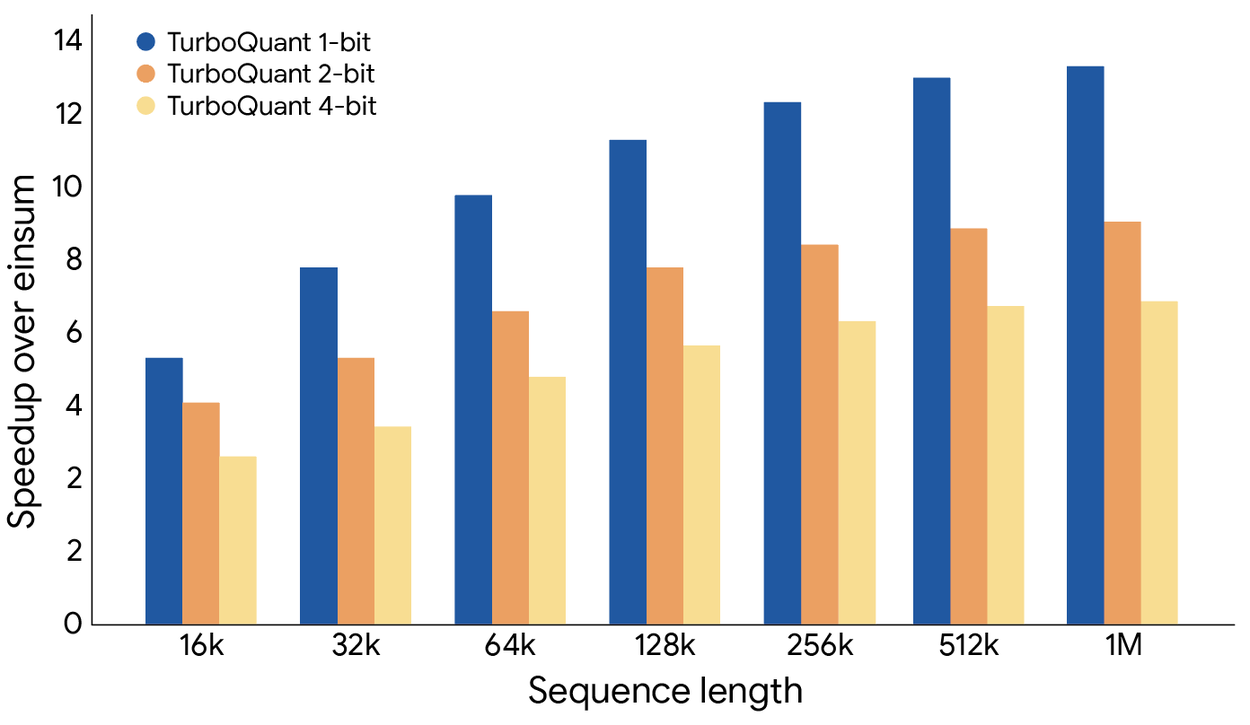
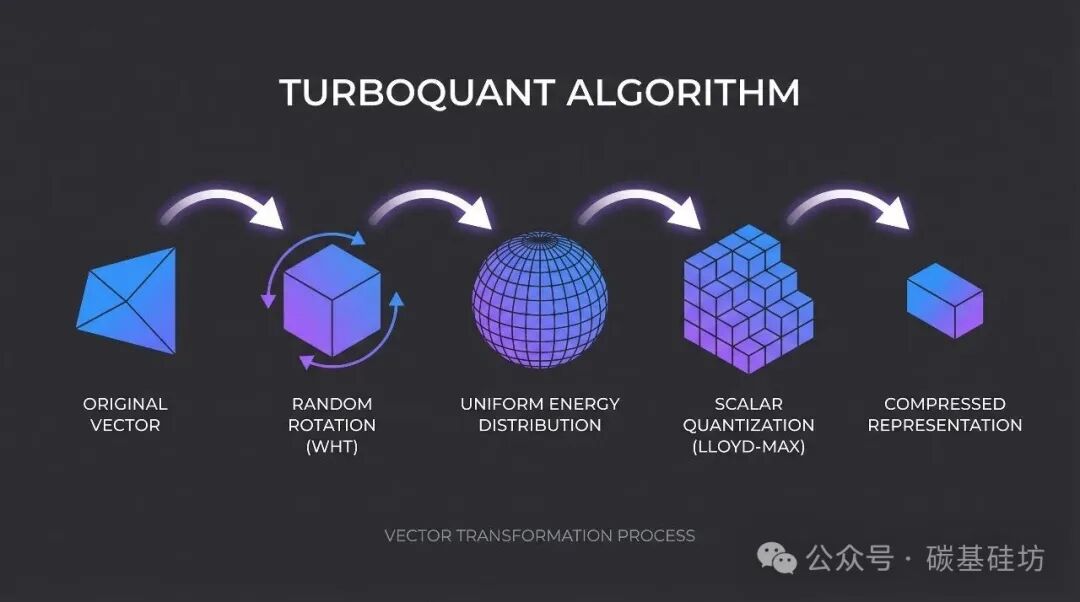
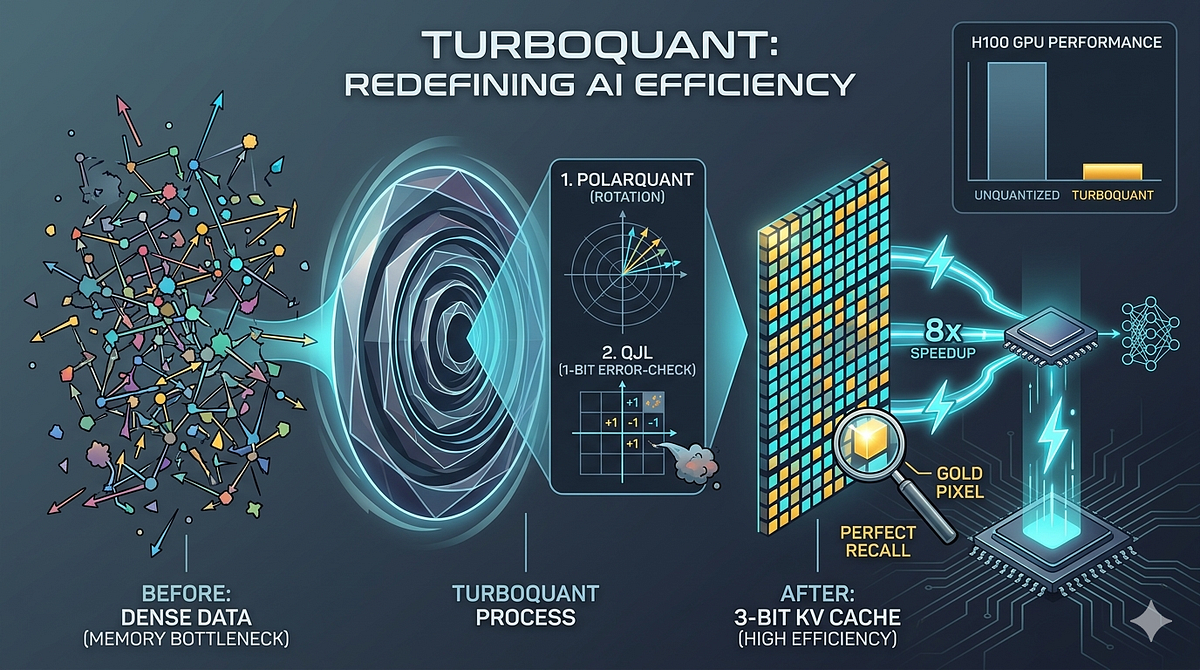
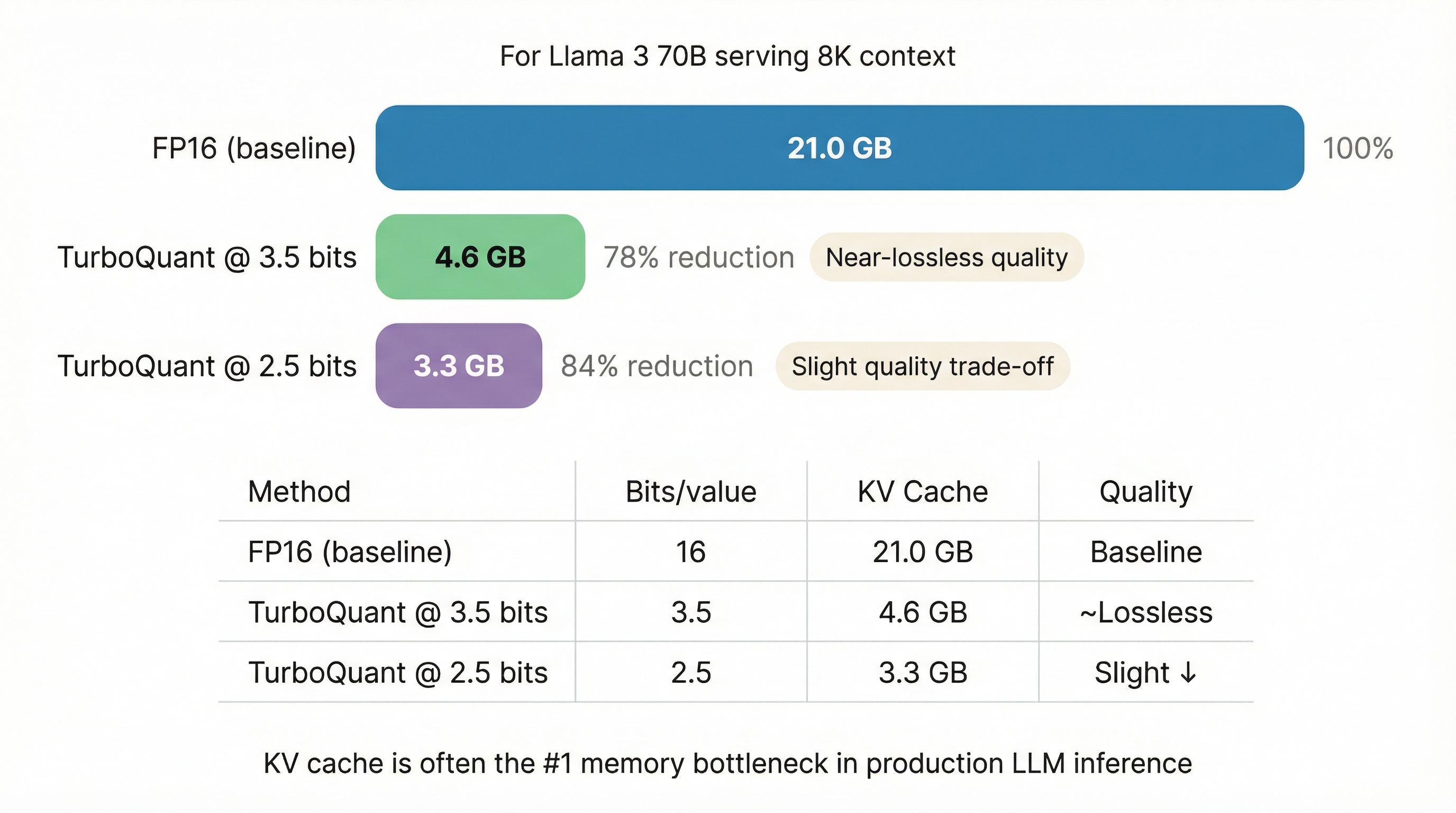
Showing 109 of 109on this page. Filters & sort apply to loaded results; URL updates for sharing.109 of 109 on this page
TurboQuant : La compression extrême qui révolutionne l'efficacité de l ...
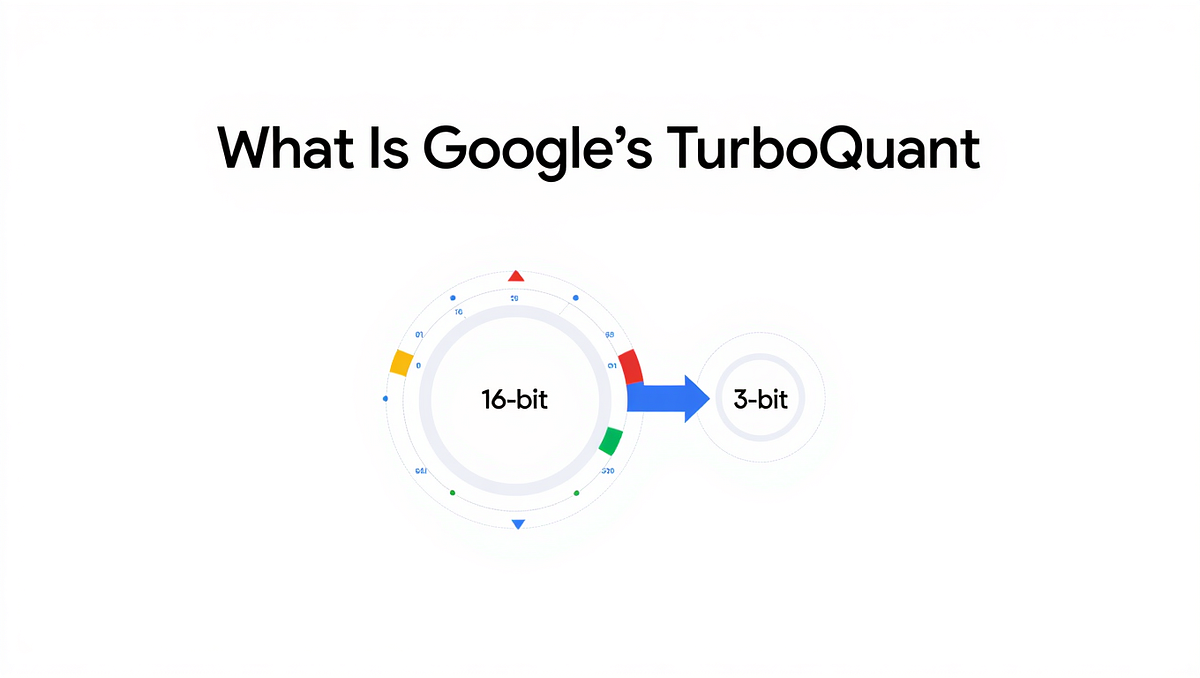
Google TurboQuant Redefines AI Model Compression Tech
TurboQuant in Practice — KV Cache Compression with llama.cpp and ...
Google TurboQuant 详解 - 汇智网
Google TurboQuant Explained: How the New AI Memory Algorithm Slashes ...
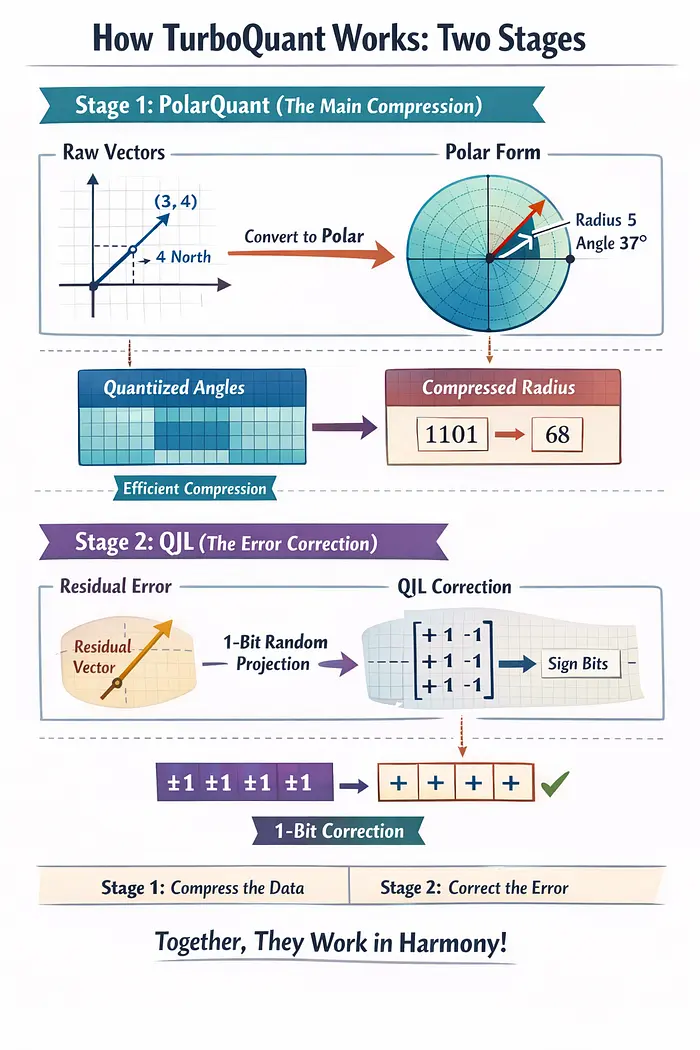
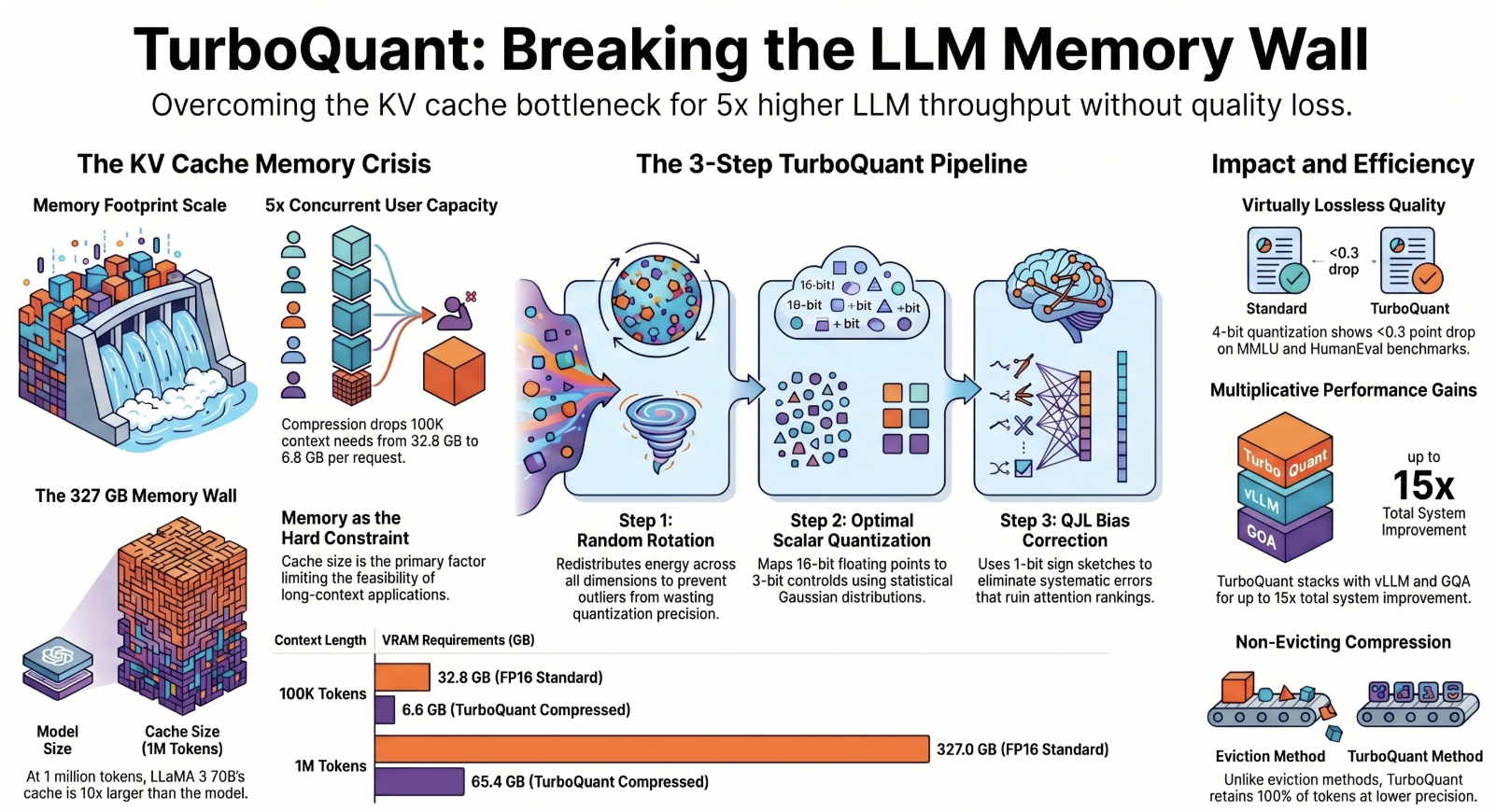
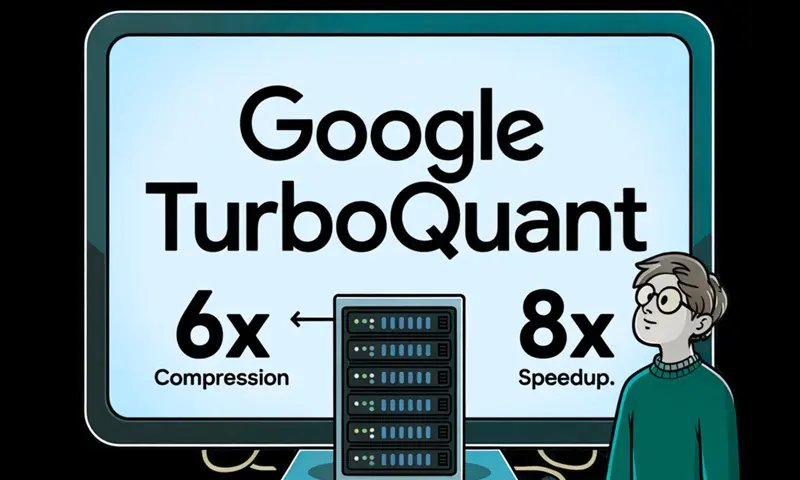
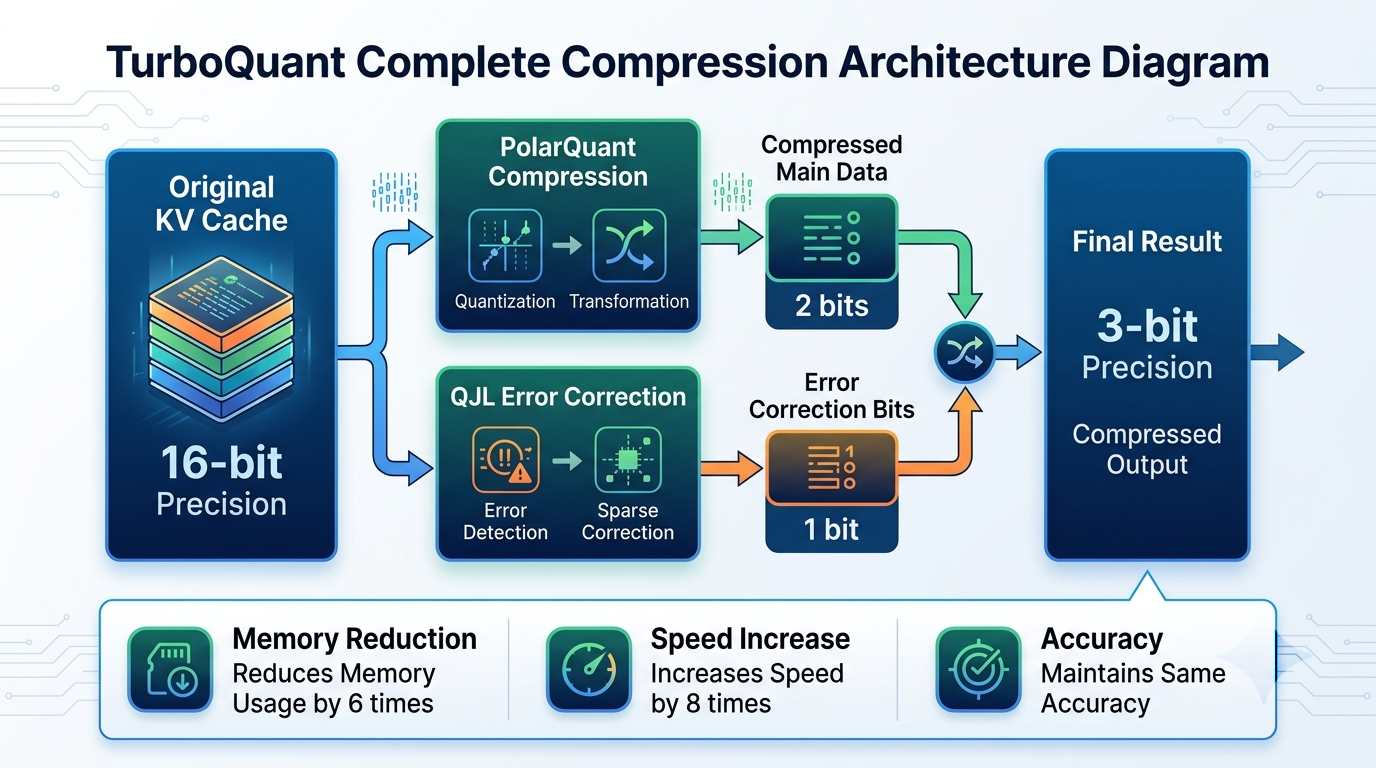
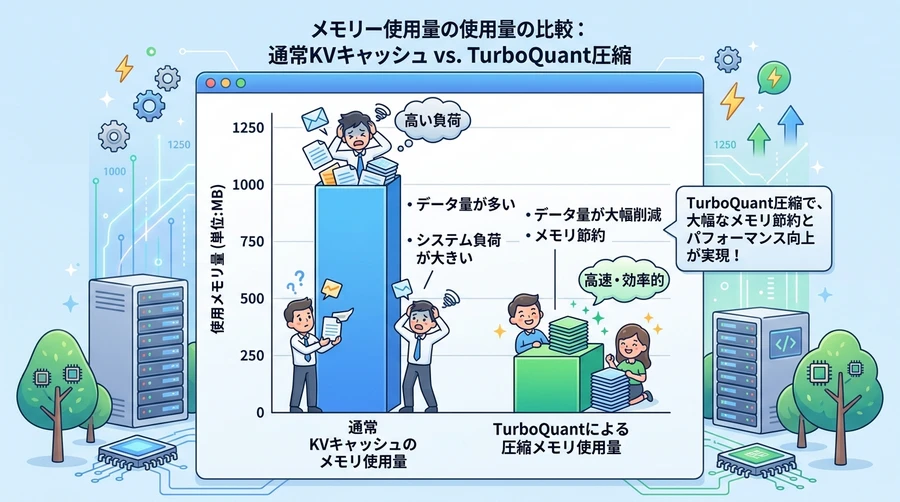
TurboQuant Explained: How KV Cache Compression Cuts LLM Memory by 6x
TurboQuant for Java Programmers: Part 4
Effective KV Compression with TurboQuant - MachineLearningMastery.com
TurboQuant.net - Independent TurboQuant Analysis
如何使用 TurboQuant — 入门指南 | TurboQuant Tools
How Google's TurboQuant Compresses LLM Memory by 6x (With Zero Accuracy ...
Google unveils TurboQuant — an algorithm that reduces AI memory usage ...
What Is Google’s TurboQuant and Why Does It Matter for AI Users? | by ...
Google TurboQuant explained
Research Briefings - TurboQuant - by Janu Verma
TurboQuant Explained: How to Cut AI Costs Without Killing Performance ...
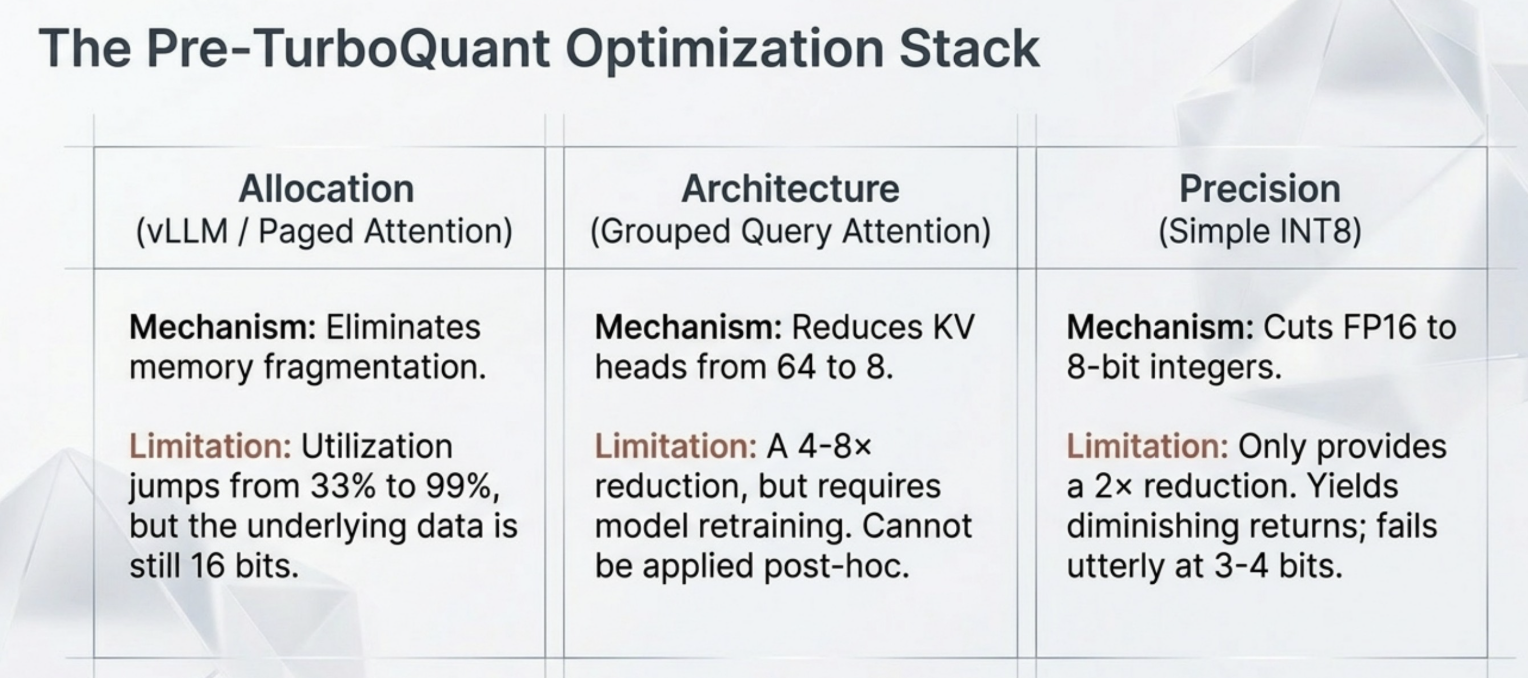
KV Cache bottleneck Part 2: The Math and Implementation of TurboQuant ...
TurboQuant - 谷歌推出的向量量化算法 | AI工具集
Google's TurboQuant Algorithm Slashes LLM Memory Use by 6x
Google Unveils TurboQuant for Efficient AI Model Compression ...
TurboQuant Explained in 2 Minutes (Google’s Big AI Breakthrough) - YouTube
TurboQuant Paper, arXiv & GitHub — Research Resources | TurboQuant Tools
Google TurboQuant boosts AI efficiency with 6x memory reduction and 8x ...
Google’s TurboQuant Breakthrough: 6× KV-Cache Efficiency with Zero ...
Google TurboQuant 详解-CSDN博客
Interpreting the Google TurboQuant Paper: A New Paradigm for Vector ...
TurboQuant PyTorch download | SourceForge.net
The Sequence AI of the Week #834: Google's AMAZING TurboQuant for ...
Google 發表 TurboQuant 壓縮演算法改善 AI 執行效率與記憶體管理 – CyberQ 賽博客
Google's TurboQuant AI Algorithm Shrinks Memory 6x, Sparks Pied Piper ...
Google TurboQuant Explained: Lower Memory Use, Big Impact on AI Industry
TurboQuant for Java Programmers: Part 3
Google TurboQuant — Paper, Tools, Benchmarks & Framework Status
TurboQuant Explained: How Google Cuts LLM Memory by 6x Without Losing ...
TurboQuant KV Cache Compression: What Changes for LLM Inference
⚡ TurboQuant 详解:AI 模型量化压缩技术从入门到精通 - 技能分享 | OpenClaw 中文社区
Flowchart of the computation program for the two-turbine model ...
How TurboQuant Works for LLMs and Why It Uses Much Less RAM - DEV Community
From one model to seven — what it took to make TurboQuant model ...
TurboQuant Google 如何讓 AI 的記憶體需求縮小 6 倍 | seo公司-鯊客科技
Google’s TurboQuant may drive more memory demand not less, analysts say
TurboQuant on Blackwell — KV Cache Compression Engine
Did Google's TurboQuant really solve the memory shortage? | YourStory
GitHub - RyanCodrai/turbovec: A vector index built on TurboQuant ...
Flowchart describing the operation of TURBO protocol. | Download ...
TurboQuant for Efficient LLMs and How Gemma 4 Utilizes It
Google Launches TurboQuant to Make AI Models More Efficient Without ...
TurboQuant: a new way of quantization (to reduce AI memory needs ...
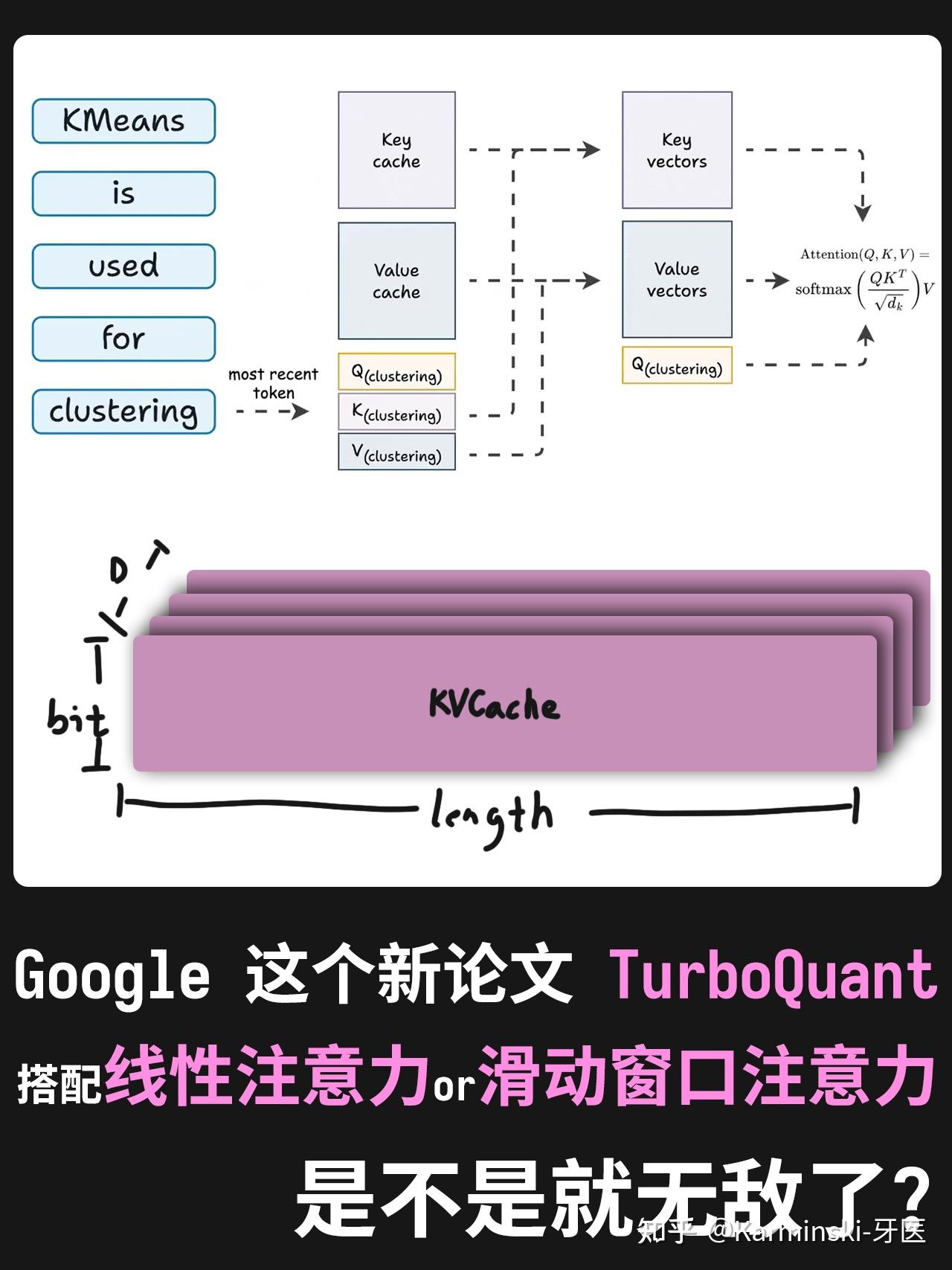
Google 一篇论文砸崩芯片股,TurboQuant 到底发现了什么? - 知乎
turboquant-torch · PyPI
TurboQuant: An Introduction to State-of-the-Art Vector Quantization for ...
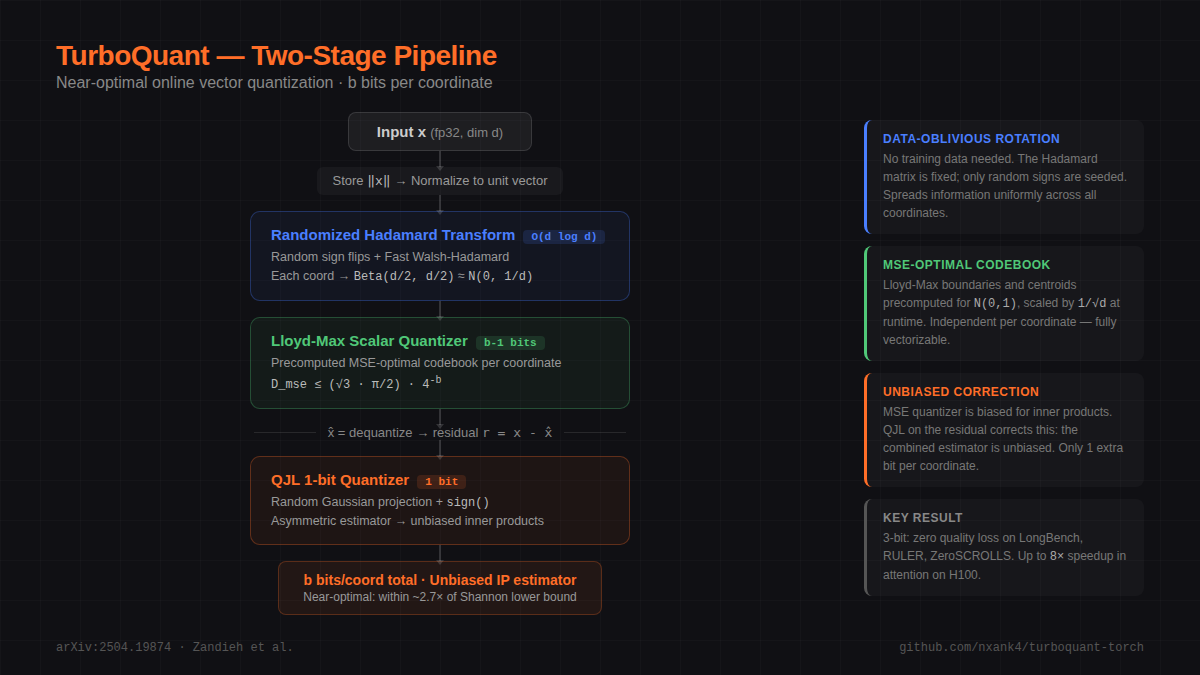
TurboQuant: Online Vector Quantization with Near-optimal Distortion ...
Here Is The Unvarnished Truth About Google's TurboQuant: Jevons Paradox ...
TurboQuant: Google Just Solved and Shrunk the Memory Wall for AI | by ...
TurboQuant: A Breakthrough Poised to Transform the Future of Search and ...
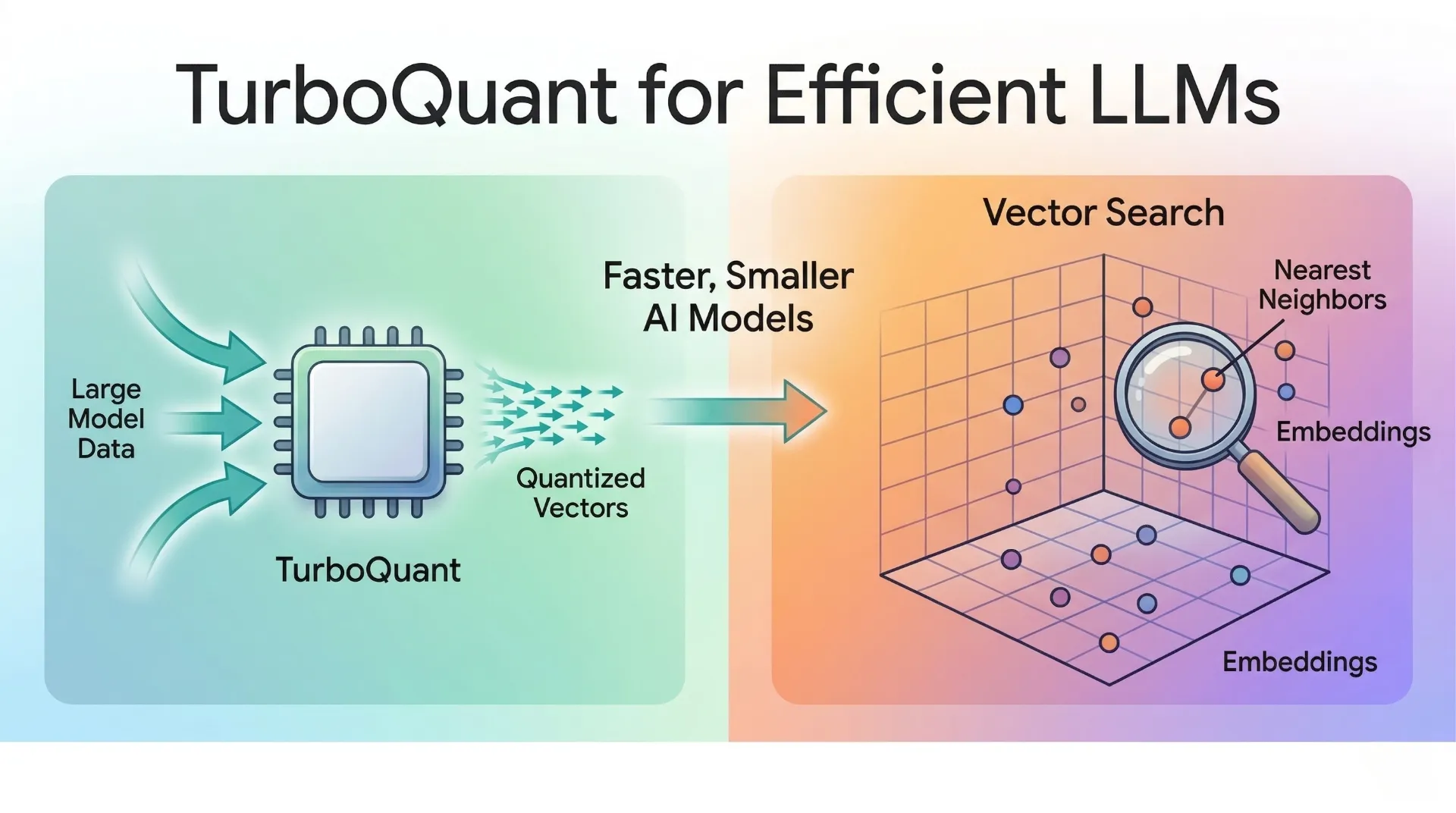
TurboQuant: Redefining AI efficiency with extreme compression
TurboQuant: Why Google’s New Compression Breakthrough Matters for the ...
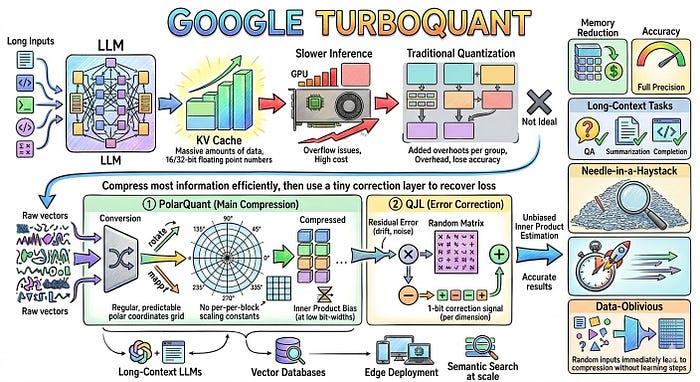
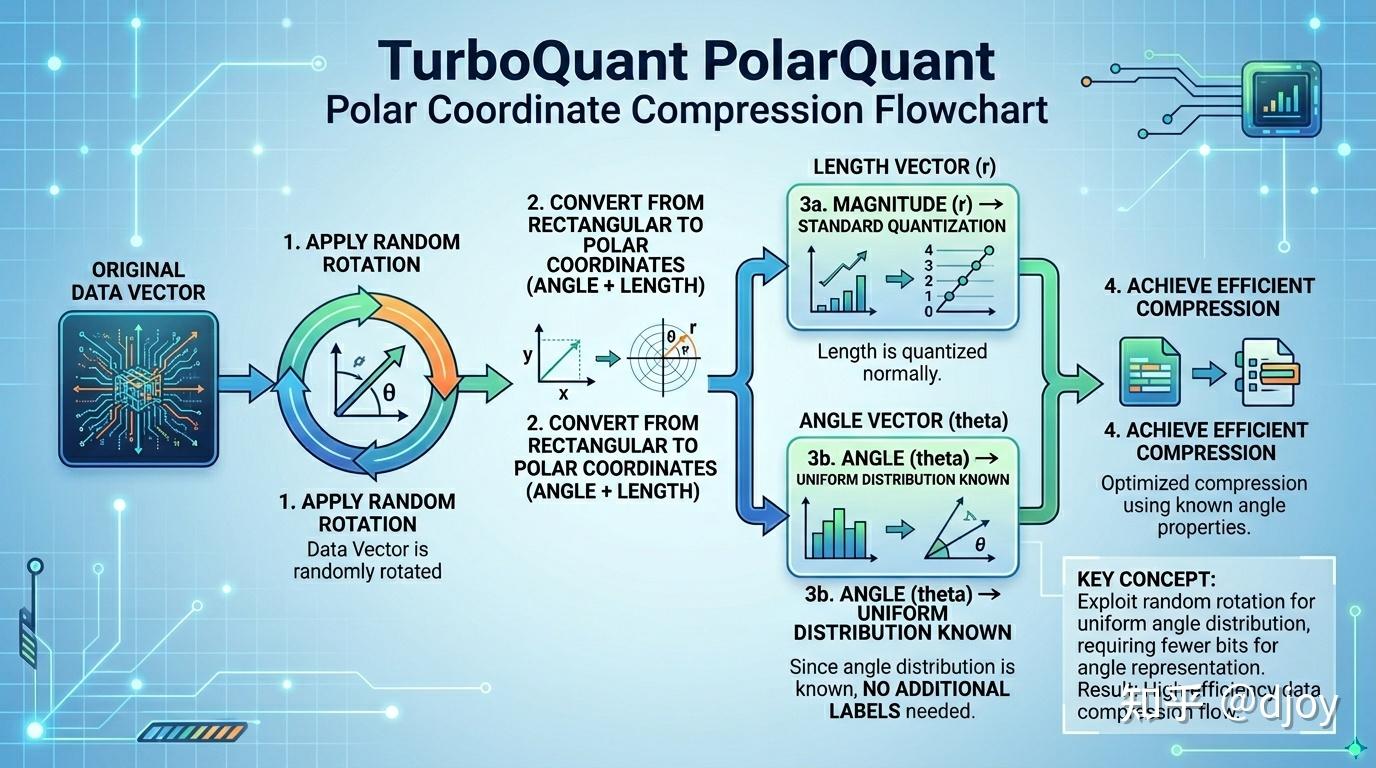
TurboQuant: How a Random Rotation Makes LLM Quantization Near-Optimal
TurboQuant: Google's AI Memory Compression Tech
TurboQuant:让大模型在长上下文场景下稳定输出_llama-cpp-turboquant-CSDN博客
TurboQuant: How Google Is Making AI Models Smaller, Faster, and Cheaper ...
Google TurboQuant: 6x KV Cache Compression for LLM Inference | Spheron Blog
TurboQuant: Redefining AI Efficiency with Extreme Compression ...
TurboQuant, Gemma 4, and the New Economics of AI Inference | by Adnan ...
TurboQuant: The Surprisingly Simple Trick That's Changing How We ...
TurboQuant: What Developers Need to Know About Google's KV Cache ...
TurboQuant详解:是什么以及如何实现6倍大语言模型内存节省 | Blog | a2a mcp
Googleの最新技術「TurboQuant」をやさしく解説!AIのメモリ不足を解決する魔法の仕組みとは? | 定年後のスローライフブログ
El nuevo algoritmo de IA "TurboQuant" de Google podría reducir los ...
A Performance Simulation Methodology for a Whole Turboshaft Engine ...
给大家写个小学水平也能理解TurboQuant的解读 - 知乎
Búsqueda vectorial Google TurboQuant: qué es y cómo funciona
TurboQuant: The Zero-Loss KV Cache Breakthrough That Will Reshape AI ...
Google's TurboQuant: extreme compression for AI
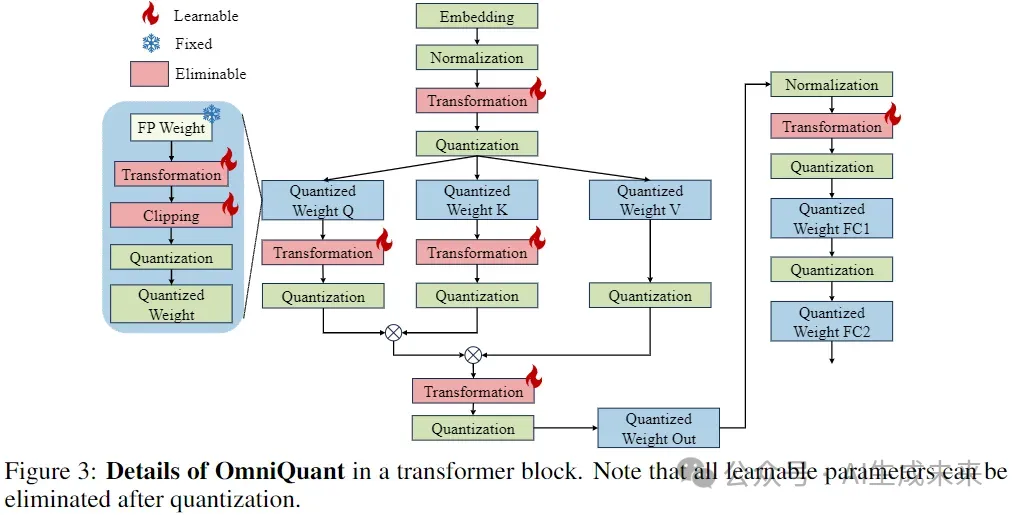
目前最优的LLM PTQ量化算法——OmniQuant-AI.x-AIGC专属社区-51CTO.COM
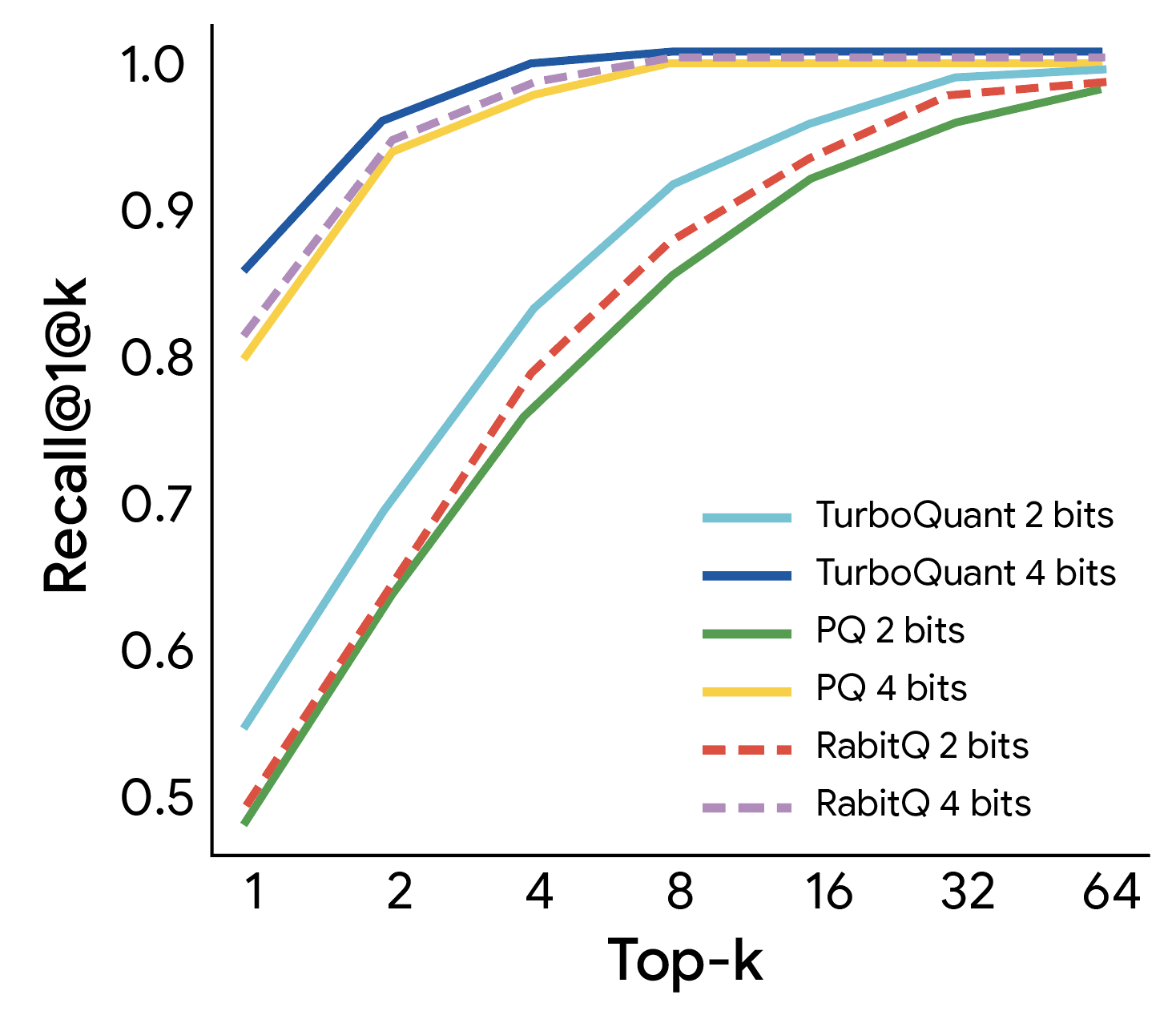
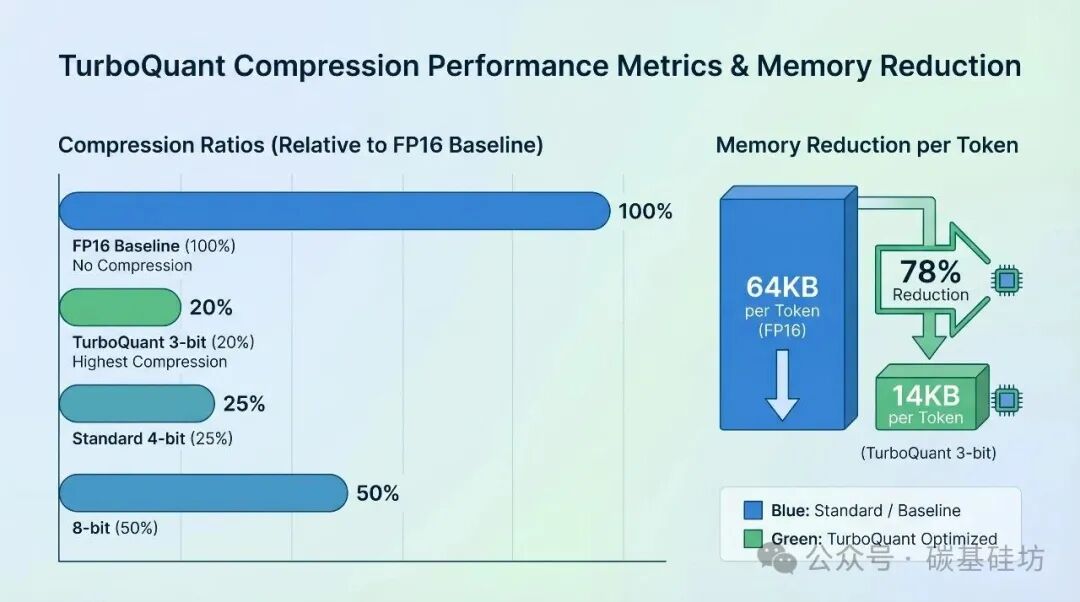
TurboQuant: Near-Optimal Vector Quantization at 3.5 Bits
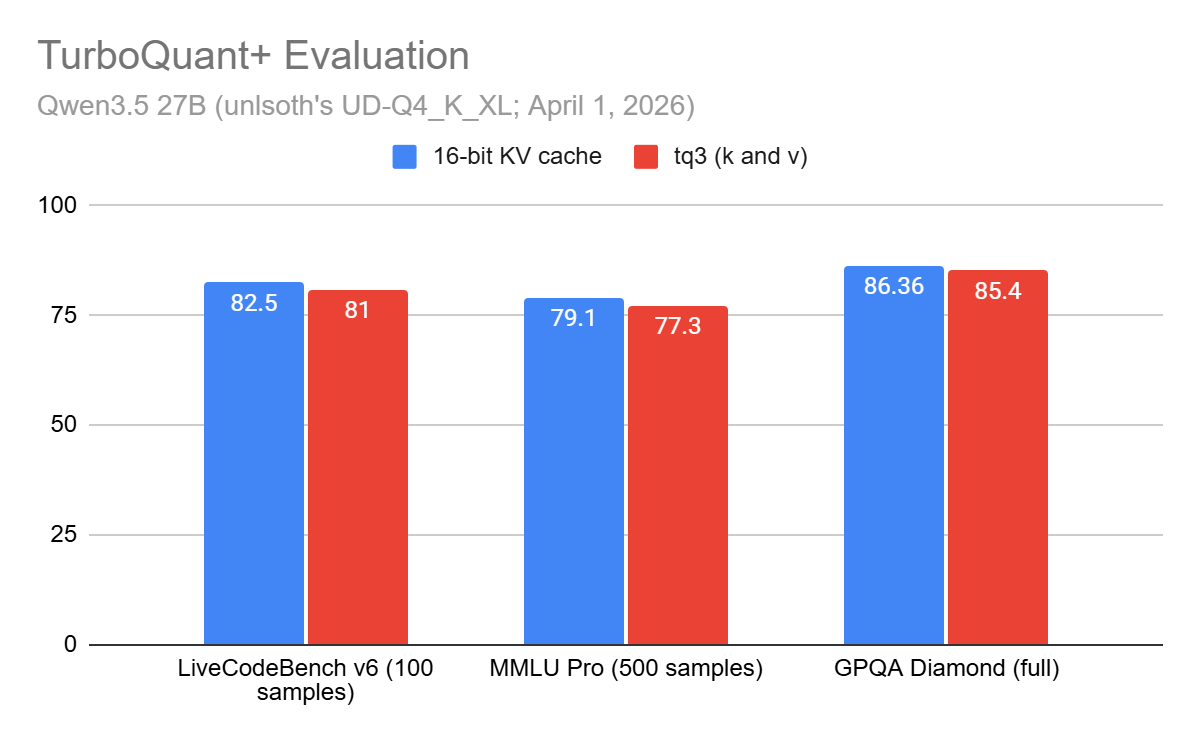
TurboQuant: ~3-bit KV Cache with Near 0 Accuracy Loss?
구글 터보퀀트(TurboQuant) 기술 개요, 성과, 적용 사례와 전망, 삼성전자와 하이닉스 주가 영향 및 증권가 전망까지
What is TurboQuant? Google's AI Memory Breakthrough Explained for Beginners
TurboQuant: Reading the KV Cache Compression Breakthrough – Kentino
TurboQuant: Teknologi Kompresi AI yang Mengguncang Pasar Memori Global ...
TurboQuant: The Paper That Moved Billions
TurboQuant: What Every Product Manager Needs to Know About Google's AI ...
TurboQuant核心技术研究学习 - 知乎
Google’s “TurboQuant” and the 2026 RAM Crisis: A Glimmer of Hope ...
TurboQuantでAIが変わる?話題の新技術とは何かをやさしく紹介 |Nさんち🏠のオススメ
[2504.19874] TurboQuant: Online Vector Quantization with Near-optimal ...
README.md · ai-engineering-at/llama-cpp-turboquant-guide at main
Google Introduces TurboQuant, Analysts Foresee Limited Impact | Let's ...
TurboQuant: Google's AI Compression That Now Runs on CPU | DCXV