Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
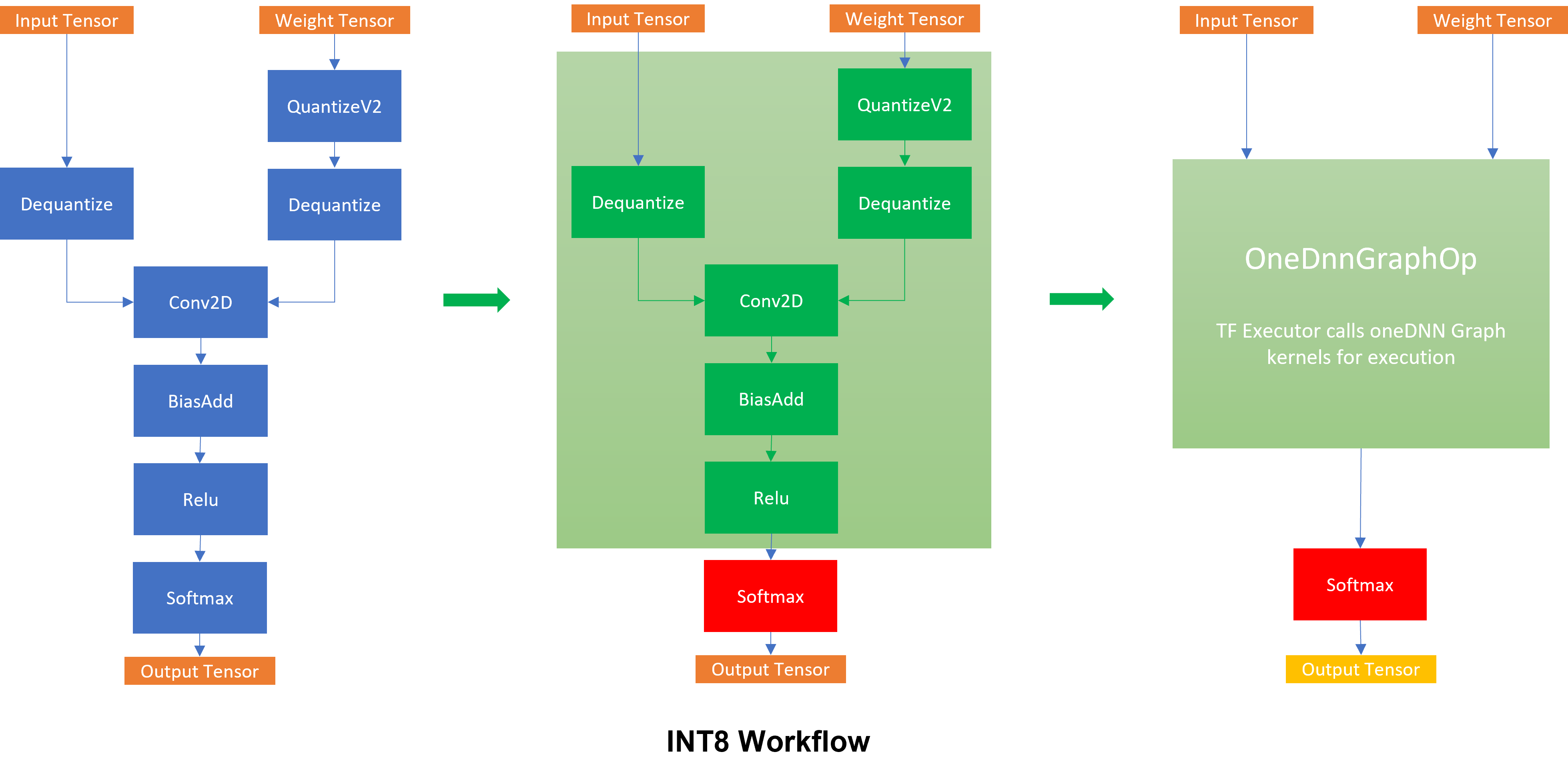
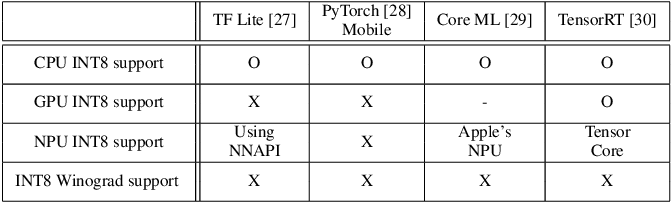
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
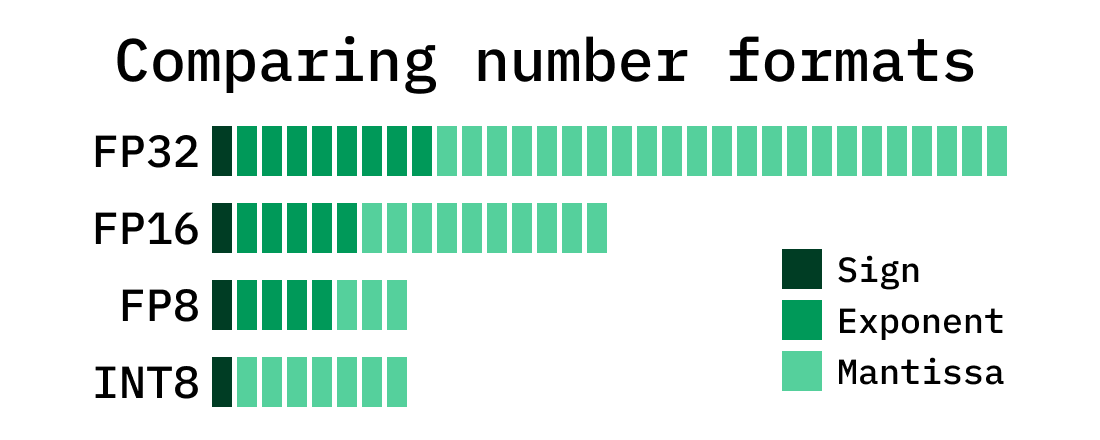
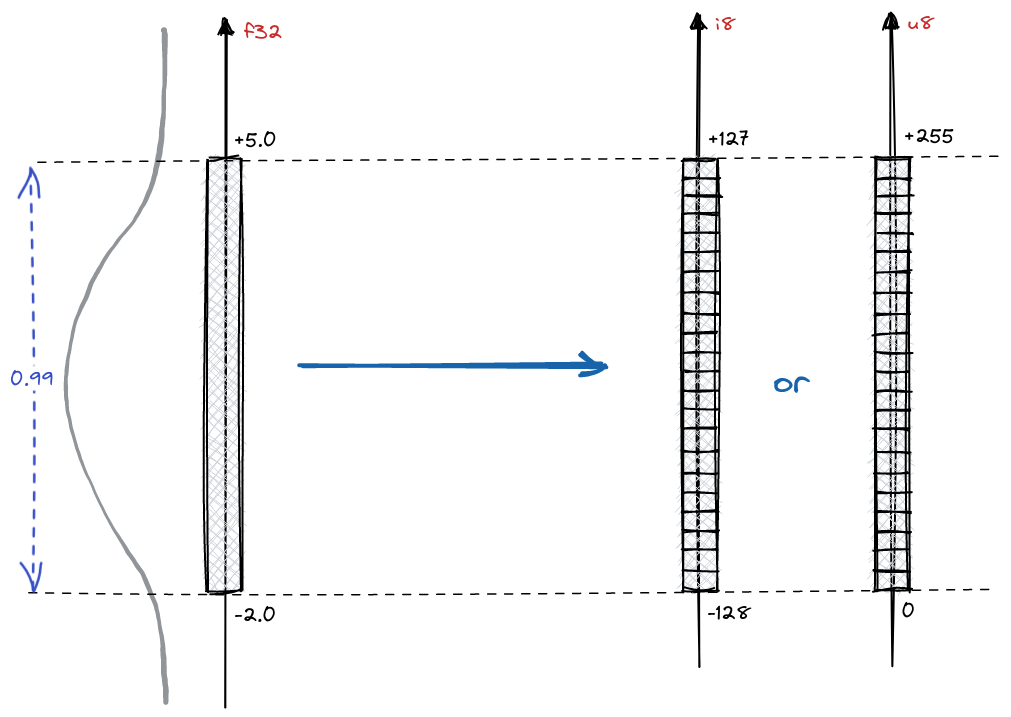
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
YOLOv10 vs. YOLOv11: INT8 Quantization Performance Comparison — Results ...
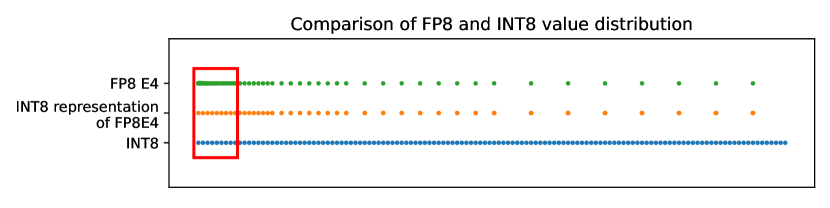
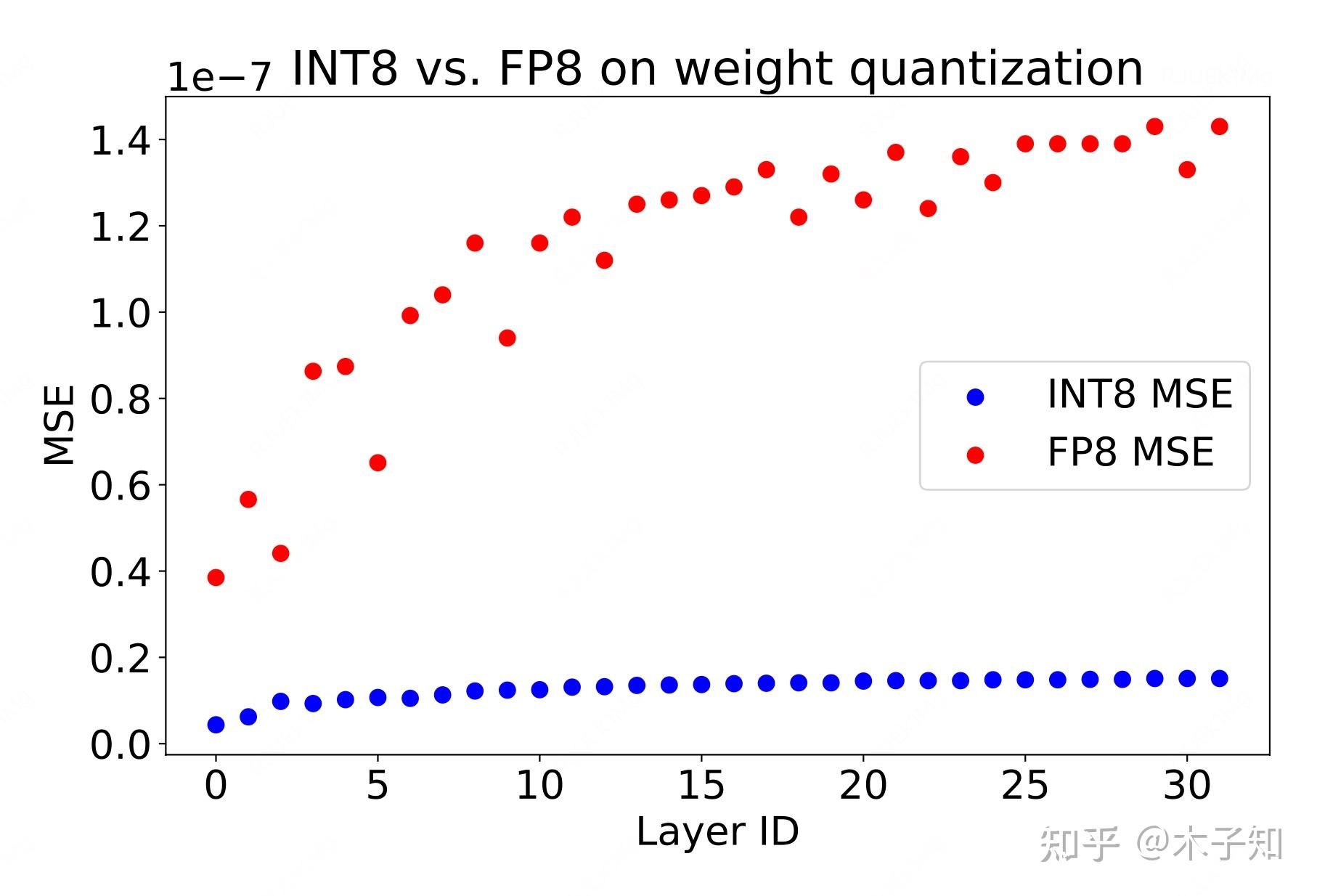
[2303.17951] FP8 versus INT8 for efficient deep learning inference
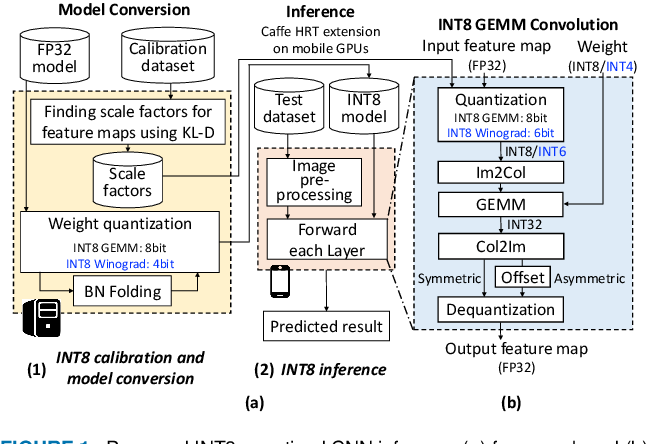
Figure 1 from Performance Evaluation of INT8 Quantized Inference on ...
INT8 Quantization for x86 CPU in PyTorch | PyTorch
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
Understanding int8 neural network quantization - YouTube
Understanding int8 vs fp16 Performance Differences with trtexec ...
Figure 2 from Performance Evaluation of INT8 Quantized Inference on ...
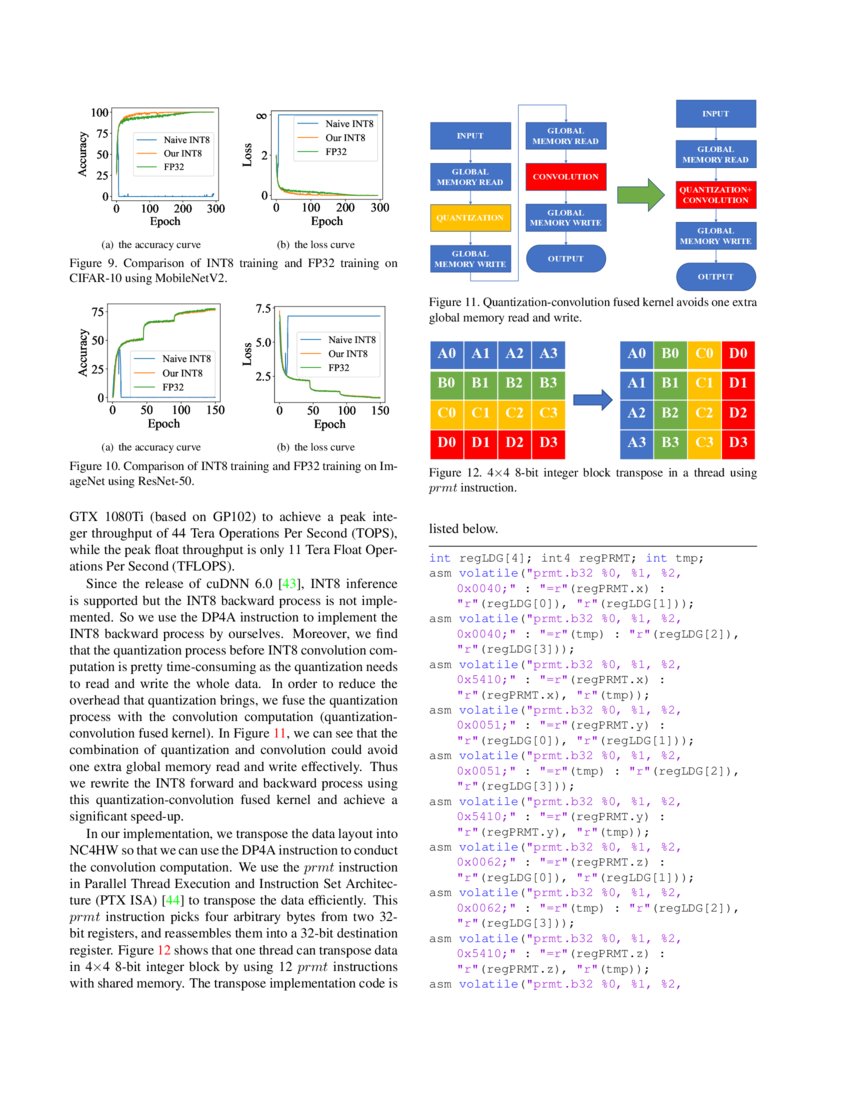
Towards Unified INT8 Training for Convolutional Neural Network | DeepAI
lightx2v/Qwen-Image-2512-Lightning · How to use the int8 model
Quark Quantized INT8 Models - a amd Collection
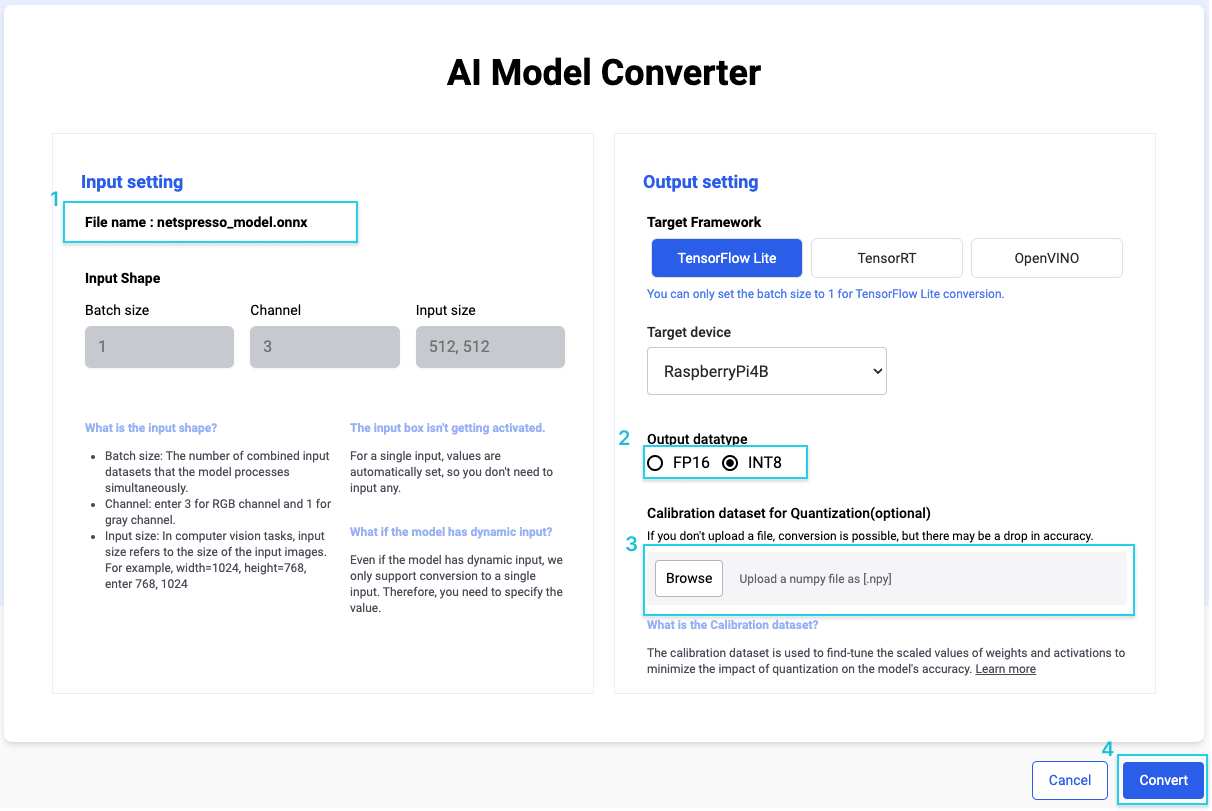
INT8 quantization with Benchmark Studio
Deep Learning Int8 Quantization – PCETSK
INT8 quantization with same model and different weights · Issue #2705 ...
Boost Your AI Models with INT8 Quantization 🚀 ONNX Static vs Dynamic ...
How to provide calibration data for INT8 quantization with dynamic ONNX ...
Top-1 accuracy of various INT8 methods for ImageNet | Download ...
Deep Learning with INT8 Optimization on Xilinx Devices - Edge AI and ...
OpenVINO INT8 Quantization for YOLO26 Models: A Hands-On Tutorial | by ...
How to quantize a Language Model to int8 using optimum | by ...
CUTLASS INT4 vs. INT8 GEMM performance comparison across different ...
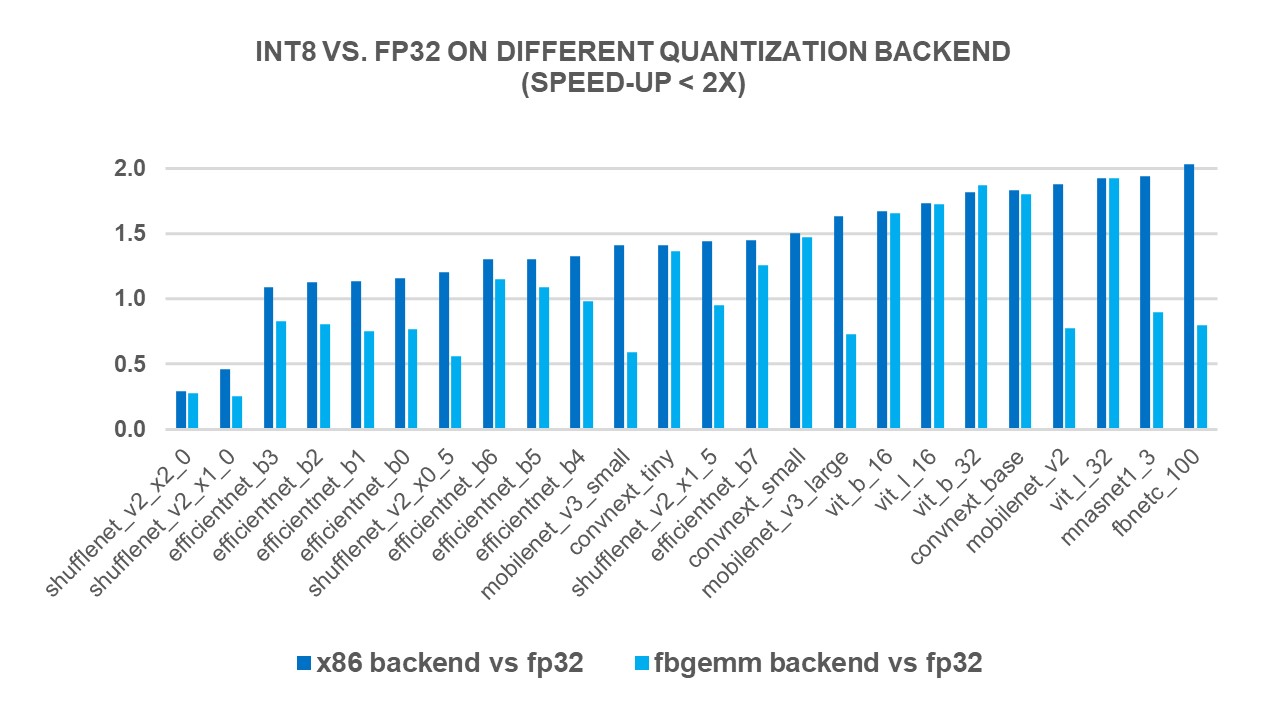
The impact of INT8 quantization on throughput. | Download Scientific ...
Local Large Language Models | Int8
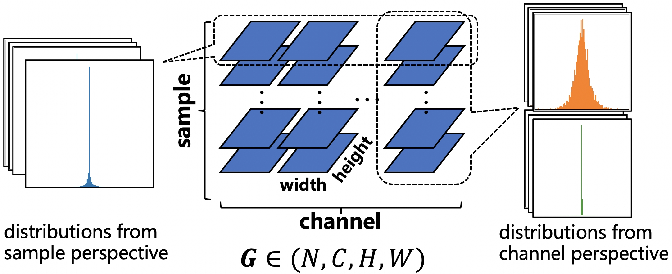
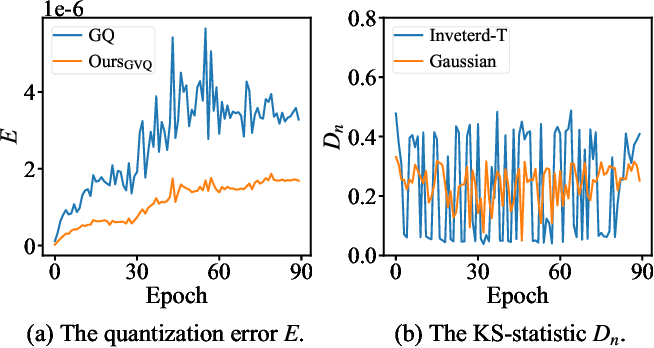
Figure 2 from Distribution Adaptive INT8 Quantization for Training CNNs ...
Table 1 from Performance Evaluation of INT8 Quantized Inference on ...
LLM推理量化:FP8 versus INT8 - 知乎
INT-FlashAttention: Enabling Flash Attention for INT8 Quantization | AI ...
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析 - NVIDIA 技术博客
How do I perform Int8 activation and int8 weight QAT and export to onnx ...
[Performance] INT8 quantized model run slower than FP32 model · Issue ...
E2E latency speedup of FasterTransformer INT8 (FT-i8), our IN8 with all ...
Some predictions made by our int8 model | Download Scientific Diagram
Jetfire: Efficient and Accurate Transformer Pretraining with INT8 Data ...
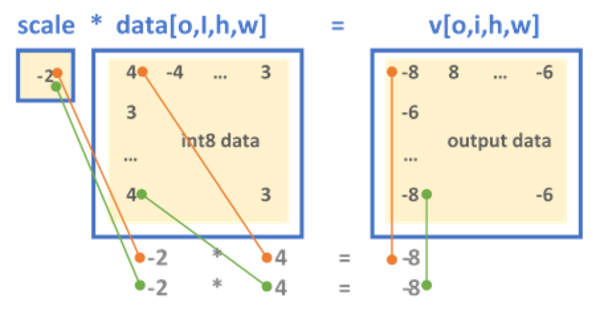
INT8 Calibration for TensorRT Inference | PDF | Integer (Computer ...
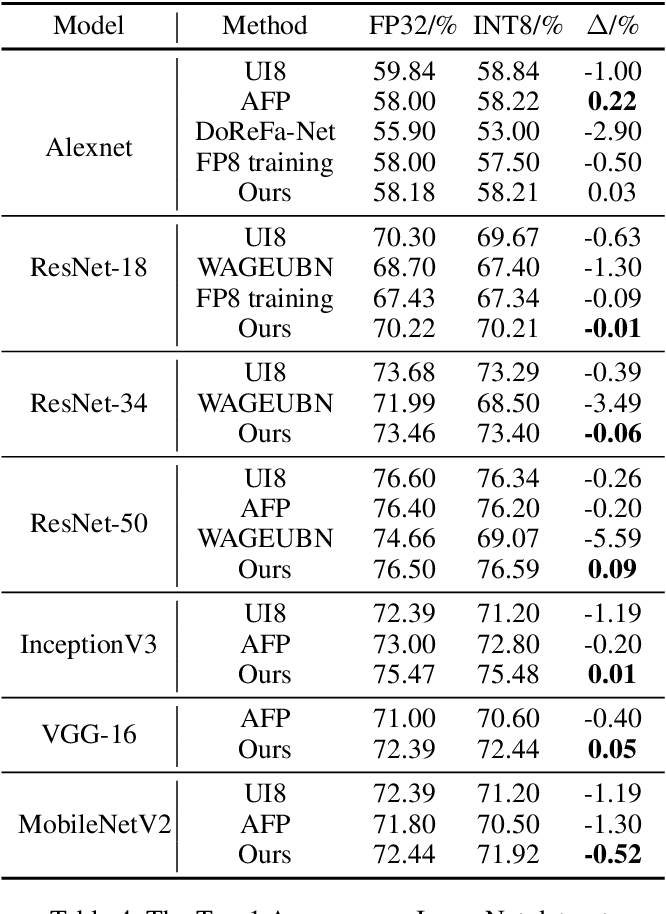
Table 4 from Distribution Adaptive INT8 Quantization for Training CNNs ...
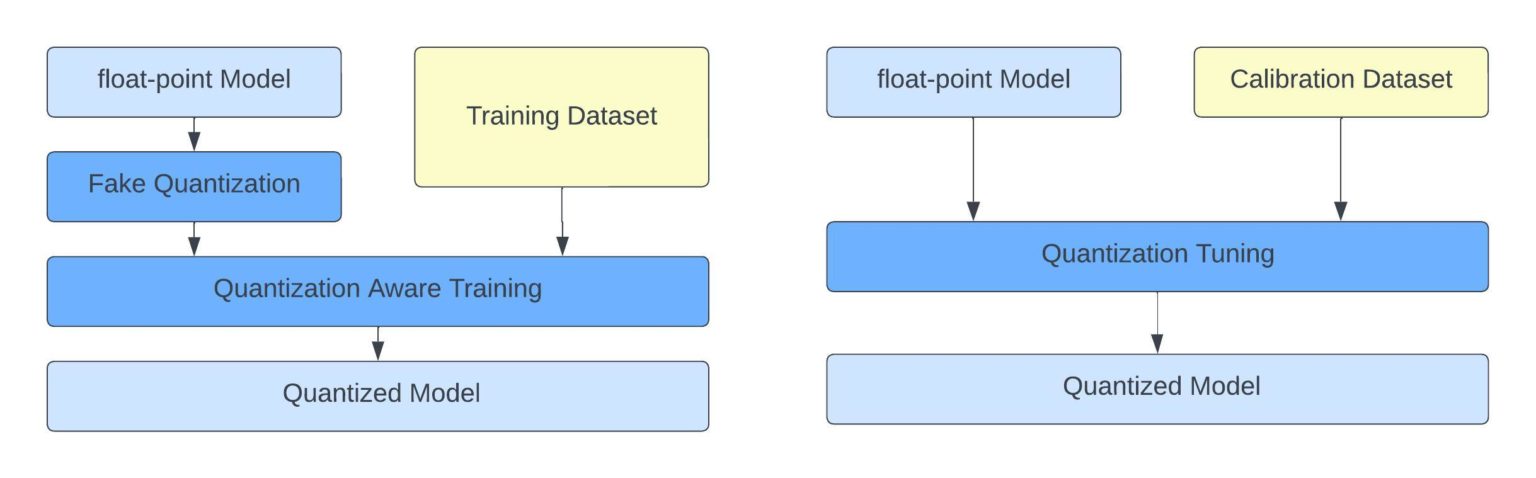
Why Calibrate? The Importance of INT8 Quantization for Efficient AI ...
How to get a real int8 quanted ONNX model? · Issue #2816 · quic/aimet ...
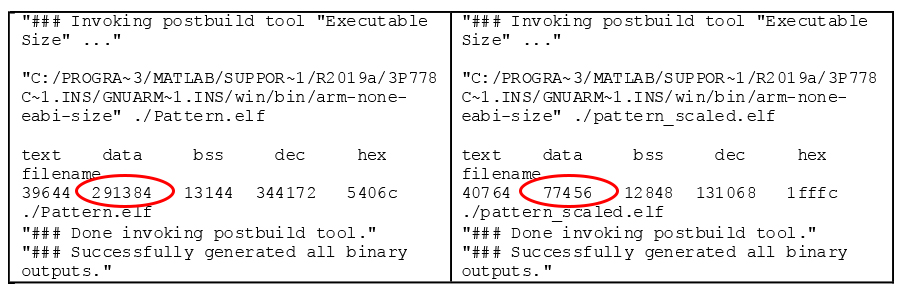
Deep Learning HDL Single To Int8 Conversion - Convert single-precision ...
Applying INT8 quantization, just like in Dorado · Issue #388 ...
Figure 1 from Distribution Adaptive INT8 Quantization for Training CNNs ...
Different output in INT8 and FP16 quantization · Issue #4990 ...
[RFC]: Int8 Activation Quantization · Issue #3975 · vllm-project/vllm ...
GitHub - haiphamcse/YOLOv7INT8: An YOLOv7 model working on INT8 precision
Int8 Inference
Speeding up object detection tasks using INT8 precision on the Jetson ...
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析-中科新远|NVIDIA网卡与 ...
A Hands-On Walkthrough on Model Quantization - Medoid AI
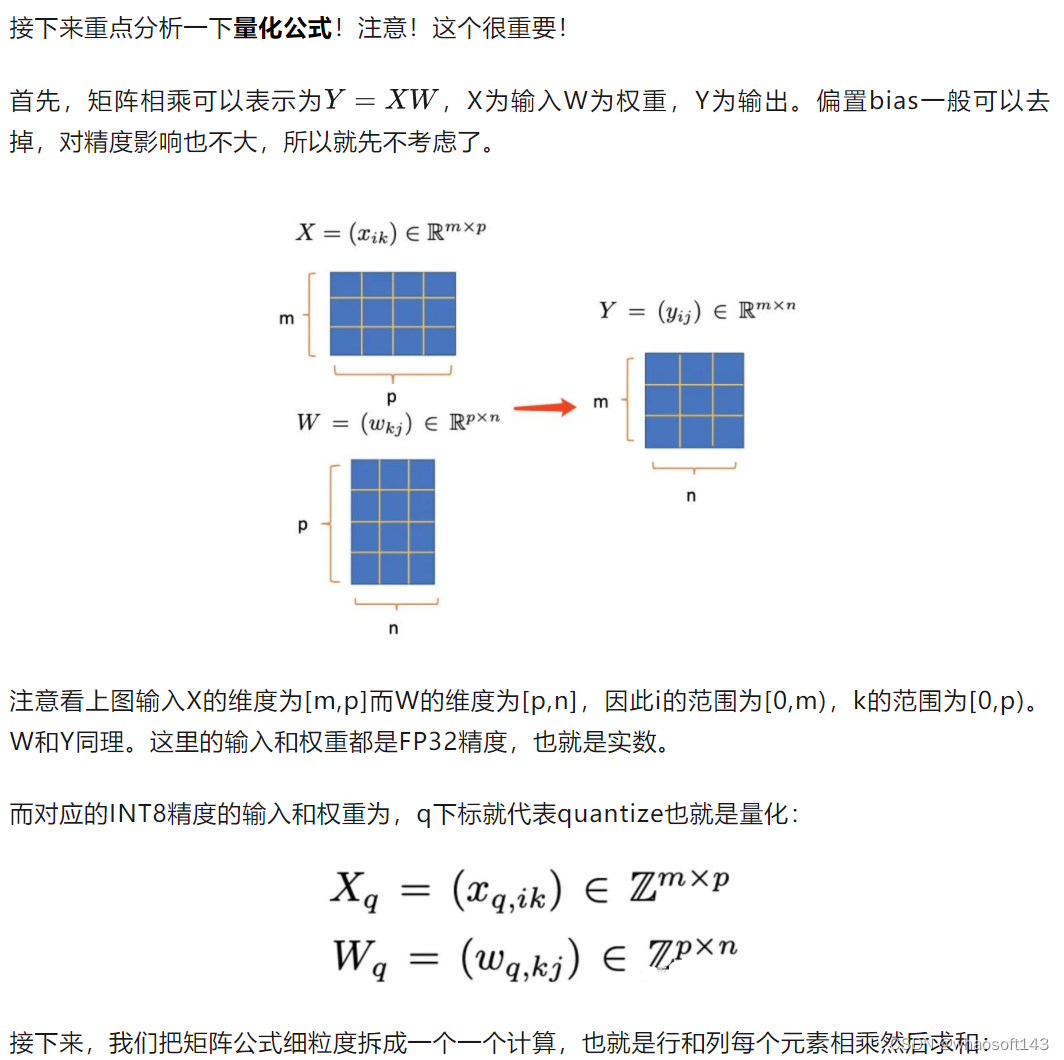
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
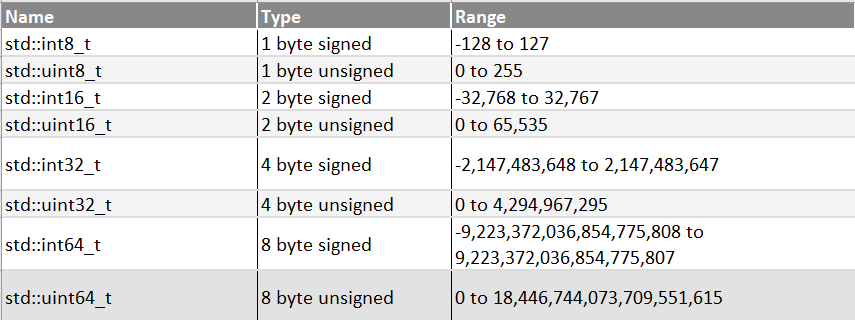
Fixed width integer types (int8) in C++
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
Quantization Methods for 100X Speedup in Large Language Model Inference
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
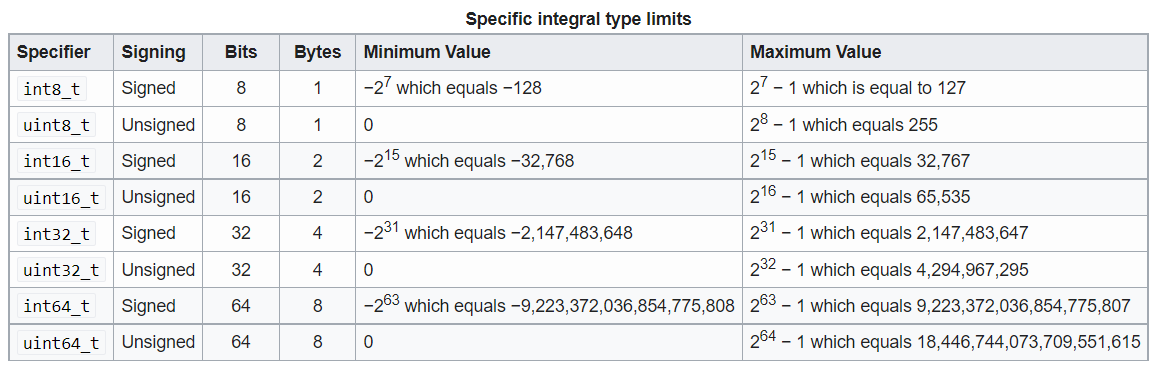
详解C语言中的int8_t、uint8_t、int16_t、uint16_t、int32_t、uint32_t、int64_t、uint64 ...
NumPy Integer Data Types Explained: int8, int16, int32, int64 Tutorial ...
iOS 和 swift 中常见的 Int、Int8、Int16、Int32和 Int64介绍「建议收藏」-腾讯云开发者社区-腾讯云
Unlocking LLM Performance: Advanced Quantization Techniques on Dell ...
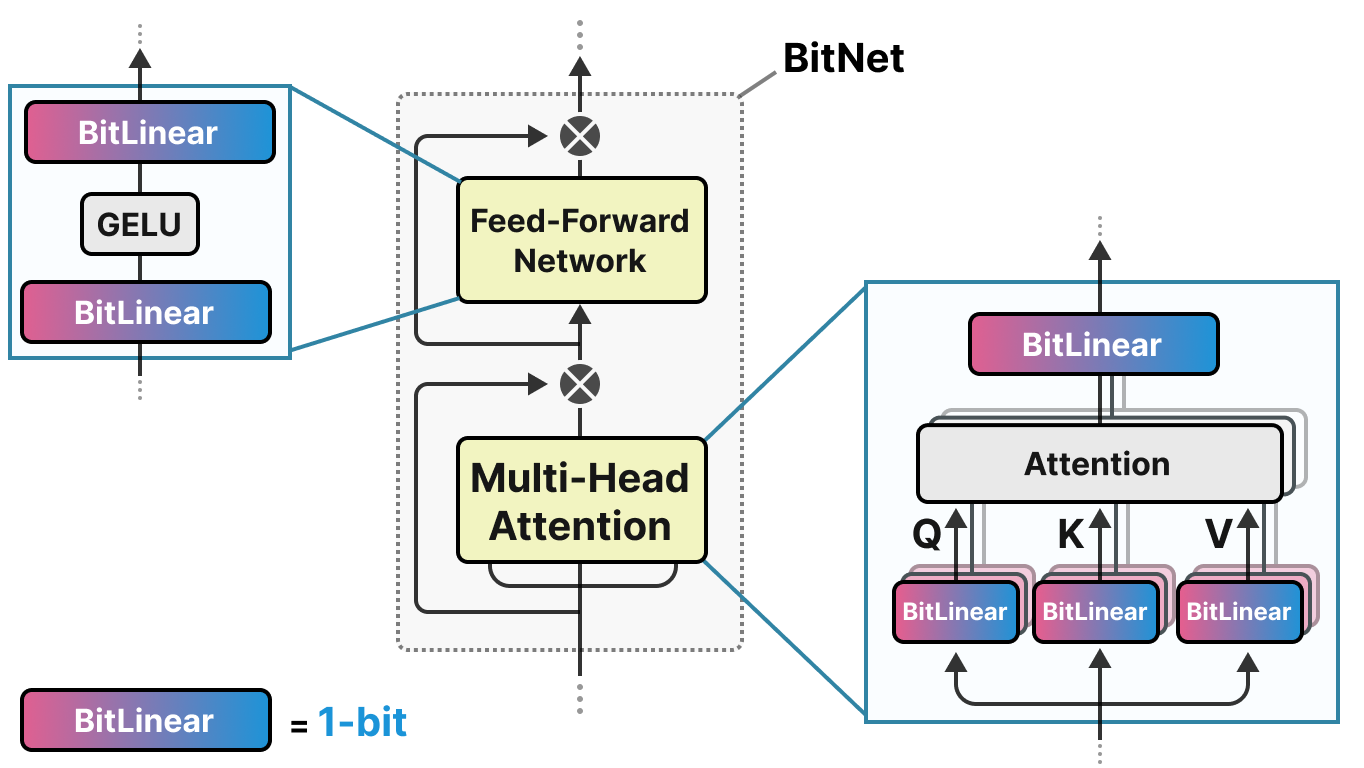
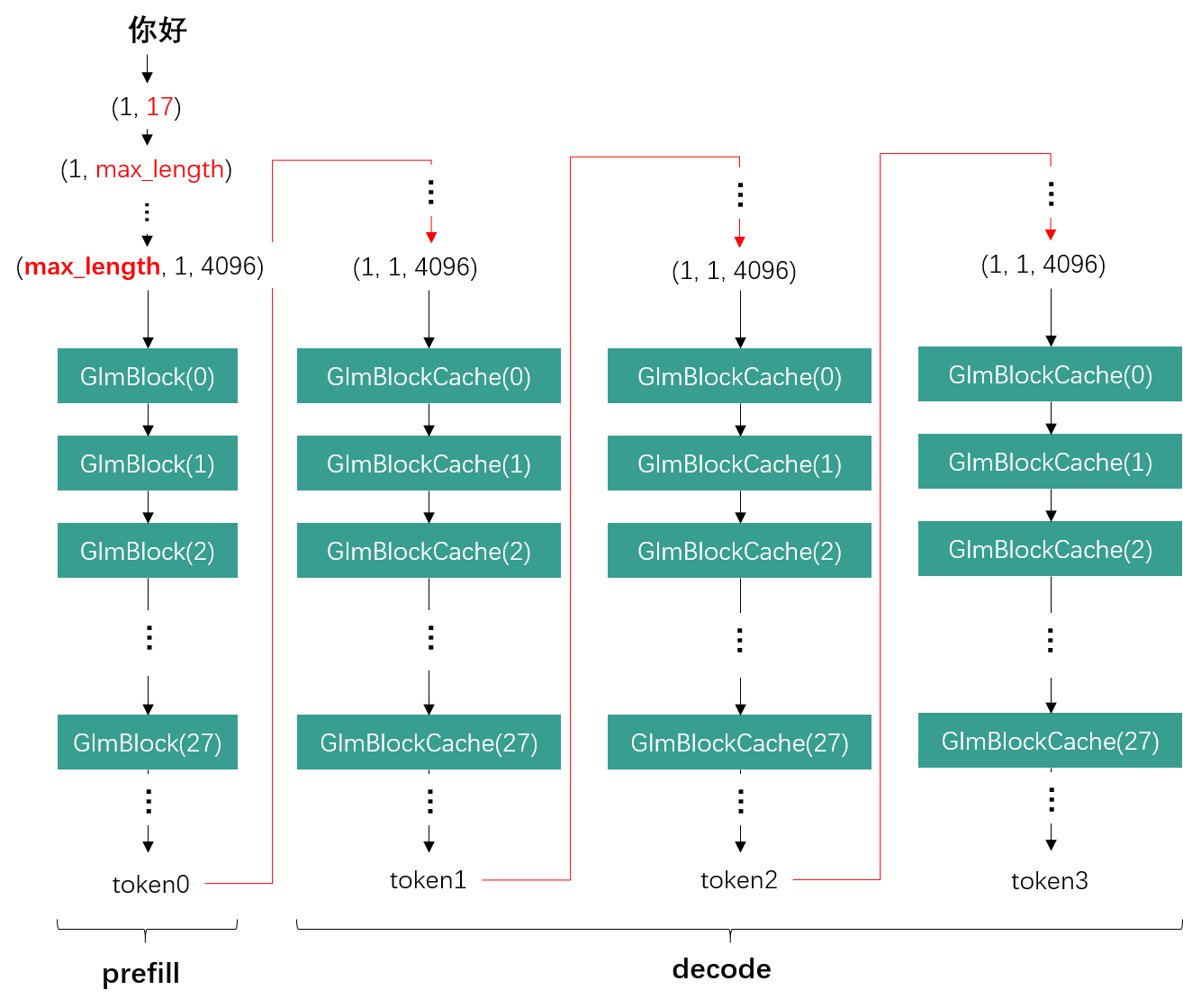
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
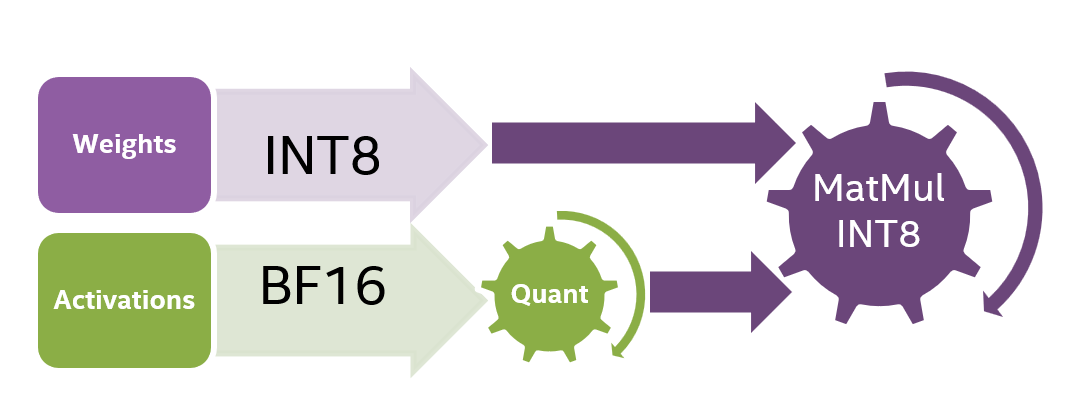
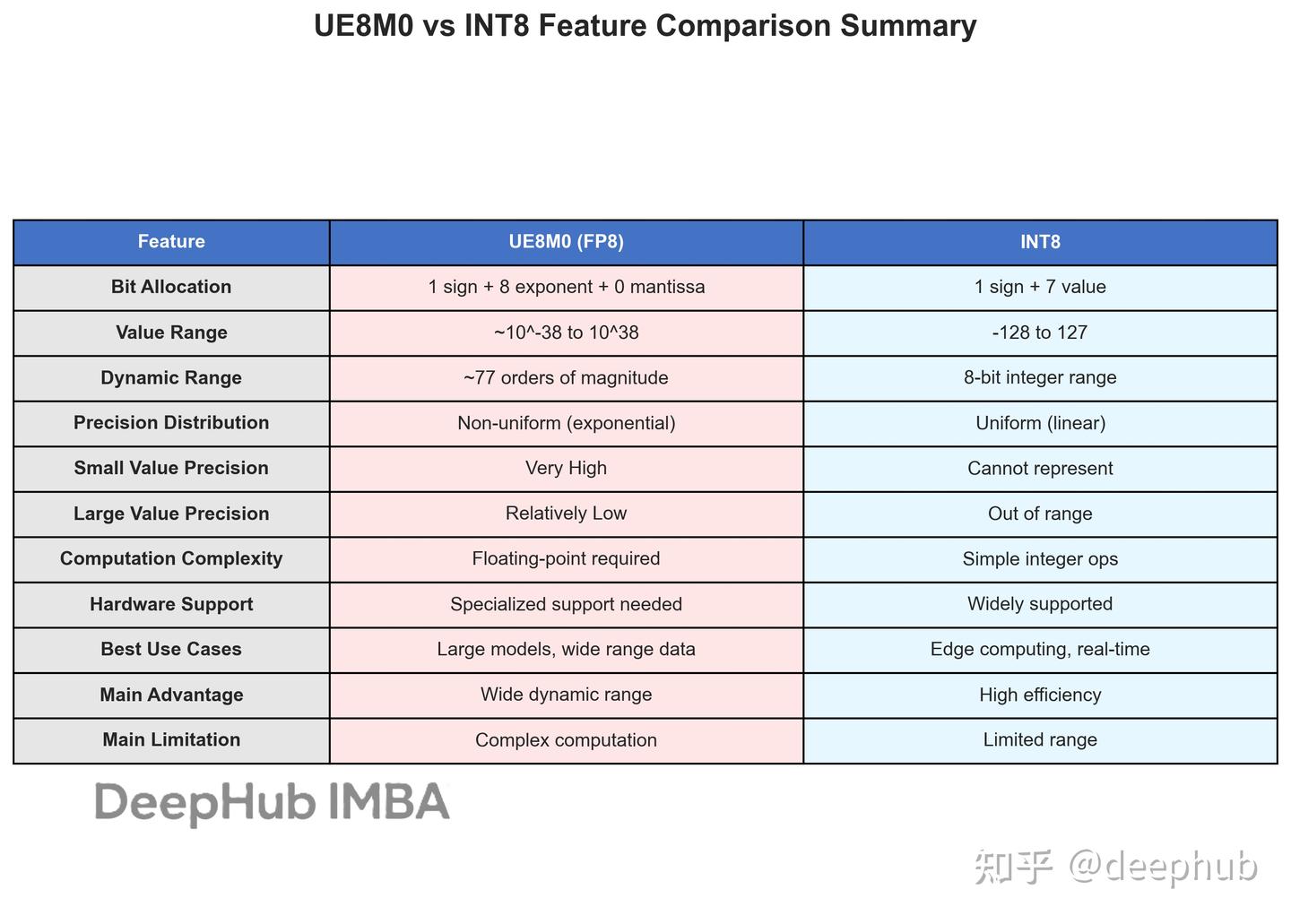
这也许就是DeepSeek V3.1性能提升的关键:UE8M0与INT8量化技术对比与优势分析 - 知乎
int8_t int16_t int32_t difference,,, int64_t, size_t and the ssize_t ...
int8_t、uint8_t、__INT 64等和size_t的阐述_uint8头文件-CSDN博客
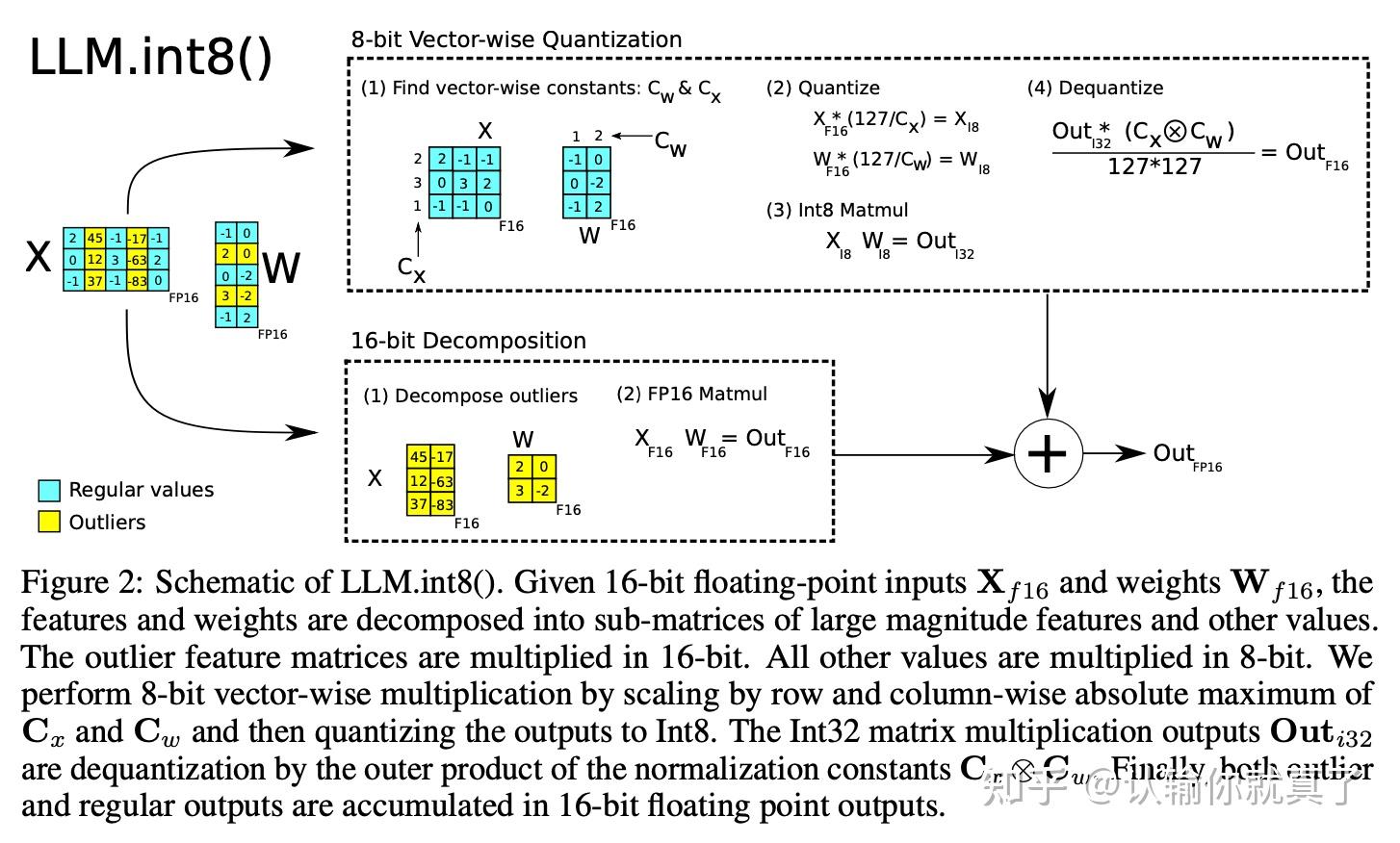
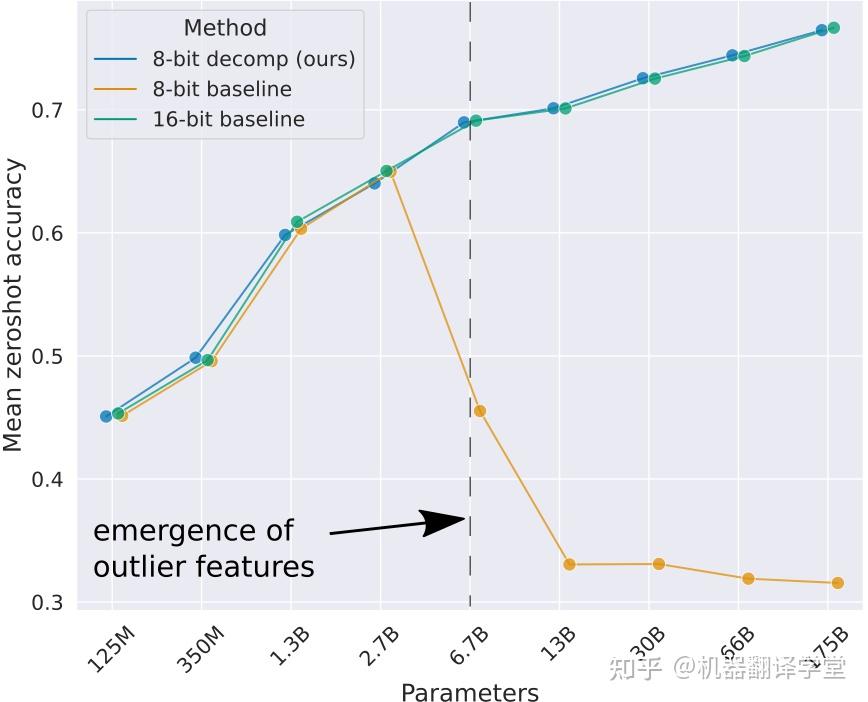
INT8模型量化:LLM.int8 - 知乎
大模型LLM.int8()量化技术原理与代码实现-CSDN博客
INT8, INT4 and Other Integer Types for Quantization
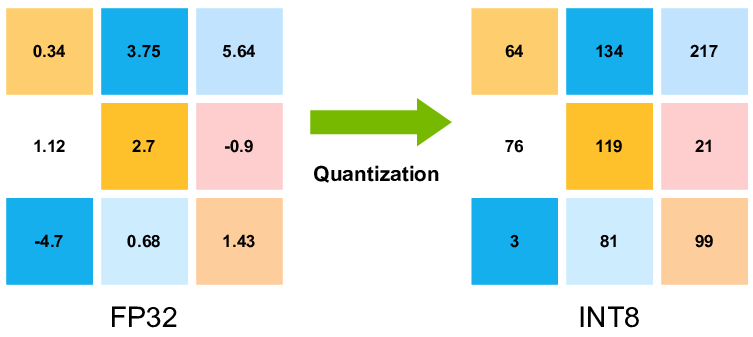
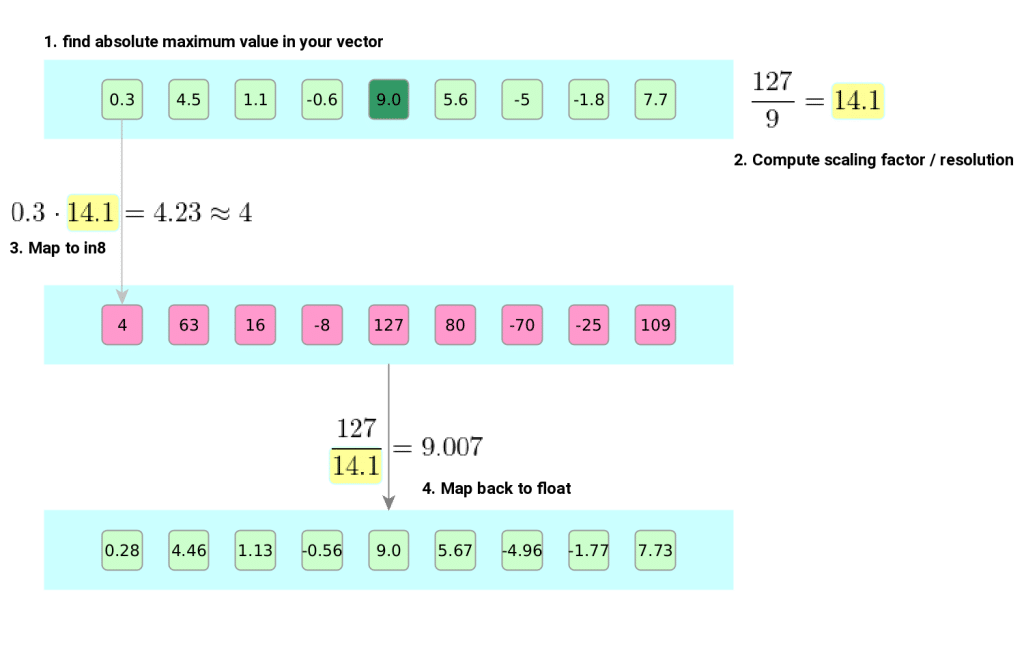
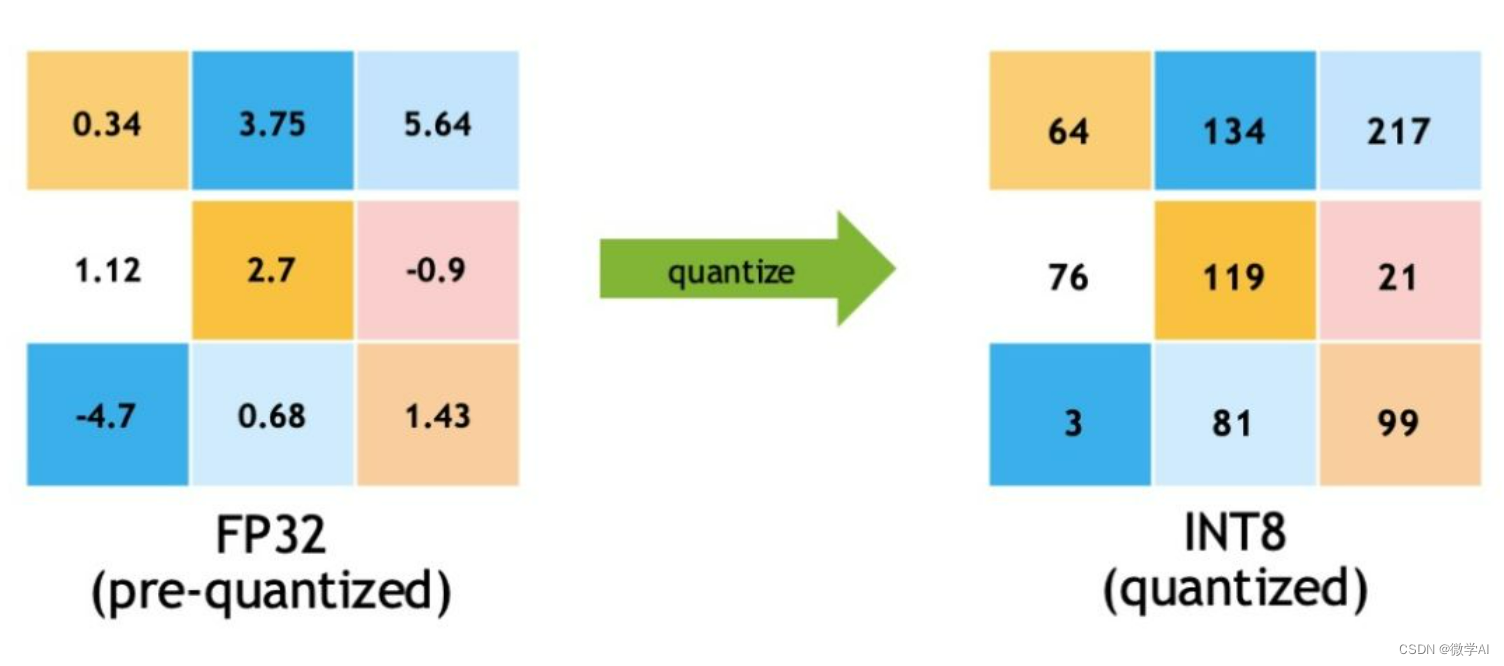
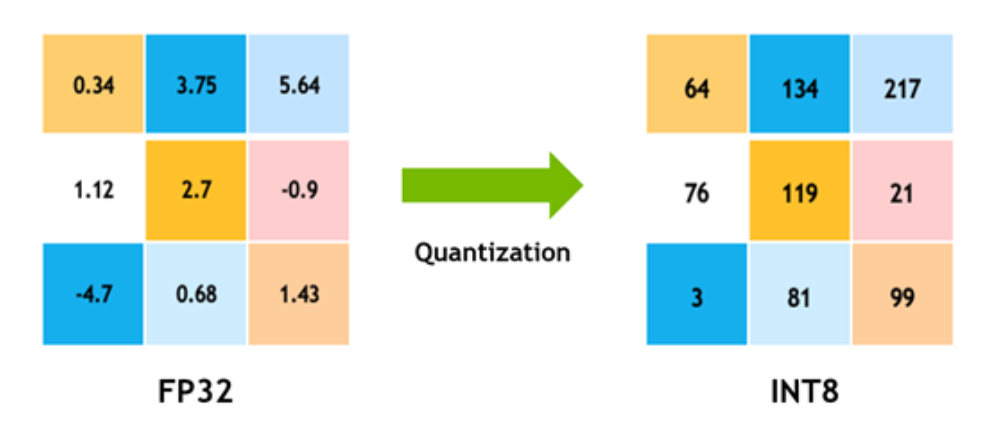
Quantization from FP32 to INT8. | Download Scientific Diagram
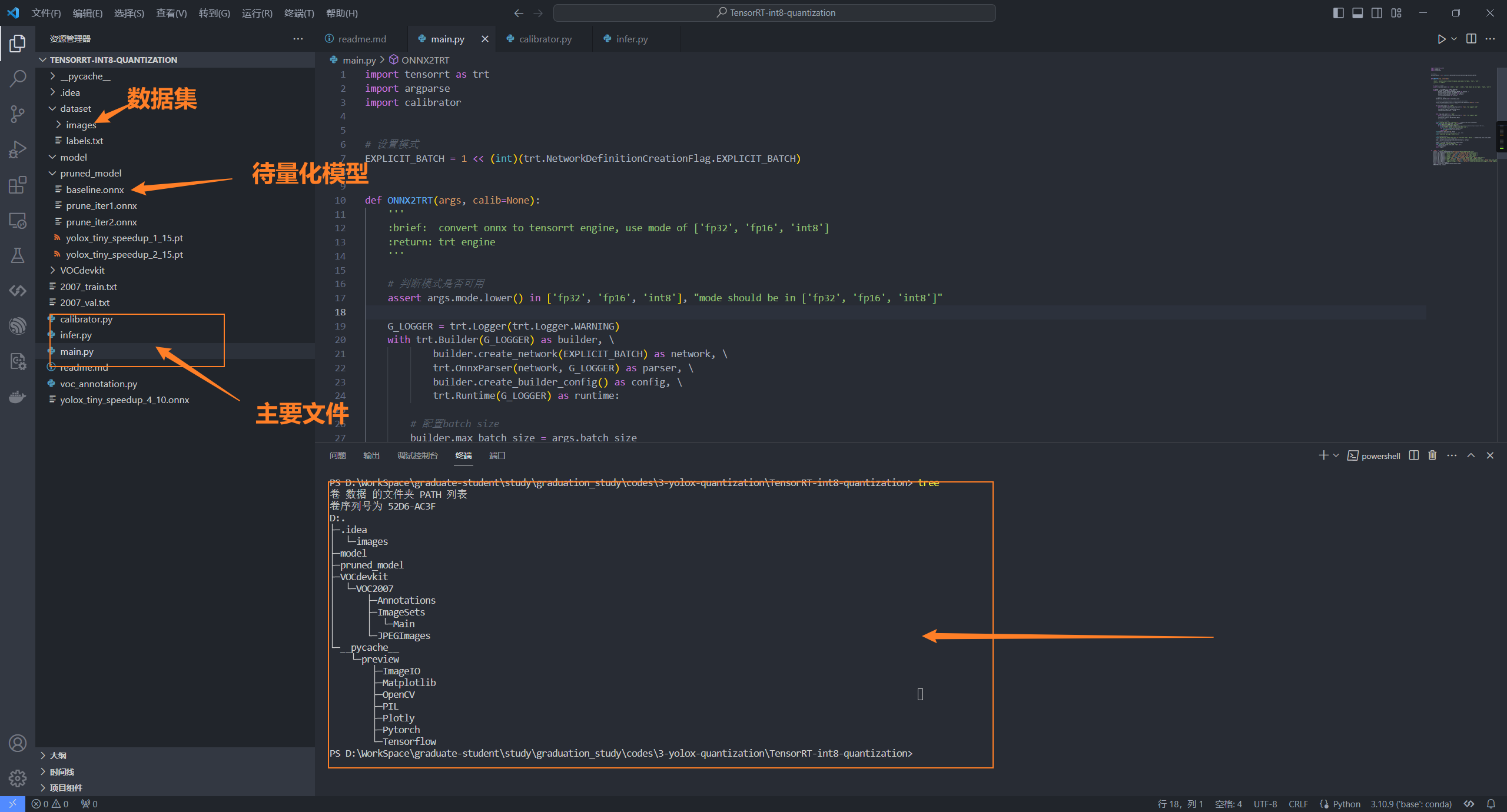
GitHub - xuanandsix/Tensorrt-int8-quantization-pipline: a simple ...
llm.int8(): Cuantización 8-bit para Transformers | MaximoFN
大模型量化之 LLM.int8()方法 - 知乎
GitHub - DK080825/simple_INT8_MAC: This project implements a simple ...
Understanding LLM.int8() Quantization — Picovoice
matlab将数据转换为int8类型 - 知乎
[Video] ប្រើ int8_t uint32_t ក្នុង Arduino ឲ្យបានត្រឹមត្រូវ - etronicskh
LLM.int8()——在大模型上使用int8量化 - 知乎
神经网络INT8量化~部署_tensorrt树莓派-CSDN博客
TensorRT部署YoloX:int8量化_yolotensorrt int8量化-CSDN博客
Scalar Quantization: Background, Practices & More | Qdrant
MobileVit在TensorRT中的int8量化实践与优化挑战-CSDN博客
7 ML Quantization Wins (INT8/FP8) Without Quality Freefall | by ...
int8とは - IT用語辞典 e-Words
用于量化的INT8、INT4及其他整数类型
FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep ...
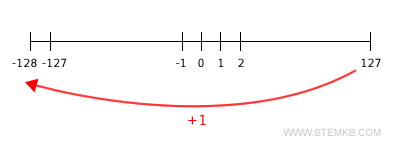
The int8() Function in Scilab | stemkb.com
发表博客之:int8 量化 原理讲解,AI推理工程师必备技能!_qdq算子参数-CSDN博客
int8,FLOPS,FLOPs,TOPS 等具体含义_int8 tops-CSDN博客
NVIDIA GPU的INT8变革:加速大型语言模型推理_CPU_什么值得买
利用TPU-MLIR实现LLM INT8量化部署 - 知乎
大模型应用:大模型量化:INT4与INT8核心差异、选型指南及代码实现.53-阿里云开发者社区
分析INT8量化对向量计算性能与召回率的影响-MaxCompute-阿里云
Figure 4 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析-CSDN博客
一分钟学会 ONNX模型INT8量化-OpenCV学堂-OpenCV学堂-哔哩哔哩视频
使用torch模拟 BMM int8量化计算。_torch.int bmm-CSDN博客
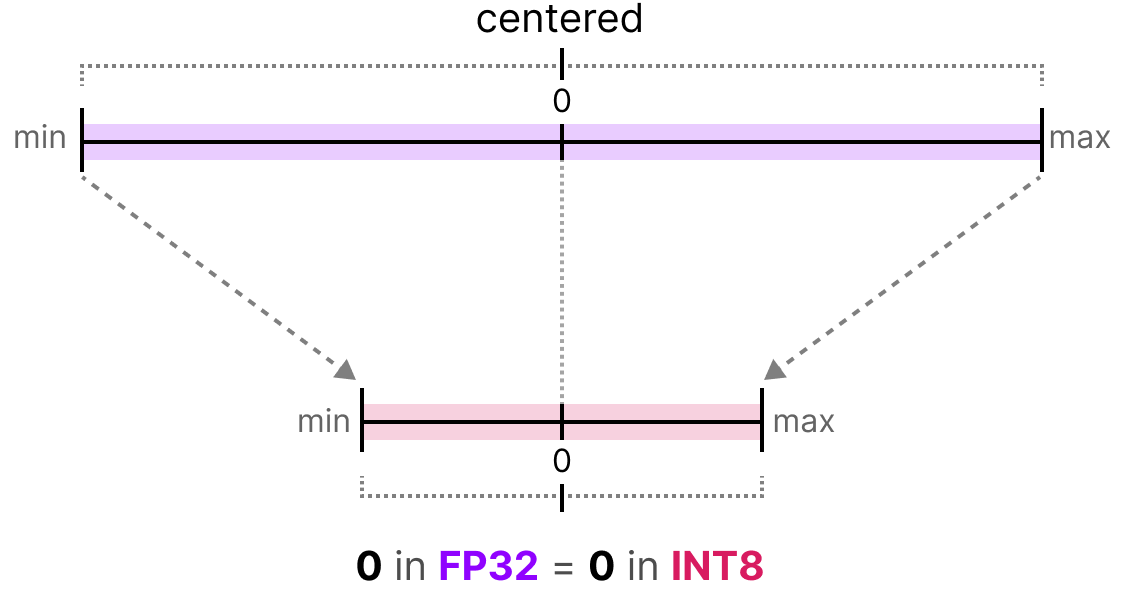
Small numbers, big opportunities: how floating point accelerates AI and ...
[논문 리뷰] Jetfire: Efficient and Accurate Transformer Pretraining with ...
Efficient Object Detection with YOLOv8 & OpenVINO on LattePanda Mu
老显卡福音!美团开源首发INT8无损满血版DeepSeek R1_腾讯新闻
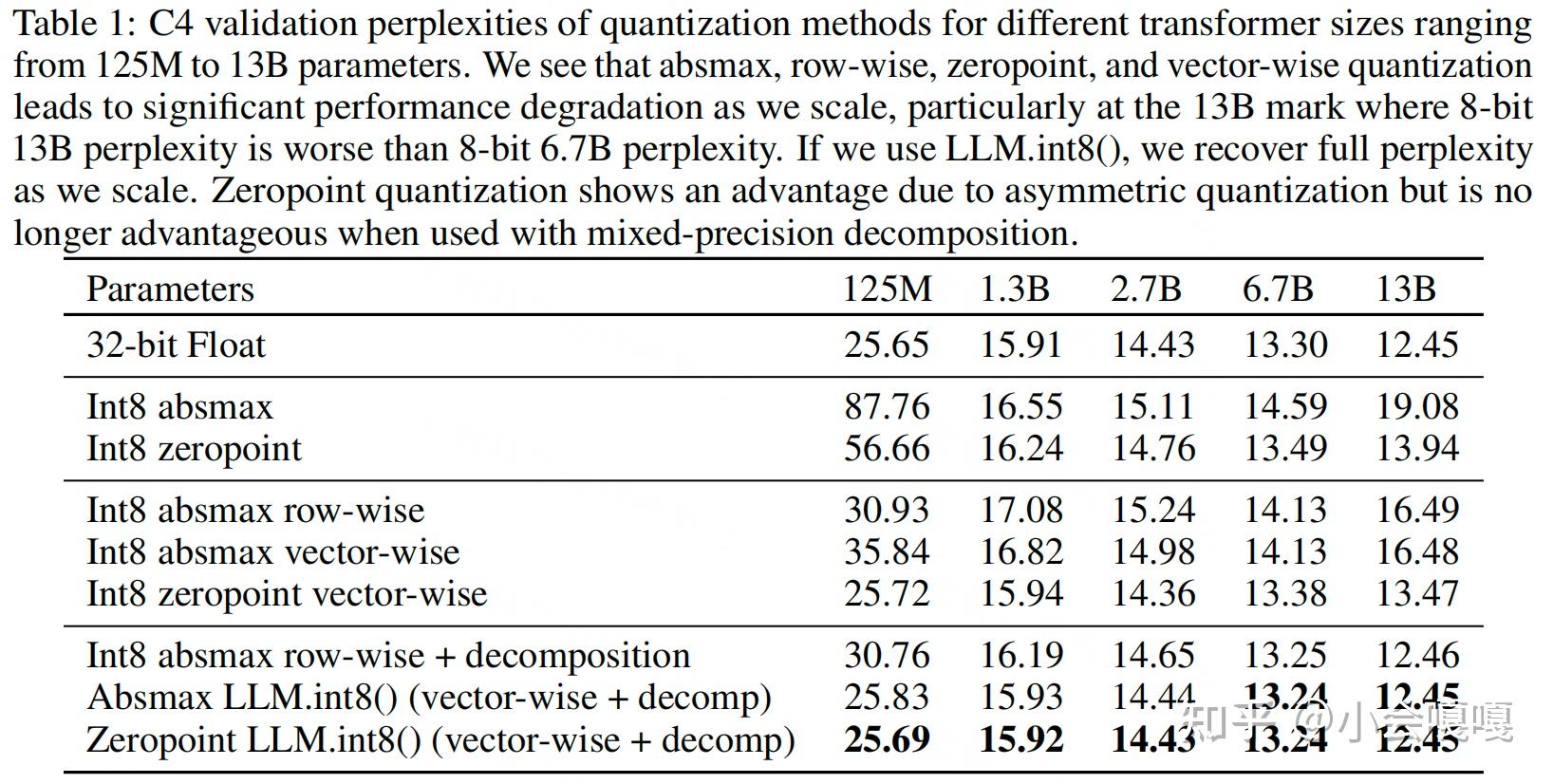
LLM.int8() 论文解析 - 知乎
Quantization INT8/INT4 — Ít bit hơn, nhỏ hơn 8x, vẫn chính xác | Trồi Sinh
GitHub - ThunderFun/ComfyUI-Wan-INT8: Custom node to load Wan in INT8.
What is the difference between INT8, INT16, INT32, INT64? - Programmer ...
FP8: Efficient model inference with 8-bit floating point numbers ...
































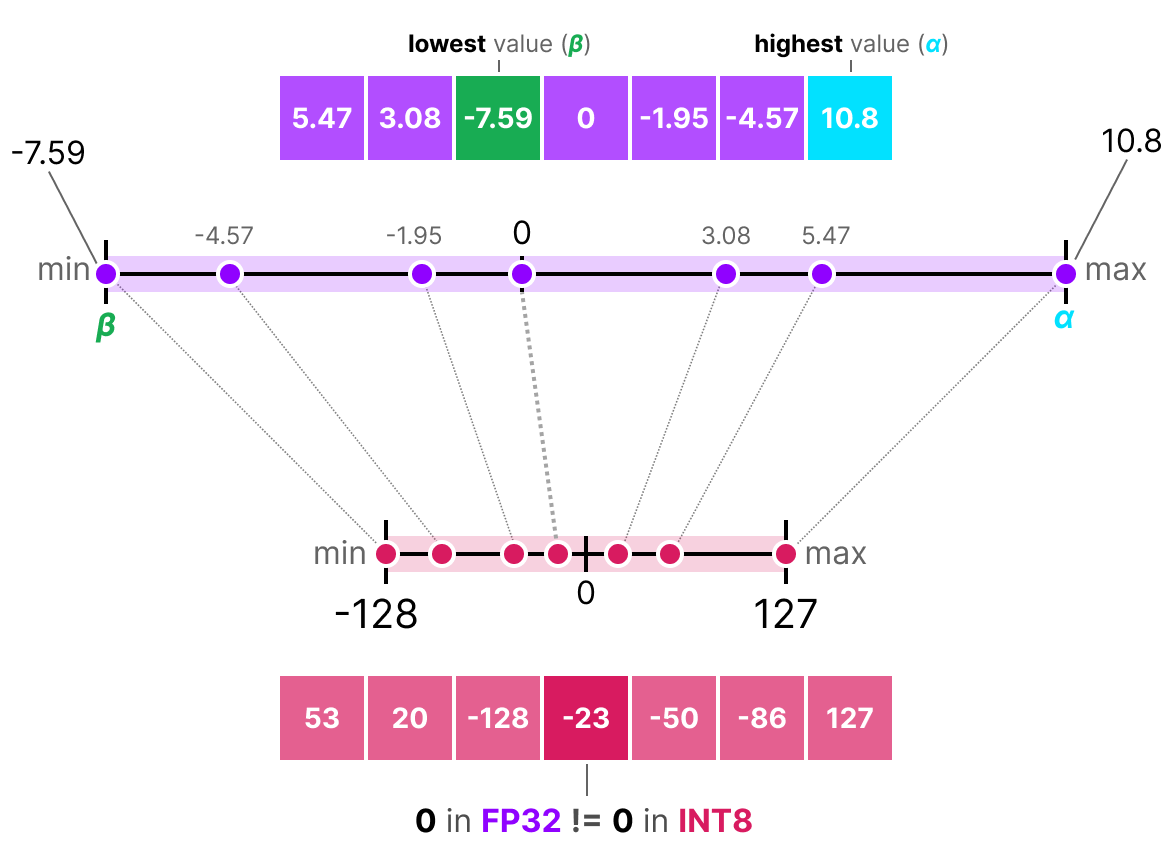
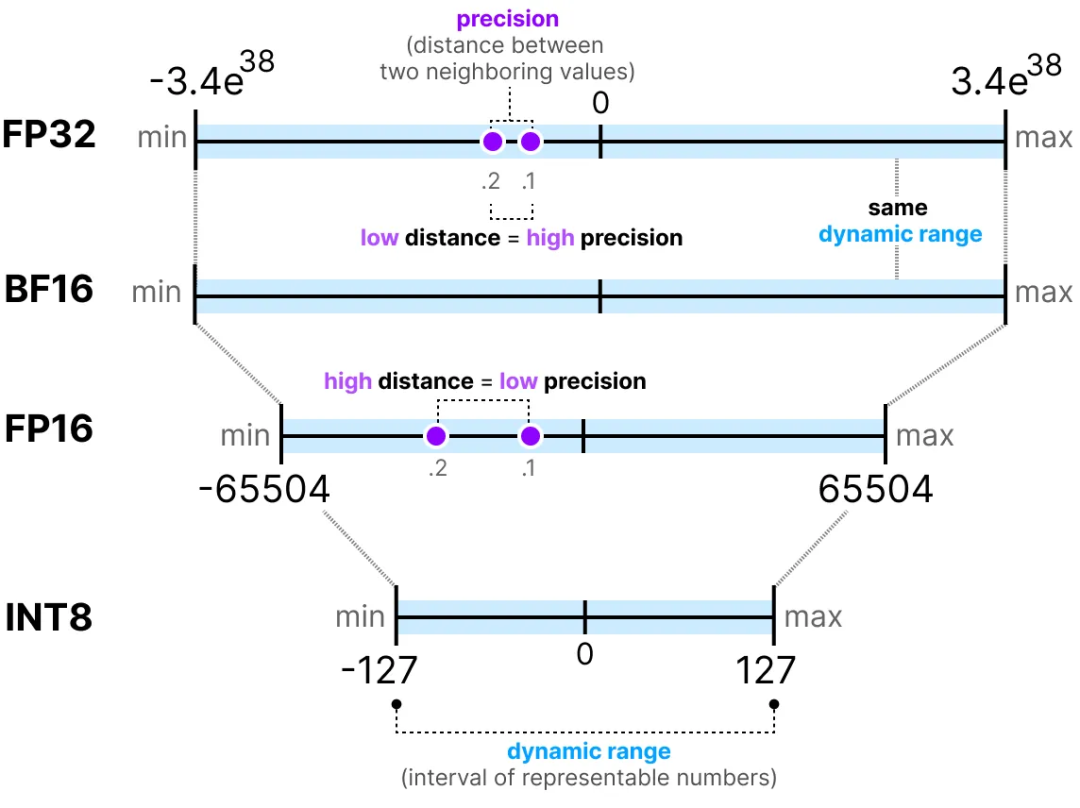
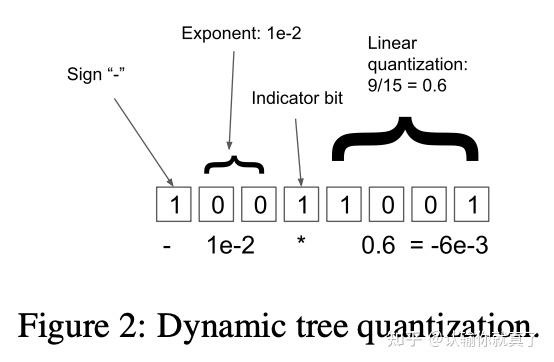



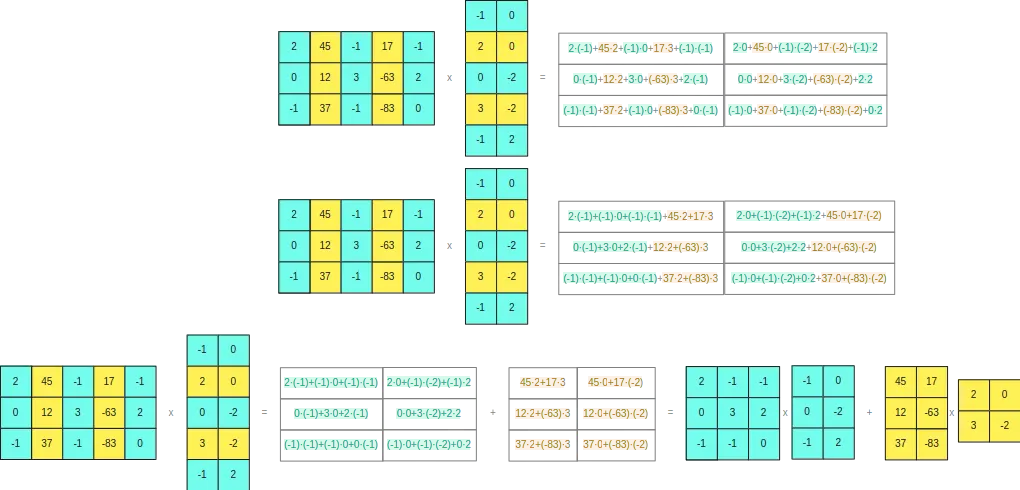




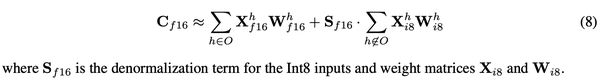





-thumbnail.webp)