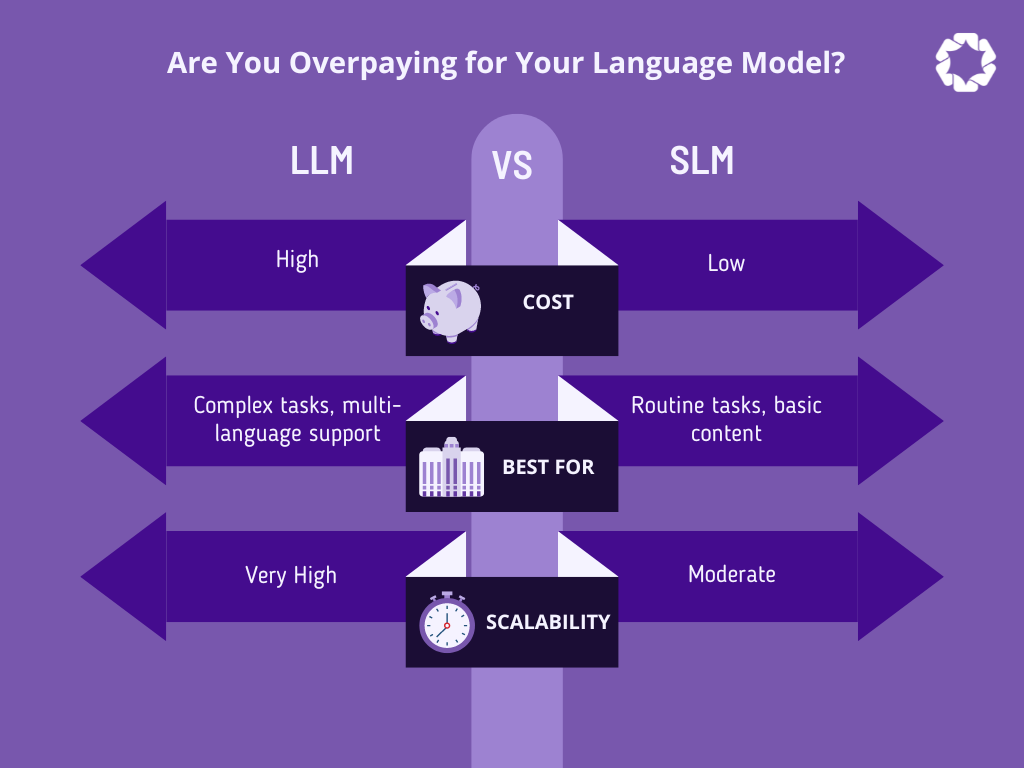
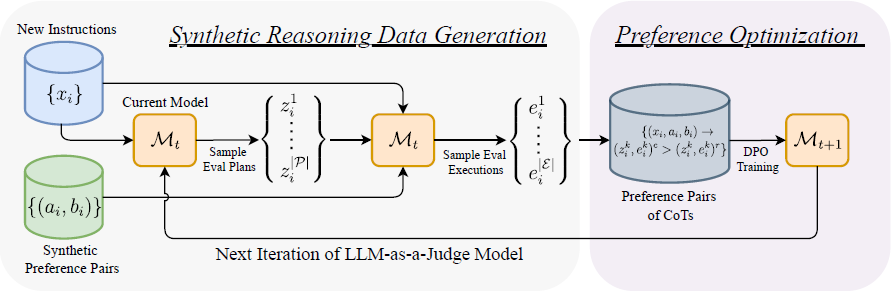
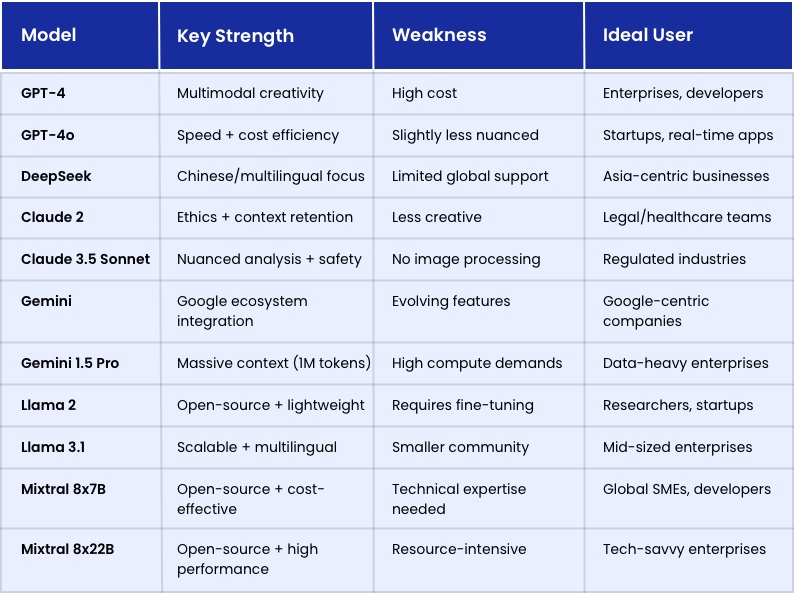
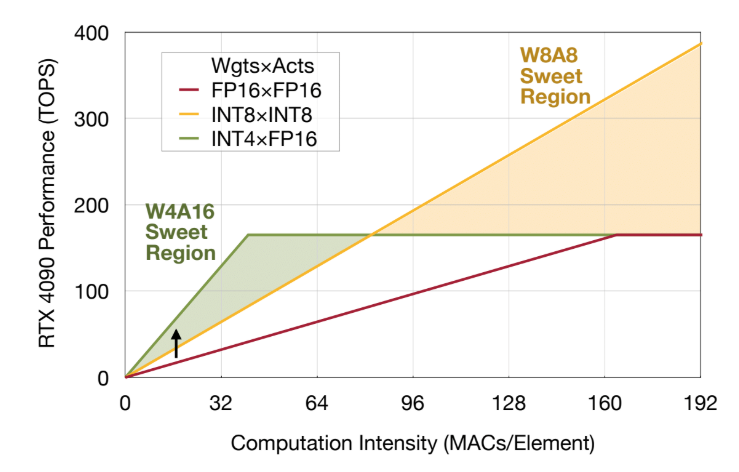
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
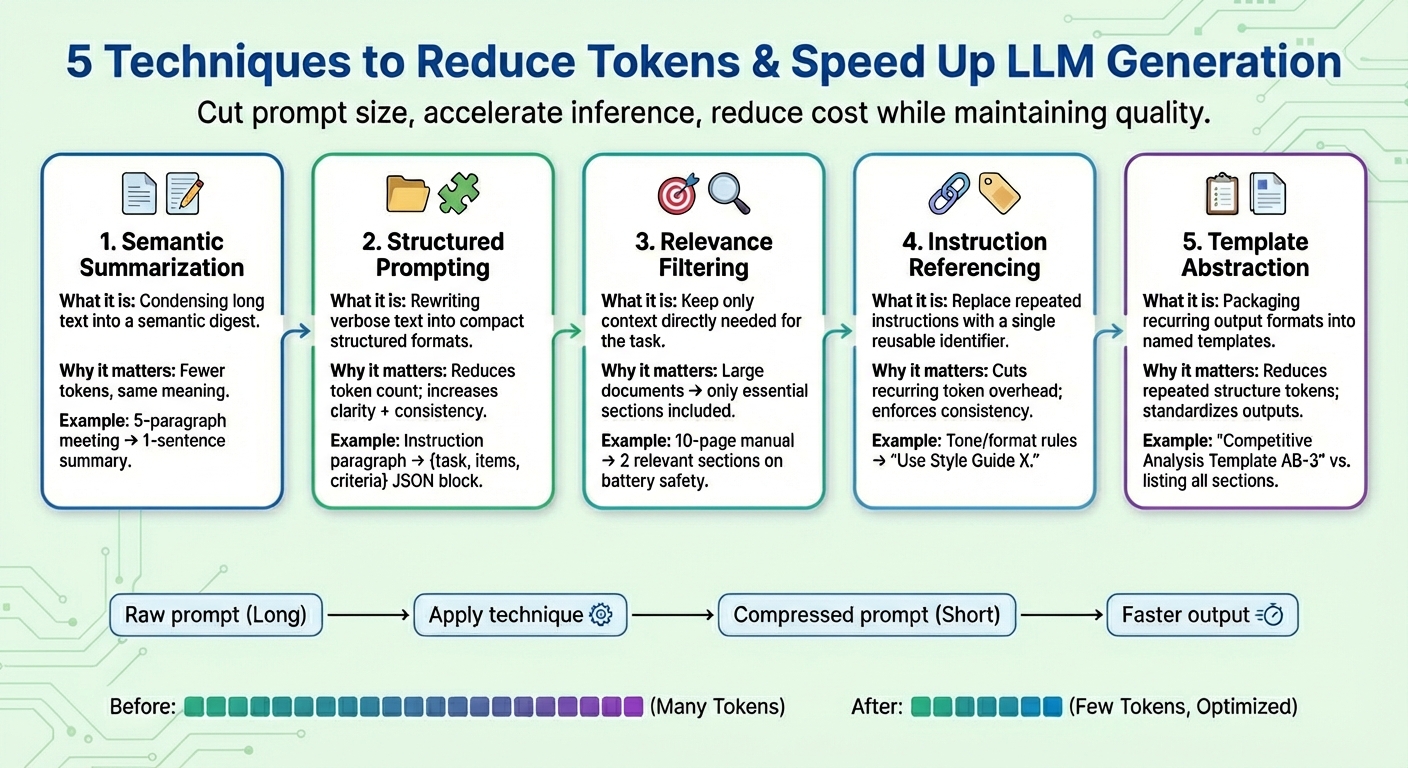
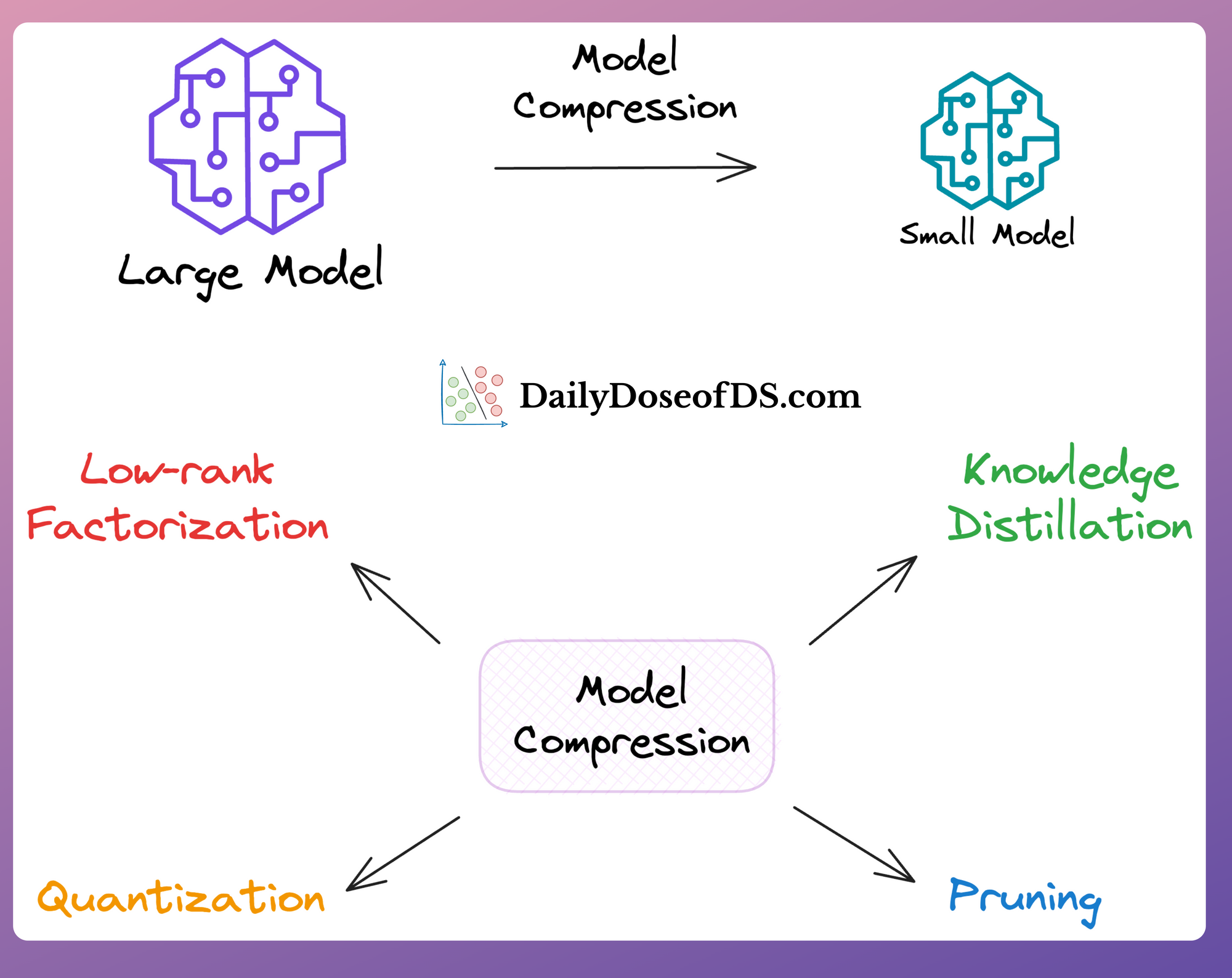
4 LLM Compression Techniques That You Can't Miss
LLMLingua: Innovating LLM efficiency with prompt compression ...
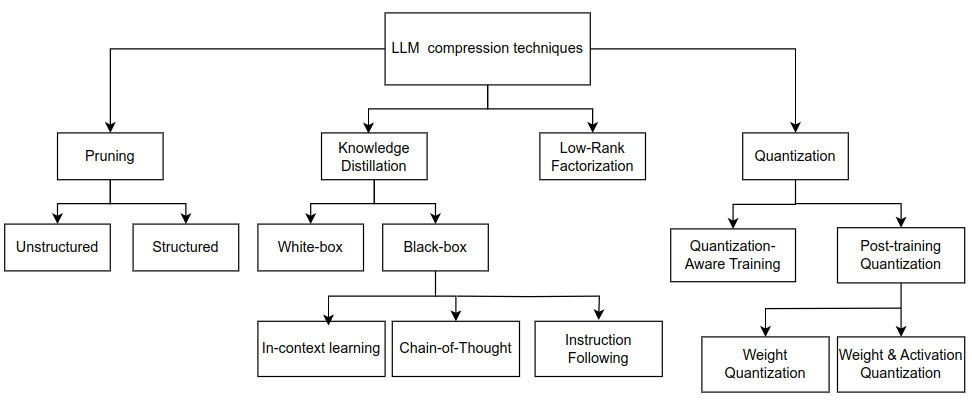
LLM Compression Techniques. Efficient Deployment of Large Language ...
LLM Compression Techniques to Build Faster and Cheaper LLMs
LLM compression and optimization: Cheaper inference with fewer hardware ...
[R] ASVD: New Method for LLM Compression Yields Up to 20% Additional ...
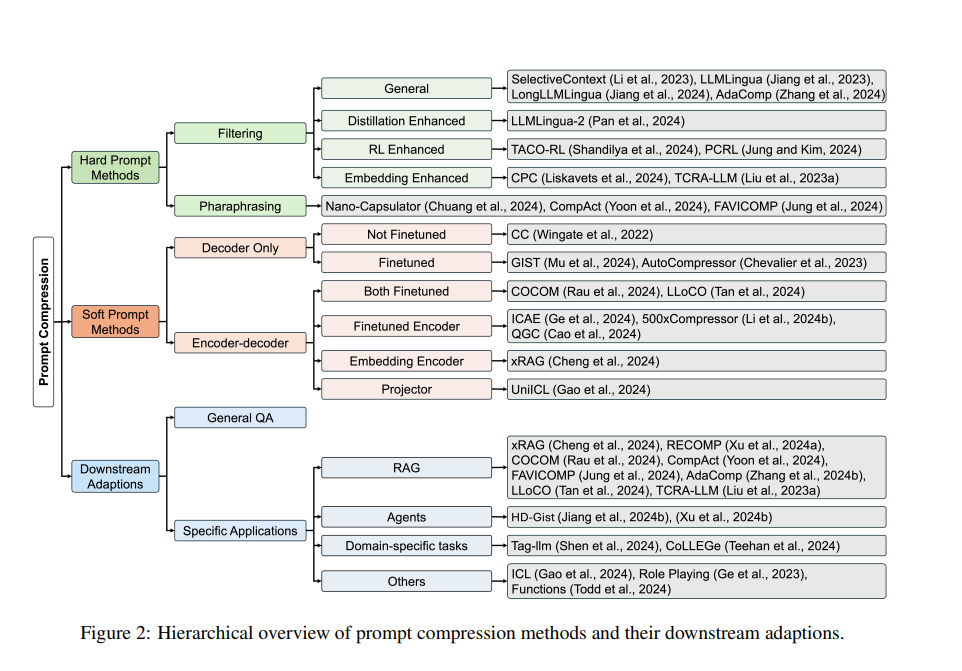
Compression Schemes - LLM Compressor Docs
Paper presentation on LLM compression | PPTX
LLM Introspective Compression
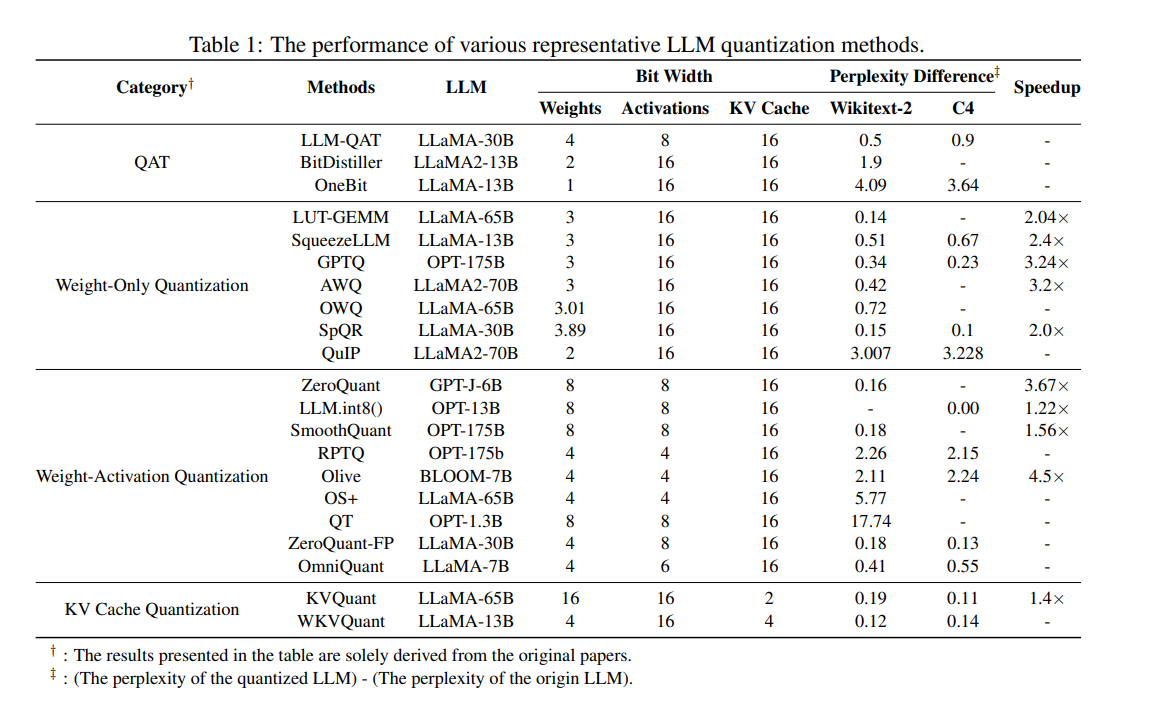
LLM Quantization: A Comprehensive Guide to Model Compression for ...
LLM Compression Techniques | PDF | Data Compression | Computing
The state of LLM compression from research to production - YouTube
The Evolution of Model Compression in the LLM Era - Origins AI
LLM Compression - a TonyMou Collection
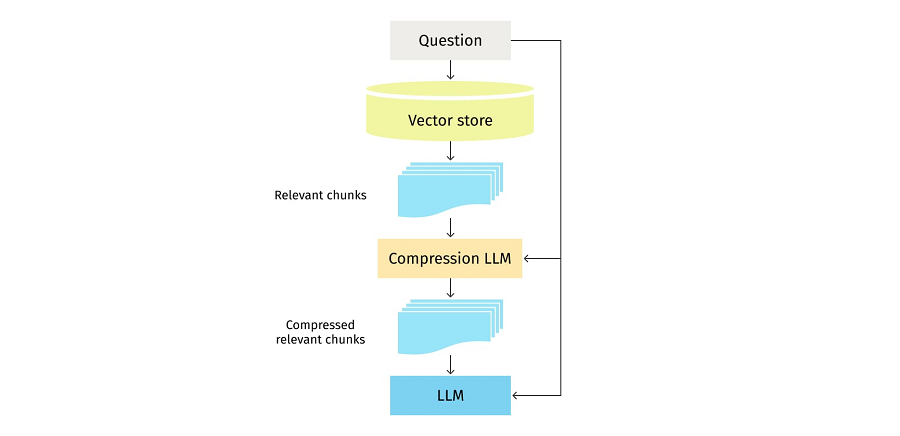
Prompt Compression for LLM Generation Optimization and Cost Reduction ...
"Unlocking Efficiency: The Future of LLM Compression and 3D Model ...
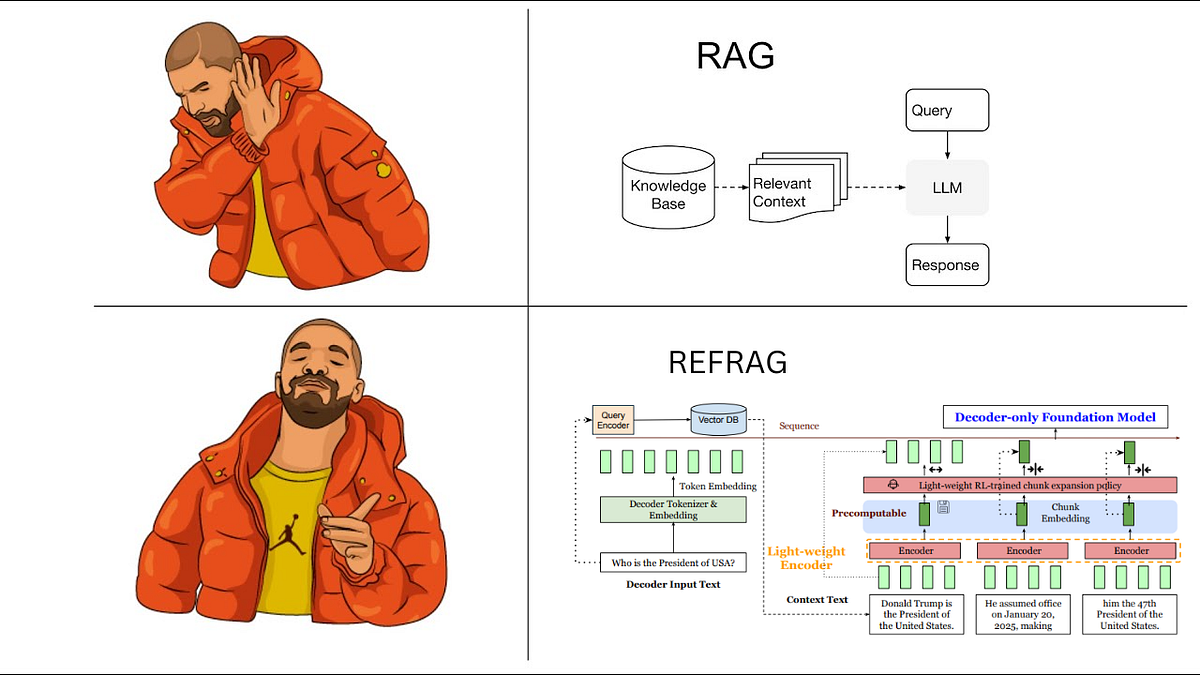
Understanding REFRAG: Efficient LLM Compression and Curriculum Learning ...
Stratégies de compression LLM pour booster les performances de l’IA
How LLM Compression Parity Improves LLM Performance | Alexander ...
Optimizing LLM size and inference : - Lossless compression for AI ...
(PDF) ReALLM: A general framework for LLM compression and fine-tuning
LLM Tutorial 21 — Model Compression Techniques: Quantization, Pruning ...
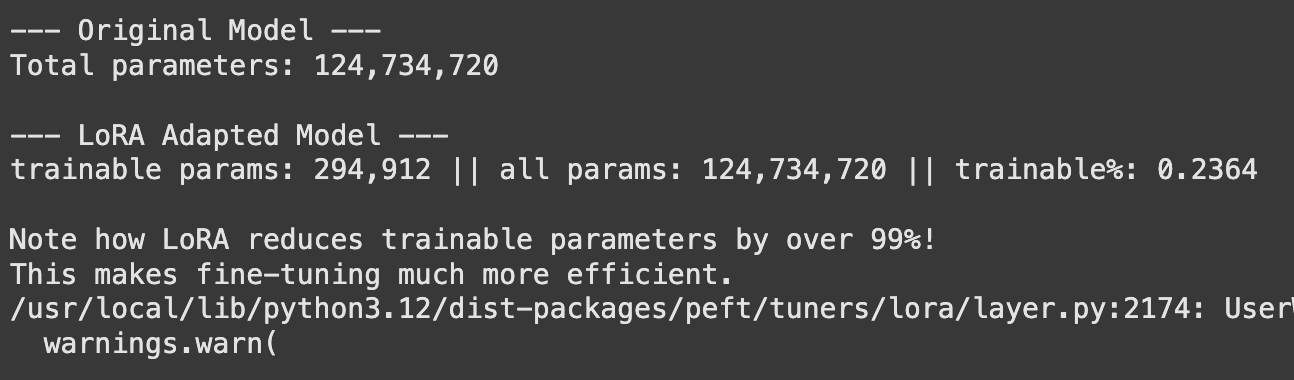
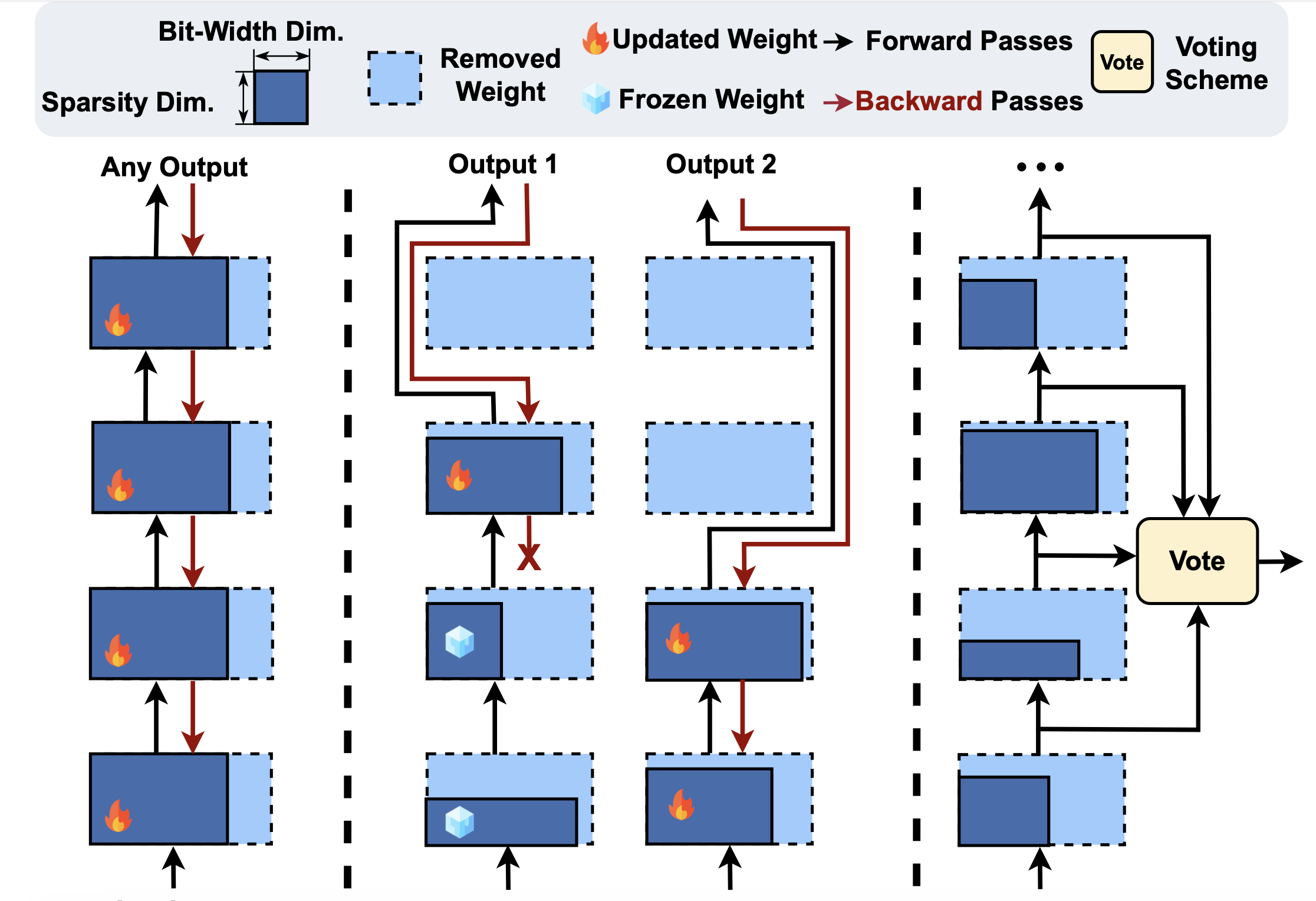
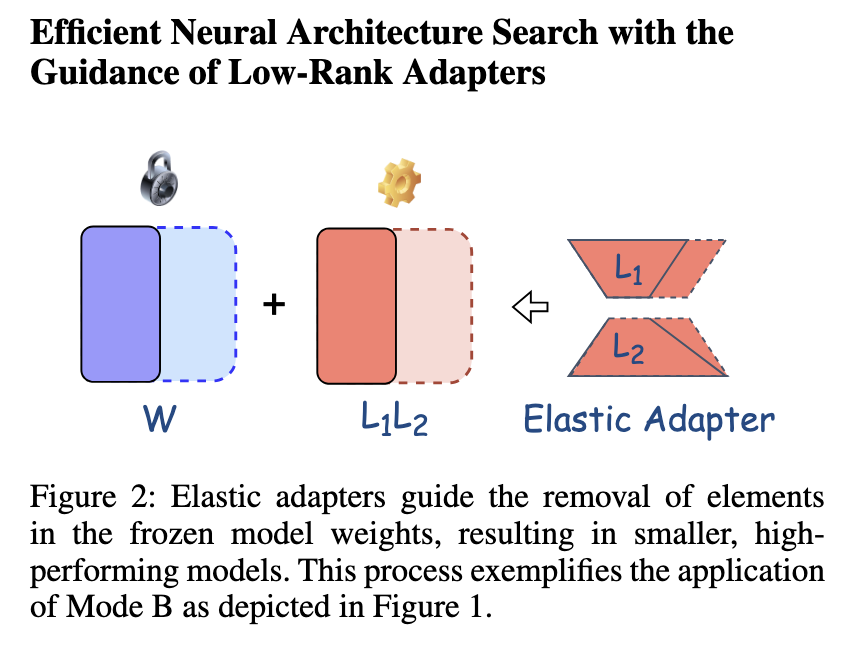
Low-Rank Adapters Meet Neural Architecture Search for LLM Compression ...
036 Model Compression | LLM concepts under 60 seconds | Model ...
GitHub - CaySue/xxk_Awesome-LLM-Compression: Awesome LLM compression ...
Compression For LLM Generation Optimization & Cost Reduction
[논문 리뷰] Lossless Compression for LLM Tensor Incremental Snapshots
LLM Compression Techniques : r/learnmachinelearning
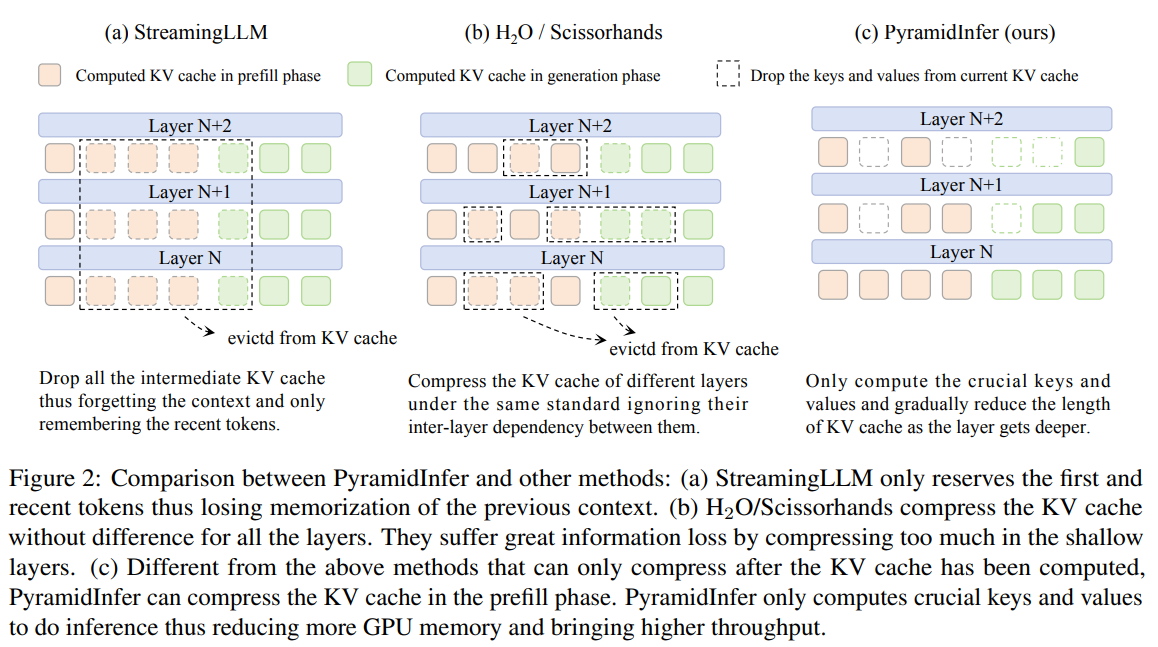
PyramidInfer: Allowing Efficient KV Cache Compression for Scalable LLM ...
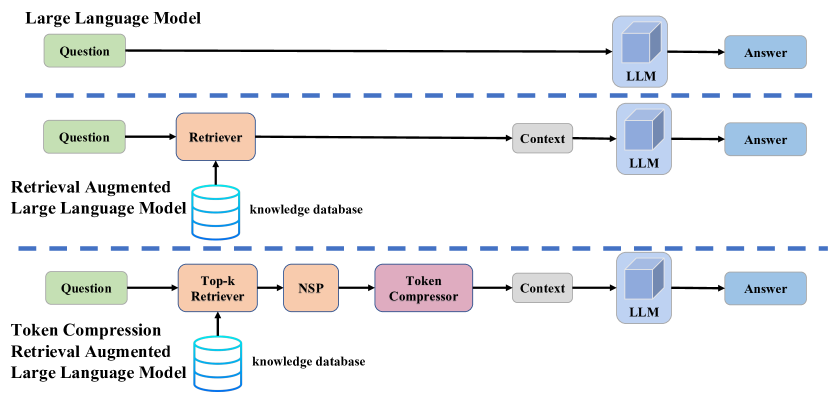
[2310.15556] TCRA-LLM: Token Compression Retrieval Augmented Large ...
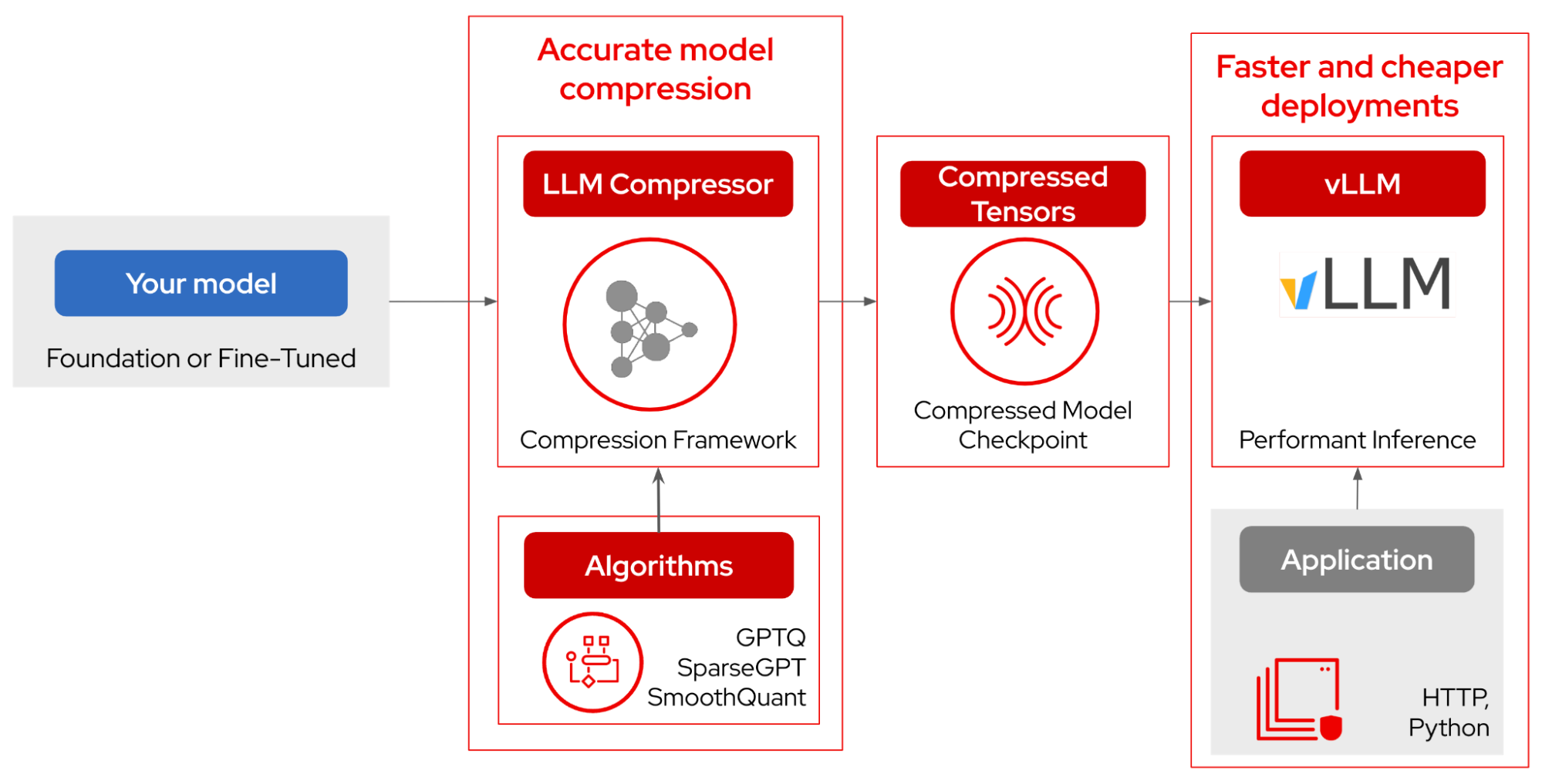
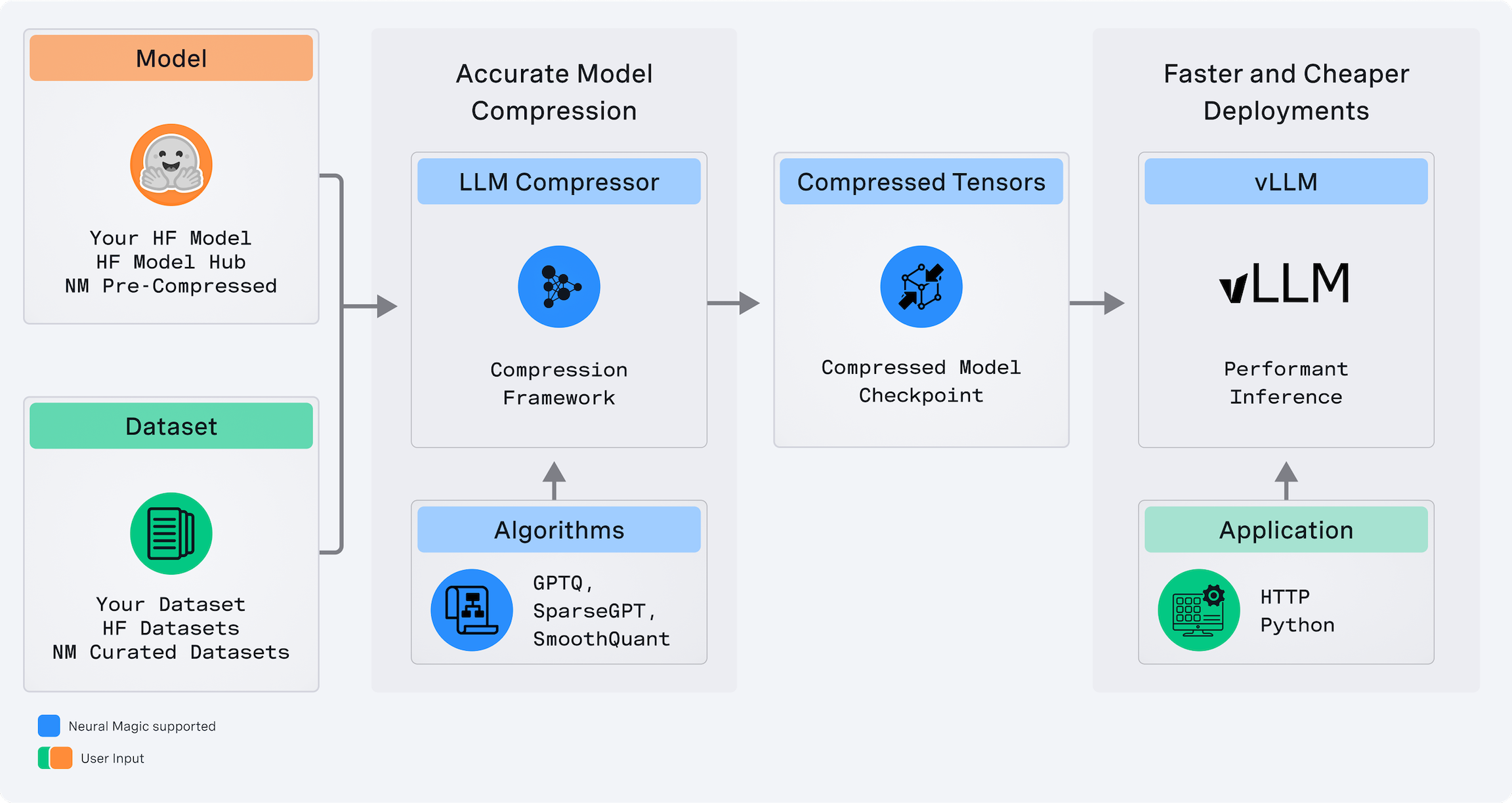
LLM Compressor is here: Faster inference with vLLM | Red Hat Developer
LLM Inference Optimization Overview - From Data to System Architecture ...
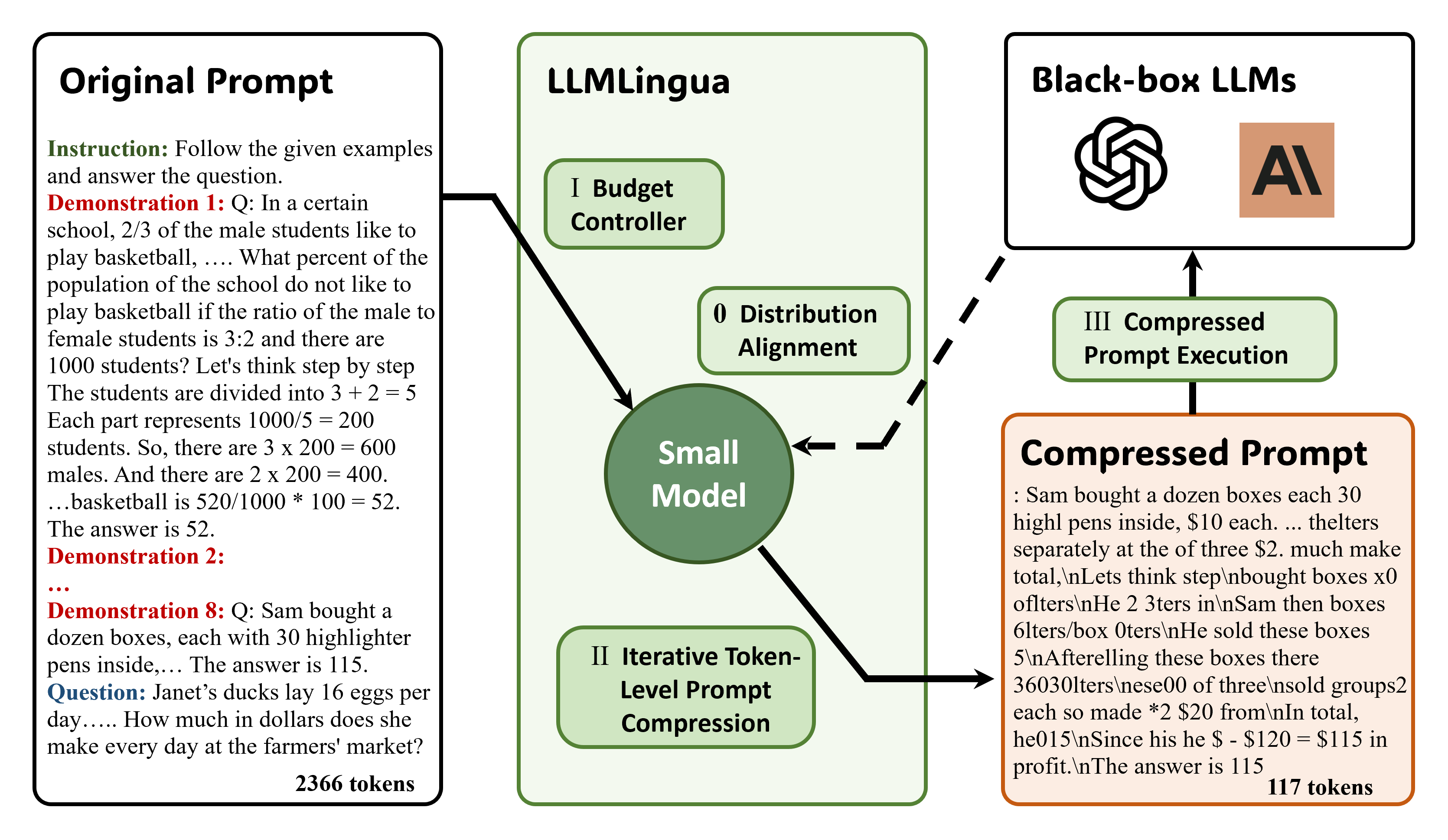
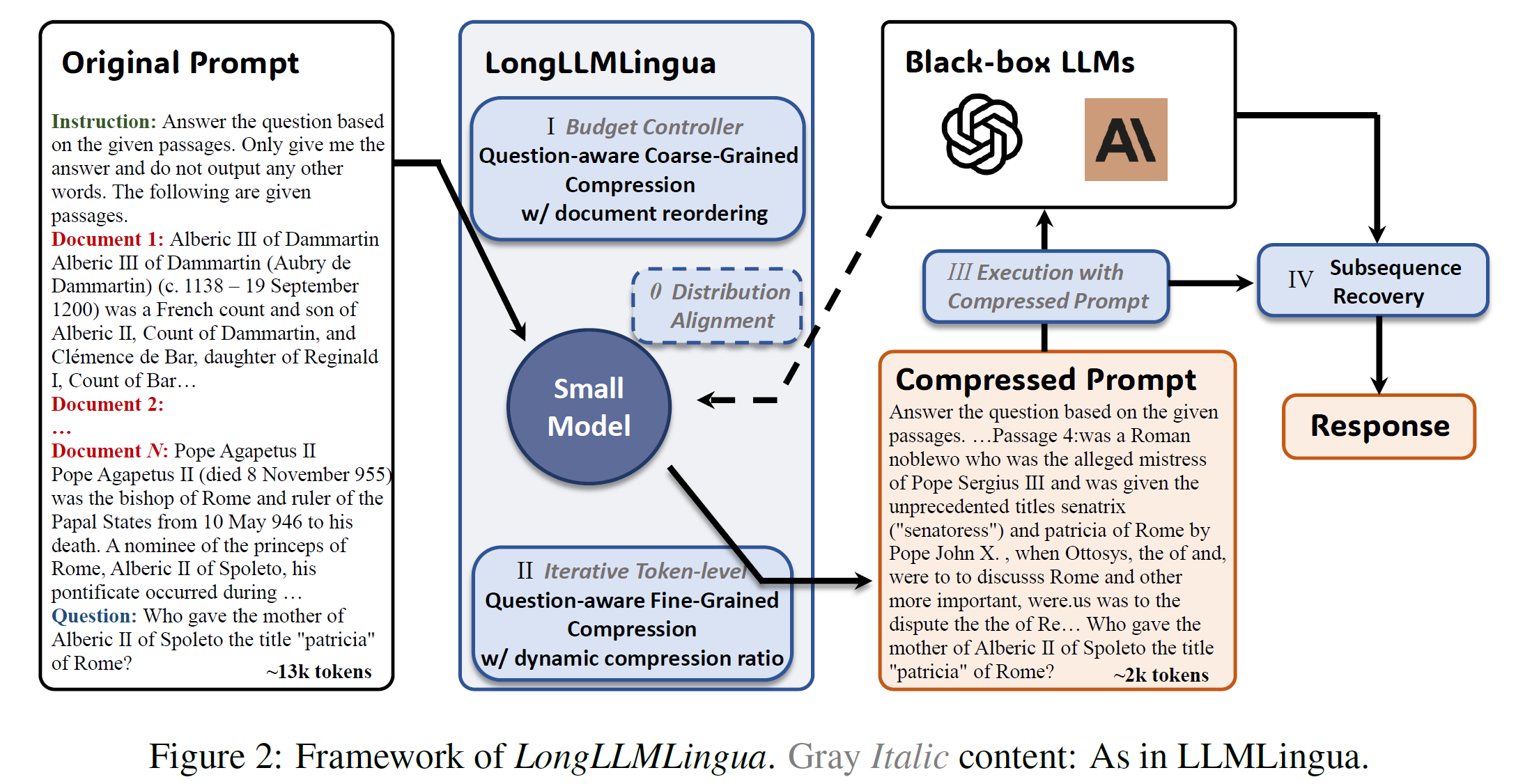
LongLLMLingua Prompt Compression Guide | LlamaIndex
Illustration of the proposed method. (a) LLM inference comprises two ...
4 Techniques to Compress LLMs Efficiently | PDF | Data Compression ...
LLMs can invent their own compression - Rajan Agarwal
Model Compression with LLM-Compressor and Deployment on Vast.ai (Part 1)
Evaluating LLM Compression: Balancing Efficiency, Trustworthiness, and ...
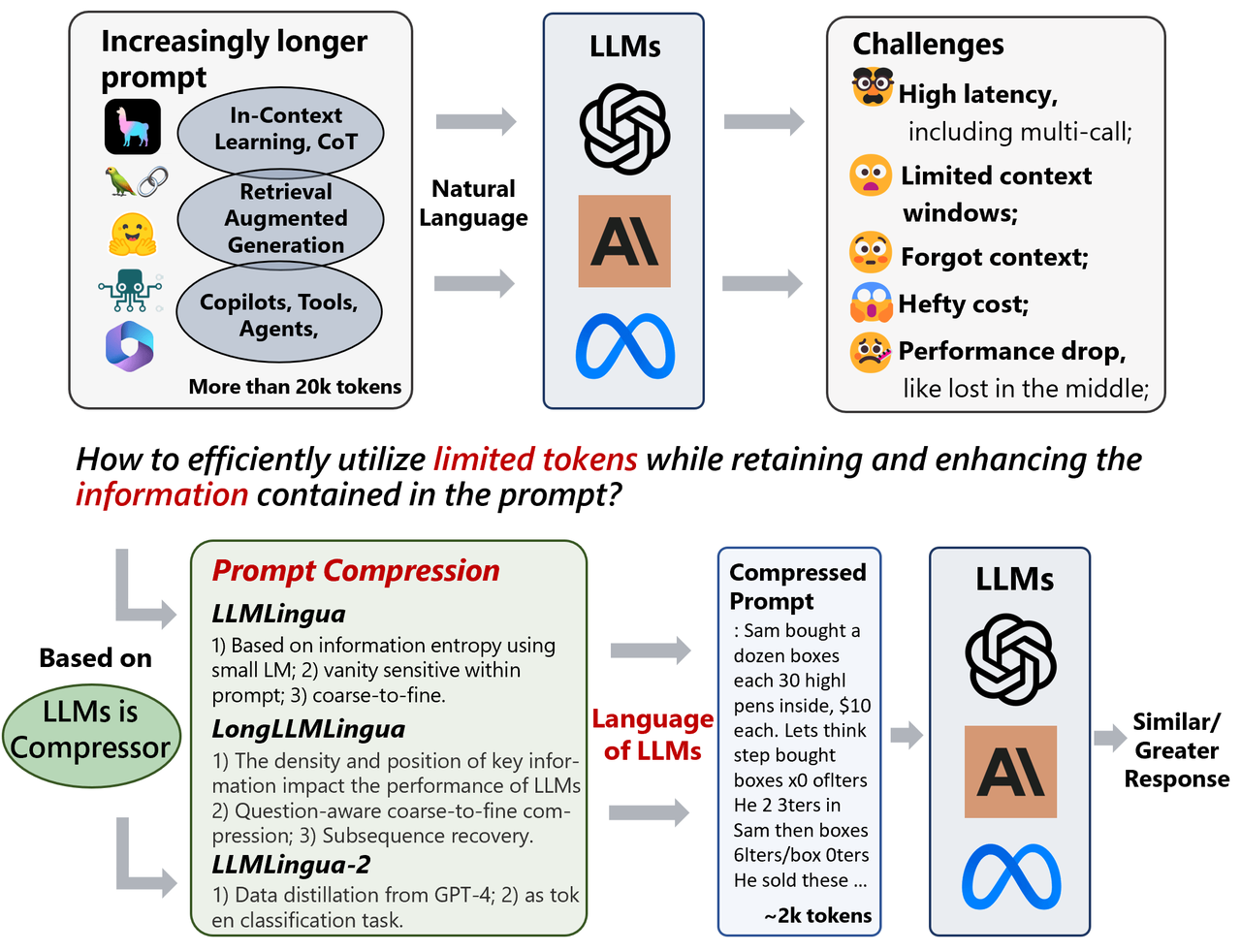
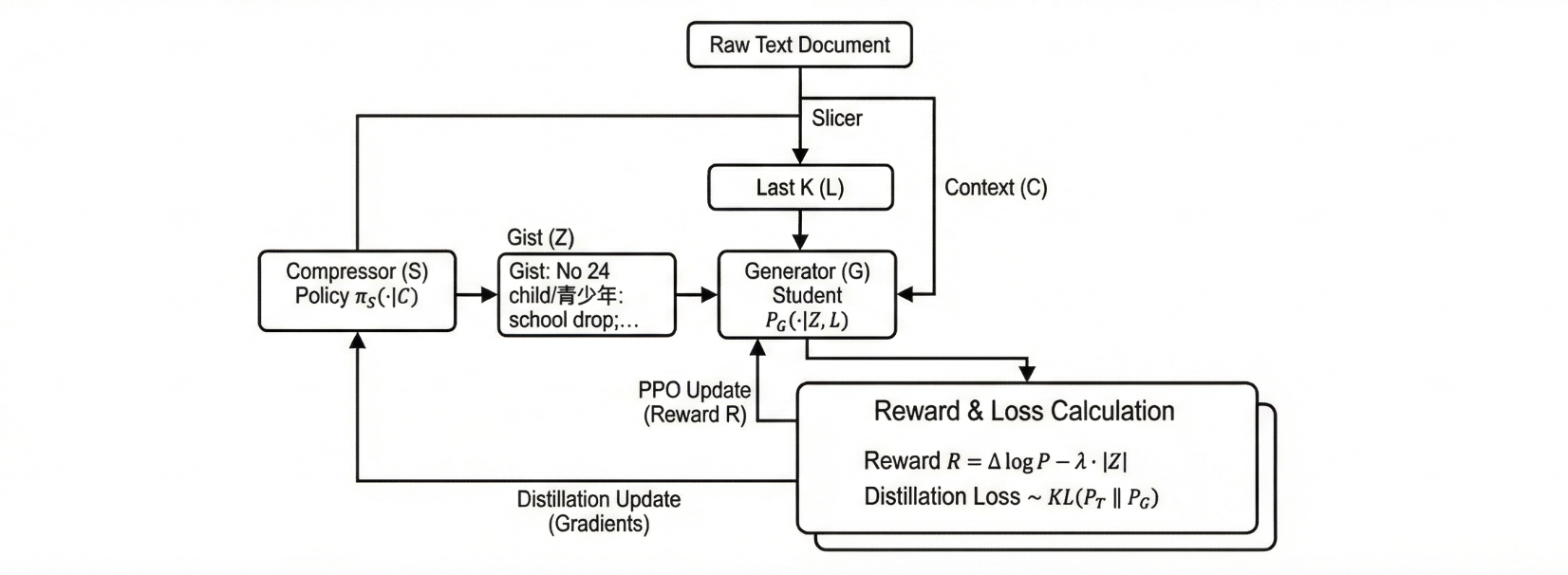
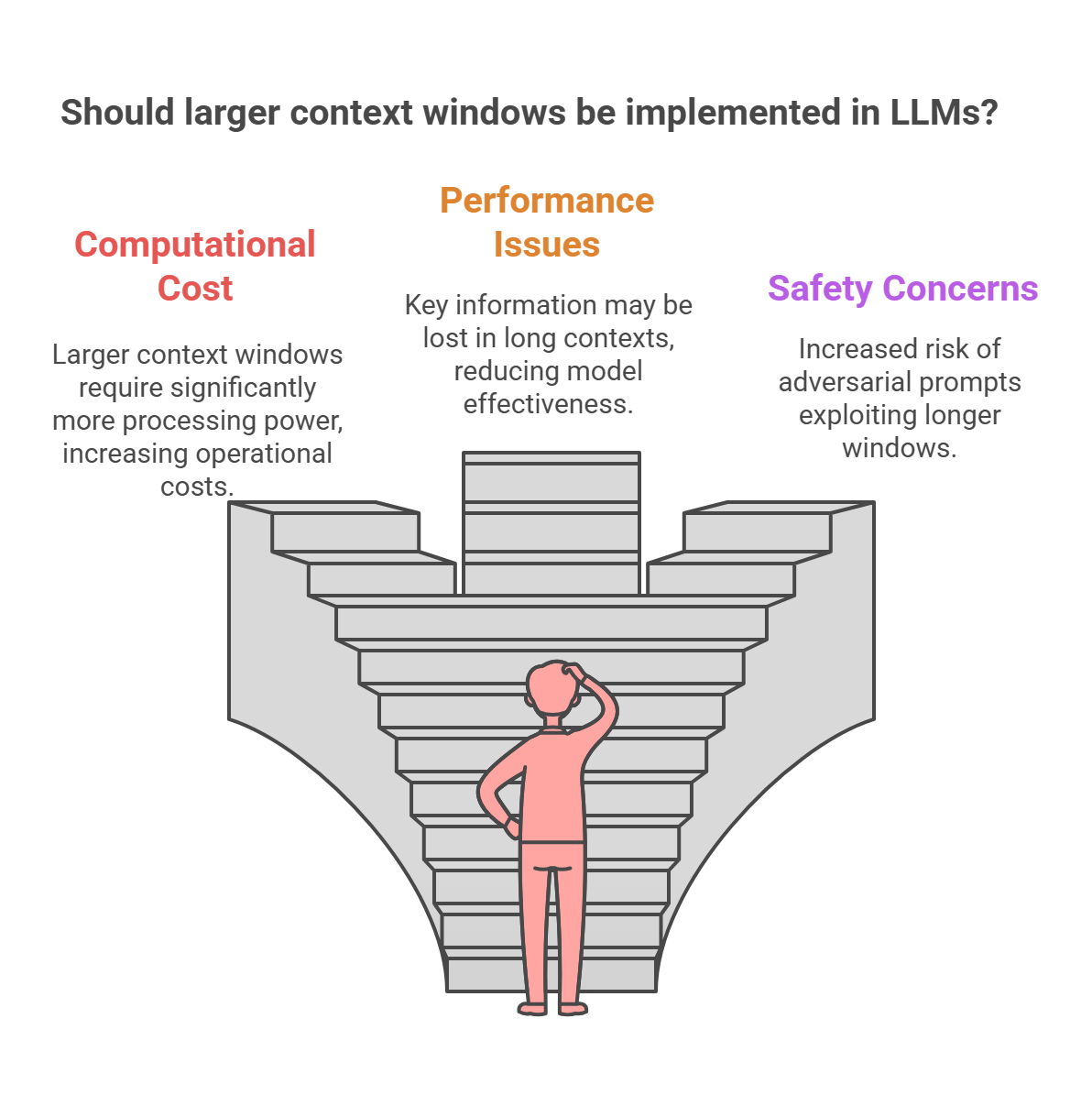
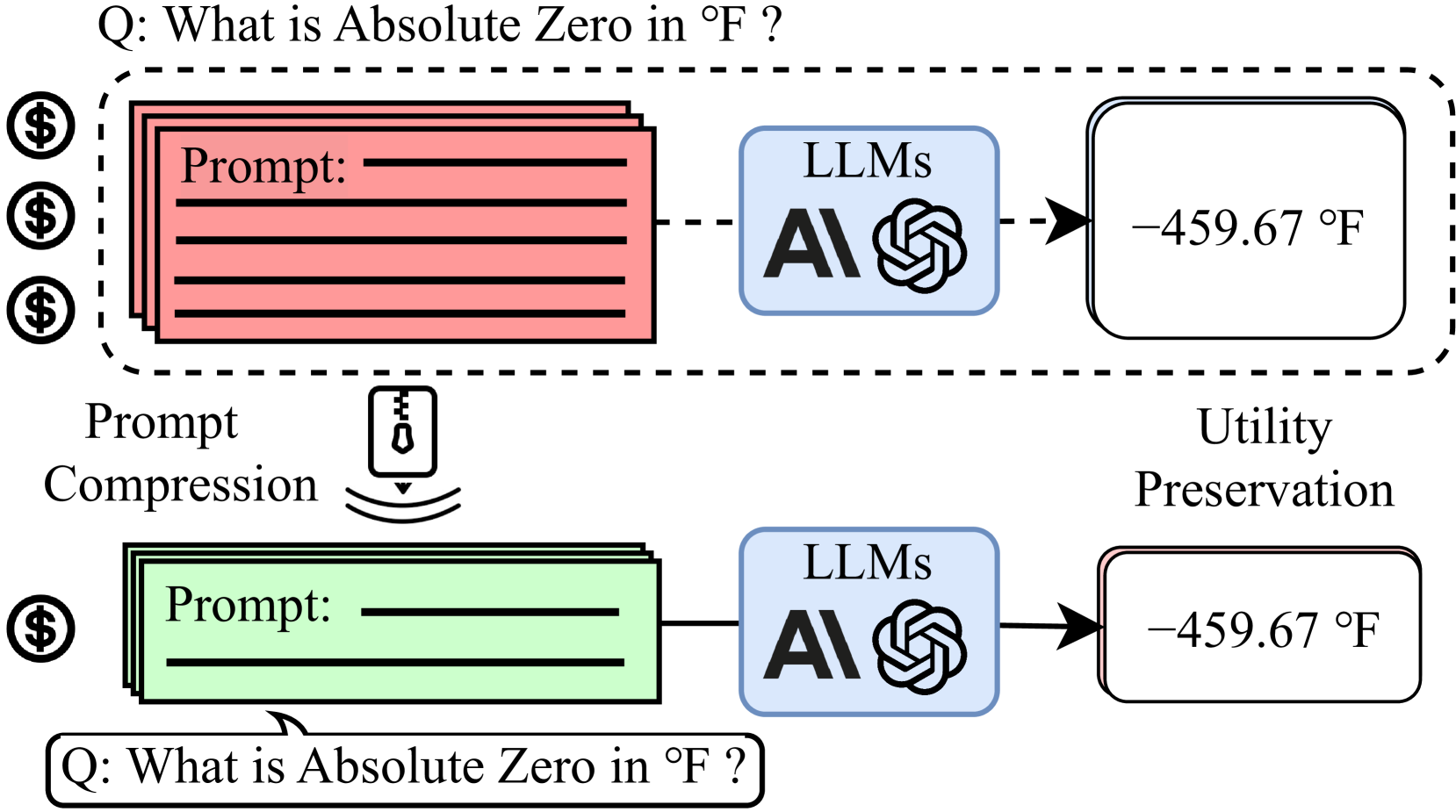
Prompt Compression in Large Language Models (LLMs): Making Every Token ...
11 Best LLM Models Developers Trust in 2026
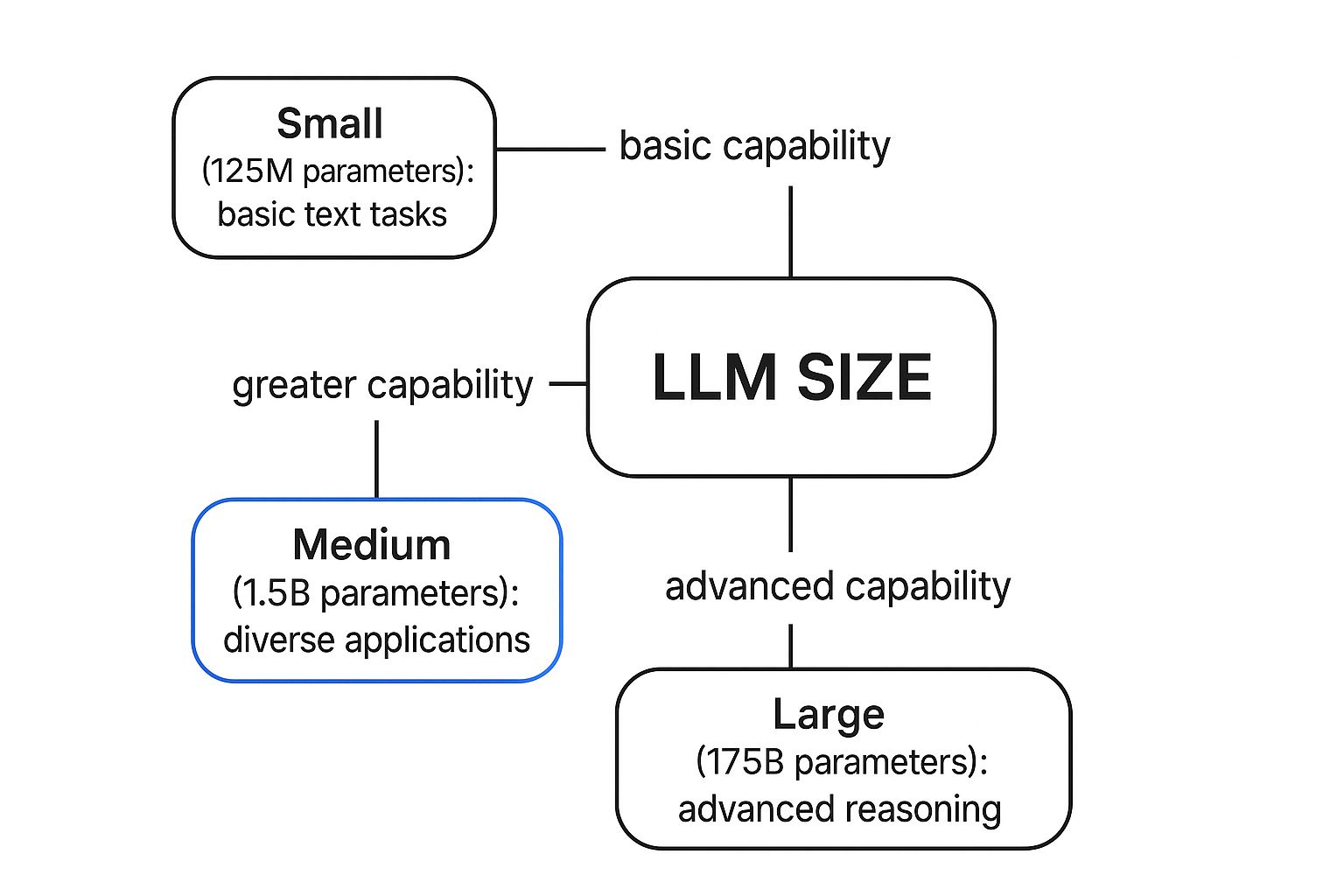
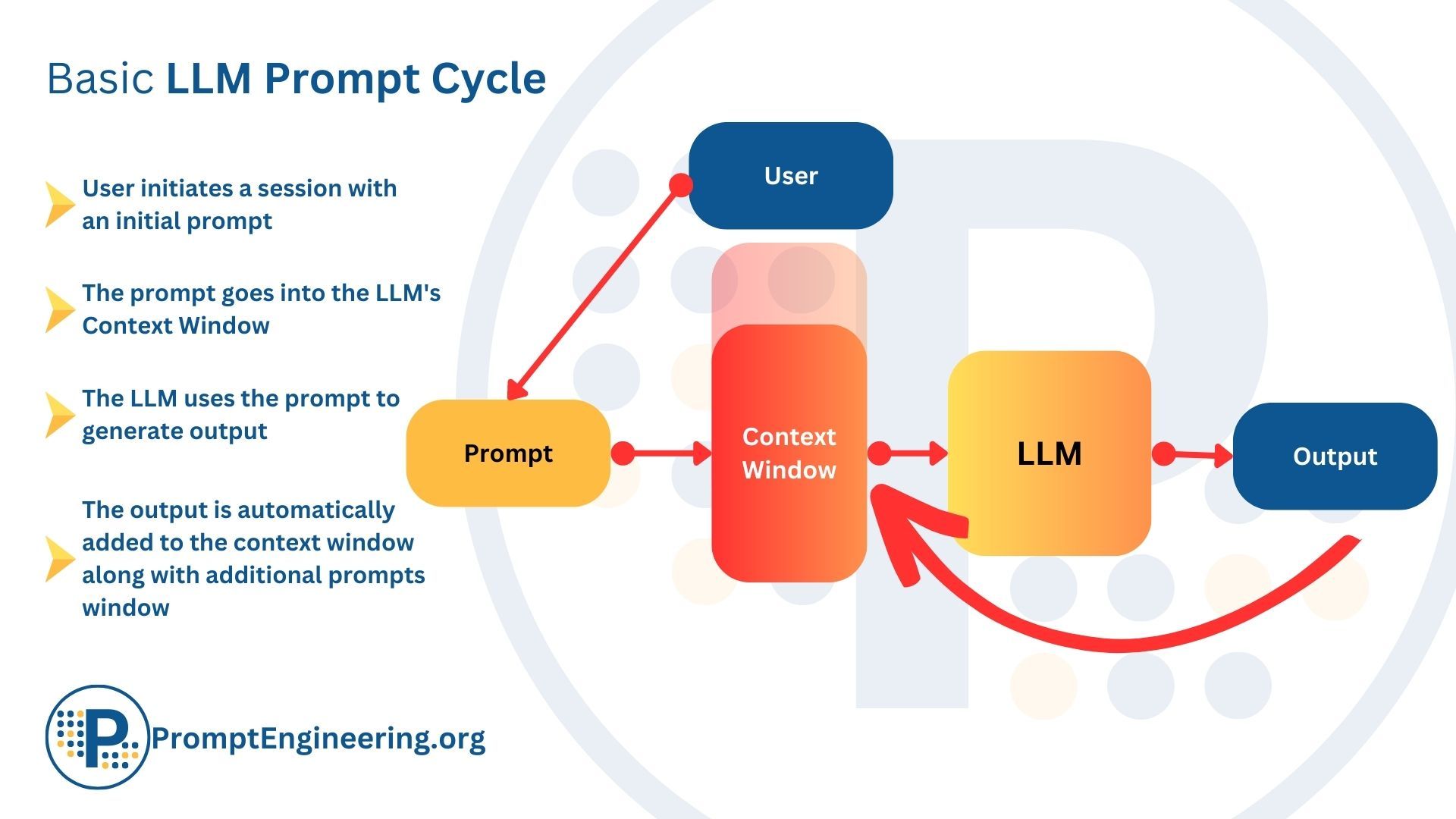
LLM Parameters and Hyperparameters Explained | by Santosh Pandey | Medium
SEM images of several LLM-105-based PBXs recovered from compression ...
LLM Compressor: Optimize LLMs for low-latency deployments | Red Hat ...
Blog Post - A Guide to the Different Types of LLM
Getting familiar with the different LLM models | by The Educative Team ...
Understanding LLM Quantization. With the surge in applications using ...
A Guide to Comparing Different LLM Chaining Frameworks | Symbl.ai
A Systematic Study of Compression Ordering for Large Language Models ...
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
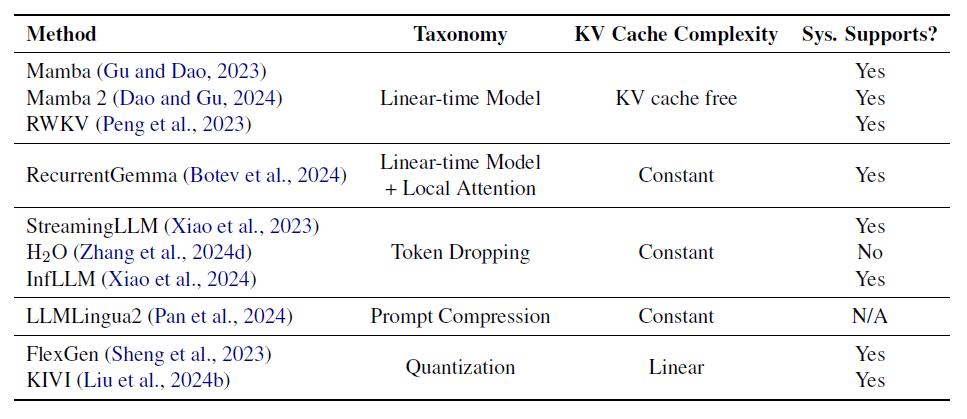
KV Cache compression with Inter-Layer Attention Similarity for ...
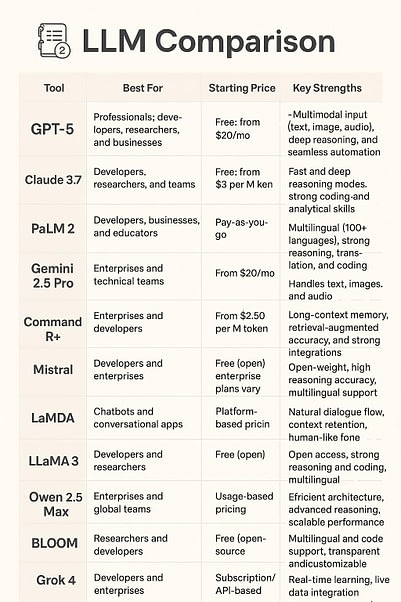
LLM Comparison: A Comparative Analysis for 2026
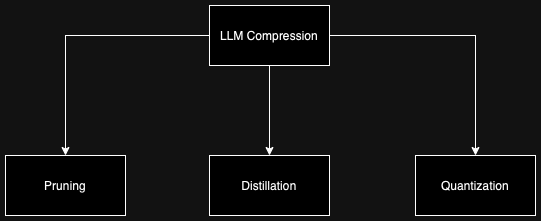
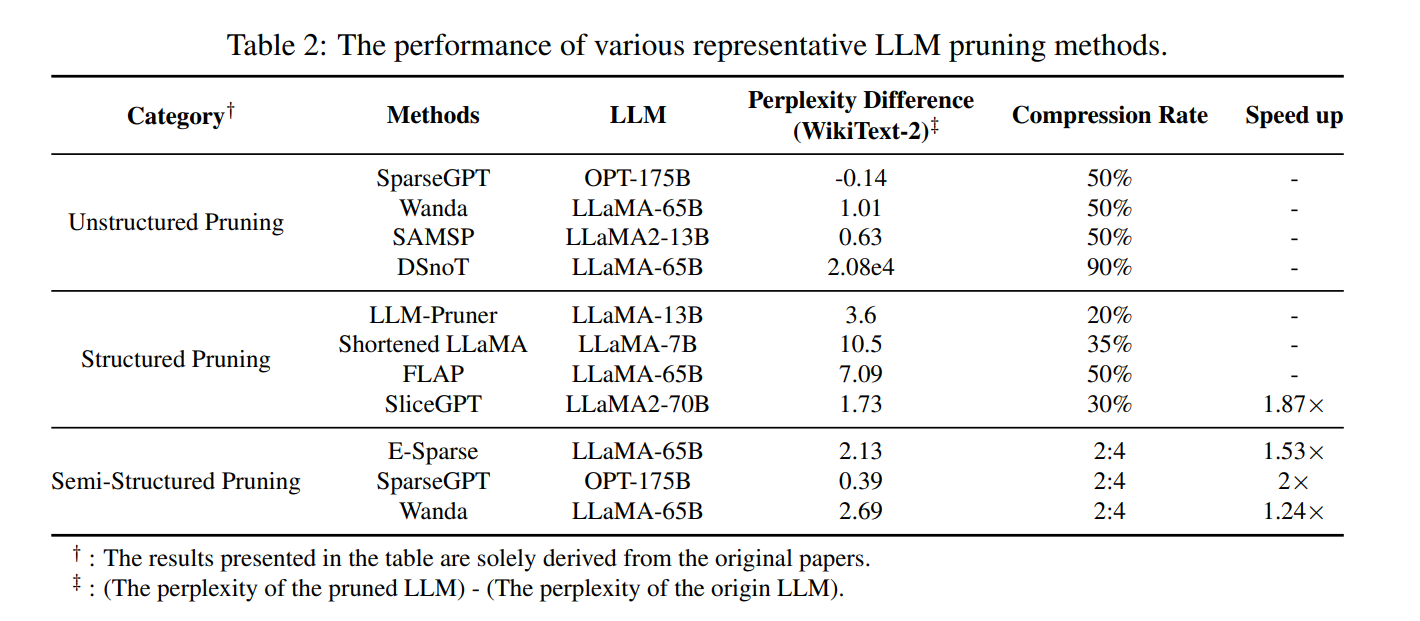
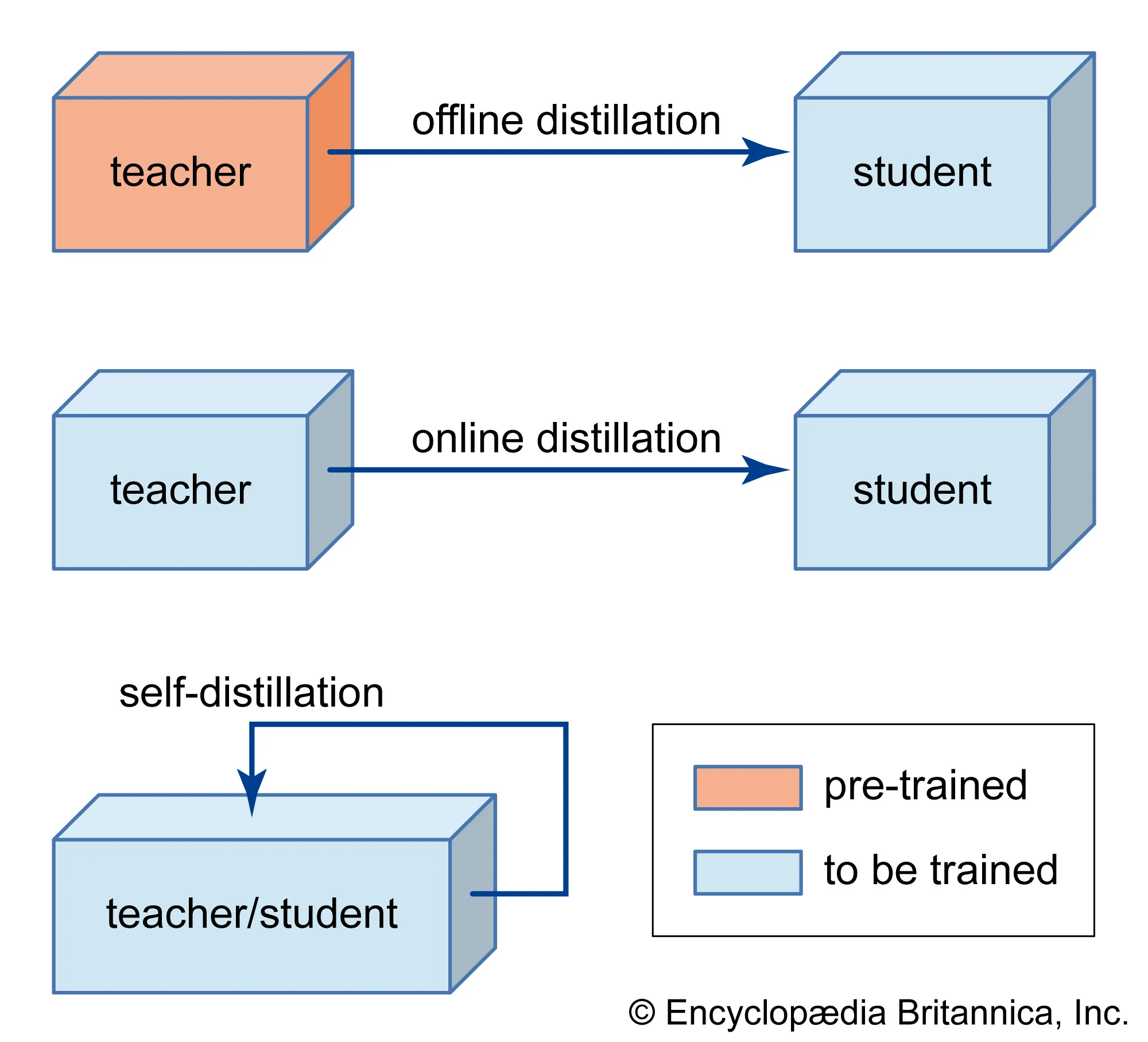
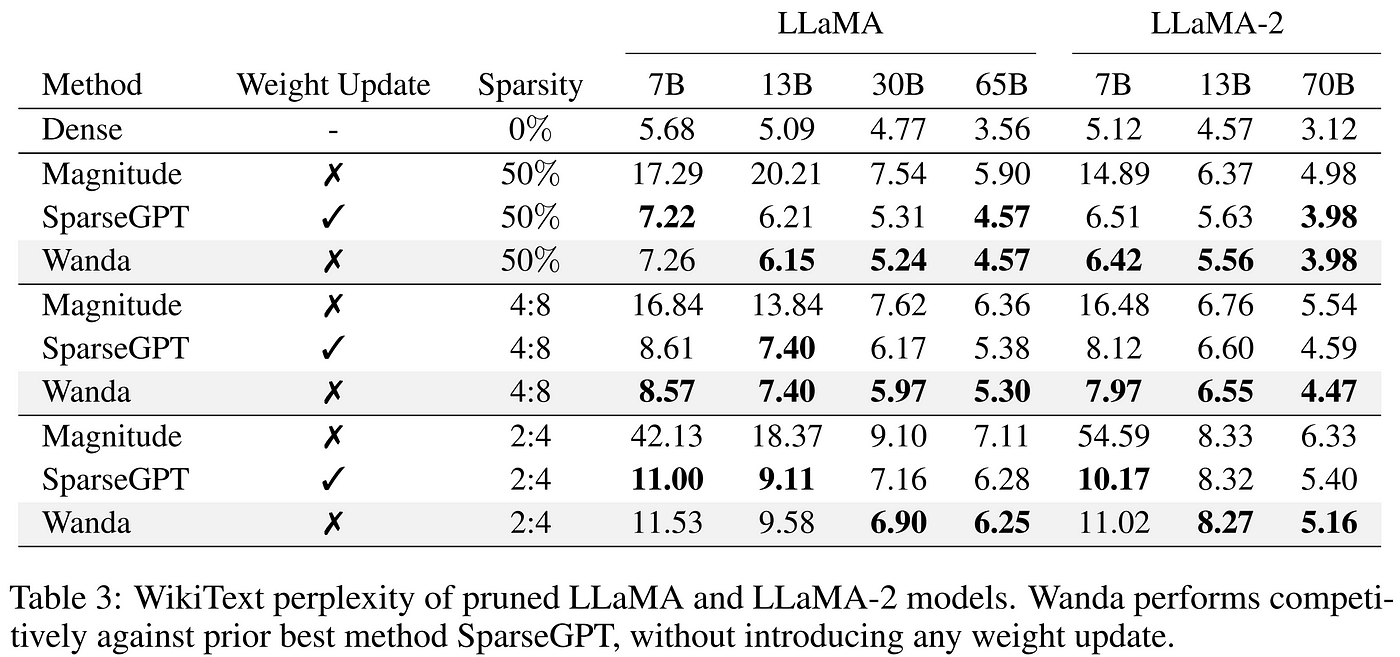
LLM Compression: Quantization, Pruning, Distillation
Getting started - LLM Compressor Docs
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
[vLLM — Quantization] AWQ: Activation-aware Weight Quantization for LLM ...
Prompt Compression: The Next Big Shift in LLM Efficiency - DEV Community
A Comprehensive Guide to Different LLM Models:
[2502.00922] Huff-LLM: End-to-End Lossless Compression for Efficient ...
Linear calibration curves of LLM | Download Scientific Diagram
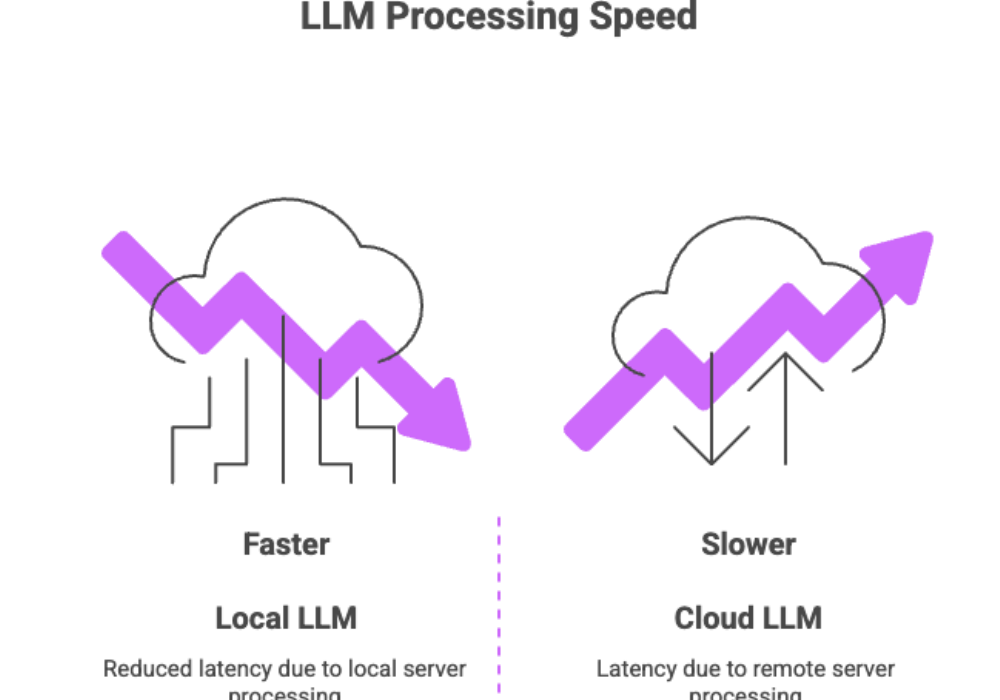
Local LLM Models Basic Setup and Use
Statistical or Sentient? Understanding the LLM Mind - Part 1 - Memory
Comparing Different LLM Architectures: A Developer’s Guide | by Gaurav ...
[논문 리뷰] Style-Compress: An LLM-Based Prompt Compression Framework ...
Compression Techniques for LLMs | Medium
LLM Grounded Diffusion — Text-to-Image Generation-feat-Diffusion
Figure 1 from More Effective LLM Compressed Tokens with Uniformly ...
(PDF) Understanding LLM Behaviors via Compression: Data Generation ...
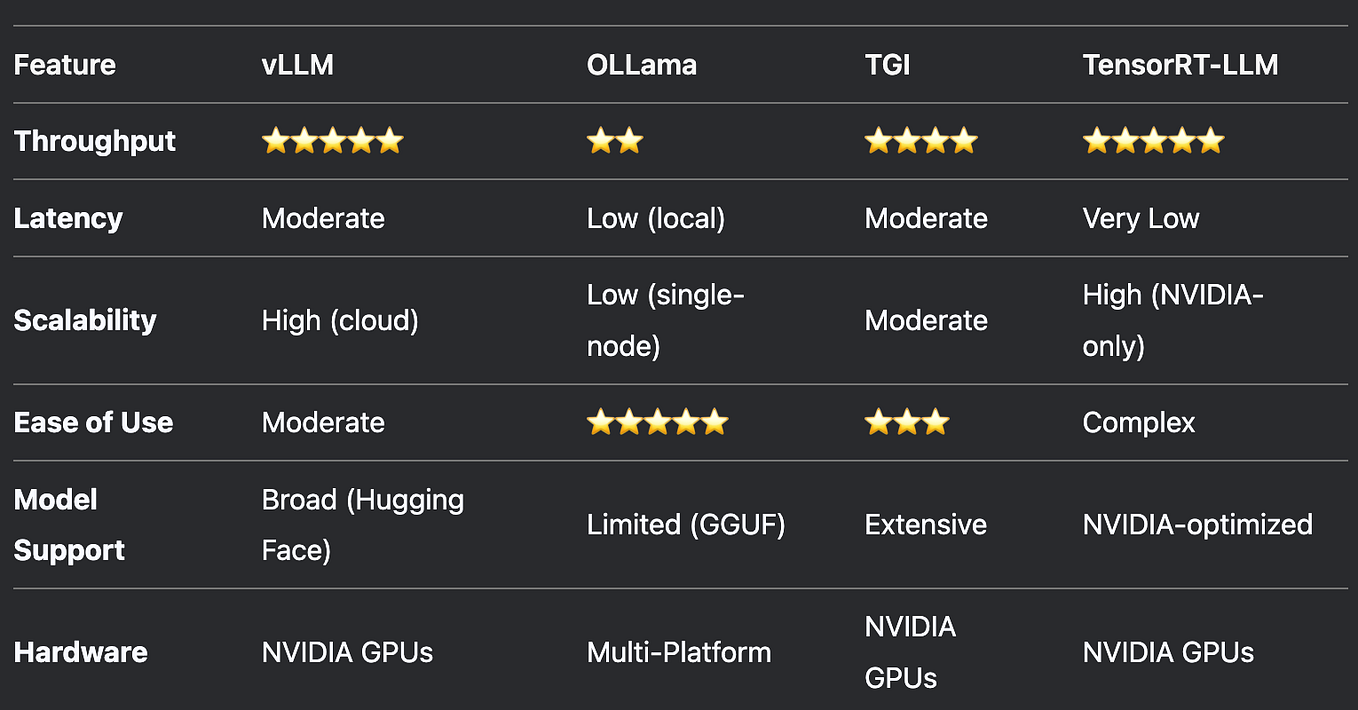
VLLM vs. Ollama: Choosing the Right Lightweight LLM Framework for Your ...
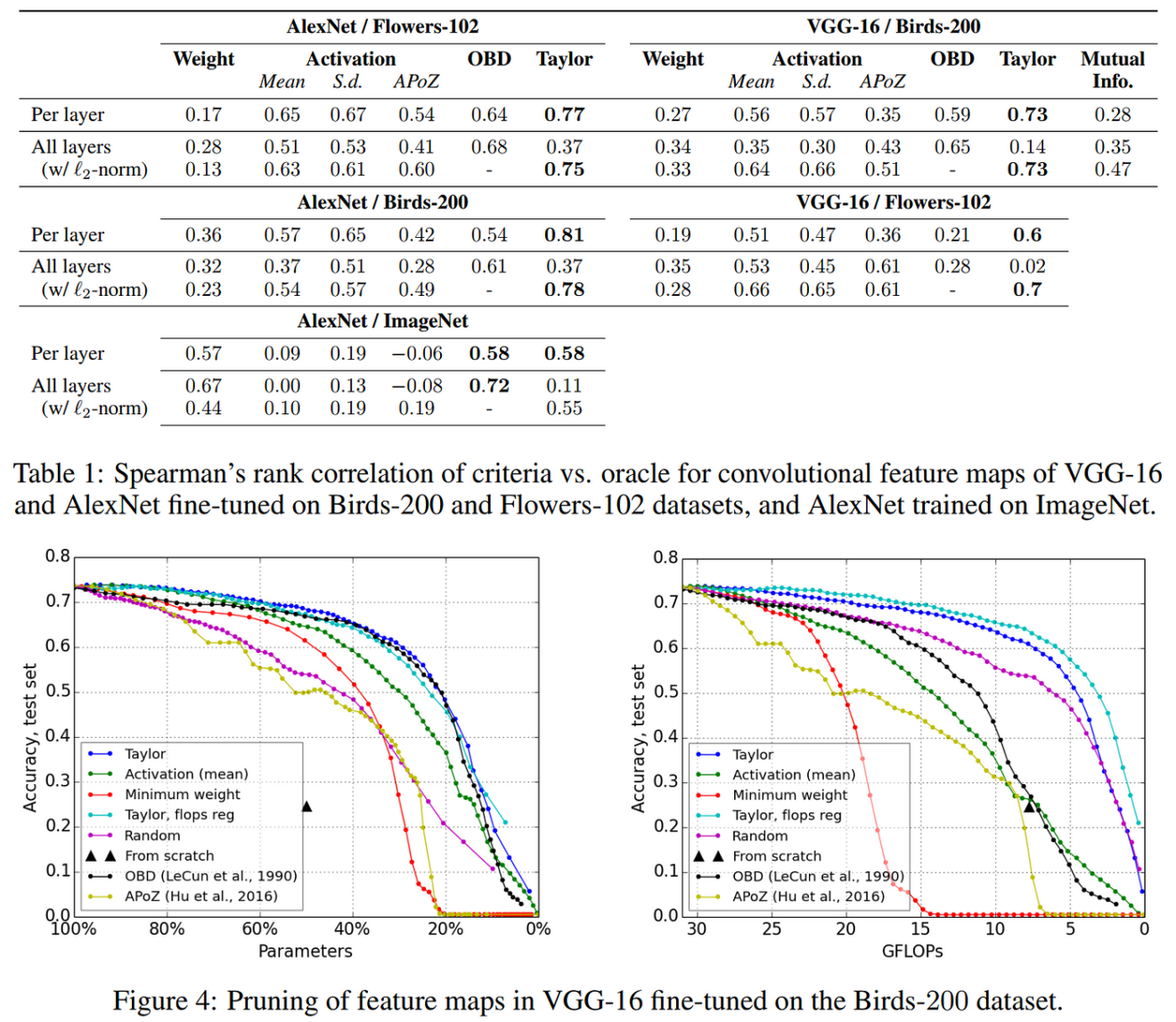
Model Compression: A Critical Step Towards Efficient Machine Learning
基于LLM的业务流程自动化_llm自动化-CSDN博客
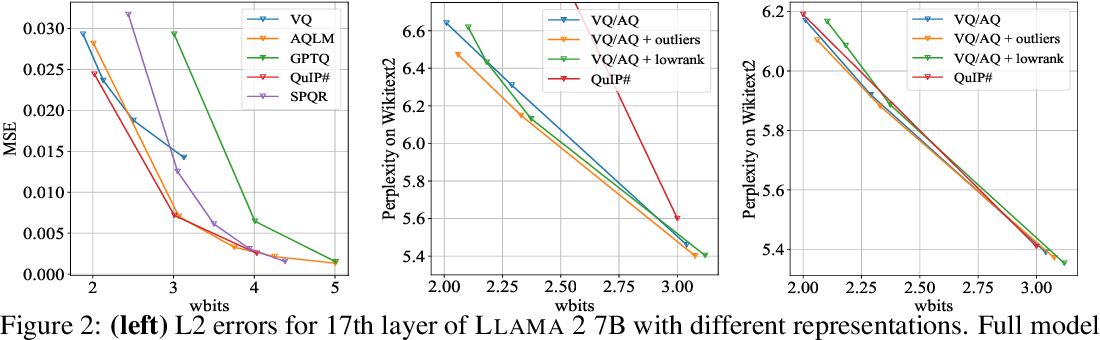
Figure 2 from PV-Tuning: Beyond Straight-Through Estimation for Extreme ...
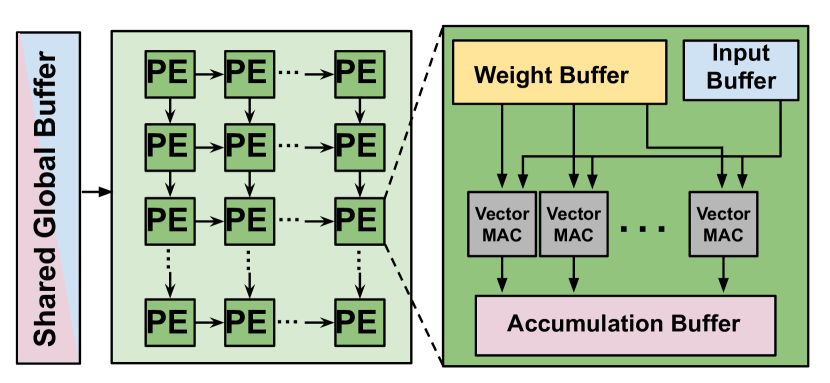
Efficient Deep Learning Infrastructures for Embedded Computing Systems ...
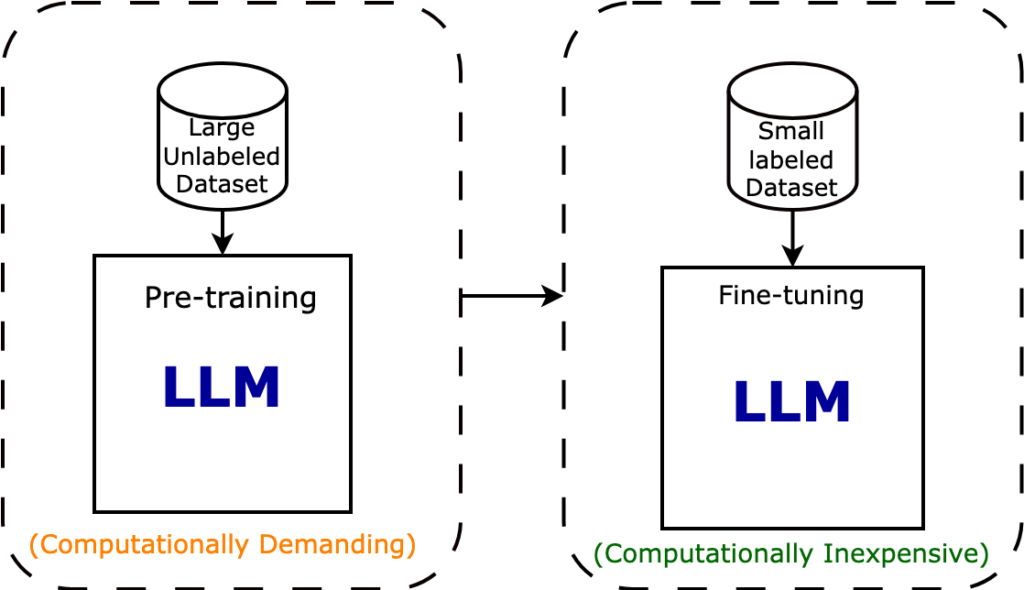
Large Language Models in Deep Learning - Intuitive Tutorials
EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge ...
GitHub - hofong428/Introduction-of-LLM-Compression: Enhance efficiency ...
GitHub - upunaprosk/Awesome-LLM-Compression-Safety: A curated list of ...
llm-compressor by vllm-project - SourcePulse
Intel Labs Explores Low-Rank Adapters and Neural Architecture Search ...
neuralmagic/LLM_compression_calibration at main
Awesome-Efficient-LLM/text_compression.md at main · horseee/Awesome ...
github- Awesome-LLM-Compression :Features,Alternatives | Toolerific
LLM-LongContext-Compression - a qiyang-attn Collection
Compressing LLMs with AWQ: Activation-Aware Quantization Explained | by ...
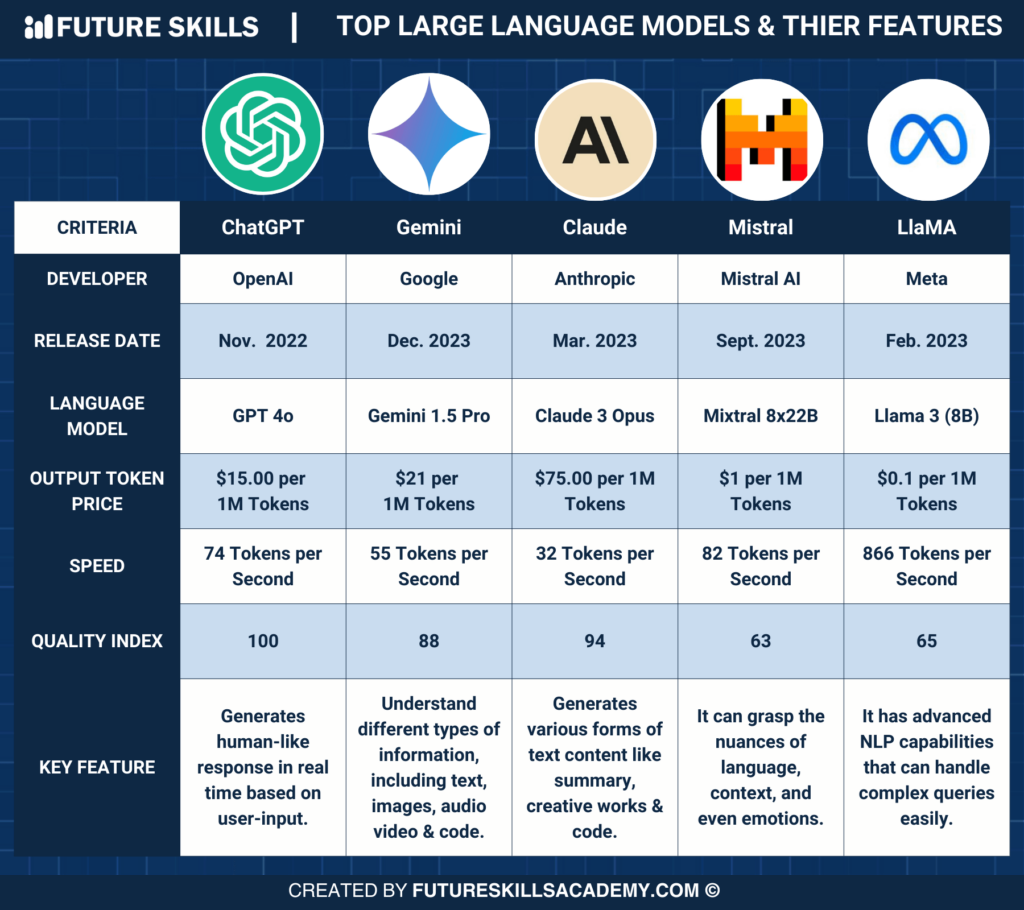
Top Large Language Models (LLMs) Comparison - Future Skills Academy
GitHub - liyucheng09/llm-compressive: Longitudinal Evaluation of LLMs ...
Selected pressure dependent X-ray diffraction patterns of LLM-105. The ...
Compressing LLMs: The Truth is Rarely Pure and Never Simple - Apple ...