Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
VISION TRANSFORMER WITH PROGRESSIVE TOKENIZATION FOR CT METAL ARTIFACT ...
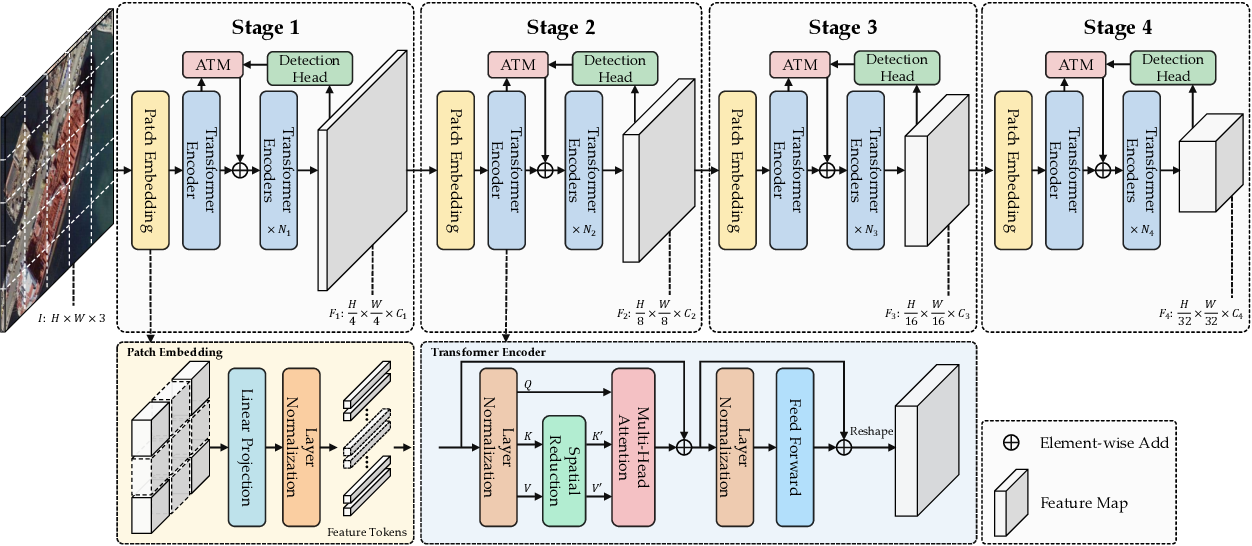
Figure 1 from Angle Tokenization Guided Multi-Scale Vision Transformer ...
(PDF) Vision Transformer with Progressive Tokenization for CT Metal ...
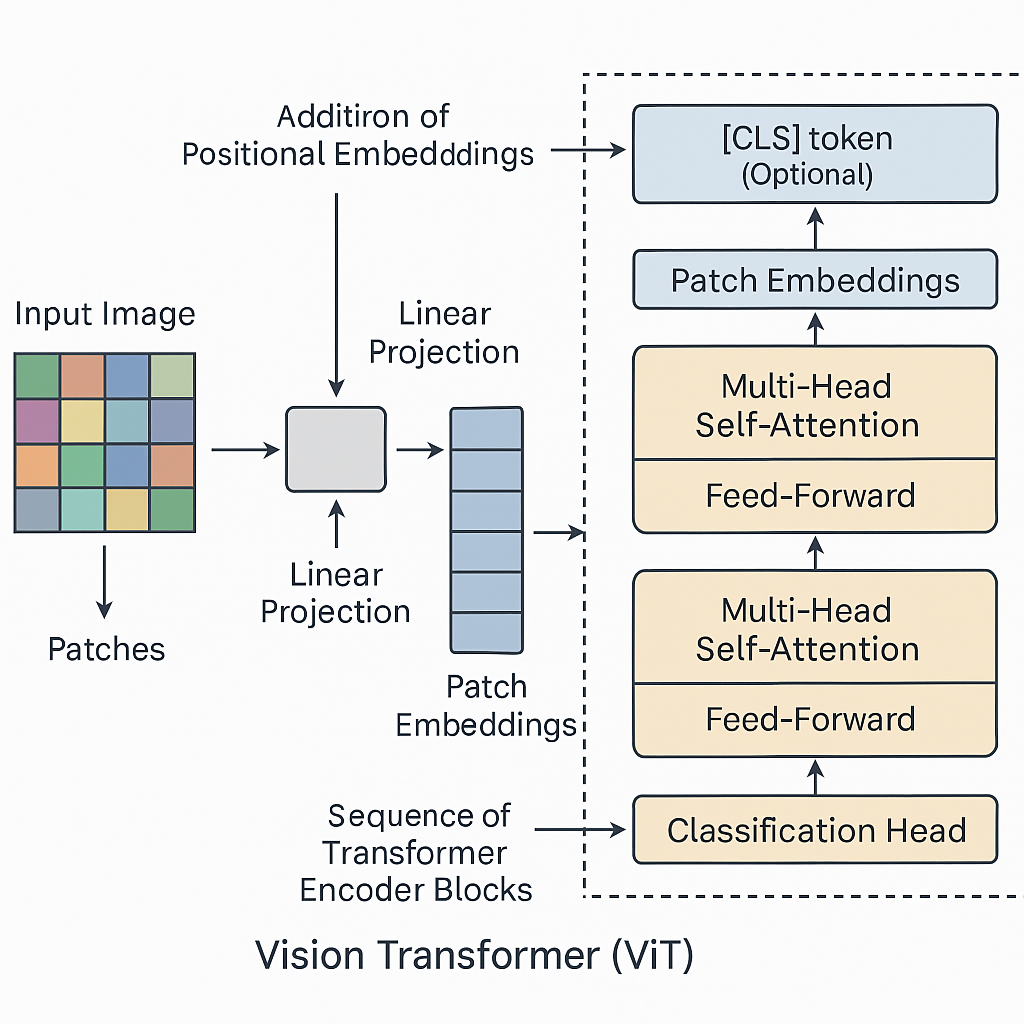
Vision Transformer in Computer Vision - GeeksforGeeks
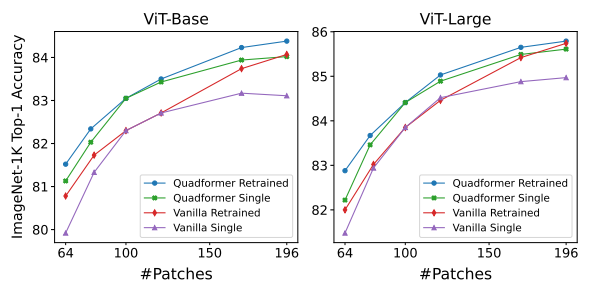
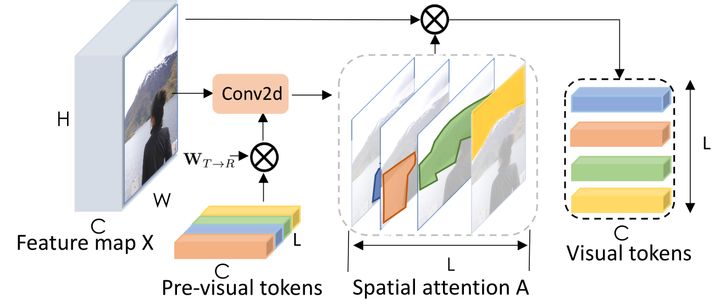
[2307.02321] MSViT: Dynamic Mixed-scale Tokenization for Vision ...
Video Vision Transformer (ViViT) - GeeksforGeeks
An Intuitive Introduction to the Vision Transformer - Thalles' blog
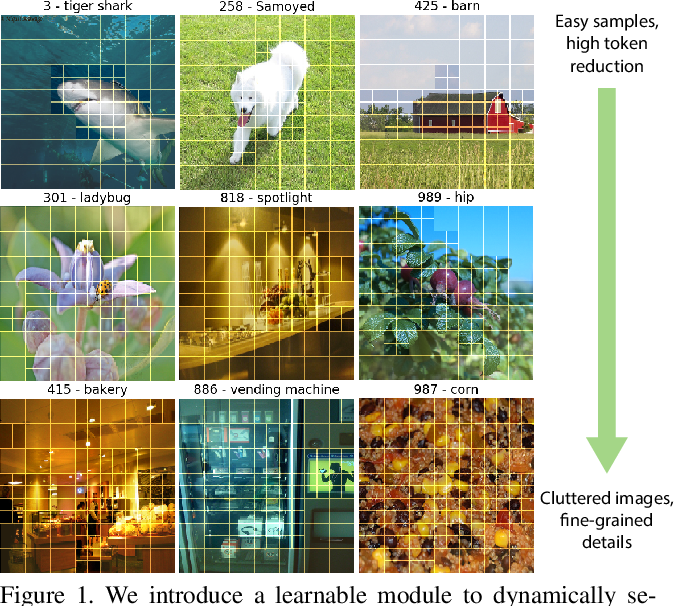
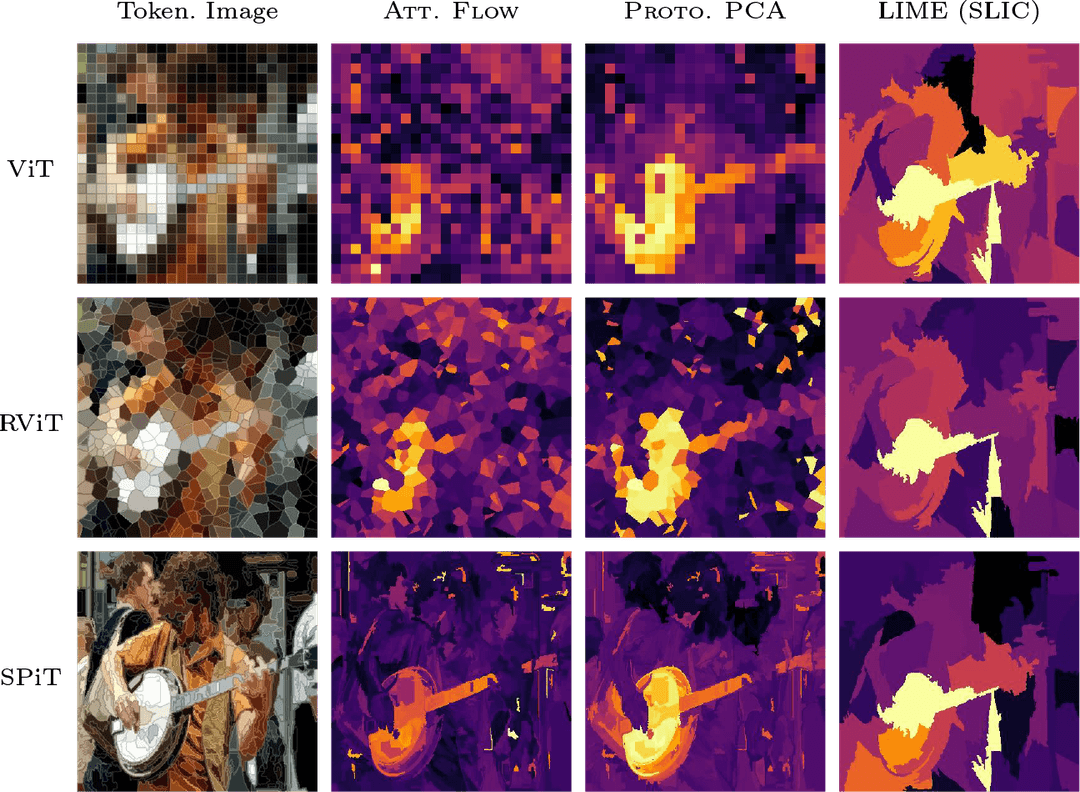
A Spitting Image: Modular Superpixel Tokenization in Vision ...
[论文评述] A Spitting Image: Modular Superpixel Tokenization in Vision ...
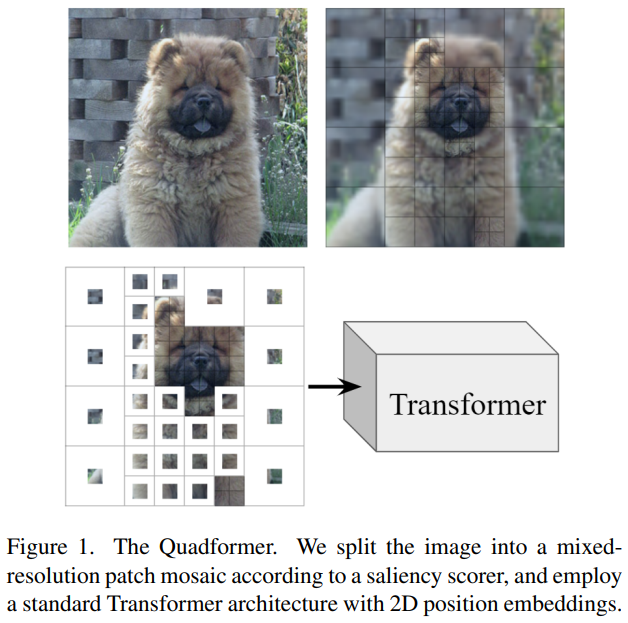
[논문 정리] Vision Transformers with Mixed-Resolution Tokenization
MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers: Paper ...
[논문 리뷰] Superpixel Tokenization for Vision Transformers: Preserving ...
Image Tokenization in Vision Transformers with Keras
MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers | DeepAI
How to build a Vision Transformer Model (Vit) and Implement it?
Vision Transformer (ViT): How It Works and How to Build It in PyTorch ...
(PDF) Superpixel Tokenization for Vision Transformers: Preserving ...
A Spitting Image: Modular Superpixel Tokenization in Vision Transformers
Modular Superpixel Tokenization in Vision Transformers - Department of ...
(PDF) A Spitting Image: Modular Superpixel Tokenization in Vision ...
Vision Transformer Model: How It Works & Benefits
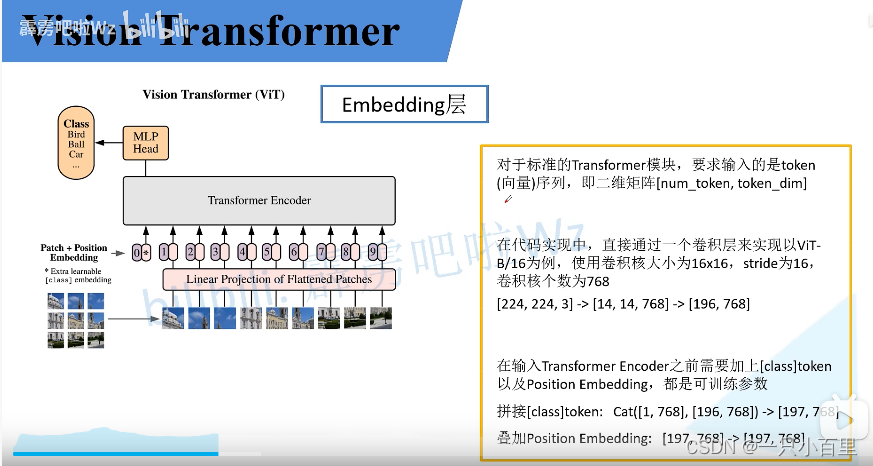
Vision Transformer 超详细解读 (原理分析 + 代码解读) (三)-极市开发者社区
Transformer Tokenization Strategies for Network Intrusion Detection ...
The architecture of Vision Transformer Model for image classification ...
(PDF) CTformer: convolution-free Token2Token dilated vision transformer ...
MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers - YouTube
The vision transformer architecture. We take 16X16X16 size of tokens in ...
Vision Transformer | LearnOpenCV
All of The Transformer Tokenization Methods | TDS Archive
MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers
Vision Transformer (ViT) Architecture Showdown | by Saqib Khan | Medium
vision transformer 详解_vision tranformer github代码-CSDN博客
Vision Transformer 超详细解读 (原理分析+代码解读) (三十) - 知乎
FDPNP9: Inside the Vision Transformer (Part 2) | Khang’s Blog
Vision Transformer 超详细解读 (原理分析+代码解读) (三十二) - 知乎
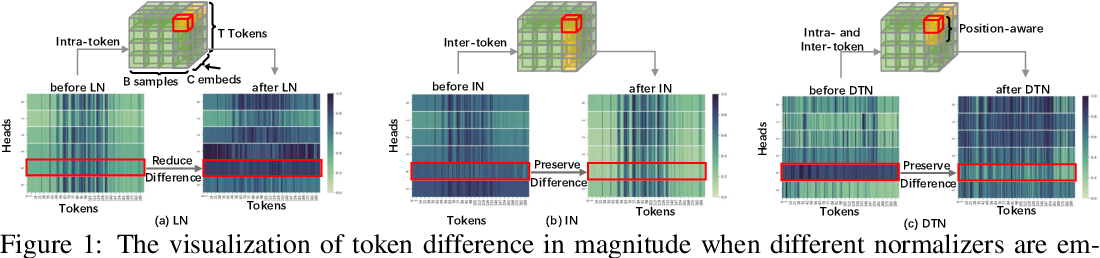
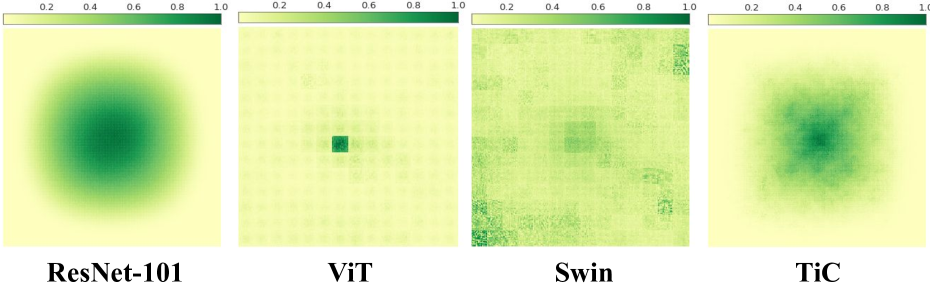
Figure 1 from Dynamic Token Normalization Improves Vision Transformer ...
How to Use Vision Transformer for Image Classification | by Eran Feit ...
Image Tokenization — The GenAI Guidebook
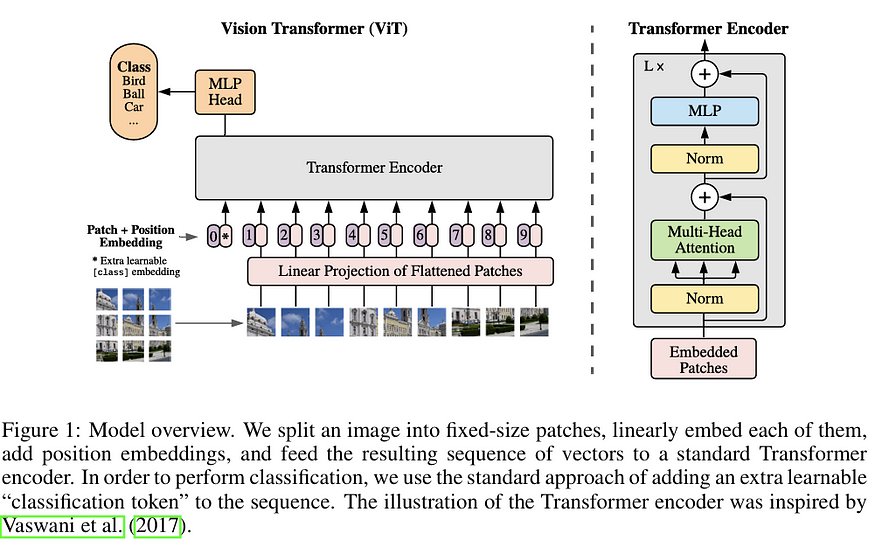
Model overview of a vision transformer. An input image is split into ...
Tokenization là gì? Khám phá cách hoạt động và ứng dụng
Vision Transformers | one minute summary | by Jeffrey Boschman | One ...
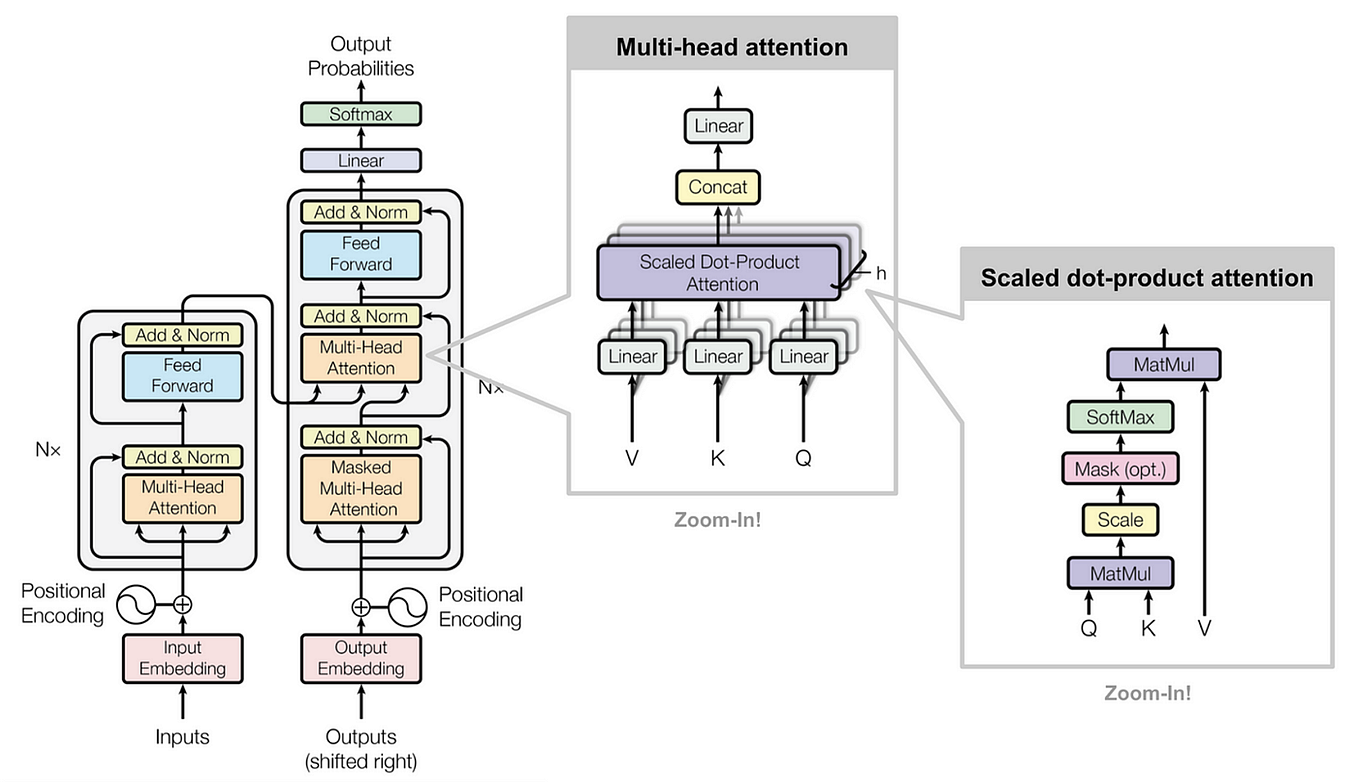
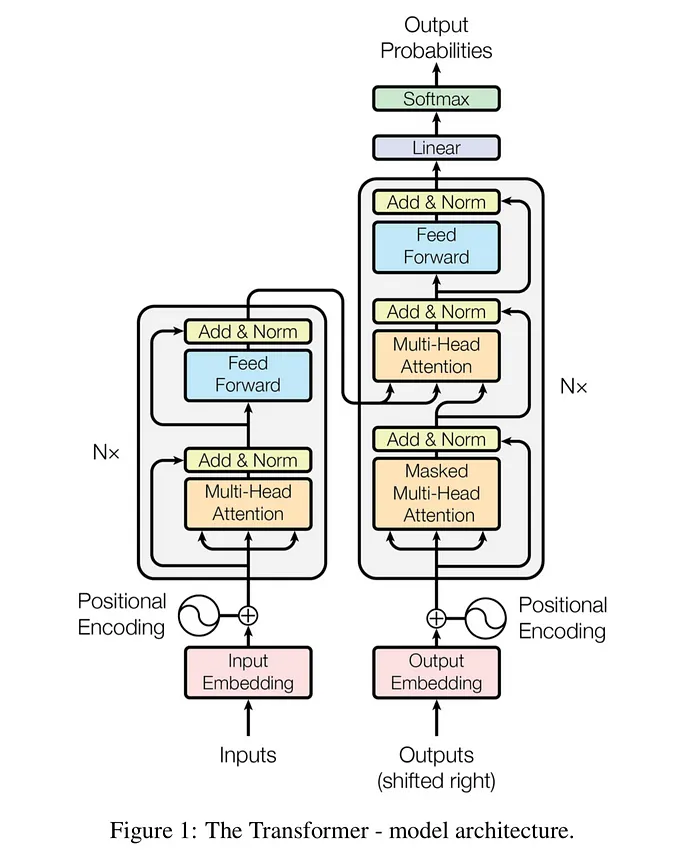
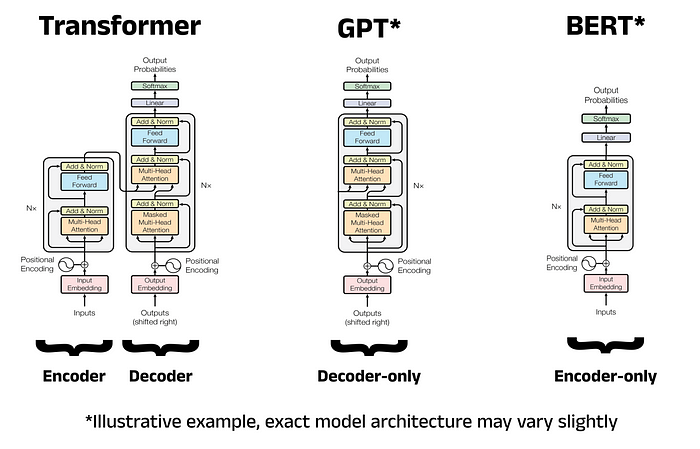
The transformer paradigm demystified | ORCHID
Vision Transformers for Image Classification: A Comparative Survey
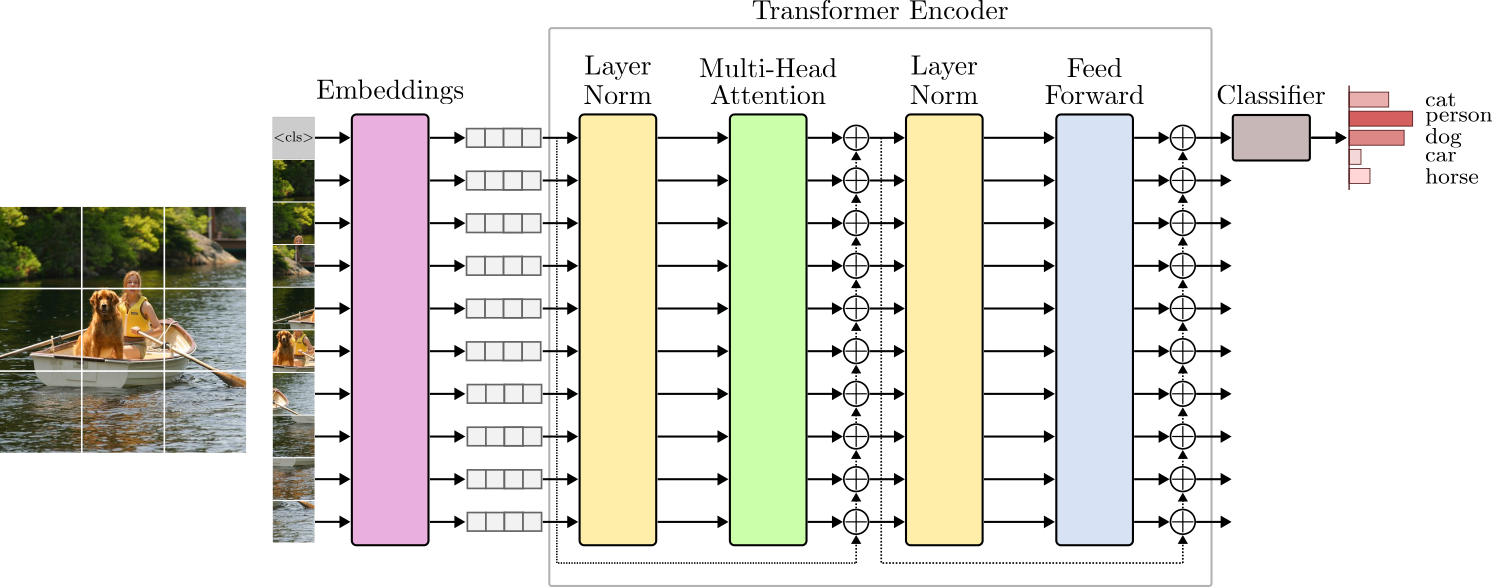
Vision Transformers, Explained | Towards Data Science
A Hands-On Guide to Vision Transformers and their Architecture
Tokenization in Transformers. The recent AI research and development ...
【解析】Token to Token Vision Transformer-CSDN博客
Tokens-to-Token Vision Transformers, Explained | Towards Data Science
Vision Transformers - by Cameron R. Wolfe, Ph.D.
26 Transformers – Foundations of Computer Vision
Vision Transformers Explained: The Future of Computer Vision?
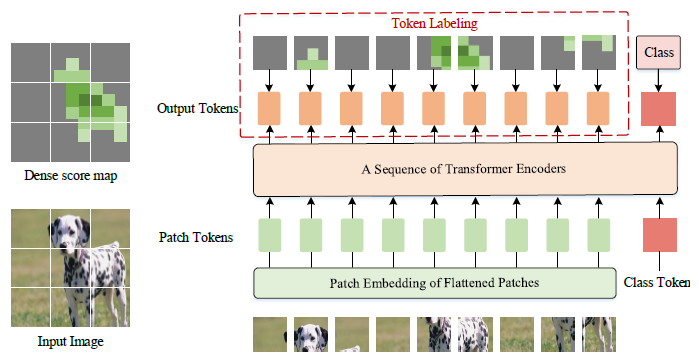
Review — All Tokens Matter: Token Labeling for Training Better Vision ...
Vision Transformers Explained at Hunter Berry blog
[2212.11115] What Makes for Good Tokenizers in Vision Transformer?
Multi-manifold Attention for Vision Transformers | DeepAI
(PDF) What Makes for Good Tokenizers in Vision Transformer?
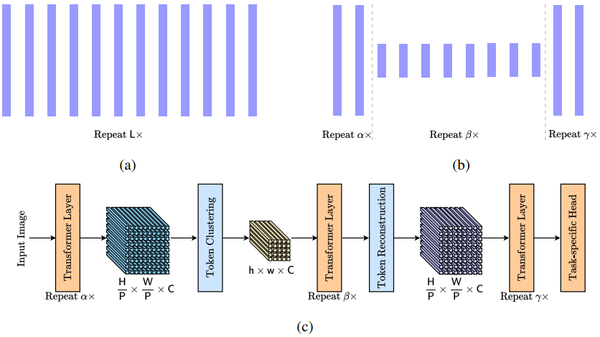
Paper page - Efficient Online Inference of Vision Transformers by ...
AE-ViT: Token Enhancement for Vision Transformers via CNN-based ...
Project : Vision-centric image tokenization in the generative ...
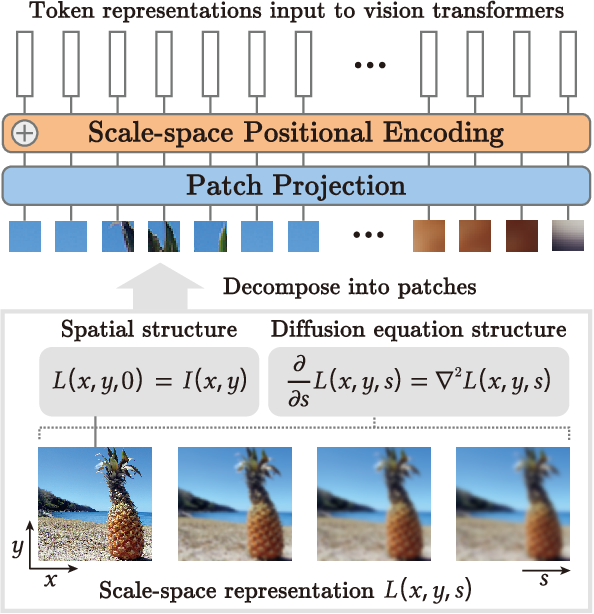
Figure 1 from Scale-space Tokenization for Improving the Robustness of ...
Researchers design more compact and interpretable image tokenization method
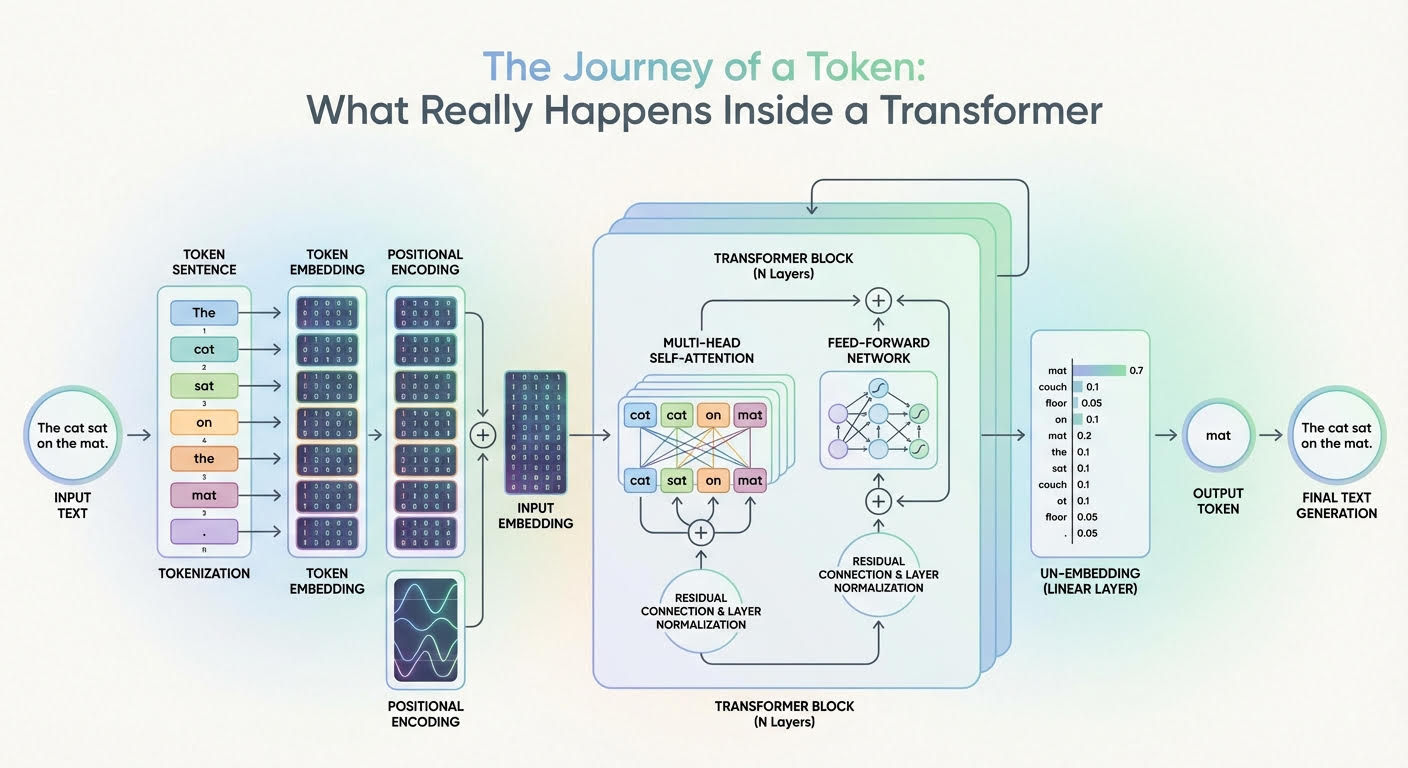
The Journey of a Token: What Really Happens Inside a Transformer | by ...
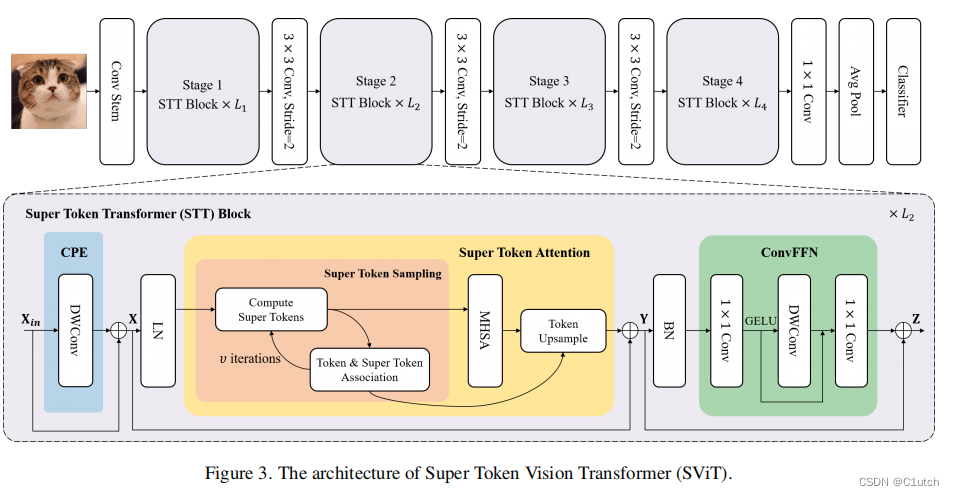
阅读论文《Vision Transformer with Super Token Sampling》-CSDN博客
FAST: Efficient Action Tokenization for Vision-Language-Action Models ...
Understanding Patch Embeddings for Vision Transformers (ViT) | by ...
what is Vision Transformers | Medium
Transformers Tokenization | PDF | Machine Learning | Computational ...
About Vision Transformers tutorials
Image Tokenization: How Vision Transformers See the World
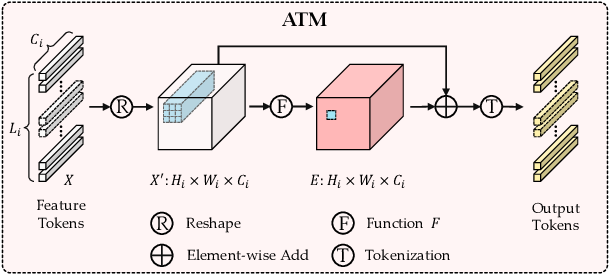
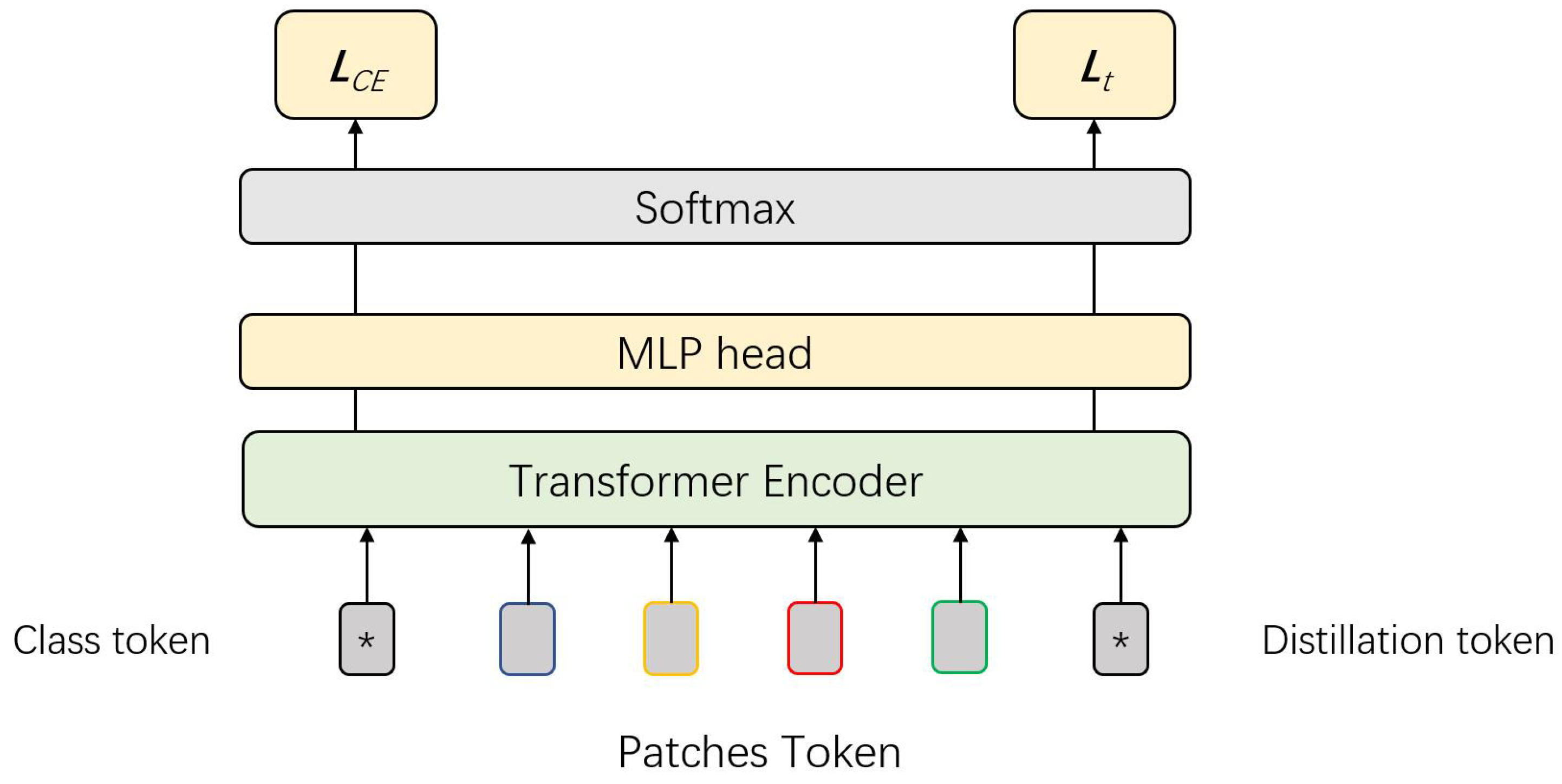
Understanding the Role of the [class] Token in Vision Transformers (ViT ...
Ahsen Khaliq on LinkedIn: Vision Transformers with Mixed-Resolution ...
Vision Transformers (ViTs)
Table 1 from Efficient Online Inference of Vision Transformers by ...
Part 1: Transformers | Tokenization and Byte Pair (BPE) | Types of ...
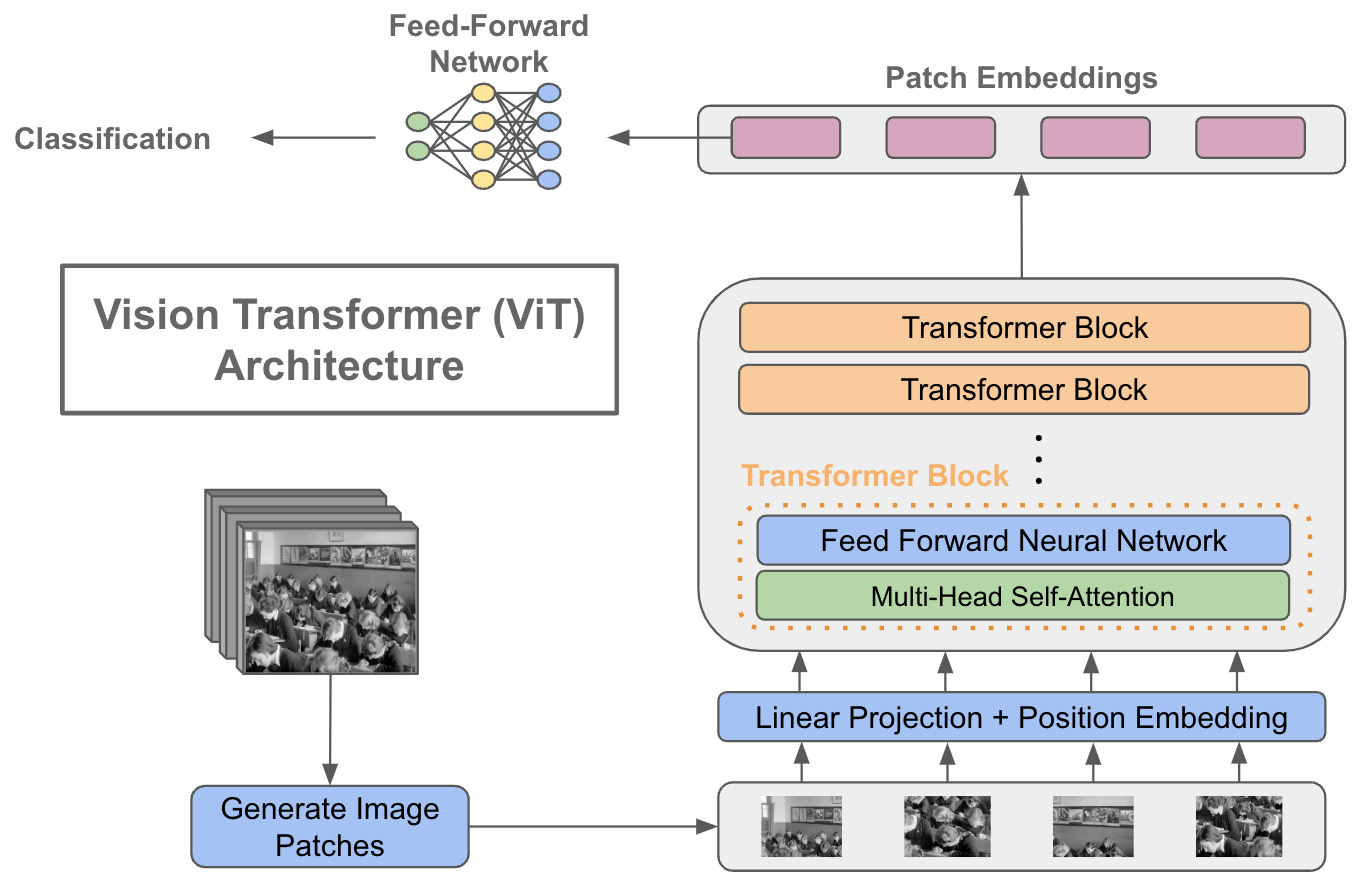
Introductory guide to Vision Transformers | Encord
Wavelet-Based Image Tokenizer for Vision Transformers | AI Research ...
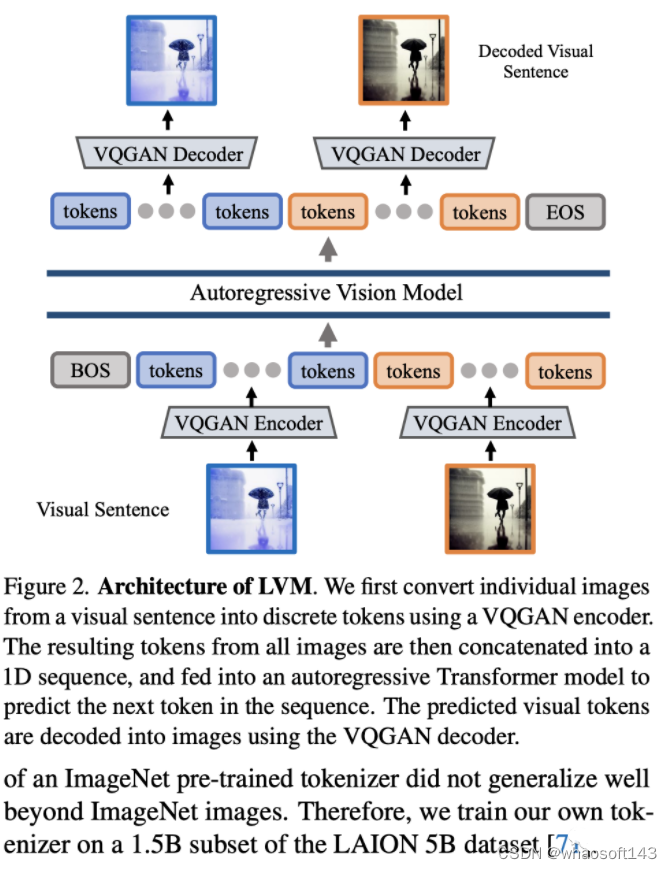
Large Vision Models-CSDN博客
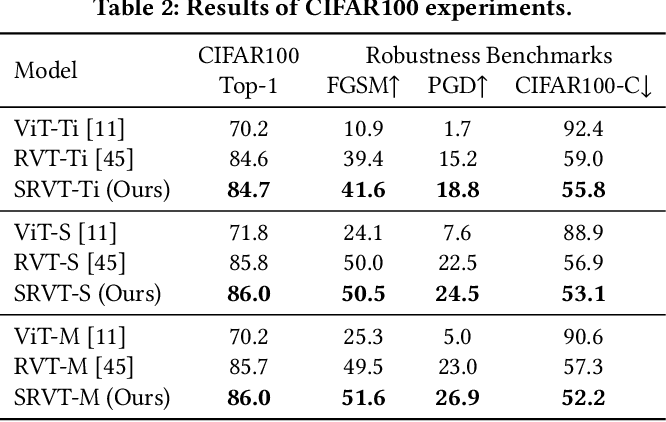
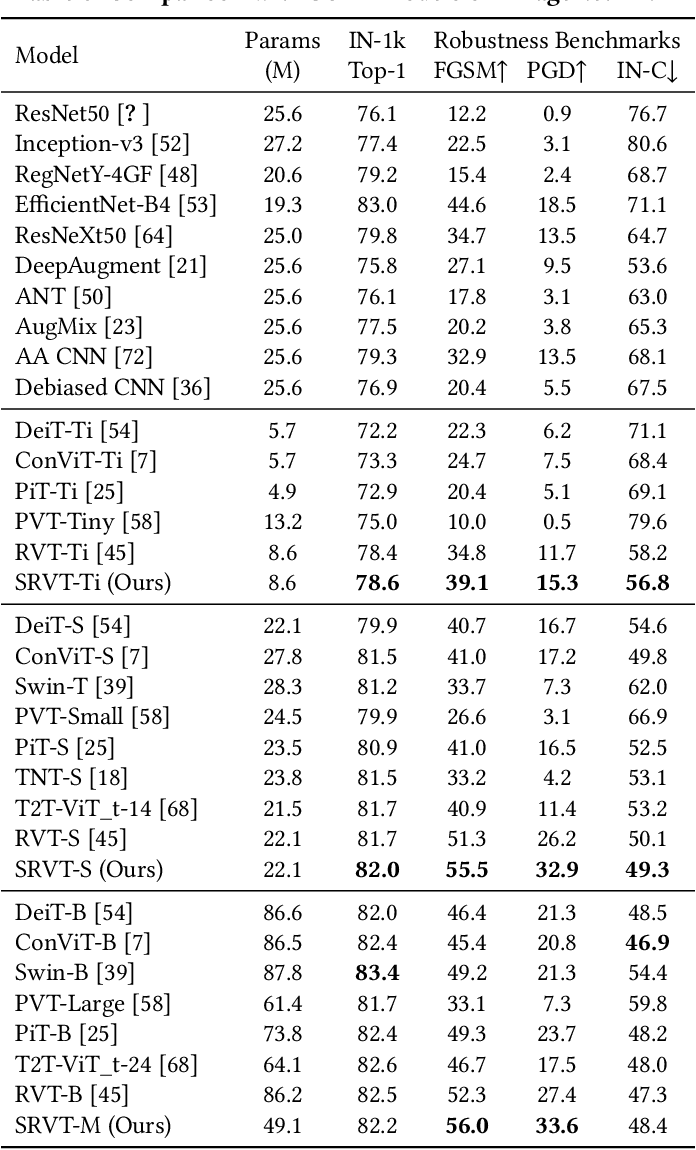
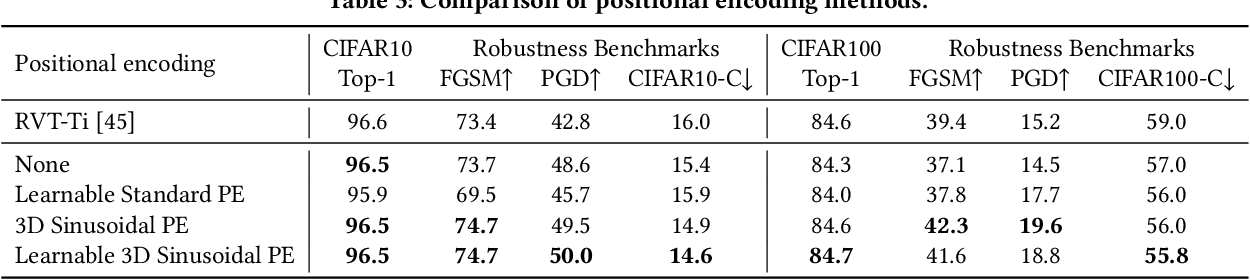
Table 2 from Scale-space Tokenization for Improving the Robustness of ...
Table 7 from Scale-space Tokenization for Improving the Robustness of ...
Vision Transformers. A Comprehensive Guide | by Erfan Khalaji | Medium
Table 6 from Scale-space Tokenization for Improving the Robustness of ...
Table 3 from Scale-space Tokenization for Improving the Robustness of ...
Tokenization in Transformers v5: Simpler, Clearer, and More Modular
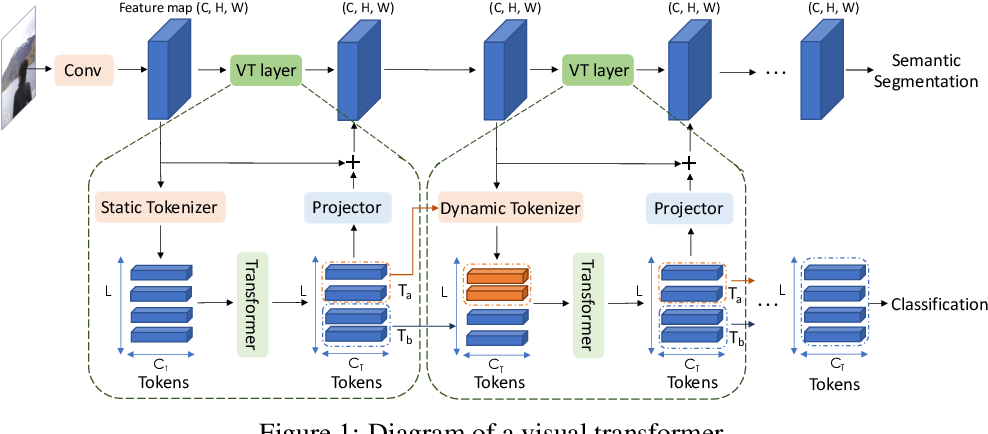
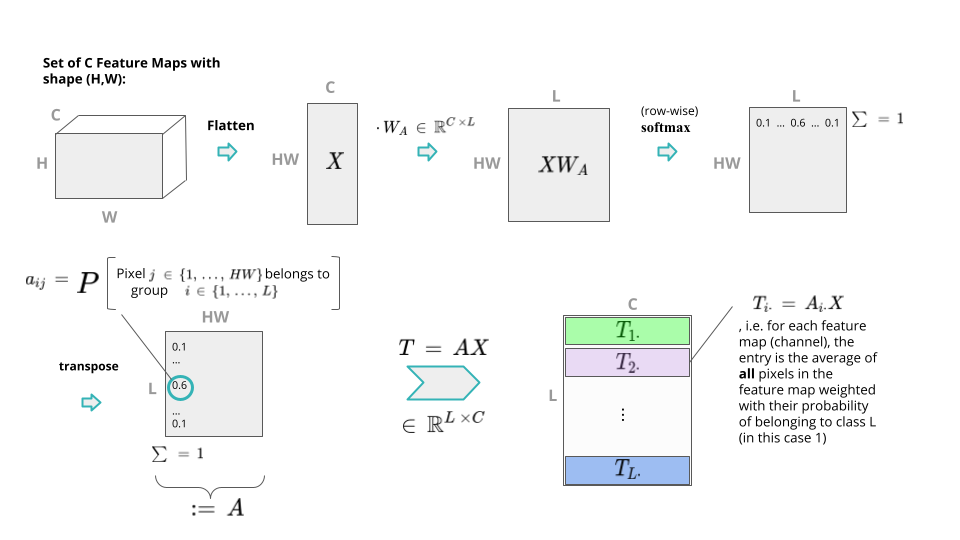
Visual Transformers: Token-based Image Representation and Processing ...
OpenAI Visual Tokenizer Explained | by Tee Kai Feng | Medium
视觉Transformer(Vision Transformer) - 郑之杰的个人网站
Visual Transformers: How an architecture designed for NLP enters the ...
Escaping the Big Data Paradigm with Compact Transformers - 郑之杰的个人网站
Breaking Language into Tokens: How Transformers Process Information?
Figure 1 from Content-aware Token Sharing for Efficient Semantic ...
seminar_report_on_visiontransformers.docx
All you need to know about Tokenization! | by Charmaine Mahachi | Apr ...