Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Working with Nvidia Tensor RT and Pose Estimation :: Okikiolu — The ...
Understanding Nvidia TensorRT for deep learning model optimization | by ...
Inference Optimization using TensorRT – DEVSTACK
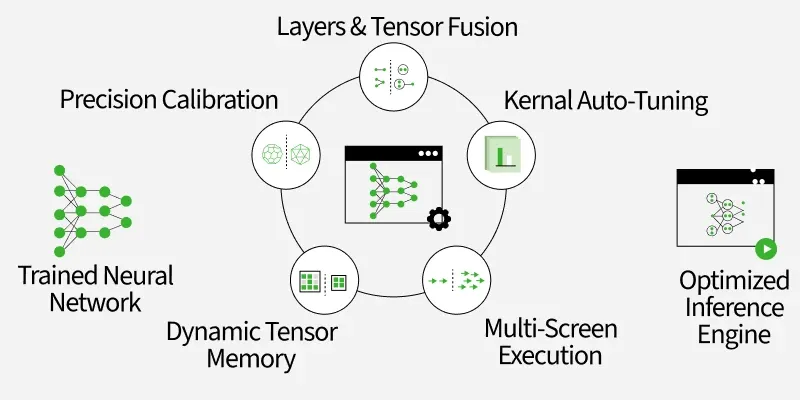
How TensorRT Works: Deep Dive into NVIDIA Inference Optimization Engine ...
Core Optimization Techniques | NVIDIA/TensorRT-Model-Optimizer | DeepWiki
How TensorRT Works: NVIDIA Inference Optimization | Abhik Sarkar
Inference Optimization with NVIDIA TensorRT - YouTube
TensorRT quantization Optimization - TensorRT - NVIDIA Developer Forums
ONNX Graph Optimization | NVIDIA/TensorRT-Model-Optimizer | DeepWiki
TensorRT LLM - NVIDIA's open source large model inference optimization ...
RAG: Performance Optimization with NVIDIA TensorRT and Quantization
NVIDIA TensorRT: Inference Optimization Toolkit for Deploying Deep ...
Optimization strategies of TensorRT. | Download Scientific Diagram
Optimization of instance-segmentation model with TensorRT. | Download ...
Kernel Optimization and AutoTuner | NVIDIA/TensorRT-LLM | DeepWiki
TensorRT-LLM Optimization | Introl Blog
TensorRT optimization steps. | Download Scientific Diagram
Model Optimization with TensorRT & ONNX Runtime
[Feature Request] More realistic benchmark and throughput optimization ...
Robust Scene Text Detection and Recognition: Inference Optimization ...
Model optimization steps using different toolkits (left to right ...
51. Model Optimization with TensorRT - My Blog
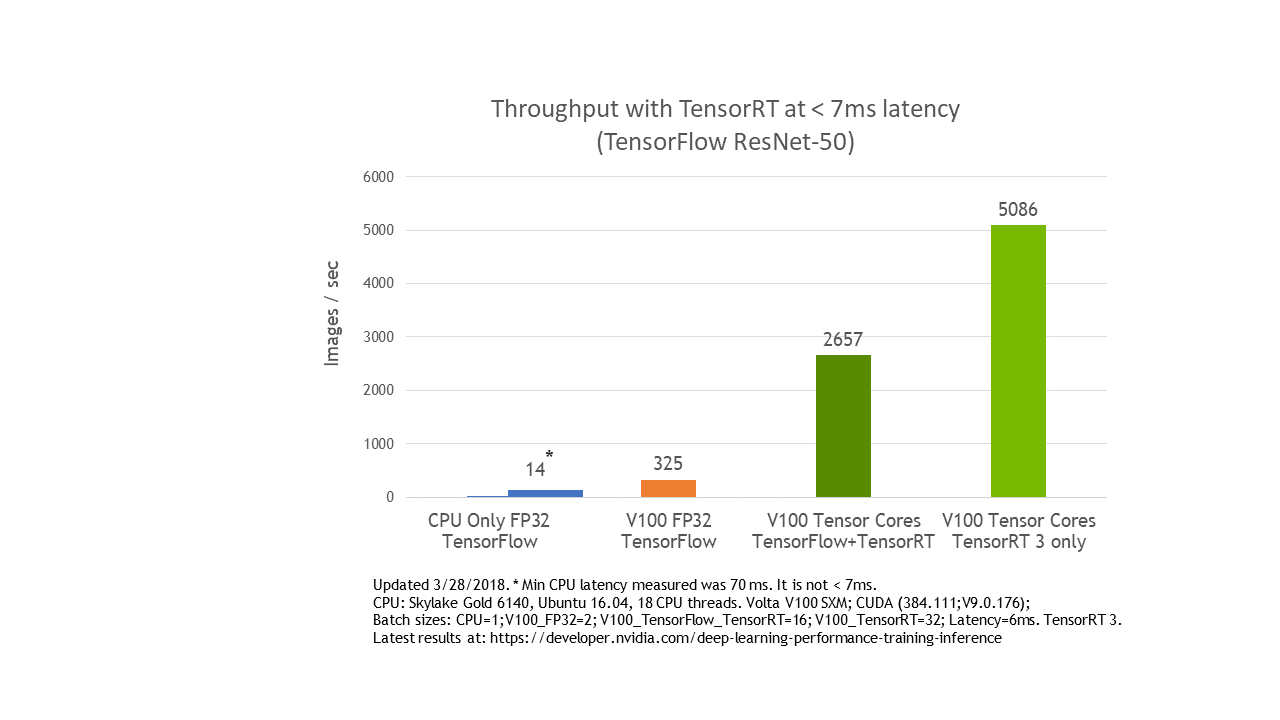
TensorRT 3: Faster TensorFlow Inference and Volta Support | NVIDIA ...
How to optimize inference using TensorRT on Jetson AGX Orin
What is NVIDIA TensorRT?
NVIDIA TensorRT Accelerates Stable Diffusion Nearly 2x Faster with 8 ...
Advanced Topics — NVIDIA TensorRT
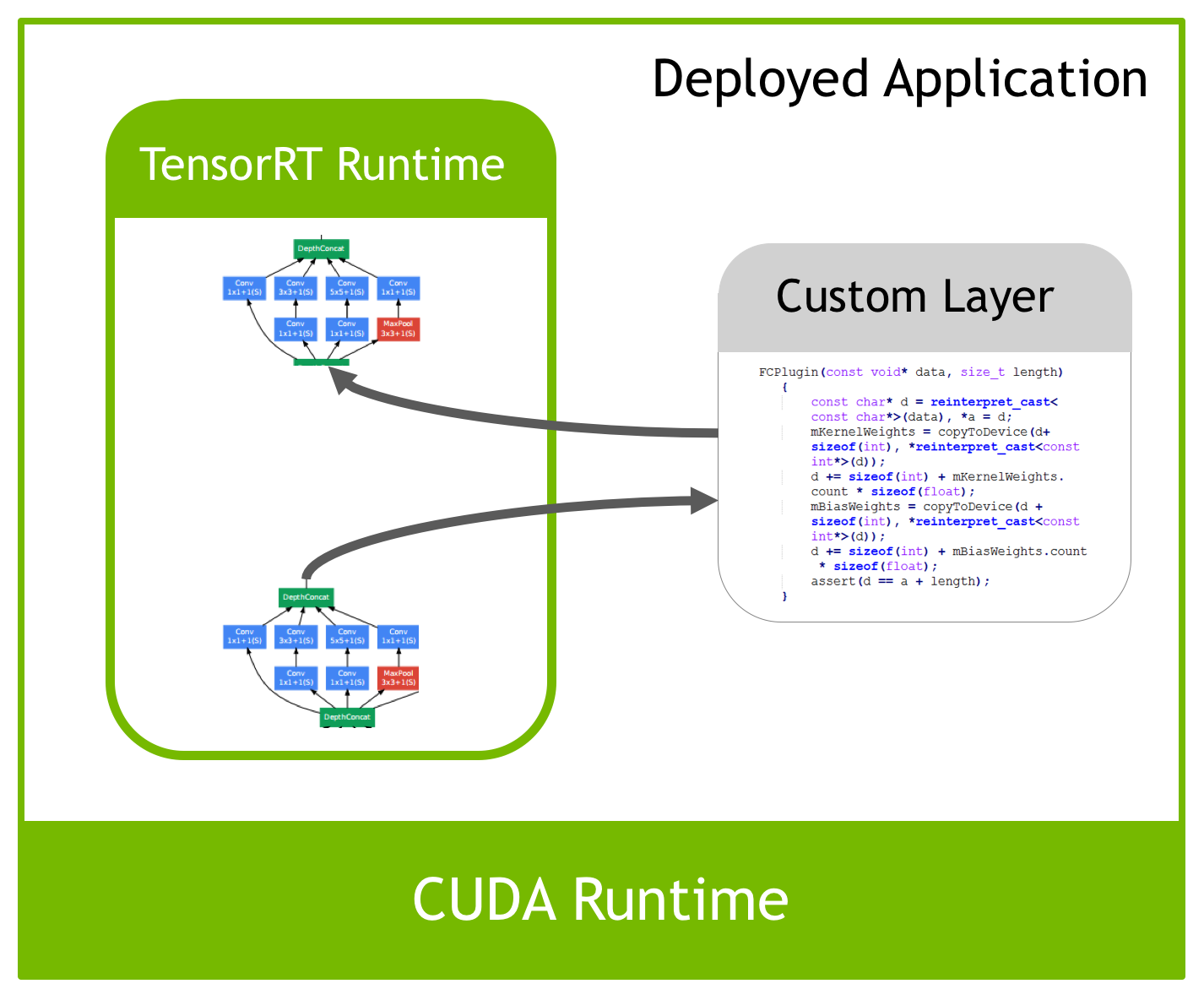
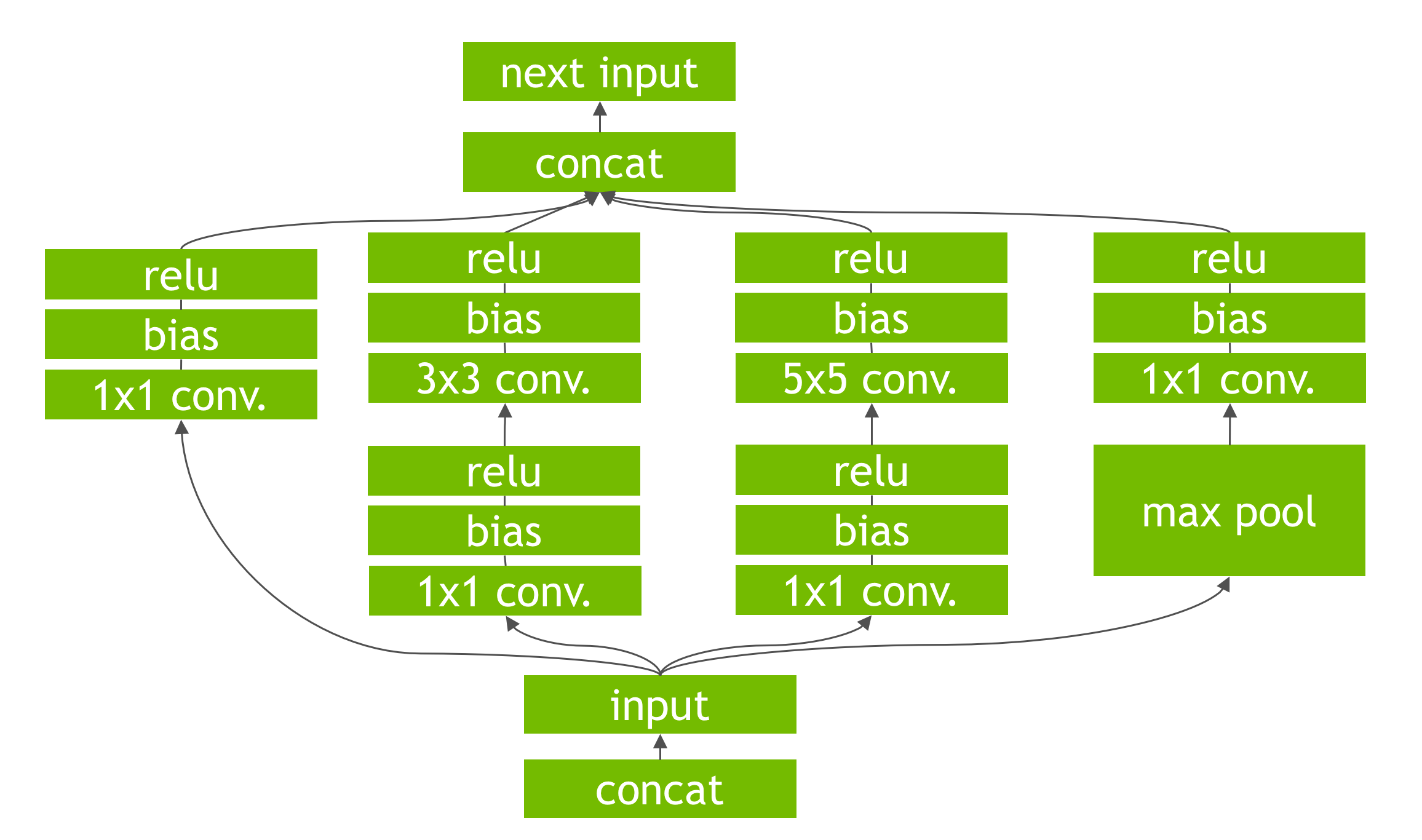
Deploying Deep Neural Networks with NVIDIA TensorRT | NVIDIA Technical Blog
NVIDIA TensorRT | NVIDIA Developer
GitHub - AllenJWZhu/BERT_TensorRT_Inference_Optimization: Inference ...
Simplifying and Accelerating Machine Learning Predictions in Apache ...
Boost inference speeds with NVIDIA TensorRT on UbiOps - UbiOps
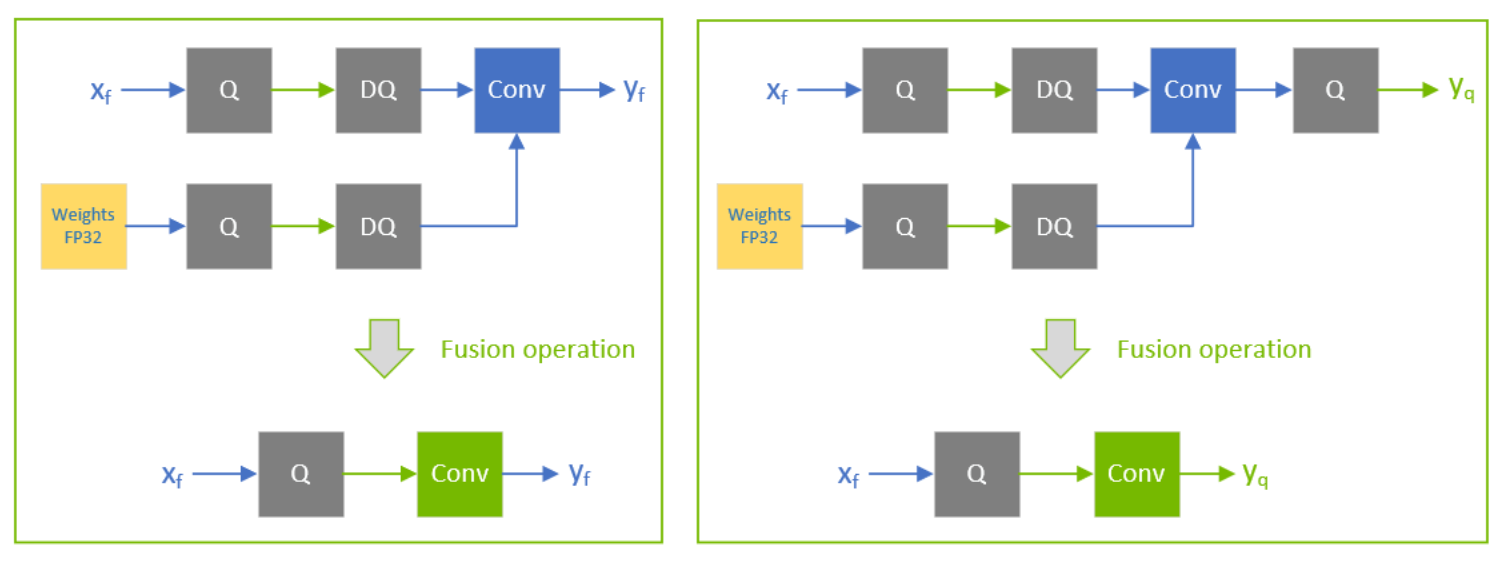
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
Optimizing NVIDIA TensorRT Conversion for Real-time Inference on ...
Speeding Up Deep Learning Inference Using TensorFlow, ONNX, and ...
Nvidia’s TensorRT 8.0 boasts faster conversational AI performance
How to Speed Up Deep Learning Inference Using TensorRT | NVIDIA ...
Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
NVIDIA TensorRT-LLM Enhancements Deliver Massive Large Language Model ...
High performance ML inference with NVIDIA TensorRT | Baseten Blog
Accelerate Generative AI Inference Performance with NVIDIA TensorRT ...
GitHub - AllenJWZhu/ViT_TensorRT_Inference_Optimization: Inference ...
NVIDIA TensorRT Model Optimizer v0.15 Boosts Inference Performance and ...
What is TensorRT? Overview & Use Case
Adaptive Inference in NVIDIA TensorRT for RTX Enables Automatic ...
TensorRT SDK | NVIDIA Developer
saved_model_cli convert to tensorRT in Tensorflow 1.13.1 .. any docs ...
NVIDIA TensorRT-LLM Now Supports Recurrent Drafting for Optimizing LLM ...
"TensorRT Optimization: Enhance Your AI Models for NVIDIA Certification ...
揭秘NVIDIA大模型推理框架:TensorRT-LLM - 知乎
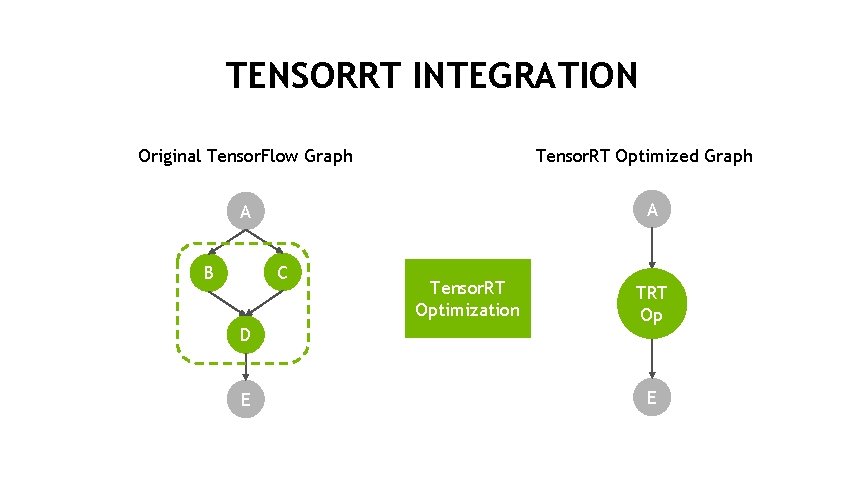
TensorRT Integration Speeds Up TensorFlow Inference | NVIDIA Technical Blog
Optimizing and Serving Models with NVIDIA TensorRT and NVIDIA Triton ...
GitHub - giranntu/NVIDIA-TensorRT-Tutorial: A tutorial for TensorRT ...
Boost inference speeds with NVIDIA TensorRT on UbiOps - UbiOps - AI ...
TensorRT Basics — GPU-Optimized Inference for Deep Learning | tutorialQ
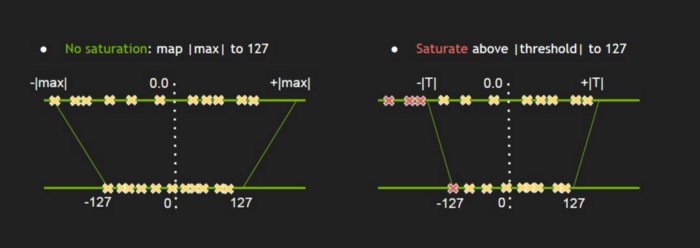
Working with Quantized Types — NVIDIA TensorRT
NVIDIA TensorRT-LLM Boosts Large Language Models Immensely, Up To 8x ...
TensorRT模型转换及部署,FP32/FP16/INT8精度区分_tensorrt engine in fp16-CSDN博客
Pruning and Distilling LLMs Using NVIDIA TensorRT Model Optimizer ...
Leveraging TensorFlow-TensorRT integration for Low latency Inference ...
TensorRTとは?NVIDIAのディープラーニング推論最適化ツールを徹底解説 – AI Front Trend
NVIDIA TensorRT 10.0 Upgrades Usability, Performance, and AI Model ...
An Expert-Level Monograph on NVIDIA TensorRT: Architecture, Ecosystem ...
高性能深度学习推断框架—TensorRT | Edward
The Power of Software Optimization: NVIDIA 2x speeds up Language Model ...
TensorRT-Model-Optimizer/docs/source/assets/model-optimizer-banner.png ...
借助 NVIDIA TensorRT-LLM 预测解码,将 Llama 3.3 的推理吞吐量提升 3 倍 - NVIDIA 技术博客
Optimize TensorFlow Serving Performance with TensorRT | MoldStud
TensorRT Model Optimizer量化和模型导出_tensorrt-model-optimizer-CSDN博客
Deploying to NVIDIA Jetson with TensorRT: Production-Grade Inference ...
TensorRT模型优化简介
GitHub - imangotap/YOLOv8-TensorRT-Optimization-For-Edge: Deployment ...
Faster YOLOv5 inference with TensorRT, Run YOLOv5 at 27 FPS on Jetson ...
Quantization flow using TensorRT (what is recommended for CNN?) · Issue ...
TensorRT-LLM/docs/source/blogs/tech_blog/blog02_DeepSeek_R1_MTP ...
TensorRT-LLM by NVIDIA - SourcePulse
AI Inference in Data Engineering: Comparing TensorRT, Triton, and ...
Writer Releases Domain-Specific LLMs for Healthcare and Finance ...
What is TensorRT? - GeeksforGeeks
How TensorRT Accelerates AI on RTX PCs | NVIDIA Blog
TensorRT survey | PPTX
High performance inference with TensorRT Integration — The TensorFlow Blog
TensorRT 简介 - 知乎
AI Product Development | IoT App Development Services Company
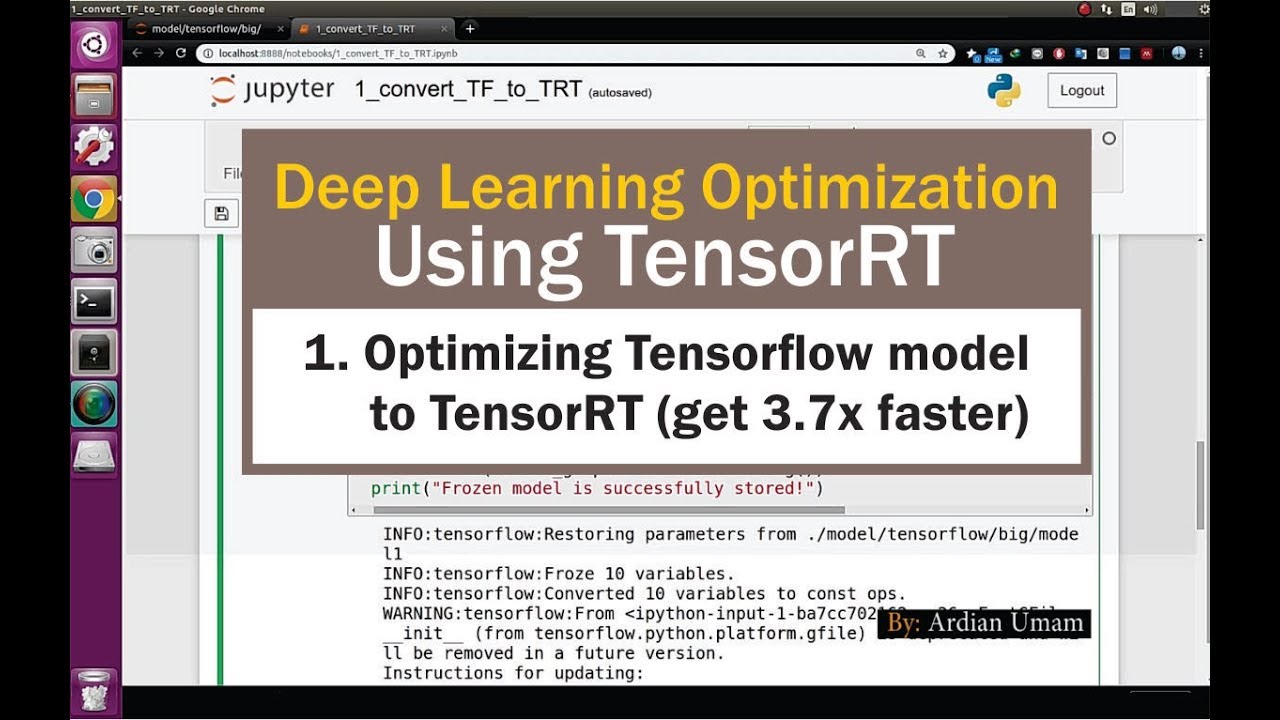
01 Optimizing Tensorflow Model Using TensorRT with 3.7x Faster ...
TENSORFLOW MODELS ACCELERATED FOR JETSON John Welsh July

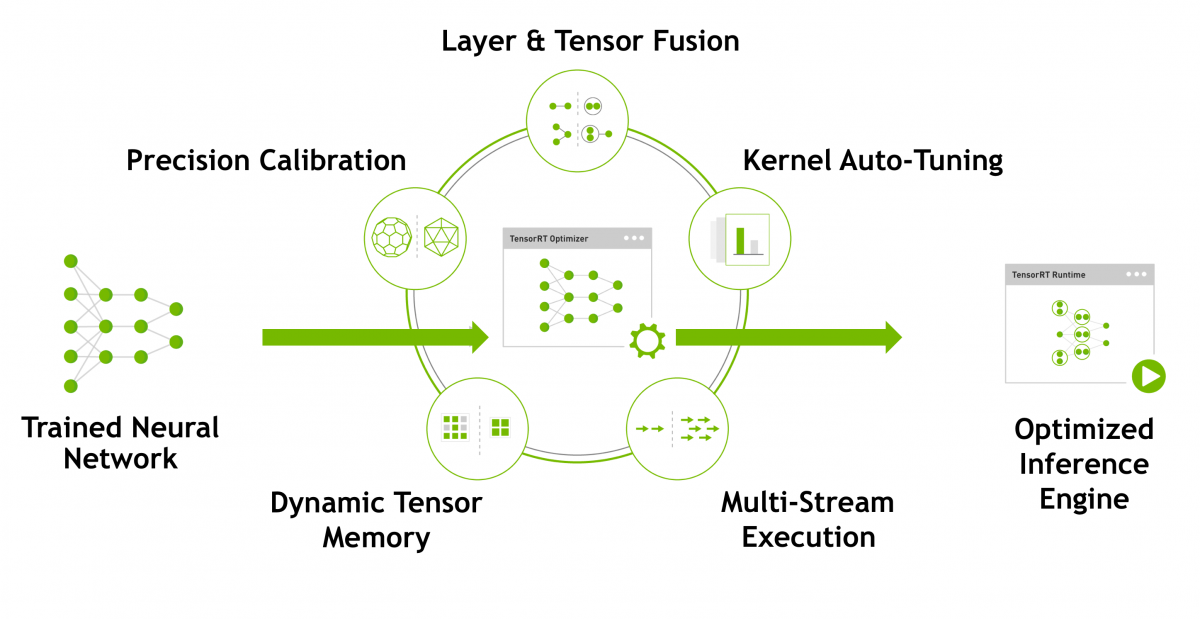
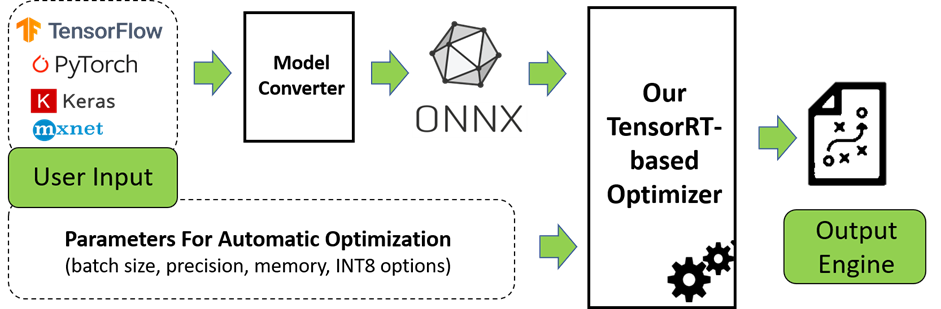
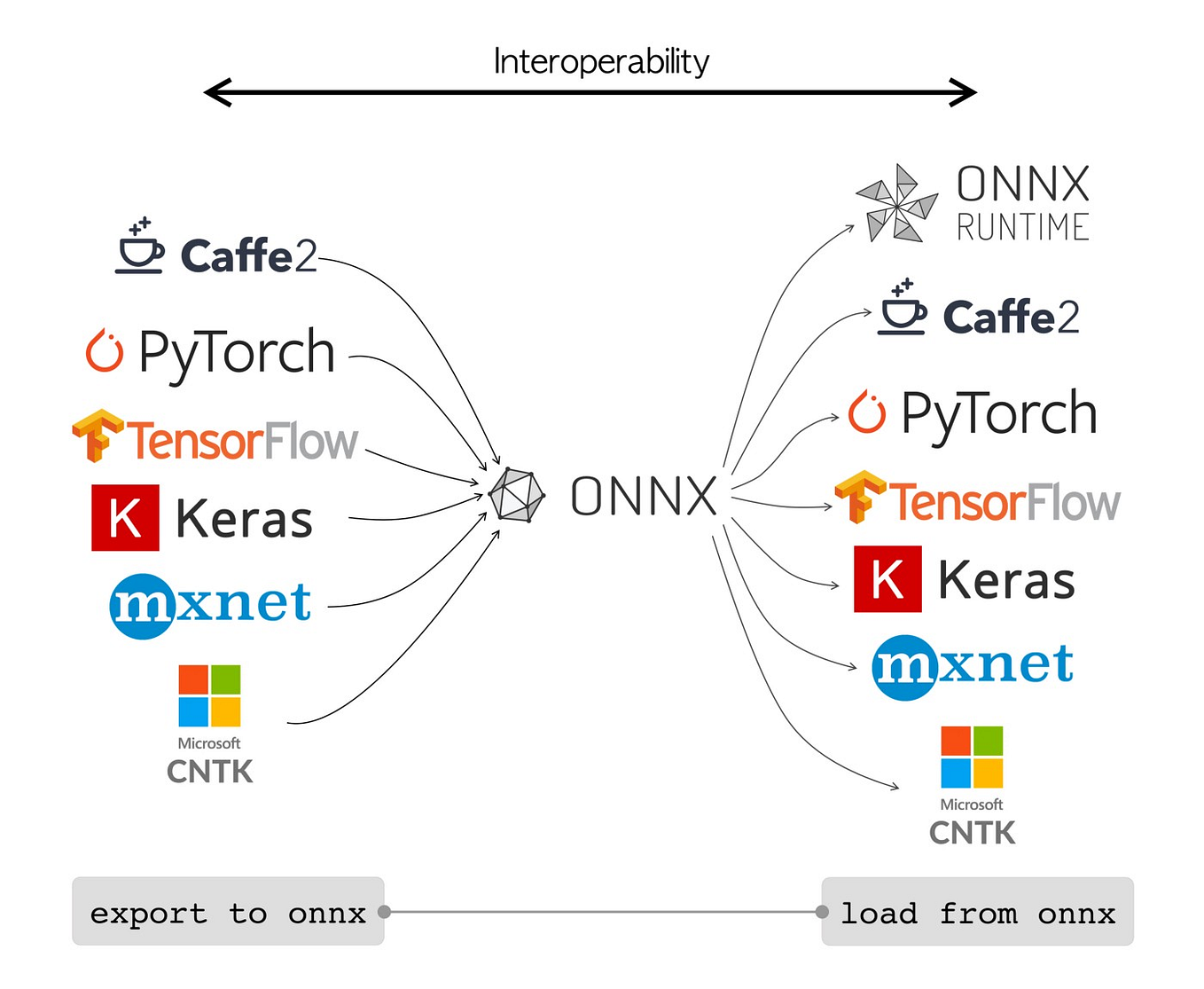


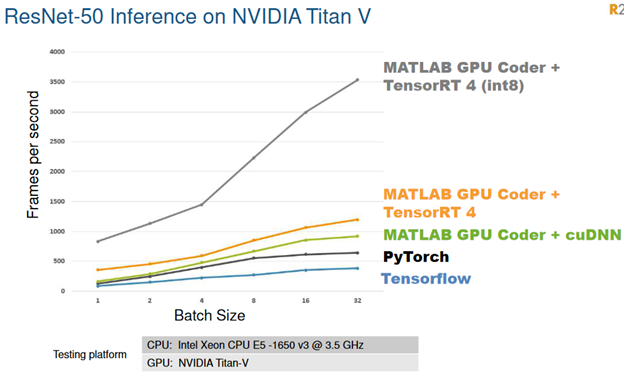












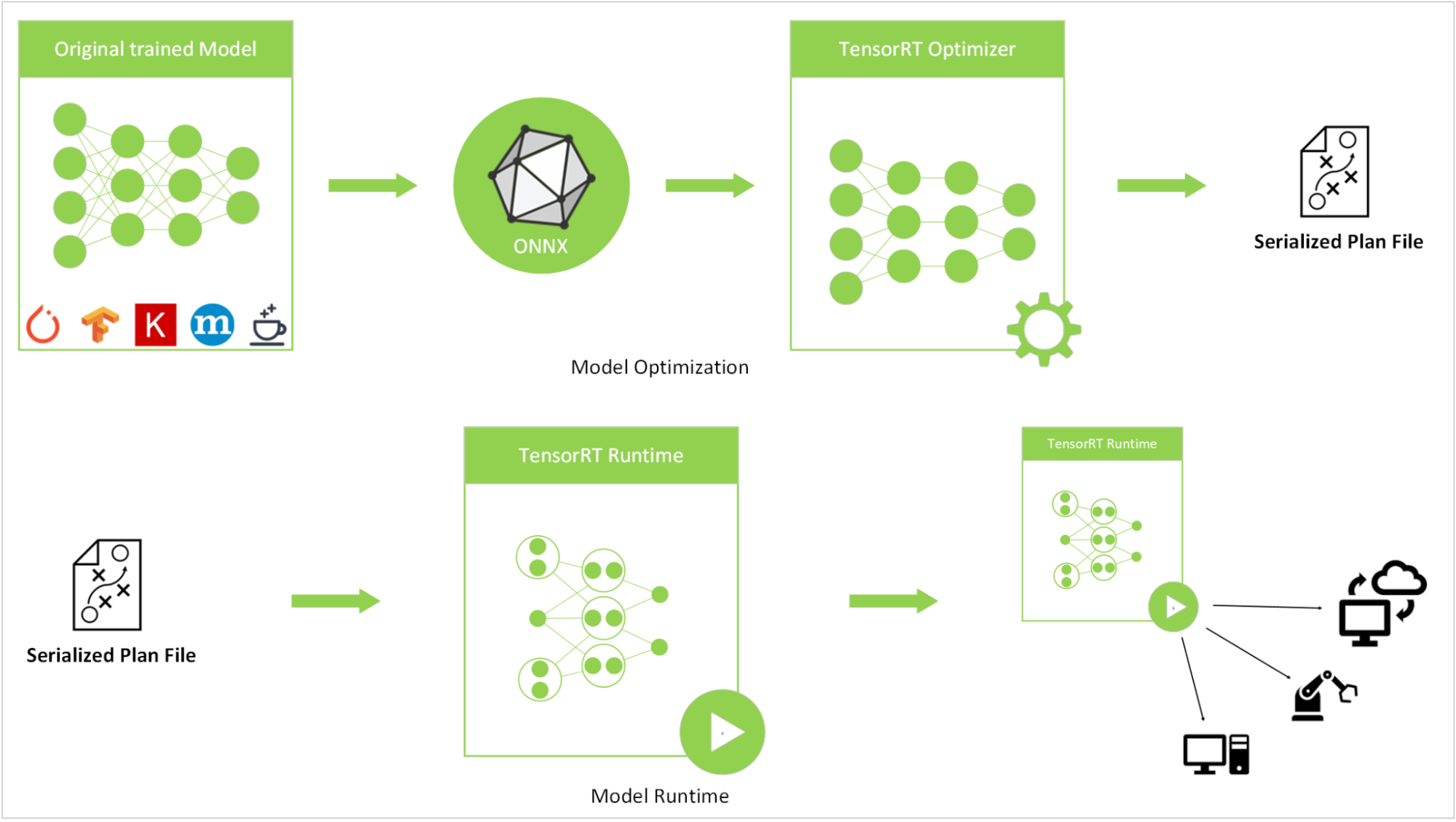

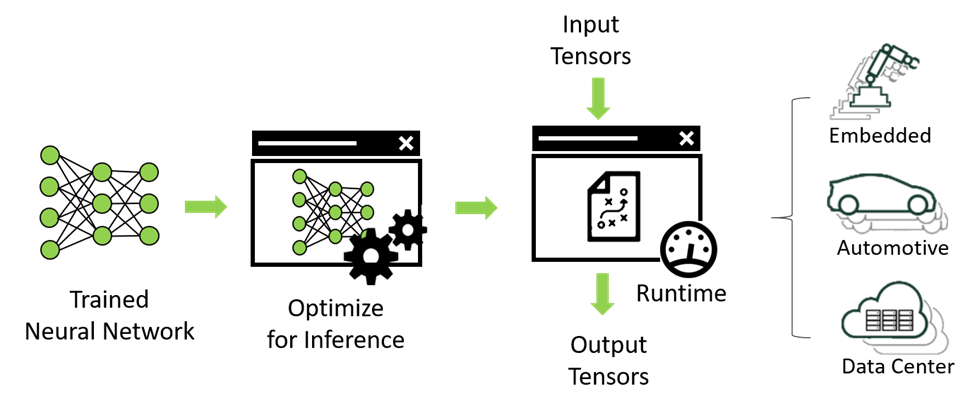

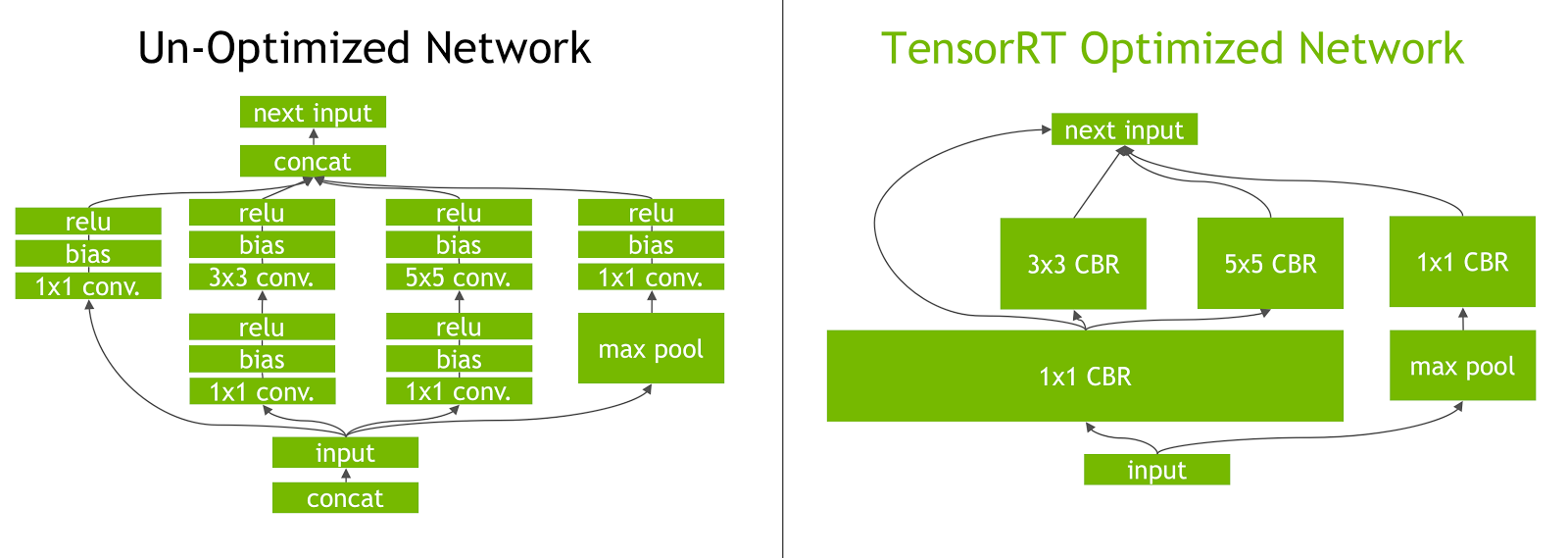
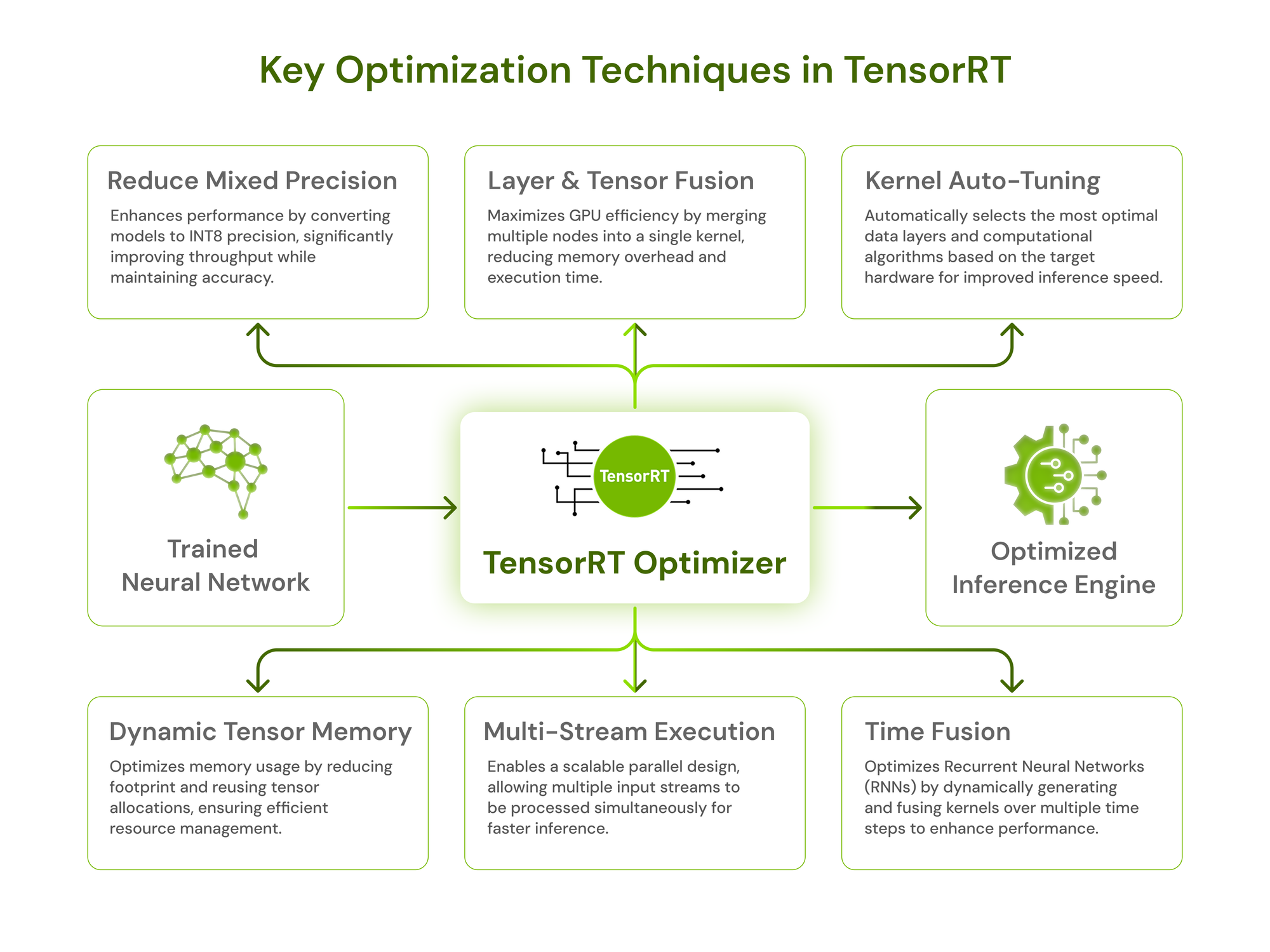


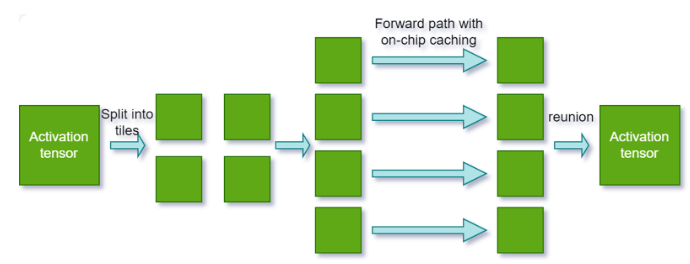
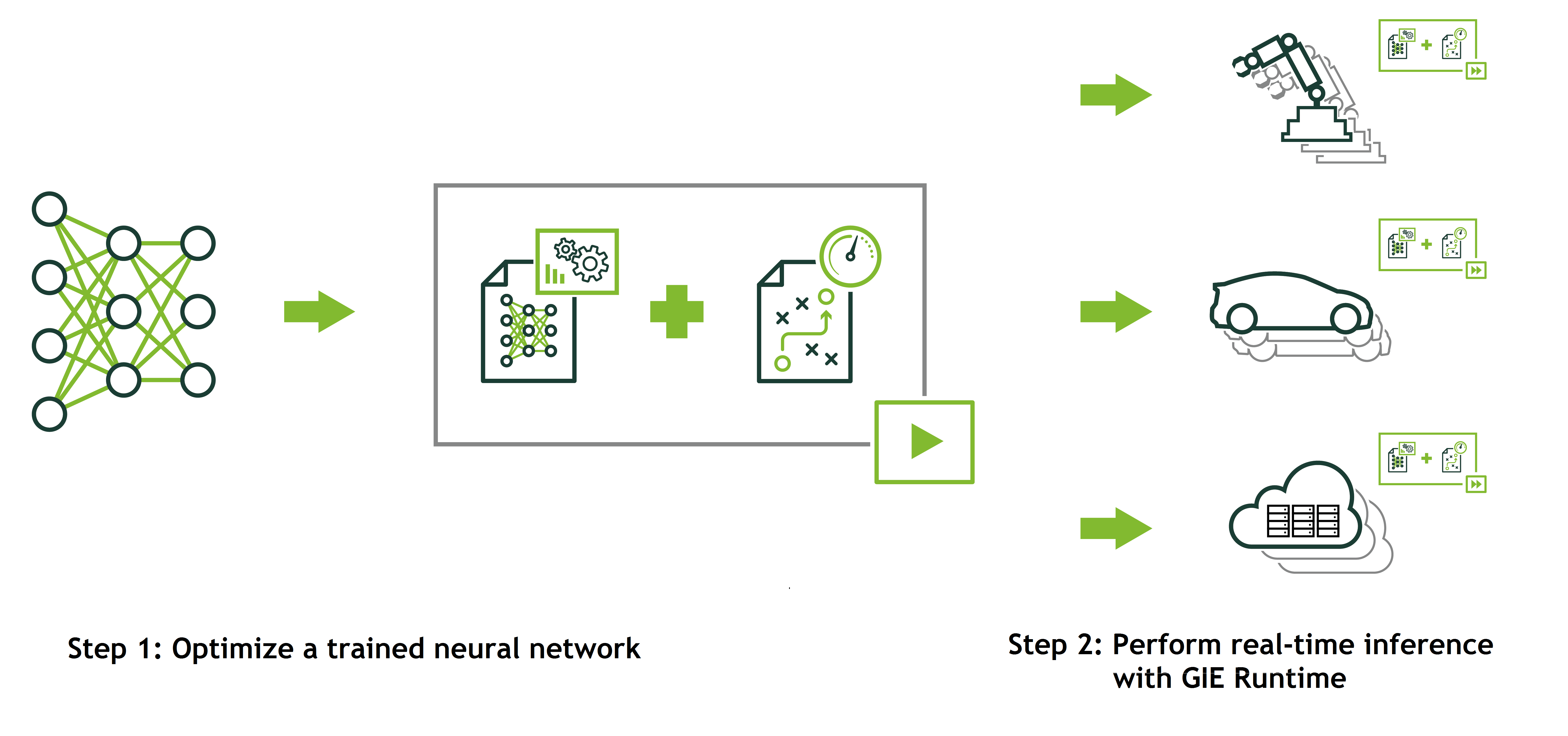


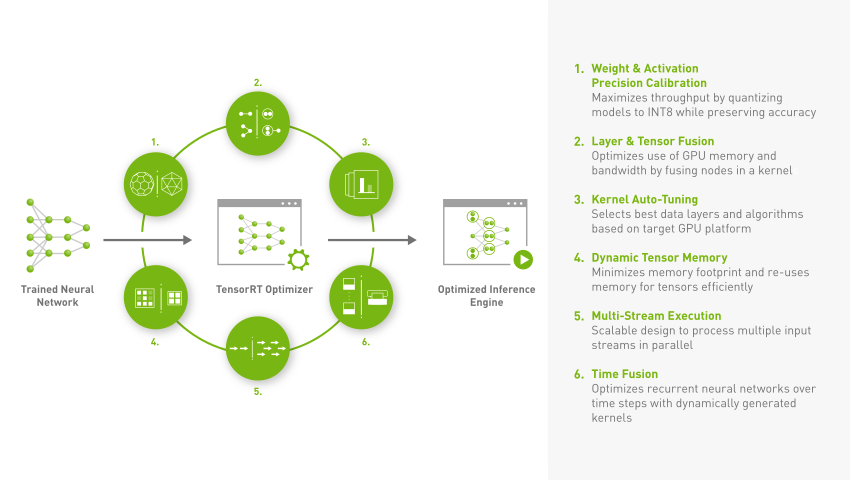
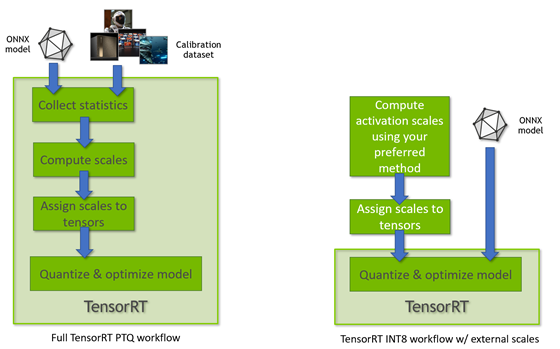
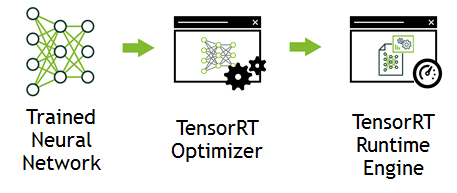
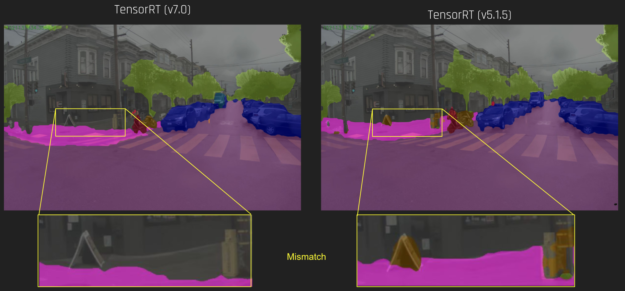
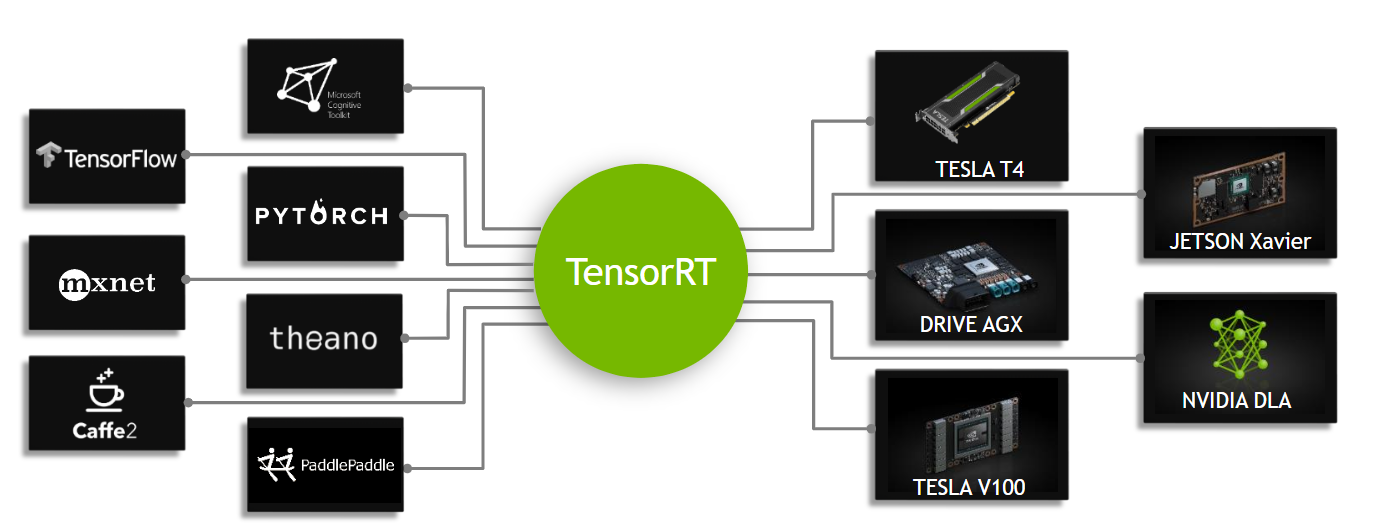
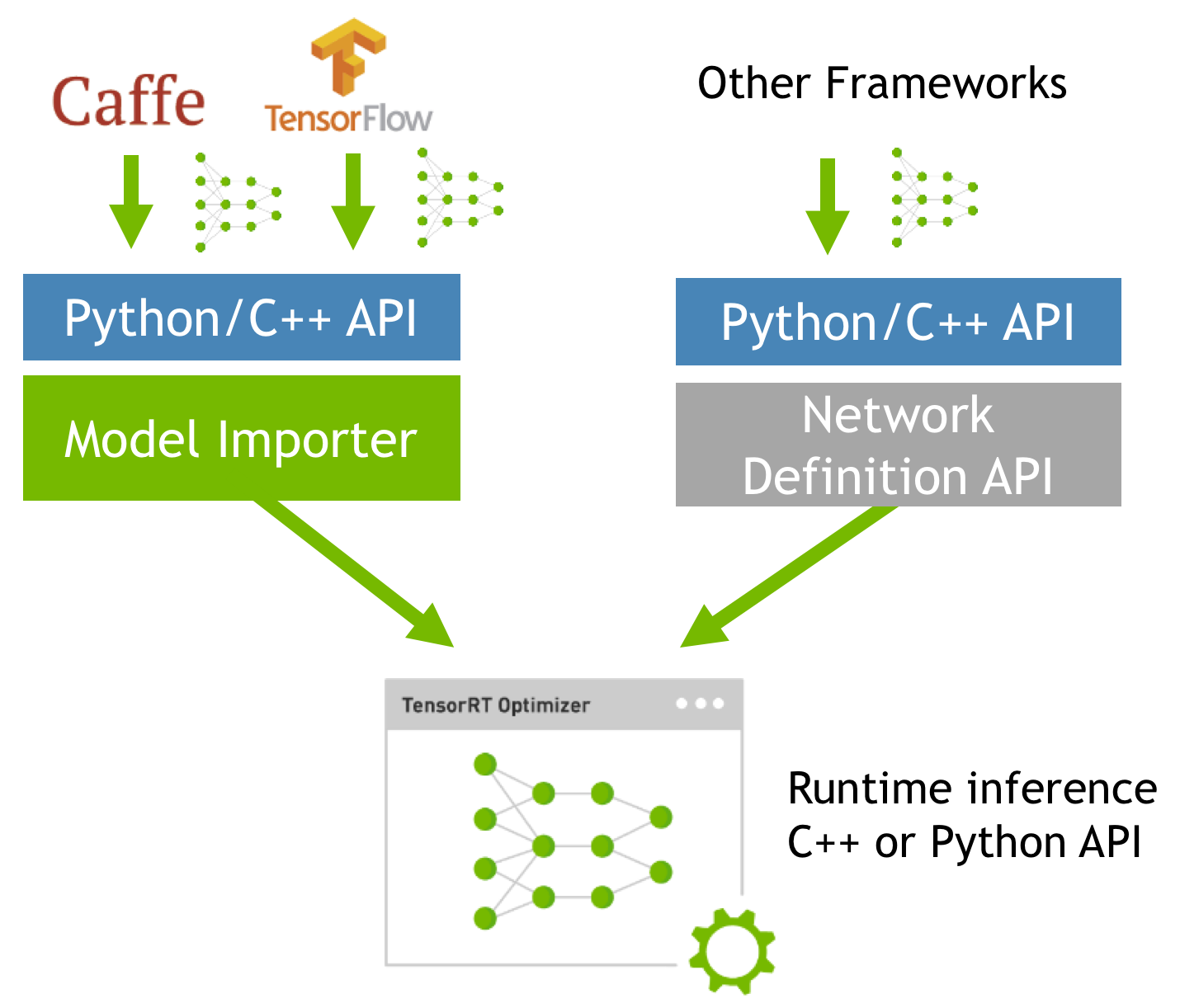






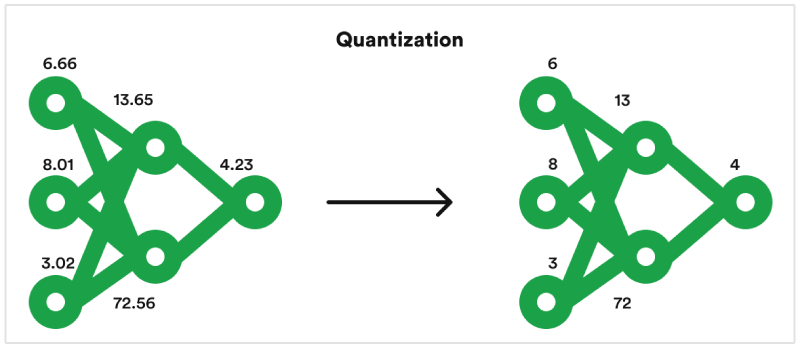

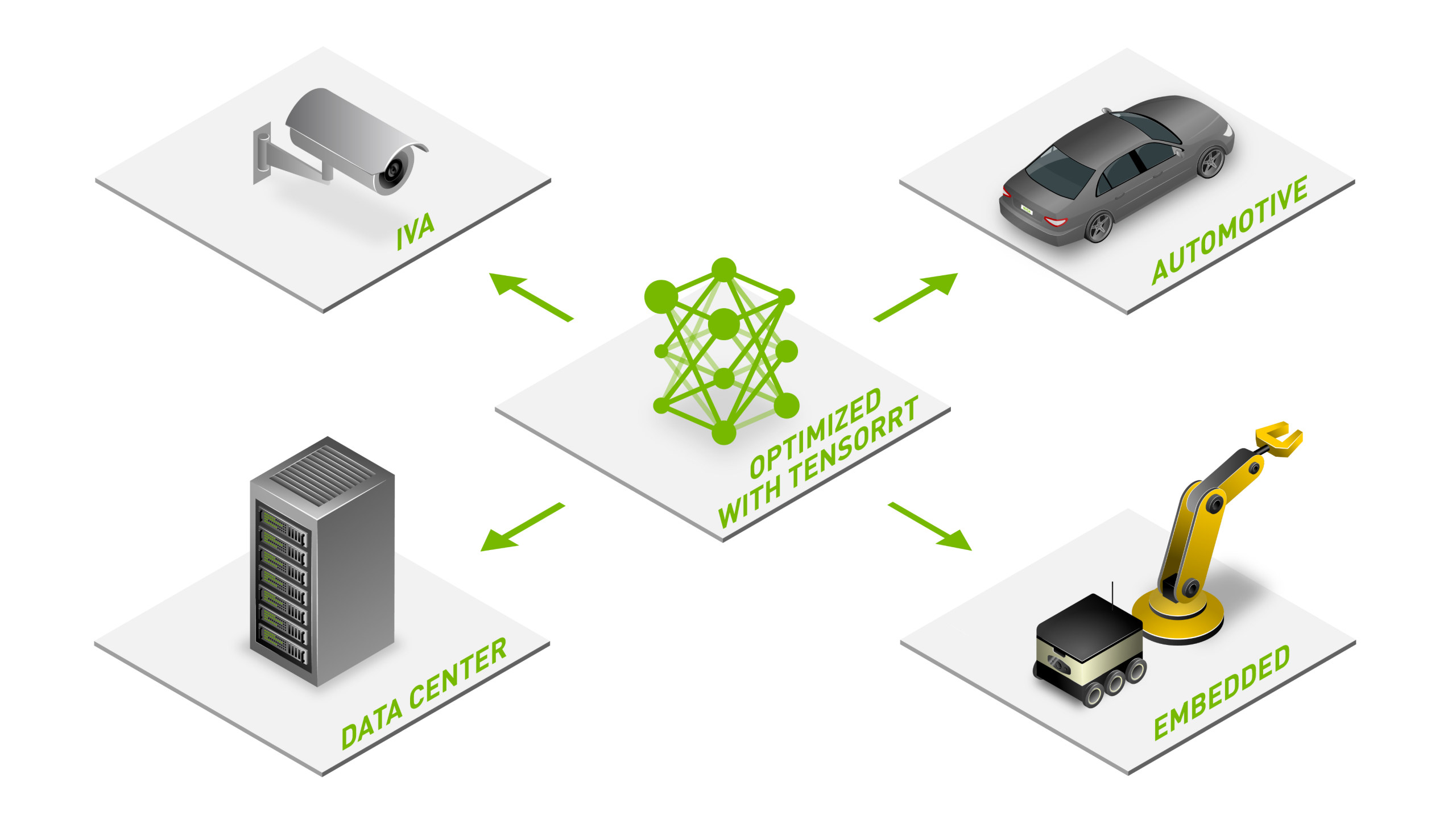





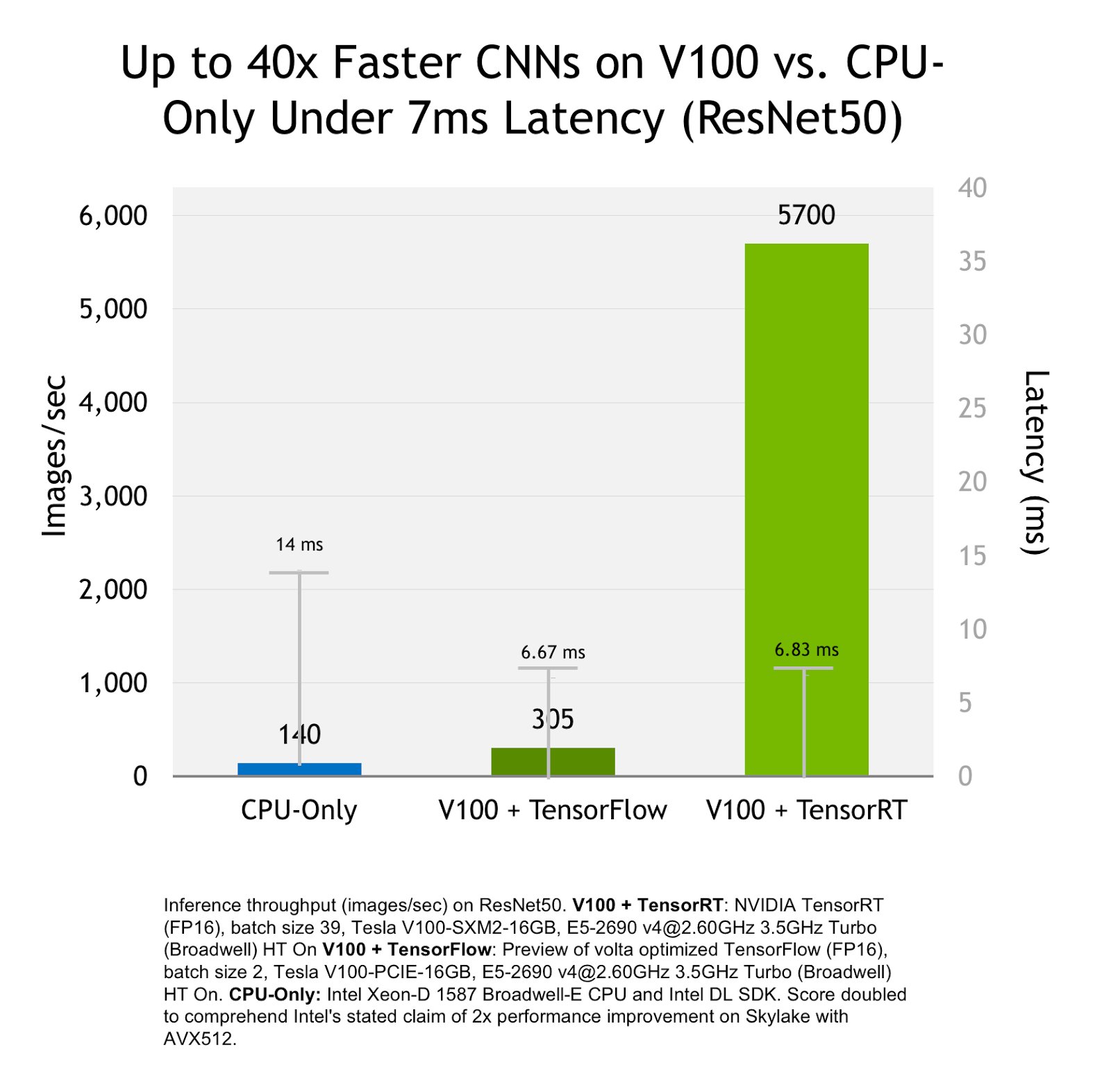

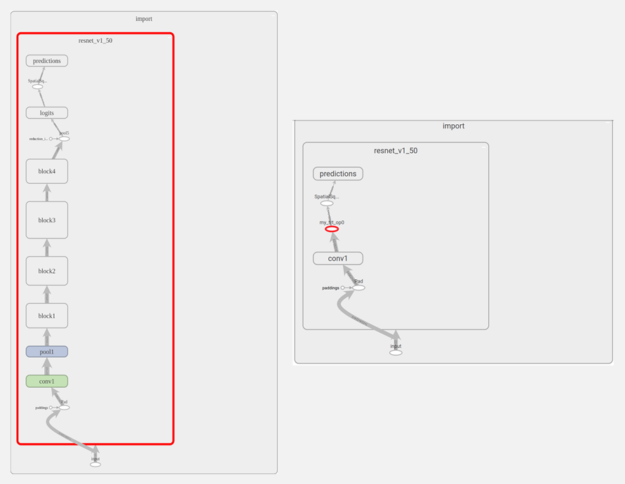































{kind=link}