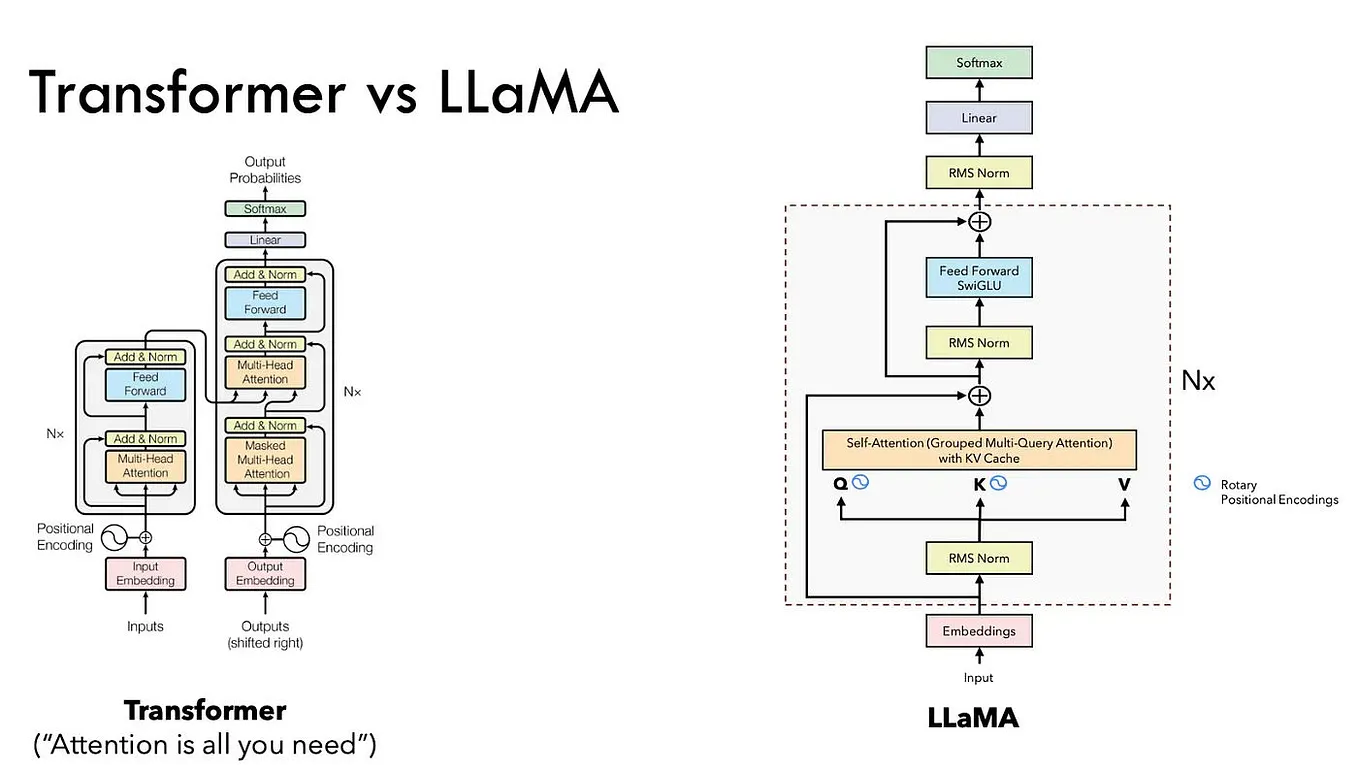
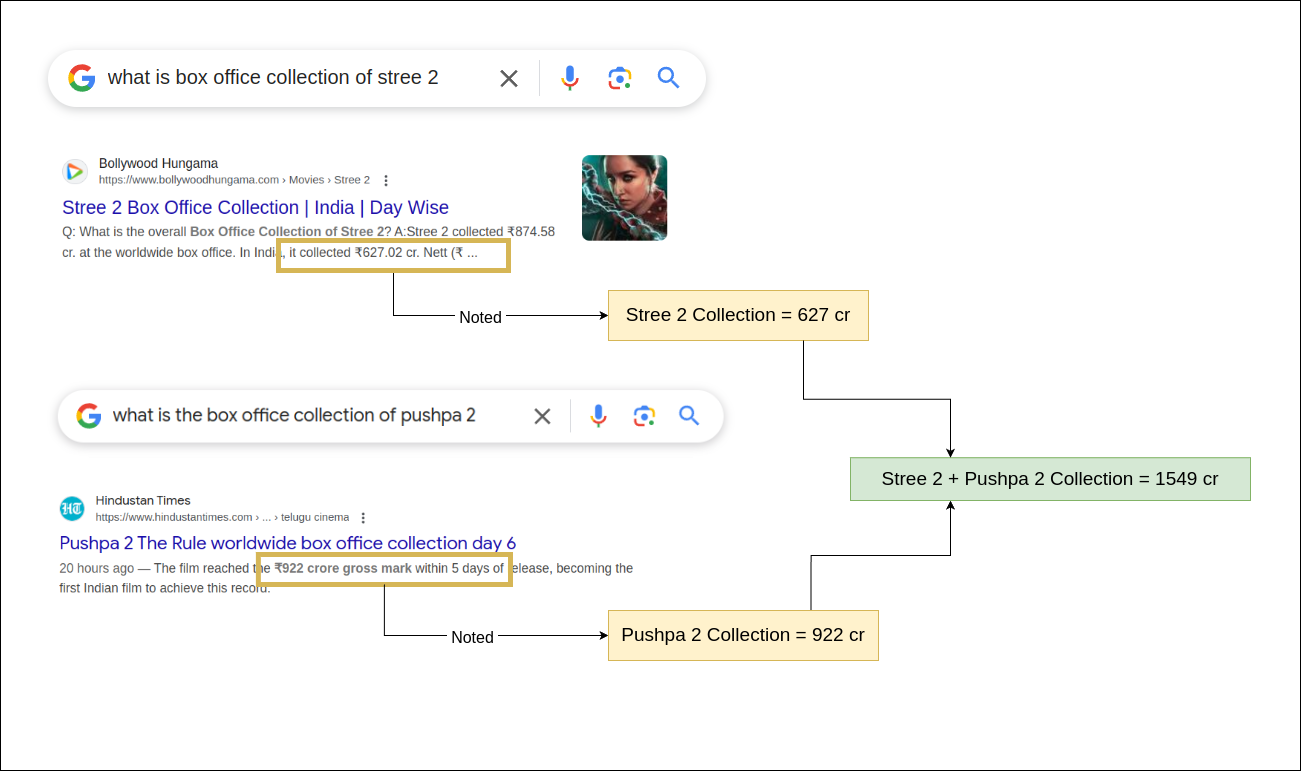
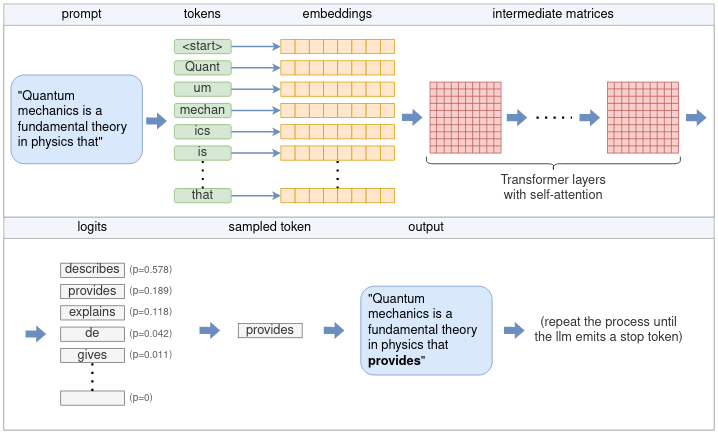
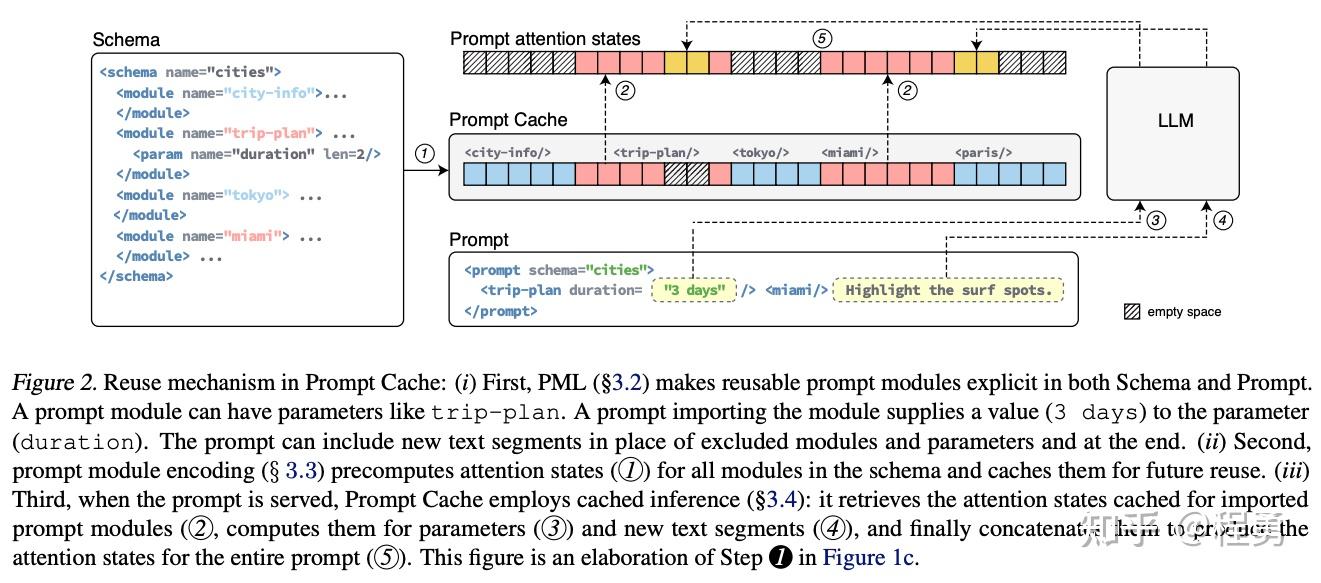
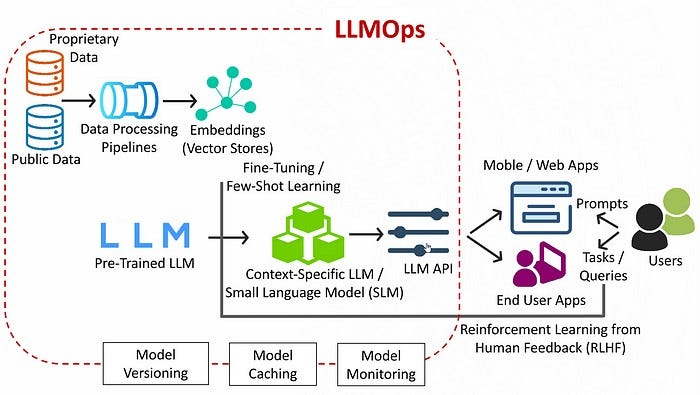
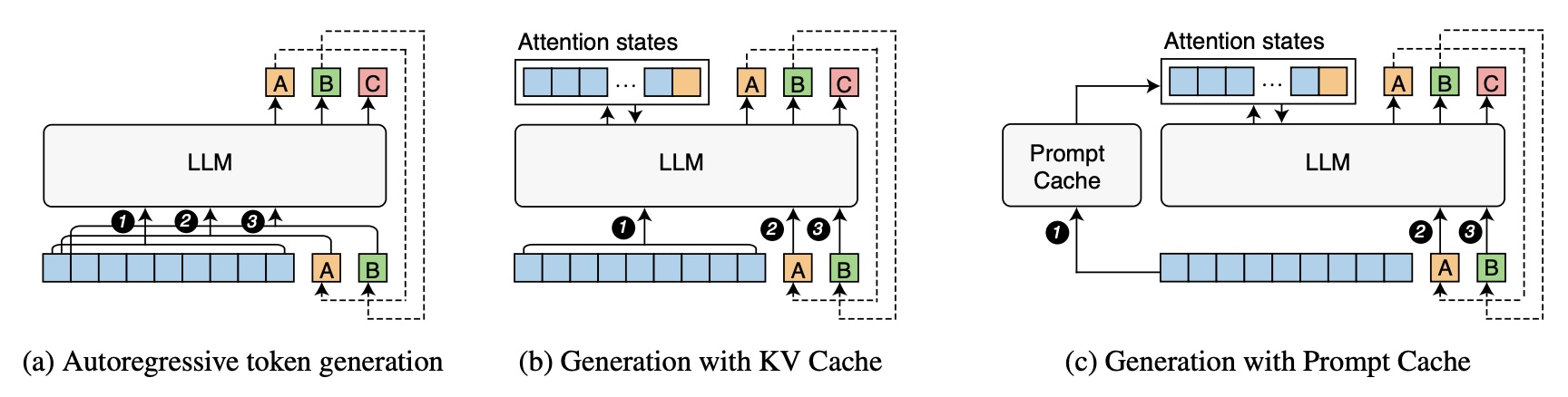
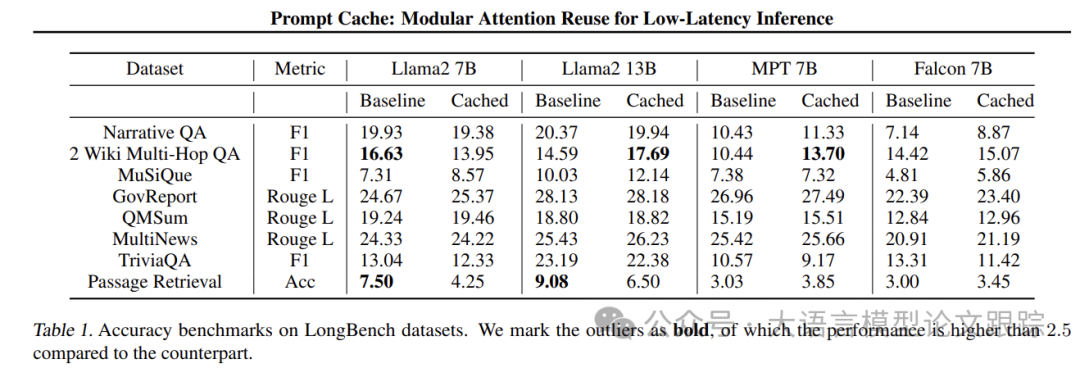
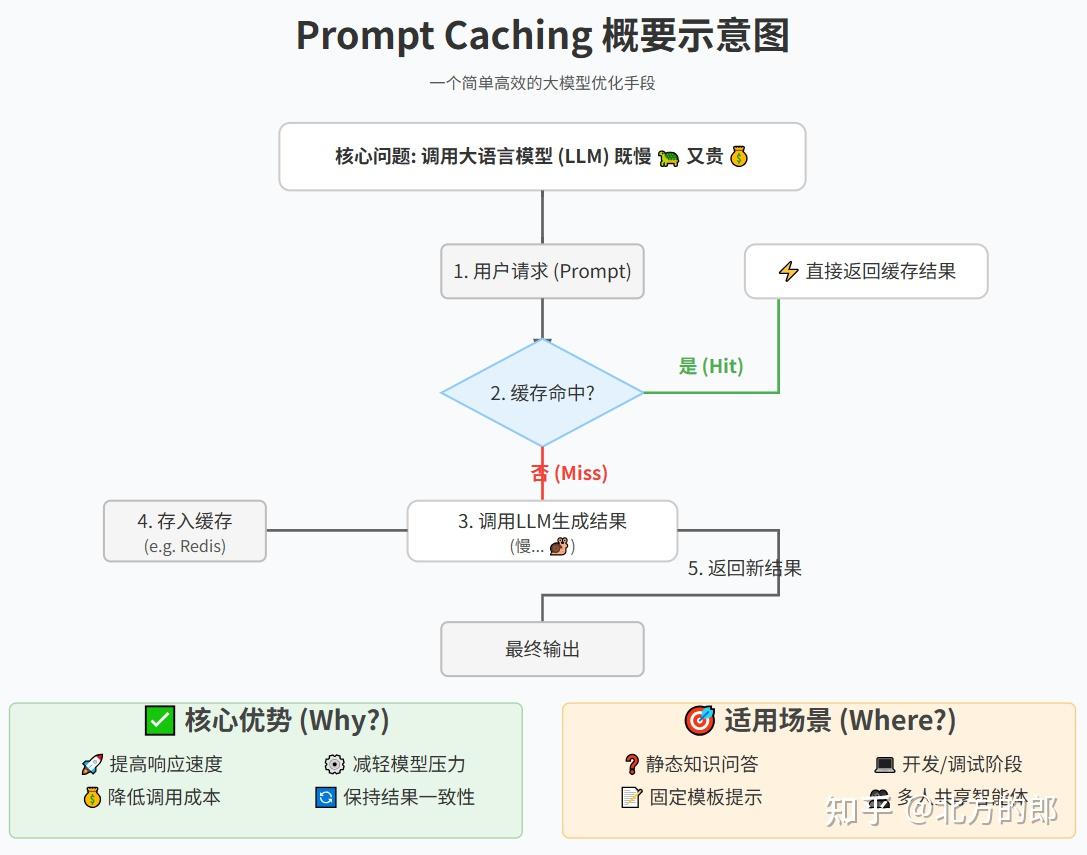
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
LLM Cache 策略:從 Prompt Cache 到 Semantic Cache | Yujun Wen
RAG-Enhanced Prompt Processor: Smarter LLM Queries with Cache by Suhaan ...
LLM Prompt Cache 深度解析:从 KV Cache 原理到大规模推理架构 - 知乎
Abordagens de cache de prompt para as aplicações que utilizam LLM | by ...
Accelerating LLM Serving with Prompt Cache Offloading via CXL - YouTube
Prompt Caching in LLM Systems. Table of Contents: - Caching Strategy ...
Cache Usage in LLMs: LangChain Cache and OpenAI Prompt Caching | Pedro ...
A Deep Dive into LLM Prompt Caching
Prompt Caching - LLM Parameter Guide - Vellum
PromptMule Prompt Cache LLMs – Numino Labs
Prompt Caching di Sistem LLM
Prompt Caching Strategies to Reduce LLM Cost | Medium
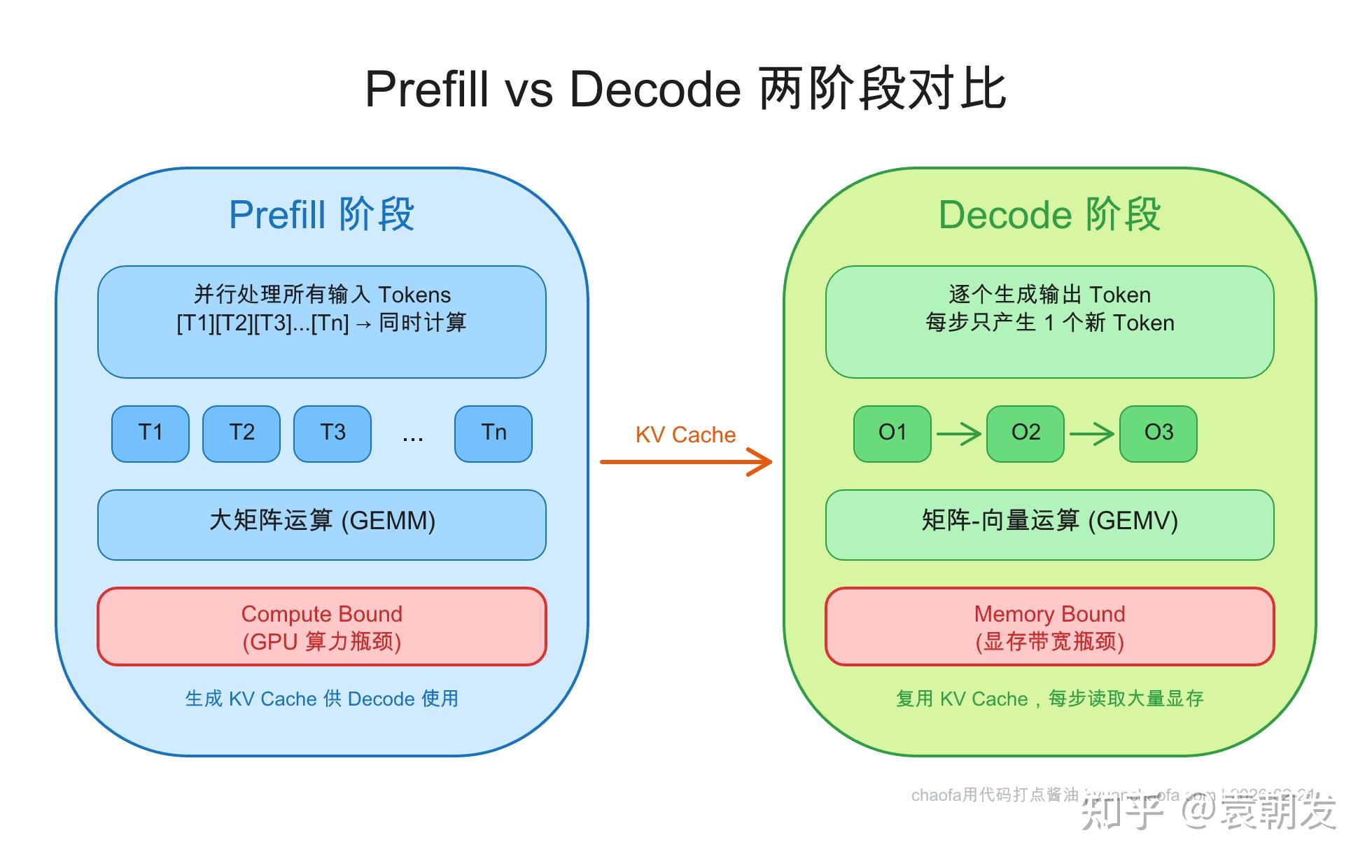
理解 KV Cache 与 Prompt Caching:LLM 推理加速的核心机制 | chaofa用代码打点酱油
Prompt Caching: The One Config Change That Cut Our LLM Costs by 90%
Prompt caching: 10x cheaper LLM tokens, but how? | ngrok blog
LLM Prompt Caching | MatterAI Blog
The Complete Guide to Prompt Caching: Cut LLM Costs by 90%
Prompt Caching: Tối Ưu Hiệu Suất và Chi Phí Khi Làm Việc Với LLM API ...
LLM Prompting: How to Prompt LLMs for Best Results
A Solutions Architect's Guide to Caching LLM Prompt Embeddings with ...
LLM Optimization: Power of Prompt Caching 💸 #ai2026 - YouTube
Prompt Caching: Saving Time and Money in LLM Applications | Caylent
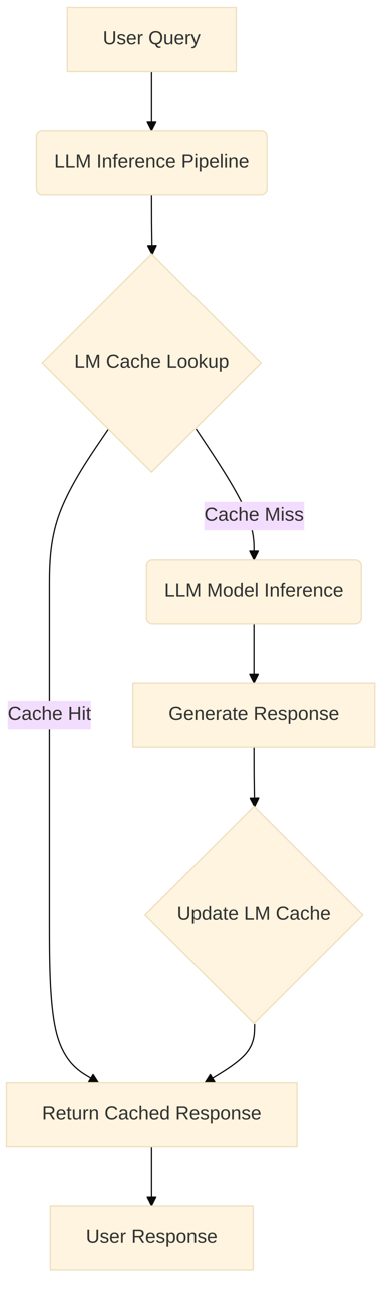
GPTCache : A Library for Creating Semantic Cache for LLM Queries — GPTCache
How Prompt Caching Supercharges LLM Performance & Reduces Costs
Comparison of LLM Prompt Caching: Cloudflare AI Gateway, Portkey, and ...
Prompt Caching: The Key to Reducing LLM Costs up to 90% | AiSDR
The Secret to Faster & Cheaper LLM Apps — Prompt Caching Explained ...
Claude Prompt Caching: Cut LLM API Costs 70% With 4 Patterns
Scaling LLM Economics: How Prompt Caching Slashes Costs and Speeds ...
Infographic: The Secret Life of an LLM Prompt
LLM Prompt Caching for Code Insights and more
Production-Grade LLM Prompt Optimization: Caching, Architecture, and ...
What is Prompt Caching : Reduce LLM cost by 90%! | by Mohamed EL ...
Prompt Caching and KV Cache: Speed Up LLM Responses
理解 KV Cache 与 Prompt Caching:LLM 推理加速的核心机制 - 知乎
Prompt Security in AI & LLM Interactions Explained Clearly
Оптимизация производительности LLM с Cache LM: архитектуры, стратегии и ...
What is Prompt Caching? Optimize LLM Latency with AI Transformers - YouTube
How Local Prompt Caching Reduces Tokens in Tool-Driven LLM Workflows
提升 LLM 推理效率的秘密武器:LM Cache 架构与实践_lmcache-CSDN博客
利用 Prompt Caching 优化 LLM 性能与成本的全方位指南 | 企业级大模型 LLM API 接口聚合平台 | n1n.ai
Securing LLM Systems Against Prompt Injection | NVIDIA Technical Blog
Effective prompt engineering based on understanding of LLM algorith ...
Prompt Cache : What is Prompt Caching? A Comprehensive Guide | by 1kg ...
Slashing LLM Costs and Latencies with Prompt Caching
Prompt Caching, phương án tiết kiệm hiệu quả khi dùng LLM qua API - Mì ...
LLM 和 KV cache 详解 | Jasmine
LLM Prompt - Cognigy Documentation
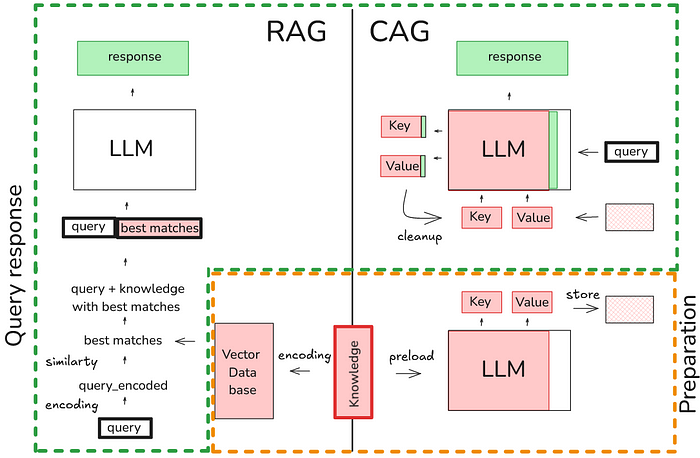
Prompt caching : le nouveau RAG ? Parlons d’une avancée majeure dans l ...
What is Prompt caching? Prompt caching has now become a common feature ...
Making LLMs Work Smarter: Understanding Prompt Caching
LLM推理:首token时延优化与System Prompt Caching - 知乎
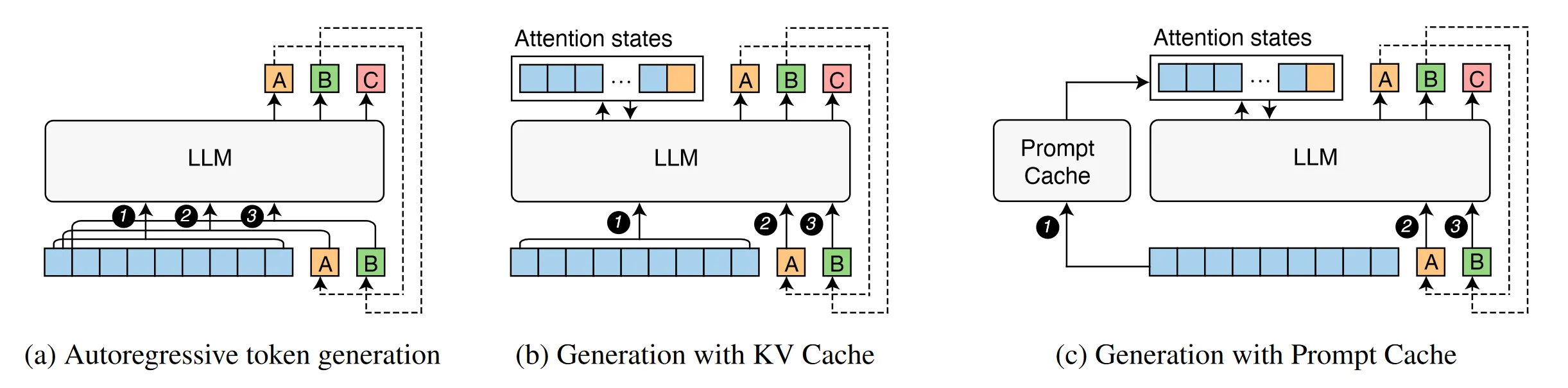
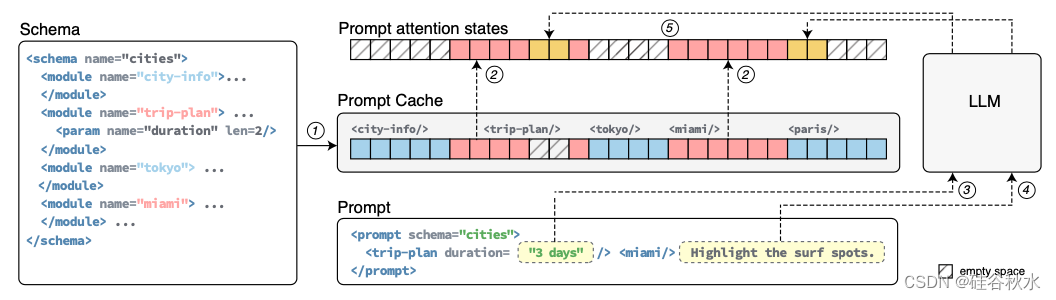
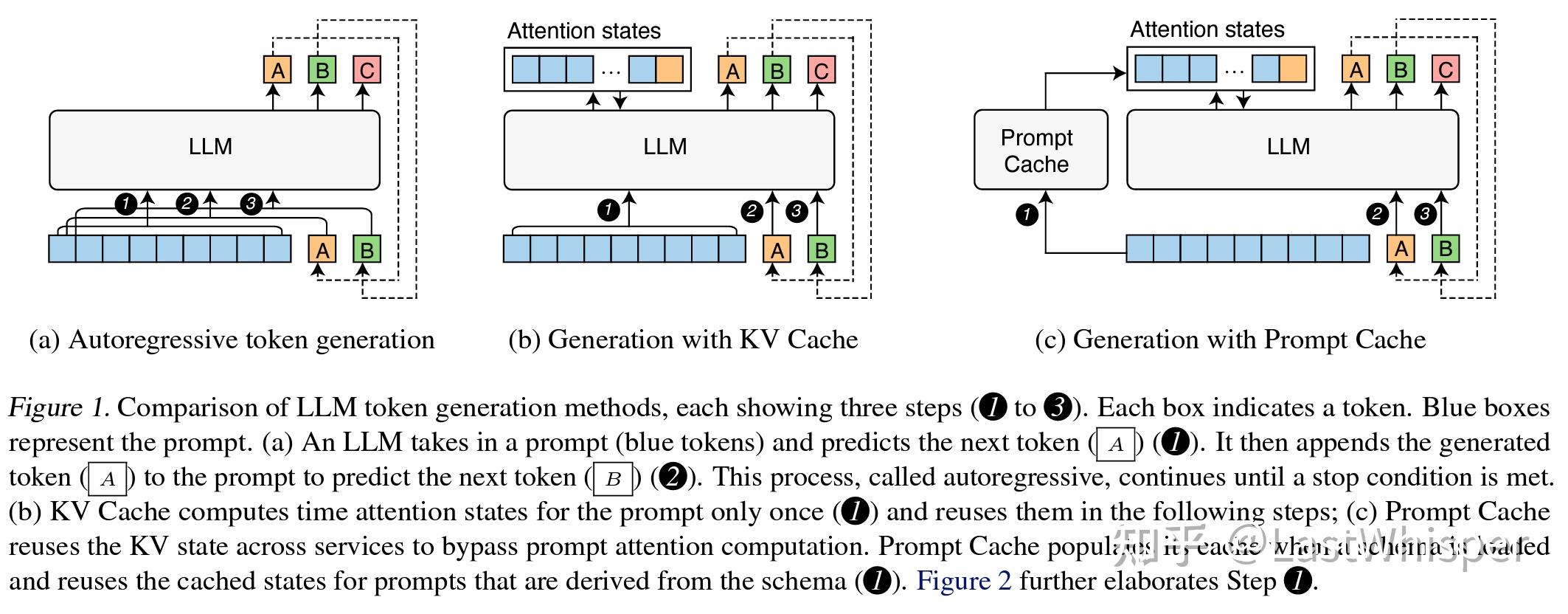
[April 2024] Prompt Cache: Modular Attention Reuse for Low-Latency ...
Prompt Cache:模块化注意重用实现低延迟推理_prompt cache: modular attention reuse for ...
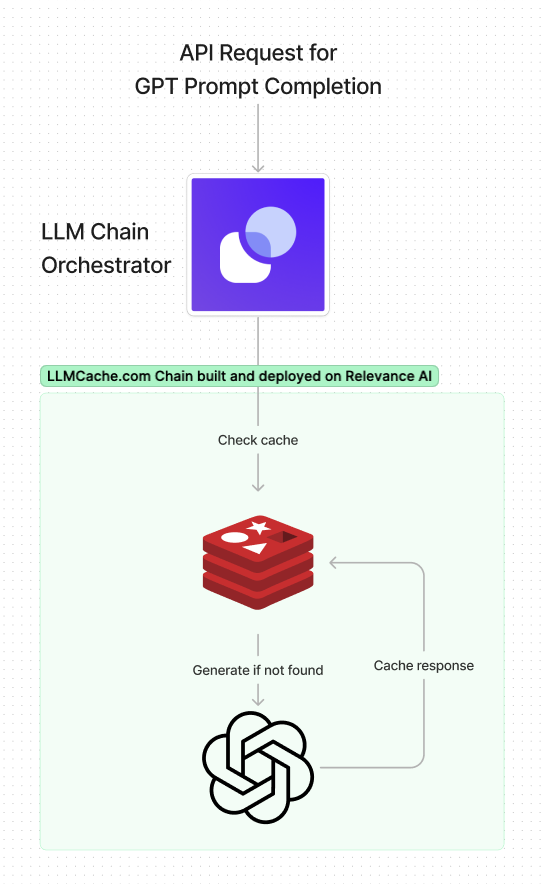
LLMCache - How to Build a Cache with Relevance AI and Redis
Prompt caching,一篇就够了。 - 知乎
GitHub - yale-sys/prompt-cache: Modular and structured prompt caching ...
Prompt Cachingを完全に理解してLLMコストを爆裂に下げる
Prompt Caching
Understanding and Coding the KV Cache in LLMs from Scratch
Semantic Caching for LLM Inference: GPTCache, Redis Vector Cache, and ...
LLM-Powered Applications with prompt caching
Mastering LLM Techniques: Inference Optimization – GIXtools
LLM Caching Isn’t Optional — Here’s How I Built It with Redis and ...
Effectively use prompt caching on Amazon Bedrock | Artificial ...
What is prompt caching? How can product managers leverage it to develop ...
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
How does prompt caching work? · Sara Zan
LLM Email Automation with n8n — Advanced Filtering, DB Caching, and ...
LLM - Generate With KV-Cache 图解与实践 By GPT-2_llm kv cache-CSDN博客
Understanding KV Cache and Paged Attention in LLMs: A Deep Dive into ...
Prompt Caching, LiteLLM, and the 8,600‑Token Bug: A Practical Guide to ...
LLM vs GPT 2026: Differences, Models, Use Cases
Prompt Caching: A Guide With Code Implementation | DataCamp
Prompt Caching in LLMs: Intuition | Langflow | Low-code AI builder for ...
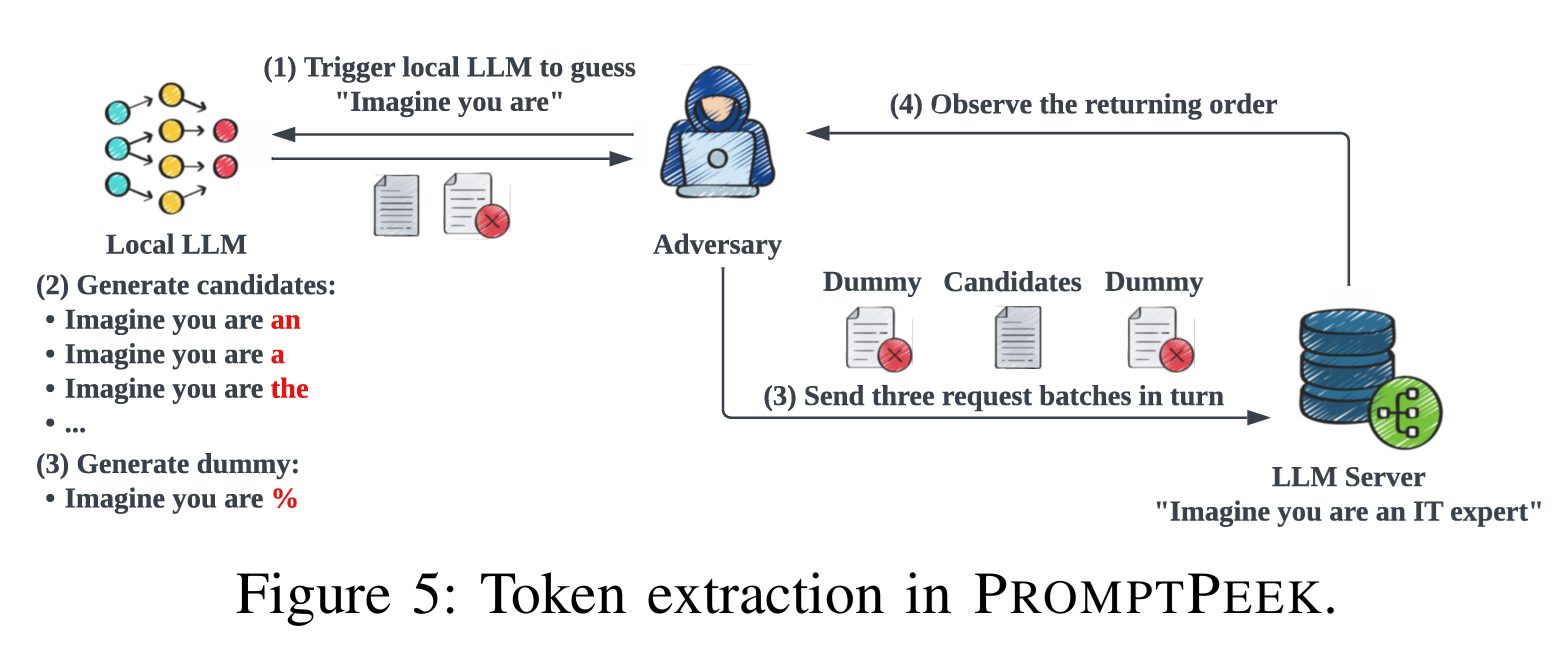
I Know What You Asked: Prompt Leakage via KV-Cache Sharing in Multi ...
GitHub - nirtz14/LLM-Cache-Optimization: Context-aware LLM caching ...
Prompt caching with LLM’s. Introduction | by Smit Agrawal | Medium
LLM Backends Under Load: Token Budgeting, Caching, and “Prompt Dedup ...
Paper page - Prompt Cache: Modular Attention Reuse for Low-Latency ...
All You Need to Know About Prompt Caching for LLMs
What is Prompt Caching ???. Imagine this: You’re interacting with a ...
Chain LLM Prompts for Advanced Use-Cases | Relevance AI
Reduce LLM Latency : KV Caching. How to serve LLMs ? | by Anuva Sharma ...
Prompt Caching - PraisonAI
Auditing Prompt Caching in Language Model APIs · HF Daily Paper Reviews ...
Caching techniques in ML systems design | UnfoldAI
Optimizing Latency and Cost via Attention, Prompt, and Semantic Caching ...
最近大厂推出的Prompt Cache到底是个啥?-CSDN博客
大模型技巧之Prompt Caching——让大模型响应更快、更省 - 知乎


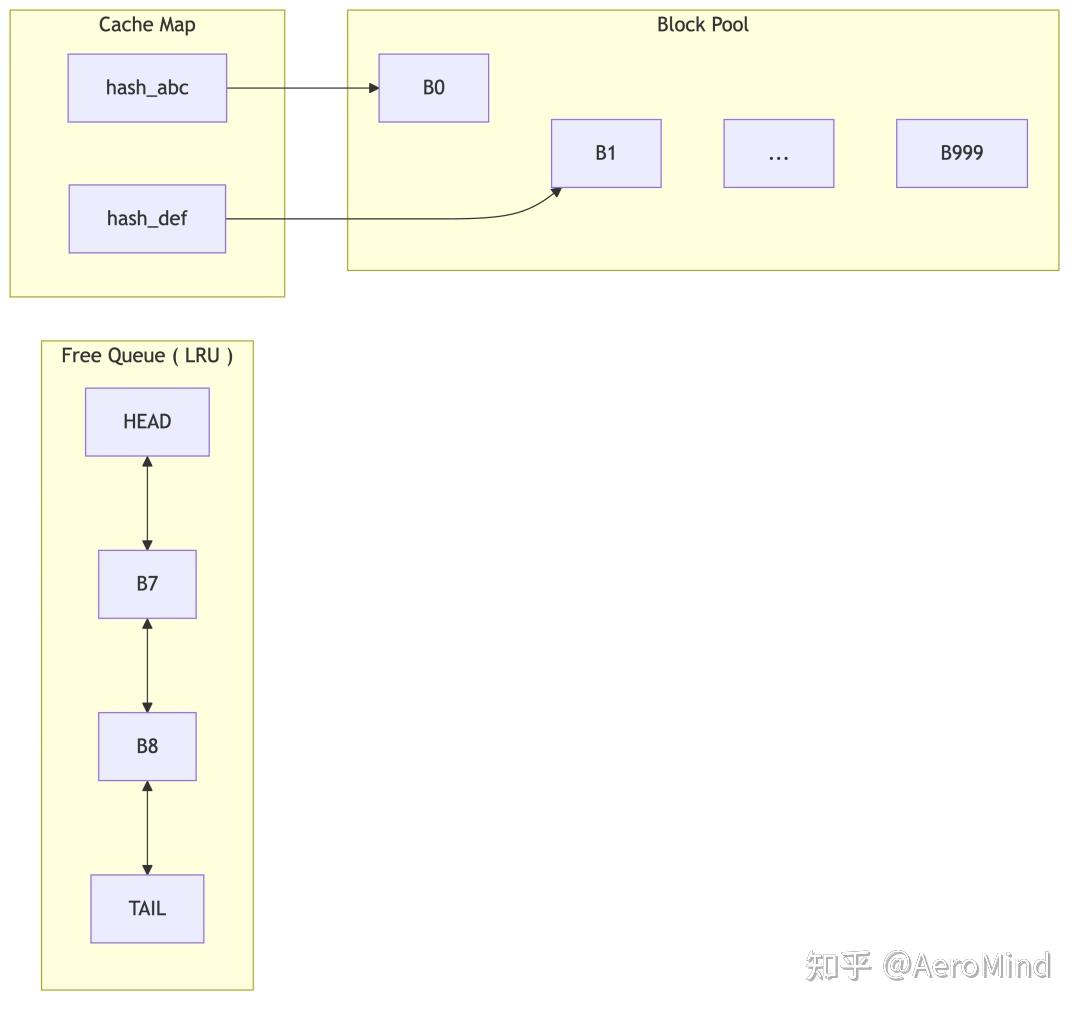
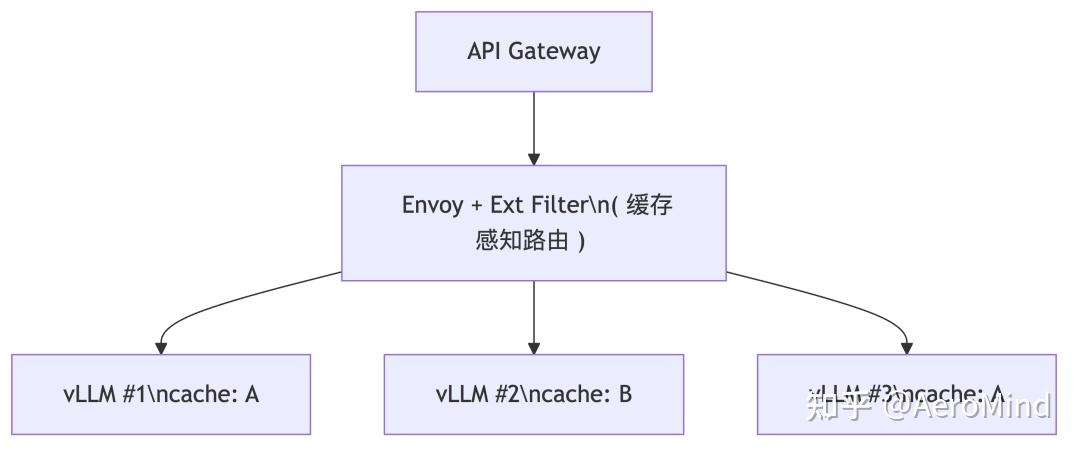
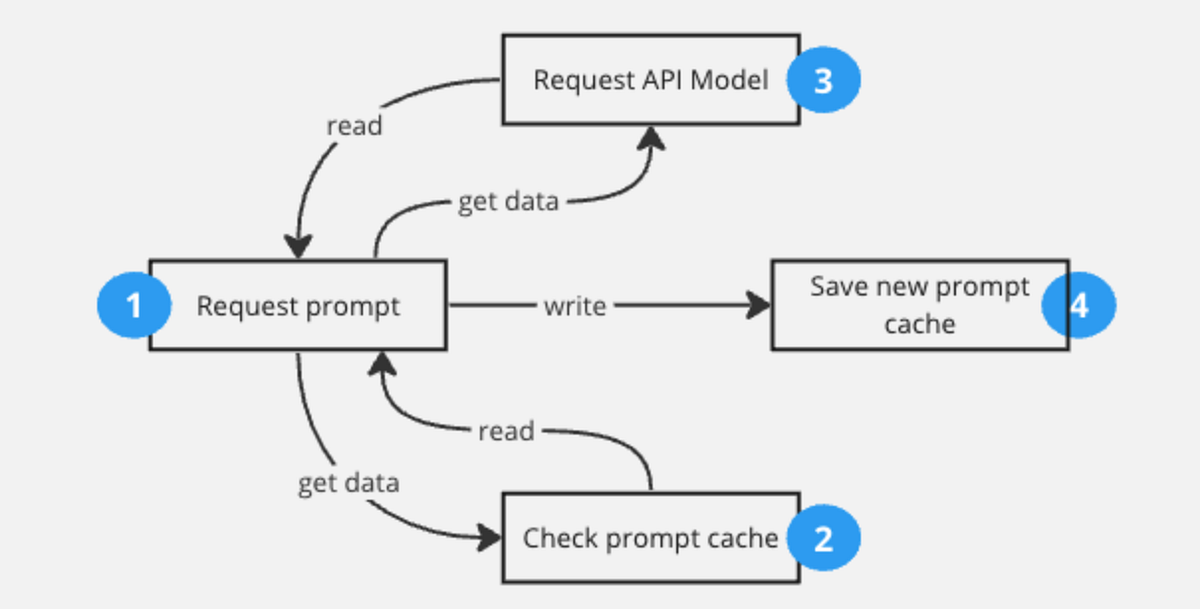

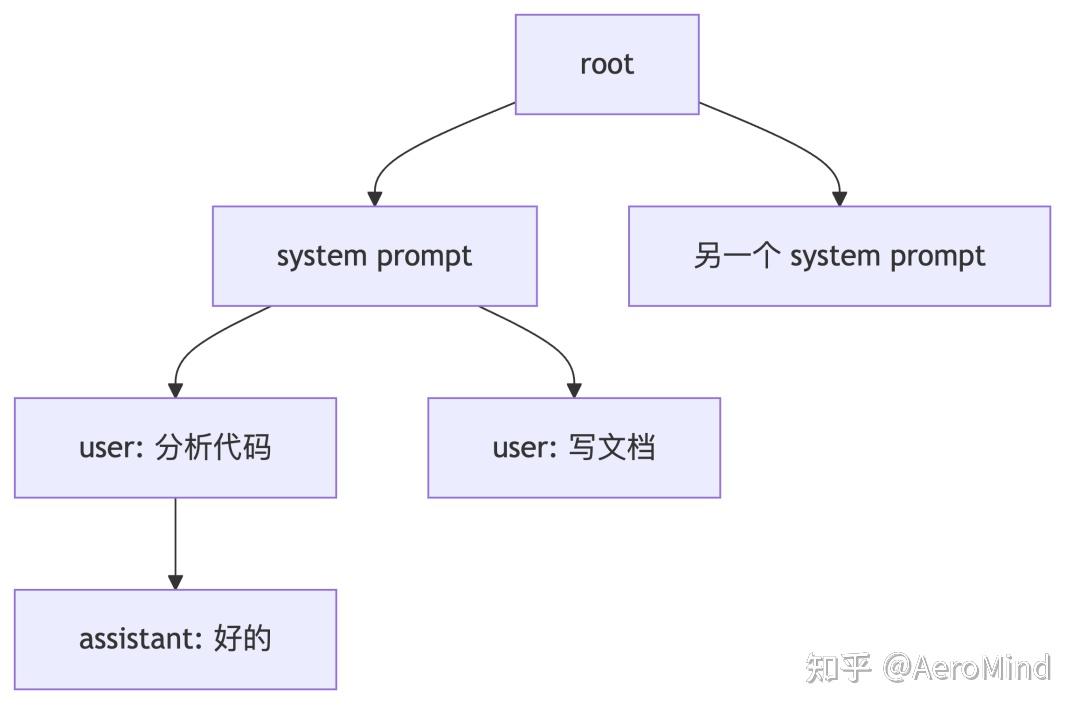
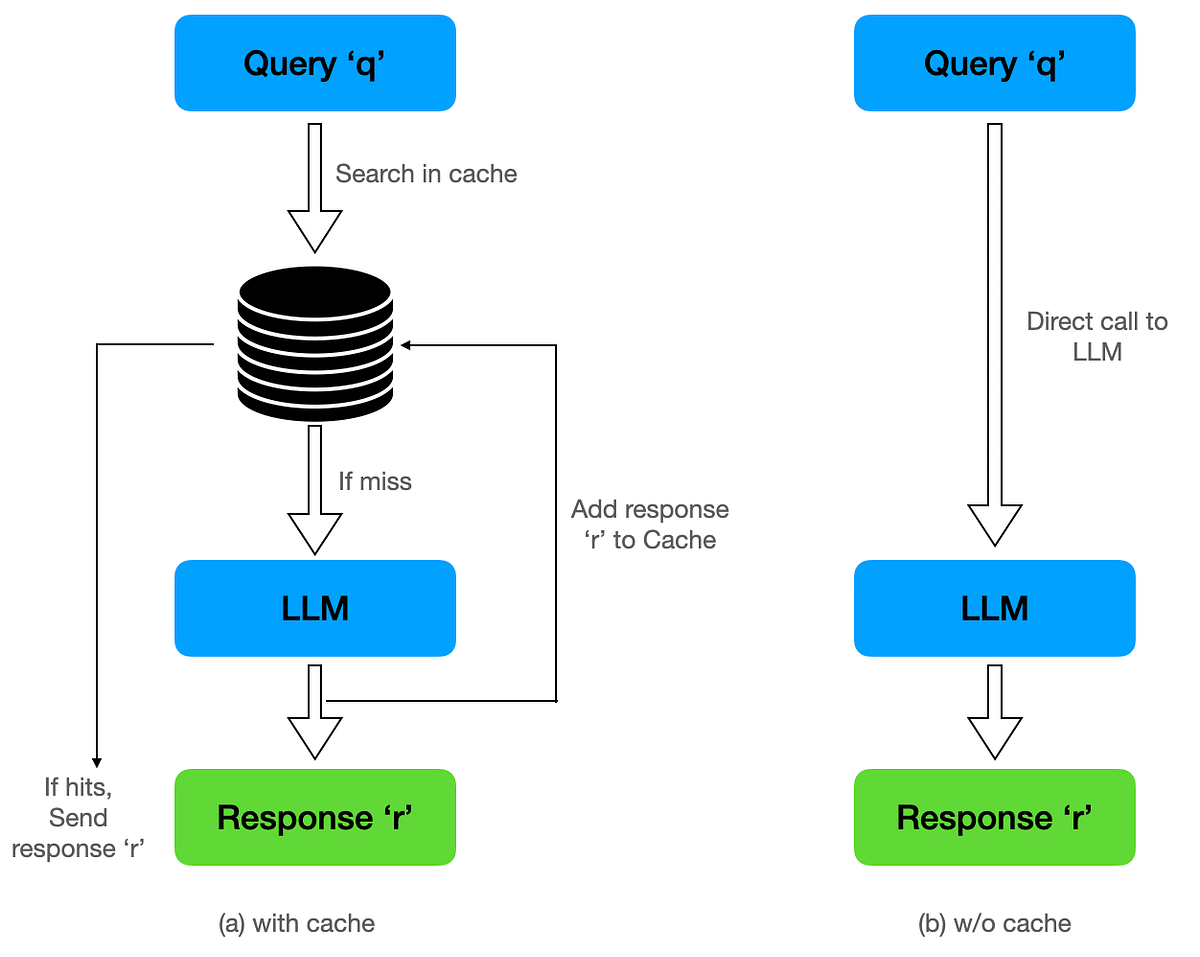

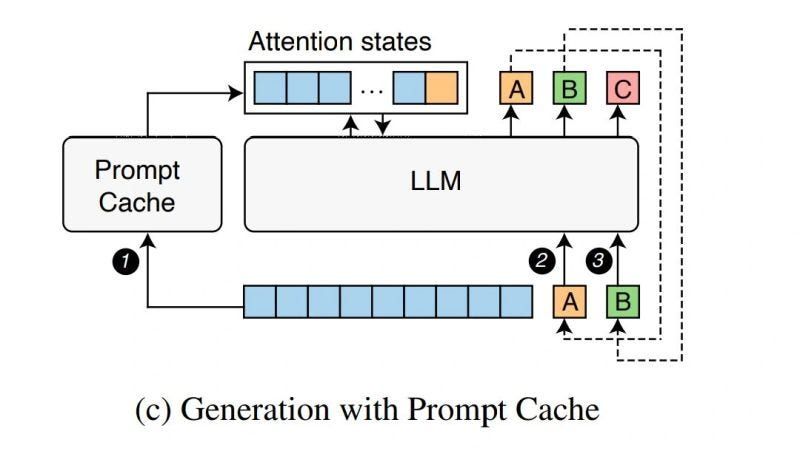


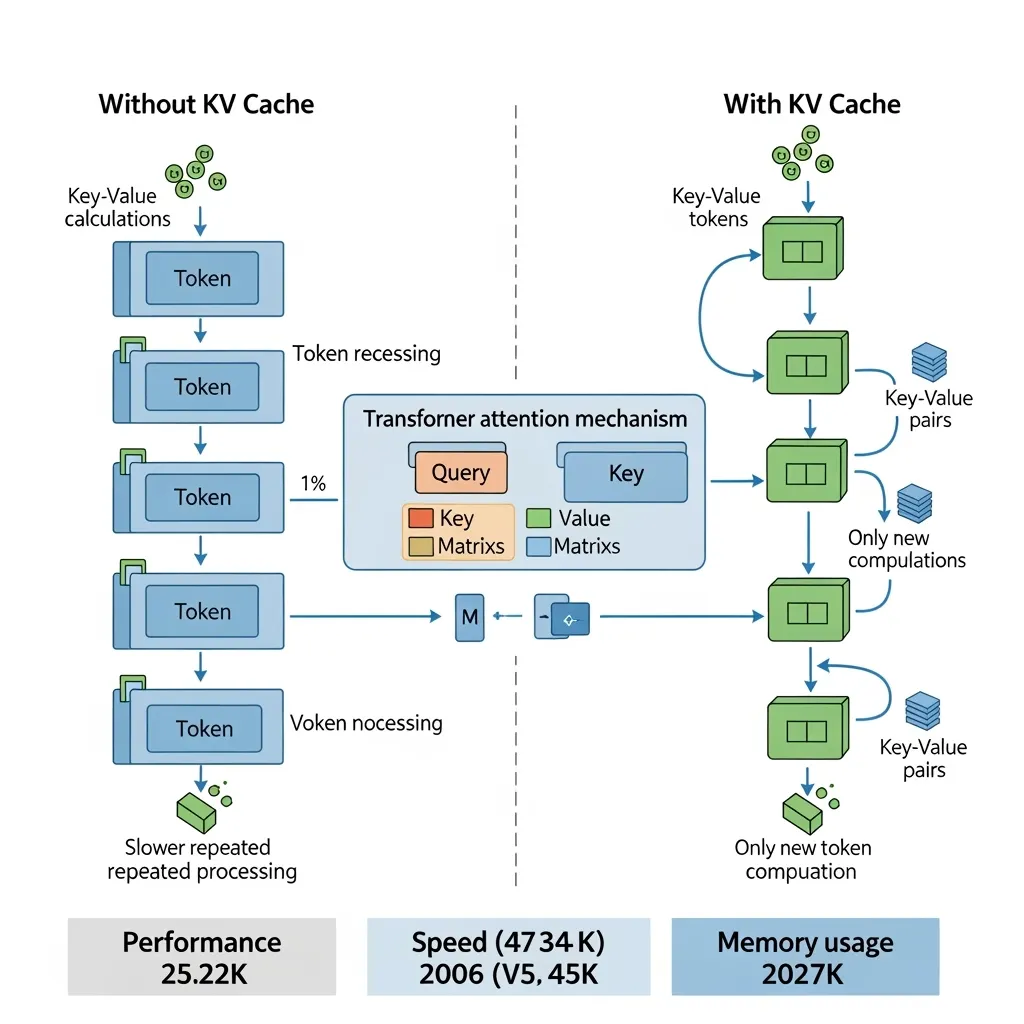
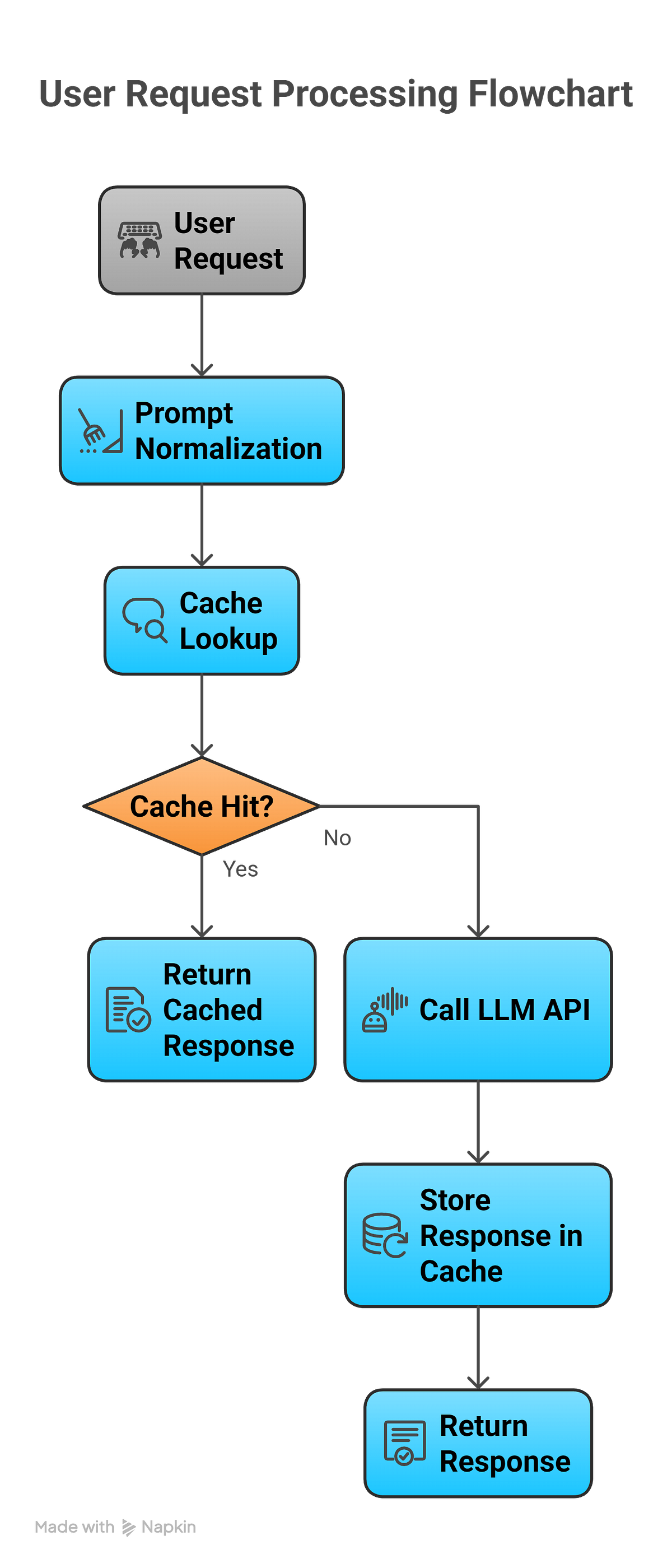
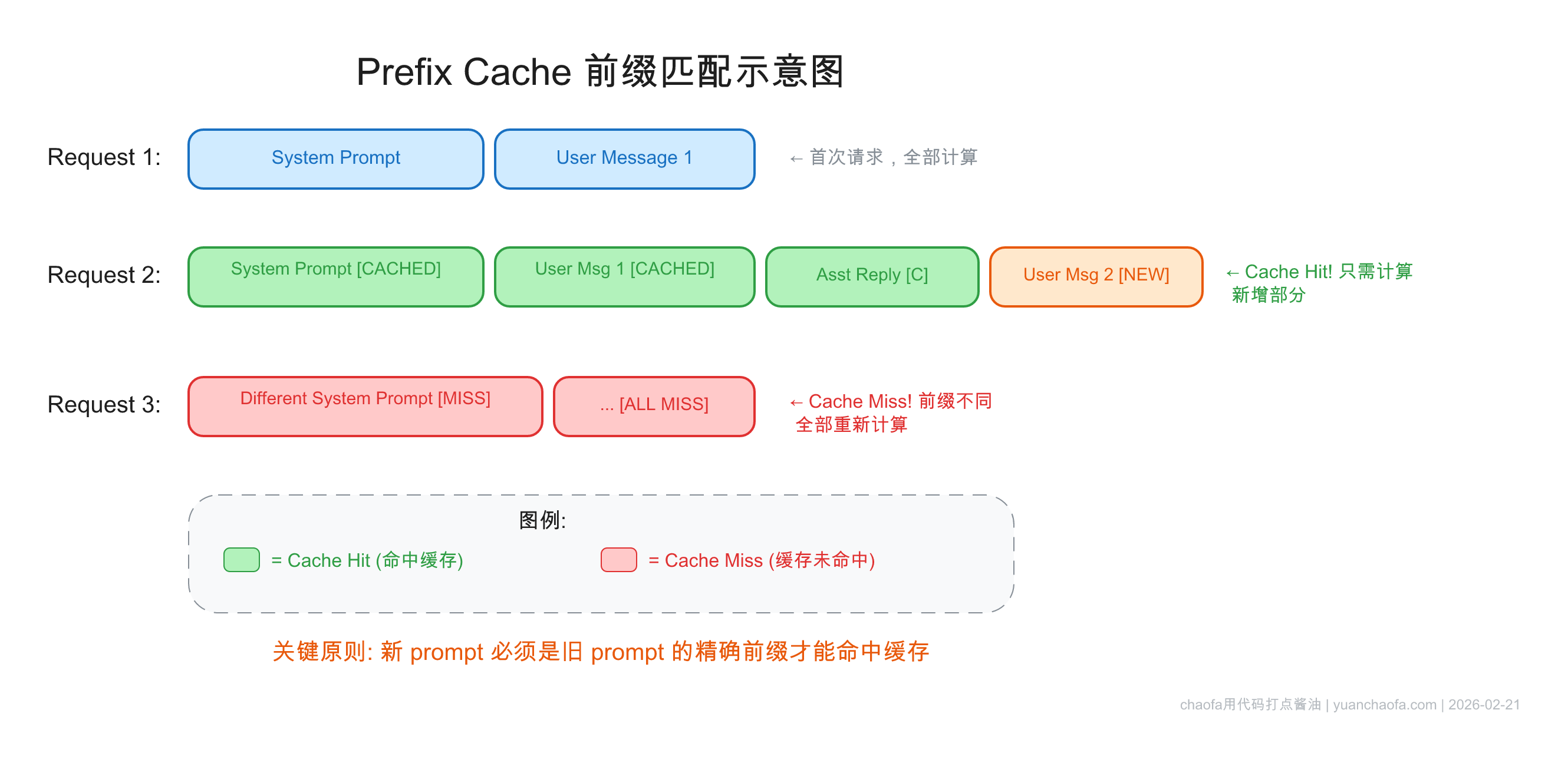

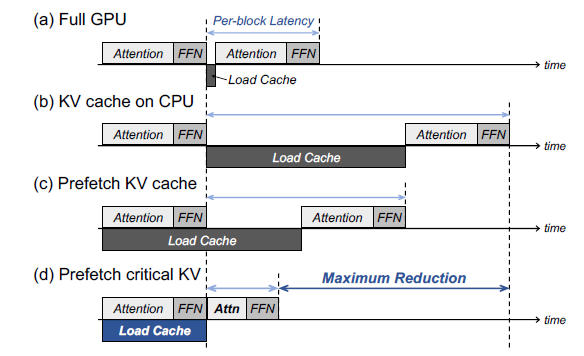

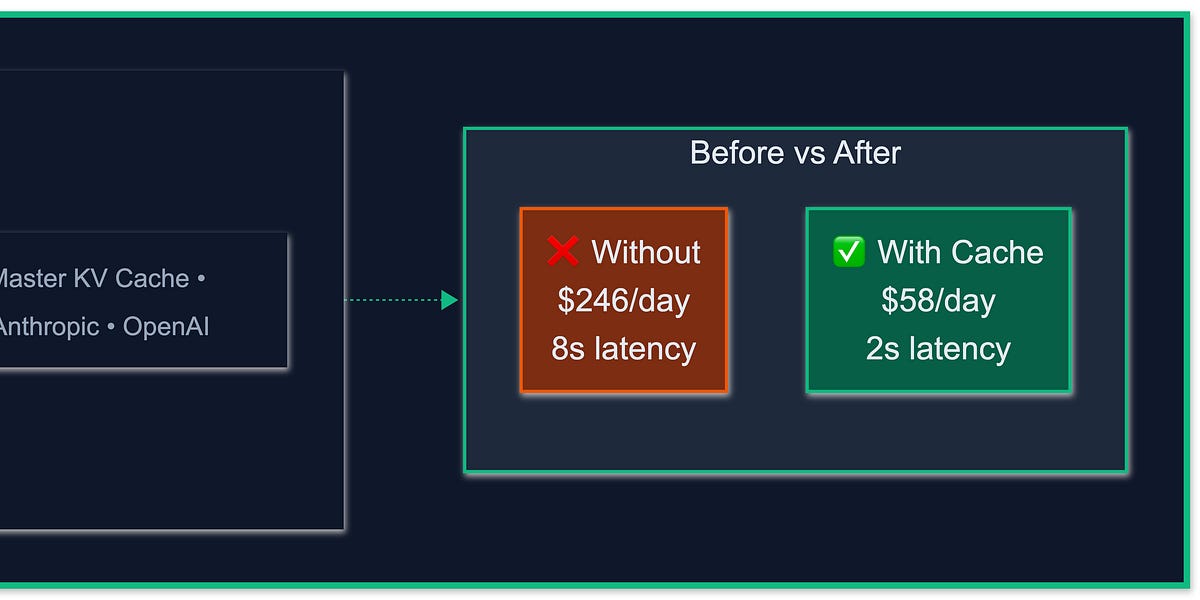






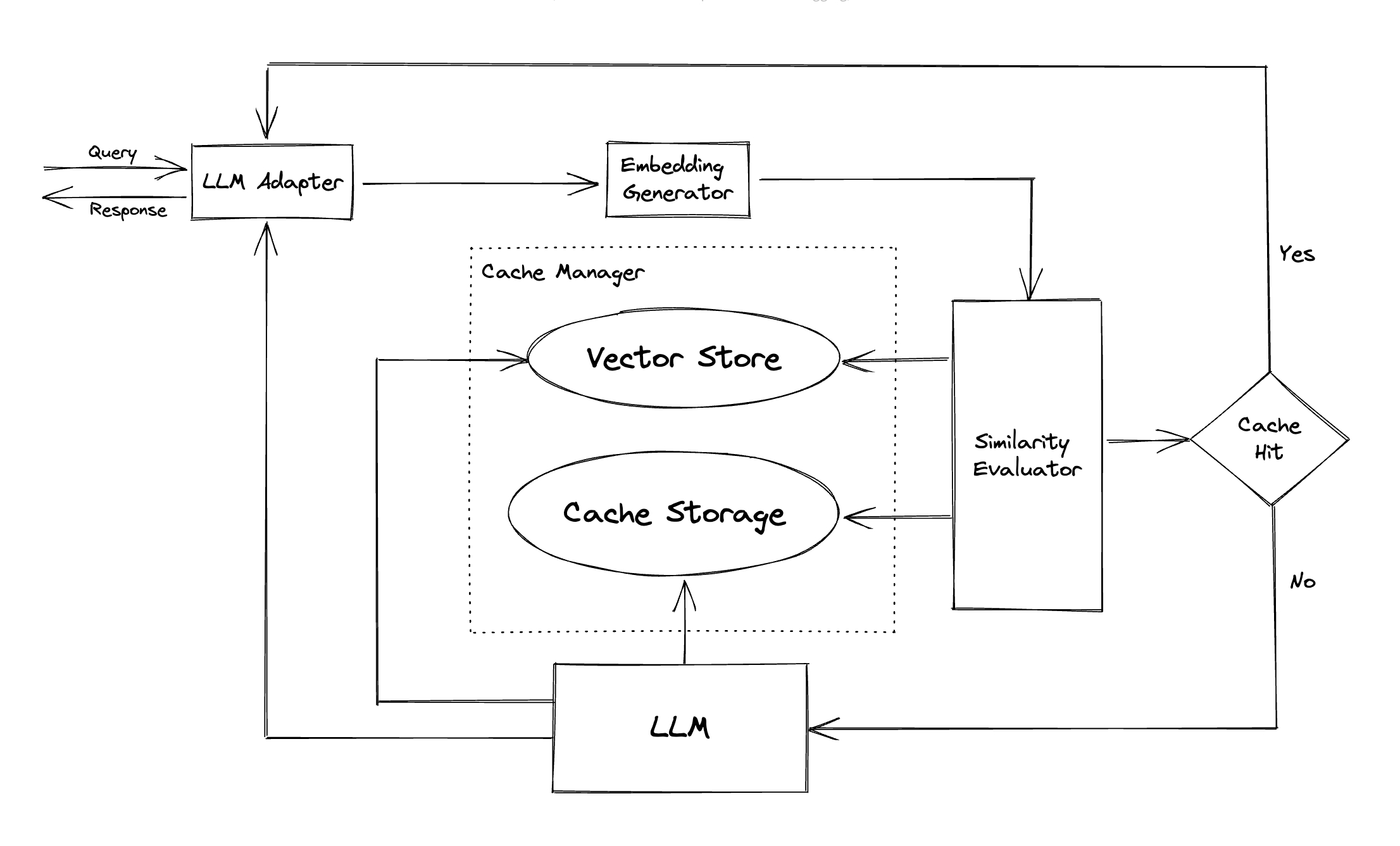




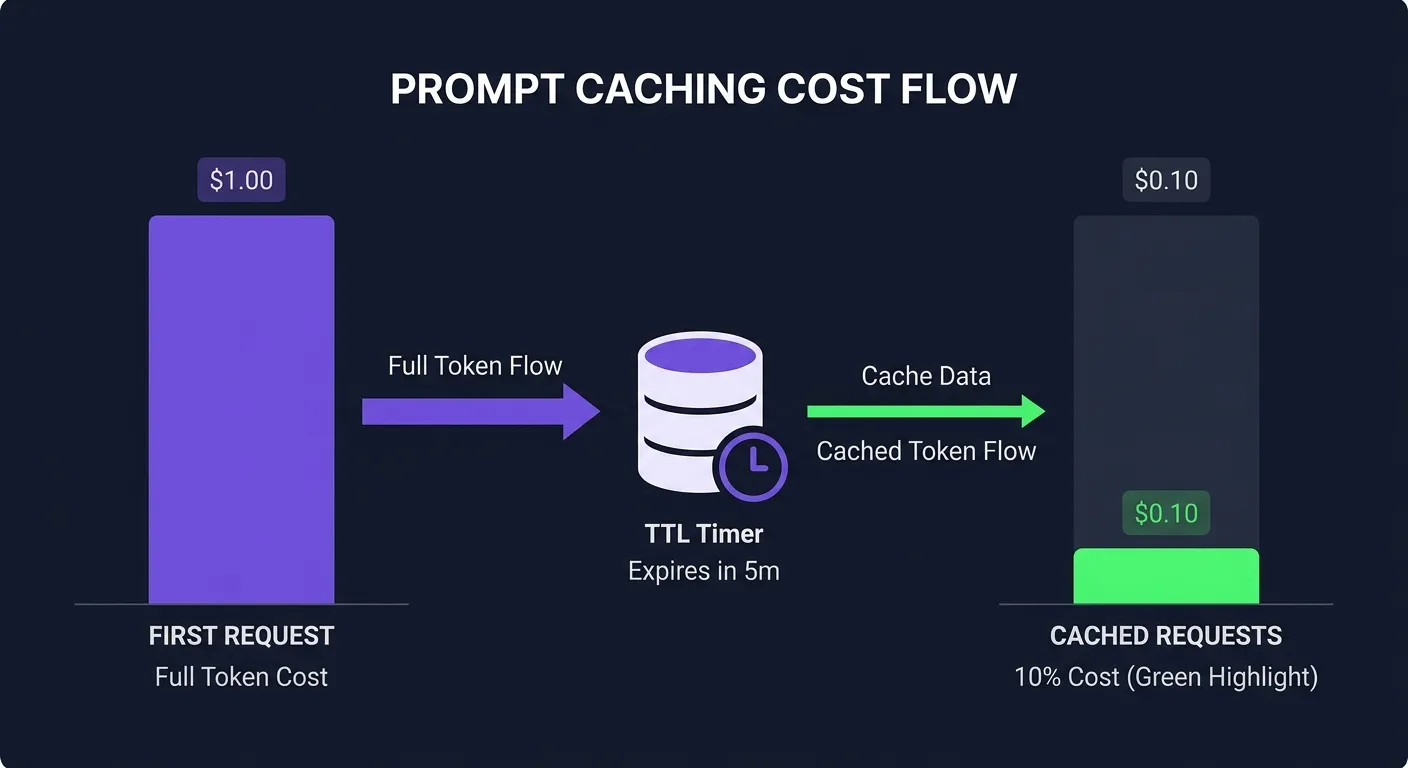
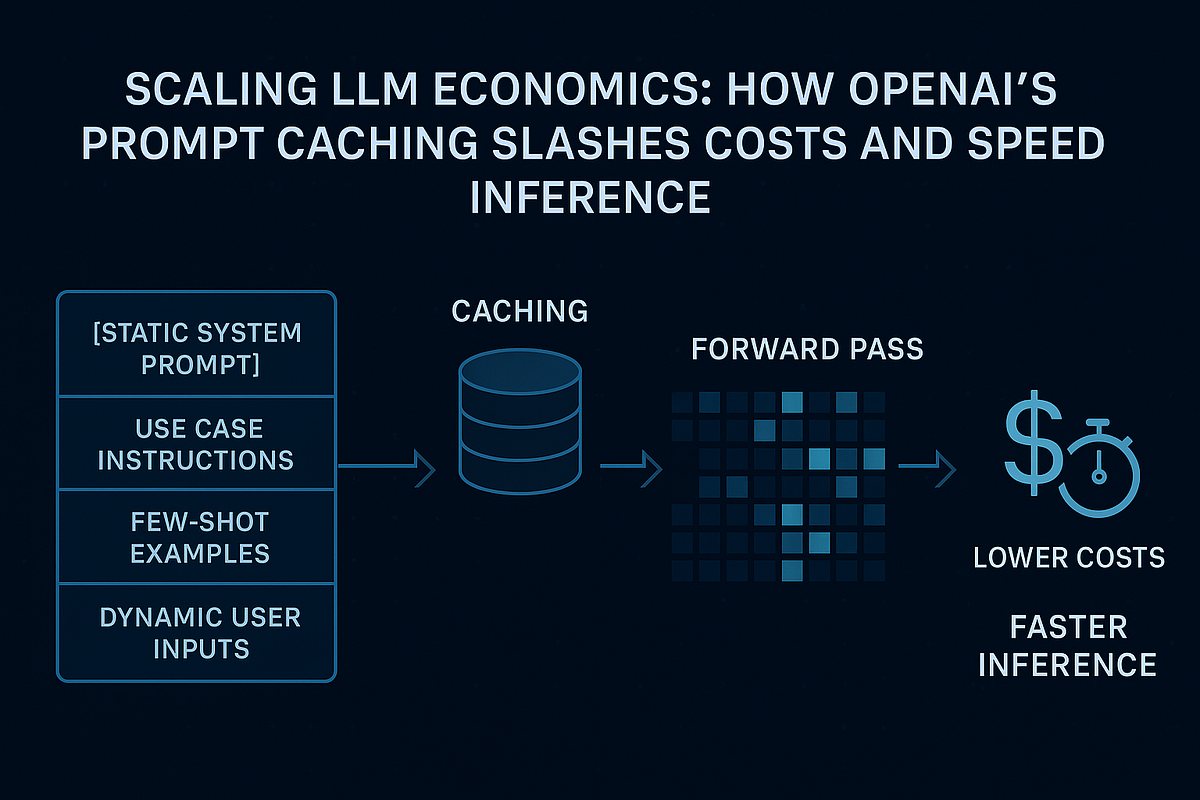




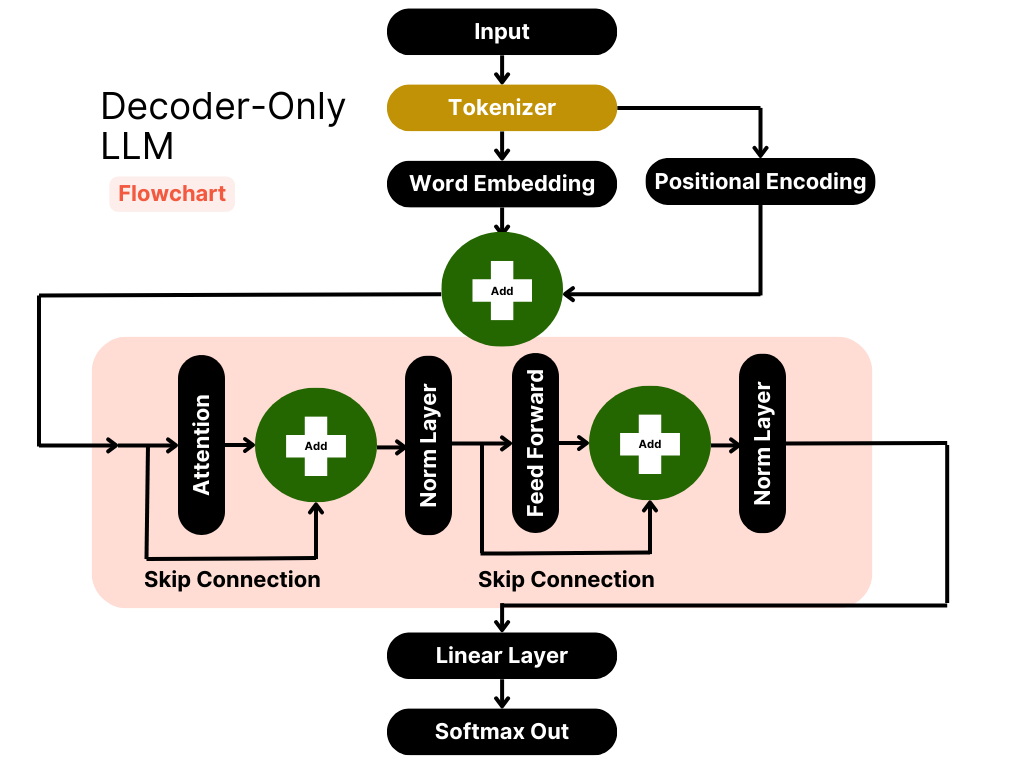
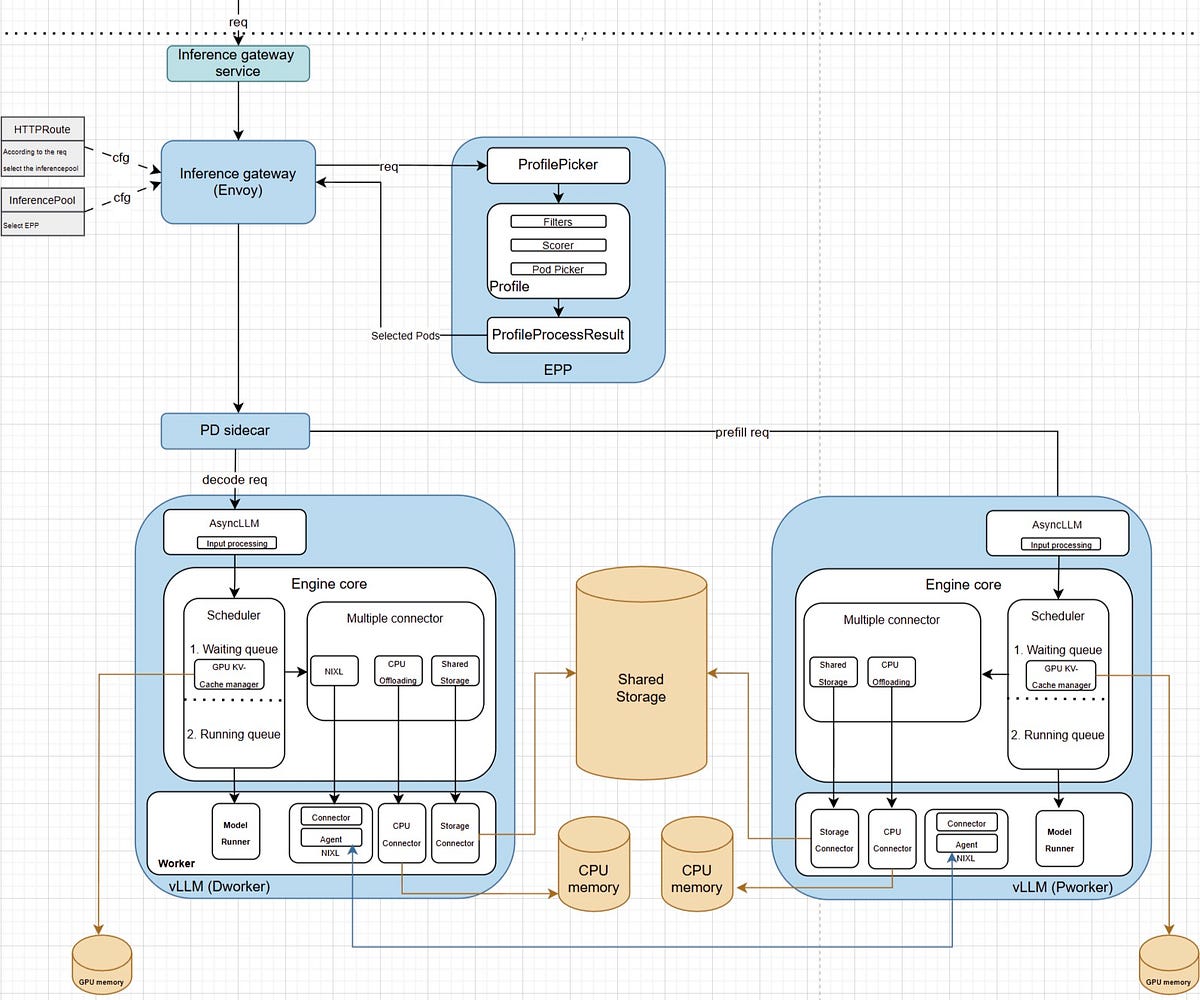
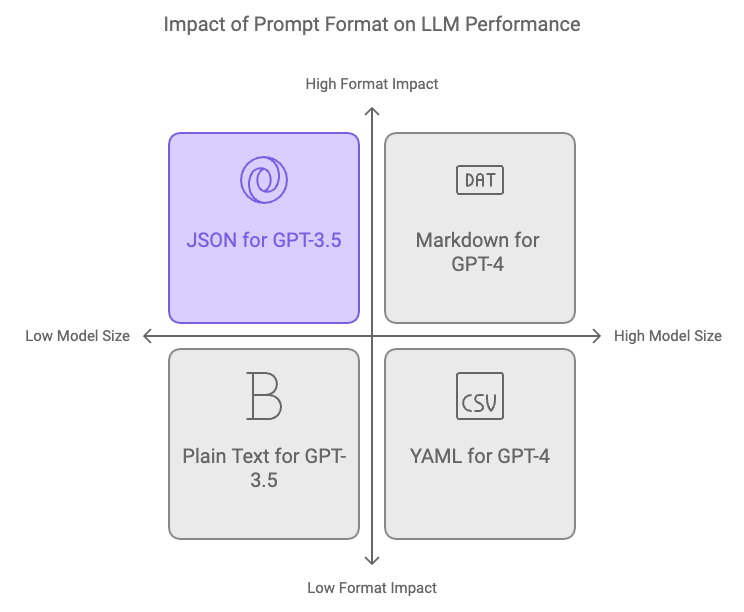


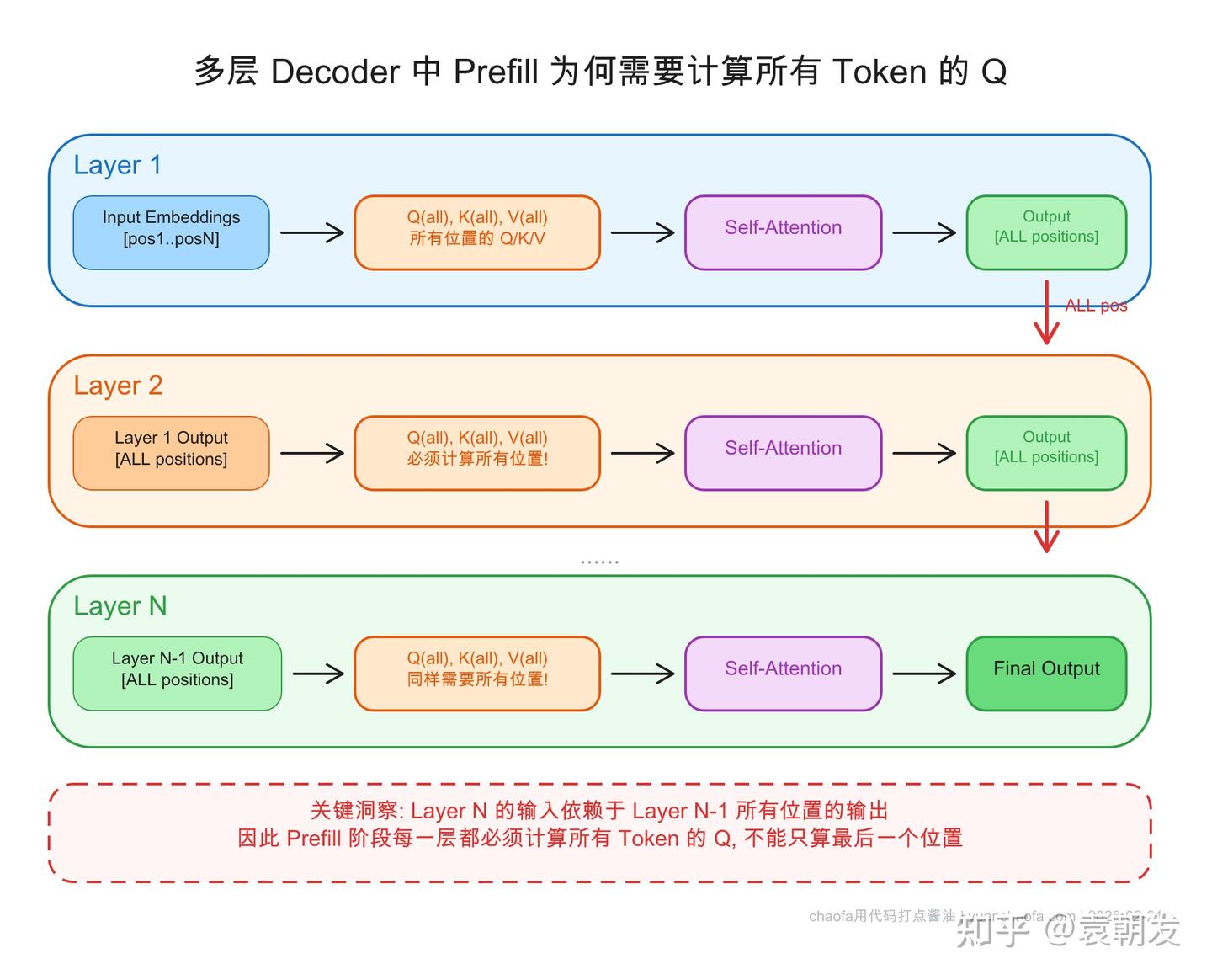
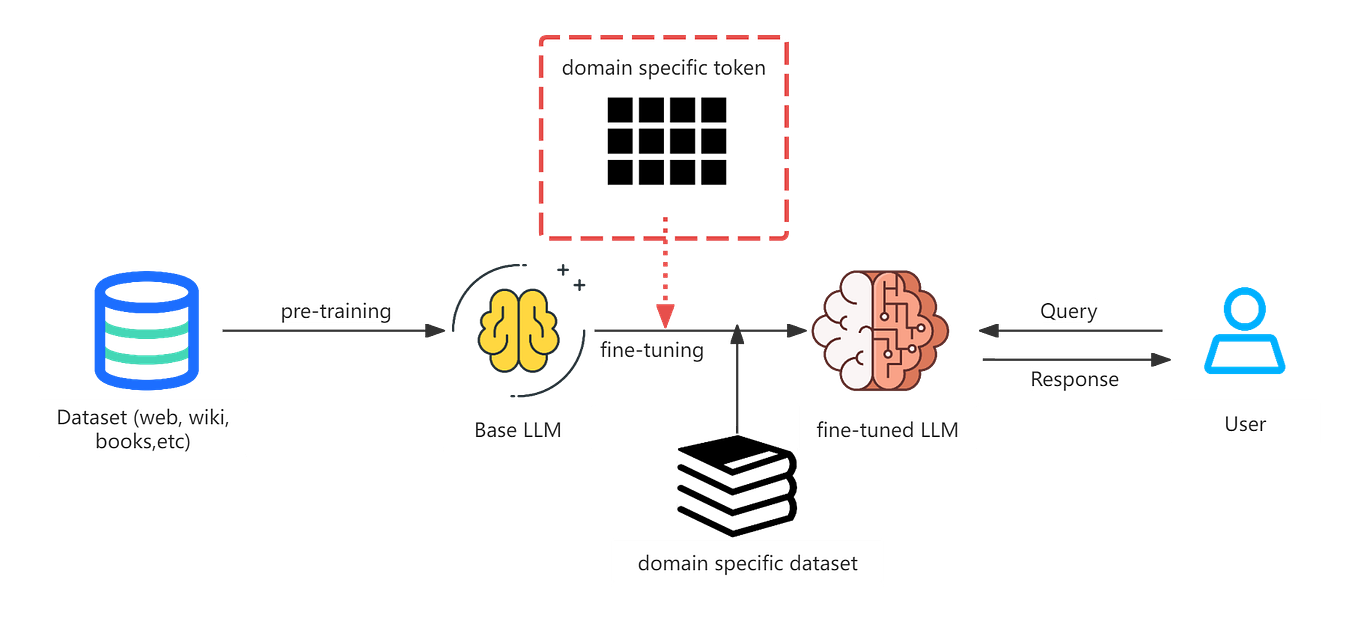


.png)