Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Compiler Handling of Quantization Scales and Zero Points
Different magnitudes of differences between quantization scales for ...
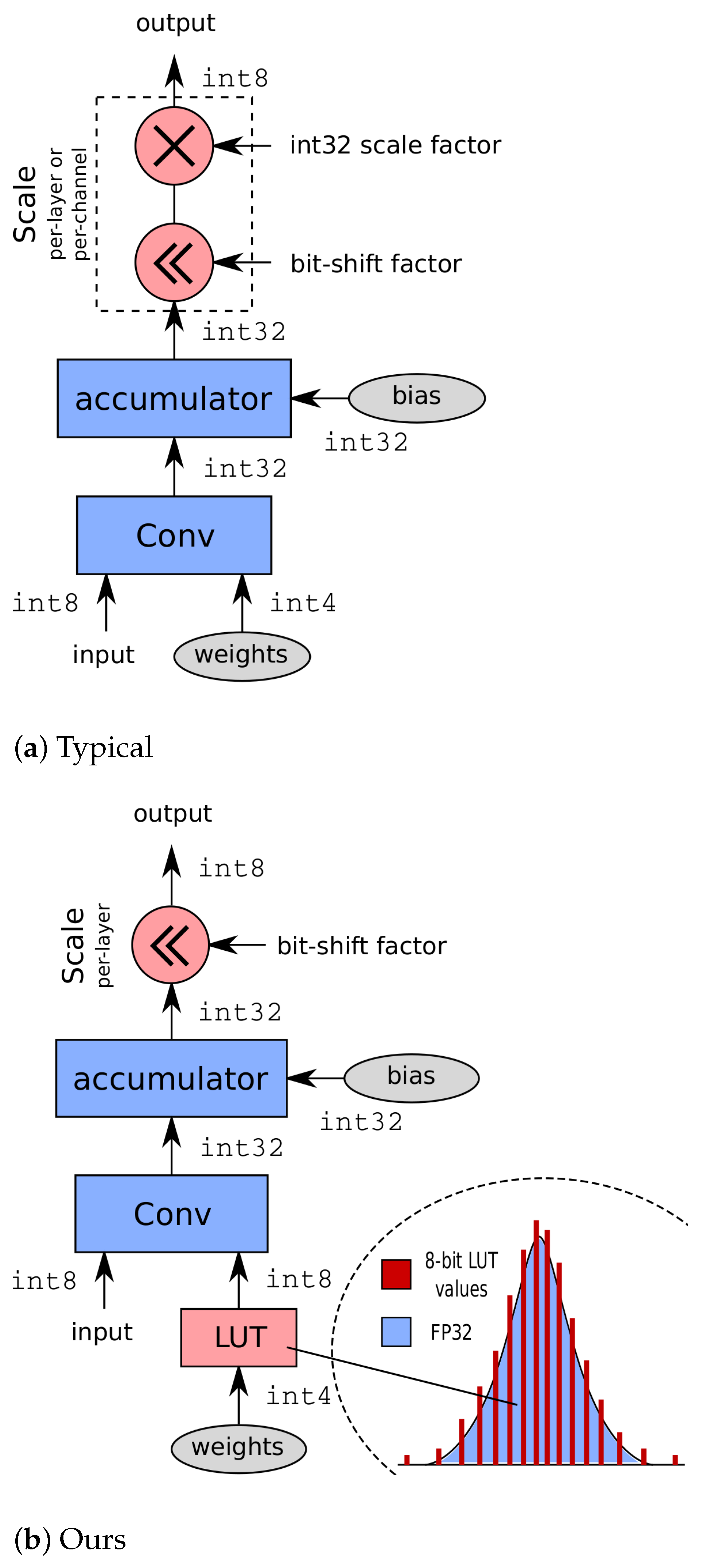
Integer-Only CNNs with 4 Bit Weights and Bit-Shift Quantization Scales ...
How to optimize large deep learning models using quantization
Quantization explained, like you are five. | Sanket Shah
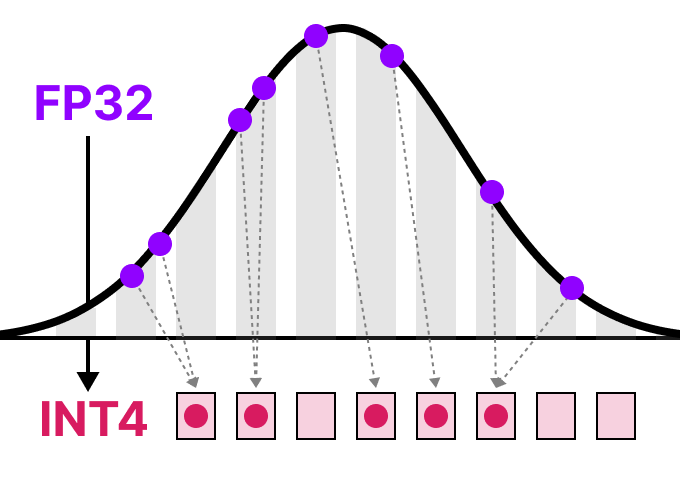
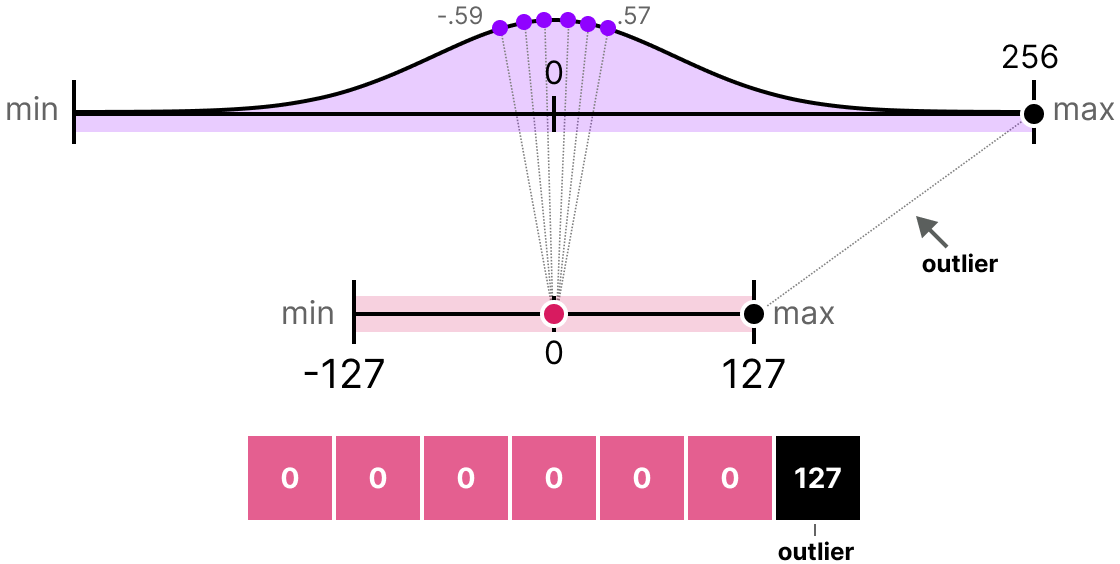
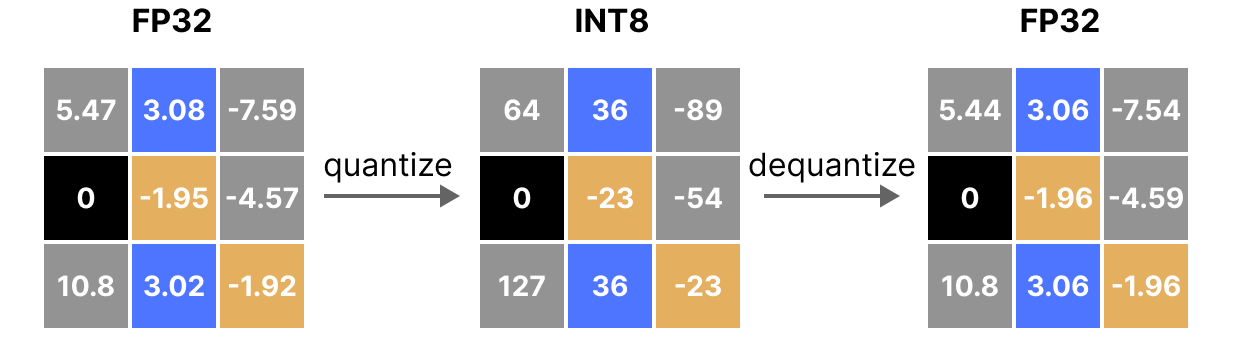
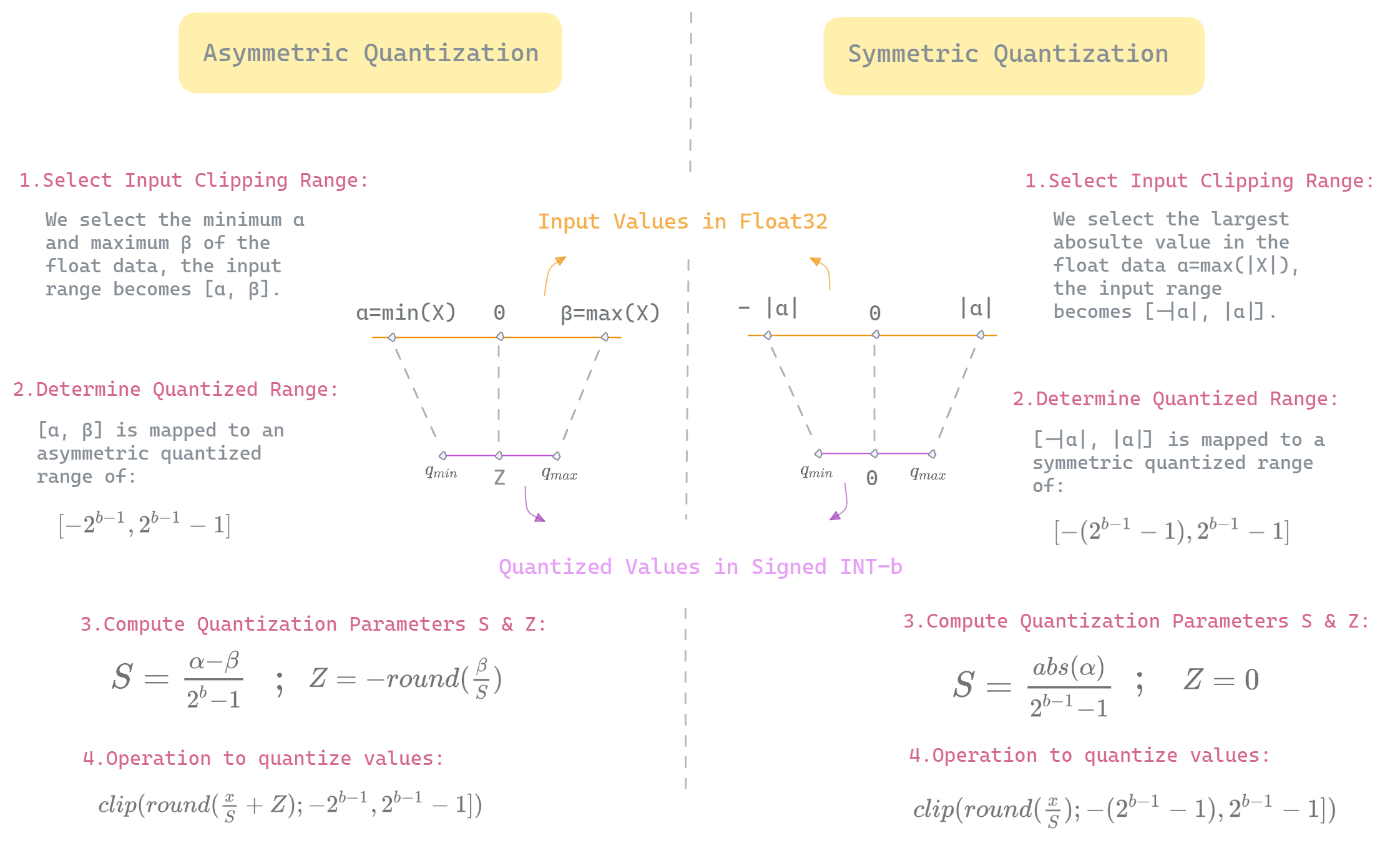
A Visual Guide to Quantization - by Maarten Grootendorst
LLM Quantization Explained: Q4, Q8, FP16 and VRAM Tradeoffs (2026)
Gemma 4 on NVIDIA GB10: Quantization Benchmarks for Local Inference ...
Huawei Unveils KVarN: A Native vLLM Backend for KV-Cache Quantization ...
Free Scales Infographics for Google Slides and PowerPoint
IoT Connected Weighing Scales | Smart Scale App & Software Development ...
GPTQ vs AWQ vs NF4: Choosing the Right LLM Quantization Pipeline
LLM Quantization Explained: Q4 vs Q8 — What's the Difference and Which ...
Cohere cracks lossless quantization and native citations with first ...
LM Studio Quantization Benchmark: Q4_K_M vs Q8_0 Tok/s on RTX 4090 ...
Quantization Configuration System | quic/aimet | DeepWiki
AWQ Quantization Guide: Deploy LLMs at Half the GPU Cost (2026 ...
Optimizing Ollama Performance on Windows: Hardware, Quantization ...
GGUF Quantization Explained: Q4_K_M vs Q8_0 vs F16 — Which to Use in ...
JKUAT MSc Public Health Biostatistics Lecture 2: Scales of Measurement ...
A Visual Guide to Quantization - Maarten Grootendorst
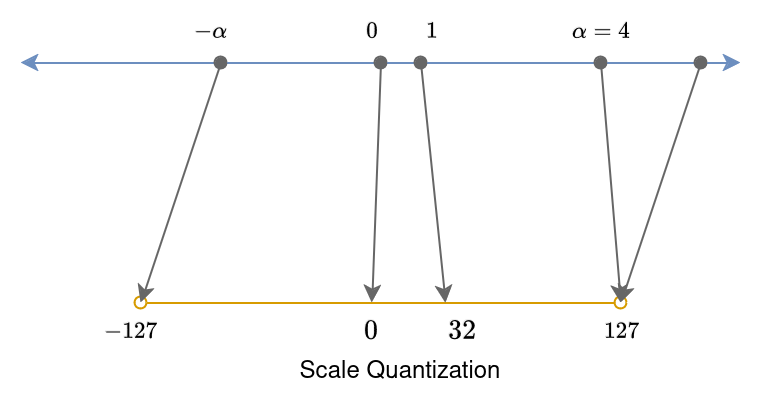
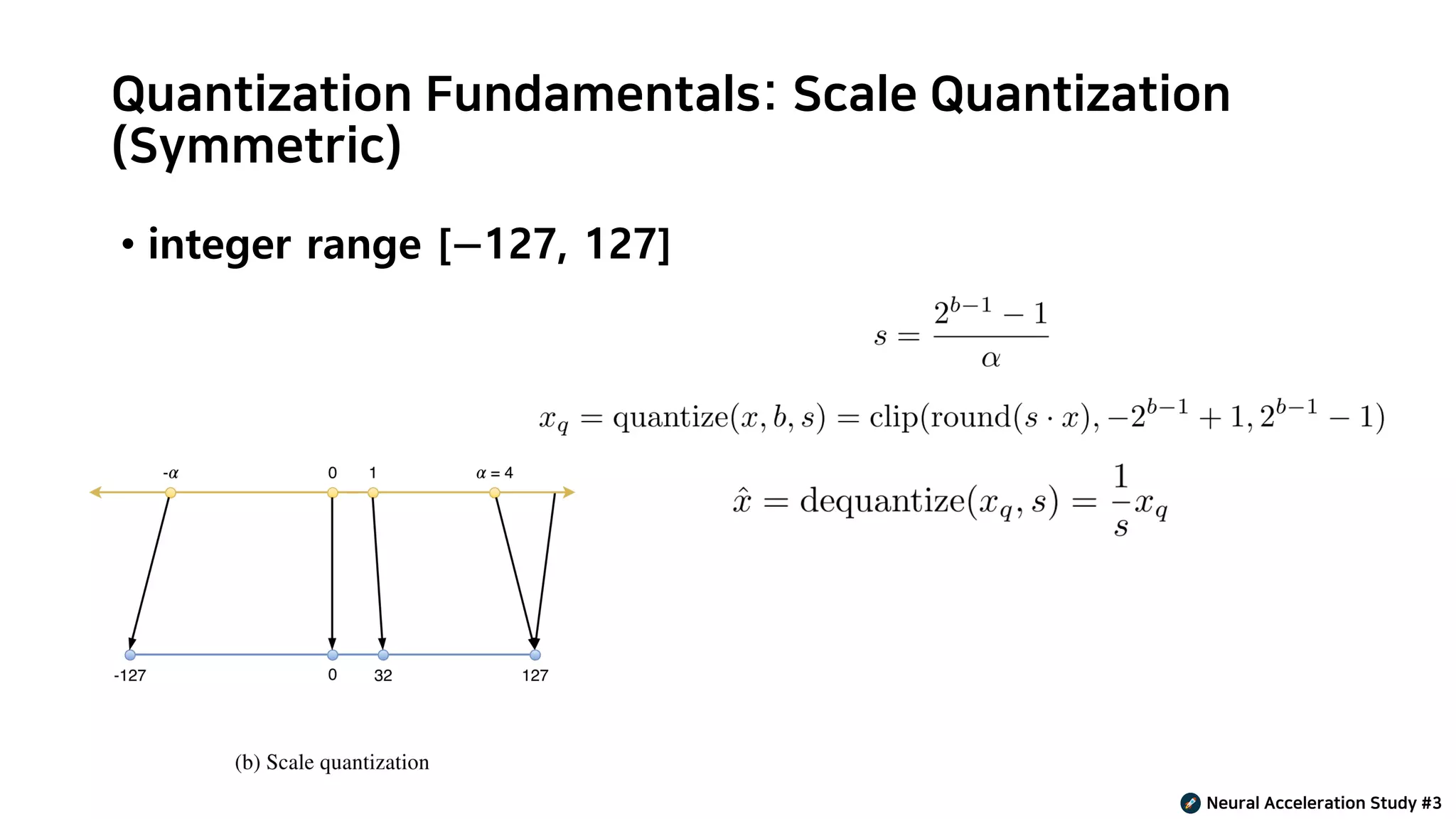
Scale Quantization : A White Paper on Neural Network Quantization – NUUWI
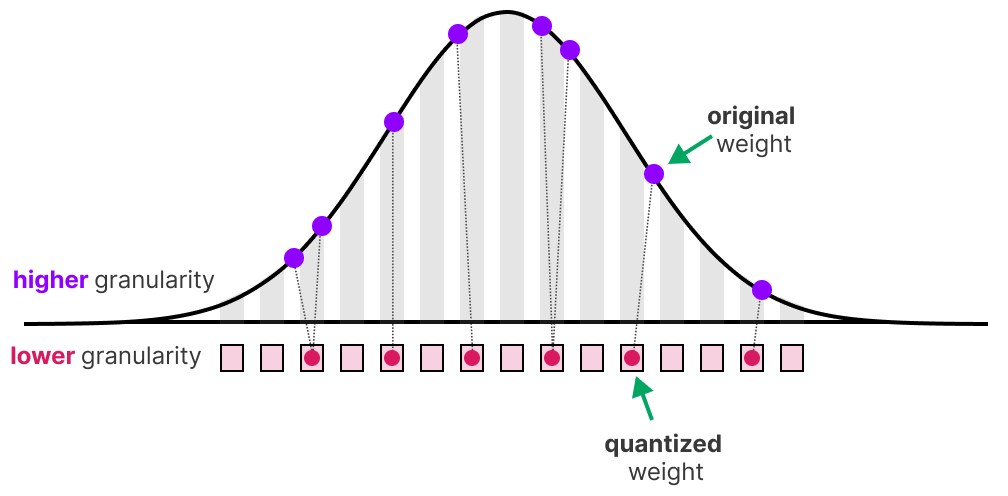
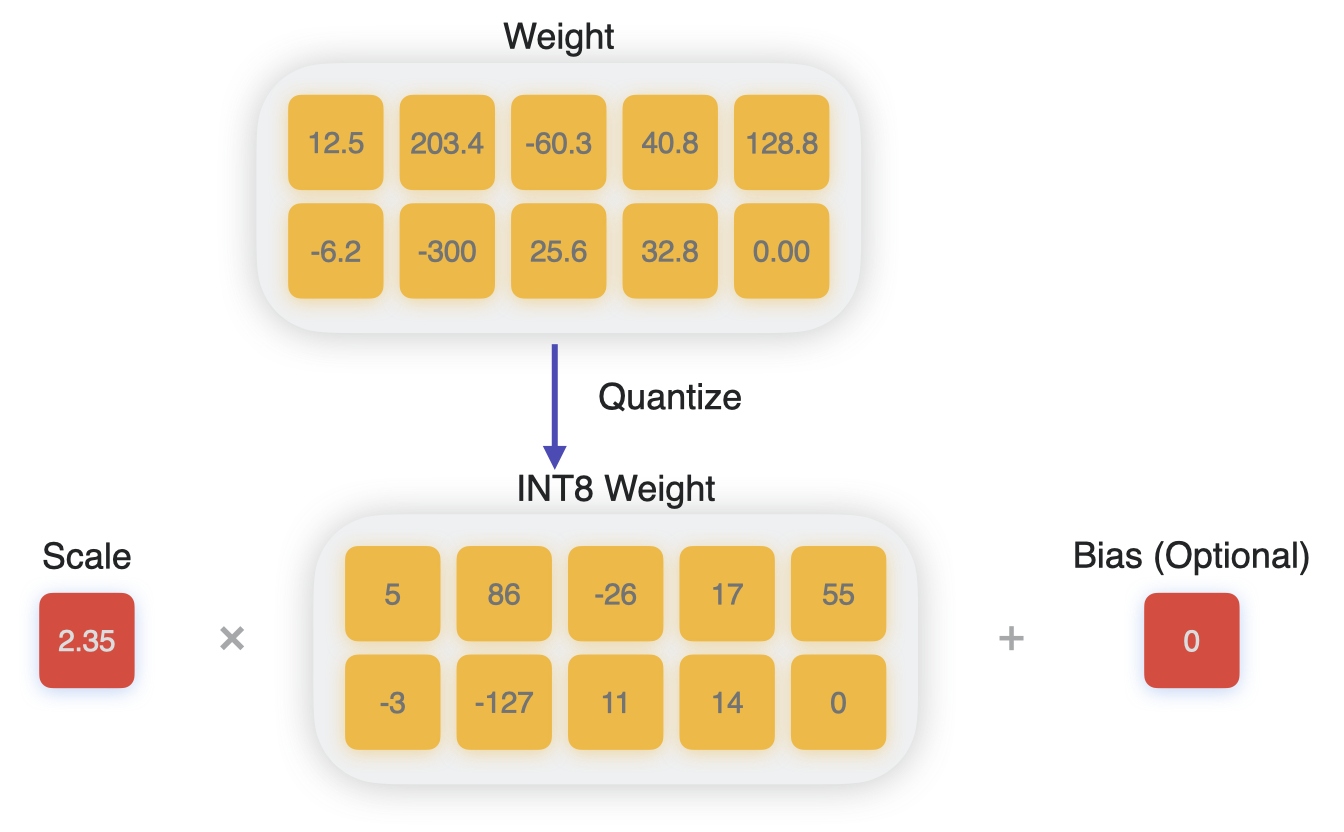
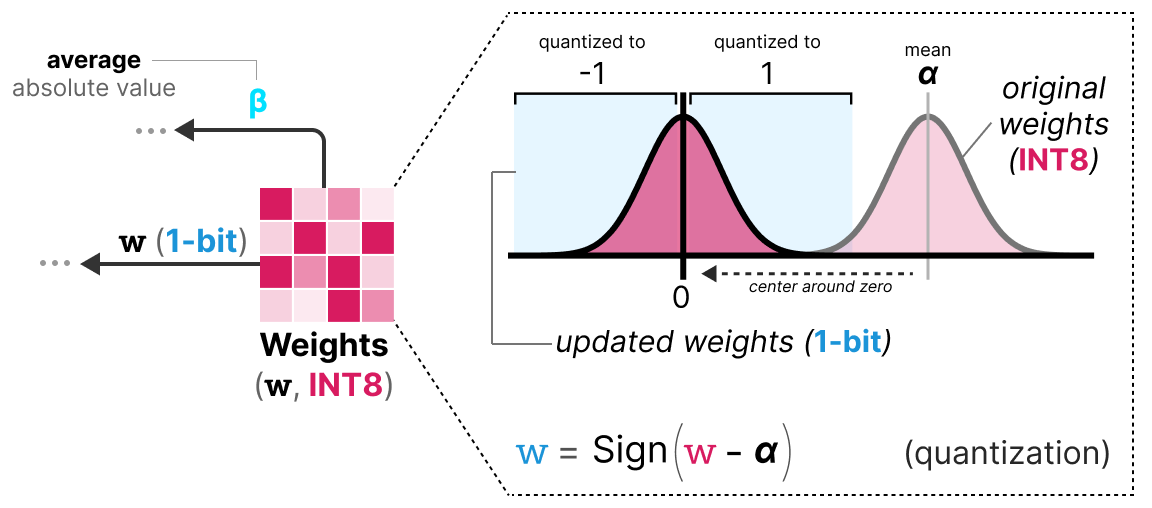
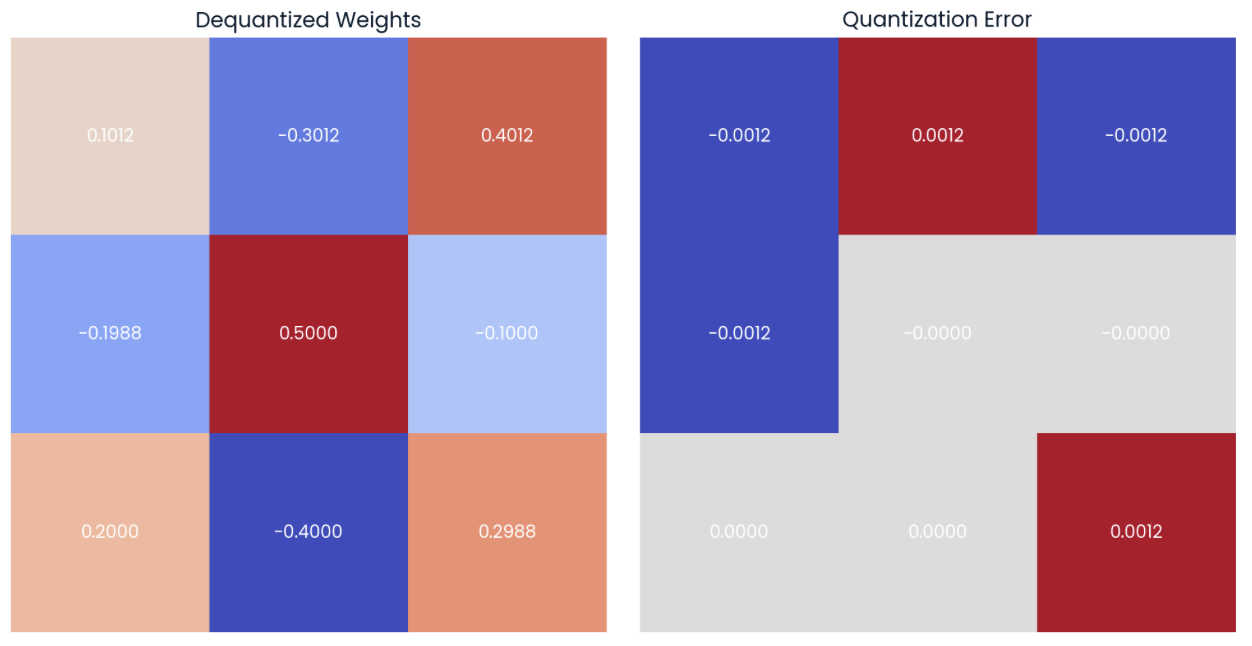
Weight Quantization Basics: Scale, Zero-Point & Calibration ...
Quantization in LLMs: Why Does It Matter?
Model Quantization - A Lazy Data Science Guide
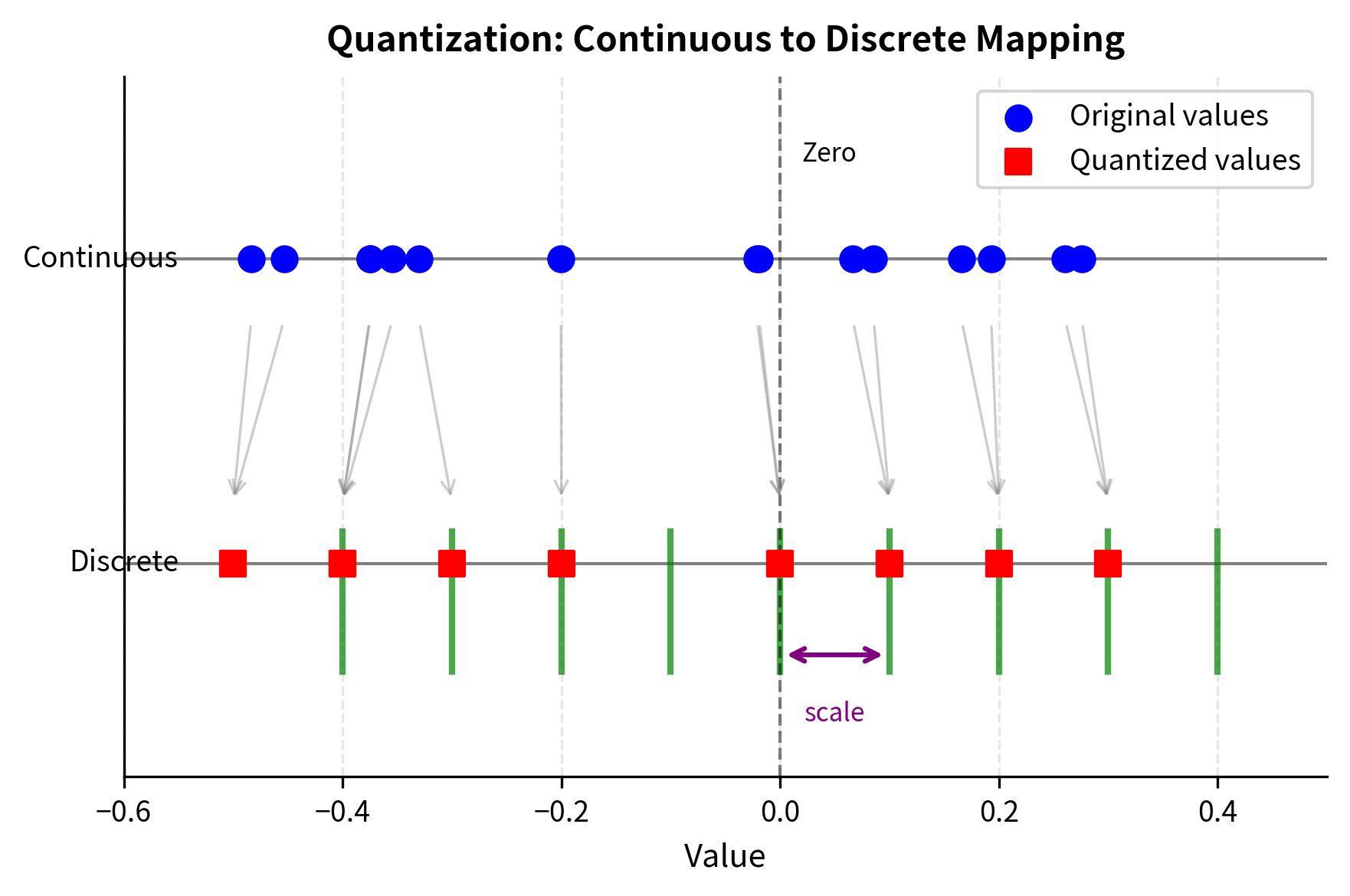
3: A visual explanation of the different uniform quantization grids for ...
Naive Quantization Methods for LLMs — a hands-on
(PDF) Intriguing Properties of Quantization at Scale
Quantization Overview — Guide to Core ML Tools
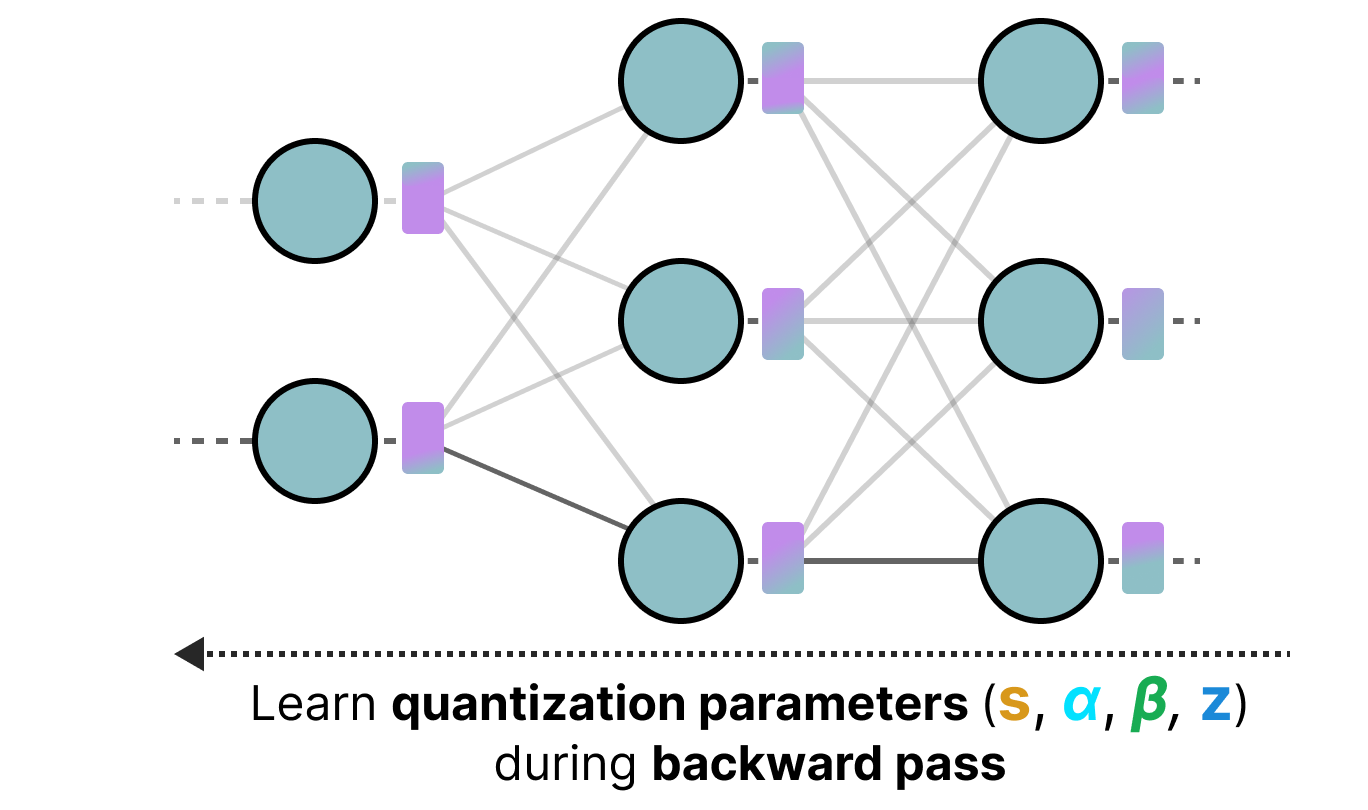
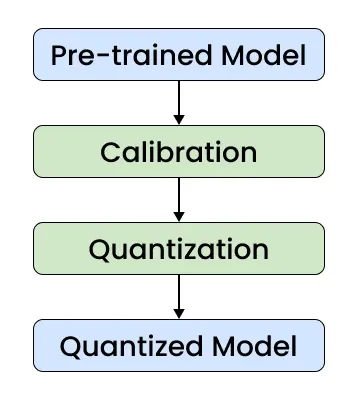
Introducing Post-Training Model Quantization Feature and Mechanics ...
We perturb along two basis vectors of one layer/block's quantization ...
The effect of varying quantization scale on the encoding quality of ...
Introduction to Quantization cooked in 🤗 with 💗🧑🍳
Integer quantization for deep learning inference: principles and ...
Maximum-(across quantization scales) of-maximum (across five video ...
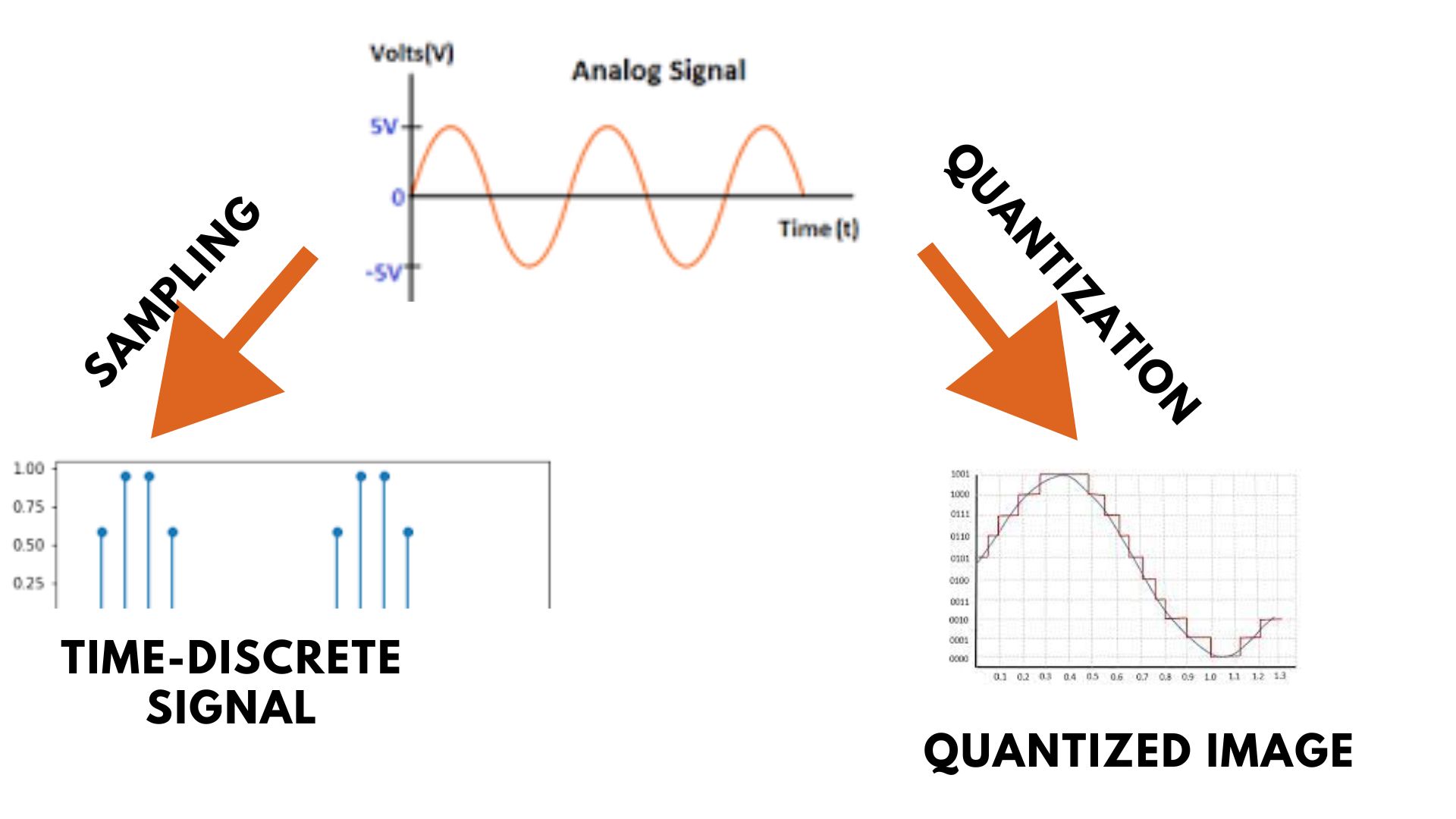
Image Sampling and Quantization - Coding Ninjas
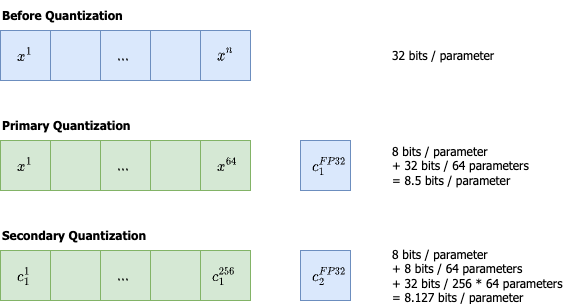
The illustration of our two-stage quantization framework. Dark green ...
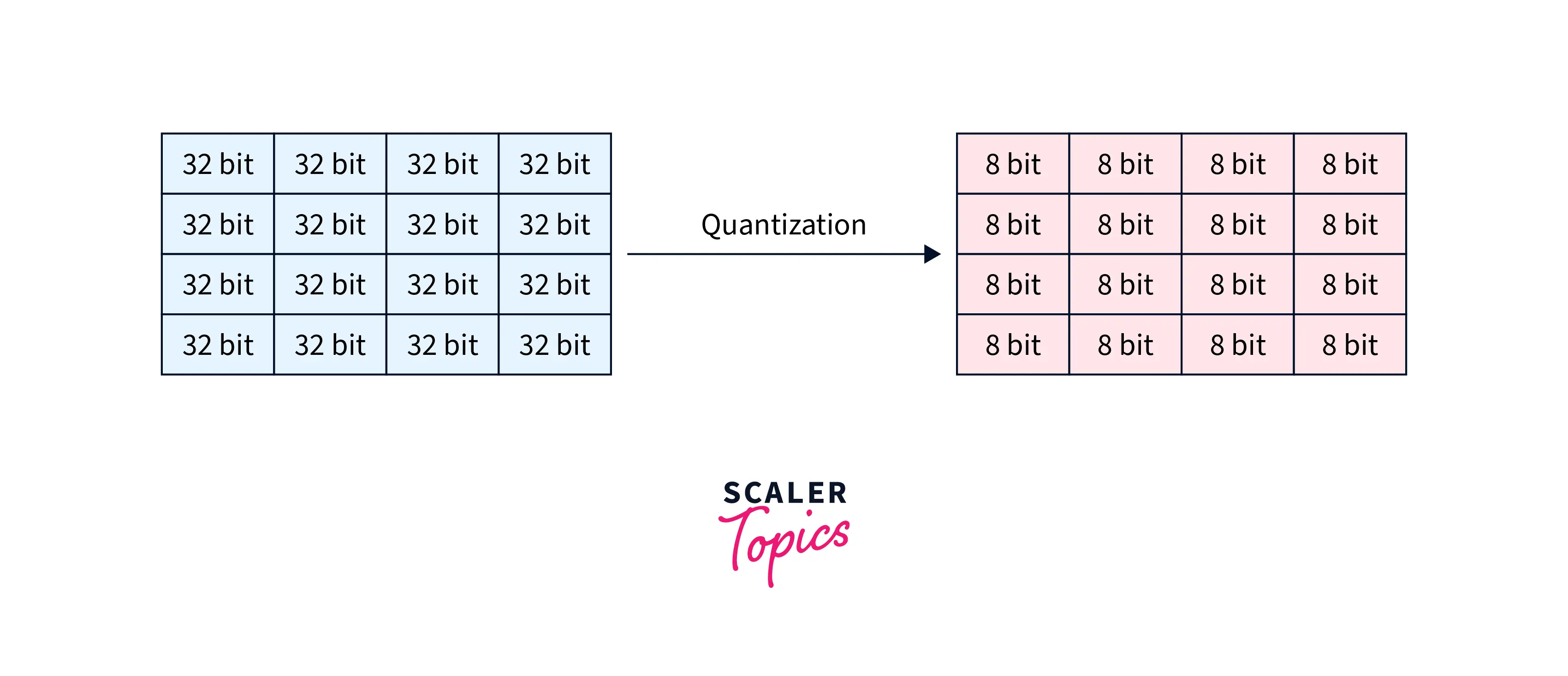
What is Quantization and how to use it with TensorFlow
The illustration of the J-image of various color quantization and ...
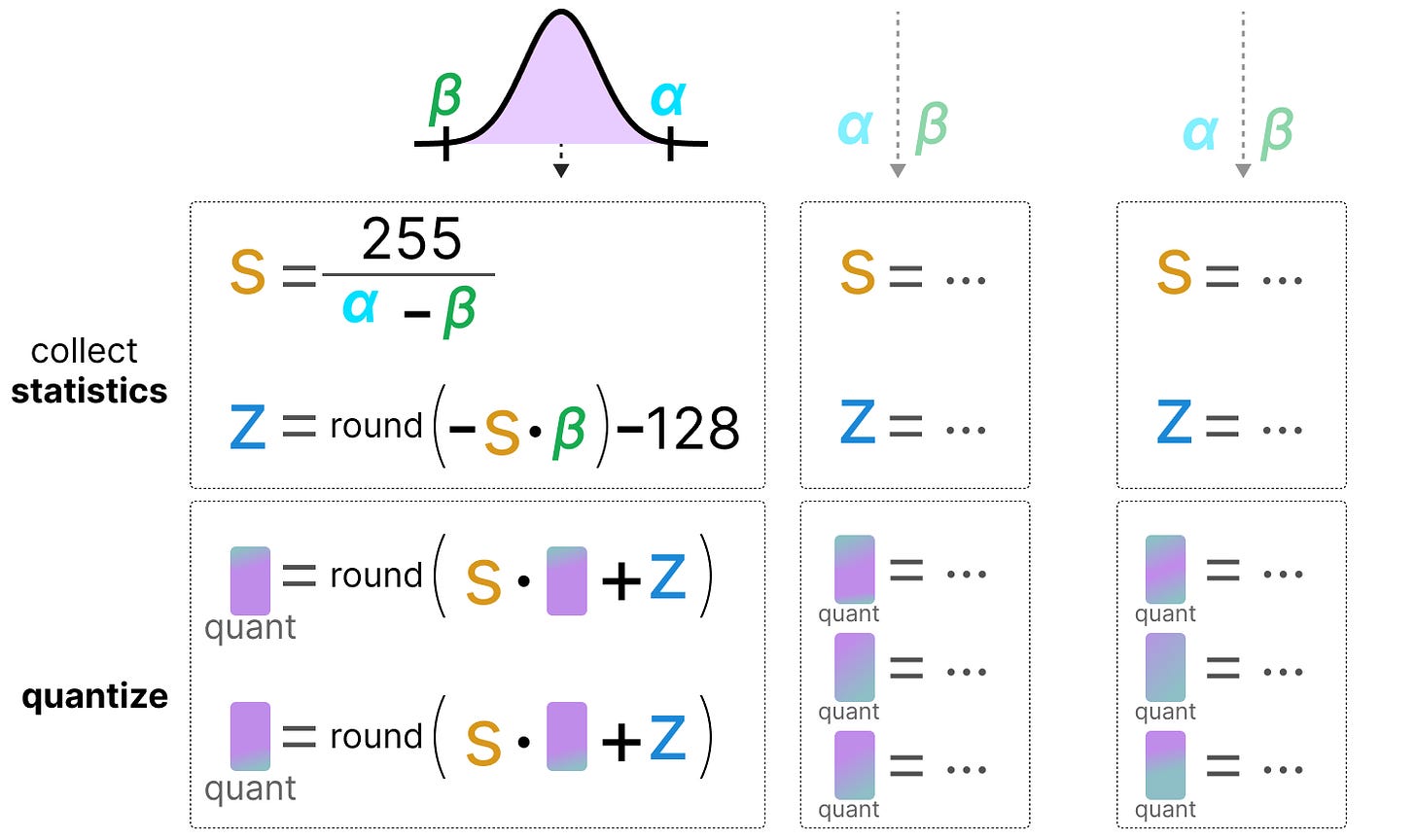
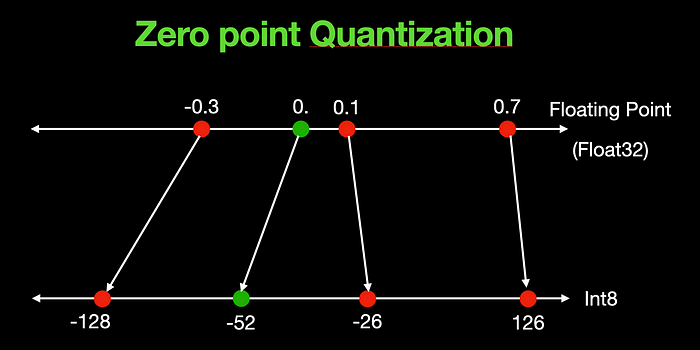
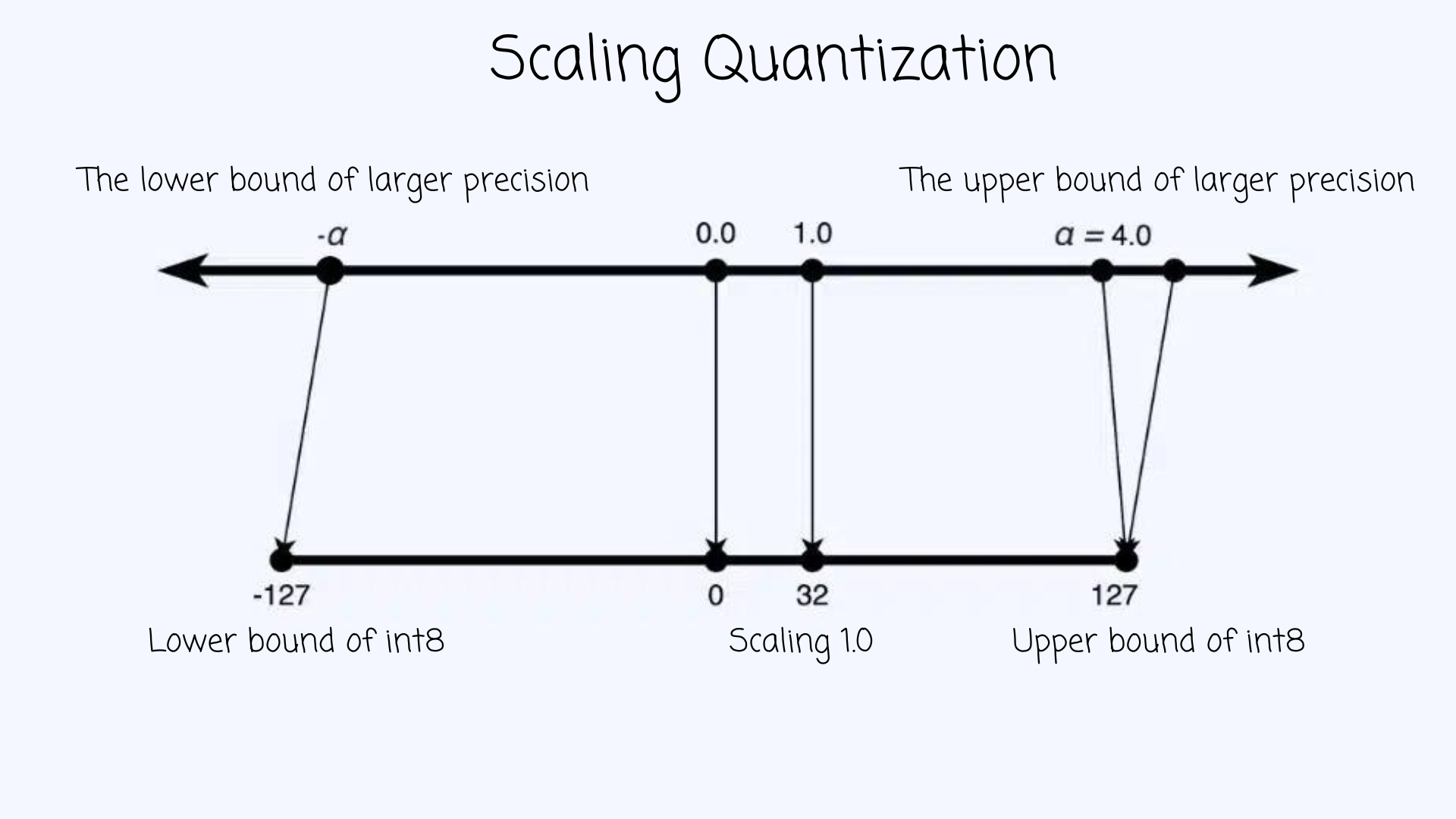
Scale and Zero Points in Quantization (Free AI Course)
Maximum (over quantization scales) of maximum (over video sequences ...
A Deep Dive into Model Quantization for Large-Scale Deployment ...
DiffQuant: Reducing Compression Difference for Neural Network Quantization
Comparing Quantization Techniques for Scalable Vector Search – Unite.AI
Quantization for Large Language Models (LLMs): Reduce AI Model Sizes ...
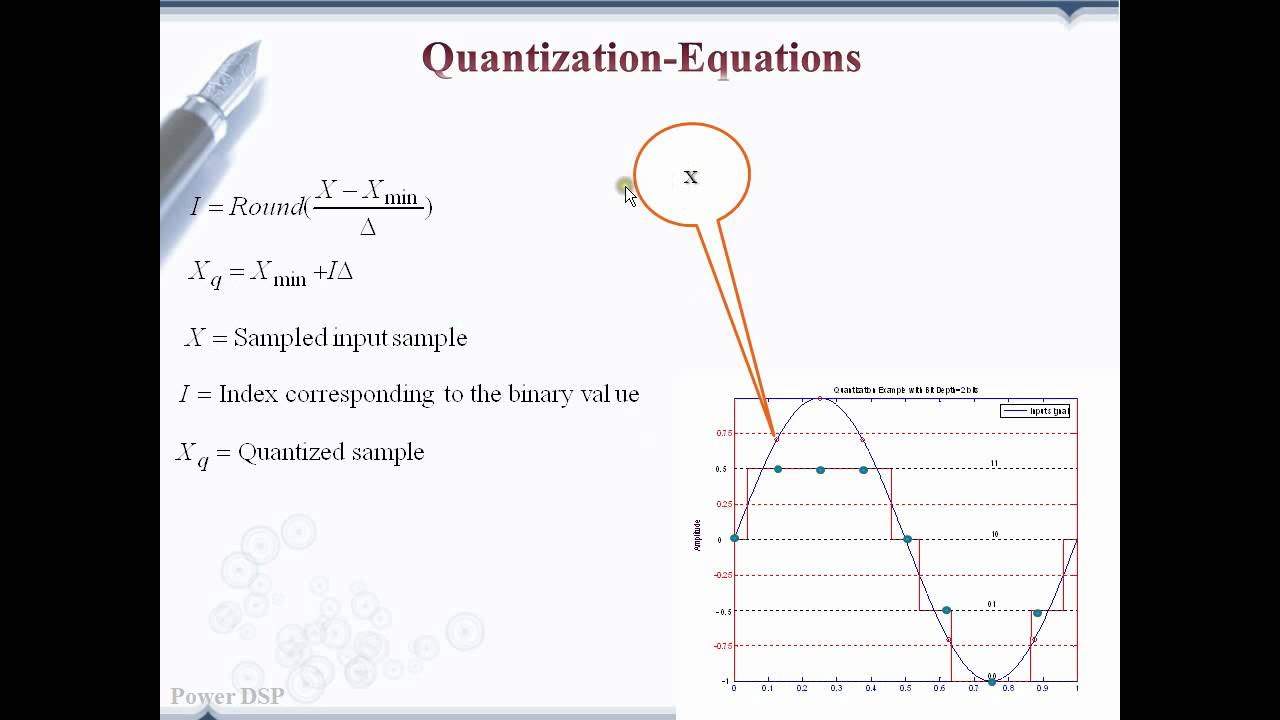
Quantization Part 3 : Quantization understanding with equations - YouTube
Model Quantization in Deep Learning
What is Quantization - GeeksforGeeks
Test performance as a function of the quantization scale, ∆, for twenty ...
Quantization Part 2: Quantization Understanding - YouTube
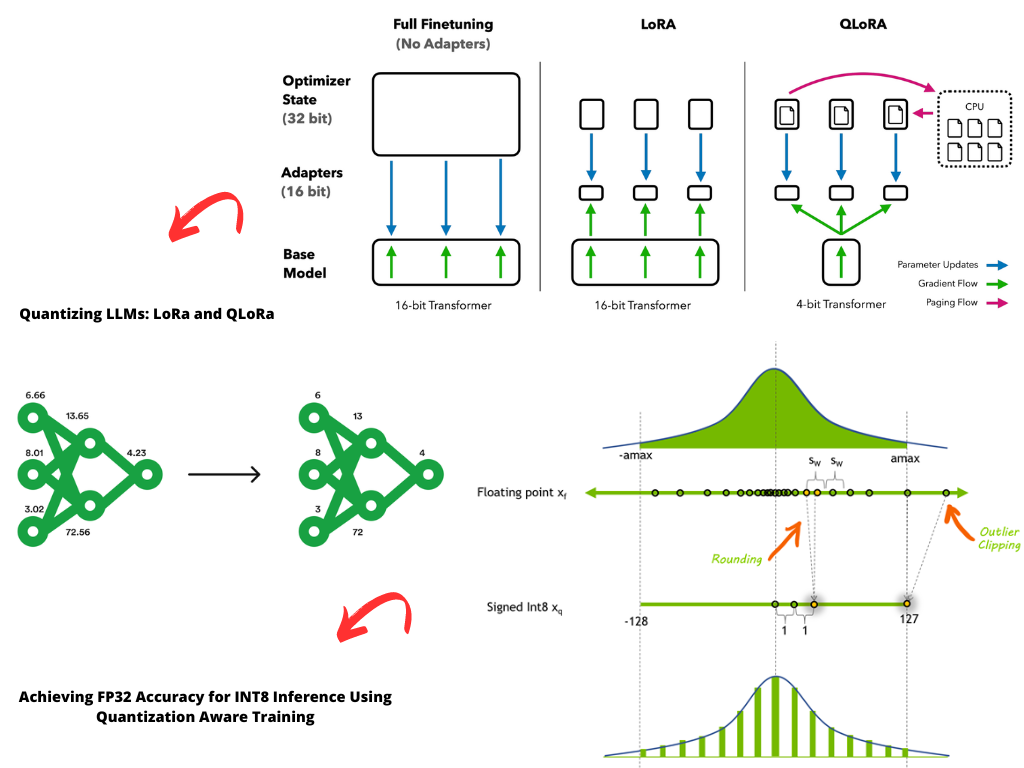
Mastering QLoRa : A Deep Dive into 4-Bit Quantization and LoRa ...
Quantization | PPTX
Quantitative Scales of Measurement | PDF | Level Of Measurement | Analysis
Image Quantization | PPTX
Illustration of the universe quantization to physical objects of ...
IBM Offers Roadmap Toward Large-Scale, Fault-Tolerant Quantum Computer ...
UK’s Oxford Quantum Circuits raises €301 million Series C to scale ...
LLM Quantization: GPTQ, AWQ, and GGUF – A Production Engineer's Guide ...
Monarch Quantum and Oratomic Announce Quantum Computing Partnership
Rice Researchers Report Dressing Matter With Light Could Lead to Large ...
NSF Announces Initiative to Launch And Scale Transformative Independent ...
Multiverse Computing Raises $215 Million to Scale Technology that ...
GlobalFoundries Opens Quantum Processor Unit Foundry: $375M CHIPS Award ...
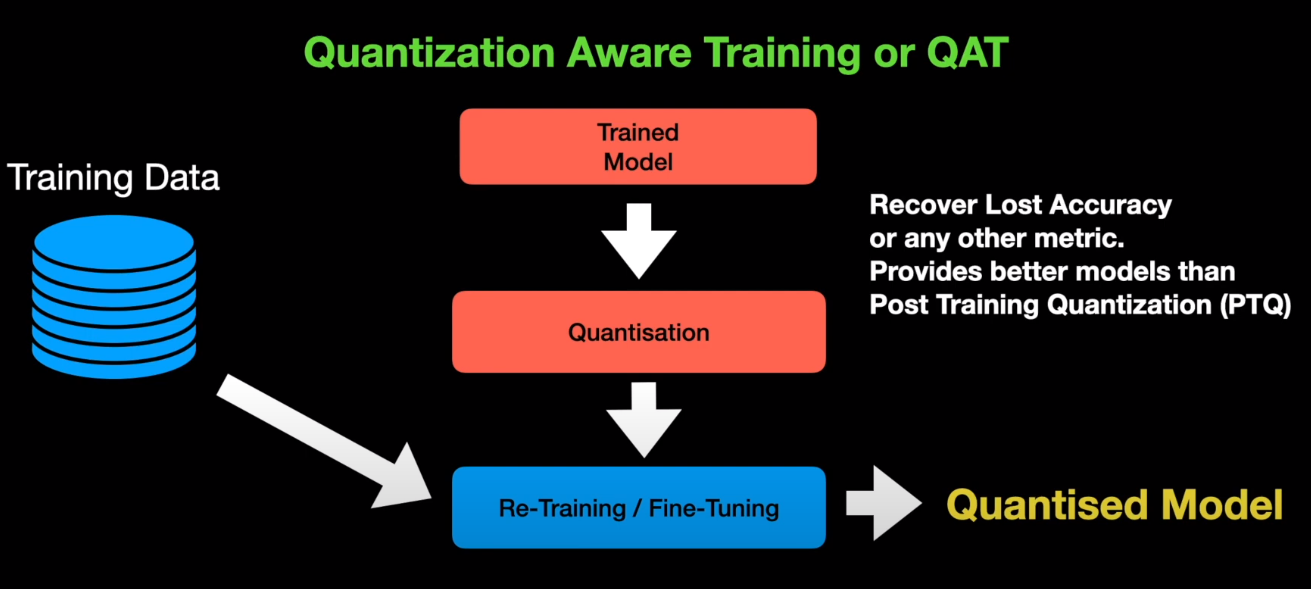
Gemma 4 with quantization-aware training
Optimizing LLMs for Performance and Accuracy with Post-Training ...
LLM Inference Optimization in 2026: Quantization, Speculative Decoding ...
QuantWare Raises $178 Million to Build World’s Most Powerful Quantum ...
QuantWare Raises $178 Million to Build Quantum Processors at an ...
€115M Series A Backs Quobly’s Quantum Processor Scale-Up
large scale quantum computing: Latest News & Videos, Photos about large ...
French firm’s new chip-building trick could scale quantum computers to ...
3D_NeuroSim_V1.0/Heterogeneous3D/modules/quantization_cpu_np_infer.py ...
Top 10 KV Cache Compression Techniques for LLM Inference: Reducing ...
How to Run NVIDIA Nemotron 3 Ultra 550B on a Budget GPU Cluster - A ...
PPT - MPEG Video (Part 2) PowerPoint Presentation, free download - ID ...
Table 1 from Integer-Only CNNs with 4 Bit Weights and Bit-Shift ...
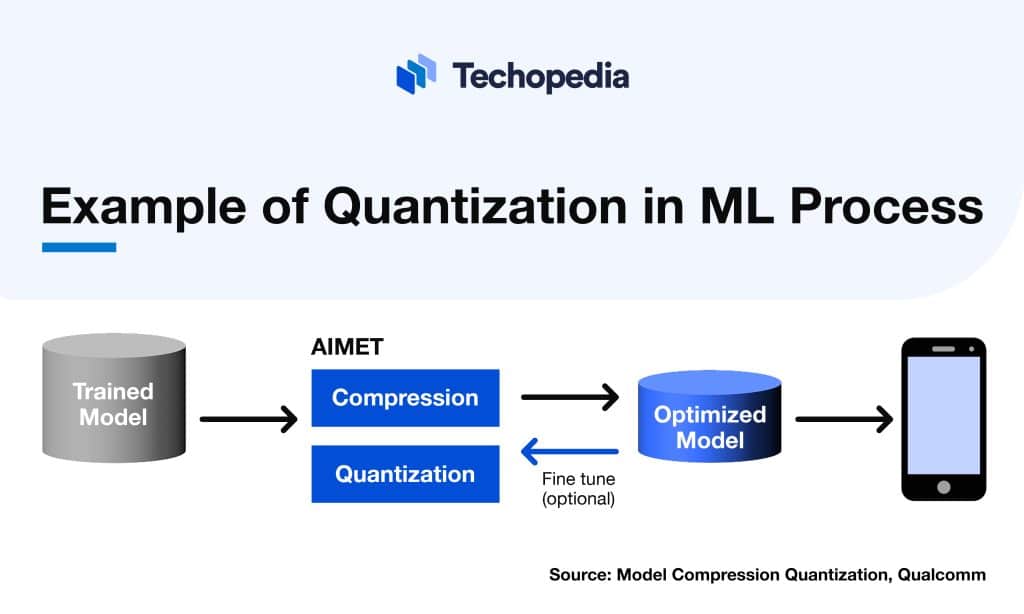
What is Quantization? Definition, Types & Examples Techopedia
PPT - Improved input-state linearization in video bitrate controllers ...
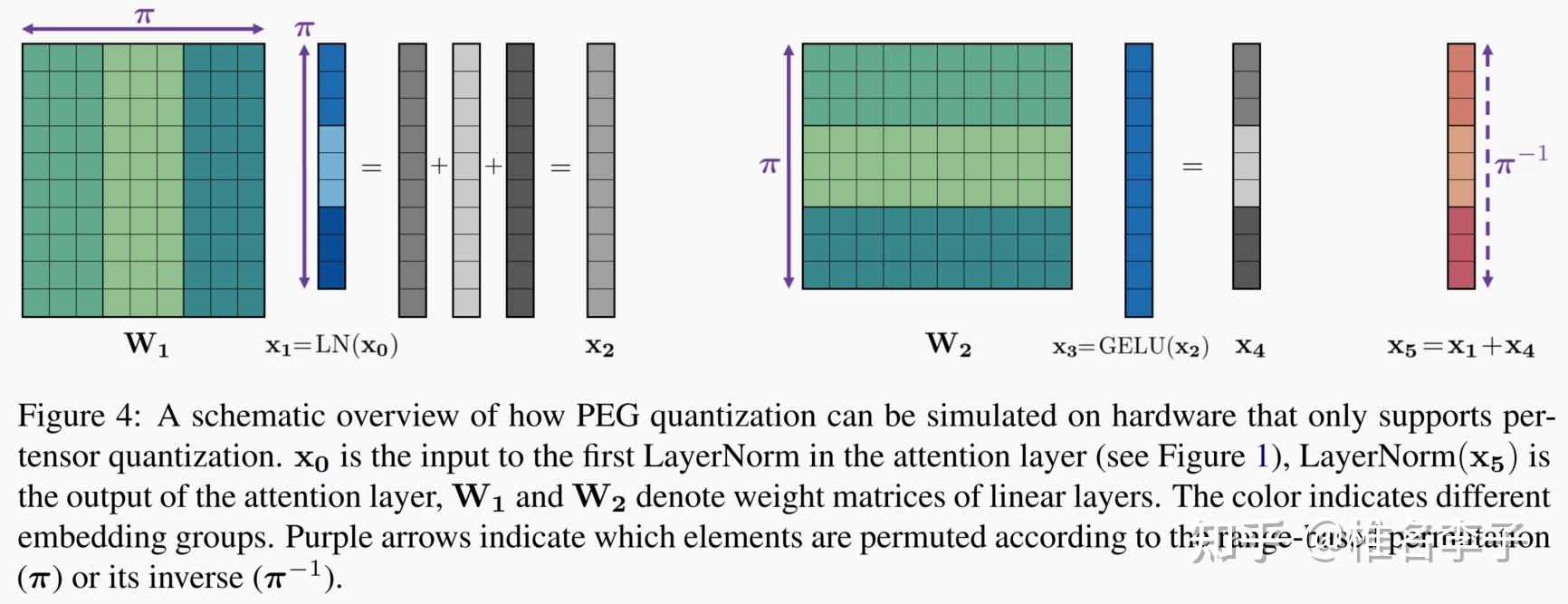
模型量化-llm量化 - 知乎
Everything You Need to Know about Vector Index Basics - Zilliz Learn
Quantization: Unlocking scalability for large language models | Qualcomm
PPT - Measurement Theory PowerPoint Presentation - ID:1254935
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析_大模型量化-CSDN博客
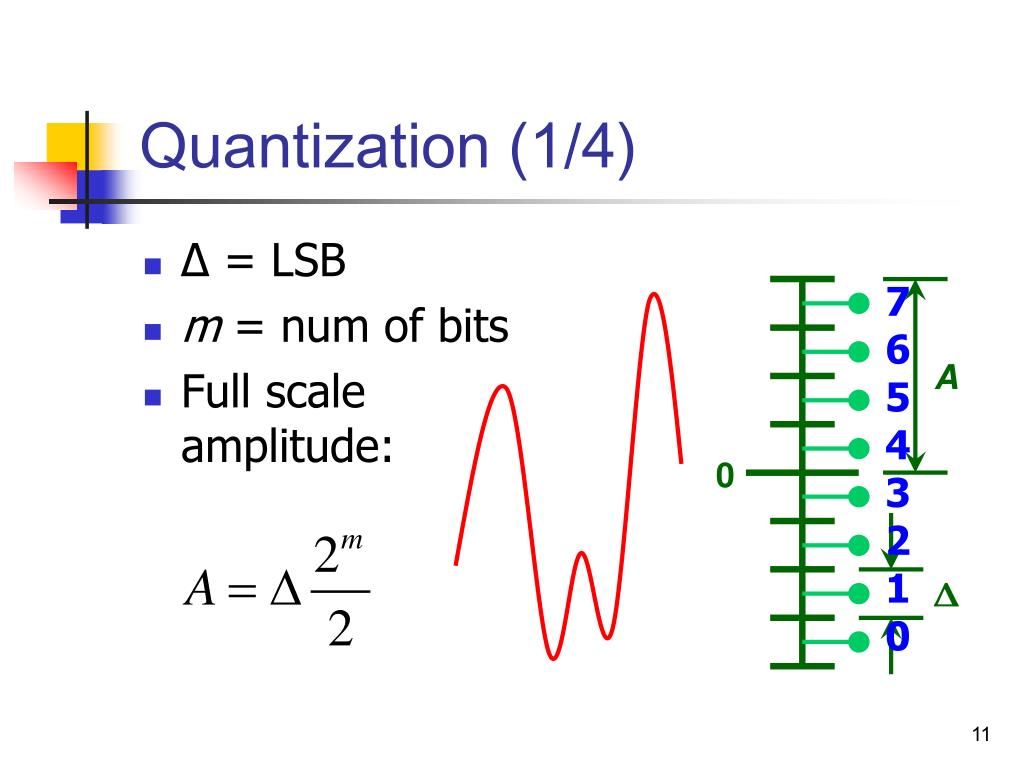
PPT - Introduction to Analog-to-Digital Converters PowerPoint ...
























.webp)


































.jpg)