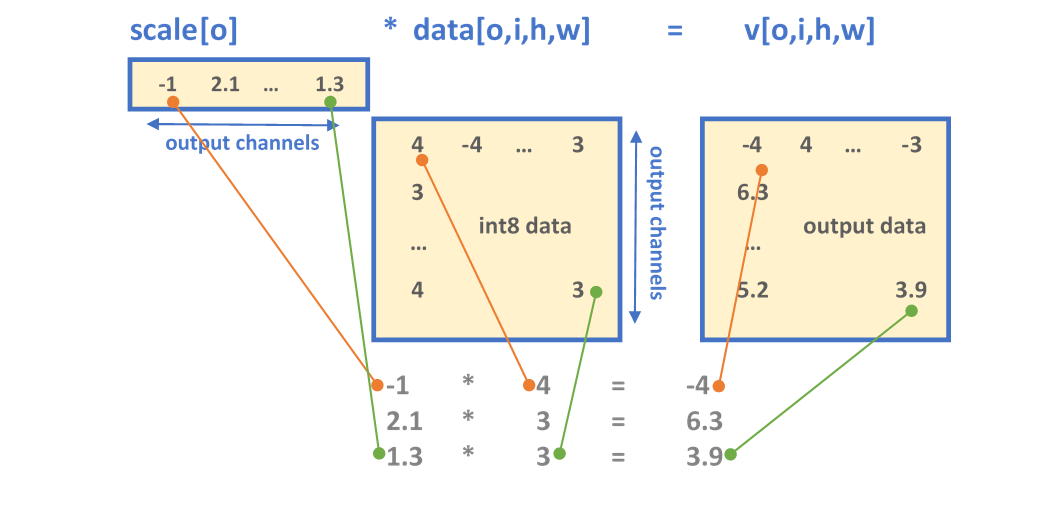
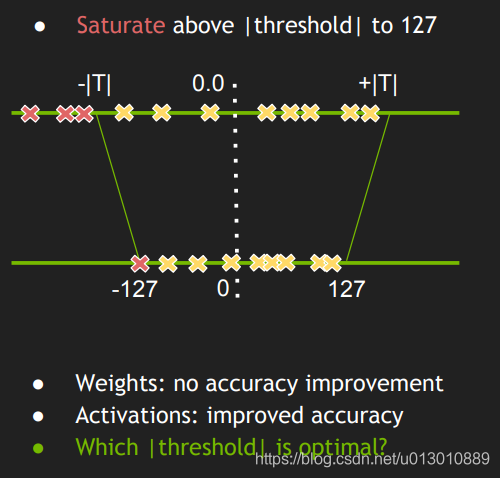
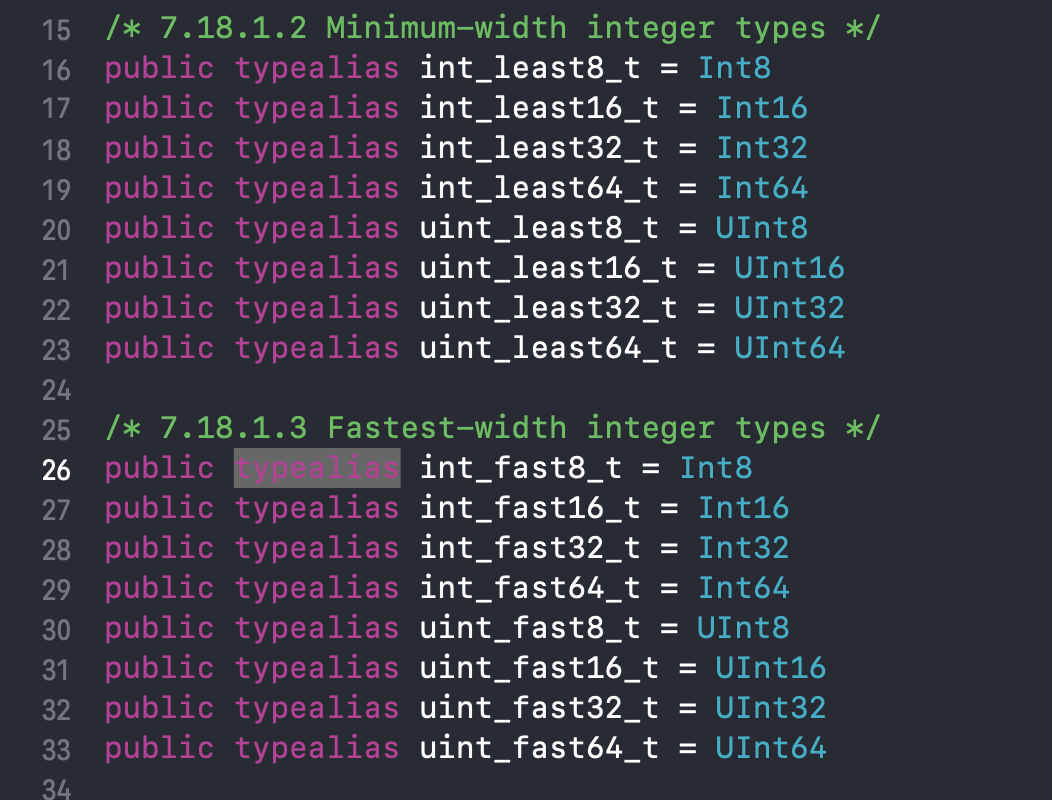
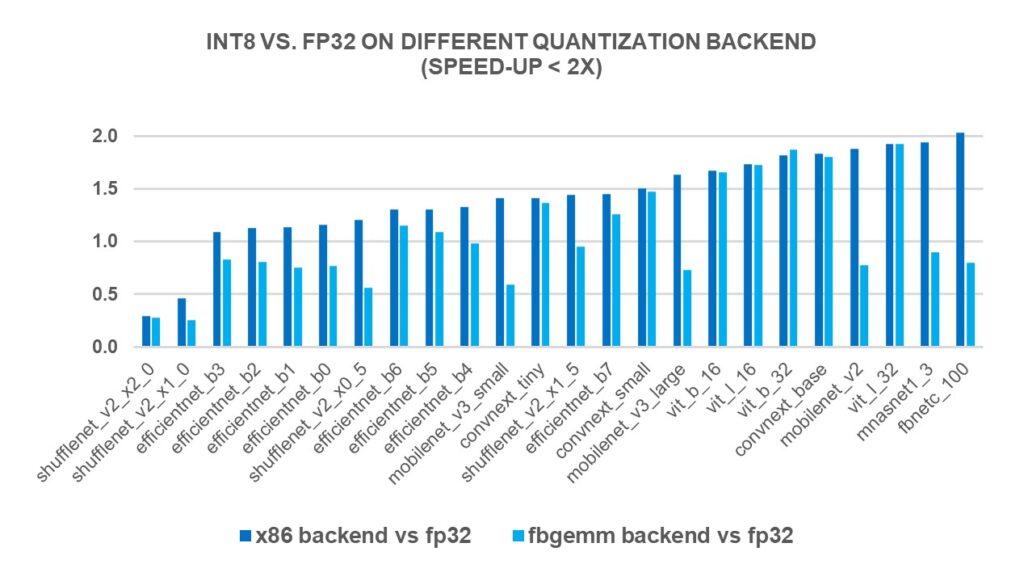
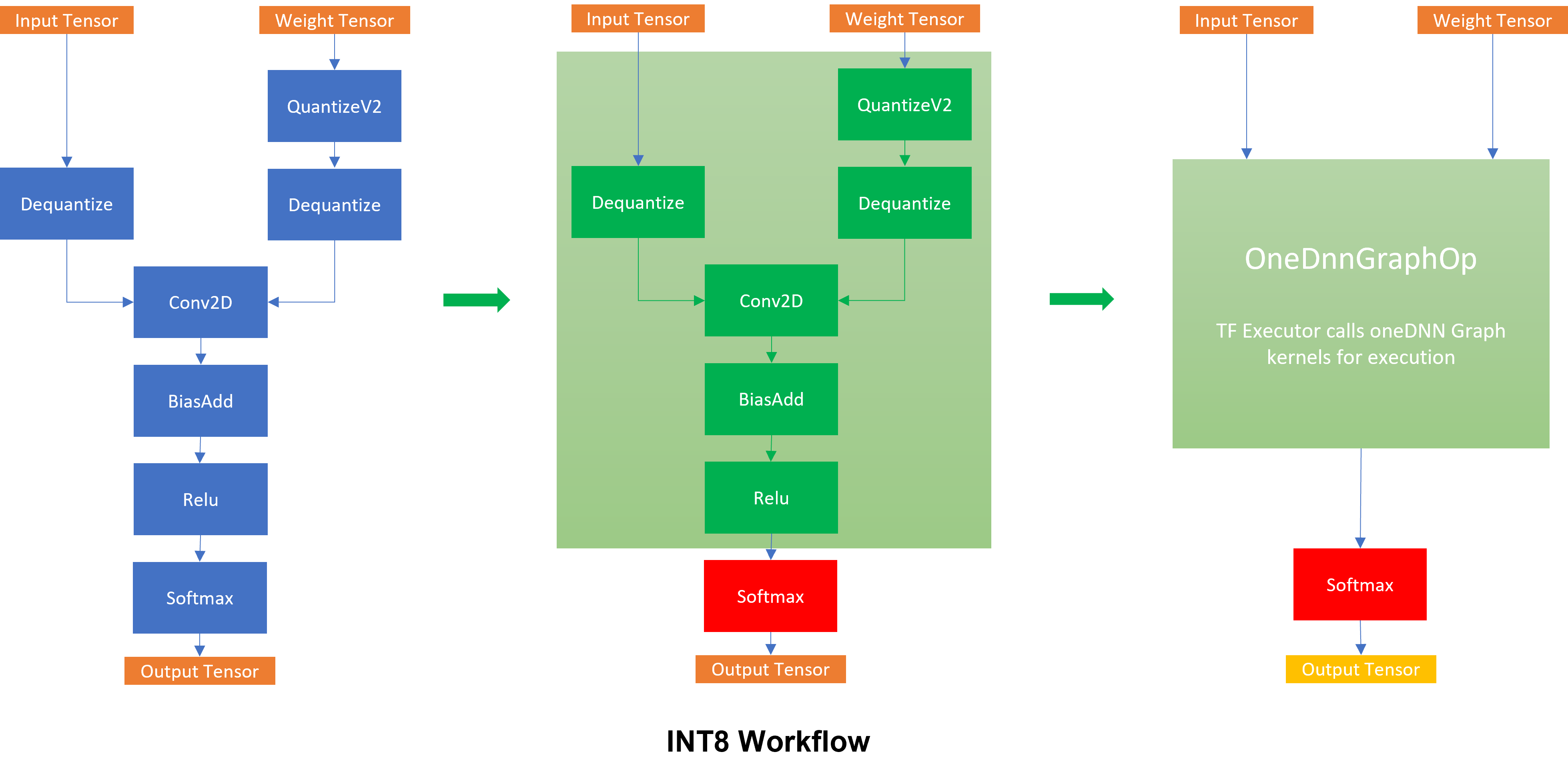
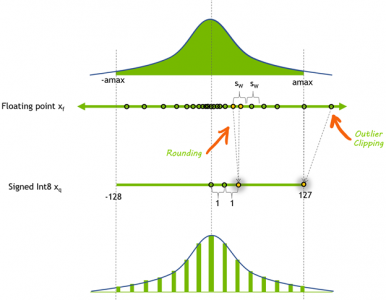
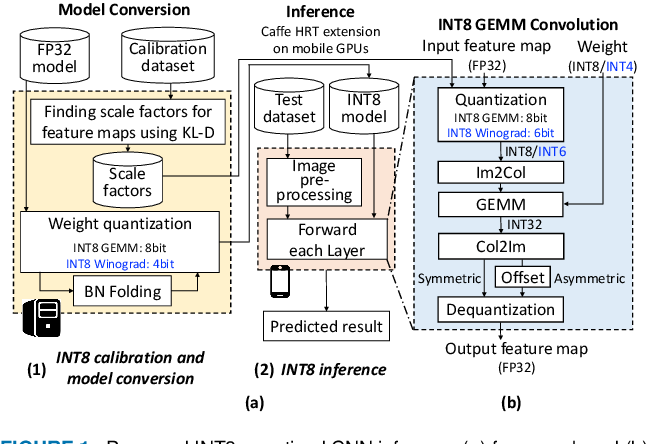
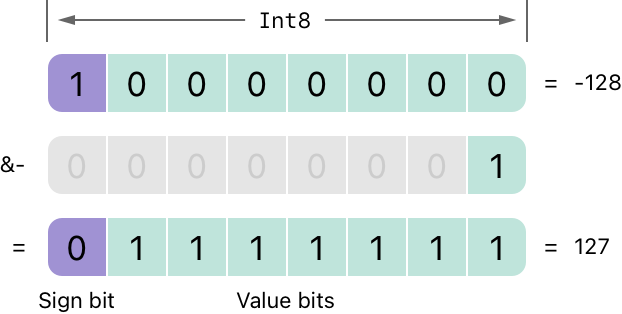
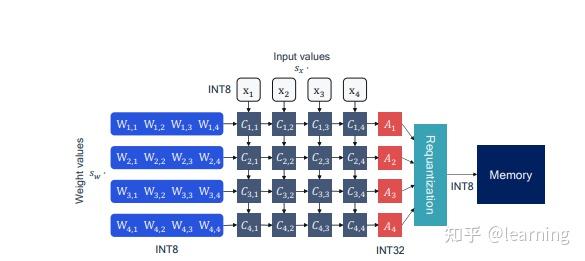
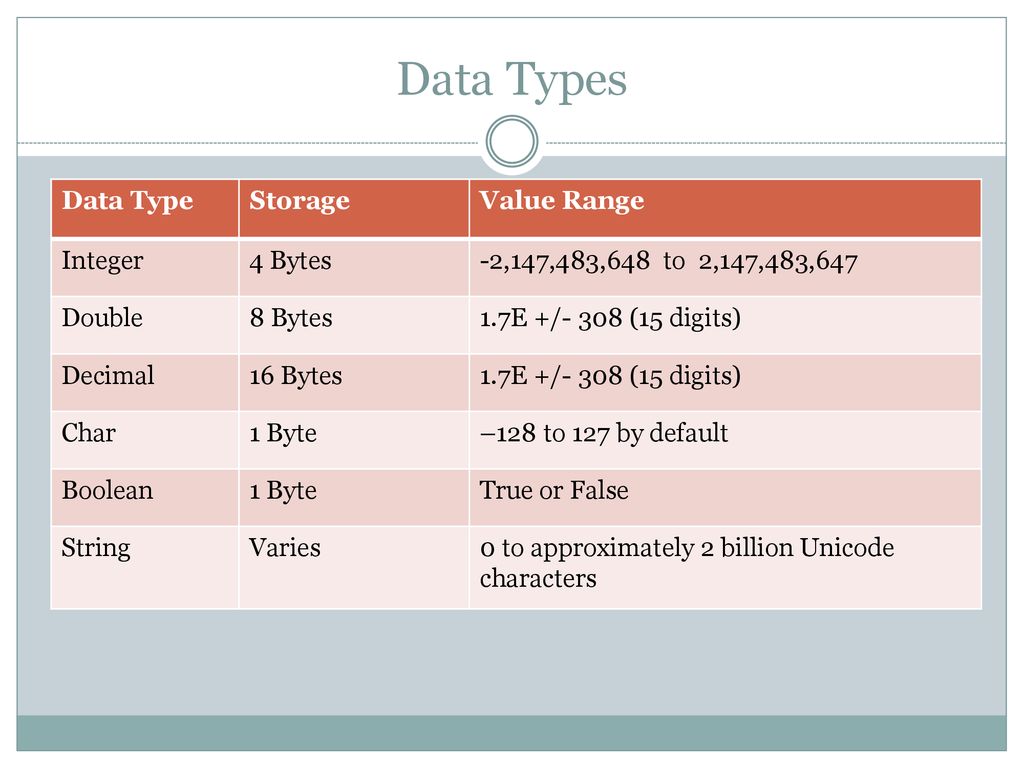
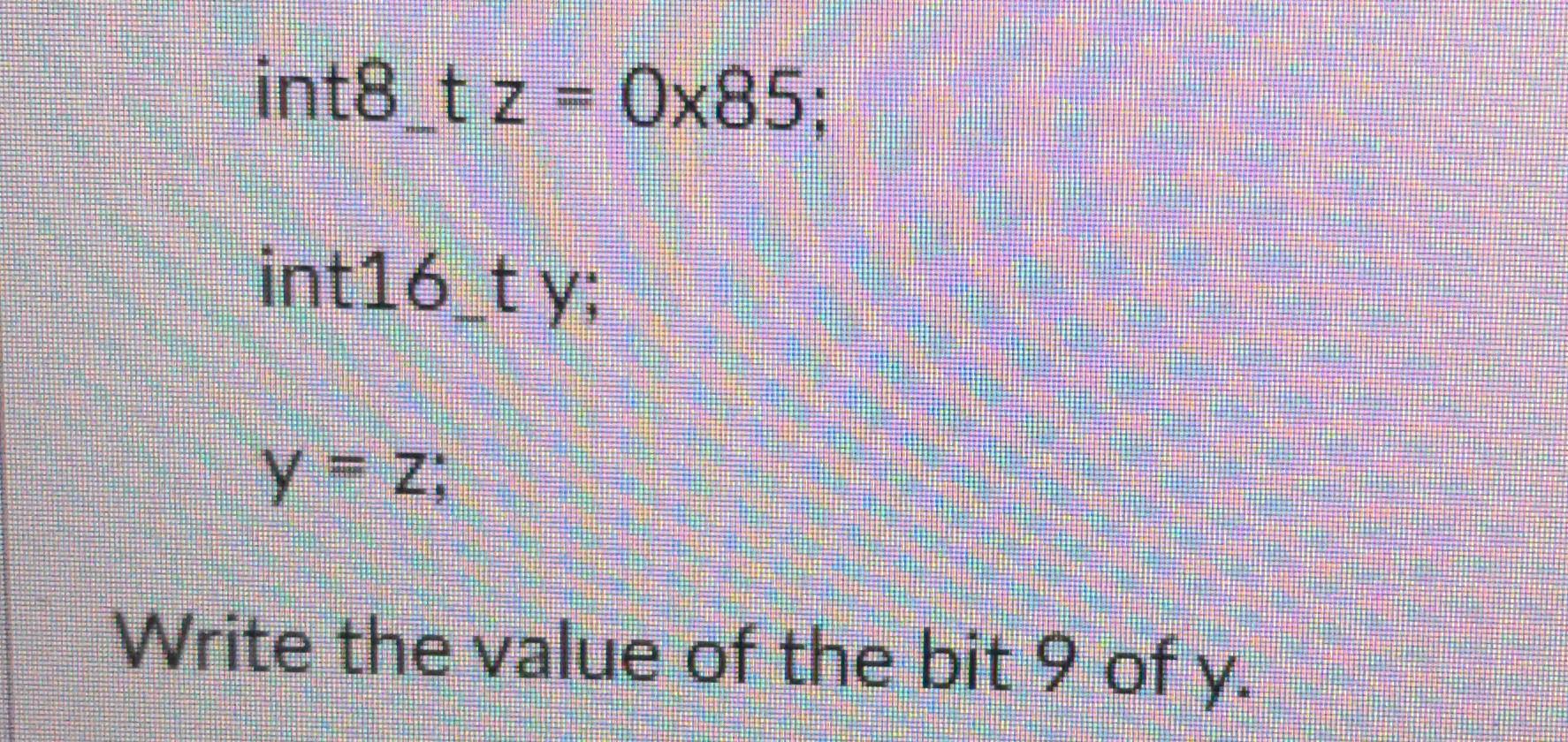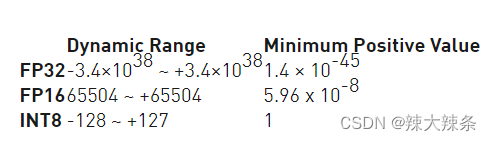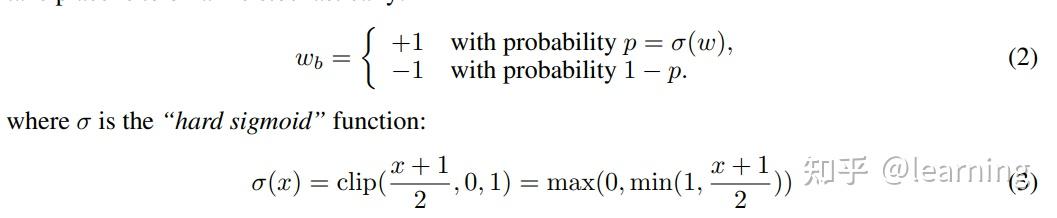Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
INT8 Quantization Basics | Rand Xie
[2303.17951] FP8 versus INT8 for efficient deep learning inference
algorithm - Can matlab's int8 function be replaced with faster ...
INT8 and INT4 Quantization ValueError · Issue #35 · moojink/openvla-oft ...
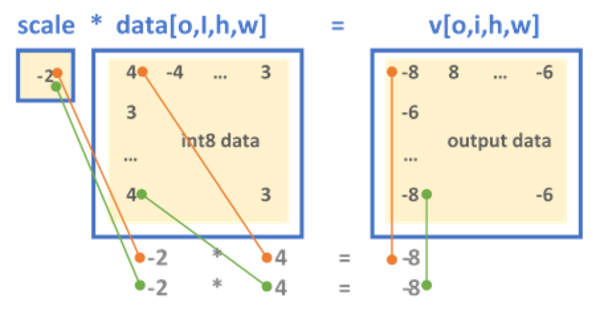
Int8 Inference
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
INT8 Calibration for TensorRT Inference | PDF | Integer (Computer ...
Solved int8 t z = Ox85: int16_ty: Y = z; Write the value of | Chegg.com
Value of the Ru−C−N Angle for ts7 and int8 after Dissociation of Ethane ...
Int8 quantization and tvm implementation - Programmer Sought
What are the values mean in the labels folder in INT8? Is it necessary ...
Int8 Inference — oneDNN v3.10.2 documentation
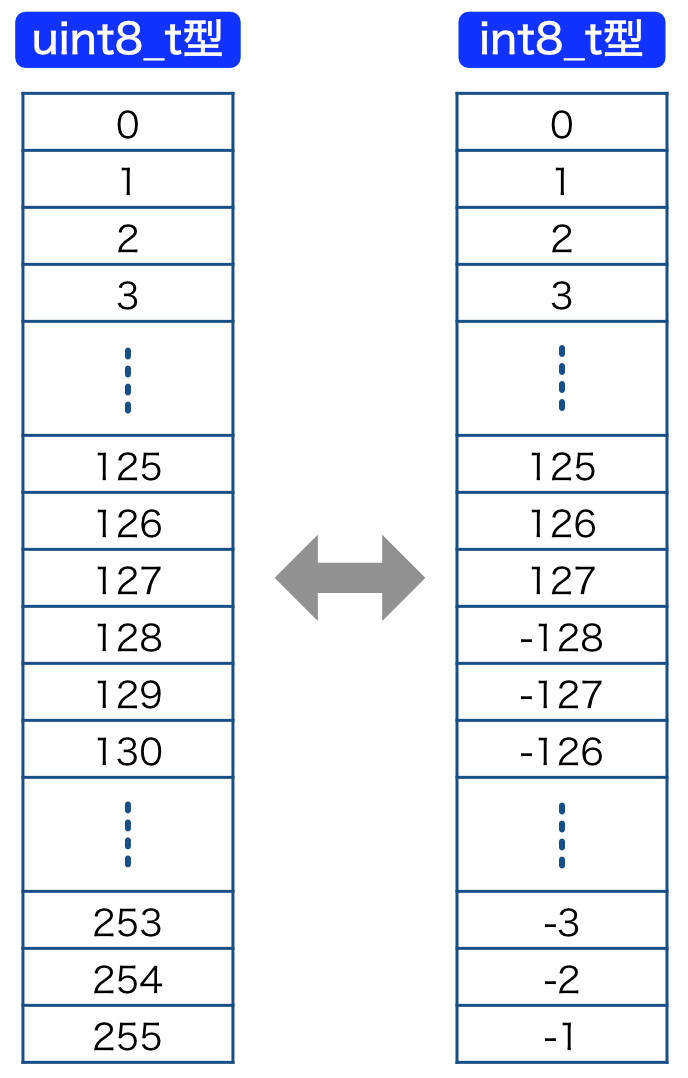
Understanding NumPy Behavior: What Happens When Array Values Exceed ...
Problem with reading INT8 number via ZCL_EXCEL_WORKSHEET=>SET_CELL ...
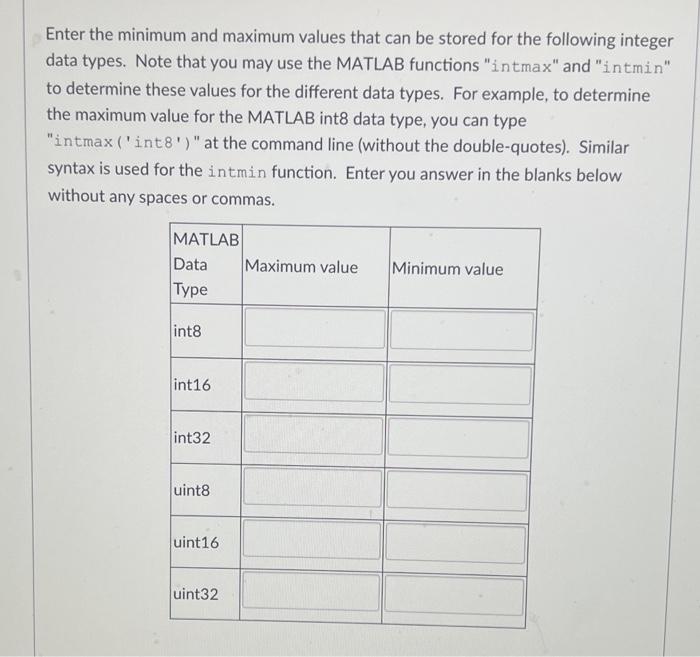
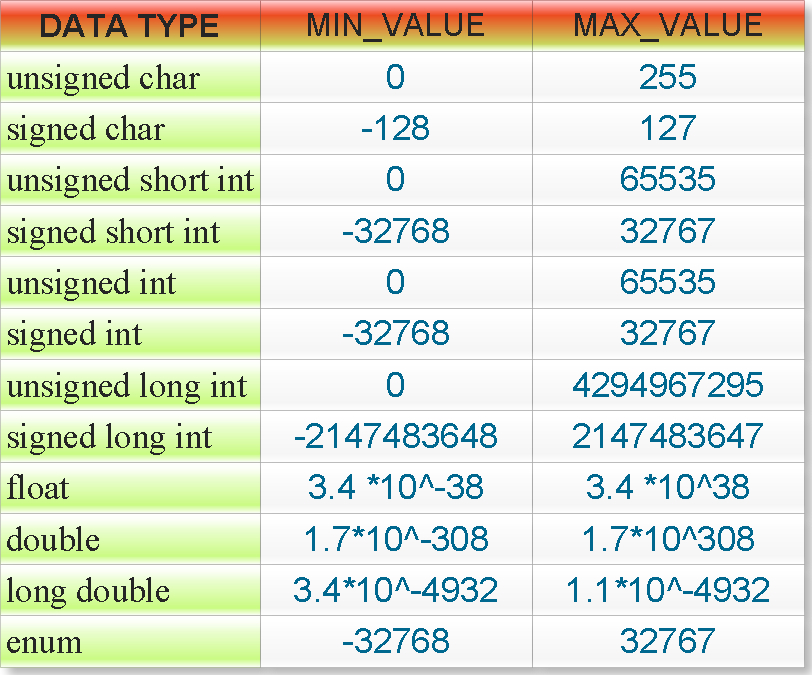
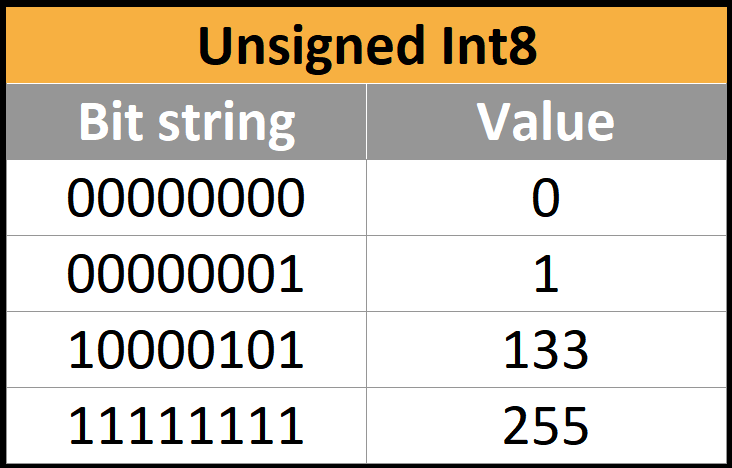
Solved Enter the minimum and maximum values that can be | Chegg.com
How to provide calibration data for INT8 quantization with dynamic ONNX ...
Top-1 accuracy of various INT8 methods for ImageNet | Download ...
Understanding int8 vs fp16 Performance Differences with trtexec ...
int4 vs int8 vs uuid vs numeric performance on bigger joins
TensorRT INT8 quantization principle and how to write a calibrator ...
Swift int8_t, int_fast8_t, int8 difference - Programmer Sought
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
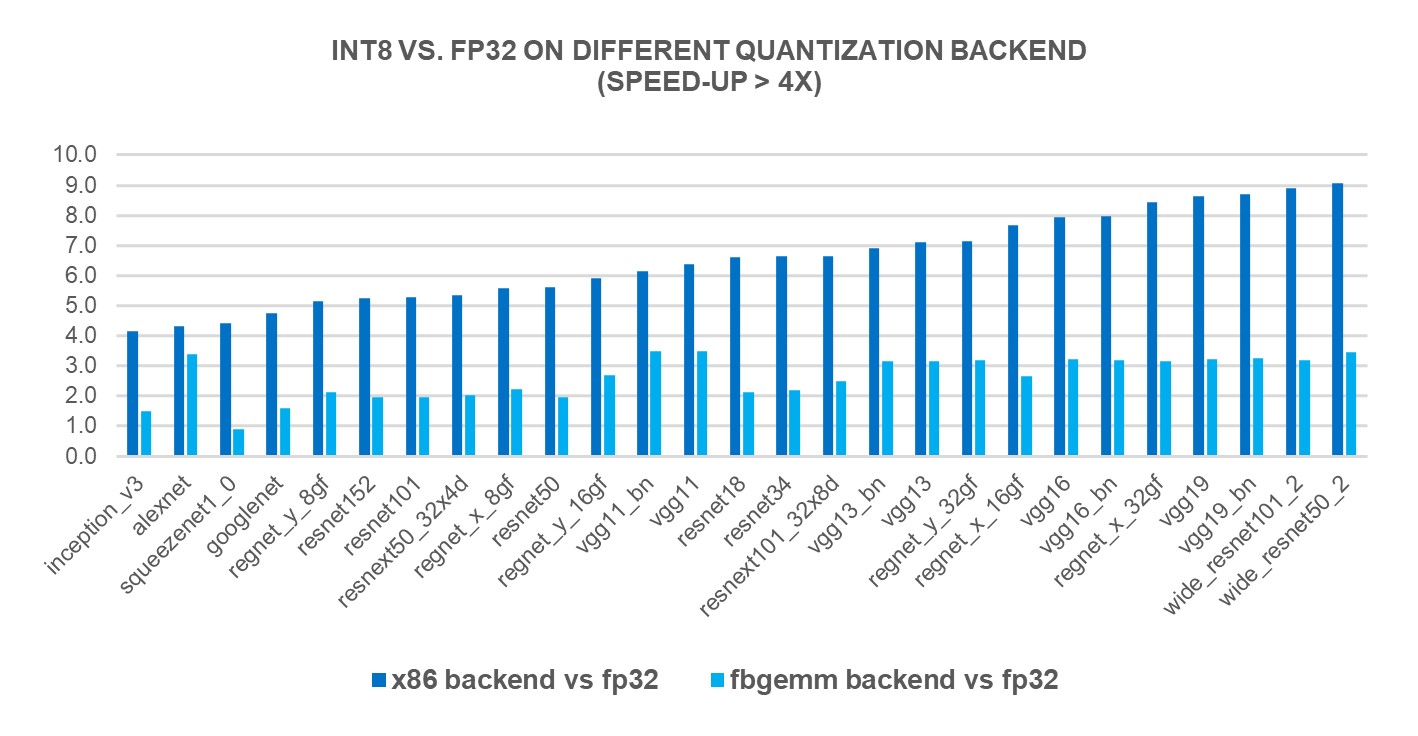
INT8 Quantization for x86 CPU in PyTorch – PyTorch
The process of converting FP32 to INT8 under TensorRT - Programmer Sought
Metrics all 0 after TensorRT INT8 export for mode val, only INT8 ONNX ...
INT8 quantization with same model and different weights · Issue #2705 ...
Understanding int8 neural network quantization - YouTube
Data layout of int8 mma with the shape of m8n8k16. | Download ...
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
Figure 1 from Performance Evaluation of INT8 Quantized Inference on ...
Improve Inference with INT8 Quantization for x86 CPU in PyTorch
Int8 inference significantly reduces the accuracy · Issue #255 · NVIDIA ...
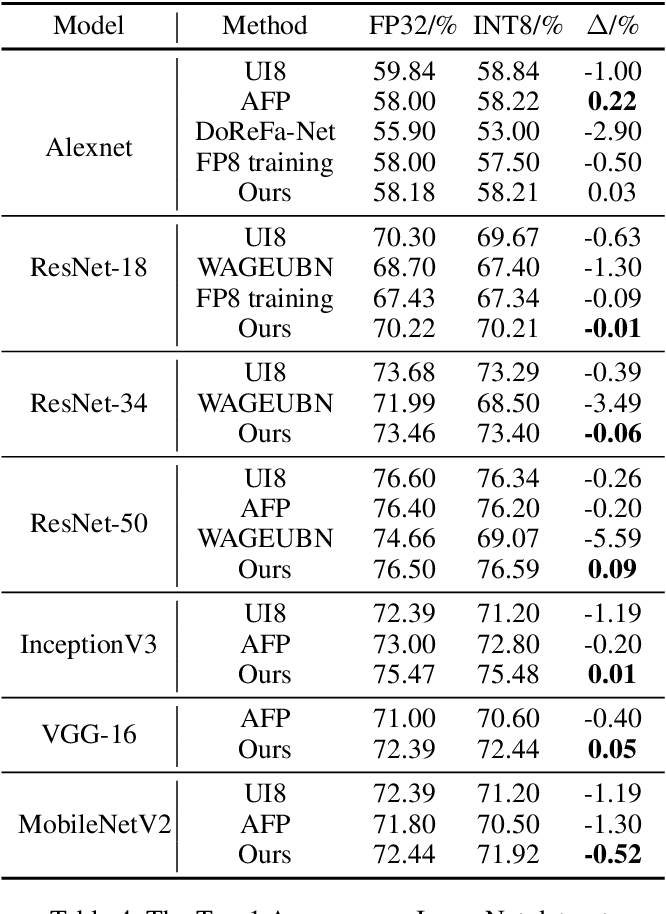
Table 4 from Distribution Adaptive INT8 Quantization for Training CNNs ...
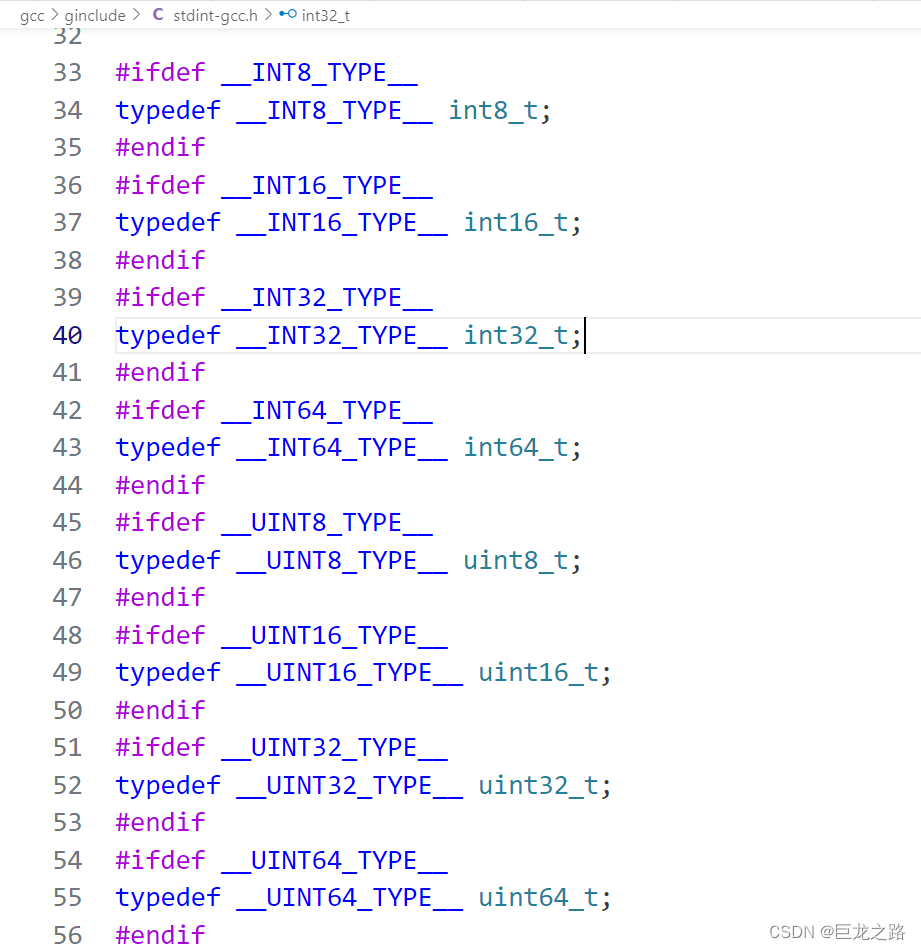
Fixed width integer types (int8) in C++
第48回 補足 - 変数の振る舞い | ツール・ラボ
Kinds of Data Types - KodeKloud
[Video] ប្រើ int8_t uint32_t ក្នុង Arduino ឲ្យបានត្រឹមត្រូវ - etronicskh
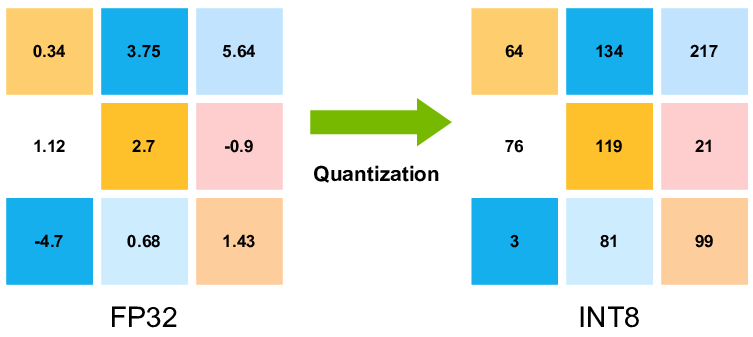
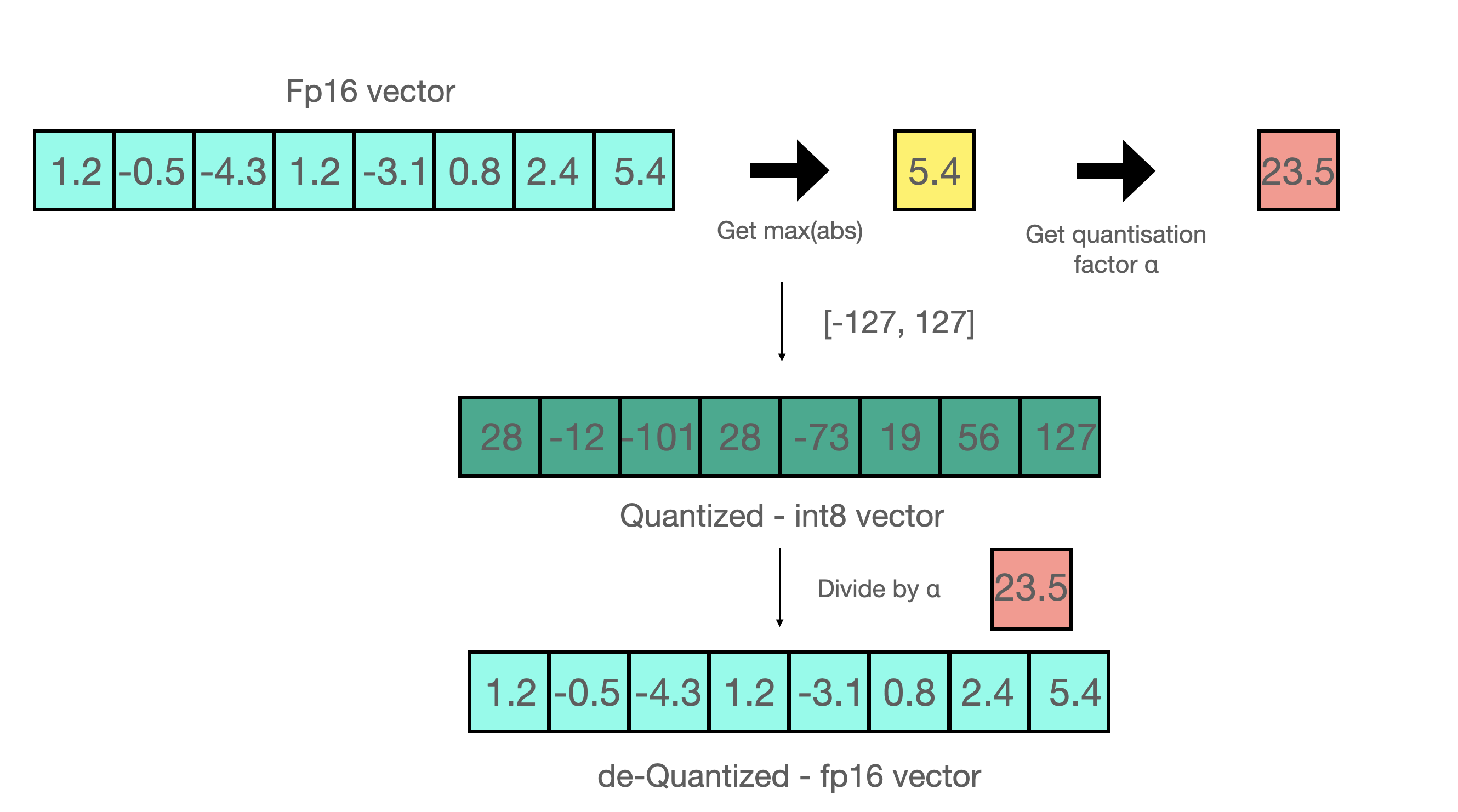
A Visual Guide to Quantization - Maarten Grootendorst
NumPy Integer Data Types Explained: int8, int16, int32, int64 Tutorial ...
QLoRA and 4-bit Quantization · Chris McCormick
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
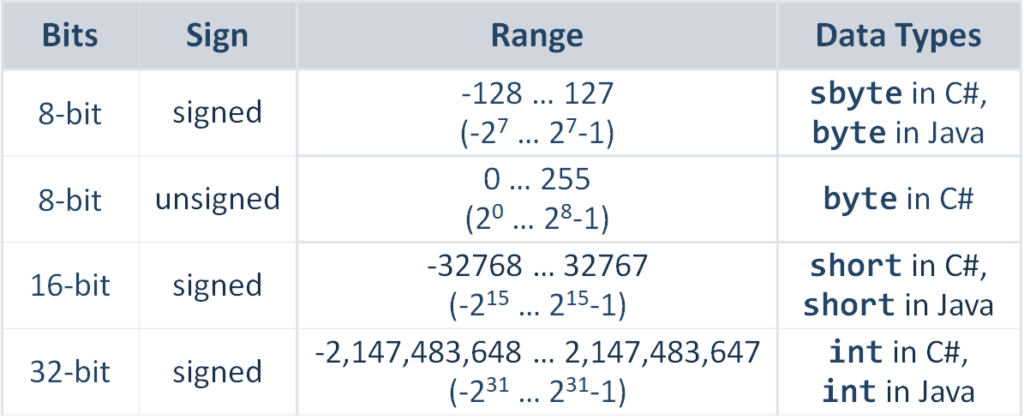
Difference between int, Int16, Int32 and Int64
iOS 和 swift 中常见的 Int、Int8、Int16、Int32和 Int64介绍「建议收藏」-腾讯云开发者社区-腾讯云
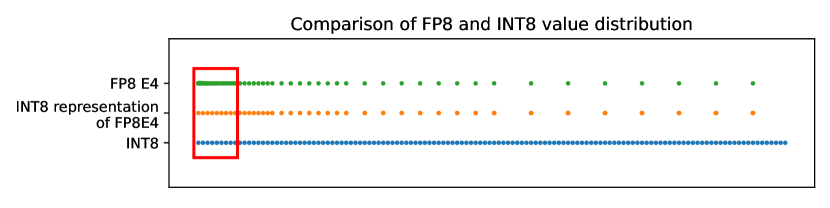
Value Distribution represented in FP8 and INT8. | Download Scientific ...
Byte Pack - Convert input signals to 8-, 16-, or 32-bit vector - Simulink
Looking at 11th Generation Intel® Processor Performance on Intel ...
Integer in ABAP, Java and JavaScript - SAP Community
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
int8_t int16_t int32_t difference,,, int64_t, size_t and the ssize_t ...
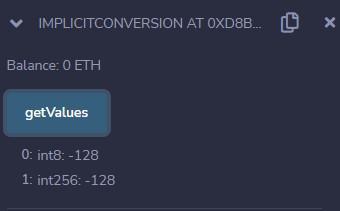
Implicit Conversions in Solidity - GeeksforGeeks
Answered: int8_t x - 16; int8_t y = Ob0111111;… | bartleby
FP8: Efficient model inference with 8-bit floating point numbers ...
A Visual Guide to Quantization - by Maarten Grootendorst
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
int int8ToInt (int8_t num) : Takes in an 8-bit signed | Chegg.com
INT8量化原理理解-CSDN博客
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
Quantization concepts · Hugging Face
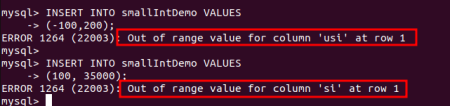
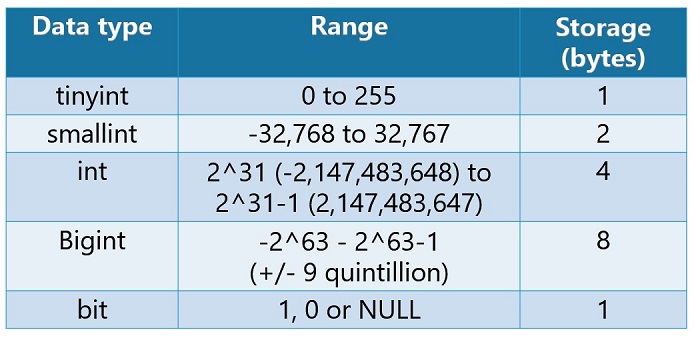
Everything You Need to Know About MySQL SMALLINT - MySQLCode
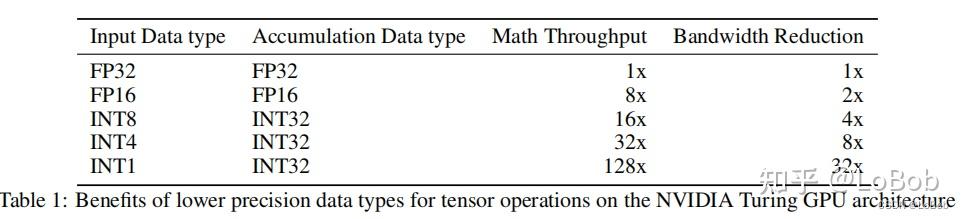
int8,FLOPS,FLOPs,TOPS 等具体含义_int8 tops-CSDN博客
Small numbers, big opportunities: how floating point accelerates AI and ...
INT8, INT4 and Other Integer Types for Quantization
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
C++ Data Types Uint8_T at Mildred Urban blog
模型量化(int8)知识梳理 - 知乎
int8とは - IT用語辞典 e-Words
Documentation
Quantization Methods for 100X Speedup in Large Language Model Inference
5 - Stdint library: uint8_t, int8_t, uint16_t, int16_t, uint32_t, int32 ...
Understand Variables and Naming Conventions - ppt download
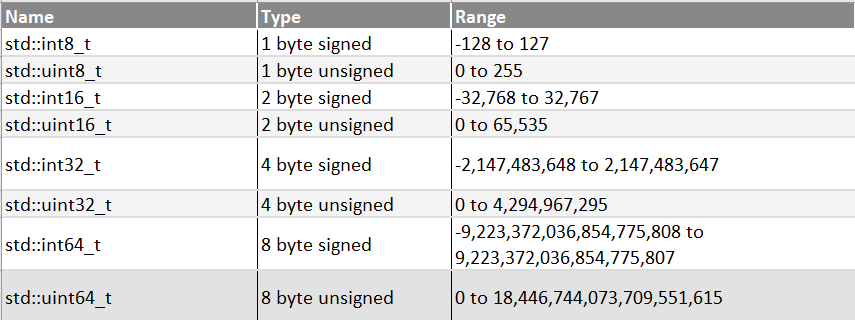
Data types: int8, int16, int32, int64
LLM Quantization Deep Dive: From FP32 to NF4, INT4, and MX Formats
KV cache 缓存与量化:加速大型语言模型推理的关键技术 - 技术栈
一起实践神经网络INT8量化系列教程(一)_神经网络量化工具使用文档-CSDN博客
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
mysql - Difference between "int" and "int(2)" data types - Stack Overflow
matlab将数据转换为int8类型 - 知乎
量化 | 深度学习Int8的部署推理原理和经验验证 - 知乎
Times required and respective operations for the readout training for ...
What is the difference between INT8, INT16, INT32, INT64? - Programmer ...
部署系列——神经网络INT8量化教程第一讲! - 知乎
Int8量化-介绍-CSDN博客
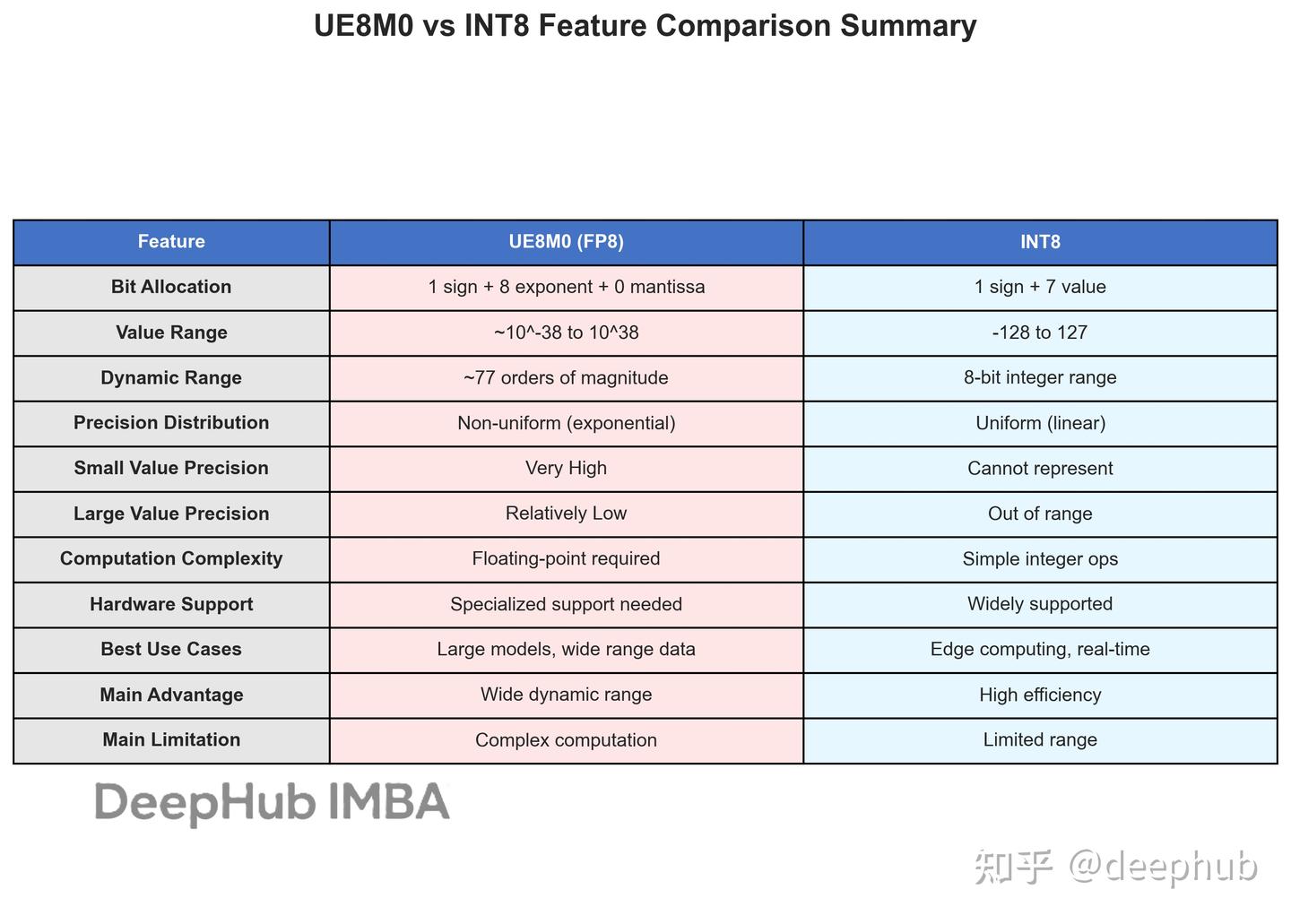
这也许就是DeepSeek V3.1性能提升的关键:UE8M0与INT8量化技术对比与优势分析 - 知乎
Scalar Quantization: Background, Practices & More | Qdrant
Variables and data types IN SWIFT | PDF
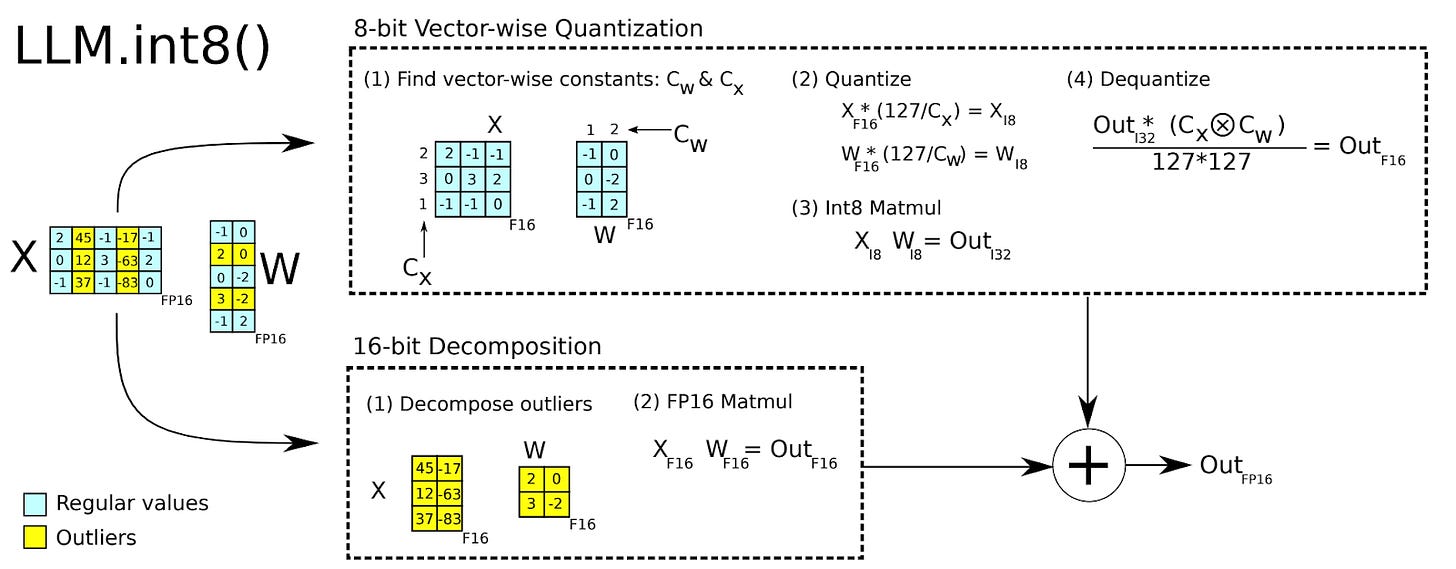
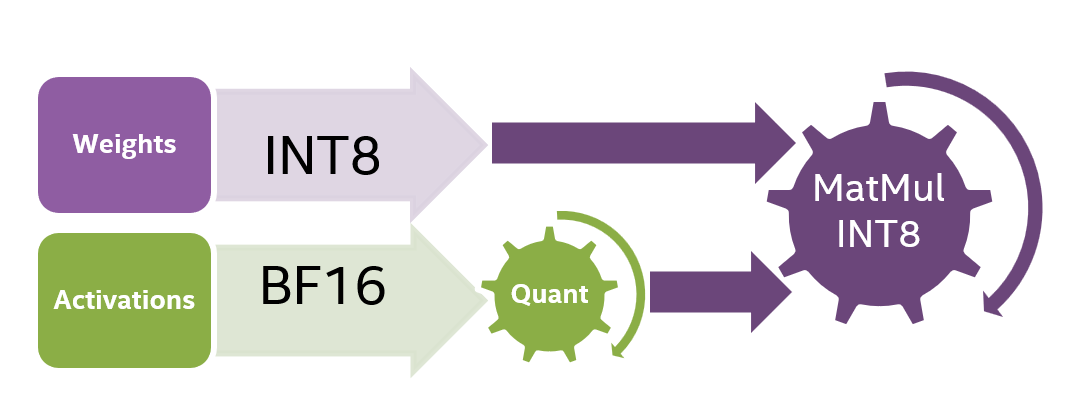
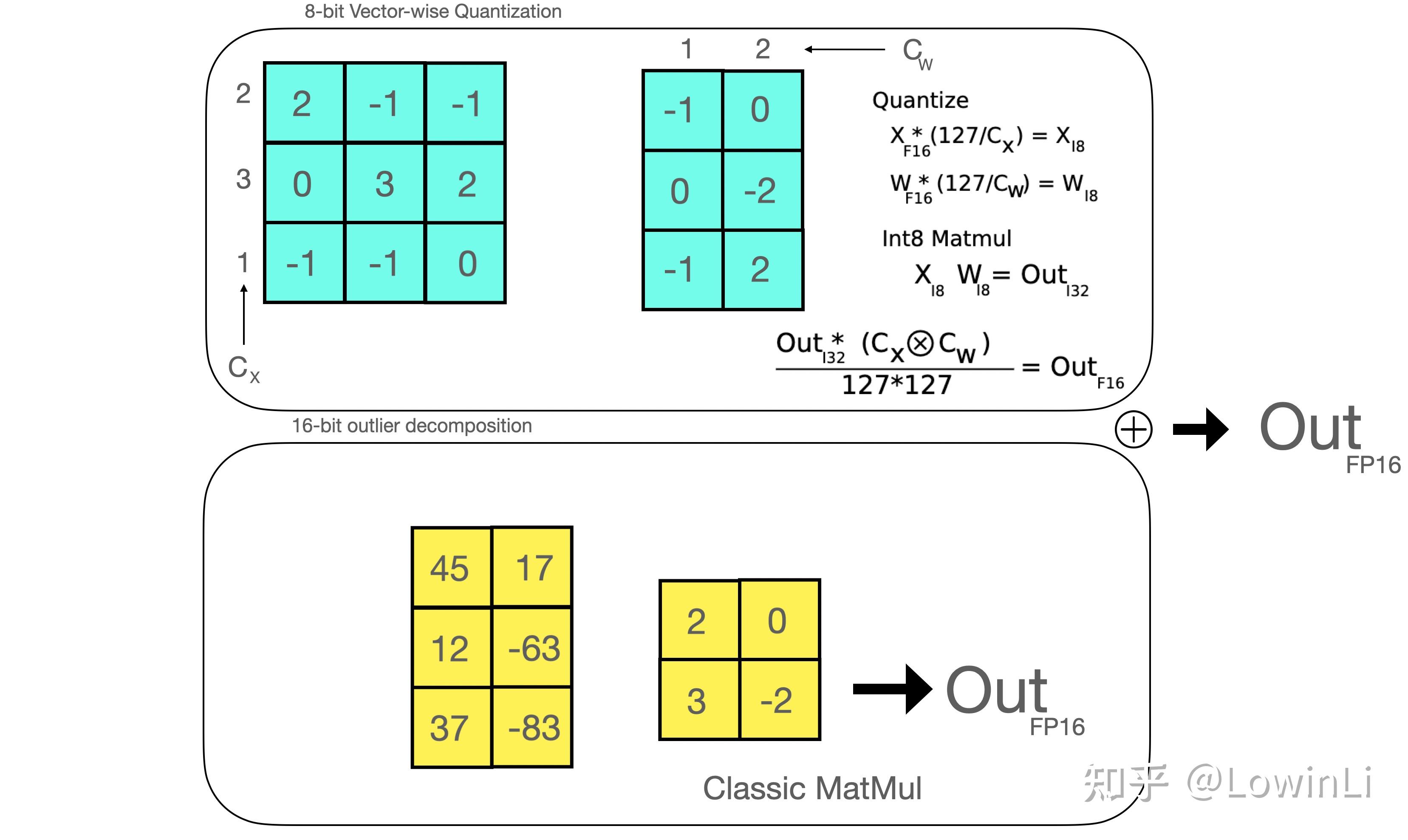
8位混合精度矩阵乘法,小硬件跑大模型 - 知乎
Integer Data Type Explained for Developers - John Deardurff (@SQLMCT)
Byte Unpack - Unpack 8-, 16-, or 32-bit input vector to multiple output ...
int8_t、uint8_t、__INT 64等和size_t的阐述_uint8头文件-CSDN博客
c programming
Bits, Bytes and Integers——二进制unsigned以及Two-complement表示,十六进制_2 byte ...
Data Representation in Computer Memory [Dev Concepts #33] - SoftUni Global
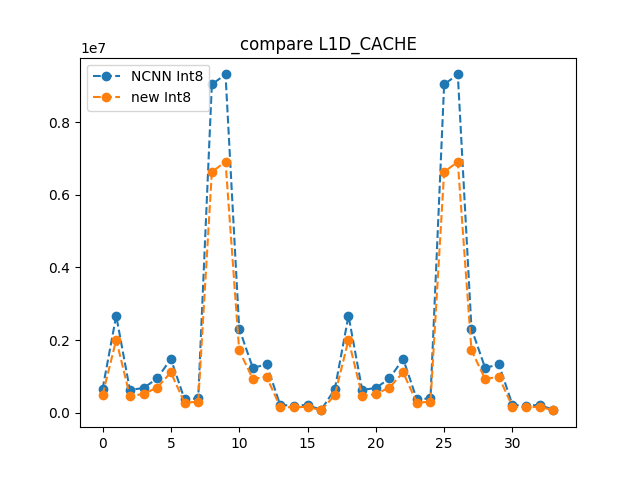
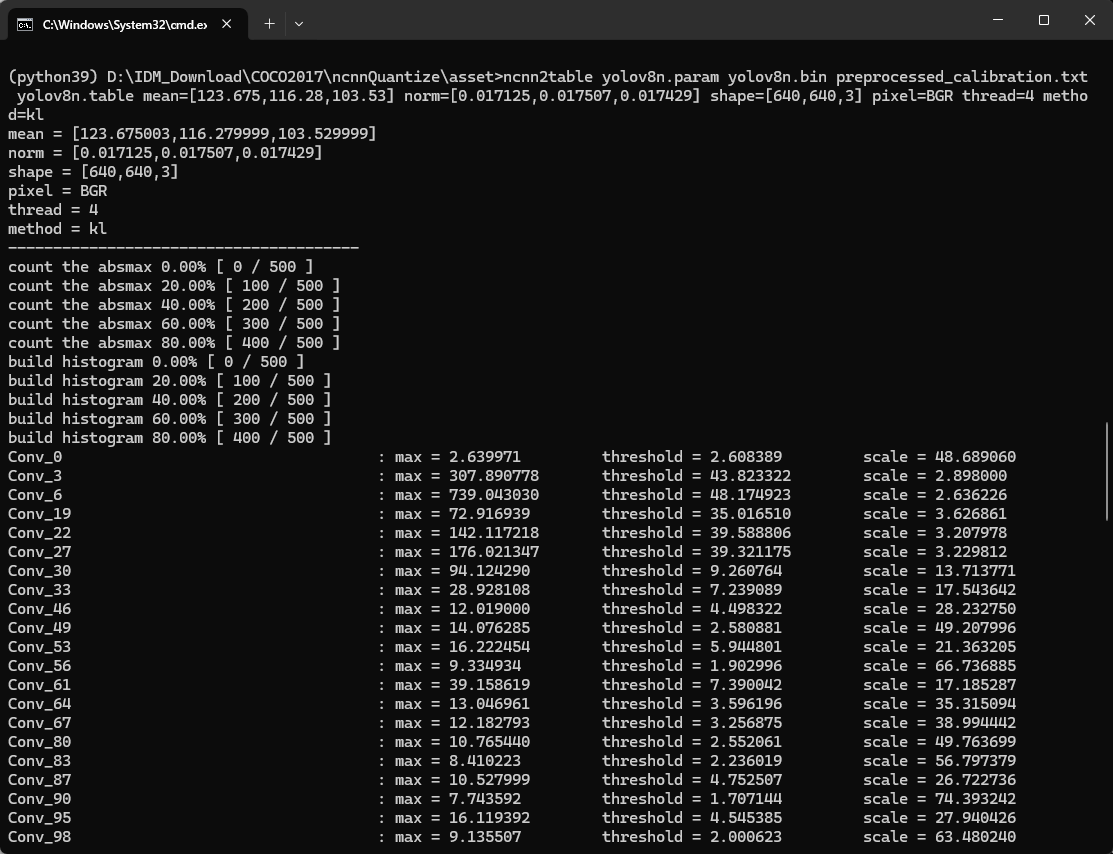
YOLOv8 → NCNN Int8:完整量化流程与校准数据指南_ncnn的yolov8 的int推理-CSDN博客
详解C语言中的int8_t、uint8_t、int16_t、uint16_t、int32_t、uint32_t、int64_t、uint64 ...
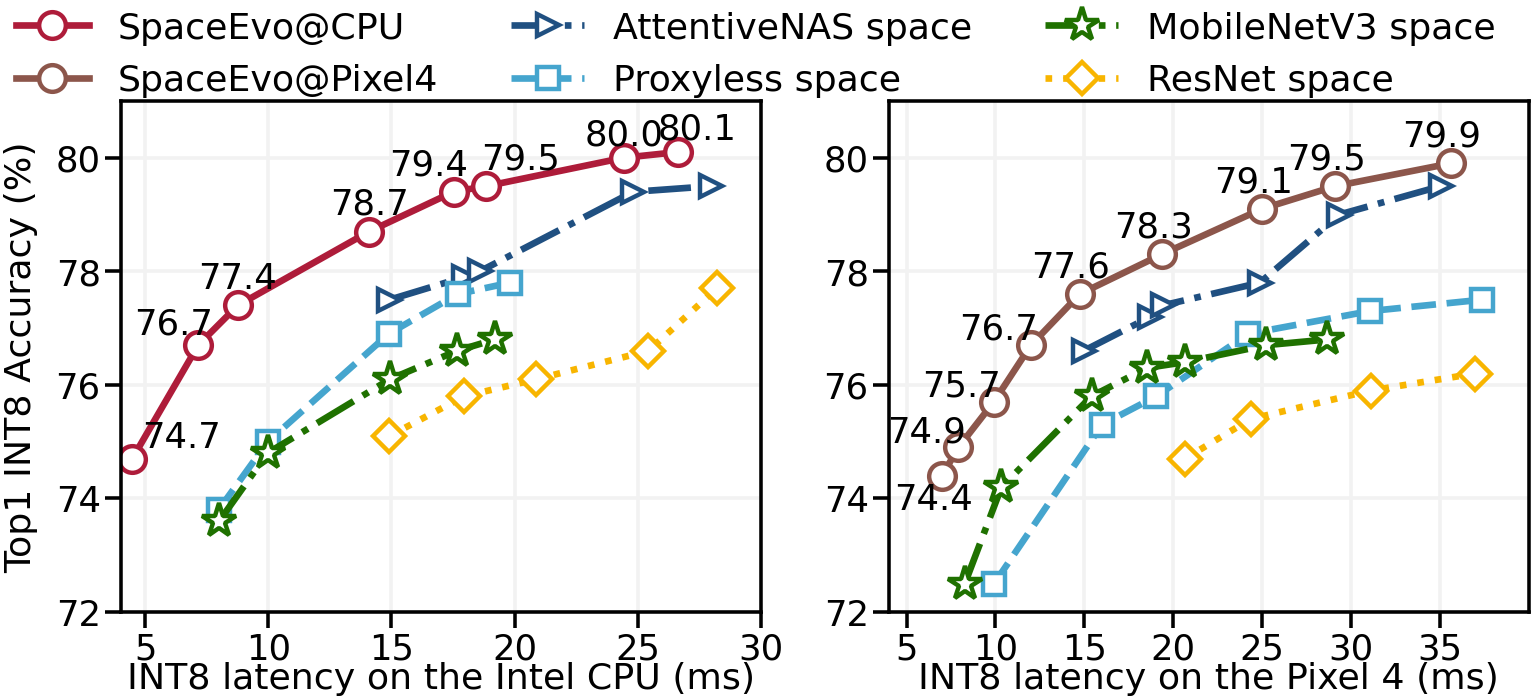
[2303.08308] SpaceEvo: Hardware-Friendly Search Space Design for ...
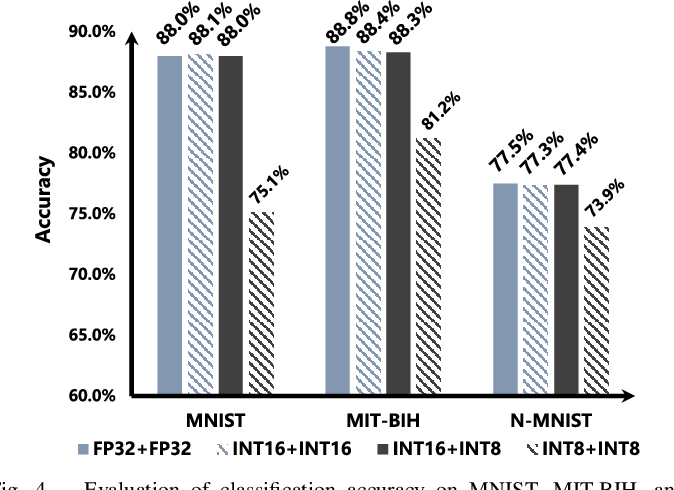
Figure 4 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
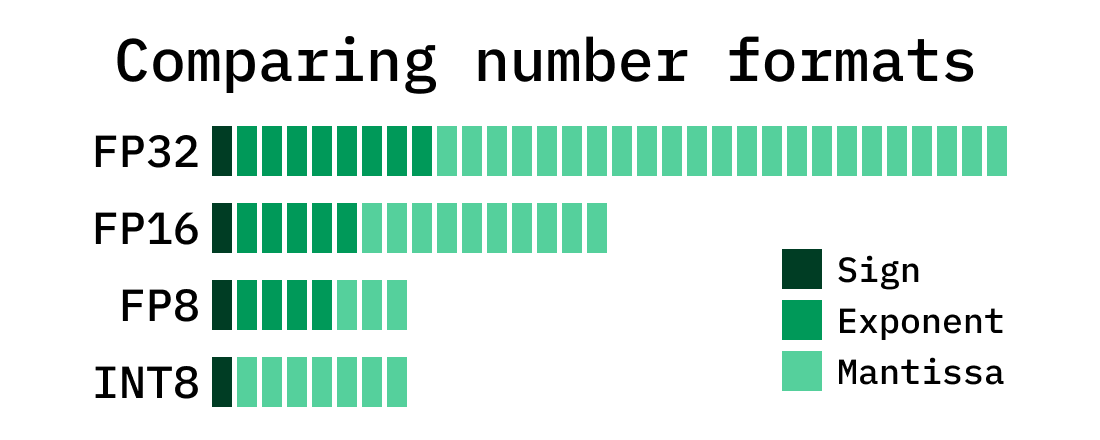
Neural Network Quantization & Number Formats From First Principles
Imagery Basics – FME Support Center
量化 | INT8量化训练 - 知乎
大模型量化之 LLM.int8()方法 - 知乎