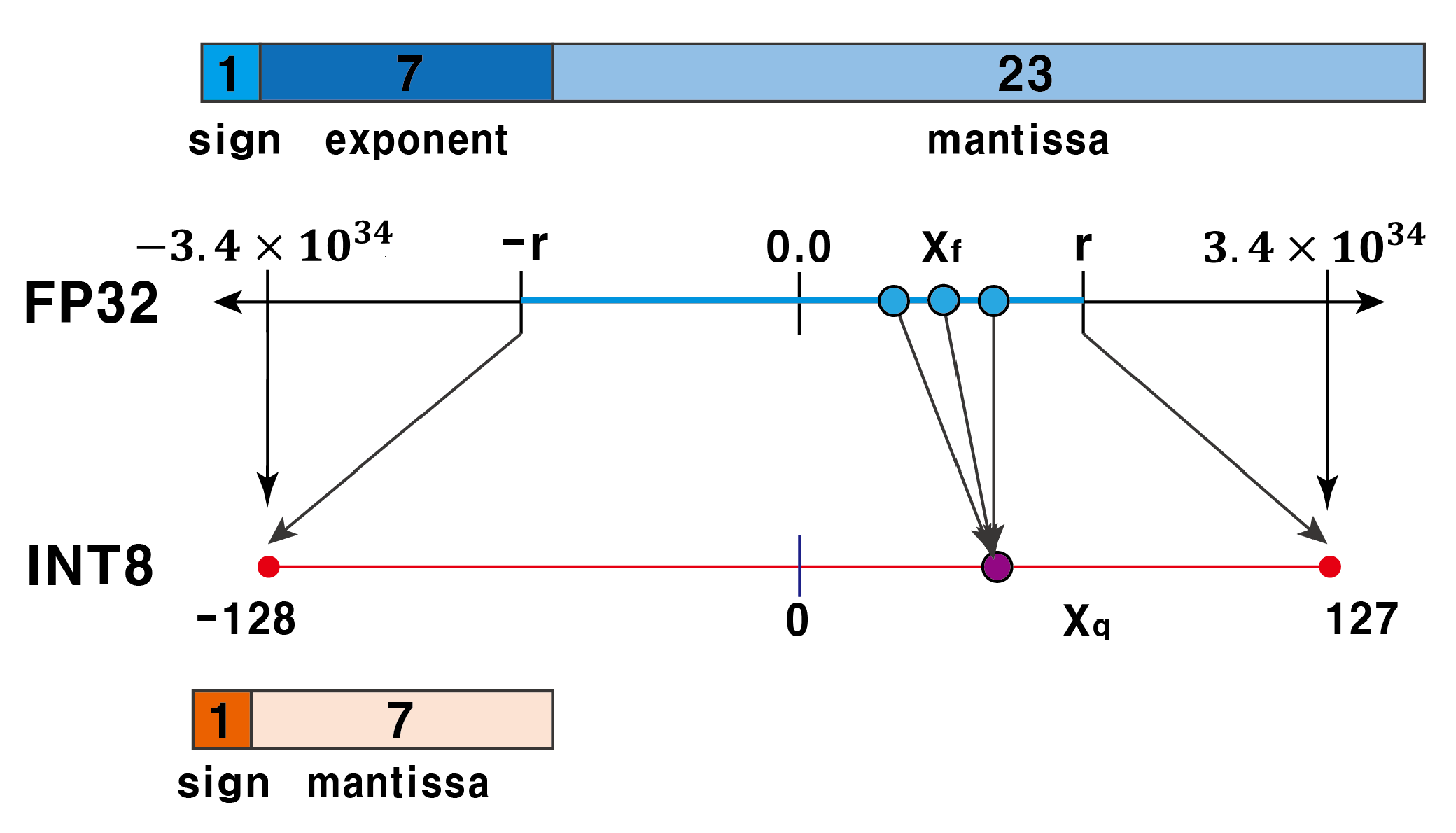
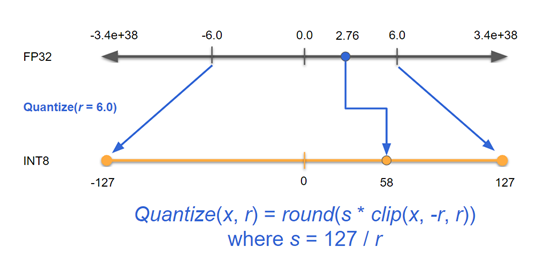
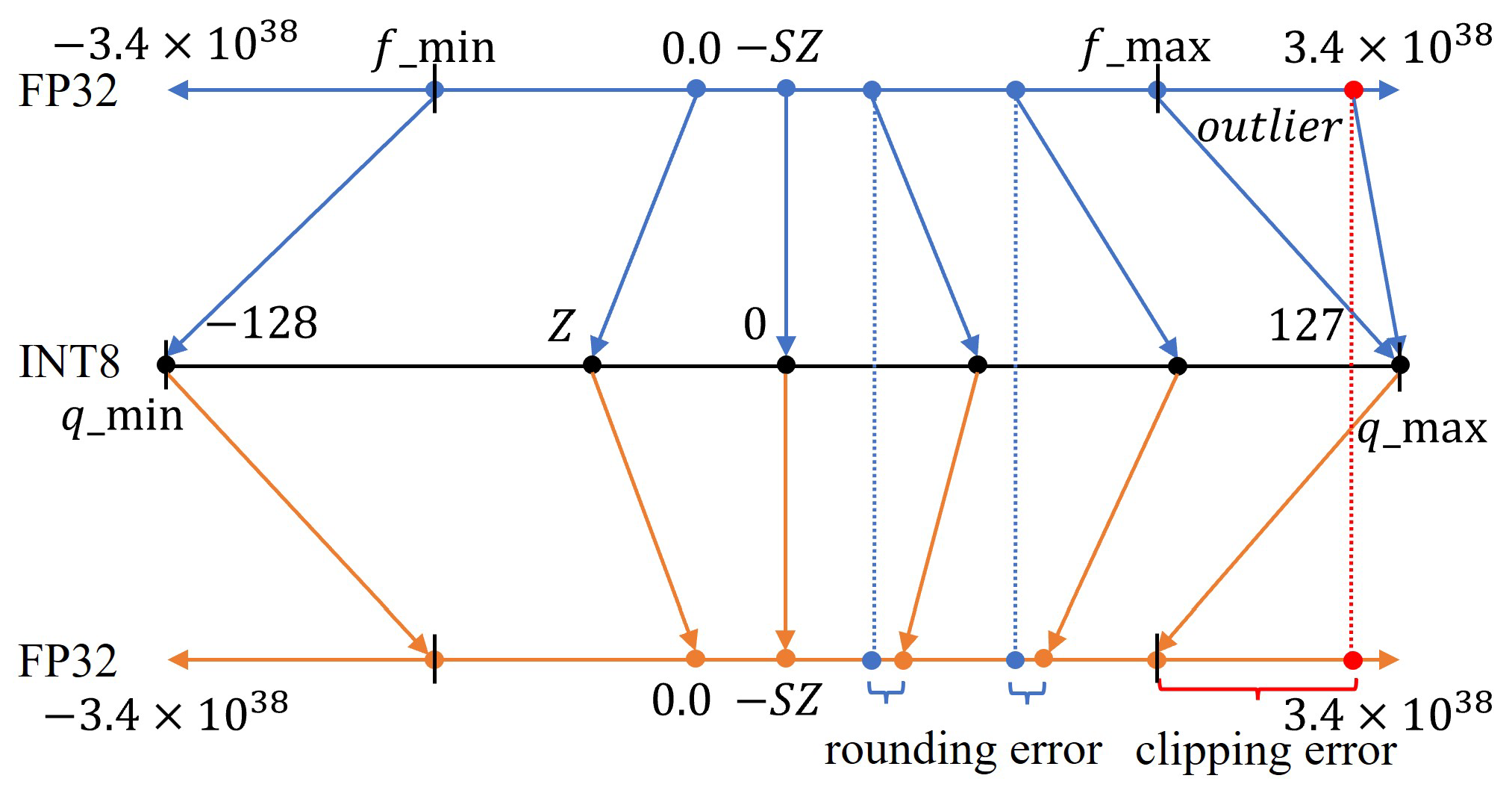
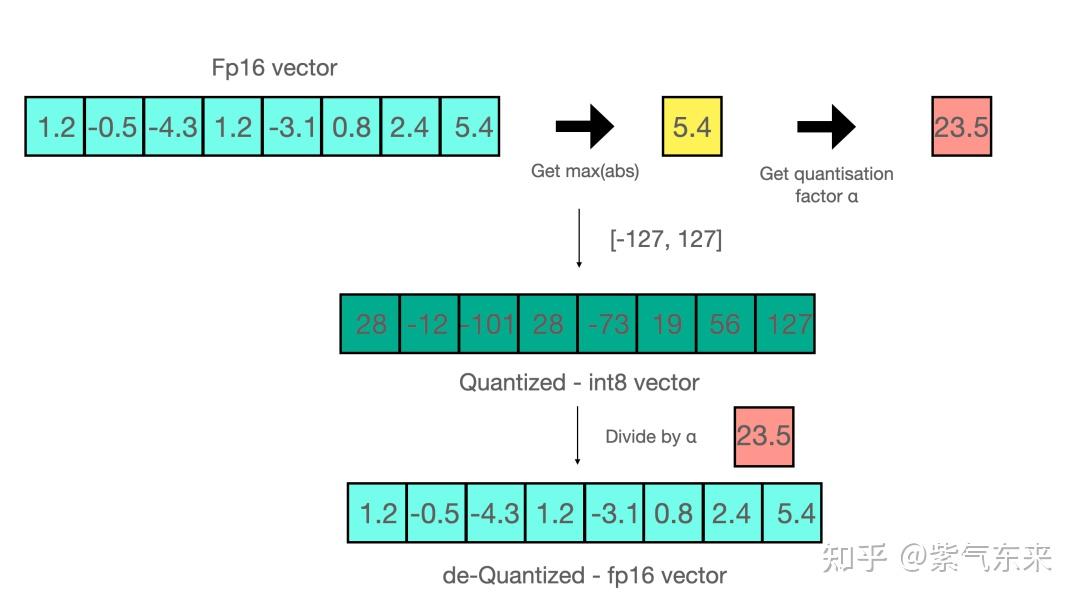
Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
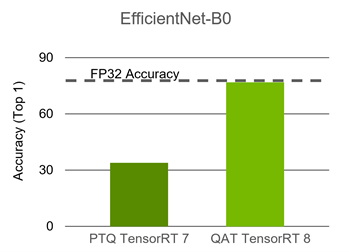
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
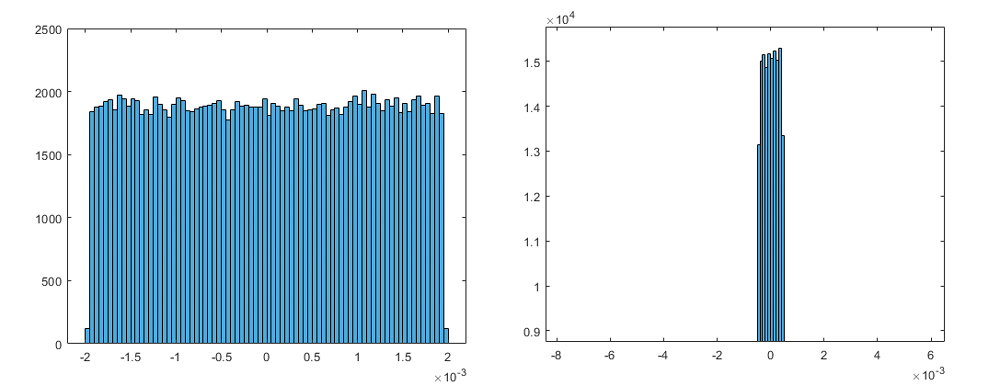
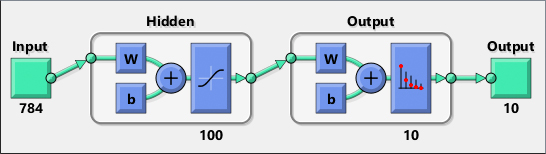
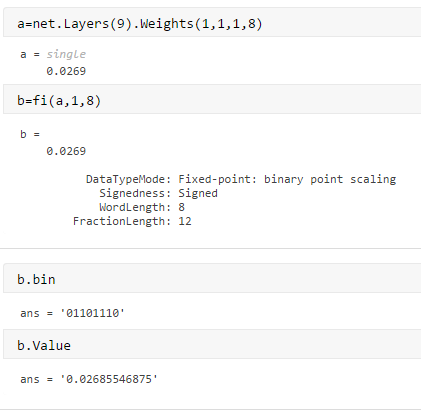
Deep Learning INT8 Quantization - MATLAB & Simulink
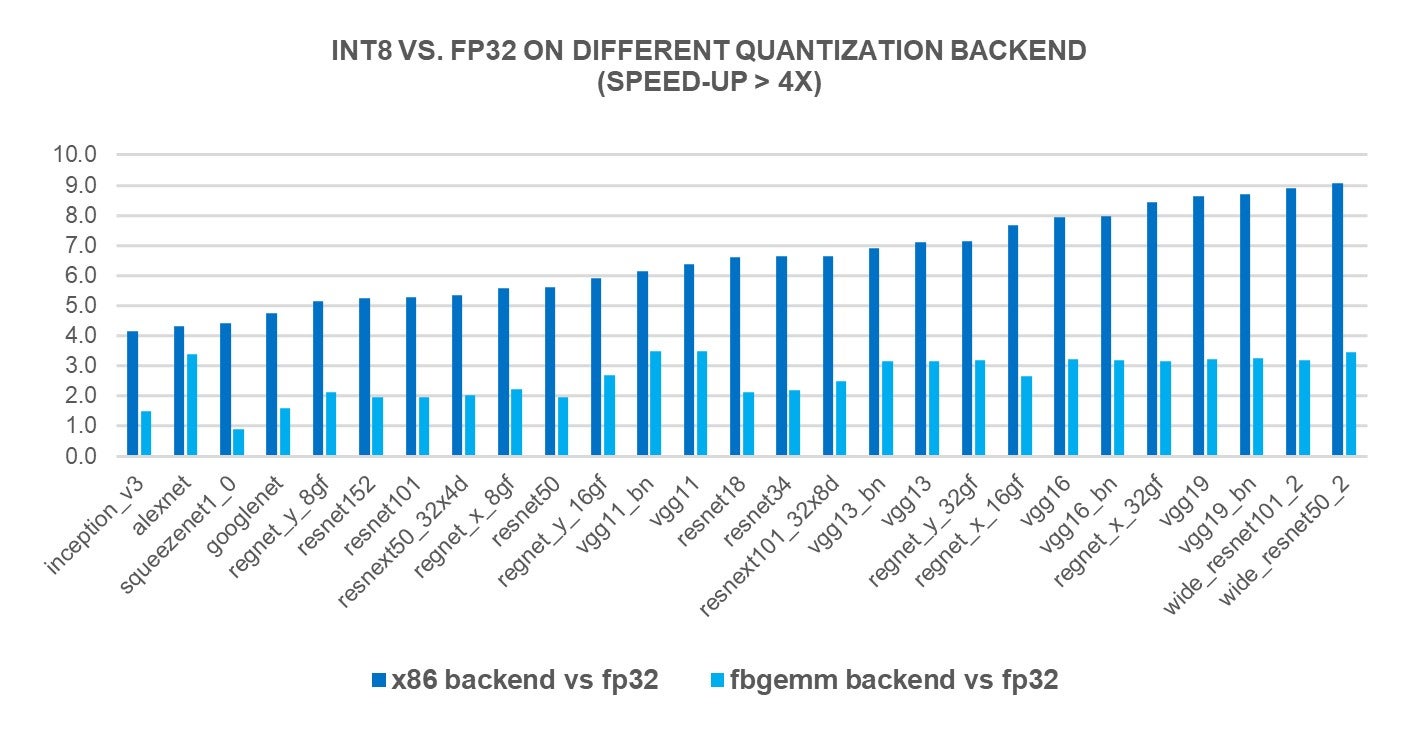
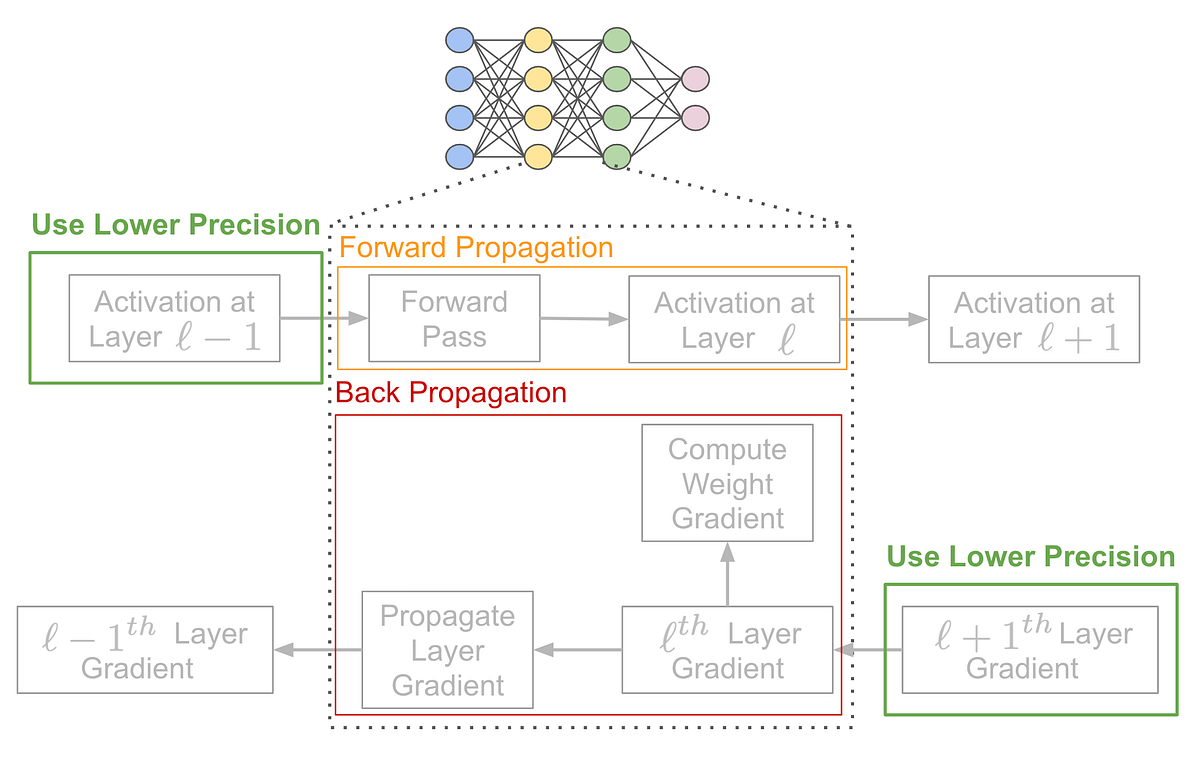
INT8 Quantization for x86 CPU in PyTorch – PyTorch
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
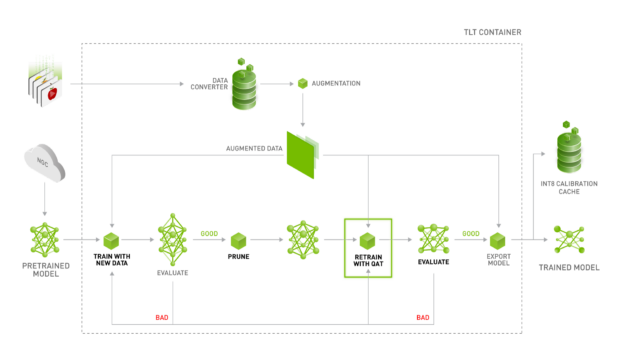
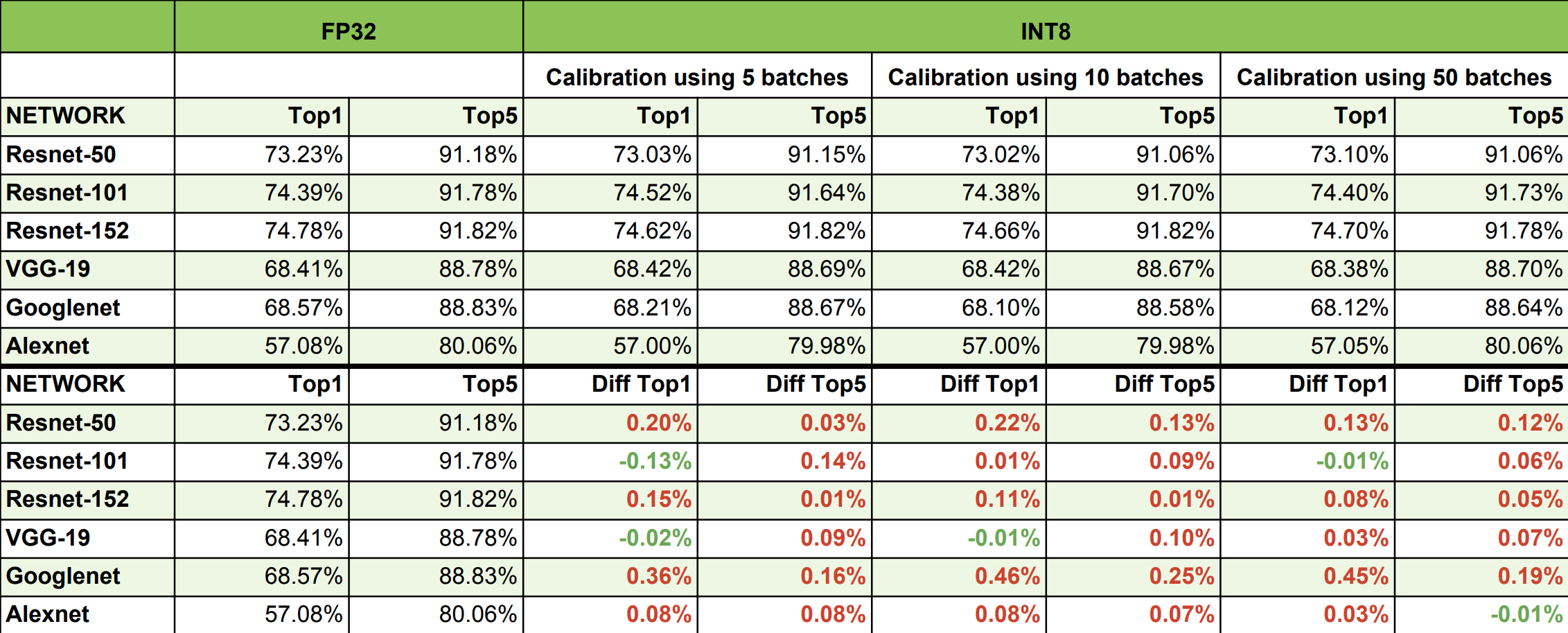
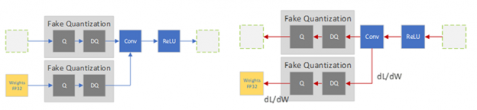
Improving INT8 Accuracy Using Quantization Aware Training and the ...
How to provide calibration data for INT8 quantization with dynamic ONNX ...
INT8 Quantization · Issue #298 · NVlabs/FoundationPose · GitHub
Boost Your AI Models with INT8 Quantization 🚀 ONNX Static vs Dynamic ...
ONNXCommunityMeetup2023: INT8 Quantization for Large Language Models ...
int8 model quantization · Issue #521 · traveller59/spconv · GitHub
How to Implement INT8 Quantization for Text Classification using ...
INT8 quantization with same model and different weights · Issue #2705 ...
INT8 Quantization Aware Training · ultralytics yolov5 · Discussion ...
Understanding int8 neural network quantization - YouTube
Int8 quantization and tvm implementation - Programmer Sought
Deep Learning INT8 Quantization MATLAB Simulink, 42% OFF
INT8 Quantization Basics | Rand Xie
The accuracy loss after INT8 quantization compared to FP16 version ...
int8 Weight and Activation Quantization - LLM Compressor Docs
Deep Learning Int8 Quantization – PCETSK
YOLOv5 Model INT8 Quantization based on OpenVINO™ 2022.1 POT API ...
YOLOv10 vs. YOLOv11: INT8 Quantization Performance Comparison — Results ...
A question about int8 explicit quantization for plugins · Issue #1616 ...
INT8 Quantization for x86 CPU in PyTorch | PyTorch
An enabling framework for int8 quantization - pre-RFC - Apache TVM Discuss
OpenVINO INT8 Quantization for YOLO26 Models: A Hands-On Tutorial | by ...
NVIDIA TensorRT INT8 & FP8 quantization accelerating SD inference : r ...
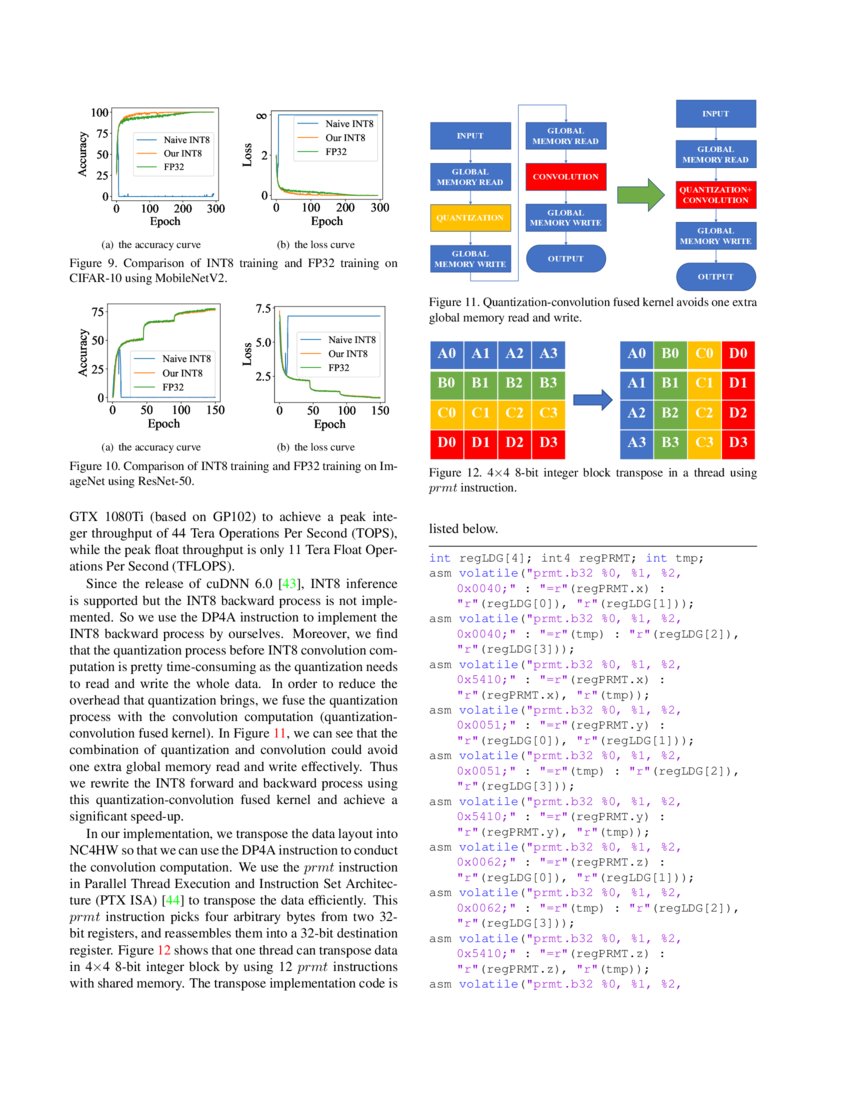
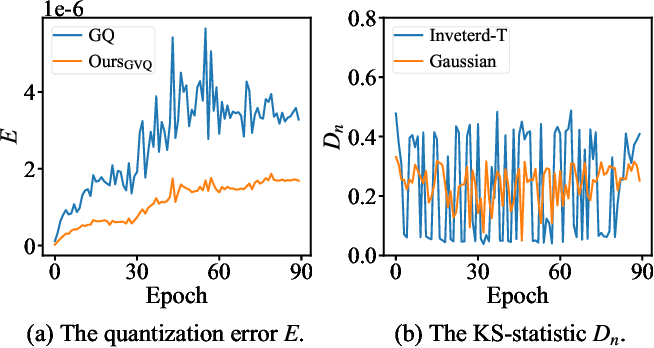
Figure 2 from Distribution Adaptive INT8 Quantization for Training CNNs ...
Figure 1 from Distribution Adaptive INT8 Quantization for Training CNNs ...
stepfun-ai/Step-3.5-Flash-Int4 · INT8 quantization for KVCache on DGX ...
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
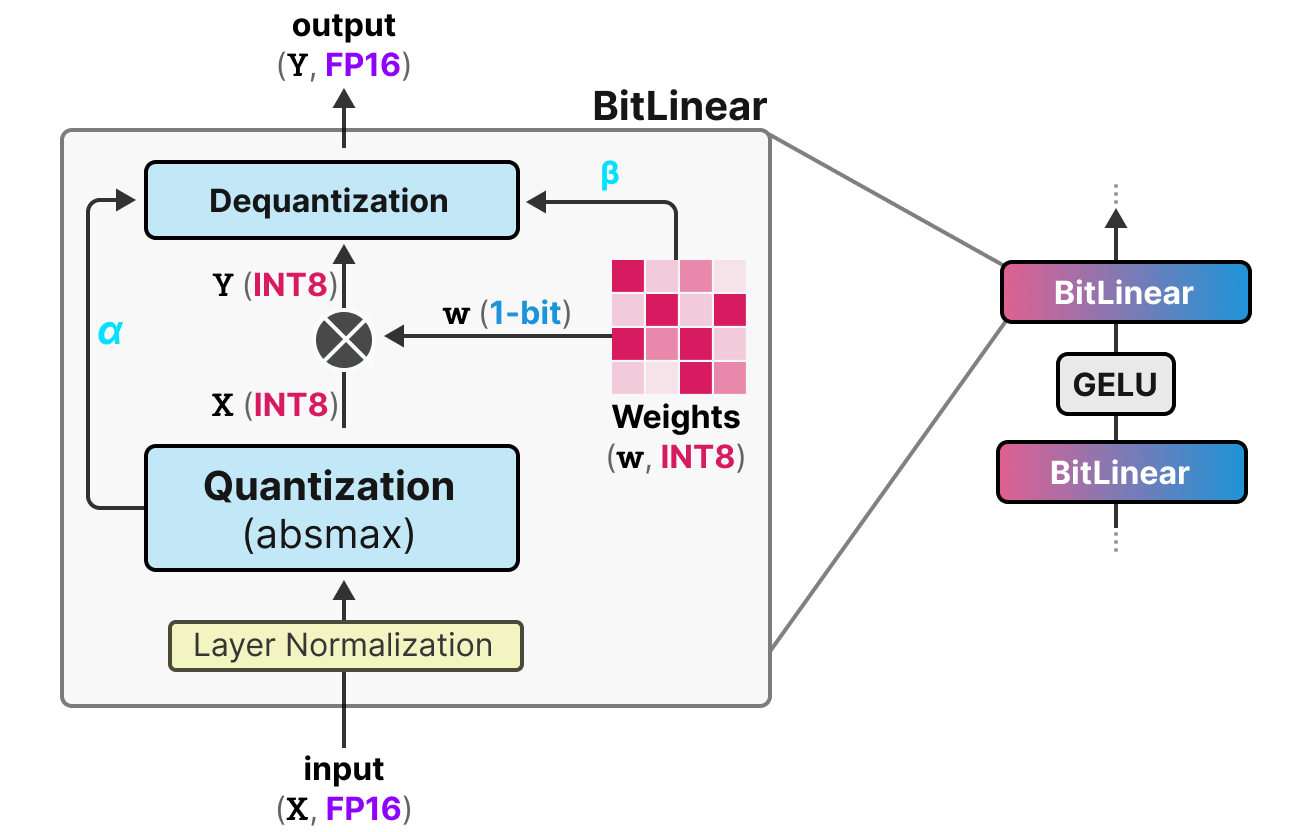
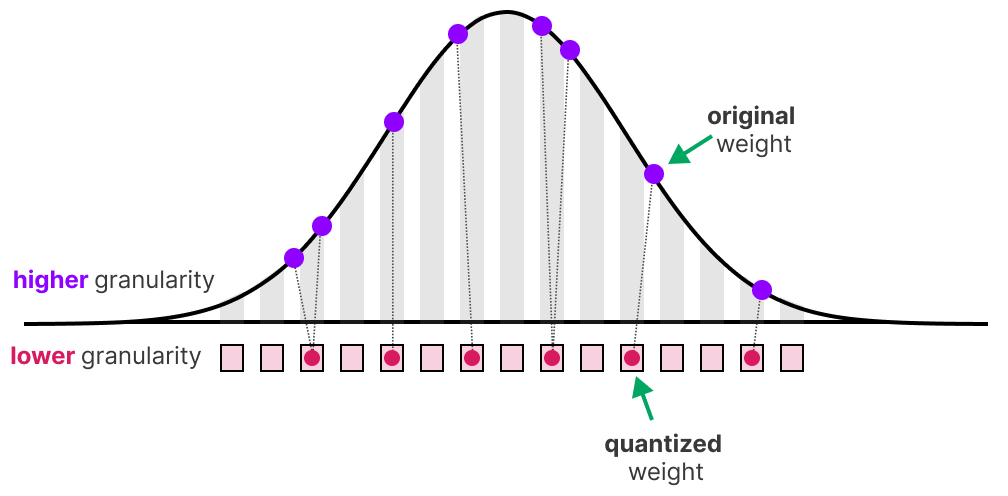
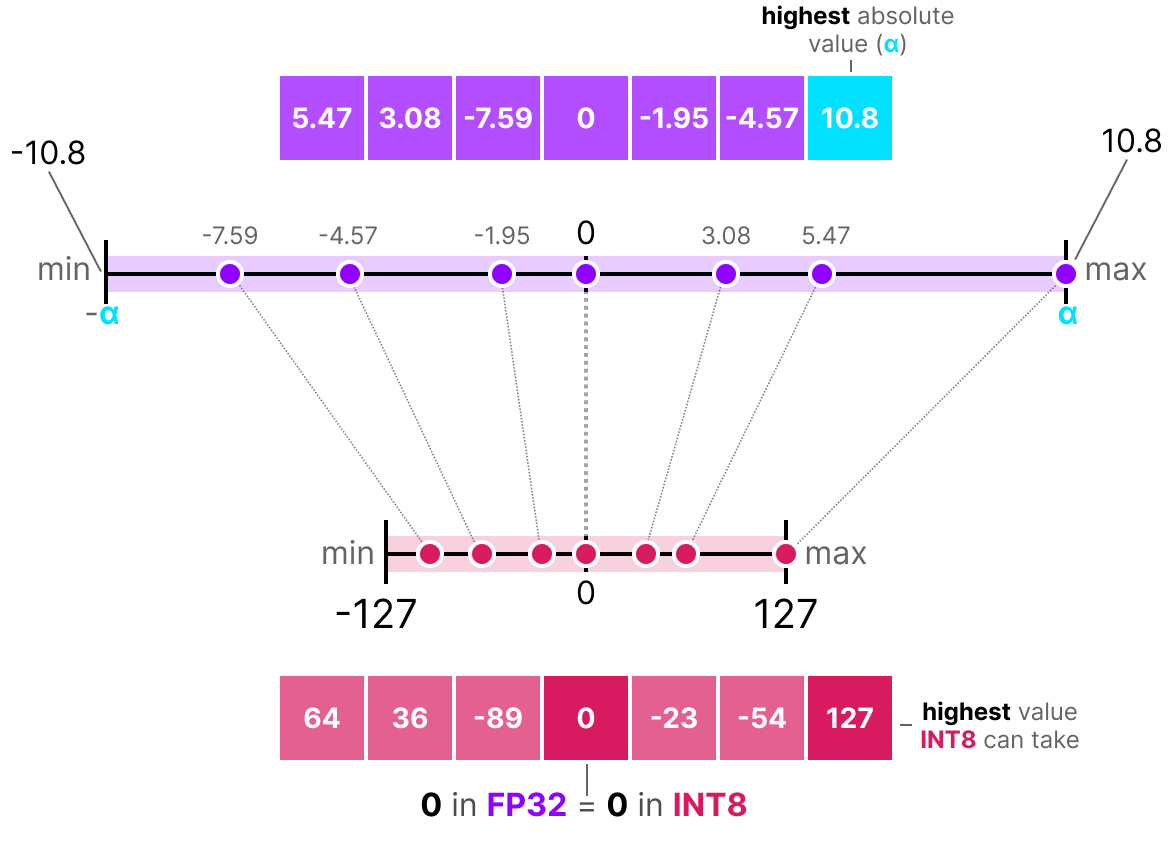
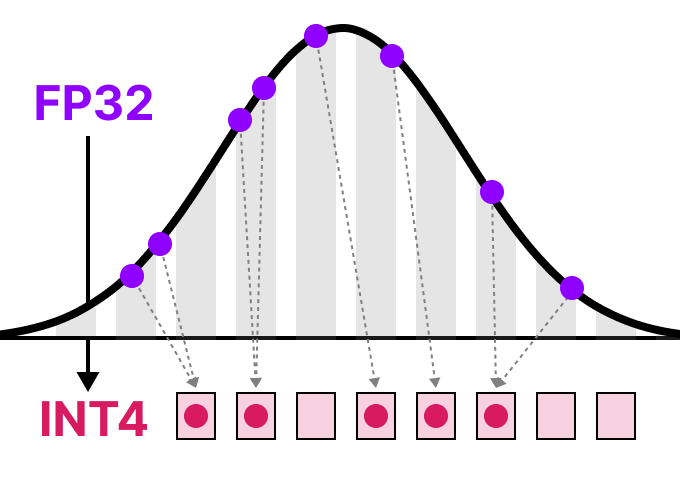
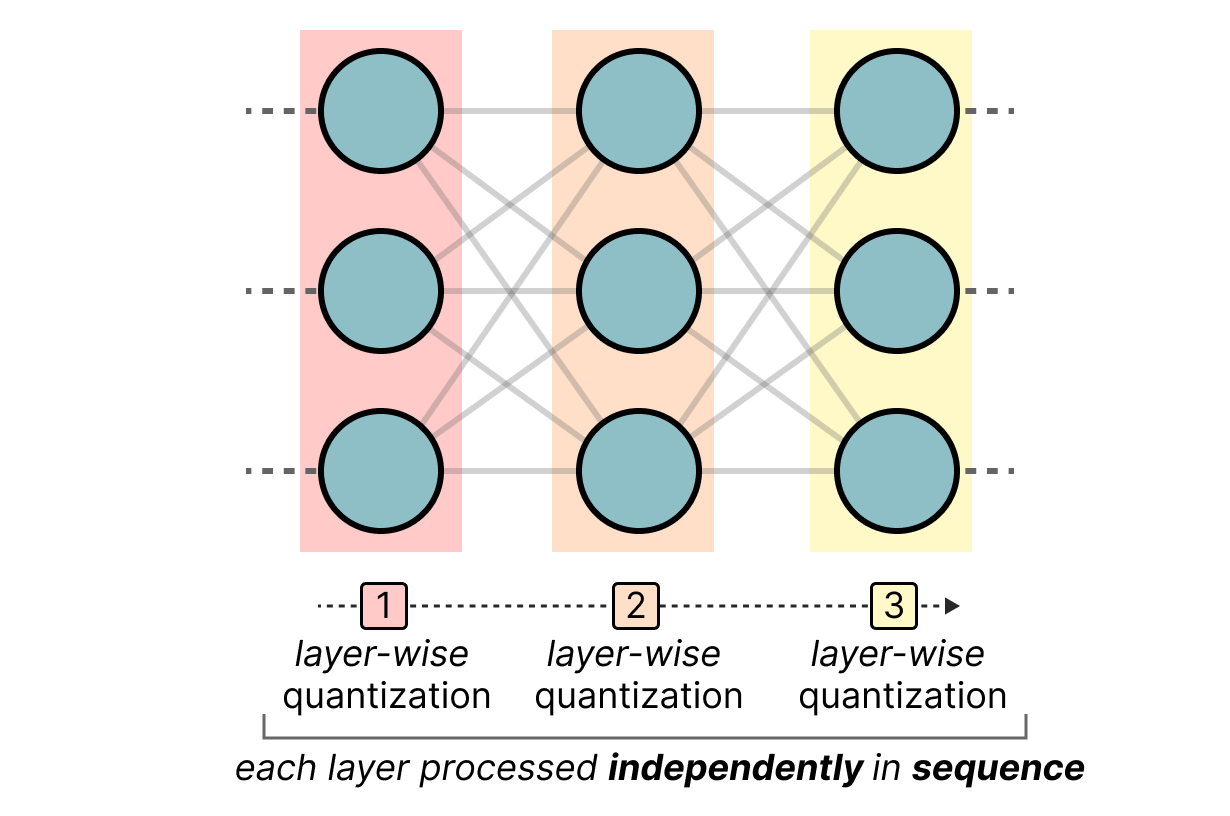
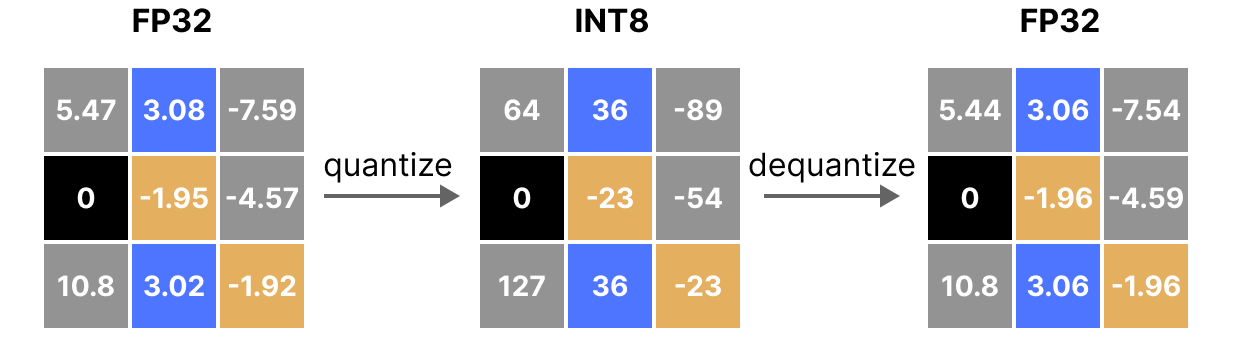
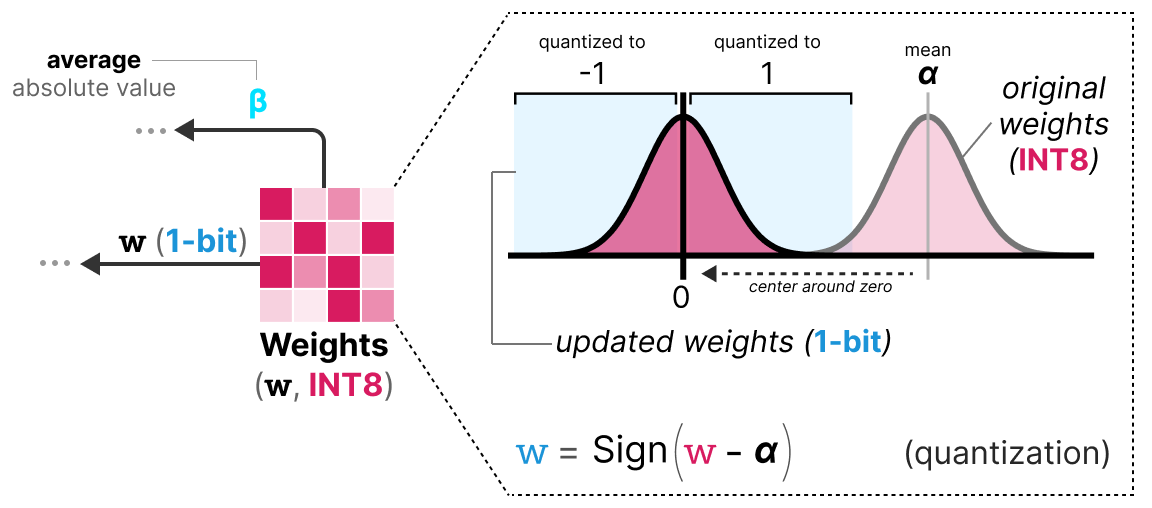
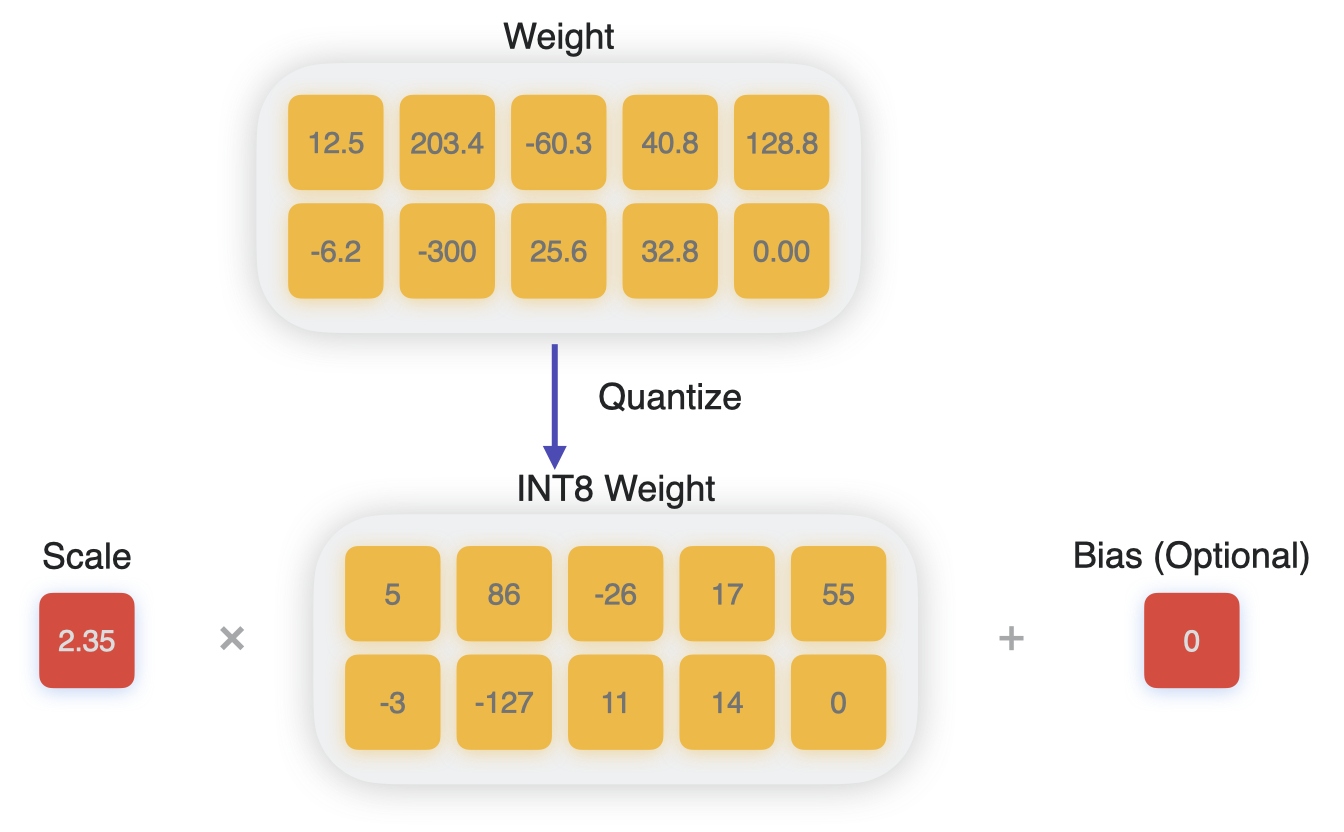
A Visual Guide to Quantization - by Maarten Grootendorst
A Hands-On Walkthrough on Model Quantization - Medoid AI
Quantization Methods for 100X Speedup in Large Language Model Inference
Quantization Overview — Guide to Core ML Tools
Shrinking AI Models by 75%: A Practical Guide to PyTorch INT8 ...
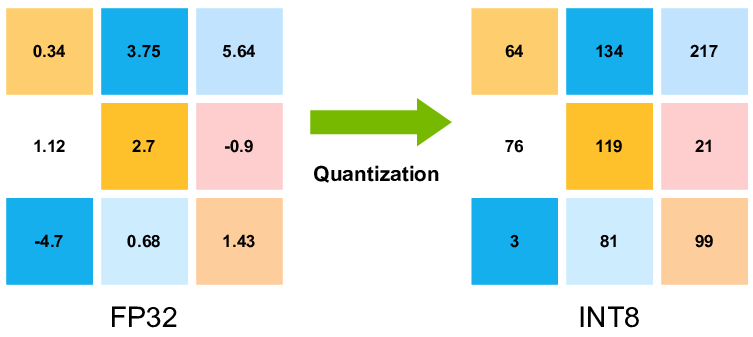
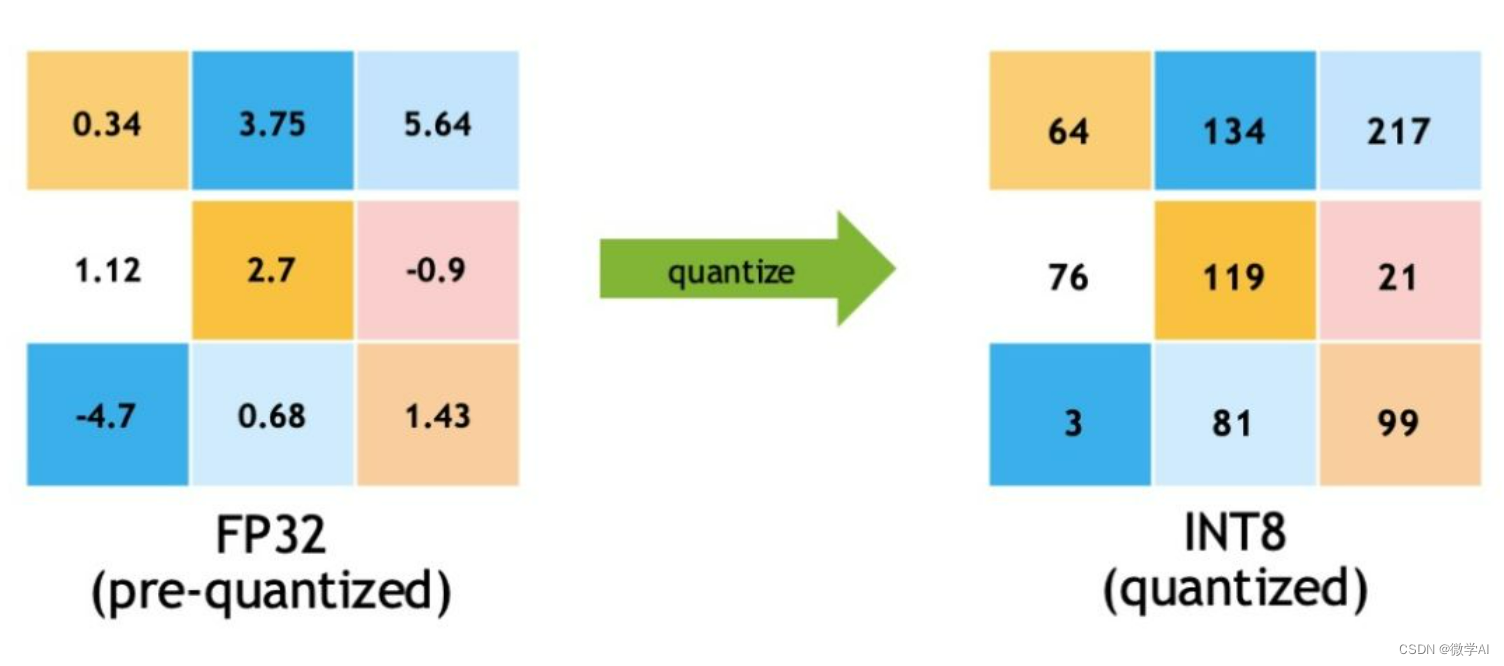
Quantization from FP32 to INT8. | Download Scientific Diagram
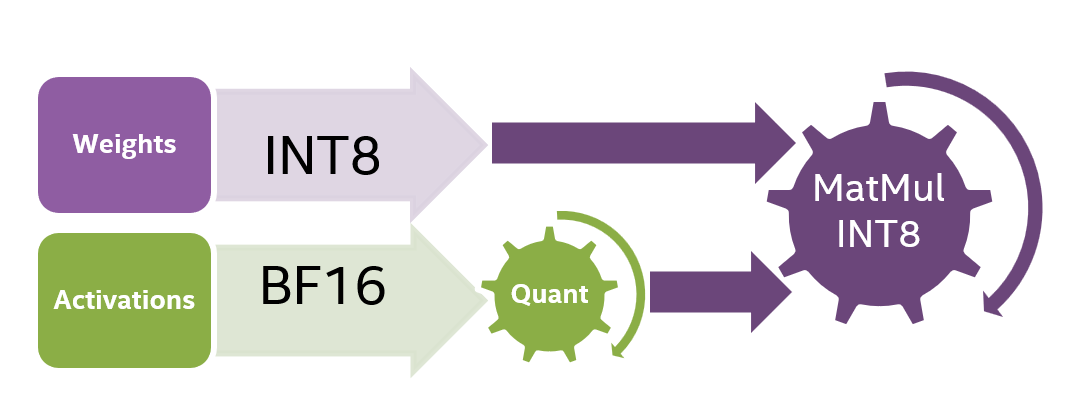
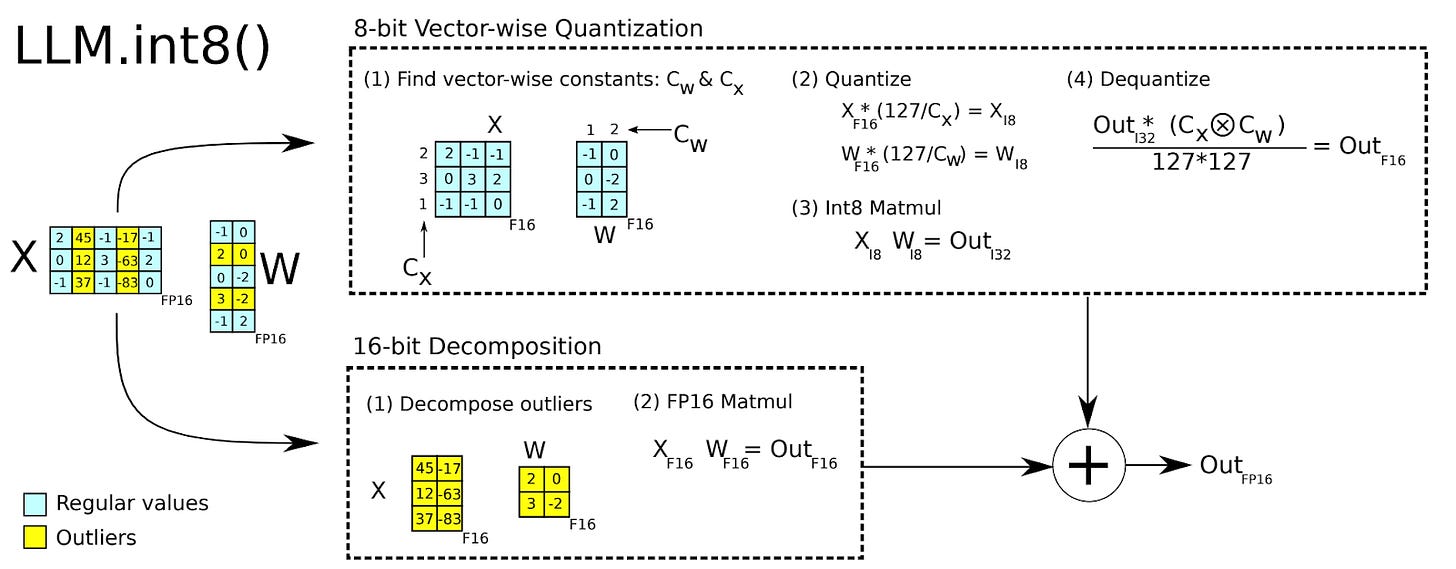
Fast and Accurate GPU Quantization for Transformers
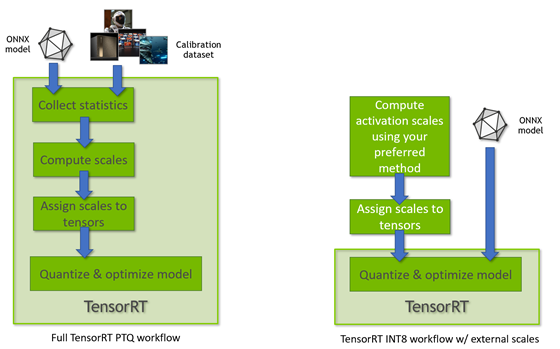
INT8 Inference of Quantization-Aware trained models using ONNX-TensorRT ...
Quark ONNX: int8 Quantized Models - a amd Collection
mAP drops a lot when Infer a INT8 quantized ONNX model. · Issue #2237 ...
Introducing Post-Training Model Quantization Feature and Mechanics ...
INT8 quantized model is very slow · Issue #6732 · microsoft/onnxruntime ...
[Performance] INT8 quantized model run slower than FP32 model · Issue ...
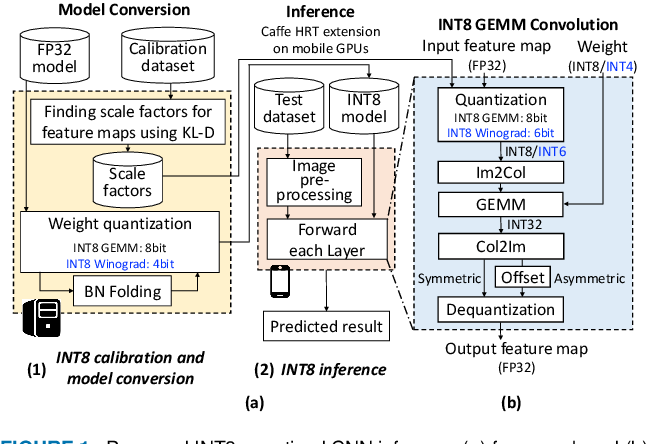
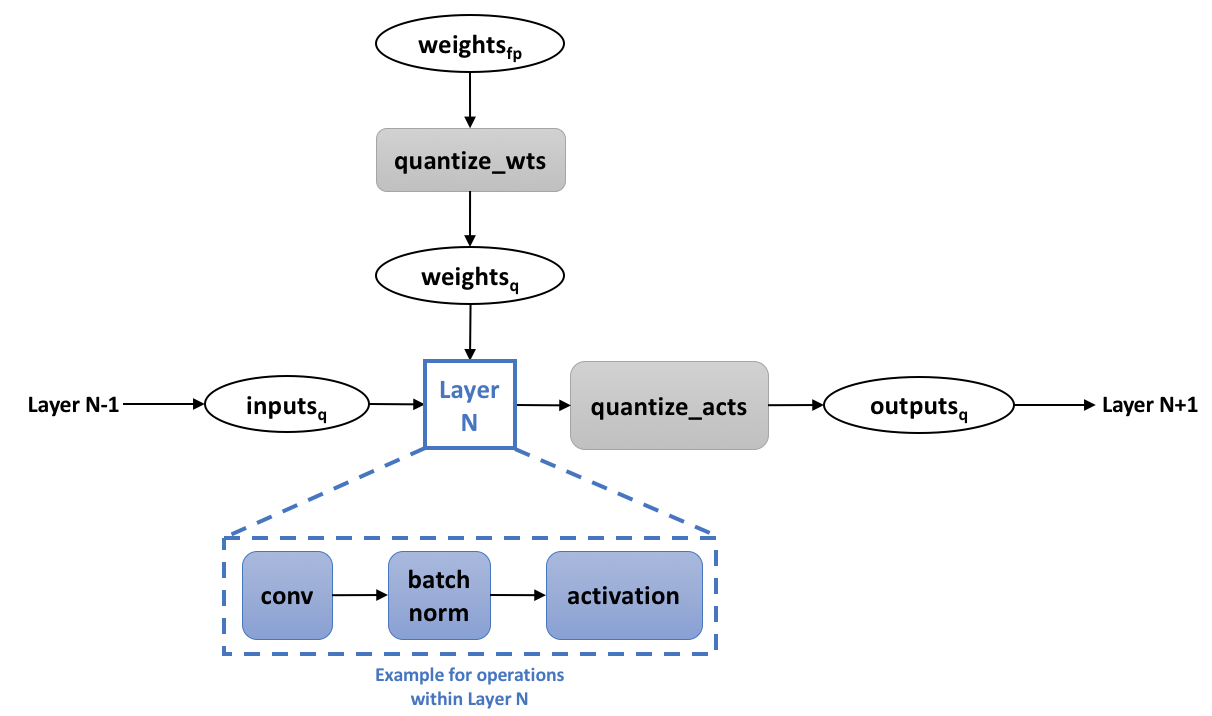
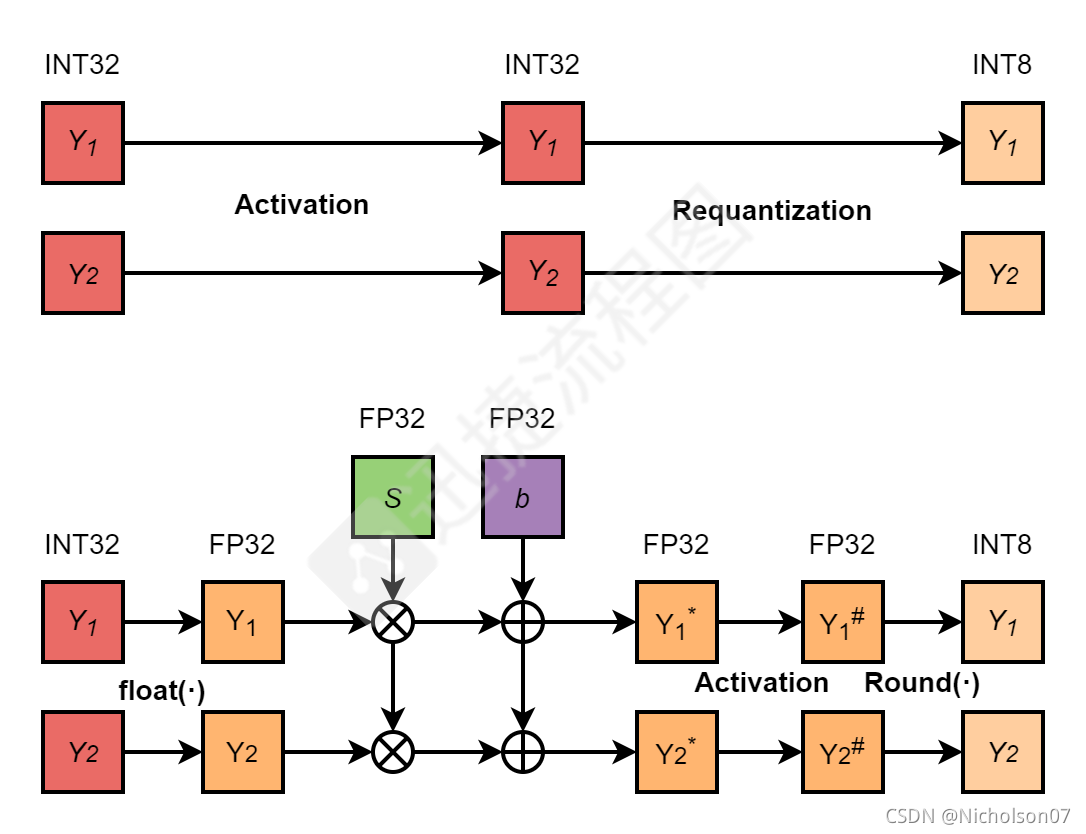
Proposed INT8 quantized CNN inference (a) framework and (b) INT8 GEMM ...
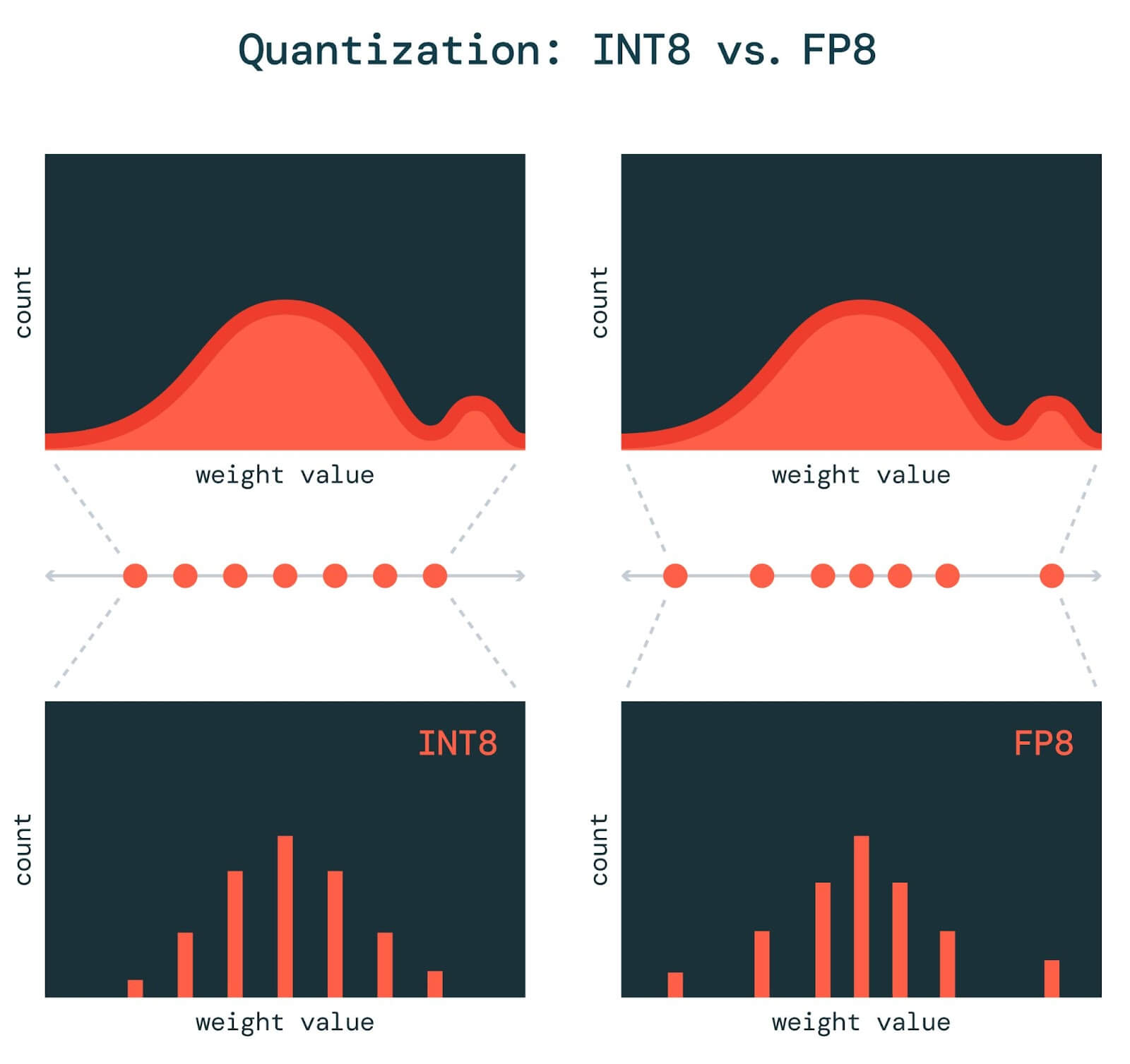
[2303.17951] FP8 versus INT8 for efficient deep learning inference
A Visual Guide to Quantization - Maarten Grootendorst
7 ML Quantization Wins (INT8/FP8) Without Quality Freefall | by ...
Figure 1 from Performance Evaluation of INT8 Quantized Inference on ...
The quantized INT8 onnx models fails to load with invalid model error ...
Figure 2 from Performance Evaluation of INT8 Quantized Inference on ...
Quantization - Neural Network Distiller
Boosting AI: The Quiet Power of Quantization - 044.EU
Towards Unified INT8 Training for Convolutional Neural Network | DeepAI
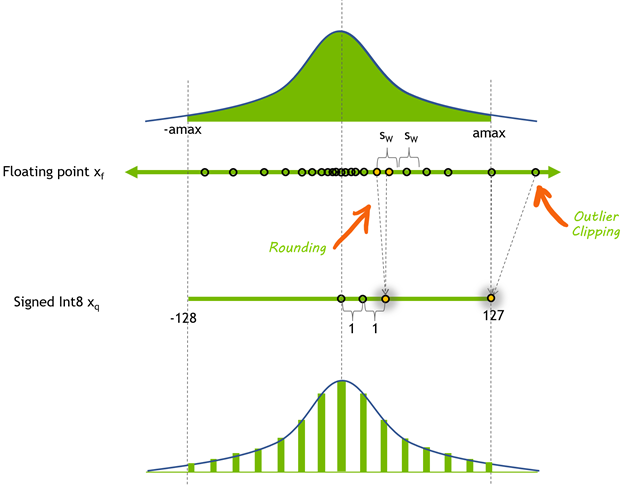
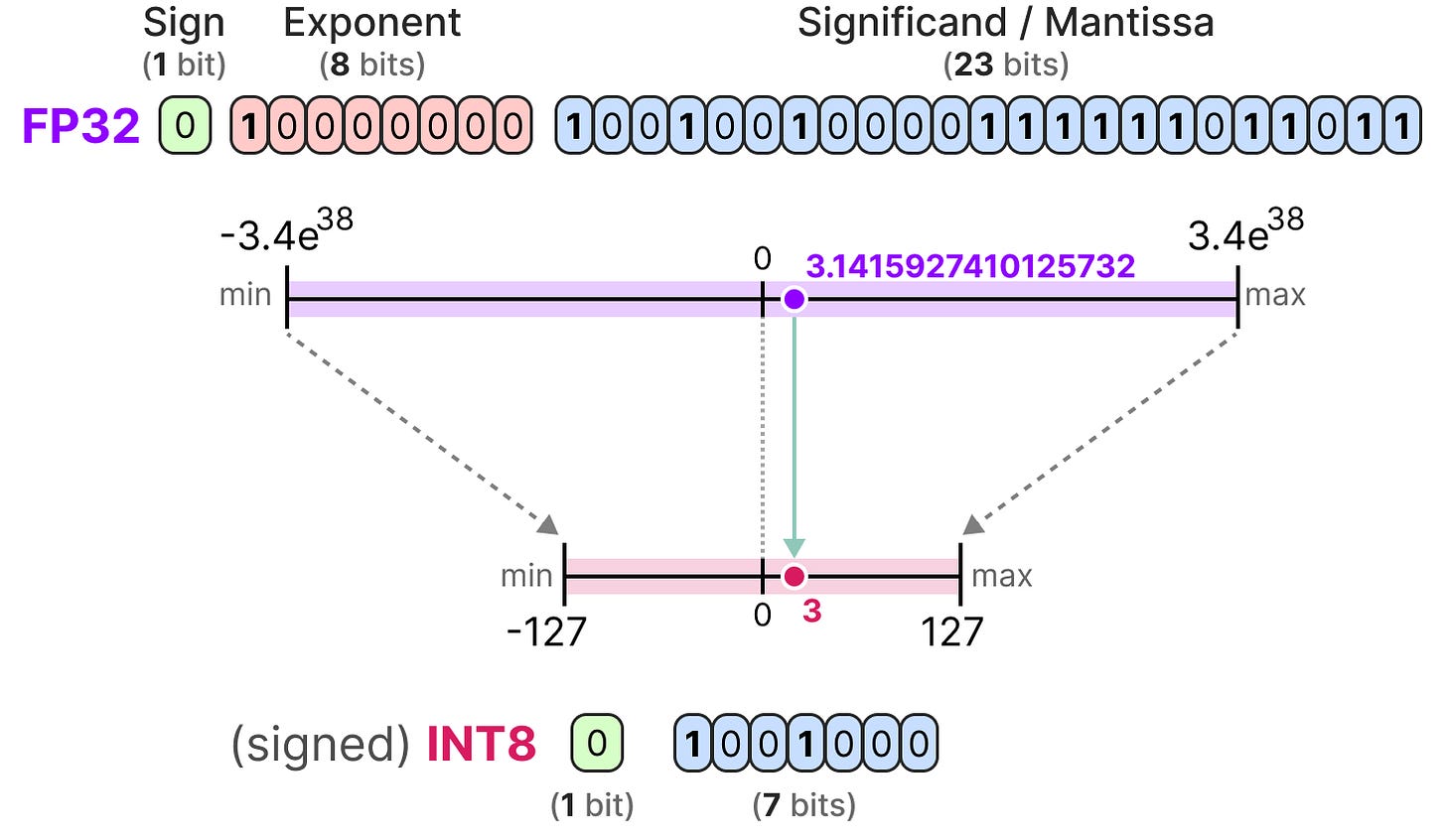
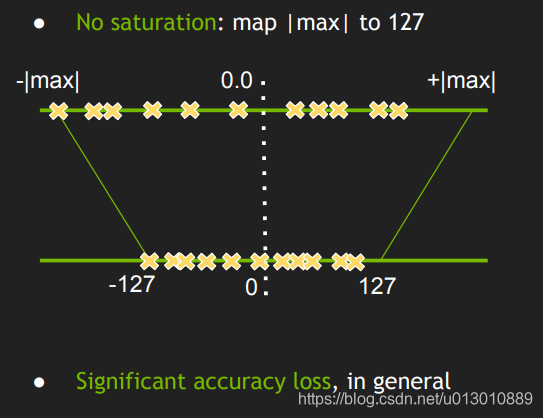
INT8, INT4 and Other Integer Types for Quantization
Improving LLM Inference Latency on CPUs with Model Quantization ...
Efficient 8-Bit Quantization of Transformer Neural Machine Language ...
CUTLASS INT4 vs. INT8 GEMM performance comparison across different ...
Applying INT8 quantization, just like in Dorado · Issue #388 ...
[BERT-Squad] INT8 quantization: The input data type must be Float32 ...
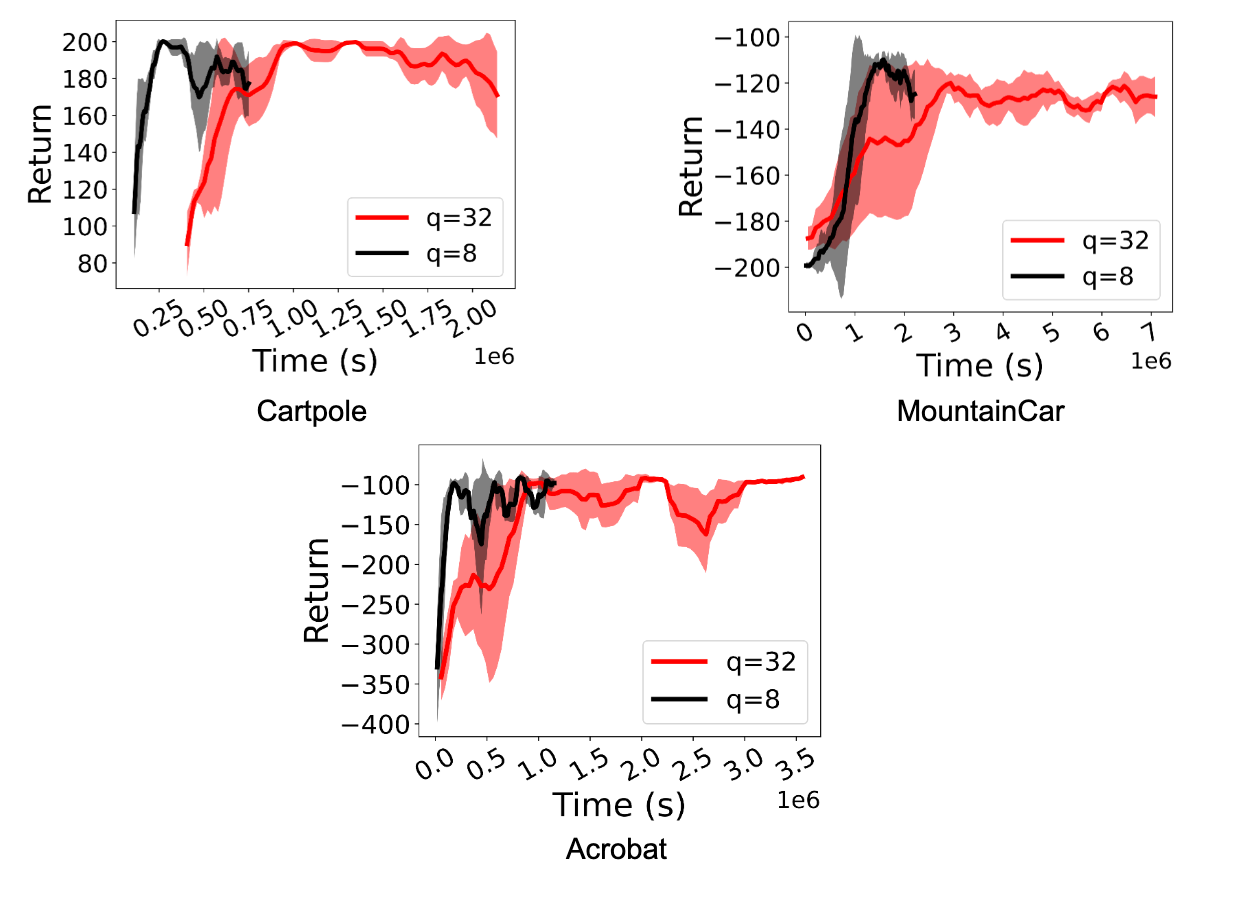
Quantization for Fast and Environmentally Sustainable Reinforcement ...
Int8 Quantized model same output on different inputs · Issue #23330 ...
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
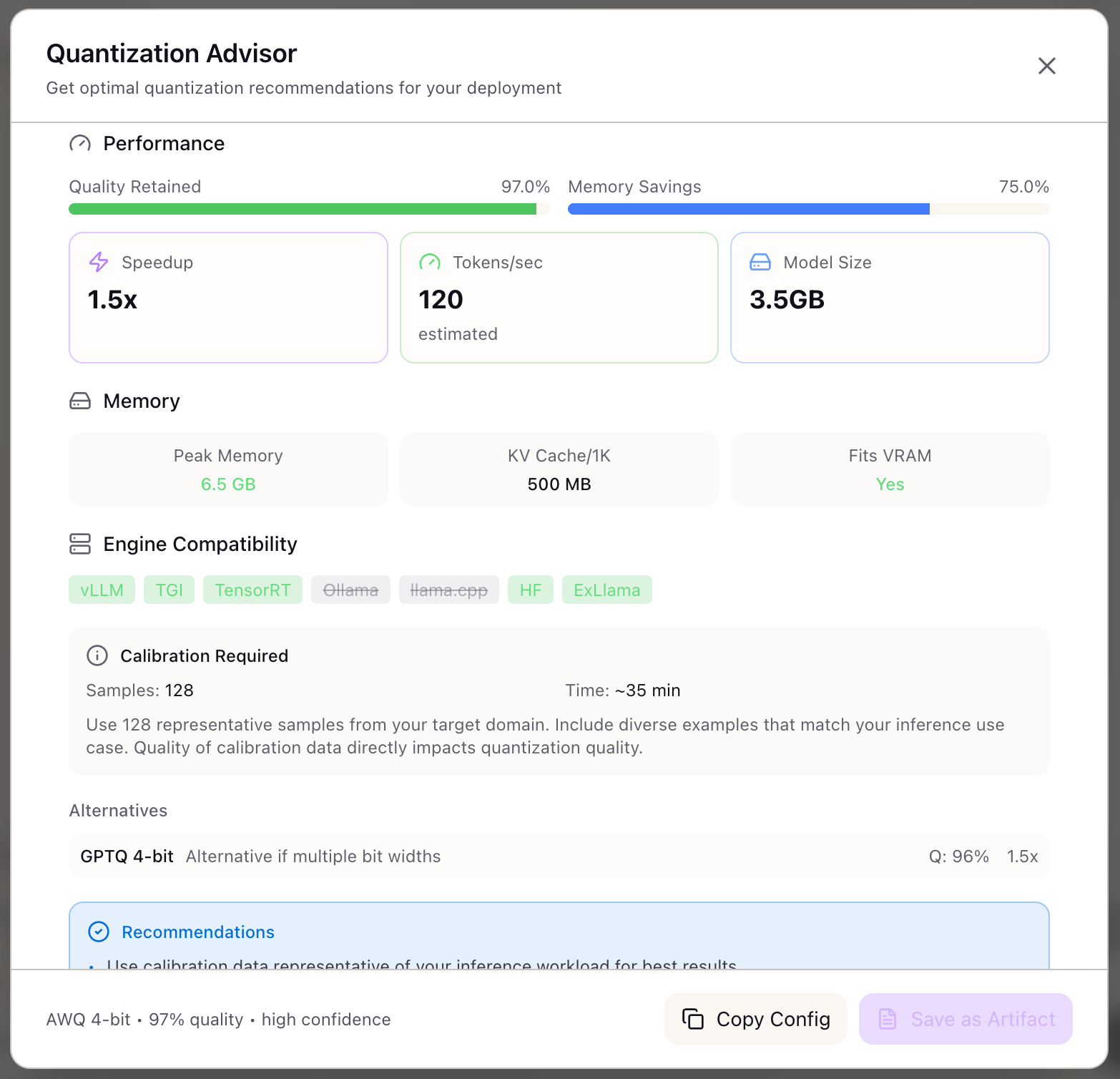
AI Model Quantization Advisor - INT8, FP16, INT4 Guide | Lattice
Optimizing LLMs for Performance and Accuracy with Post-Training ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
Google Colab
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
A Method of Deep Learning Model Optimization for Image Classification ...
Object Detection on GPUs in 10 Minutes | NVIDIA Technical Blog
Deep Learning Performance Characterization on GPUs for Various ...
GitHub - xuanandsix/Tensorrt-int8-quantization-pipline: a simple ...
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
Small numbers, big opportunities: how floating point accelerates AI and ...
Quantization: Reducing Model Precision (FP16, INT8)
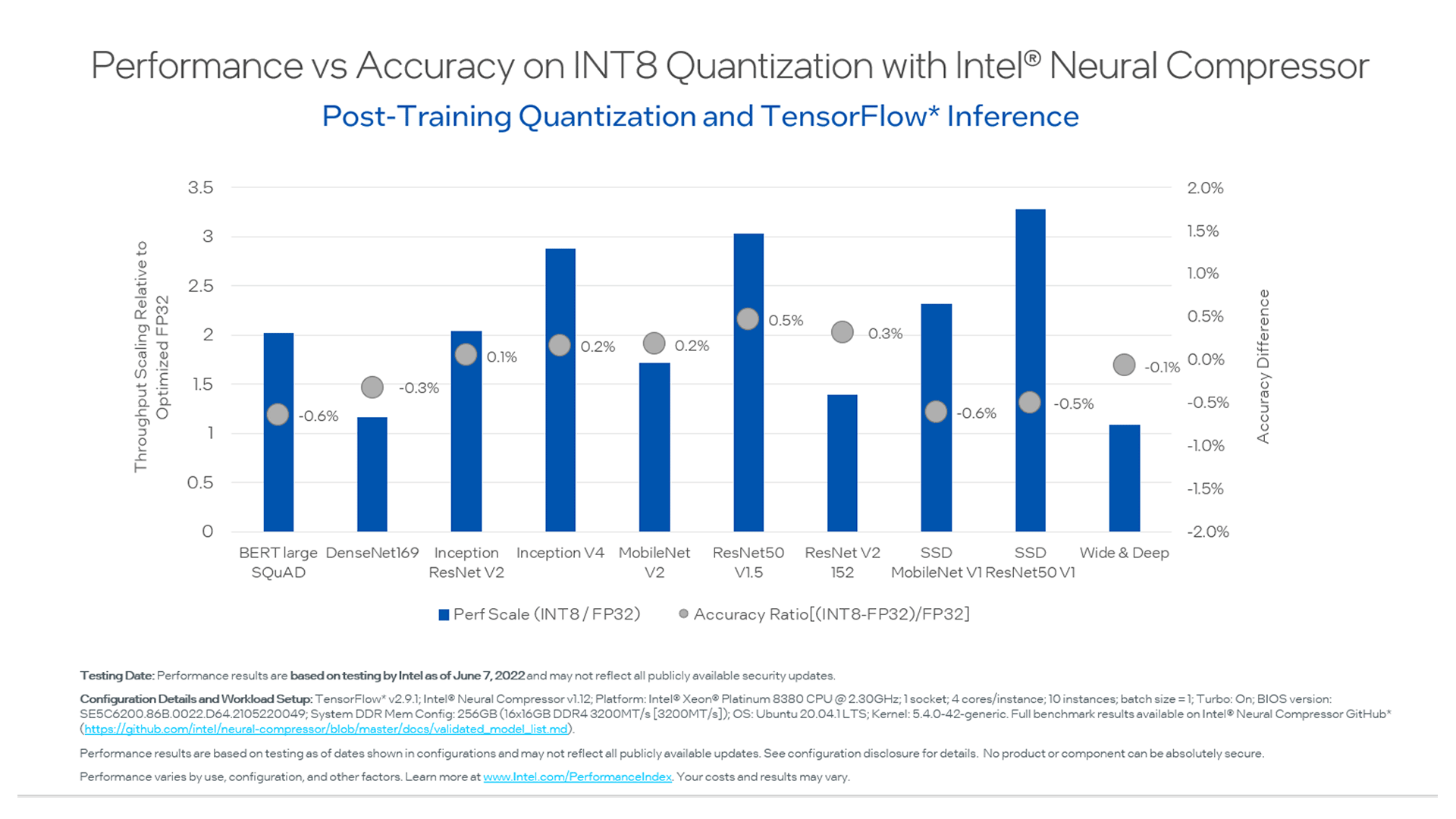
Perform Model Compression Using Intel® Neural Compressor
利用TensorRT实现INT8量化感知训练QAT_tensorrt int8量化-CSDN博客
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
SamMikaelson/deepseek-ocr-int8-quantized · Hugging Face
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
TensorRT INT8量化原理与实现(非常详细)-CSDN博客
NVIDIA TensorRT Accelerates Stable Diffusion Nearly 2x Faster with 8 ...
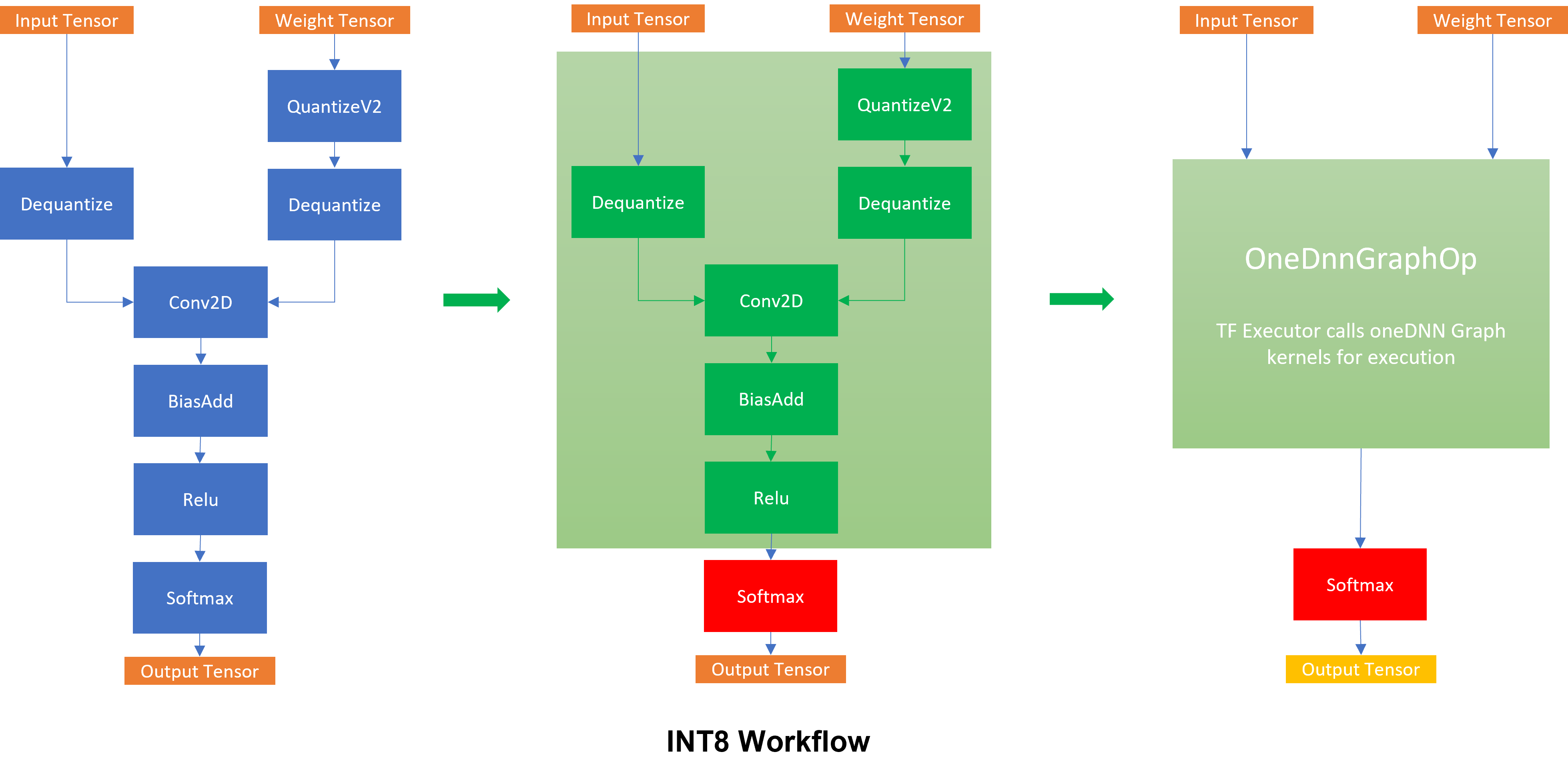

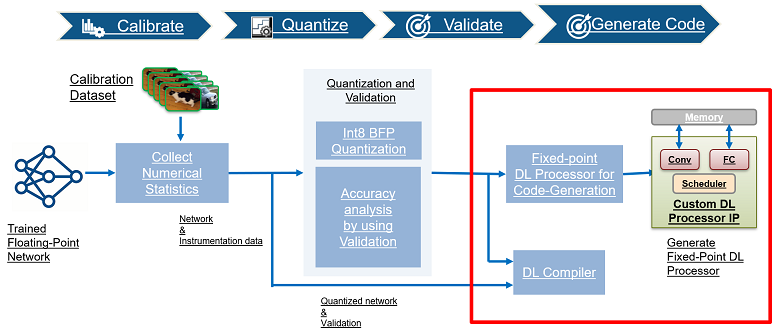
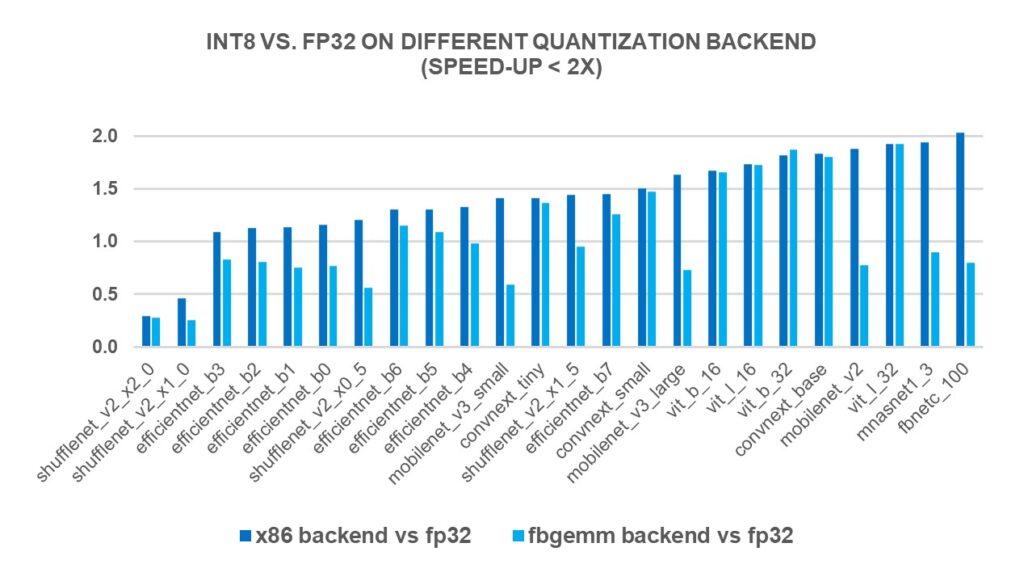
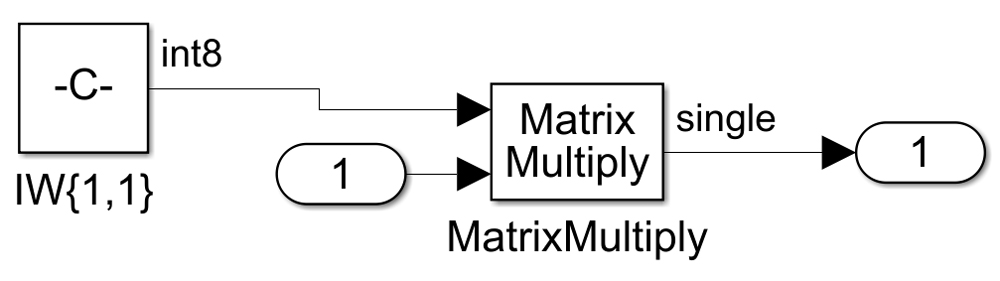









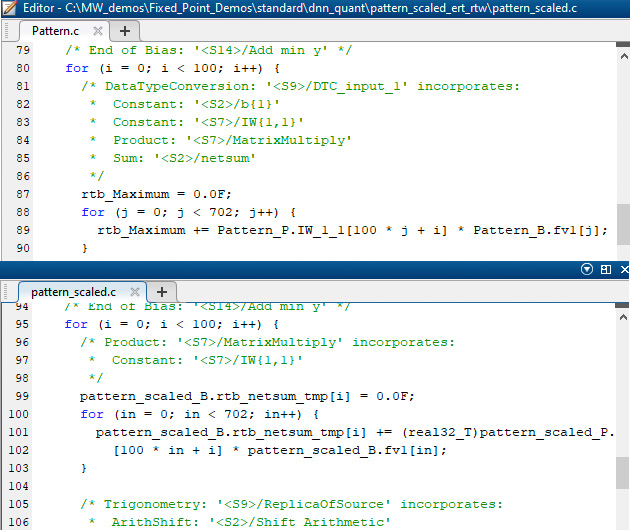
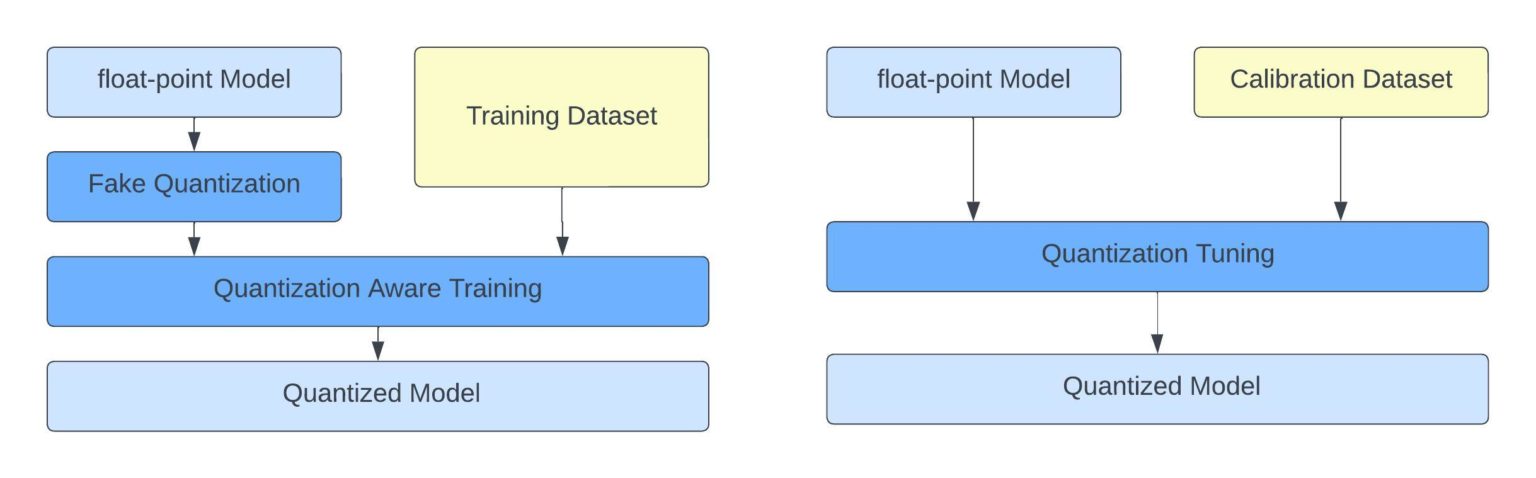
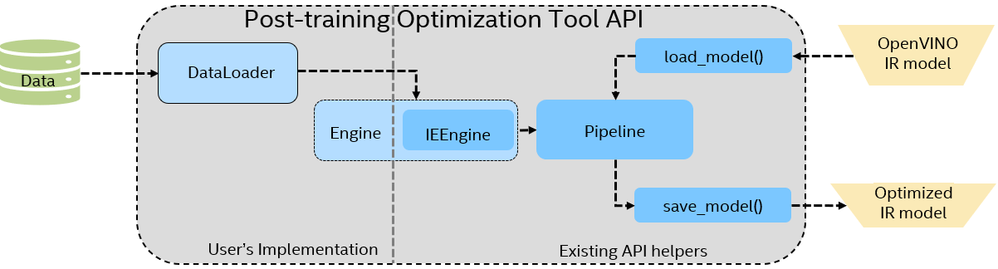
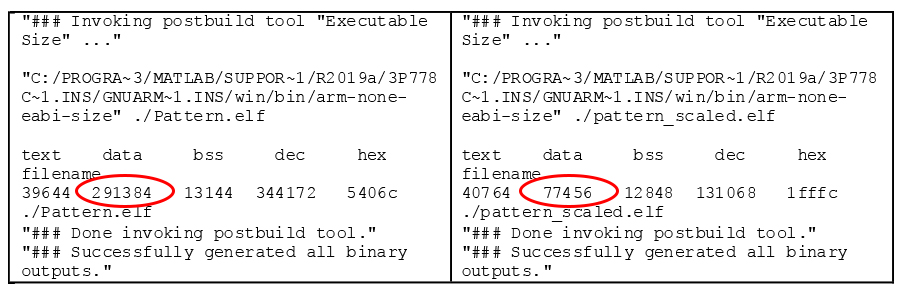

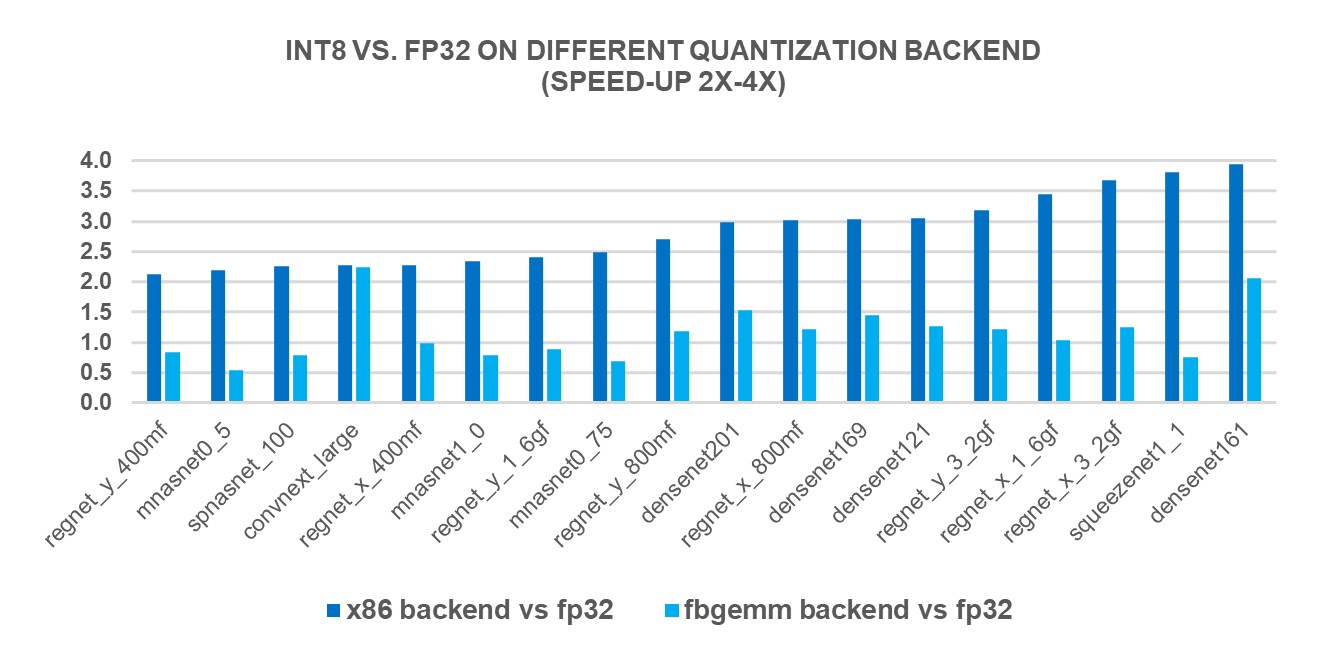
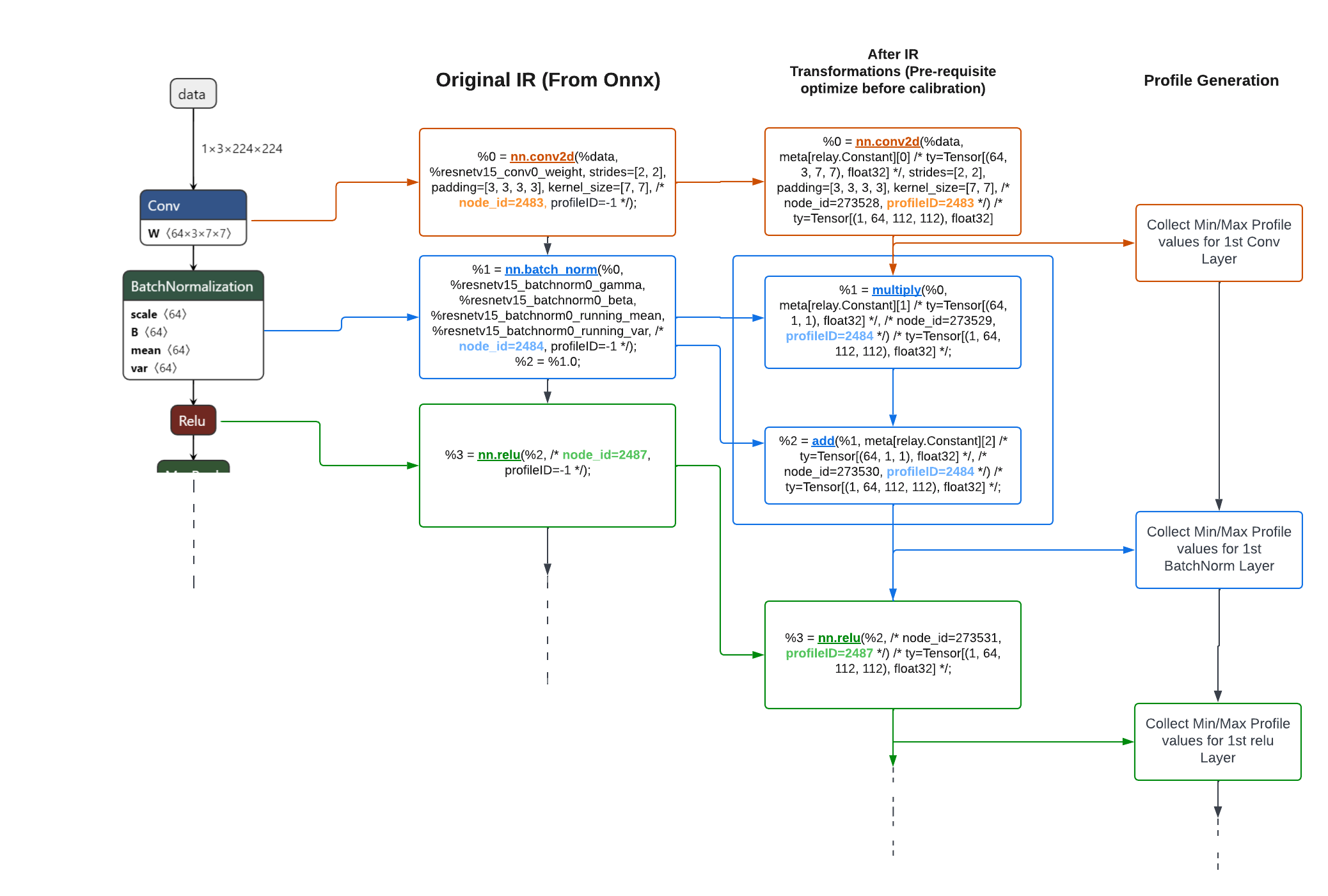
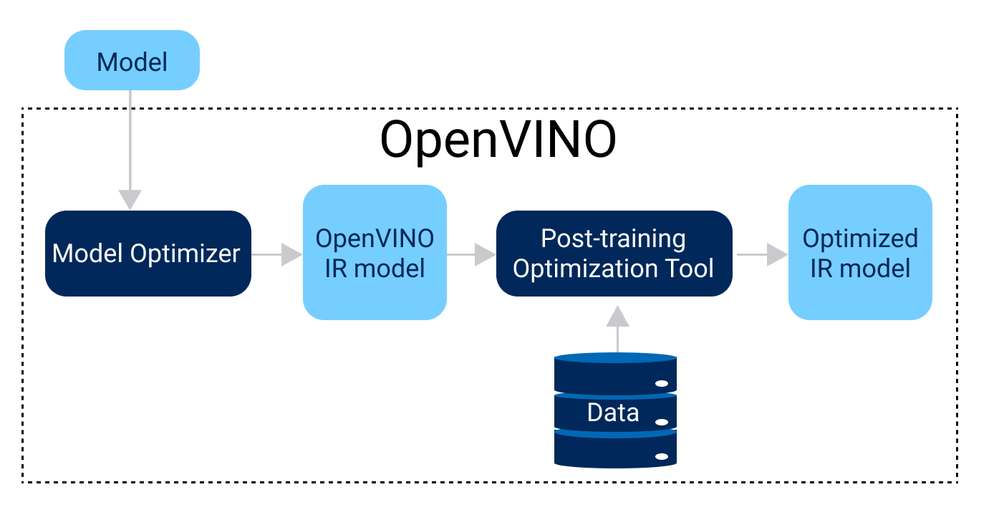


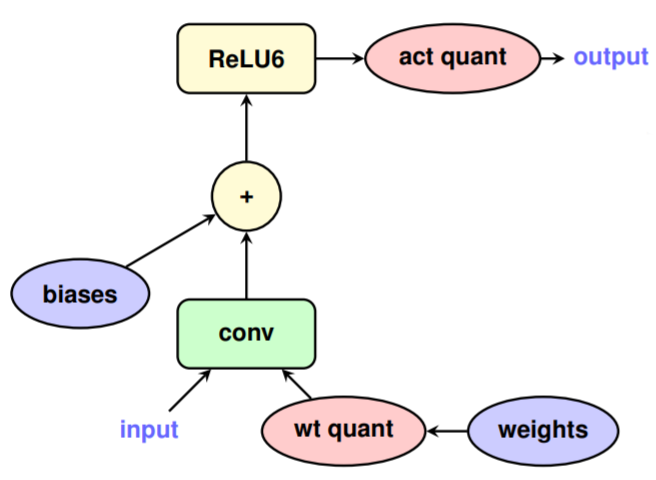



















.webp)