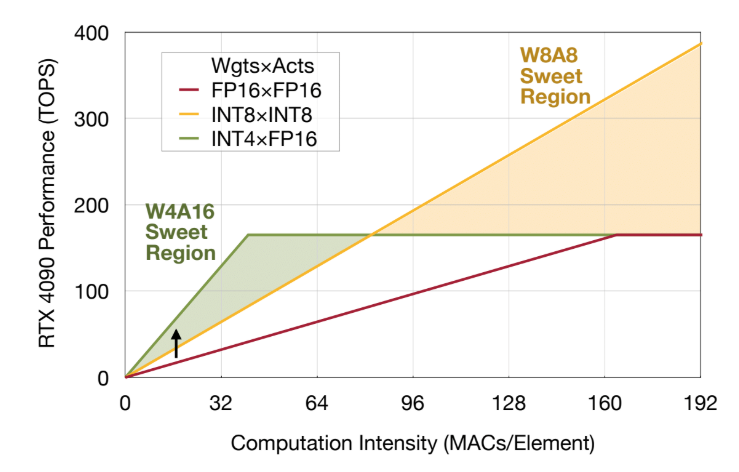
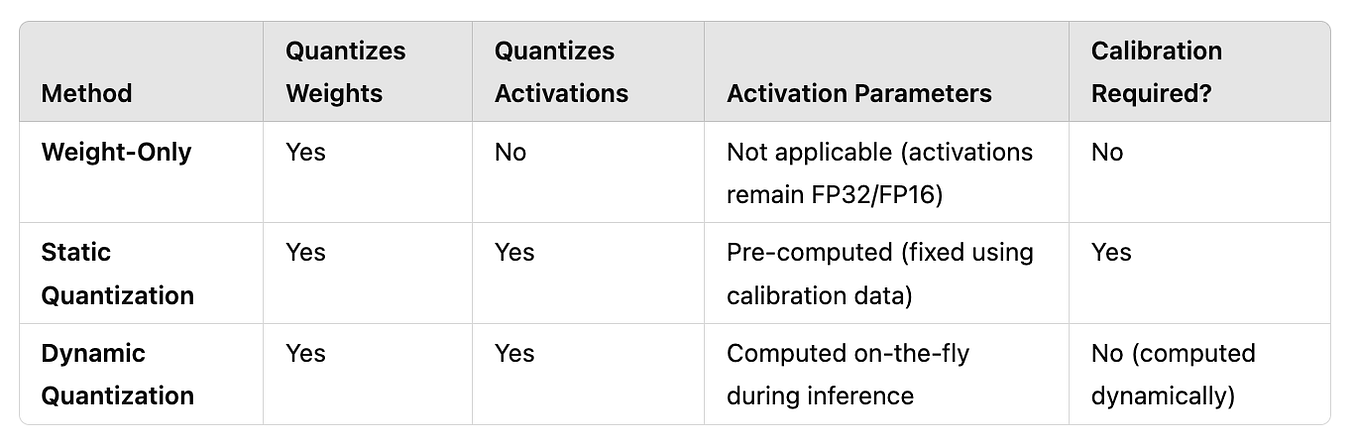
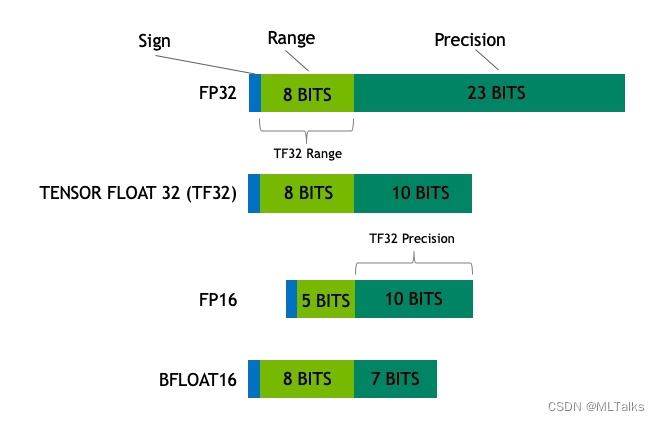
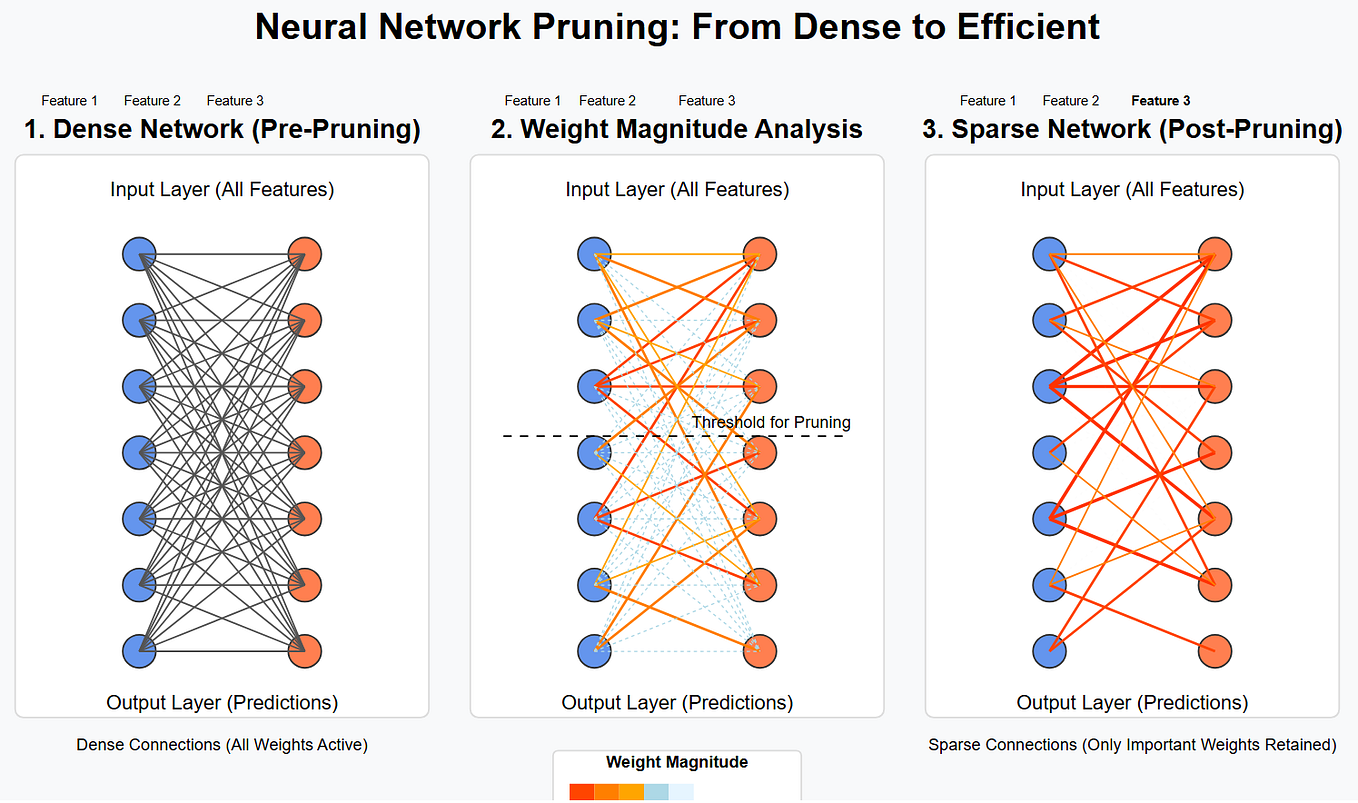
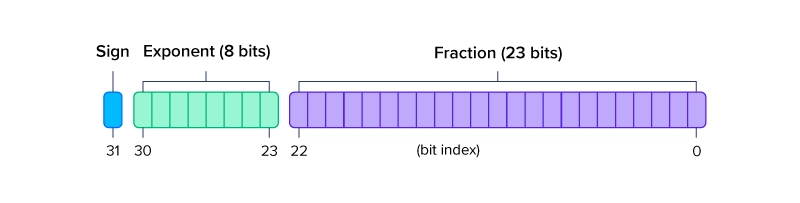
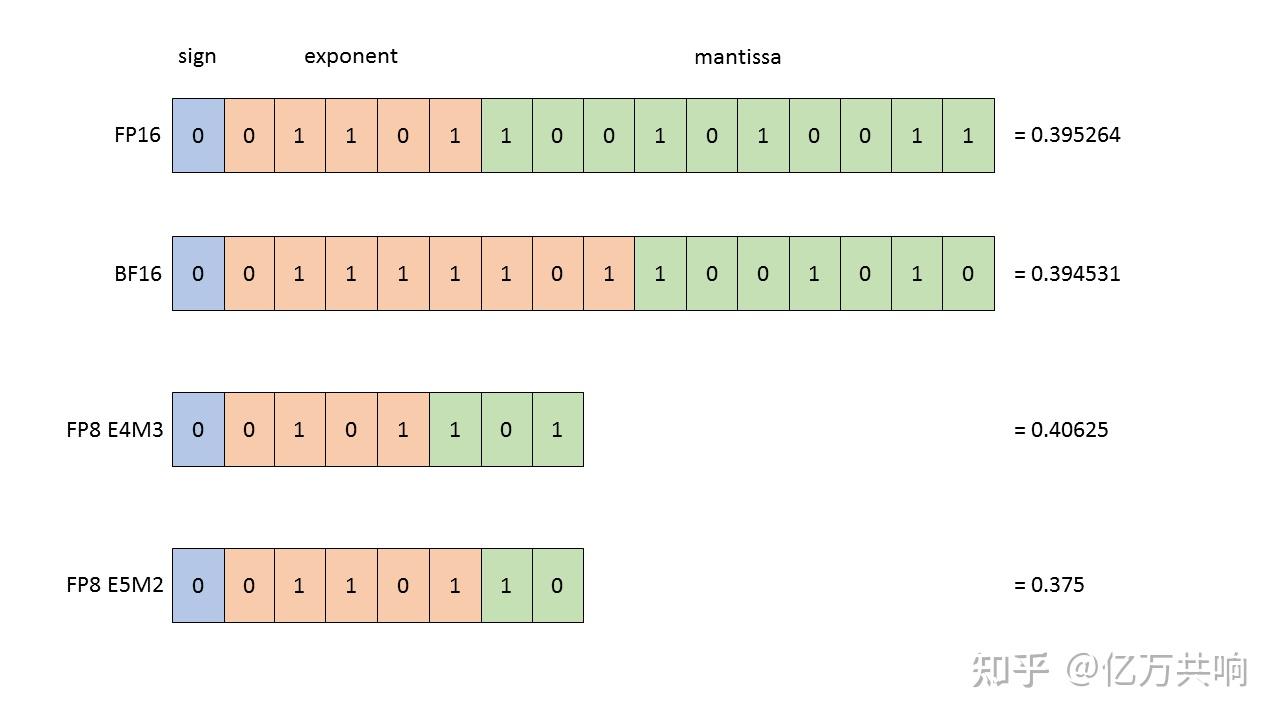
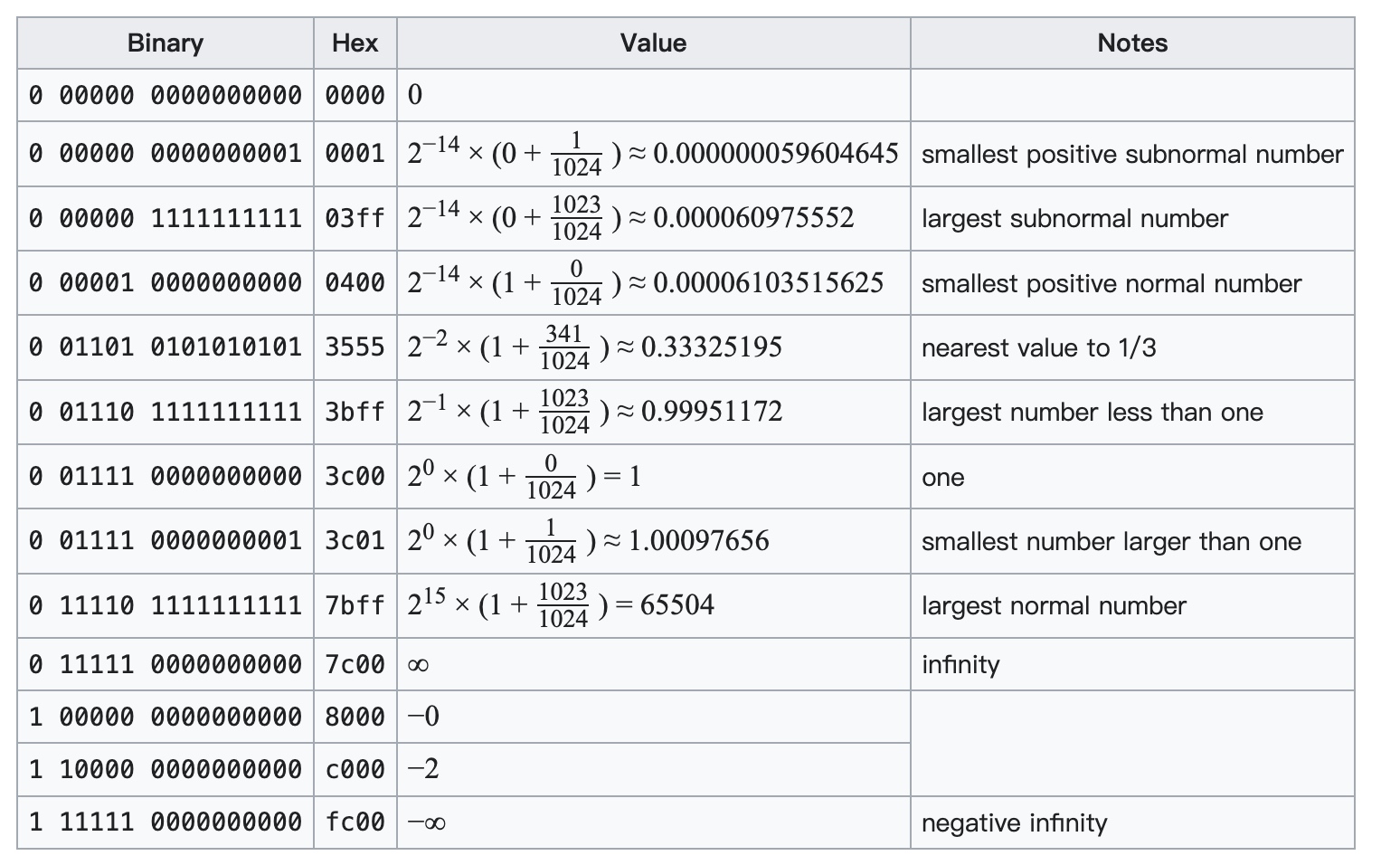
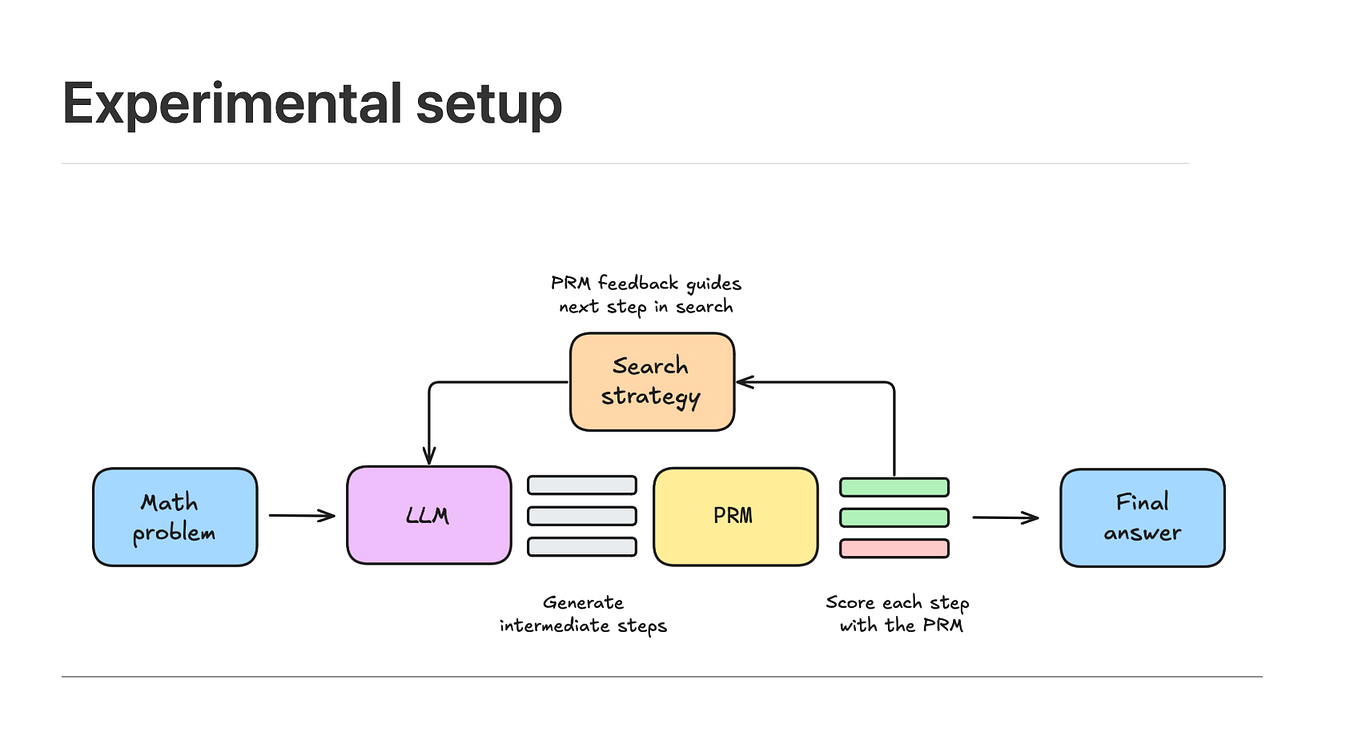
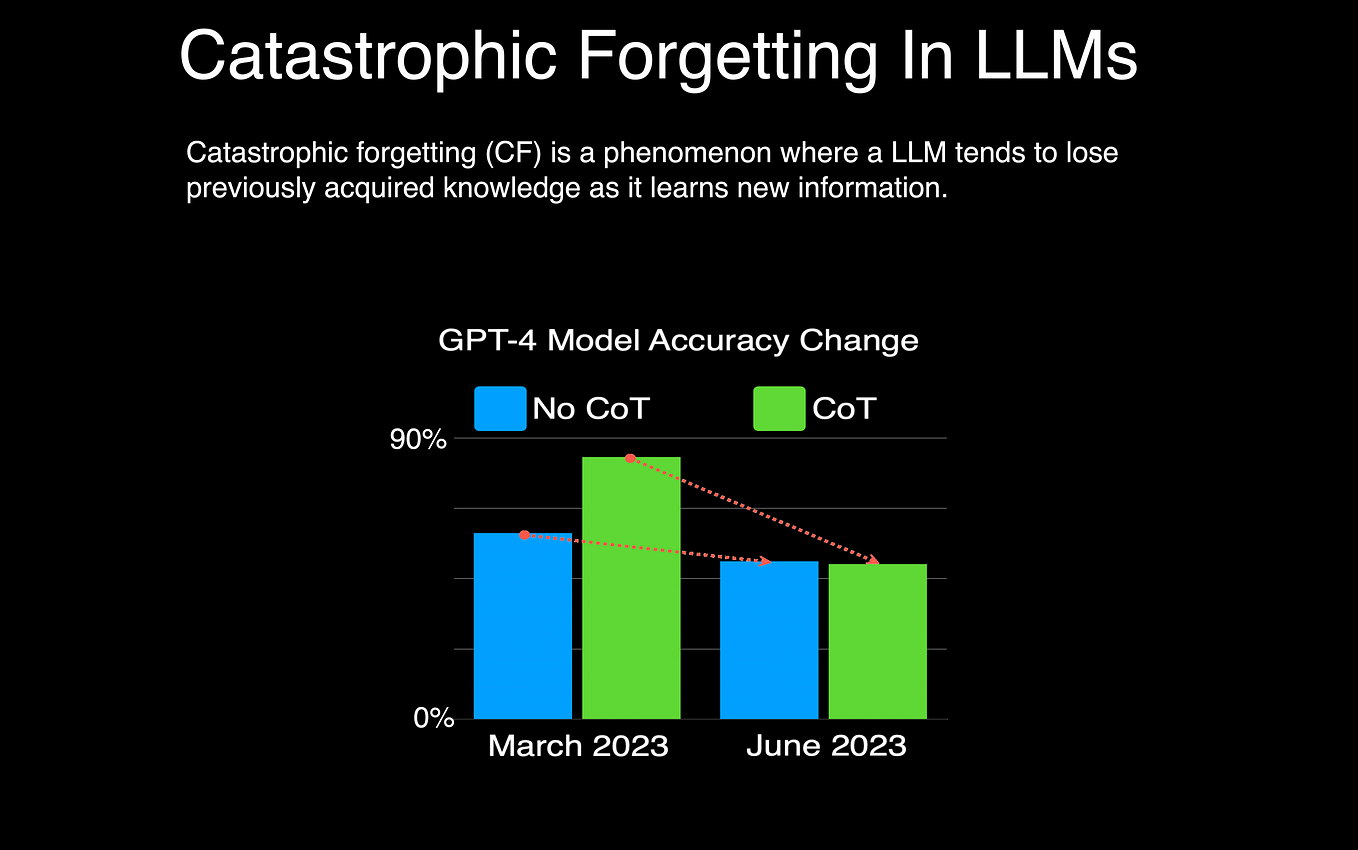
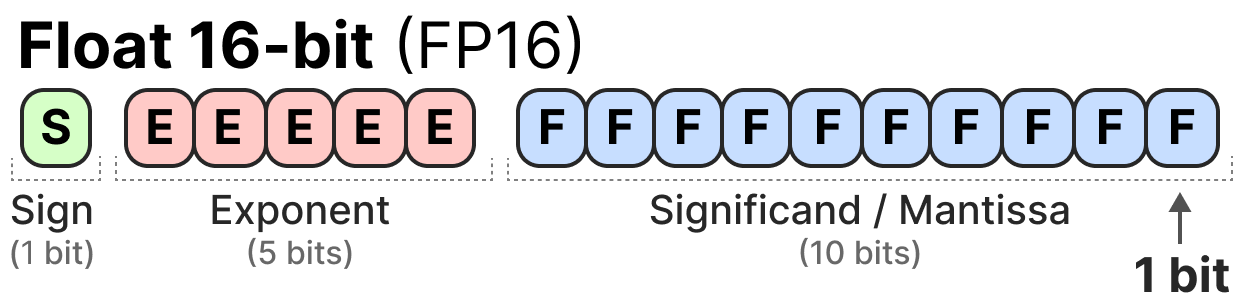
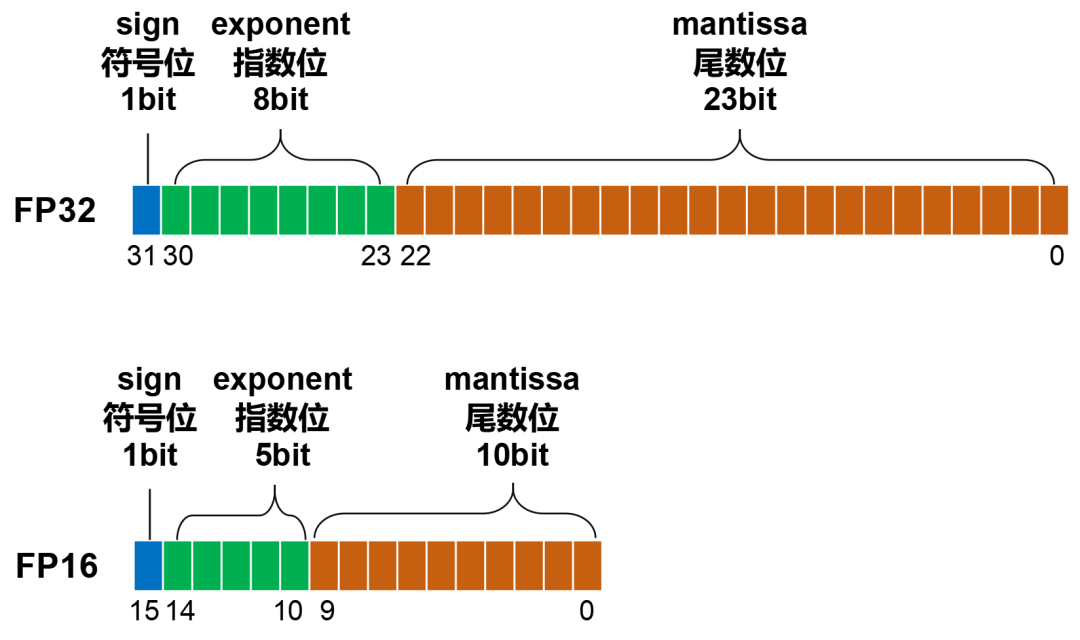
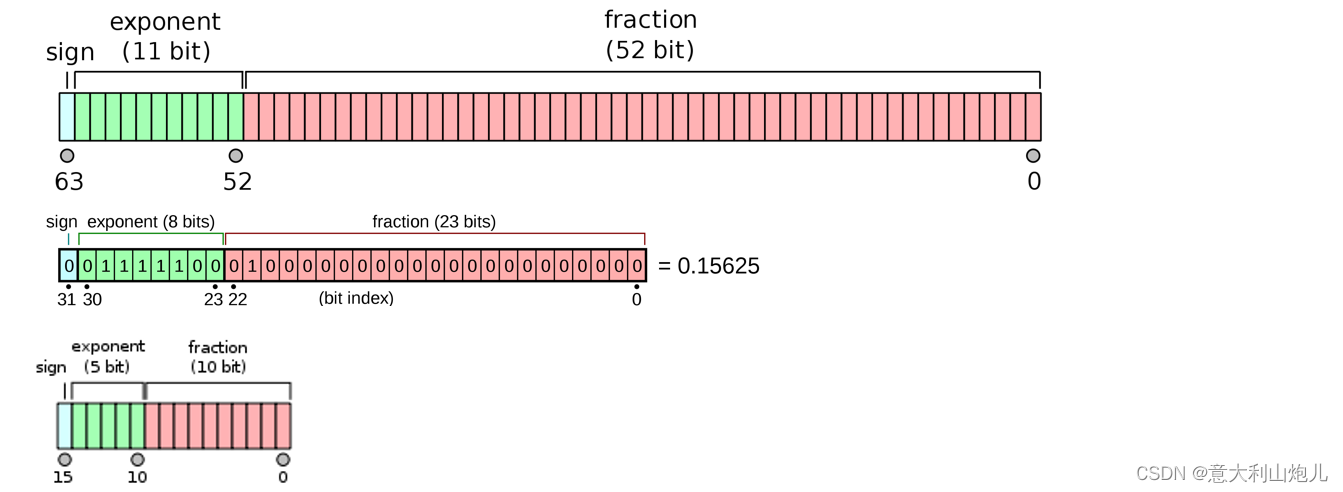
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Quantization Benchmarks: FP16 vs INT8 vs GPTQ vs AWQ — Which One ...
Quantization FP16 model using pytorch_quantization and TensorRT · Issue ...
Different output in INT8 and FP16 quantization · Issue #4990 ...
PyTorch to Torchscript with FP16 Quantization · Issue #9430 ...
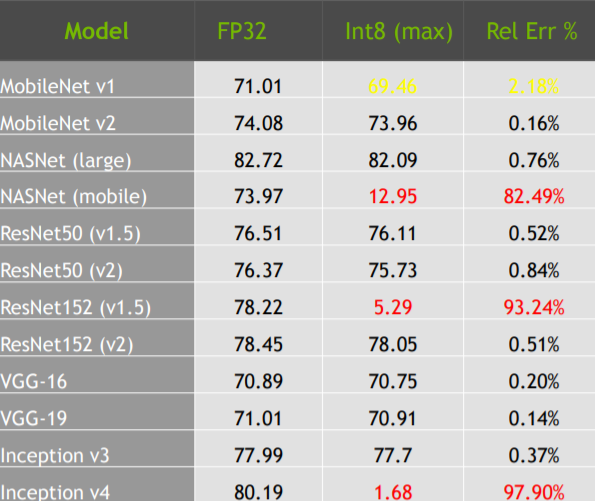
The accuracy loss after INT8 quantization compared to FP16 version ...
tflite quantization to fp16 only quantized input · Issue #55785 ...
Quantization Aware Training. Или как правильно использовать fp16 ...
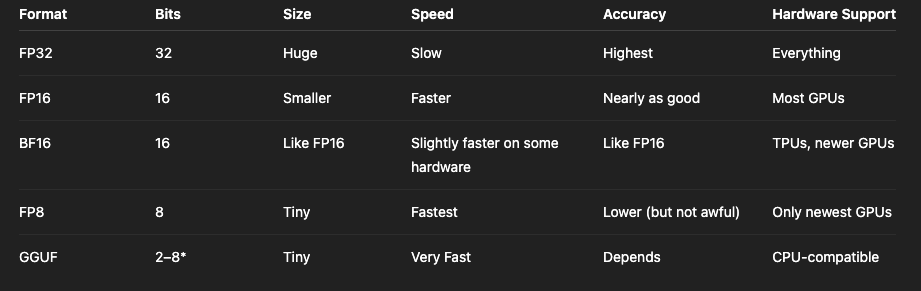
Quantization Explained: Q4_K_M vs AWQ vs FP16 for Local LLMs | SitePoint
LLM Quantization Explained: Q4, Q8, FP16 and VRAM Tradeoffs (2026)
Geek Out Time: Experimenting with FP32 vs. FP16 Quantization on Google ...
FP16 quantization does not seem to work well · Issue #520 · NVIDIA-AI ...
yolov8n runs slower on CPU and GPU after FP16 quantization · Issue ...
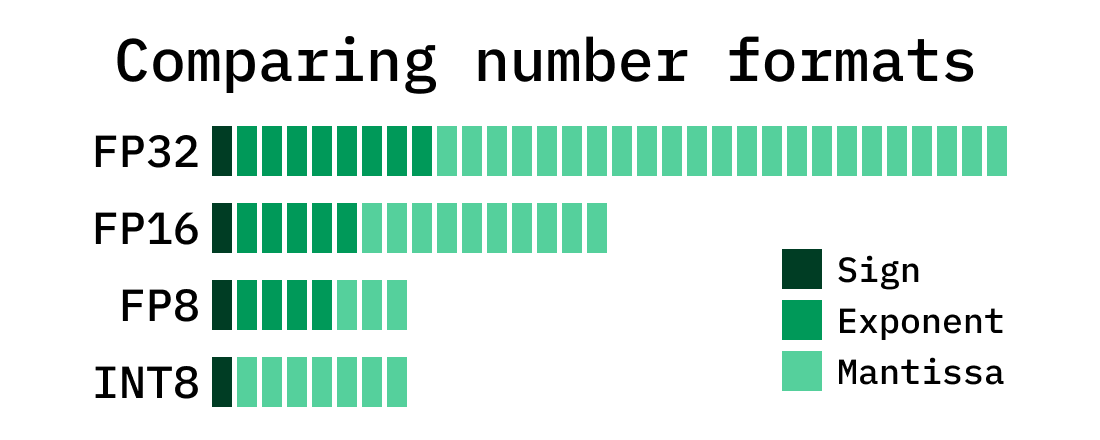
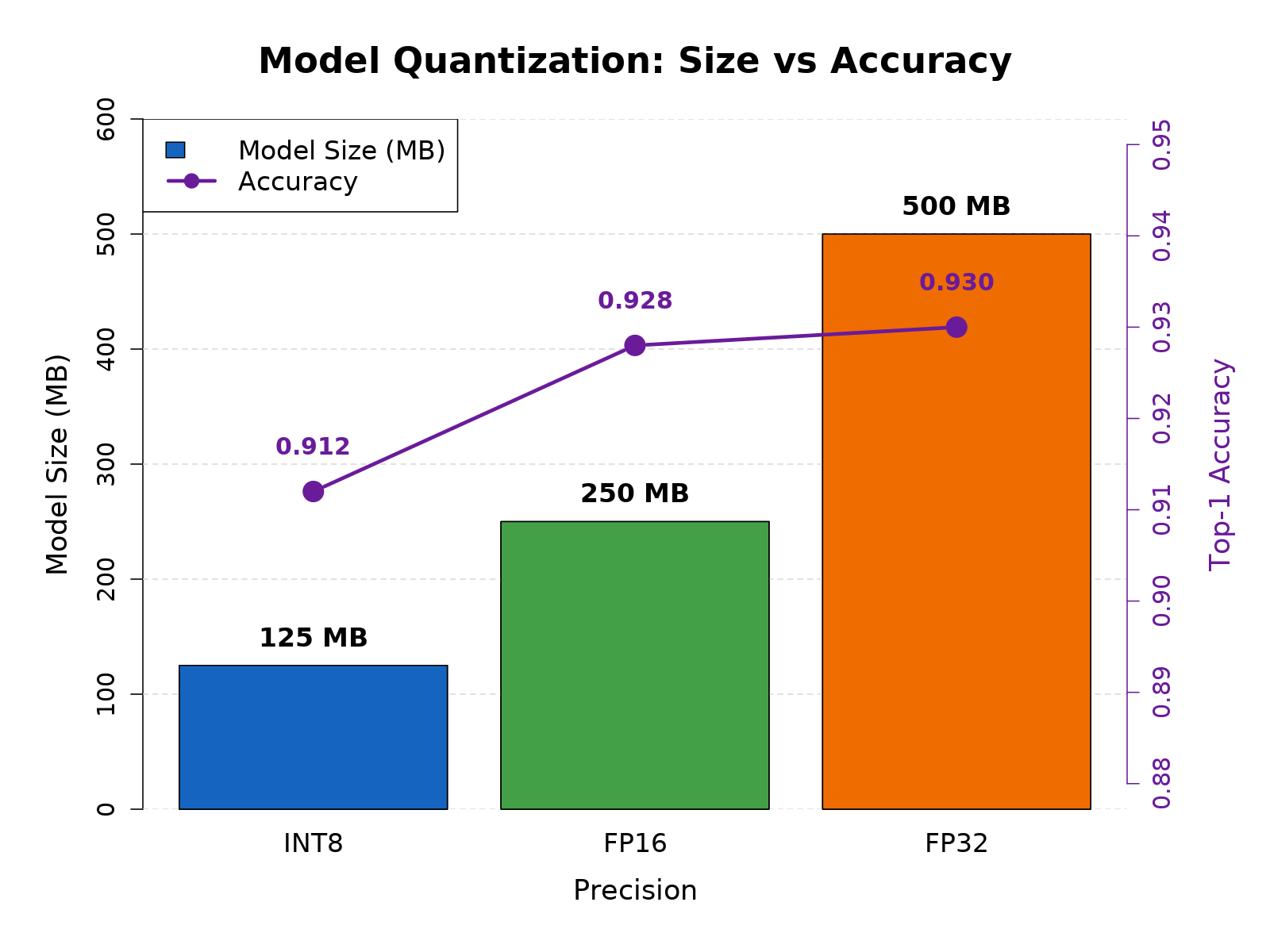
Quantization Techniques Comparison: INT8 vs INT4 vs FP16 for Model ...
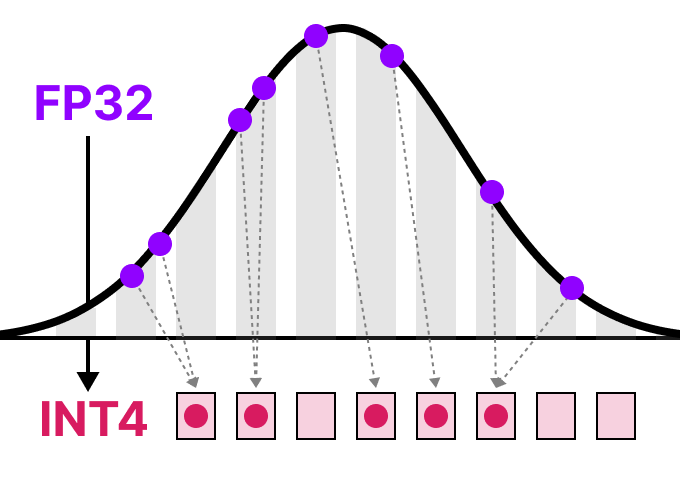
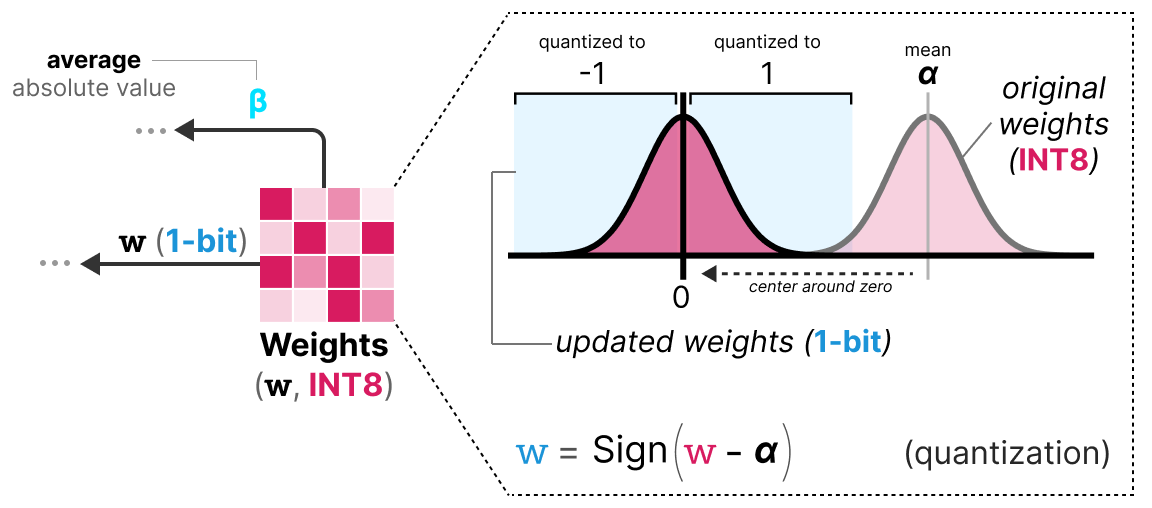
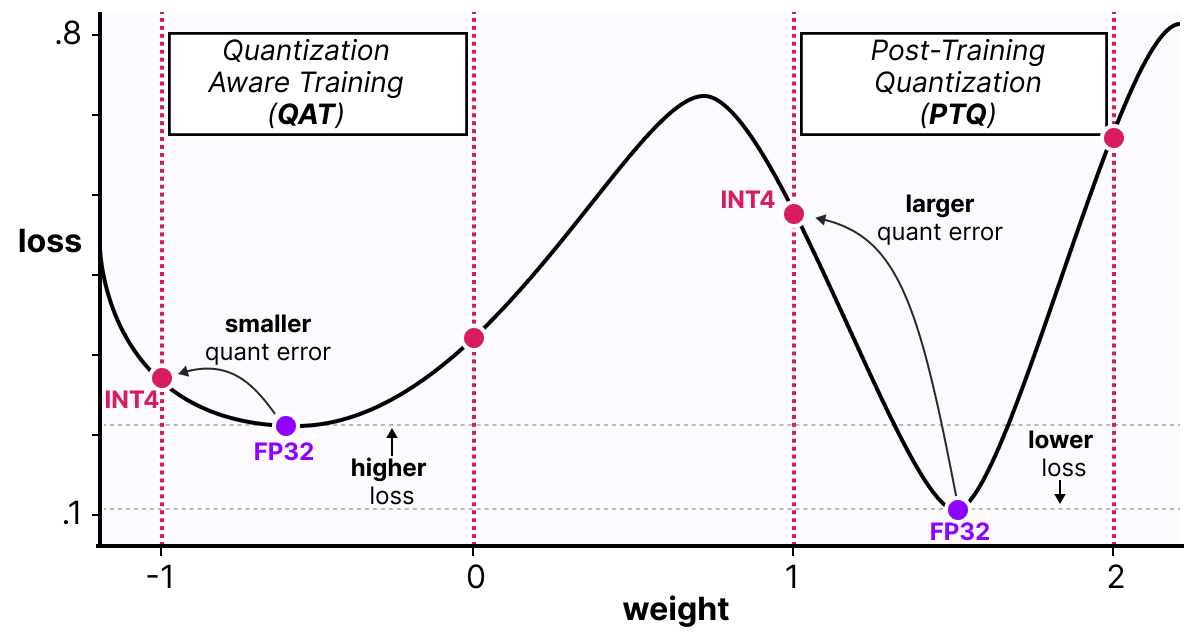
A Visual Guide to Quantization - Maarten Grootendorst
Key Factors in AI's Advancement: Research Papers, Quantization ...
Quantization from FP32 to FP16. | Download Scientific Diagram
4-bit LLM training and Primer on Precision, data types & Quantization
Quantization in LLMS (Part 1): LLM.int8(), NF4 | TensorTunes
Quantization: INT8 vs FP16 vs FP32 | MetricGate
A Visual Guide to Quantization - by Maarten Grootendorst
Quantizing LLMs Step-by-Step: Converting FP16 Models to GGUF ...
Quantization in LLMs: Why Does It Matter?
TensorFlow Model Optimization Toolkit — float16 quantization halves ...
Model Quantization in Deep Learning
[LLM 101] What Is Quantization? Q4, Q8, FP16 Explained — ai-muninn
Simple FP16 and FP8 training with unit scaling
FP8 Quantization for Ultra-Low Latency AI | AI Tutorial | Next Electronics
LLM Quantization Explained: FP32, FP16, BF16, and INT8 Formats
Quantization — Cours Deep Learning
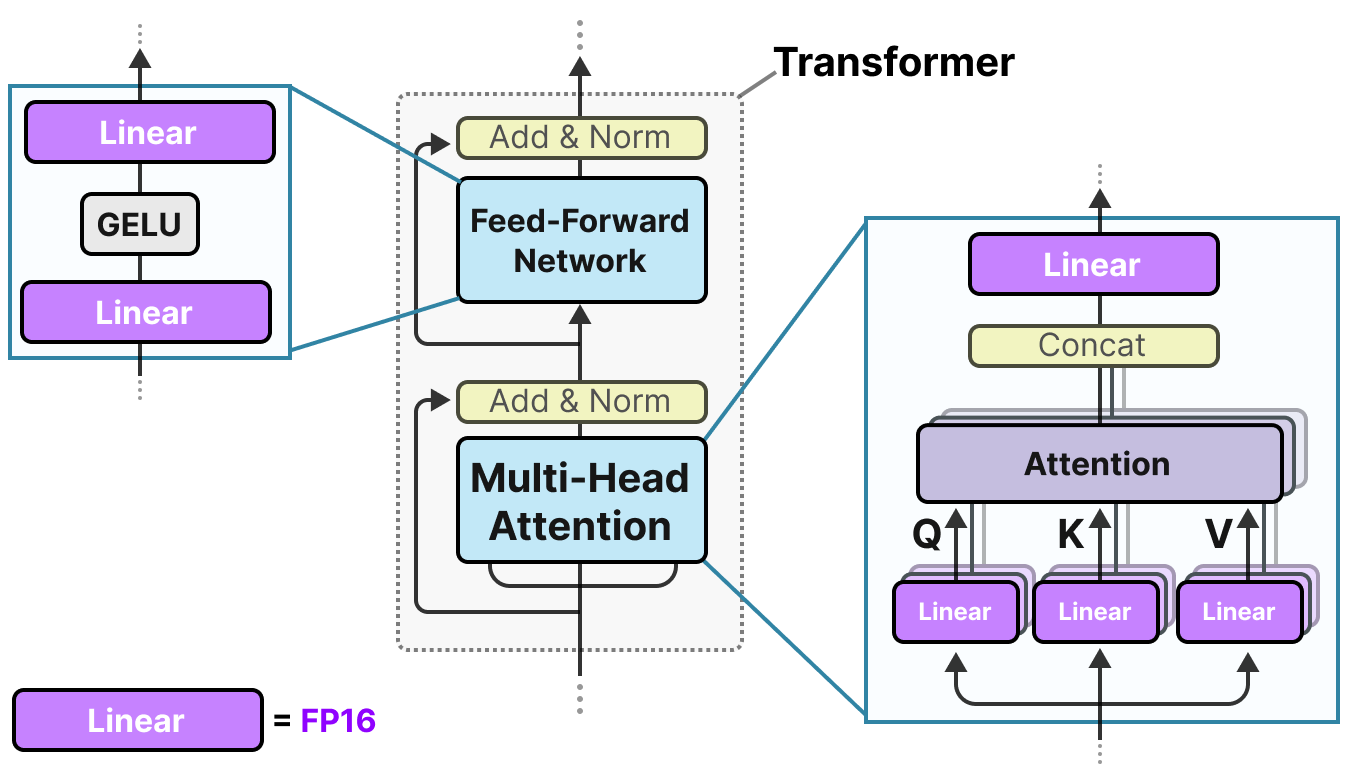
Fast and Accurate GPU Quantization for Transformers
Model Quantization 1: Basic Concepts | by Florian June | Medium
AI Model Quantization Advisor - INT8, FP16, INT4 Guide | Lattice
BF16 与 FP16 在模型上哪个精度更高呢 - 知乎
Post training quantization of models trained in 16-bit floating point ...
(PDF) Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 ...
Model Quantization: Post-Training Quantization Using NVIDIA Model ...
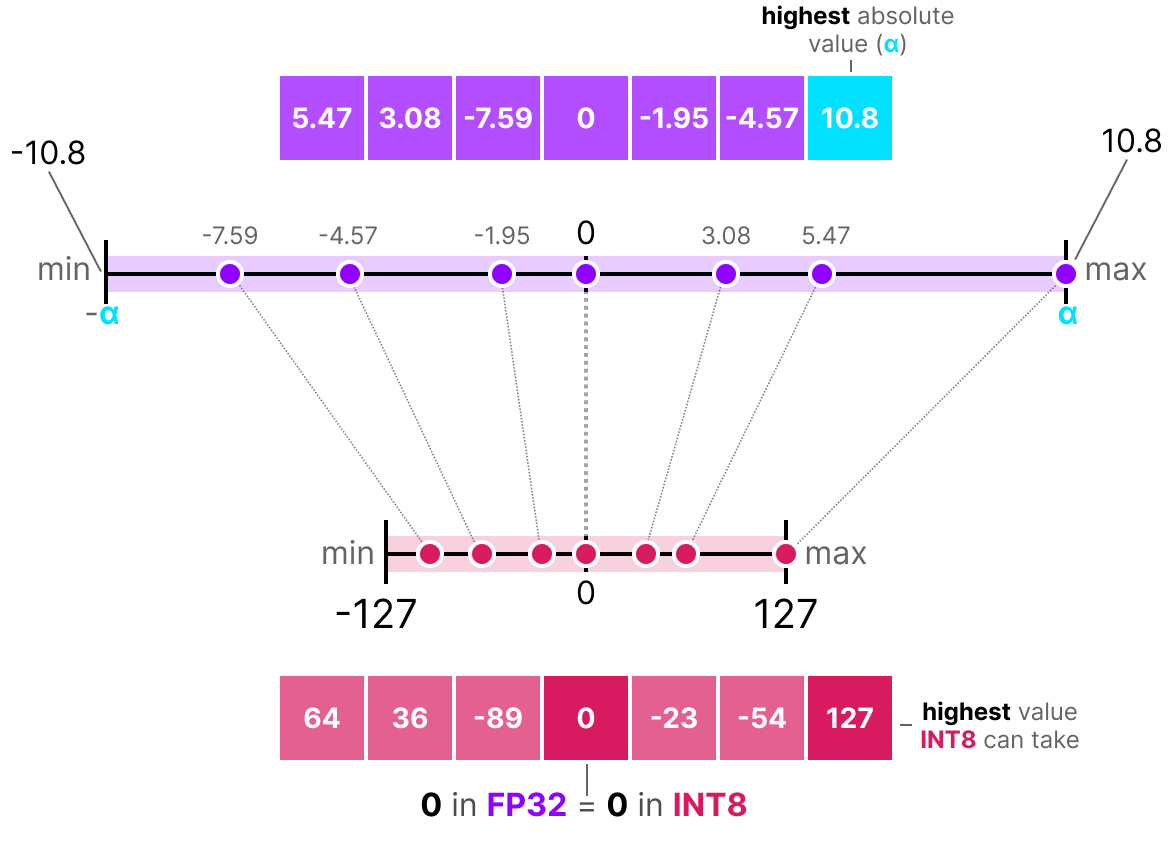
Introduction to Weight Quantization | Towards Data Science
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
Improving LLM Inference Latency on CPUs with Model Quantization ...
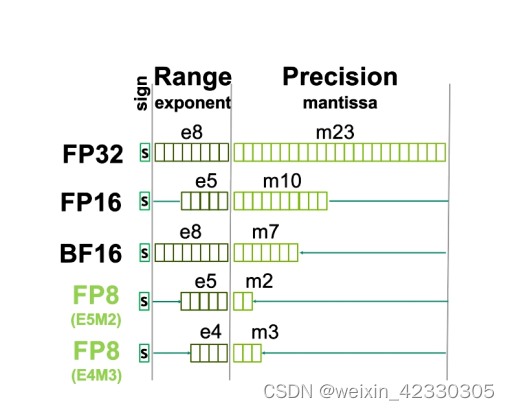
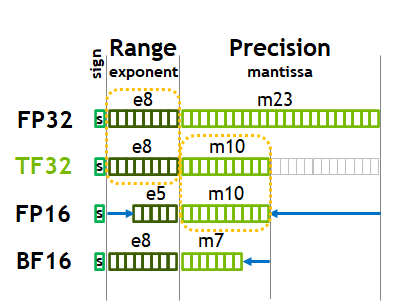
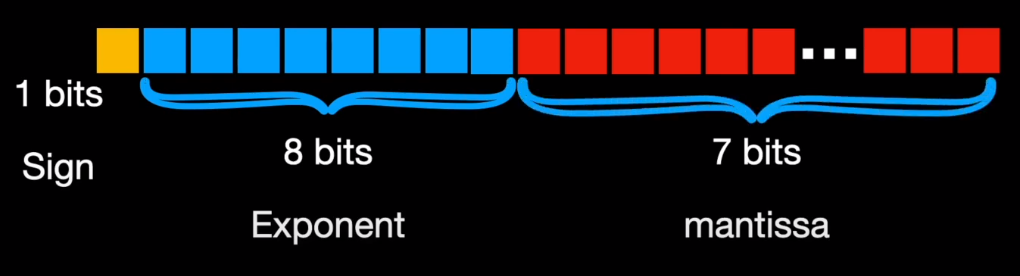
Precision Comparison: FP64 FP32 FP16 TF32 BF16 INT8
Perplexity vs time for standard FSDP (FP32 weights and FP16 gradients ...
Ablation study comparing the post-quantization PSNR drop from FP16 when ...
Layer-wise quantization sensitivity analysis for mixedprecision ...
fp16 shows `quantization unknown` when running `ollama show` · Issue ...
Data Types Explained: FP32 vs FP16 vs BF16 in Deep Learning - YouTube
Integer quantization for deep learning inference: principles and ...
Optimizing OpenSearch with Faiss FP16 scalar quantization: Enhancing ...
Making FP16 and FP8 easy to use with our new unit scaling library
Optimizing LLMs for Performance and Accuracy with Post-training ...
Model Quantization: Concepts, Methods, and Why It Matters - NViNiO News ...
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
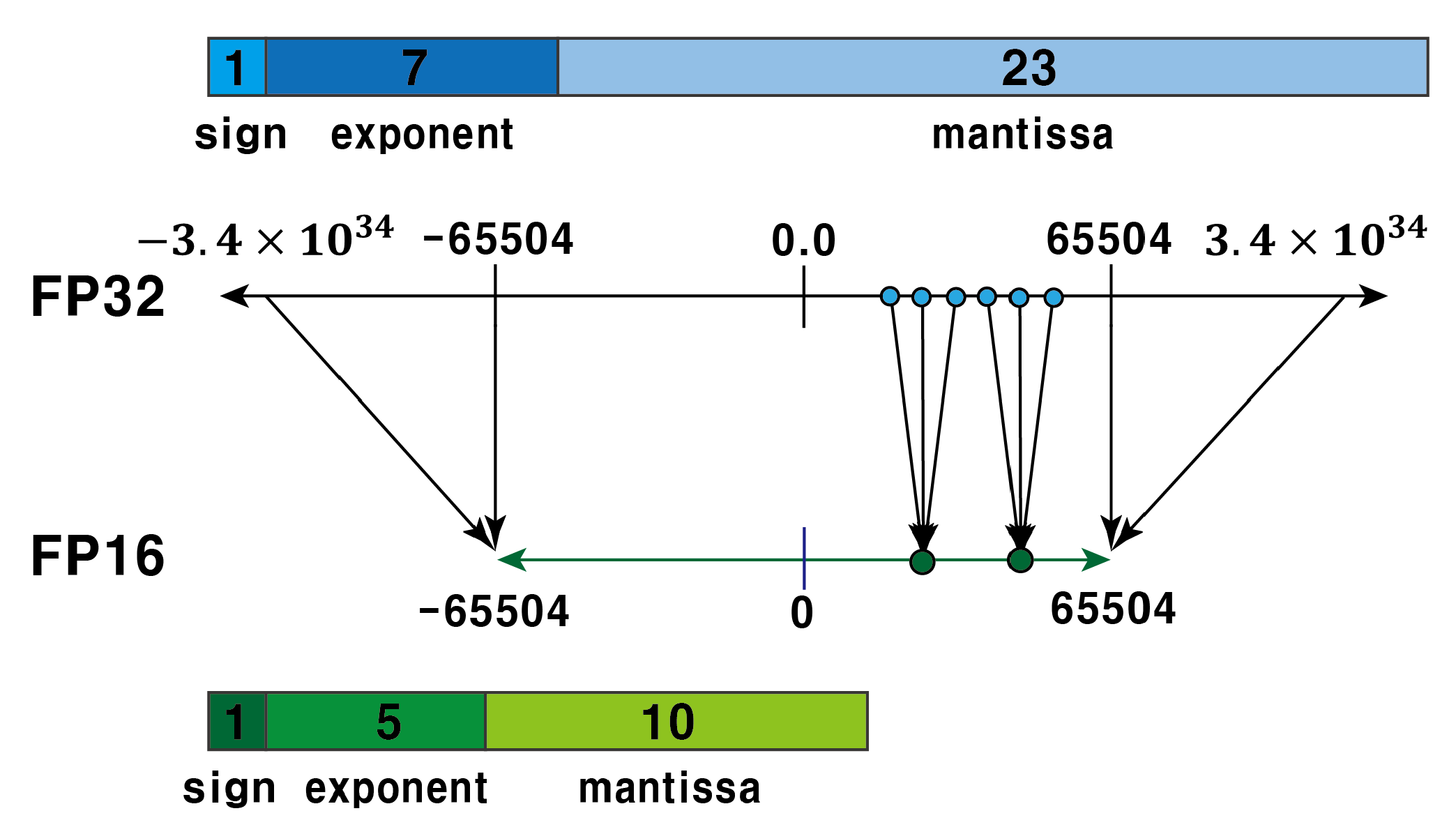
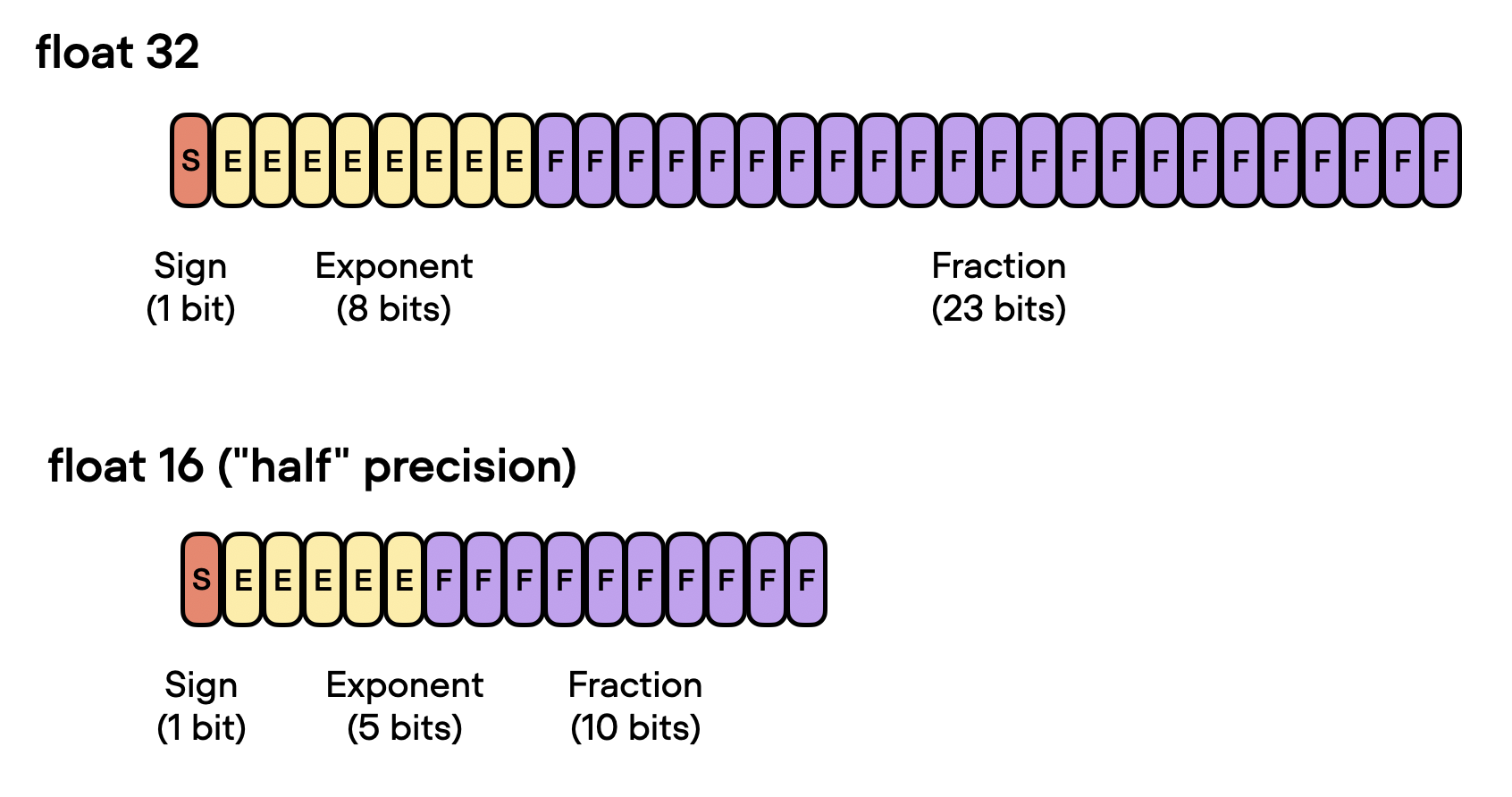
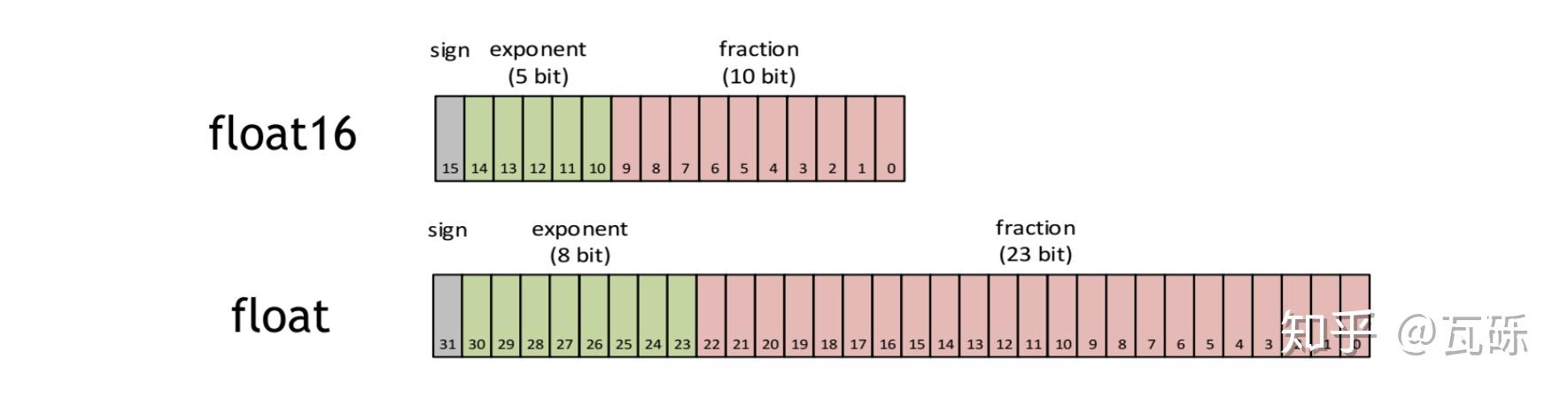
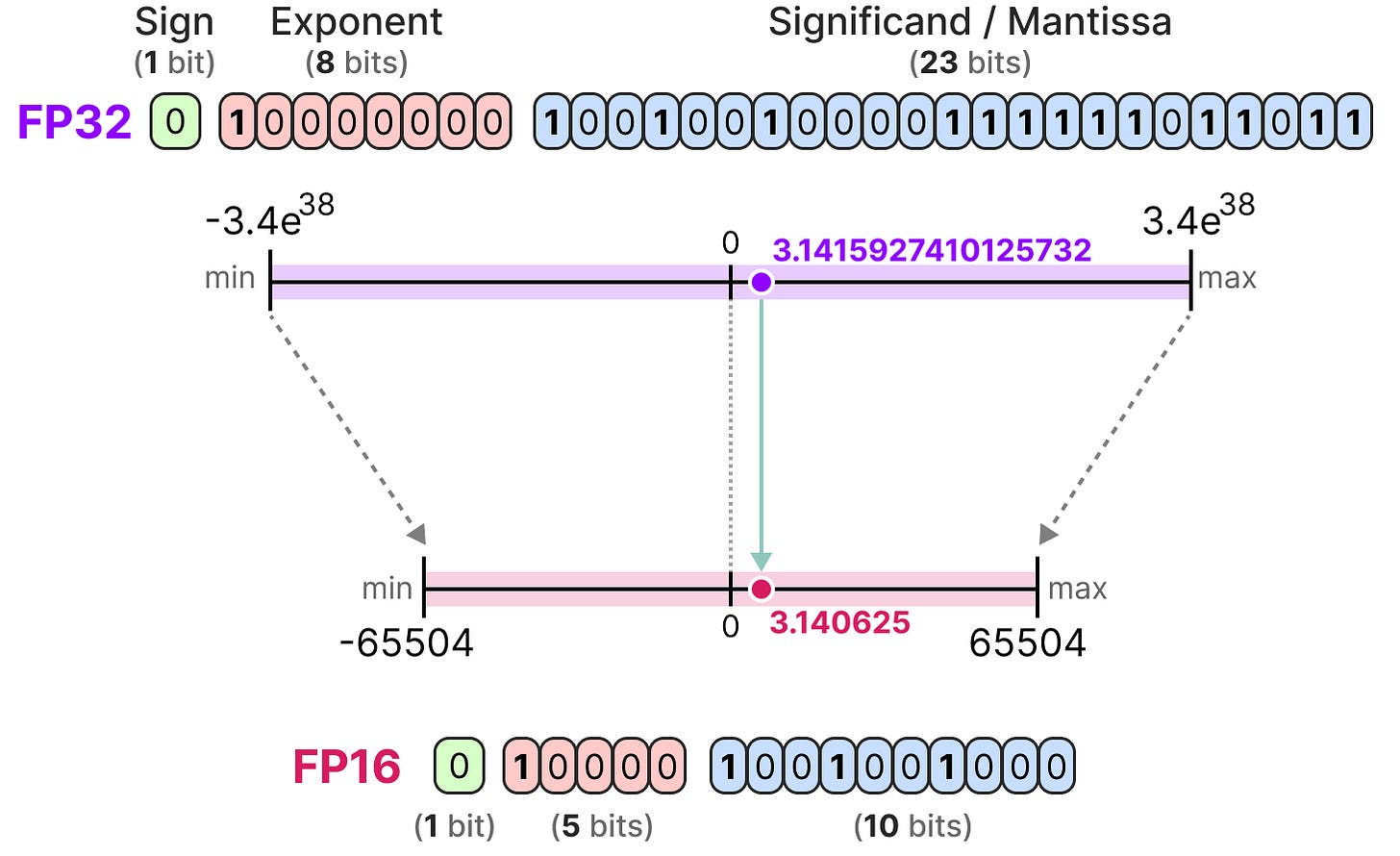
What is FP64, FP32, FP16? Defining Floating Point | Exxact Blog
Quantization: Reducing Model Precision (FP16, INT8)
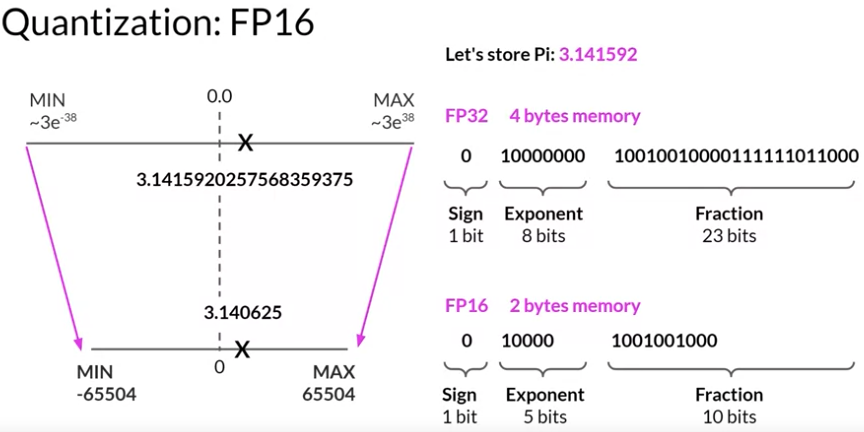
Floating Point Numbers: (FP32 and FP16) and Their Role in Large ...
FP16数据格式详解-CSDN博客
计算精度对比:FP64, FP32, FP16, BFLOAT16, TF32 - 知乎
FP16数据格式详解 | MLTalks
大模型开发中的浮点数精度选择:FP32、FP16、BF16详解! - 知乎
Optimizing LLMs for Performance and Accuracy with Post-Training ...
模型量化1-概述1:量化的过程就是选取合适量化参数(scale factor,zero point,clipping value)以及数据映射 ...
A2C rewards for fp32, fp16, and int8 policies. | Download Scientific ...
Cuantización — Deep Learning Course
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
【干货】大模型算力优化全攻略——FP32、FP16、INT8数据格式精讲与实战应用_fp16和fp32-CSDN博客
Faster Dynamically Quantized Inference with XNNPack — The TensorFlow Blog
浮点运算的定点化_bf16和fp16-CSDN博客
Picking the Right Size Brain: FP16, BF16, FP8, GGUF and What They ...
“DNN Quantization: Theory to Practice,” a Presentation from AMD | PDF
A Method of Deep Learning Model Optimization for Image Classification ...
realtime_ai_systems_academia.pptx
STOI and PESQ scores and memory footprint of the quantized TinyDenoiser ...
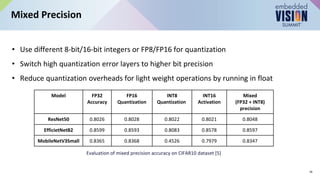
Accelerating Large Language Models with Mixed-Precision Techniques ...
Automatic Mix Precision — MindSpore master documentation
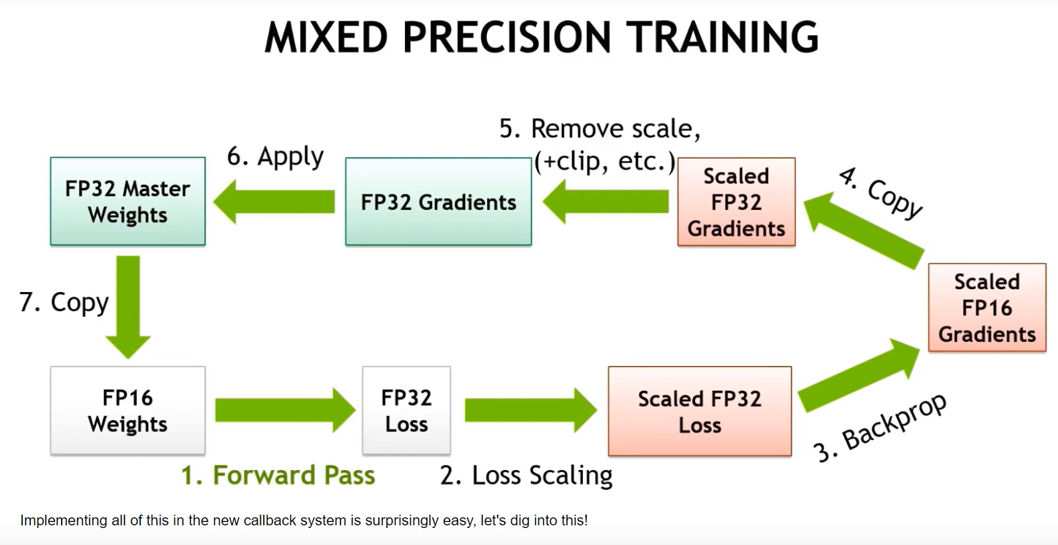
Training using half-precision floating point (fp16) can be up to 3x ...
基于Apex的混合精度加速:半精度浮点数FP16 - stardsd - 博客园
FP64、FP32、FP16、FP8简介-CSDN博客
FP32, FP16, BF16 и FP8 — разбираемся в основных типах чисел с плавающей ...
FP8: Efficient model inference with 8-bit floating point numbers ...
FP16\FP32\INT8\混合精度的含义-CSDN博客
Averaged accuracy on PIQA, Winogrande, LAM-BADA, and HellaSwag of OPTs ...
Paper page - Spectra: A Comprehensive Study of Ternary, Quantized, and ...
Top 5 AI Model Optimization Techniques for Faster, Smarter Inference ...













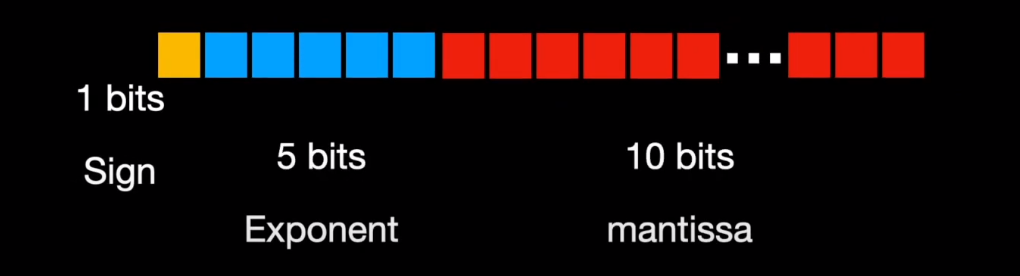
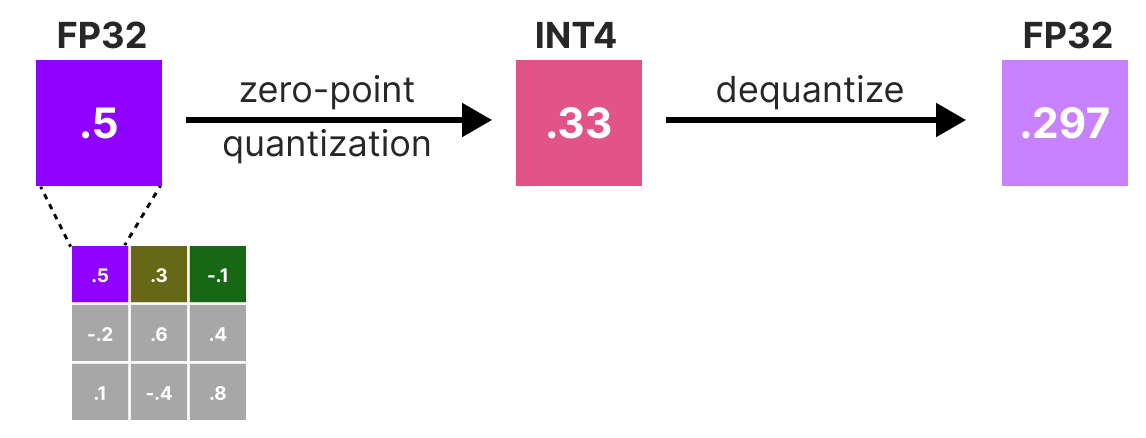

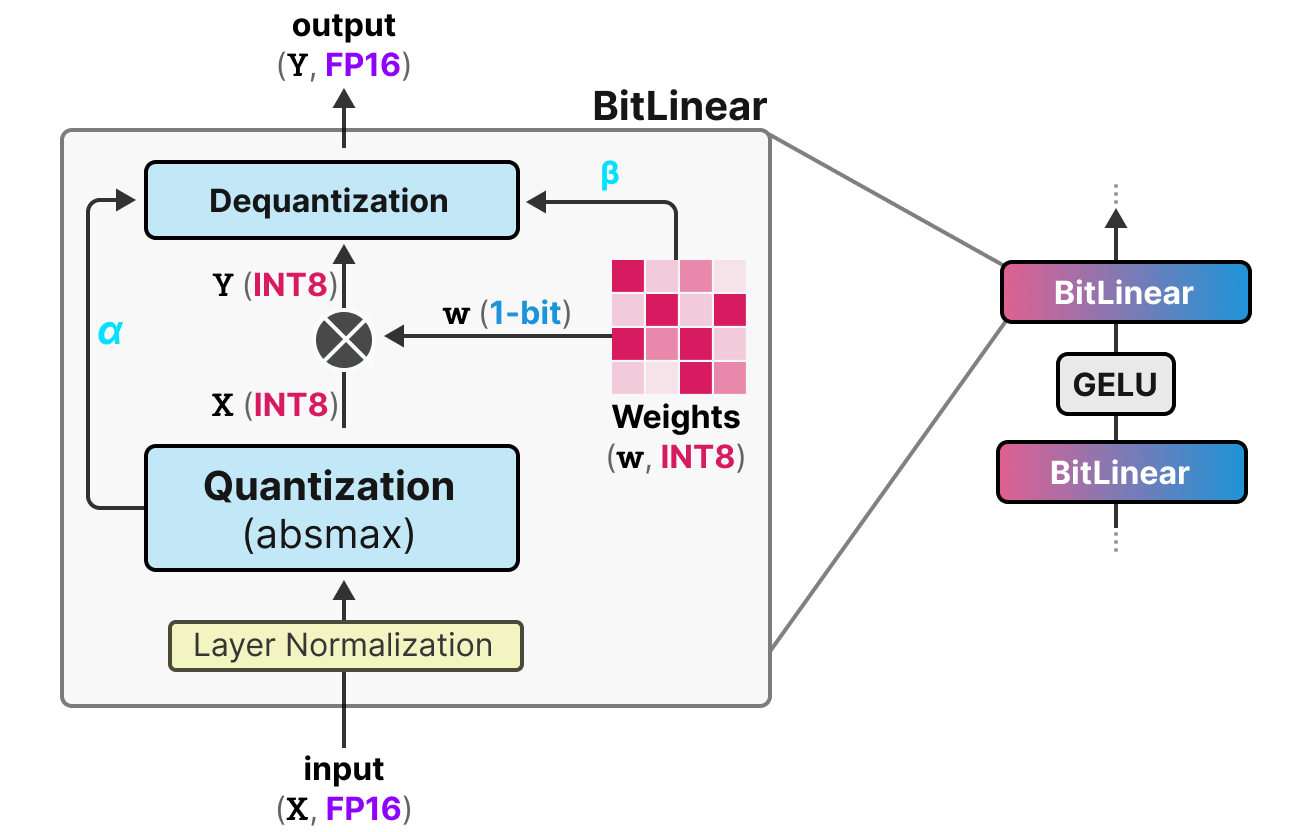





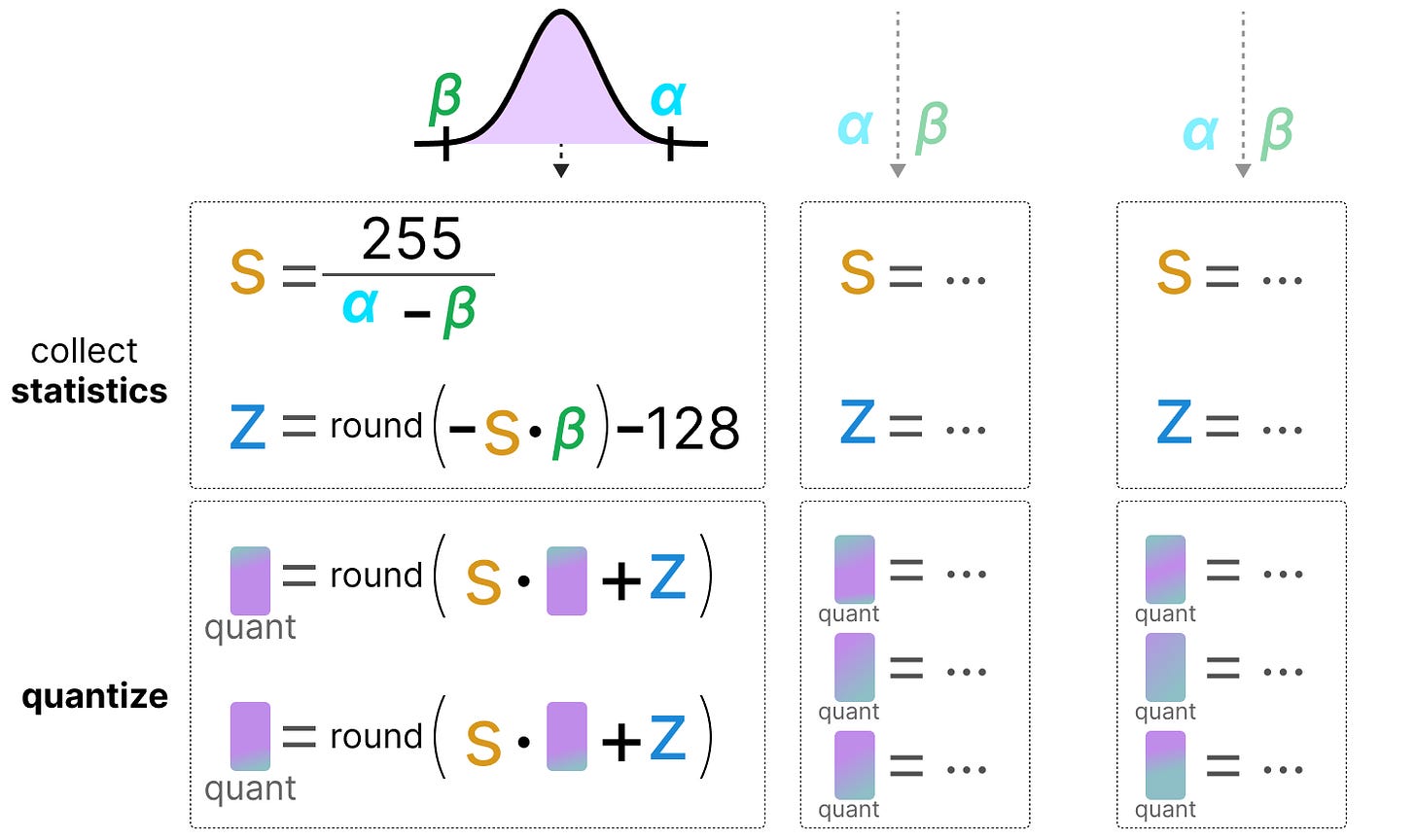
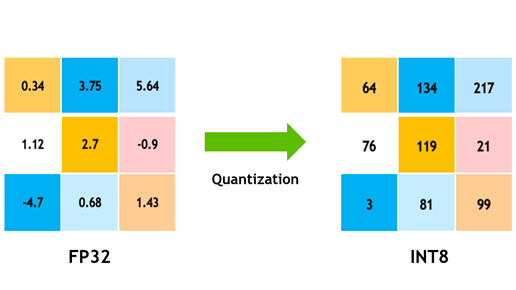
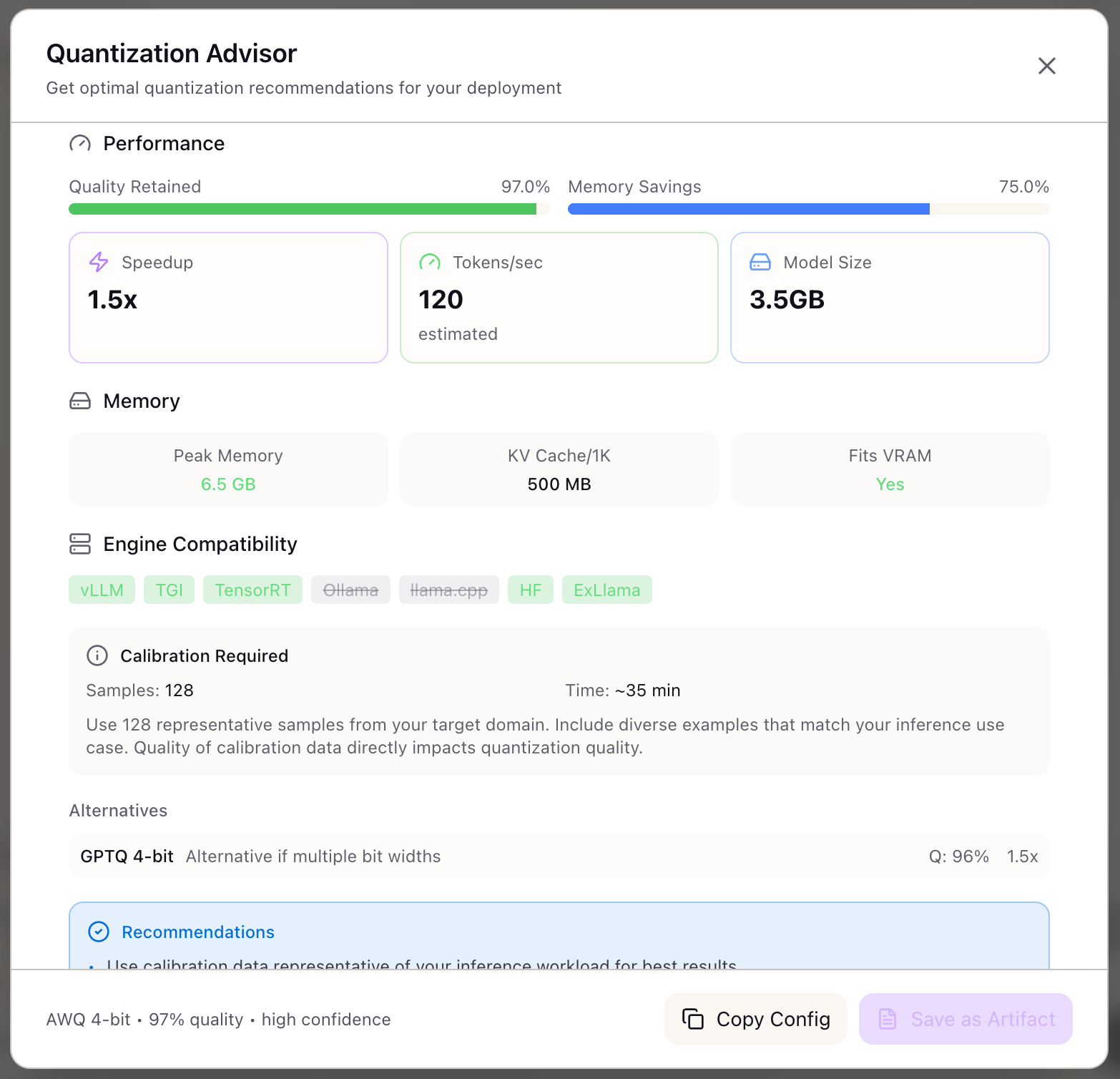
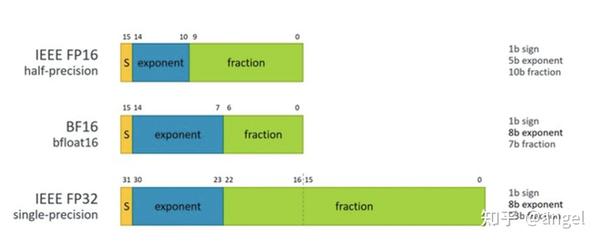



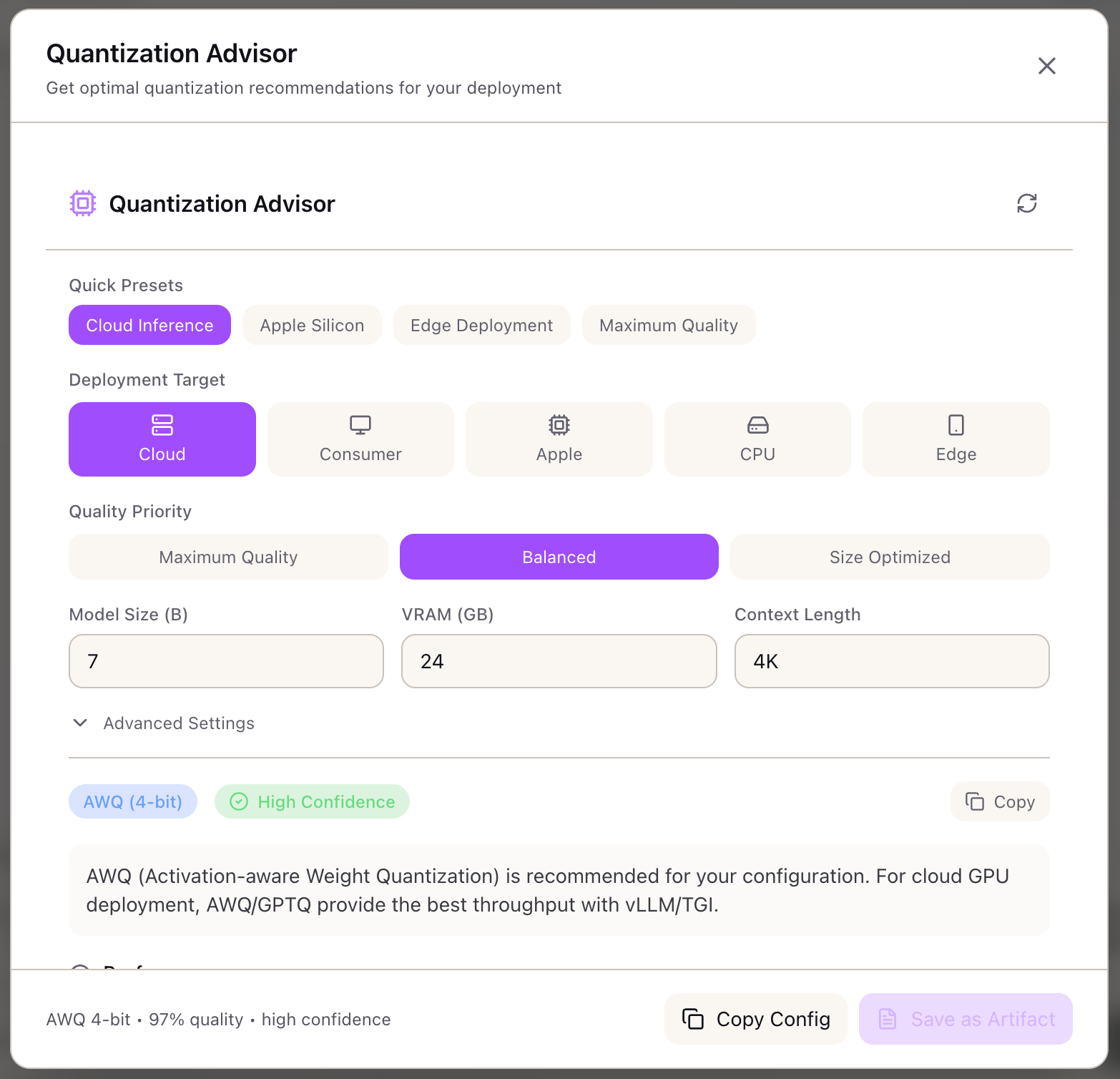












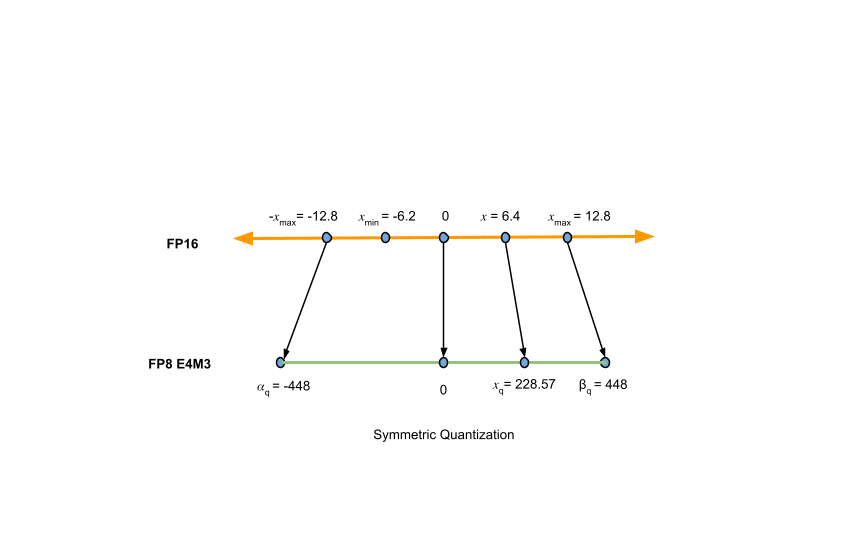
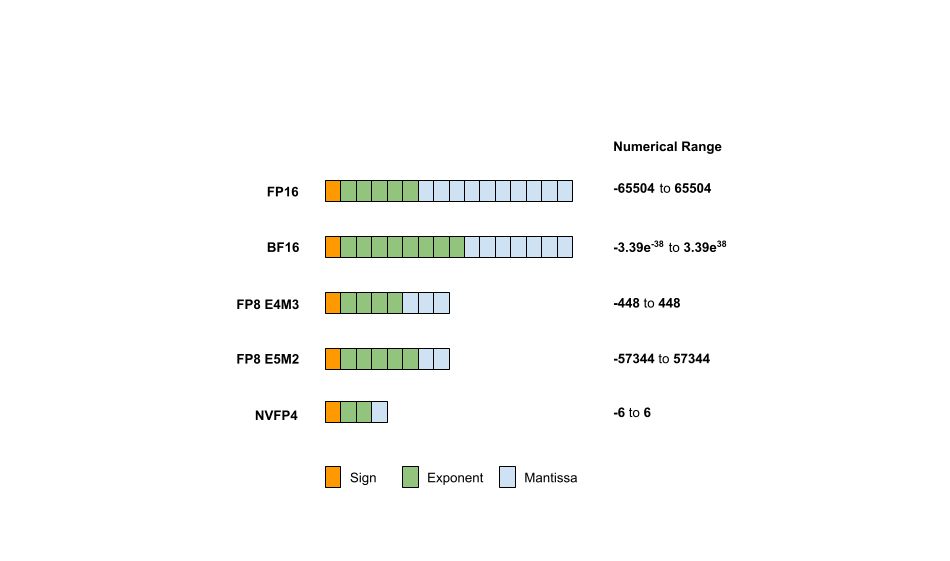
.jpg?format=webp)