, Latency & Examples Explained (2026)
[Best viewed in color] An illustration of the various phases of ...
Not enough memory to handle prefill tokens. · Issue #943 · huggingface ...
Generation, inference, and decision in a model of precued orientation ...
Rules of thumb for setting `max-batch-total-tokens` and `max-batch ...
ML & AI in business: definitions and model training methods
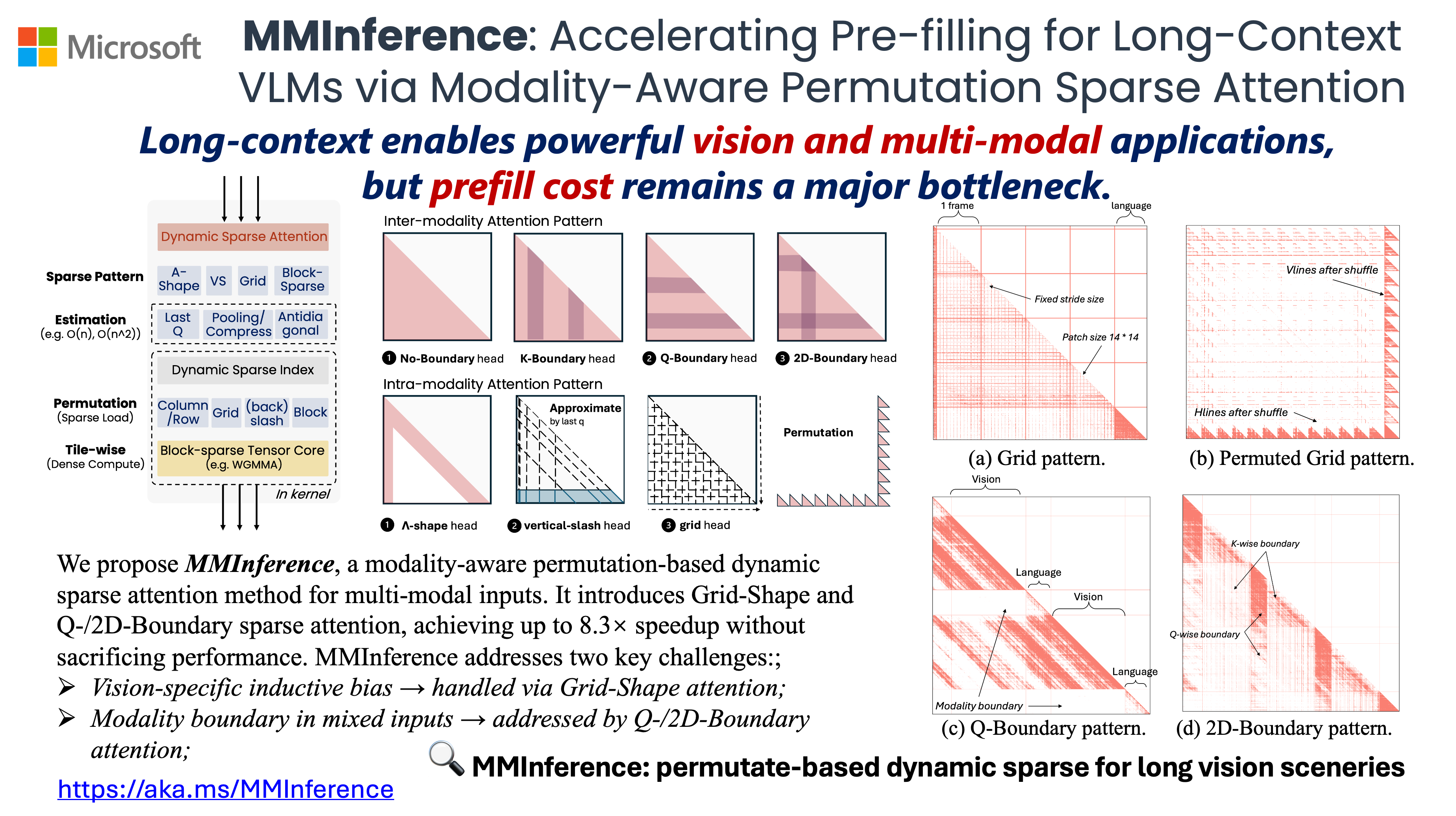
MMInference: Accelerating Pre-filling for Long-Context VLMs via ...
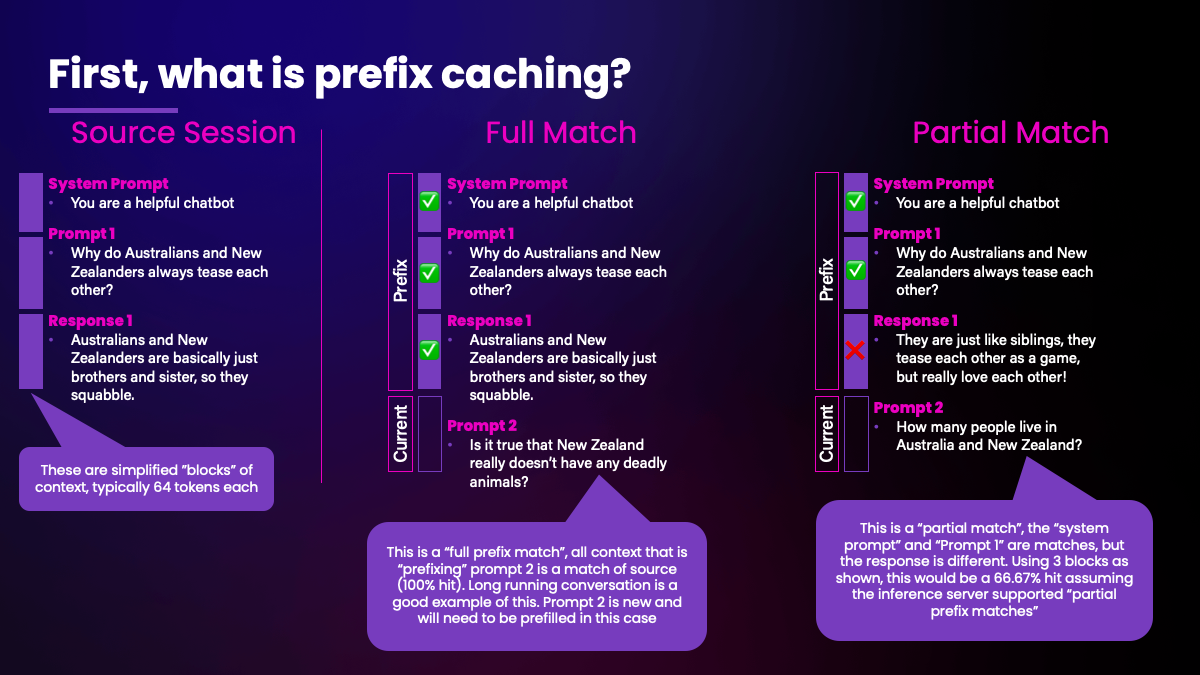
[Triton编程][进阶]📚vLLM Triton Prefix Prefill Kernel图解 - 知乎