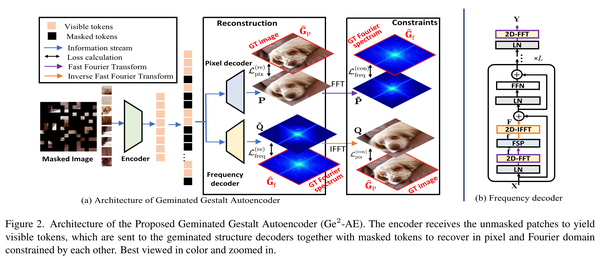
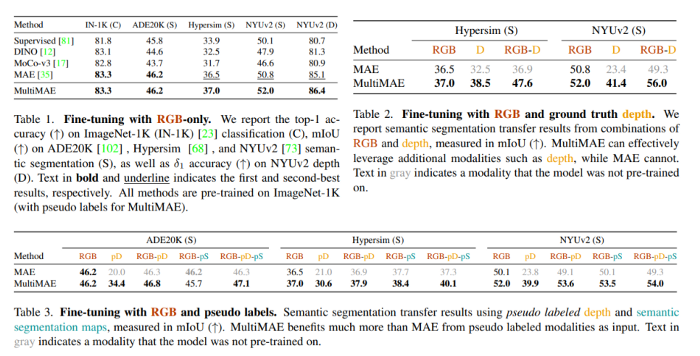
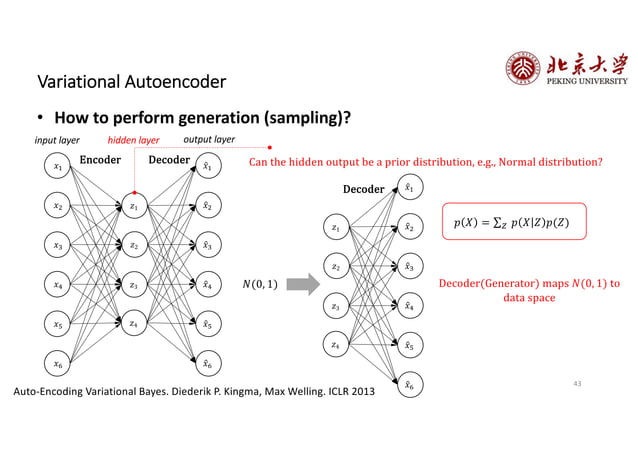
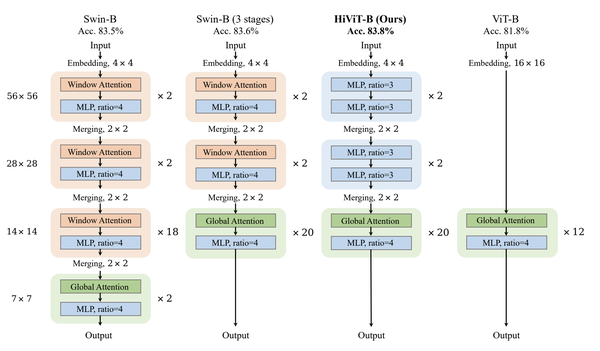
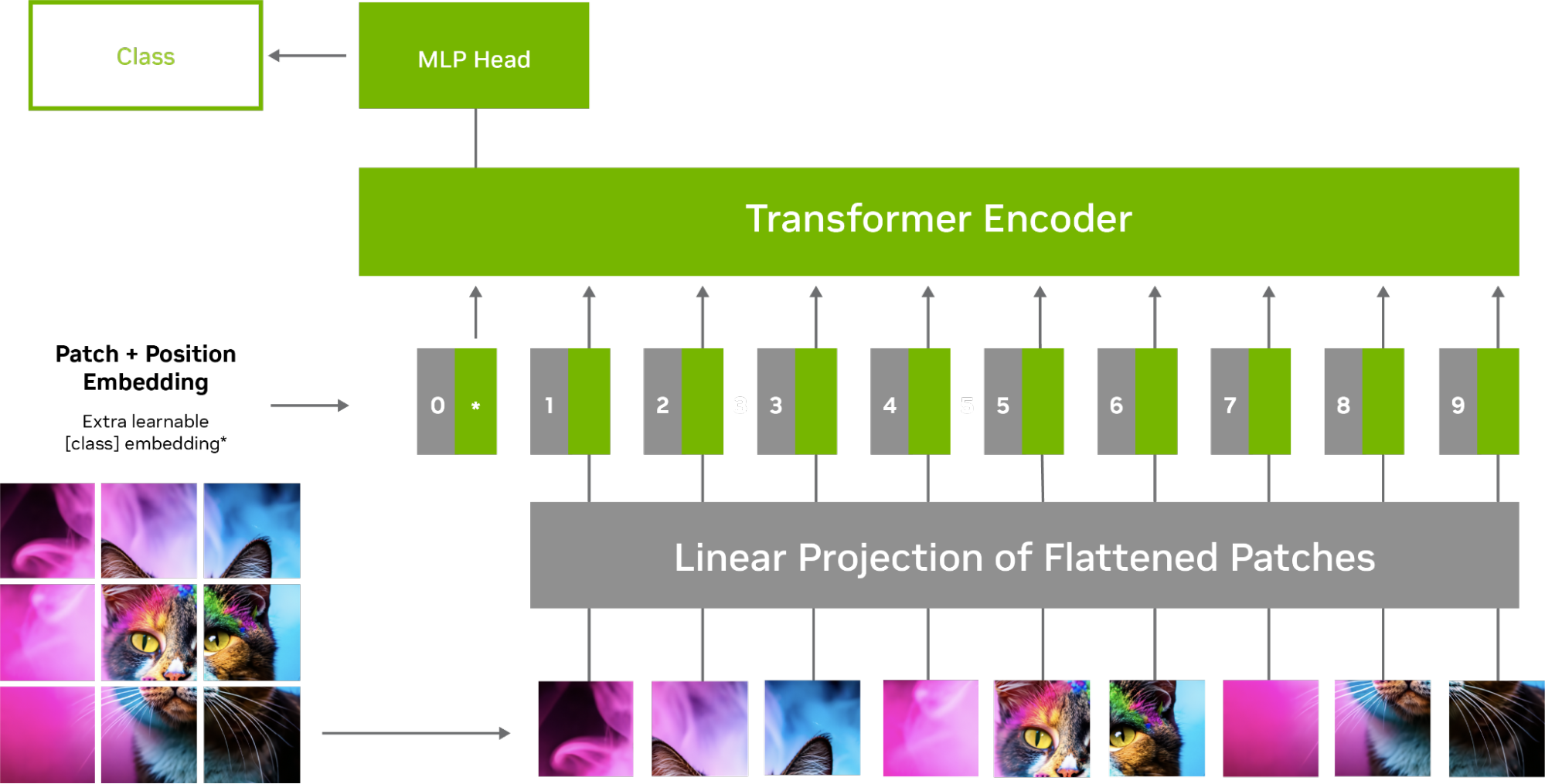
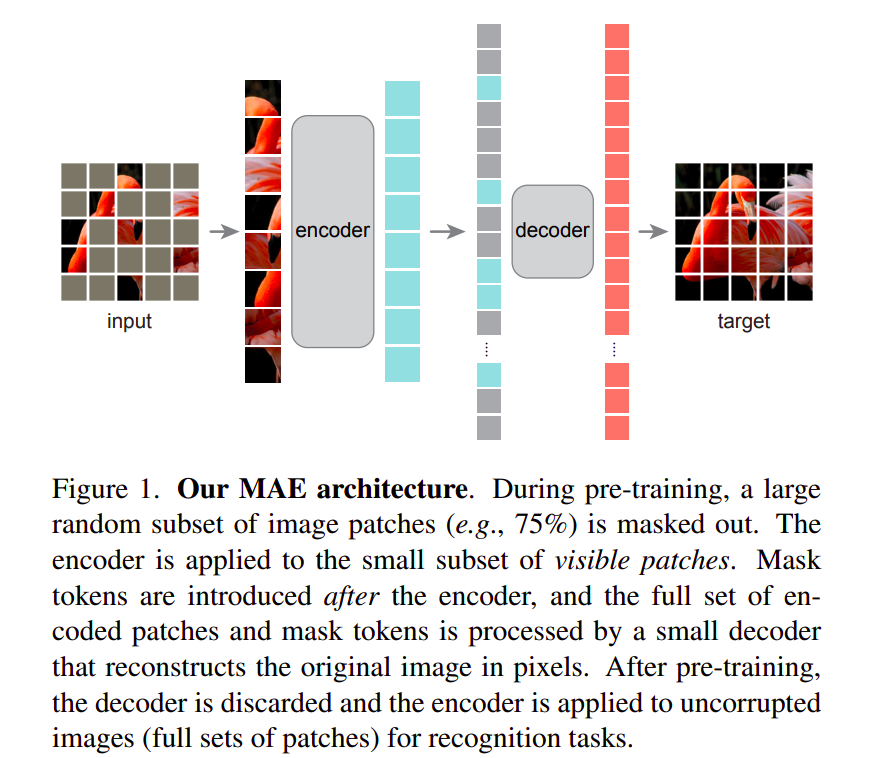
Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
Masked Autoencoder Vit at Kate Ogilvy blog
[2301.07382] ViT-AE++: Improving Vision Transformer Autoencoder for ...
论文笔记(六) Vision Transformer & Masked Autoencoder - 知乎
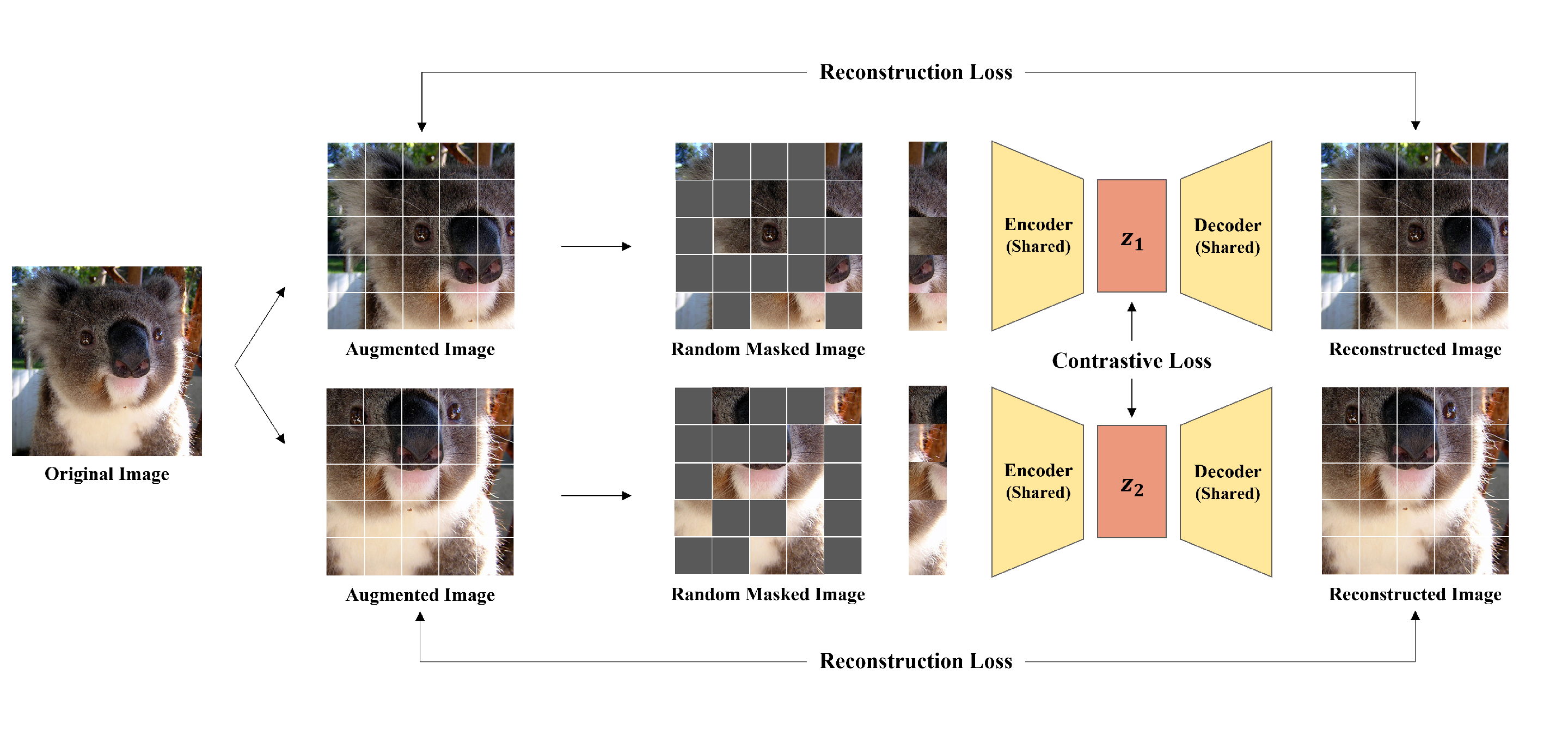
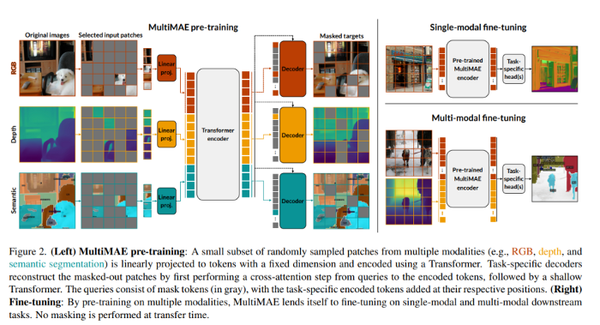
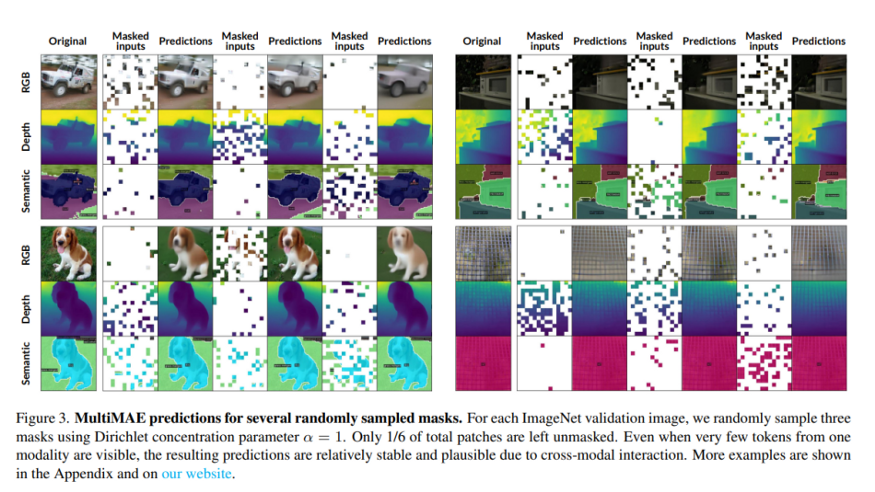
Multi-View Masked Autoencoder for General Image Representation
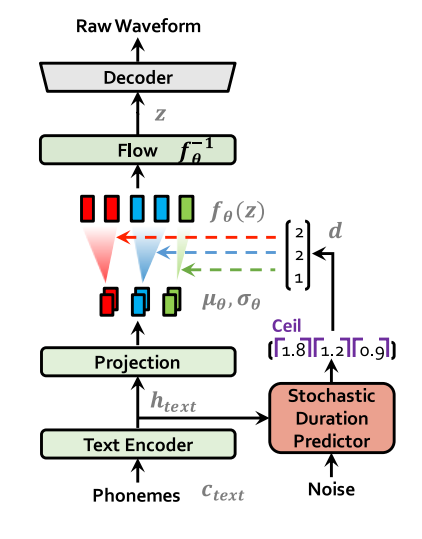
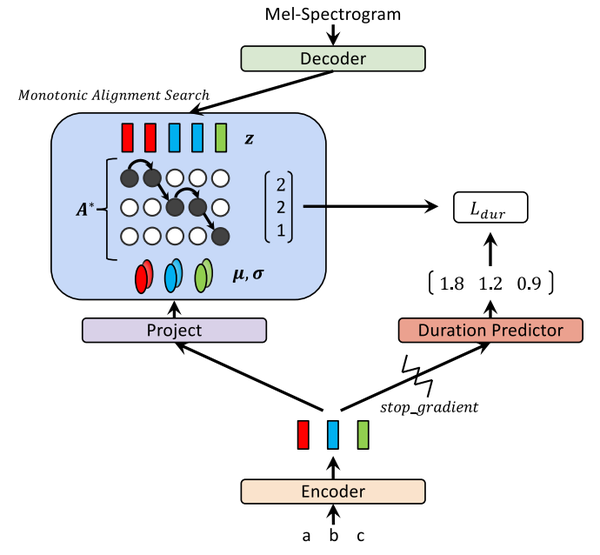
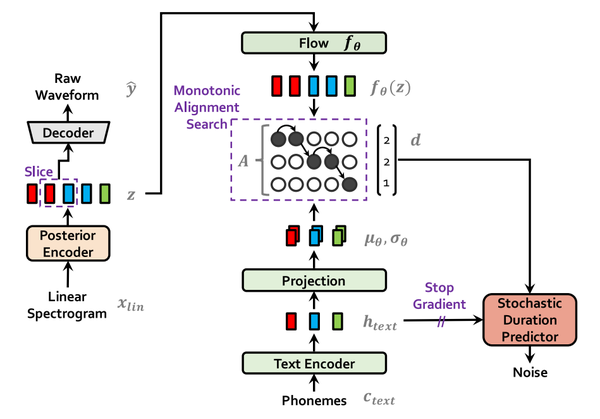
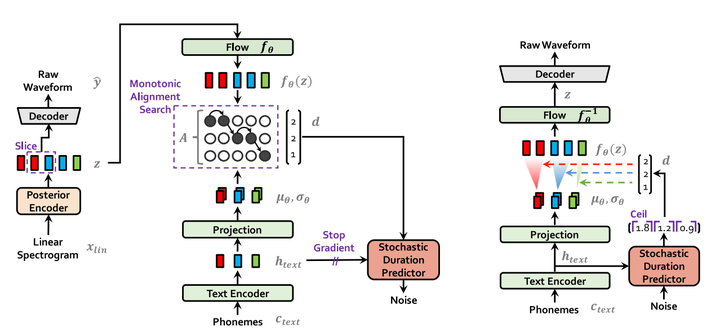
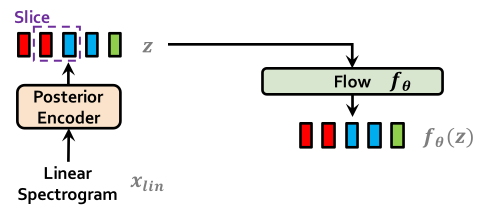
VITS: Conditional Variational Autoencoder with Adversarial Learning for ...
Resulted retrieved images based on a Convolutional autoencoder image ...
ViT-AE++: Improving Vision Transformer Autoencoder for Self-supervised ...
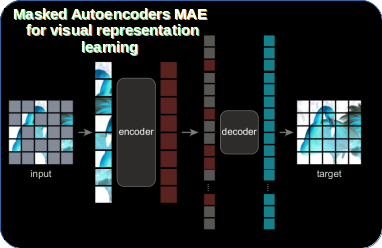
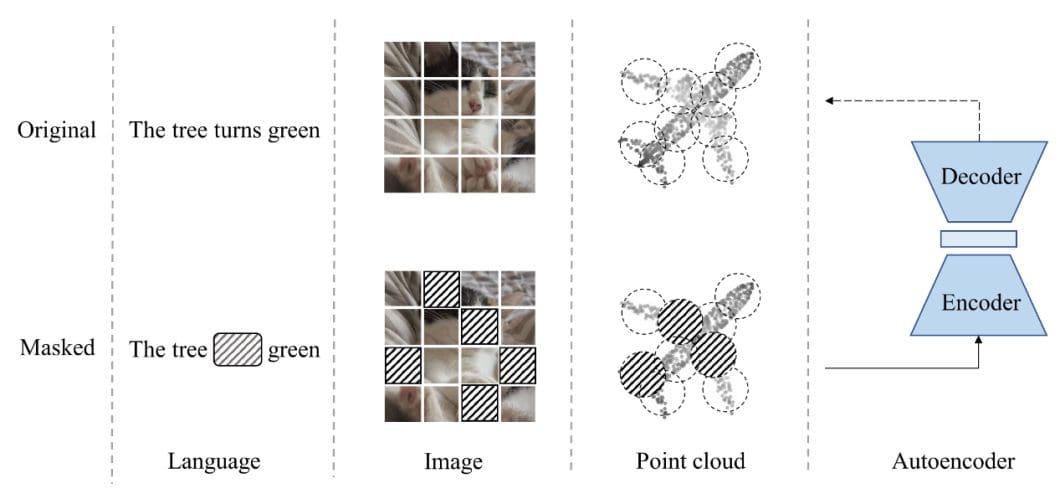
Masked autoencoder (MAE) for visual representation learning. Form the ...
Multi-modal Multi-task Masked Autoencoder:一种简单、灵活且有效的 ViT 预训练策略 - 知乎
CNN-based autoencoder architecture. Arrows indicate the direction of ...
(PDF) ViT-DAE: Transformer-driven Diffusion Autoencoder for ...
(PDF) ViT-AE++: Improving Vision Transformer Autoencoder for Self ...
ViT-DAE: Transformer-driven Diffusion Autoencoder for Histopathology ...
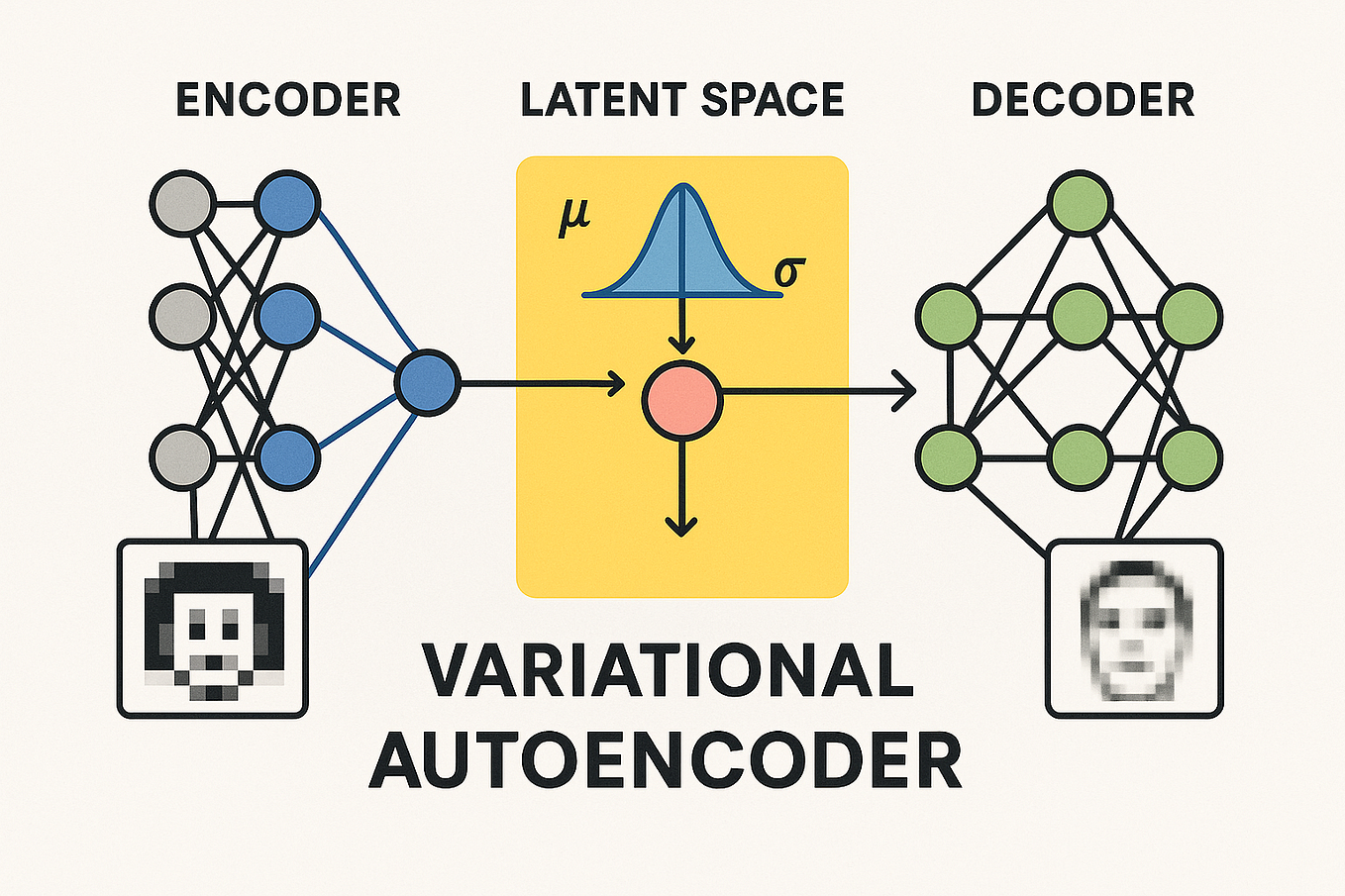
Variational Autoencoder (VAE) | Personal blog of Boris Burkov
GitHub - shree180103/Masked-Autoencoder-GAN-loss: Made an ViT ...
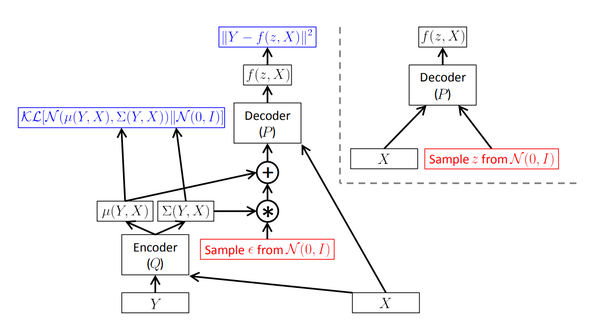
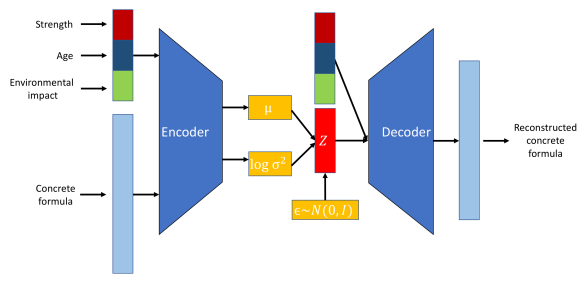
Variational Autoencoder (VAE) and Reparameterization Trick - Revisiting ...
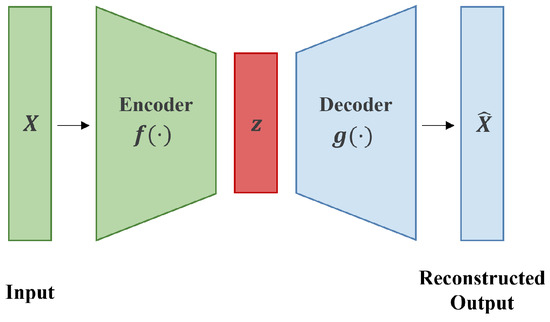
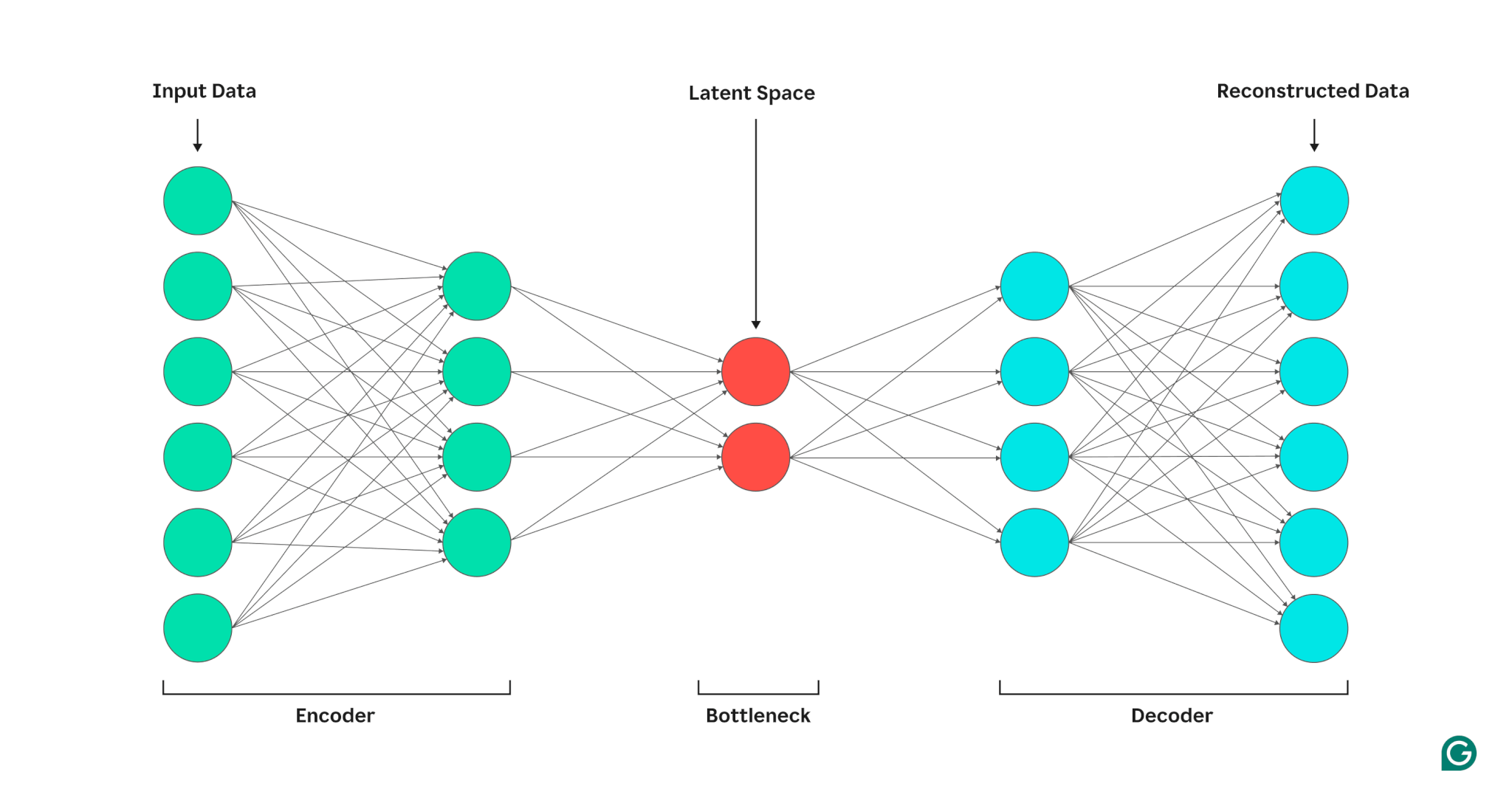
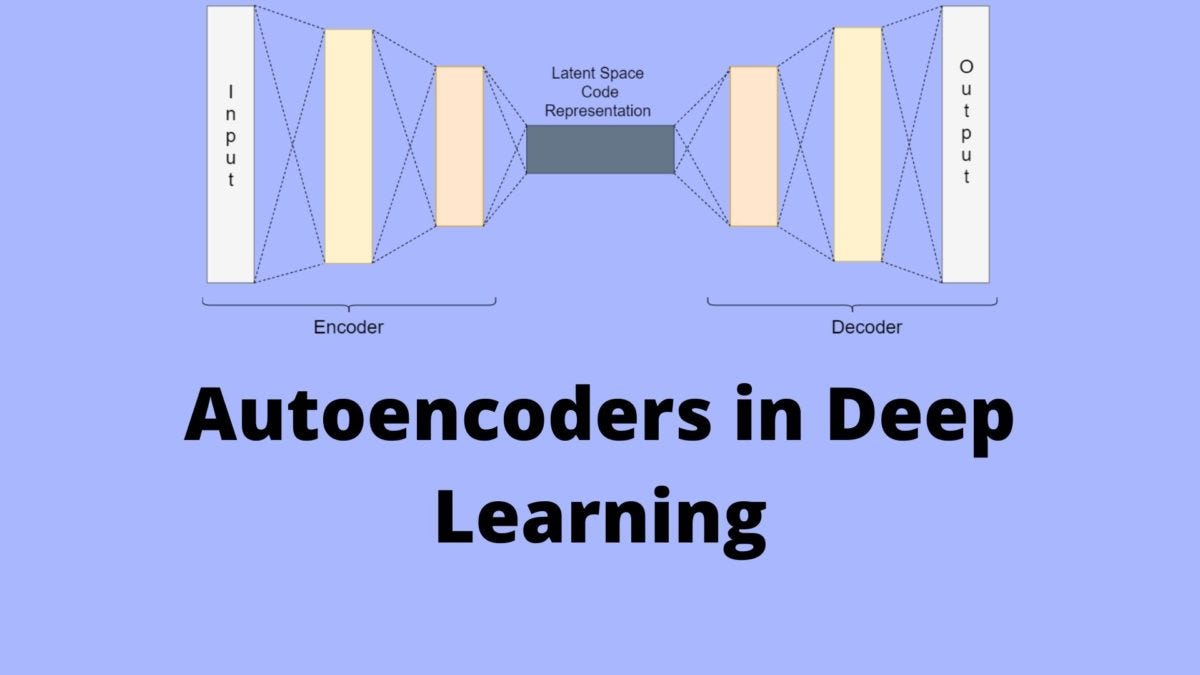
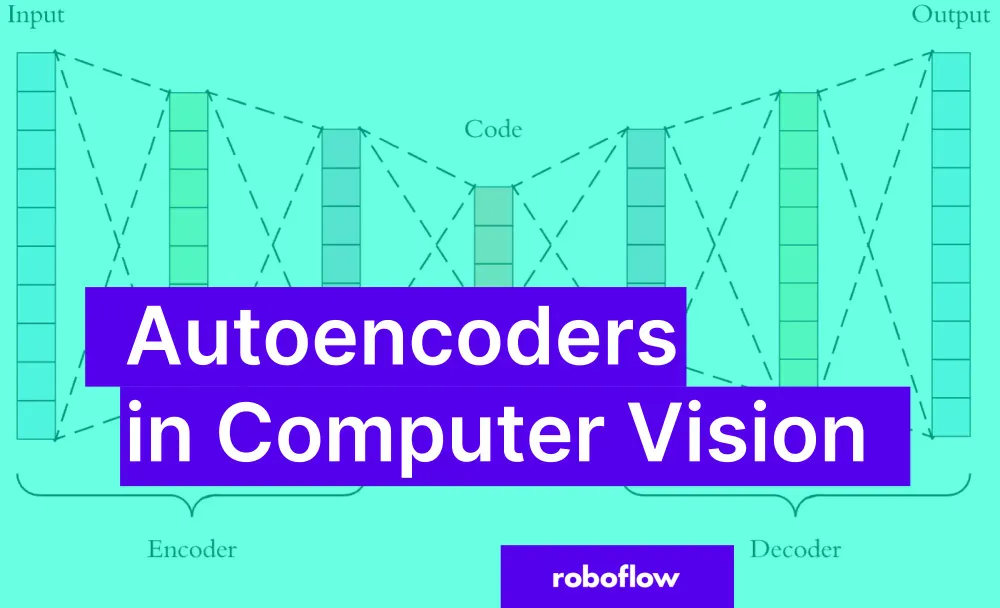
What Is an Autoencoder in Deep Learning?
Mask Autoencoder 各类变体 - 知乎
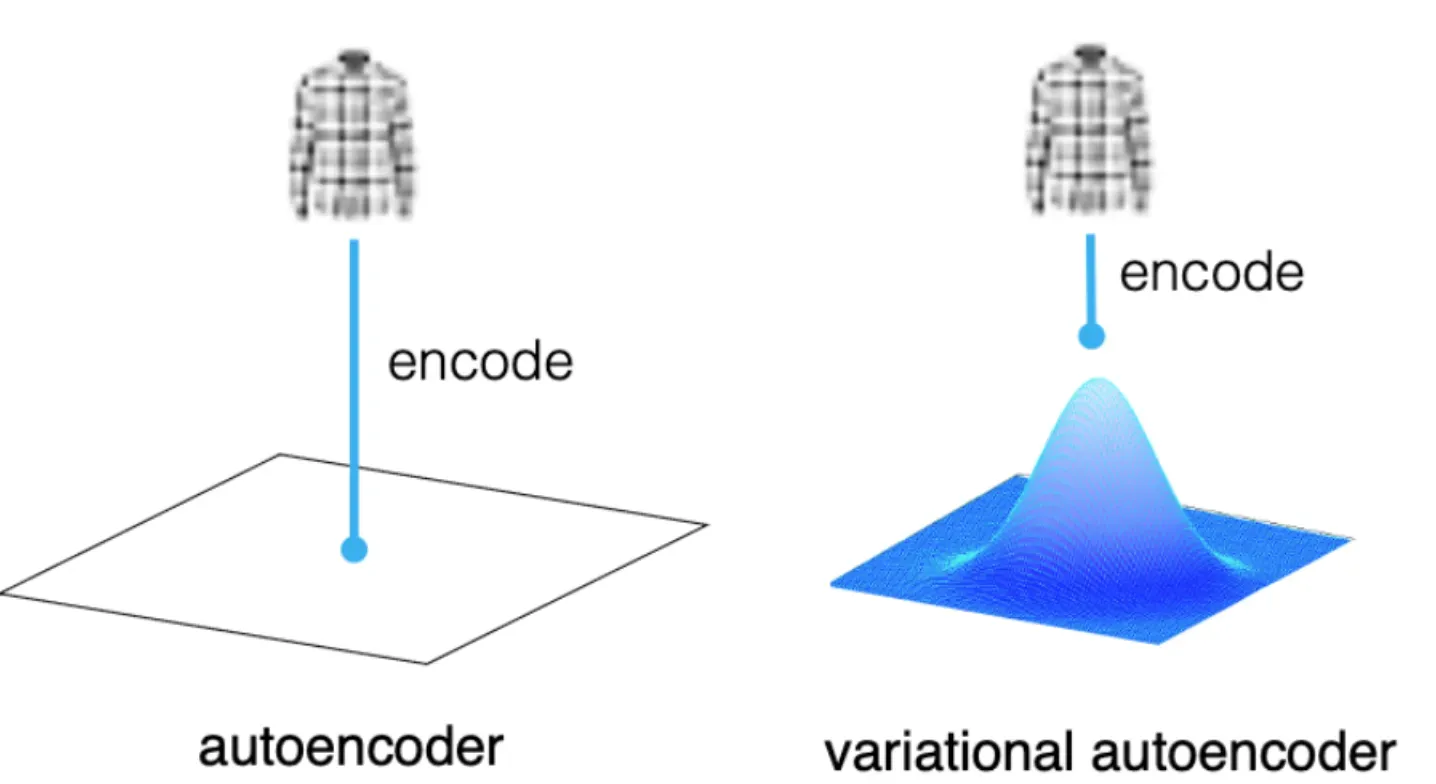
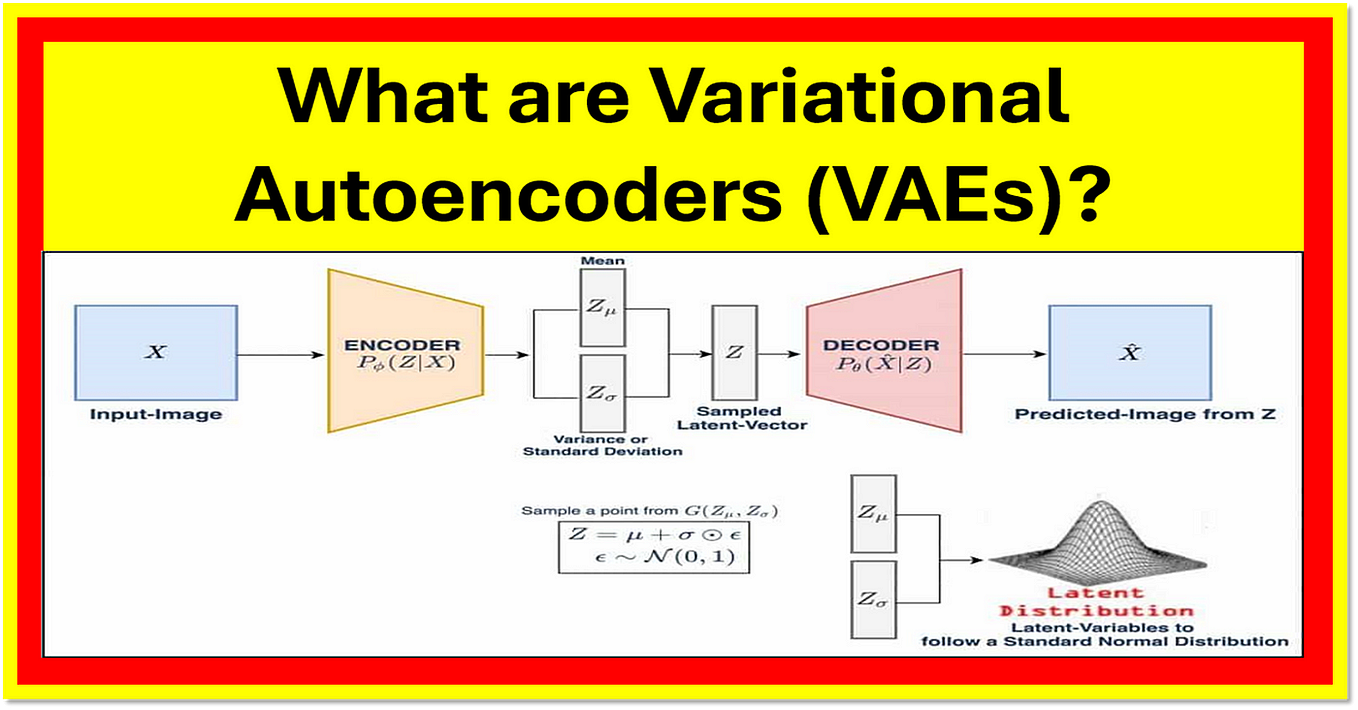
What is Variational Autoencoder & how it works | BotPenguin
Variational Autoencoder (VAE) - What Is It, Explained, Examples
ML Lec 19 Autoencoder | PDF | Machine Learning | Artificial Intelligence
Autoencoder Implementation Guide | PDF | Algorithms
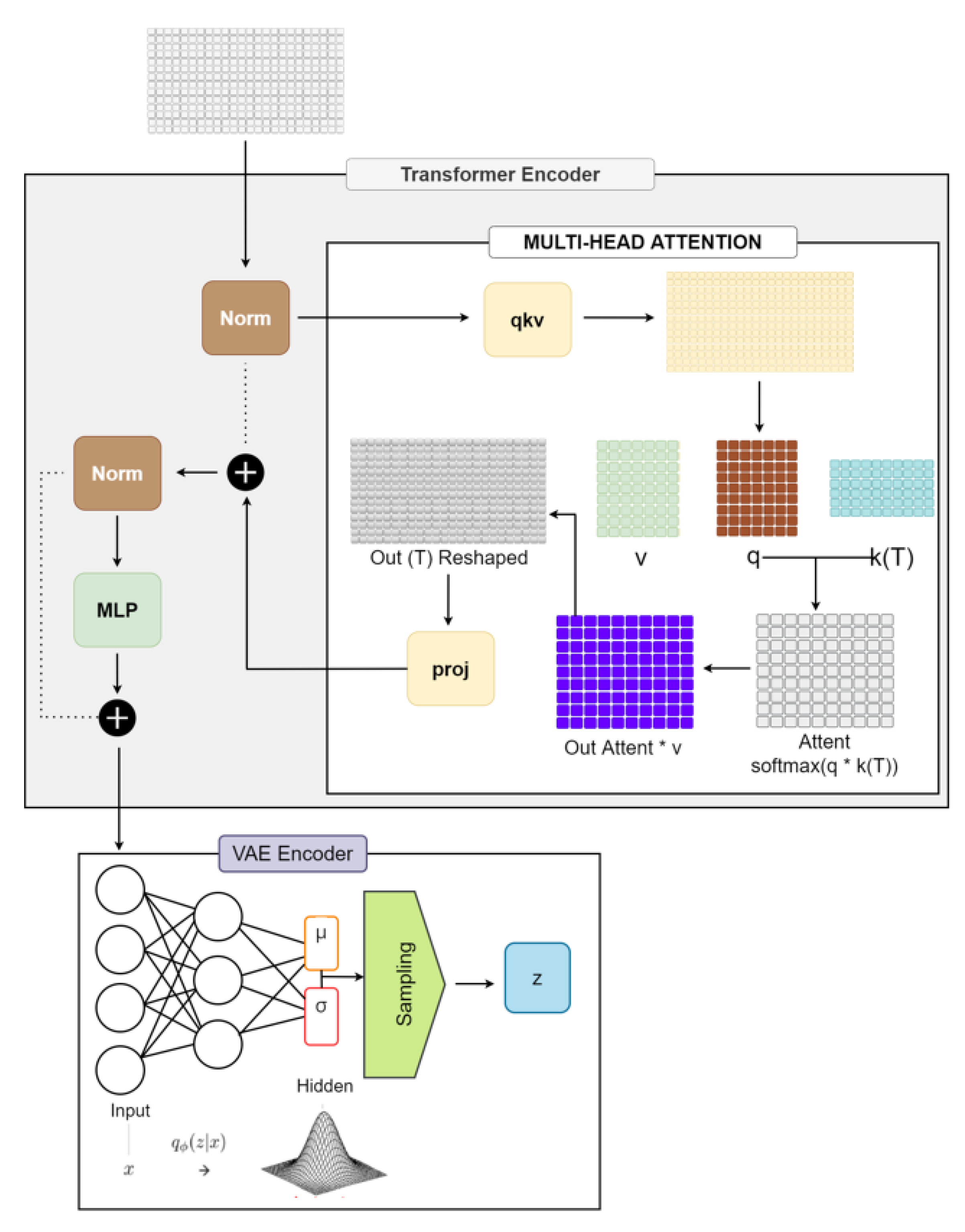
Overview of the proposed encoder-decoder architecture using a ViT ...
Explanation of Autoencoder to Variontal Auto Encoder | PPT
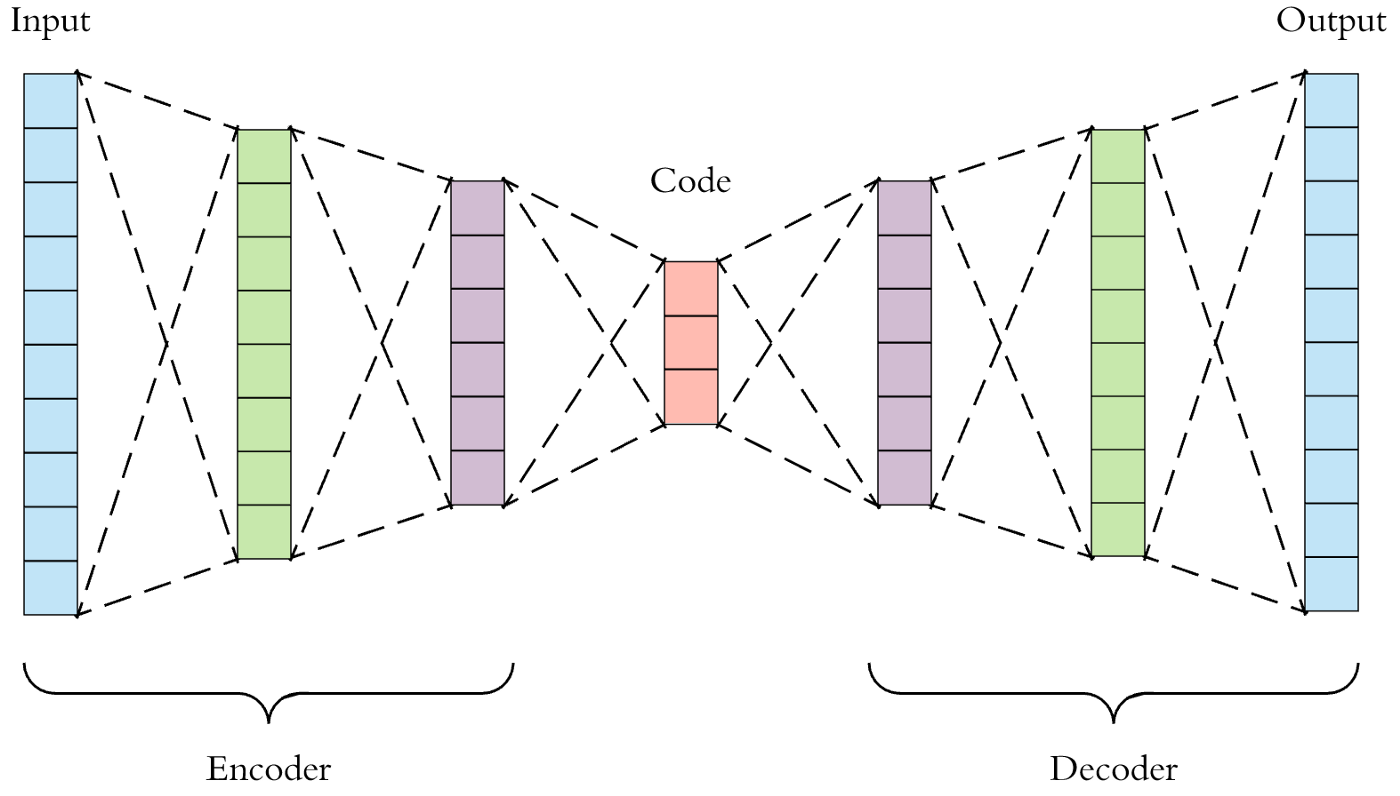
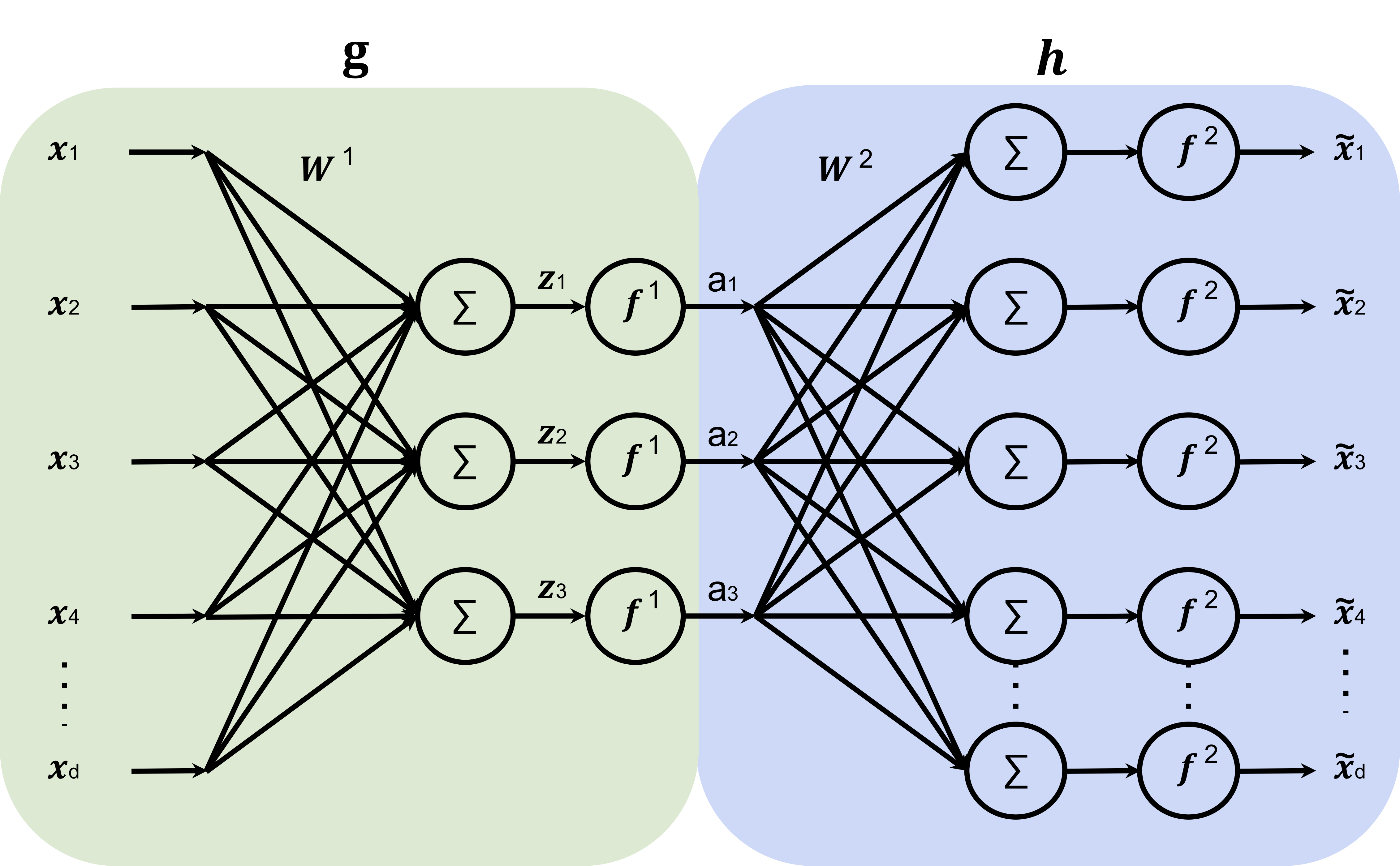
Structure of autoencoder and stacked autoencoder. (a) A three-layers ...
Variational Autoencoder Tutorial: VAEs Explained | Codecademy
What Is Convolutional Autoencoder at Sarah Boydston blog
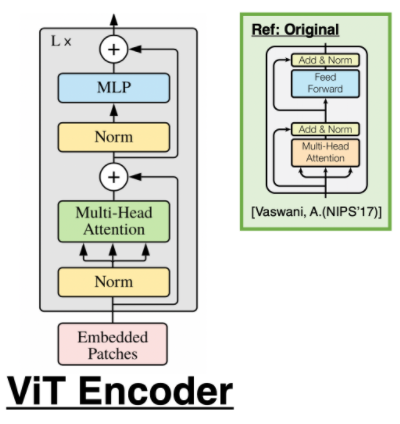
Overall architecture of the ViT encoder. | Download Scientific Diagram
The ViT-based encoder architecture. The ViT model takes an input image ...
VITS:Conditional Variational Autoencoder with Adversarial Learning ...
The architecture of the ViT-based encoder and decoder, where both ...
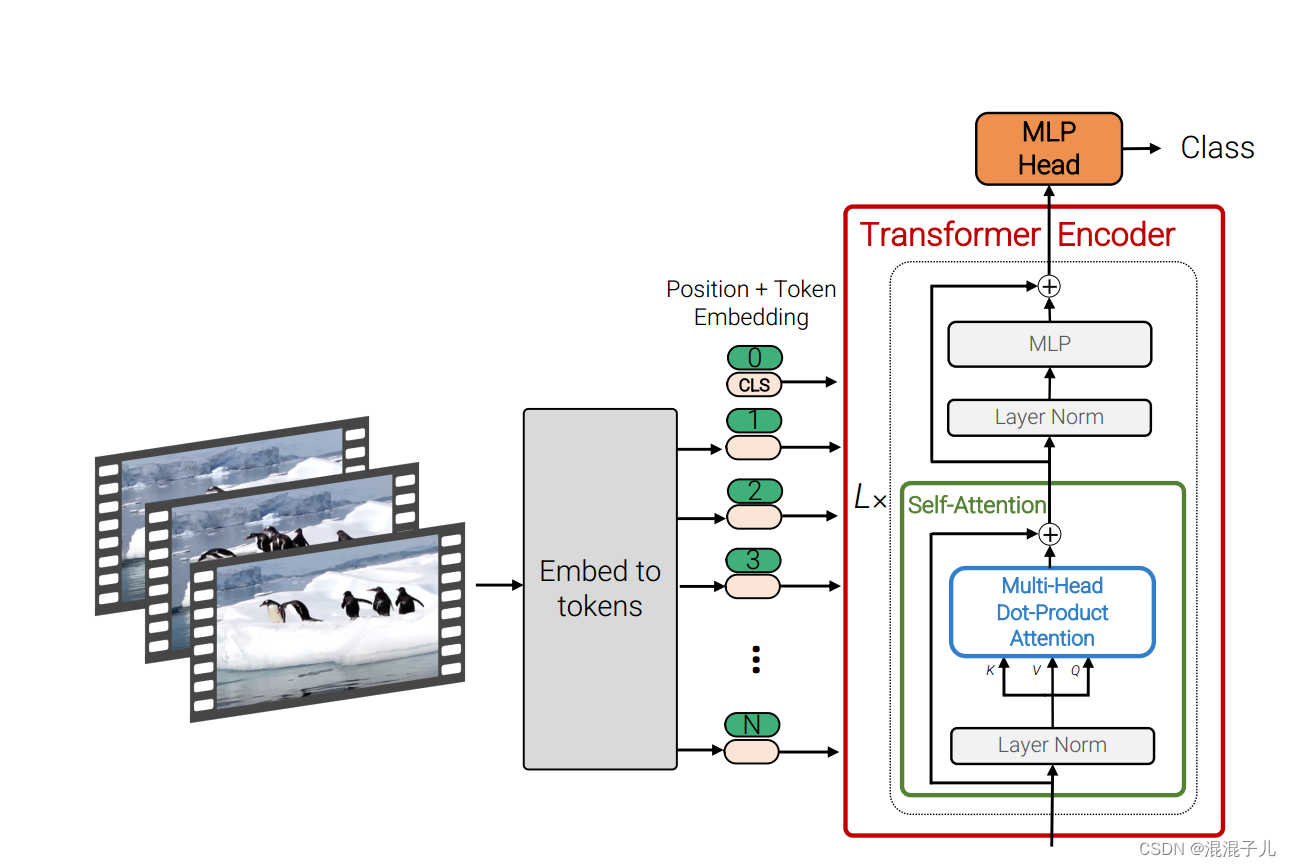
Dissecting the Vision Transformer (ViT): Architecture and Key Concepts ...
Improve Accuracy and Robustness of Vision AI Apps with Vision ...
MITCriticalData/Sentinel-2_ViT_Autoencoder_RGB · Hugging Face
从ViT到MAE,transformer架构改造Autoencoder_vit autoencoder-CSDN博客
Vision Transformers (ViT) for Self-Supervised Representation Learning ...
ViV-Ano: Anomaly Detection and Localization Combining Vision ...
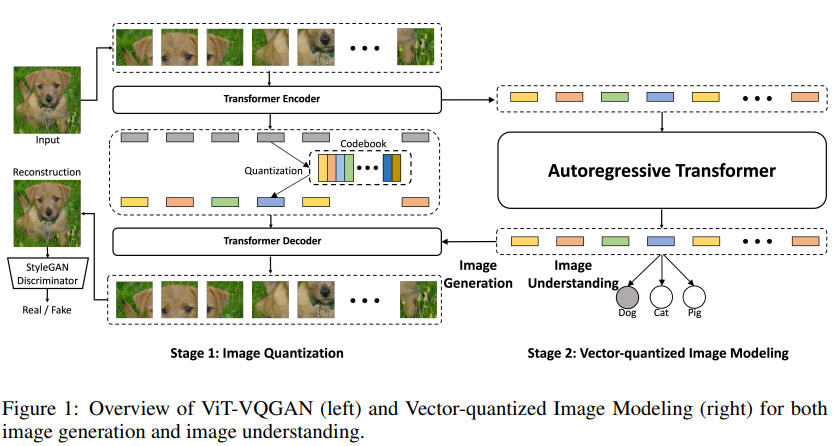
以ViT-VQGAN为范式,梳理AutoEncoder模型的原理、训练与debug过程 - k0pa - 博客园
Conceptual illustration of the variational autoencoder. | Download ...
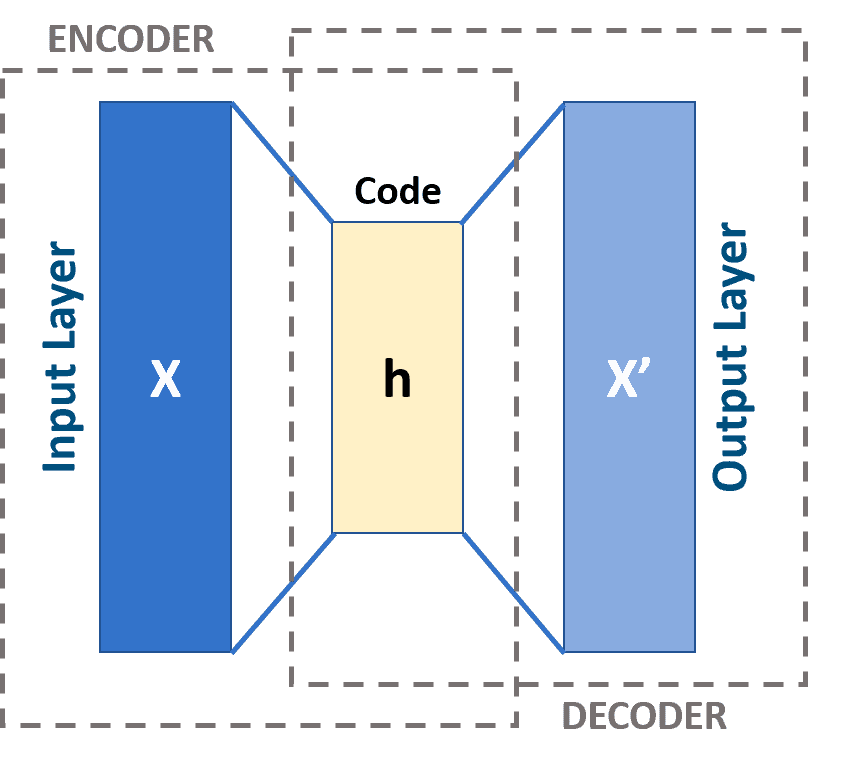
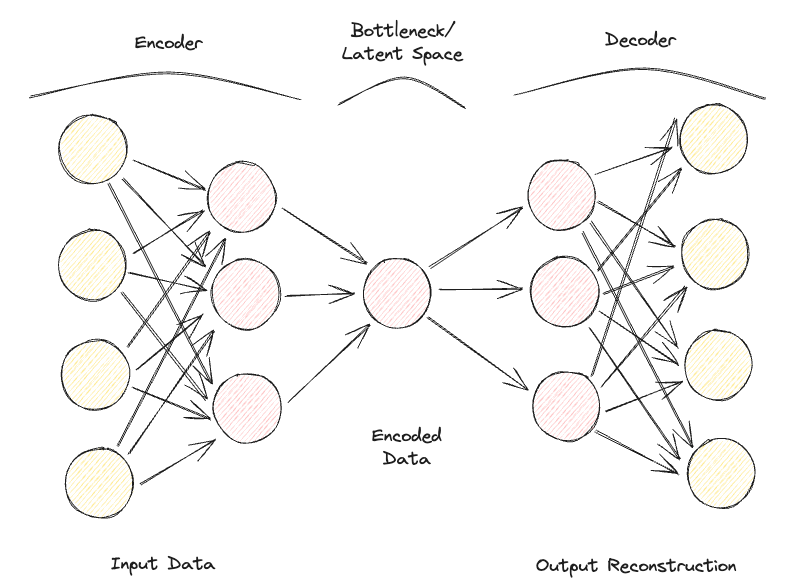
What is an Autoencoder?
A Gentle Introduction to Variational Autoencoders: Concept and PyTorch ...
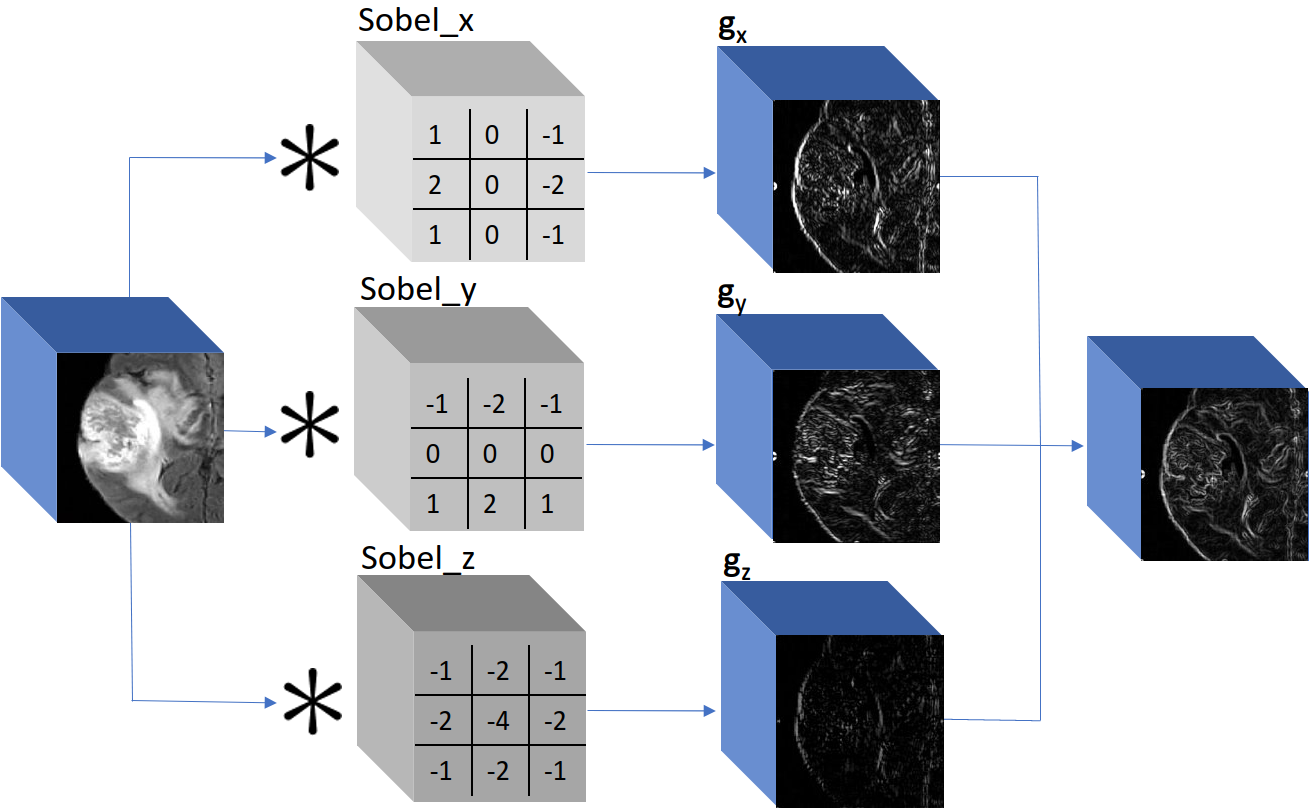
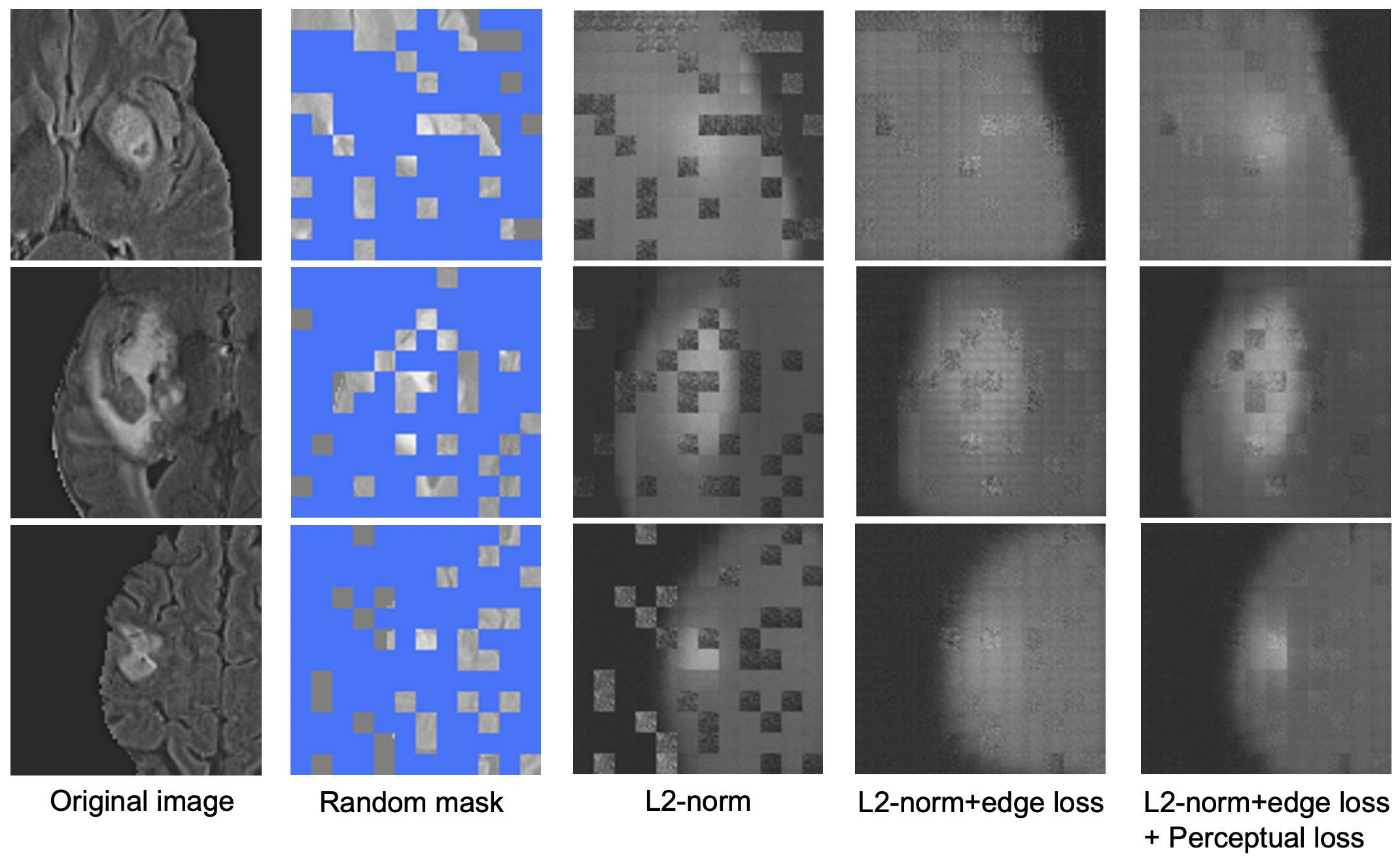
Automatic identification of Parkinsonism using clinical multi-contrast ...
[논문 리뷰] Vision Transformers with Autoencoders and Explainable AI for ...
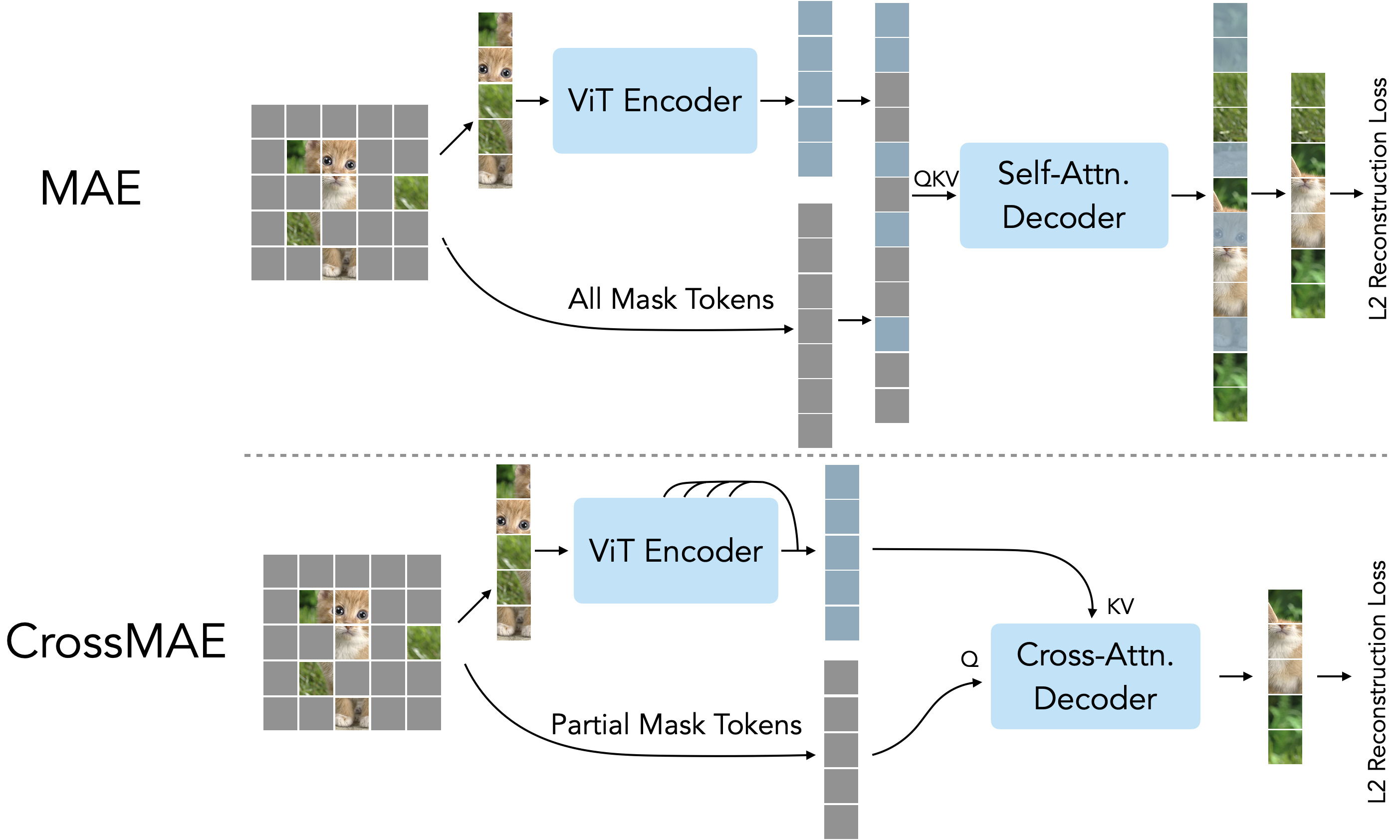
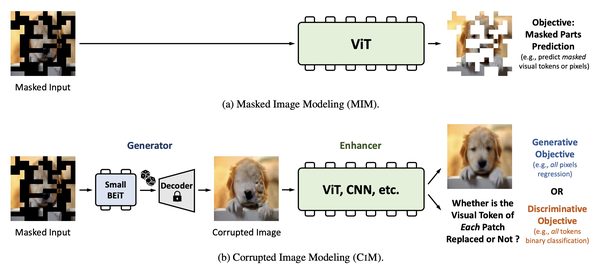
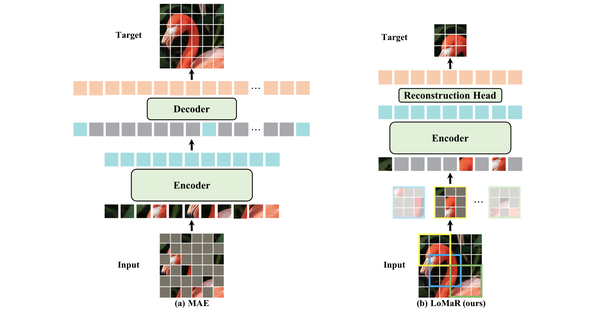
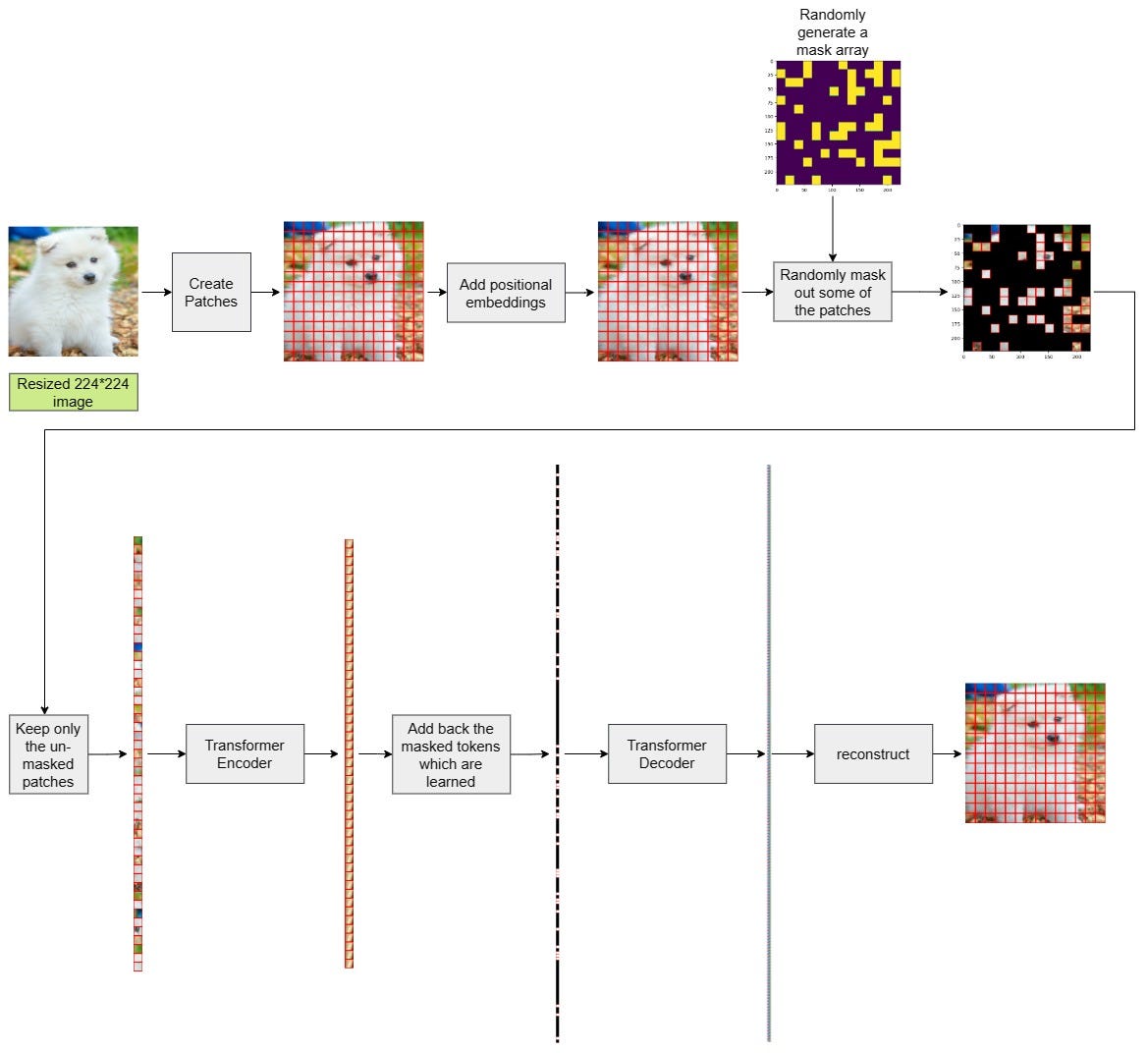
Masked Autoencoders Are Scalable Vision Learners | by Souvik Mandal ...
AE-ViT: Token Enhancement for Vision Transformers via CNN-based ...
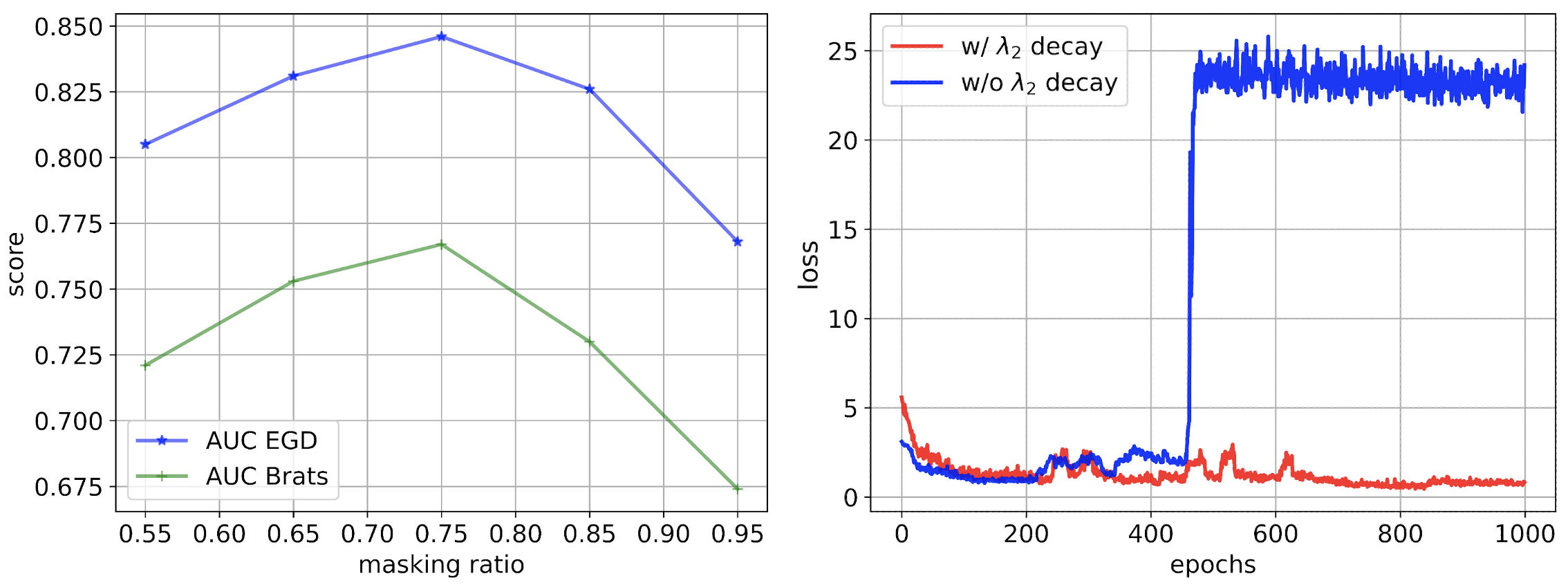
Overview of masked spectrogram autoencoders for efficient pretraining
GitHub - francis-de-ladu/masked-vit-autoencoder-einops
GitHub - chinmay5/vit_ae_plus_plus: Code base for the paper ViT-AE++ ...
AE-ViT: Token Enhancement for Vision Transformers via CNN-Based ...
U-ViT/libs/autoencoder.py at main · baofff/U-ViT · GitHub
Autoencoders 101: Decoding the Power of Self-Supervised Learning | by ...
Variational Auto-Encoder
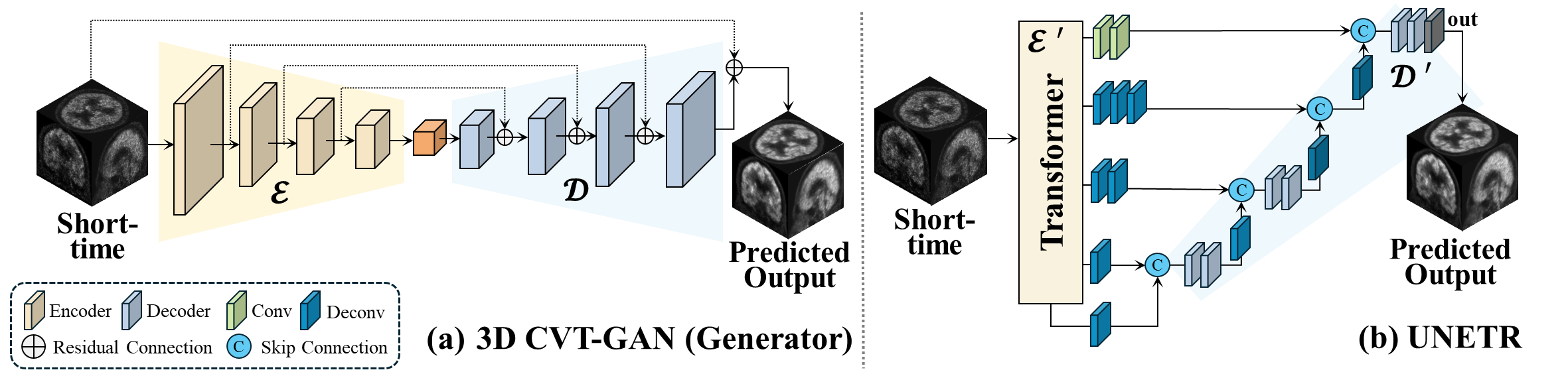
Schematic of the hybrid autoencoder/transformer model. | Download ...
Masked Autoencoders (MAE) for Vision | AI Tutorial | Next Electronics
Vision Transformer for classification on medical images. Practical uses ...
CNN Model for Time-Series Analysis | by Akash Singh | Medium
Batch Normalization for Training Neural Networks (with PyTorch) | by ...
GitHub - benaa1995/Vector-Quantized-Variational-Autoencoder
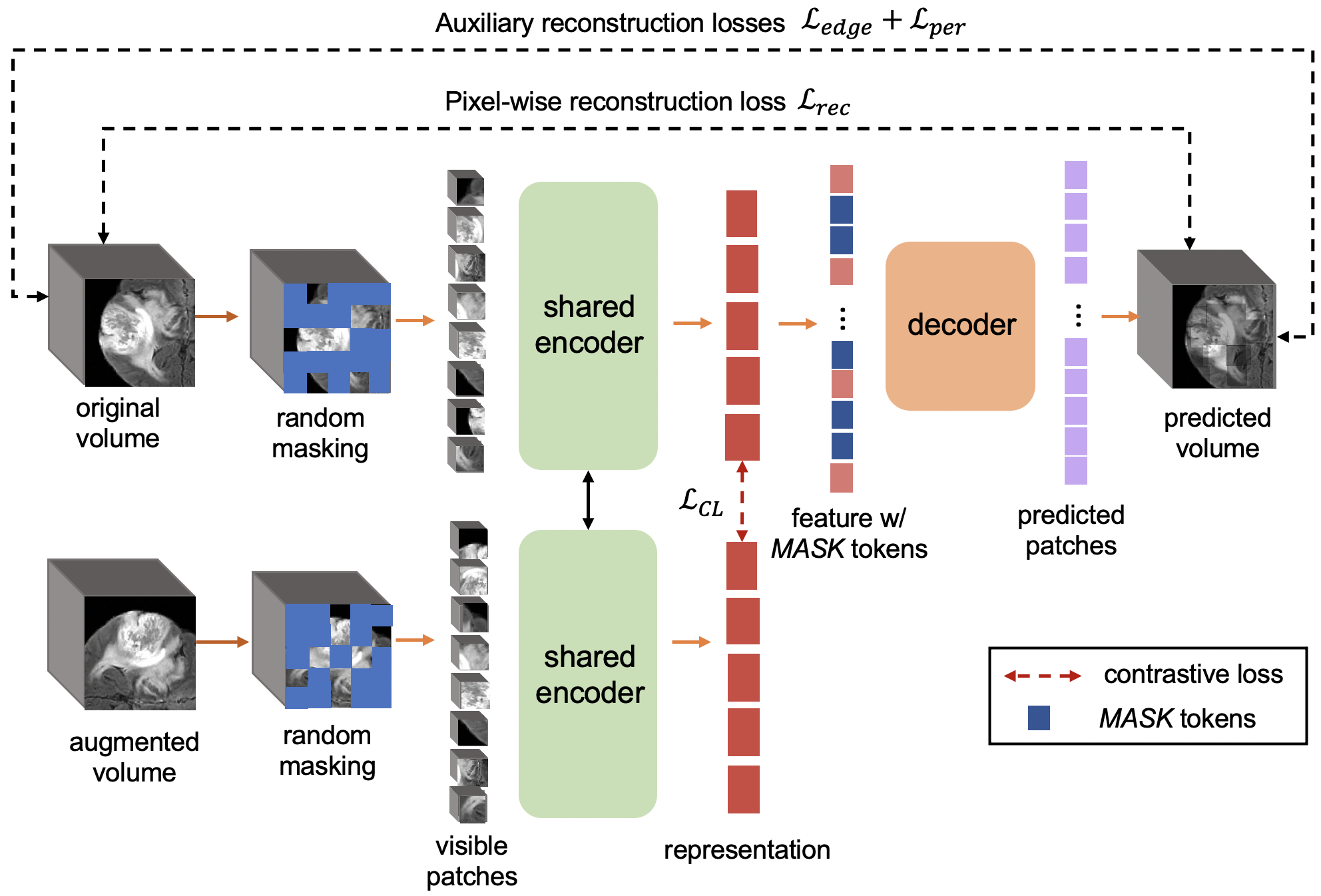
Applying masked autoencoder-based self-supervised learning for high ...
Sparse Autoencoders for More Interpretable RLHF - Laker Newhouse
从ViT到MAE,transformer架构改造Autoencoder_mae vit-CSDN博客
Deep Autoencoder-Based Integrated Model for Anomaly Detection and ...
Variational Encoder (변분 인코더)란? :: Life
autoencoder/svg_autoencoder_dinov3s16p_vit-s_epoch40.yaml · howlin/SVG ...
Auto-encoders Sequential or Functional API? Which one to choose? | by ...
Variational Autoencoders: How They Work and Why They Matter | DataCamp
GitHub - AMC-CBN/MAE-Vit-Tiny: PyTorch implementation of Masked ...
8 Representation Learning (Autoencoders) – 6.390 - Intro to Machine ...
Vision Transformer (ViT) Decoder详解、代码实现与图像重建应用 | AwesomeML
【论文笔记】Video Vision Transformer(ViViT)-CSDN博客
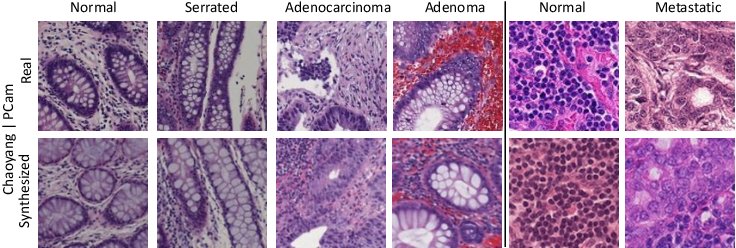
Real and synthesized images using ViT-DAE on NCT-CRC | Download ...
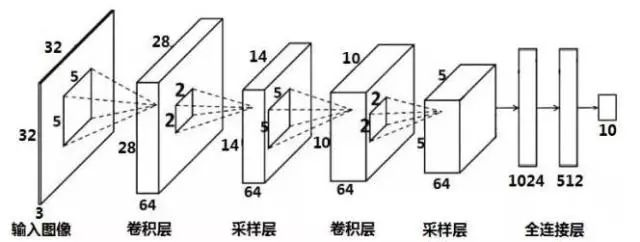
Vision Transformer Image Classification — MindSpore master documentation
The encoder and decoder configurations. ViT-series refers to three ...
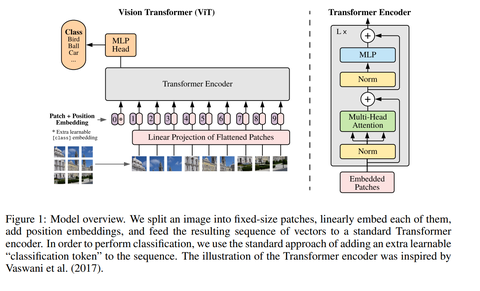
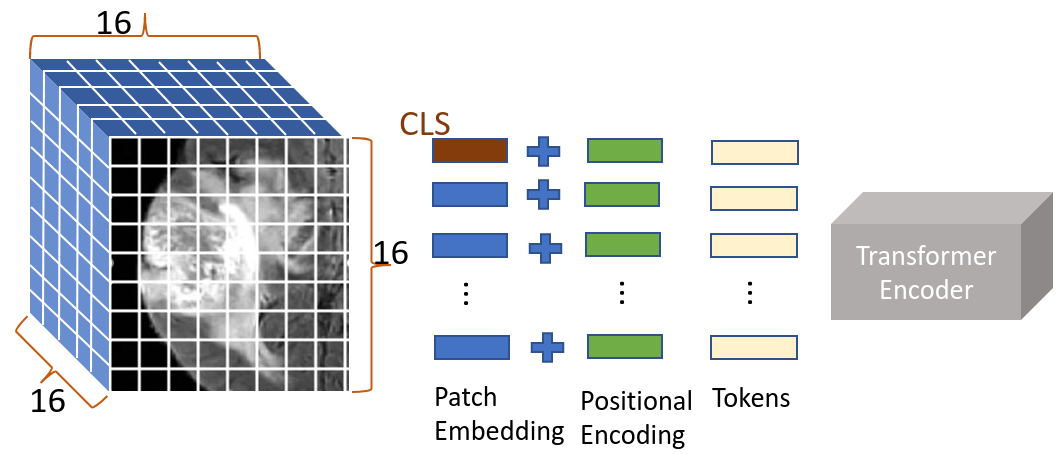
[VIT 코드와 함께보기] An Image is Worth 16x16 Words: Transformers for Image ...
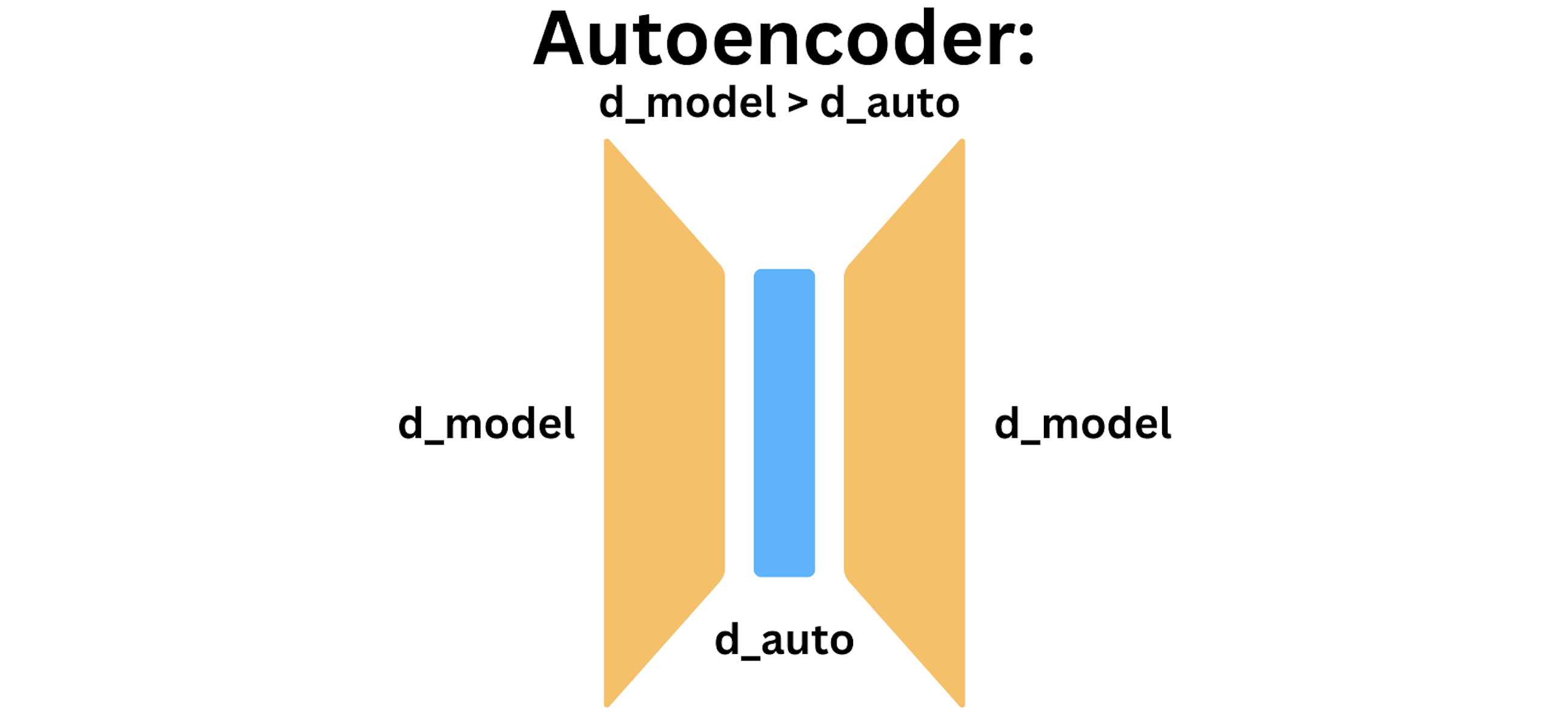
Exploring Autoencoders: Basics, Uses, and Applications
fushengzhiyu/ViT-Adapter
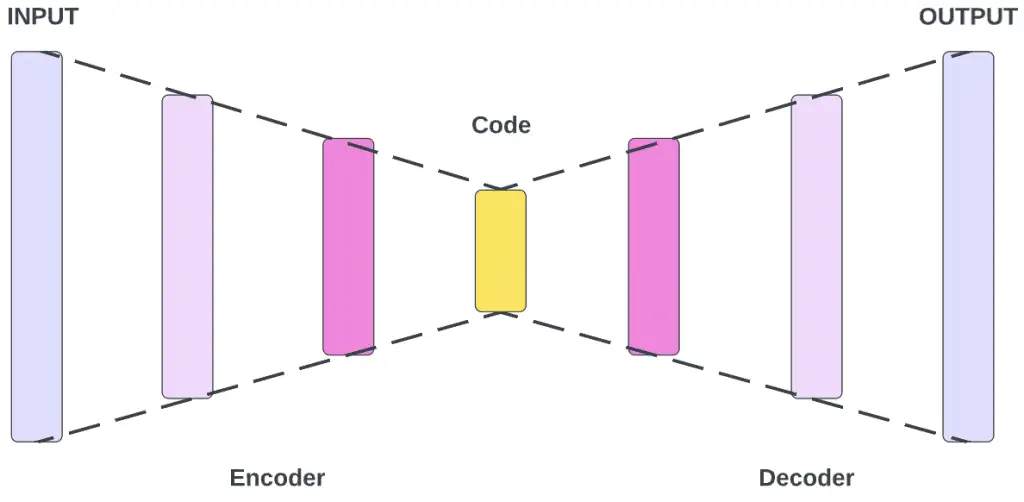
An Introduction to Autoencoders: Everything You Need to Know
GitHub - iliassarbout/ViT-Masked-Auto-Encoders-for-low-resolution-images
Sparse Autoencoders in Deep Learning - GeeksforGeeks
MICV
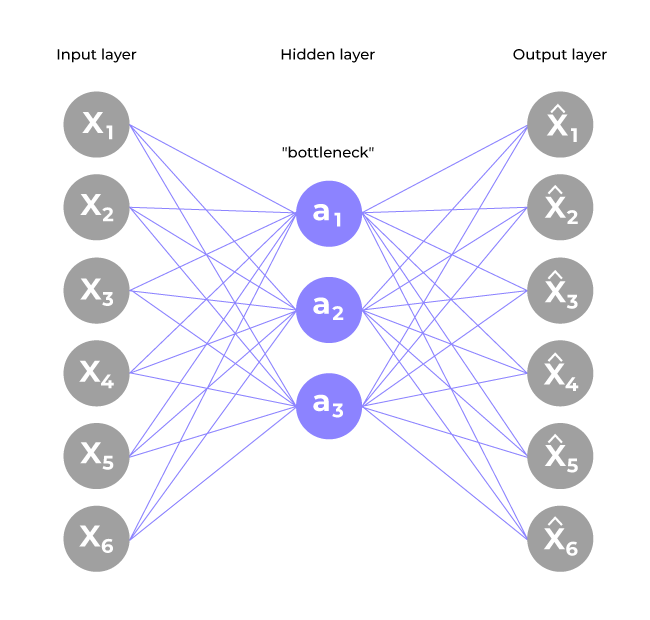
Structure of the autoencoder. | Download Scientific Diagram
RT-ViT: Real-Time Monocular Depth Estimation Using Lightweight Vision ...
Introduction to Autoencoders: From The Basics to Advanced Applications ...
Introduction to Autoencoders and Common Issues and Challenges ...