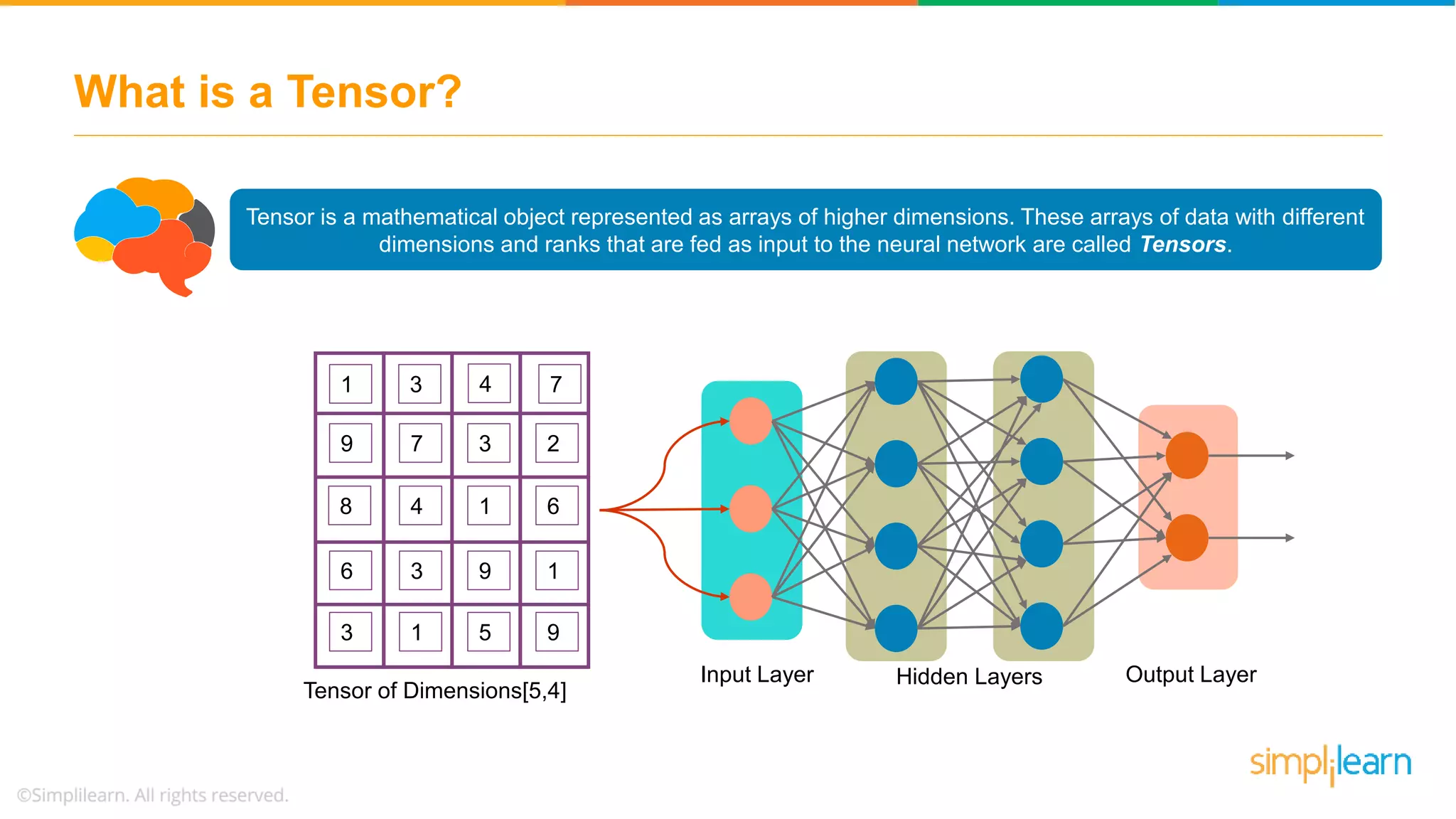
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
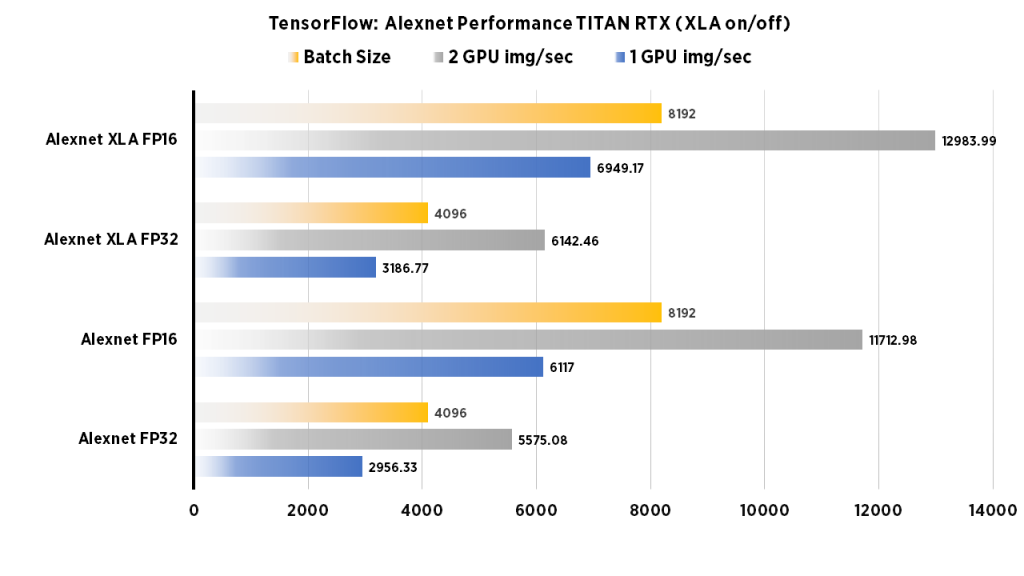
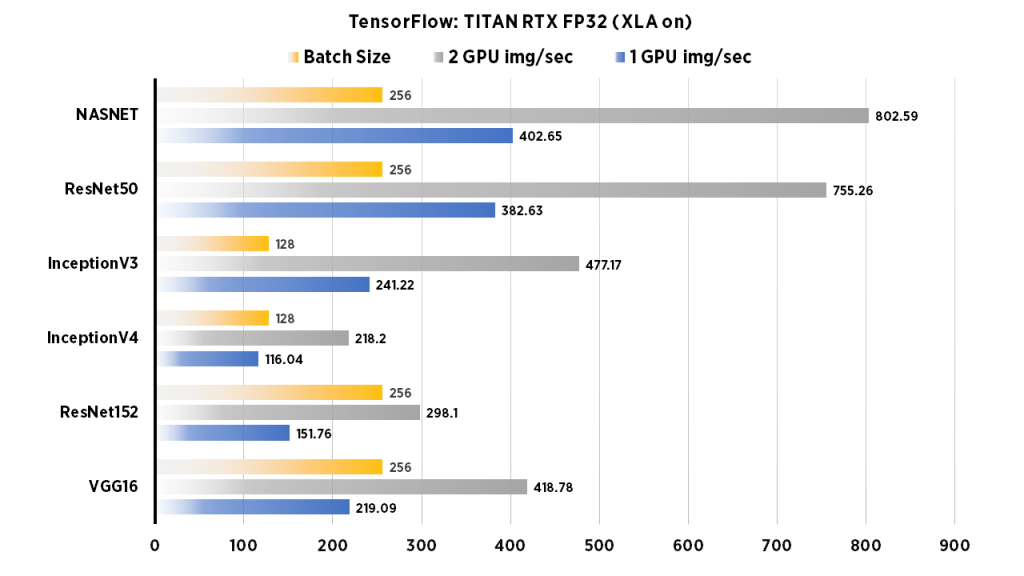
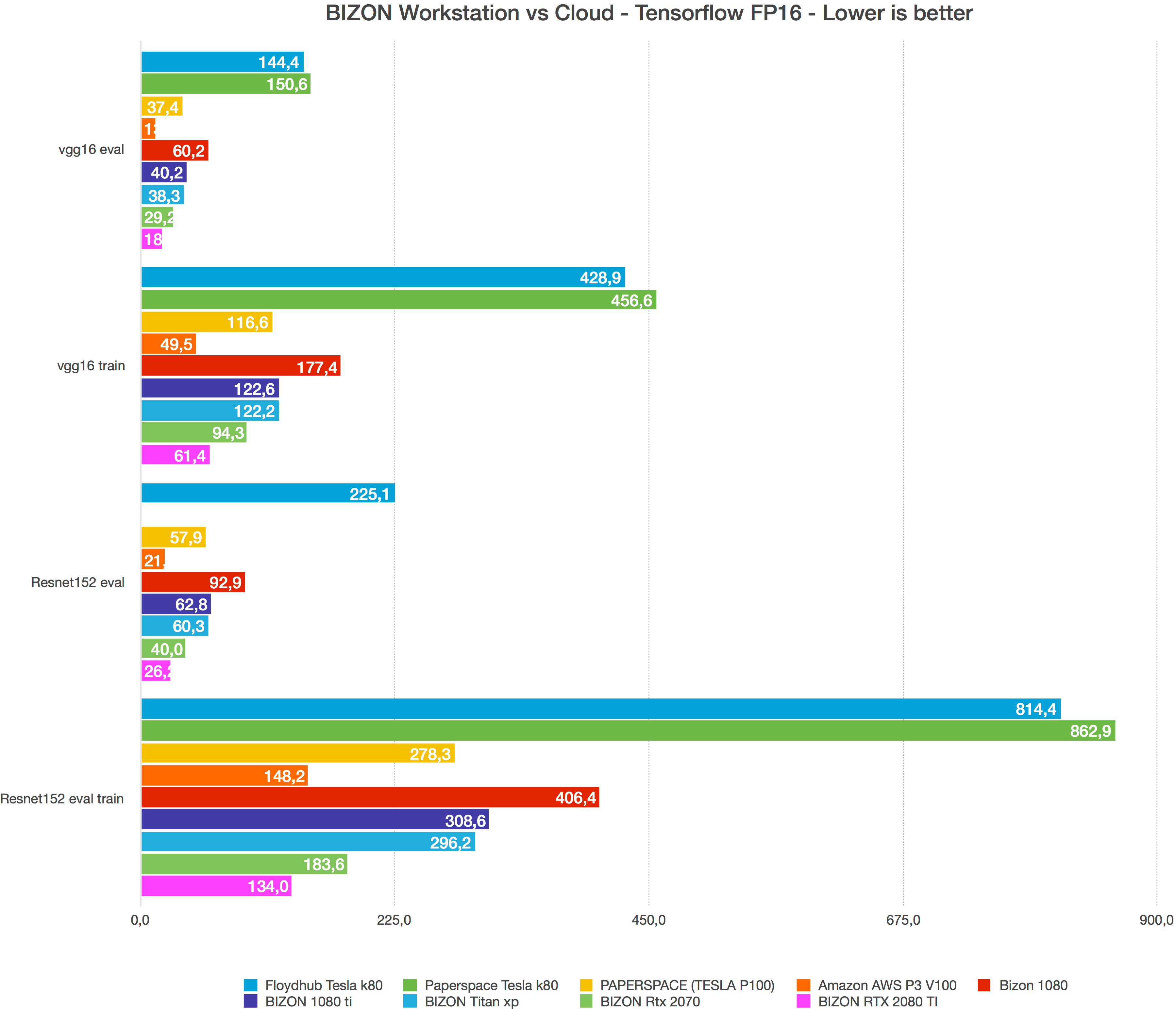
TITAN RTX Benchmarks for Deep Learning in TensorFlow 2019: XLA, FP16 ...
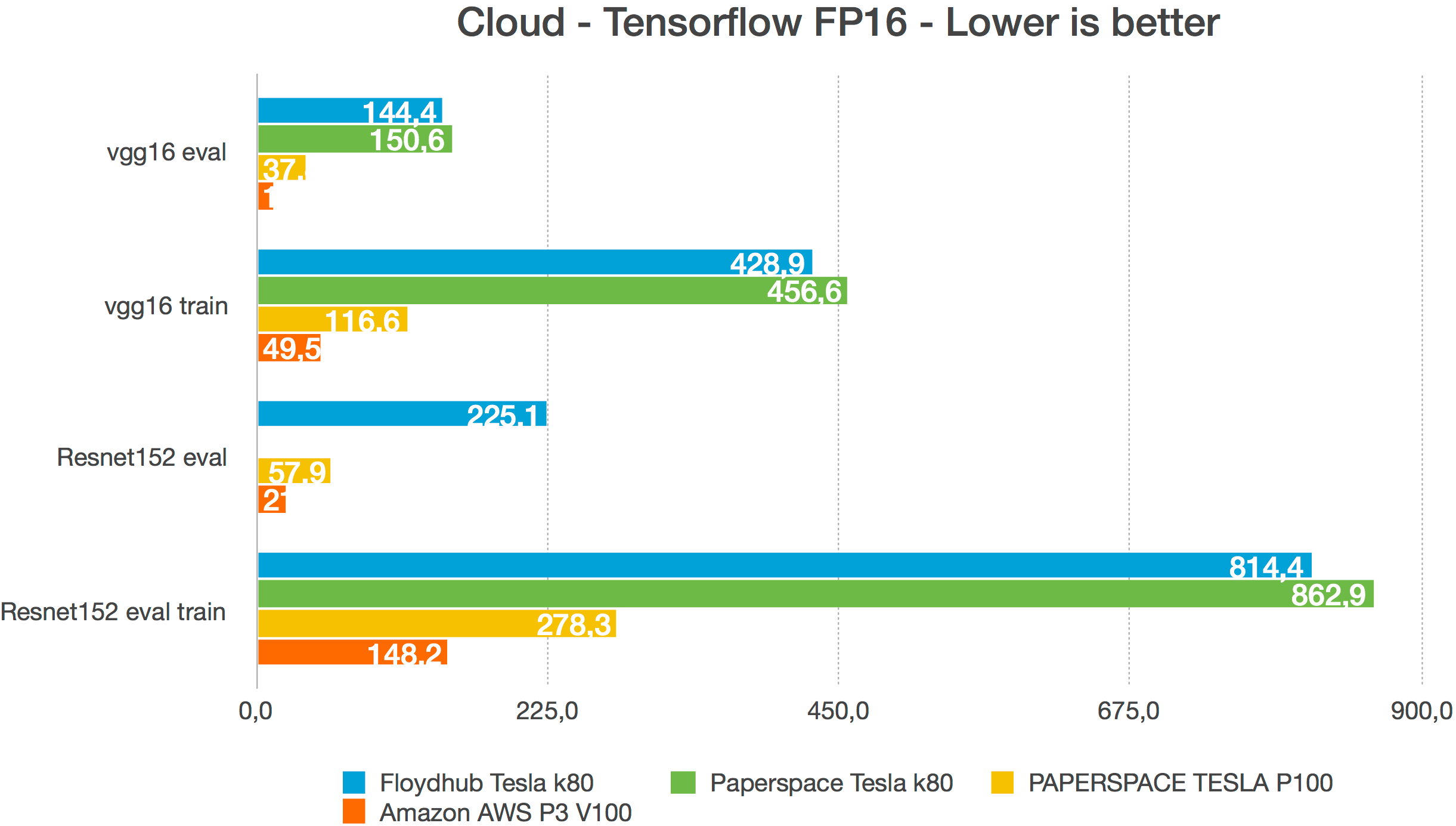
Tensorflow automatic mixed precision fp16 slower than fp32 on official ...
[Tensorflow] Tensorflow Run Time - FP32 + FP16 + INT8 - YouTube
TensorFlow Lite's New FP16 Half-Precision Assist Sees Inference ...
tensorflow - No speed up with TensorRT FP16 or INT8 on NVIDIA V100 ...
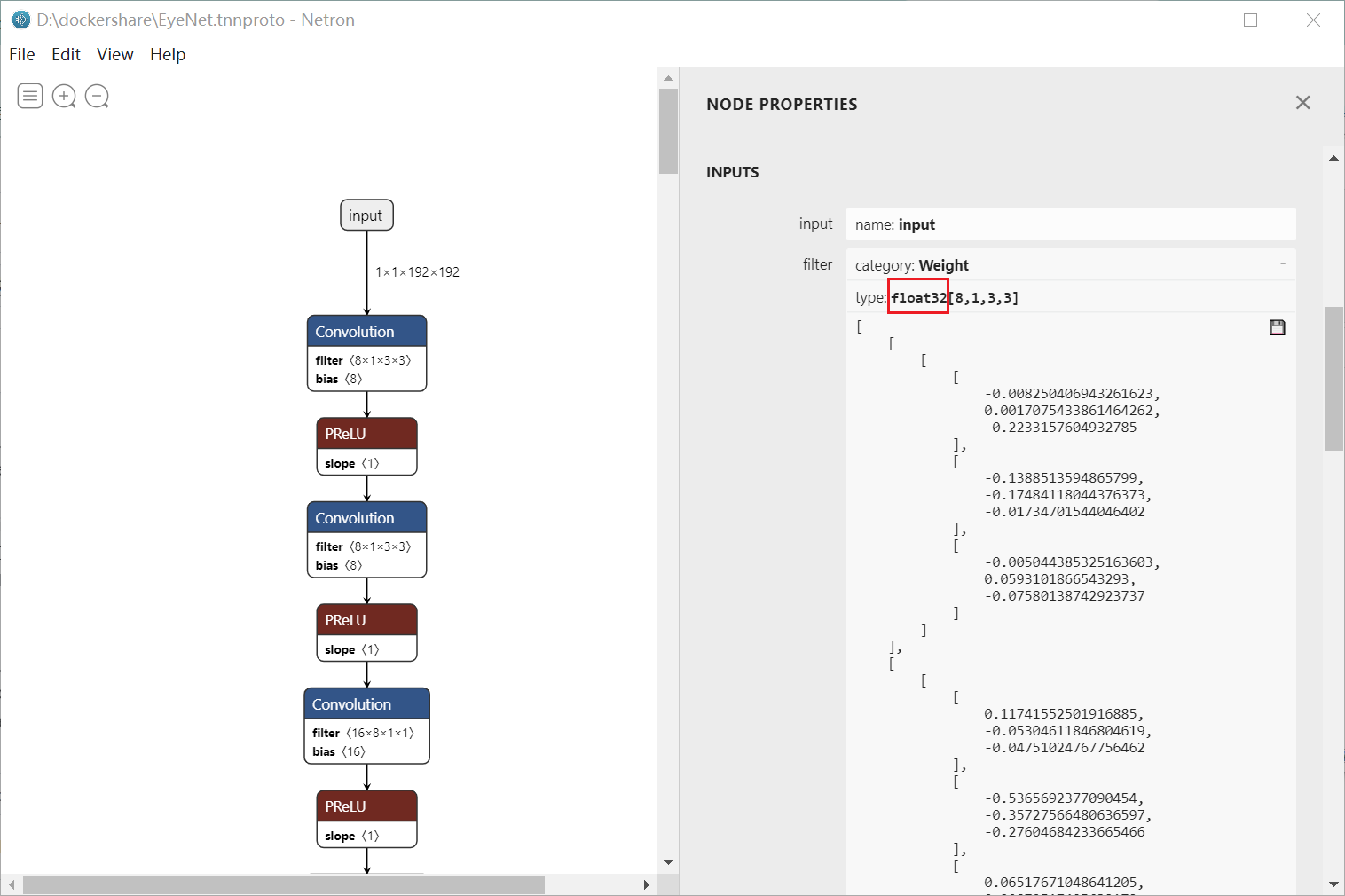
The conversion of Tensorflow model to FP16 model was problematic in GPU ...
The performance of fp16 is quite bad. · Issue #5592 · tensorflow ...
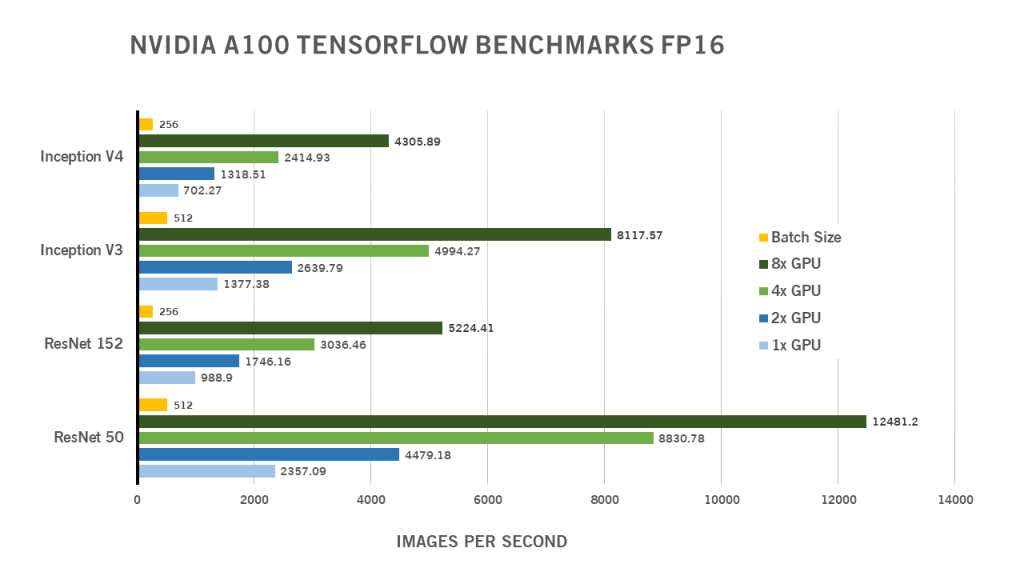
Accelerating TensorFlow on NVIDIA A100 GPUs | NVIDIA Technical Blog
tensorflow fp16训练
NVIDIA A100 Deep Learning Benchmarks for TensorFlow | Exxact Blog
Quantization Aware Training. Или как правильно использовать fp16 ...
Object detection C++ FP16 inference · Issue #147 · tensorflow/tensorrt ...
TensorFlow Model Optimization Toolkit — float16 quantization halves ...
GroupNorm + FP16 instability · Issue #2550 · tensorflow/addons · GitHub
fp16 support in the Object Detection API [Feature request] · Issue ...
How to save fp16 model in mixed precision training?(official resnet ...
Performance regression for FP16 Relu kernel from TF2.6 to TF2.7 · Issue ...
Converted fp16 or int8 model require up to 10 minutes to startup ...
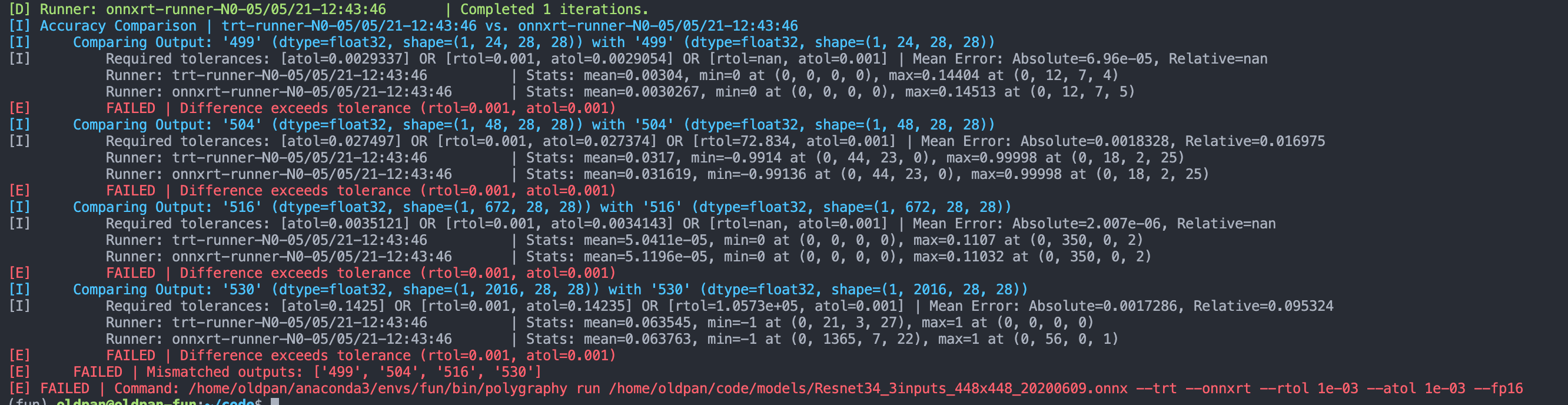
No Speedup or Size Savings After FP16 / INT8 with TensorRT · Issue ...
EleutherAI/gpt-j-6b · ValueError: Attempting to unscale FP16 gradients.
FP16 slower than FP32 · Issue #15585 · tensorflow/tensorflow · GitHub
Missing fp16 ops when converting from TF to TFLite · Issue #59288 ...
tflite quantization to fp16 only quantized input · Issue #55785 ...
What's new in TensorFlow 2.16 — The TensorFlow Blog
Multi-GPU training with gradient propagation in FP16 with XLA fails ...
Support for half-floats (float16/fp16) · Issue #1300 · tensorflow ...
Roberta fp16 got wrong inference results · Issue #2466 · NVIDIA ...
TensorRT Inferencing using TF-TRT framework FP32 vs FP16 - Jetson AGX ...
Is it possible to convert a FP16 checkpoints to be compatible with FP32 ...
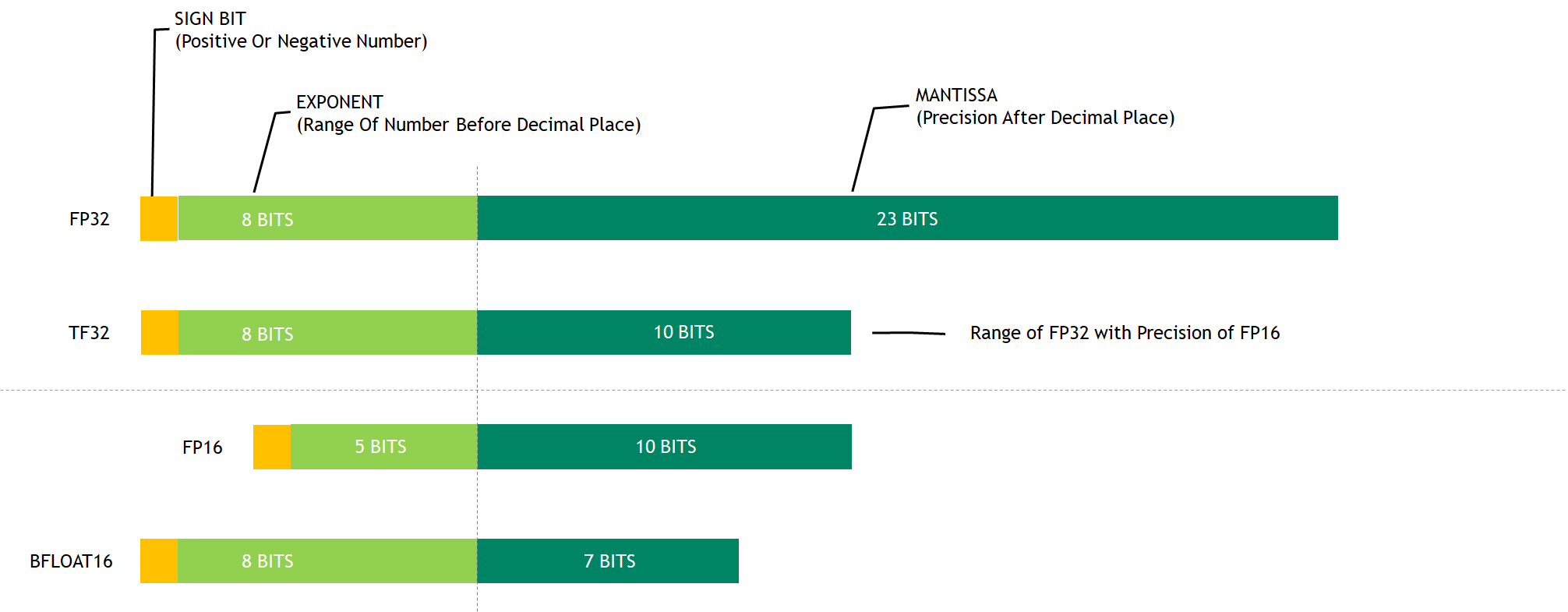
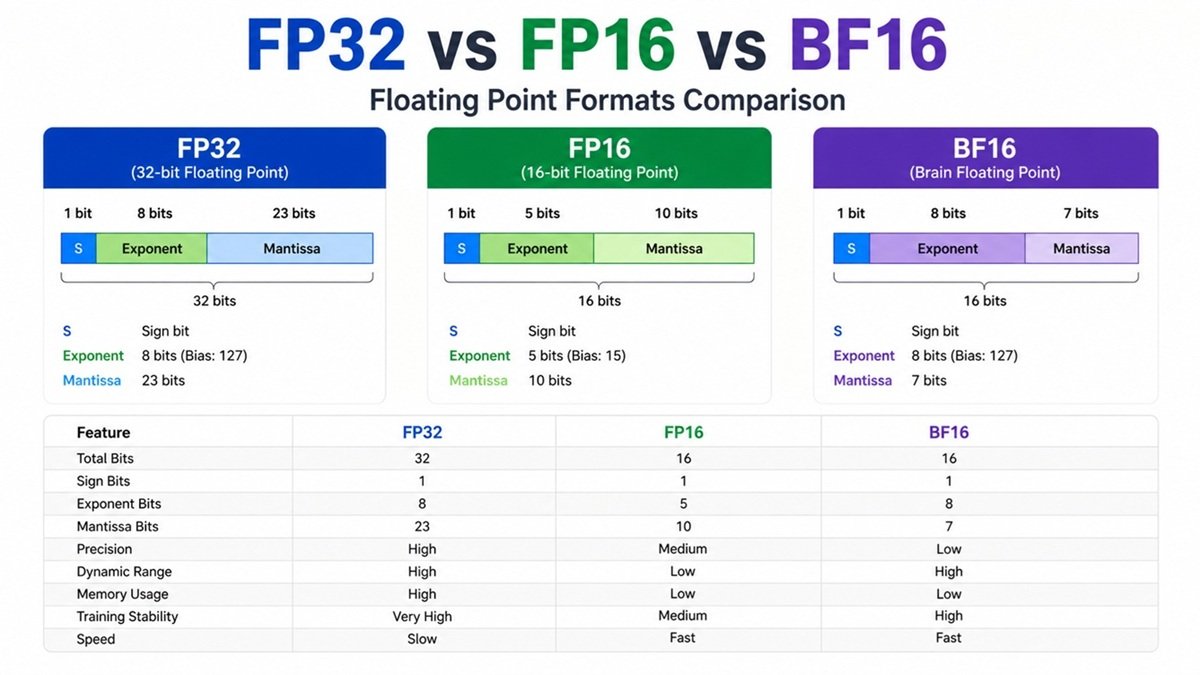
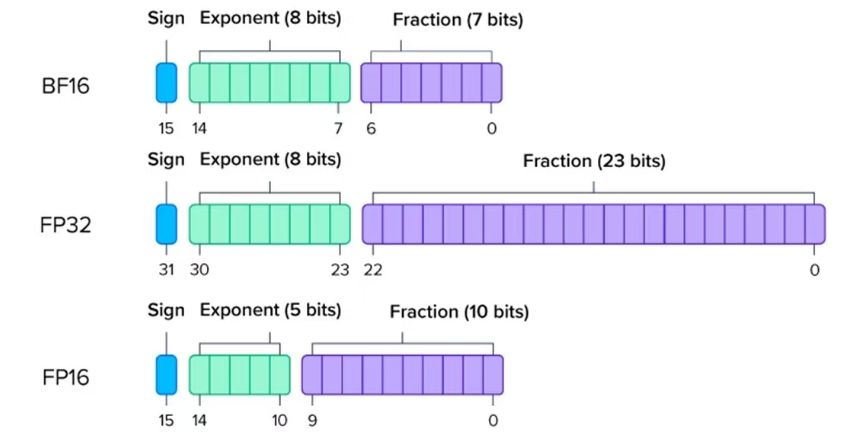
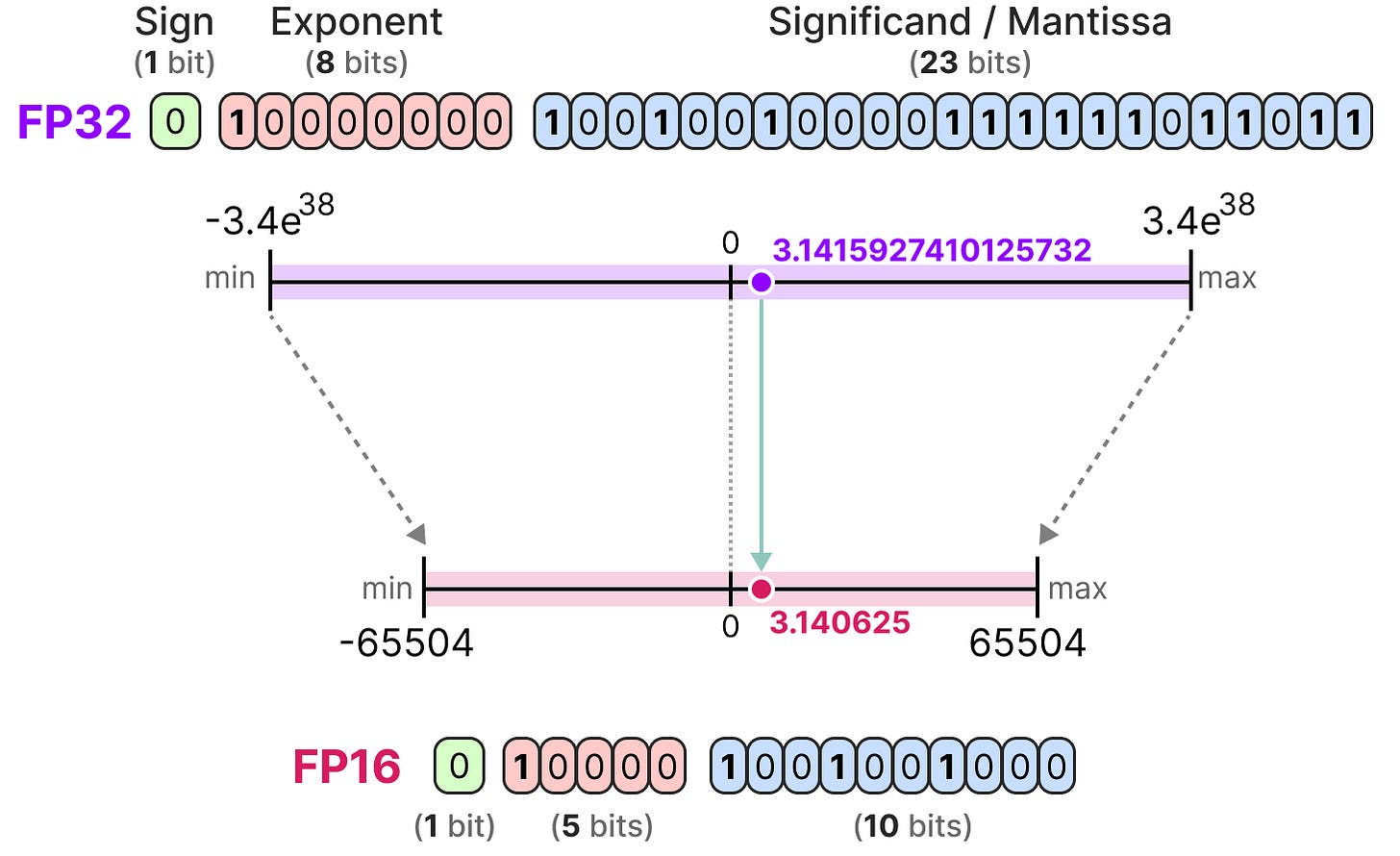
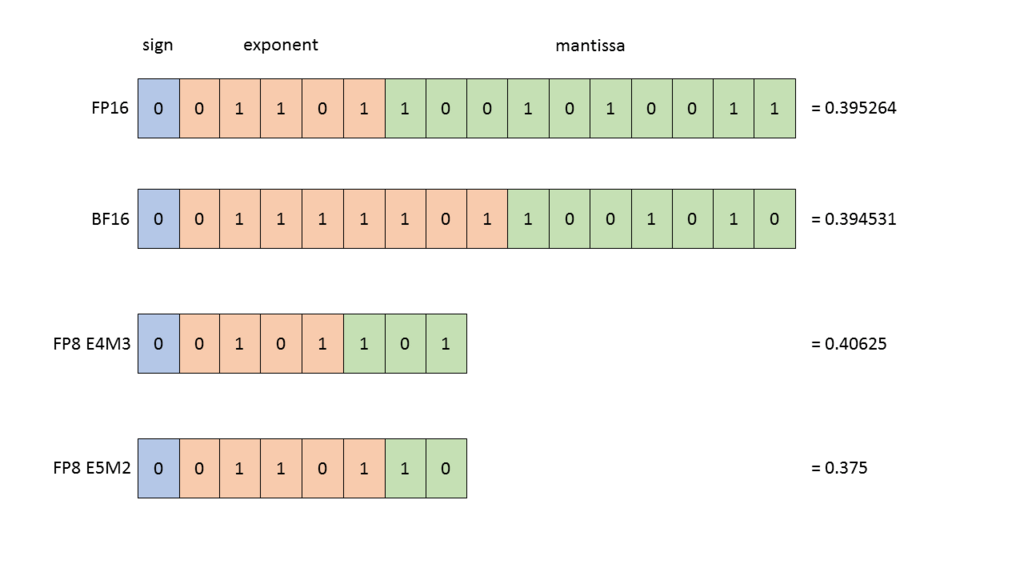
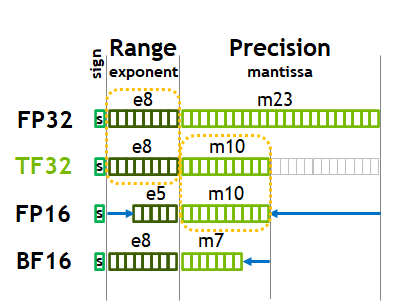
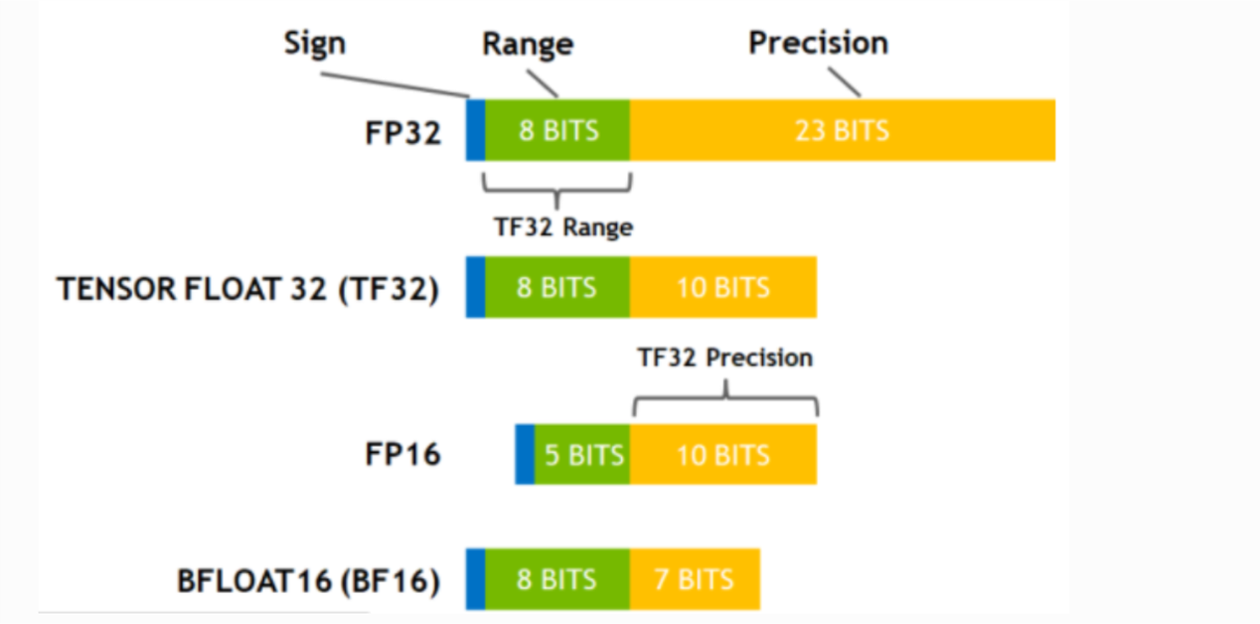
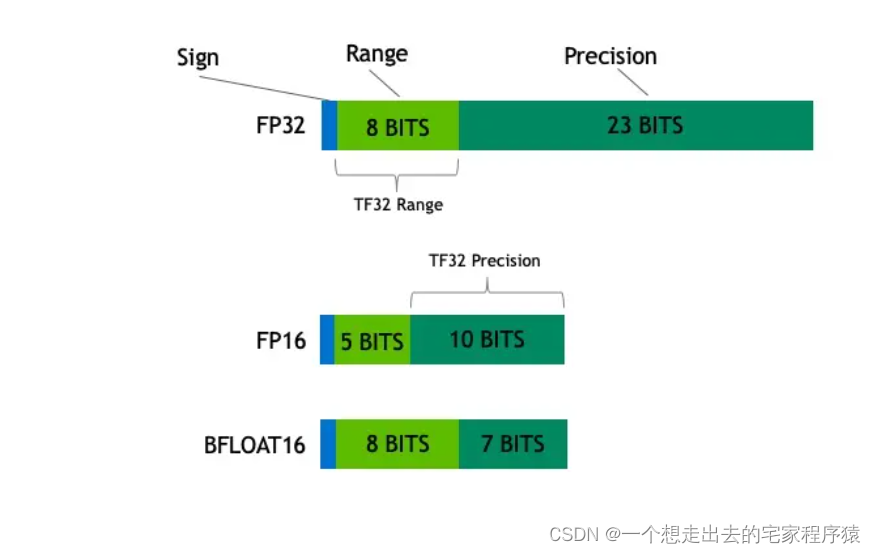
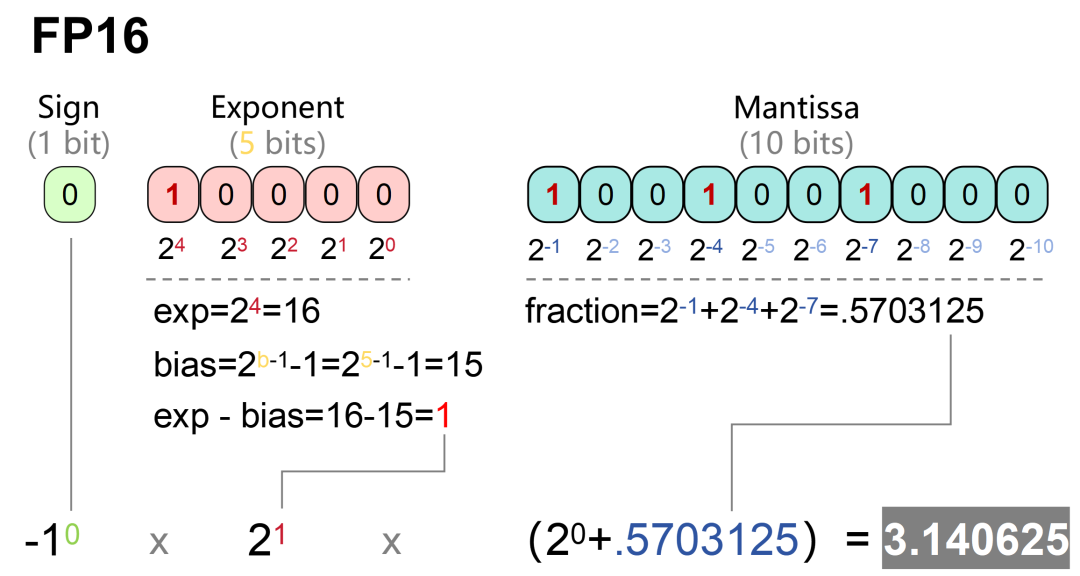
FP32 vs FP16 vs BF16: Complete Guide for AI, Deep Learning, and Modern ...
BF16 与 FP16 在模型上哪个精度更高呢【bf16更适合深度学习计算,精度更高】-CSDN博客
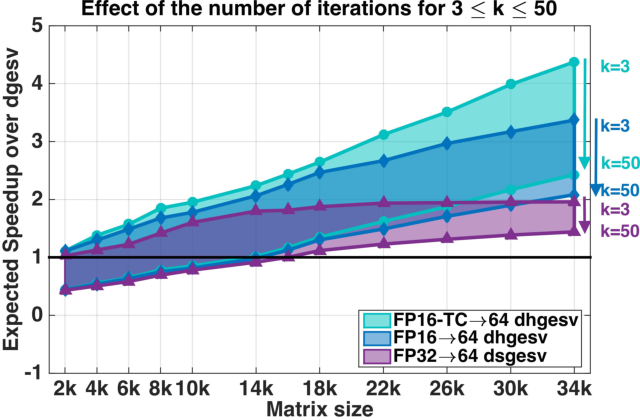
Figure 4 from Harnessing GPU Tensor Cores for Fast FP16 Arithmetic to ...
TensorFlow Tutorial | Deep Learning With TensorFlow | TensorFlow ...
Quantization FP16 model using pytorch_quantization and TensorRT · Issue ...
google/flan-t5-xxl · Only BF16 Work. FP16 and 8INT generate non-sense ...
Guide to FP8 & FP16: Accelerating AI - Convert FP16 to FP8?
Data Types Explained: FP32 vs FP16 vs BF16 in Deep Learning - YouTube
How to improve the accuracy of FP16 model ? · Issue #4168 · NVIDIA ...
Precision Comparison: FP64 FP32 FP16 TF32 BF16 INT8
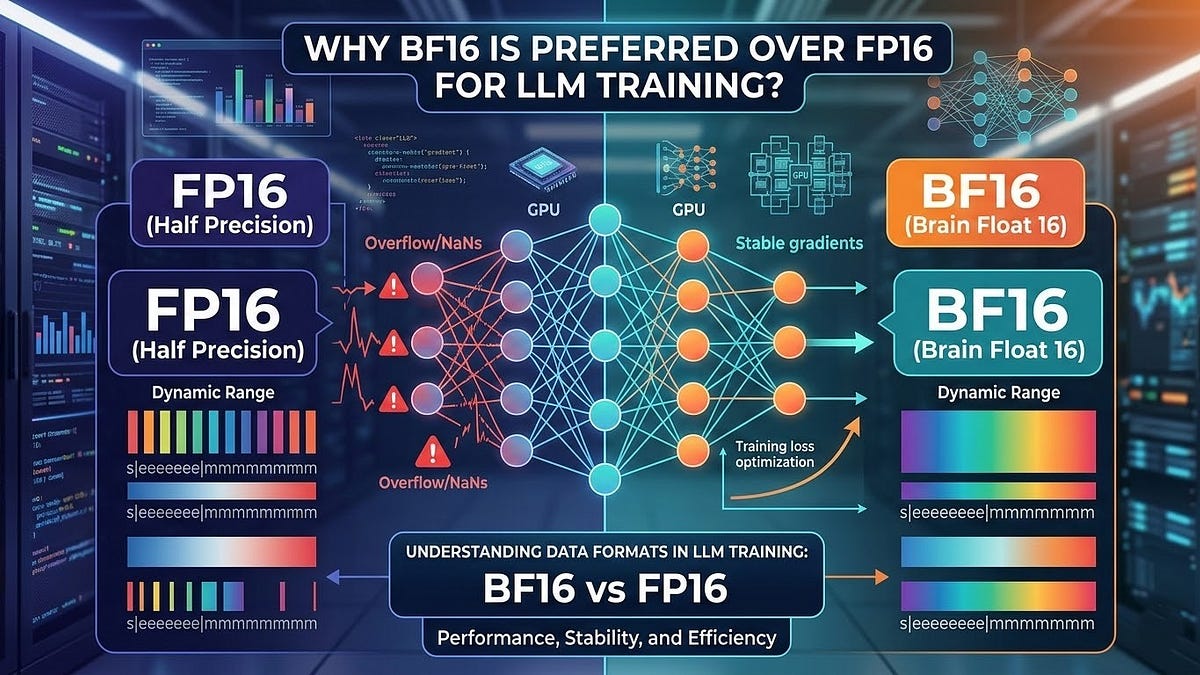
Why BF16 is preferred over FP16 for LLM Training?
Simple FP16 and FP8 training with unit scaling
无法转成fp16格式/ fail to convert the model to fp16 format · Issue #1809 ...
RTX 3090 vs RTX 4090 for AI: Performance, FP16 Throughput & Upgrade ...
FP16 on embedded Jetson TX1
Tag: FP16 | NVIDIA Technical Blog
How to use FP16 precision in C++ · Issue #1754 · NVIDIA/TensorRT · GitHub
Running a fully FP16 precision engine from a FP32 ONNX model in ...
How to convert the output tensor from FP16 to FP32 w/ ov 2.0 C++ API ...
"Fp16 precision has been set for a layer or layer output, but fp16 is ...
No speed improvement between FP16 and INT8 TensorRT models · Issue ...
A Basic Introduction to Tensorflow | 2024
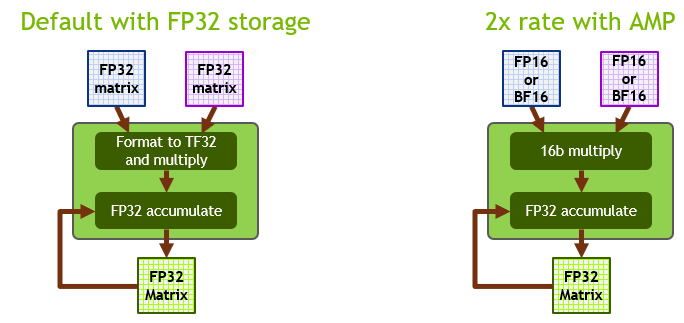
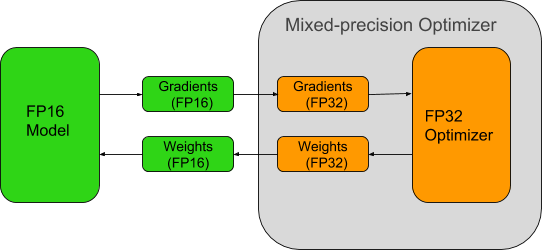
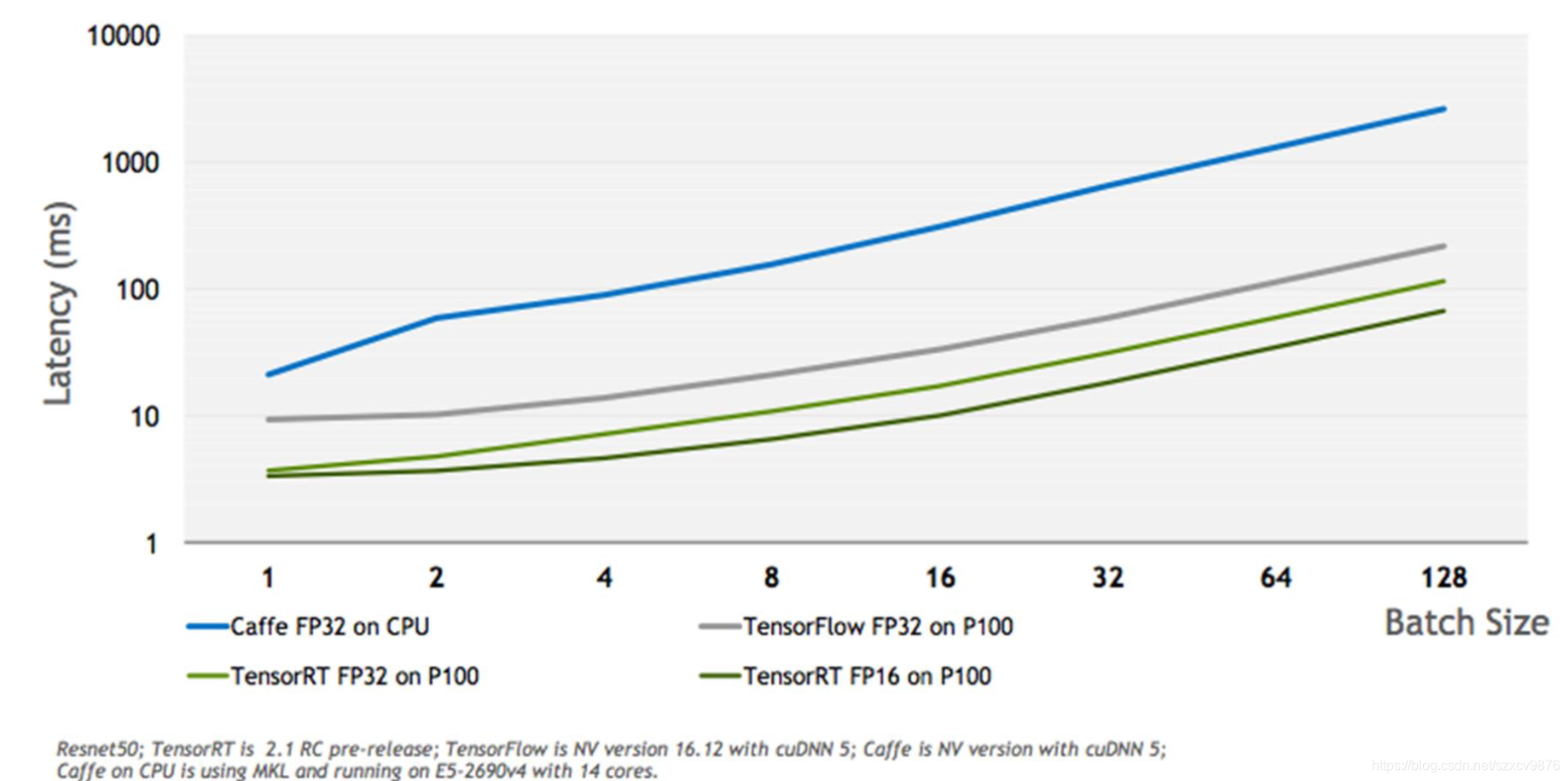
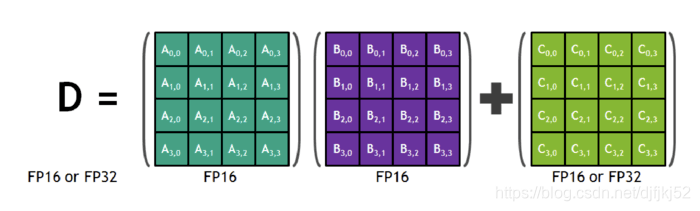
Automatic Mixed Precision for NVIDIA Tensor Core Architecture in ...
【腾讯二面】高频考点:BF16和FP16的区别,深度解析助你通关!_fp16和bf16-CSDN博客
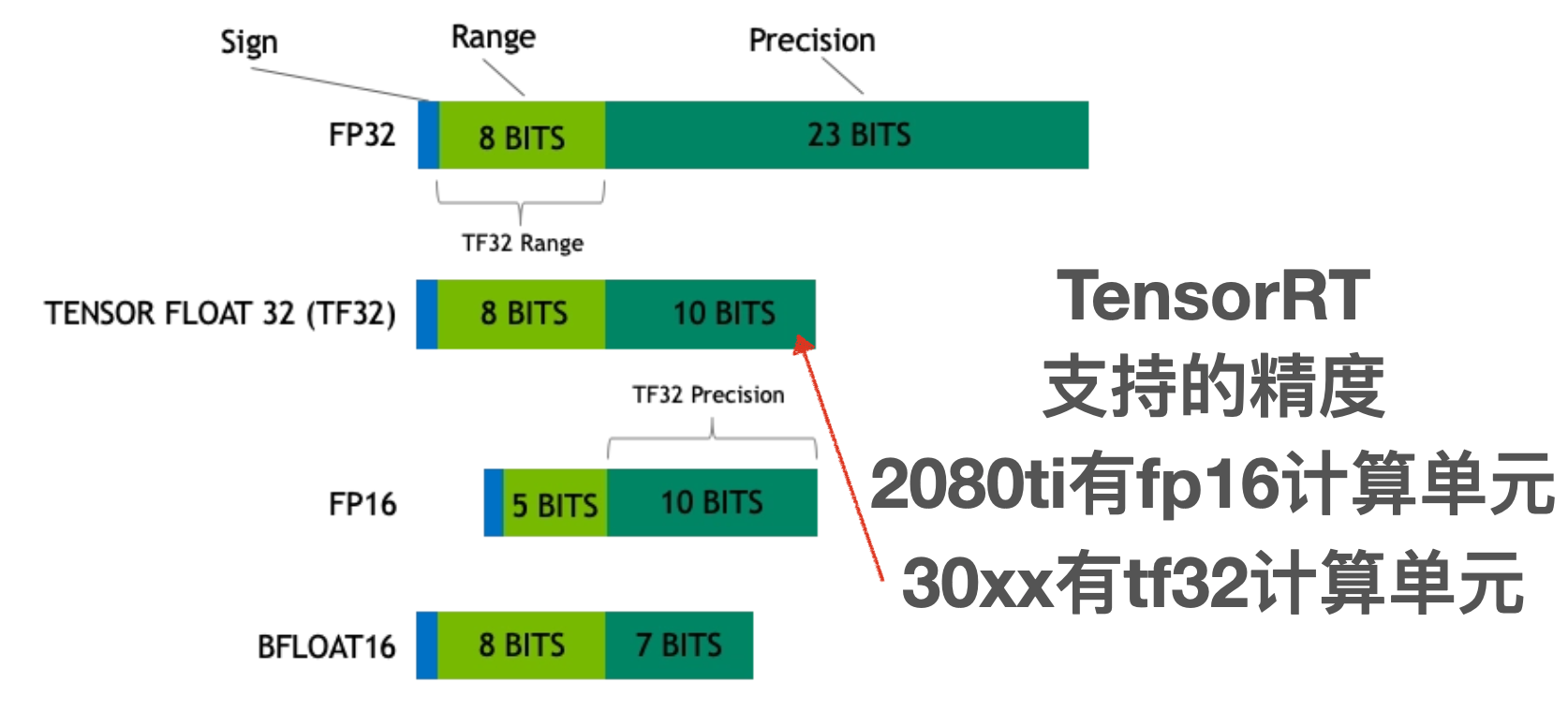
TensorRT模型转换及部署,FP32/FP16/INT8精度区分_tensorrt engine in fp16-CSDN博客
NVIDIA Hopper 深入研究架构 - NVIDIA 技术博客
Blog - Prebuilt vs Building your own Deep Learning Machine vs GPU Cloud ...
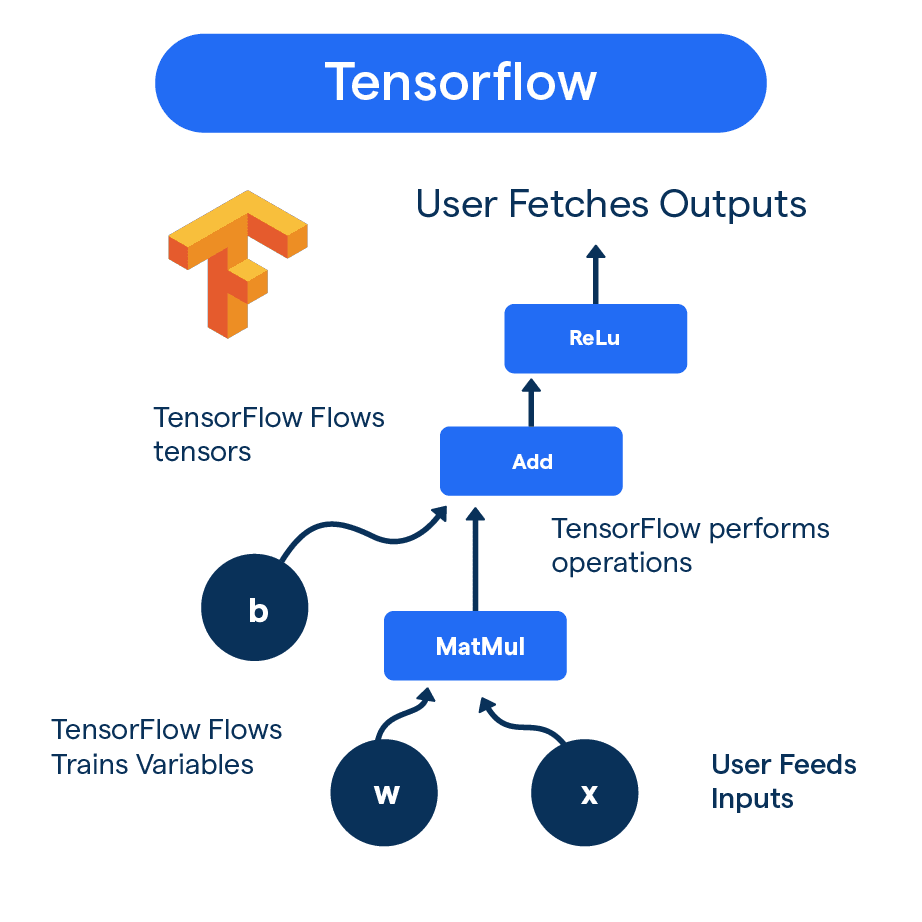
TensorFlow: What is it and How Does it Work?
Hardware Recommendations for AI Development | Puget Systems
TensorFlow-v2.9指南:混合精度训练加速FP16实战配置-CSDN博客
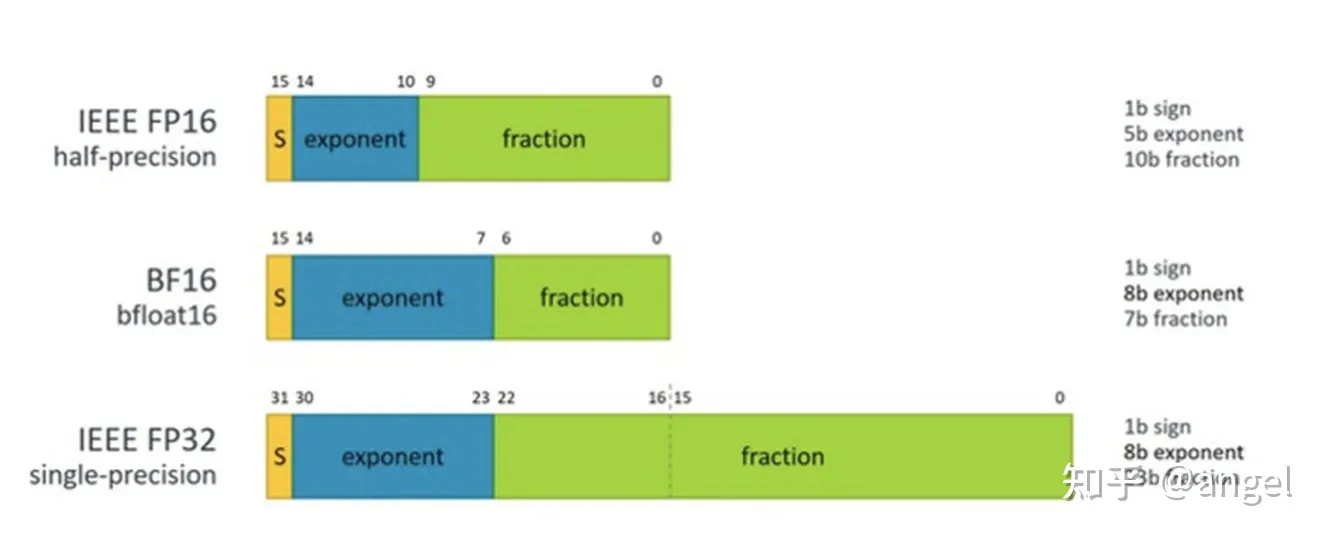
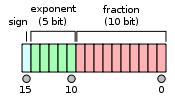
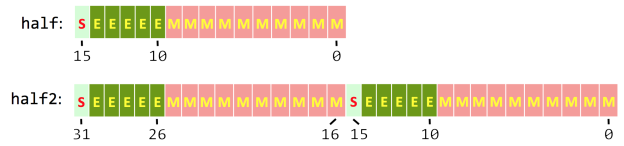
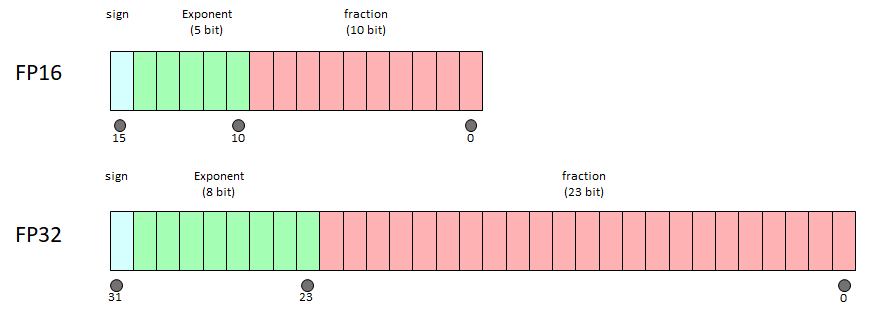
FP16、FP32 及全系列浮点格式全解析:从半精度到四倍精度-CSDN博客
Getting started with TensorFlow: A Machine Learning tutorial | Tiny ...
小白必看:v1-5-pruned-emaonly-fp16.safetensors入门指南-CSDN博客
TensorFlow下构建高性能神经网络模型的最佳实践-搜狐
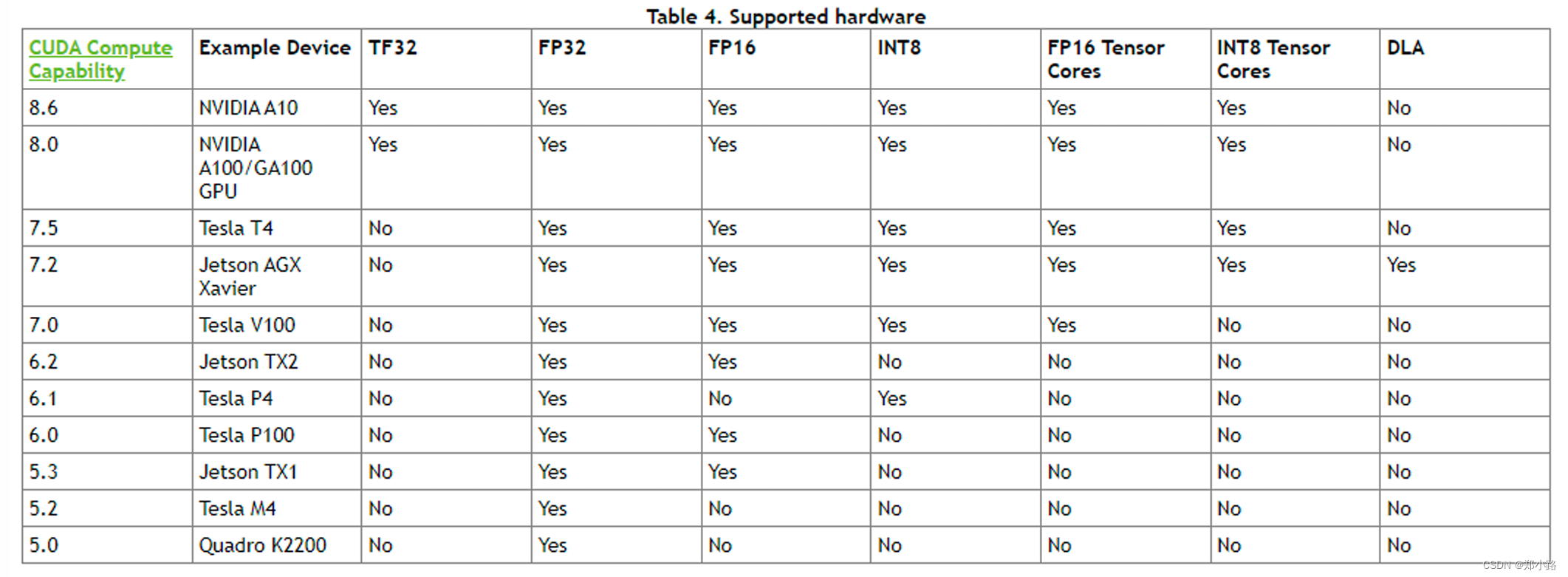
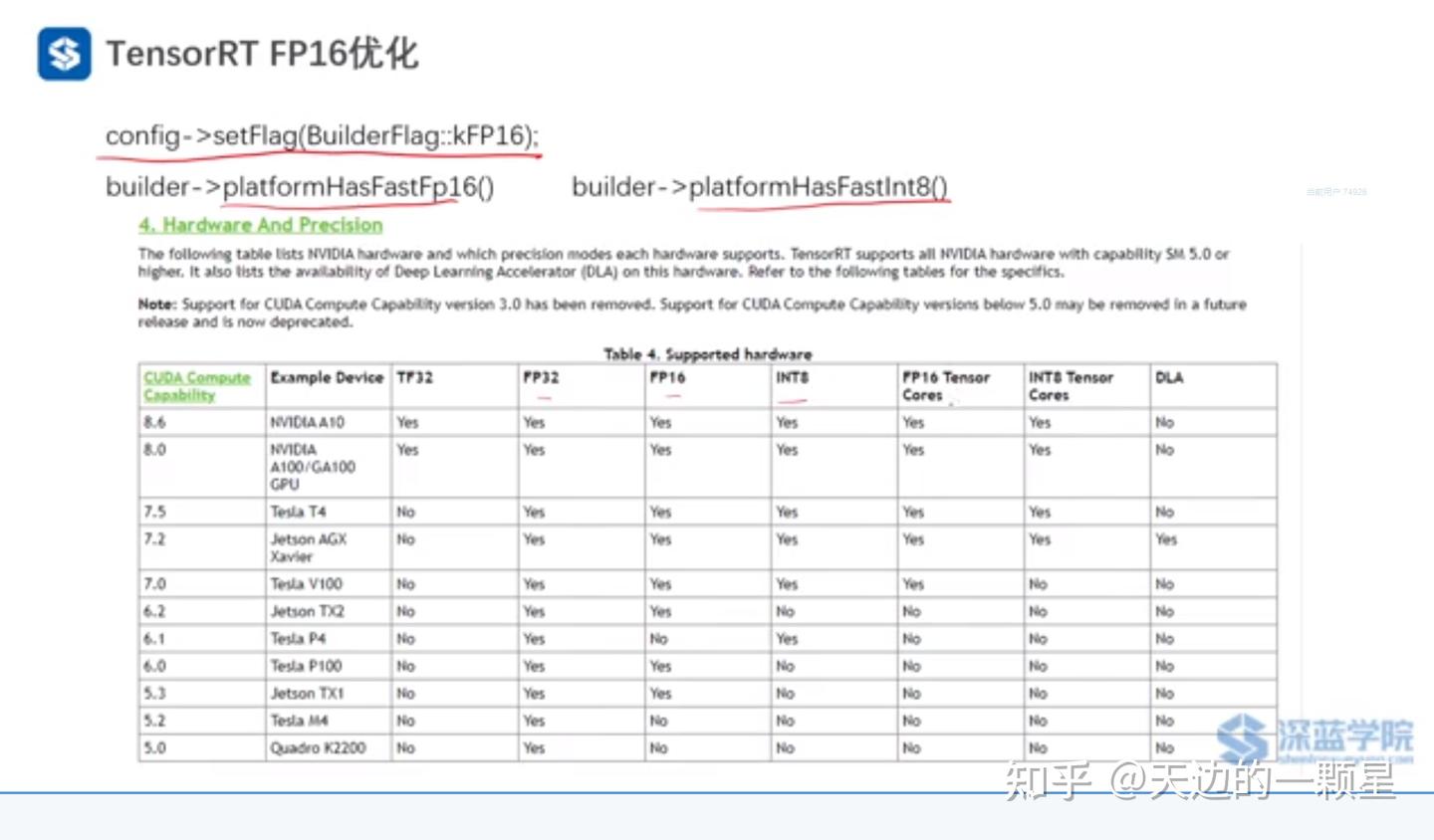
TensorRT:FP16优化加速的原理与实践_tensorrt fp16-CSDN博客
(抛砖引玉)TensorRT的FP16不得劲?怎么办?在线支招! - 知乎
Automatic Mix Precision — MindSpore master documentation
Developer Guide - NVIDIA Docs
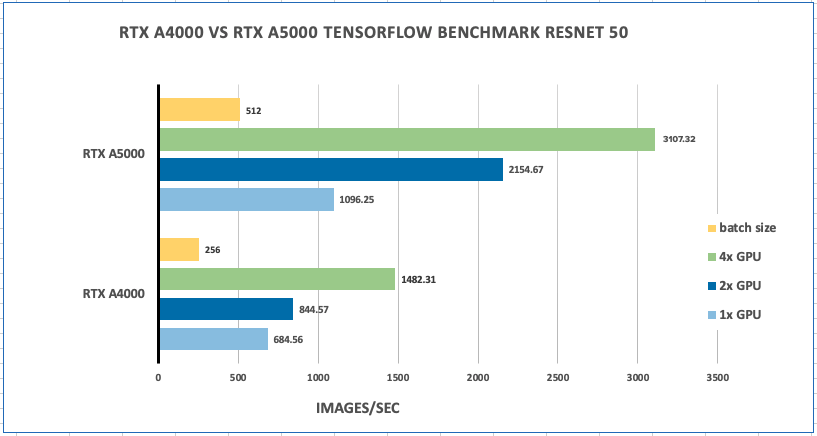
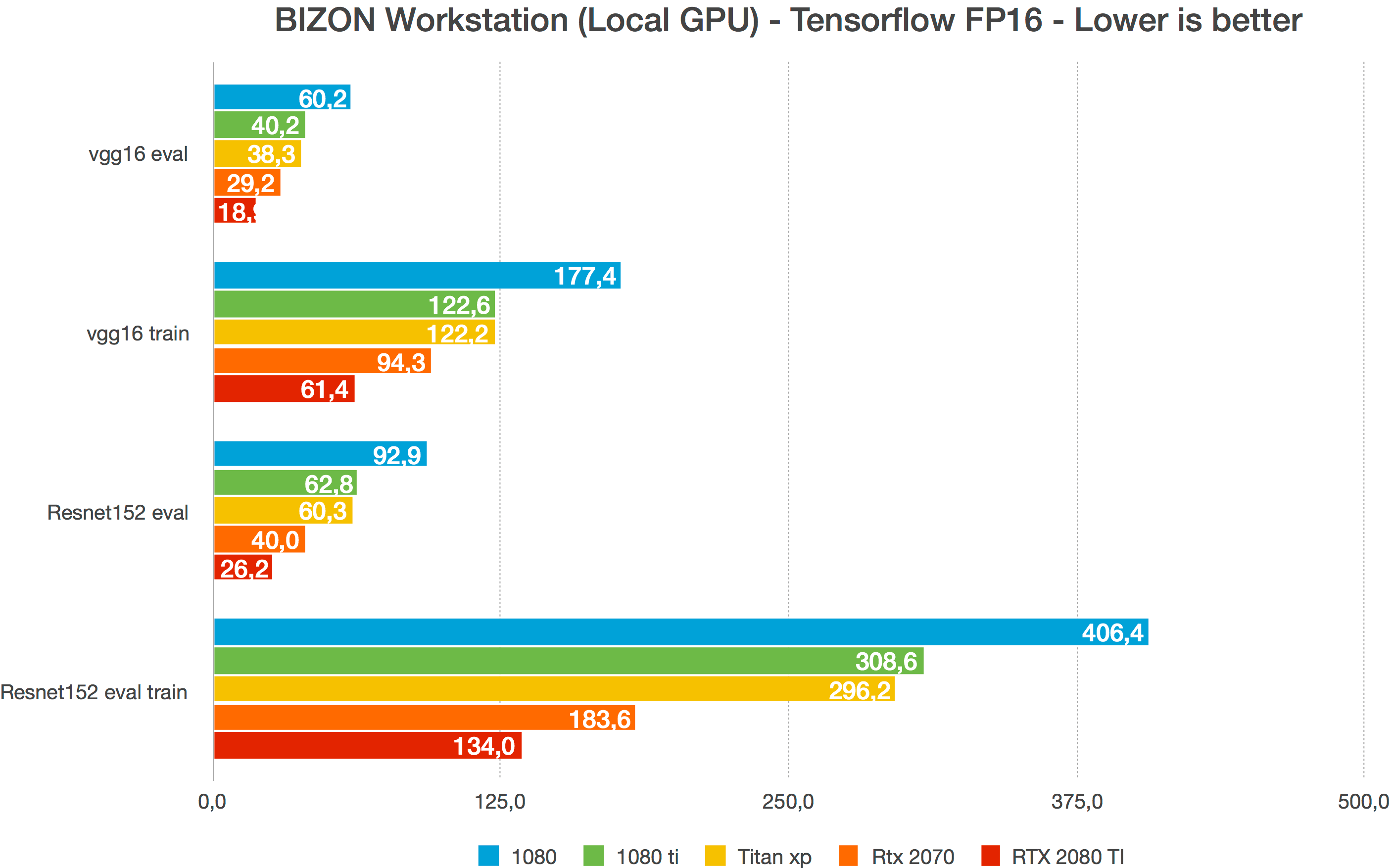
NVIDIA RTX A4000, A5000 and A6000 Comparison: Deep Learning Benchmarks ...
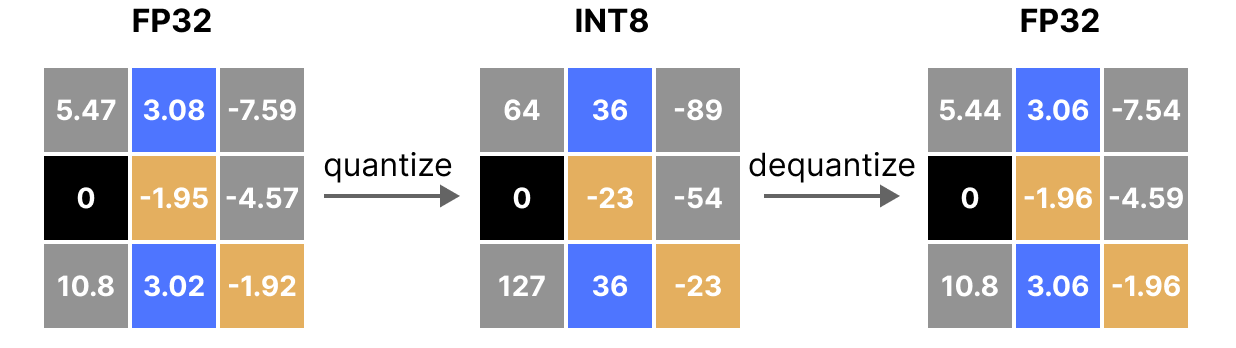
A Visual Guide to Quantization - by Maarten Grootendorst
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
小白必读:到底什么是FP32、FP16、INT8?-电子工程专辑
TensorRT详细入门指北,如果你还不了解TensorRT,过来看看吧_tensor drt-CSDN博客
加速PyTorch, Tensorflow等框架的推理流程_tf32和fp32-CSDN博客
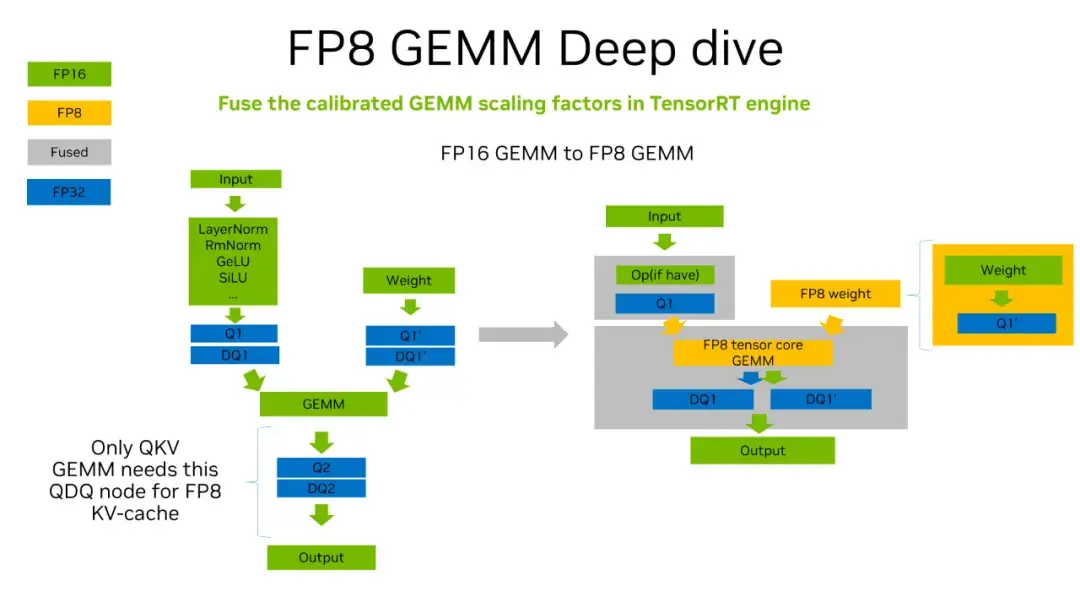
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析 - 知乎
ML Engineering
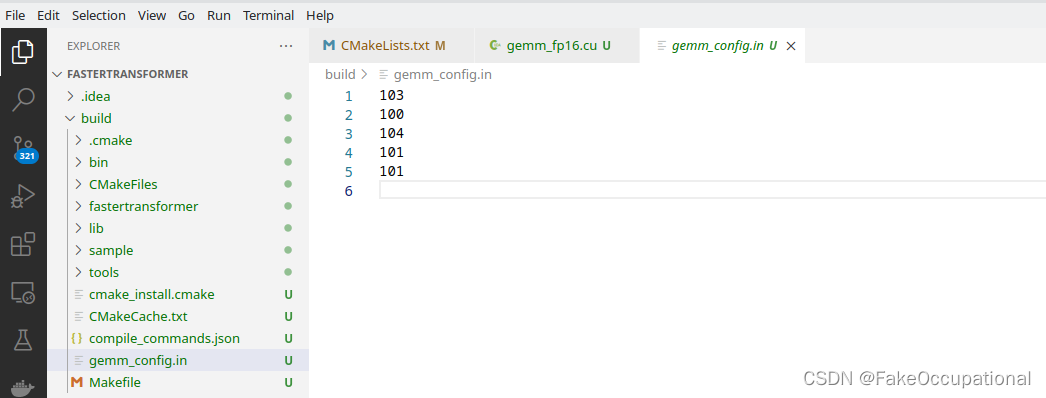
FasterTransformer 001 start up-CSDN博客
CUDA使用FP16进行半精度运算_怎么使用半精度计算-CSDN博客
想提速但TensorRT的FP16不得劲?怎么办?在线支招!-腾讯云开发者社区-腾讯云
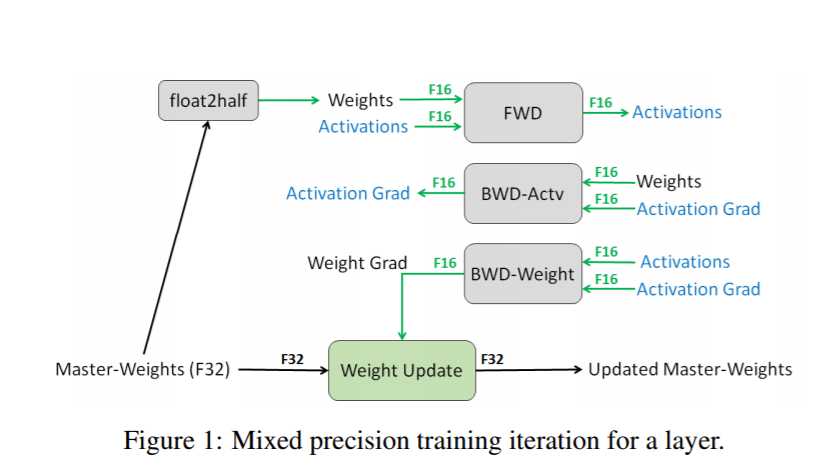
Pytorch混合精度(FP16&FP32)(AMP自动混合精度)/半精度 训练(一) —— 原理(torch.half)-CSDN博客
fp16和fp32,神经网络混合精度训练,PYTORCH 采用FP16,Libtorch采用FP16,神经网络混合精度三种避免损失 ...
一文讲清楚大模型涉及到的精度:FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8-CSDN博客
TNN行业首发Arm 32位 FP16指令加速,理论性能翻倍 - 知乎
TensorRT debug及FP16浮点数溢出问题分析_tensorrt fp16溢出-CSDN博客
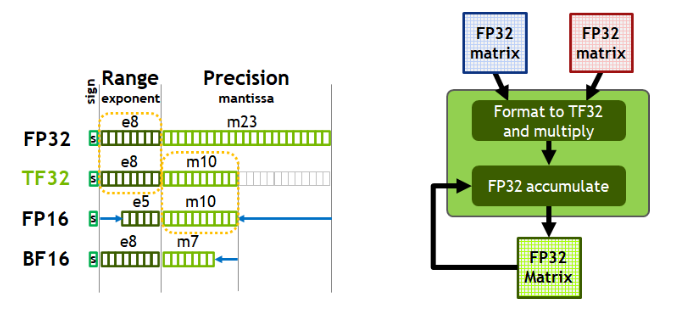
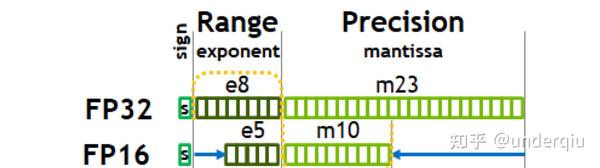
从一次面试搞懂 FP16、BF16、TF32、FP32 - 知乎
大模型中的计算精度——FP32, FP16, bfp16之类的都是什么???_混合精度训练和fp32的区别-CSDN博客
TensorFlow: A Game Changer for Development
Quantization in LLMS (Part 1): LLM.int8(), NF4 | TensorTunes
BF16 vs FP16: Key Differences, Precision, and Best Use Cases
PyTorch vs TensorFlow:Comparison for Deep Learning
Arm Community
GPU基本知识 | shushu学通信
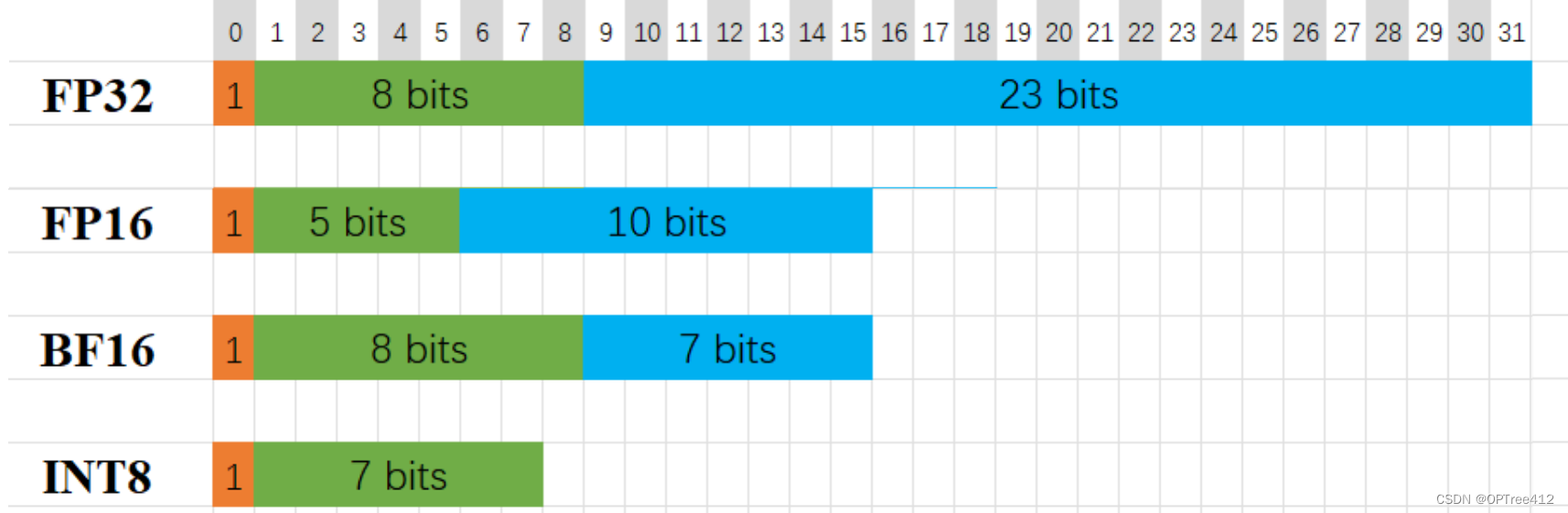
fp32、fp16、bf16介绍与使用_fp32和fp16算力区别-CSDN博客
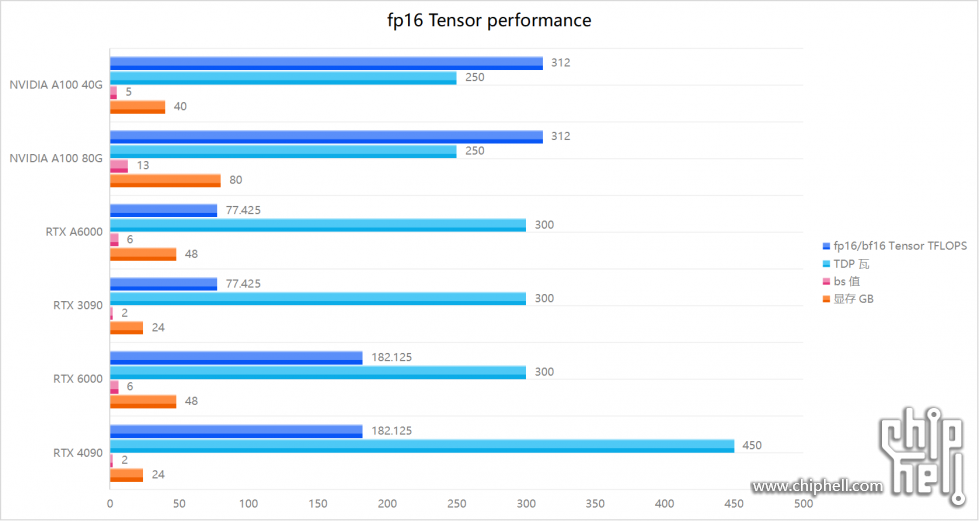
[分享]RTX A6000 fp16性能 和bf16性能 《补交测试数据》 - 电脑讨论(新) - Chiphell - 分享与交流用户体验
fp16与fp32简介与试验_fp16和fp32-CSDN博客
【干货】大模型算力优化全攻略——FP32、FP16、INT8数据格式精讲与实战应用_fp16和fp32-CSDN博客
TensorRT 量化加速 - 知乎