Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
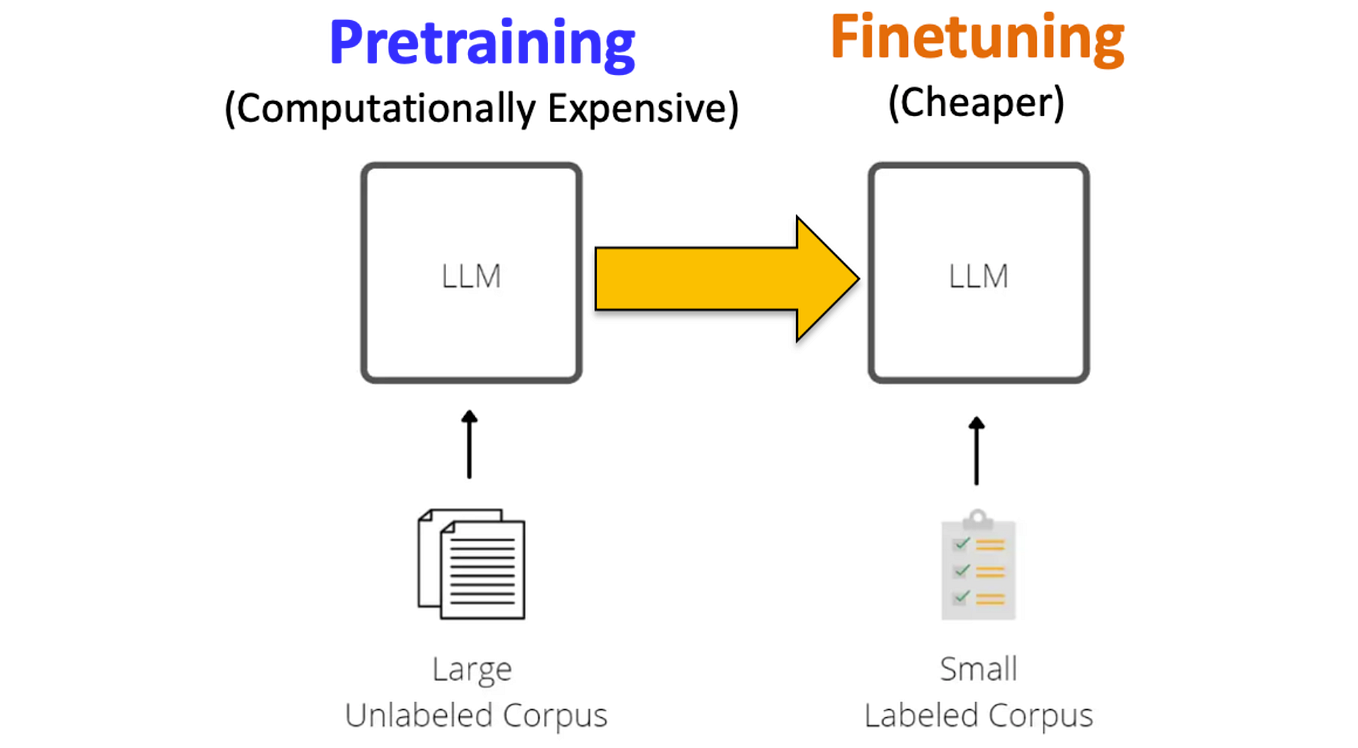
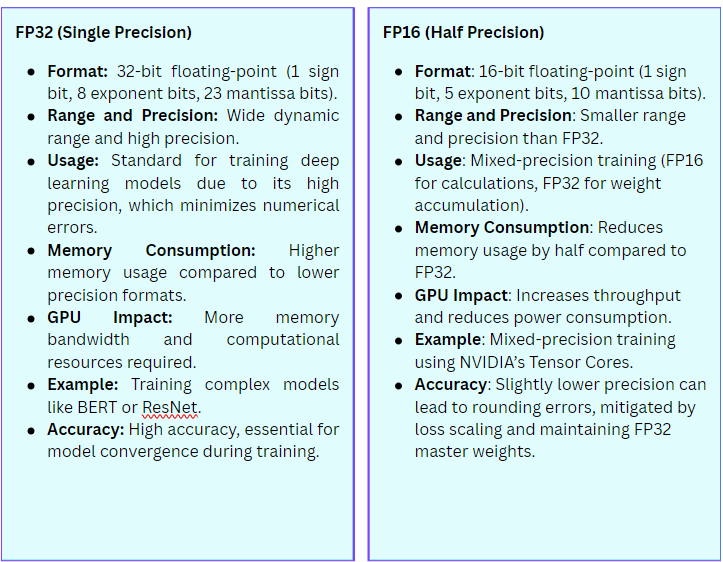
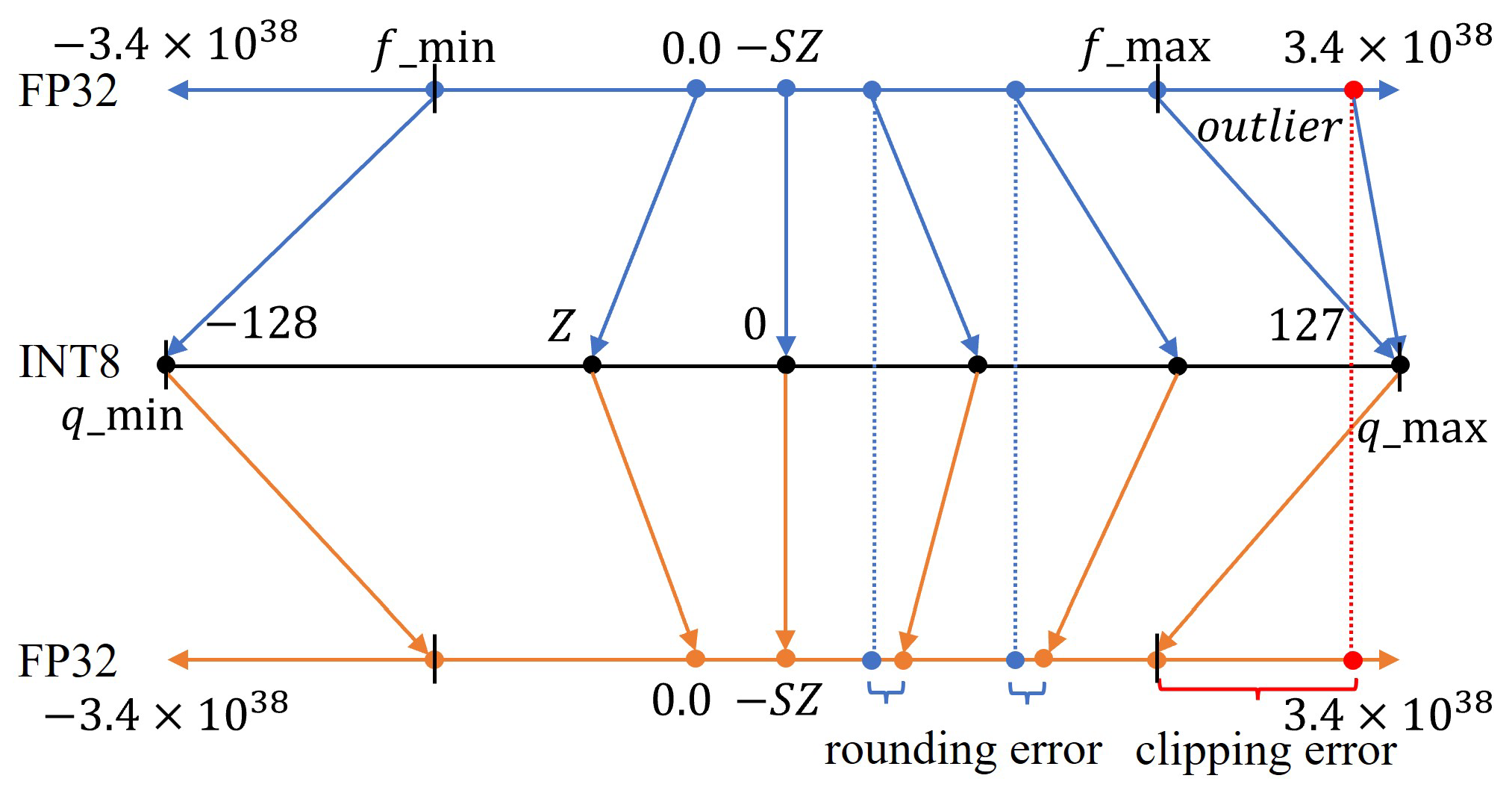
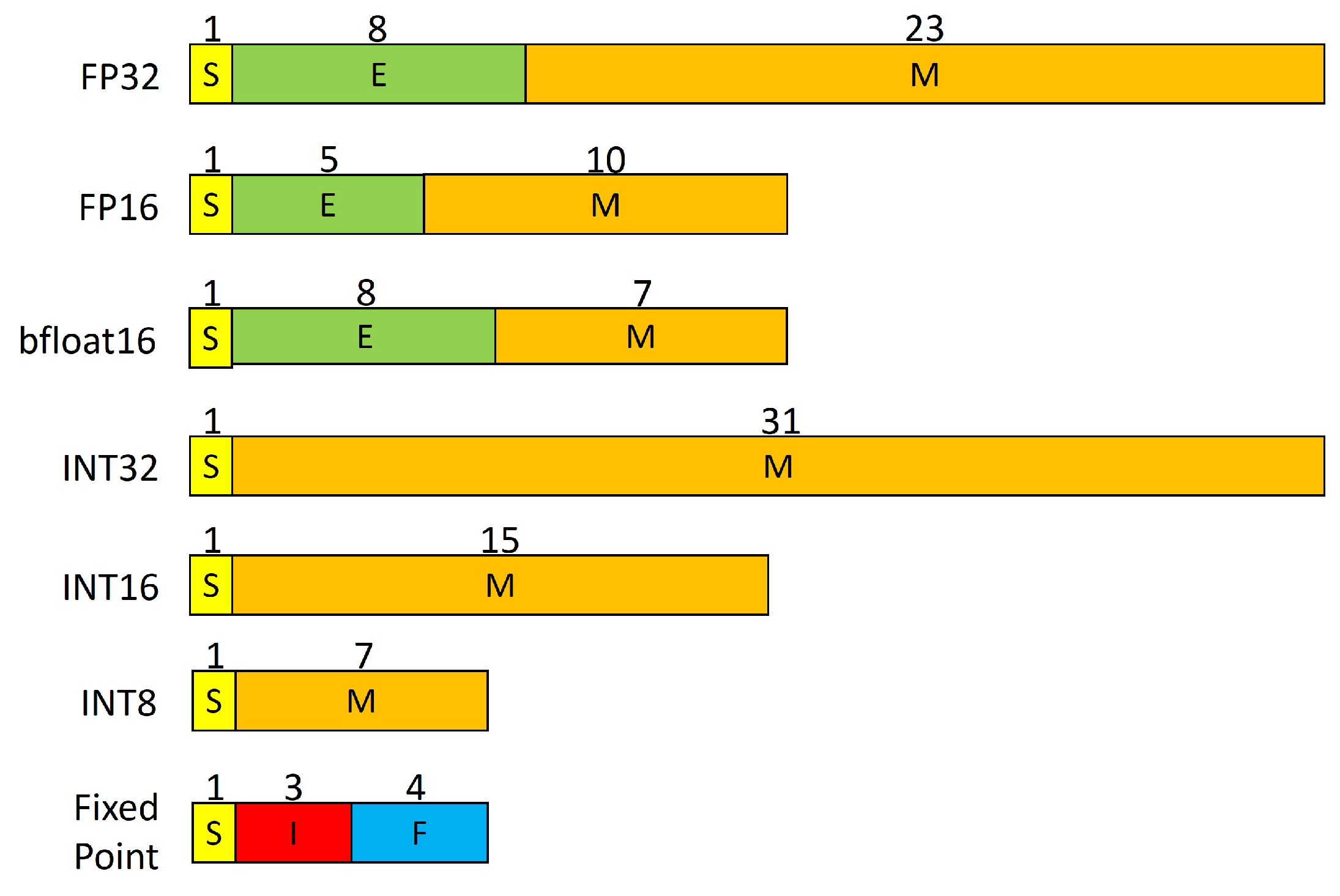
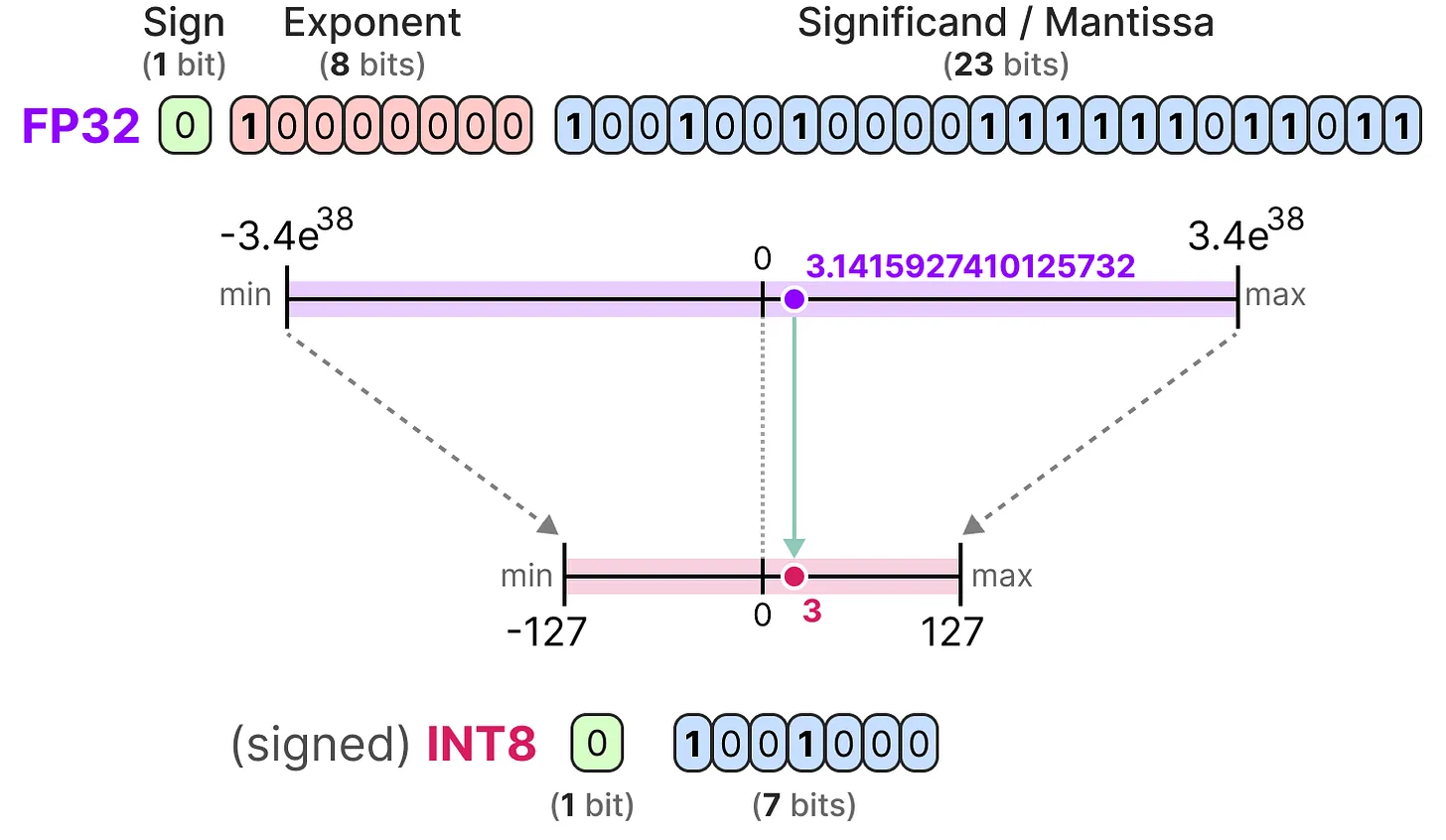
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
how to check precision of each layer after quantize to INT8 model ...
Speeding up object detection tasks using INT8 precision on the Jetson ...
polygraphy : how to comparing tensorrt precision between int8 and fp32 ...
Algorithms selected propblem while use int8 precision · Issue #778 ...
low precision on INT8 inference CPU version · Issue #21 · AlexeyAB ...
Precision Comparison: FP64 FP32 FP16 TF32 BF16 INT8
GitHub - haiphamcse/YOLOv7INT8: An YOLOv7 model working on INT8 precision
Out of memory error when trying to convert model using INT8 precision ...
Model INT8 Precision Machined 90 Degree Angle Fixture
Model INT8 Precision Machined 11 Degree Bevel Fixture
Model INT8 Precision Machined 45 Degree Angle Fixture
Numerical Precision in Machine Learning: FP16, FP32, and INT8 | by ...
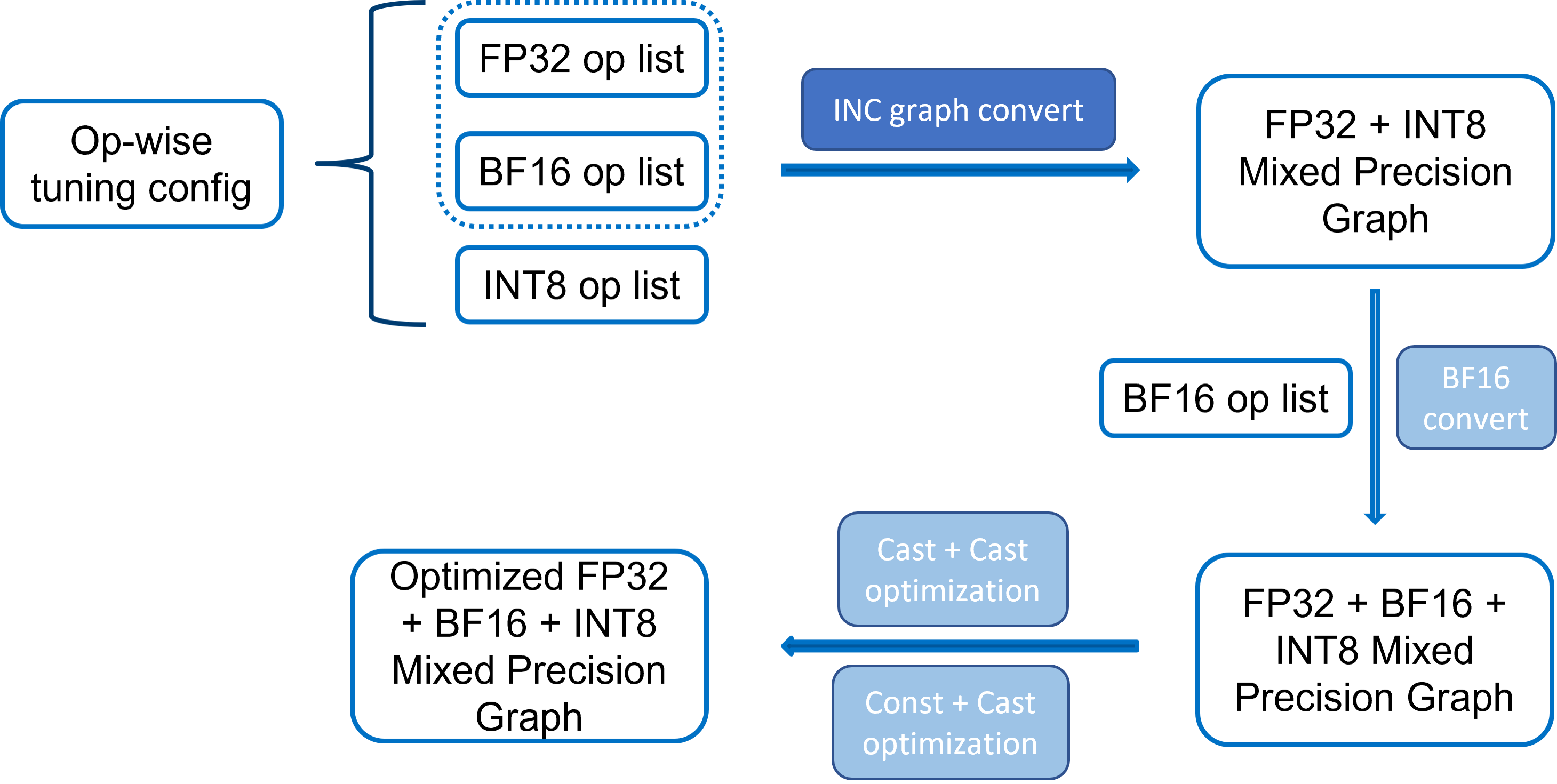
Turn ON Auto Mixed Precision during Quantization — Intel® Neural ...
Quantization: Reducing Model Precision (FP16, INT8)
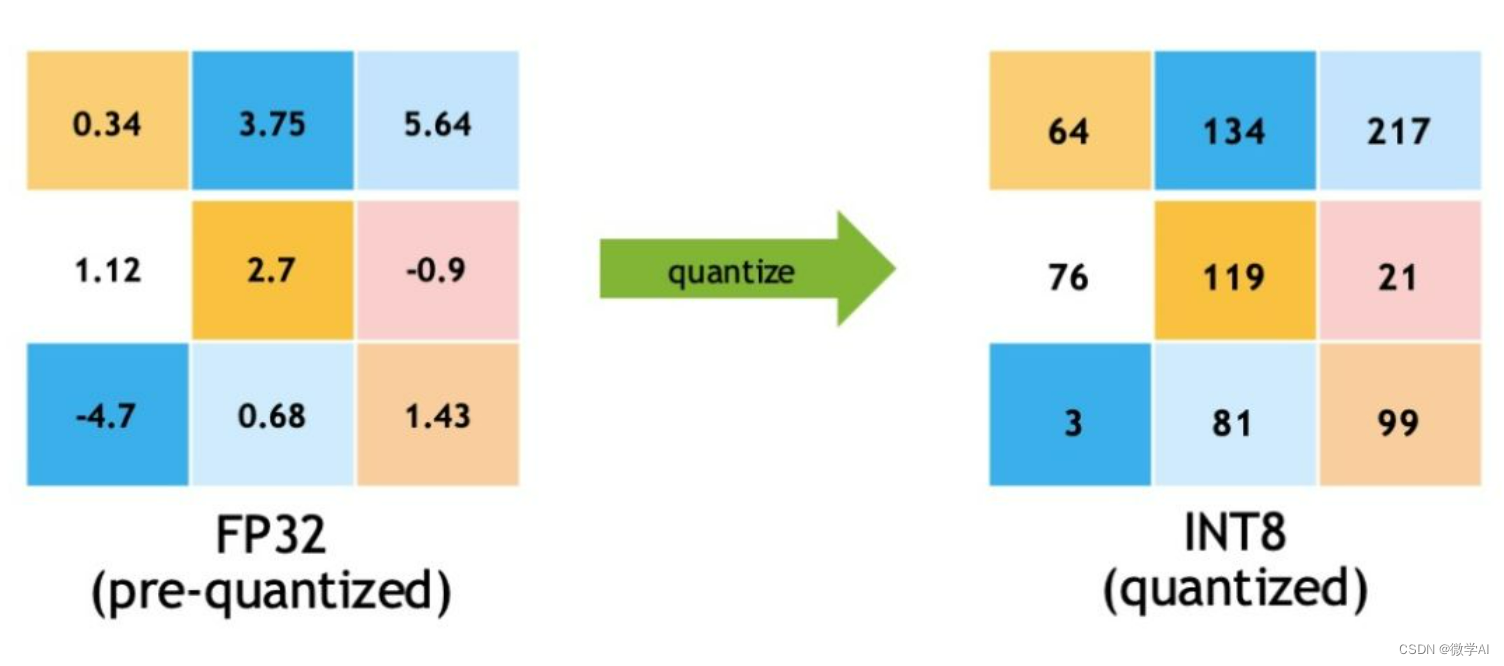
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
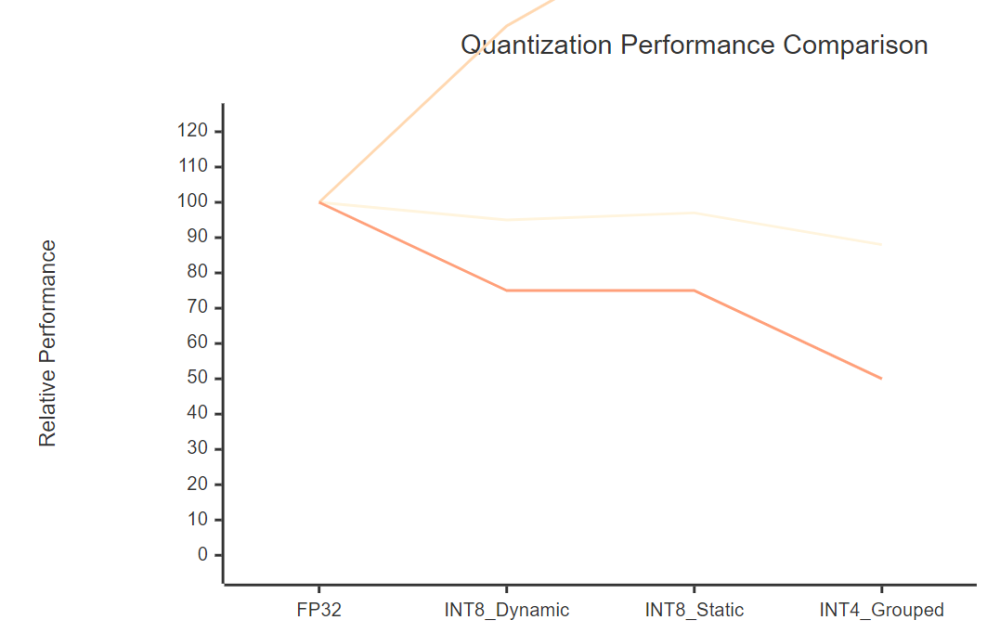
YOLOv10 vs. YOLOv11: INT8 Quantization Performance Comparison — Results ...
When inferring in int8 precision, must we call setDynamicRange() for ...
Various spectrum HV precision used in HOMS-TC. (a) FP32 precision, (b ...
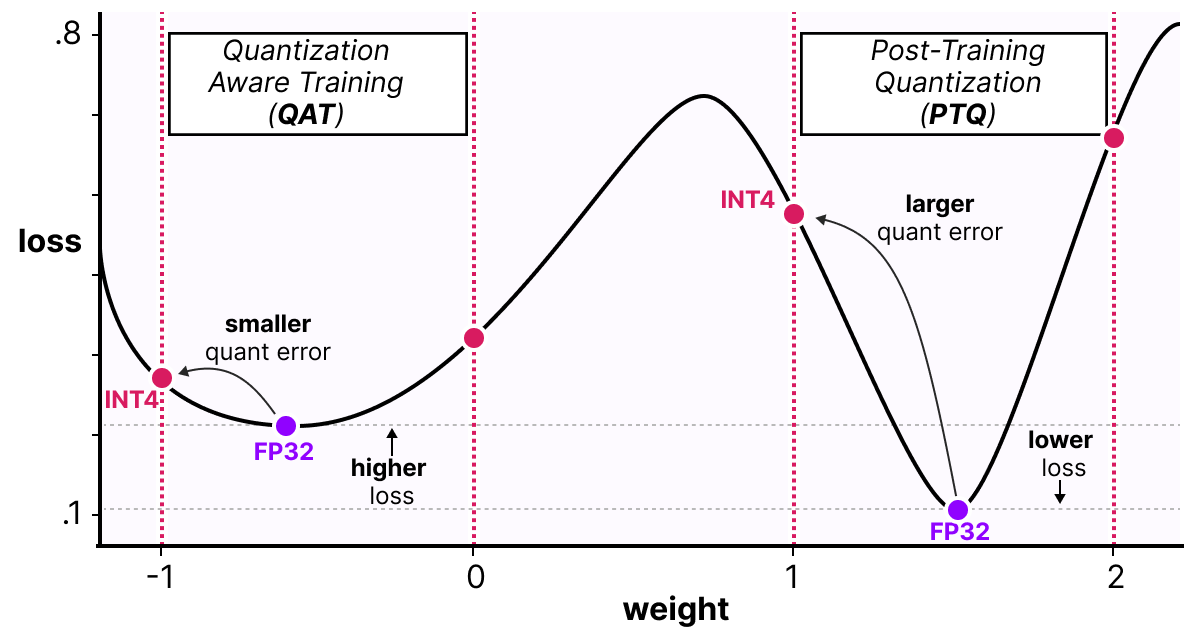
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
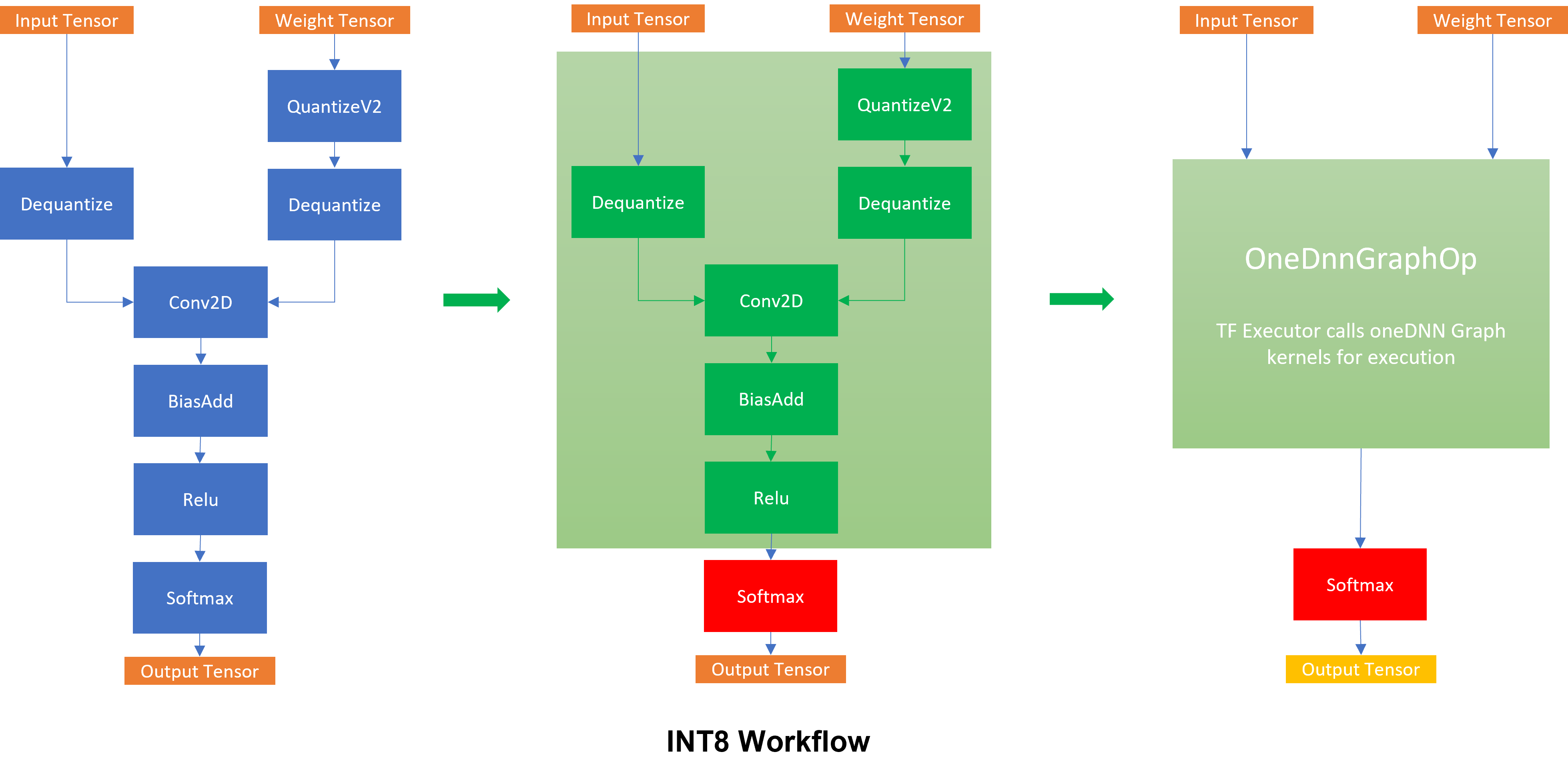
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
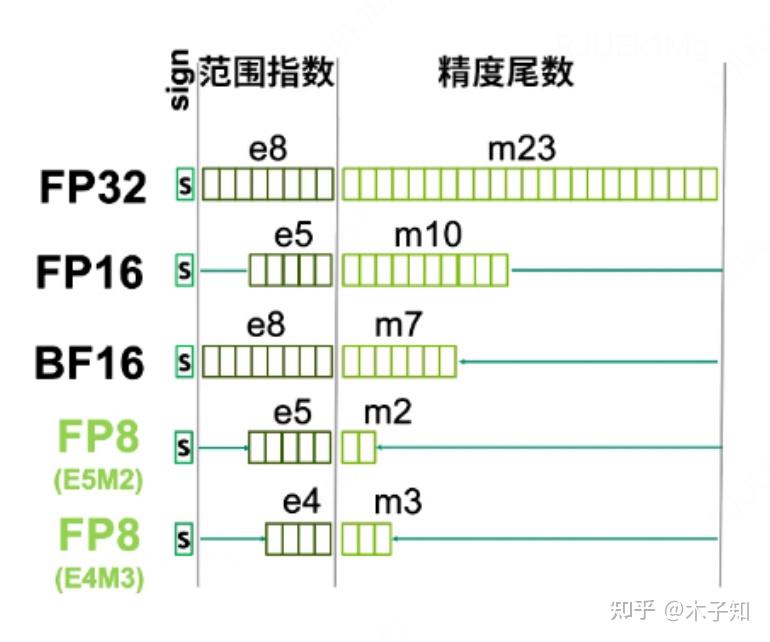
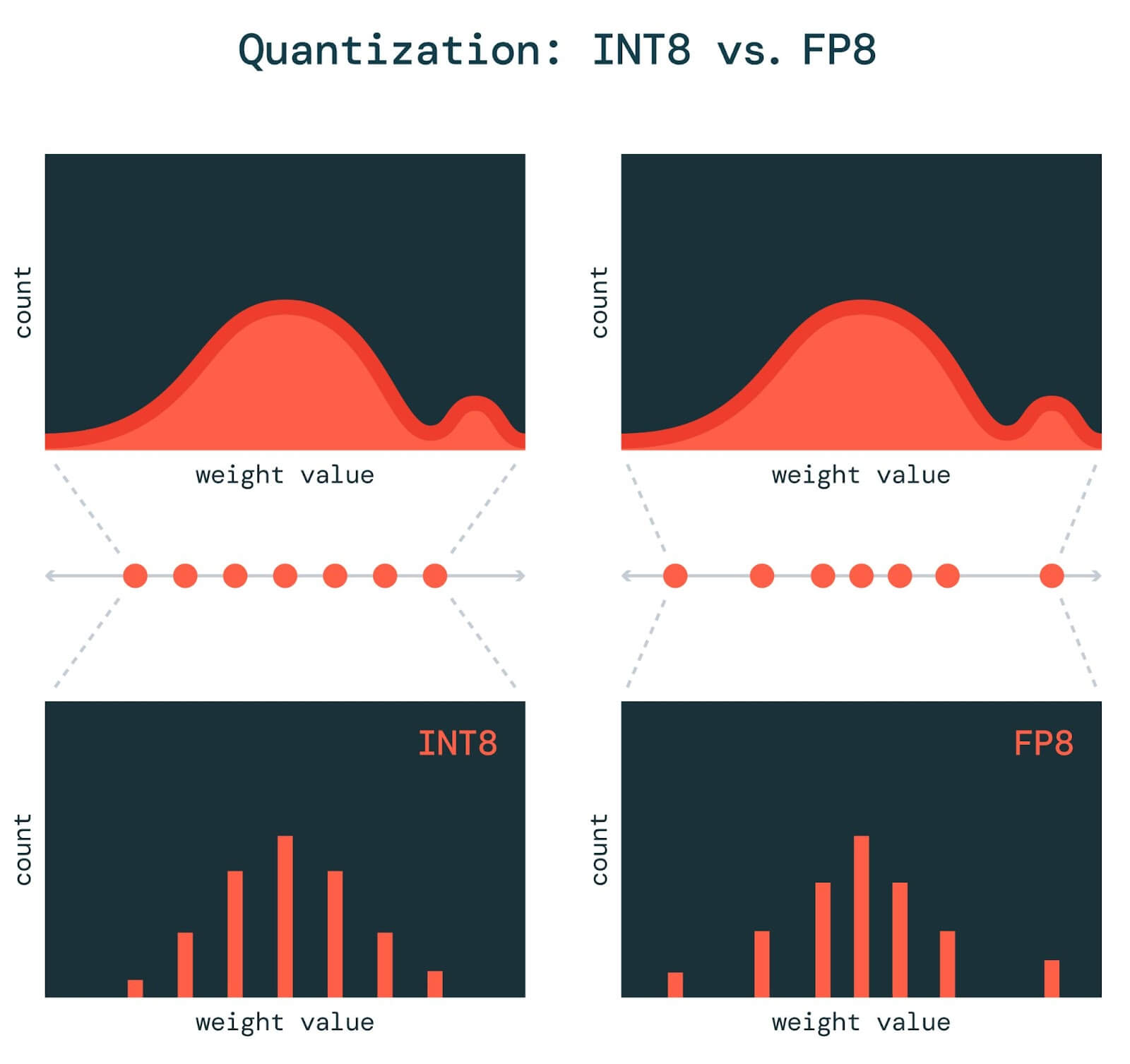
[2303.17951] FP8 versus INT8 for efficient deep learning inference
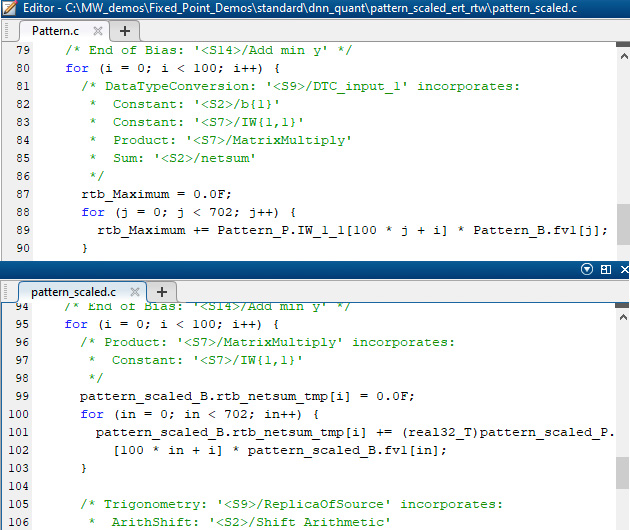
Deep Learning HDL Single To Int8 Conversion - Convert single-precision ...
Improving INT8 Accuracy Using Quantization Aware Training and the ...
INT8 Quantization for x86 CPU in PyTorch | PyTorch
How to Convert a Custom-Trained YOLO11 Model to a TensorRT INT8 Engine ...
GTC 2020: Toward INT8 Inference: Deploying Quantization-Aware Trained ...
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析 - NVIDIA 技术博客
GPU Latency failure for FP16, INT8, mixed precision (FP16+INT8) models ...
Shrinking AI Models by 75%: A Practical Guide to PyTorch INT8 ...
INT8 vs. FP32: Optimizing AI object recognition in video streams - DDT
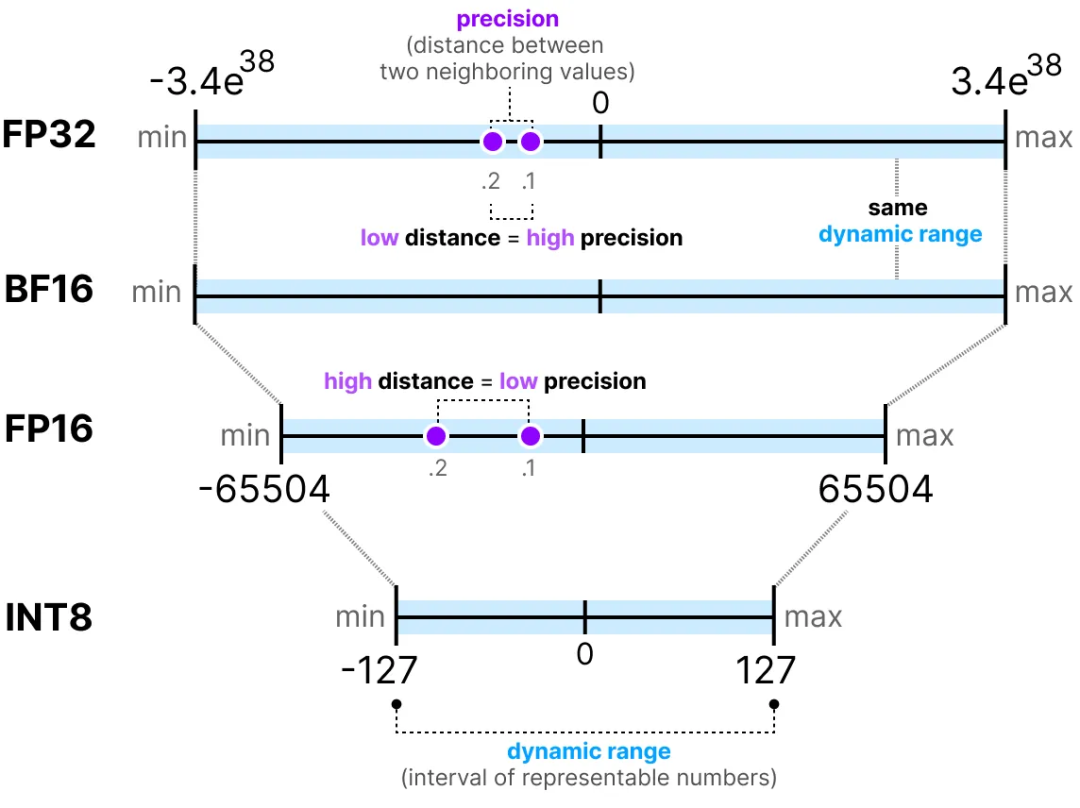
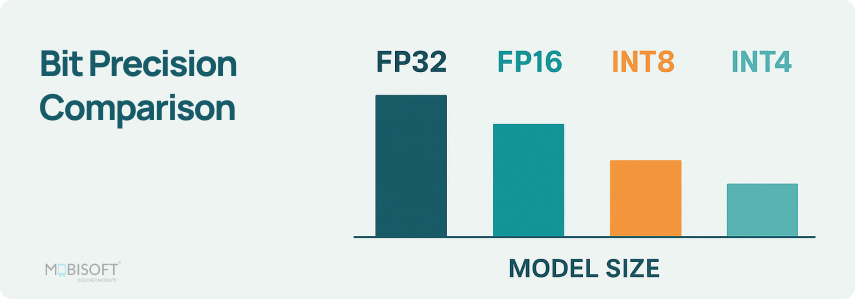
Deep Learning Model Precision: FP32, BF16, INT8 and INT4 – Insights ...
Lower Numerical Precision Deep Learning Inference and Training
Top-1 accuracy of various INT8 methods for ImageNet | Download ...
LLM推理量化:FP8 versus INT8 - 知乎
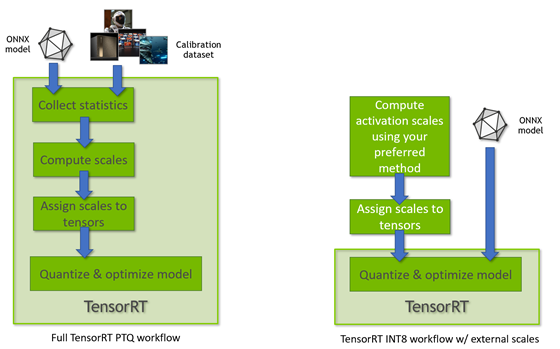
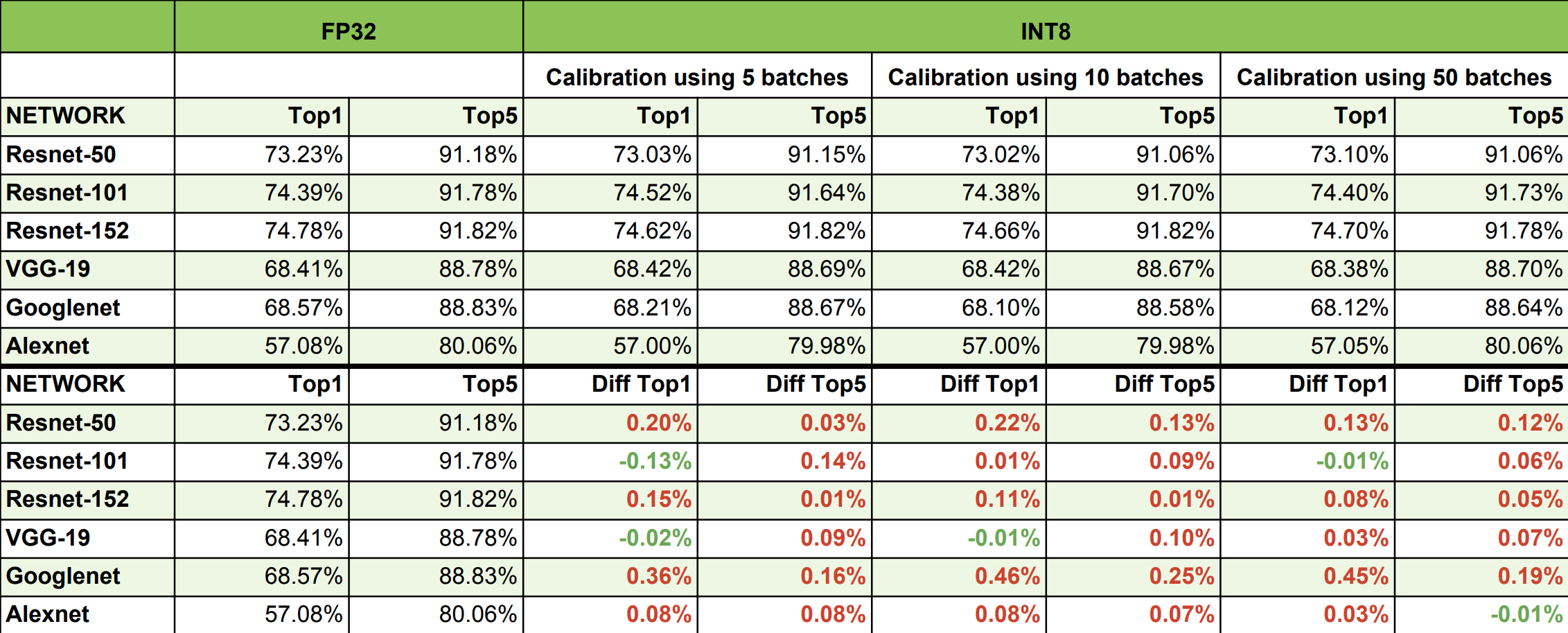
INT8 Calibration for TensorRT Inference | PDF | Integer (Computer ...
INT8 Quantization Basics | Rand Xie
Figure 9 from FP8 versus INT8 for efficient deep learning inference ...
Optimizing LLMs for Performance and Accuracy with Post-Training ...
FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep ...
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
Object Detection on GPUs in 10 Minutes | NVIDIA Technical Blog
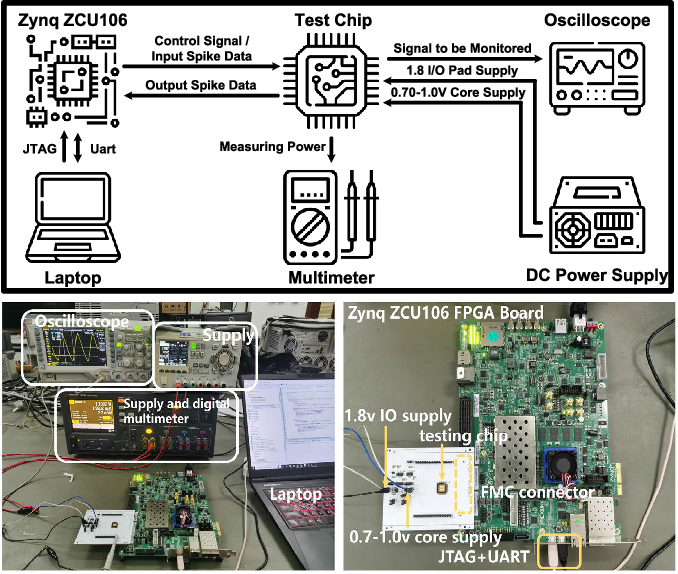
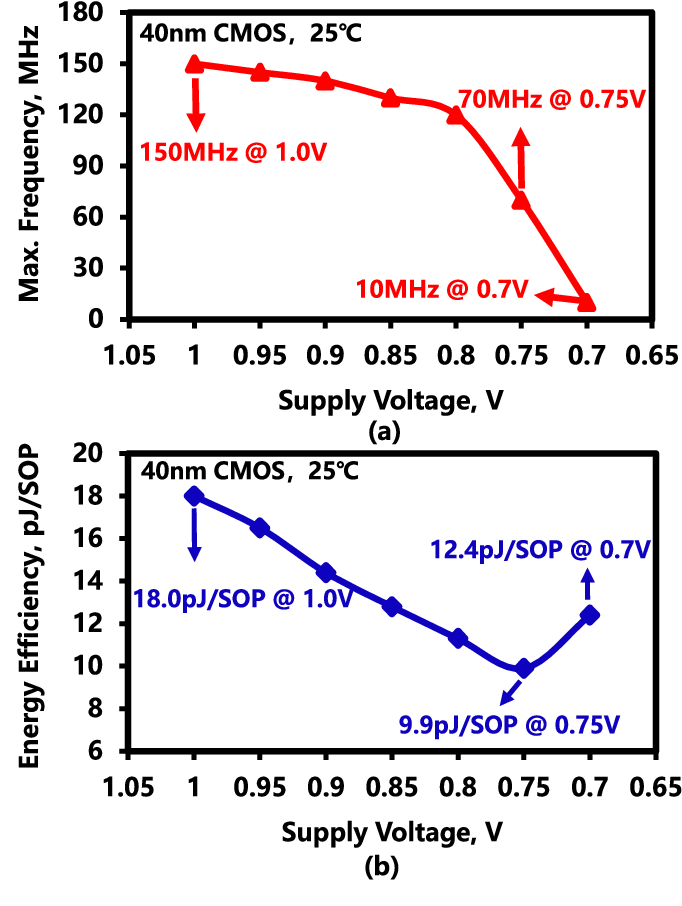
Figure 4 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
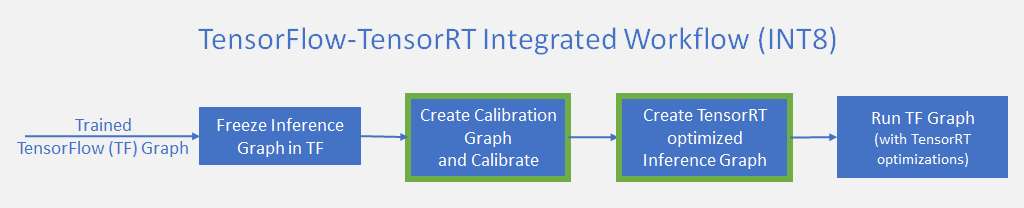
Speed up TensorFlow Inference on GPUs with TensorRT — The TensorFlow Blog
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
Deep Learning Performance Characterization on GPUs for Various ...
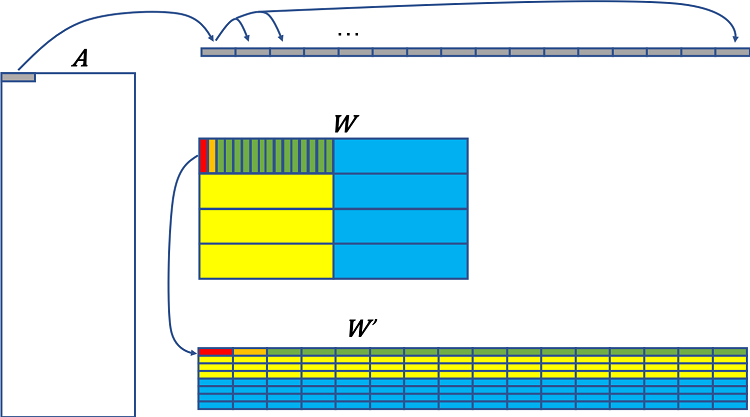
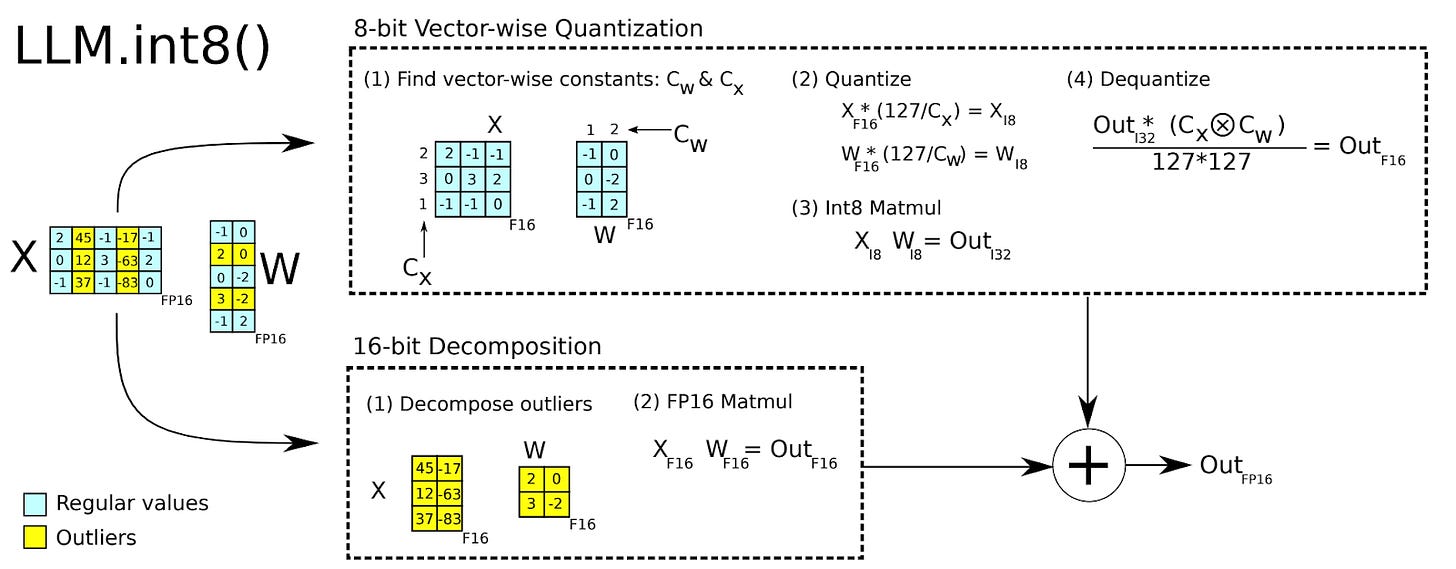
大模型LLM.int8()量化技术原理与代码实现-CSDN博客
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
Quantization Methods for 100X Speedup in Large Language Model Inference
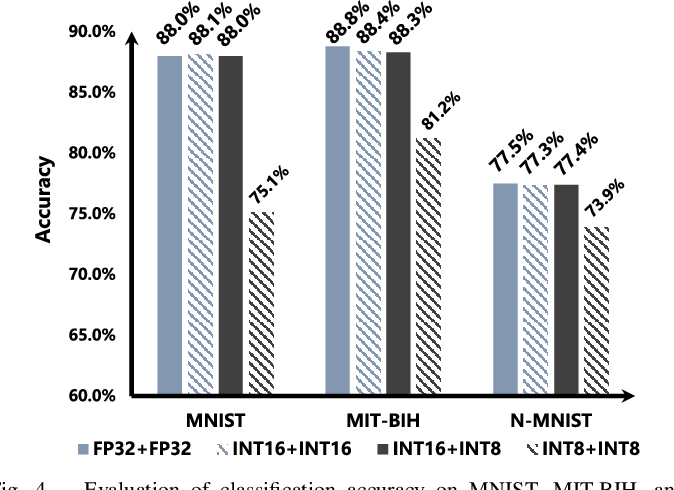
Test Report: Strong performance for AI image classification workloads ...
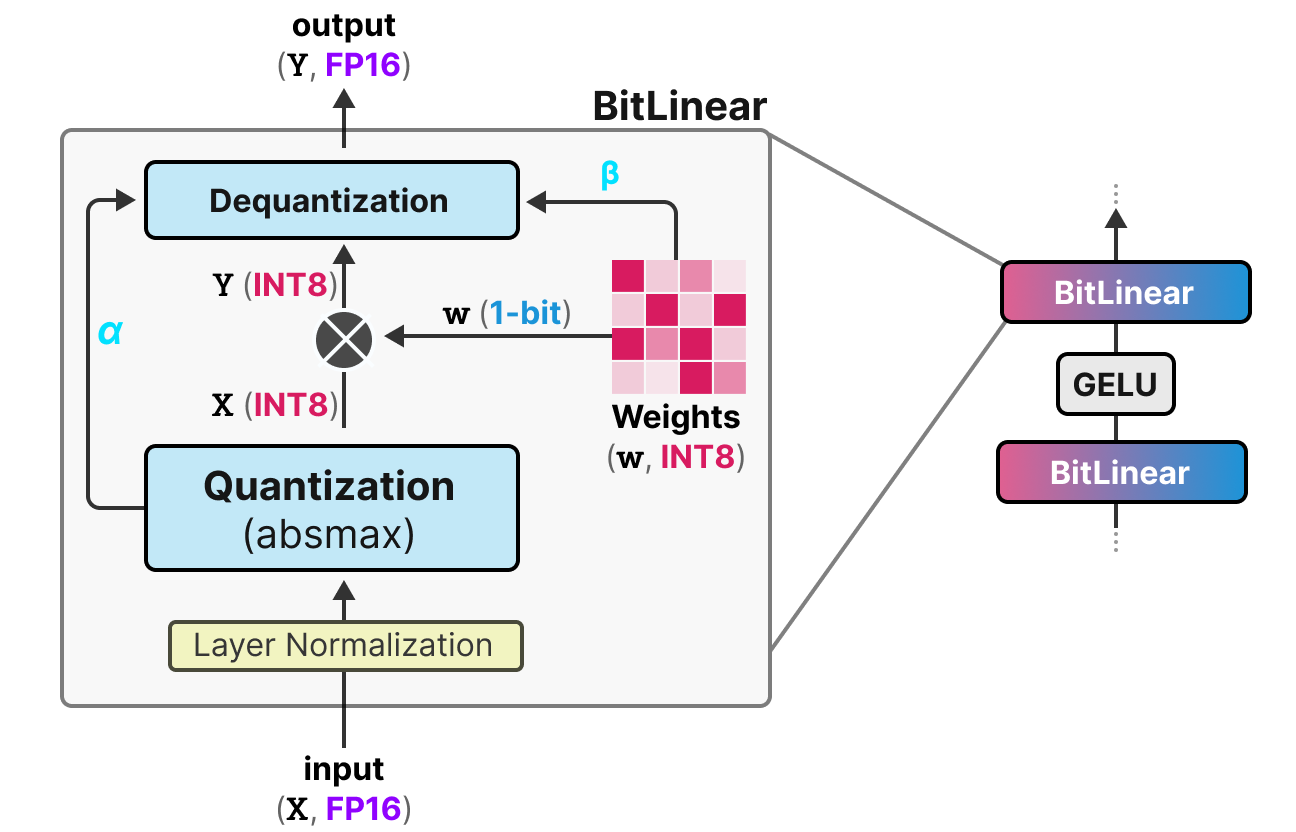
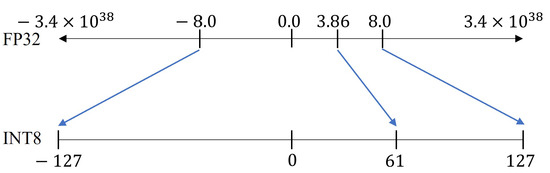
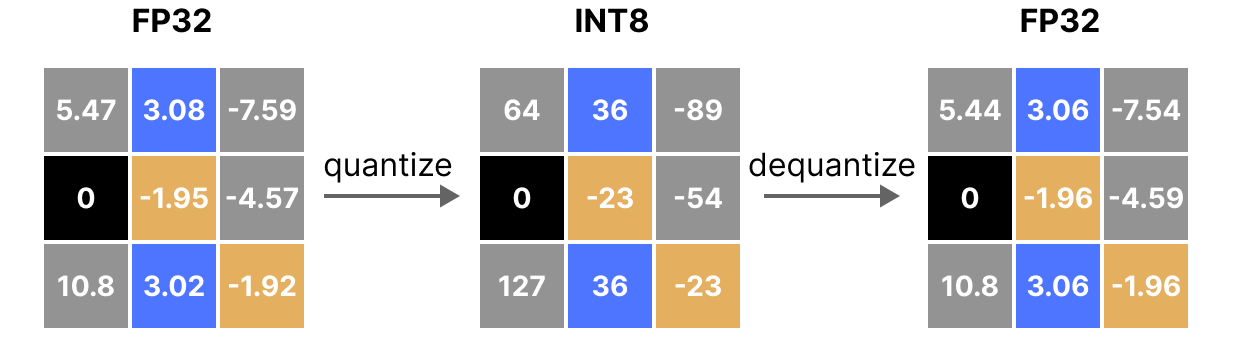
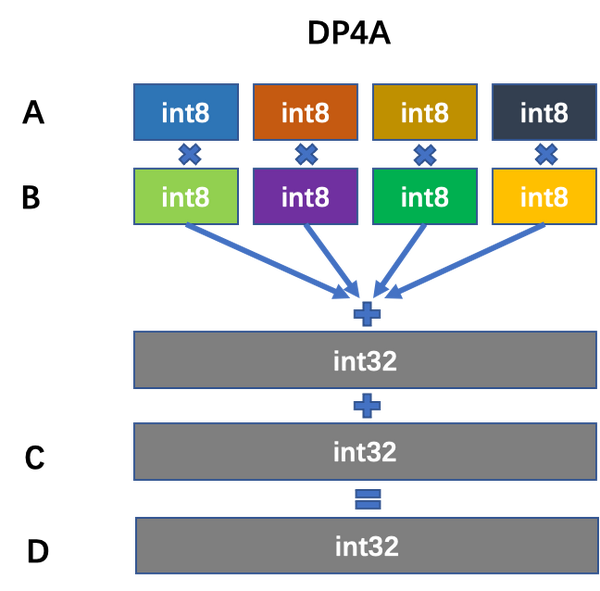
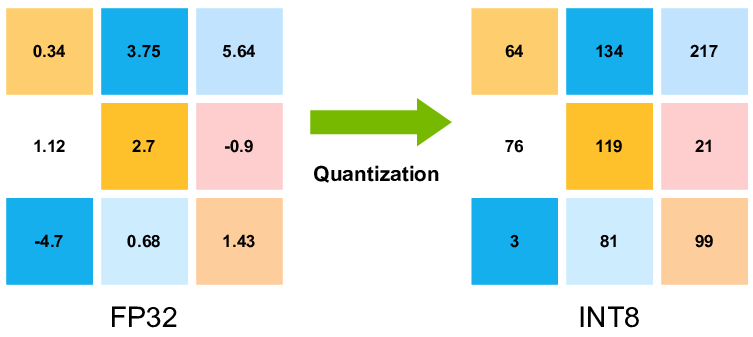
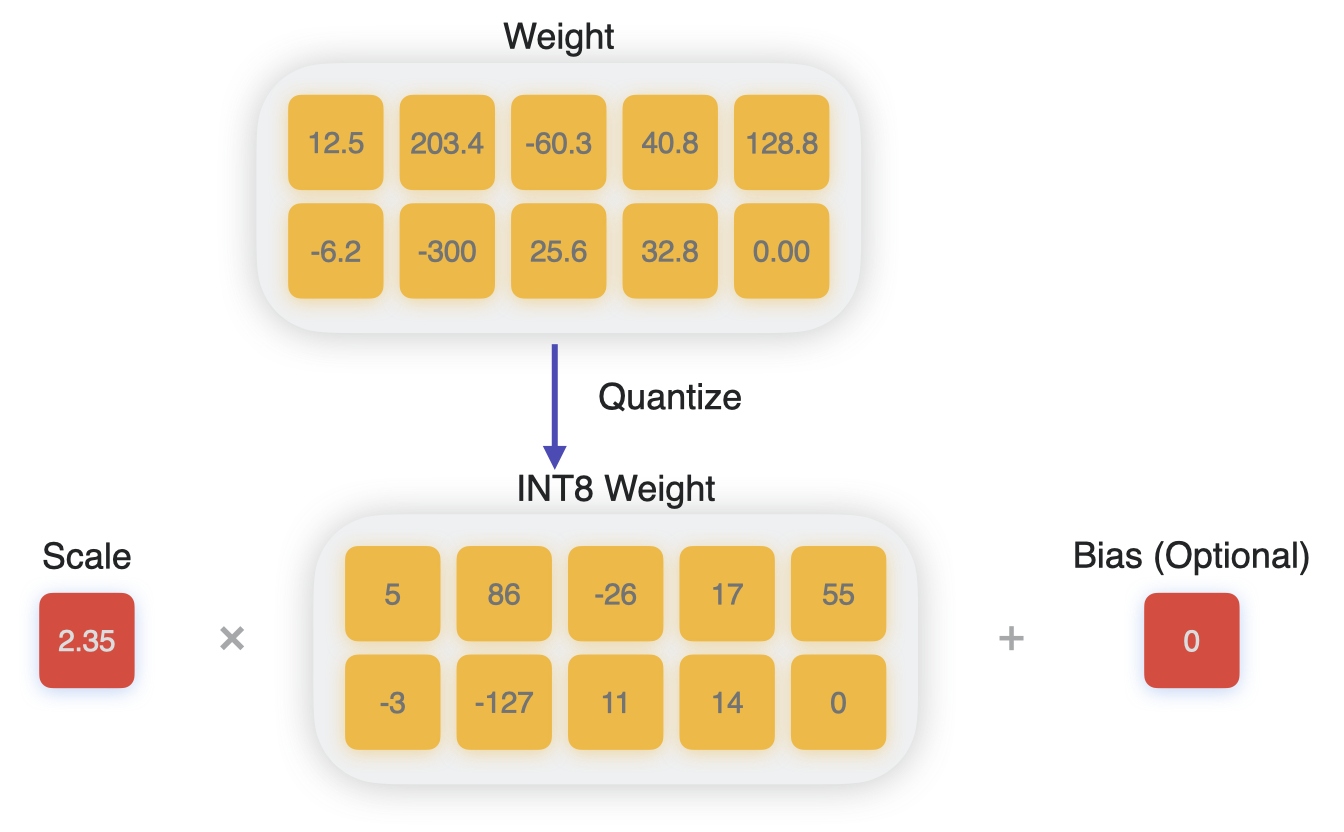
A Visual Guide to Quantization - by Maarten Grootendorst
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
MNN CUDA支持int8推理,矩阵乘可提速一倍! - 知乎
Boost LLMs with PyTorch on Intel® Xeon® Processors
Figure 11 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
大模型量化部署进阶:从 INT8/INT4 原理到高性能推理实战 - 知乎
Figure 3 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
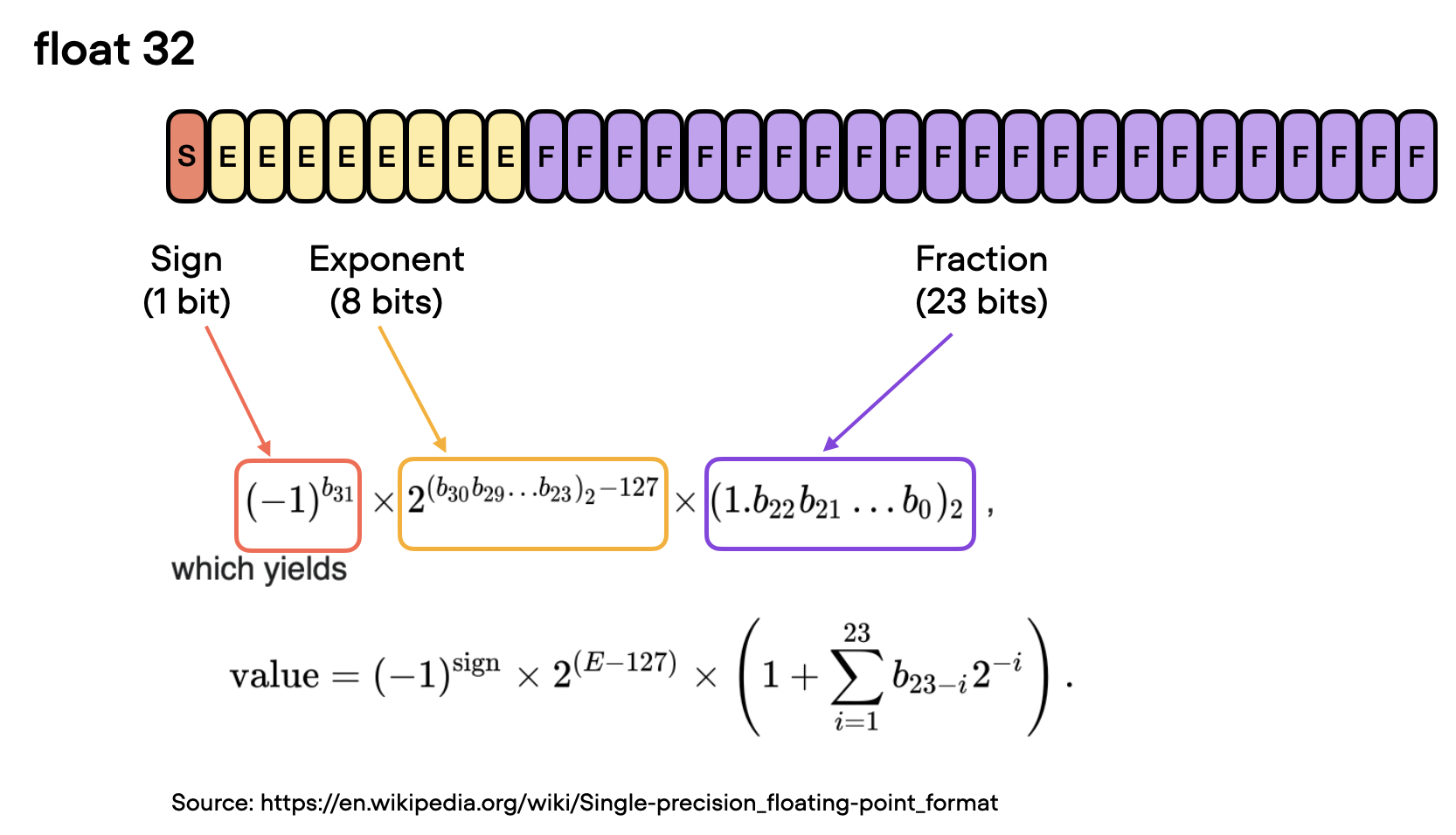
Small numbers, big opportunities: how floating point accelerates AI and ...
Quantization Overview — Guide to Core ML Tools
How to Speed up Deep Learning Models - Speaker Deck
Figure 12 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
DetectNet_v2 - NVIDIA Docs
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
Accelerating Transformers with NVIDIA cuDNN 9 | NVIDIA Technical Blog
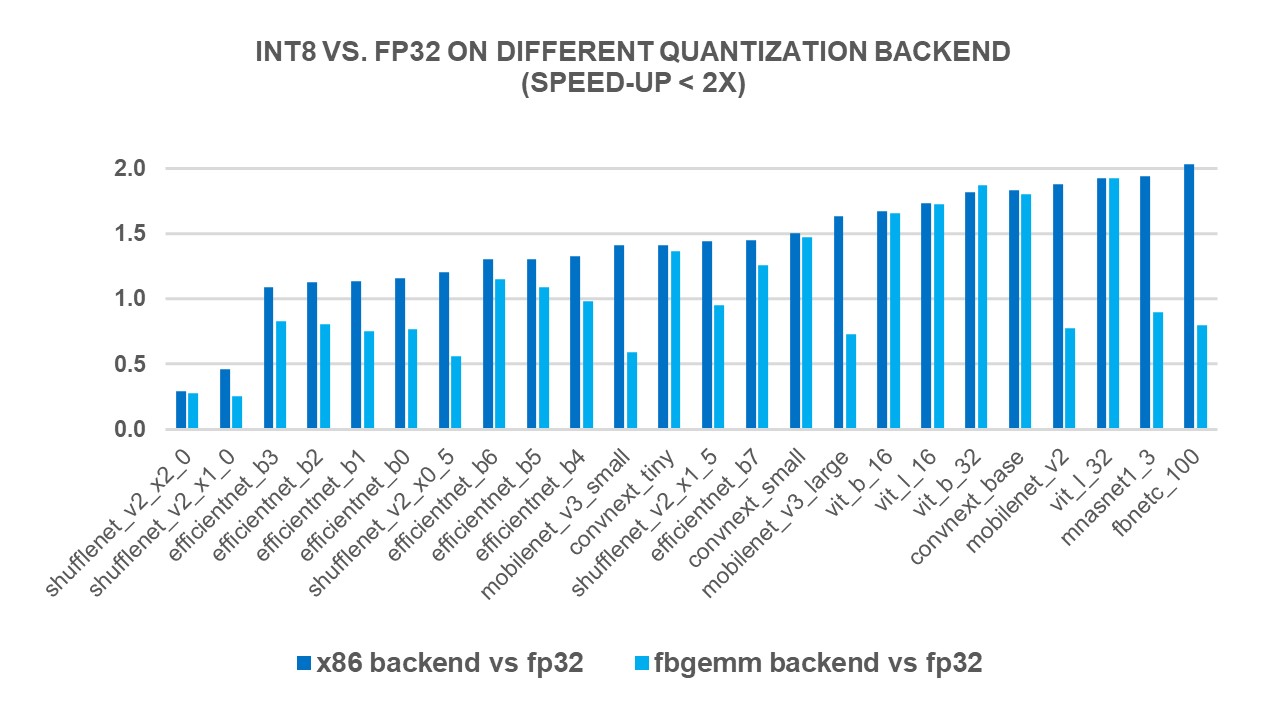
模型量化大揭秘:INT8、INT4量化对推理速度和精度的影响测试-腾讯云开发者社区-腾讯云
Figure 13 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
Boosting AI: The Quiet Power of Quantization - 044.EU
FP8 Quantization for Ultra-Low Latency AI | AI Tutorial | Next Electronics
大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析-CSDN博客
Accelerating Large Language Models with Mixed-Precision Techniques ...
Fast and Accurate GPU Quantization for Transformers
Quantization — Deep Learning Course
10分钟内基于gpu的目标检测 - 吴建明wujianming - 博客园
What is Quantization in LLM? A Complete Guide to Optimizing AI
Deploy YOLOv8 with TensorRT and DeepStream SDK | Seeed Studio Wiki
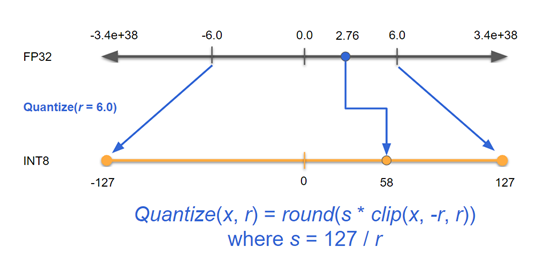
TensorRT(5)-INT8校准原理 | arleyzhang
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客