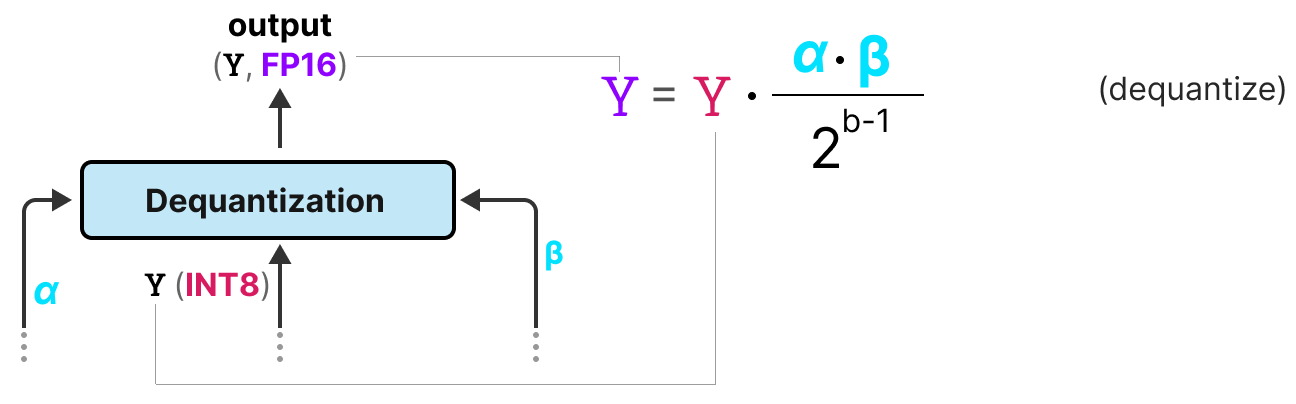
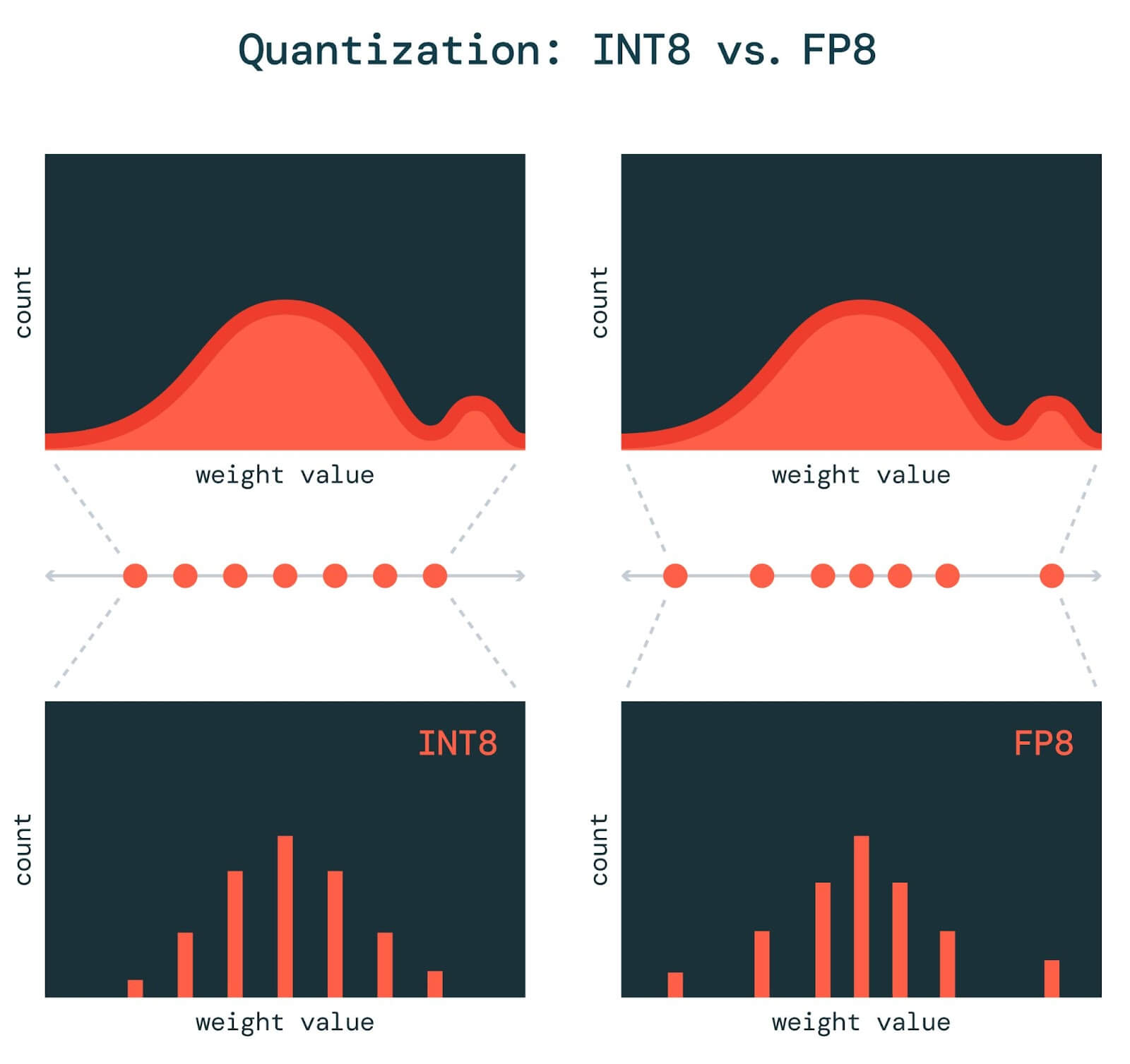
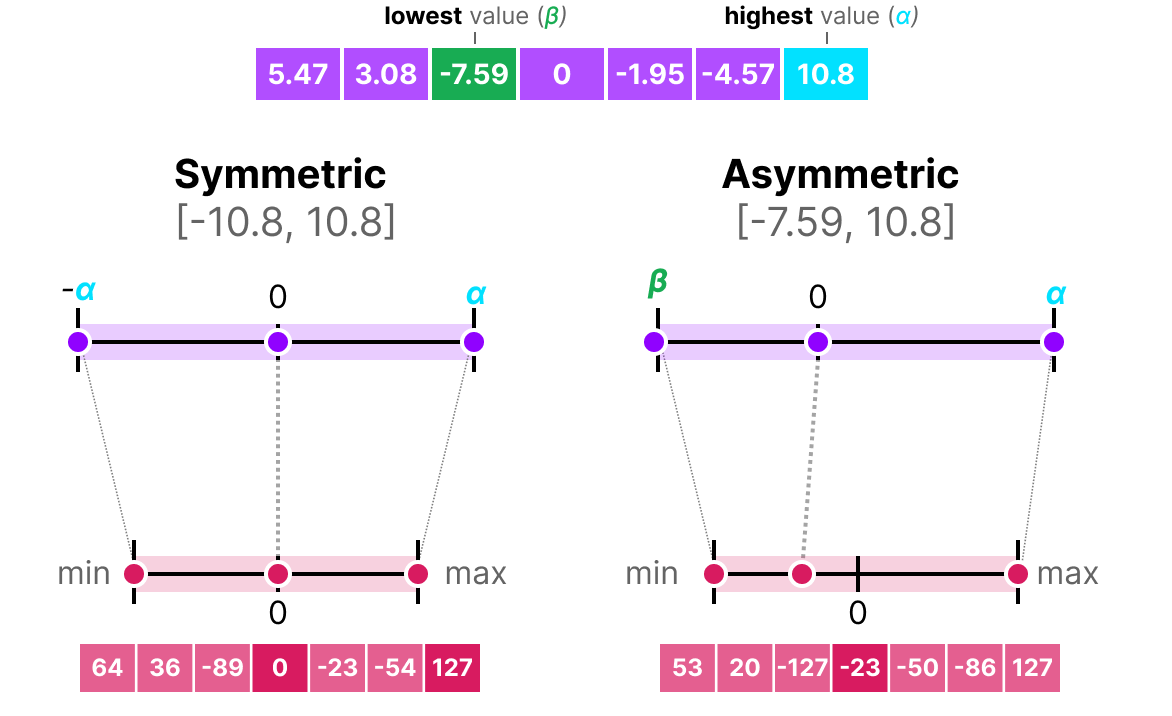
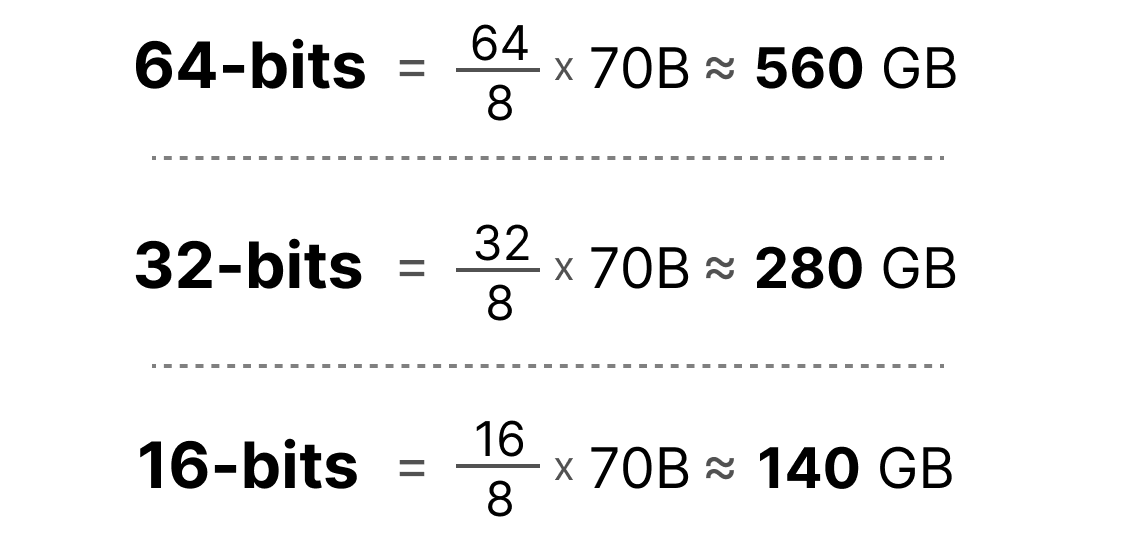Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
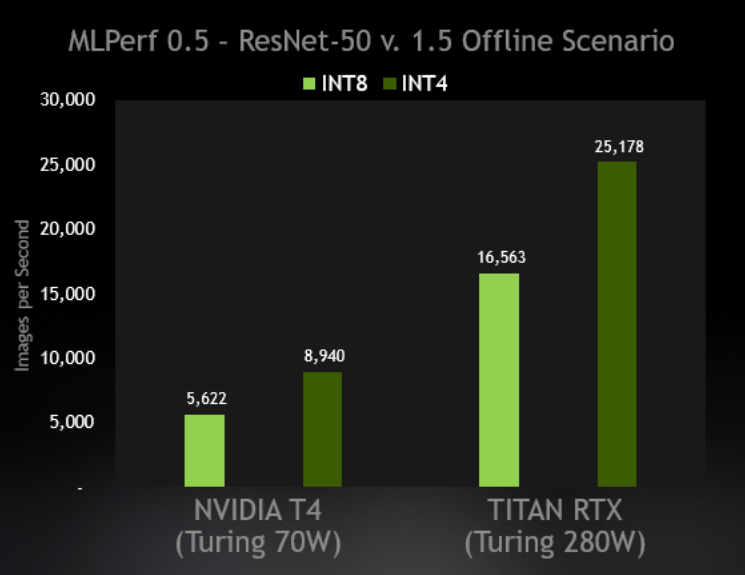
CUTLASS INT4 vs. INT8 GEMM performance comparison across different ...
int4 vs int8 vs uuid vs numeric performance on bigger joins
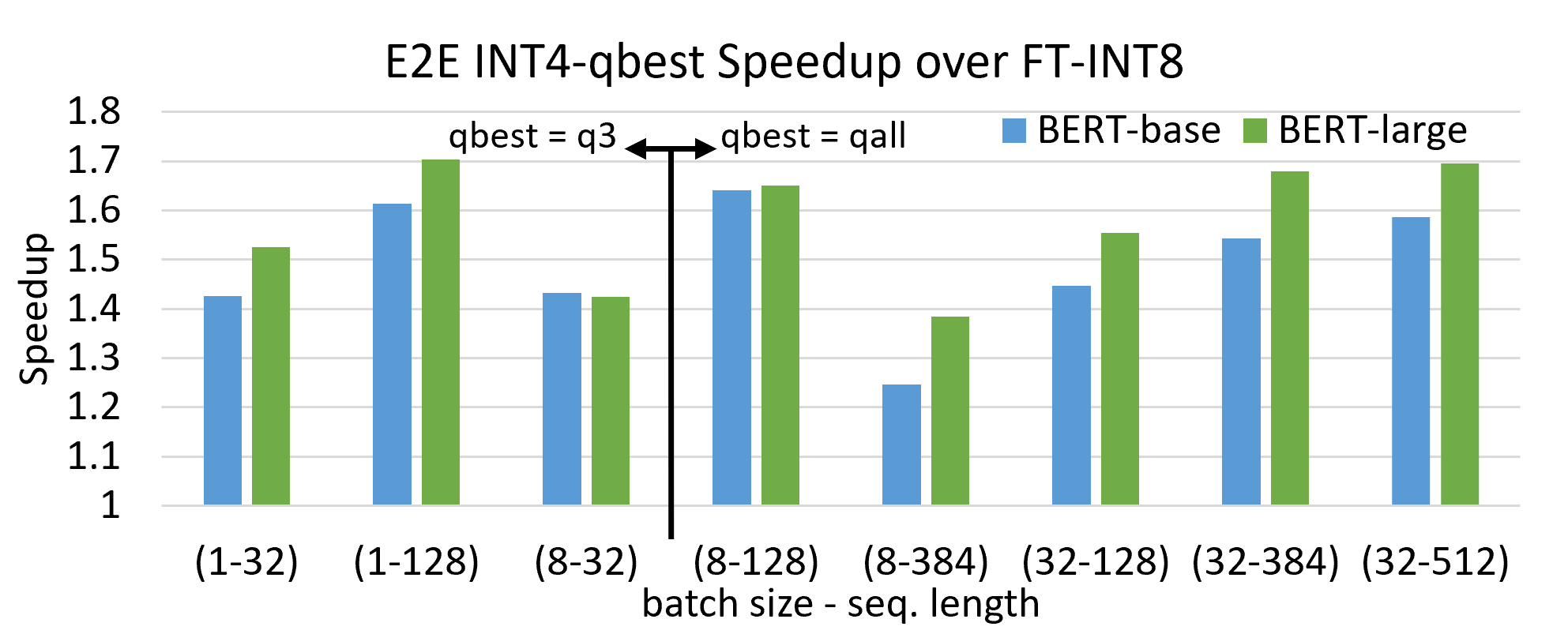
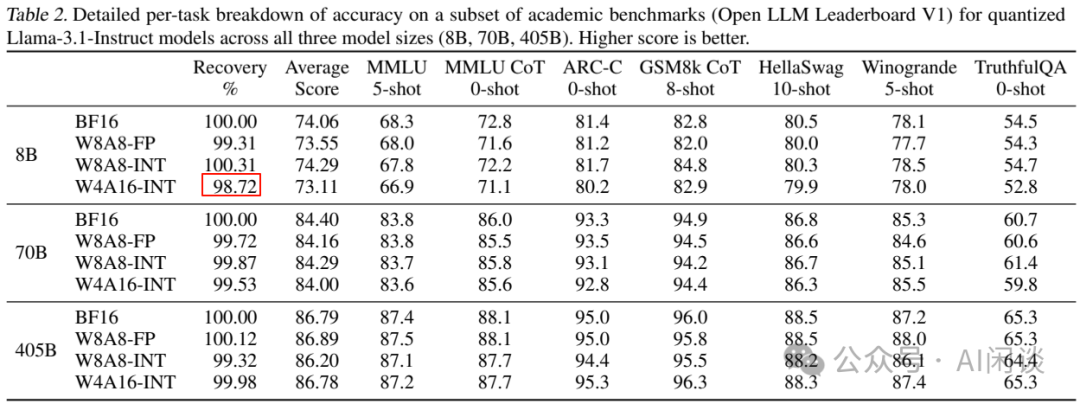
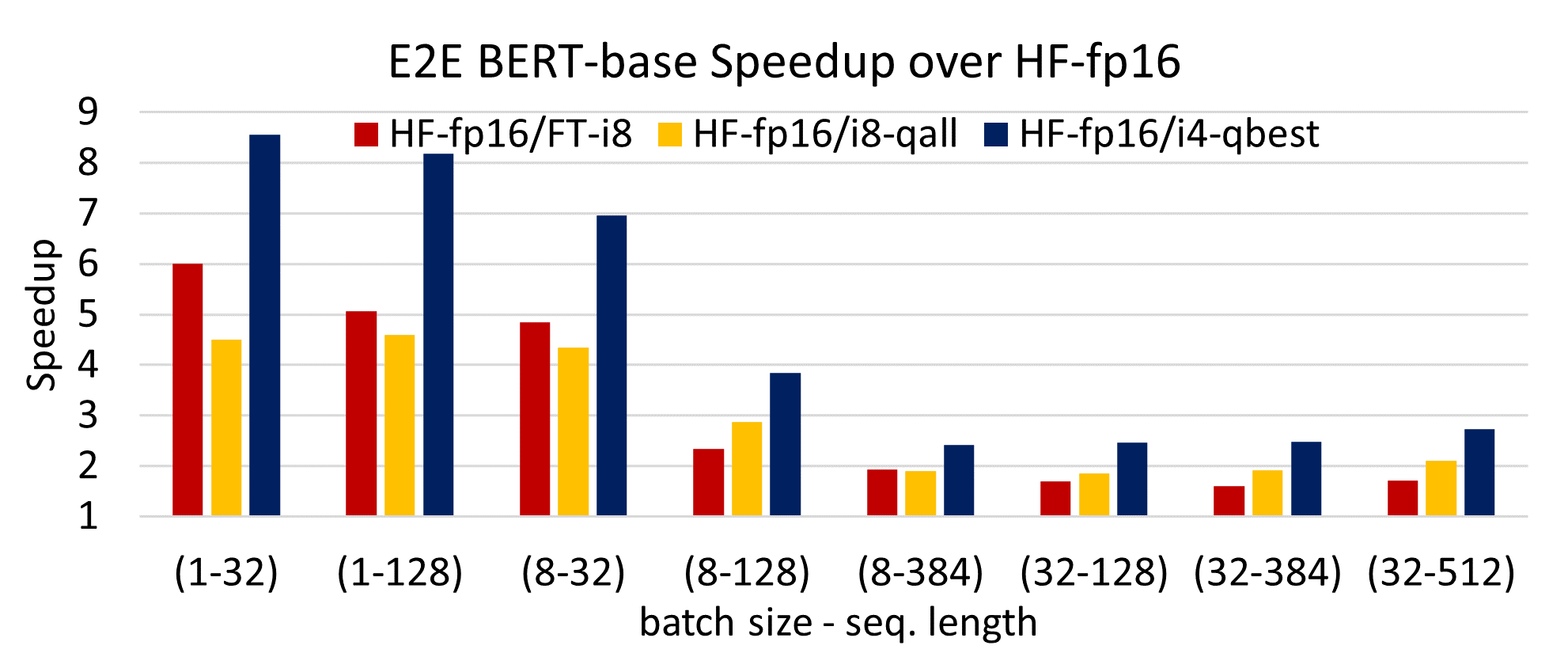
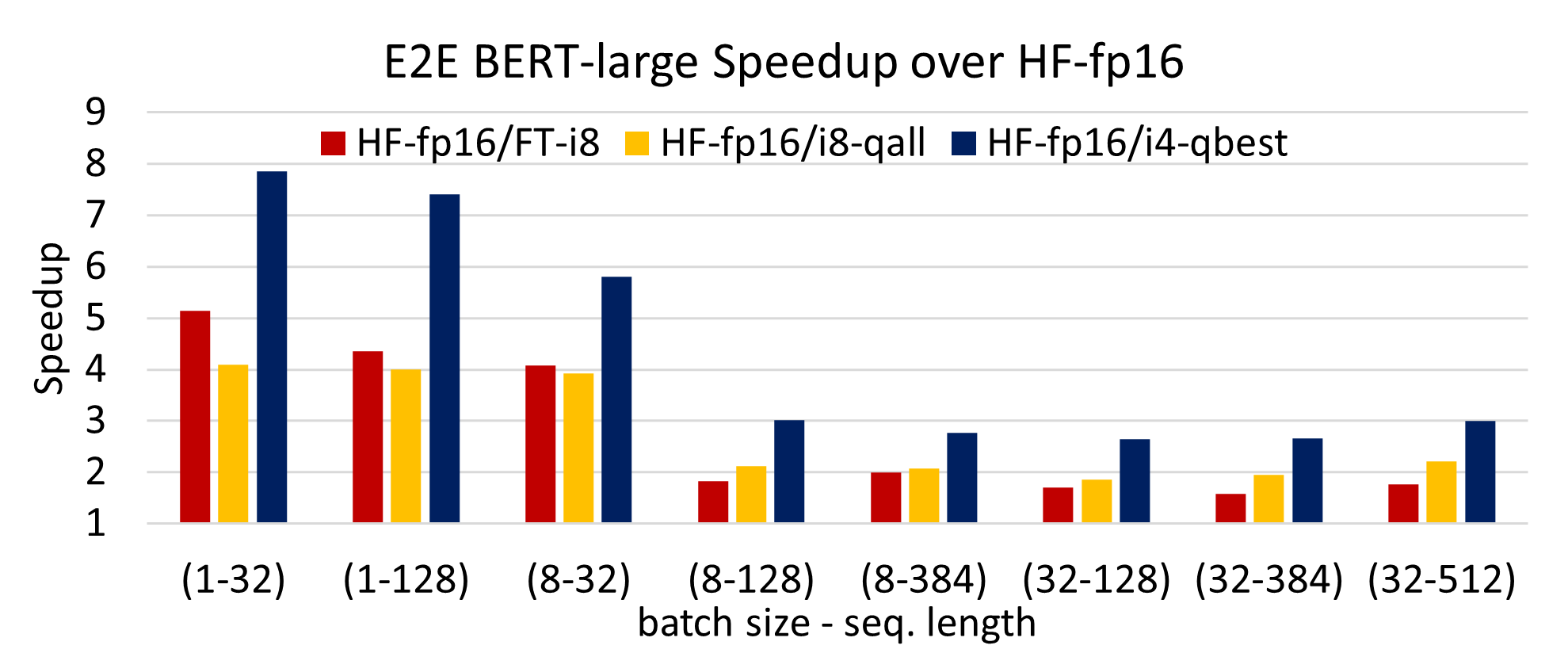
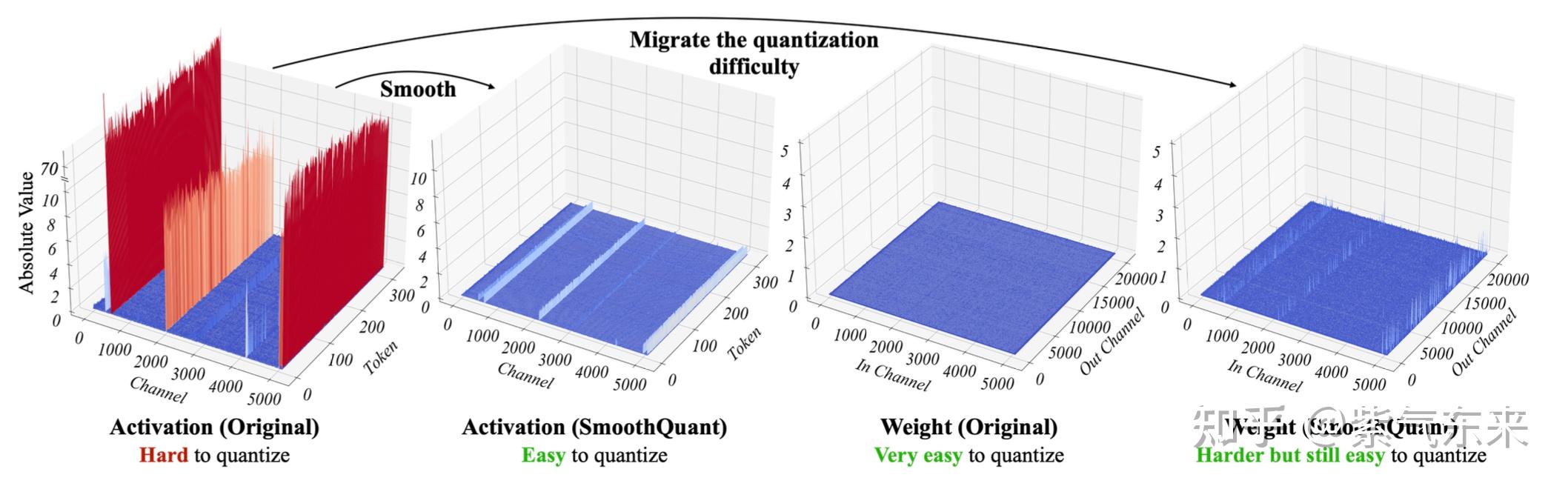
E2E latency speedup of (a) our INT4 over INT8 with all four parts ...
面试官:为什么需要量化,为什么 int4 / int8 量化后大模型仍能保持性能? - 知乎
INT8 and INT4 Quantization ValueError · Issue #35 · moojink/openvla-oft ...
microsoft/Phi-3.5-mini-instruct-onnx · DirectML INT4 and INT8 AWQ model ...
Can vllm support quantized INT4 and INT8 models? Whether there is a ...
KV Cache INT8 and INT4 quantization precision reduction · Issue #772 ...
Could you upload the INT4 quantization and INT8 quantization model to ...
LLM 推理量化评估:FP8、INT8 与 INT4 的全面对比_int4和fp8-CSDN博客
[RFC][Tensorcore] INT4 end-to-end inference - pre-RFC - Apache TVM Discuss
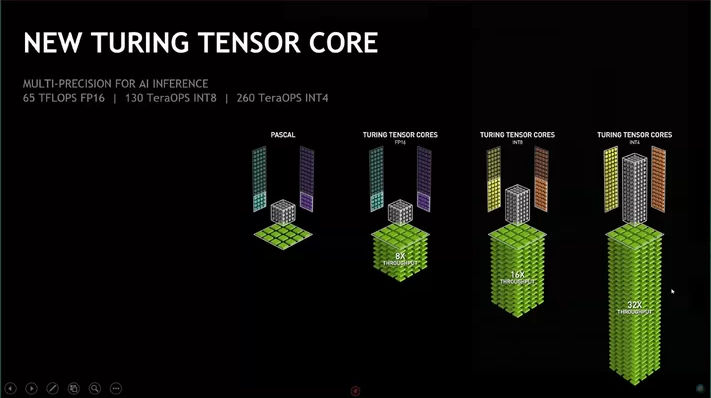
Int4 Precision for AI Inference | NVIDIA Technical Blog
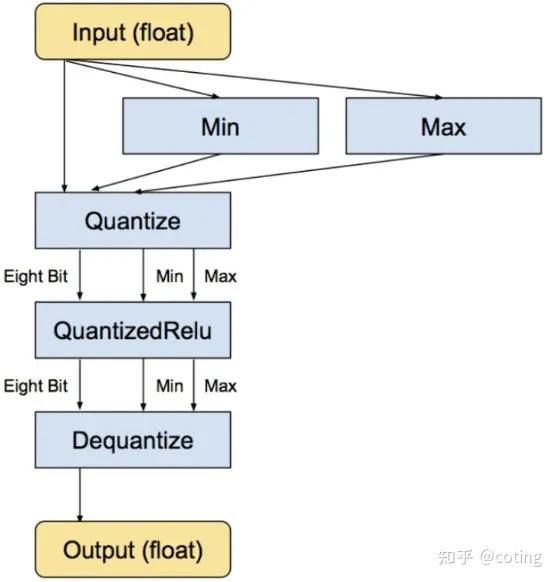
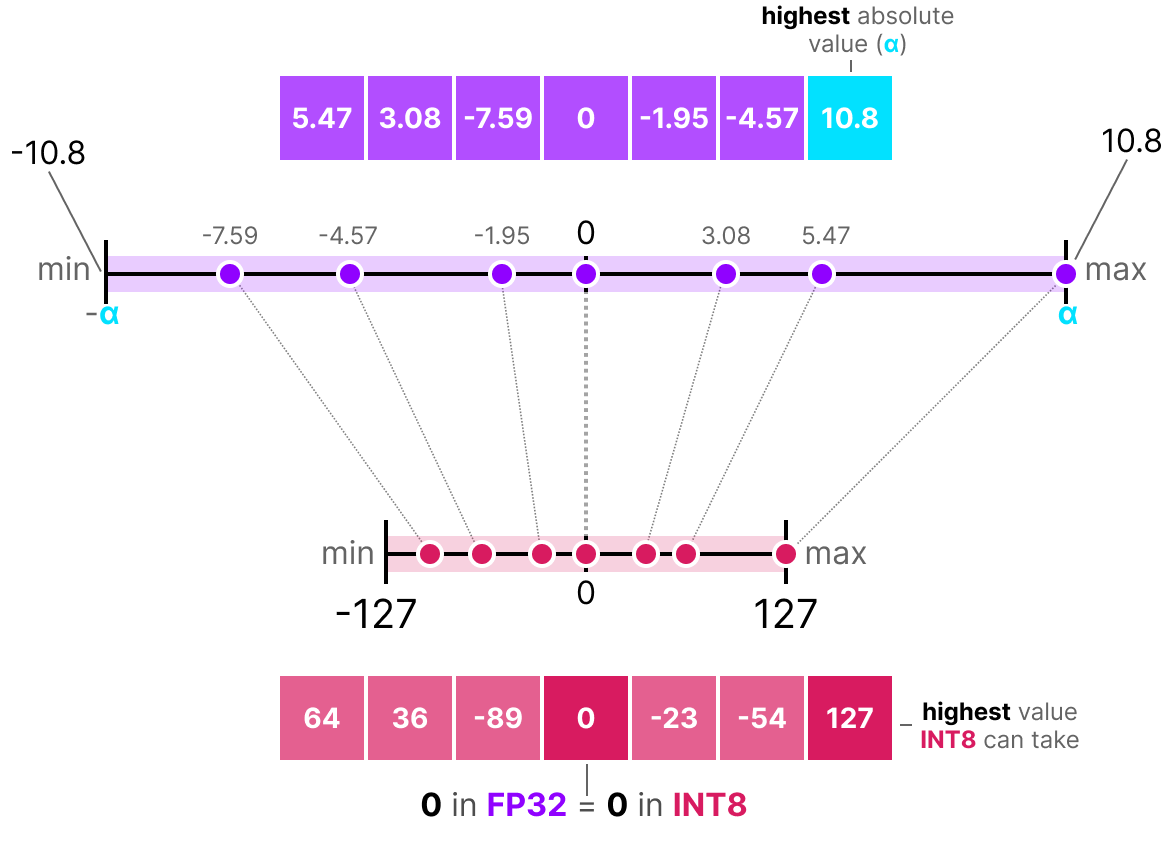
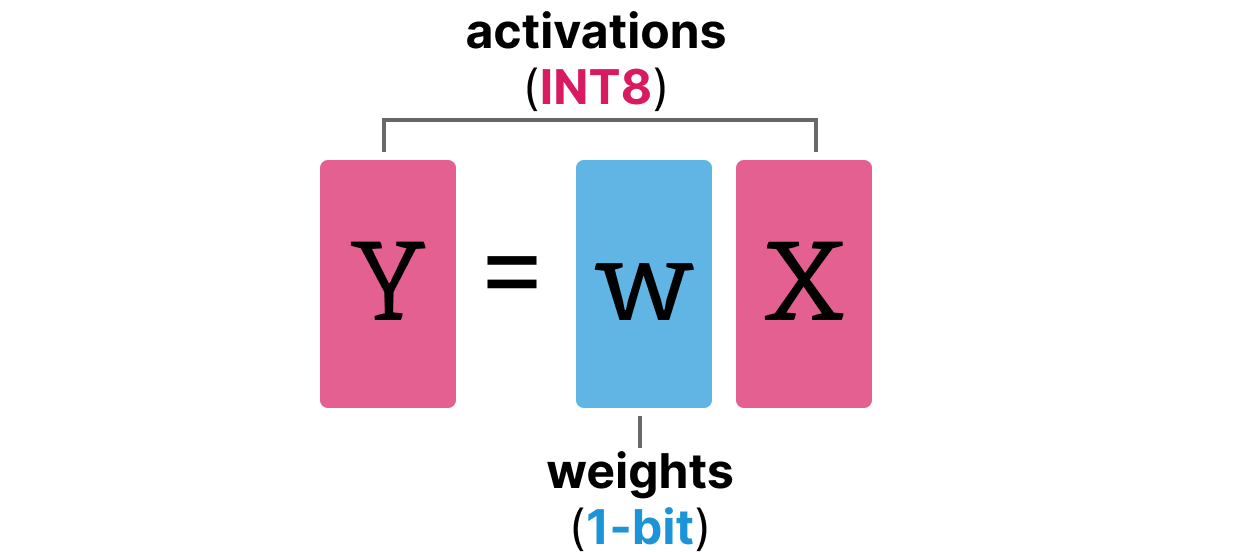
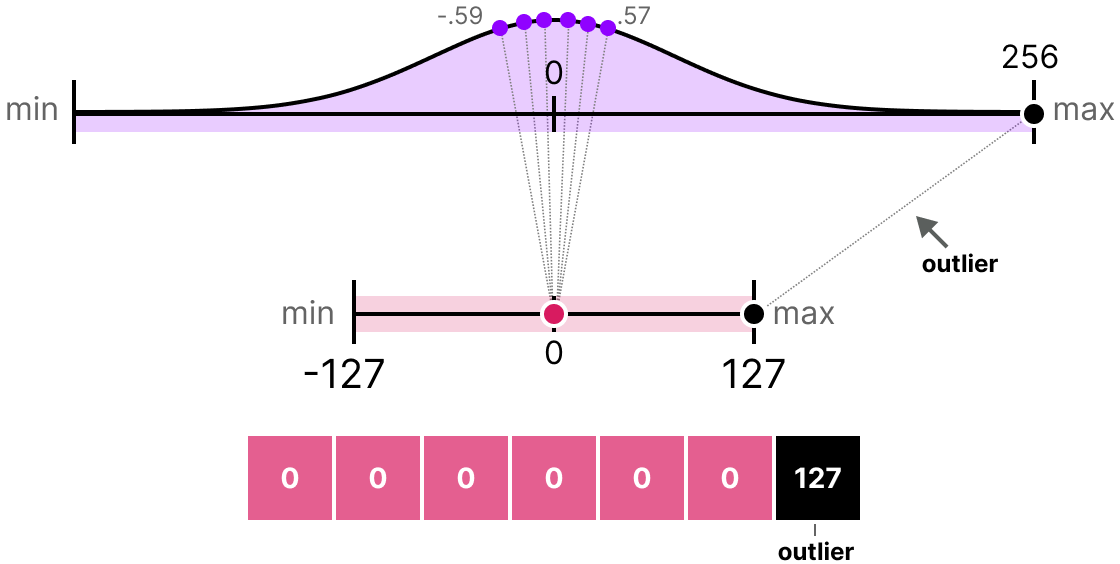
INT8, INT4 and Other Integer Types for Quantization
[2301.12017] Understanding INT4 Quantization for Language Models ...
[2303.17951] FP8 versus INT8 for efficient deep learning inference
stepfun-ai/Step-3.5-Flash-Int4 · INT8 quantization for KVCache on DGX ...
Why INT4 is presented as performance of GPUs? - Deep Learning - fast.ai ...
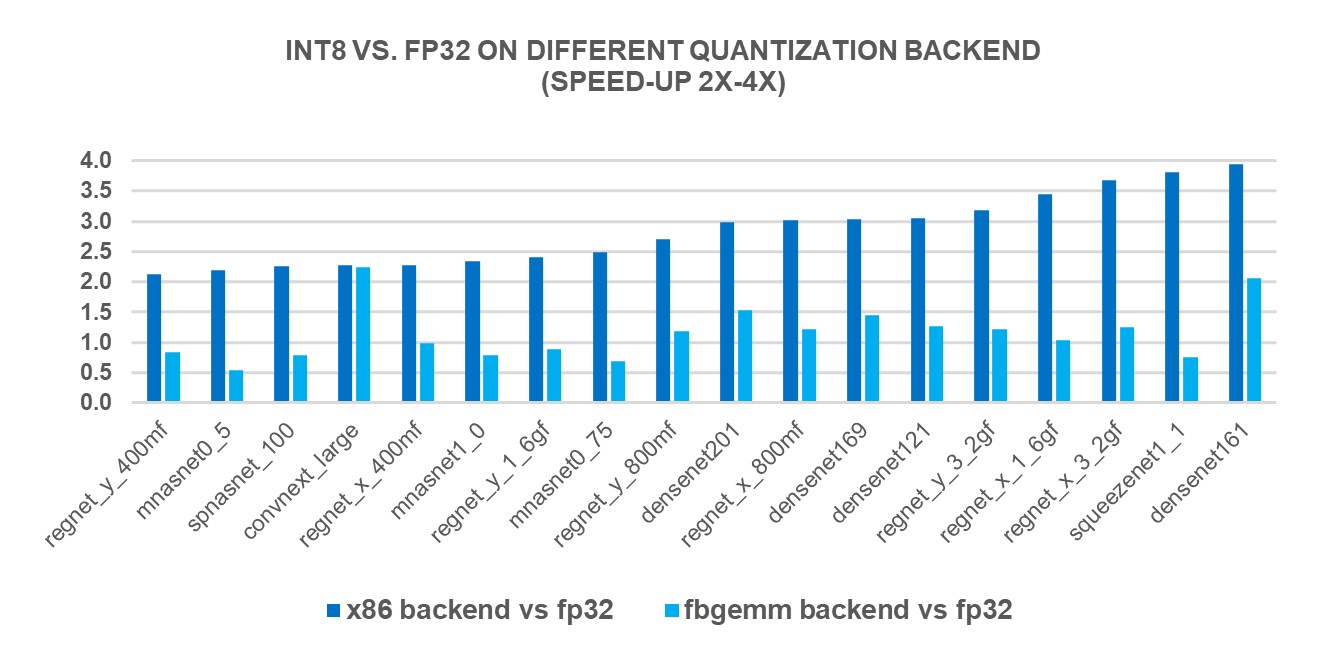
INT8 Quantization for x86 CPU in PyTorch | PyTorch
LLM 推理量化评估:FP8、INT8 与 INT4 的全面对比 - 知乎
[QST] INT8 (and potentially INT4) Convolution Kernel with Additional ...
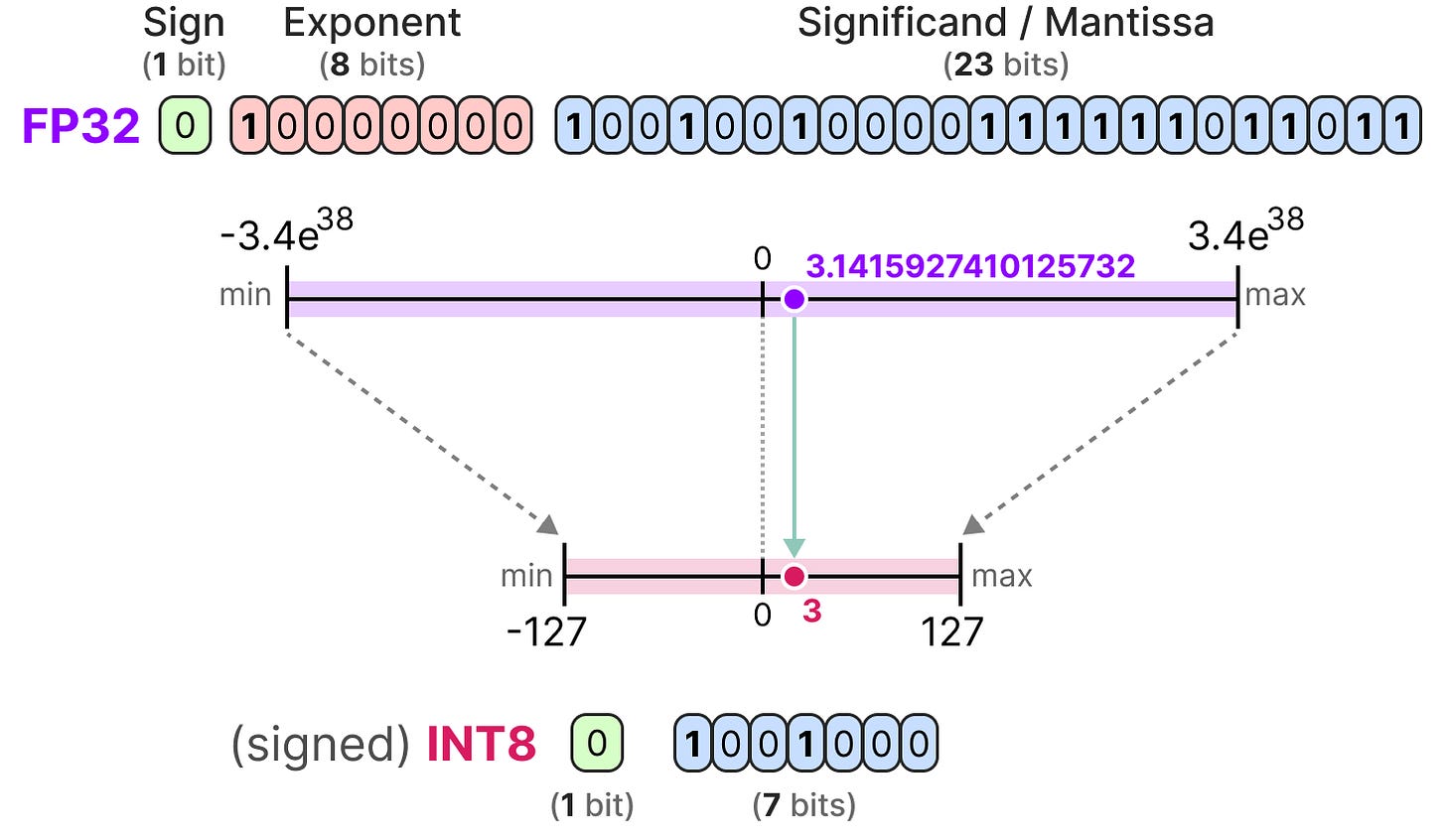
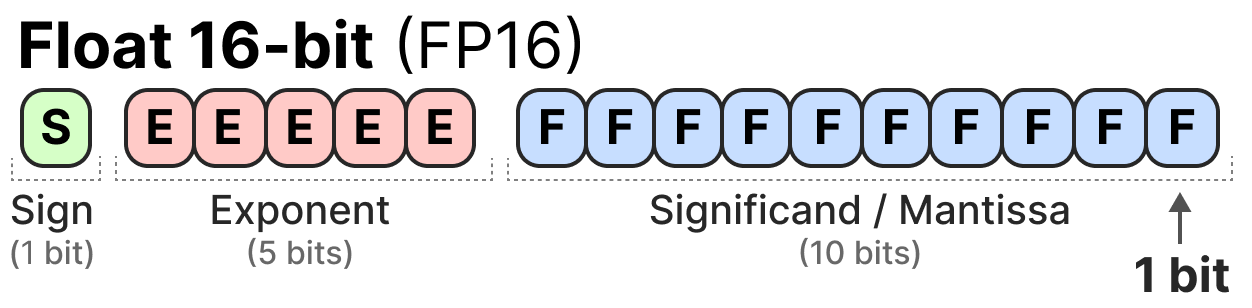
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
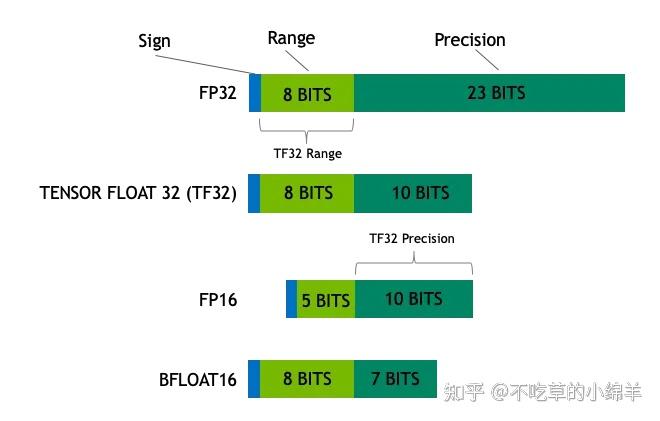
Precision Comparison: FP64 FP32 FP16 TF32 BF16 INT8
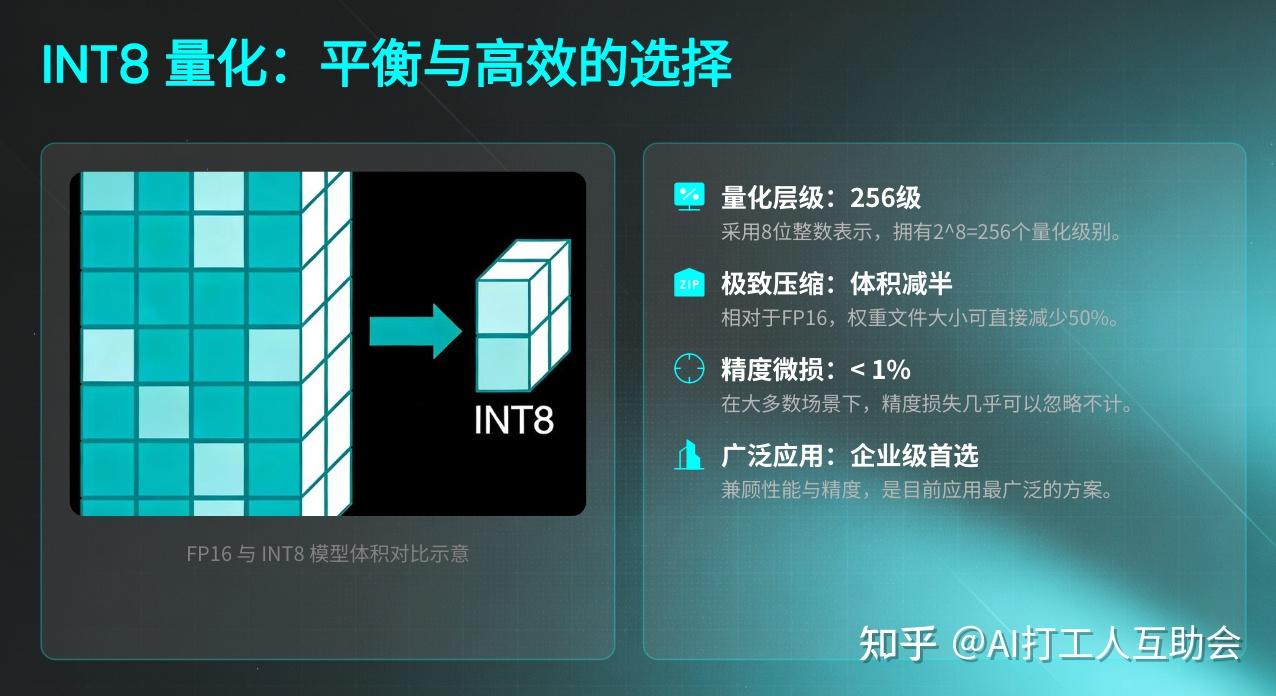
大语言模型的模型量化(INT8/INT4)技术-CSDN博客
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
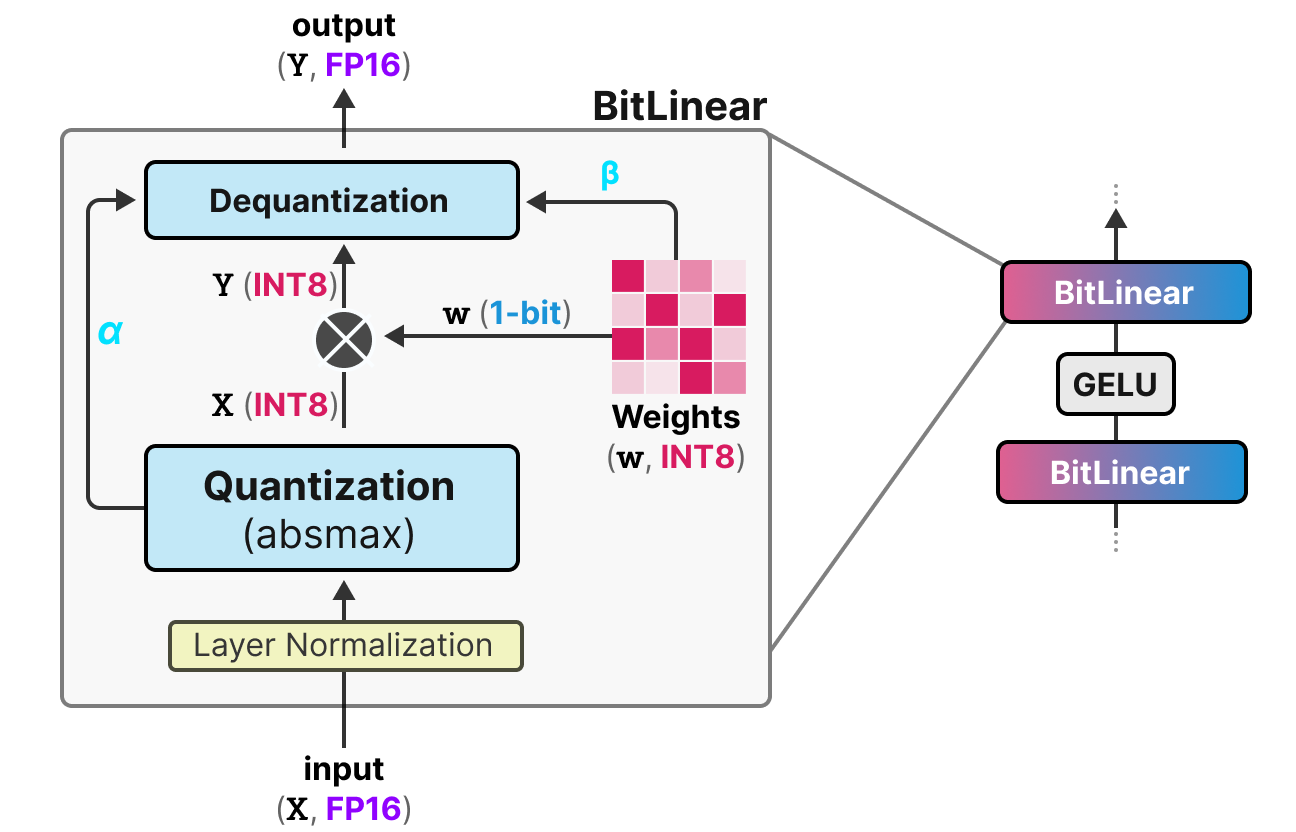
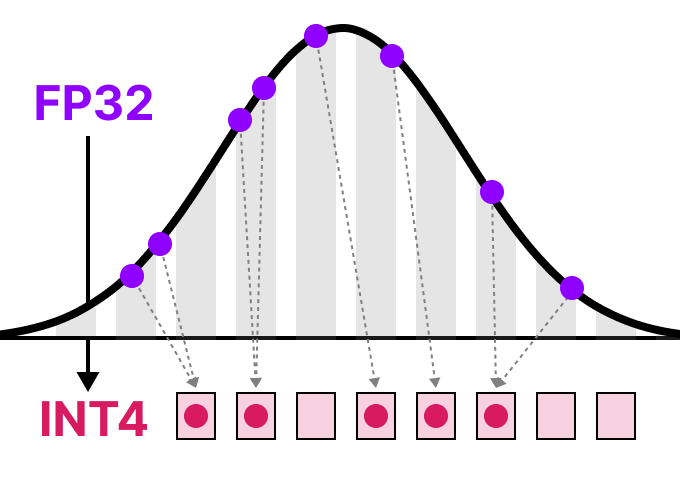
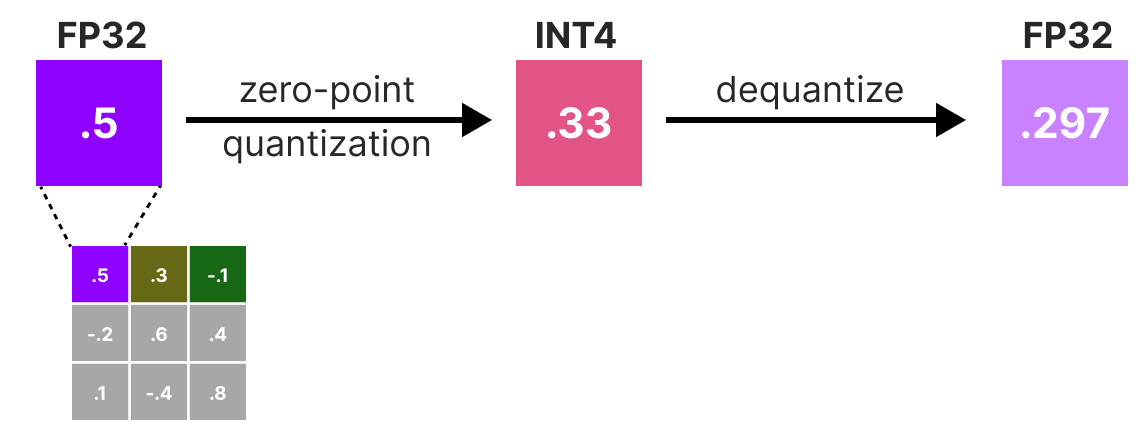
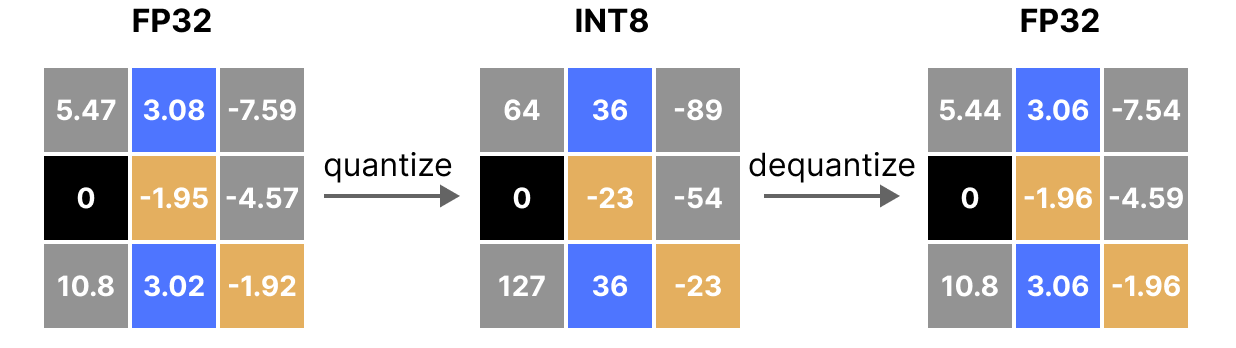
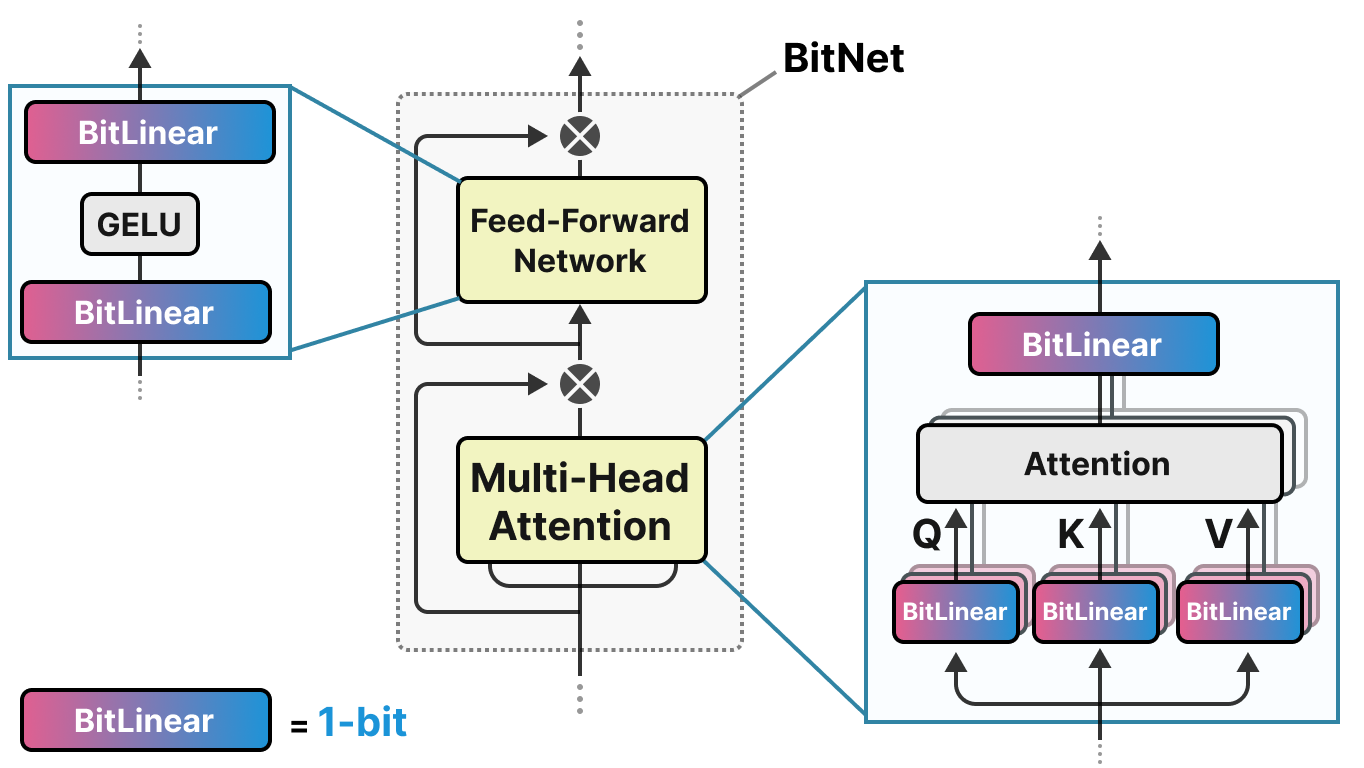
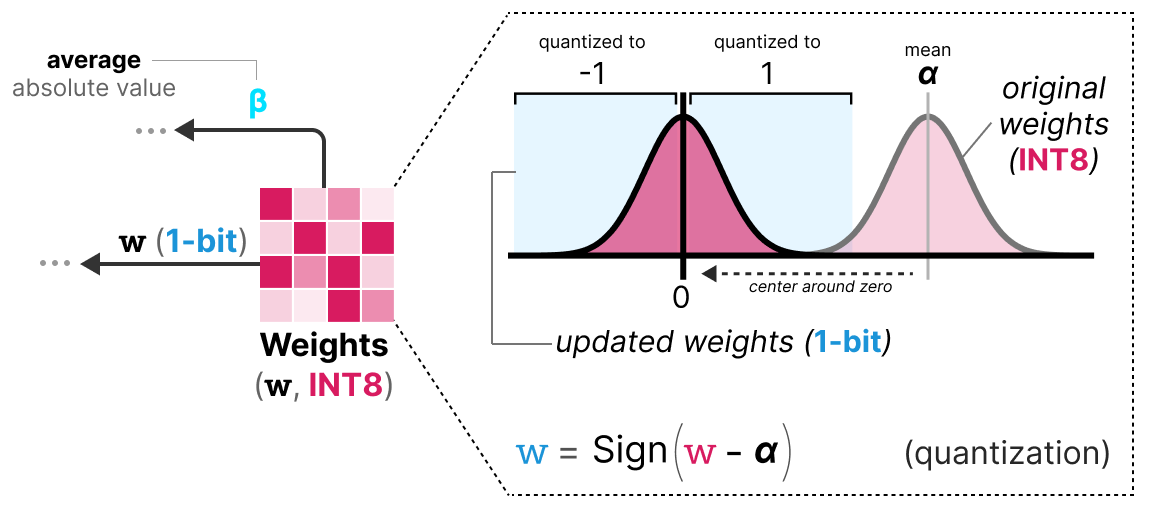
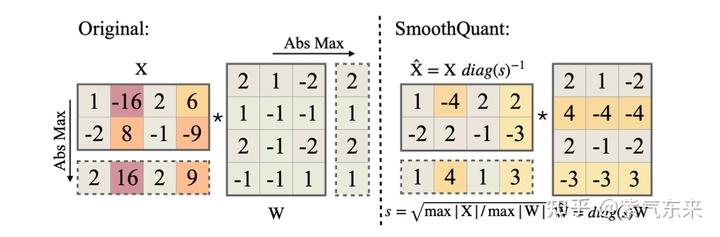
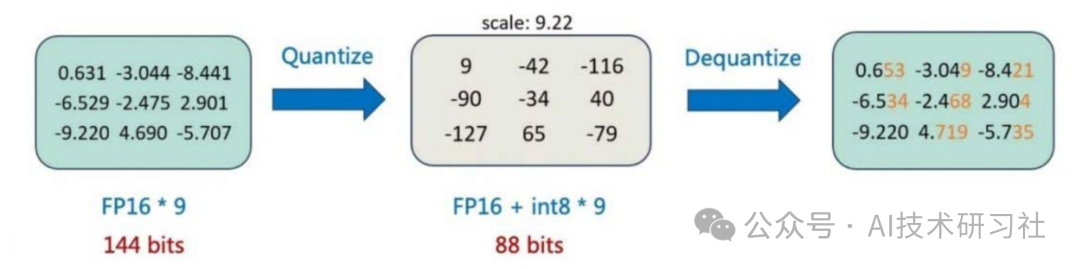
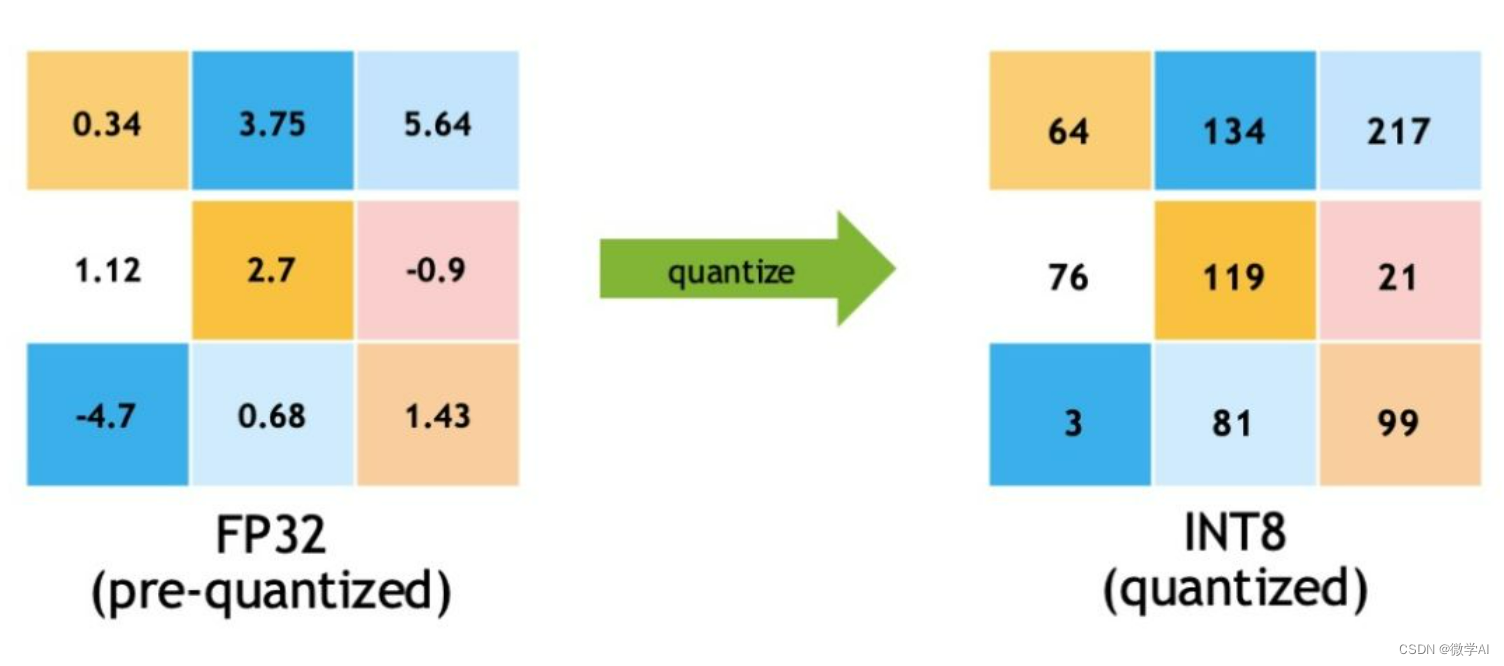
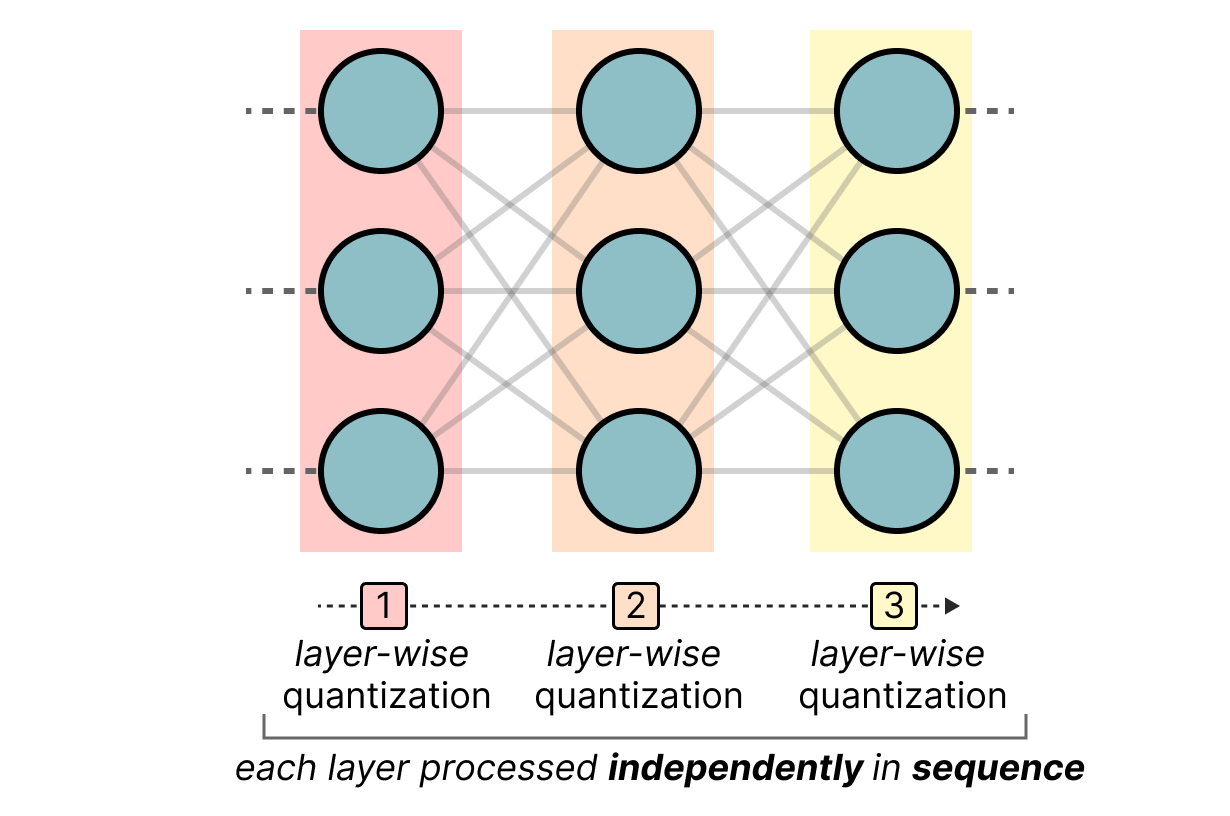
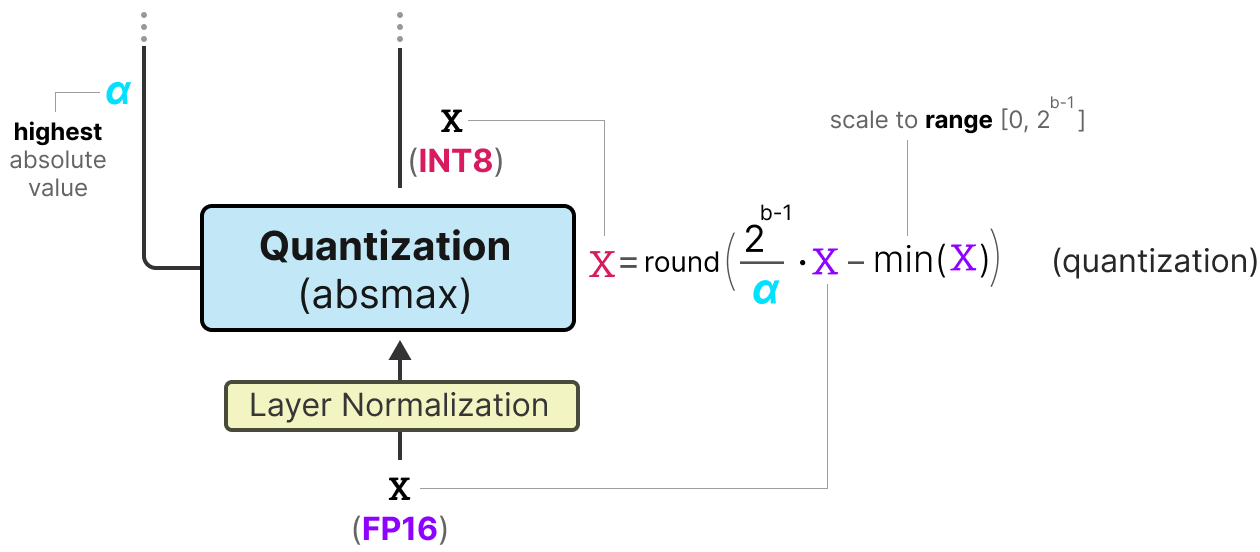
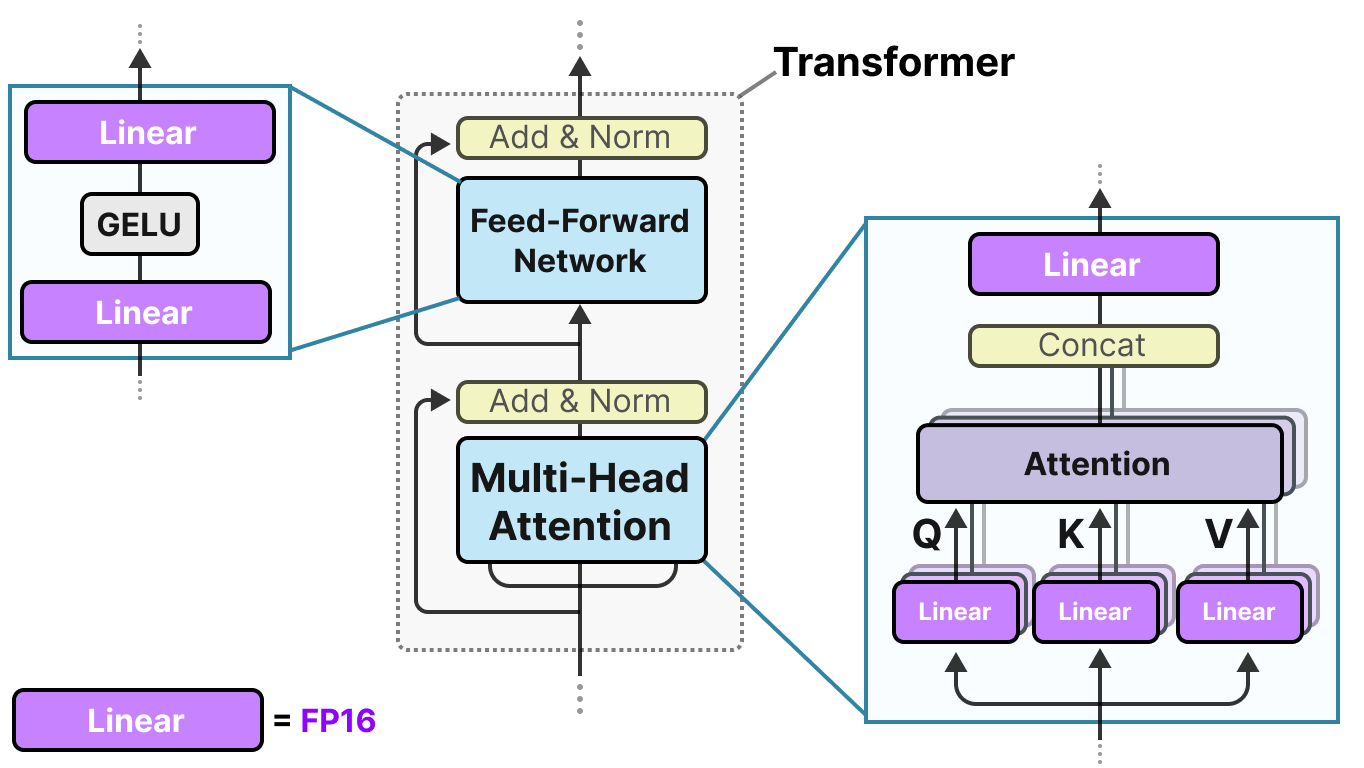
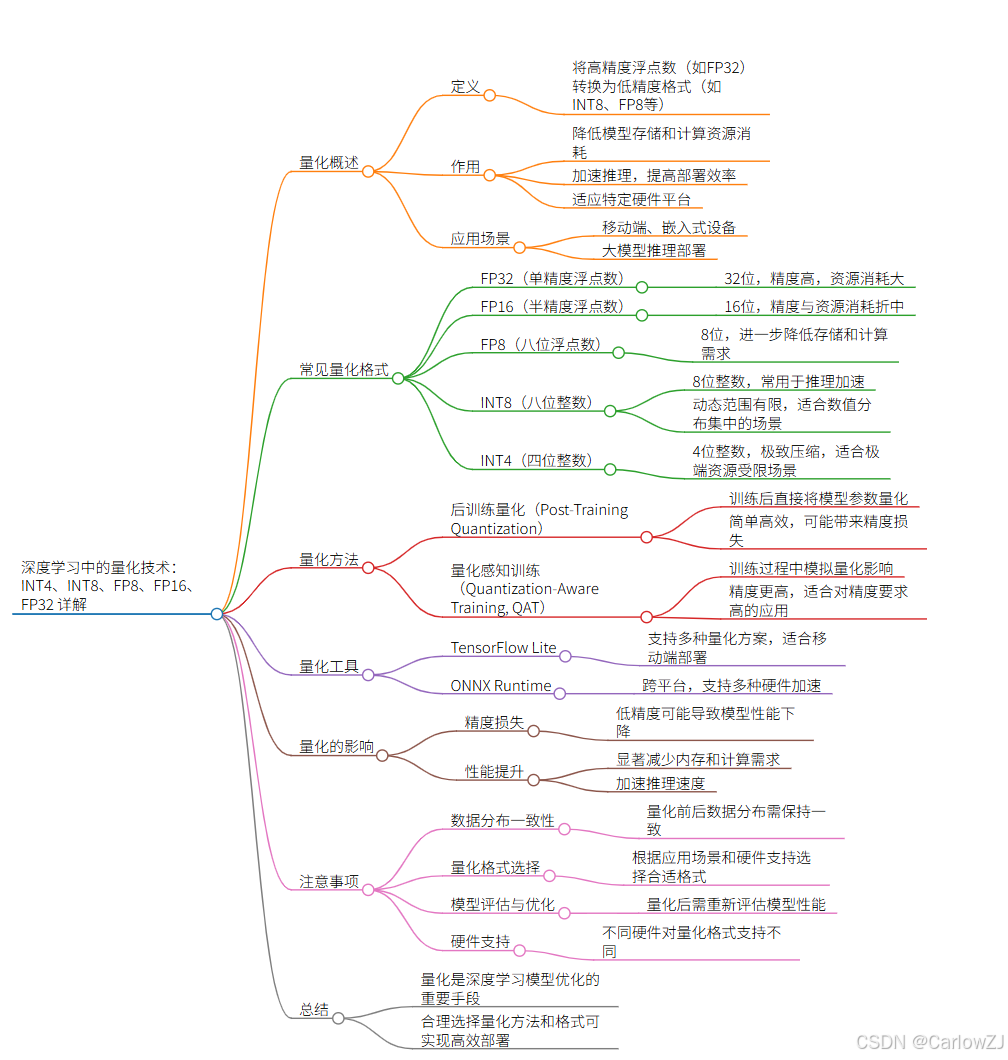
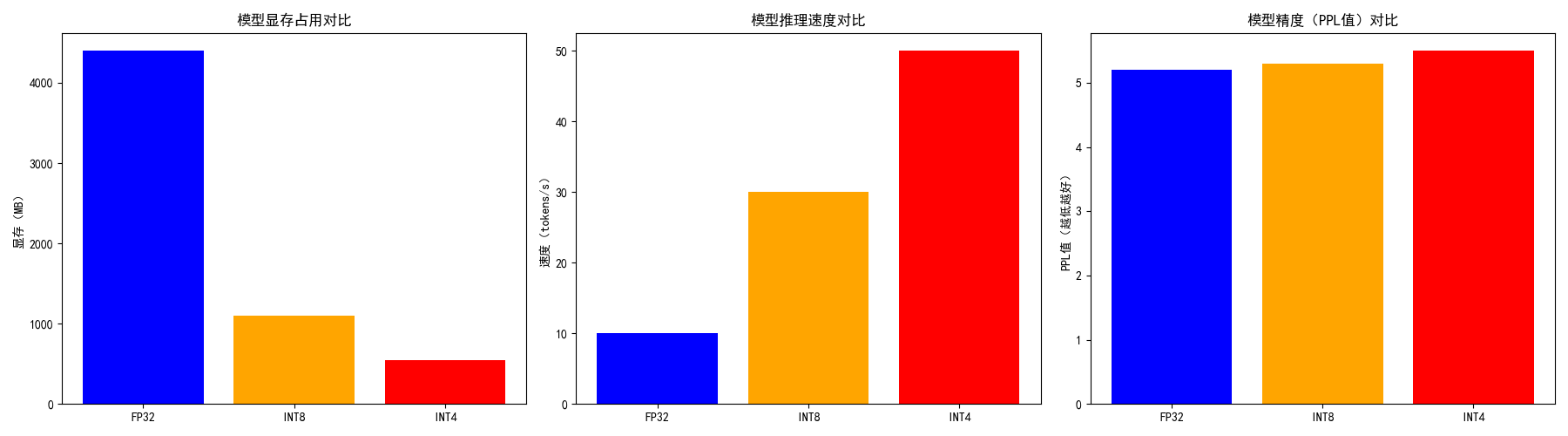
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
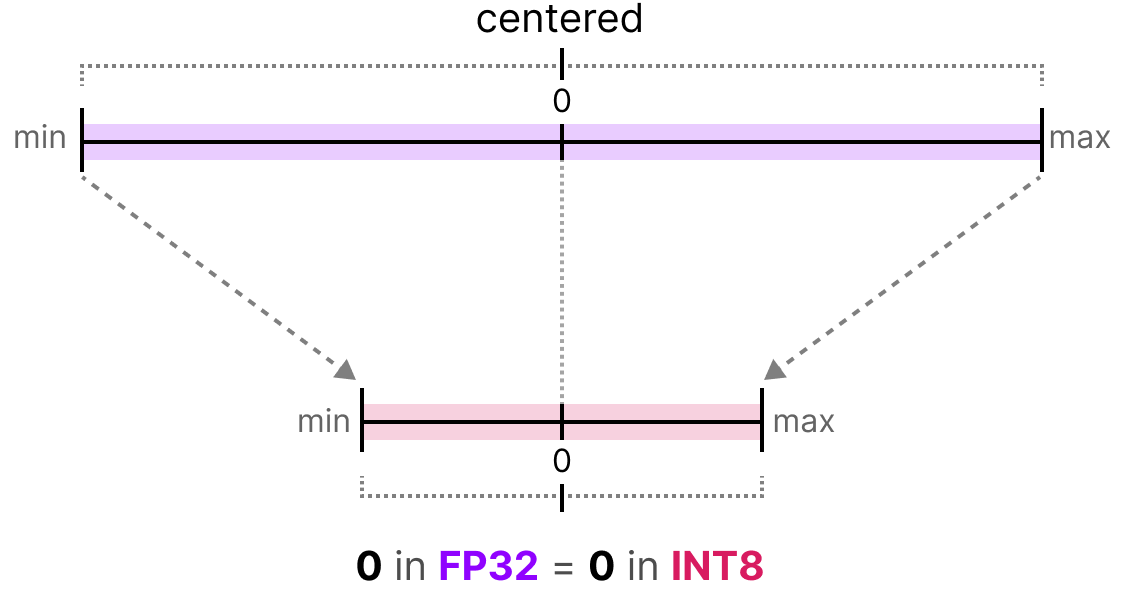
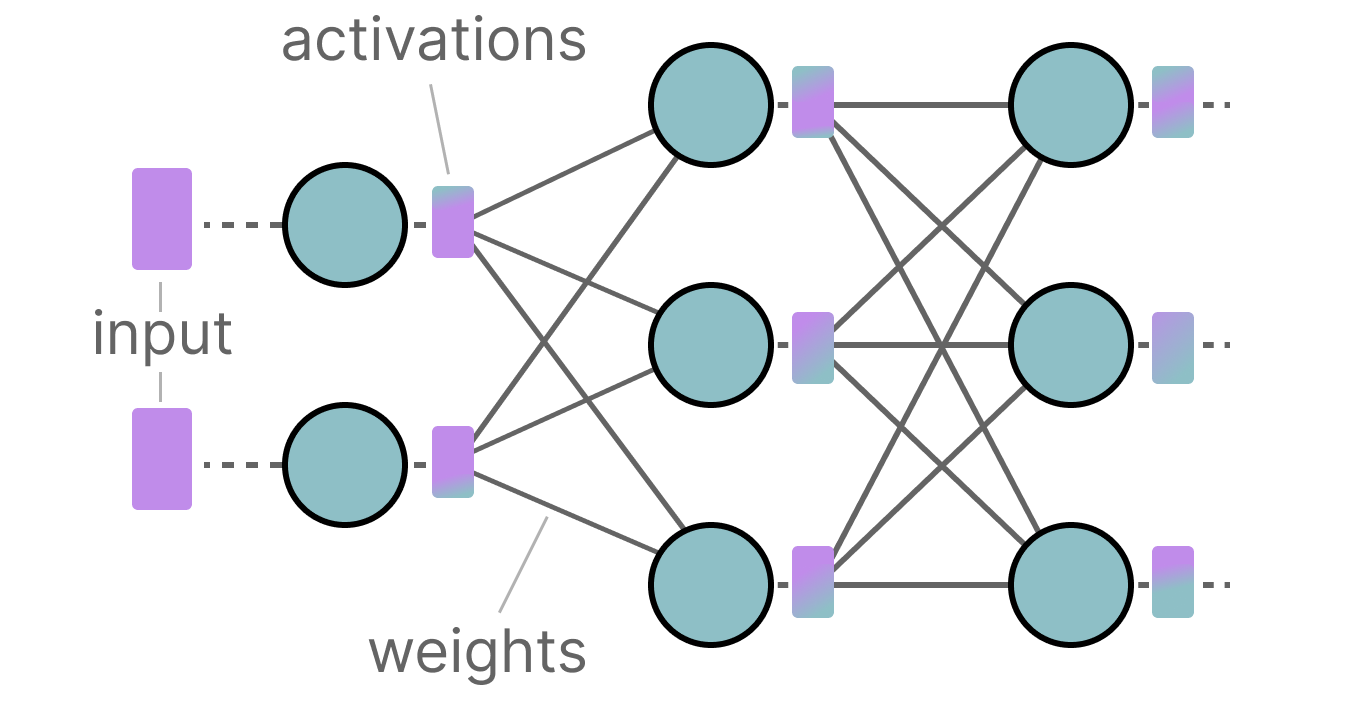
Understanding data types
FP32, BF16,int8, int4的区别 - 知乎
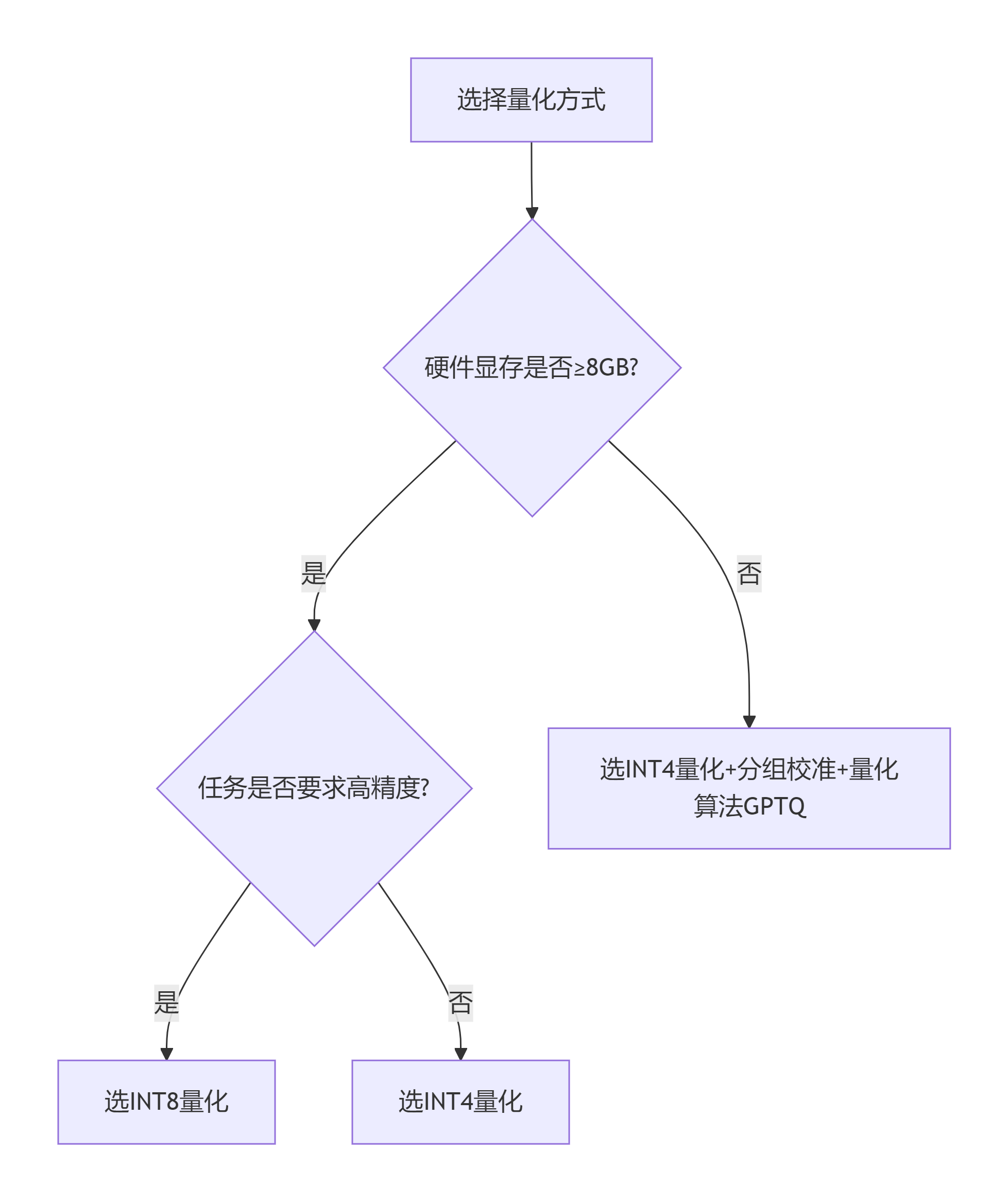
大模型量化部署进阶:从 INT8/INT4 原理到高性能推理实战 - 知乎
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度_风闻
大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析_顺其自然~-MCP技术社区
【科普】大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析 - 墨天轮
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
小白也能懂!INT4、INT8、FP8、FP16、FP32量化 - 53AI-AI知识库|企业AI知识库|大模型知识库|AIHub
LLM(十一):大语言模型的模型量化(INT8/INT4)技术 - 知乎
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
Model Memory Requirements Explained: How FP32, FP16, BF16, INT8, and ...
大模型应用:大模型量化:INT4与INT8核心差异、选型指南及代码实现.53-腾讯云开发者社区-腾讯云
模型量化大揭秘:INT8、INT4量化对推理速度和精度的影响测试-腾讯云开发者社区-腾讯云
用于量化的INT8、INT4及其他整数类型
小白也能懂!INT4、INT8、FP8、FP16、FP32量化_独钓渔的技术博客_51CTO博客
README.md · pytorch/Phi-4-mini-instruct-INT8-INT4 at main
iOS 和 swift 中常见的 Int、Int8、Int16、Int32和 Int64介绍「建议收藏」-腾讯云开发者社区-腾讯云
Quantization INT8/INT4 — Ít bit hơn, nhỏ hơn 8x, vẫn chính xác | Trồi Sinh
mysql - Difference between "int" and "int(2)" data types - Stack Overflow
高性能 LLM 推理框架的设计与实现-51CTO.COM
模型量化大揭秘:INT8、INT4量化对推理速度和精度的影响测试 - 技术栈
README.md · larryliu0820/Qwen3-0.6B-INT8-INT4-ExecuTorch-XNNPACK at main
大模型应用:大模型量化:INT4与INT8核心差异、选型指南及代码实现.53-阿里云开发者社区
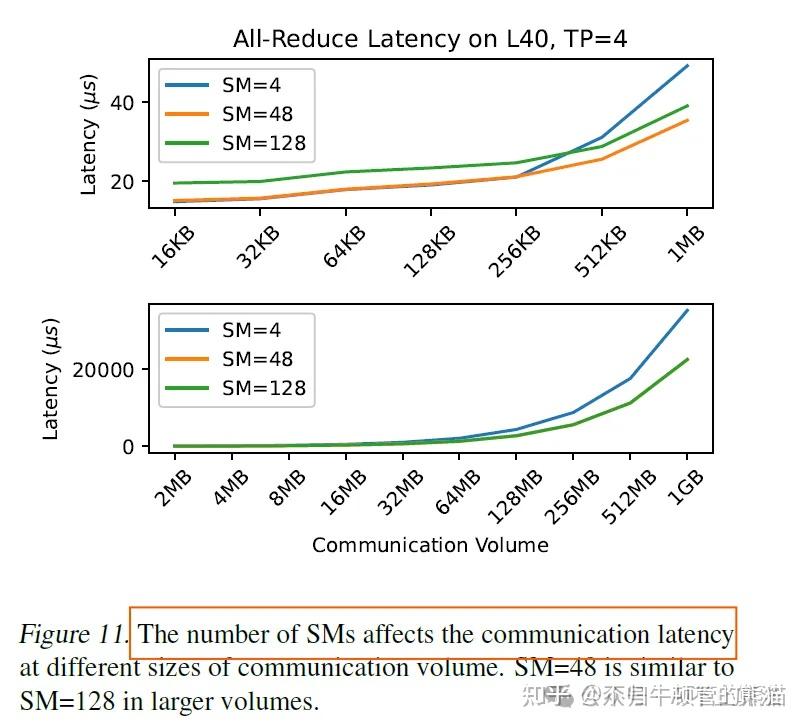
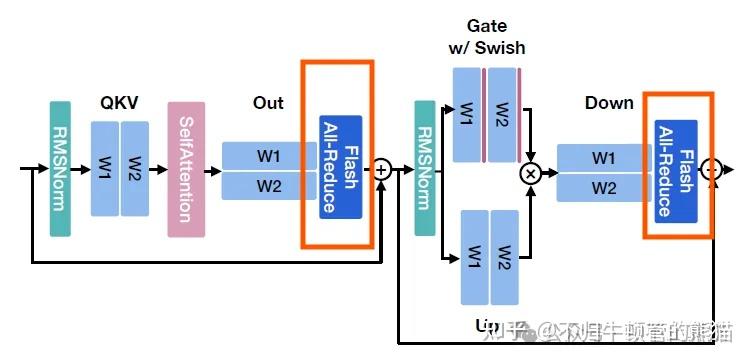
大模型通信算子--int8/int4 custom AllReduce kernel的动机、挑战和设计 - 知乎
深度学习中的量化技术:INT4、INT8、FP8、FP16、FP32 详解-CSDN博客
大模型应用:大模型量化:INT4与INT8核心差异、选型指南及代码实现.53_未闻花名AI的技术博客_51CTO博客
Quantization Methods for 100X Speedup in Large Language Model Inference
metascroy/Qwen3-4B-int8-int4-unsloth · Hugging Face
【新品发布】正式进入RK3588开源鸿蒙4.0时代 - 触觉智能 - 博客园
[QST] how can i do w4a8 (int4 * int8) using cutlass? · Issue #1370 ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
int4/int8量化后是否支持CPU推理? · Issue #325 · hiyouga/ChatGLM-Efficient-Tuning ...
有没有考虑支持双卡int8的方案,int4毕竟是有一定的精度损失 · Issue #531 · kvcache-ai ...