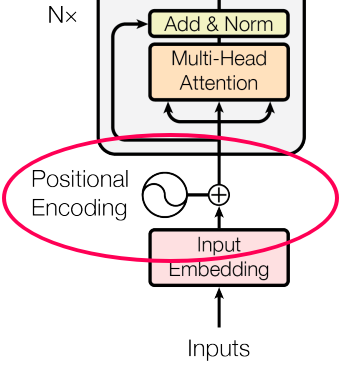
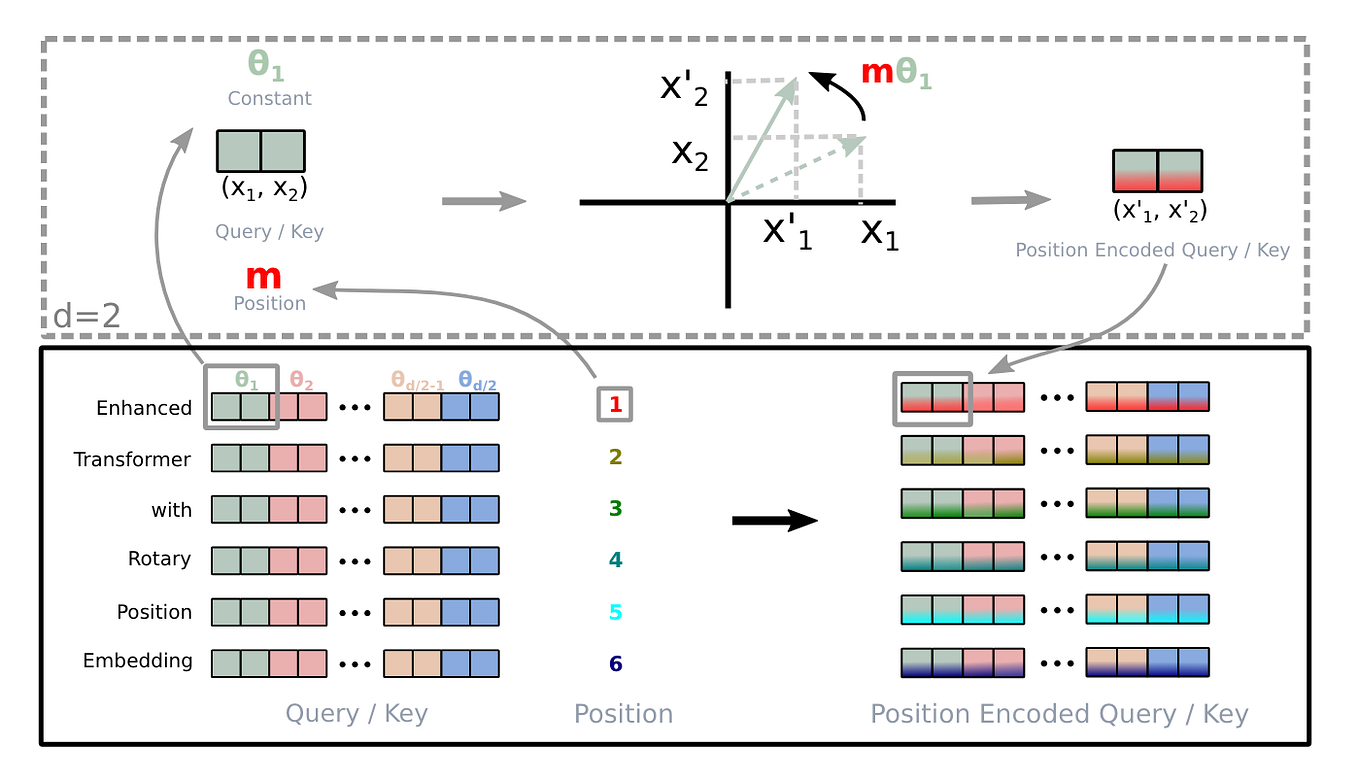
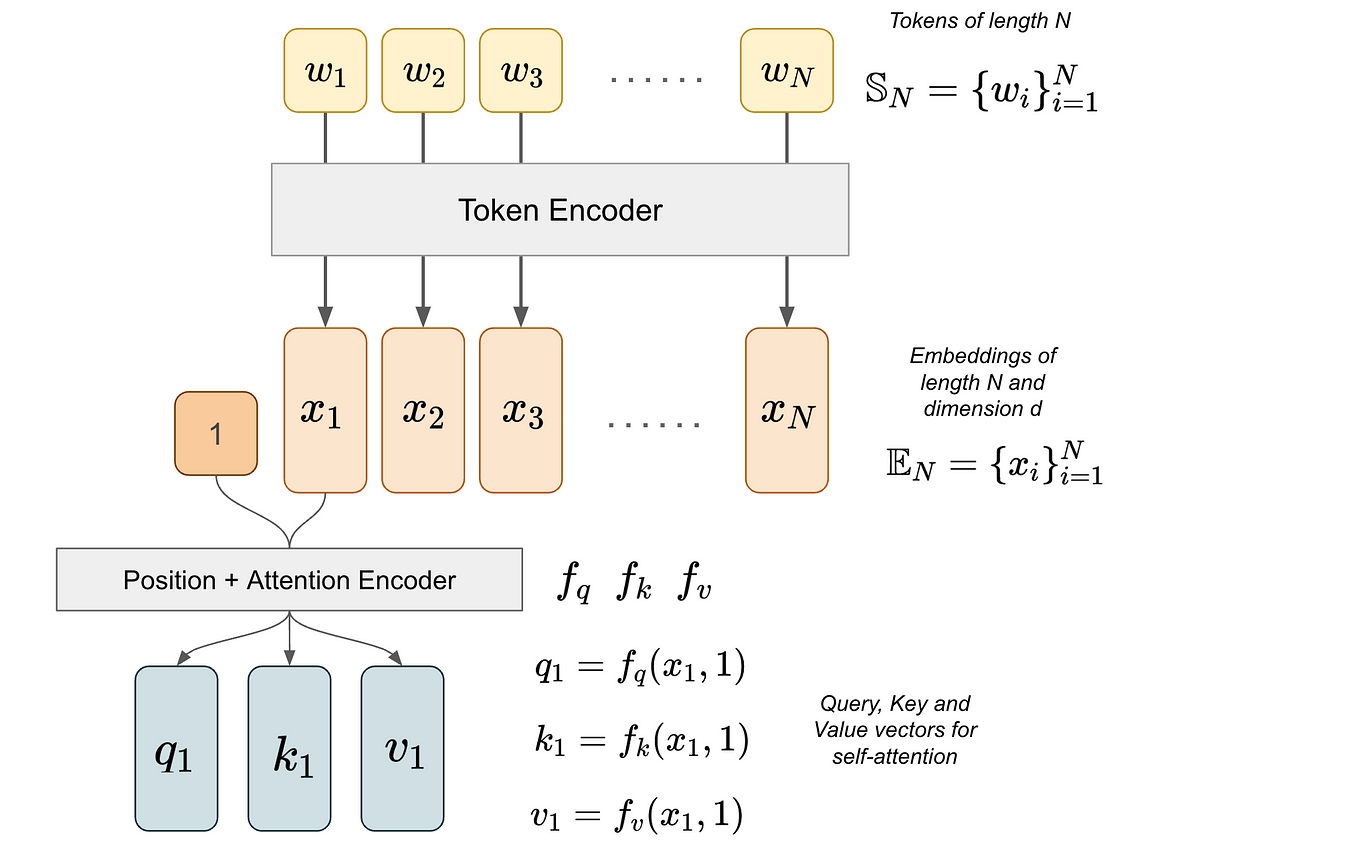
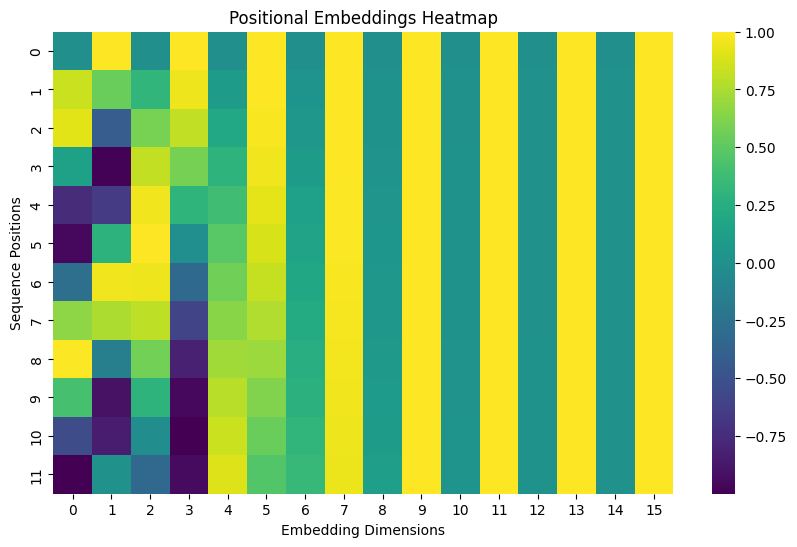
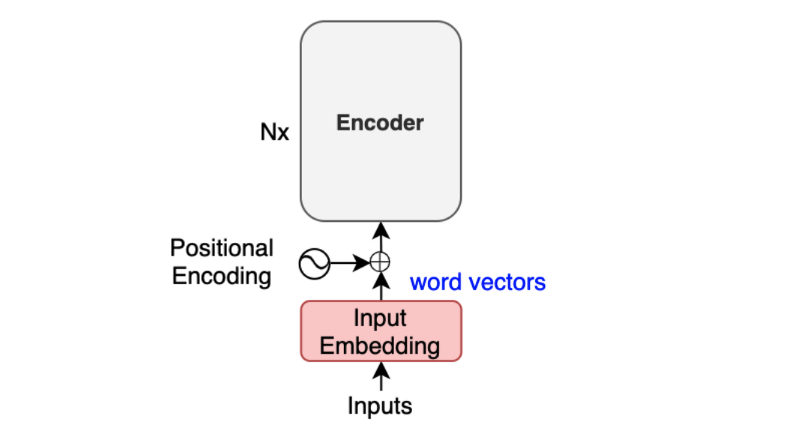
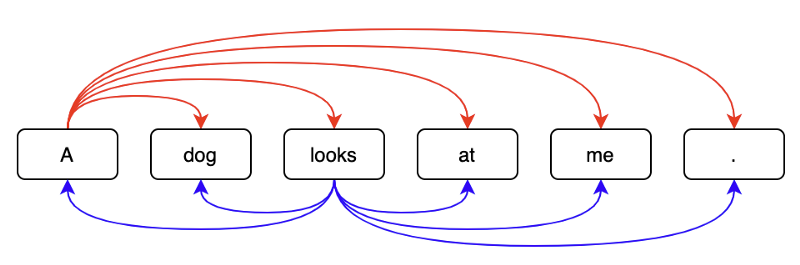
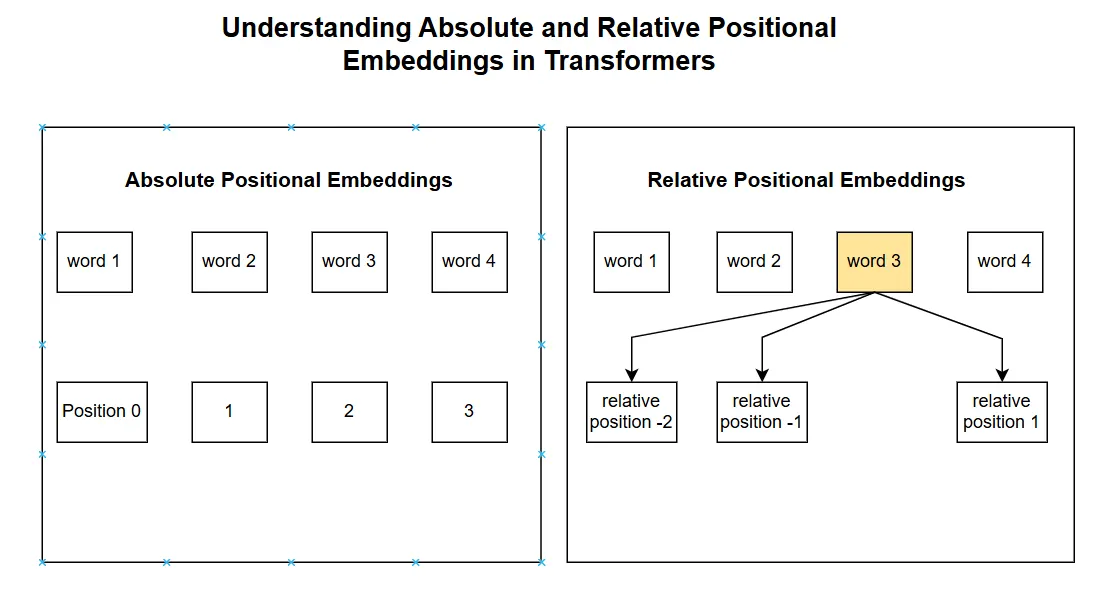
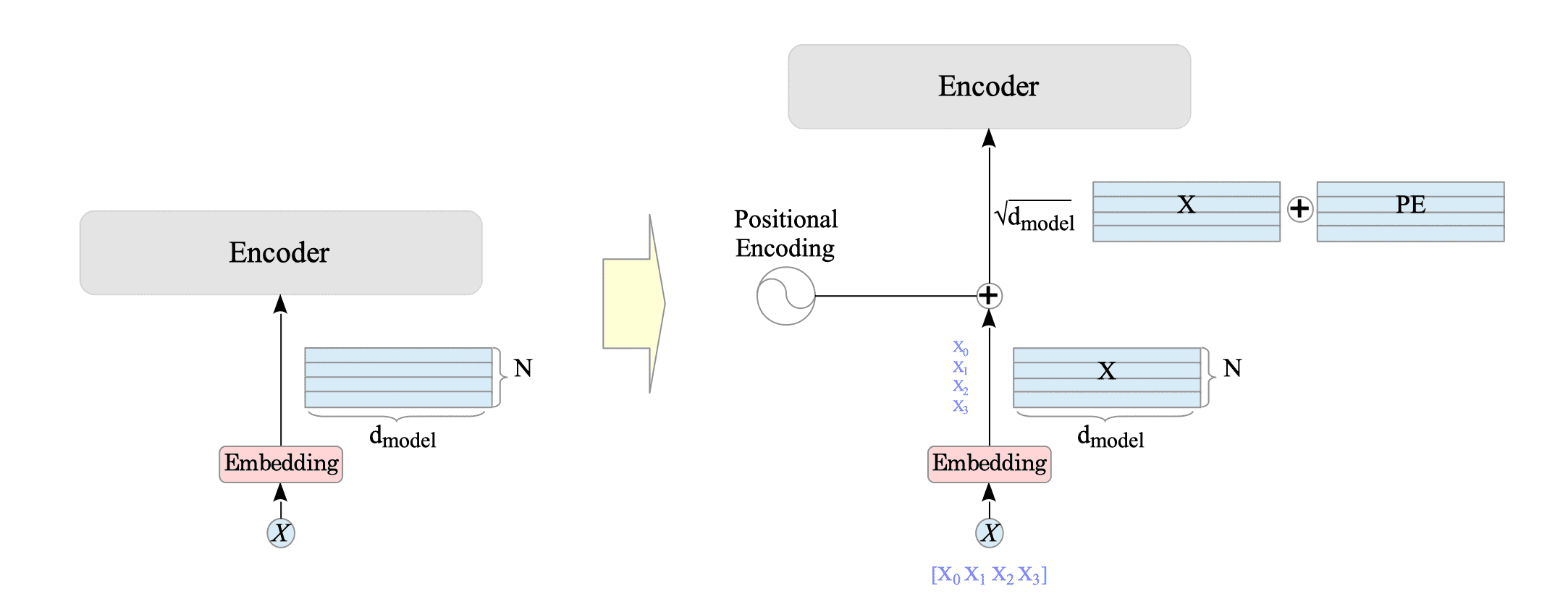
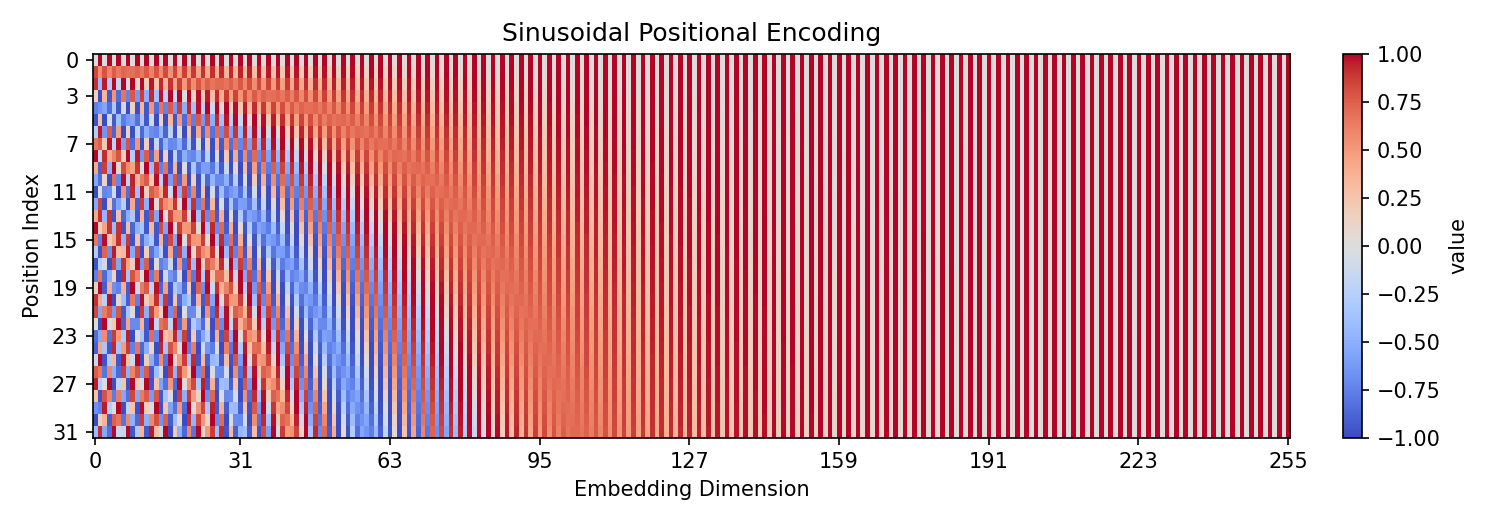
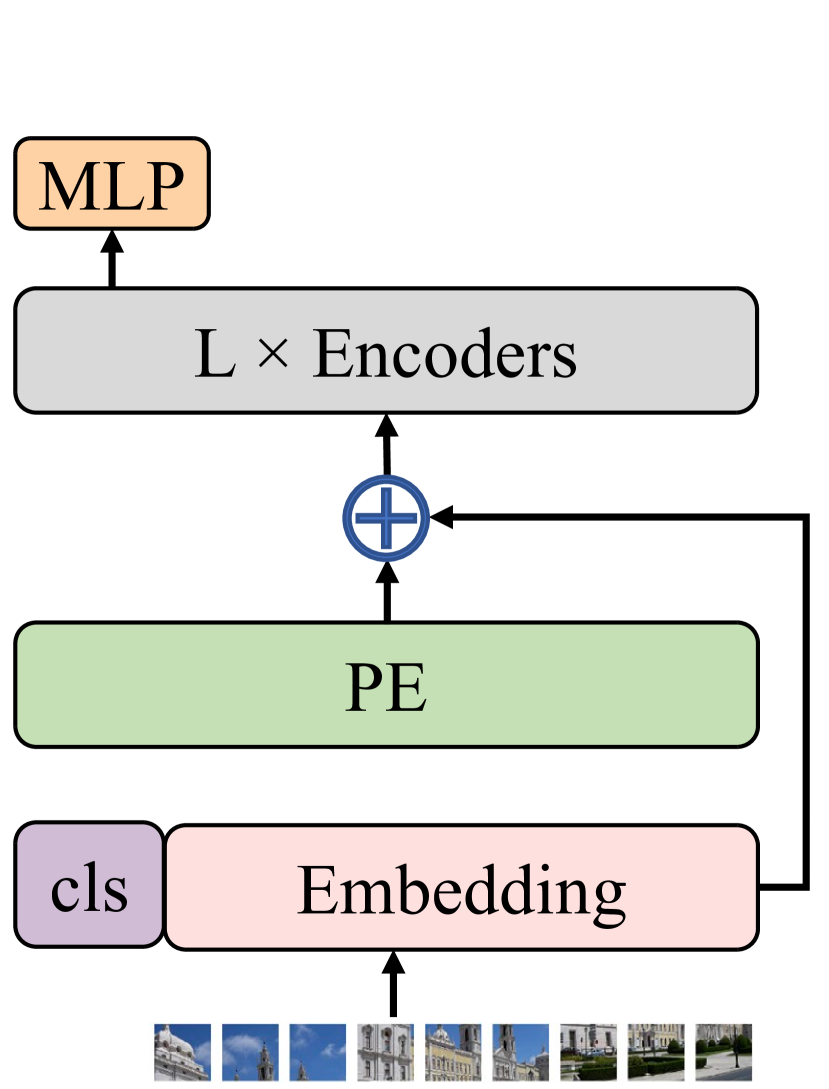
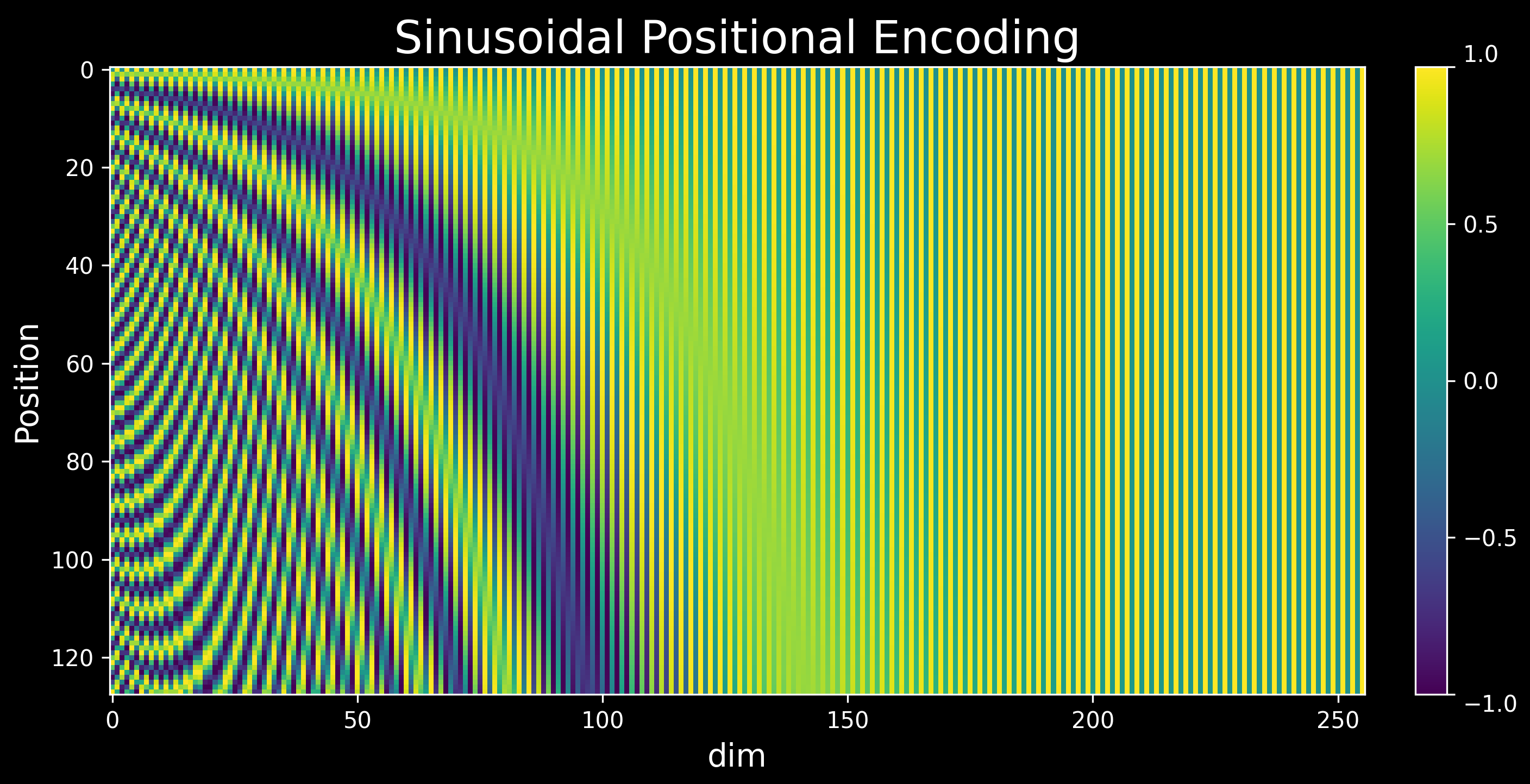
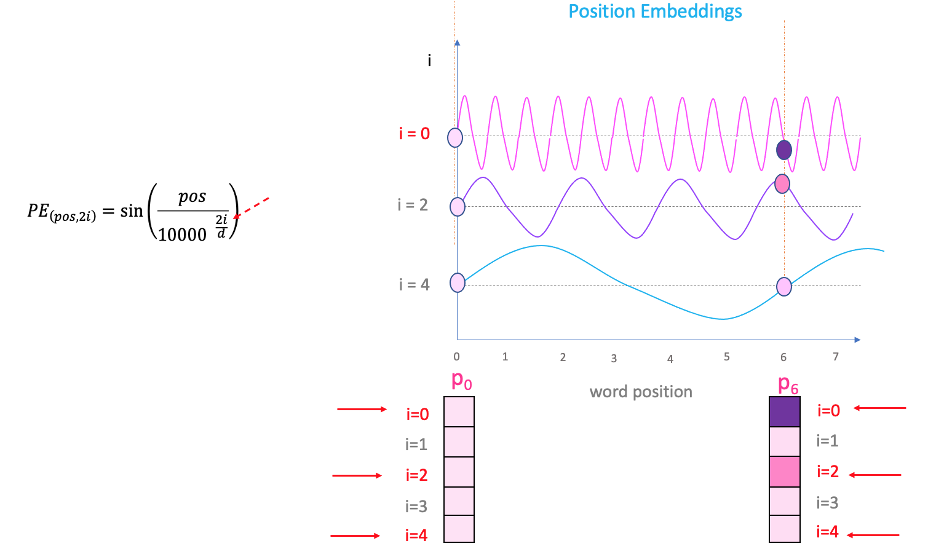
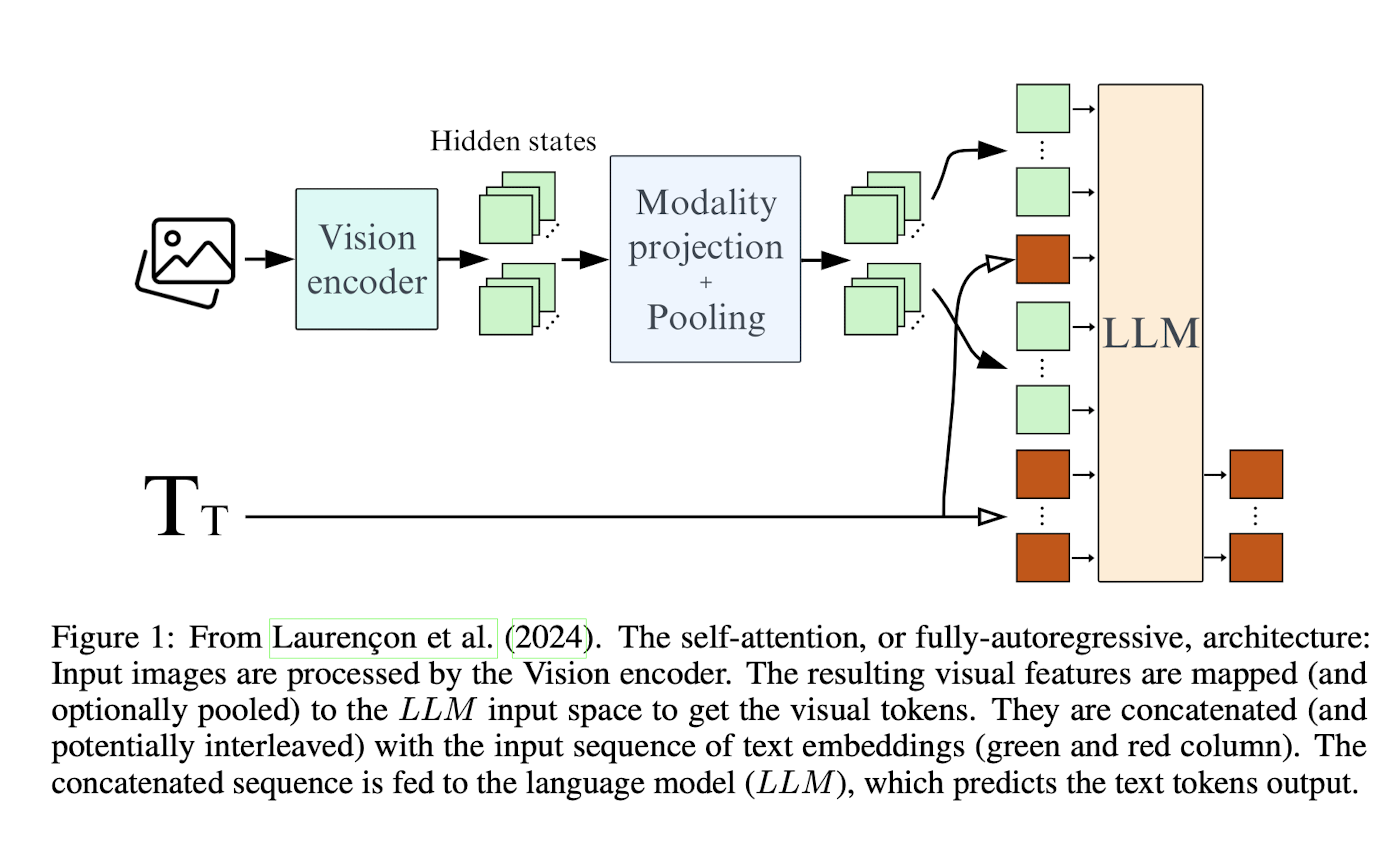
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
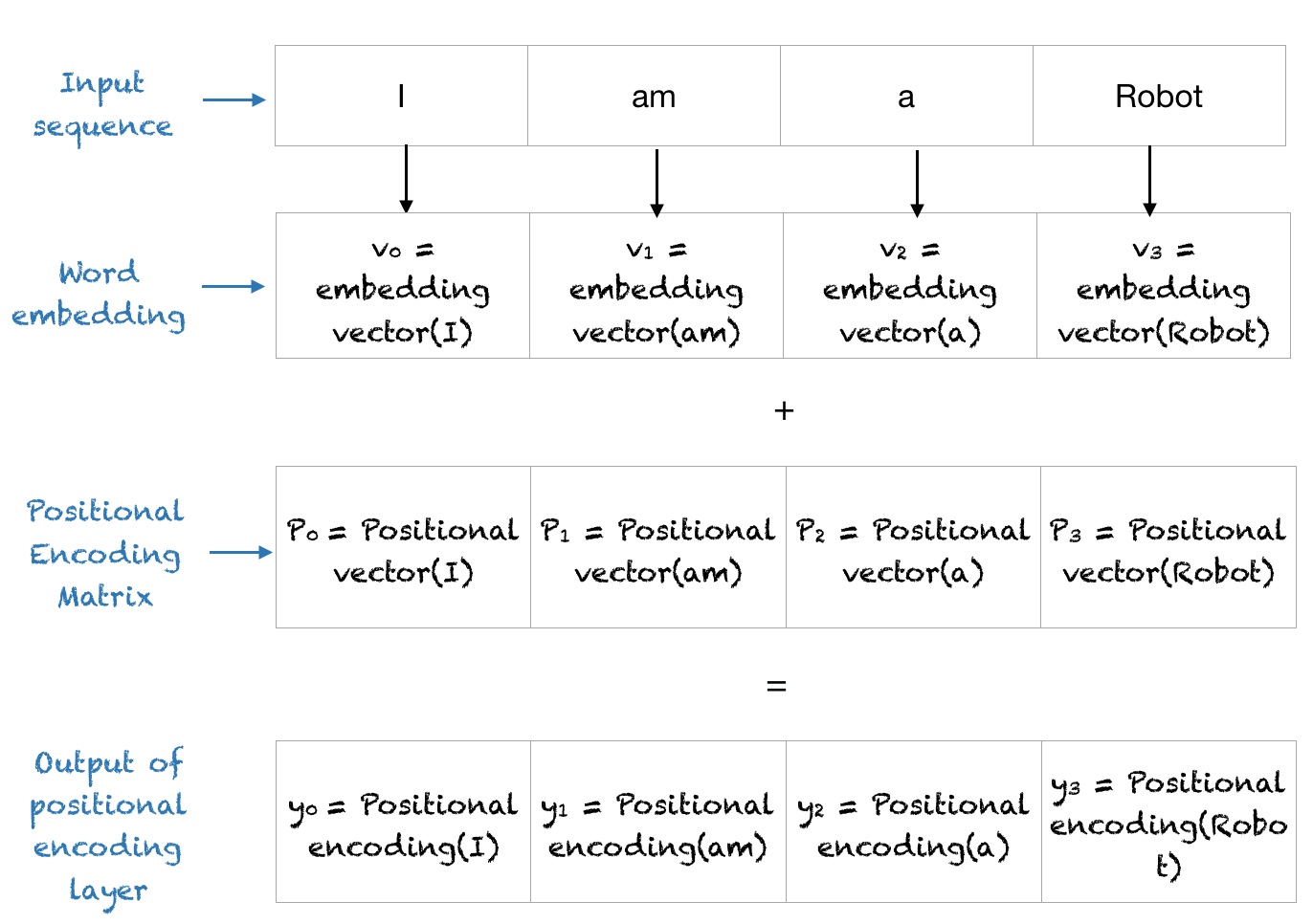
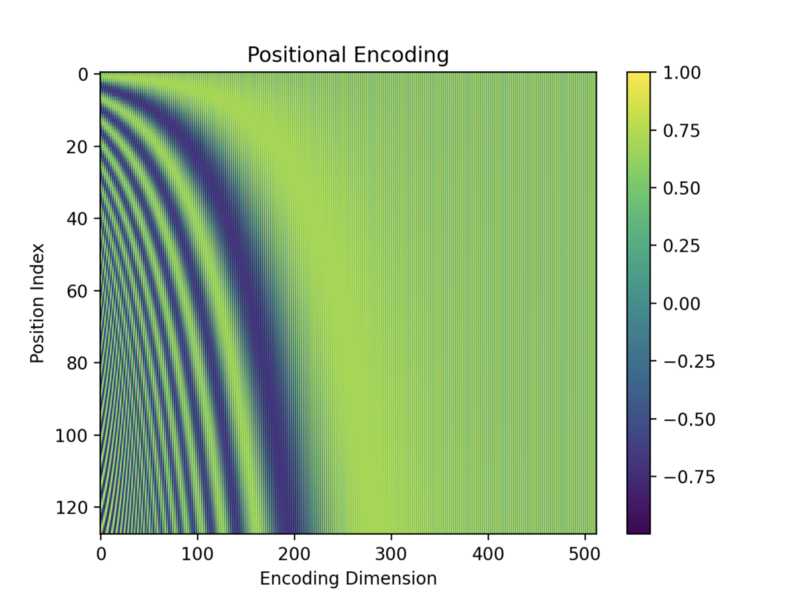
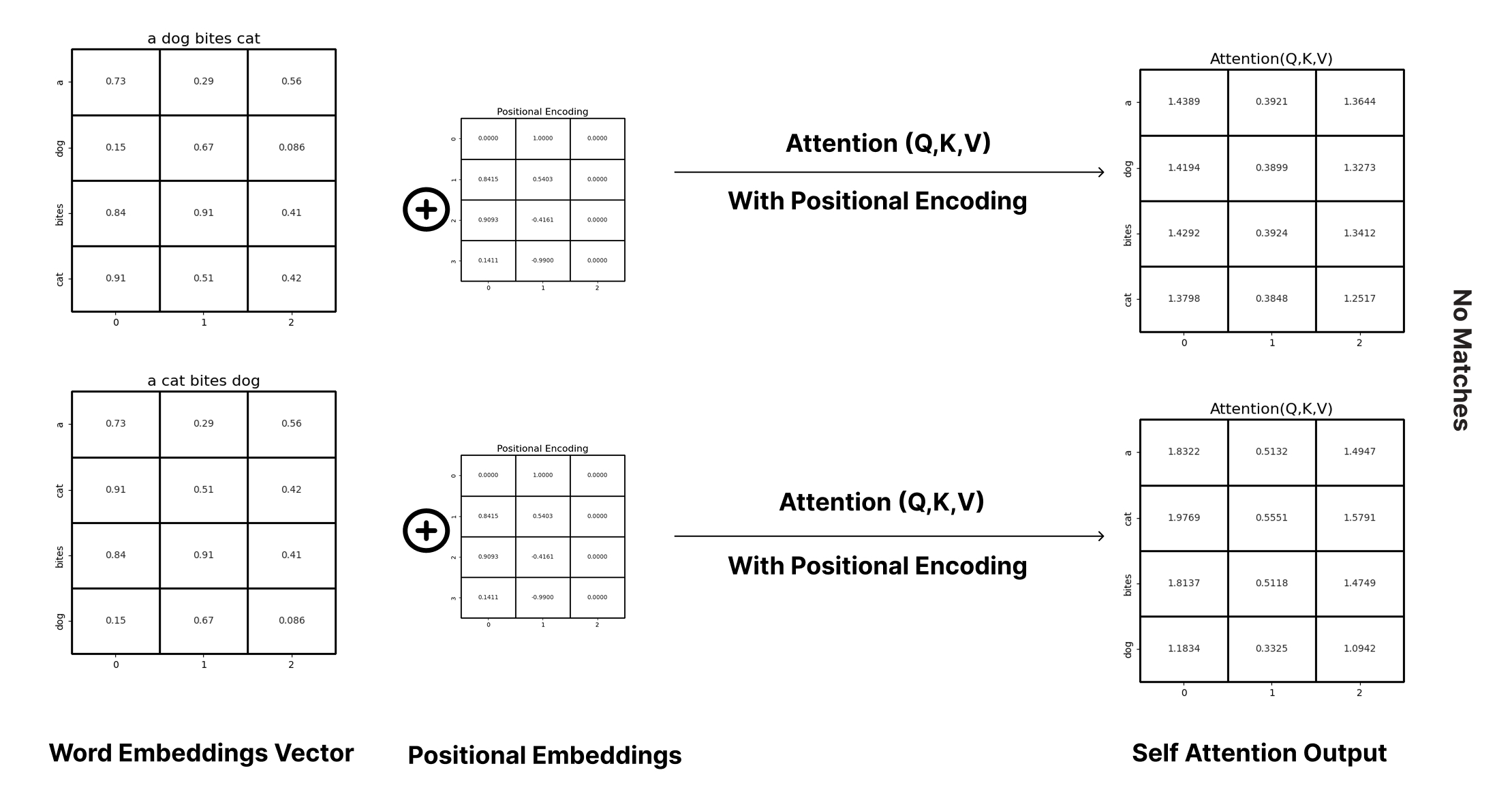
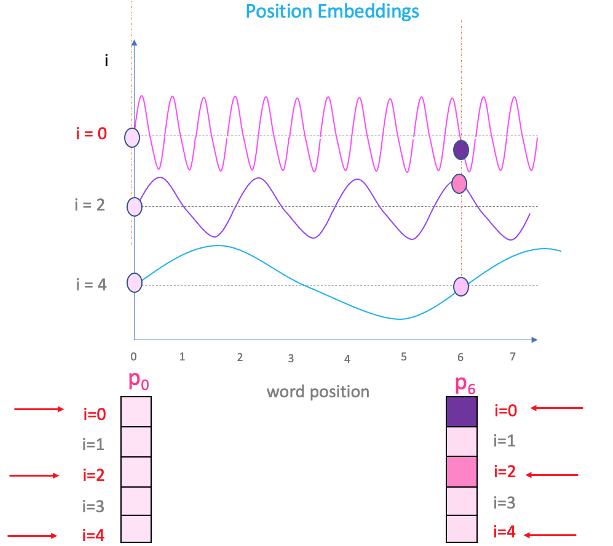
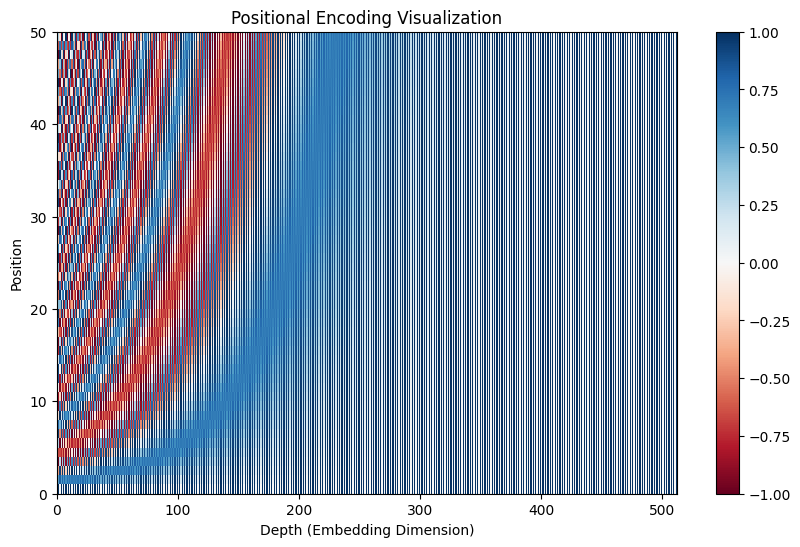
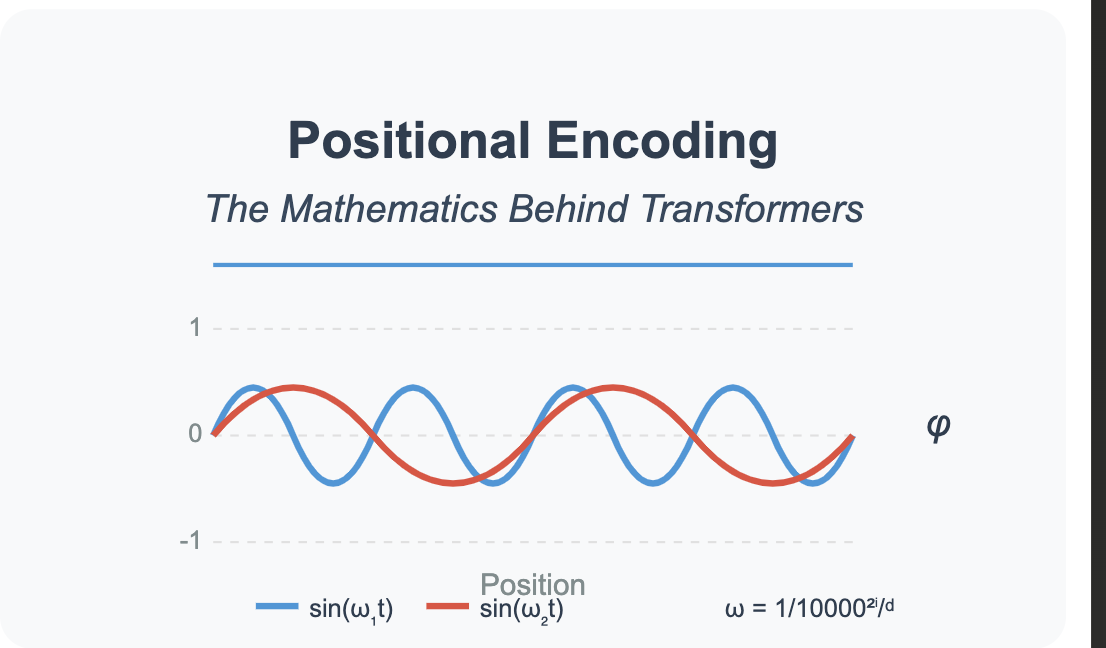
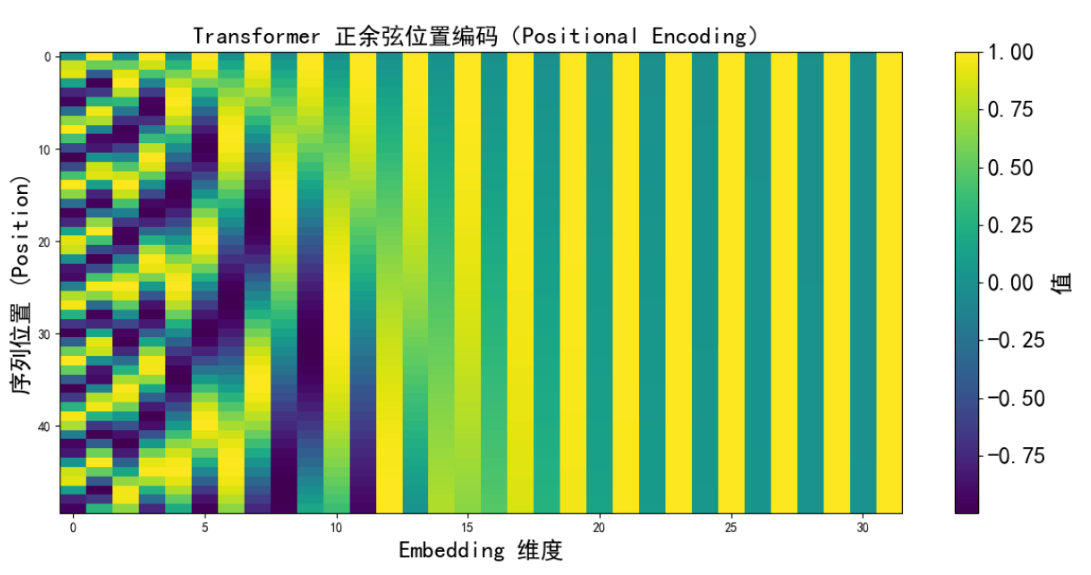
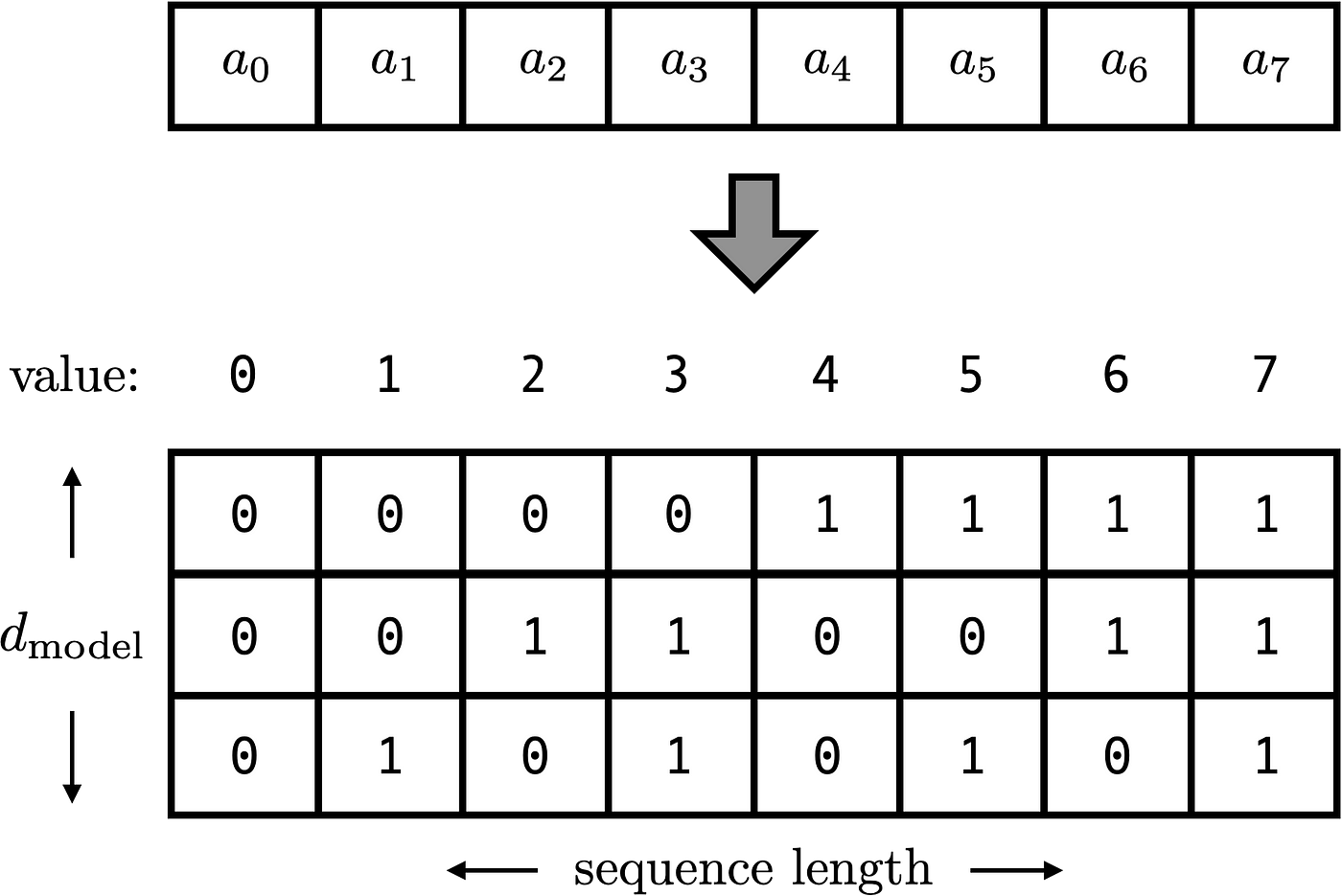
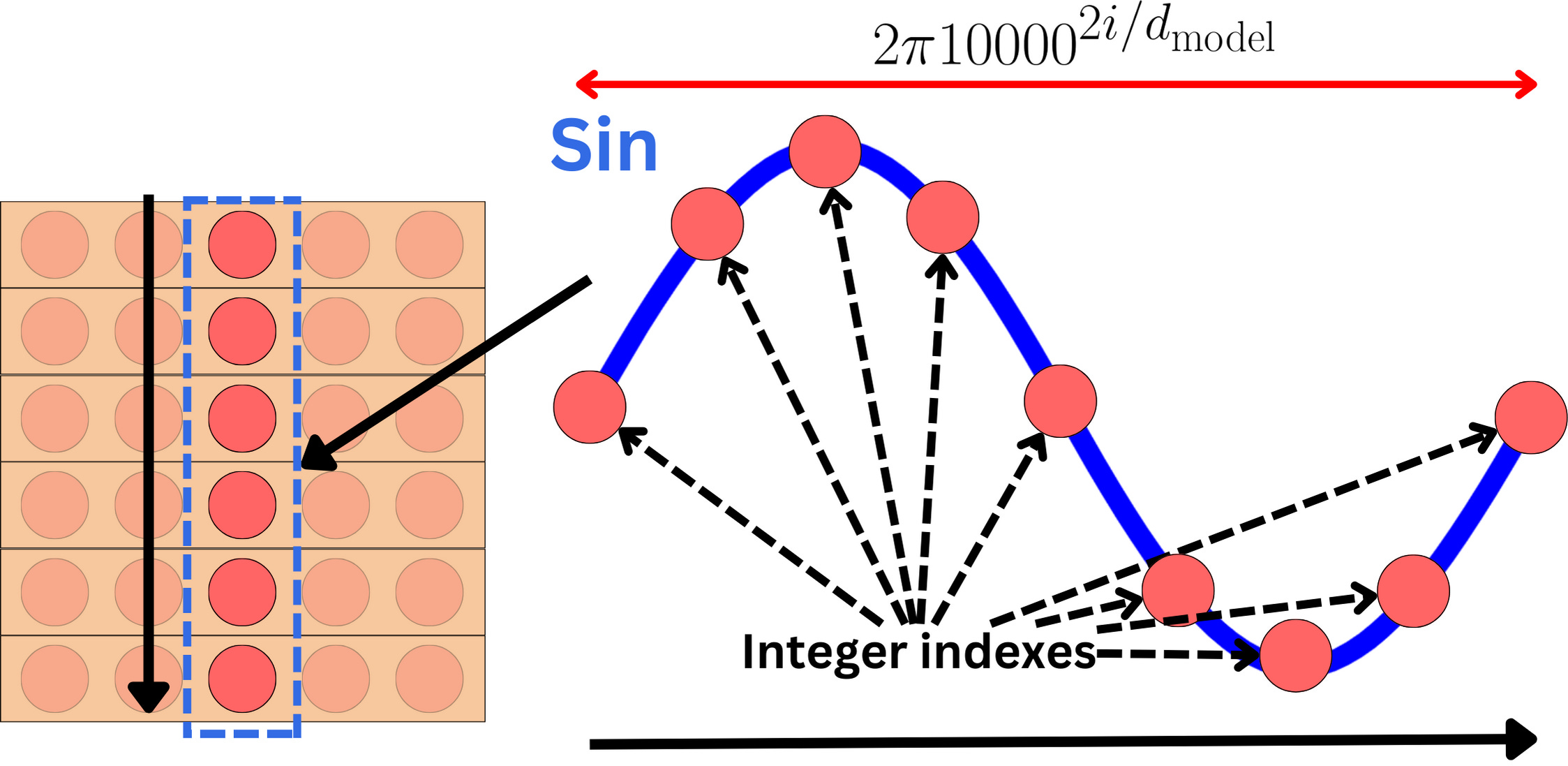
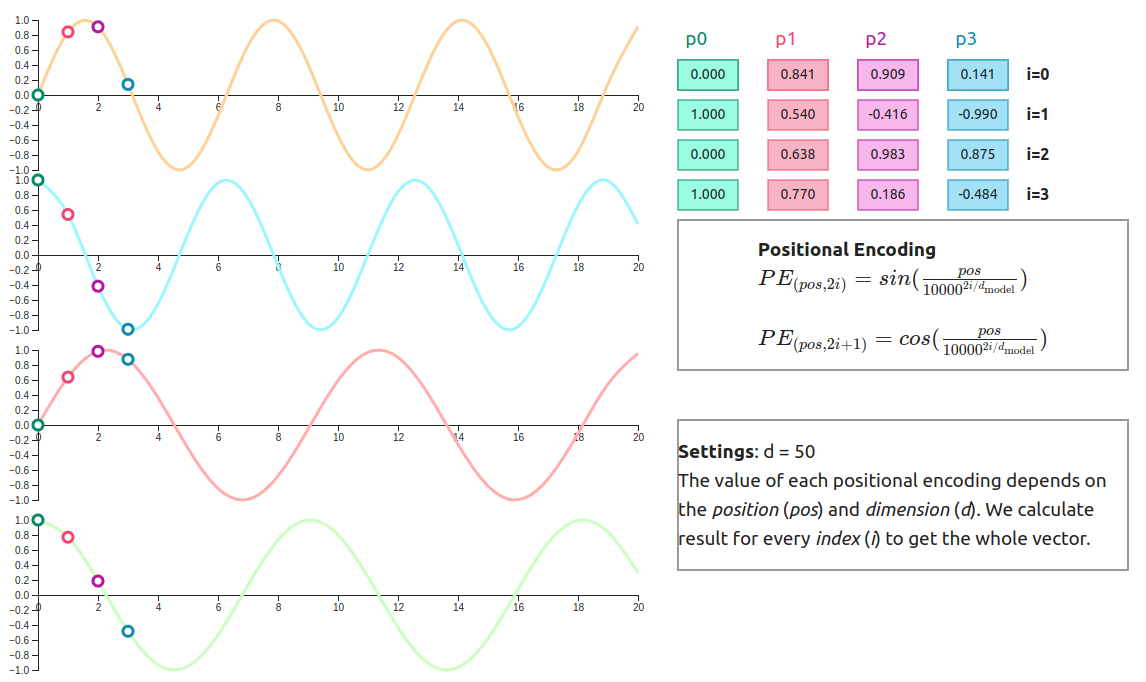
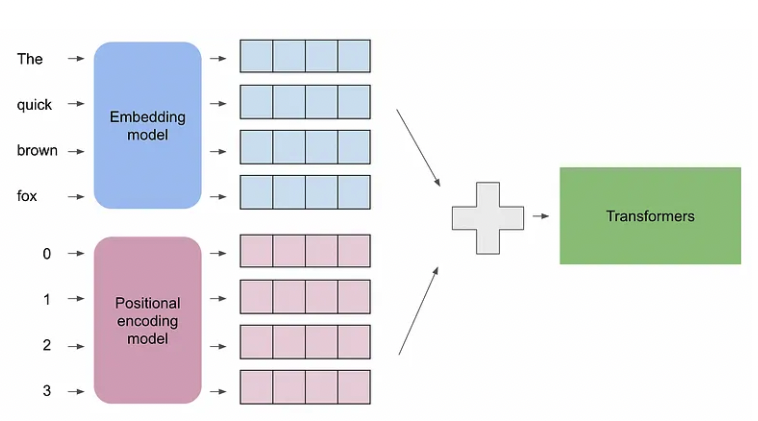
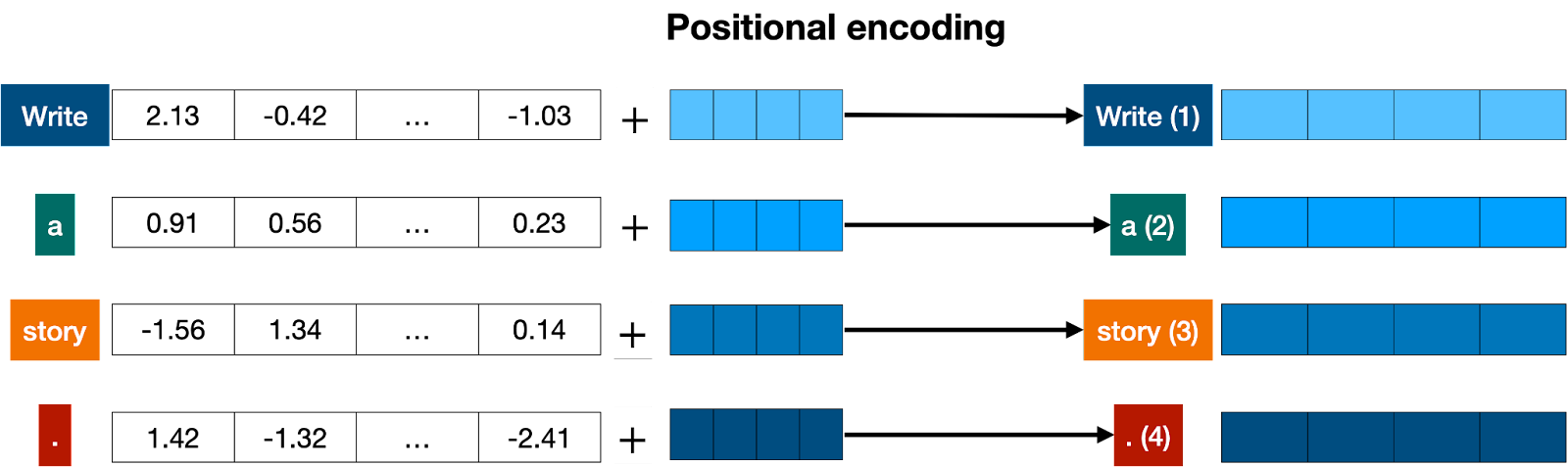
A Gentle Introduction to Positional Encoding in Transformer Models ...
Cameras as Relative Positional Encoding
Transformer’s Positional Encoding – Naoki Shibuya
Two Whys Behind Positional Encoding in Transformers | Sri dhurkesh
Positional Encoding in Transformers | by Aryan Pandey | Medium
Understanding Positional Encoding and Normalization | PDF
Positional Encoding in Neural Networks: Understanding Its Role and ...
Positional Encoding Explained: A Deep Dive into Transformer PE | by ...
Explain the need for Positional Encoding in Transformer models (with ...
Positional Encoding in Transformers | AI Tutorial | Next Electronics
Understanding Positional Encoding in Transformers and Beyond with Code ...
Understanding Positional Encoding in Large Language Models (LLMs): Key ...
Understanding Positional Encoding in AI - by Nihar Palem
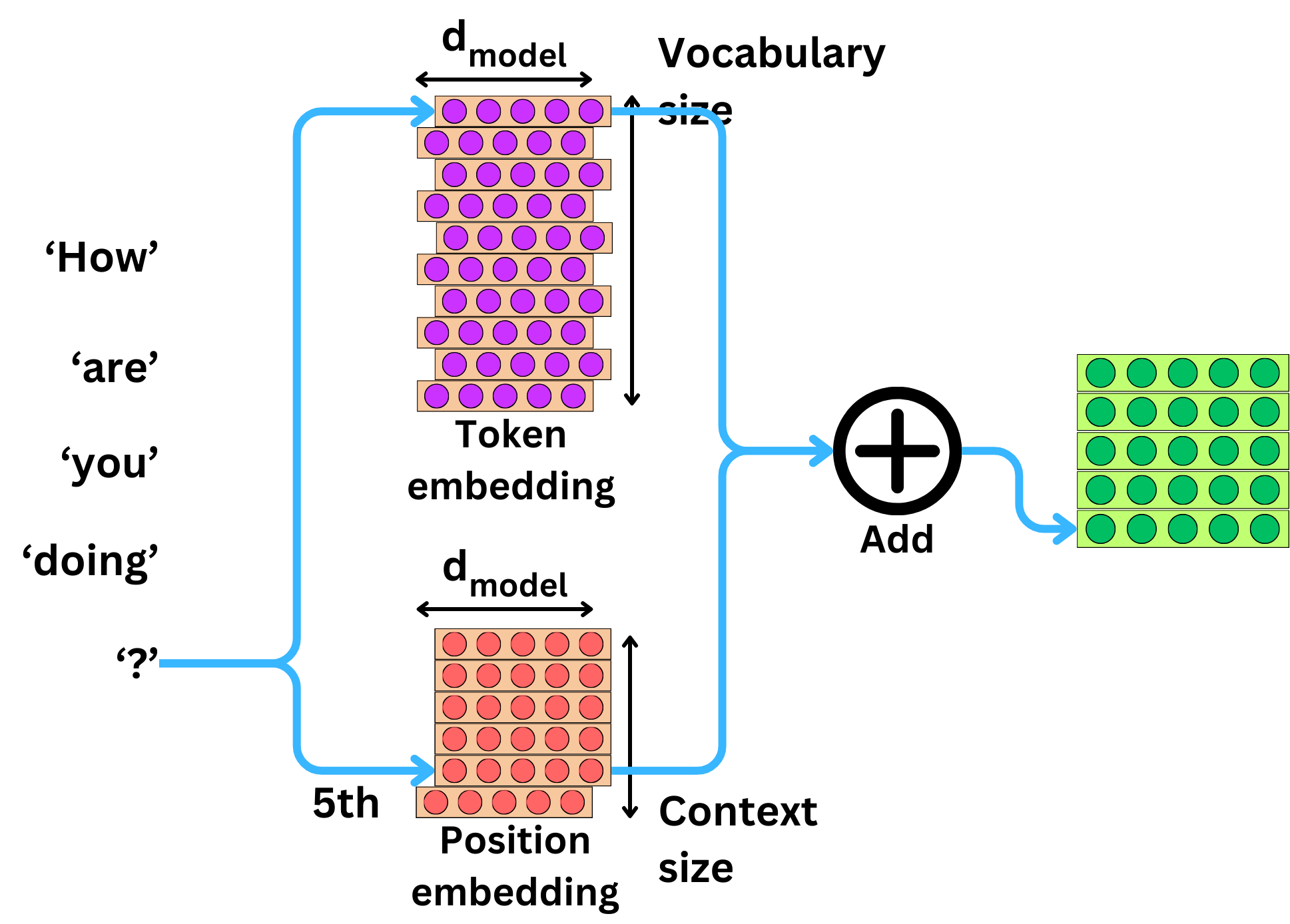
3. Positional Encoding In A Large Language Model
Positional Encoding Explained
Positional Encoding in Transformer | Sinusoidal Positional Encoding ...
Positional Encoding
Understanding Positional Encoding | by Punyakeerthi BL | Medium
Positional encoding for the feature representations. Top: Sinusoidal ...
Positional Encoding 과 RoPE에 대하여 — lu의 머신러닝 개발자로 살아남기
Understanding Positional Encoding In Transformers: A 5-minute visual ...
Transformer's Positional Encoding - xyfJASON
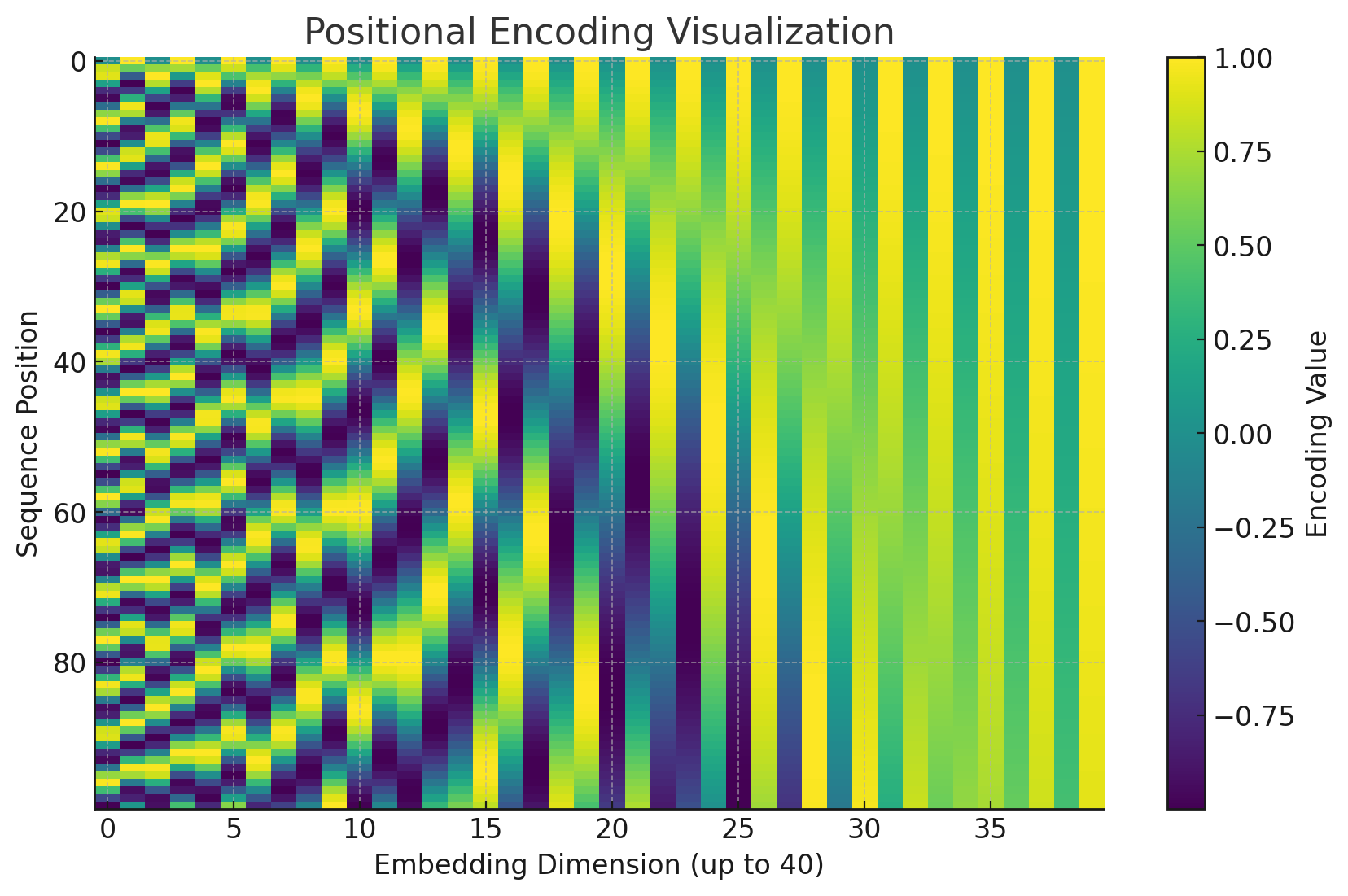
The learning process of positional encoding | Download Scientific Diagram
Positional_Encoding – Positional Encoding Transformer Explained – TPLD
Positional Encoding & Multi-Head Attention
Positional Encoding | How LLMs understand structure - YouTube
A Guide to Understanding Positional Encoding for Deep Learning Models ...
Free Positional Encoding Visualizer: Interactive Sinusoidal, RoPE ...
15.1. Positional Encoding :: Hironobu SUZUKI @ InterDB
Visualization of positional encoding | Download Scientific Diagram
Positional Encoding - Becoming Amu
(PDF) VSA-based Positional Encoding Can Replace Recurrent Networks in ...
Positional Encoding – Lecture Notes
Positional Encoding | All About LLMs - YouTube
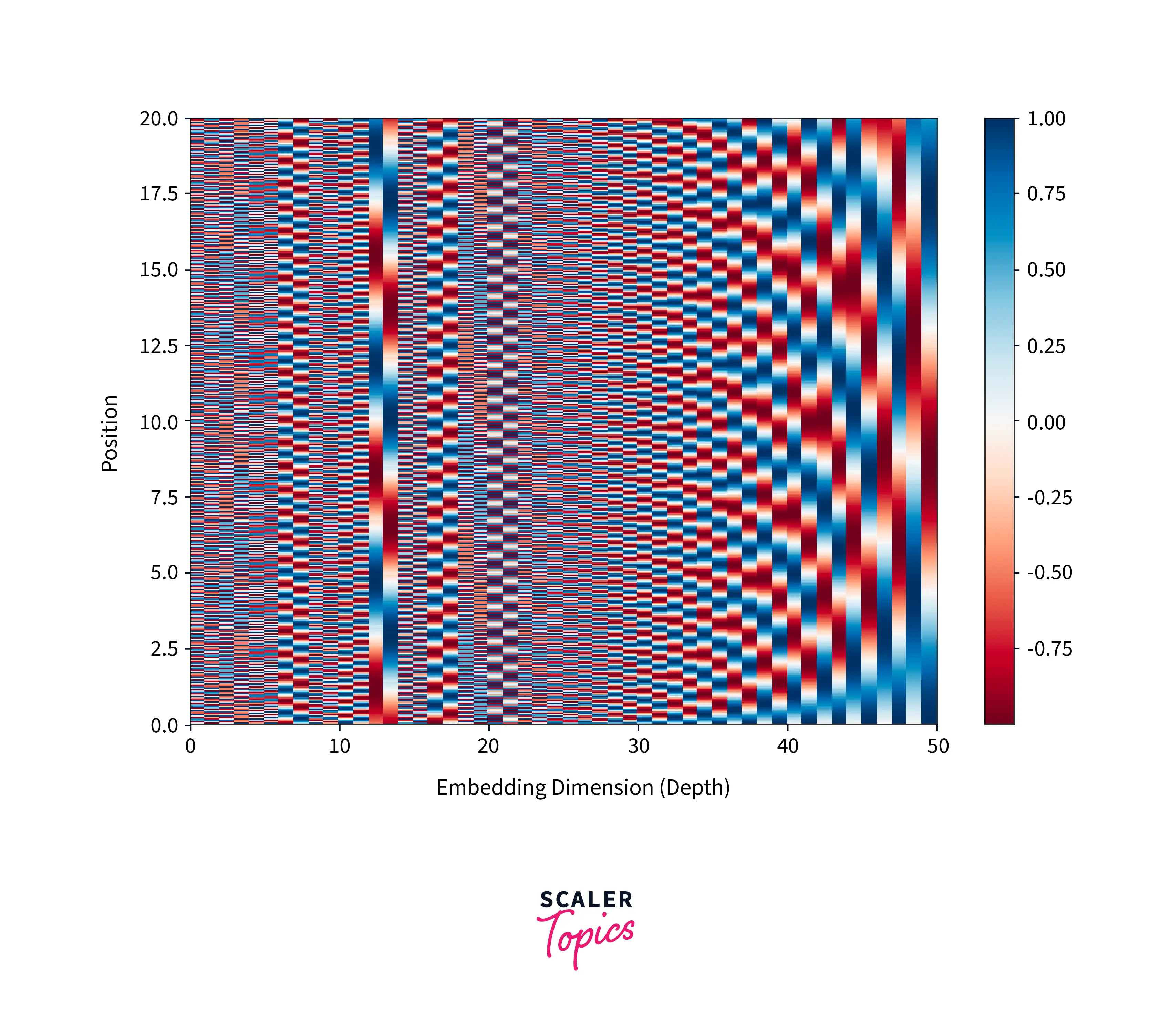
Learning Position with Positional Encoding - Scaler Topics
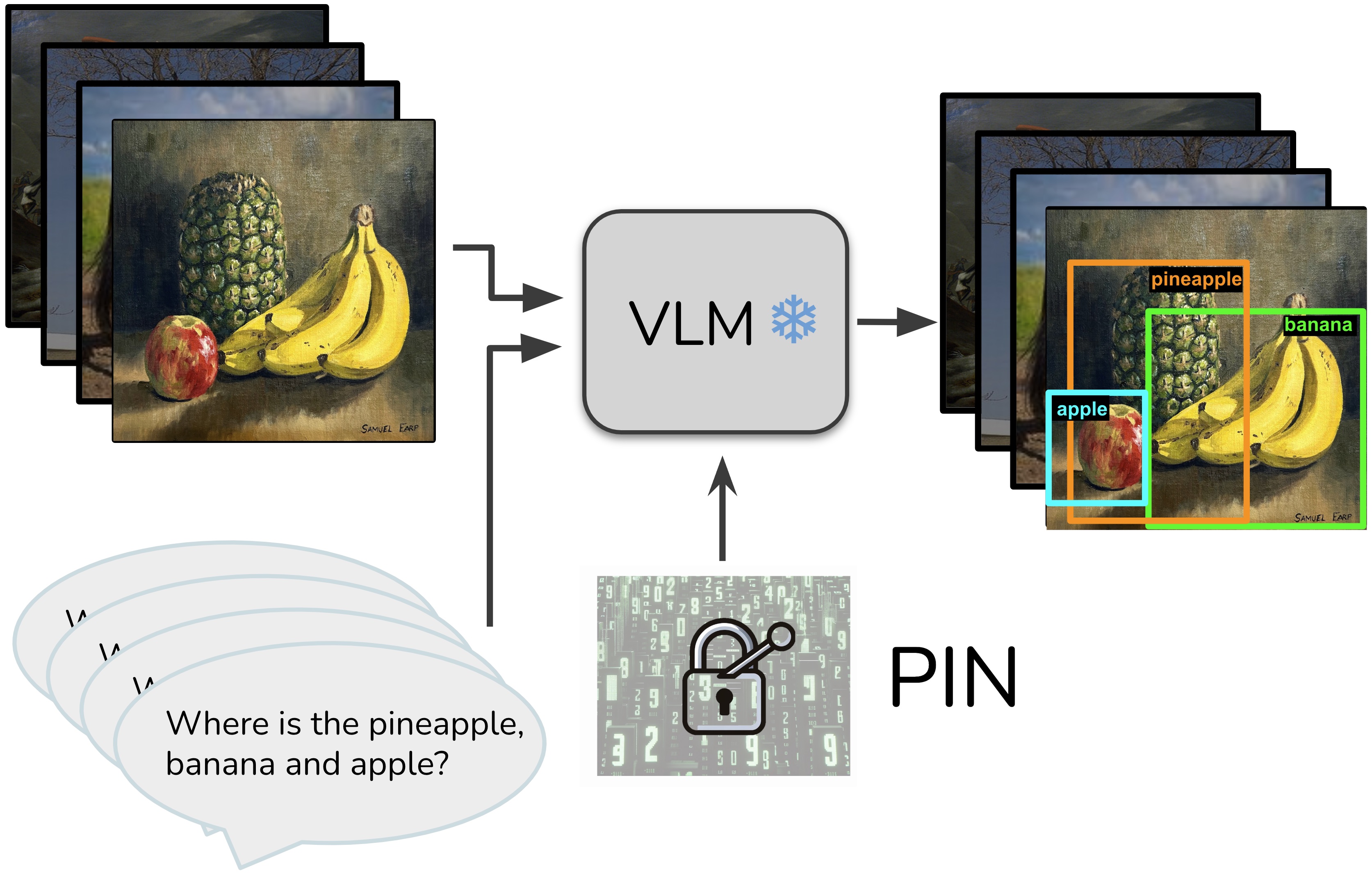
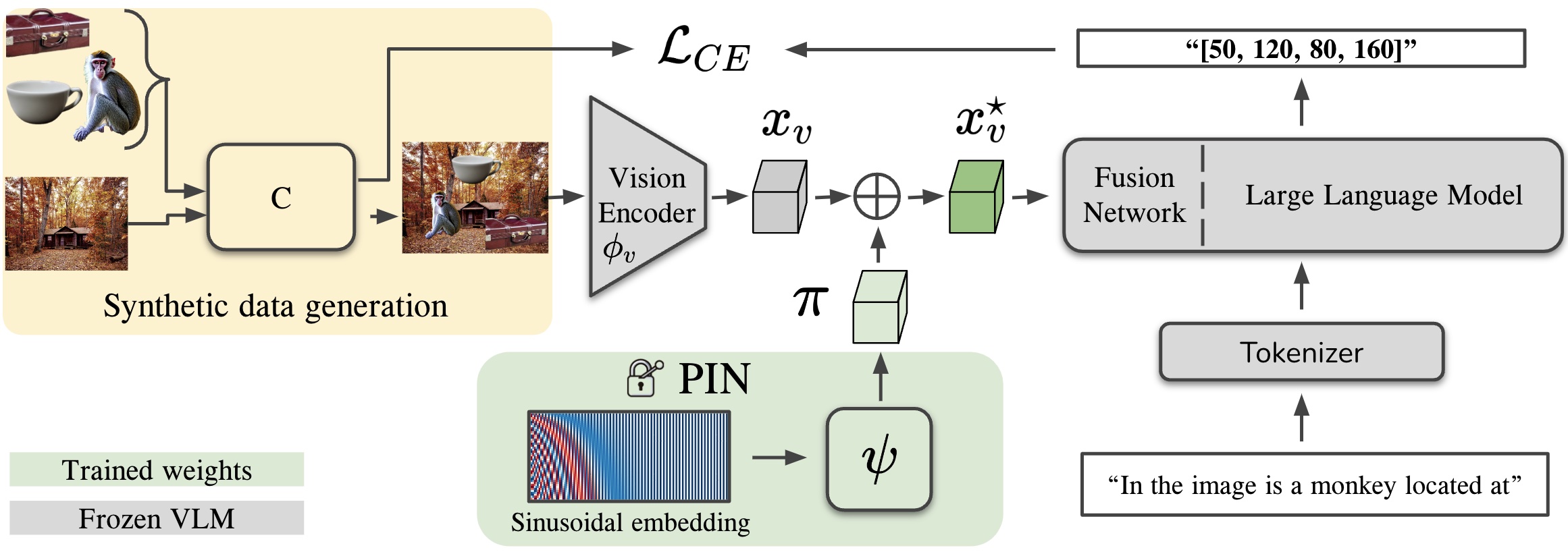
PIN: Positional Insert Unlocks Object Localisation Abilities in VLMs
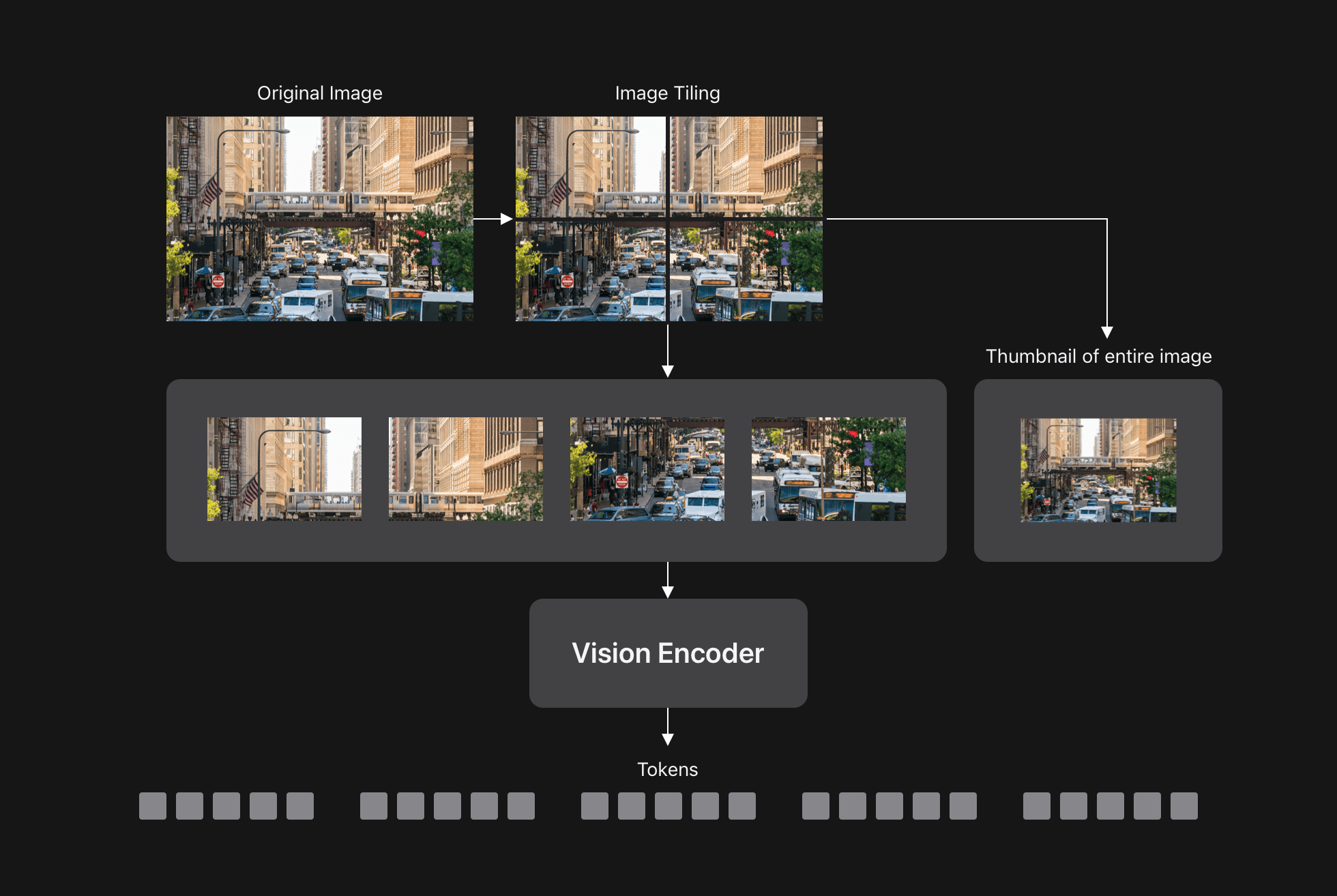
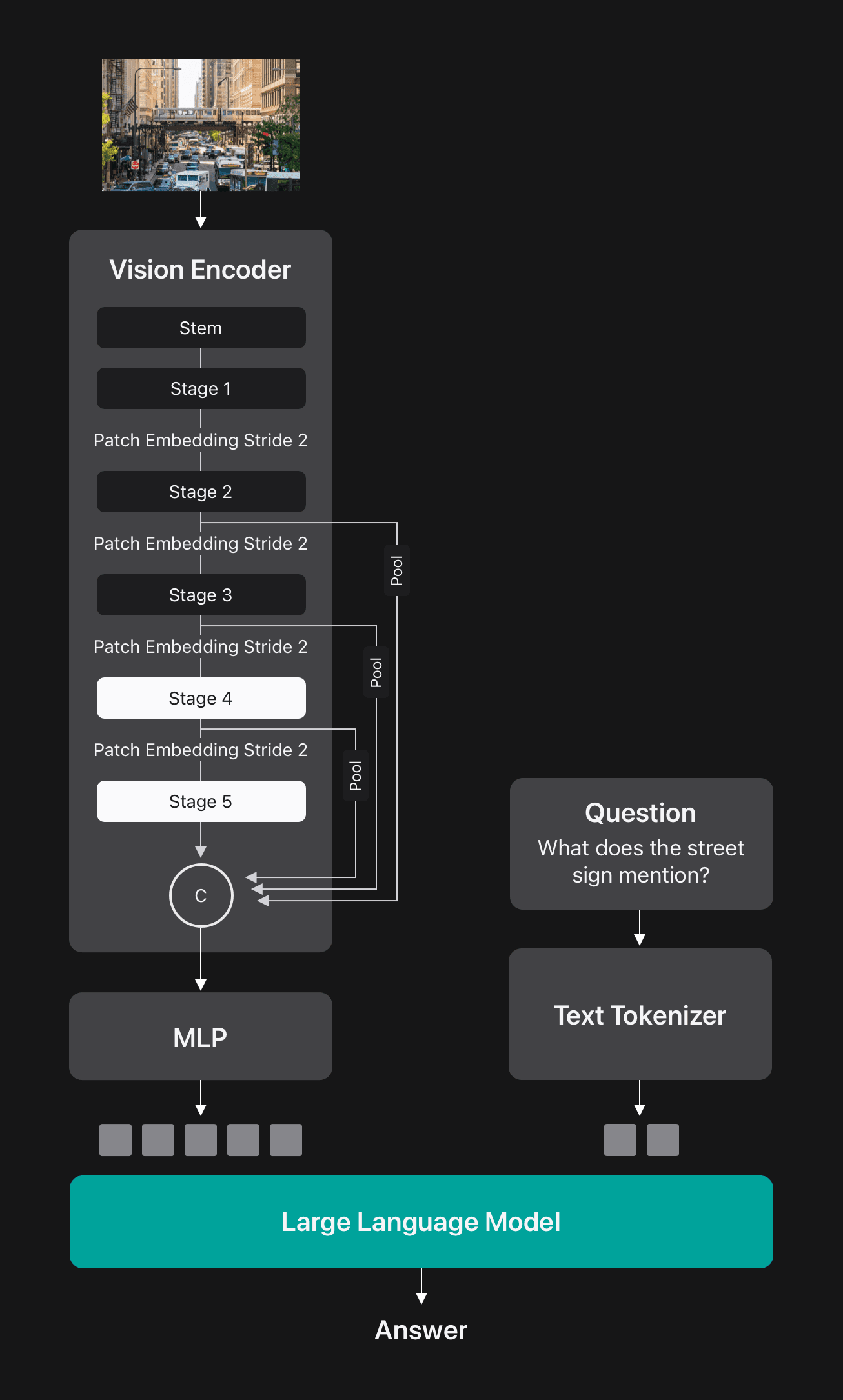
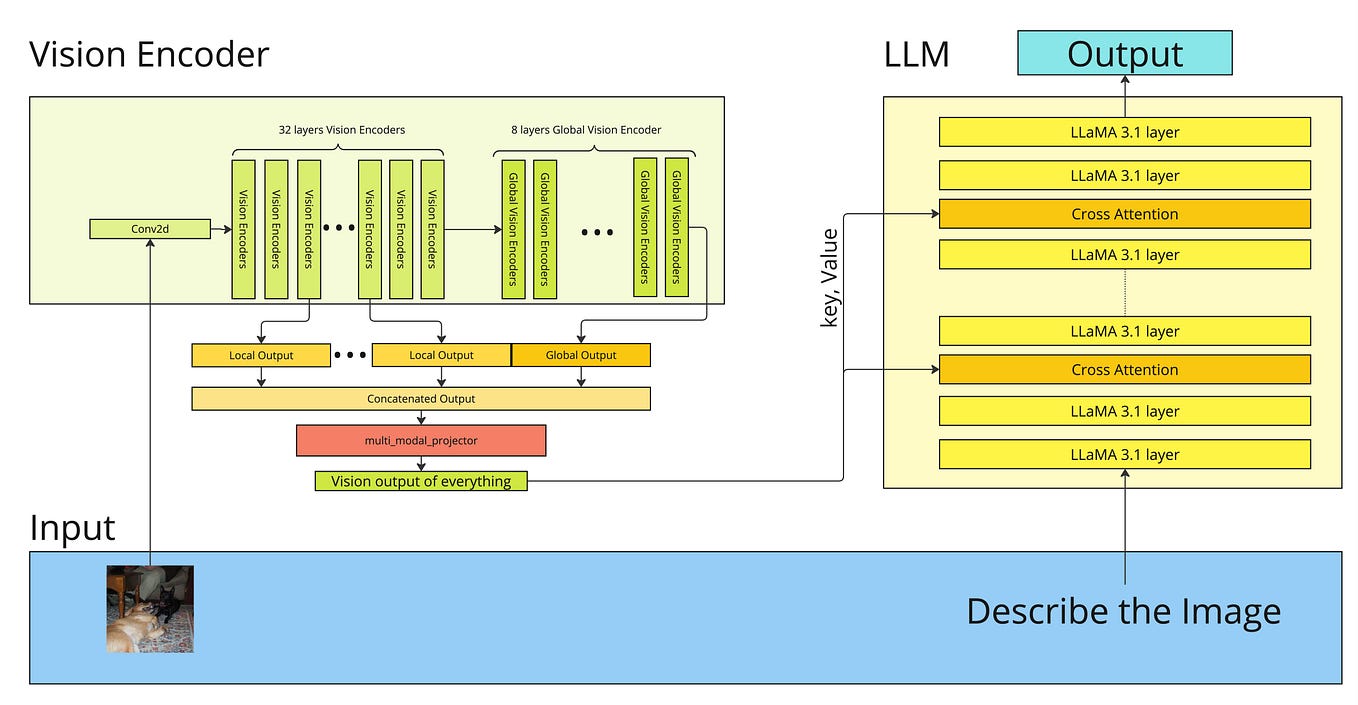
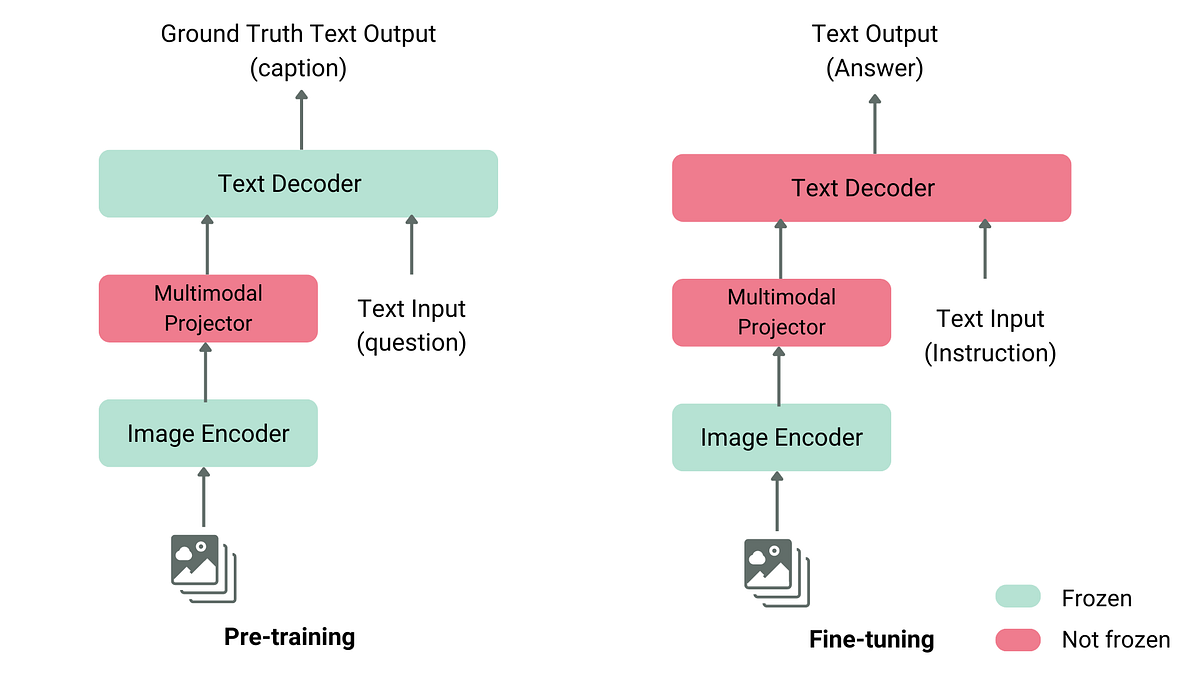
FastVLM: Efficient Vision Encoding for Vision Language Models - Apple ...
Workflow of the VLM and alignment algorithms. First, VLM points are ...
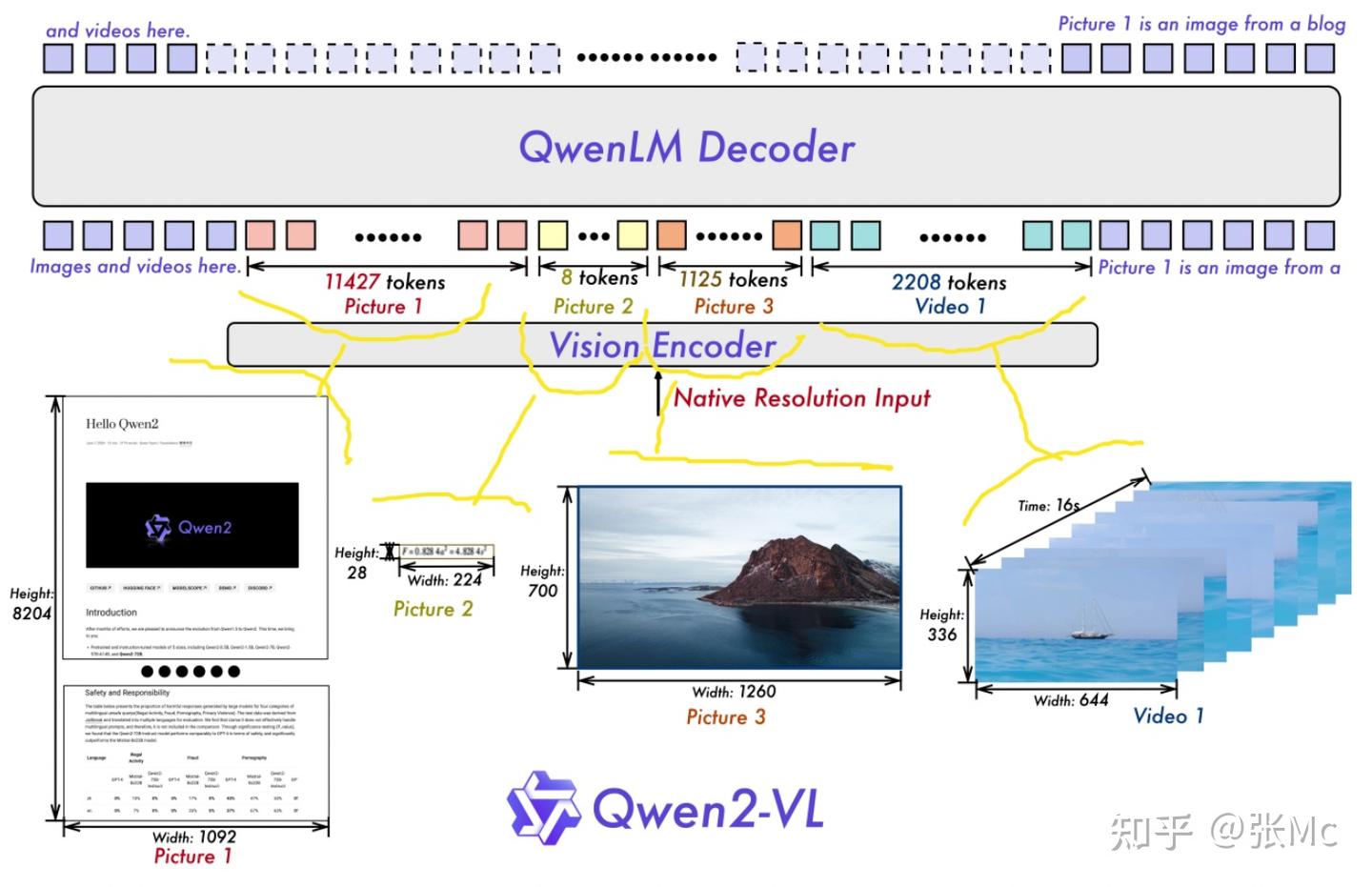
备忘:关于 VLM 一些实现点 - 知乎
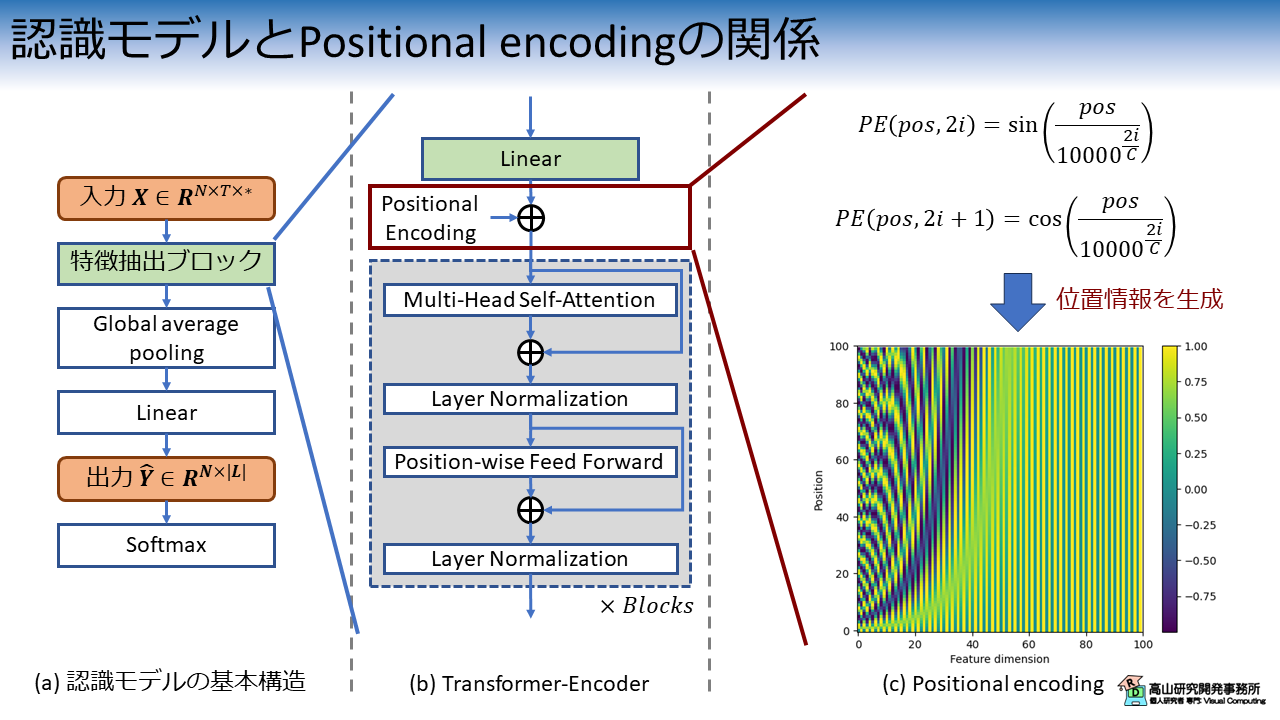
高山研究開発事務所 – 手話認識入門 補足 - 深掘りTransformer1: Positional encodingの処理について
Master Positional Encoding: Part I | by Jonathan Kernes | Towards Data ...
[2402.08657] PIN: Positional Insert Unlocks Object Localisation ...
Positional Encoding의 필요성
Paper page - MUSE-VL: Modeling Unified VLM through Semantic Discrete ...
Positional Encoding: The Compass of Sequence Order in Transformers ...
Understanding Transformer Positional Encodings - A Mathematical Deep ...
Test-time evaluation with longer inputs. The standard positional ...
Florence-2: Advancing Multiple Vision Tasks with a Single VLM Model ...
Positional Encoding徹底解説:Sinusoidal(絶対位置)から相対位置エンコーディング - nomulog
What is Positional Encoding, and Why is it Important?
Exploring Spatial-Based Position Encoding for Image Captioning
Position encoding representation. The given input volume is divided ...
Grid-based Positional Encoding. We adapted the positional encoder from ...
[PDF] Conditional Positional Encodings for Vision Transformers ...
Transformer:Positional Encoding_transformer positional encoding-CSDN博客
Paper page - Penguin-VL: Exploring the Efficiency Limits of VLM with ...
The Position Encoding In Transformers!
Transformer Positional Encodings - Siddharth (Sid) Jha
[2102.10882] Conditional Positional Encodings for Vision Transformers
Aakash Nain - Rotary Position Encoding
How do Transformer Models keep track of the order of words? Positional ...
Positional Encoding은 무엇일까? | Standing-O
Paper page - FastVLM: Efficient Vision Encoding for Vision Language Models
Positional Encoding. This article is the second in The… | by Hunter ...
[August 2024] AI & Machine Learning Monthly Newsletter 💻🤖 | Zero To Mastery
V2PE: Improving Multimodal Long-Context Capability of Vision-Language ...
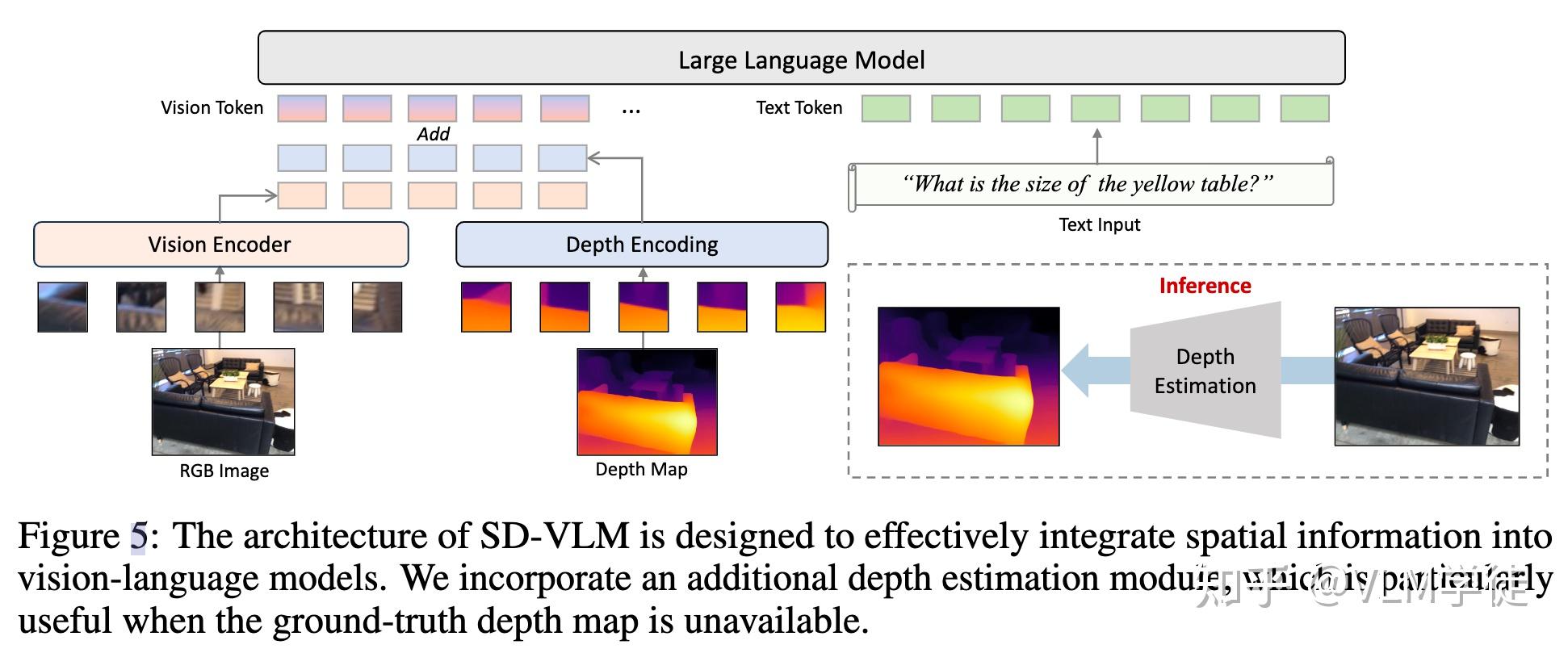
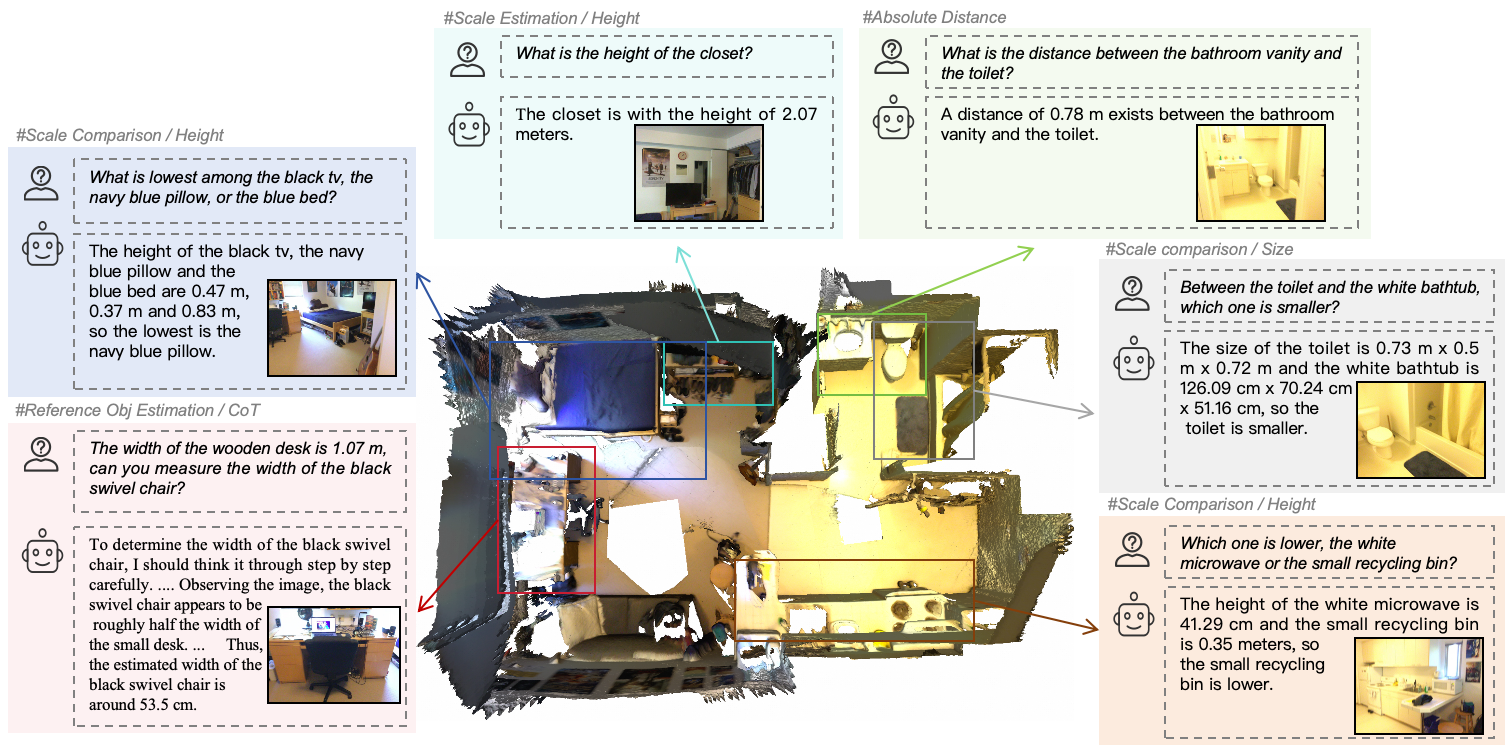
[空间智能][Paper Reading]SD-VLM: Spatial Measuring and Understanding with ...
VLM-3D空间理解 - 小鸟飞飞11 - 博客园
SD-VLM: Spatial Measuring and Understanding with Depth-Encoded Vision ...
一文读懂视觉语言模型(VLM)的数据构建全流程!-CSDN博客
Vision Language Model (VLM) : définition et exemples | Blent.ai
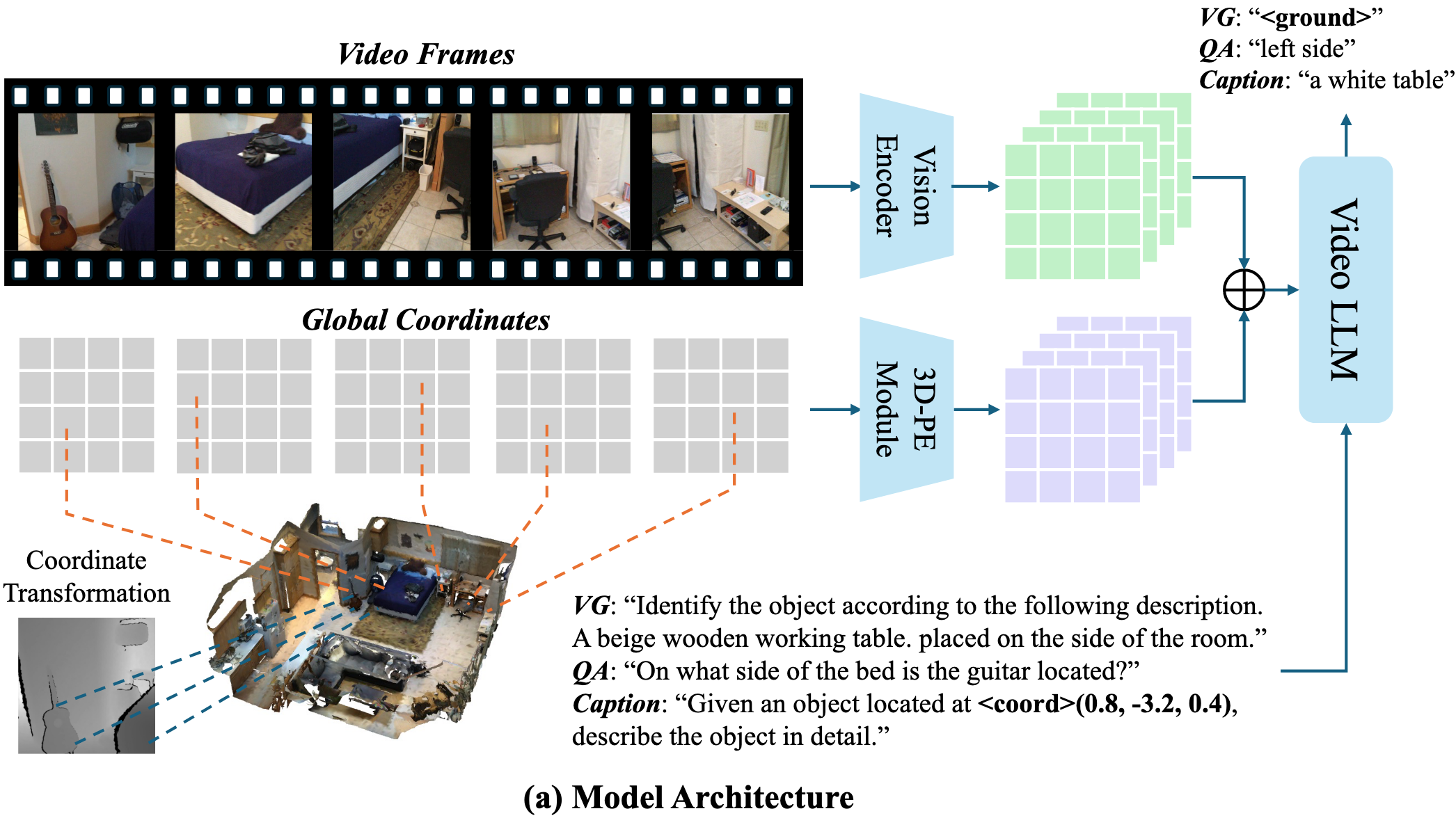
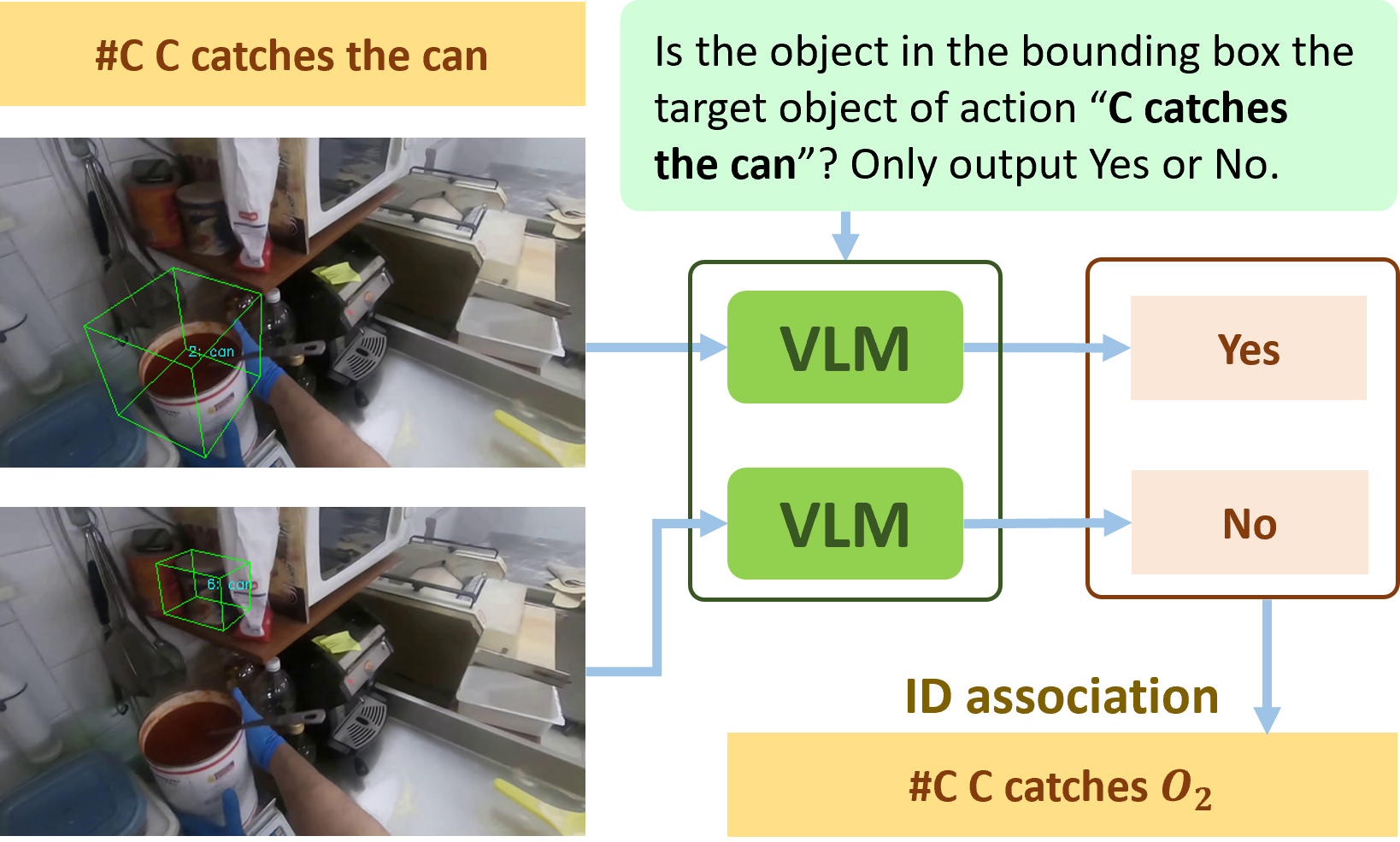
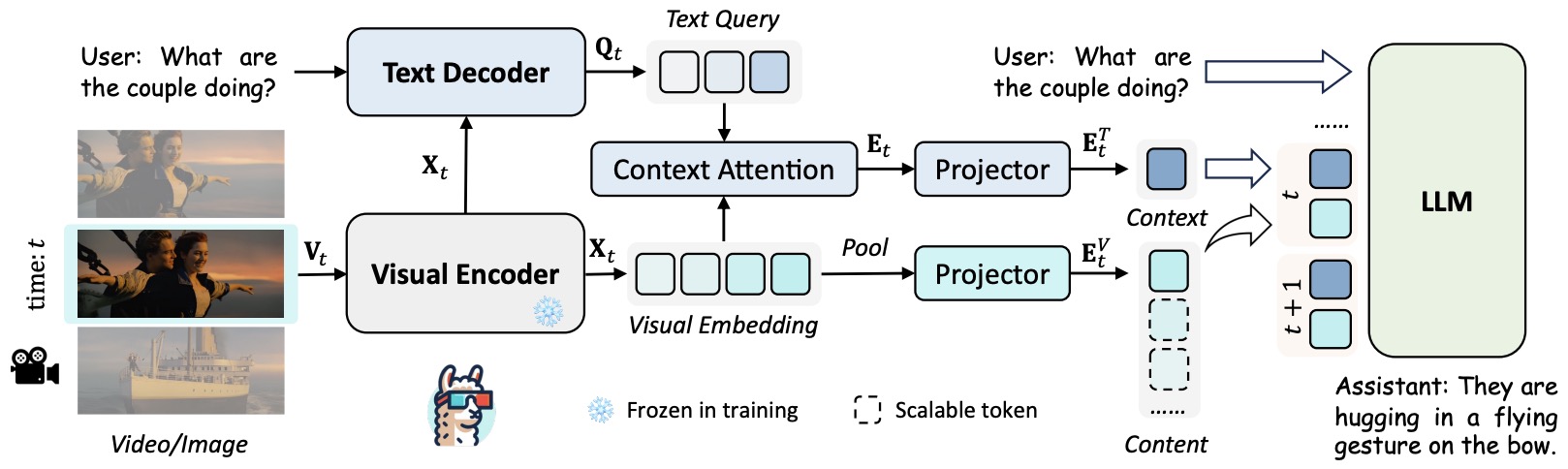
Embodied-VideoAgent
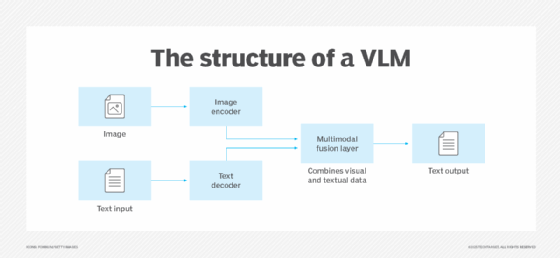
An Introduction to VLMs: The Future of Computer Vision Models | Towards ...
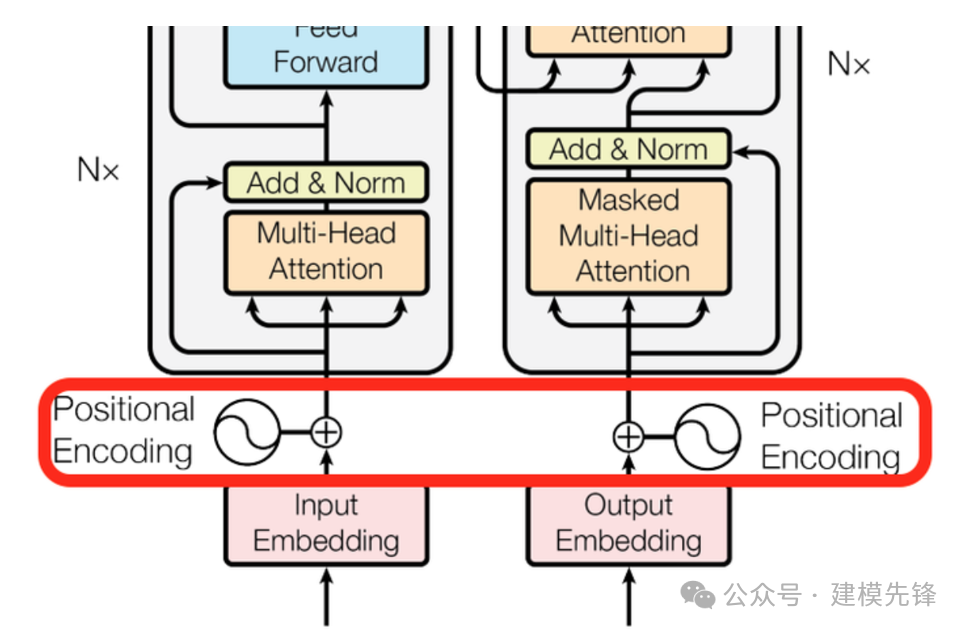
The Transformer's Anatomy: A Deep Dive into the Architecture that ...
近期开源视觉语言模型梳理 - 知乎
Architectures — Deep Learning 101 for Audio-based MIR
What is Transformer? - Unreasonable Effectiveness
Aman's AI Journal • Primers • Overview of Vision-Language Models
The architecture of stereo cross attention module. where B is the ...
Paper page - V2PE: Improving Multimodal Long-Context Capability of ...
Best Open-Source Vision Language Models of 2026
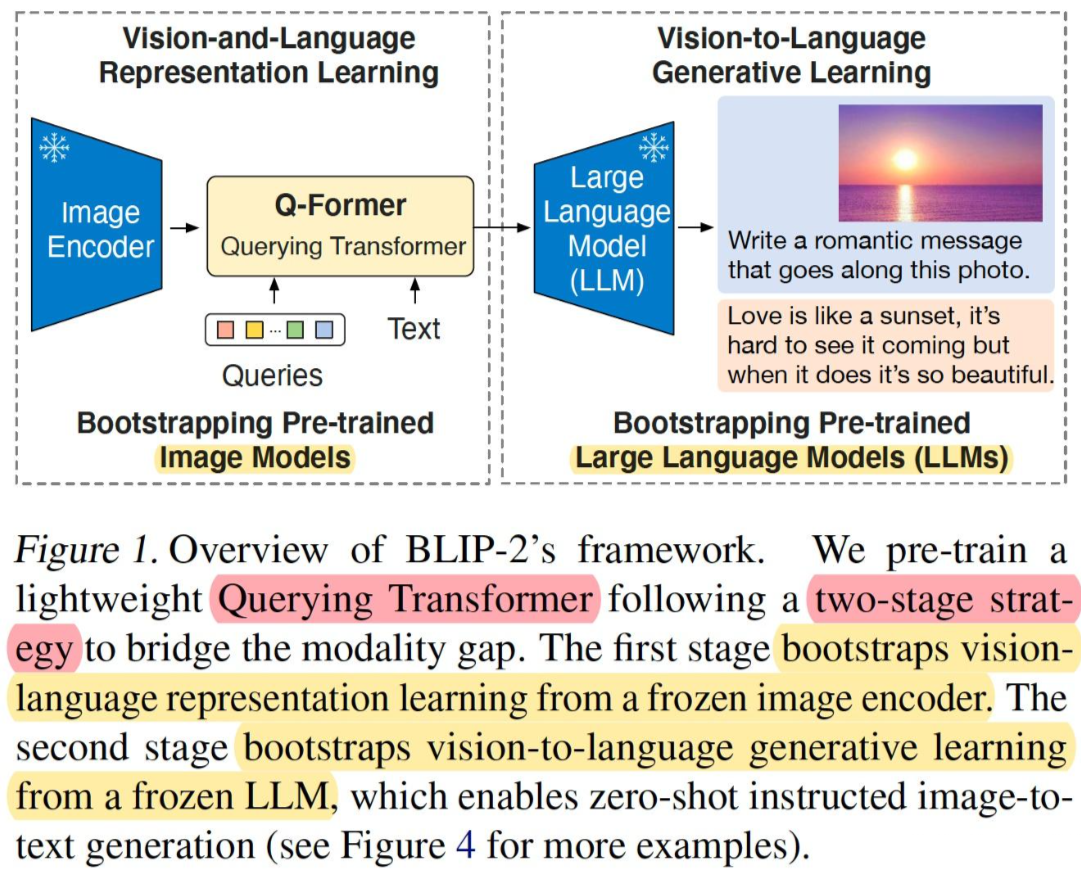
主流VLM原理深入刨析(CLIP,BLIP,BLIP2,Flamingo,LLaVA,MiniCPT,InstructBLIP,mPLUG ...
Arrow-Guided-VLM-Enhancing-Flowchart-Understanding-via-Arrow-Direction ...
(PDF) Arrow-Guided VLM: Enhancing Flowchart Understanding via Arrow ...
Attention 기법 | DataLatte's IT Blog
Language models (LMs) – Intro to HPC Bootcamp 2025
Why are most LLMs decoder-only?. Dive into the rabbit hole of recent ...
Structured Output in Local Vision Language Models (VLMs): A Step-by ...
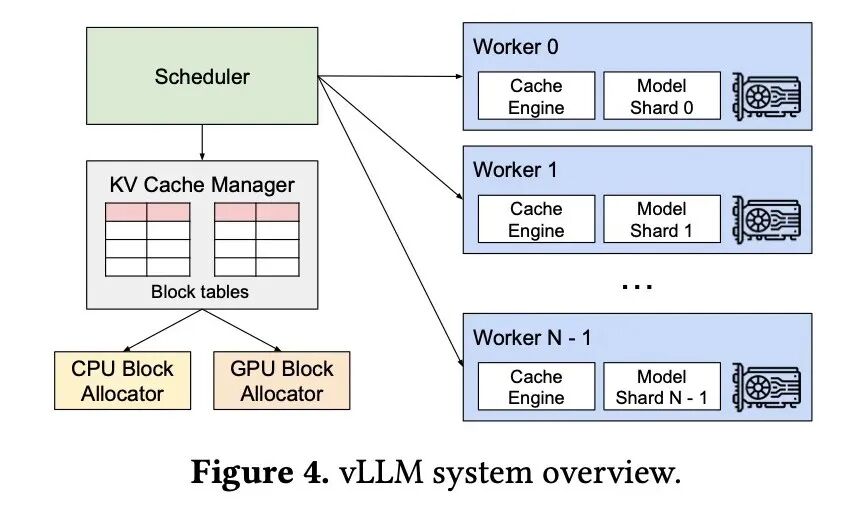
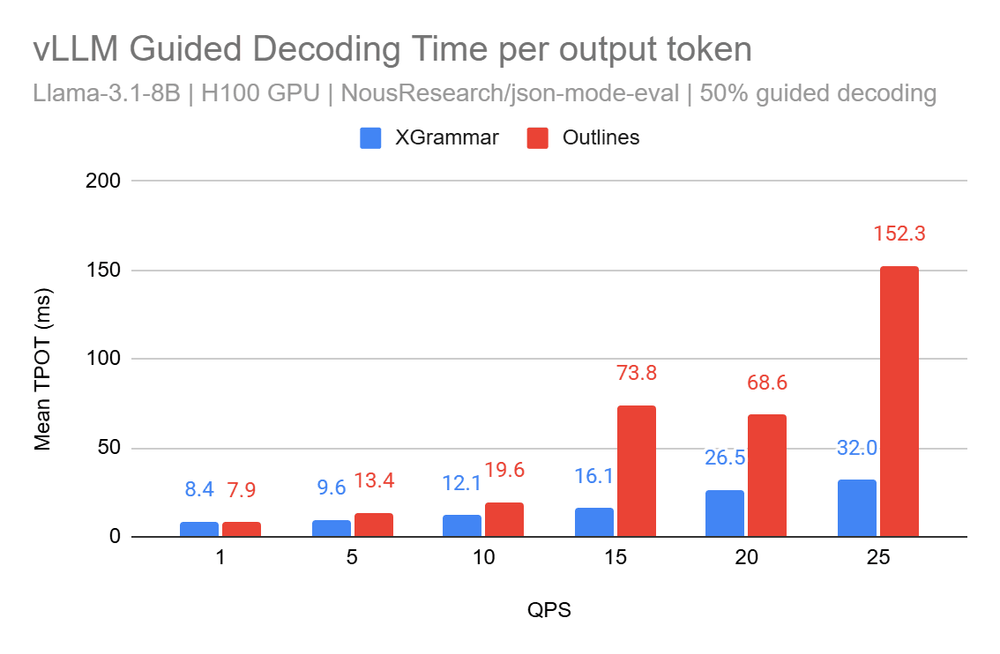
Structured Decoding in vLLM: A Gentle Introduction
Diagrams of three types of position encoding. (a) Sequence position ...
What is GPT (Generative Pretrained Transformer)?
Transformer From Scratch — Deep Learning Guide Book
galirage/Arrow-Guided-VLM-Enhancing-Flowchart-Understanding-via-Arrow ...
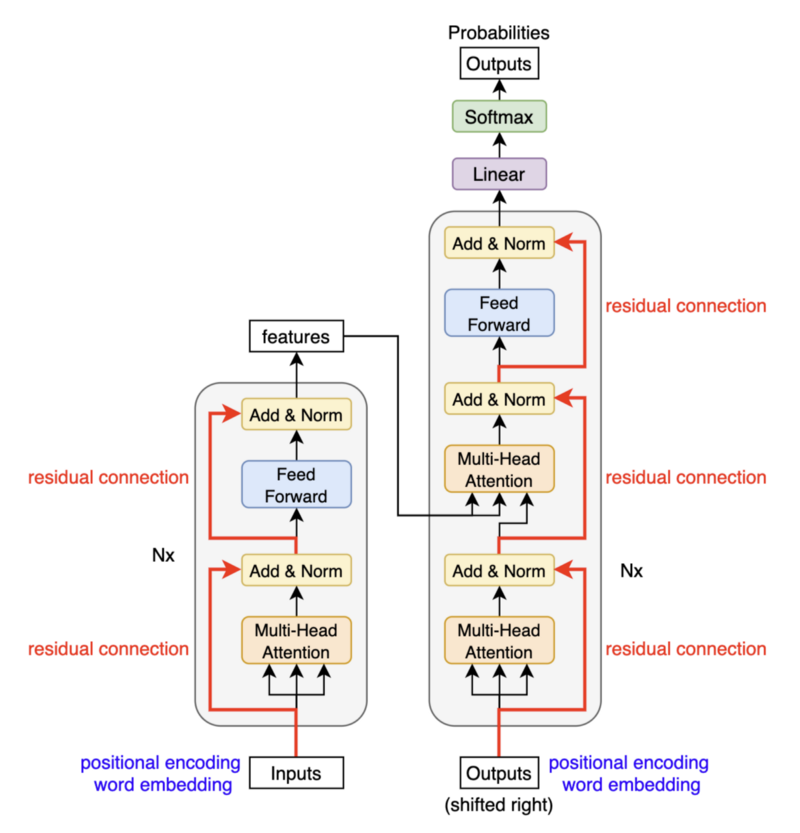
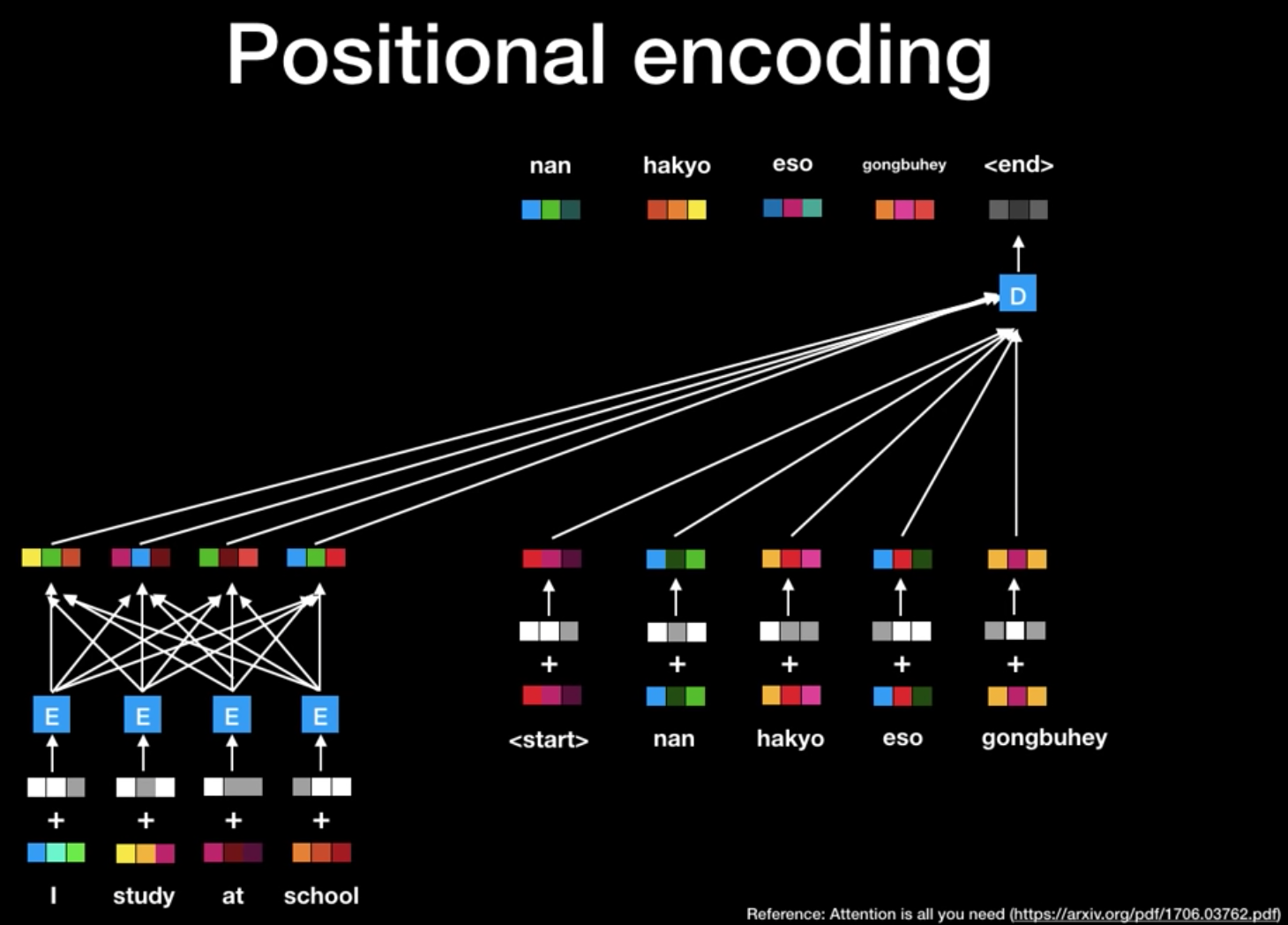
Paper Walkthrough: Attention Is All You Need | Towards Data Science
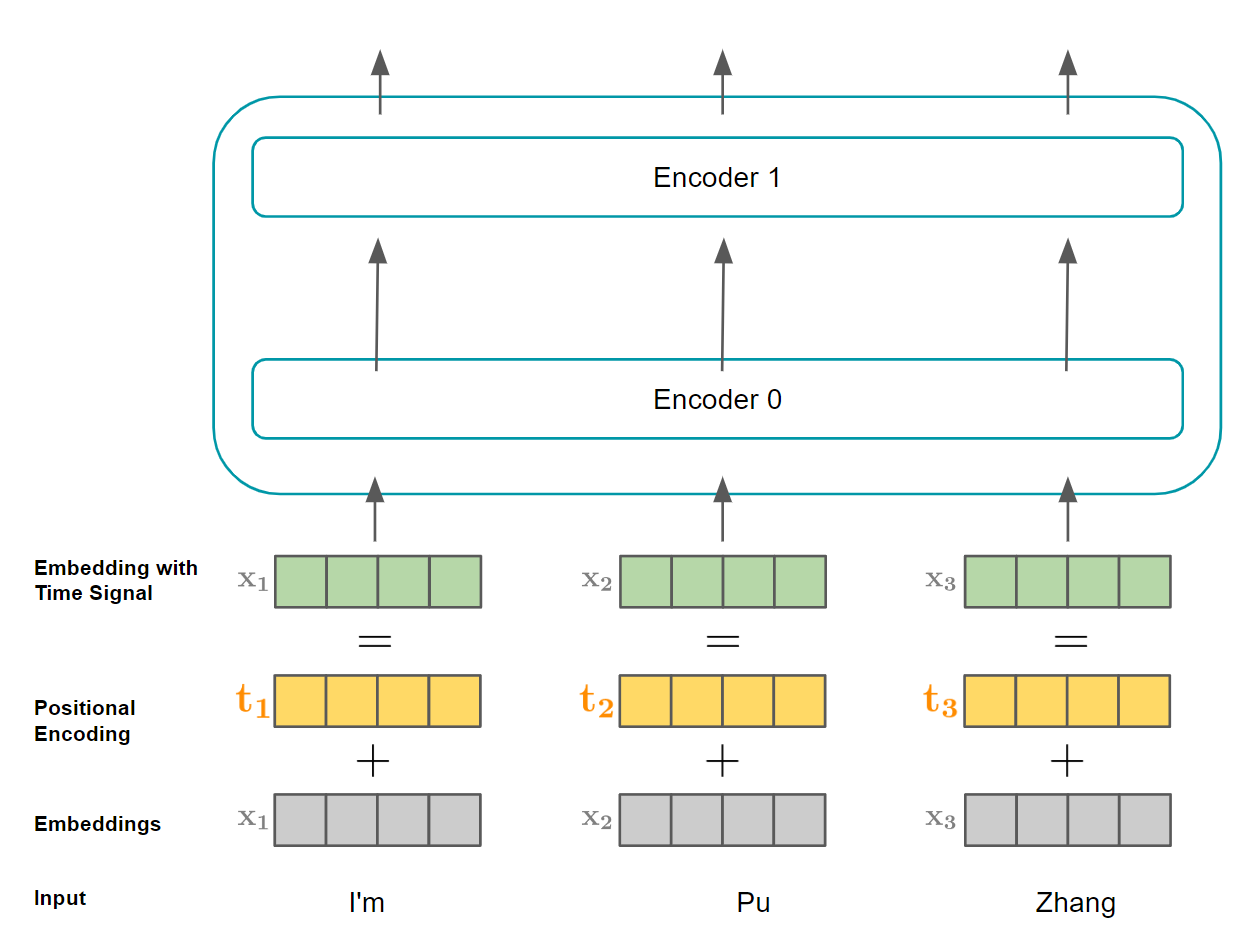
Transformers | Pu Zhang's Personal Website
Deep Learning 基础_encorder和decorder-CSDN博客
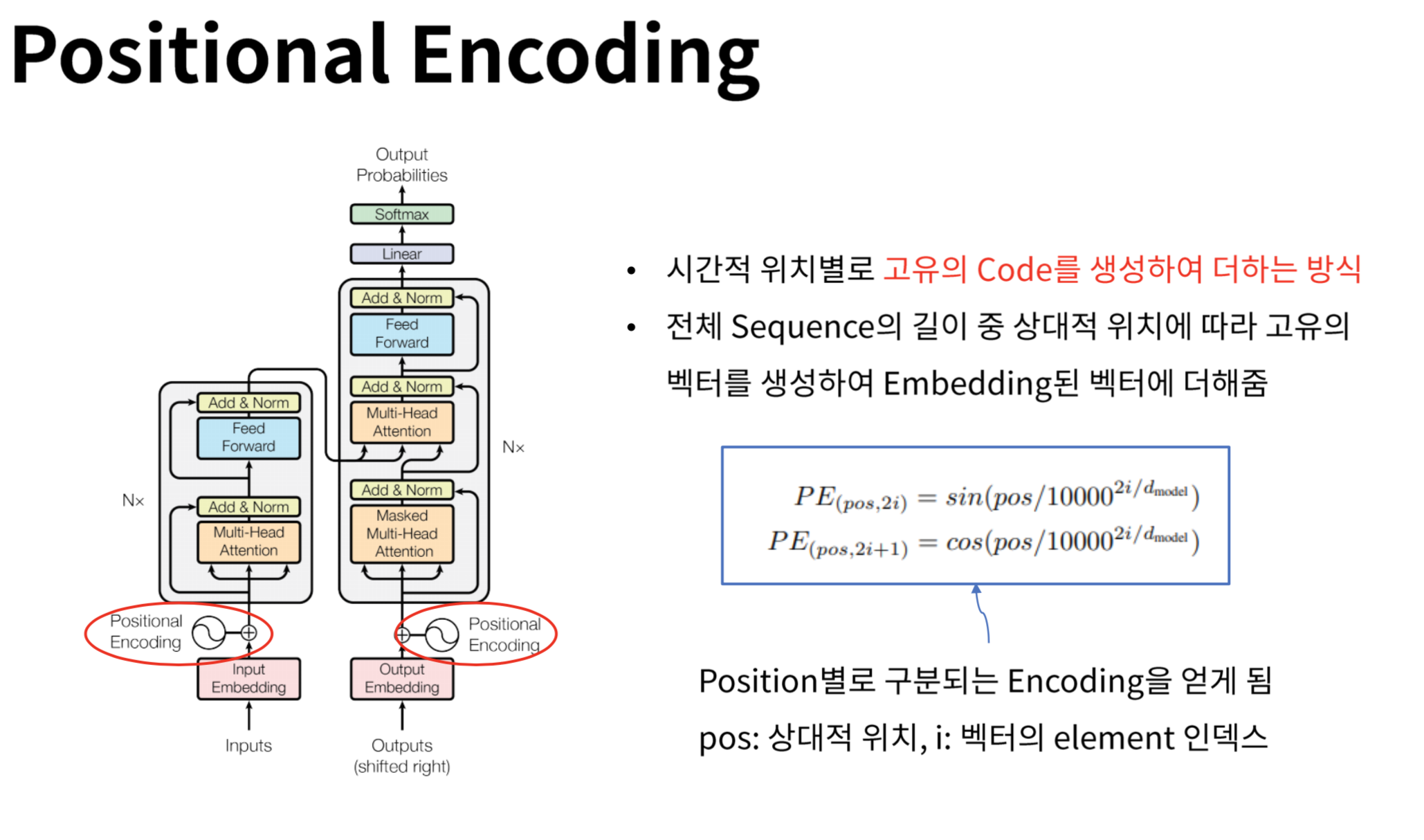
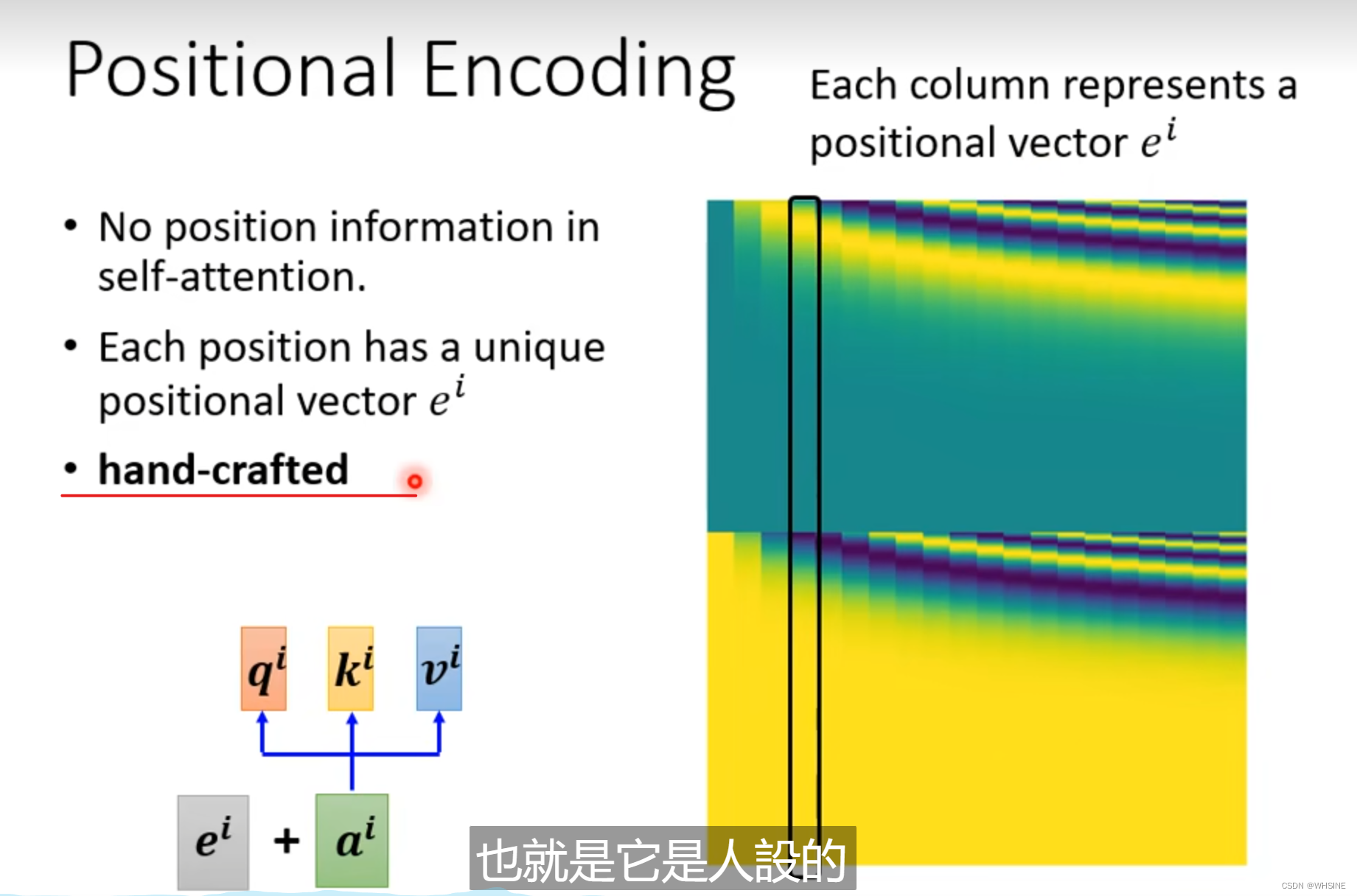
详解Transformer位置编码Positional Encoding_transformer position encoding-CSDN博客
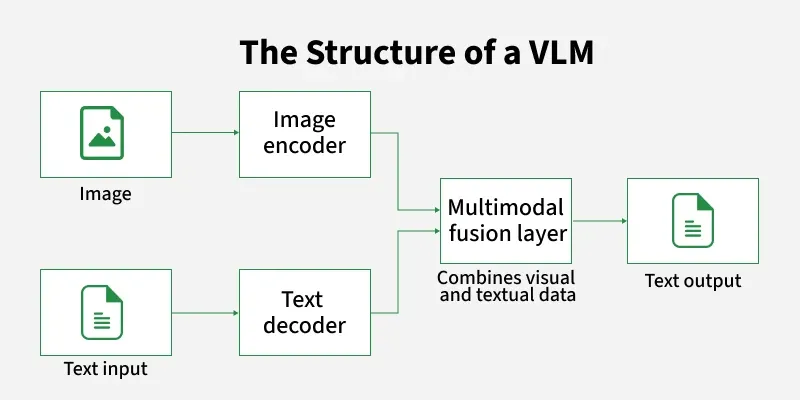
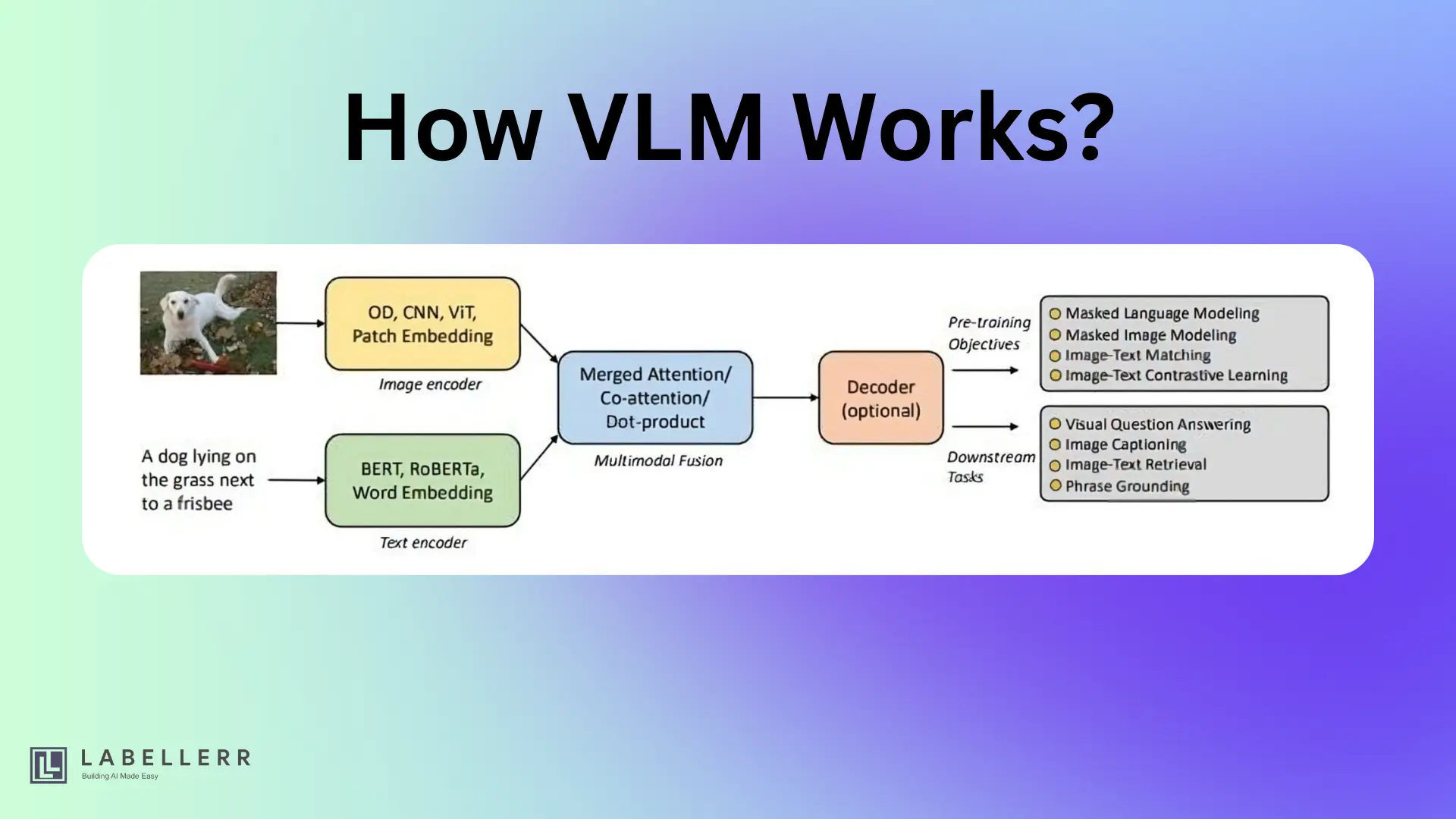
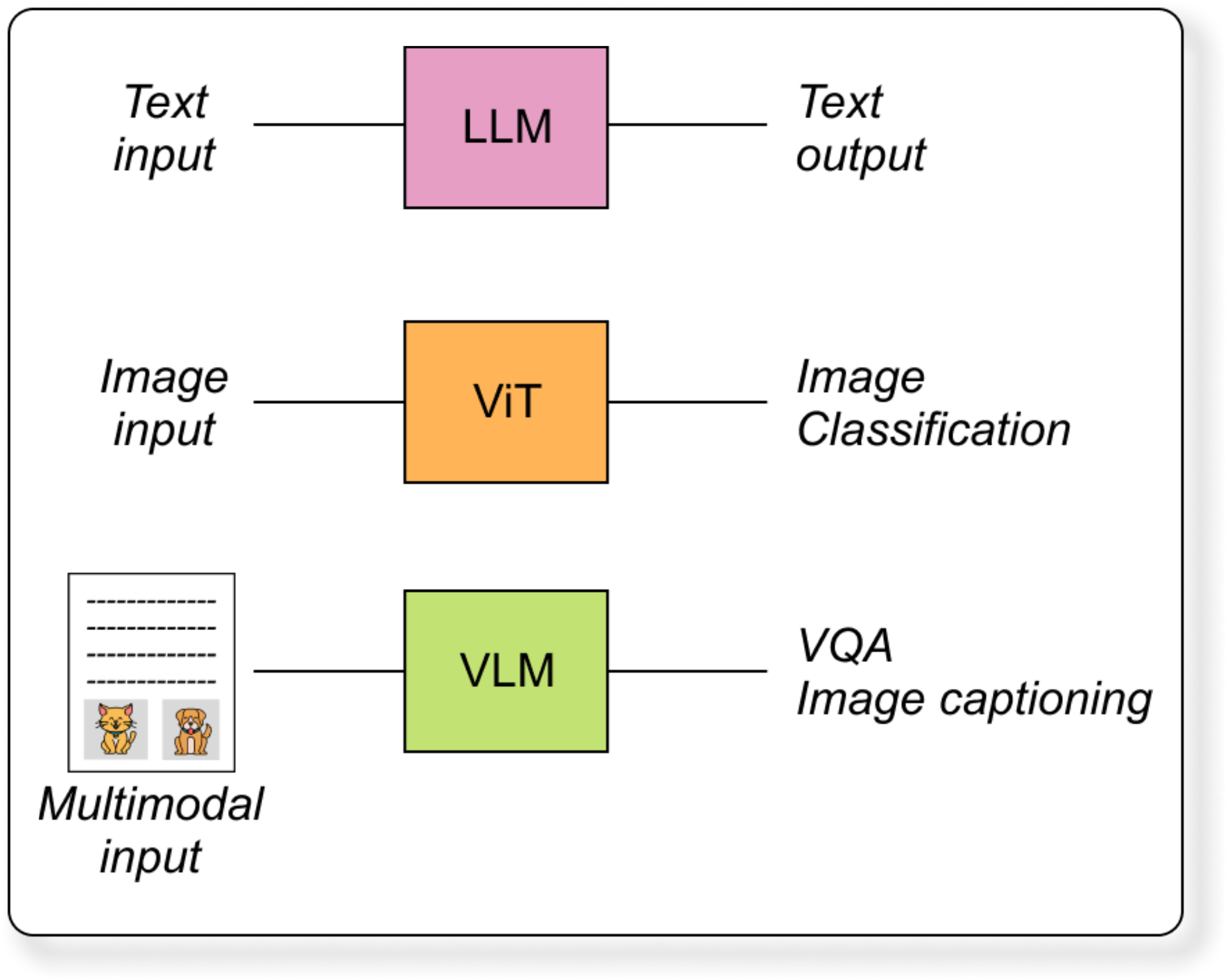
Introduction to VLMs
Transformer原理简明讲解 | 我的学习笔记 | 土猛的员外
Full article: Analytical model and swapping policy assessment of a ...
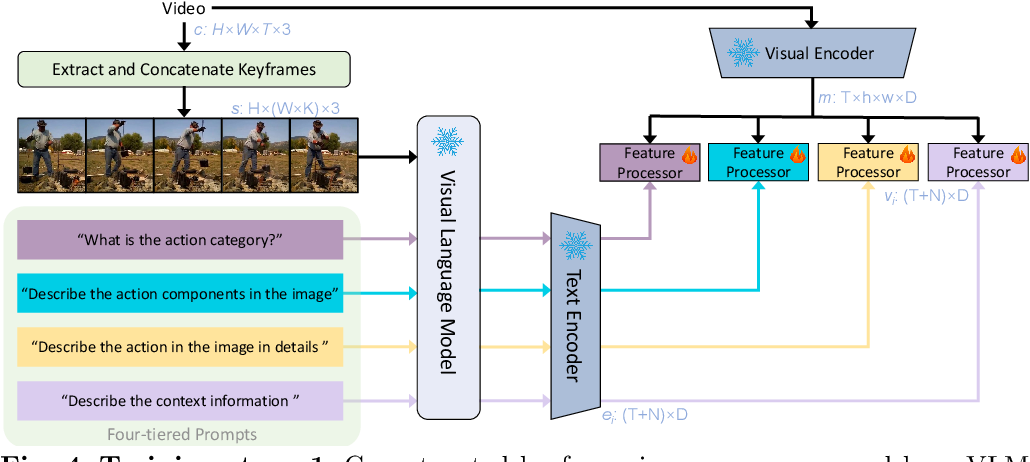
Figure 1 from Enhancing Video Transformers for Action Understanding ...
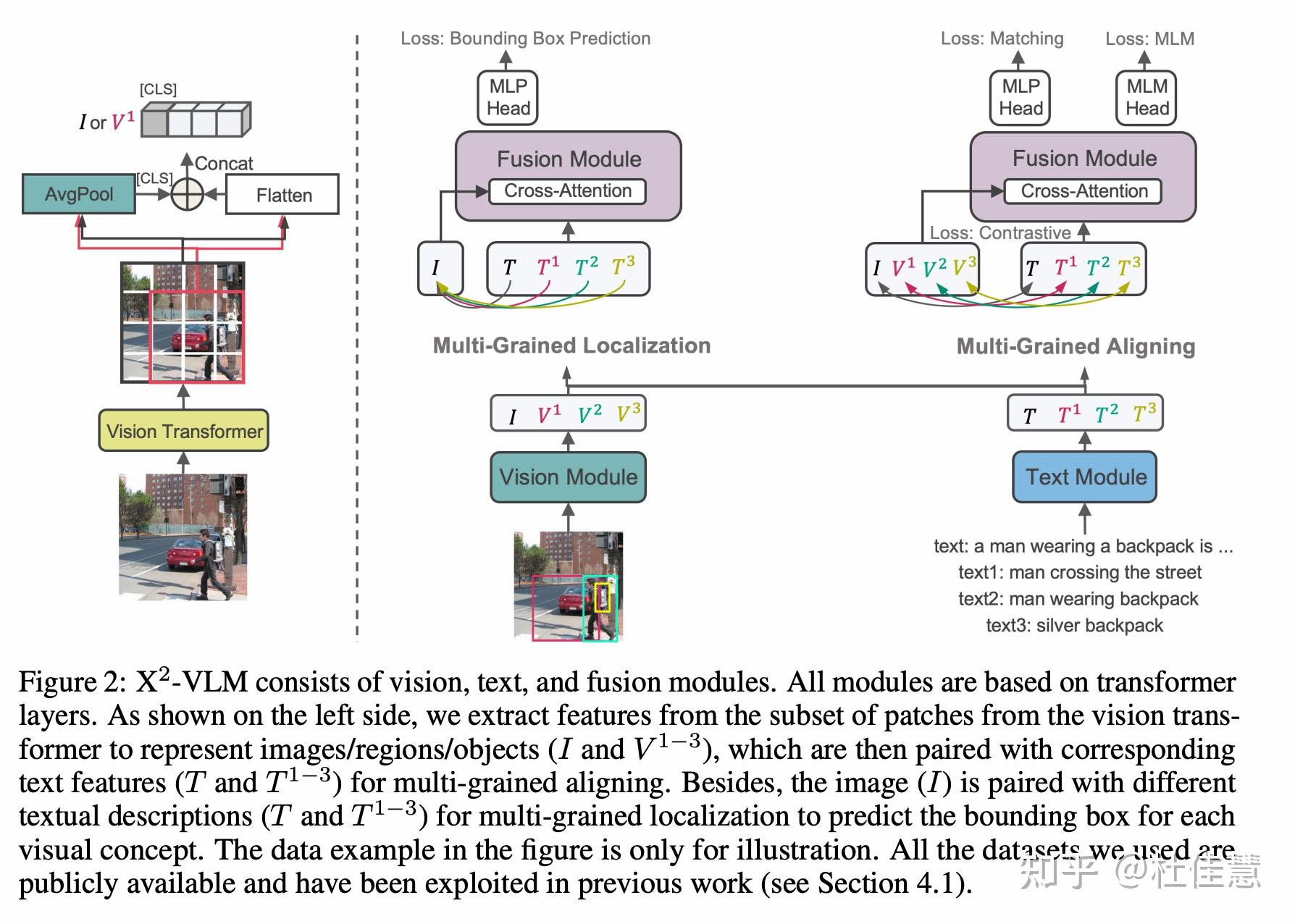
[2211.12402] X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks
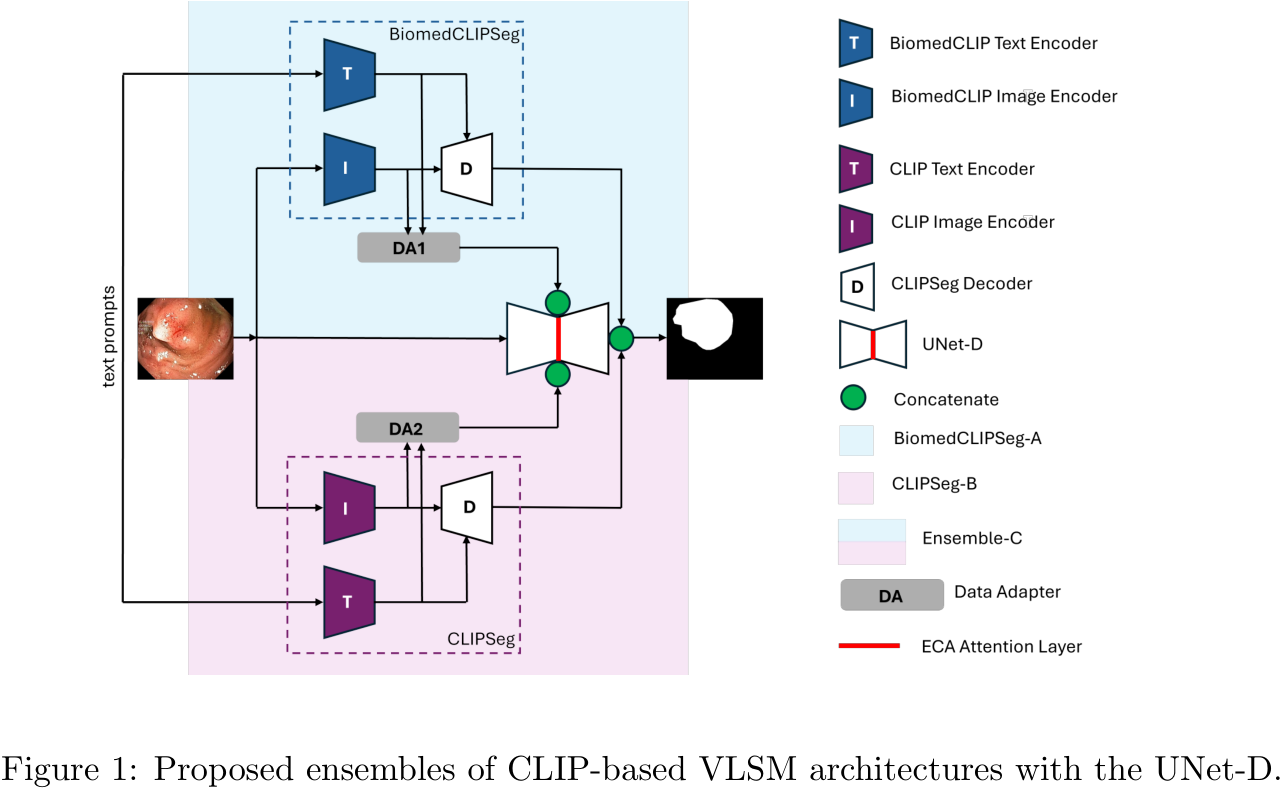
当VLM遇上CNN:简单的模型集成,带来医疗影像分割性能巨大提升 - 知乎
X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks - 知乎
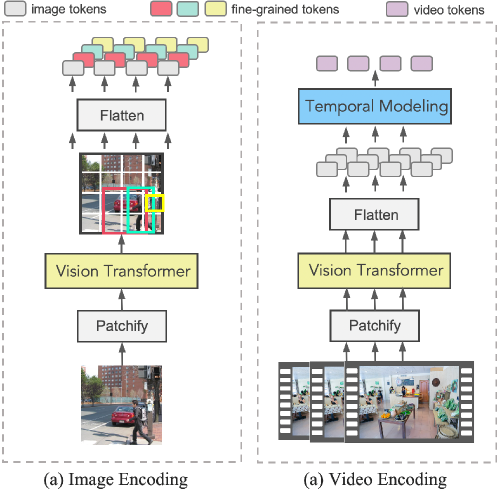
Implementation of Vision language models (VLM) from scratch: A ...