Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Medusa: Simple LLM Inference Acceleration Framework with Multiple ...
[Paper Review] Medusa: Simple LLM Inference Acceleration Framework with ...
M: Simple LLM Inference Acceleration Framework With Multiple Decoding ...
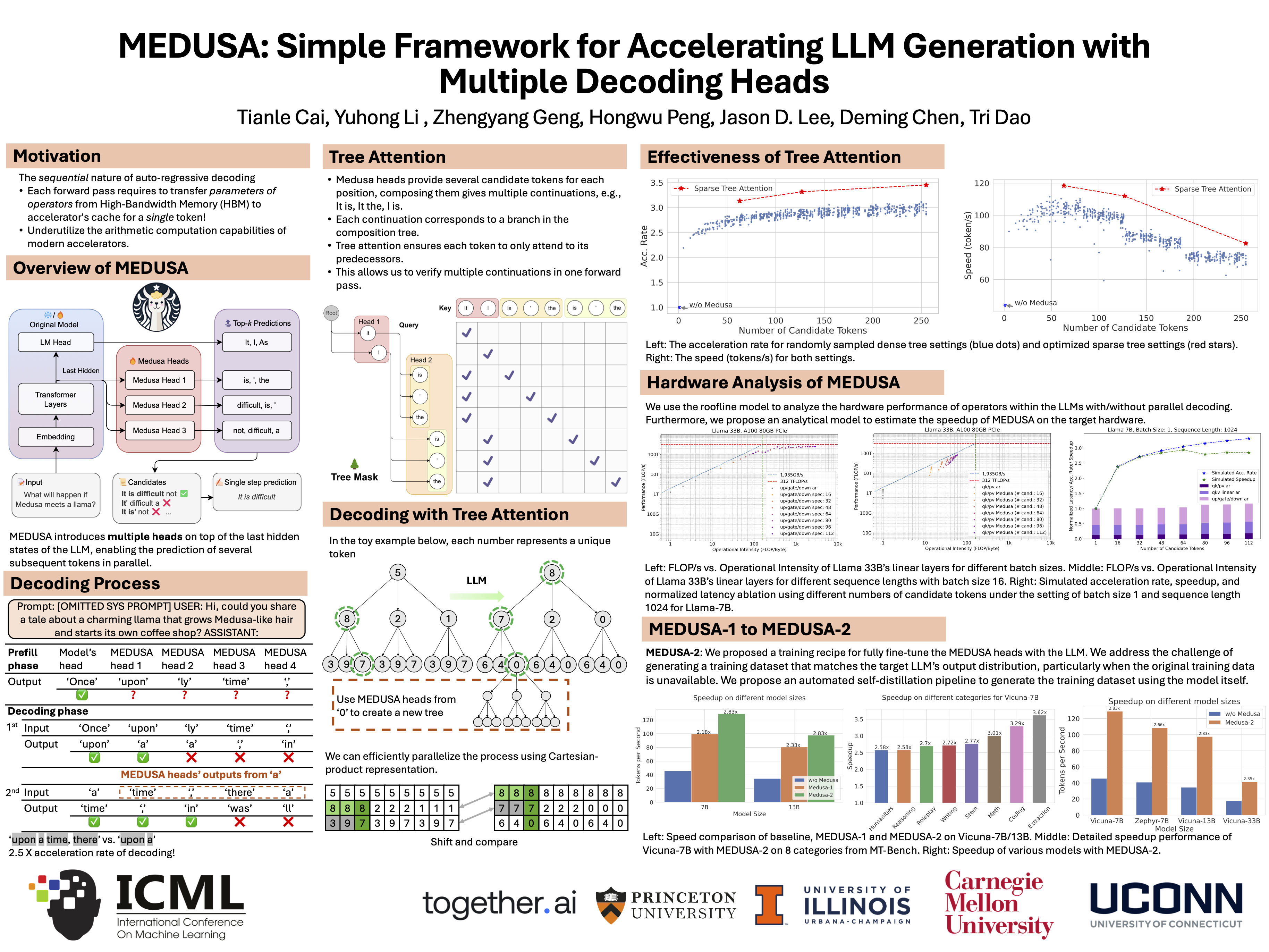
ICML Poster Medusa: Simple LLM Inference Acceleration Framework with ...
[IDSL Seminar'25] MEDUSA: Simple LLM Inference Acceleration Framework ...
[Paper Reading] Medusa: Simple LLM Inference Acceleration Framework ...
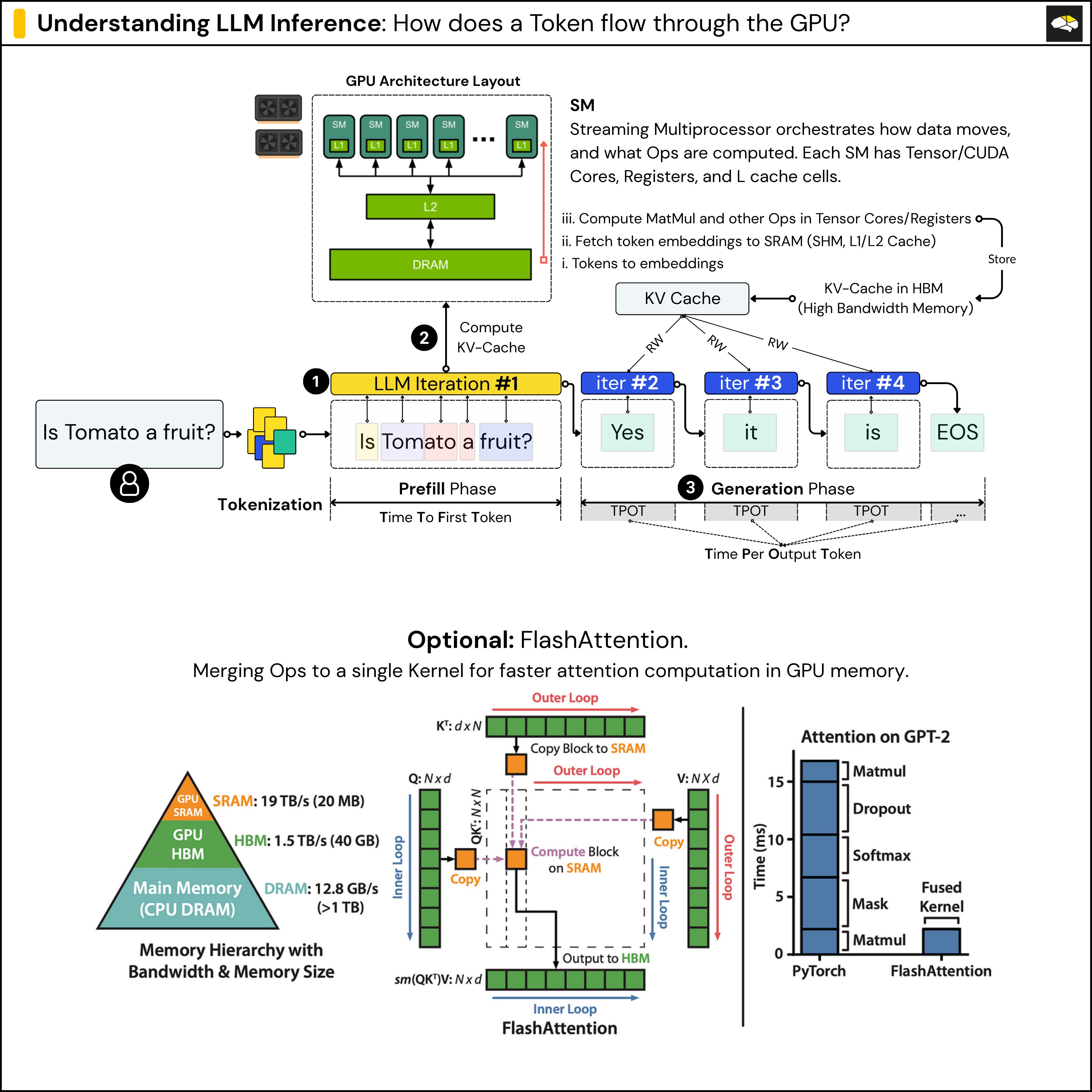
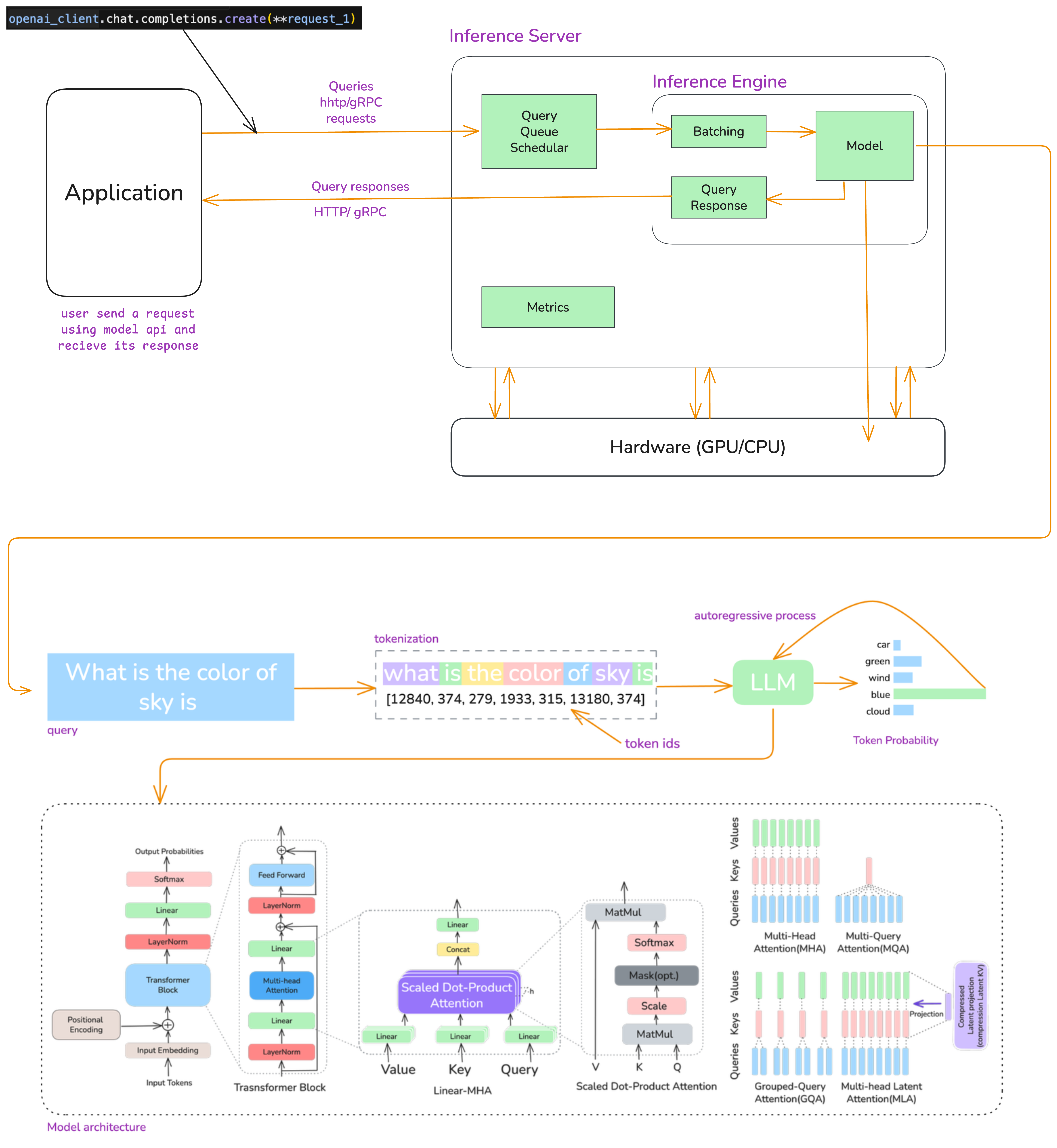
Understanding LLM Inference - by Alex Razvant
LLM Inference - Hw-Sw Optimizations
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
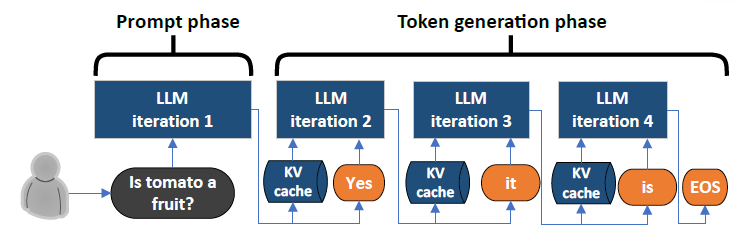
LLM Inference Stages Diagram | Stable Diffusion Online
Illustration of the proposed method. (a) LLM inference comprises two ...
How LLM Inference Engines Work: A Restaurant Analogy | by Tony Seah ...
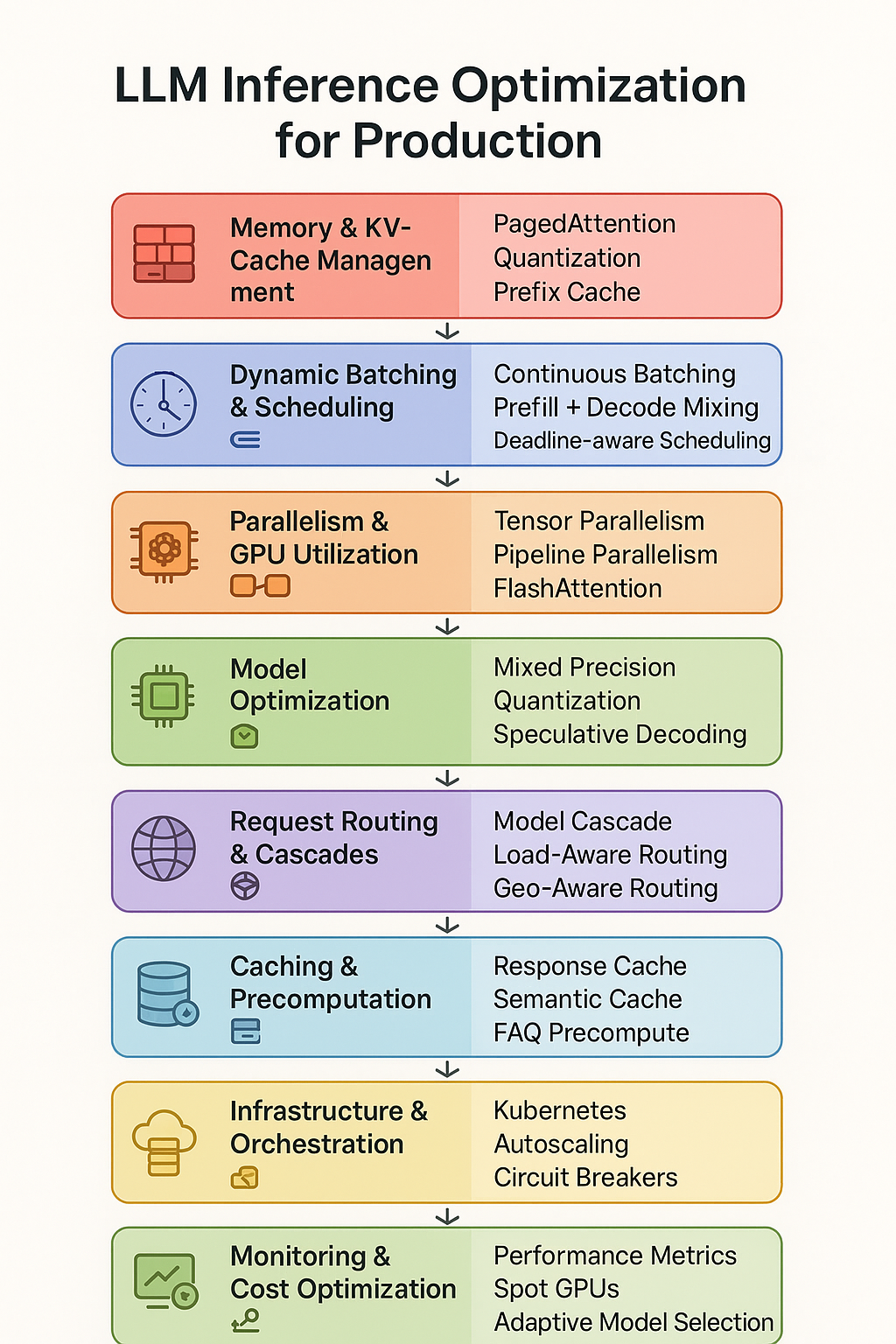
LLM Inference Optimization Techniques | Clarifai Guide
How continuous batching enables 23x throughput in LLM inference ...
How does LLM inference work? | LLM Inference Handbook
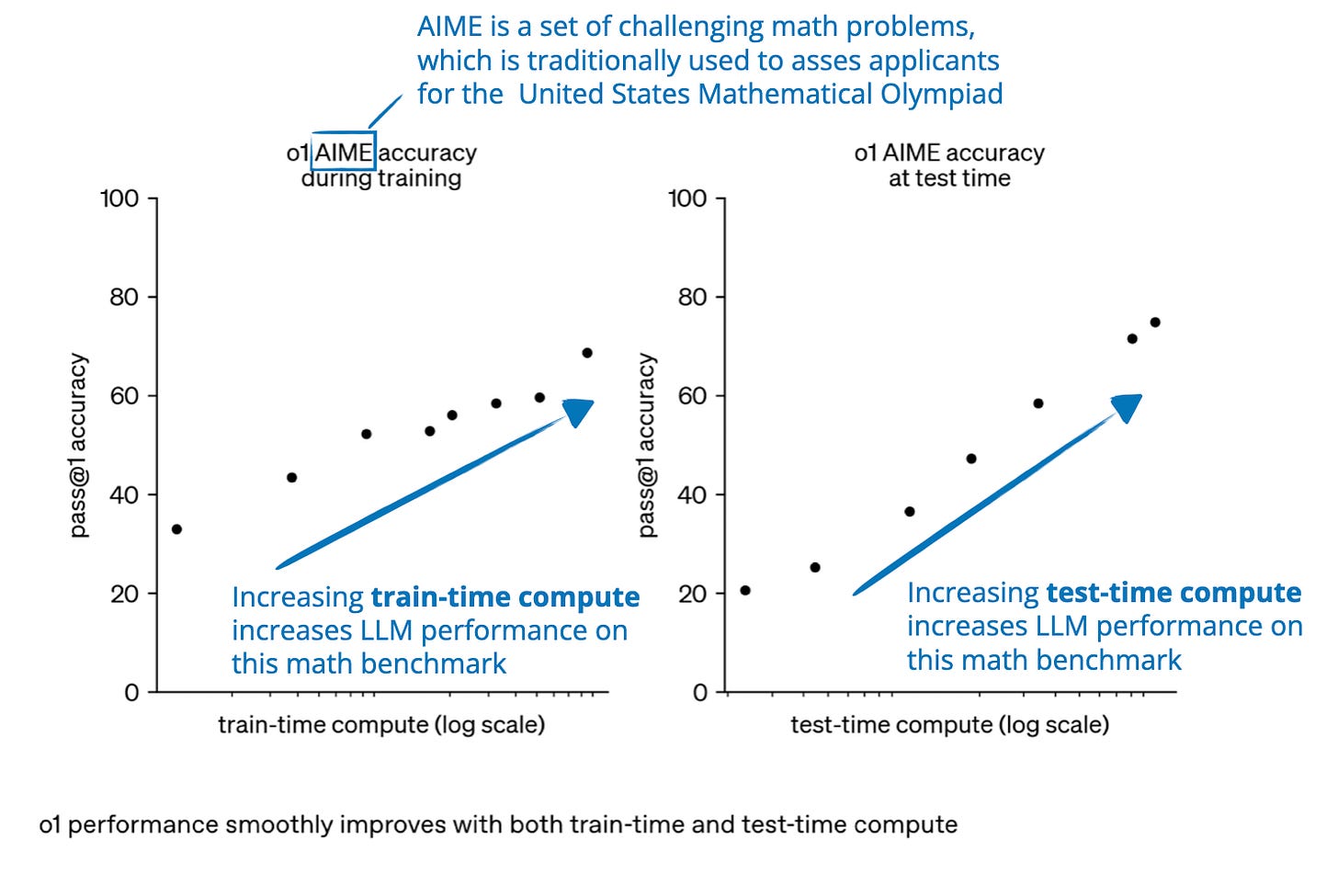
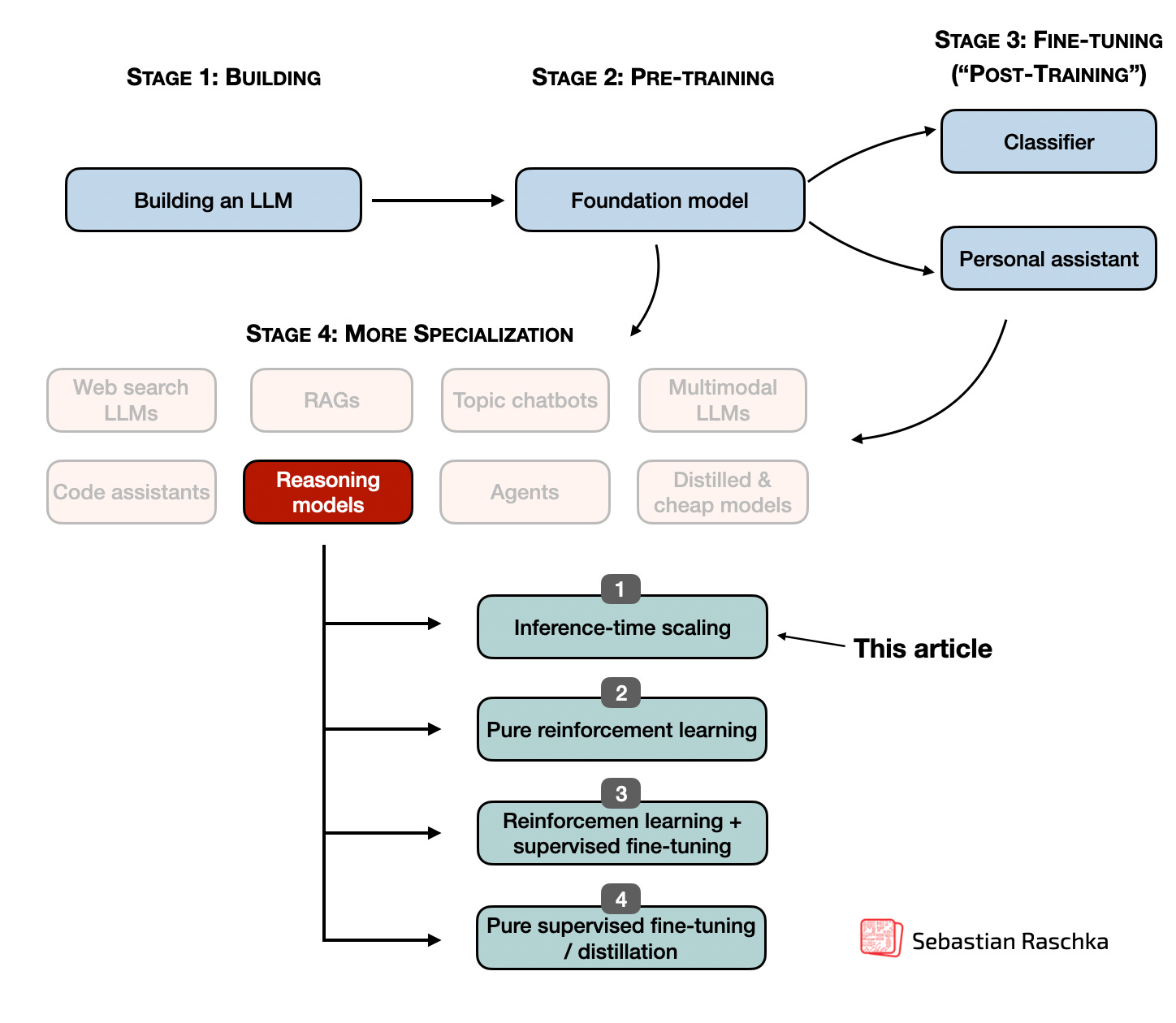
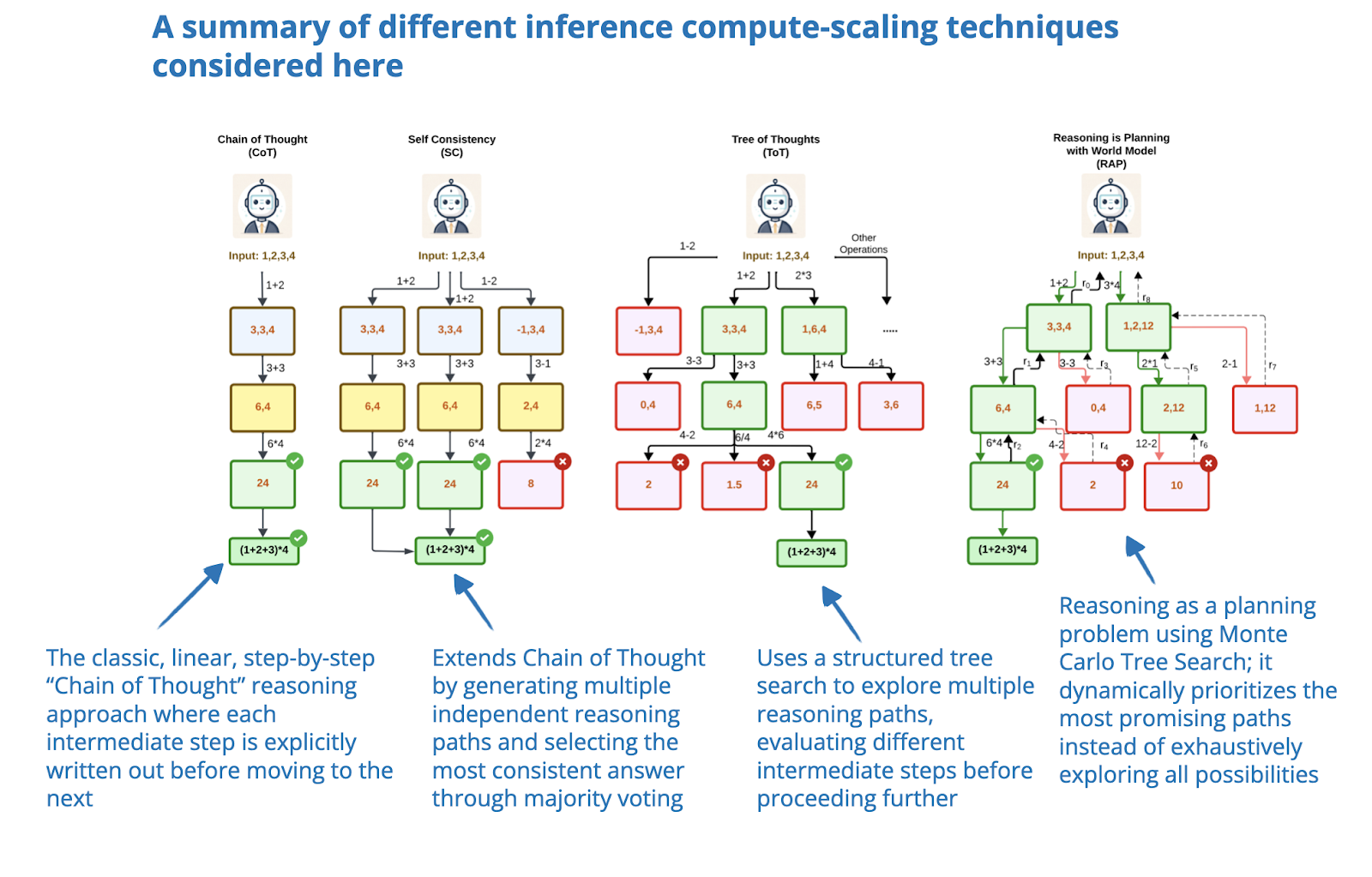
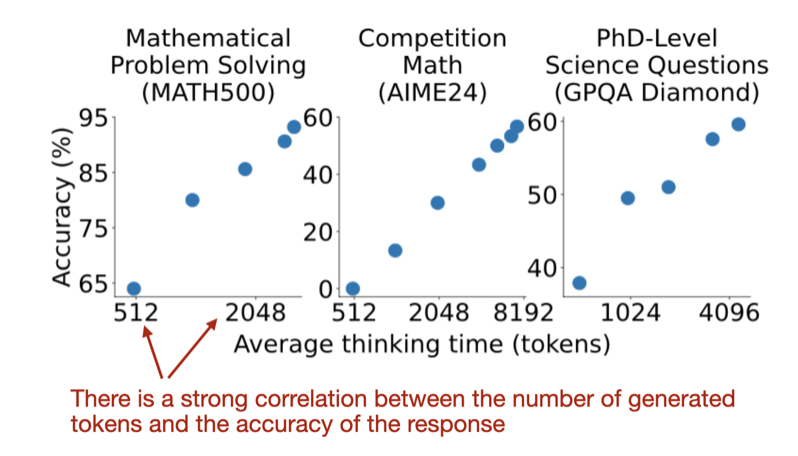
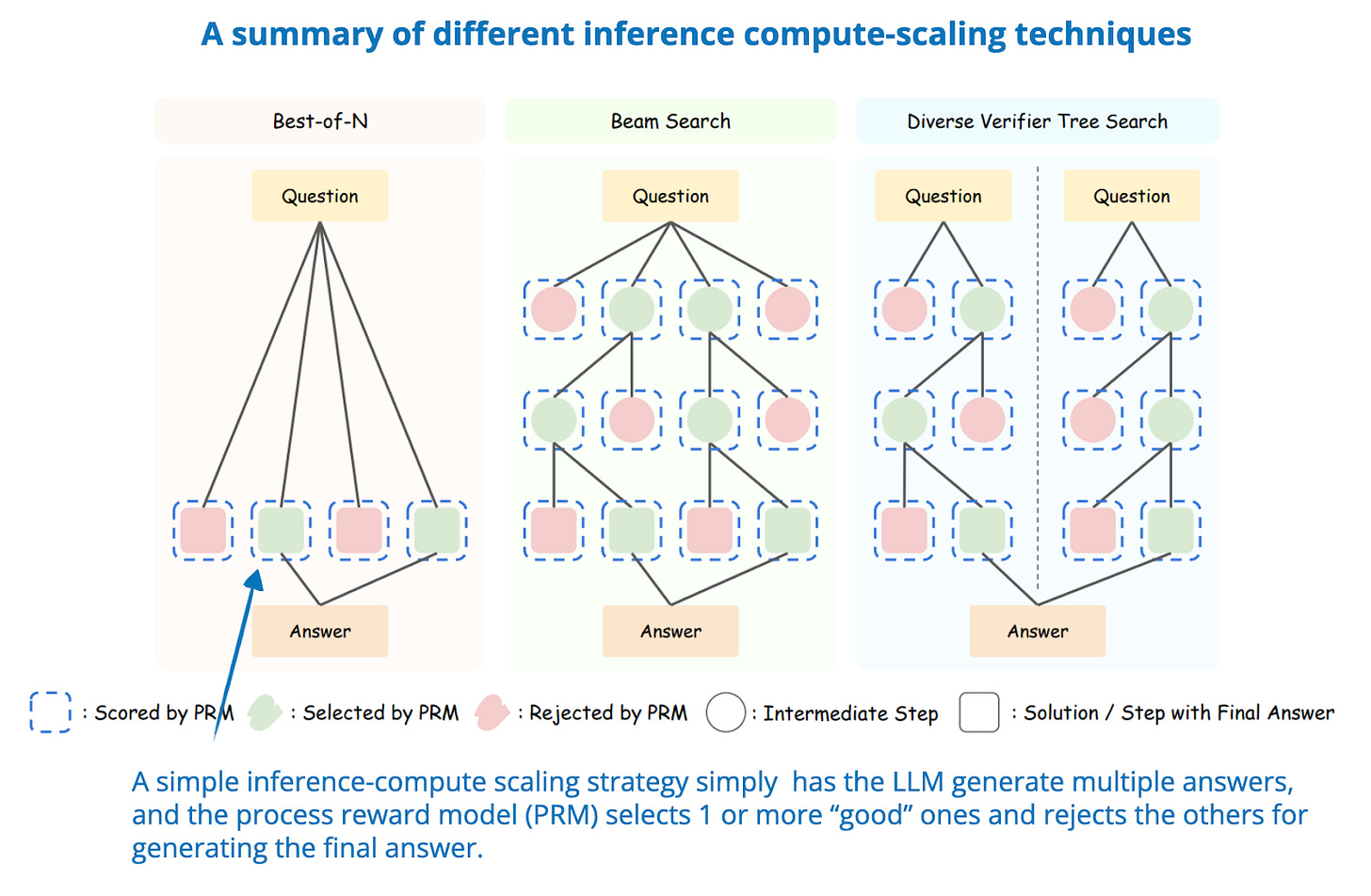
The State of LLM Reasoning Model Inference
LLM Inference Series: 1. Introduction | by Pierre Lienhart | Medium
LLM Inference Latency Metrics Explained | PDF | Mean | Latency ...
Speculative Decoding in vLLM: Complete Guide to Faster LLM Inference ...
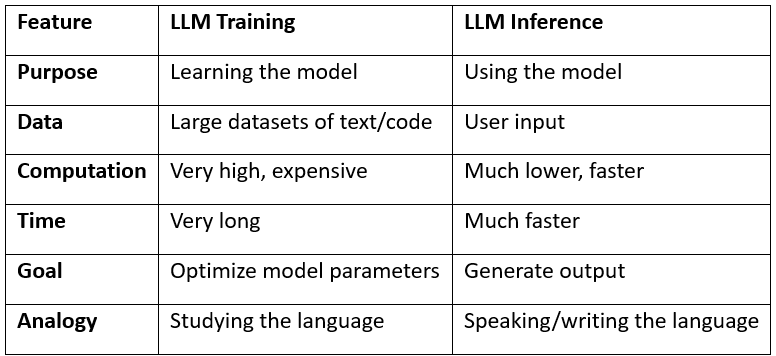
LLM Inference v_s Fine-Tuning | PDF | Cognitive Science | Computational ...
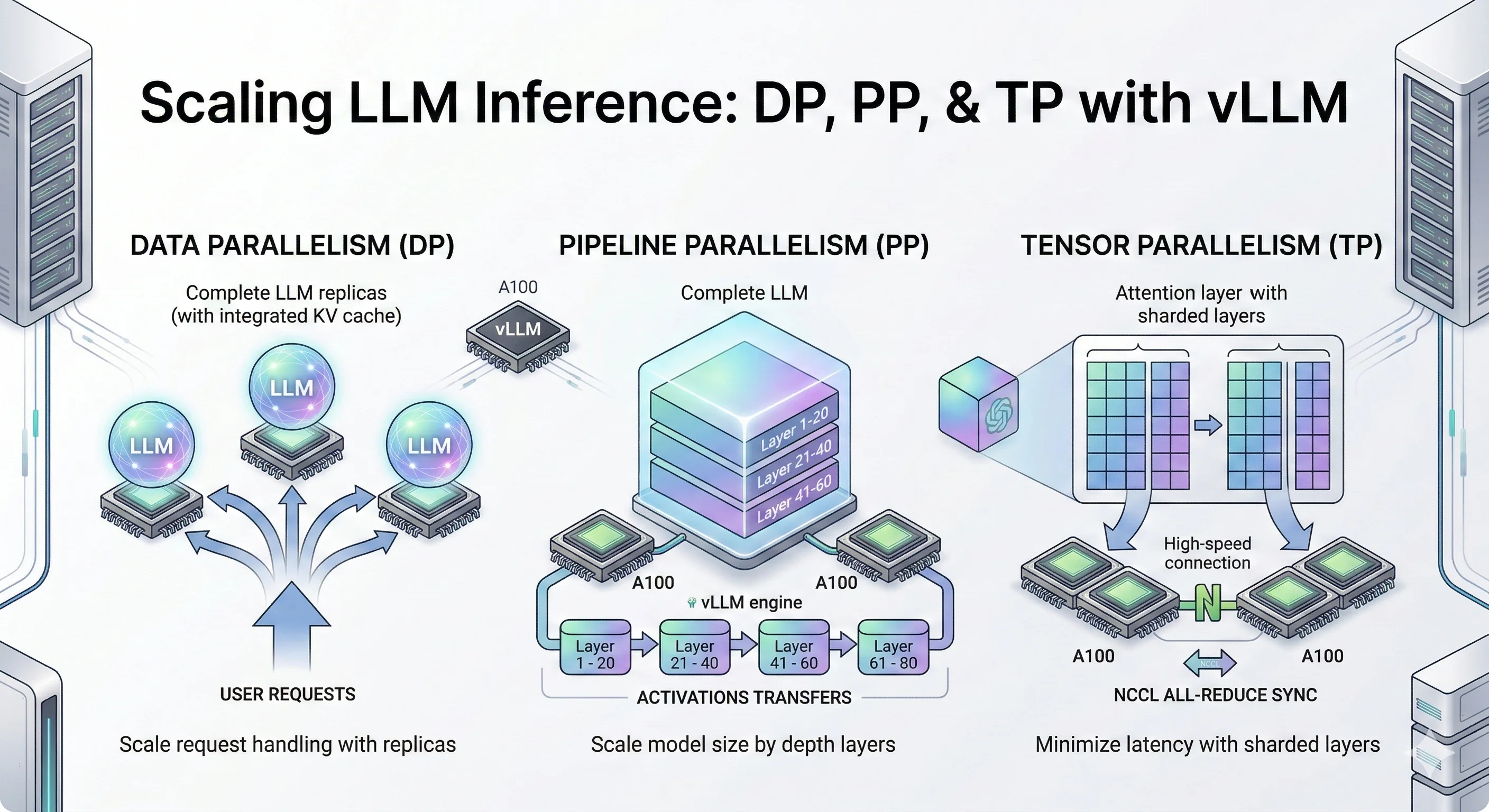
LLM Inference Optimization in Production: A Technical Deep Dive | by ...
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
LLM Inference
LLM inference techniques
Production-Grade LLM Inference at Scale with KServe, llm-d, and vLLM ...
A guide to LLM inference and performance
(PDF) Improving the inference performance of LLM with code
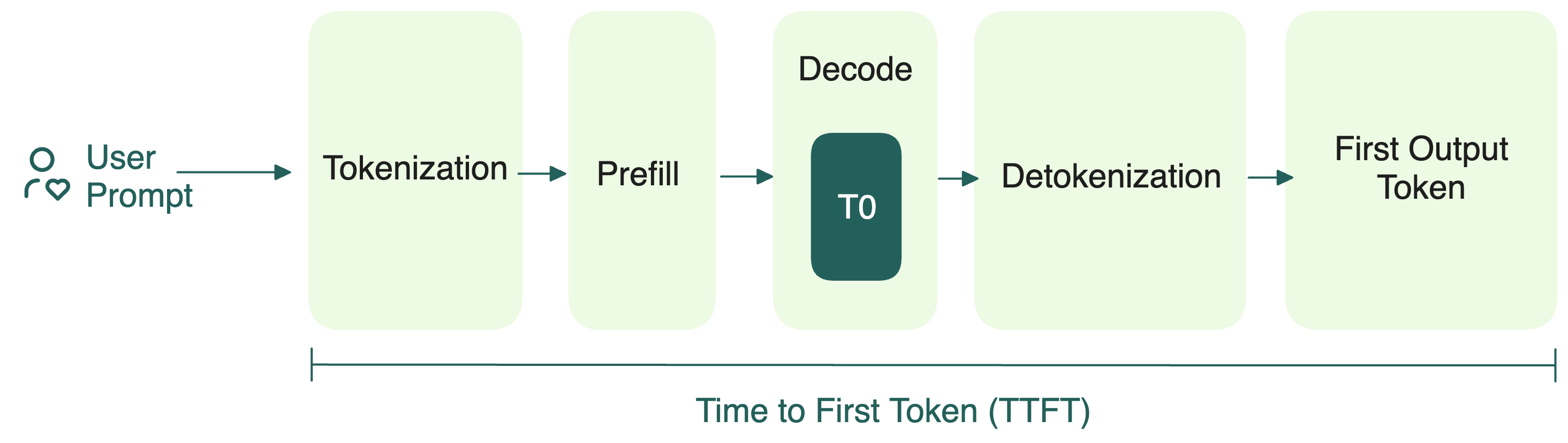
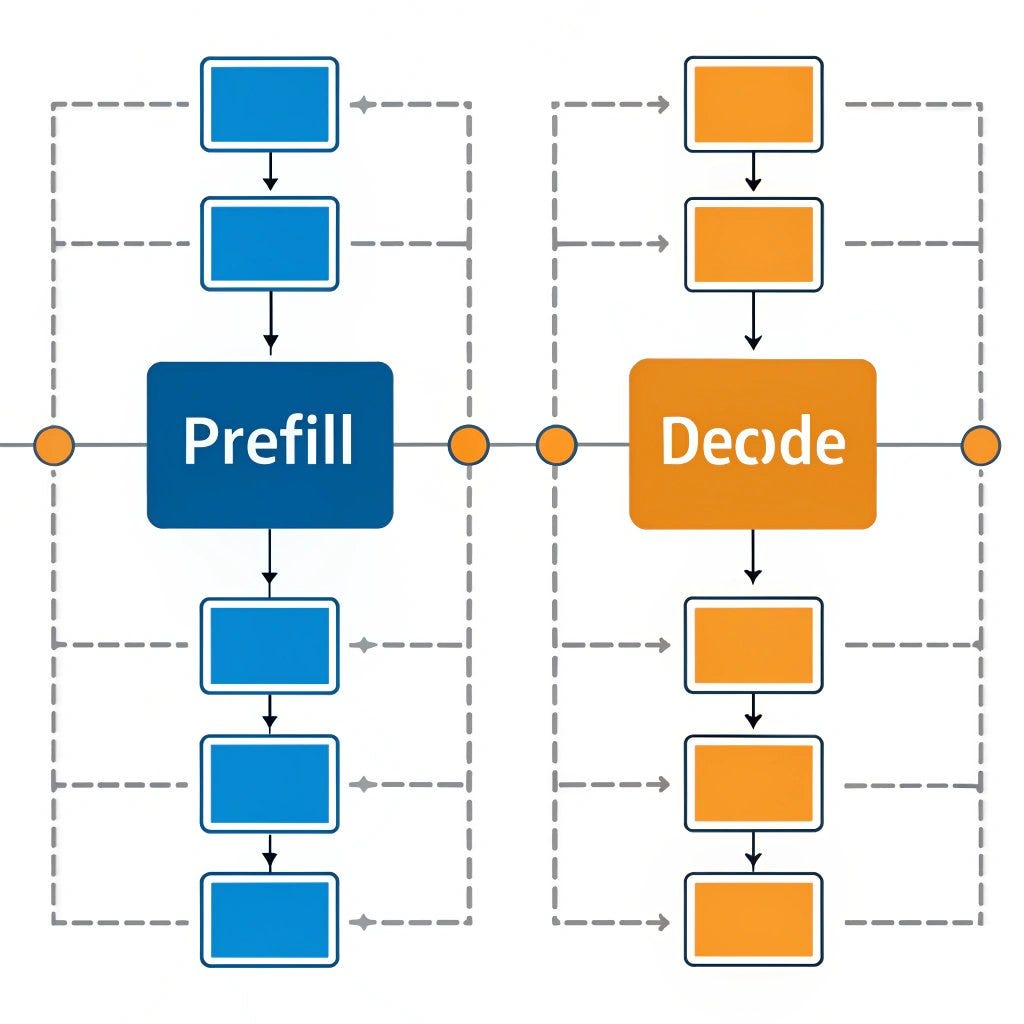
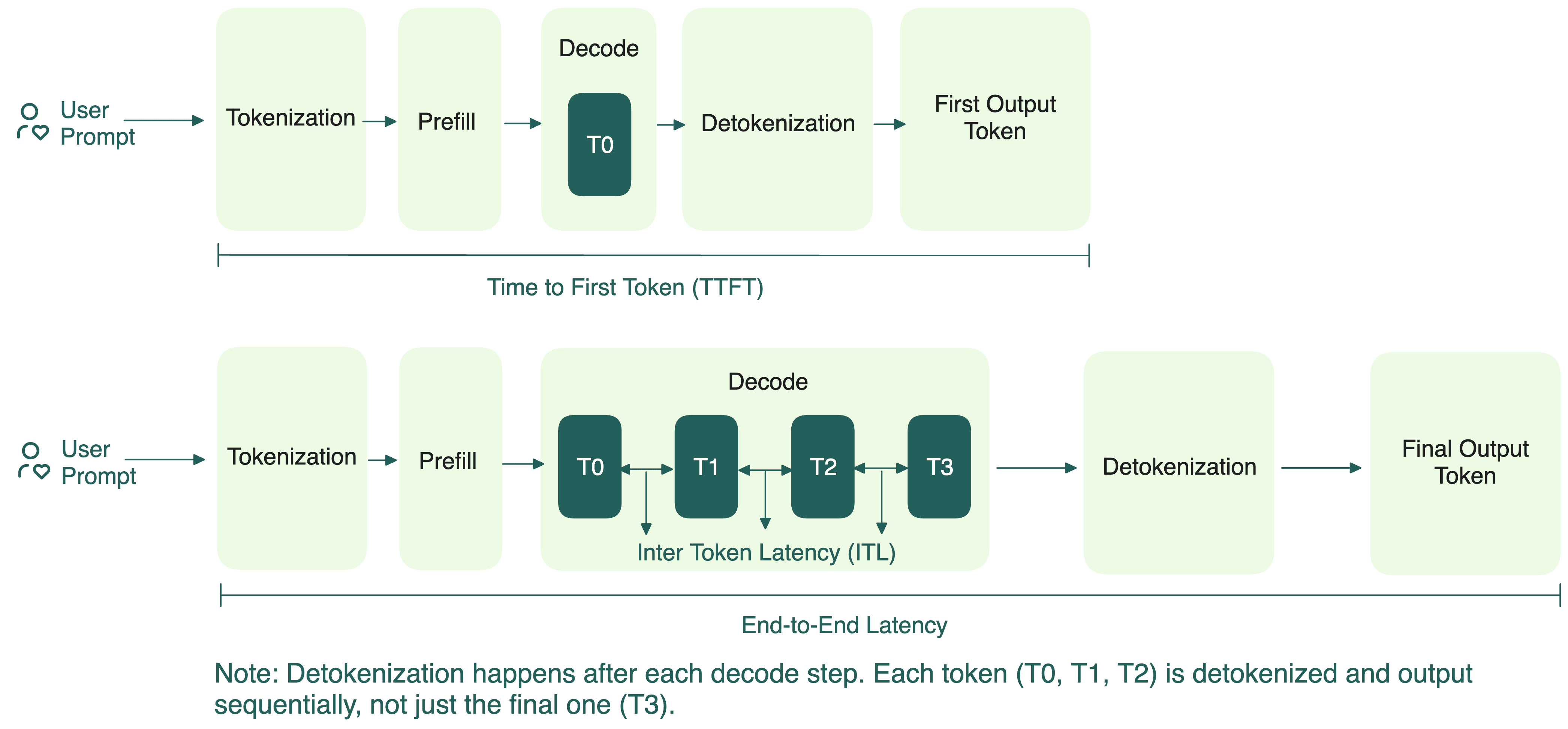
LLM Inference Explained: Prefill vs Decode and Why Latency Matters ...
Just simple AI-business // LLM inference/FT | by evoailabs | Medium
This One Detail Explains Most of LLM Inference Performance - Coder Legion
Efficient LLM Inference and Serving with vLLM
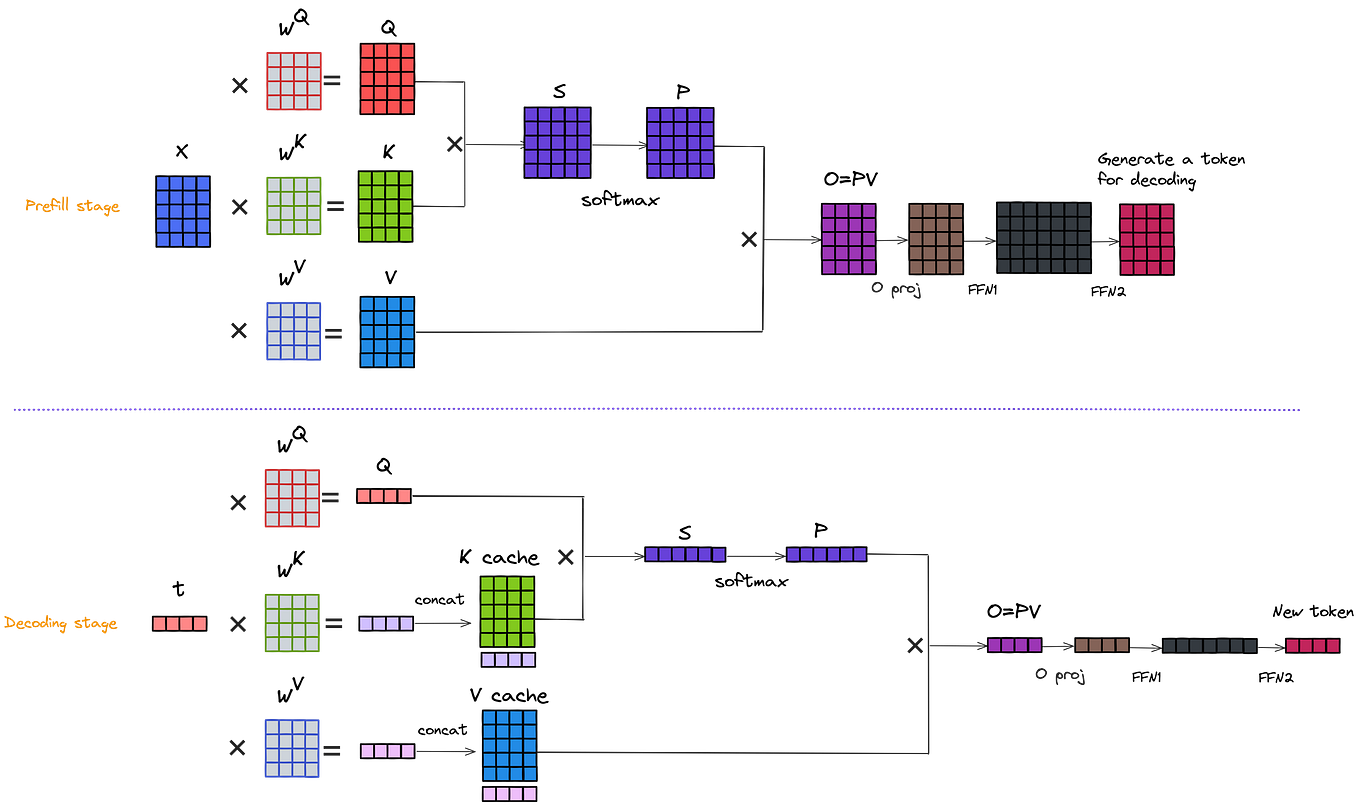
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
LLM Inference Parameters Explained Visually
AI/ML Infra Meetup | A Faster and More Cost Efficient LLM Inference ...
Deep Dive: Optimizing LLM inference - YouTube
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
LLM inference optimization: Model Quantization and Distillation - YouTube
Want to build a fast LLM inference engine from scratch? | Karn Singh
LLM Inference on Edge: A Fun and Easy Guide to run LLMs via React ...
Run LLM inference at maximum throughput | Modal Docs
Illustration of the privacy-preserving LLM inference. The LLM inference ...
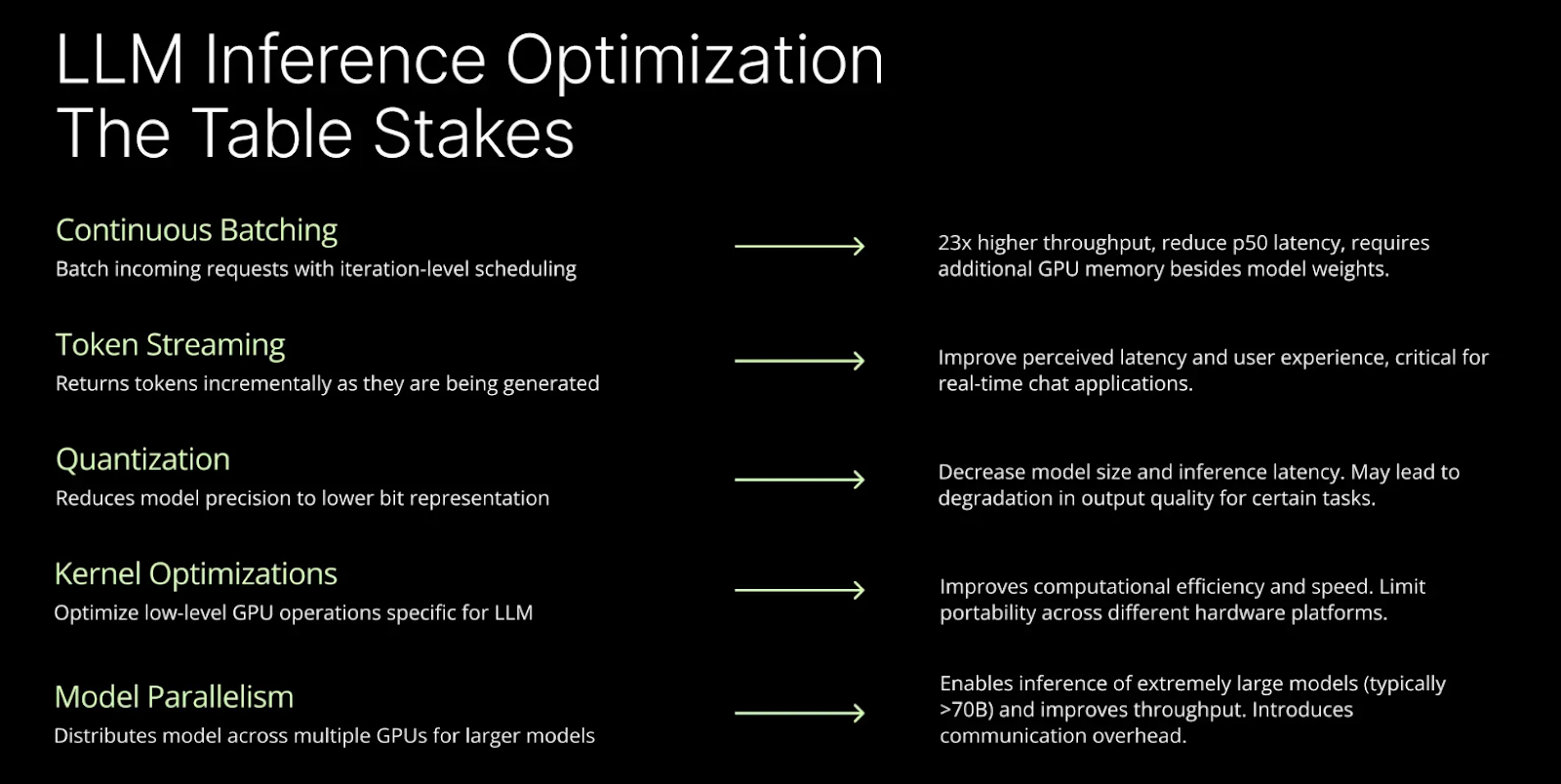
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
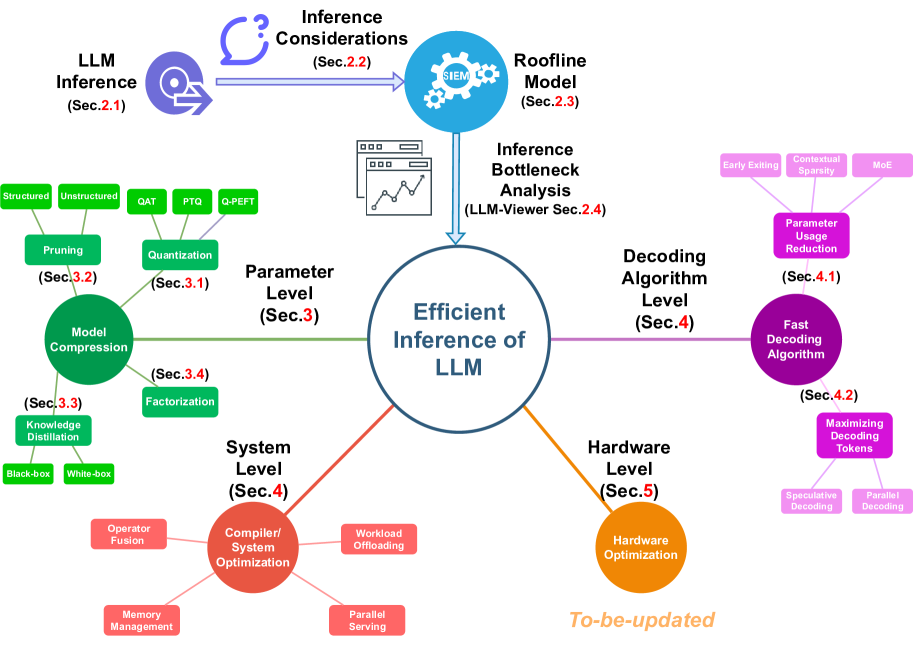
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
Choosing The Right Inference Framework - LLM Inference Handbook | PDF ...
What Is LLM Inference? Batch Inference In LLM Inference
LLM Inference Unveiled: Survey and Roofline Model Insights - 知乎
A Survey of LLM Inference Systems | alphaXiv
LLM Inference | opendatalab/MinerU-HTML | DeepWiki
Why is LLM Inference Optimization Important in 2026?
(PDF) Scalable Inference Systems for Real-Time LLM Integration
Overview of an Example LLM Inference Setup - YouTube
10 Strategies to Optimize LLM Inference Costs | thealpha posted on the ...
How to Scale LLM Inference - by Damien Benveniste
LLM Inference Optimization Overview - From Data to System Architecture
LLM Inference - a andreapie Collection
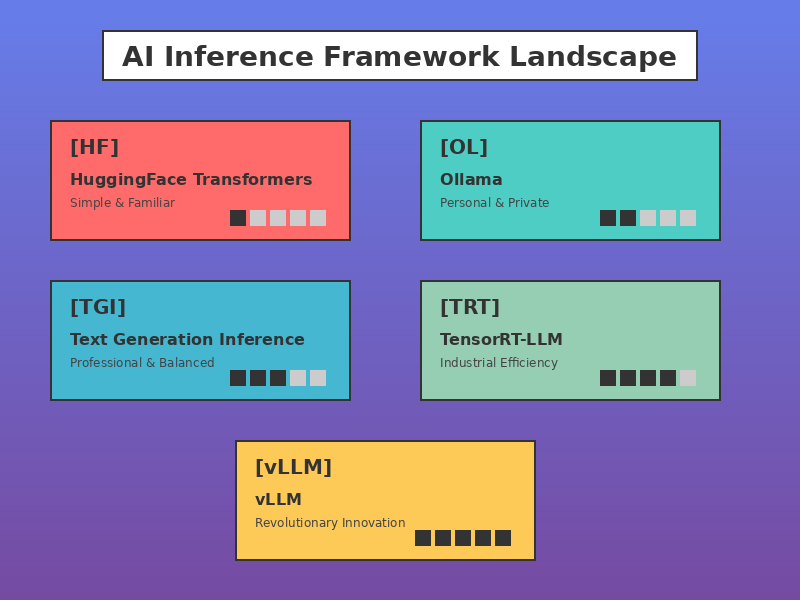
LLM Inference ( vLLM , TGI, TensorRT ) | by Pratik | Medium
LLM Inference Essentials
Optimizing LLM inference on Amazon SageMaker AI with BentoML’s LLM ...
LLM Inference Bottlenecks
LLM Inference - EcoLogits
LLM Inference Explained
คู่มือ LLM Inference ฉบับใหม่จุดประกายการถกเถียงเรื่อง Ollama กับการใช้ ...
How to Architect Scalable LLM & RAG Inference Pipelines
Star Attention: Efficient LLM Inference over Long Sequences | AI ...
LLM Inference Hardware: Emerging from Nvidia's Shadow
How LLM really works: From Training to Talking – The Power of Inference
High-performance LLM inference | Modal Docs
LLM Inference Unveiled: Survey and Roofline Model Insights
What Is LLM Inference? Process, Latency & Examples Explained (2026)
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
Topic 23: What is LLM Inference, it's challenges and solutions for it
The Emerging LLM Stack: A Comprehensive Guide for Developers - Helicone
The State of LLM Reasoning Models
Guide to Self-hosting LLM Systems - Zilliz blog
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
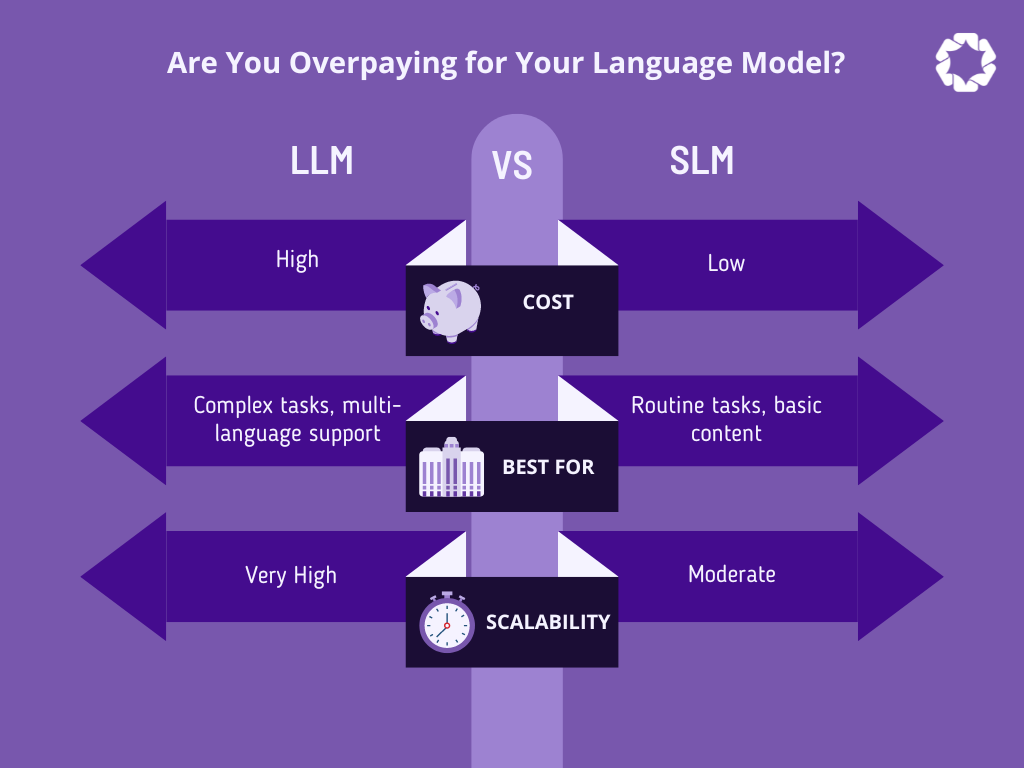
What is LLM Model Inference?
What is LLM Inference? • luminary.blog
The 4 patterns of LLM Inference. | Alex Razvant
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
Optimizing AI Performance: A Guide to Efficient LLM Deployment
The Best NVIDIA GPUs for LLM Inference: A Comprehensive Guide | by ...
Optimizing LLM Inference. Optimization begins where architectures… | by ...
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
Understanding LLM Inference: How AI Generates Words | DataCamp
The Hitchhikers Guide to LLM Agent
LLM — Inference. What are the configuration parameters… | by Pelin ...
llm-d: Kubernetes-native distributed inferencing | Red Hat Developer
GitHub - Dheenathsunder/Introductio-Simple-LLM-Inference-on-CPU-and ...
Link Start :: SAO Blog
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
inference.ipynb · Pito8/simple-llm-finetuner at main
Comprehensive Analysis and Selection Guide for Large Language Model ...
llm-inference · PyPI
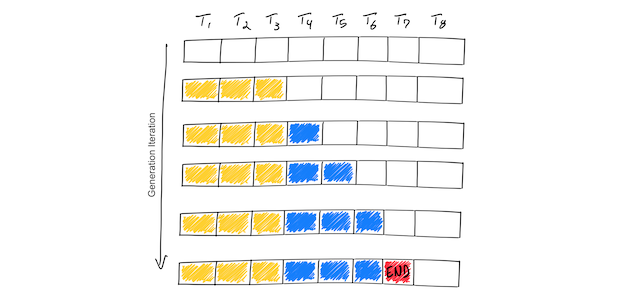
Optimizing Large Language Model Inference: A Deep Dive into Continuous



















-png.png?width=4320&height=2160&name=AI%20Model%20Training%20vs%20Inference%20(1)-png.png)










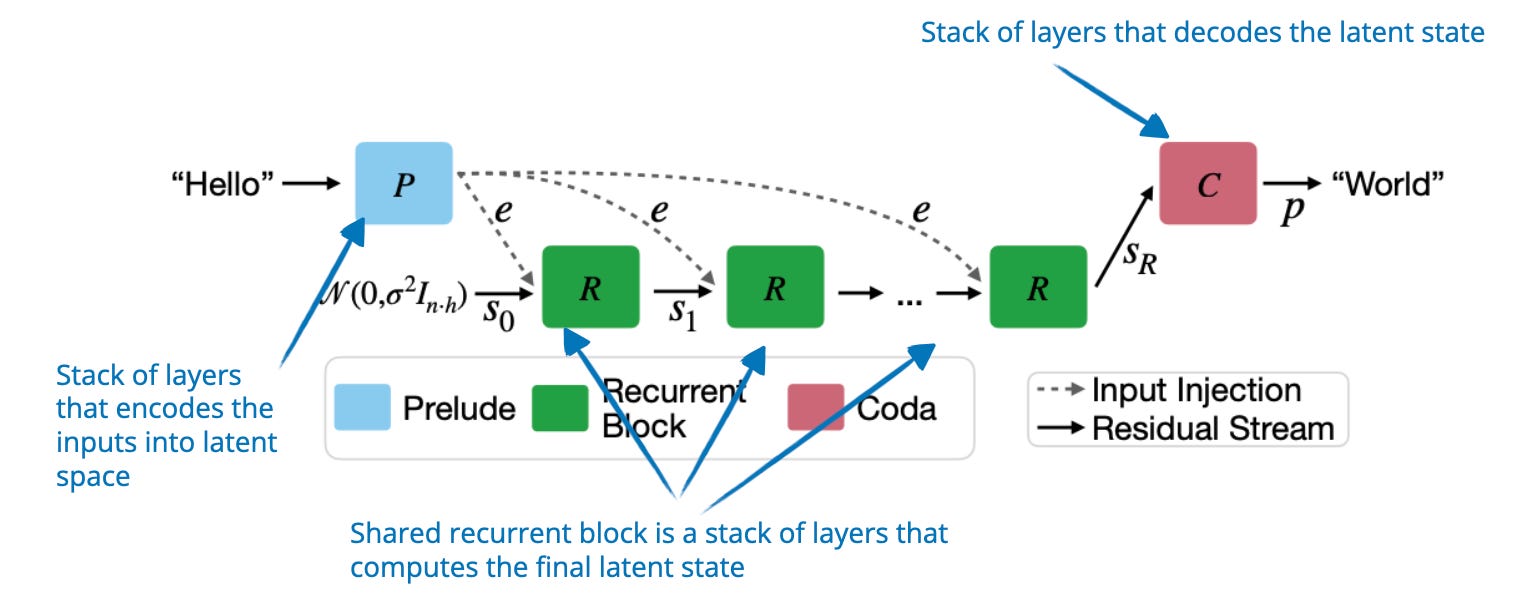

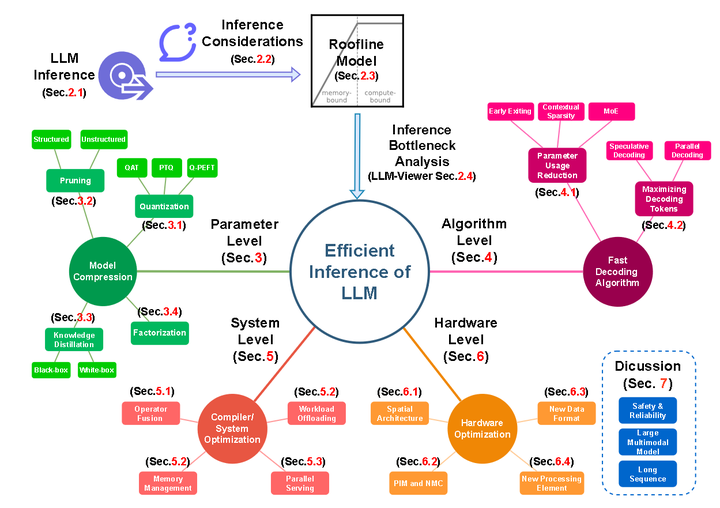


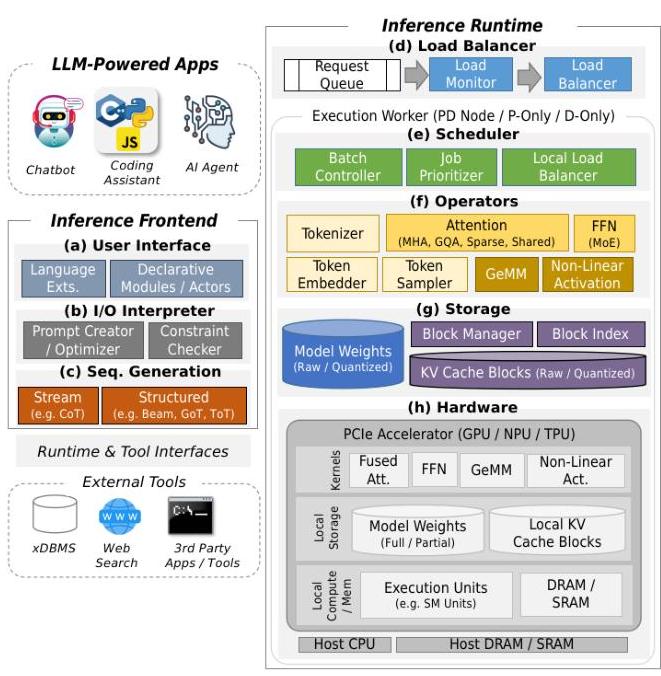








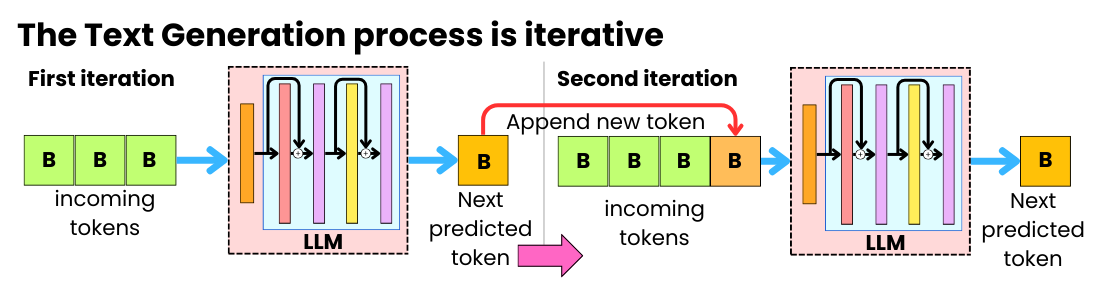



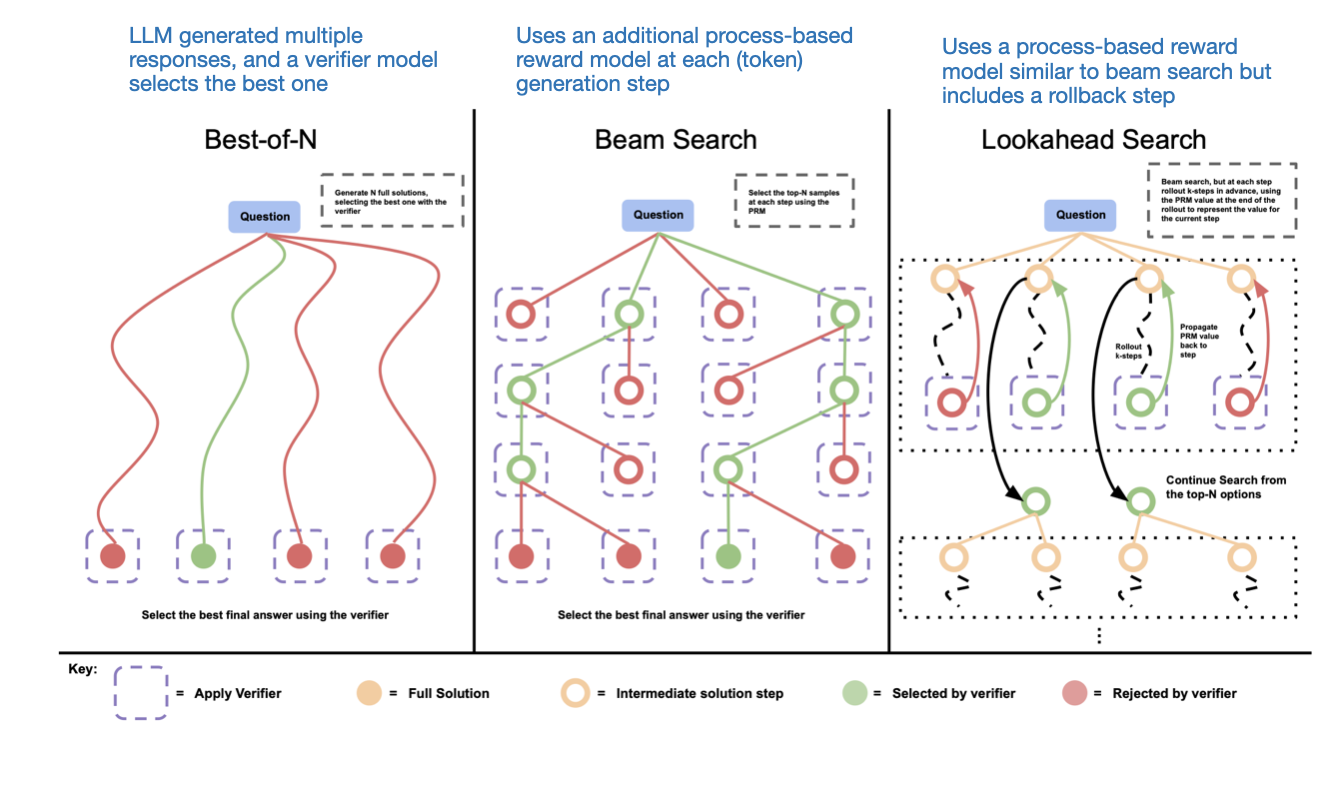
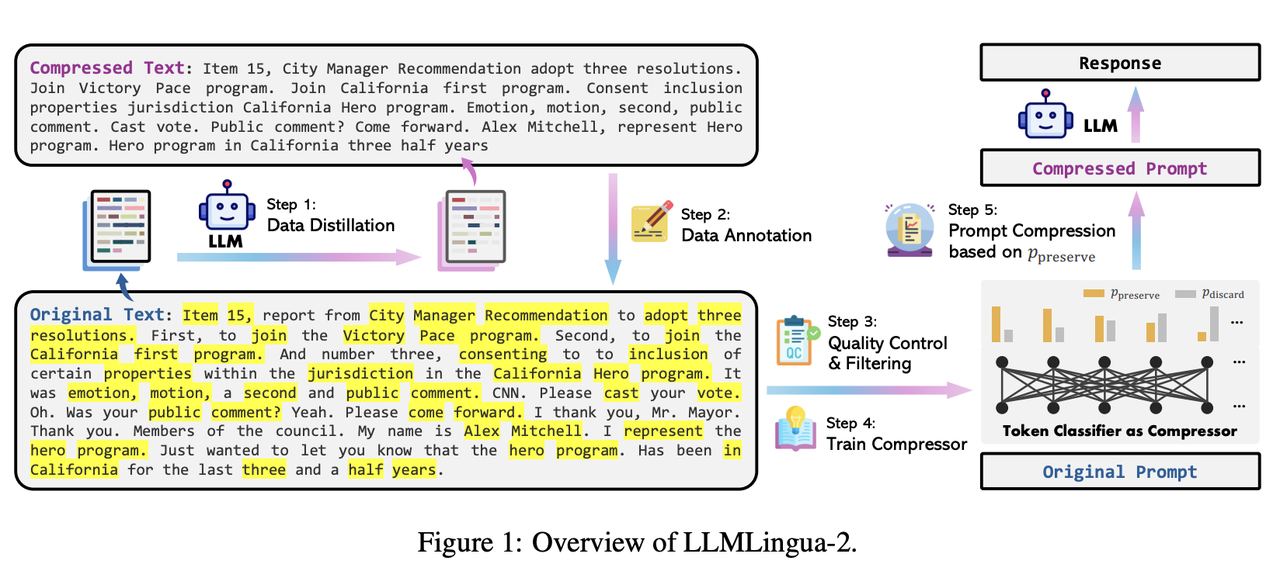
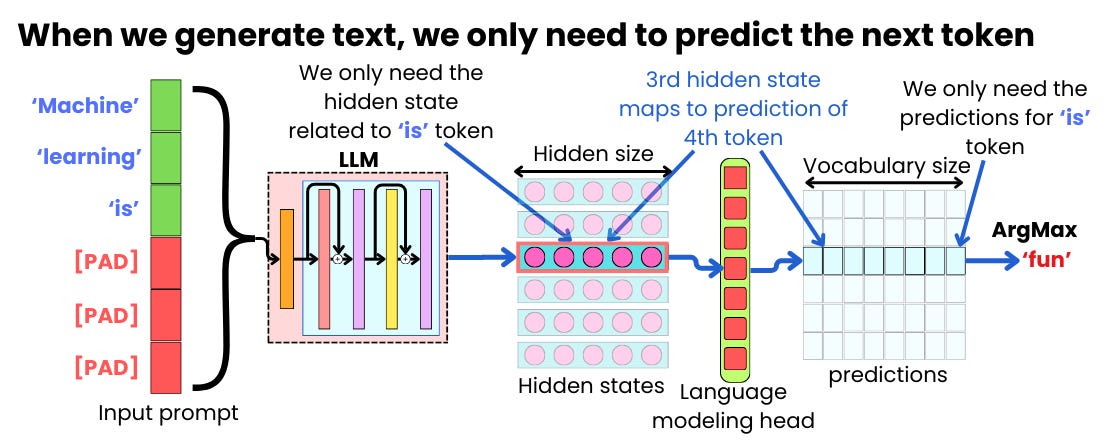





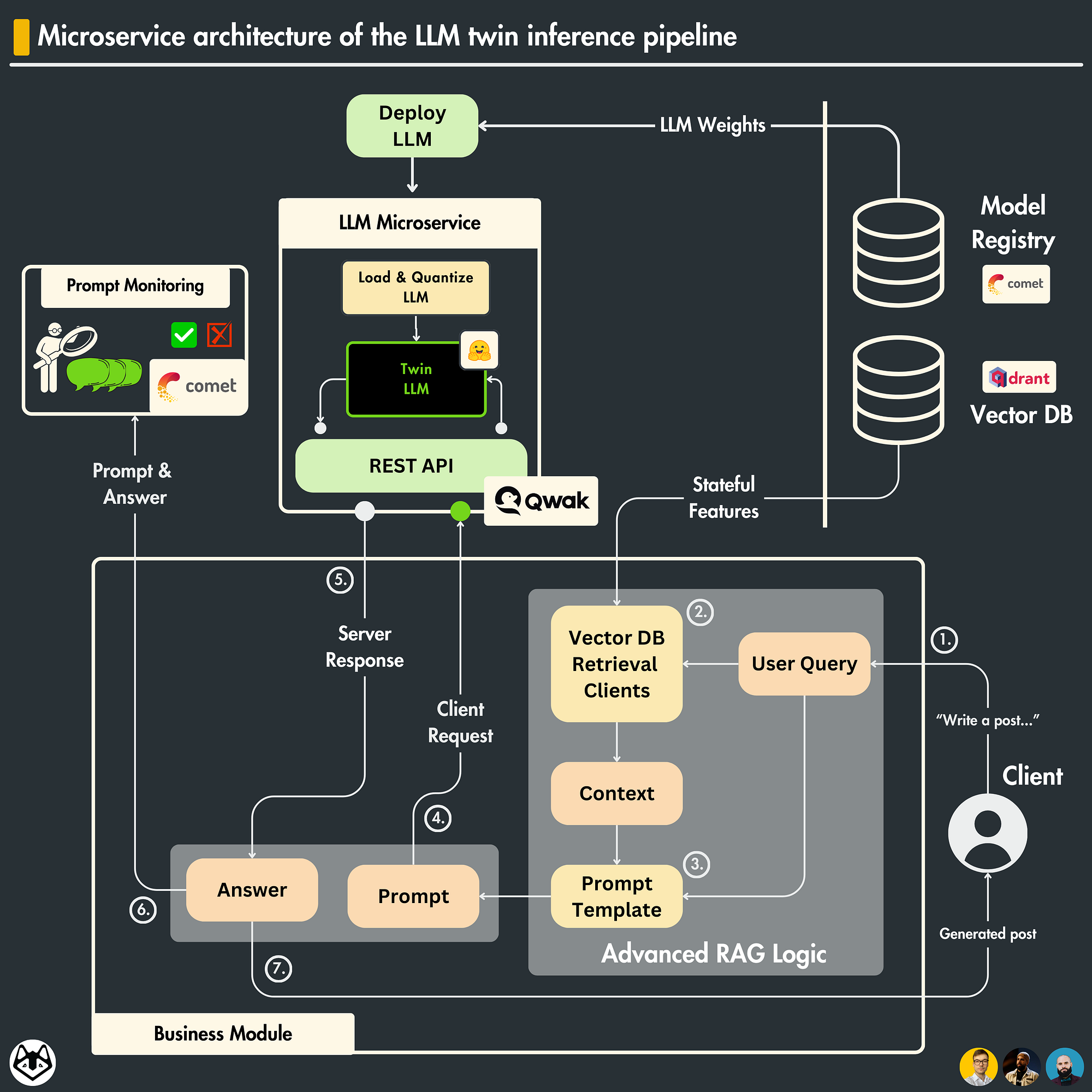

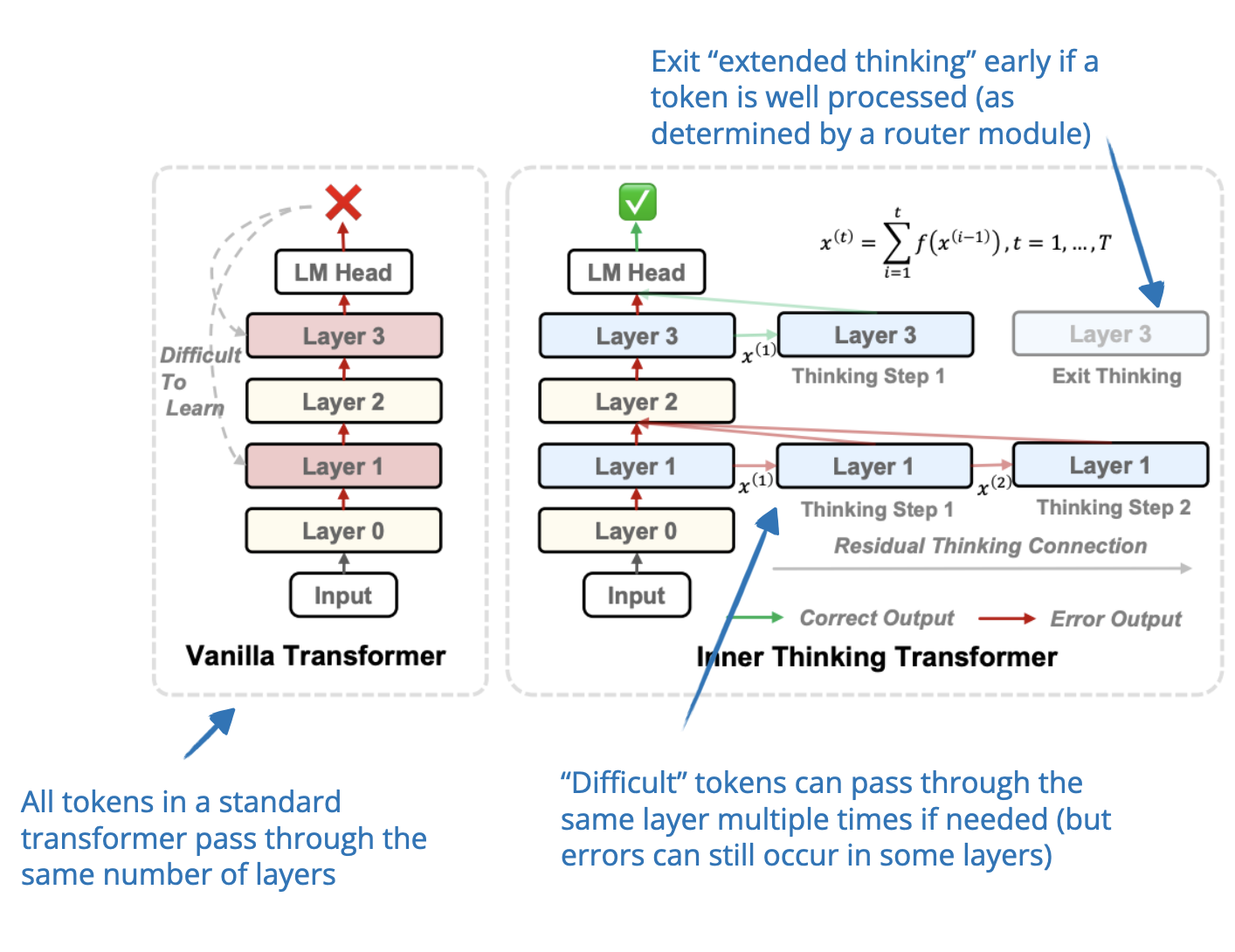




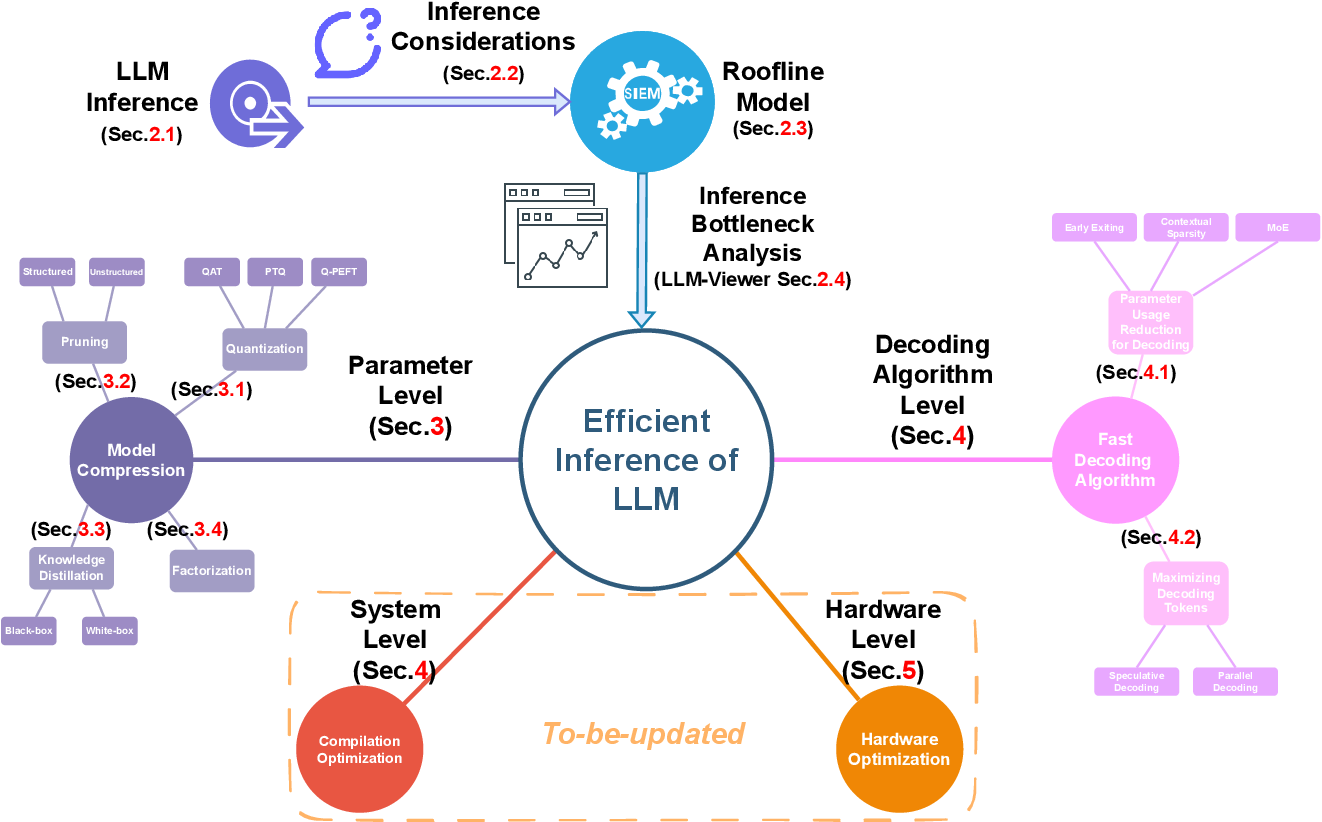

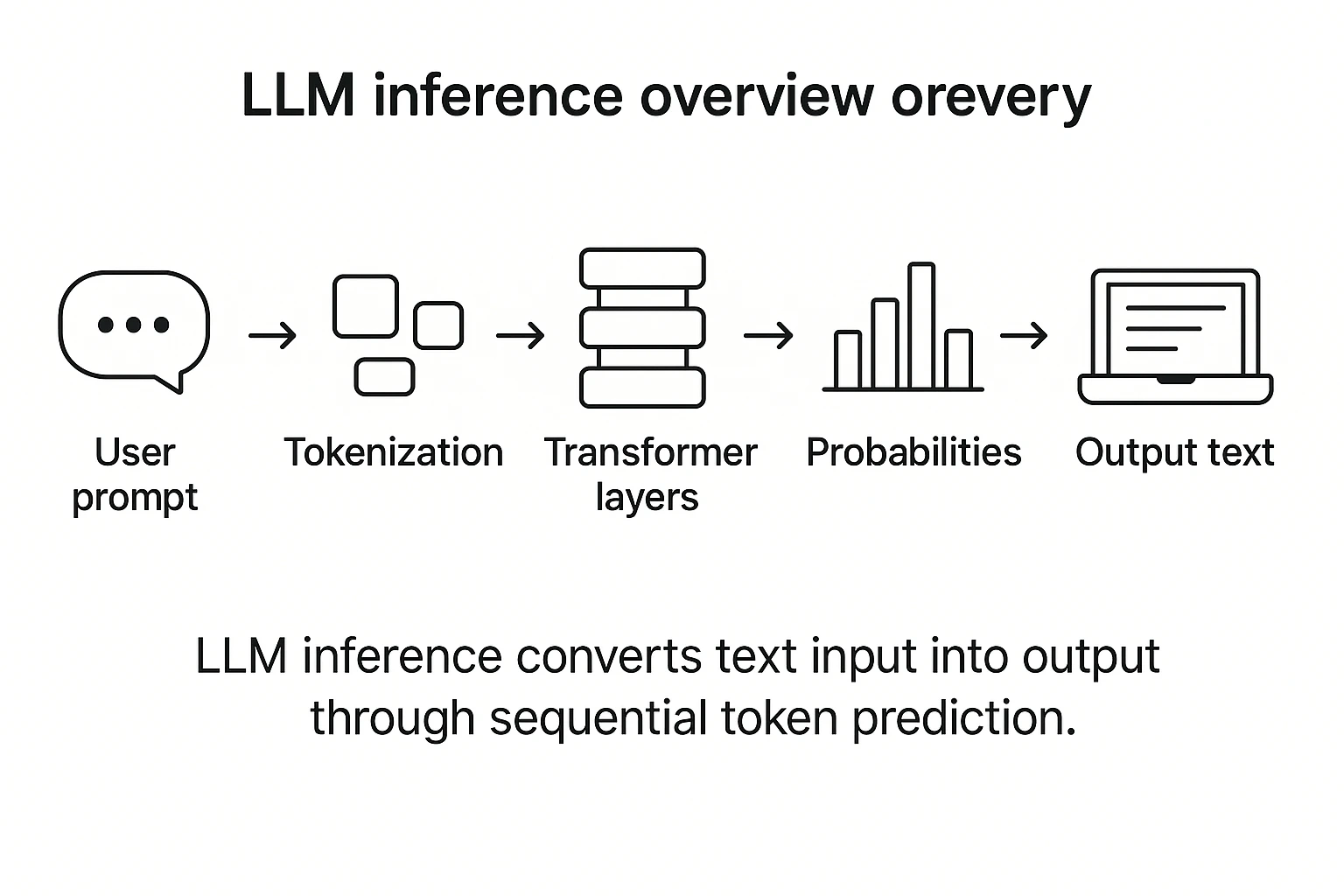


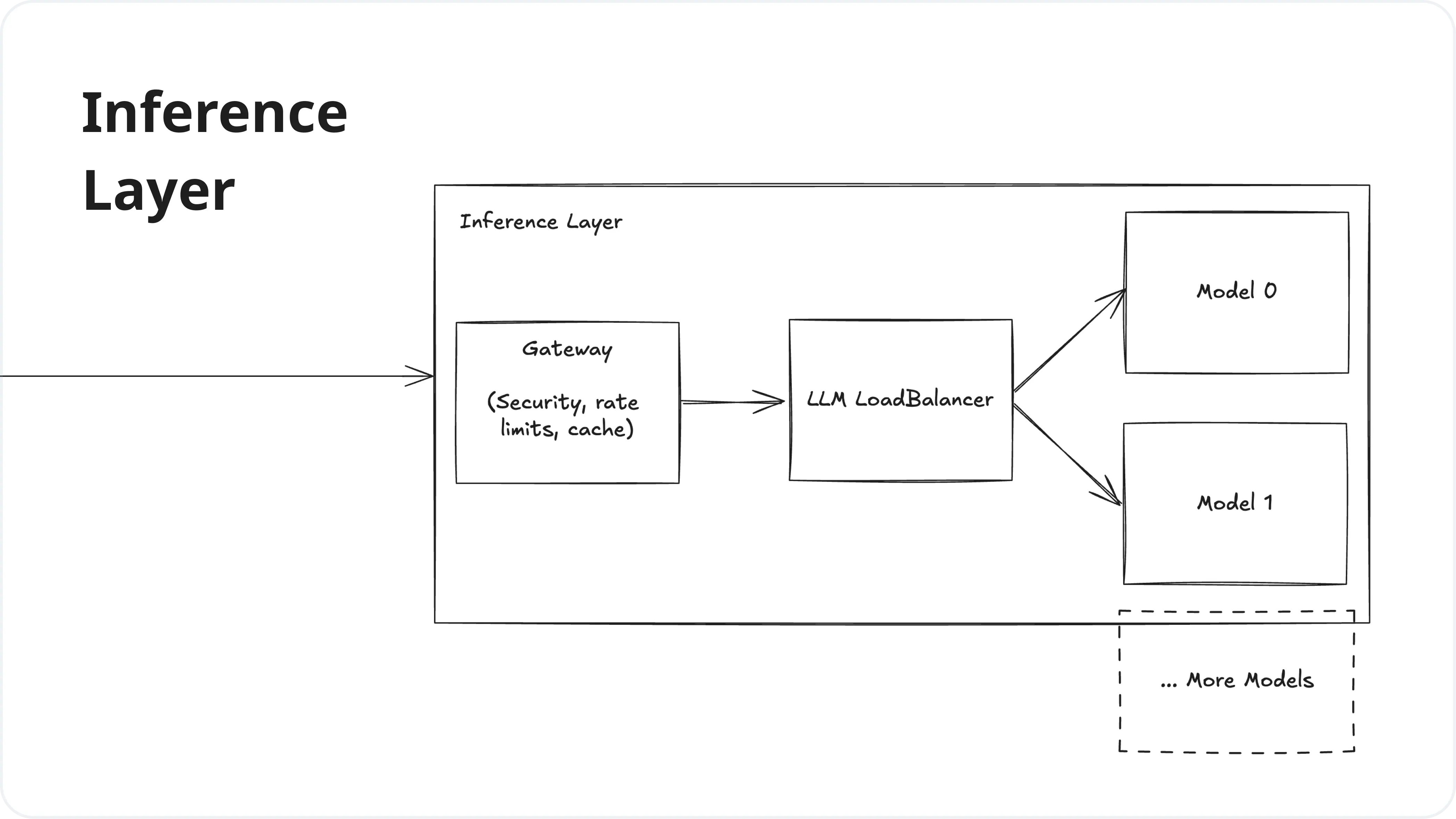











.png)



