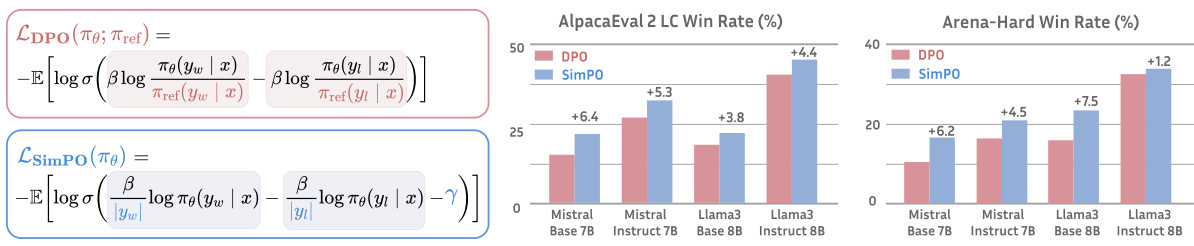
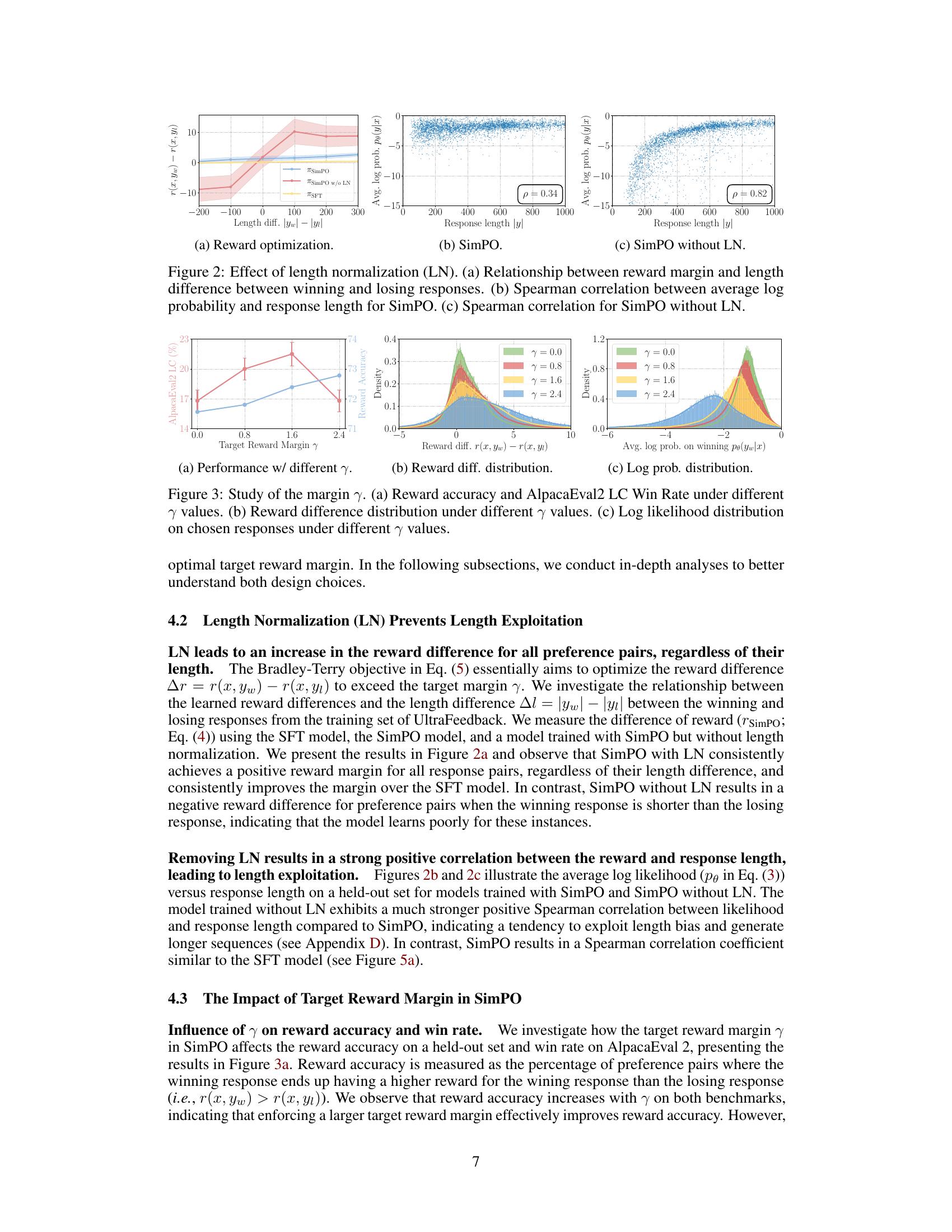
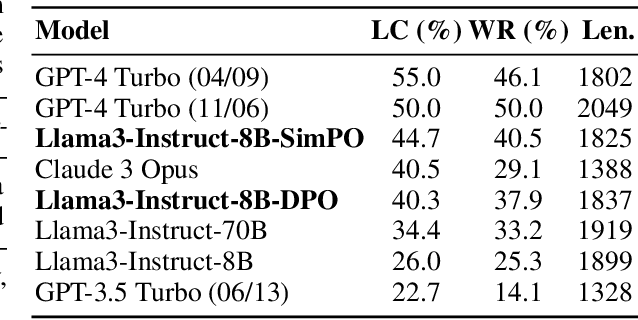
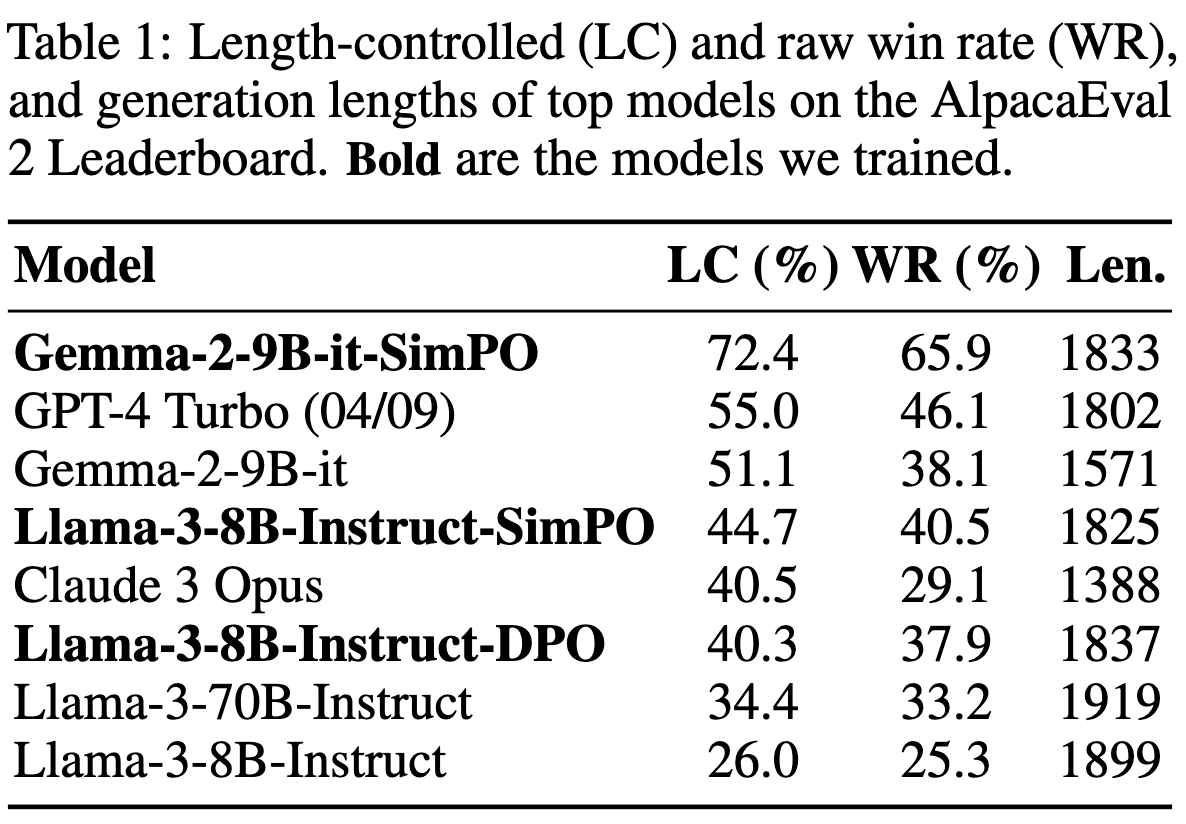
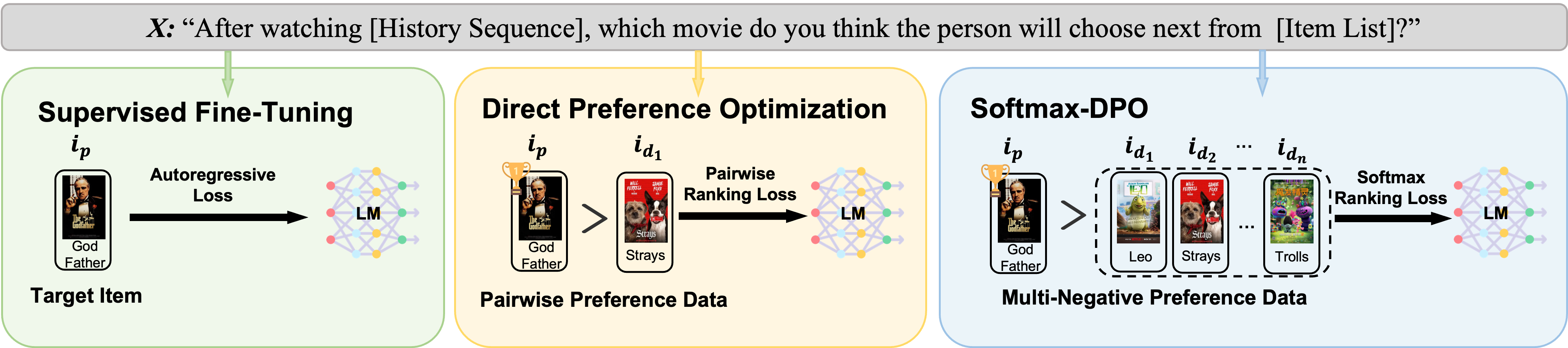
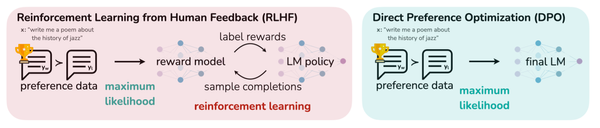
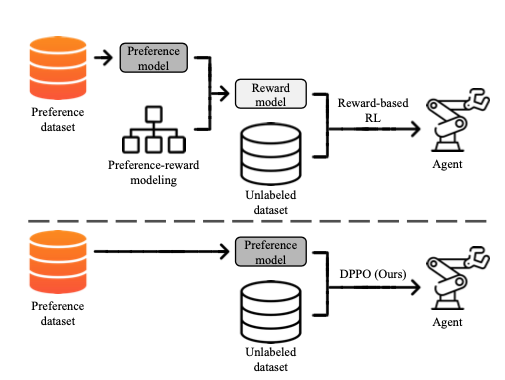
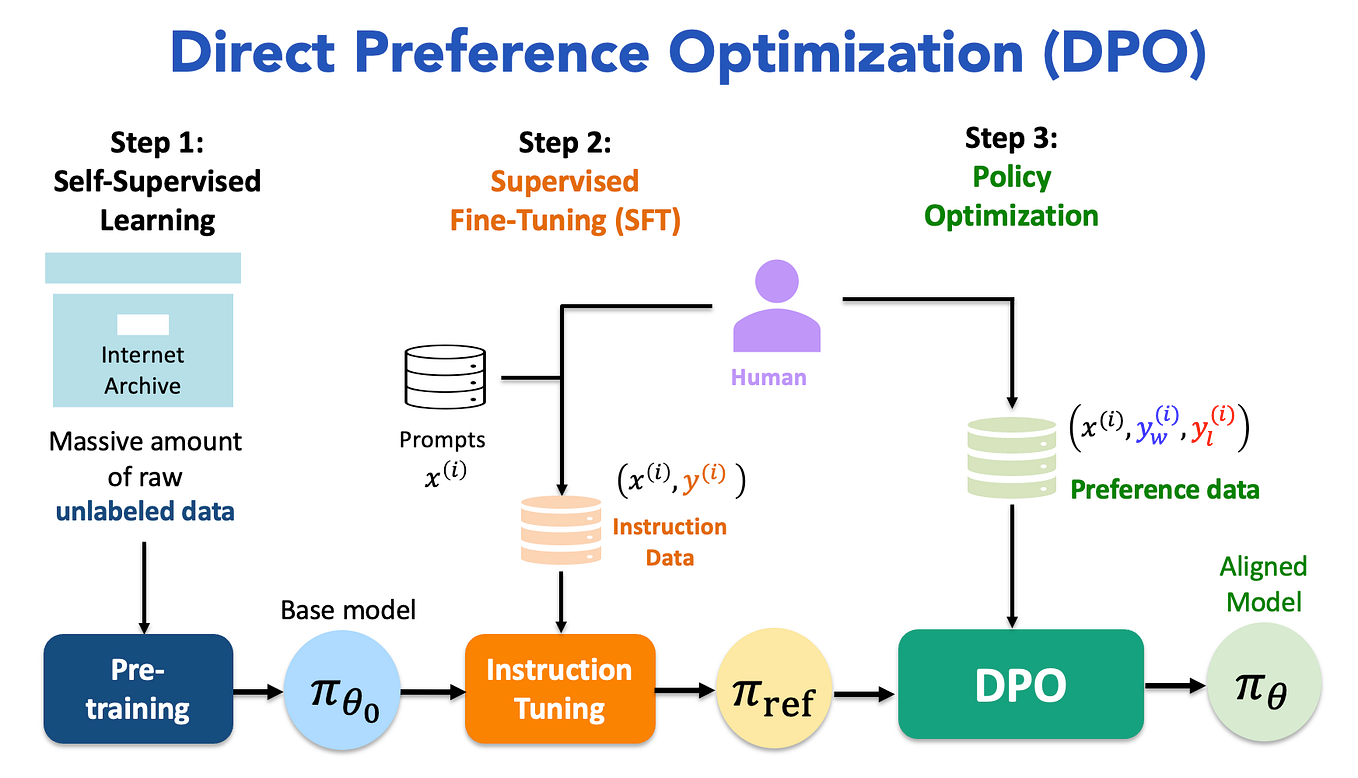
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
SimPO: Simple Preference Optimization with Reference-Free Reward ...
[PDF] SimPO: Simple Preference Optimization with a Reference-Free ...
NeurIPS Poster SimPO: Simple Preference Optimization with a Reference ...
[논문 리뷰] SafeDPO: A Simple Approach to Direct Preference Optimization ...
Table 3 from SimPO: Simple Preference Optimization with a Reference ...
SimPO: Simple Preference Optimization with a Reference-Free Reward ...
[RL] SimPO: Simple Preference Optimization with a Reference-Free Reward ...
🤓 Simple Preference Optimization (SimPO) is a new algorithm for ...
SimPO - Simple Preference Optimization - New RLHF Method - YouTube
[2024 Best AI Paper] SimPO: Simple Preference Optimization with a ...
Paper page - SimPO: Simple Preference Optimization with a Reference ...
SimPO: Simple Preference Optimization with a Reference-Free Reward - 智源社区论文
SimPO: Simple Preference Optimization with a Reference-Free Reward - 知乎
GitHub - RAY2L/SimPOW: SimPOW: Simple Preference Optimization with WEIGHTS
Table 2 from SimPO: Simple Preference Optimization with a Reference ...
Table 1 from SimPO: Simple Preference Optimization with a Reference ...
Direct Preference Optimization (DPO): A simple and straightforward ...
SimPO Simple Preference Optimization with a Reference Free Reward ...
Understanding Direct Preference Optimization (DPO) for LLMs | Cameron R ...
Direct Preference Optimization (DPO)
Thinking LLMs: How Thought Preference Optimization Transforms Language ...
Walber Cardoso on LinkedIn: SimPO (Simple Preference Optimization ...
Direct Preference Optimization Using Sparse Feature-Level Constraints ...
Model Agnostic Preference Optimization for Medical Image Segmentation ...
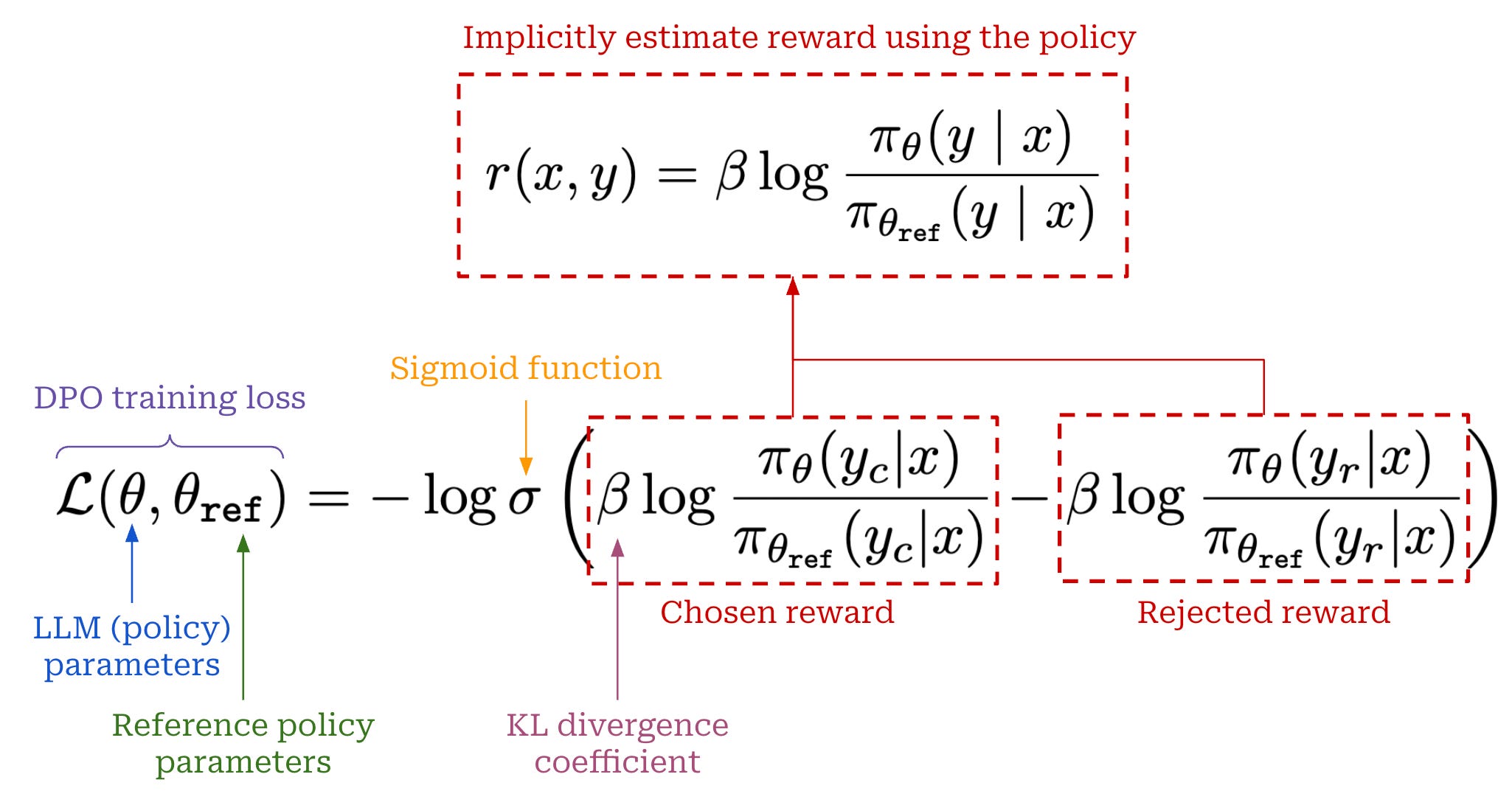
Direct Preference Optimization (DPO): Your Language Model is Secretly a ...
Direct Preference Optimization of Video Large Multimodal Models from ...
Understanding Direct Preference Optimization | by Matthew Gunton ...
Direct Preference Optimization (DPO) - How to fine-tune LLMs directly ...
Understanding Direct Preference Optimization | Towards Data Science
Fine-tune Llama 3 using Direct Preference Optimization
(PDF) Preference Optimization by Estimating the Ratio of the Data ...
Aman's AI Journal • Primers • Preference Optimization
Introduction to Direct Preference Optimization (DPO)
Direct Preference Optimization (DPO) in Language Model alignment | UnfoldAI
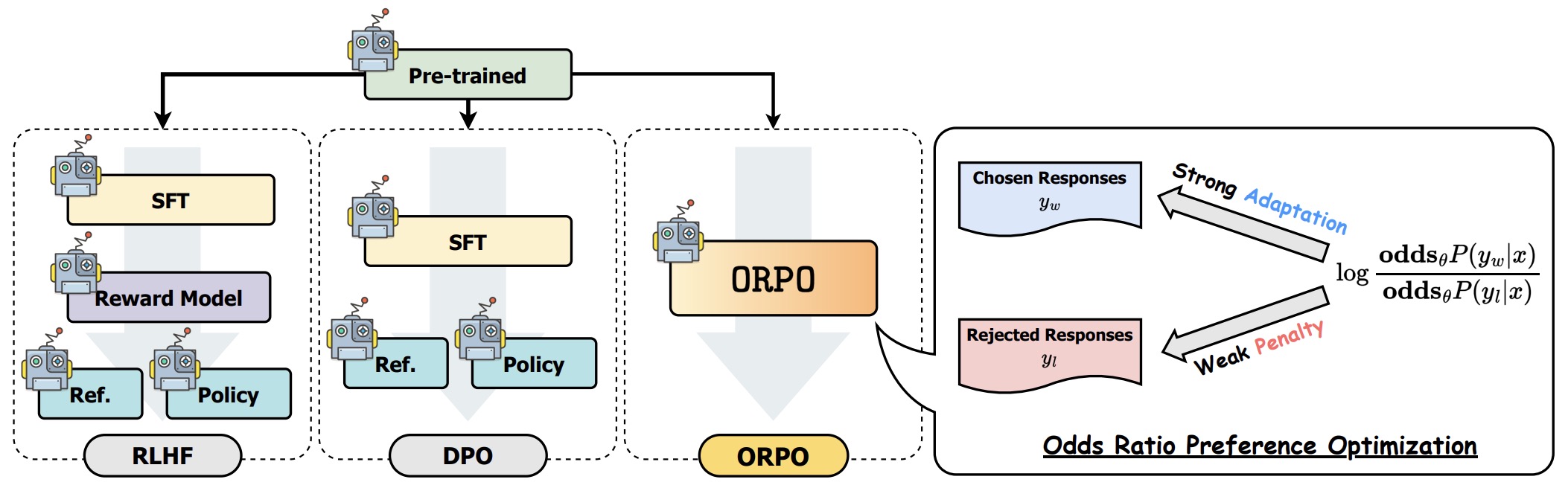
GitHub - princeton-nlp/SimPO: [NeurIPS 2024] SimPO: Simple Preference ...
TSO: Self-Training with Scaled Preference Optimization
Self-Play Preference Optimization (SPPO): Innovating Machine Learning ...
Direct Preference Optimization (DPO) | by João Lages | Medium
Iterative Preference Optimization for Improving Reasoning Tasks in ...
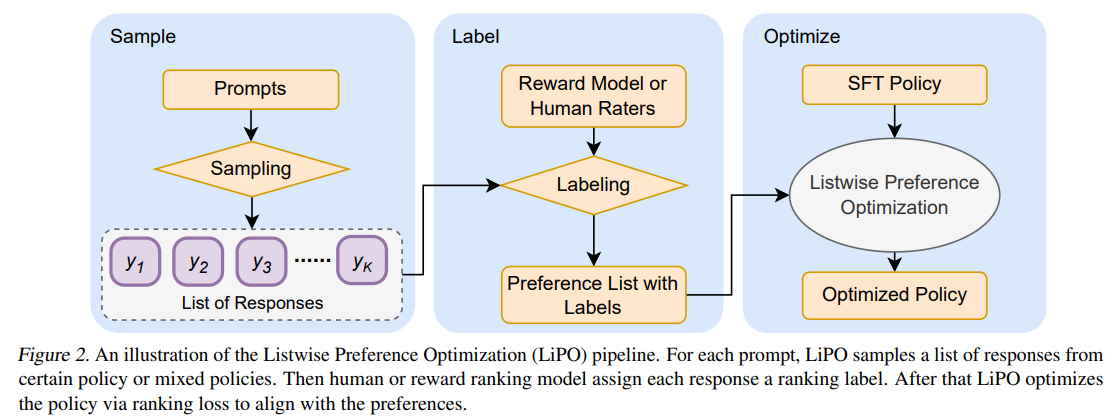
Google AI Research Introduces Listwise Preference Optimization (LiPO ...
Accelerated Preference Optimization for Large Language Model Alignment ...
Quantization, Direct Preference Optimization (DPO), and Advanced ...
SimPO:一个不需要reward model 的对齐优化方法:有跟DPO 进行对比_simpo: simple preference ...
Self-Consistency Preference Optimization
Self-Play Preference Optimization for Language Model Alignment
Preference Optimization - a lv12 Collection
[论文评述] Preference Optimization for Combinatorial Optimization Problems
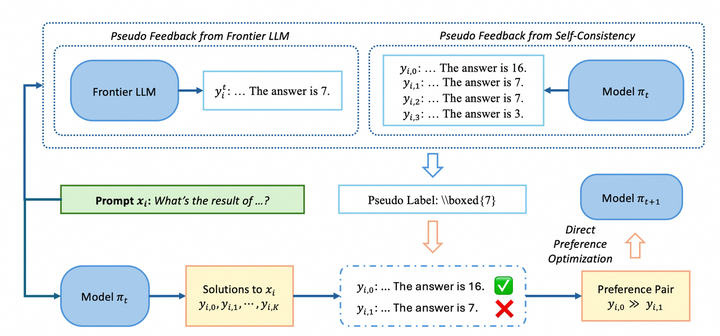
(PDF) Preference Optimization for Reasoning with Pseudo Feedback
[2404.19733] Iterative Reasoning Preference Optimization
(PDF) Aircraft Selection Using Preference Optimization Programming (POP)
Self-Improving Robust Preference Optimization | AI Research Paper Details
Self Consistency Preference Optimization — Paper review | by Sulbha ...
95% Confidence Intervals for Simple preference model configuration ...
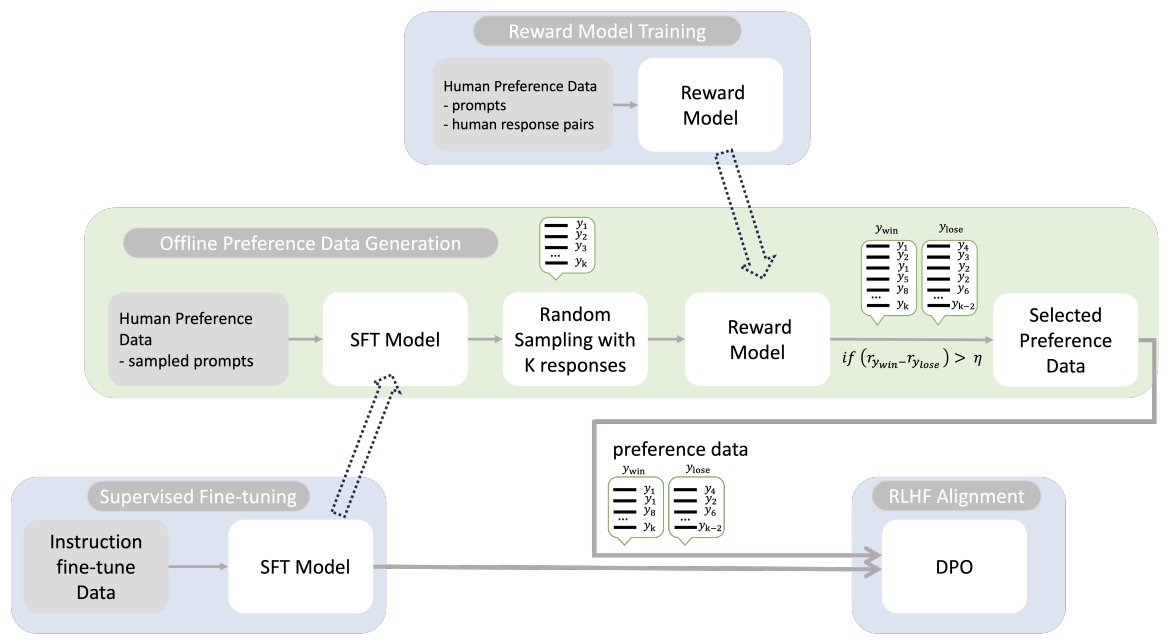
Direct Preference Optimization (DPO) vs RLHF/PPO (Reinforcement ...
Preference Optimization for Reasoning with Pseudo Feedback(模型自迭代方法) - 知乎
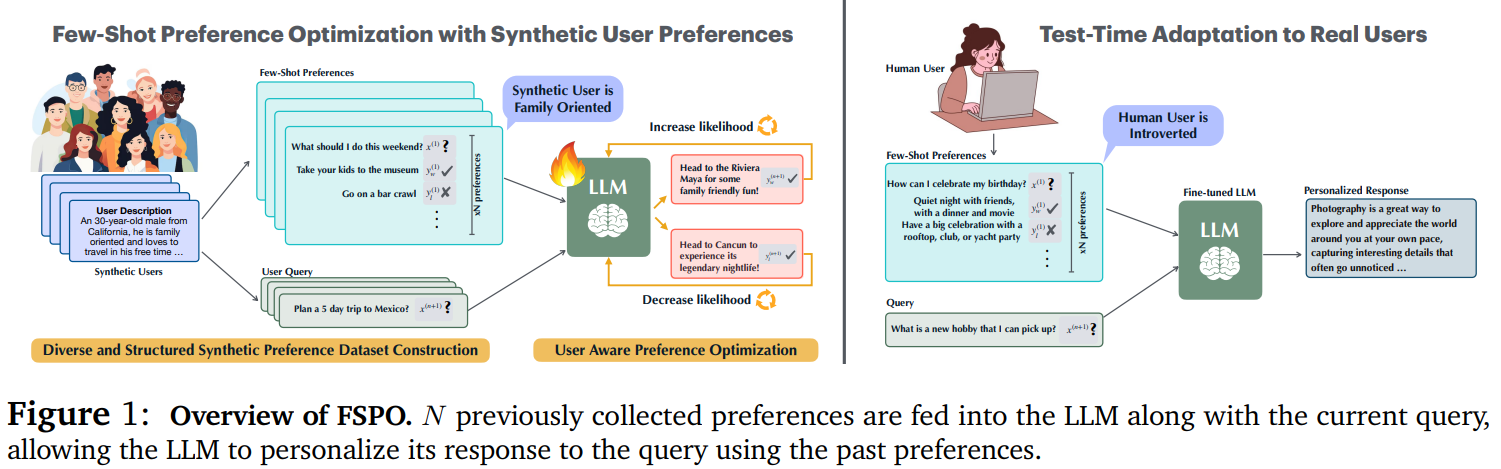
Few-Shot Preference Optimization (FSPO): A Novel Machine Learning ...
Preference Card Optimization 201: Surgical Supply Cost Containment – Part 2
Book Launch: Employee Preference Optimization
Preference Training for LLMs in a Nutshell
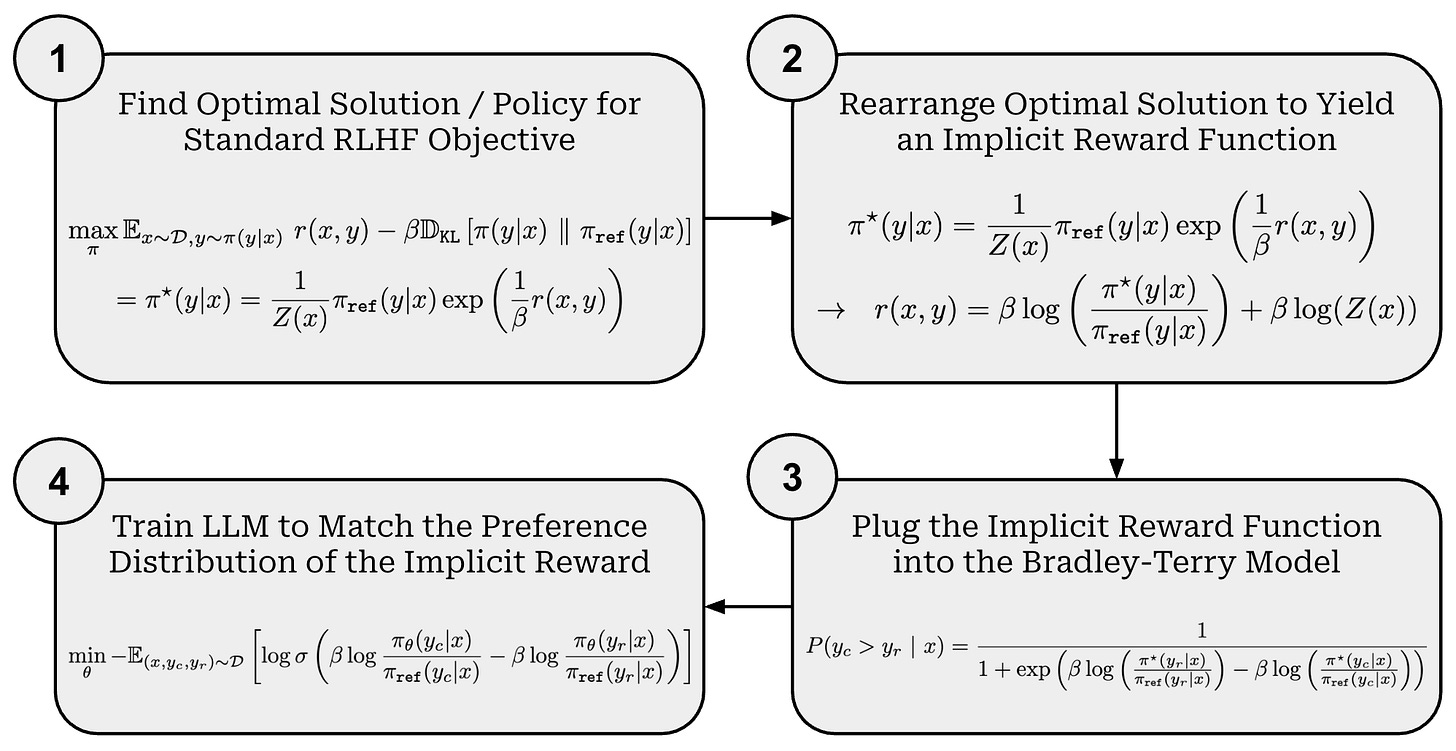
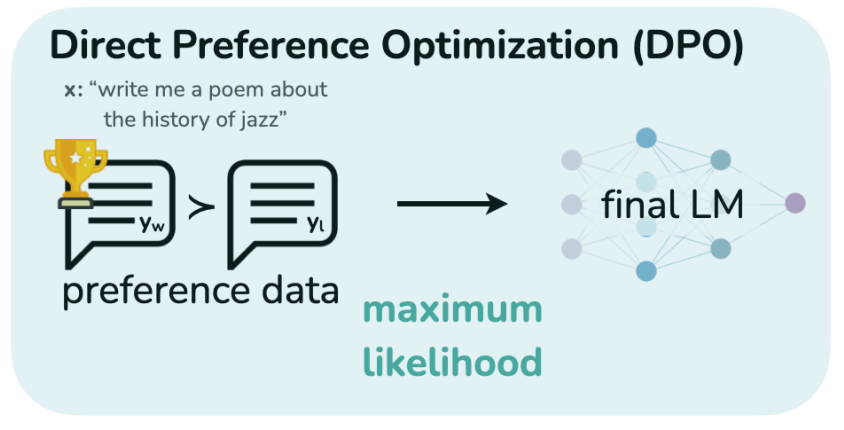
Direct Preference Optimization: Your Language Model is Secretly a ...
SimPO算法-Simple Preference Optimizationwith a Reference-Free Reward -CSDN博客
What is Direct Preference Optimization? | Deepchecks
【论文阅读】理解DPO,《Direct Preference Optimization: Your Language Model is ...
Paper page - Pre-DPO: Improving Data Utilization in Direct Preference ...
Free Video: Aligning Language Models with LESS Data and Simple ...
Soft Preference Optimization: Aligning Language Models to Expert ...
[2410.08458] Simultaneous Reward Distillation and Preference Learning ...
Paper page - Direct Preference Optimization: Your Language Model is ...
[2309.06657] statistical rejection sampling improves preference ...
Preference-Optimized Pareto Set Learning for Blackbox Optimization | AI ...
[论文评述] Chain of Preference Optimization: Improving Chain-of-Thought ...
DPO(Direct Preference Optimization):LLM的直接偏好优化 - 知乎
Direct Preference Optimization: Advancing Language Model Fine-Tuning
Baobab Tech - Direct Preference Optimization: A New Approach to Fine ...
(PDF) GLISp-r: a preference-based optimization algorithm with ...
Direct Preference-based Policy Optimization without Reward Modeling ...
Yoga-LLM, Part 2: Instruction Fine-tuning | by Vijayasri Iyer | GoPenAI
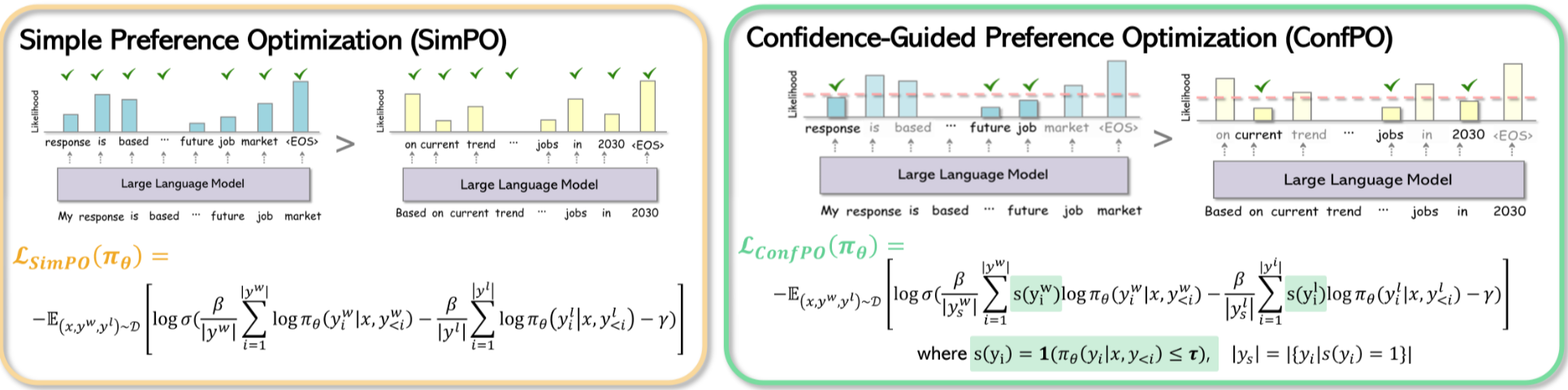
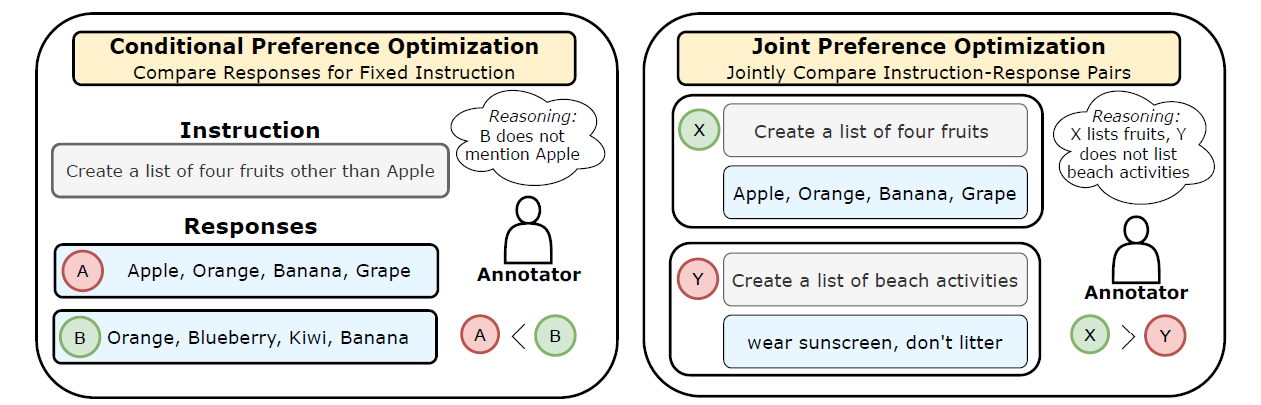
[论文评述] ConfPO: Exploiting Policy Model Confidence for Critical Token ...
Do You Really Need Reinforcement Learning (RL) in RLHF? A New Stanford ...
Getting Started with the SimPO Model: A Guide for Developers - fxis.ai
LLM Alignments [Part 1: Overview] | by yAIn | Medium
[大模型 13] 偏好学习新作,ODPO 和 SimPO - 知乎
Optimizing Language Models for Human Preferences is a Causal Inference ...
GitHub - OPTML-Group/Unlearn-Simple: [NeurIPS25] Official repo for ...
GitHub - eric-mitchell/direct-preference-optimization: Reference ...
SimPO:一种简单而高效的无参考奖励偏好优化方法 - 懂AI
RLHF and alternatives: DOVE
(PDF) An interactive preference-based evolutionary algorithm for multi ...