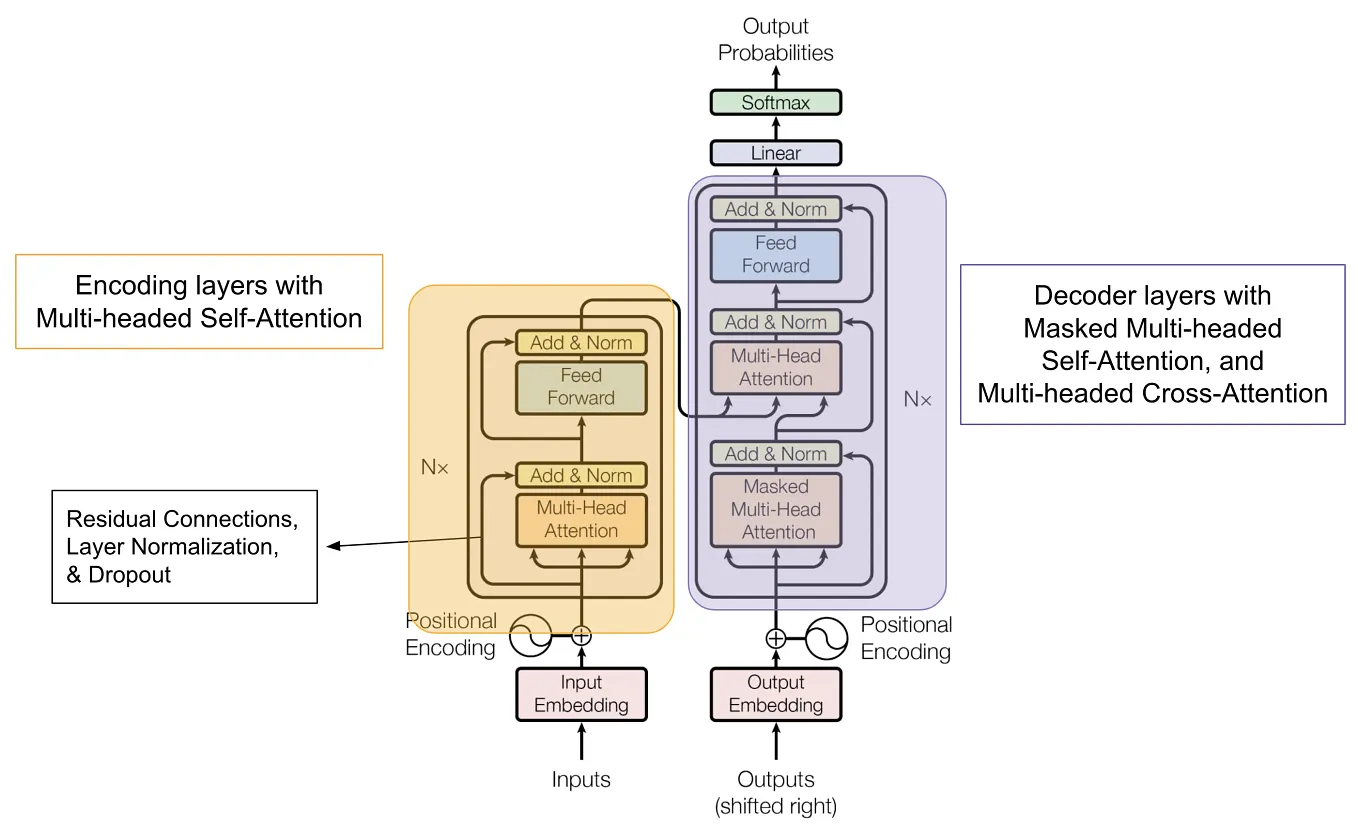
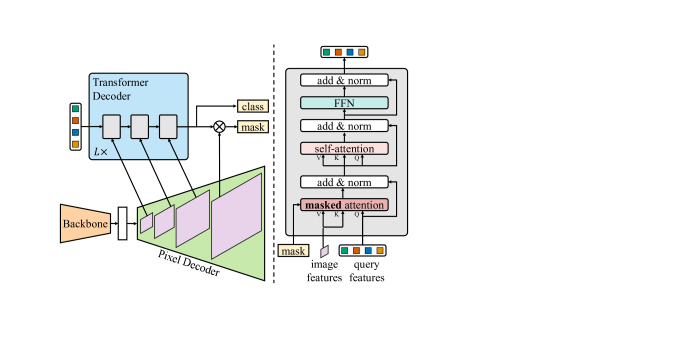
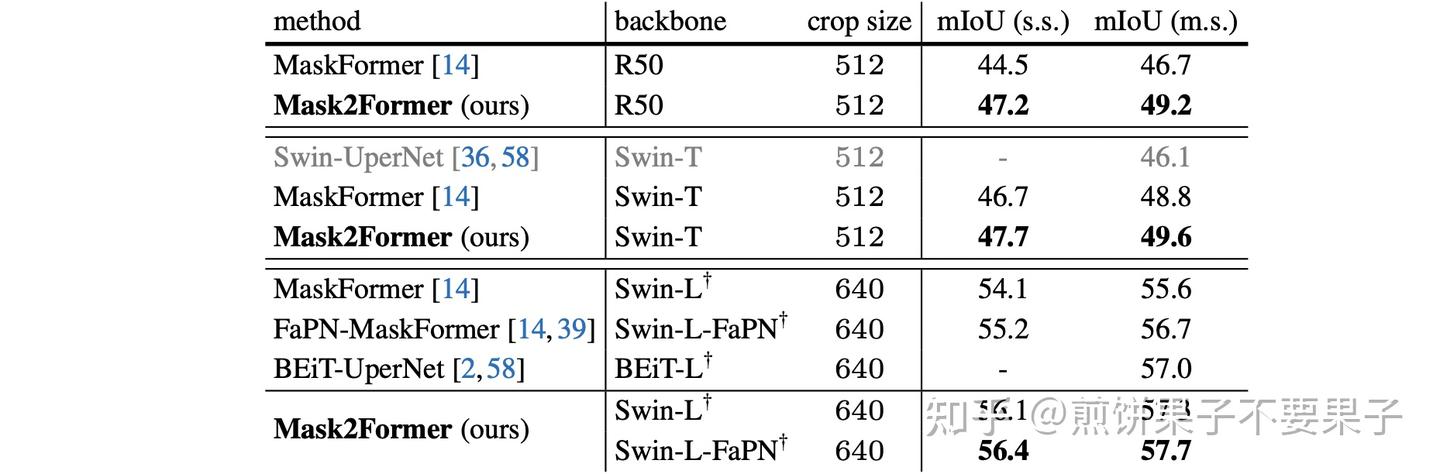
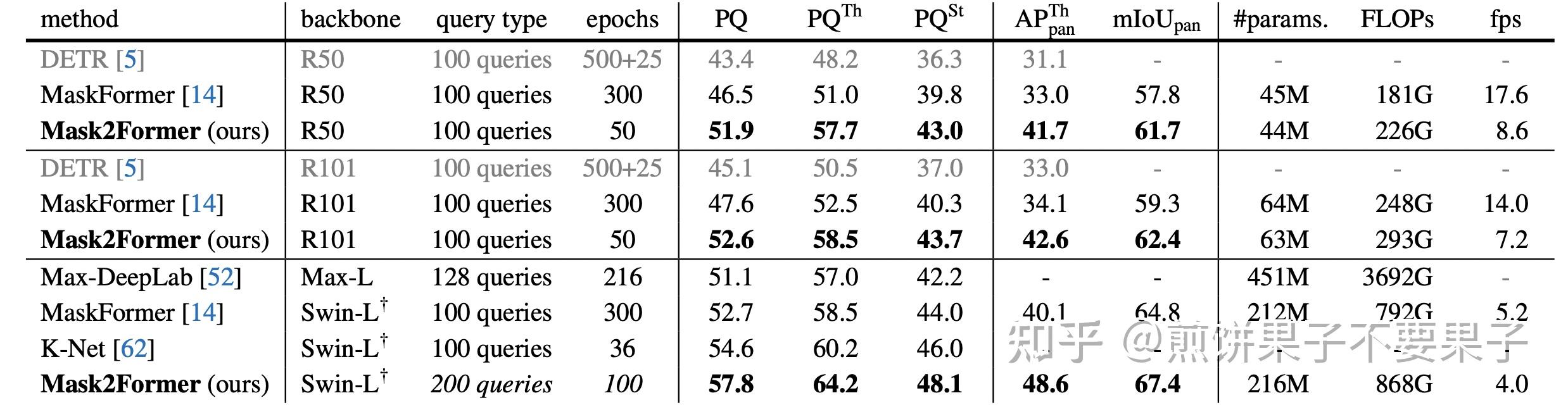
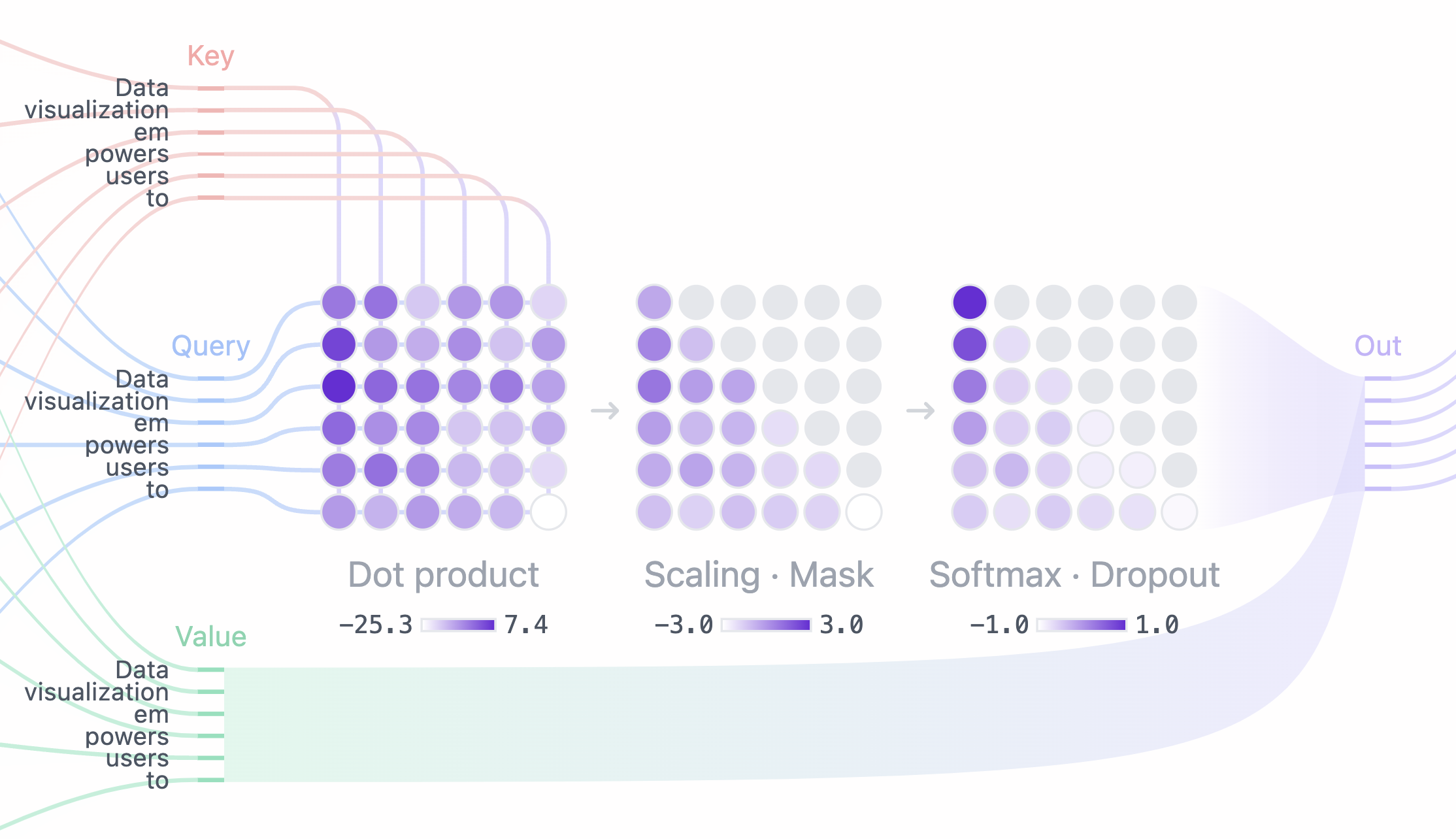
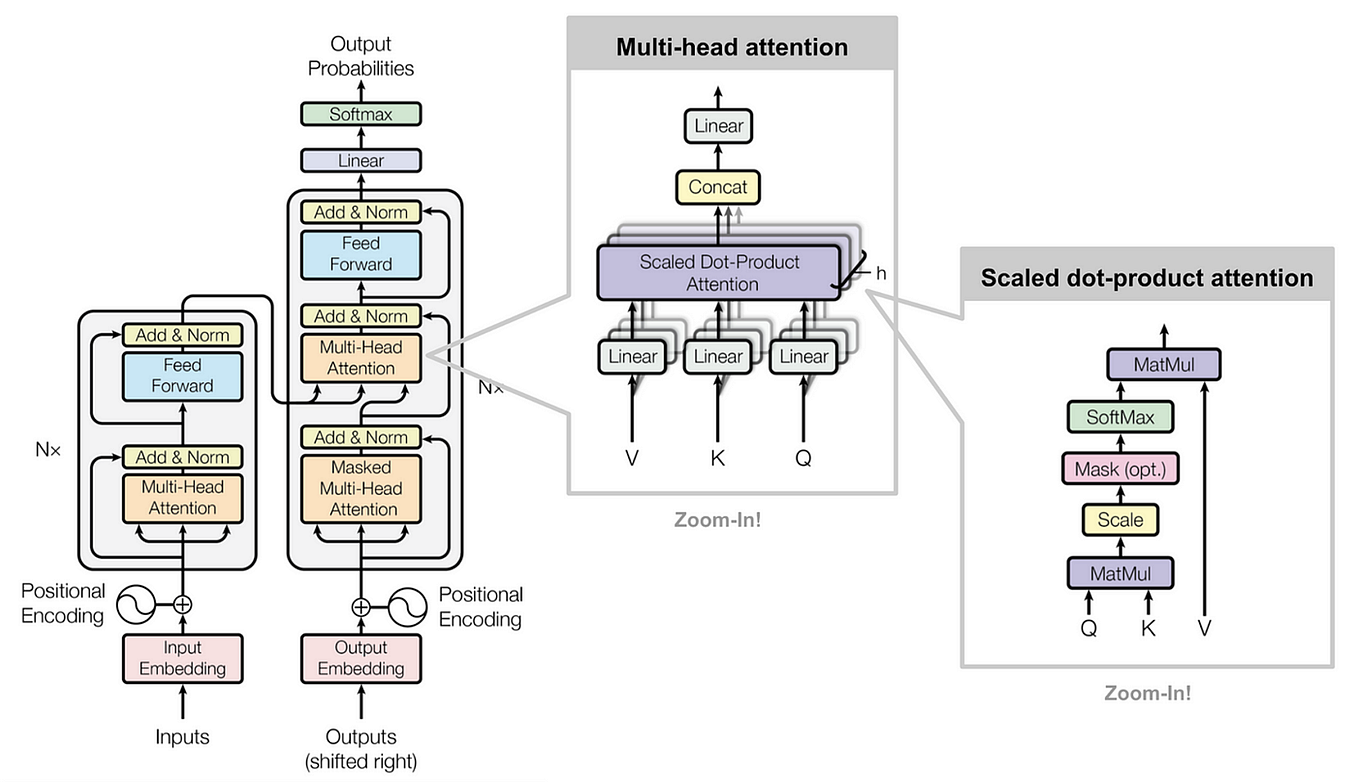
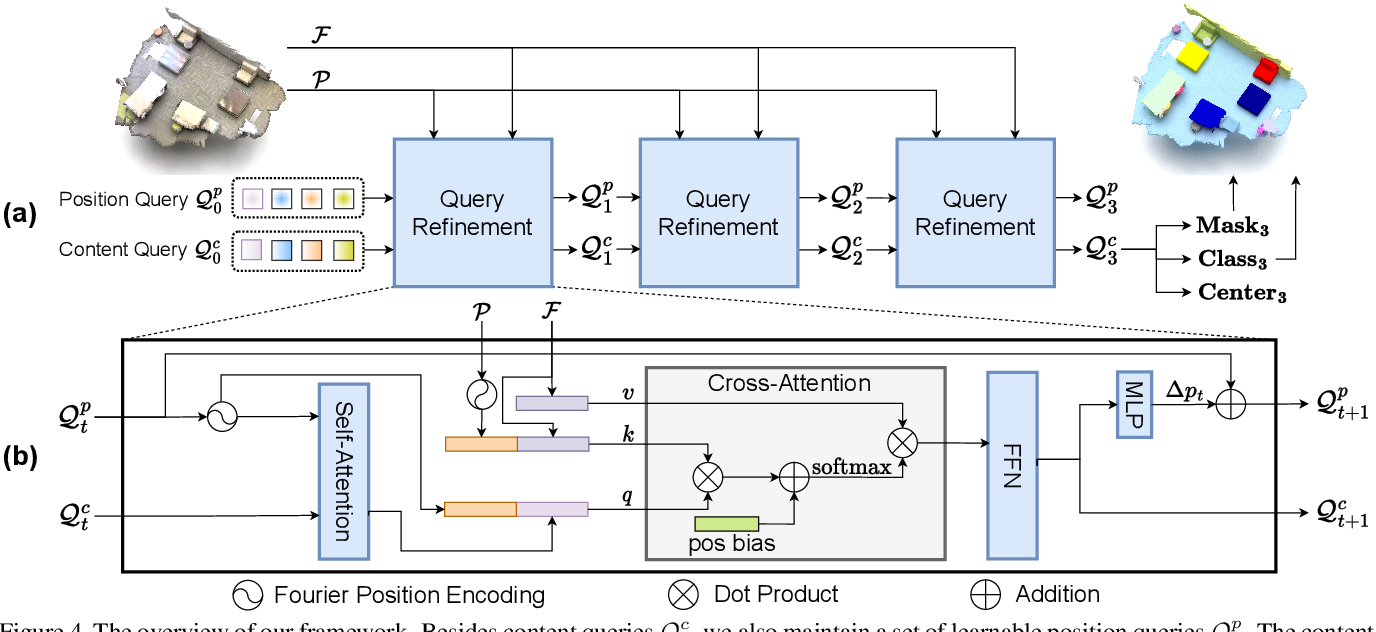
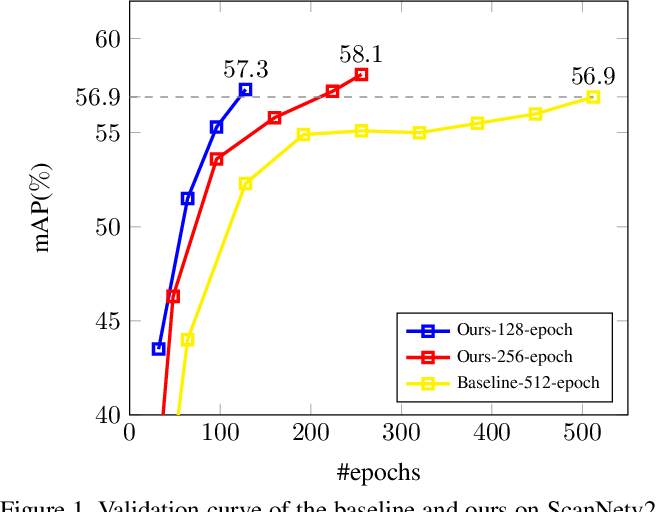
Showing 118 of 118on this page. Filters & sort apply to loaded results; URL updates for sharing.118 of 118 on this page
(PDF) Mask Attention Networks: Rethinking and Strengthen Transformer
TAMFormer: Multi-Modal Transformer with Learned Attention Mask for ...
Mask Attention Networks: Rethinking and Strengthen Transformer - ACL ...
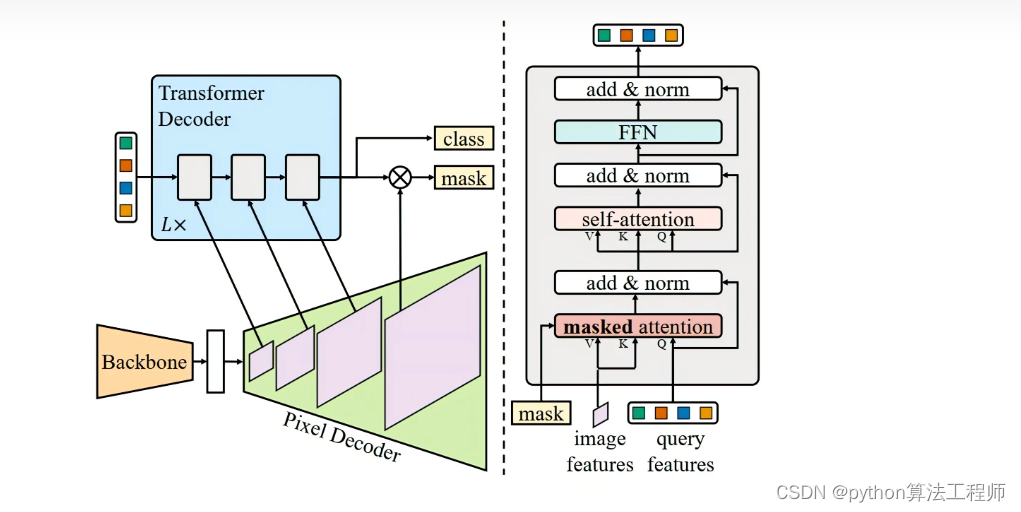
MaskFormer2 : Masked-attention Mask Transformer for Universal Image ...
How to implement seq2seq attention mask conviniently? · Issue #9366 ...
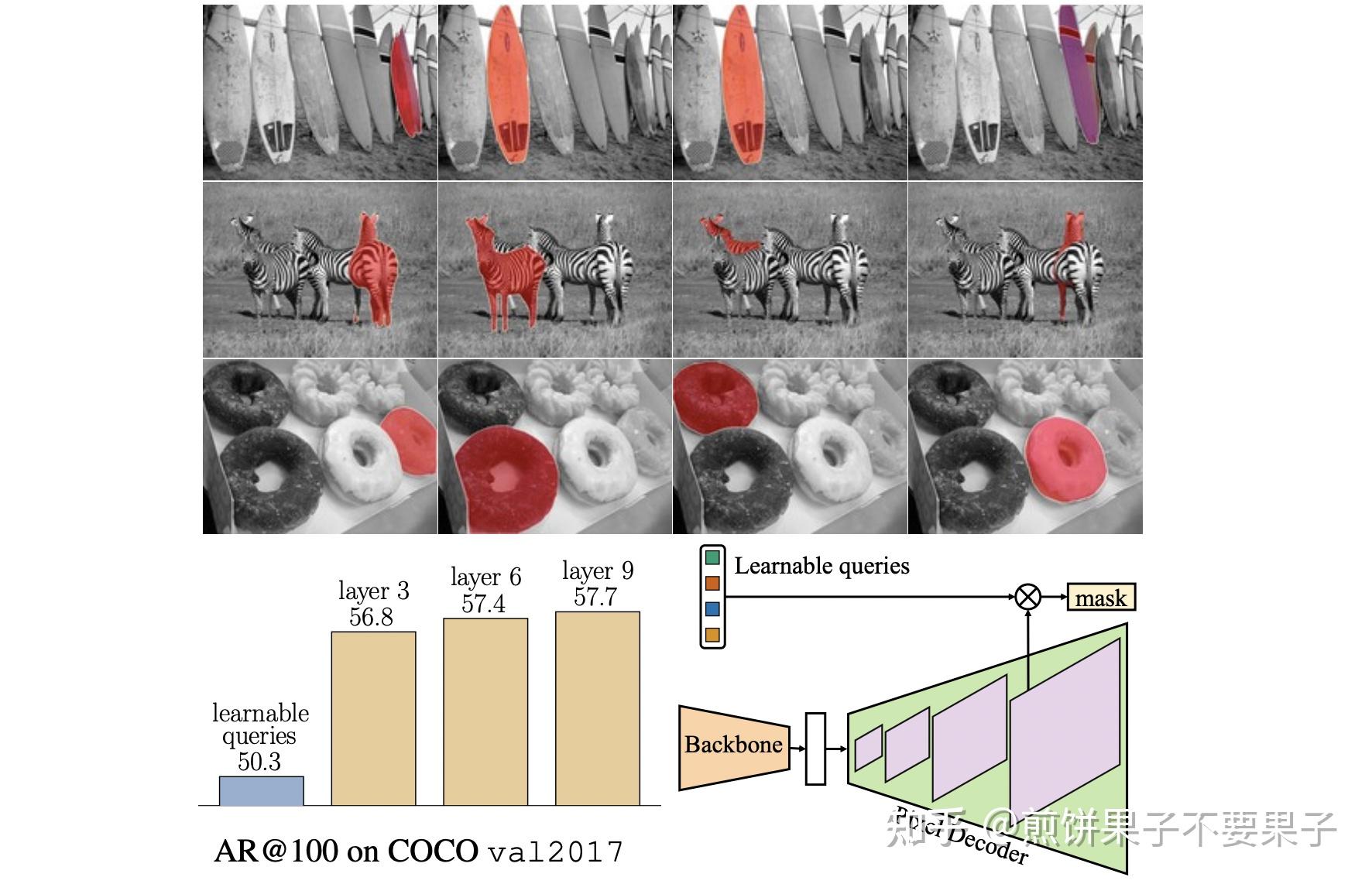
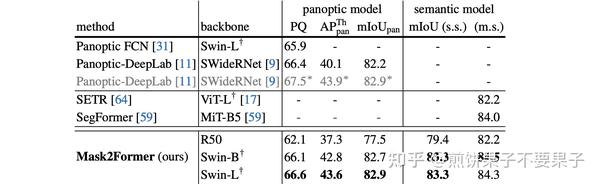
Mask2Former来了!用于通用图像分割的 Masked-attention Mask Transformer - 知乎
【论文笔记】Mask2Former: Masked-attention Mask Transformer for Universal ...
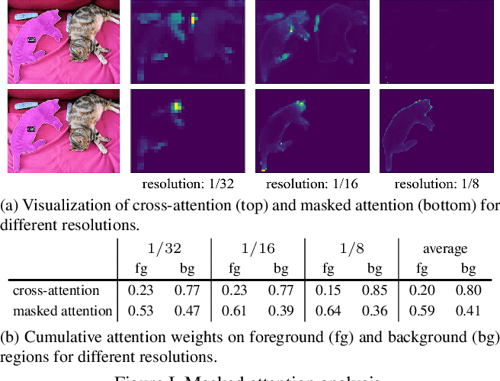
The detailed illustration of axial mask attention in P-transformer on ...
Figure 1 from Apply Masked-attention Mask Transformer to Instance ...
三十六章:Masked-attention Mask Transformer for Universal Image Segmentation ...
【Mask Attention】Masked-attention Mask Transformer for Universal Image ...
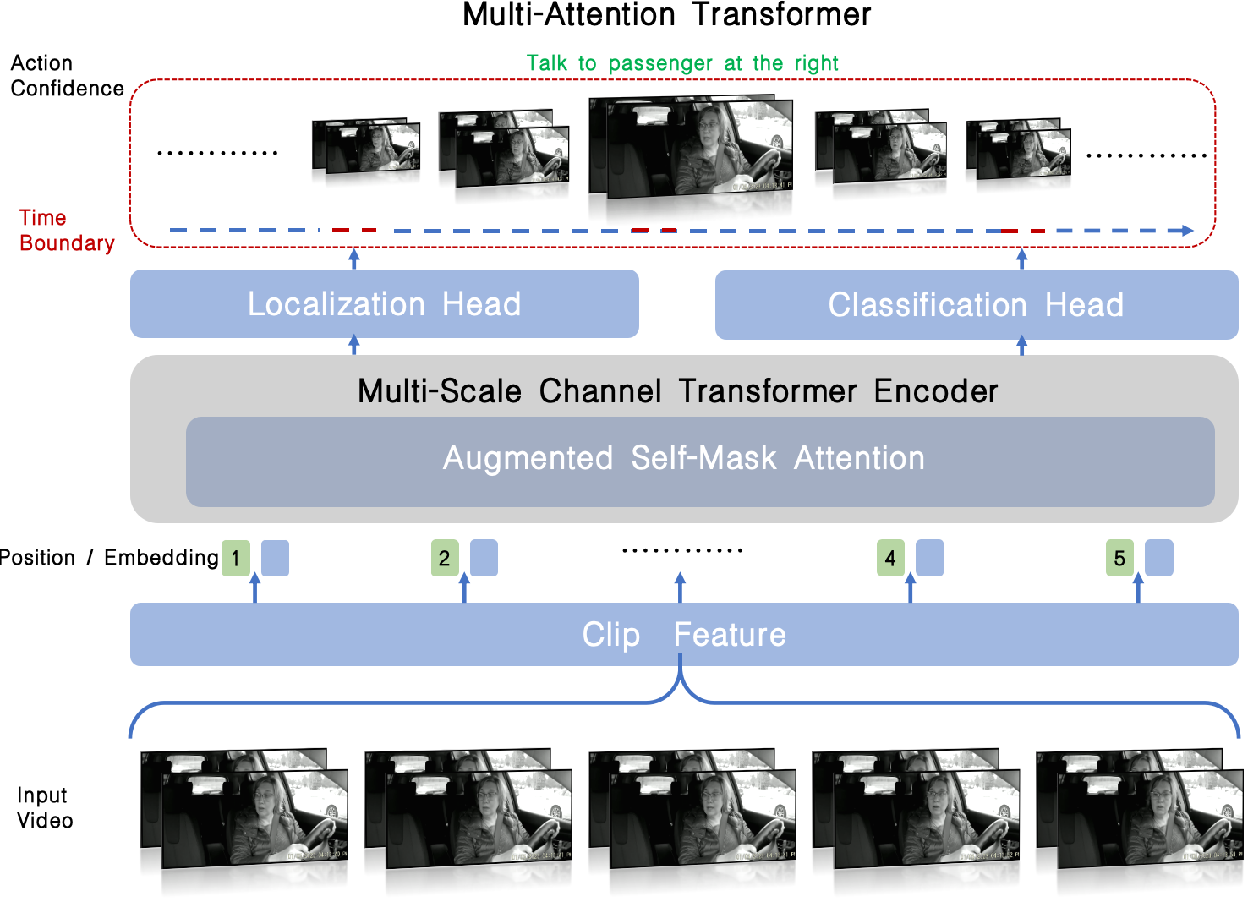
Figure 2 from Augmented Self-Mask Attention Transformer for ...
[Mask2Former] Masked-attention Mask Transformer for Universal Image ...
Learning JAX by Building Flexible Transformer Attention Masks: From ...
Revisiting Mask Transformer from a Clustering Perspective
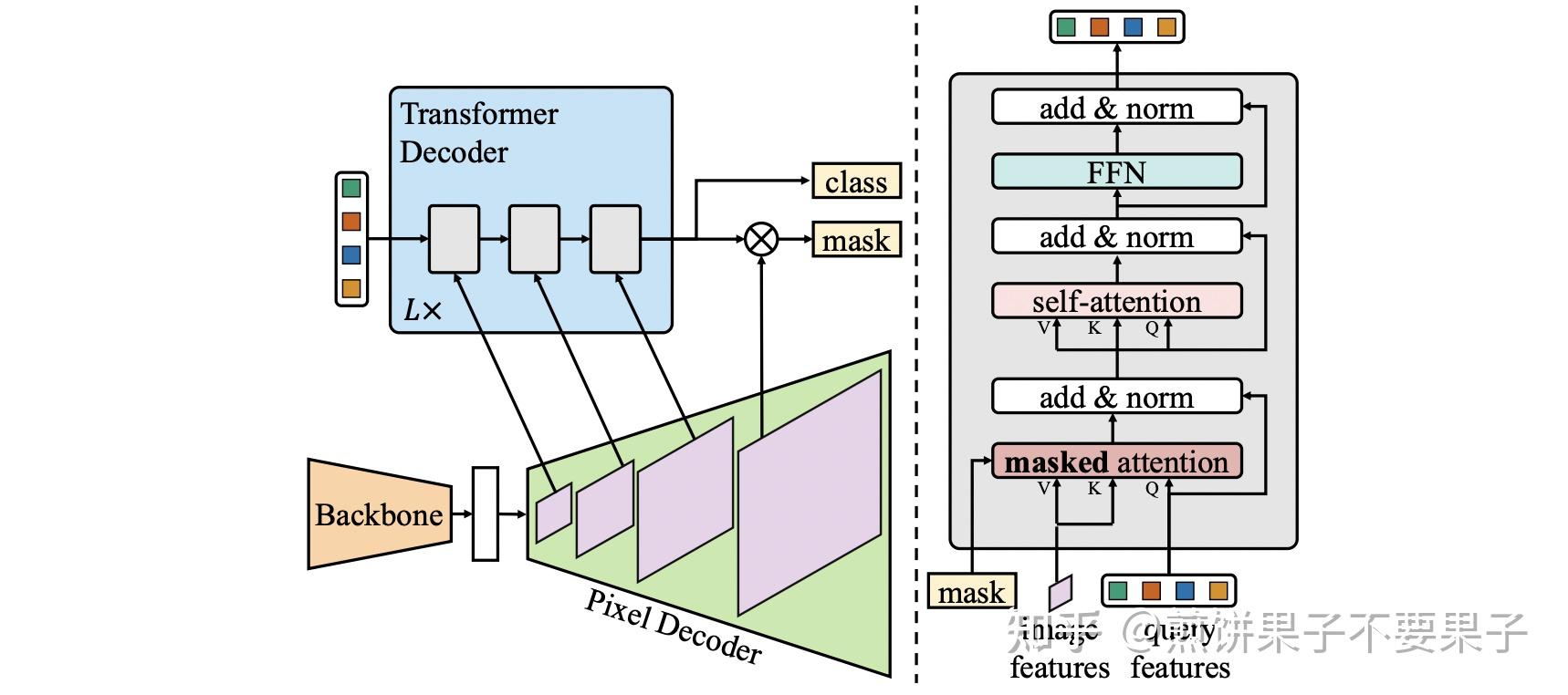
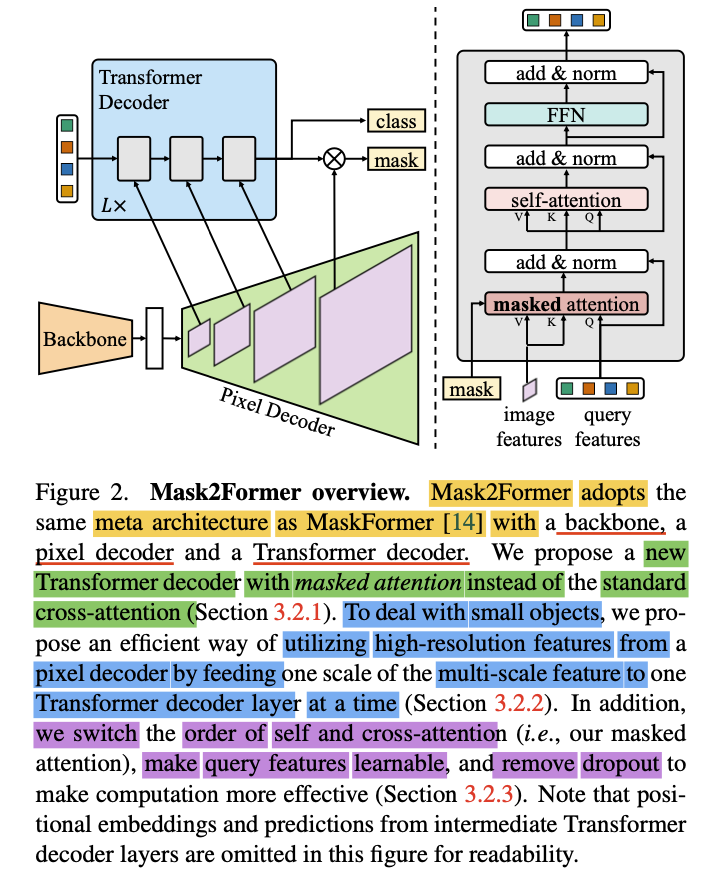
Masked-attention Mask Transformer for Universal Image Segmentation ...
[PDF] Masked-attention Mask Transformer for Universal Image ...
Paper page - Masked-attention Mask Transformer for Universal Image ...
Allow passing 2D attention mask · Issue #27640 · huggingface ...
Masked-attention Mask Transformer for Universal Image Segmentation | DeepAI
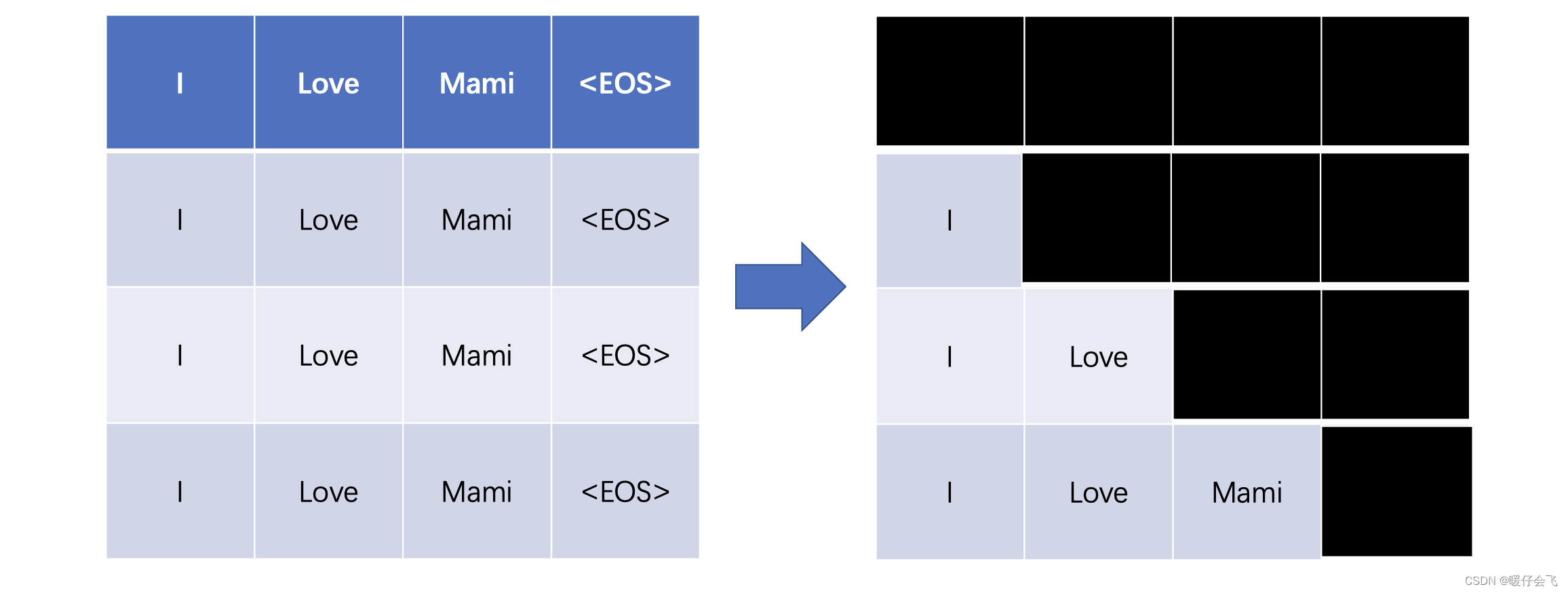
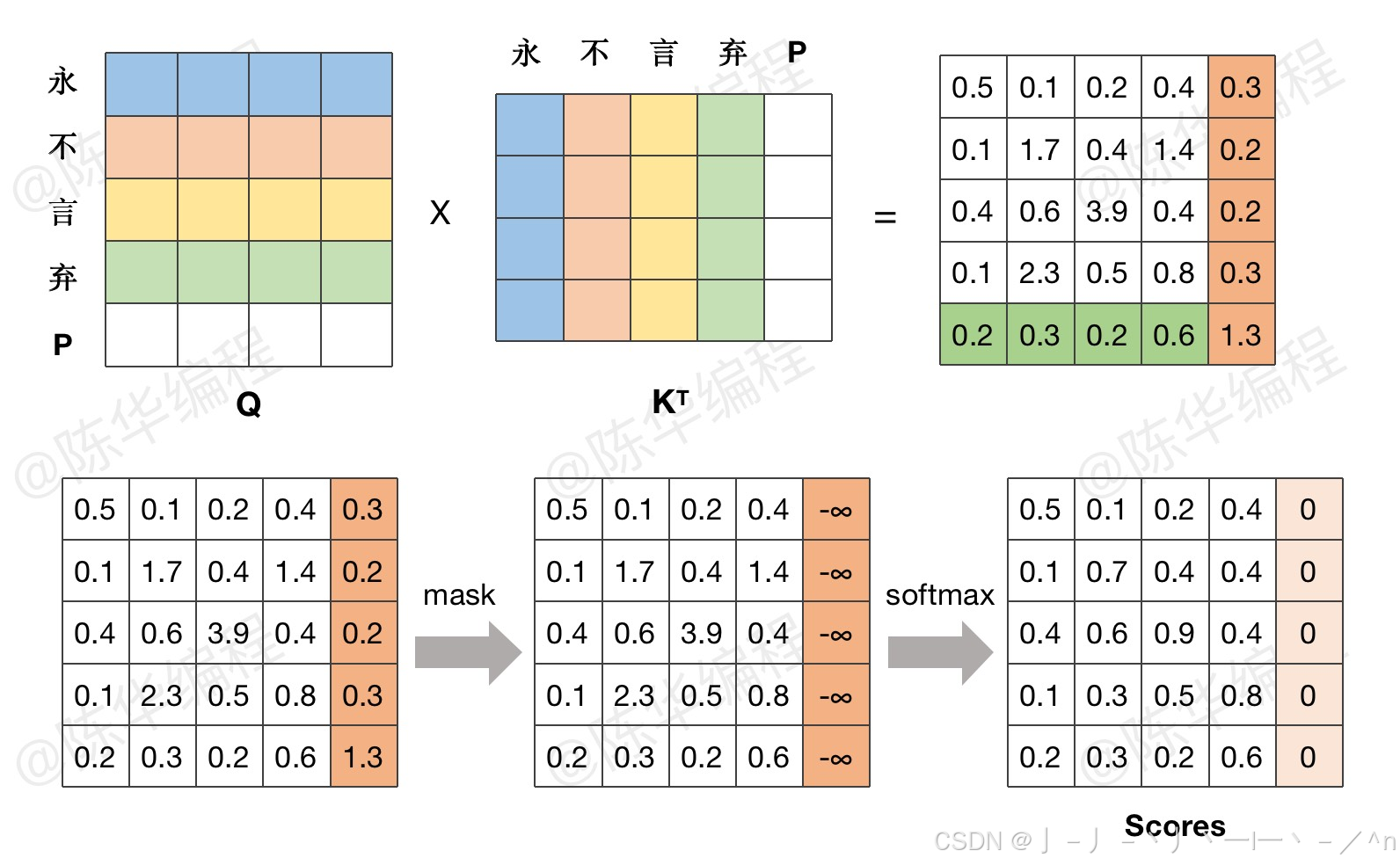
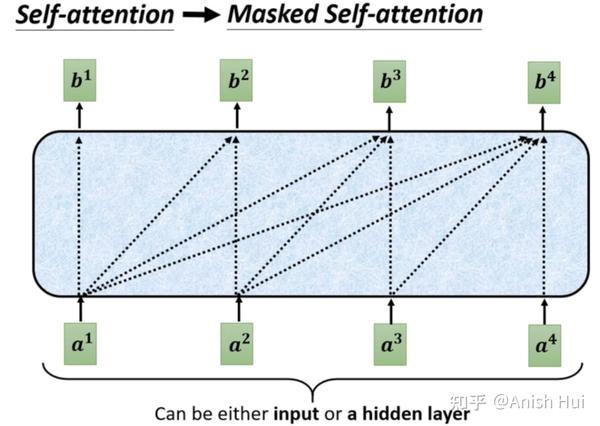
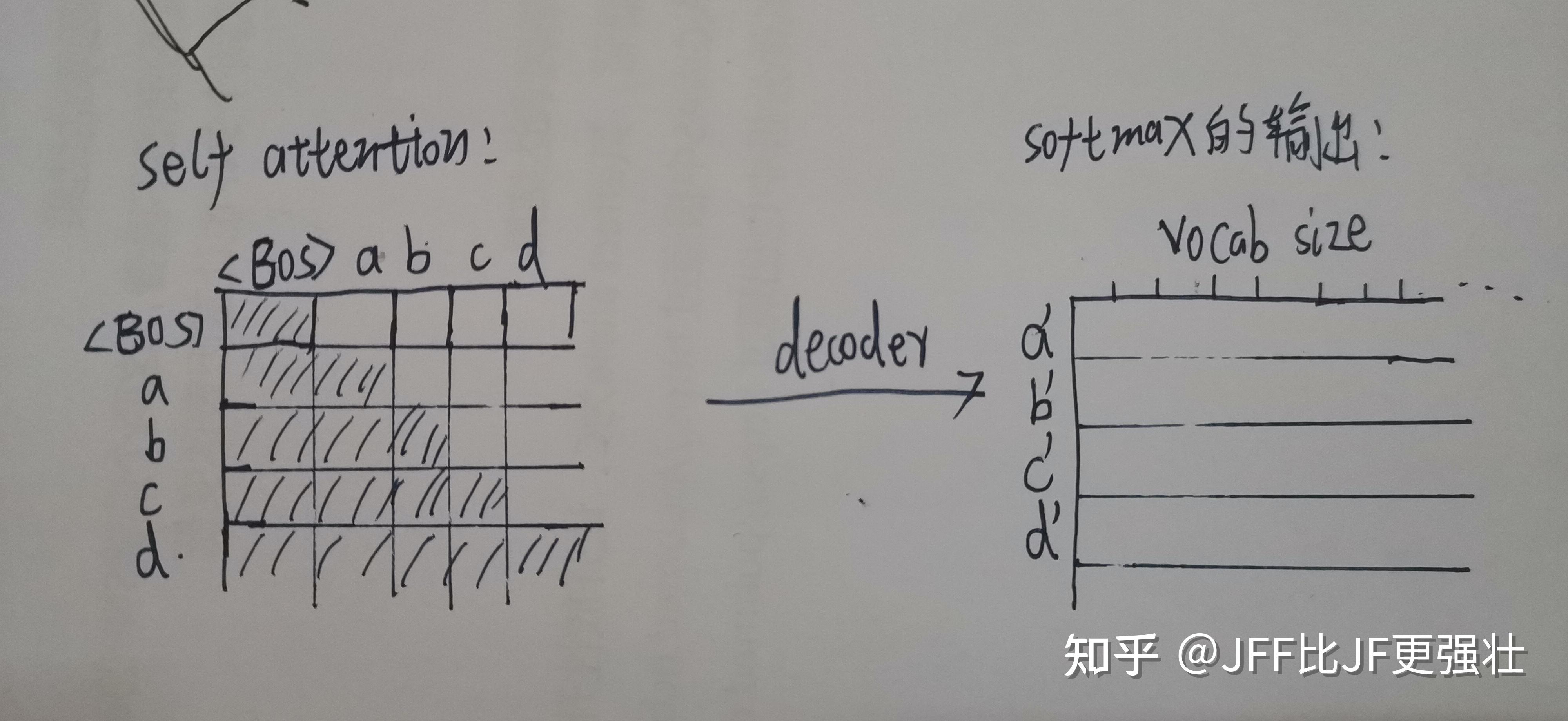
Transformer 解读之:用一个小故事轻松掌握 Decoder 端的 Masked Attention,为什么要使用 Mask ...
Hands-On Transformer Deep Dive: Part 1 — Masked Attention Explained ...
81 .Masked Attention in Transformer | PDF
Masked Multi Head Attention in Transformer | by Sachinsoni | Medium
【Mask2Former】Masked-attention Mask Transformer for Universal Image ...
A Gentle Introduction to Attention Masking in Transformer Models ...
The Transformer Attention Mechanism - MachineLearningMastery.com
(PDF) FastVDT: Fast Transformer With Optimised Attention Masks and ...
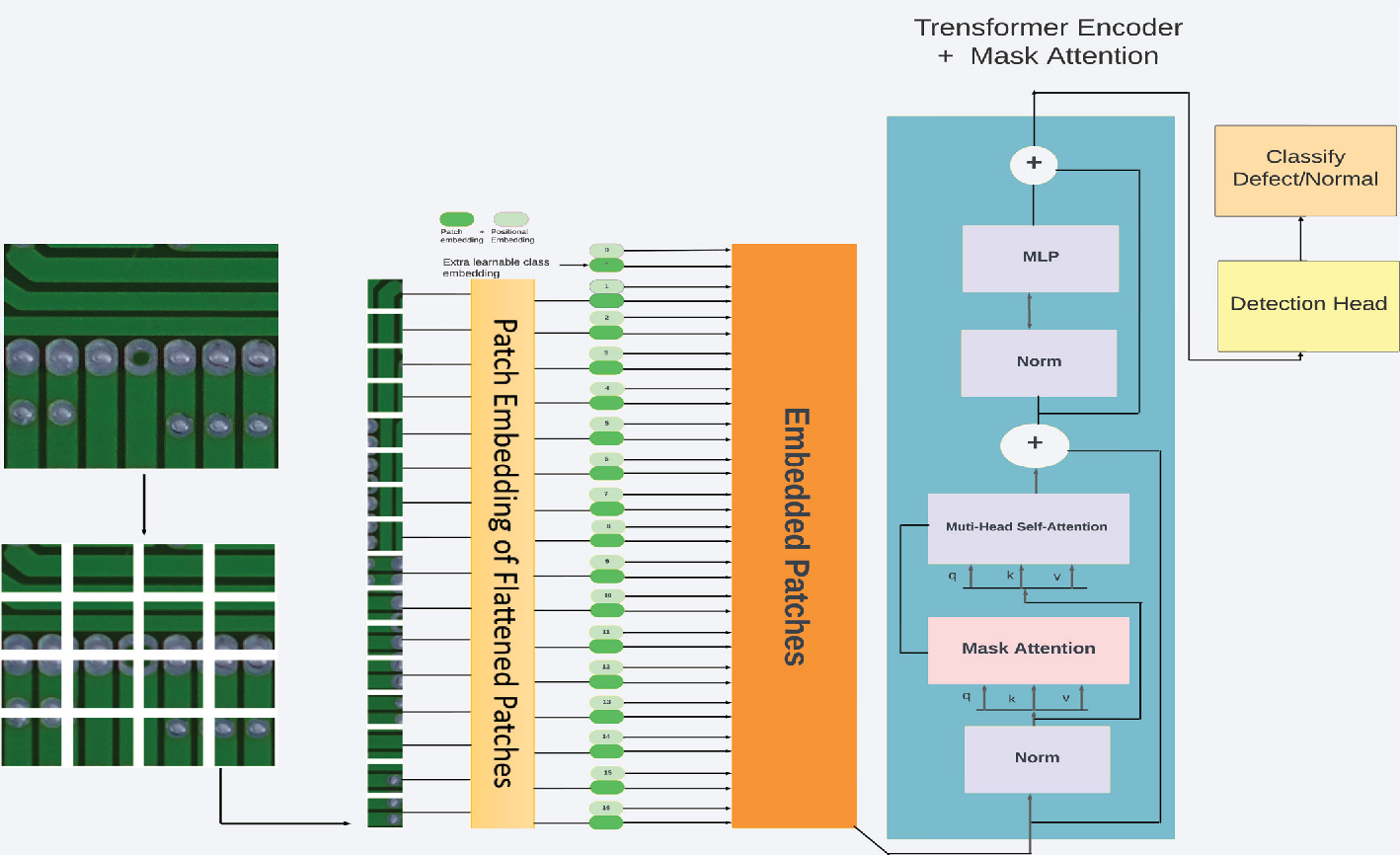
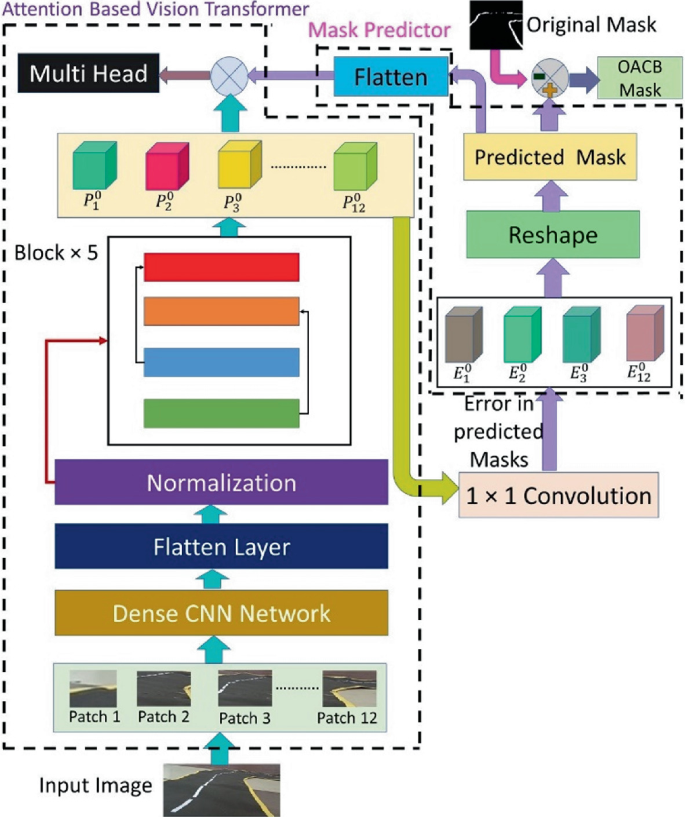
Figure 1 from Mask Attention-Based Vision Transformer (MA-ViT) for PCB ...
Exploring Masked Attention in Transformer Models: A Technique for ...
GitHub - yashbonde/mask_attention_transformer: Simple attention APIs ...
Glossing over the T5: Text-to-Text Transfer Transformer | Nihal D'Souza
Mask2Former来了!用于通用图像分割的 Masked-attention Mask Transformer-CSDN博客
Mask-Attention-Free Transformer for 3D Instance Segmentation
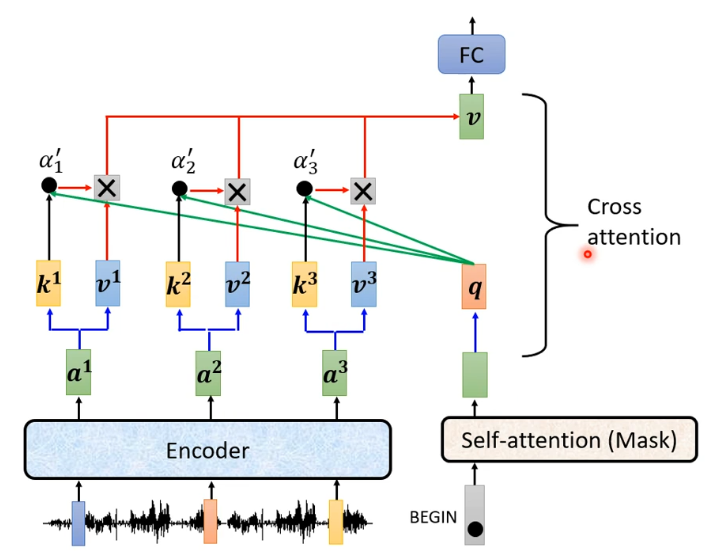
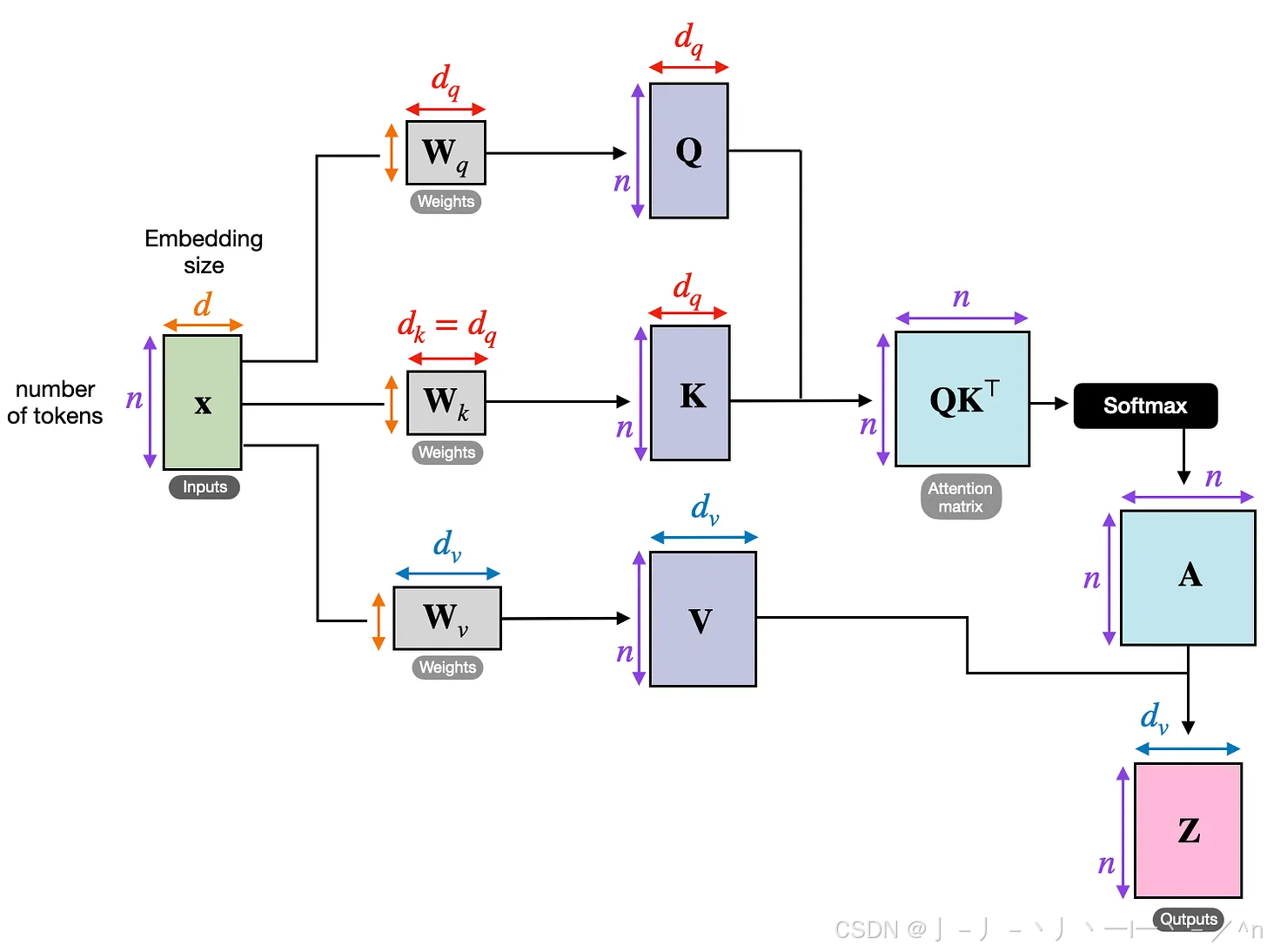
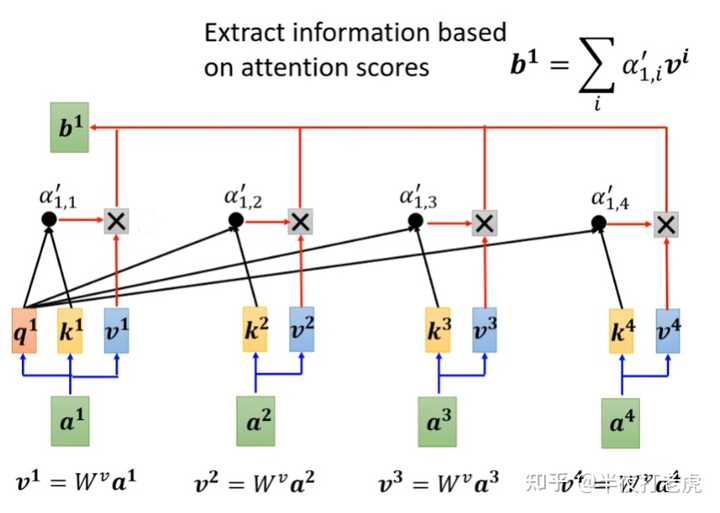
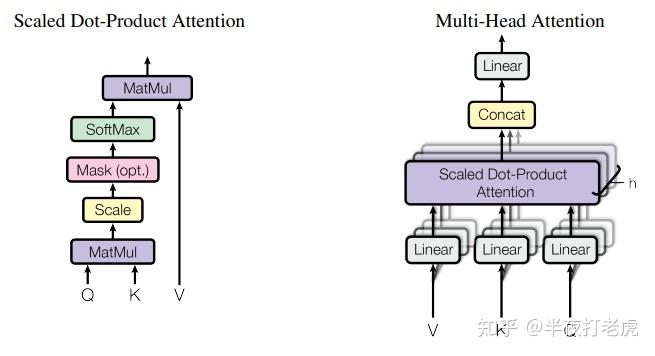
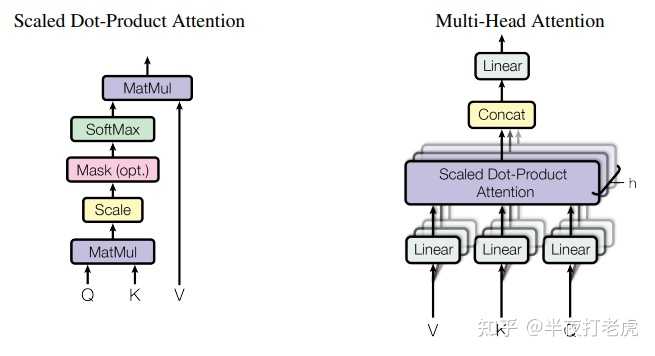
图解Transformer模型(Multi-Head Attention)_transformer multi-head attention ...
The Transformer Model
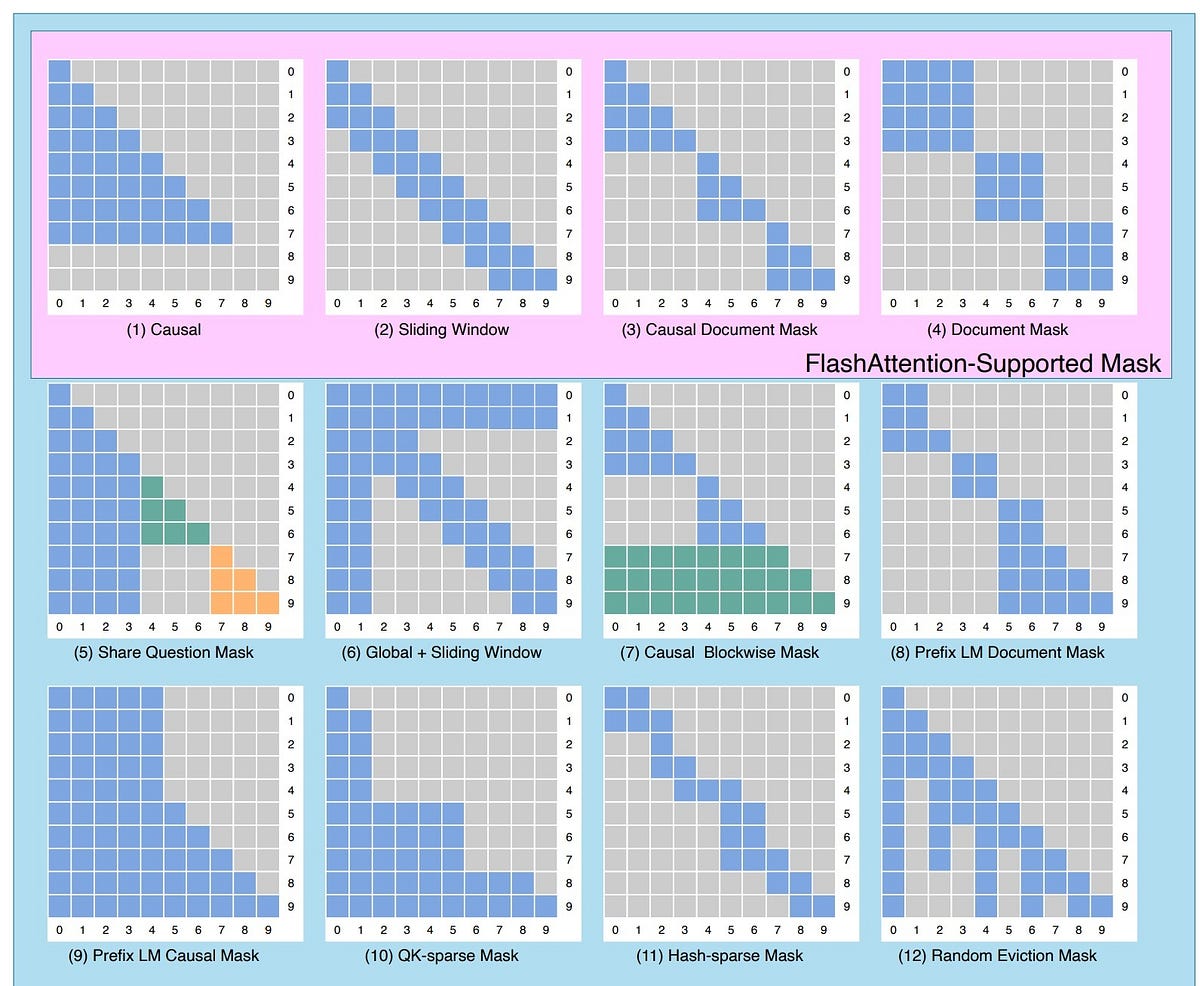
Illustration of the three types of attention masks for a hypothetical ...
(PDF) Mask-Attention-Free Transformer for 3D Instance Segmentation
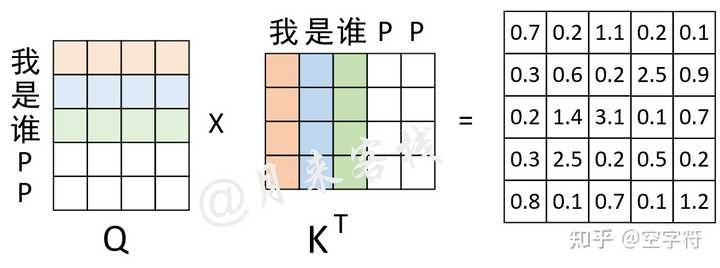
从训练和预测的角度来理解Transformer中Masked Self-Attention的原理_masked self attention ...
The Illustrated Transformer From Scratch - Innovative Digital ...
Advanced Transformer Architectures in Modern LLMs
Figure 2 from Mask-Attention-Free Transformer for 3D Instance ...
Transformers Mask Superhero Mask A4 Size Ready to Print Digital ...
Masked Attention Transformers - Sequence Models - DeepLearning.AI
Megatron Mask | Transformers Megatron Mask | Superhero Mask | A4 Size ...
(PDF) TableStructureFormer: an improved masked-attention mask ...
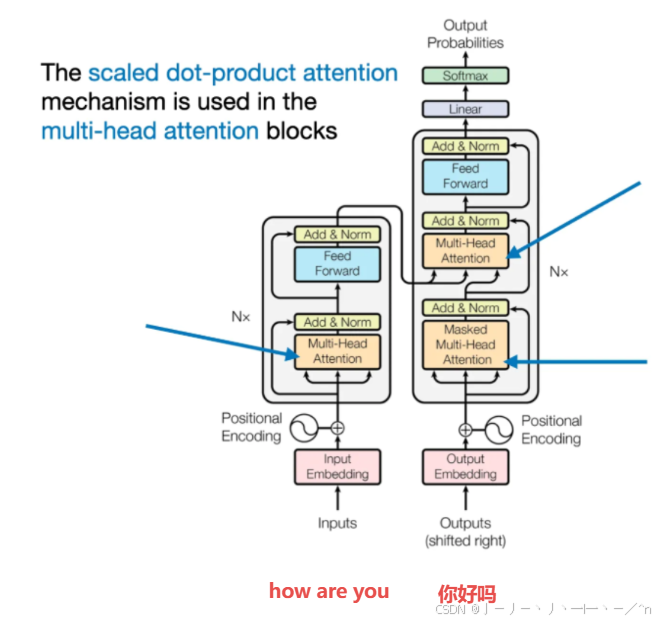
Transformer Explainer: LLM Transformer Model Visually Explained
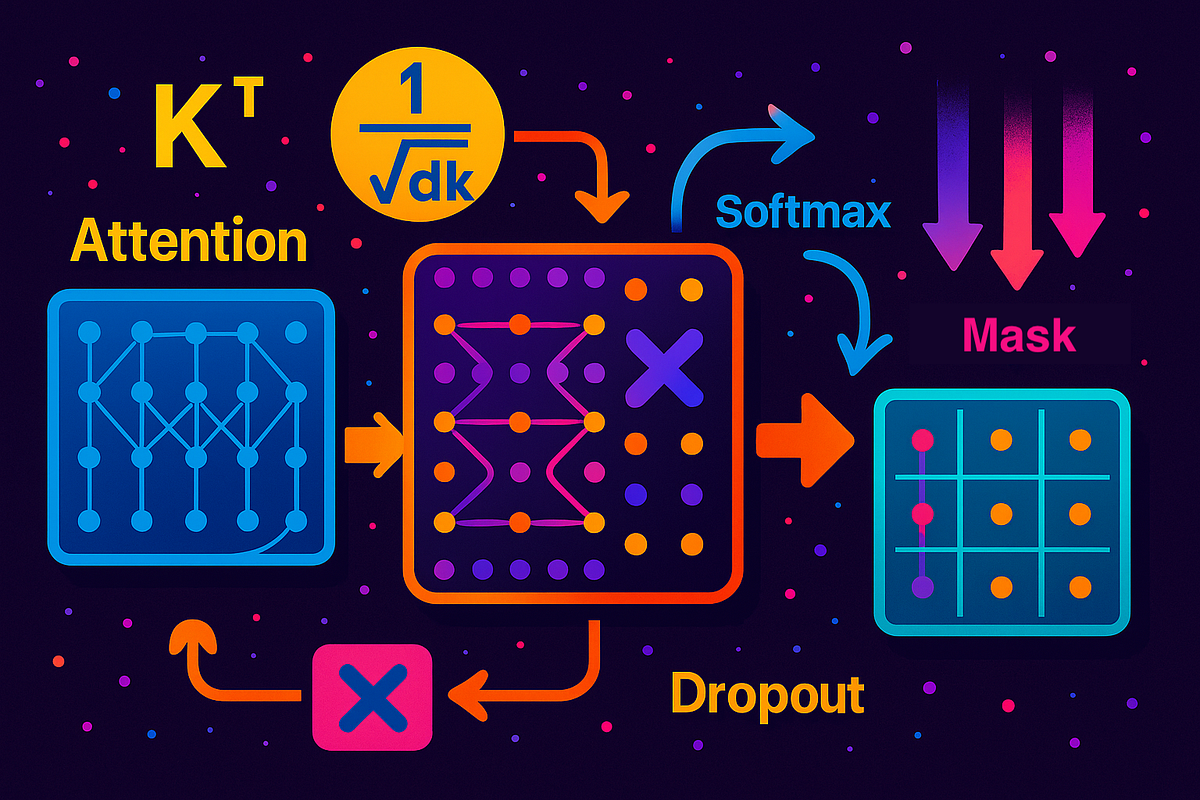
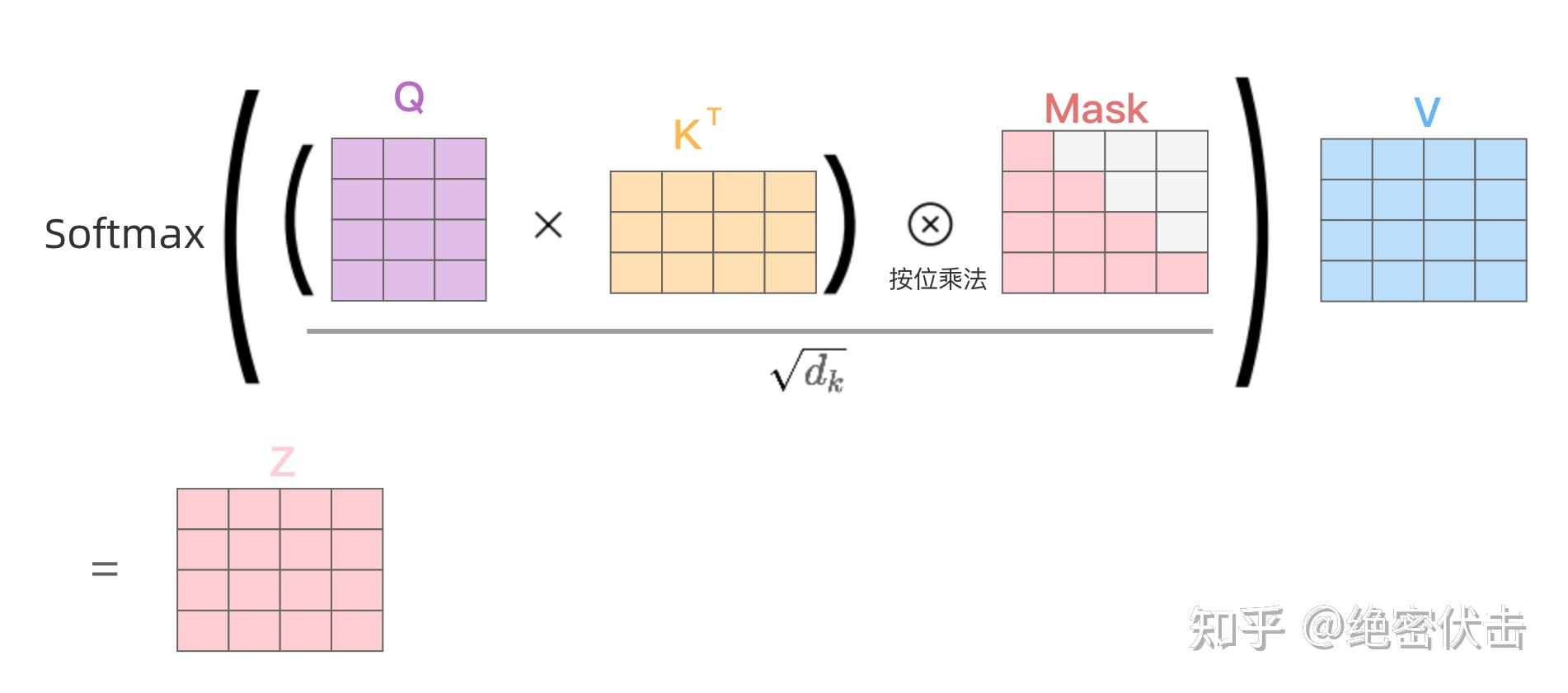
Transformer 中self-attention以及mask操作的原理以及代码解析_mask self attention-CSDN博客
Transformer step by step--Masked Self-Attention_mask self attention-CSDN博客
Transformer Architectures - Hugging Face LLM Course
What is the role and significance of attention masks in models ...
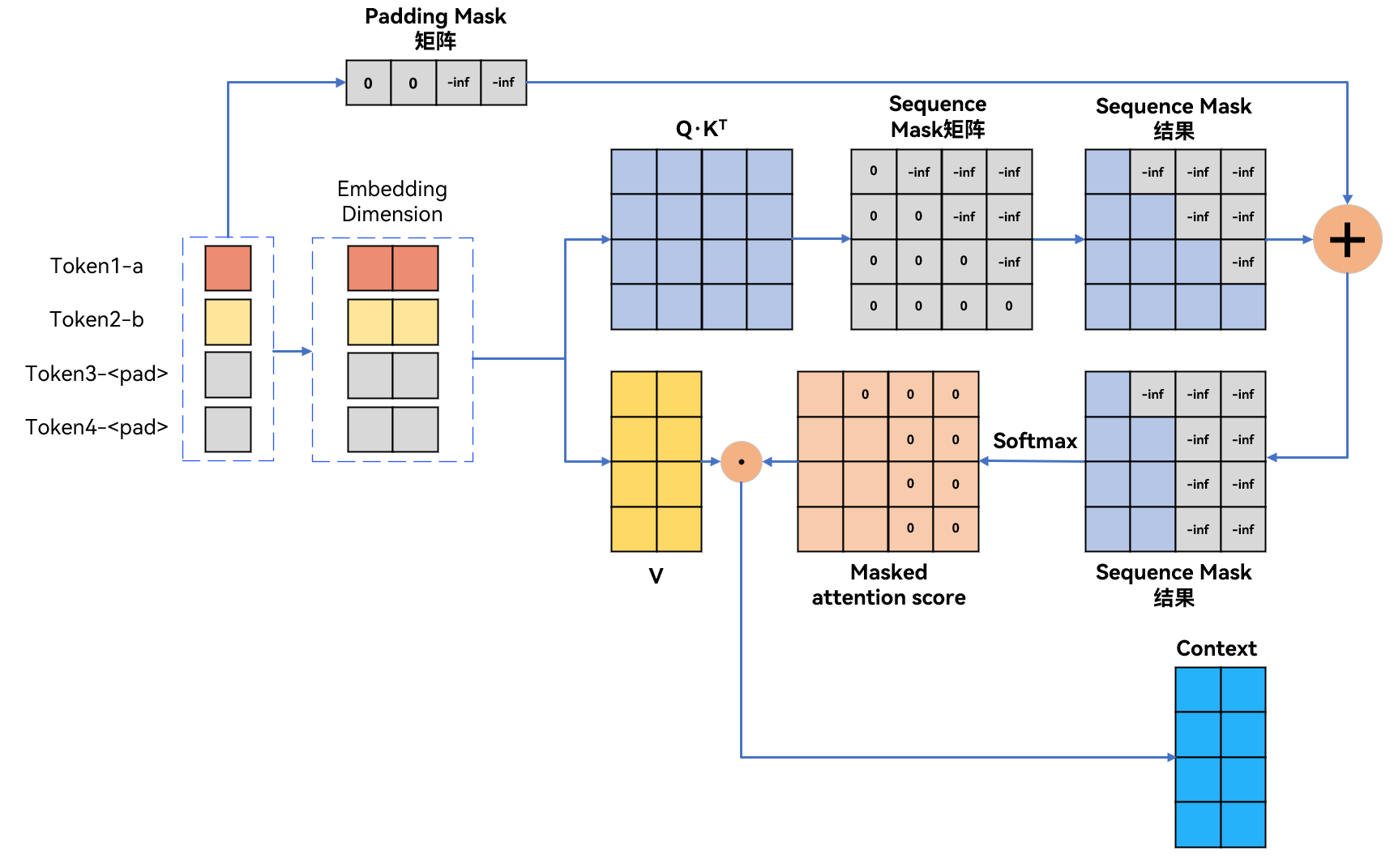
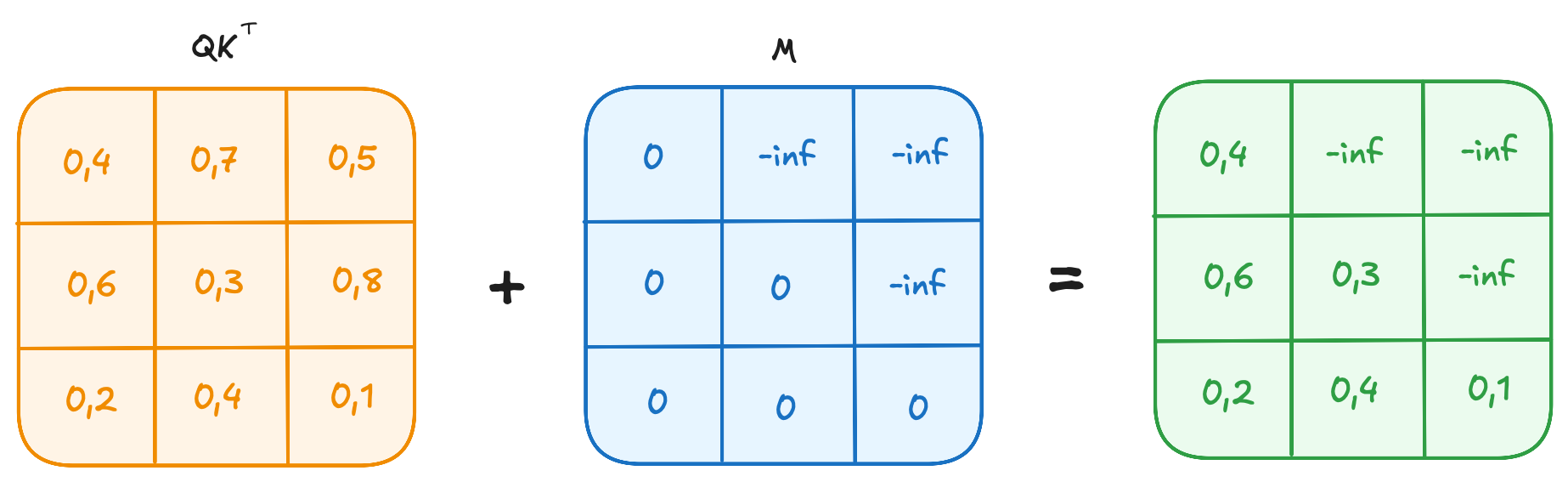
Transformer模型:Decoder的self-attention mask实现_self attention mask-CSDN博客
Figure 4 from Mask-Attention-Free Transformer for 3D Instance ...
Attention Masking: Controlling Information Flow in Transformers ...
Mask-Attention-Free Transformer for 3D Instance Segmentation: Paper and ...
Attention is All You Need — Here’s What That Really Means | by Purav ...
Swin Transformer:层级式特征图与移动窗口注意力机制 | Yan Tang
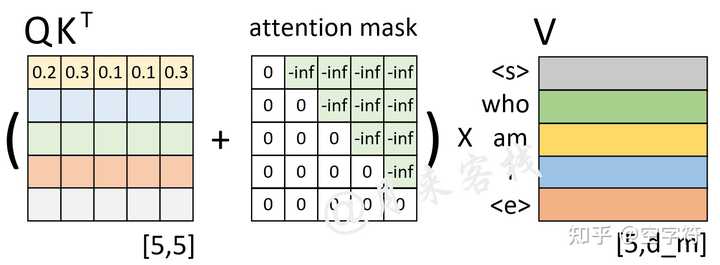
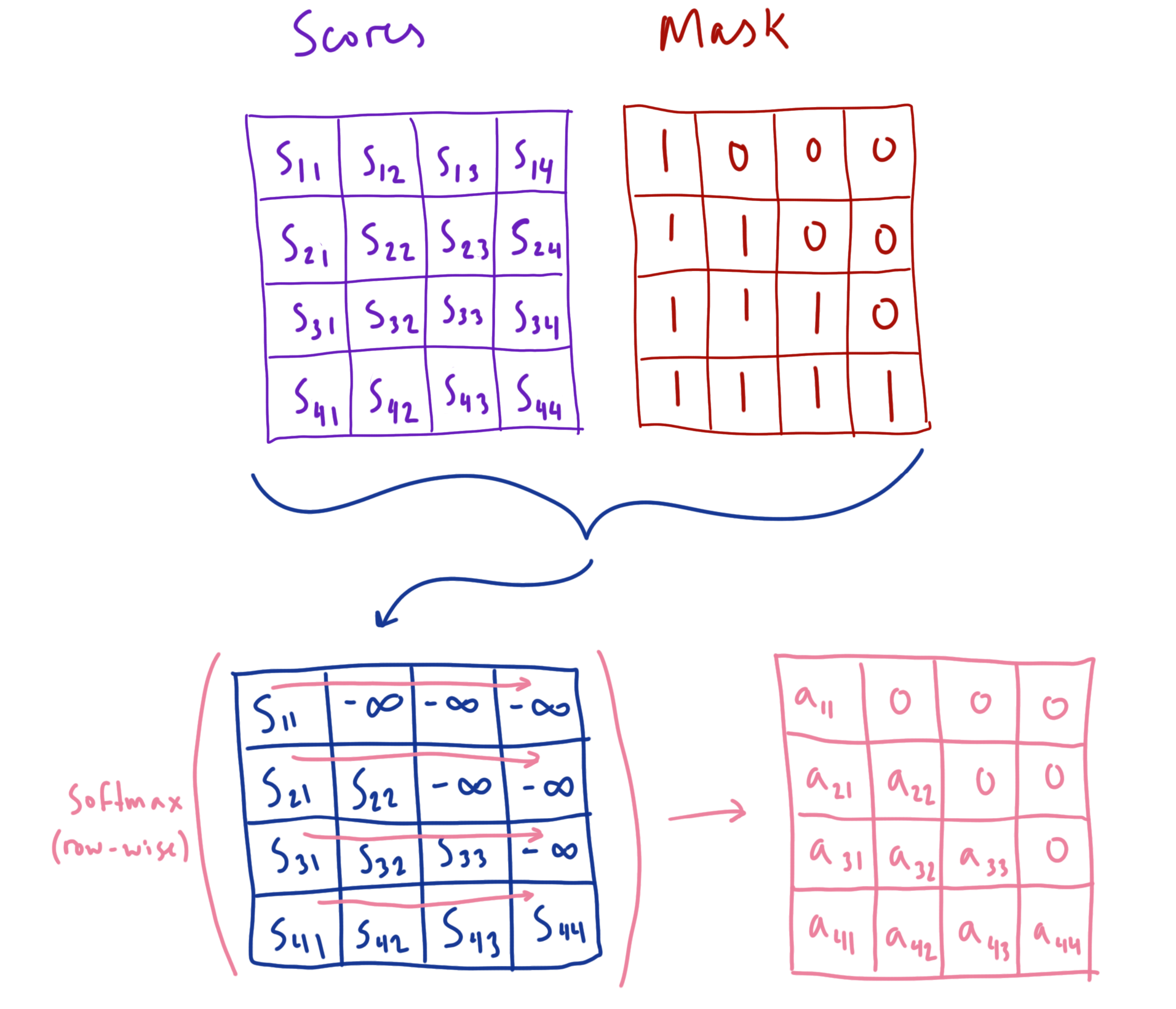
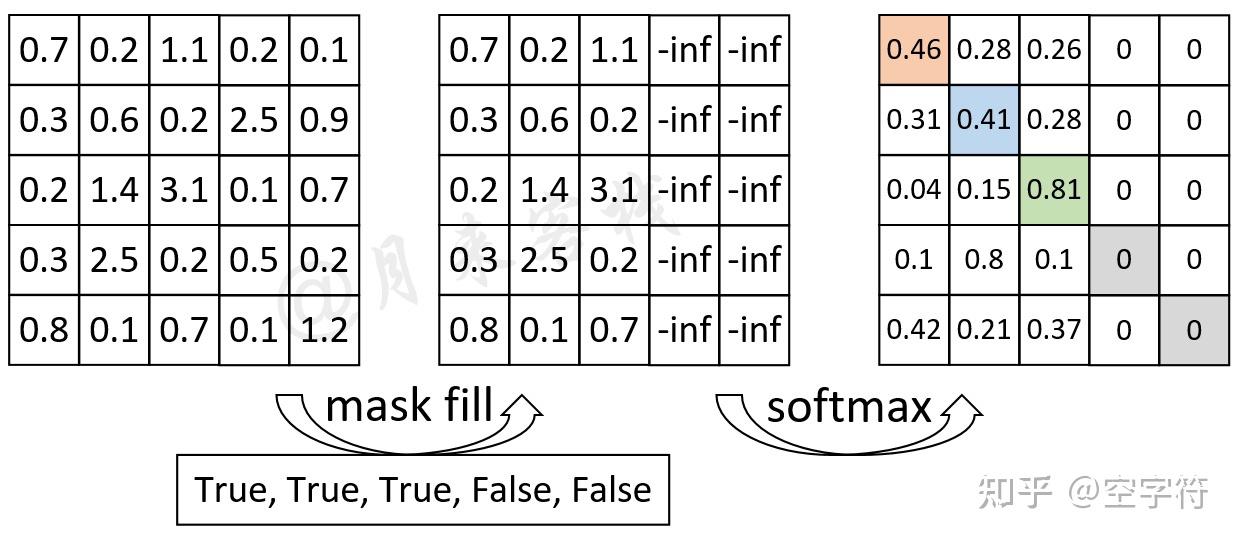
模型结构|解读transformer模型中三种attention和mask(一)_casual mask-CSDN博客
Attention-mask 在transformer模型框架中的作用_attention mask-CSDN博客
transformer中: self-attention部分是否需要进行mask? - 知乎
Transformer以及attention机制介绍 - 知乎
4D masks support in Transformers
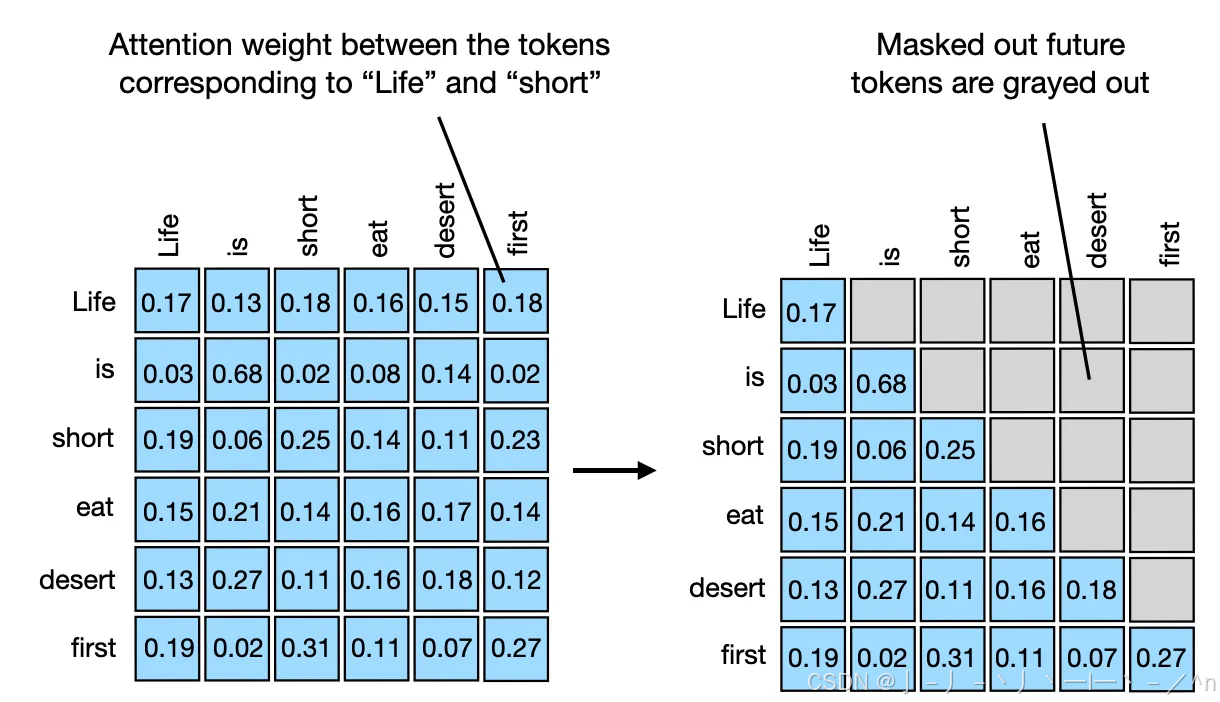
【深度学习】Transformer中的mask机制超详细讲解_transformer mask-CSDN博客
生成模型的中Attention Mask说明-CSDN博客
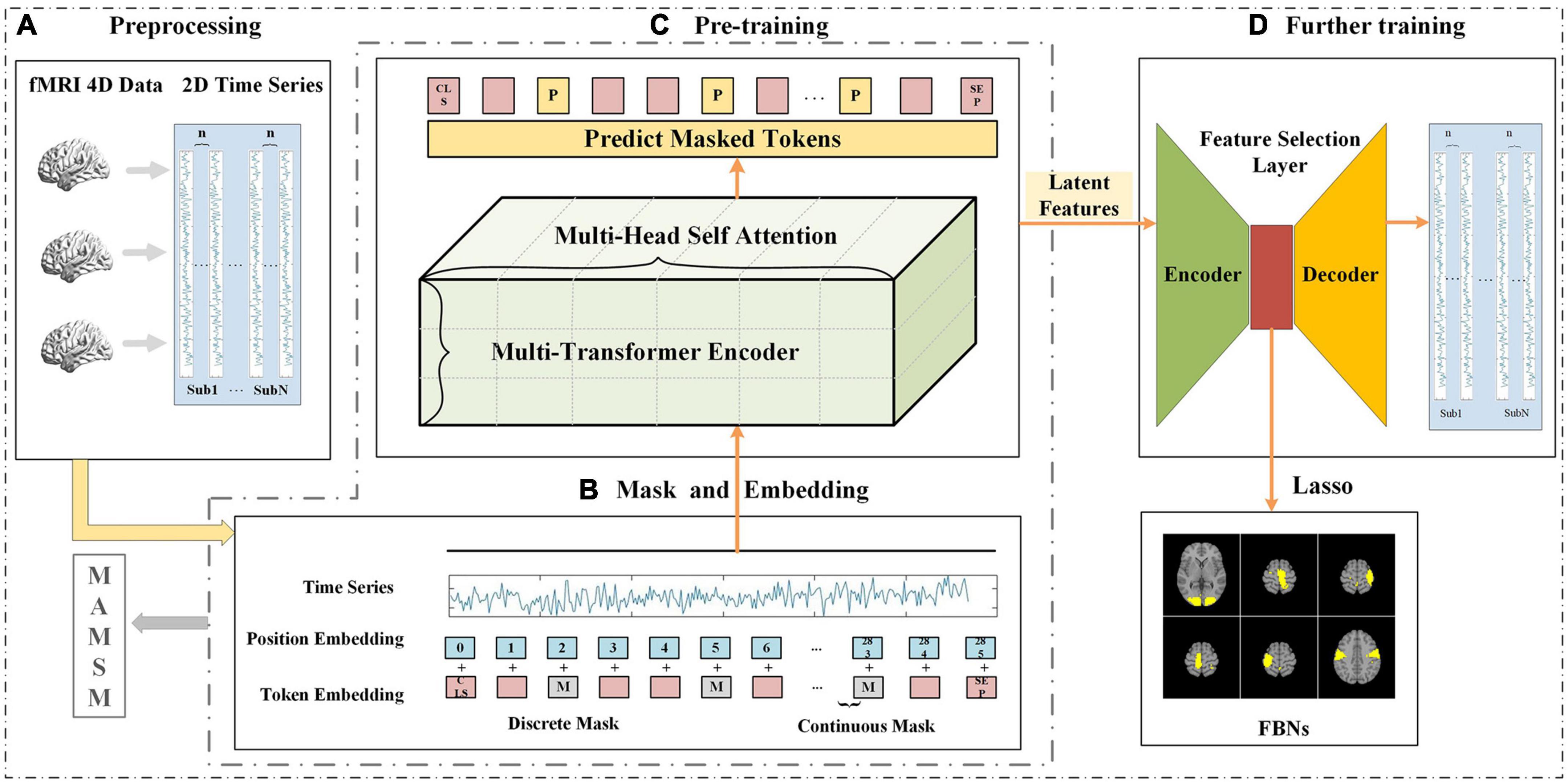
Frontiers | Multi-head attention-based masked sequence model for ...
custom 4d attention_mask as transformers .forward() argument · Issue ...
从训练和预测角度来理解Transformer中Masked Self-Attention的原理 - 知乎
Transformers Authentic Masks for Kids, Assortment | Party Expert
transformer学习笔记:self-attention_transformer attention部分公式-CSDN博客
Amazon.com: Transformers Toys Rise of the Beasts Movie Bumblebee ...
Transformers - Part 7 - Decoder (2): masked self-attention - YouTube
小杰-自然语言处理(eleven)——transformer系列——Attention中的mask_attention mask-CSDN博客
트랜스포머 (Transformer) · Data Science
Transformers Rise of the Beasts Converting Masks Wave 1 Case
Transformers in a Nutshell · Jordan Lazzaro Blog
How Do Transformers Work to Outperform Traditional NLP Models? | Marius ...
Transformers Rise of the Beasts 2-in-1 Optimus Prime Blaster & 2-in-1 ...
Unveiling Superior Lane Detection Techniques Through the Synergistic ...
一文了解Transformer全貌(图解Transformer)
注意力机制与Transformers - mumumu1 - 博客园
【图像任务】Transformer系列.3_efficient and explicit modelling of image ...
Transformer训练及测试阶段的self-attention mask理解 - 知乎