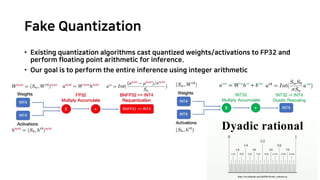
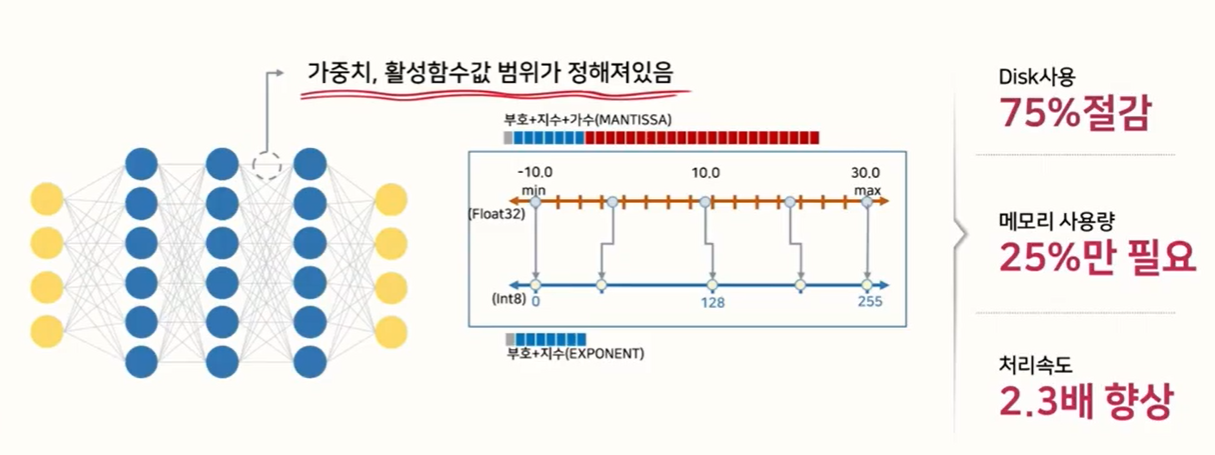
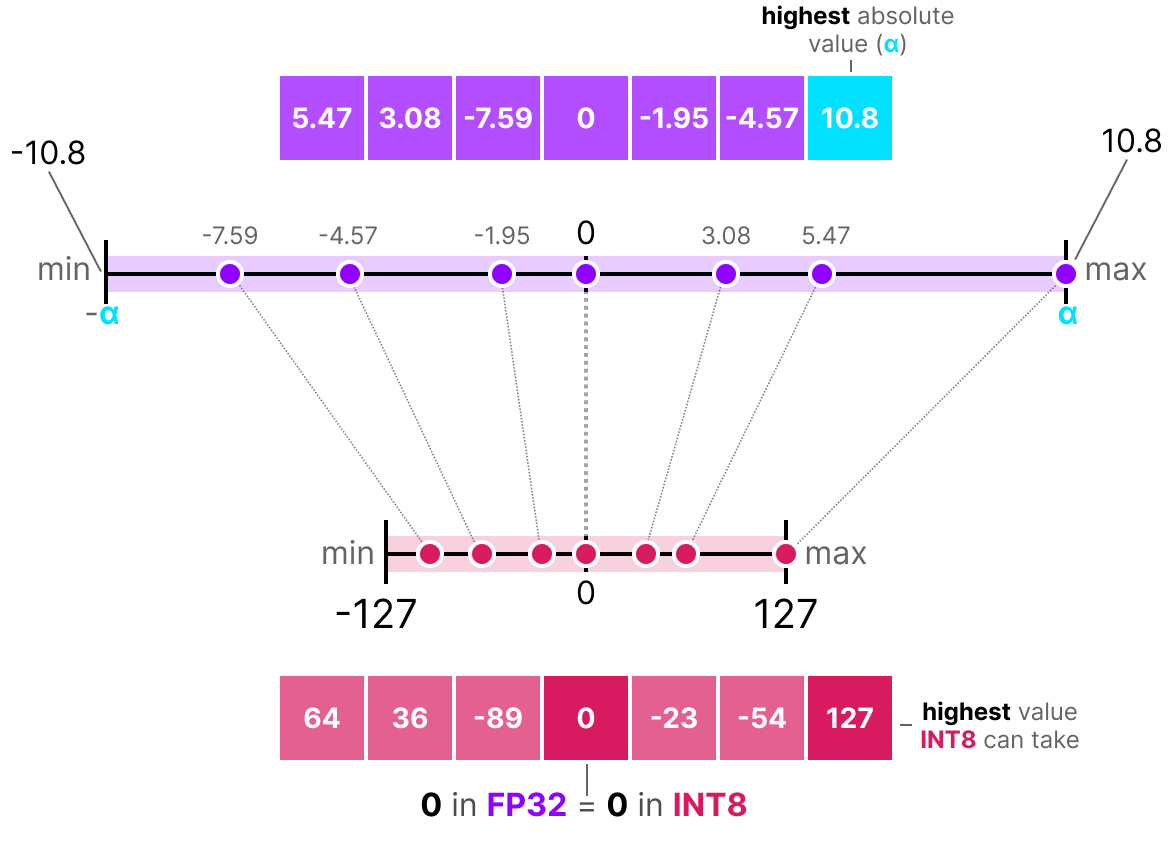
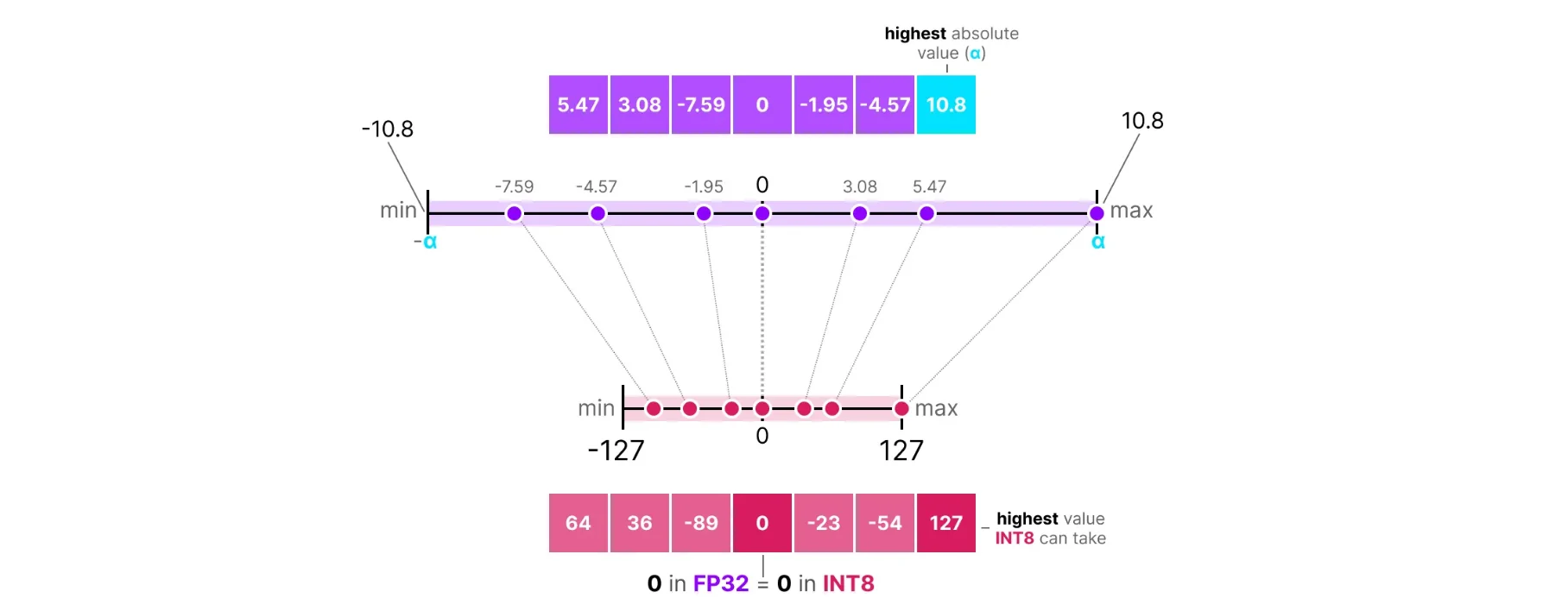
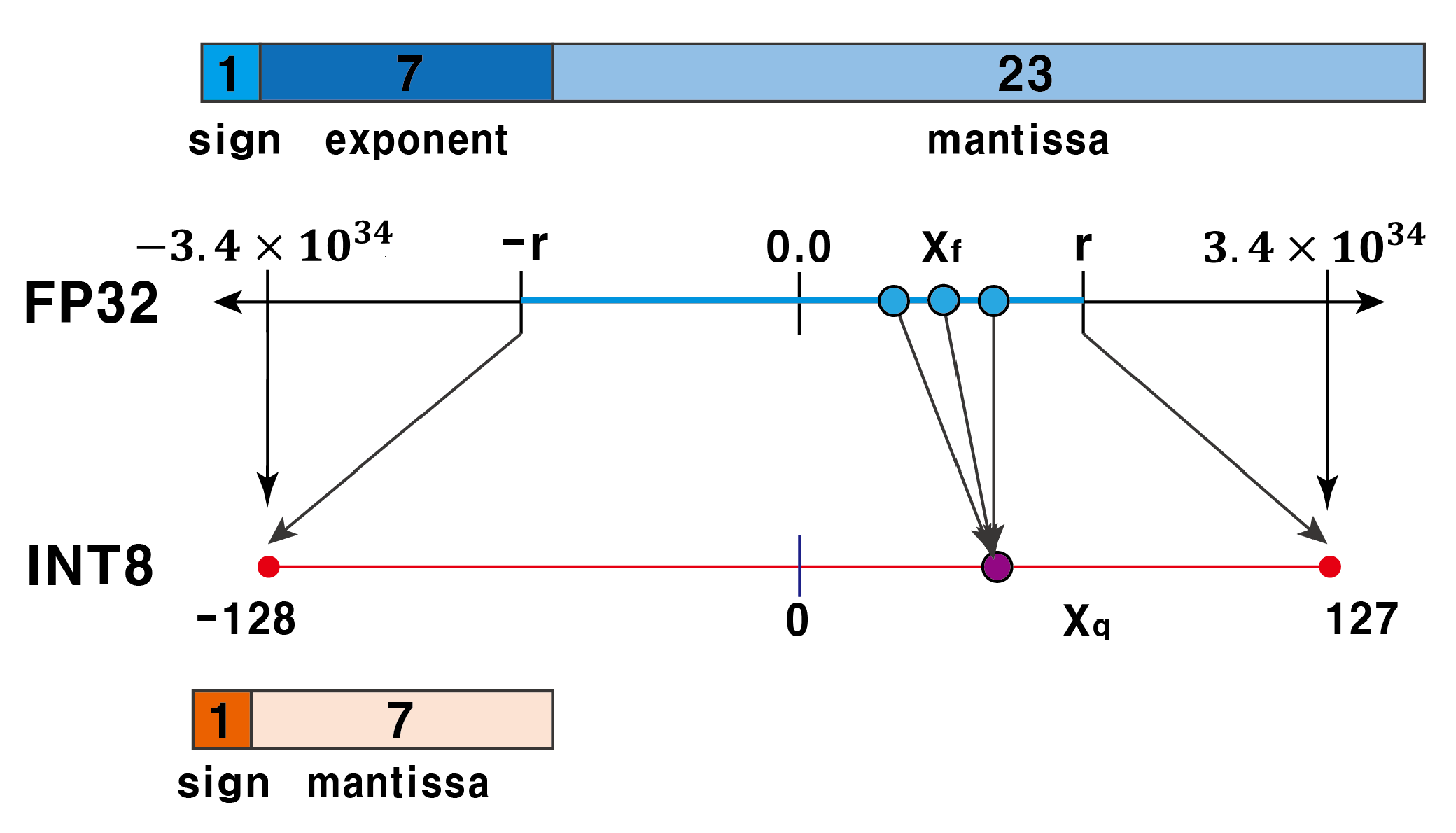
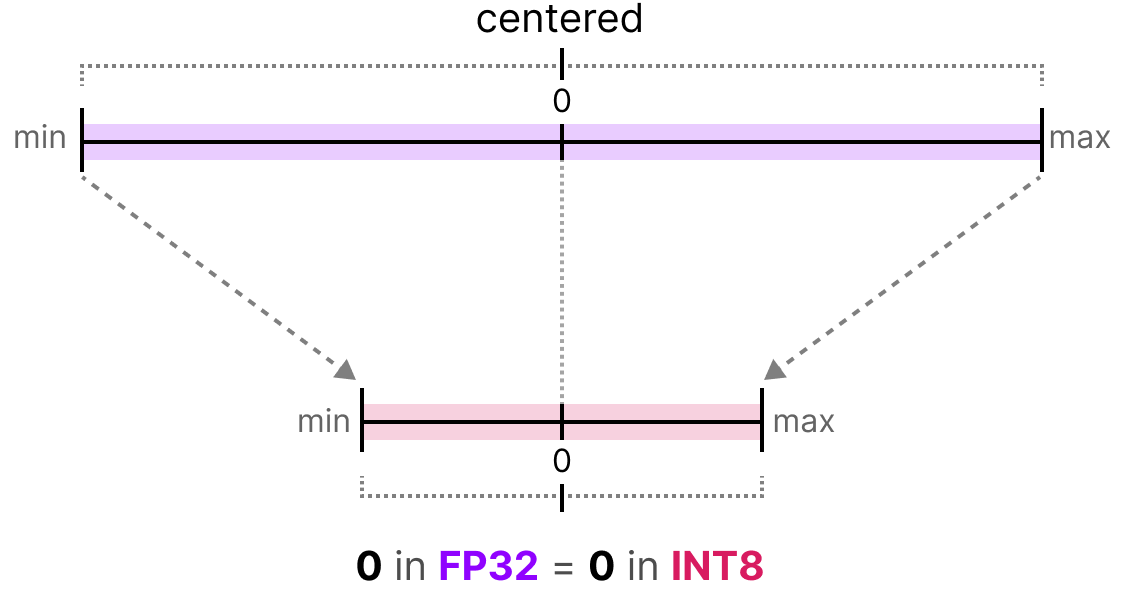
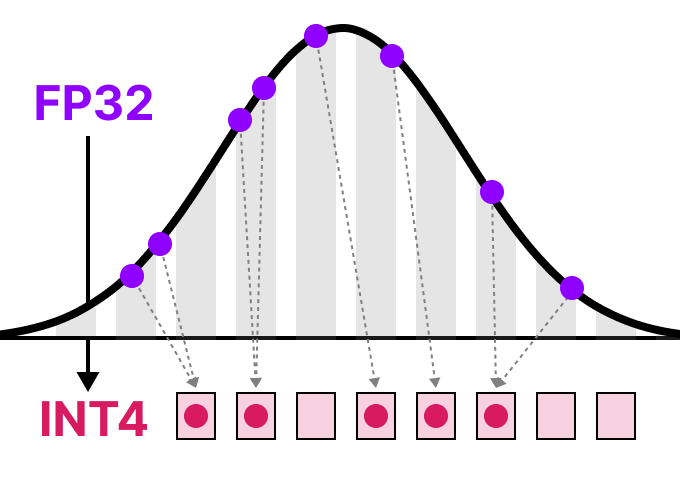
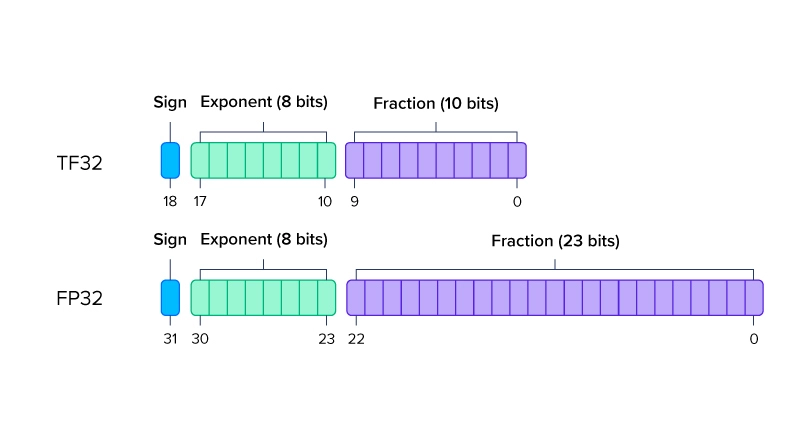
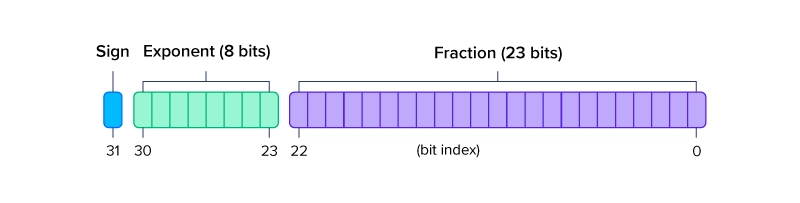
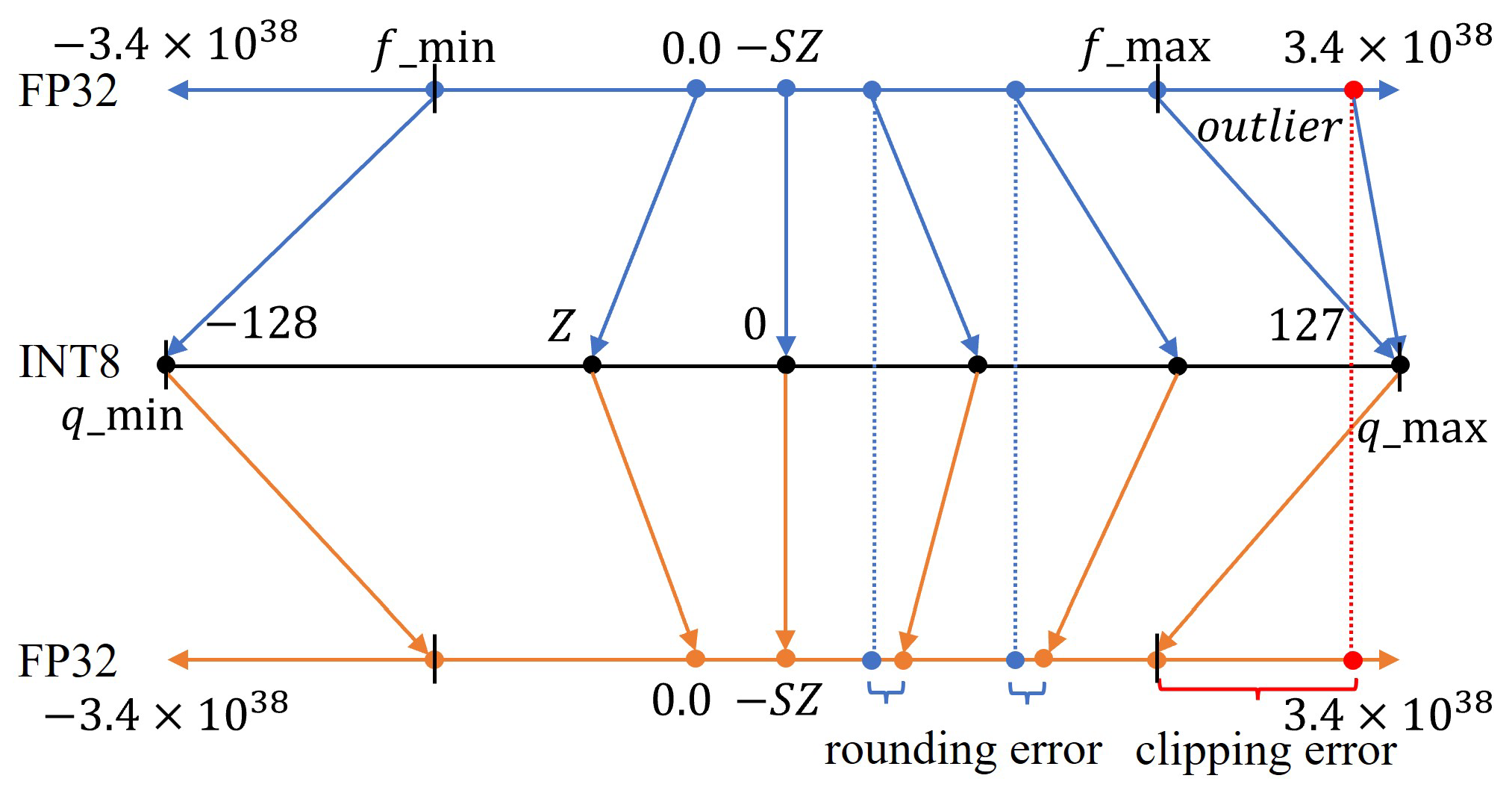
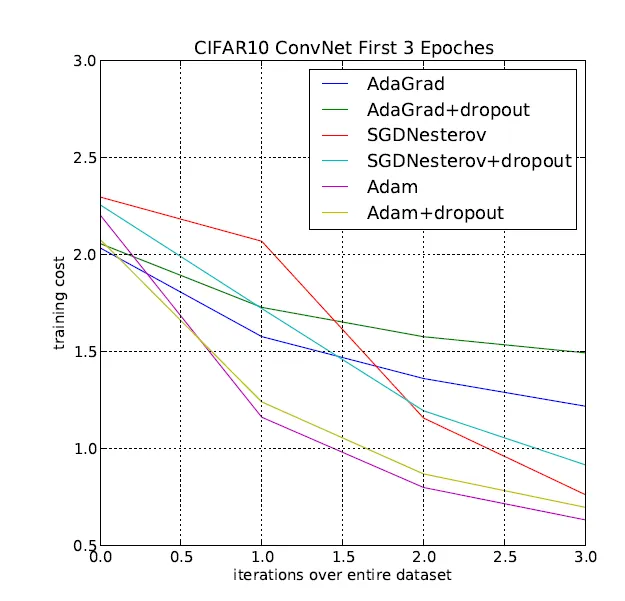
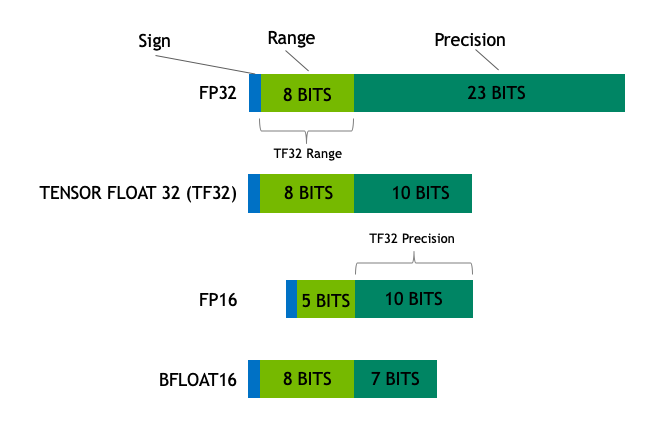
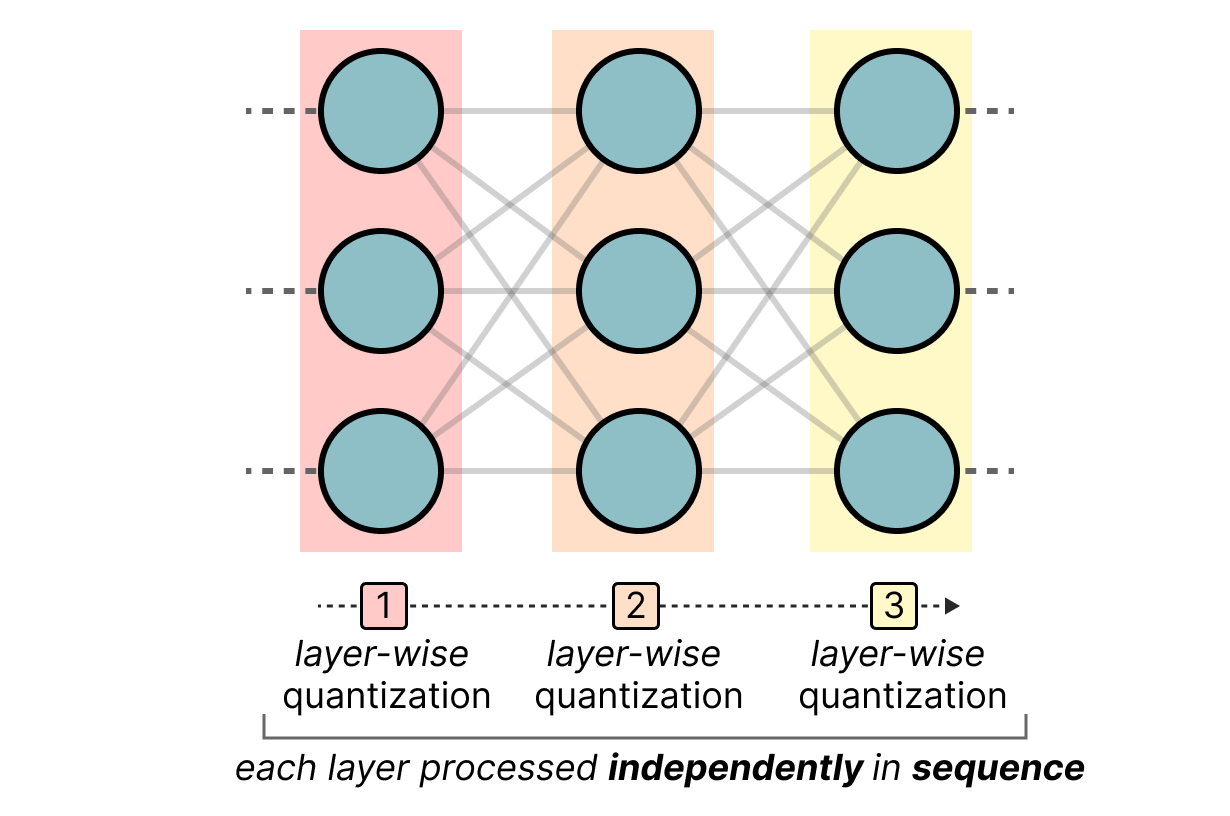
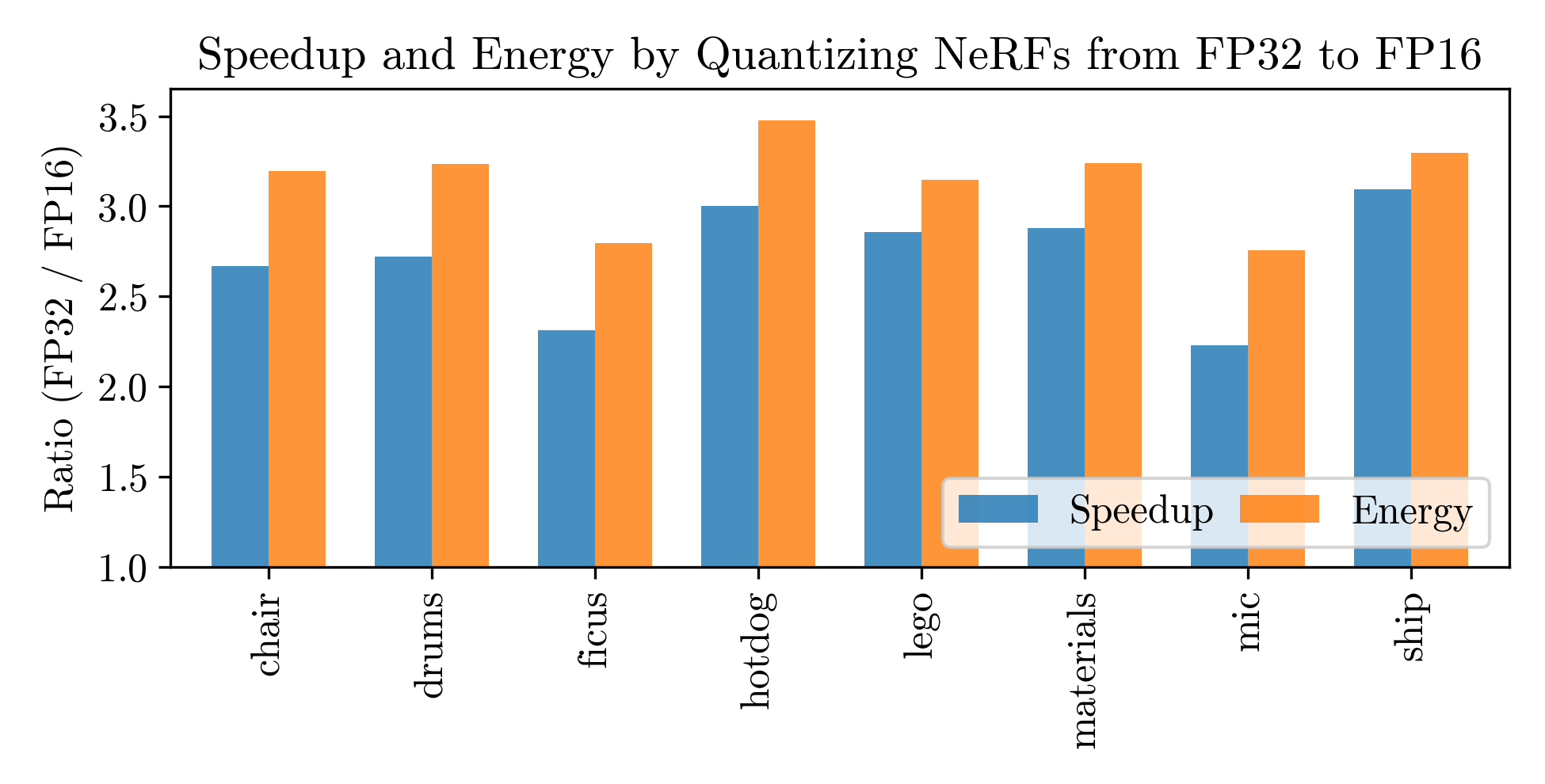
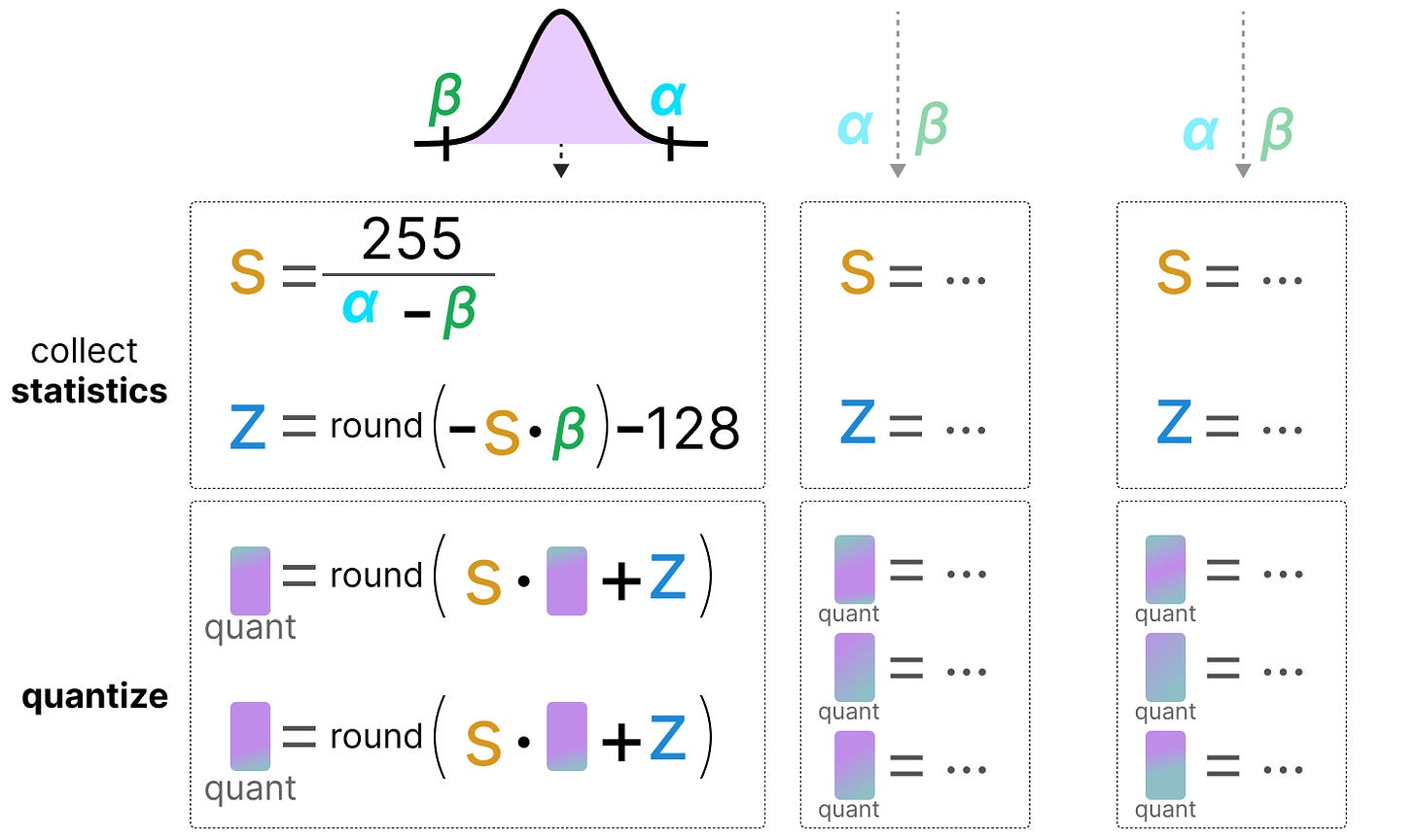
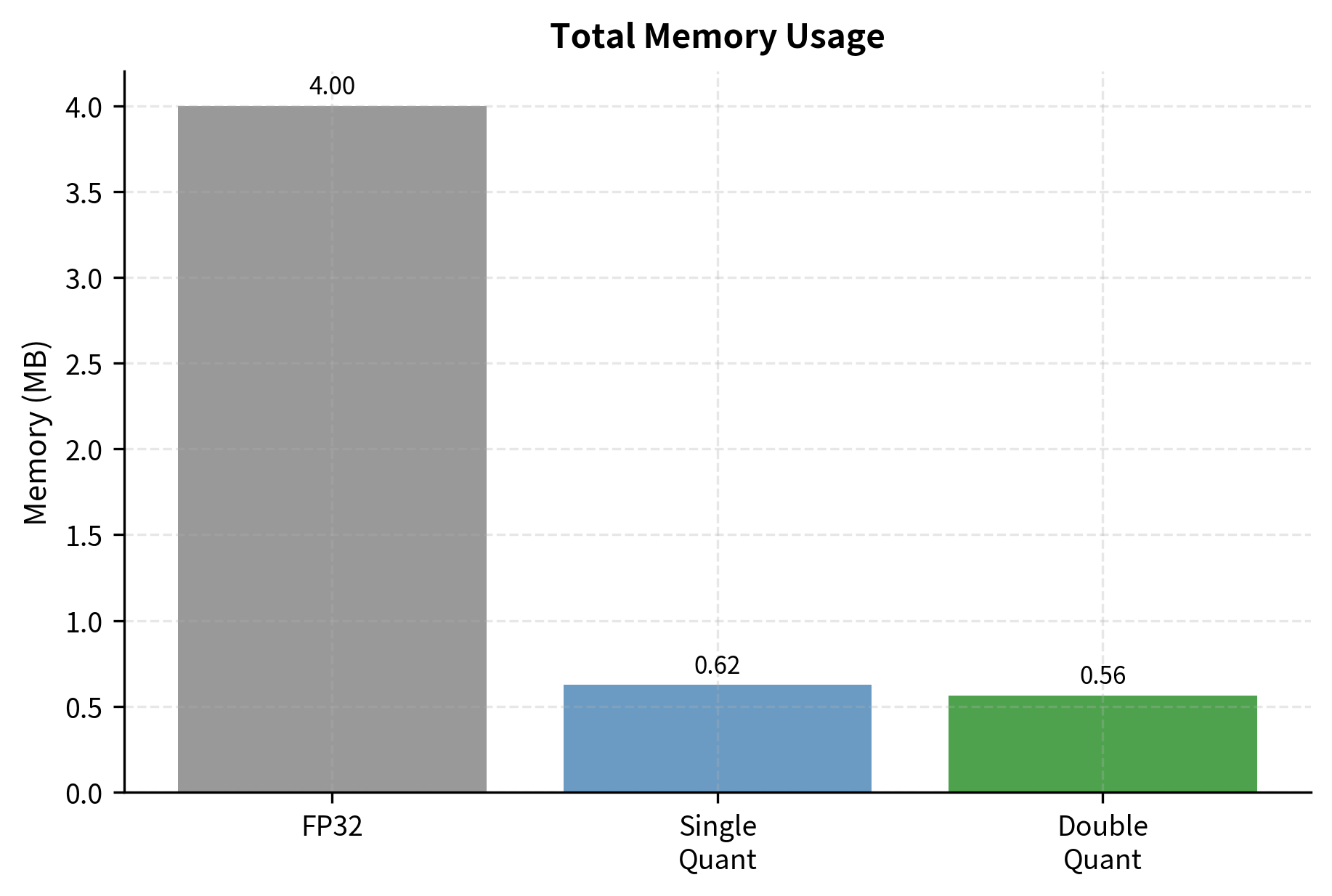
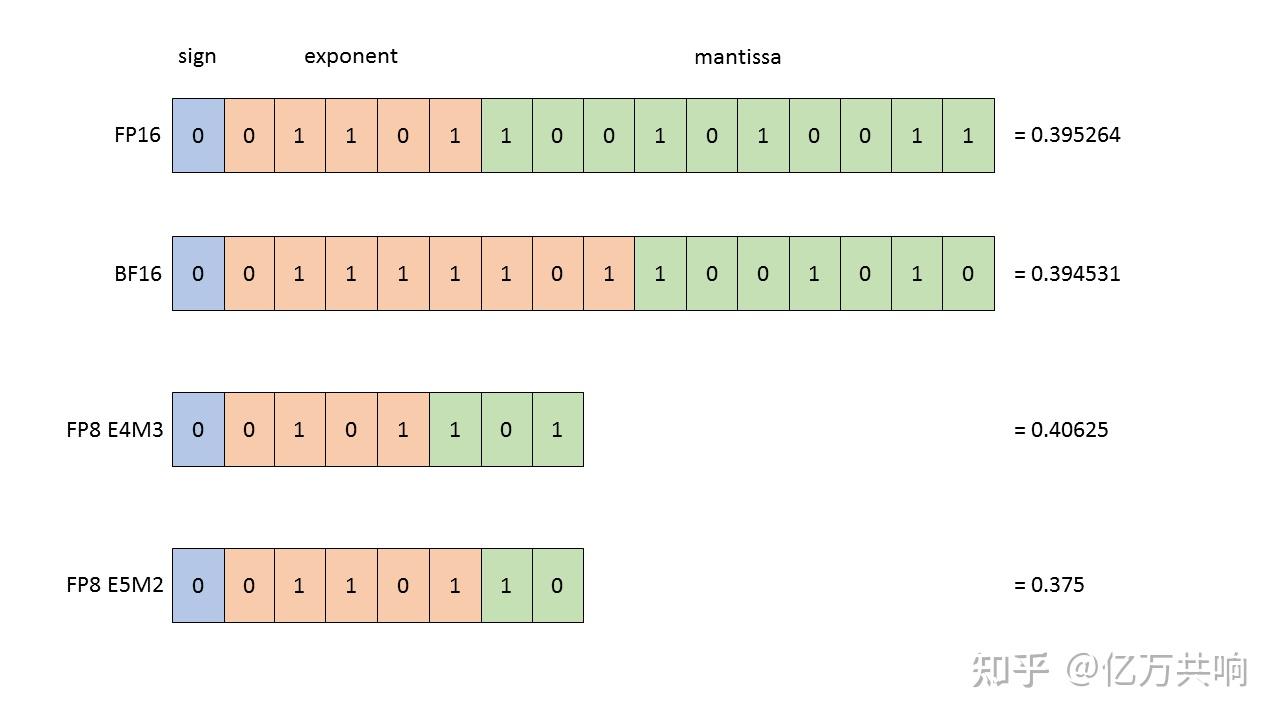
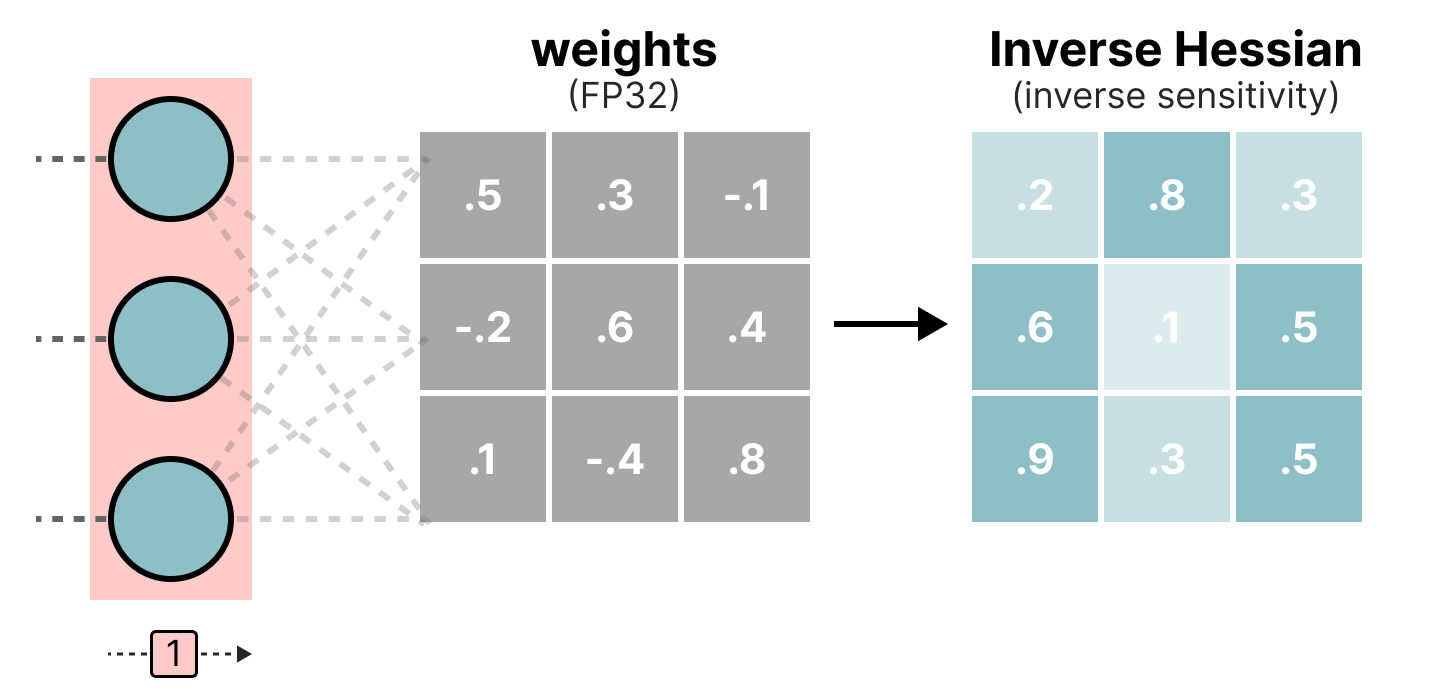
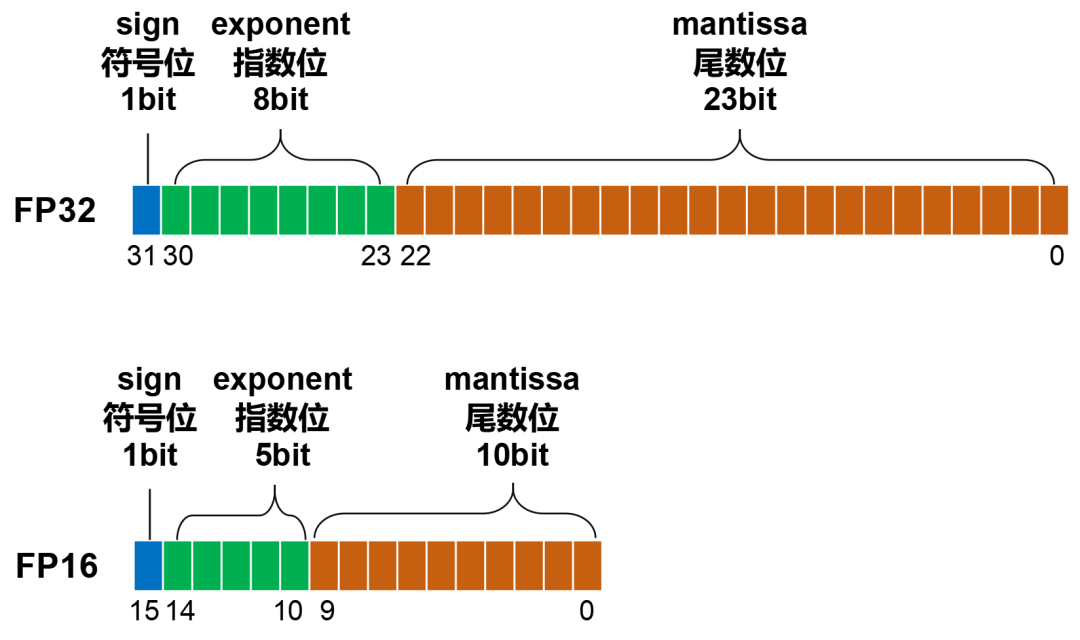
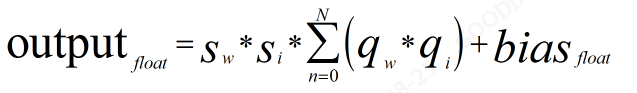Showing 108 of 108on this page. Filters & sort apply to loaded results; URL updates for sharing.108 of 108 on this page
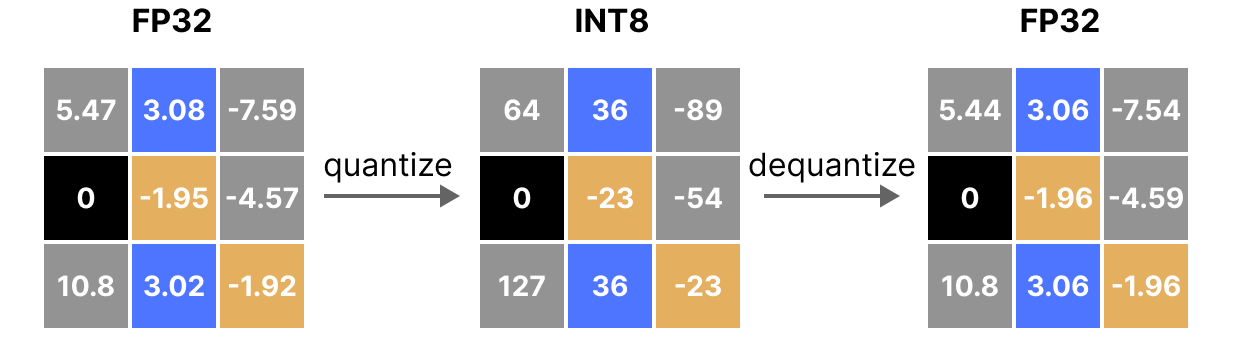
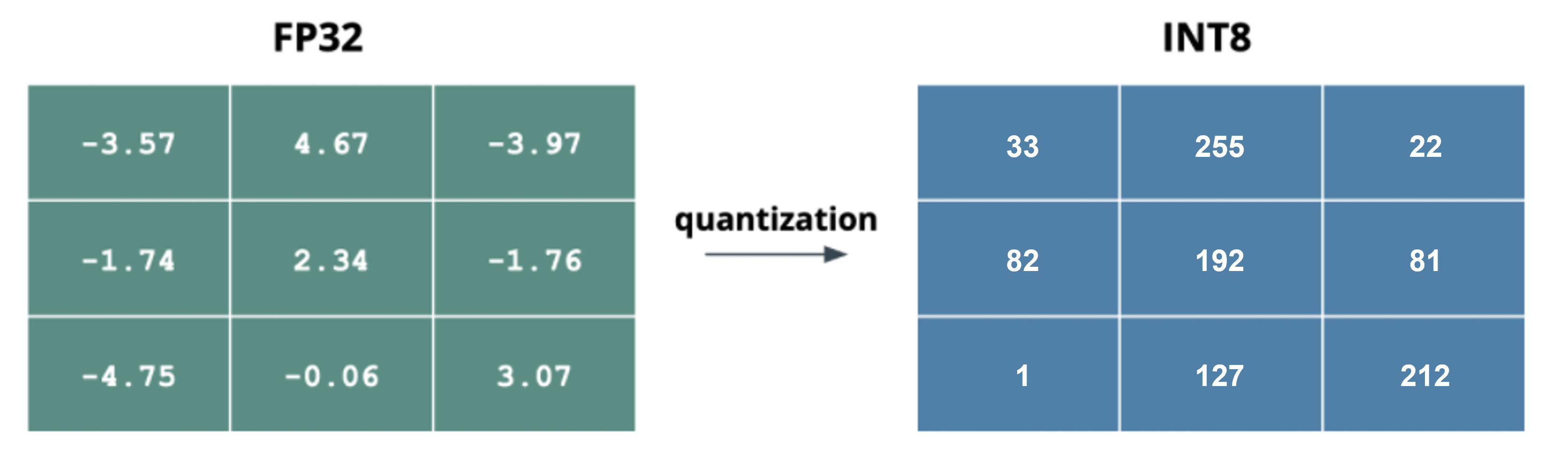
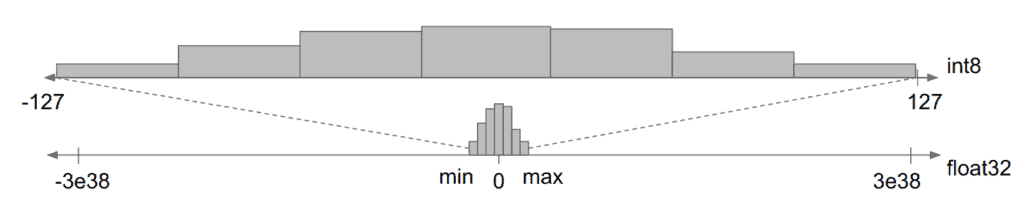
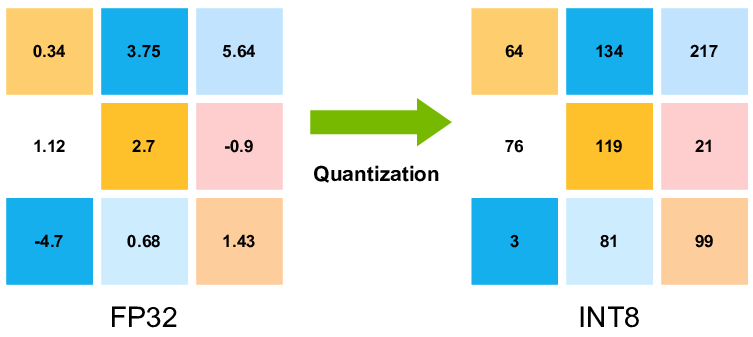
Quantization from FP32 to INT8. | Download Scientific Diagram
An overview of quantization and compilation of FP32 bits NN model ...
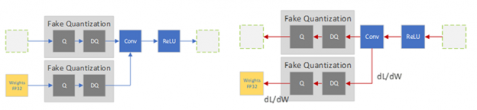
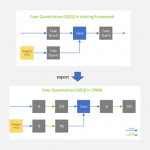
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
[QST] Quantization from fp32 to nvf4? · Issue #2076 · NVIDIA/cutlass ...
python - INT8 quantization for FP32 matrix multiplication - Stack Overflow
LLM Quantization Deep Dive: From FP32 to NF4, INT4, and MX Formats
The precision is still fp32 after quantization · Issue #207 · ModelTC ...
A Visual Guide to Quantization - by Maarten Grootendorst
Key Factors in AI's Advancement: Research Papers, Quantization ...
A Hands-On Walkthrough on Model Quantization - Medoid AI
Weight distribution of FP32 model, model quantized using the proposed ...
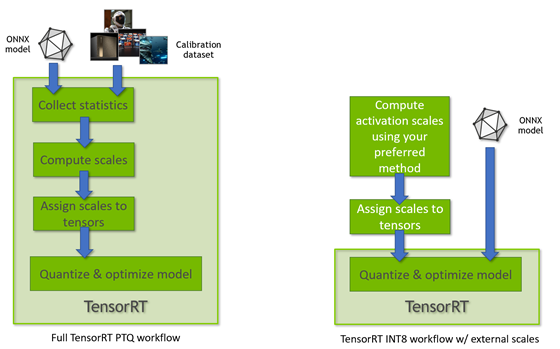
利用 NVIDIA TensorRT 量化感知训练实现 INT8 推理的 FP32 精度 - 广州市迈进信息科技有限公司/研云创服务器
HAWQ-V3: Dyadic Neural Network Quantization | PDF
Quantization for Fast and Environmentally Sustainable Reinforcement ...
딥러닝의 Quantization (양자화)와 Quantization Aware Training - gaussian37
FP8 Quantization for Ultra-Low Latency AI | AI Tutorial | Next Electronics
Practical tips for better quantization results - Fritz ai
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
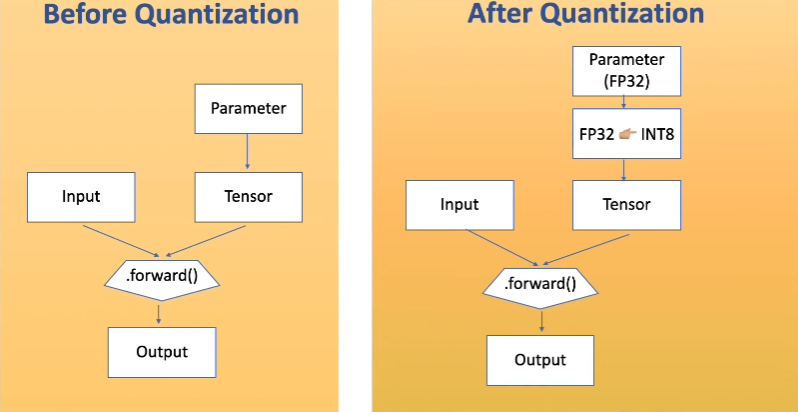
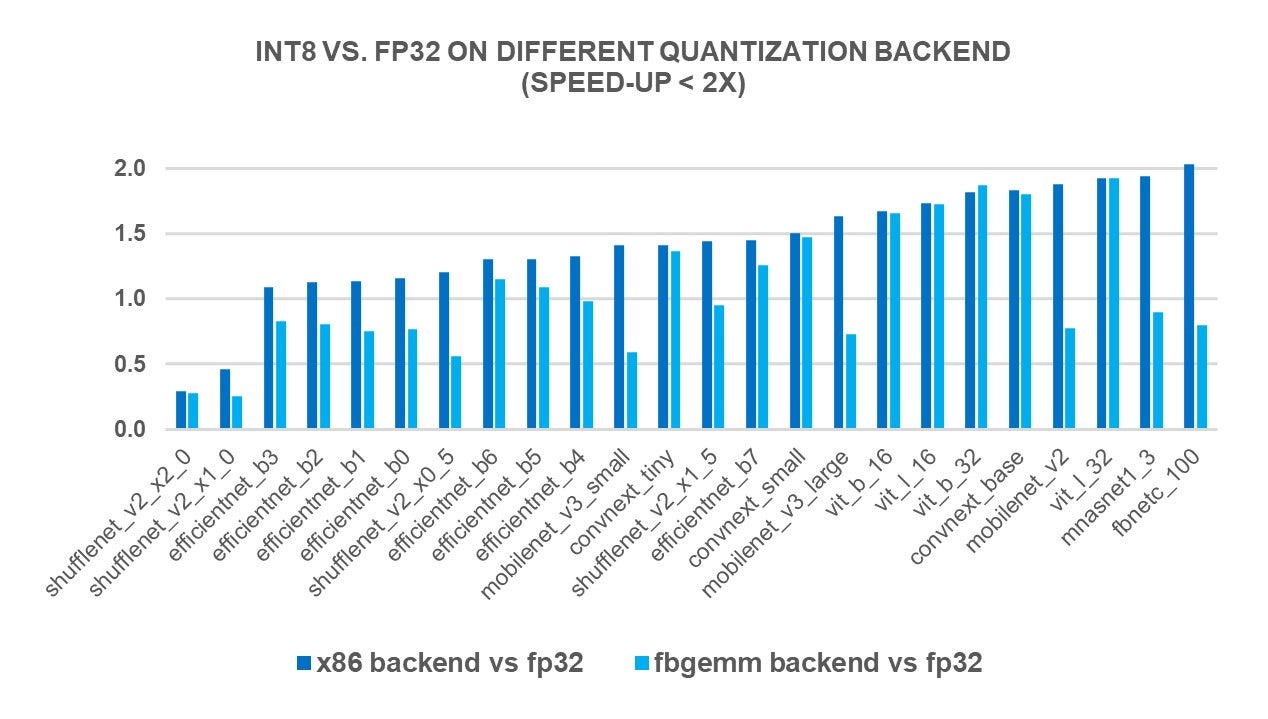
INT8 Quantization for x86 CPU in PyTorch – PyTorch
LLM Quantization Explained: FP32, FP16, BF16, and INT8 Formats
Quantization Methods for 100X Speedup in Large Language Model Inference
Improving LLM Inference Latency on CPUs with Model Quantization ...
Quantization in LLMS (Part 1): LLM.int8(), NF4 | TensorTunes
Extremely Low Bit Transformer Quantization for On-Device NMT | PDF
DiffQuant: Reducing Compression Difference for Neural Network Quantization
Can the output of operator QuantizedConv2d is fp32? - quantization ...
| Quantization inference results for all 8 GLUE tasks and the average ...
Model Quantization for Production-Level Neural Network Inference
ShareChat Blog - Neural Network Compression Using Quantization
Quantized GeMM using fp32 for Q/DQ layers - TensorRT - NVIDIA Developer ...
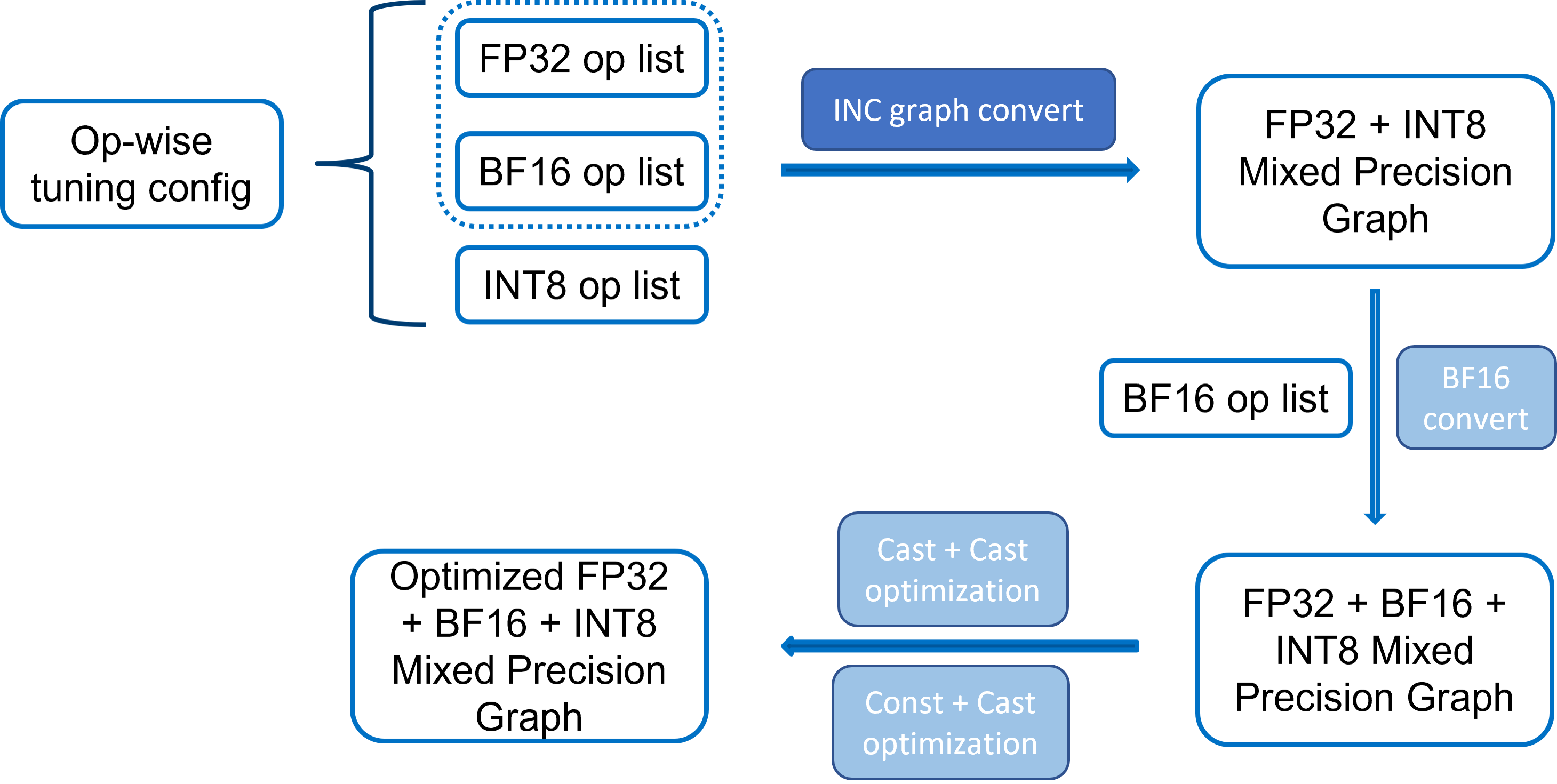
Turn ON Auto Mixed Precision during Quantization — Intel® Neural ...
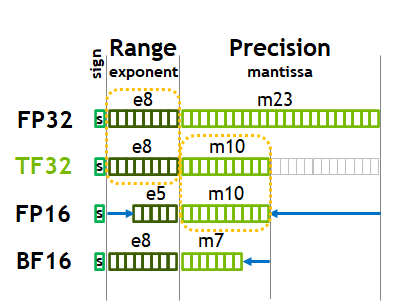
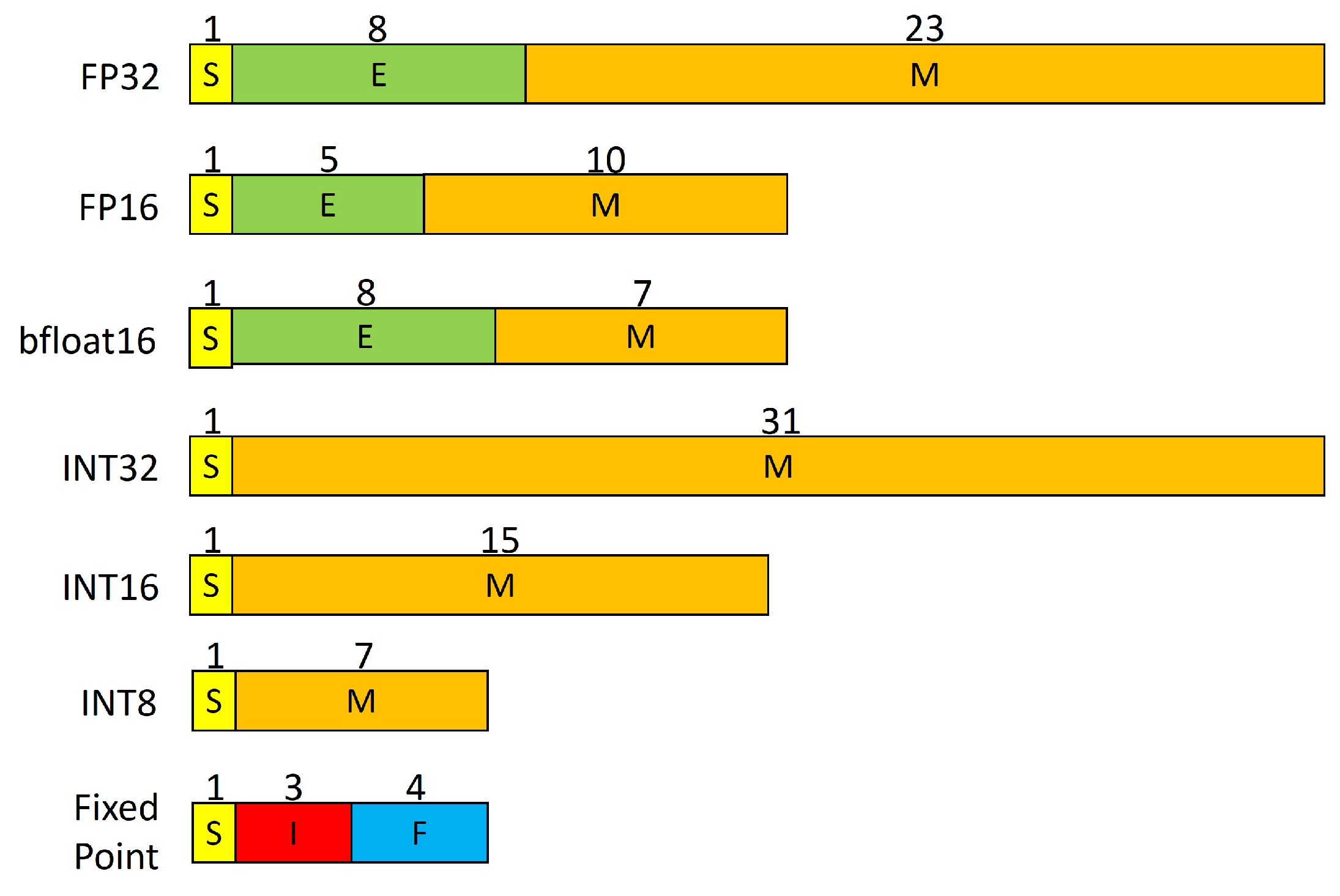
Precision Comparison: FP64 FP32 FP16 TF32 BF16 INT8
Post Training Quantization with OpenVINO Toolkit
Small numbers, big opportunities: how floating point accelerates AI and ...
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
A Method of Deep Learning Model Optimization for Image Classification ...
Deep Learning Performance Characterization on GPUs for Various ...
GIN accuracy during FP32, Quantization-Aware (QAT) and... | Download ...
量化算法概述 — MindSpore master 文档
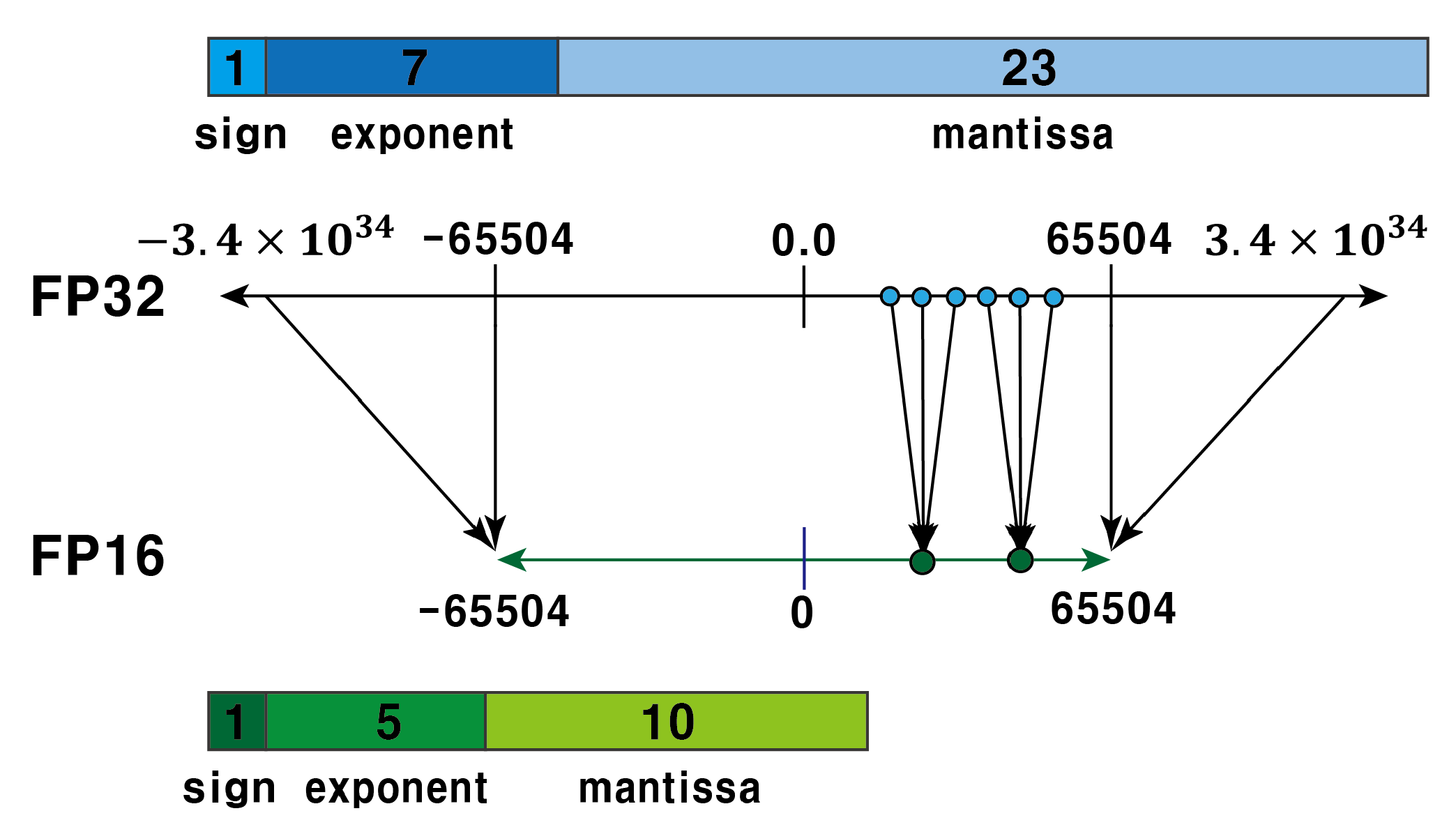
What is FP64, FP32, FP16? Defining Floating Point | Exxact Blog
top-1 accuracy of fp32, Tensorflow's INT4-8 and AB INT4- 4 ...
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
EdgeFusion: On-device Text-to-Image Generation — Nota AI
QLoRA - How to Fine-Tune an LLM on a Single GPU | Towards Data Science
A Deep Dive into LLM Quantization: FP32, BF16, INT8, NF4 & QLoRA | by ...
Automatic Mix Precision — MindSpore master documentation
LLM量化综合指南(8bits/4bits) - 知乎
Accelerating NeRFs
什麼是模型量化(Quantization)?解析FP32、FP16、BF16、int8、int4與GGUF的關聯
Floating Point Numbers: (FP32 and FP16) and Their Role in Large ...
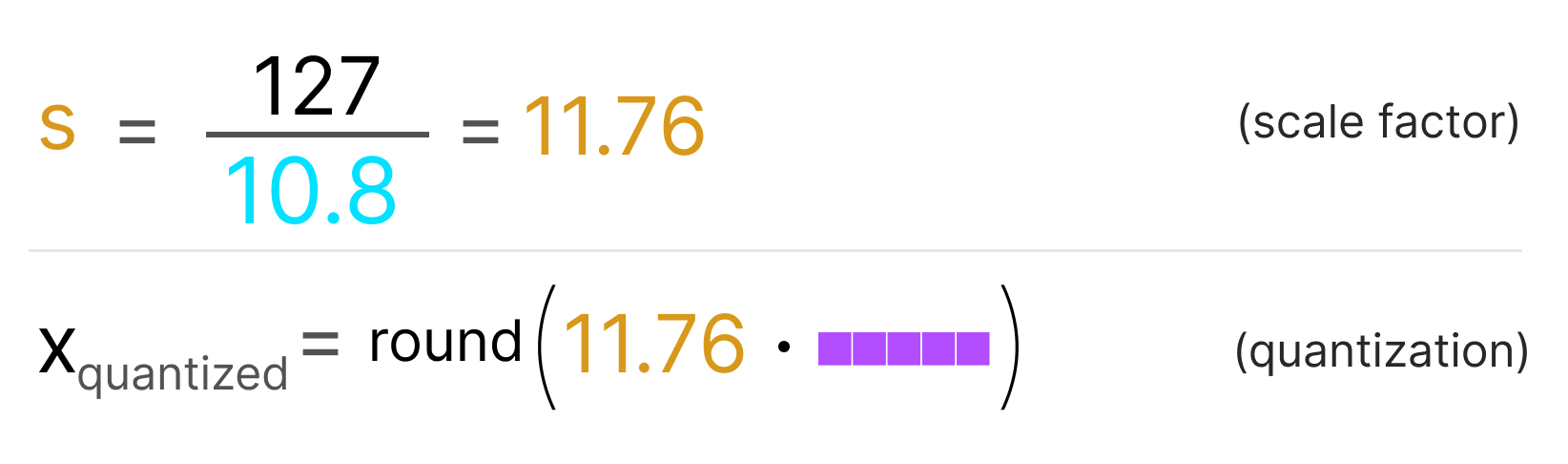
模型量化1-概述1:量化的过程就是选取合适量化参数(scale factor,zero point,clipping value)以及数据映射 ...
[Quantization stable diffusion model sd2.1 fp into onnx int8][pytorch ...
Định nghĩa Floating Point Precision - FP64, FP32, FP16 là gì? - Blog ...
로봇 ML 모델의 경량화 2부: 양자화 인식 훈련 | 우아한형제들 기술블로그
What is Vector Quantization? - Zilliz Learn
Visual comparison between FP32, W8A16, W8A16 with softmax quantized to ...
FP64、FP32、FP16、FP8简介-CSDN博客
AIMET Model Zoo | Quantized Accuracy Now | Qualcomm
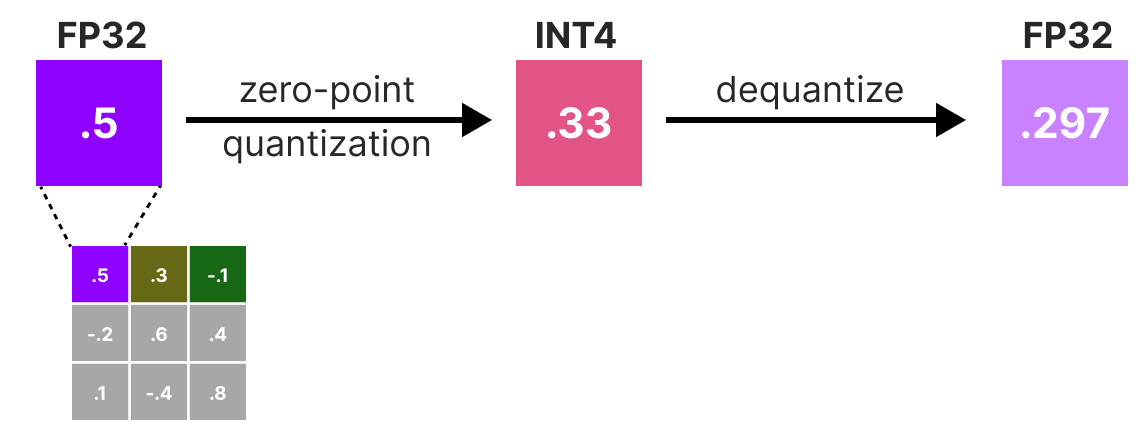
INT4 Quantization: Group-wise Methods & NF4 Format for LLMs ...
计算精度对比:FP64, FP32, FP16, BFLOAT16, TF32 - 知乎
What you will need to know about model quantization.
unsloth/DeepSeek-R1-GGUF · What is the base precision type(FP32/FP16 ...
【干货】大模型算力优化全攻略——FP32、FP16、INT8数据格式精讲与实战应用_fp16和fp32-CSDN博客
QUIDAM: A Framework for Quantization-aware DNN Accelerator and Model Co ...
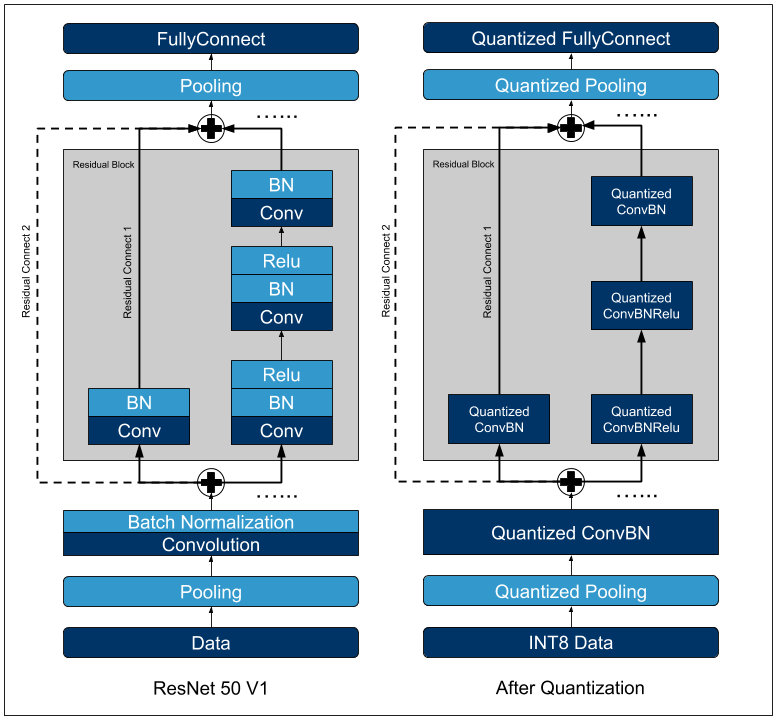
GitHub - gongouveia/Resnet-Quantization-Experiments: Tools for per ...