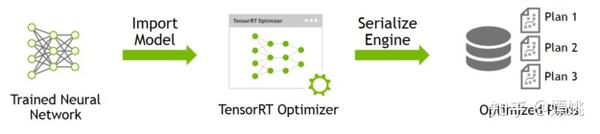
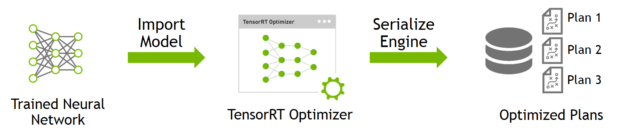
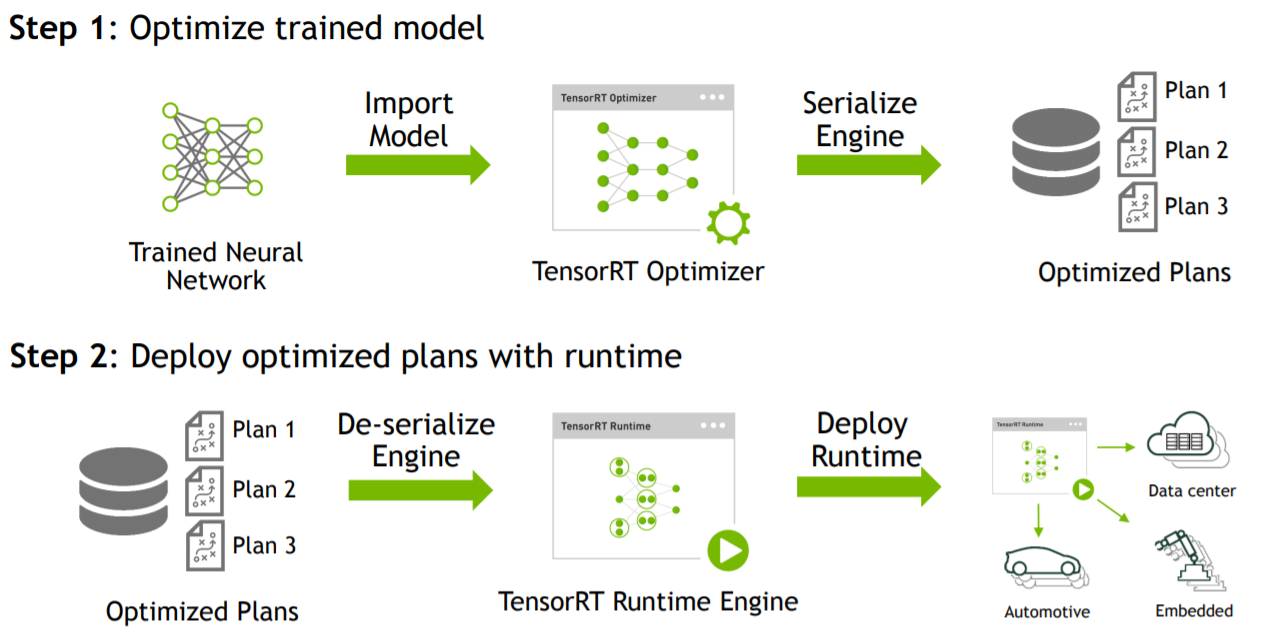
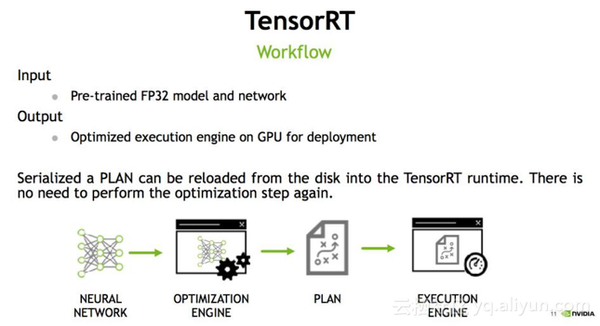
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
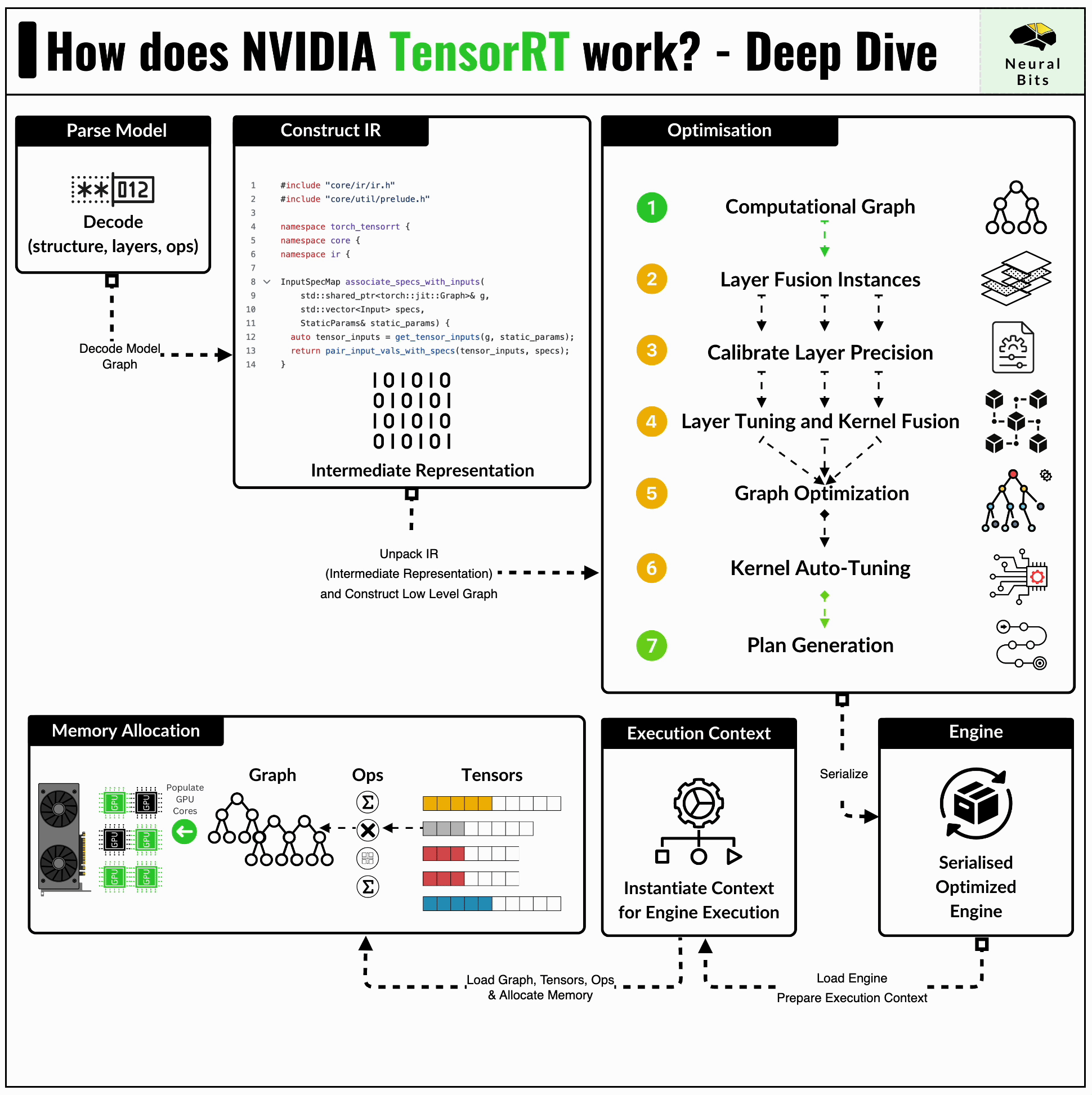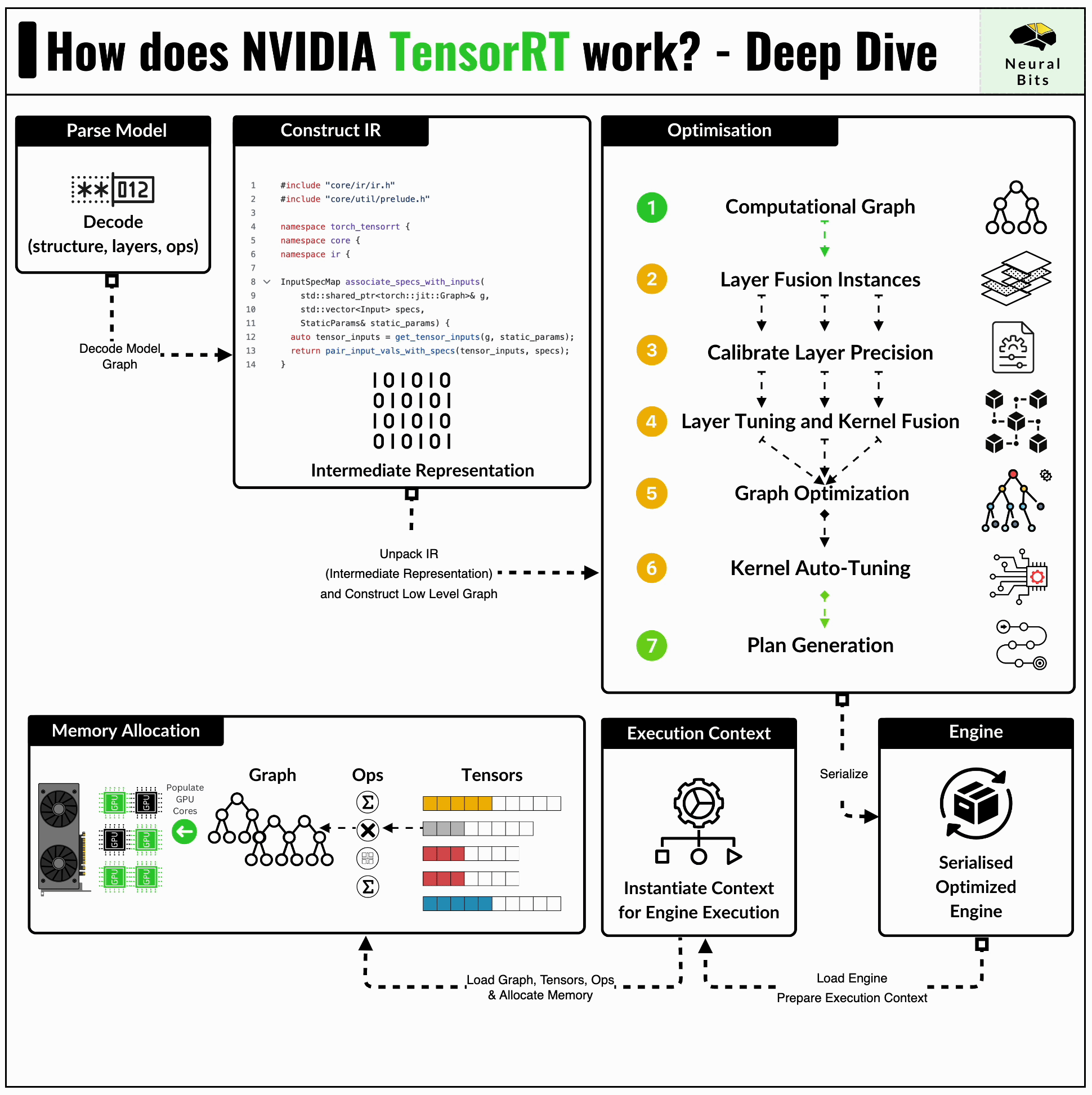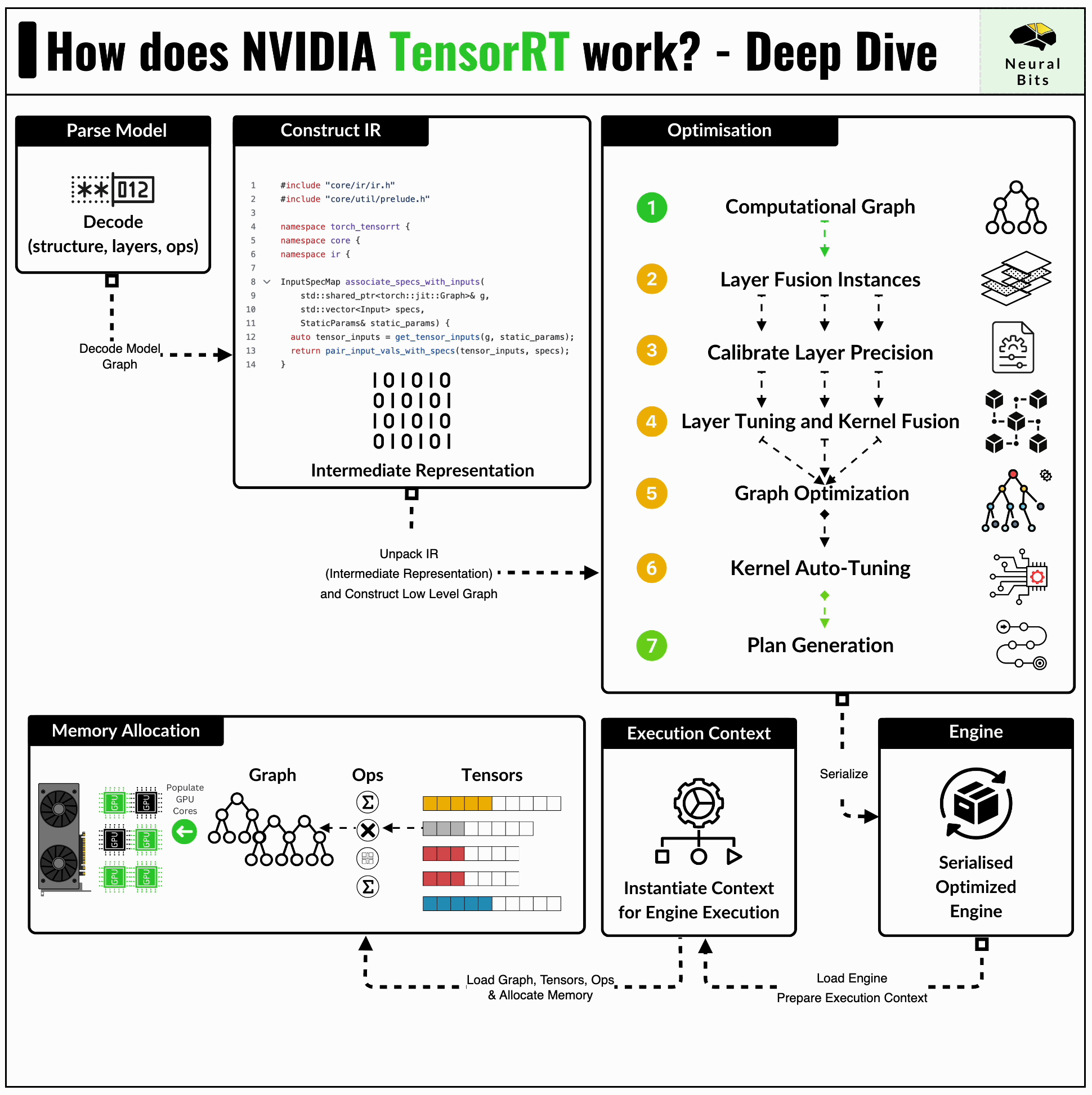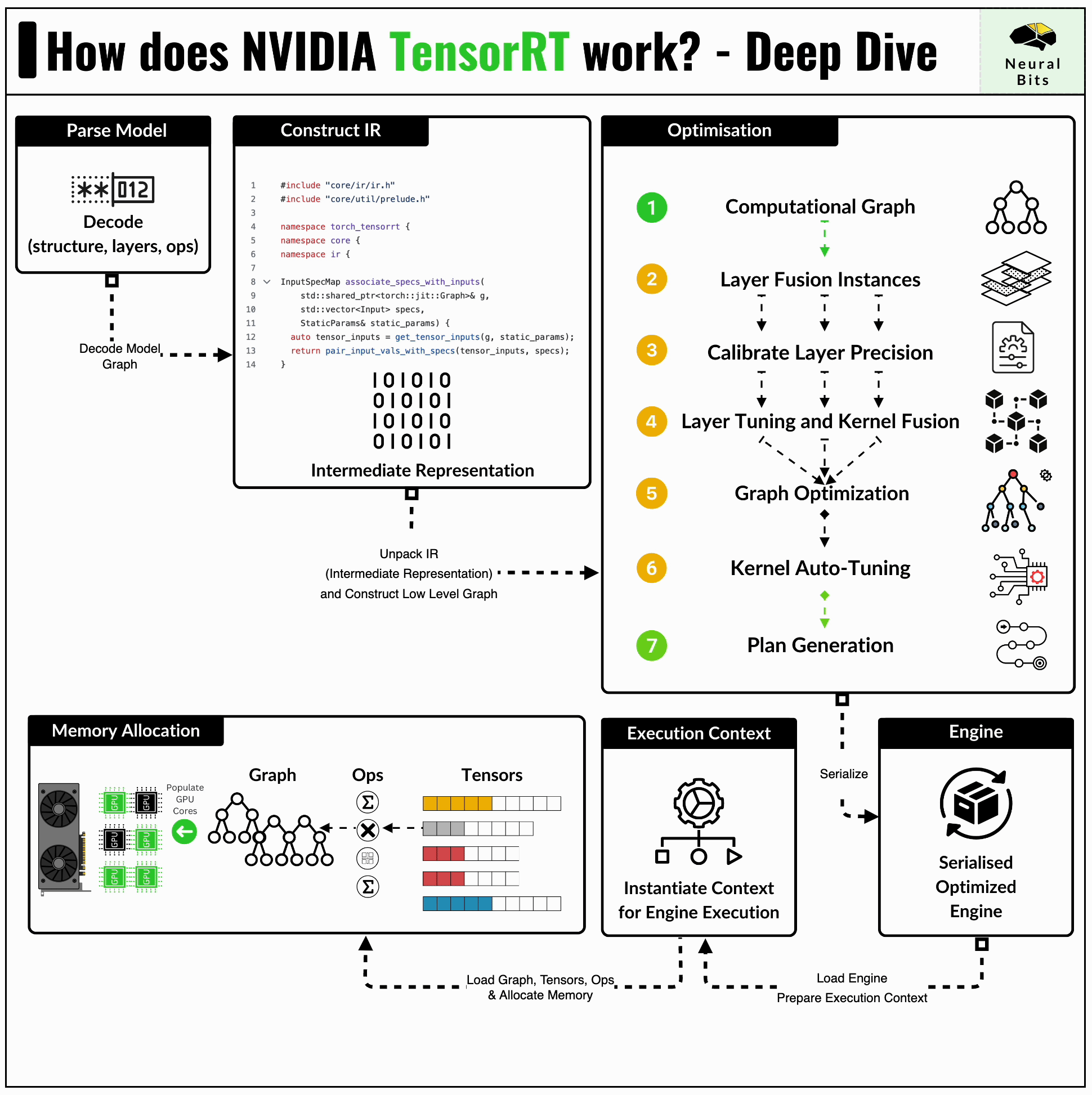
How TensorRT Works: Deep Dive into NVIDIA Inference Optimization Engine ...
tensorrt engine inference · Issue #19354 · ultralytics/ultralytics · GitHub
Run inference with TensorRT engine on Jetson Orin Nano 4GB - Help Docs ...
GPU utility and throughput for inference with TensorRT engine with ...
Error reported in build TensorRT inference engine for the bert model ...
TensorRT engine inference use GPU memory not from a certain device as ...
Speed Up Unreal Engine NNE Inference with NVIDIA TensorRT for RTX ...
TensorRT 3: Faster TensorFlow Inference and Volta Support | NVIDIA ...
High performance inference with TensorRT Integration — The TensorFlow Blog
Inference Optimization using TensorRT – DEVSTACK
How to optimize inference using TensorRT on Jetson AGX Orin
NVIDIA TensorRT for RTX Introduces an Optimized Inference AI Library on ...
NVIDIA TensorRT Inference Server and Kubeflow Make Deploying Data ...
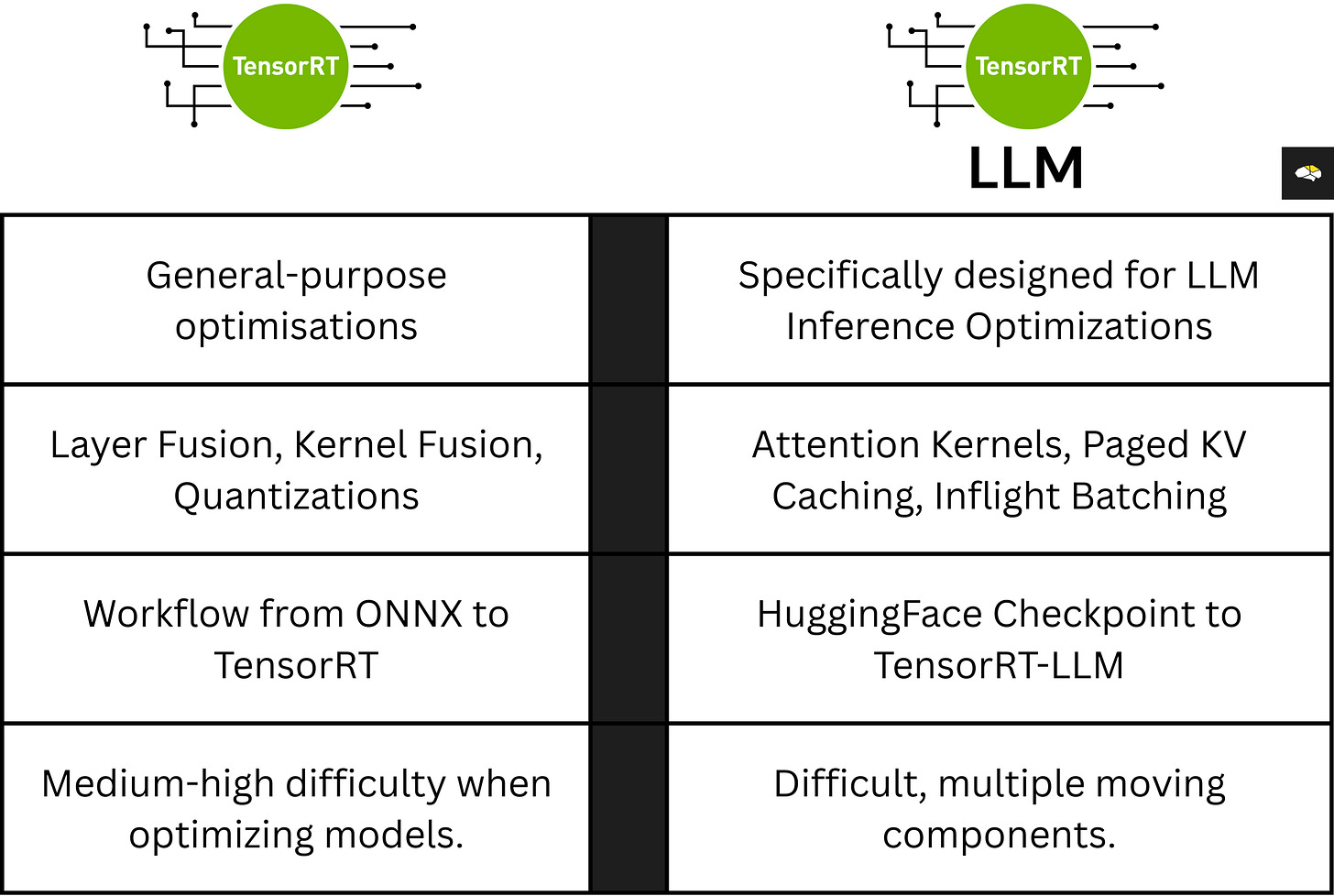
TensorRT vs vLLM: The Complete Guide to LLM Inference Engines
Speeding Up Deep Learning Inference Using NVIDIA TensorRT (Updated ...
Tensorrt – Powering Faster AI Inference
Engine Tools and Debugging — NVIDIA TensorRT
Neural Machine Translation Inference with TensorRT 4 | NVIDIA Technical ...
GTC 2020: TensorRT inference with TensorFlow 2.0 | NVIDIA Developer
How to call TensorRT's inference engine SDK through C++ or C#? · Issue ...
TensorRT Integration Speeds Up TensorFlow Inference | NVIDIA Technical Blog
How To Run Inference Using TensorRT C++ API | LearnOpenCV
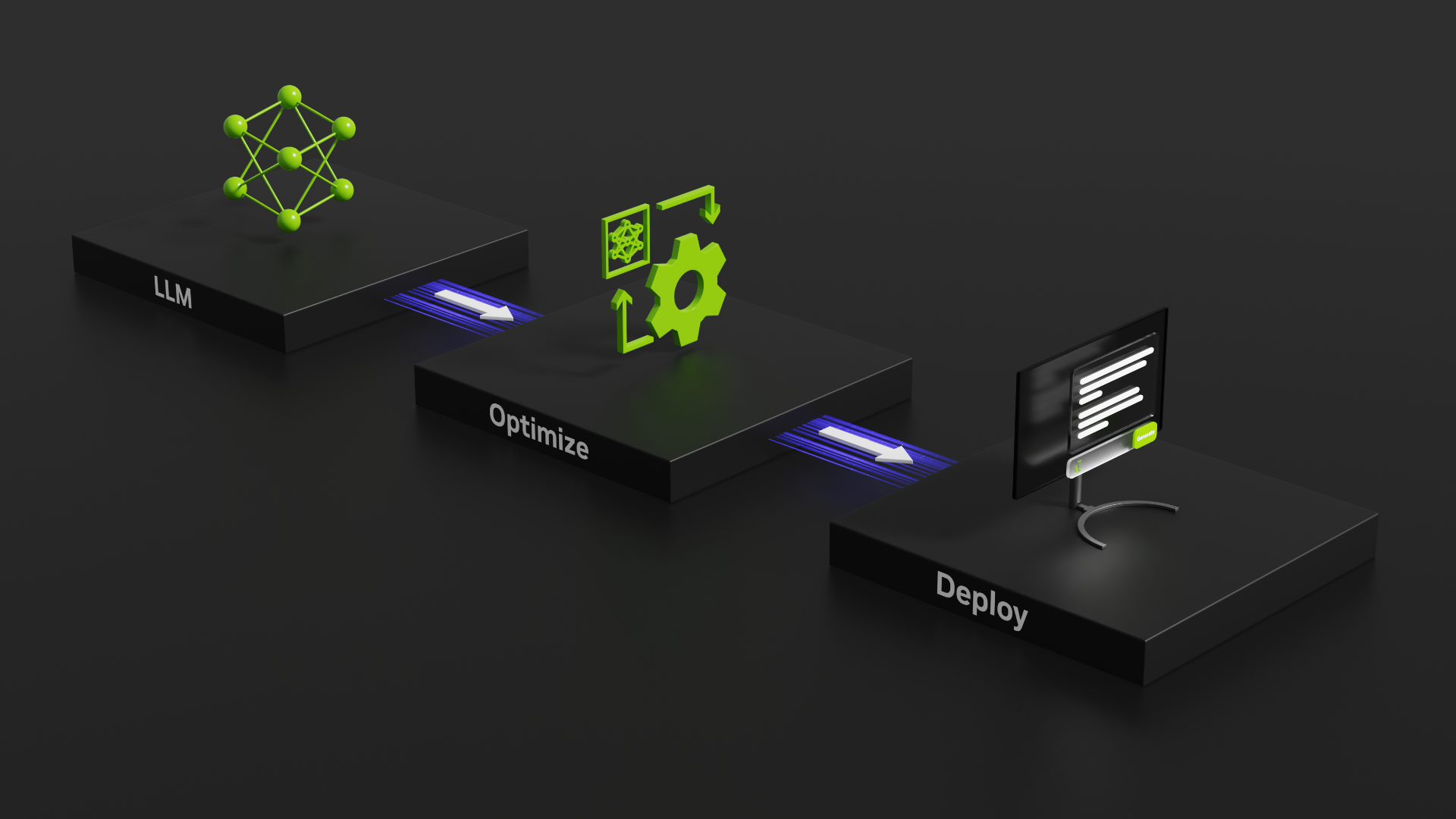
Automating Inference Optimizations with NVIDIA TensorRT LLM AutoDeploy
How to Speed Up Deep Learning Inference Using TensorRT | NVIDIA ...
NVIDIA TensorRT – Inference 최적화 및 가속화를 위한 NVIDIA의 Toolkit - NVIDIA ...
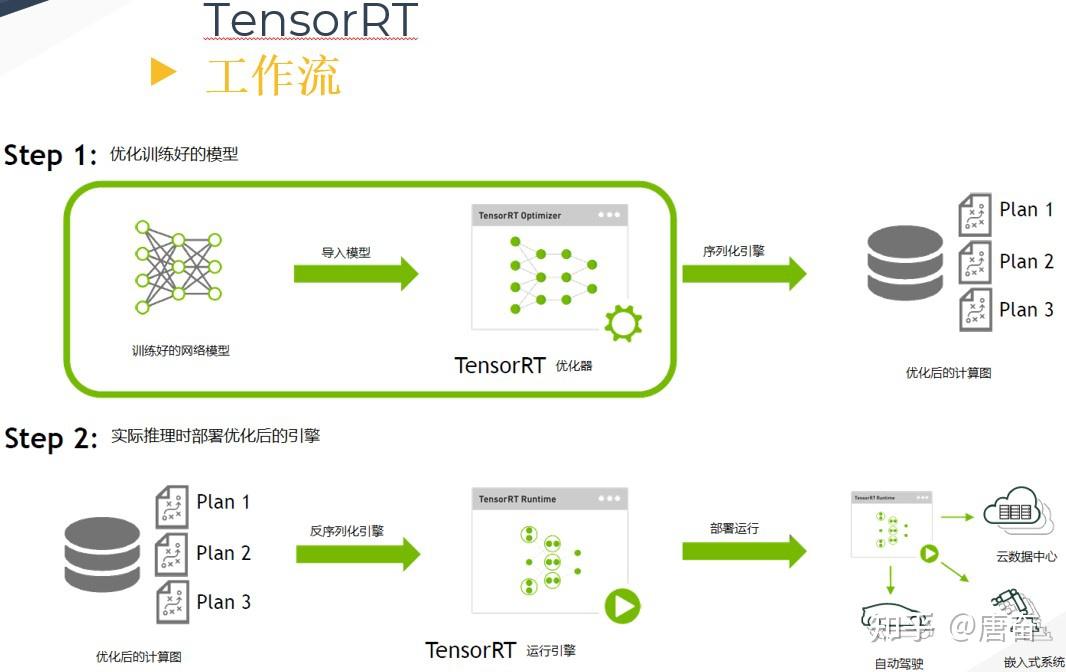
TensorRT inference optimization process. | Download Scientific Diagram
Build TensorRT Engine MSI Installation Procedure
Automating Inference Optimizations with NVIDIA TensorRT LLM AutoDeploy ...
GitHub - piotrostr/infer-trt: Interface for TensorRT engines inference ...
Inference Optimization Engines Like TensorRT That Help You Accelerate ...
Open Inference Engine Comparison | Features and Functionality of TGI ...
Accelerating Inference in TensorFlow with TensorRT User Guide - NVIDIA Docs
Speeding Up Deep Learning Inference Using TensorRT | NVIDIA Technical Blog
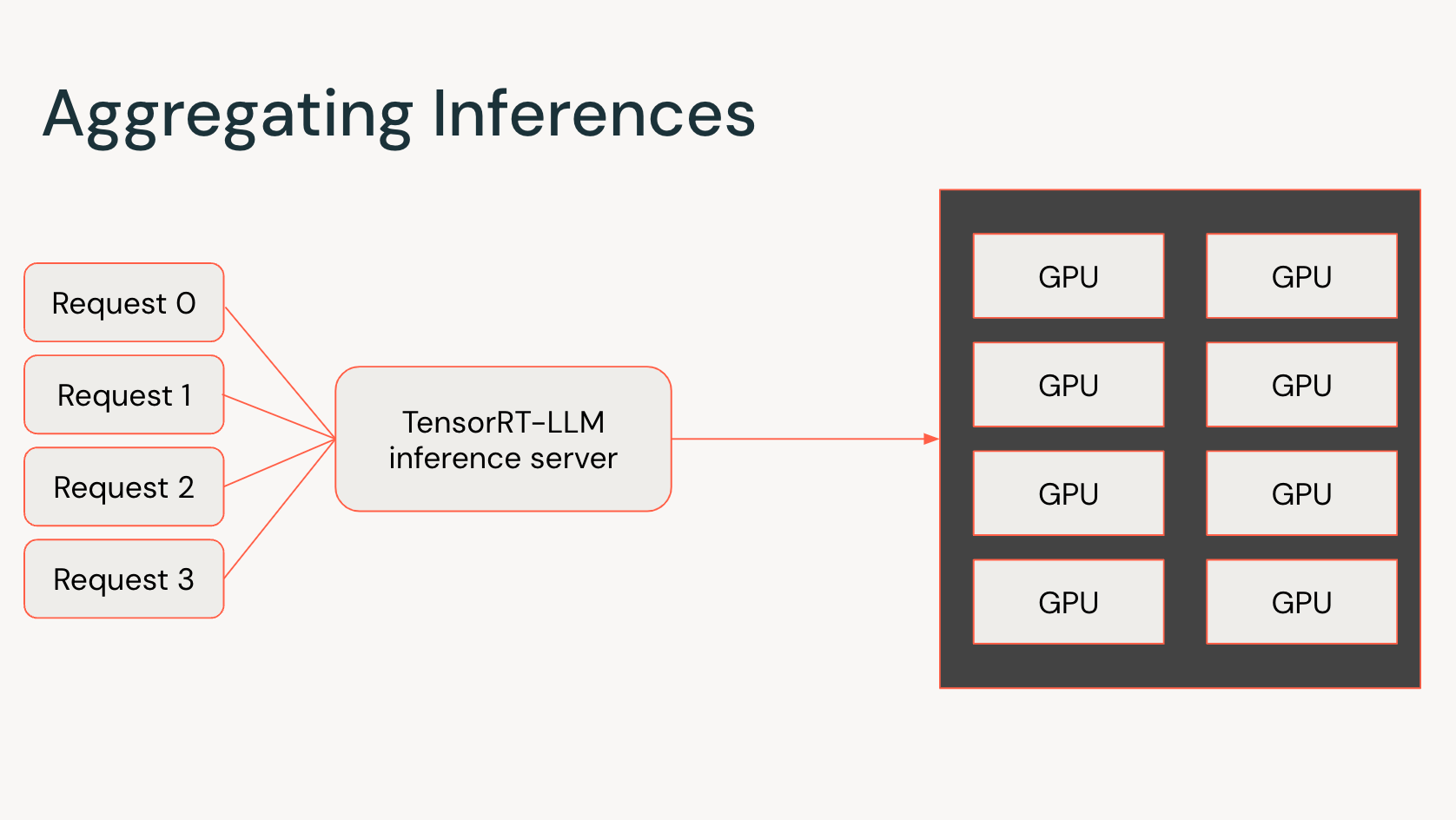
Accelerate Generative AI Inference Performance with NVIDIA TensorRT ...
GenAI with TensorRT LLM inference Engine: Simplifying Documentation ...
Adaptive Inference in NVIDIA TensorRT for RTX Enables Automatic ...
TensorRT SDK | NVIDIA Developer
End-to-End AI for NVIDIA-Based PCs: NVIDIA TensorRT Deployment | NVIDIA ...
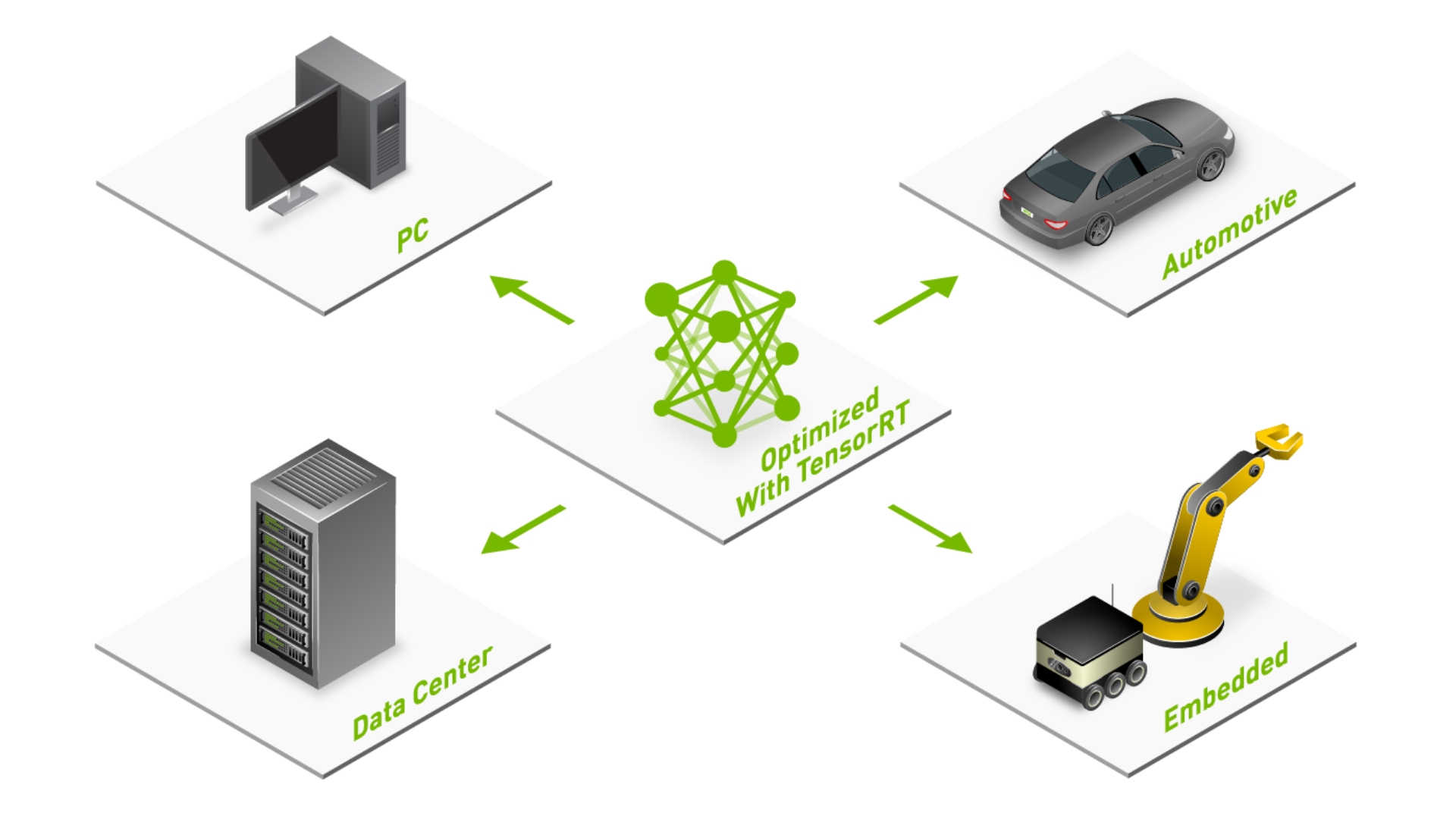
NVIDIA TensorRT | NVIDIA Developer
Leveraging TensorFlow-TensorRT integration for Low latency Inference ...
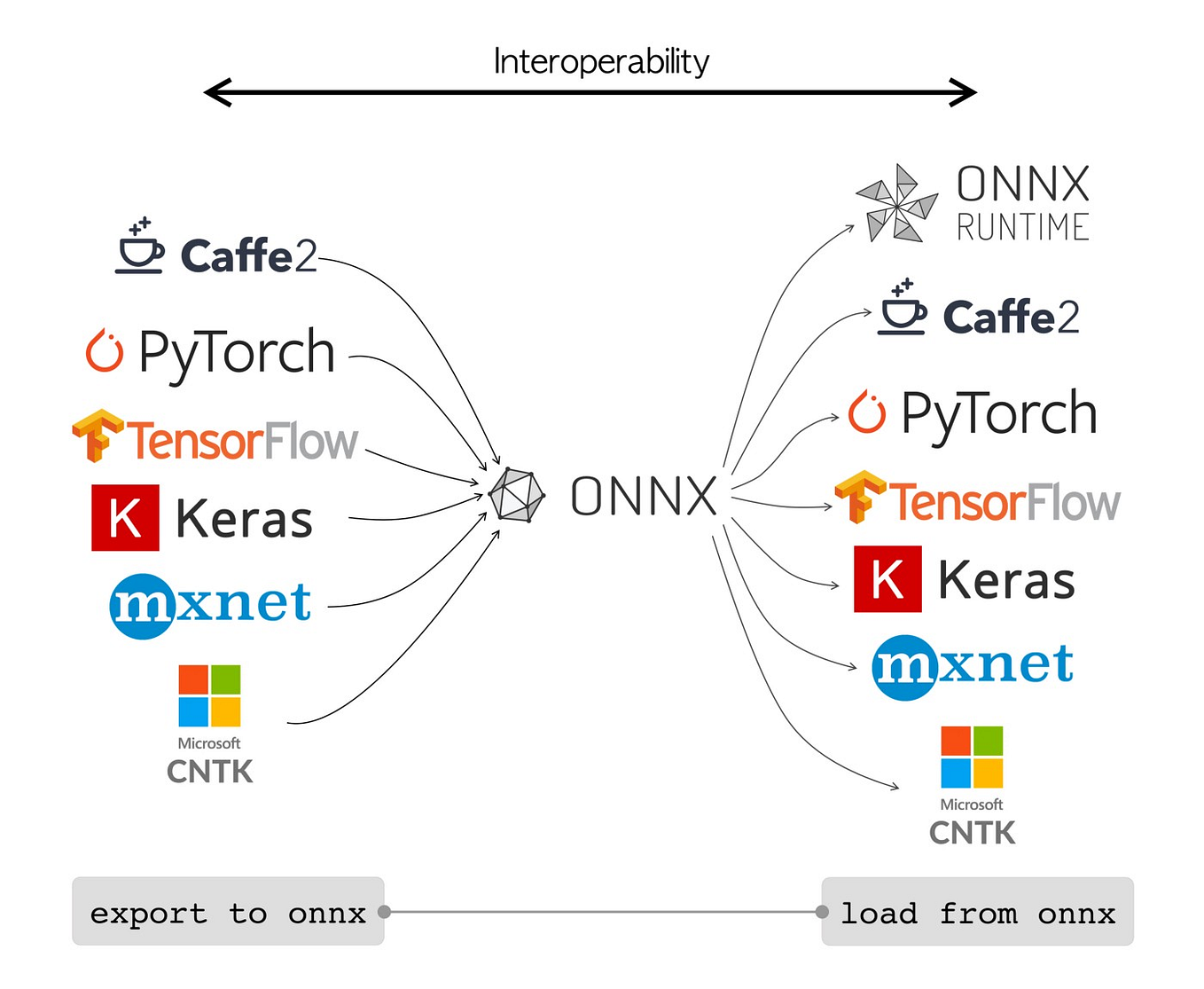
Speeding Up Deep Learning Inference Using TensorFlow, ONNX, and ...
Deploying Deep Neural Networks with NVIDIA TensorRT | NVIDIA Technical Blog
Accelerating LLM and VLM Inference for Automotive and Robotics with ...
Accelerating Inference Up to 6x Faster in PyTorch with Torch-TensorRT ...
The AI Engineer's Guide to Inference Engines and Frameworks
Integrating NVIDIA TensorRT-LLM with the Databricks Inference Stack ...
Accelerating Model inference with TensorRT: Tips and Best Practices for ...
A Comparative Analysis of Modern AI Inference Engines for Optimized ...
Video: Introduction to Recurrent Neural Networks in TensorRT | NVIDIA ...
TensorRT 基础笔记 - 知乎
Optimum-Nvidia - TensorRT-LLM optimized inference engines - a Hugging ...
TensorRT Inference引擎简介及加速原理简介-CSDN博客
GitHub - parlaynu/inference-tensorrt: Convert ONNX models to TensorRT ...
Accelerating Long-Context Inference with Skip Softmax in NVIDIA ...
Best LLM Inference Engines (2026): vLLM, SGLang & TensorRT-LLM | Yotta Labs
GenAI Inference Engines: TensorRT-LLM vs vLLM vs Hugging Face TGI vs ...
The new NVIDIA TensorRT, a high-performance neural network inference ...
TensorRT integration - UbiOps Technical Documentation
Accelerate In-Vehicle AI with TensorRT Edge-LLM and Jetson T4000 ...
GitHub - AllenJWZhu/BERT_TensorRT_Inference_Optimization: Inference ...
TREx で NVIDIA TensorRT Engines を探る - NVIDIA 技術ブログ
深度学习部署架构:以 Triton Inference Server(TensorRT)为例_禅与计算机程序设计艺术的技术博客_51CTO博客
What is an Inference Engine? Types, Functions, and Nected’s Approach ...
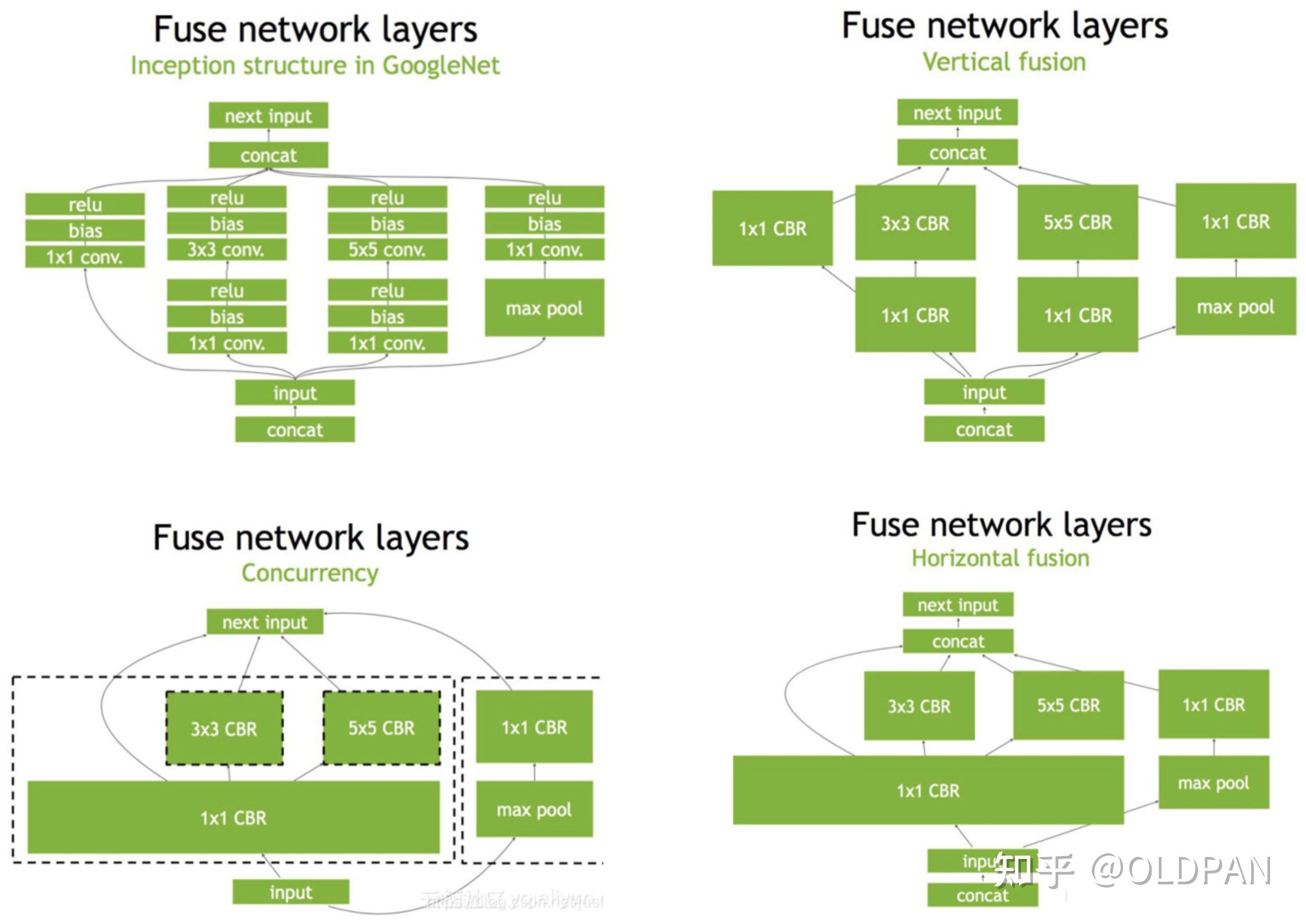
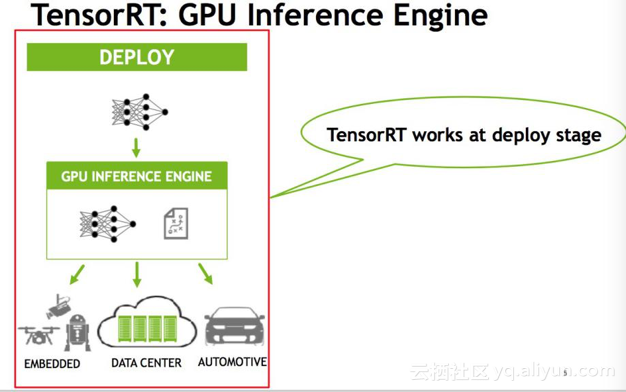
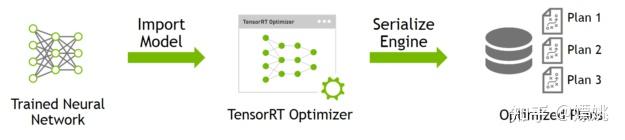
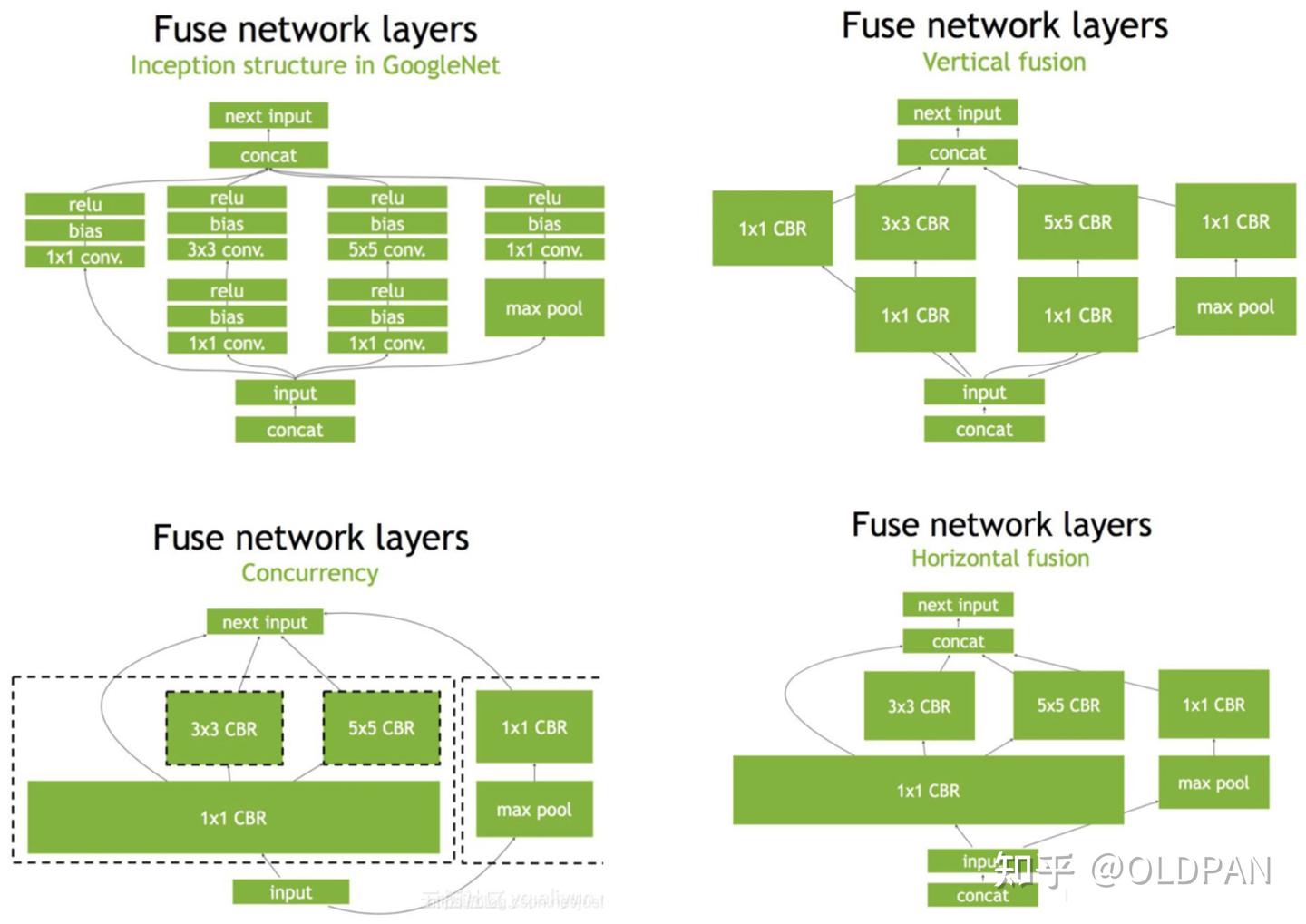
浅谈TensorRT的优化原理和用法 - 知乎
TensorRT(1)-介绍-使用-安装 | arleyzhang
高性能深度学习推断框架—TensorRT | Edward
Simplifying and Accelerating Machine Learning Predictions in Apache ...
GitHub - TejasBob/TensorRT-5_Inference_Engine_Python: TensorRT-5 based ...
GitHub - MrLaki5/TensorRT-onnx-dockerized-inference: Dockerized ...
高性能深度学习支持引擎实战——TensorRT - 知乎
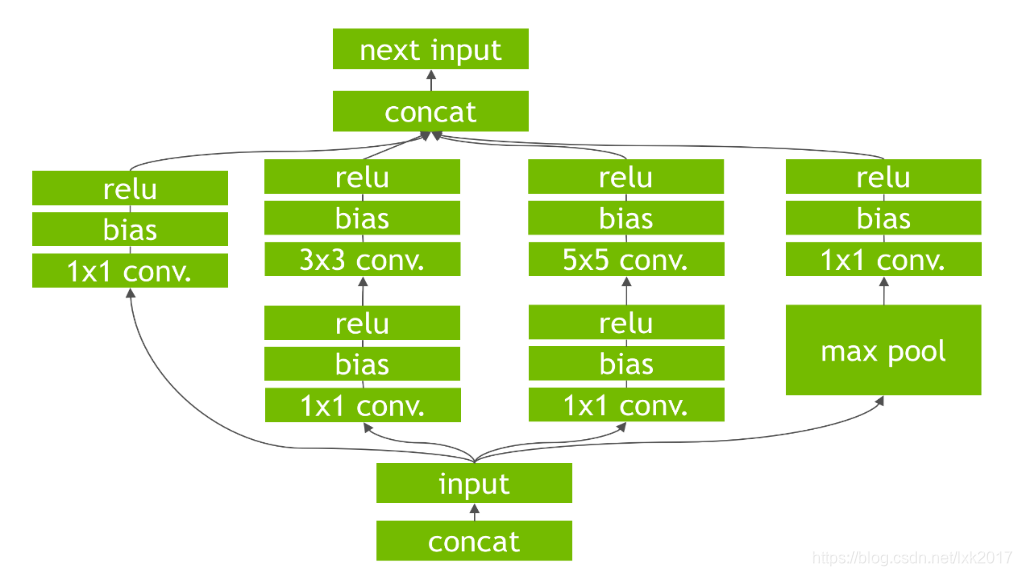
终于把TensorRT的engine模型的结构图画出来了! - 知乎
GitHub - efficient-edge/e2e-detection: Test PyTorch/TensorFlow models ...
A Friendly Introduction to TensorRT: Building Engines | by Vilson ...
Turbocharging Meta Llama 3 Performance with NVIDIA TensorRT-LLM and ...
Model Weights File Formats in Machine Learning
GitHub - chenxuniu/LLM-Inference-Engine-Benchmark: A comprehensive ...



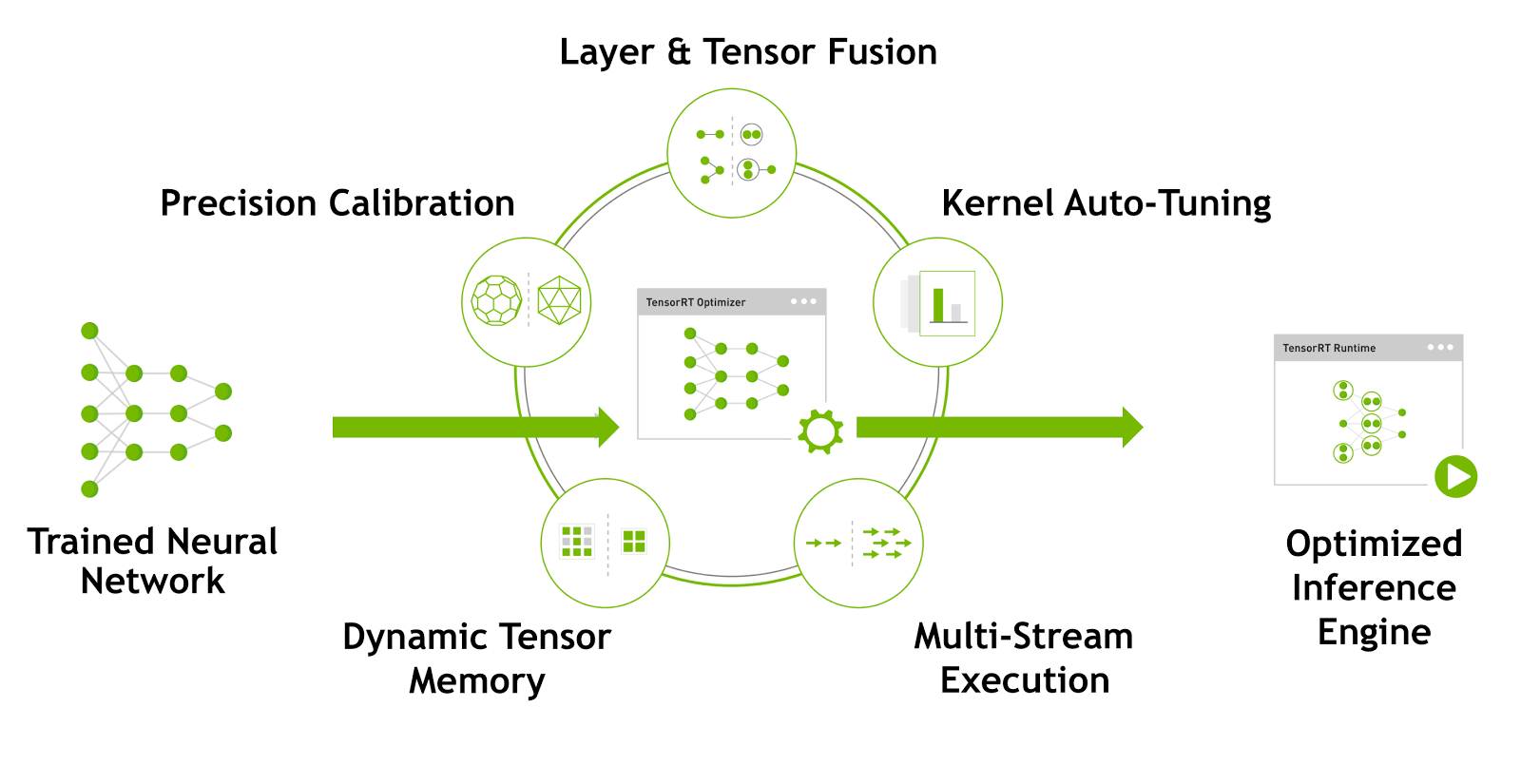
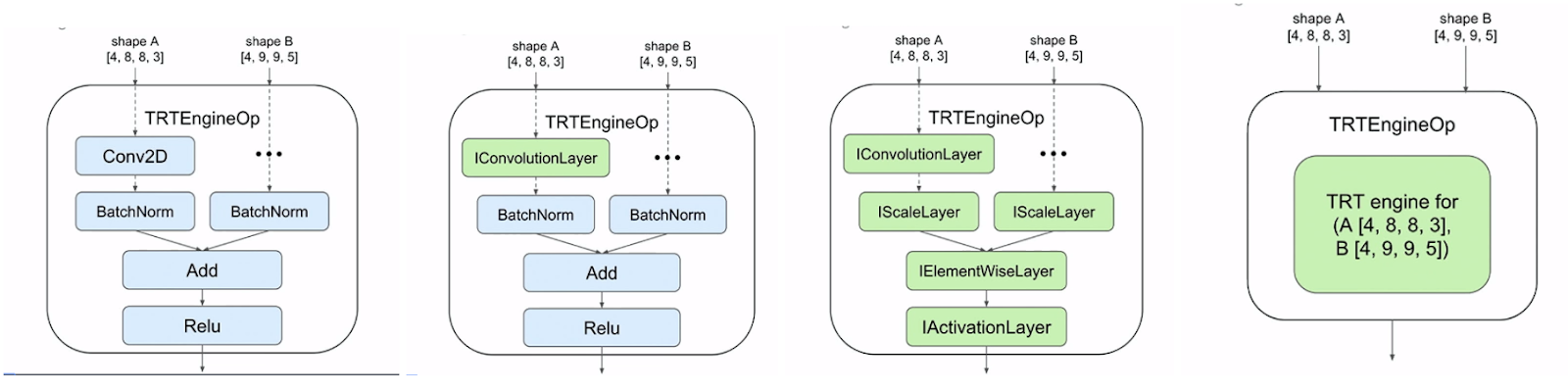
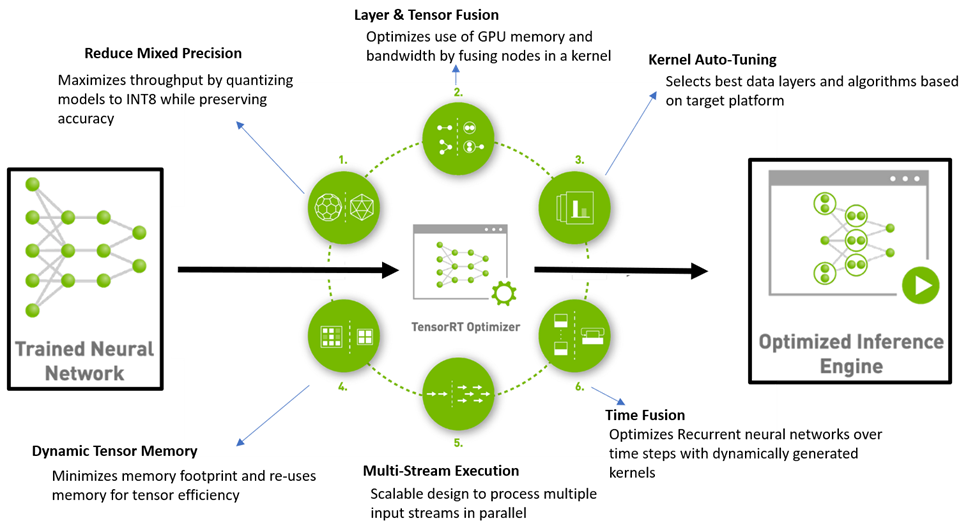
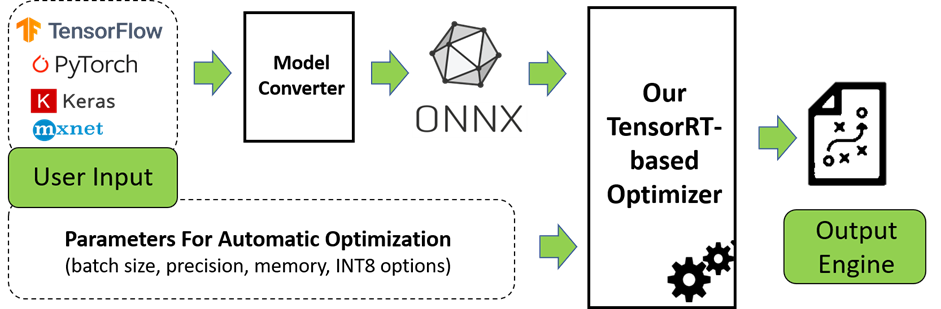
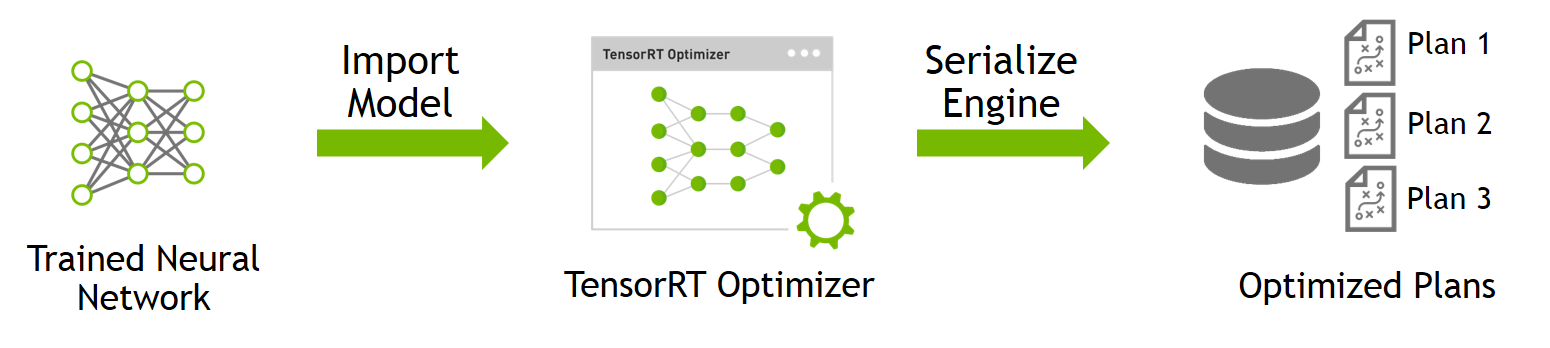
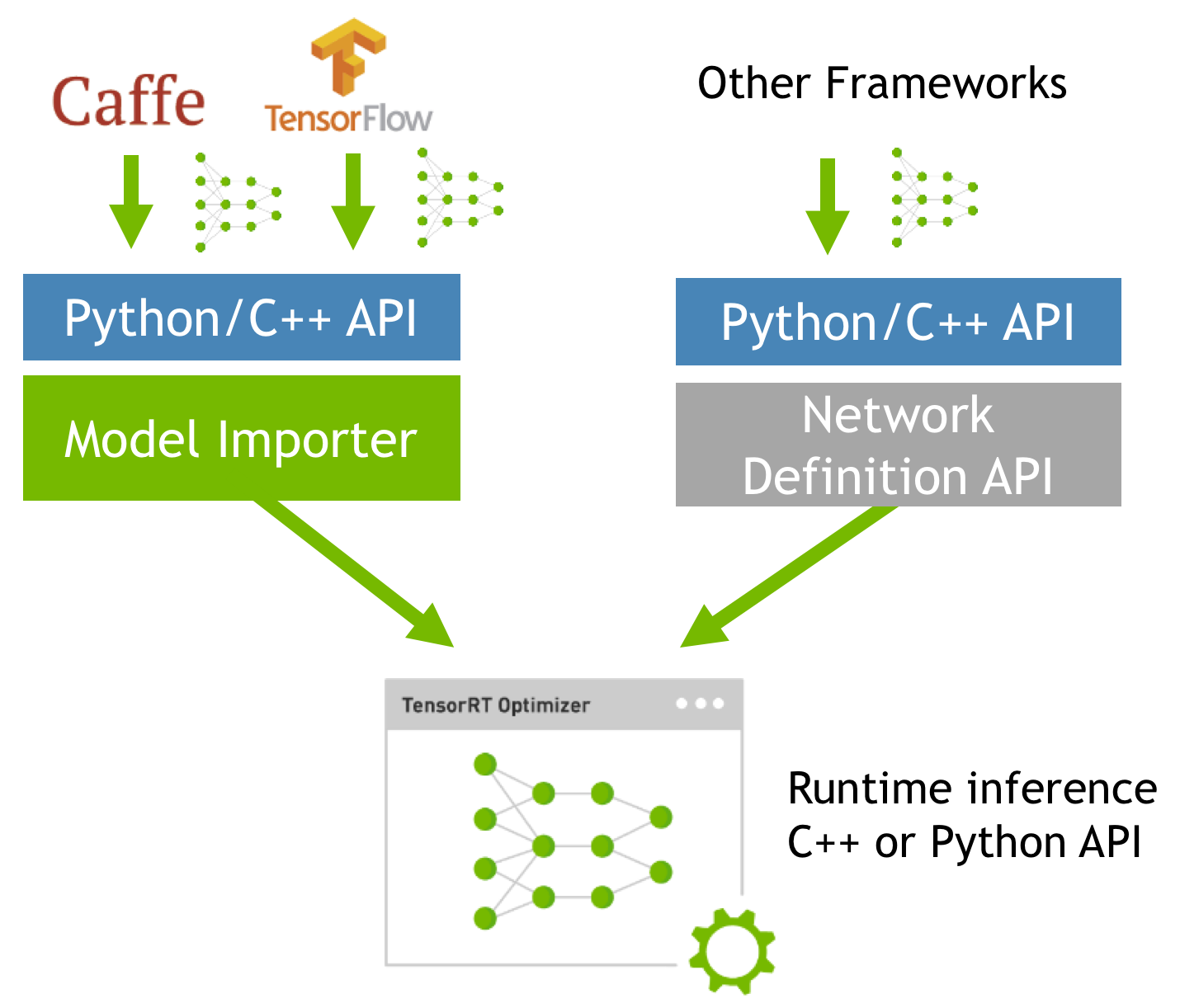
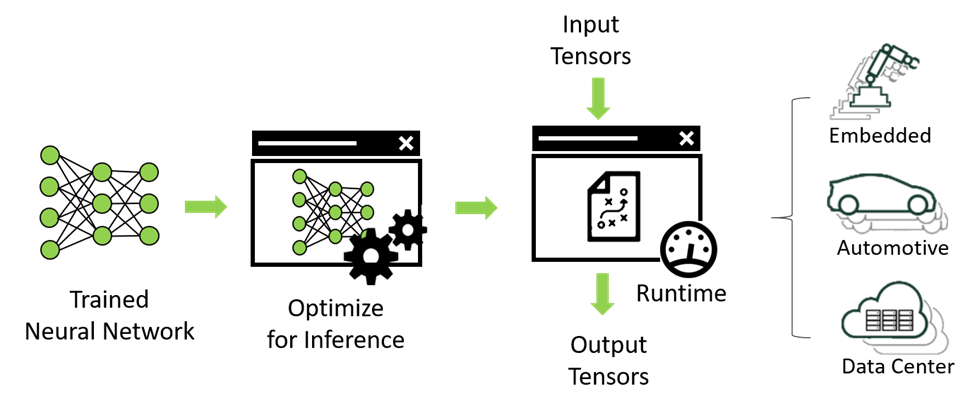
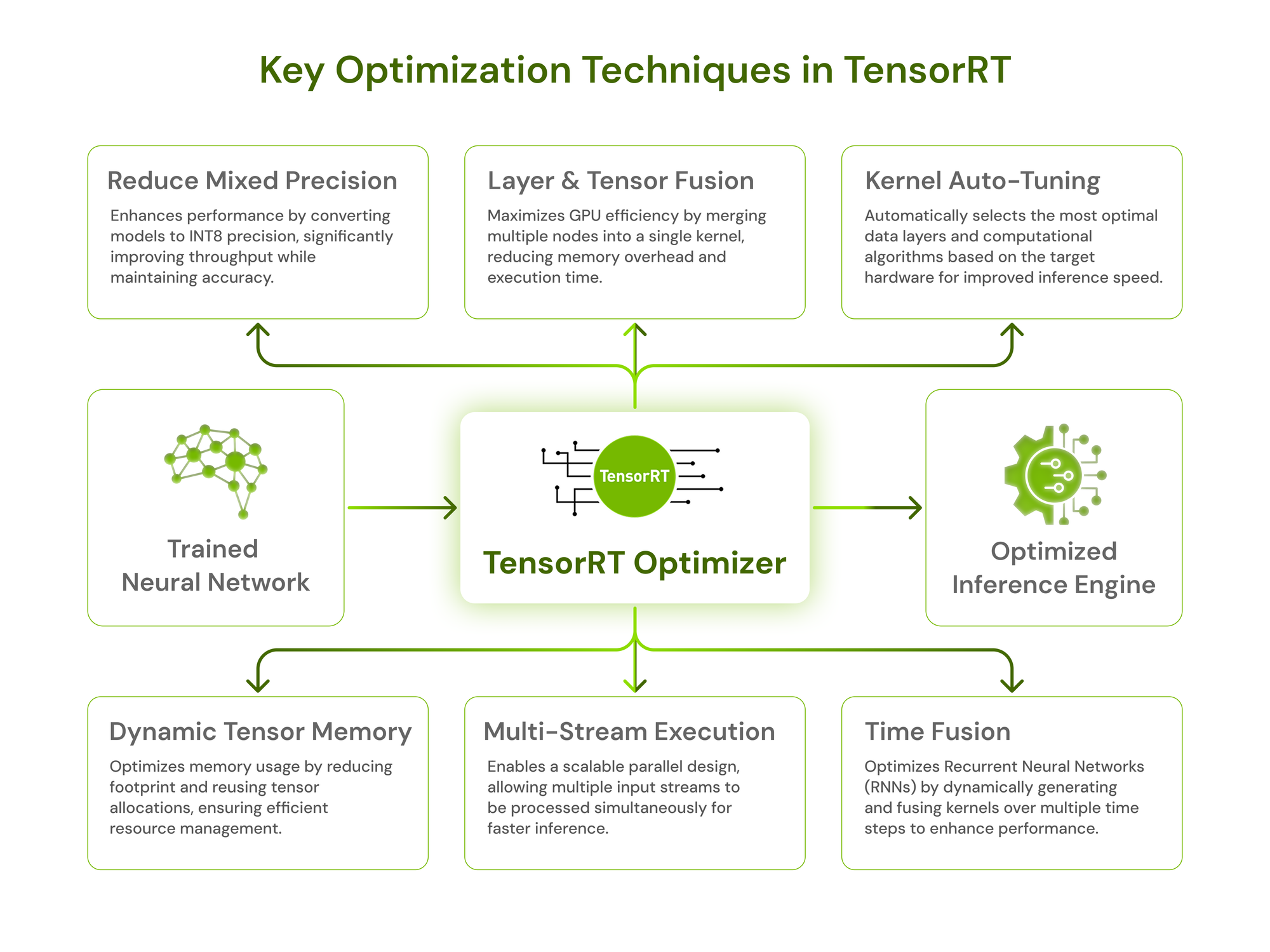


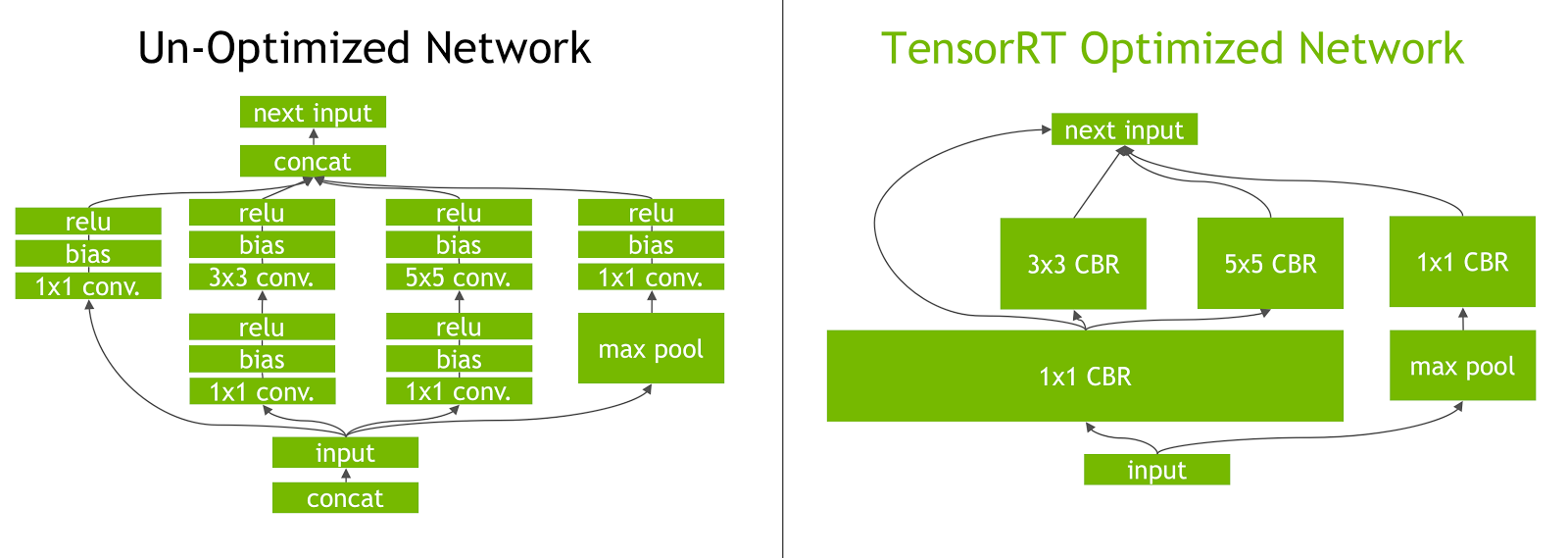

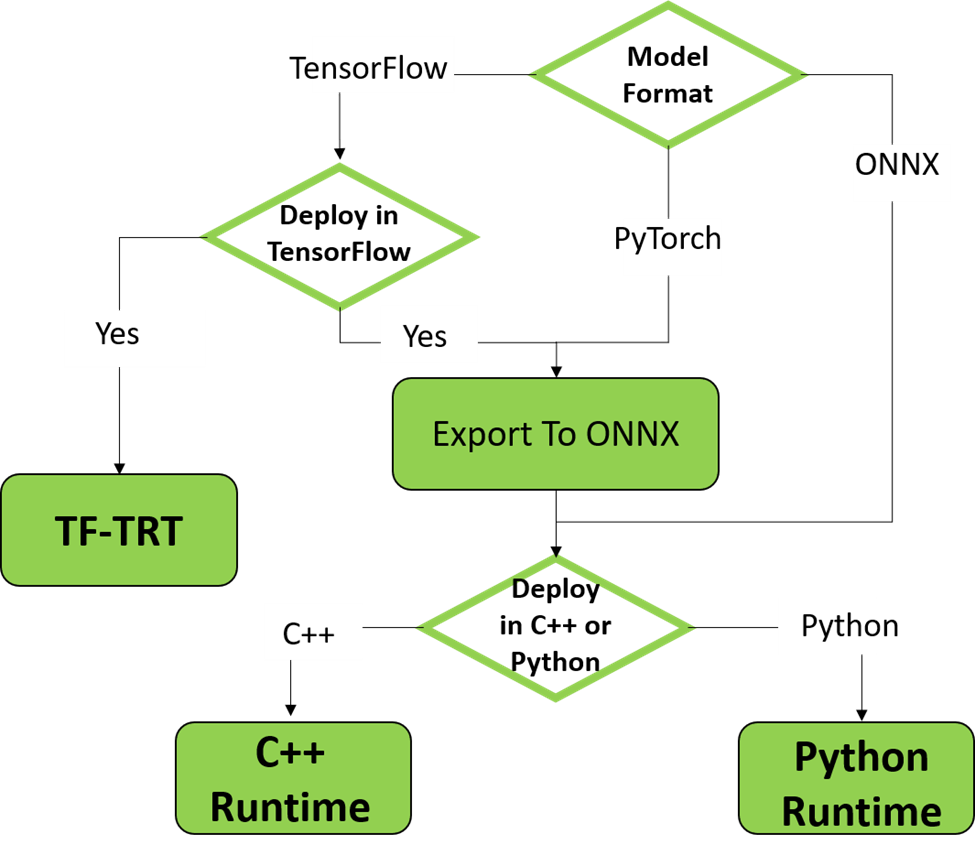
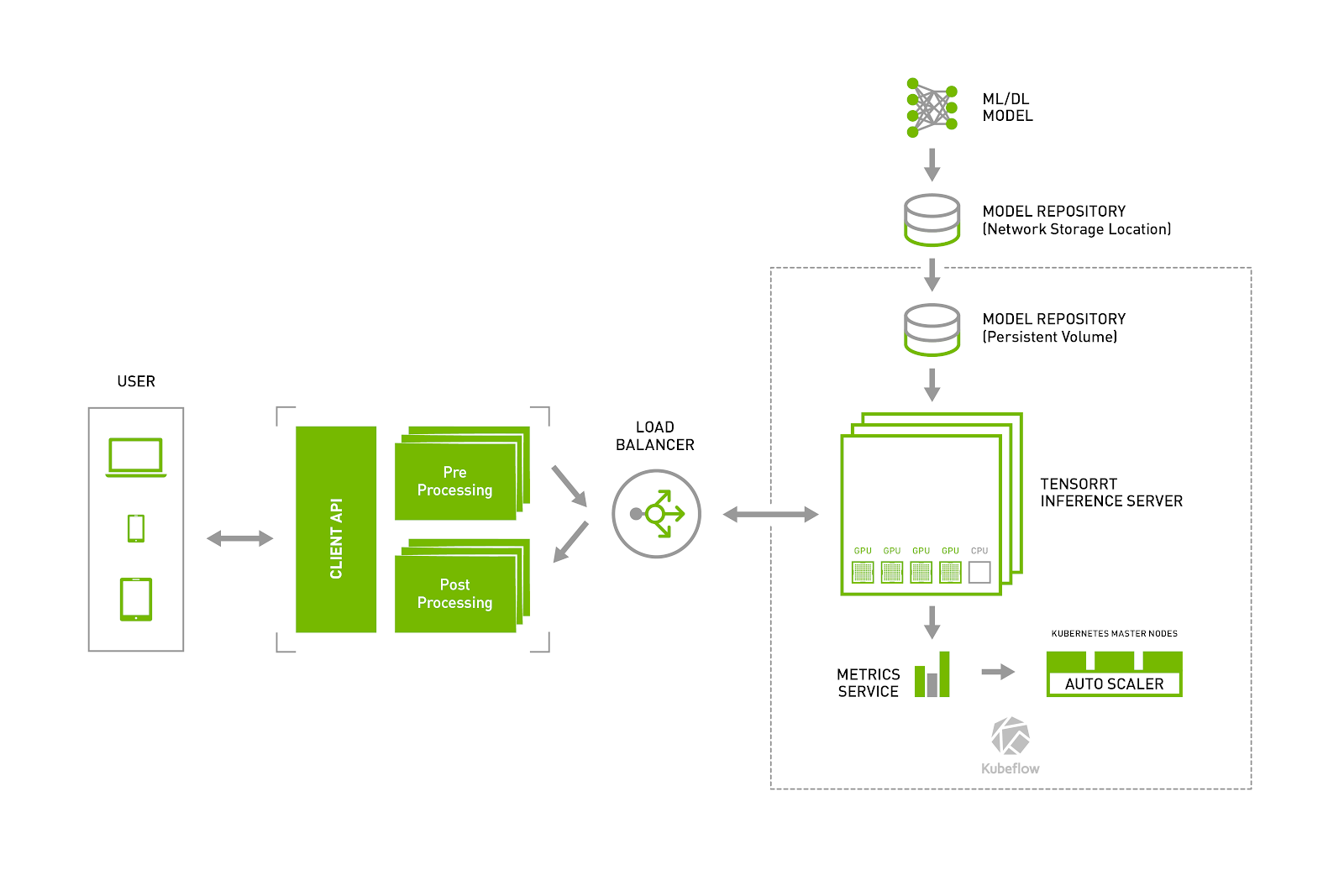

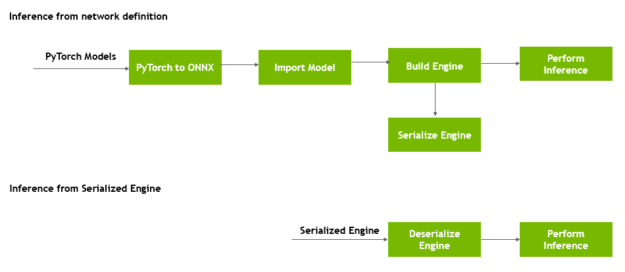







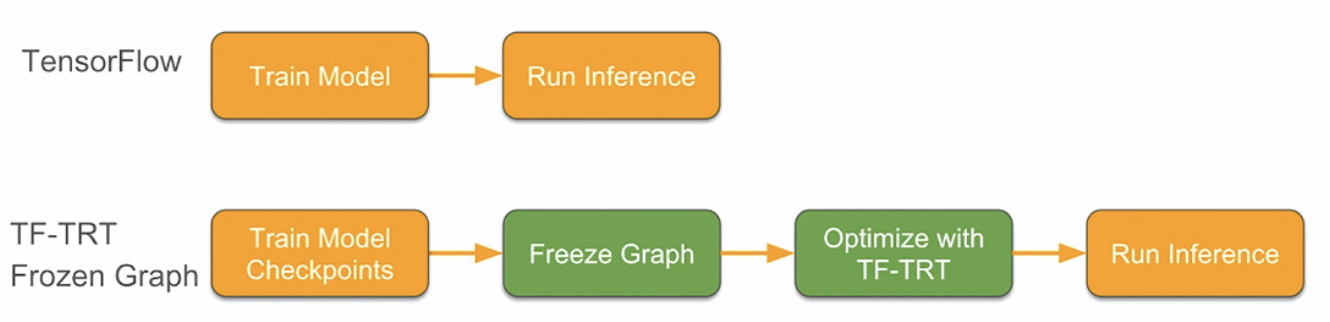








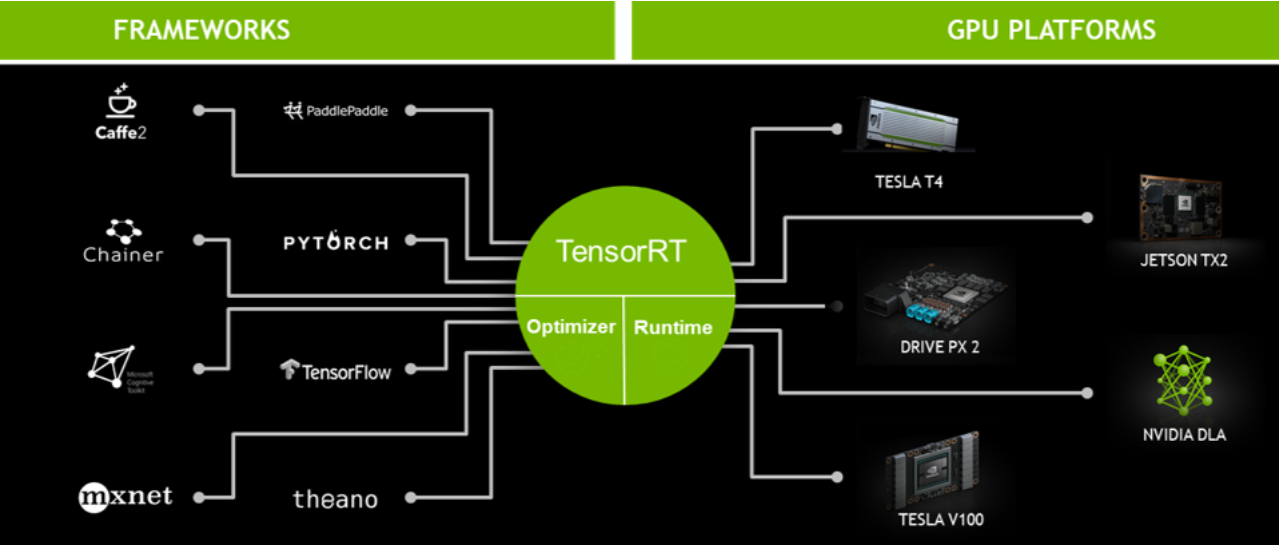

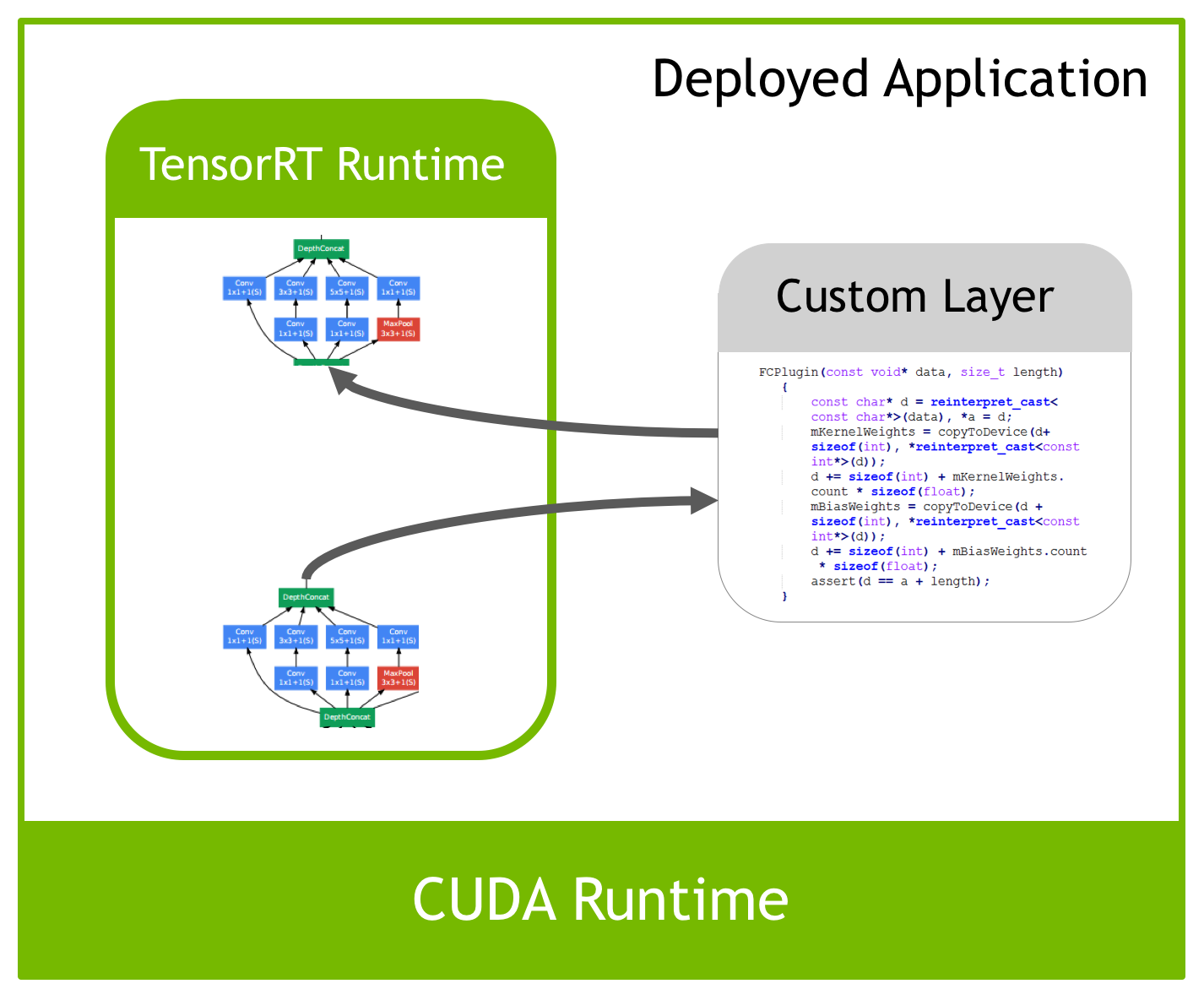
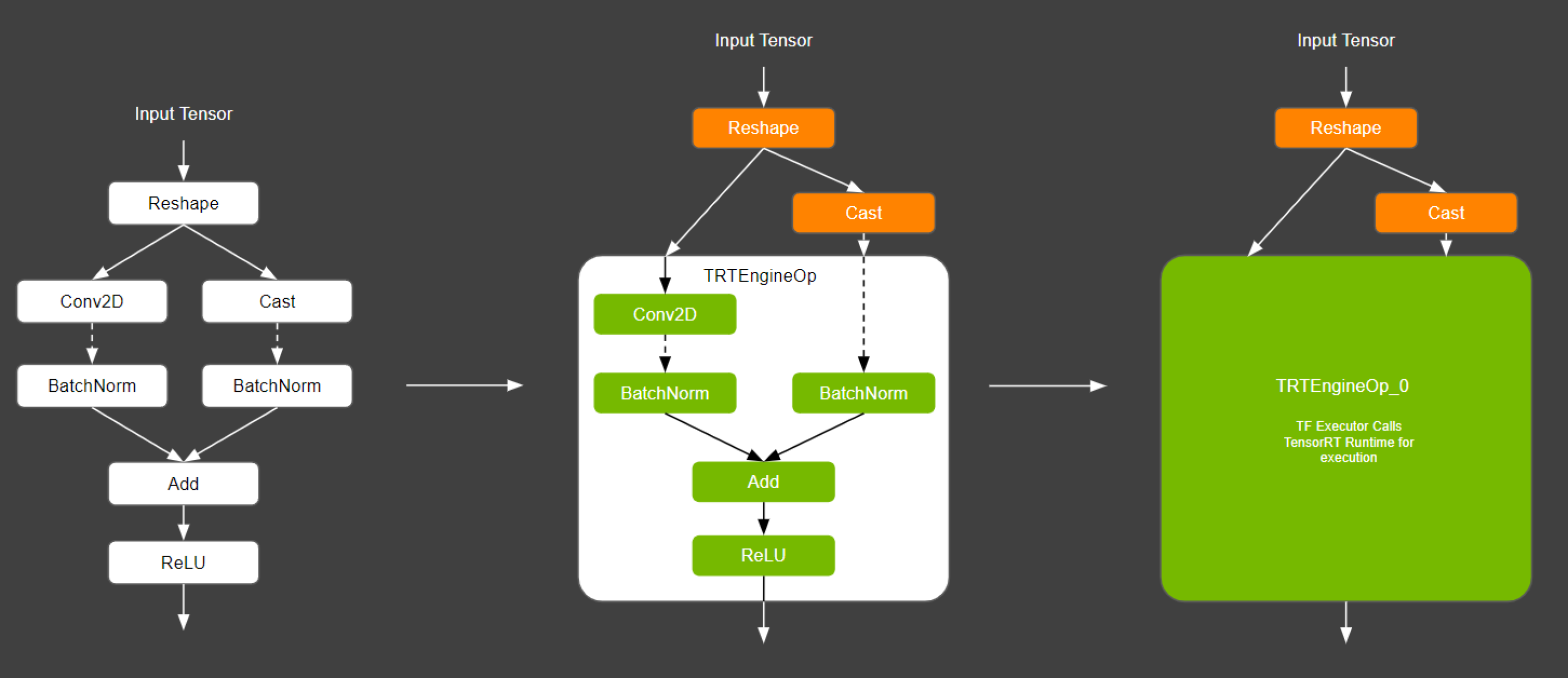








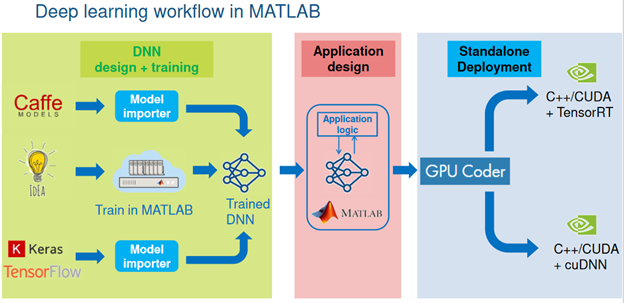




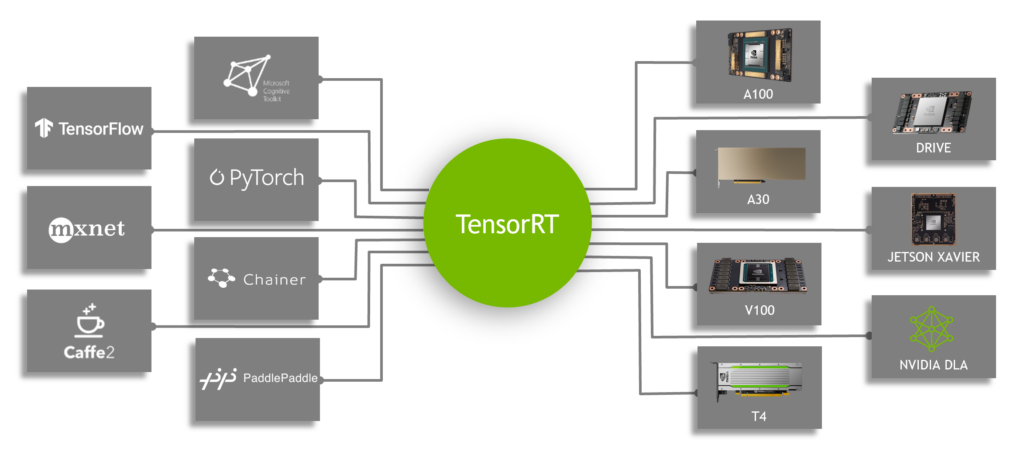

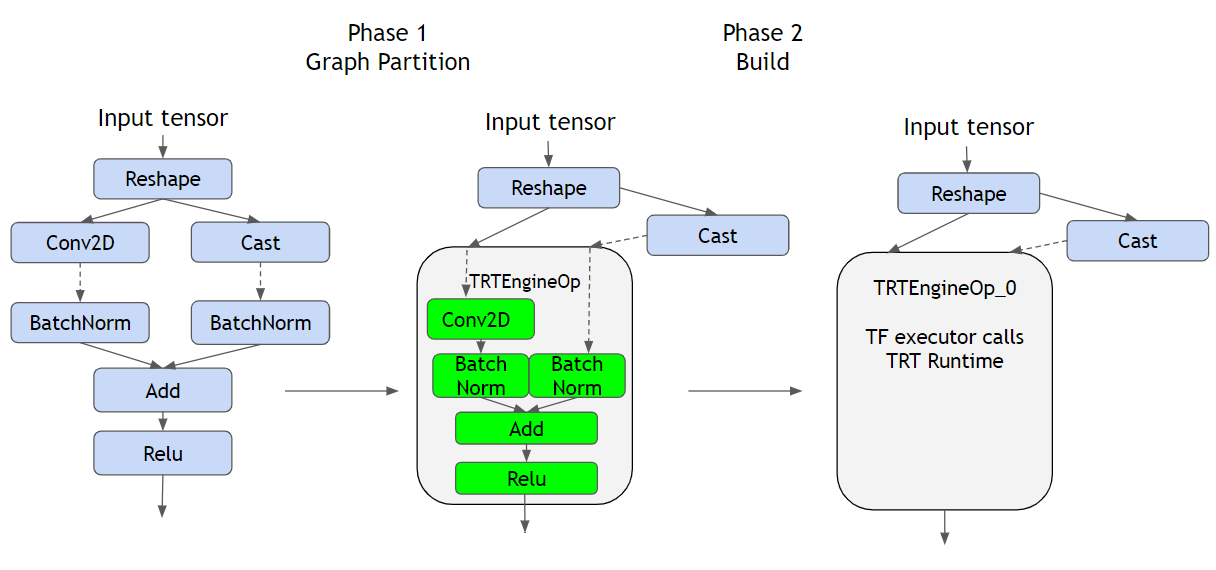
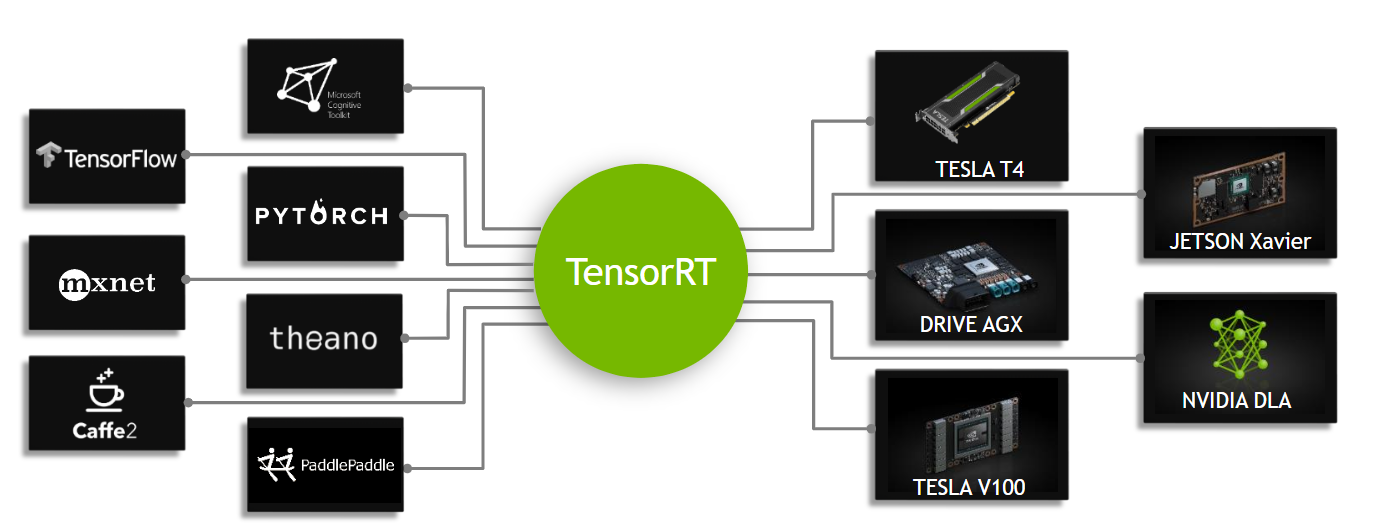















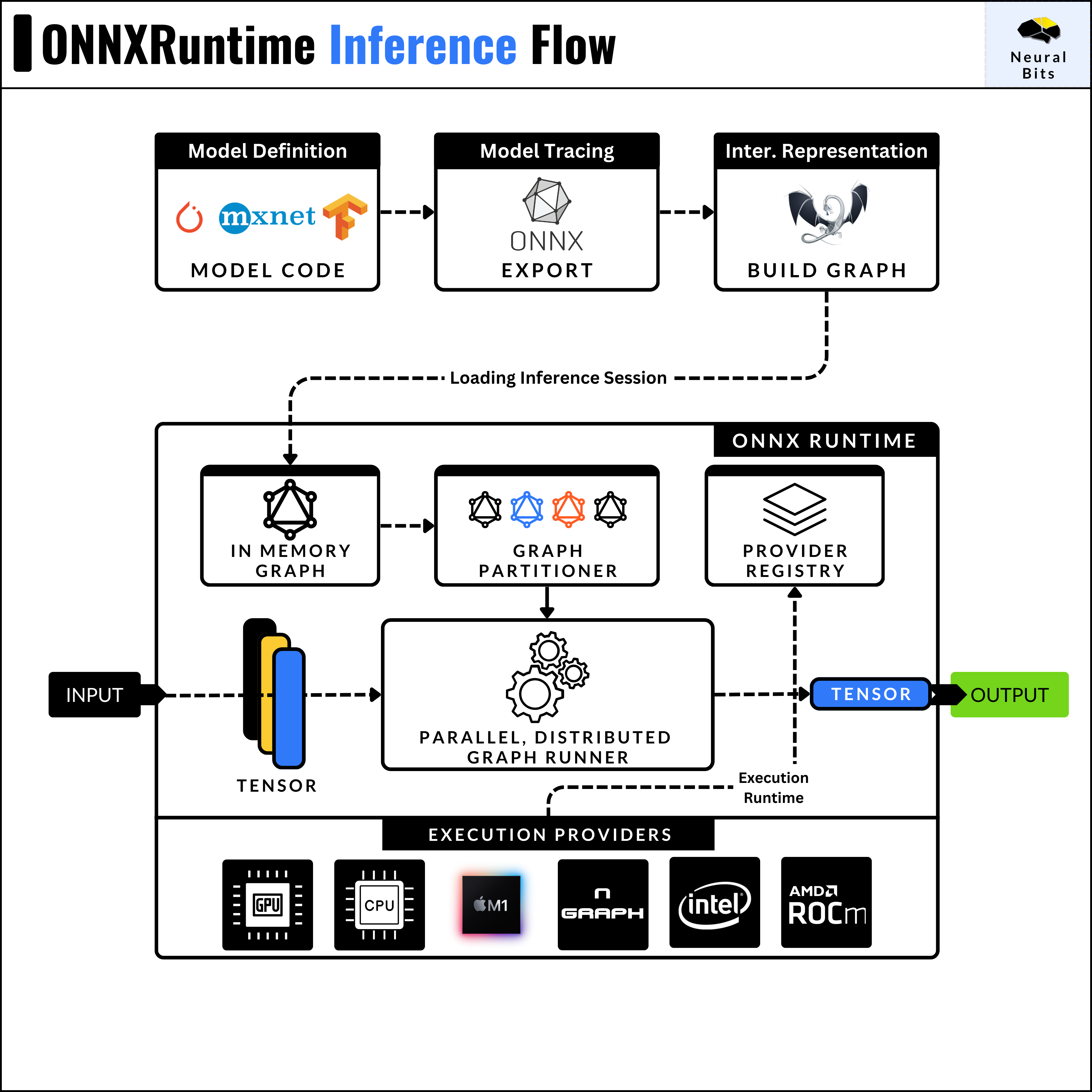



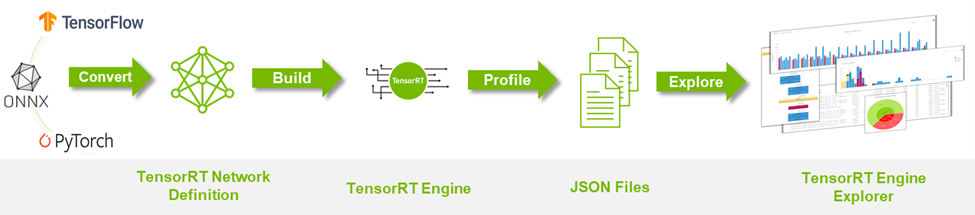

.png)