Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Efficient Weights Quantization of Convolutional Neural Networks Using ...
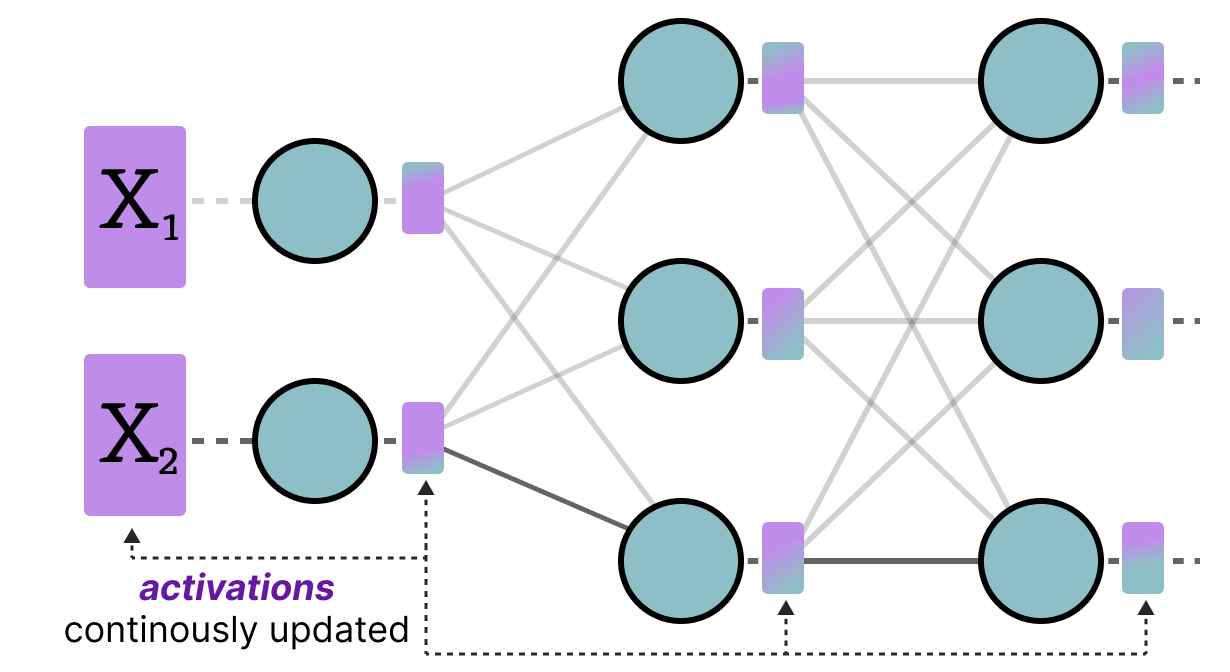
(a) An illustration of complex weights quantization in a coherent ...
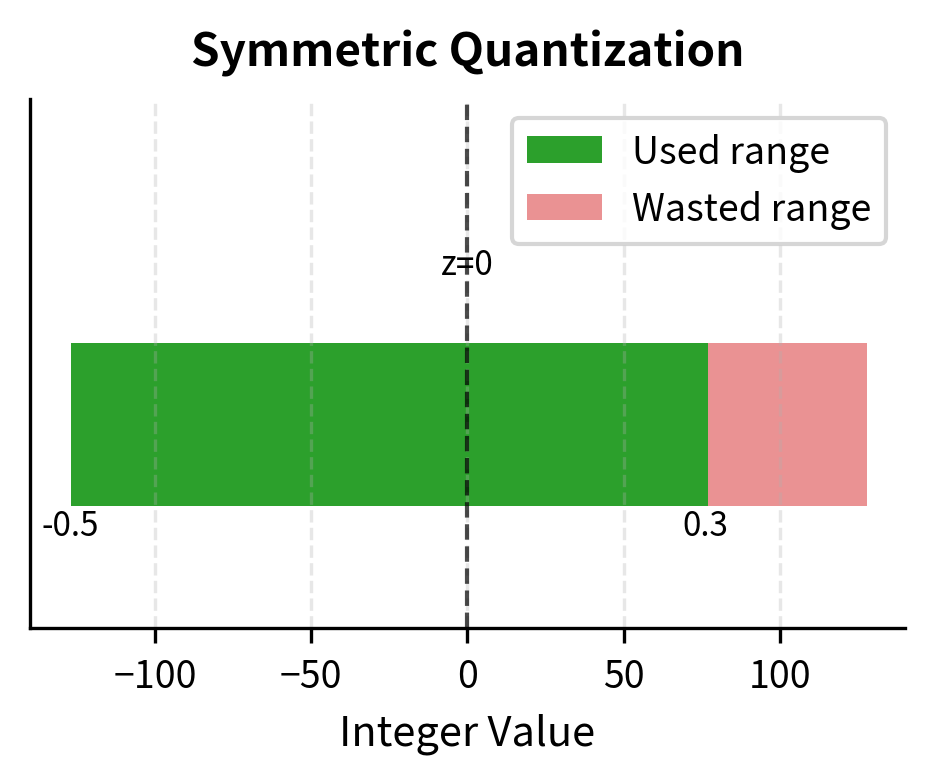
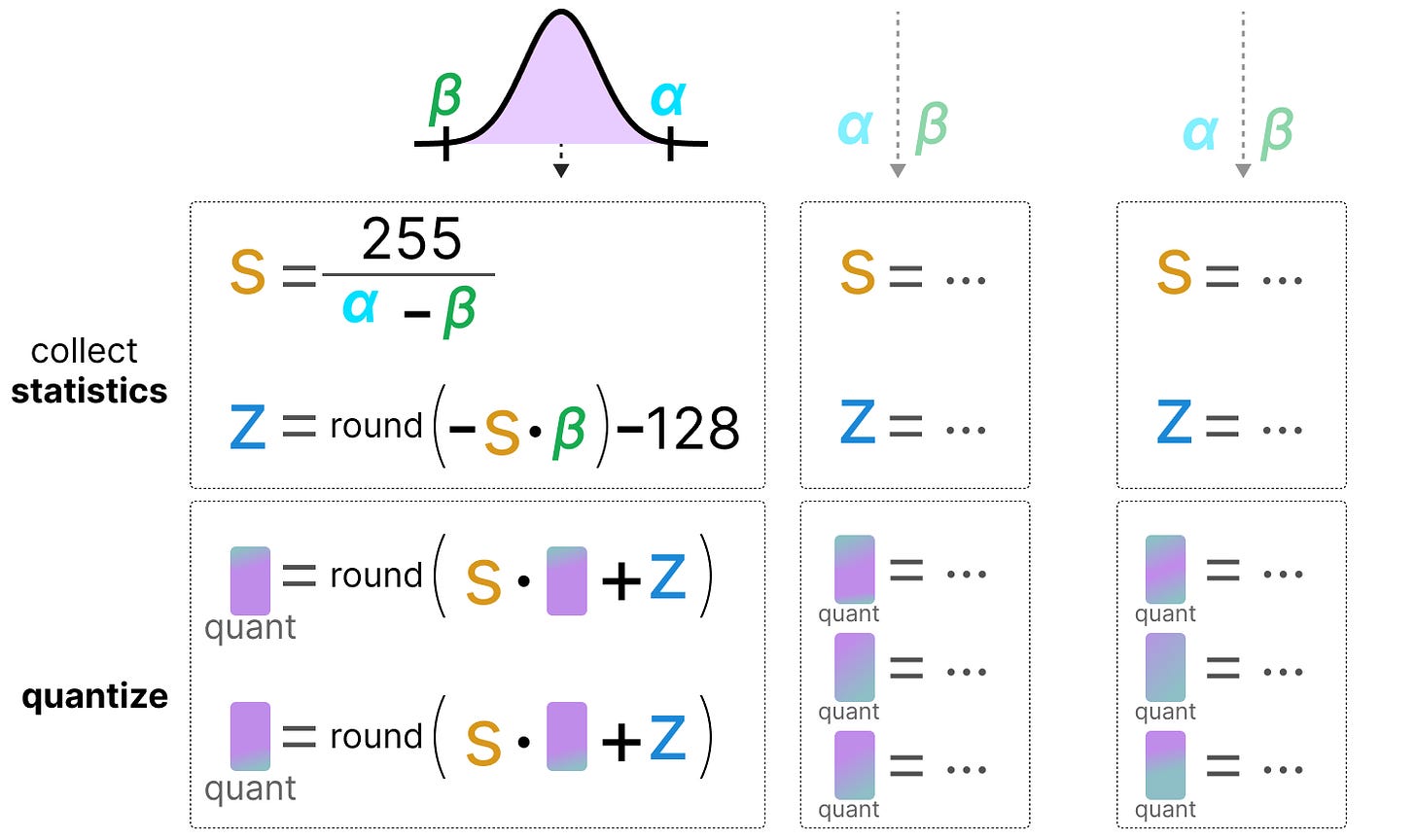
Symmetric quantization of weights (top) and asymmetric quantization of ...
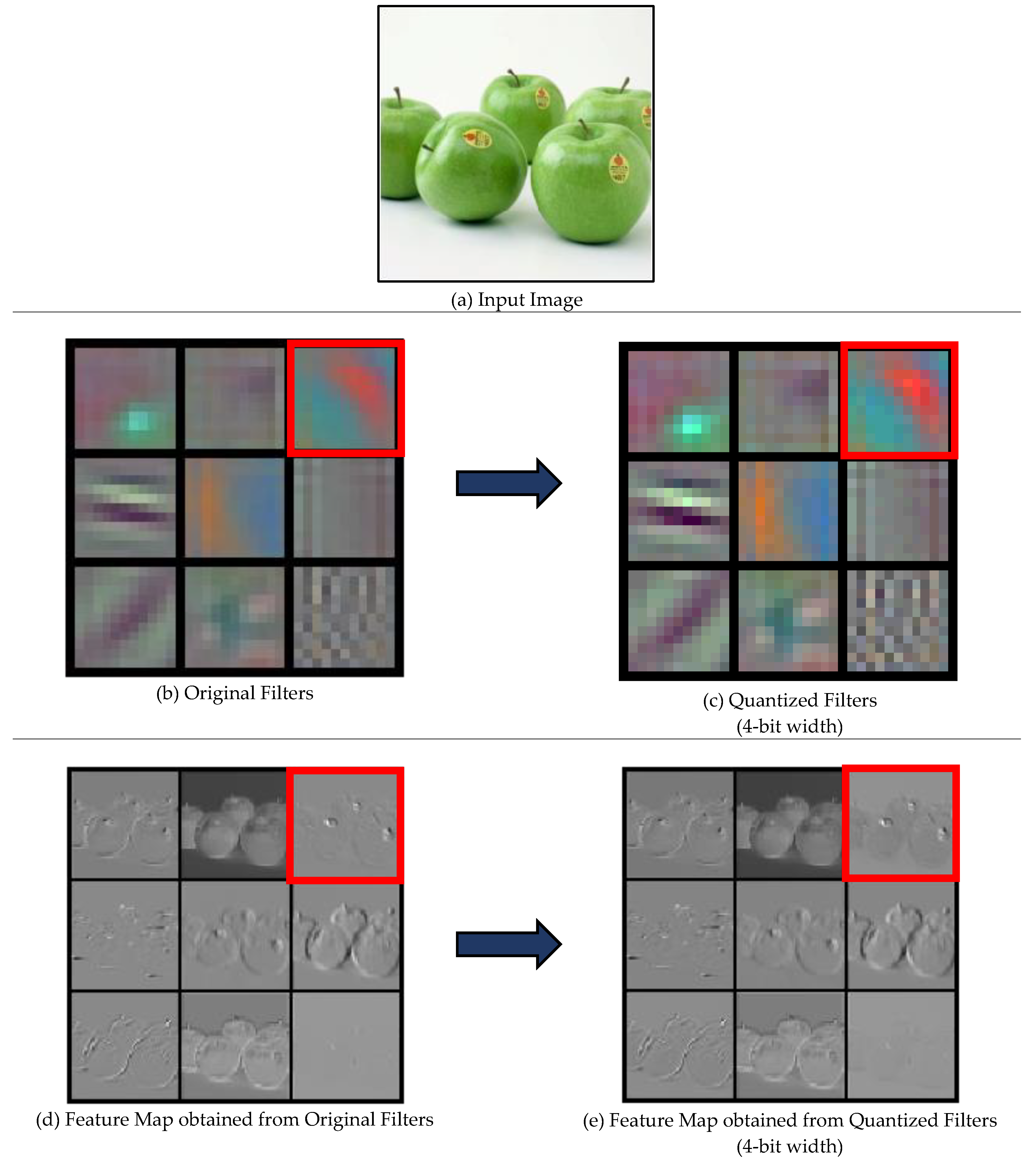
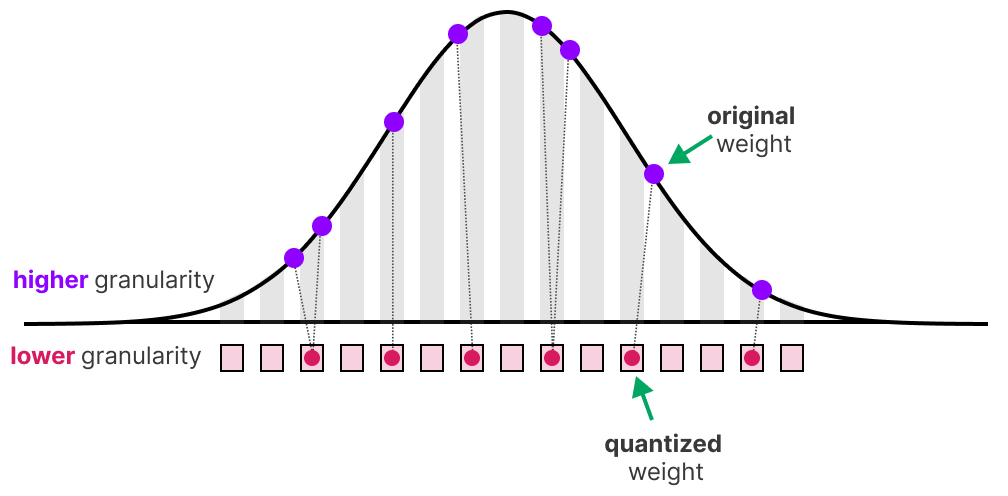
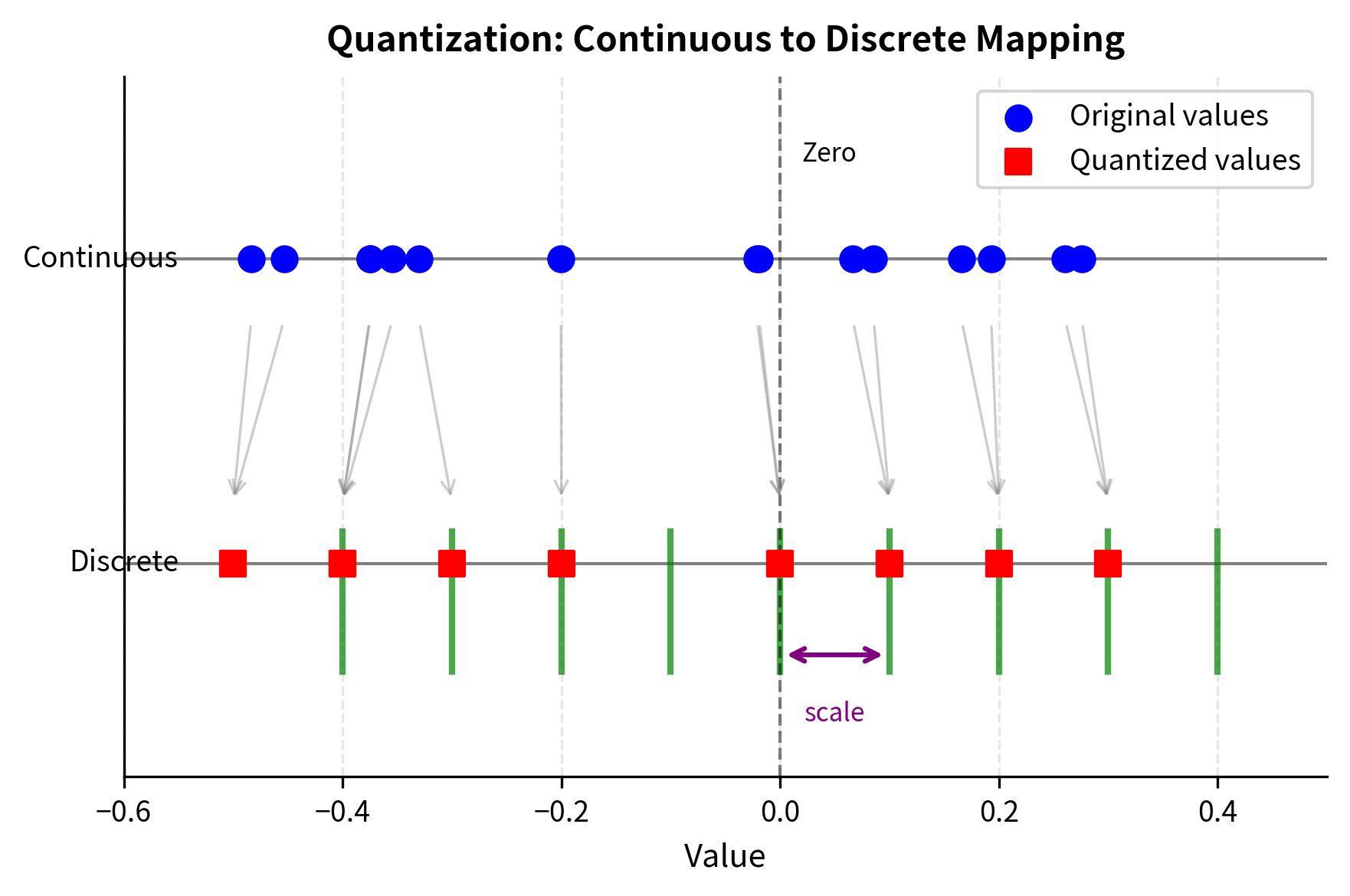
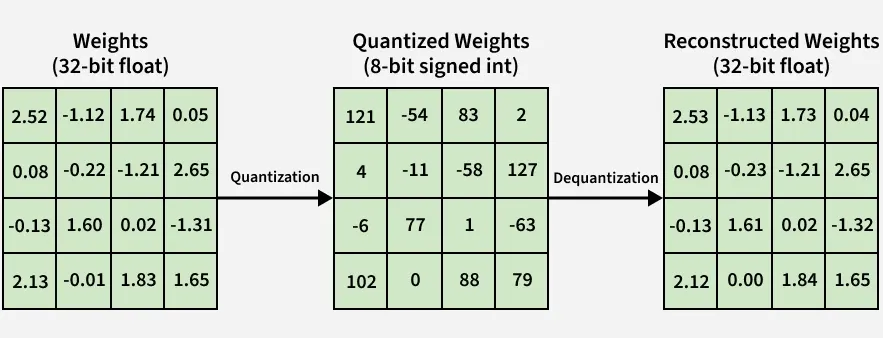
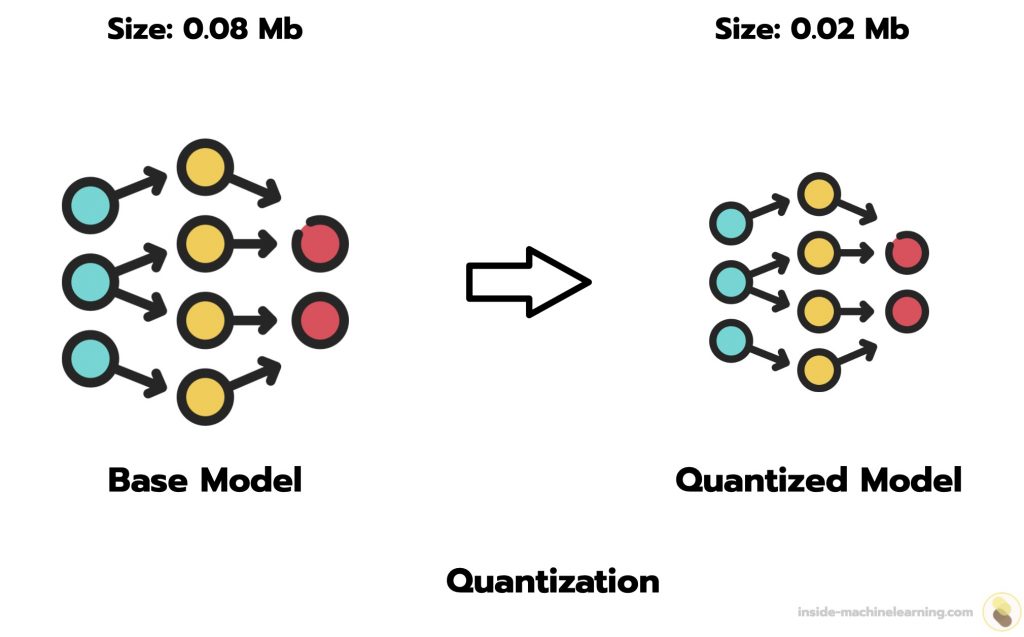
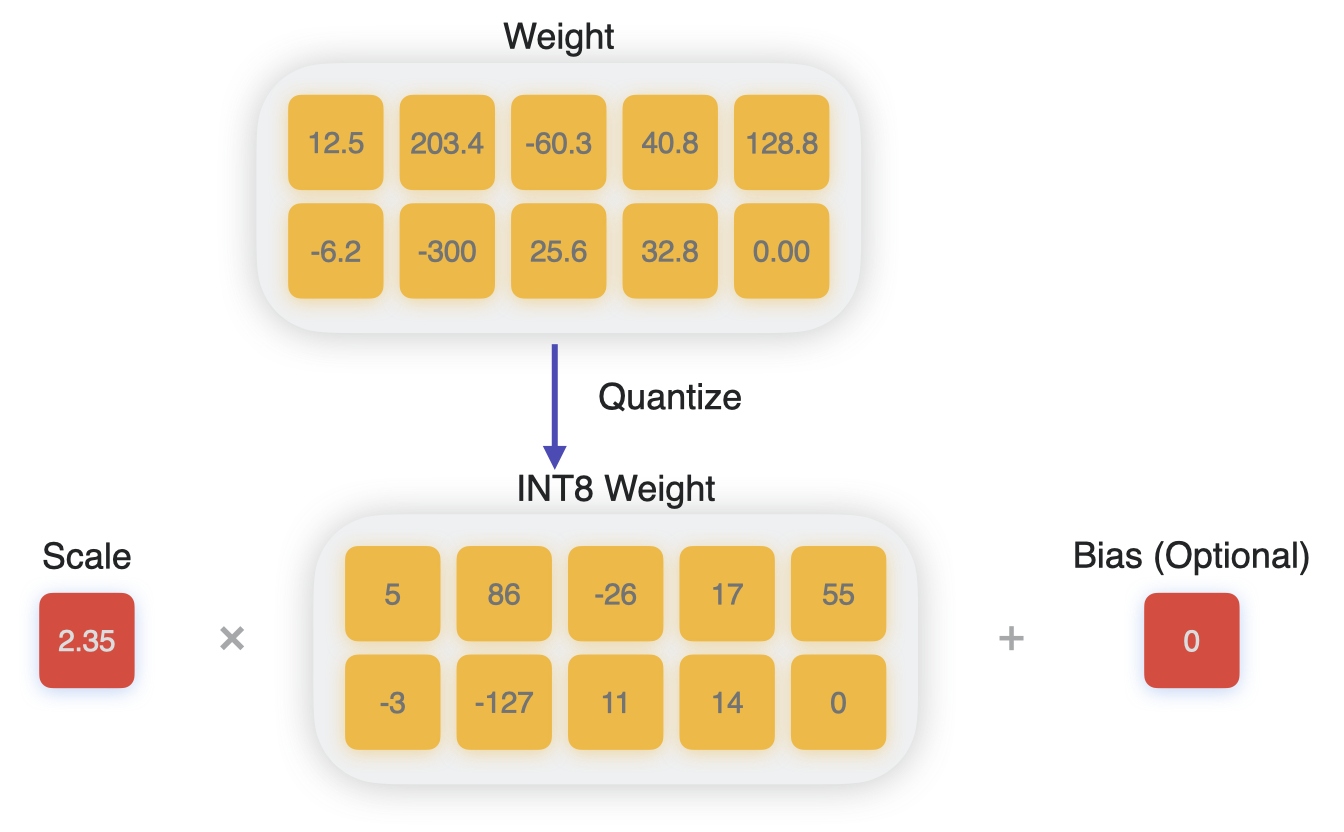
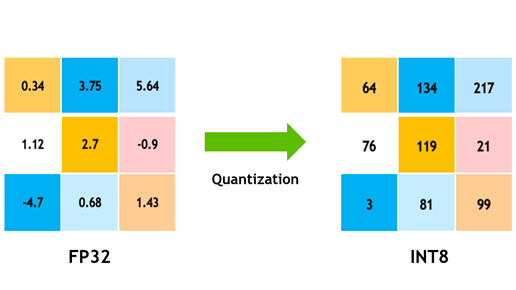
The quantization process where the network weights are compressed via ...
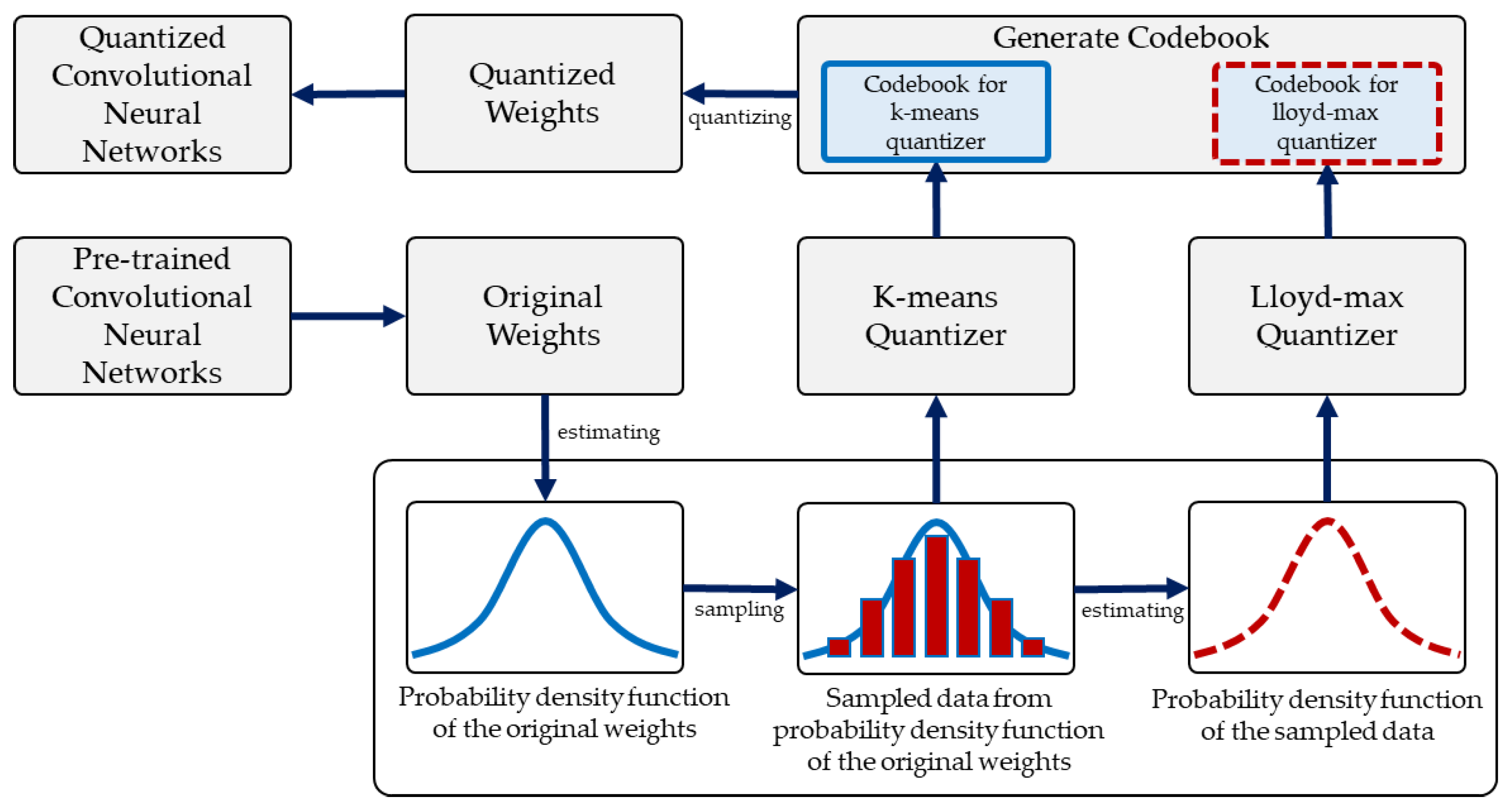
Overview of weights quantization using the kernel density estimation ...
4: Manual Quantization Tool: The original values of a set of weights ...
Time comparison of quantization noise and weights sharing strategy ...
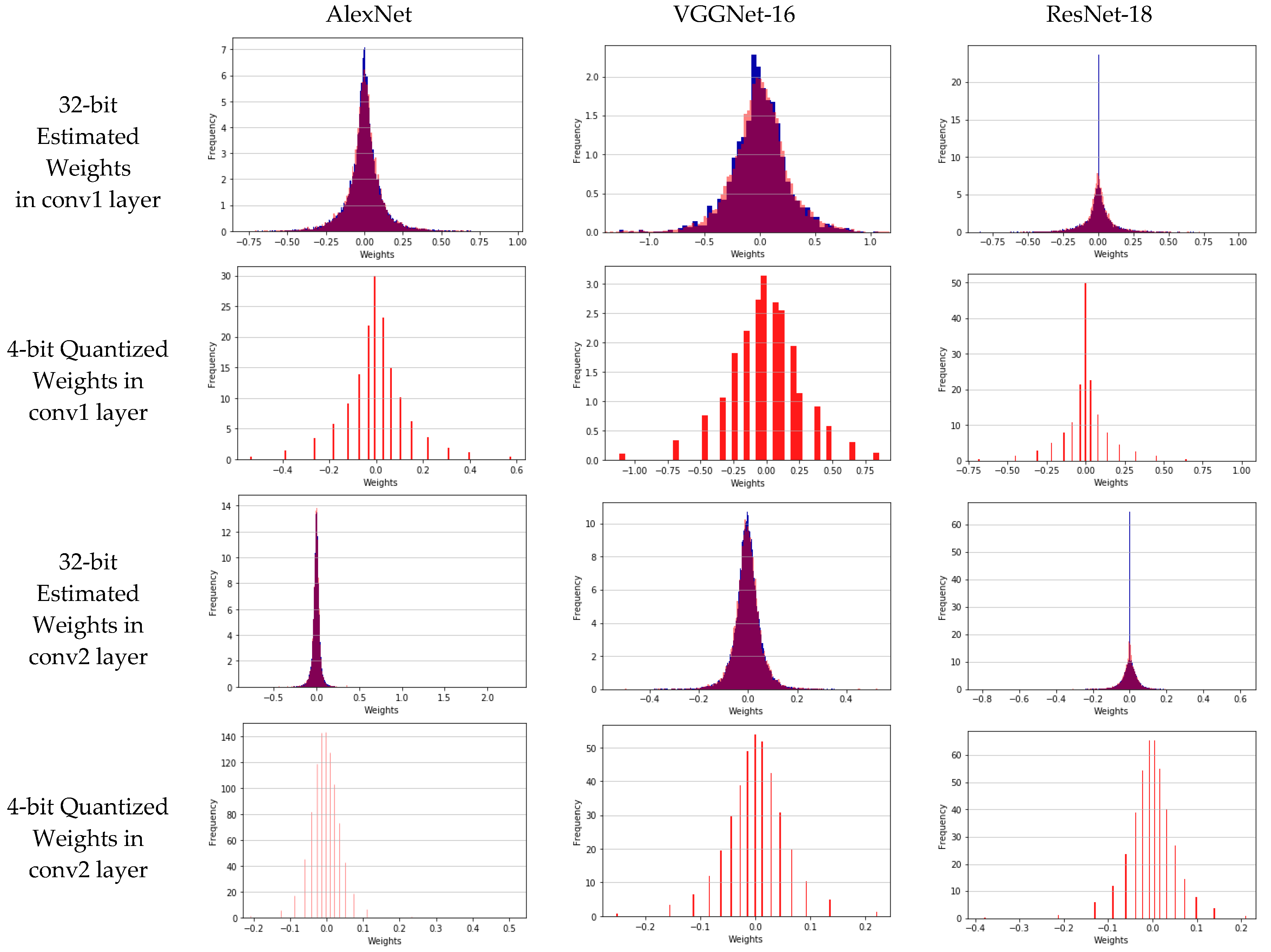
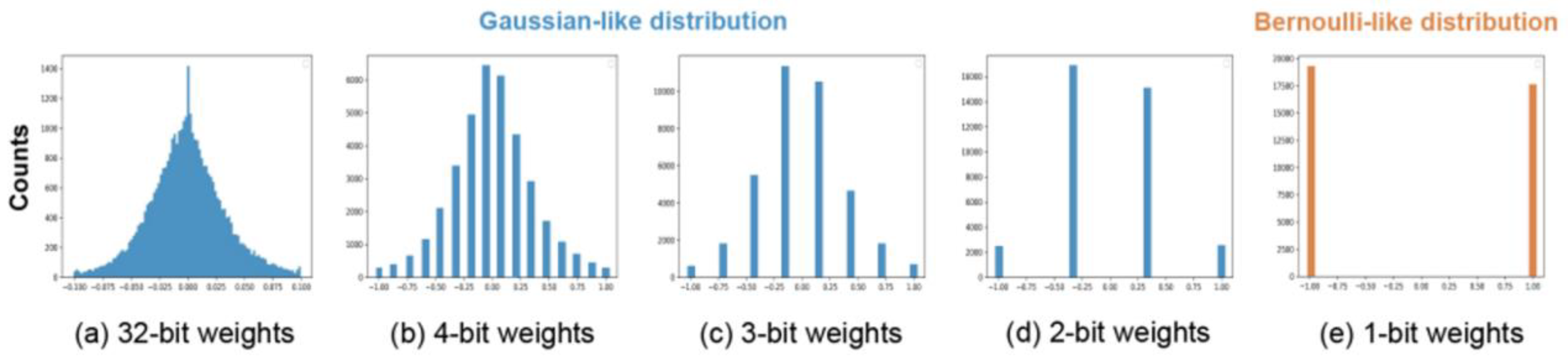
The distribution of weights with the quantization levels of 2 bits, 3 ...
[논문 리뷰] Column-wise Quantization of Weights and Partial Sums for ...
Quantization function used for calculating the weights (edges) between ...
A Visual Guide to Quantization - Maarten Grootendorst
Introduction to Weight Quantization | Towards Data Science
A Visual Guide to Quantization - by Maarten Grootendorst
Introduction to Weight Quantization - Origins AI
Study of Weight Quantization Associations over a Weight Range for ...
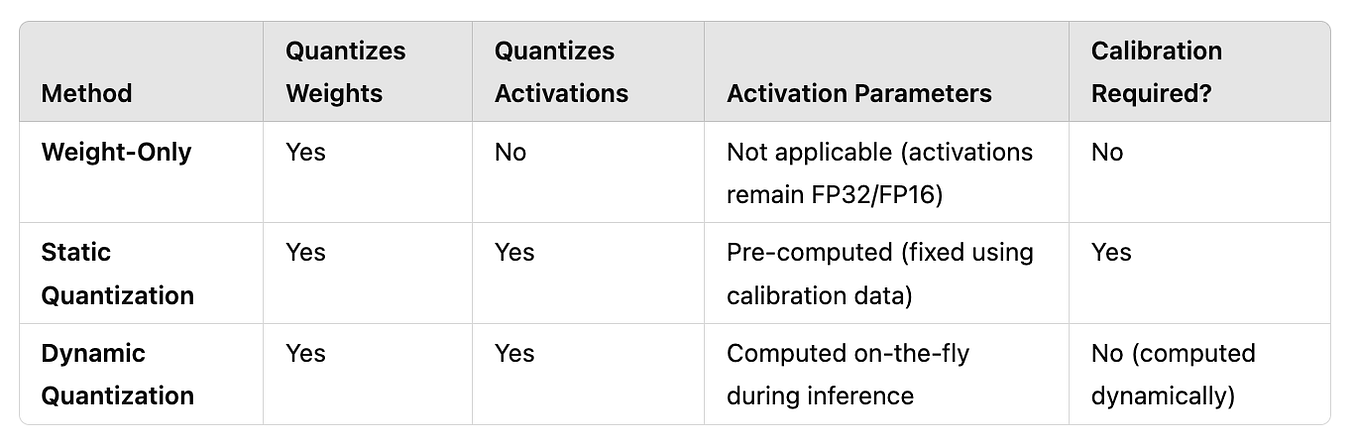
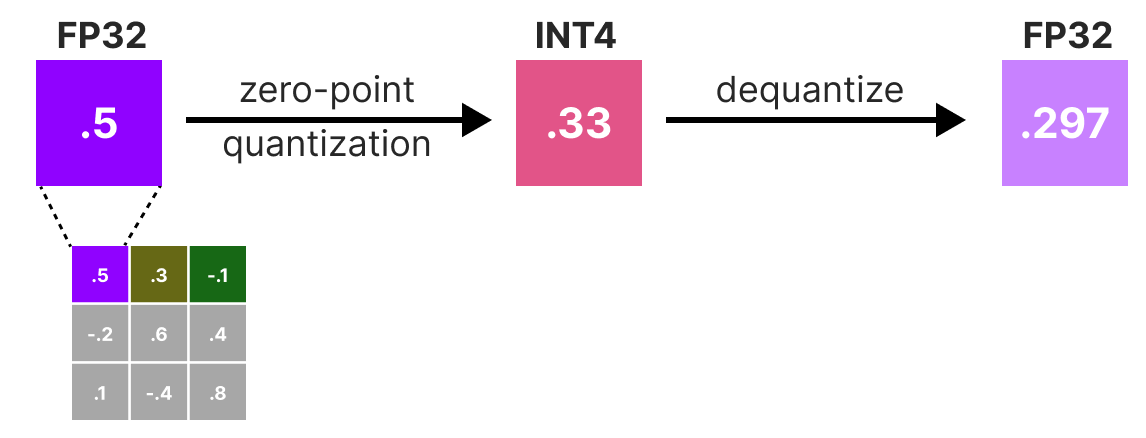
Weight Quantization Basics: Scale, Zero-Point & Calibration ...
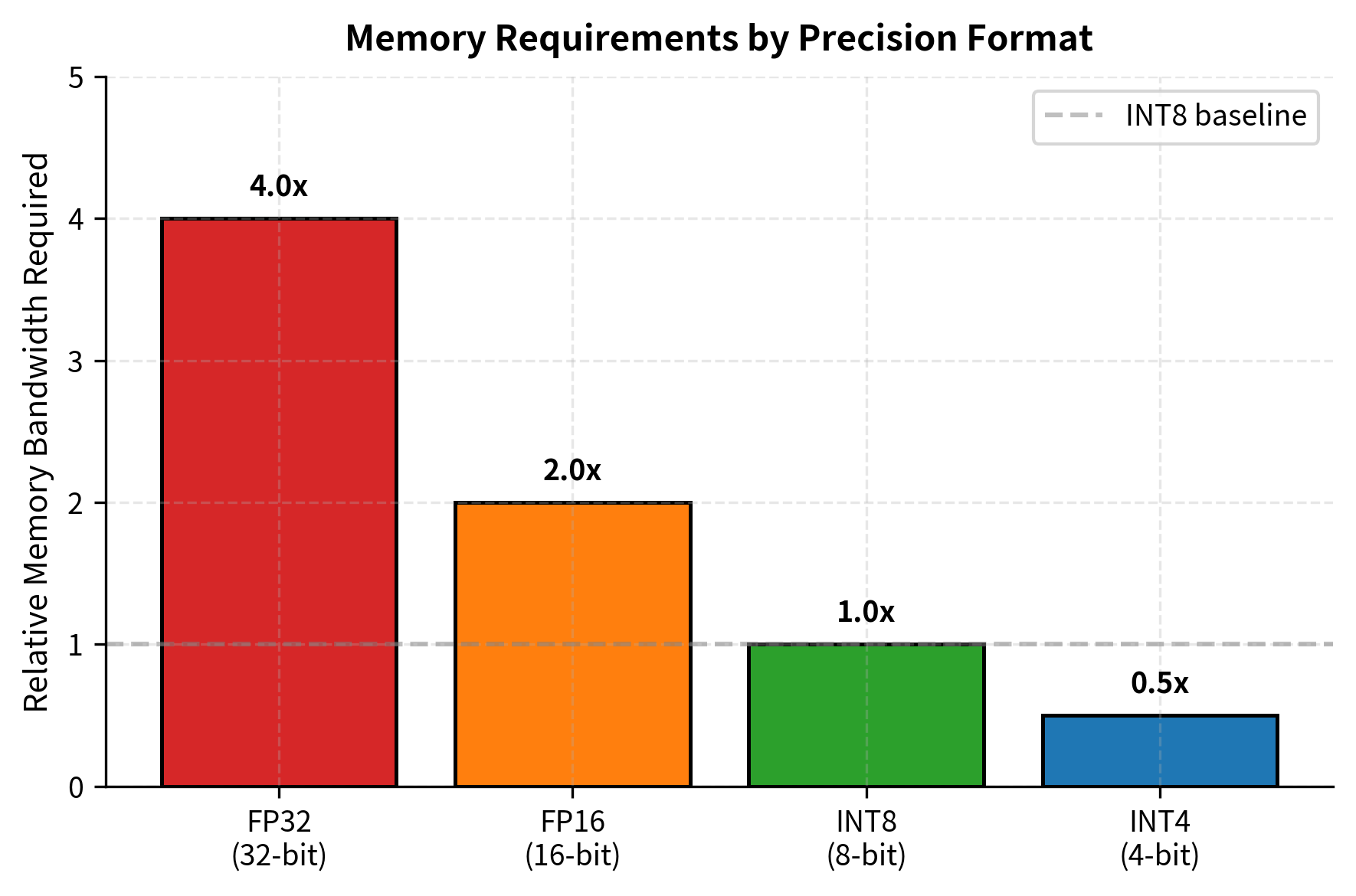
LLM Quantization Impact Leaderboard 2026: INT4 vs FP16 | Awesome Agents
Concept Deep Dive: Quantization - Mistral AI Cookbook | Mistral Docs
Ollama Model Quantization Guide: GGUF Format and Accuracy Loss Analysis ...
70 Percent VRAM Cut With AMD AI Quantization - One News Page VIDEO
Weights & Biases - $50M Raised - Reviews & Alternatives | StartupHub.ai
Quantization Explained: Q4 vs Q8 vs FP16 — What You Actually Lose ...
Gemma 4 on NVIDIA GB10: Quantization Benchmarks for Local Inference ...
GGUF Quantization Explained: Q4_K_M vs Q5_K_M vs Q8 Which to Pick (2026 ...
ADAPTIVE QUANTIZATION METHOD FOR ANALOG IN-MEMORY COMPUTING SYSTEMS ...
Huawei Unveils KVarN: A Native vLLM Backend for KV-Cache Quantization ...
NVFP4 vs MXFP4: 4-Bit Quantization Format Decision Guide for LLM ...
LLM Quantization Explained: Q4 vs Q8 — What's the Difference and Which ...
TurboQuant: Reducing LLM Memory Usage With Vector Quantization | Hackaday
Cohere cracks lossless quantization and native citations with first ...
Llama.cpp GGUF Quantization Guide: Optimize Local LLM Performance (2026)
AWQ Quantization Guide: Deploy LLMs at Half the GPU Cost (2026 ...
Q4_K_M vs Q5_K_M vs Q8 — Which GGUF Quantization Should You Use? (2026 ...
Pyramid Vector Quantization | PPTX
Quantization Methods Overview | vllm-project/vllm | DeepWiki
What is Quantization - GeeksforGeeks
OIML Calibration Weights - Interlab NZ
GGUF Quantization Explained: Q4_K_M vs Q8_0 vs F16 — Which to Use in ...
[논문 리뷰] P$^2$-ViT: Power-of-Two Post-Training Quantization and ...
Google releases Gemma 4 QAT weights on Hugging Face — Intelligence Feed ...
The 'one set' weights rule will transform your arms - here's how to do ...
Pcs Unit 5: Digital Representation of Analog Signals and Quantization ...
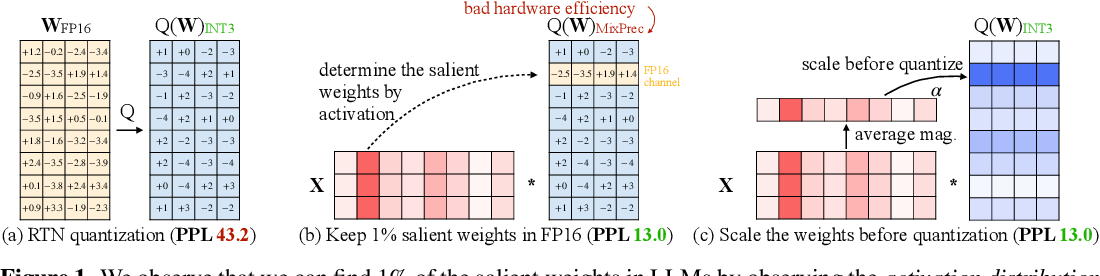
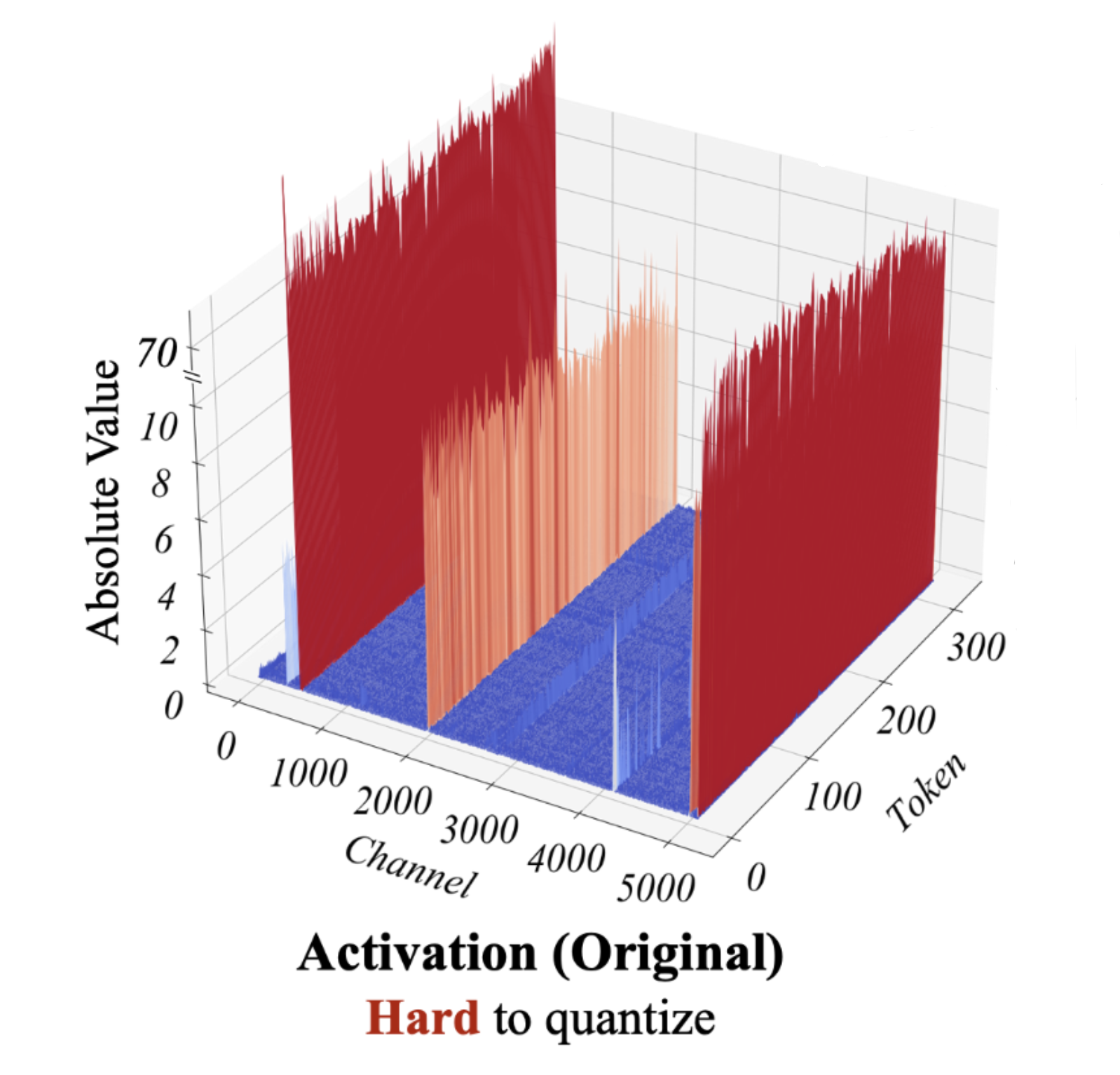
AWQ: Activation-aware Weight Quantization for LLM Compression and ...
Descargar Weights APK Última Versión 1.14.5 para Android
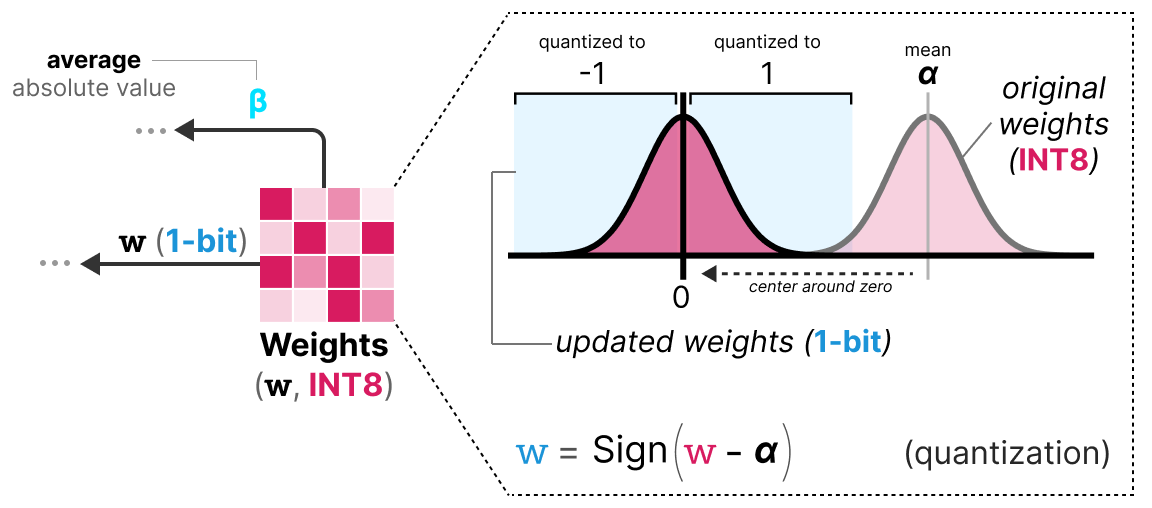
Weights quantization: 1. Clip the real-valued weights to the interval ...
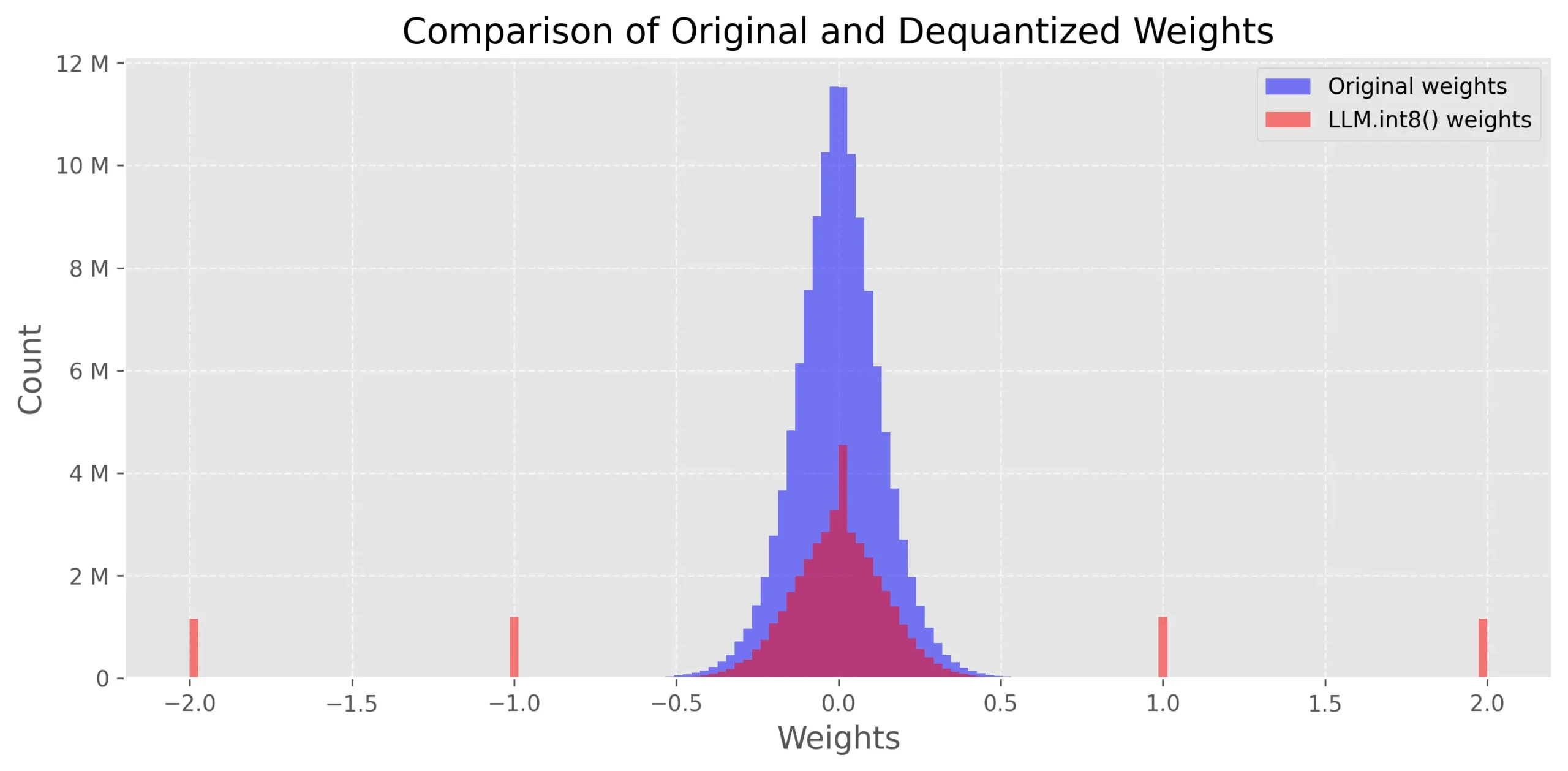
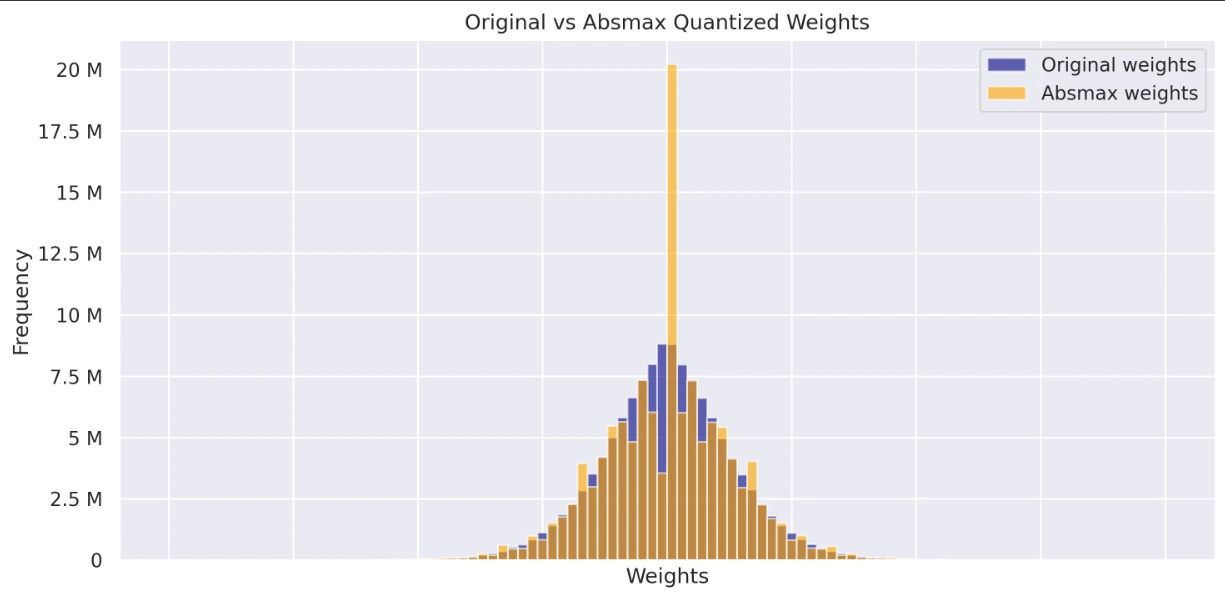
a Result of the weight quantization. After the weight quantization ...
What is Quantization and how to use it with TensorFlow
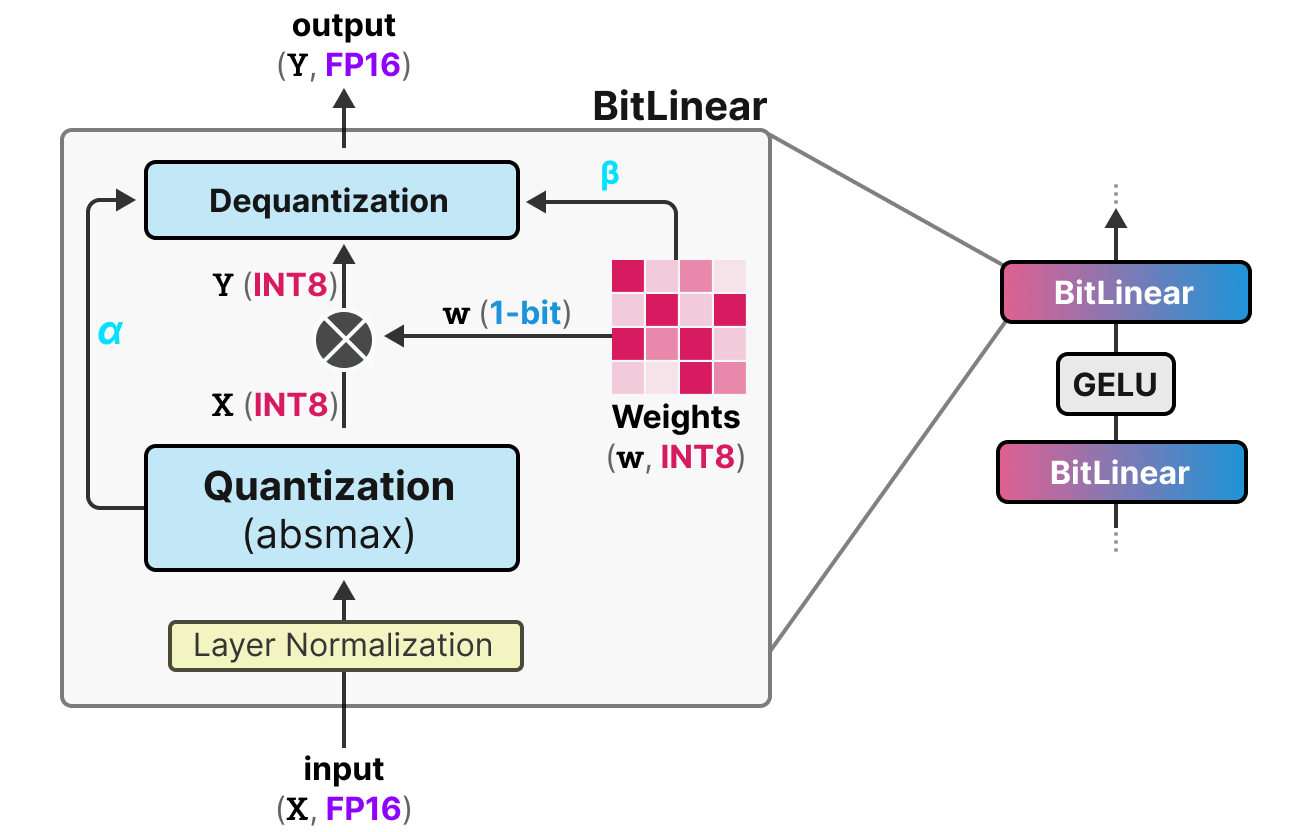
Understanding Activation-Aware Weight Quantization (AWQ): Boosting ...
LLM Quantization Methods: GPTQ, AWQ, GGUF - Cast AI
Log2 based (right) quantization for exemplar layer floating point ...
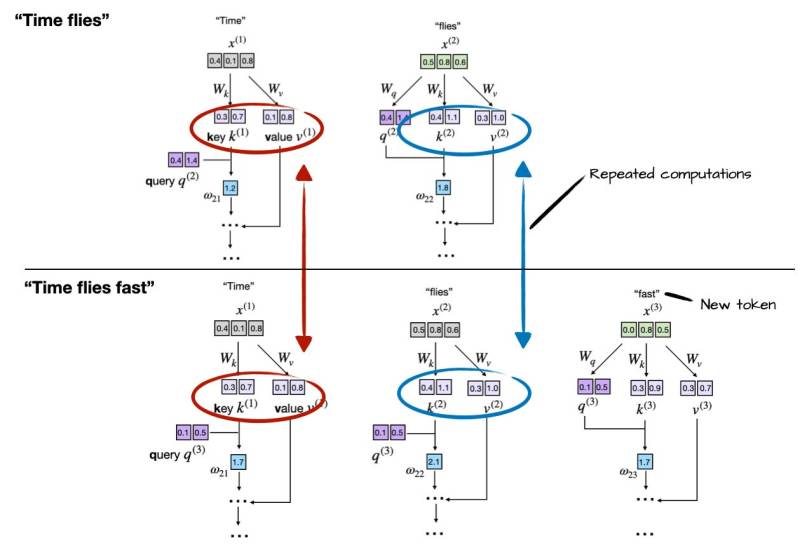
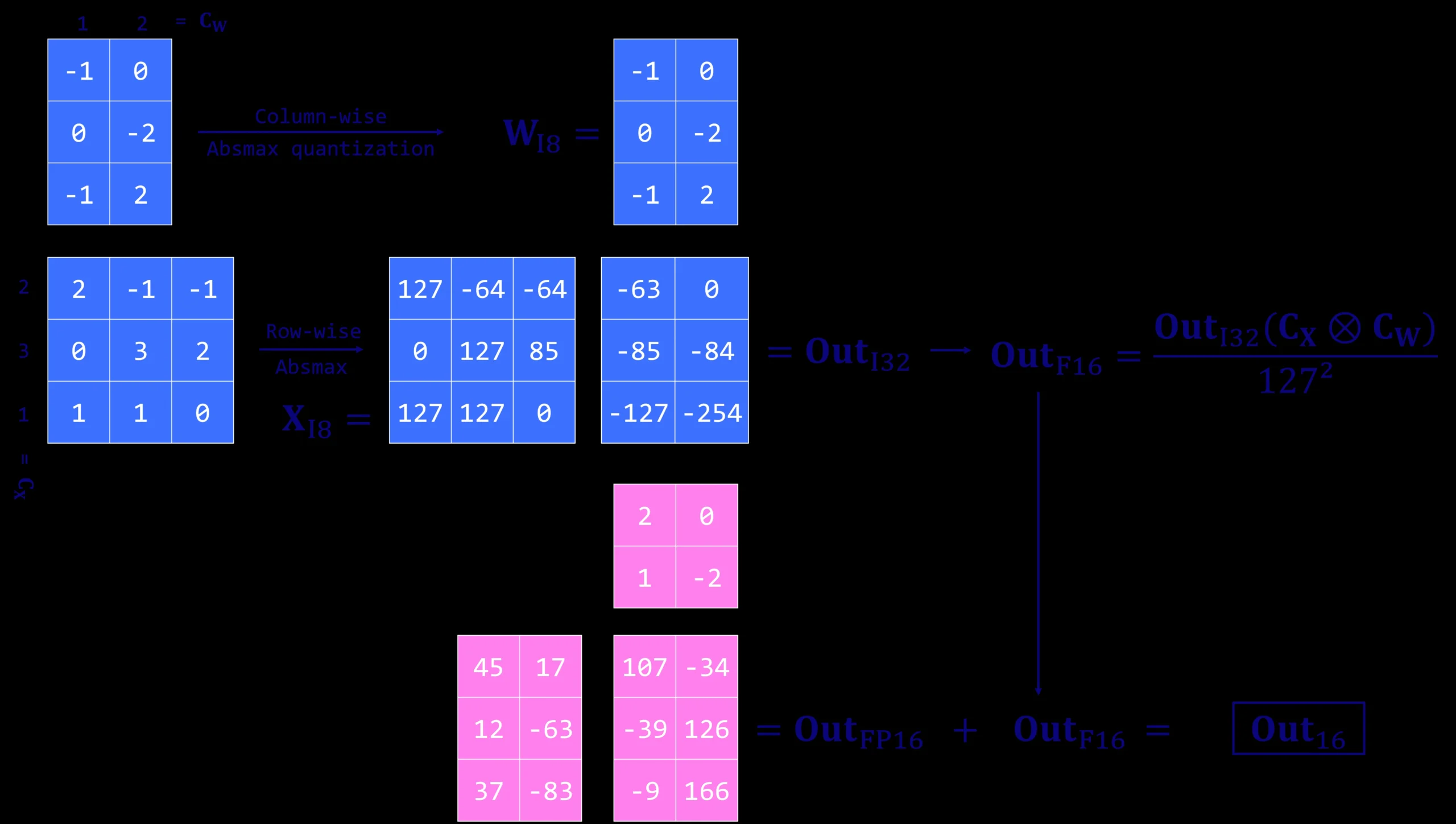
How Quantization Works: From a Matrix Multiplication Perspective ...
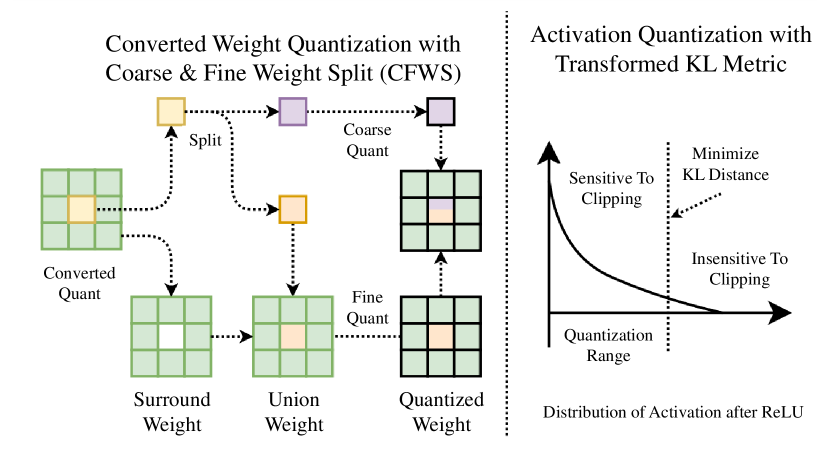
[2312.10588] Post-Training Quantization for Re-parameterization via ...
Quantization Overview — Guide to Core ML Tools
Neural Network Weight Quantization
How to optimize large deep learning models using quantization
AWQ: Activation-aware Weight Quantization Explained
(PDF) The Effects of Weight Quantization on Online Federated Learning ...
Selectq Calibration Data Selection For Post-Training Quantization at ...
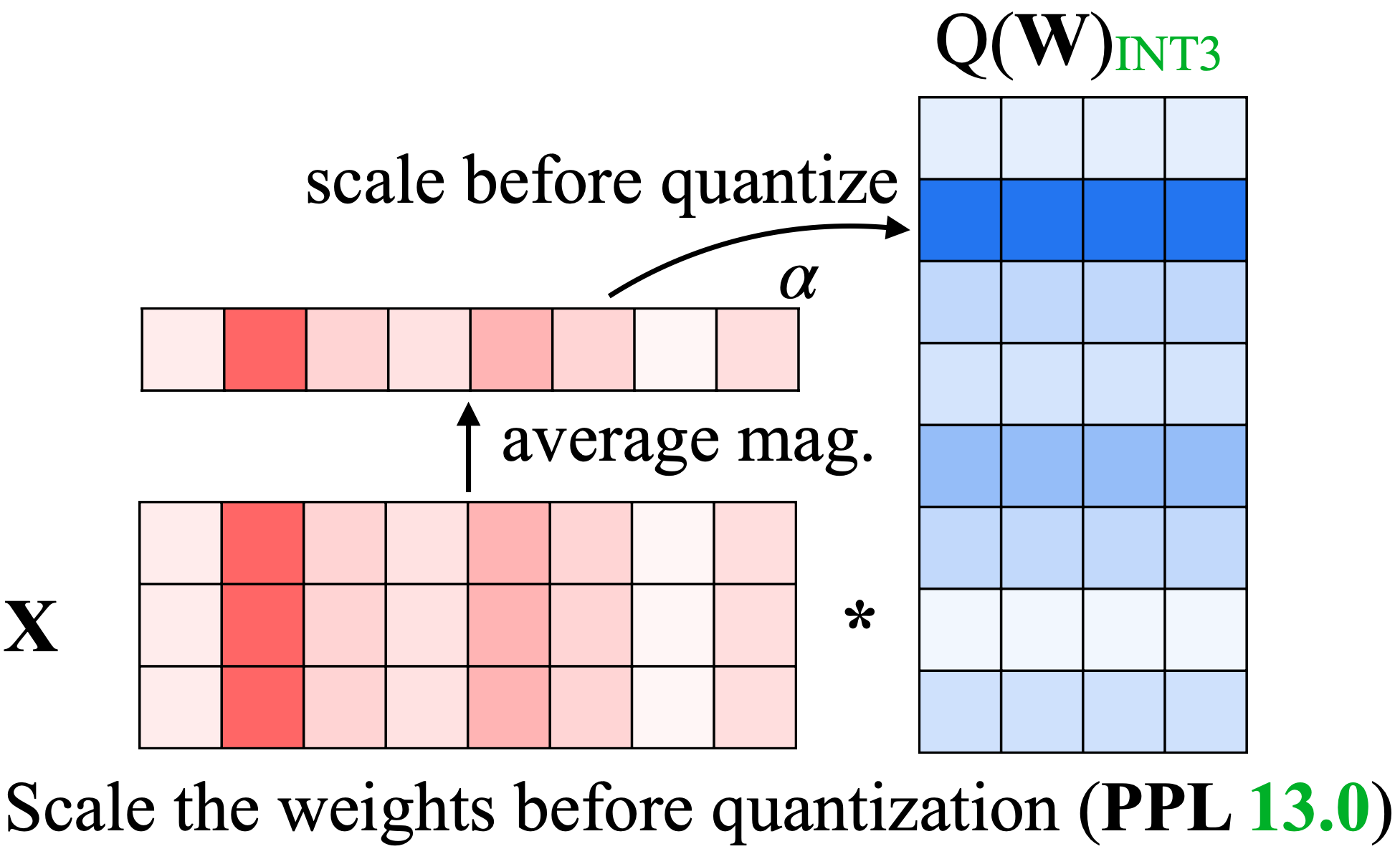
Example of a signed 4-bit quantized weights tensor and α = 0.16 ...
(PDF) Weight Quantization for Multi-Layer Perceptrons using Soft-Weight ...
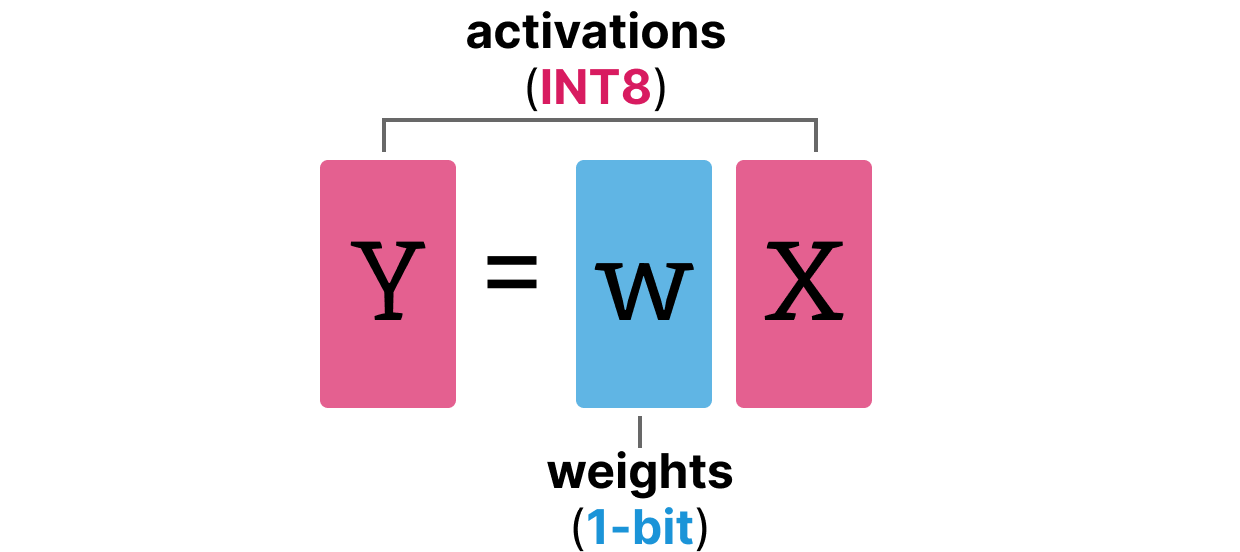
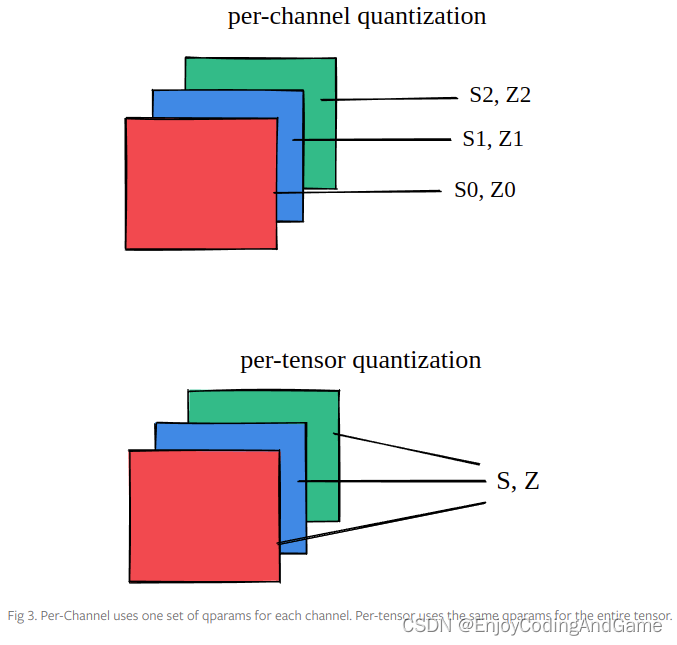
(a) Weight and activation quantization scheme, (b) Memory footprint of ...
Model Quantization 1: Basic Concepts | by Florian June | Medium
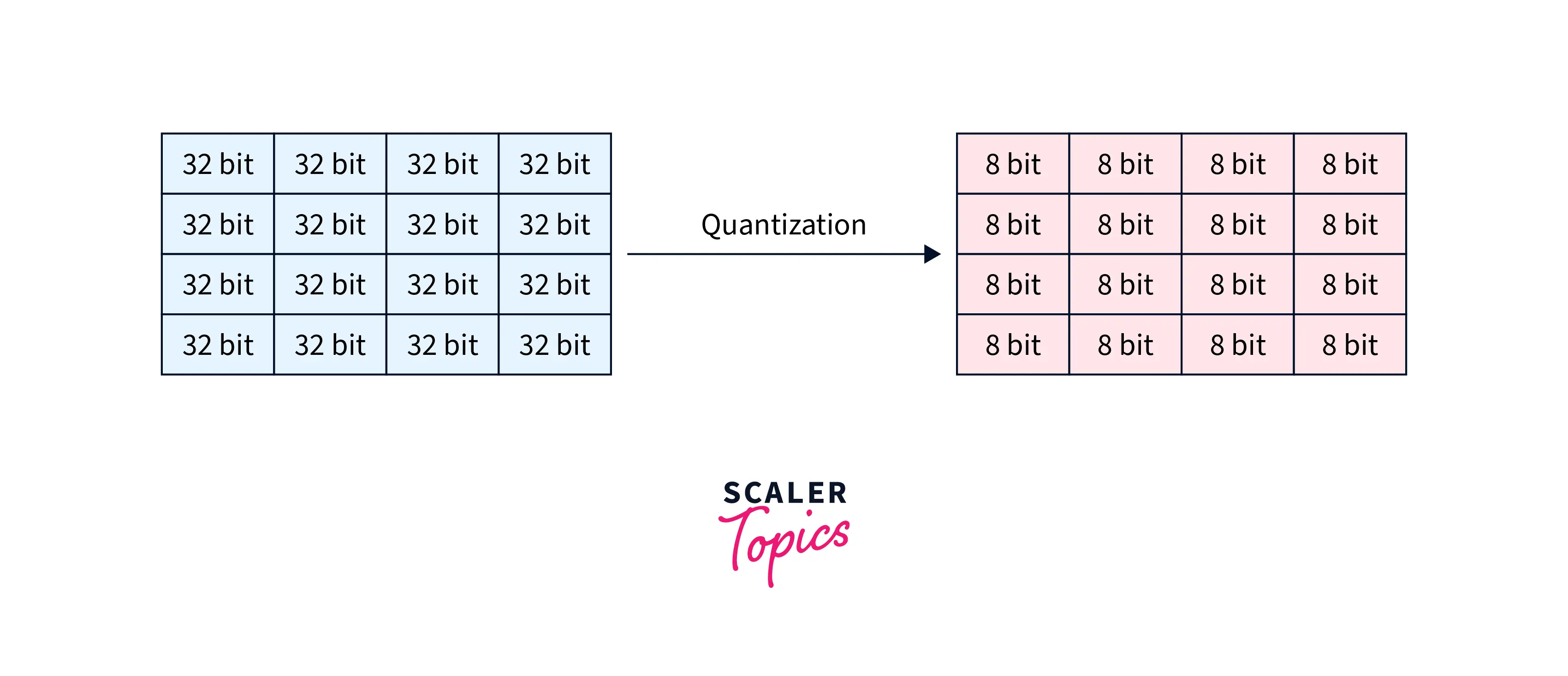
Quantization and Pruning - Scaler Topics
Top LLM Quantization Methods and Their Impact on Model Quality
[PDF] AWQ: Activation-aware Weight Quantization for On-Device LLM ...
A weight quantization scheme based on a codebook. | Download Scientific ...
Introduction To Weight Quantization PDF | PDF | Arithmetic | Applied ...
Quantization-Aware Training (QAT) | Unsloth Documentation
Q4 vs Q5 vs Q6 vs Q8 Quantization: Real Quality Loss Numbers for Local ...
LLM Inference Optimization: Quantization, KV Cache, and Serving at ...
LLM Inference Optimization in 2026: Quantization, Speculative Decoding ...
TurboQuant vs Traditional Model Quantization: What’s the Difference ...
Meta Llama 3 Optimized CPU Inference with Hugging Face and PyTorch ...
MSU AI Club
Accuracy tradeoffs between regularization and quantization. (a) Feature ...
notion image
Bimodal-Distributed Binarized Neural Networks
Meet SpQR (Sparse-Quantized Representation): A Compressed Format And ...
Weight evolution of high precision weight, quantized weight and the DW ...
ImageNet Top-1 accuracy with weight quantization. | Download Scientific ...
PyTorch QAT(量化感知训练)实践——基础篇-易微帮