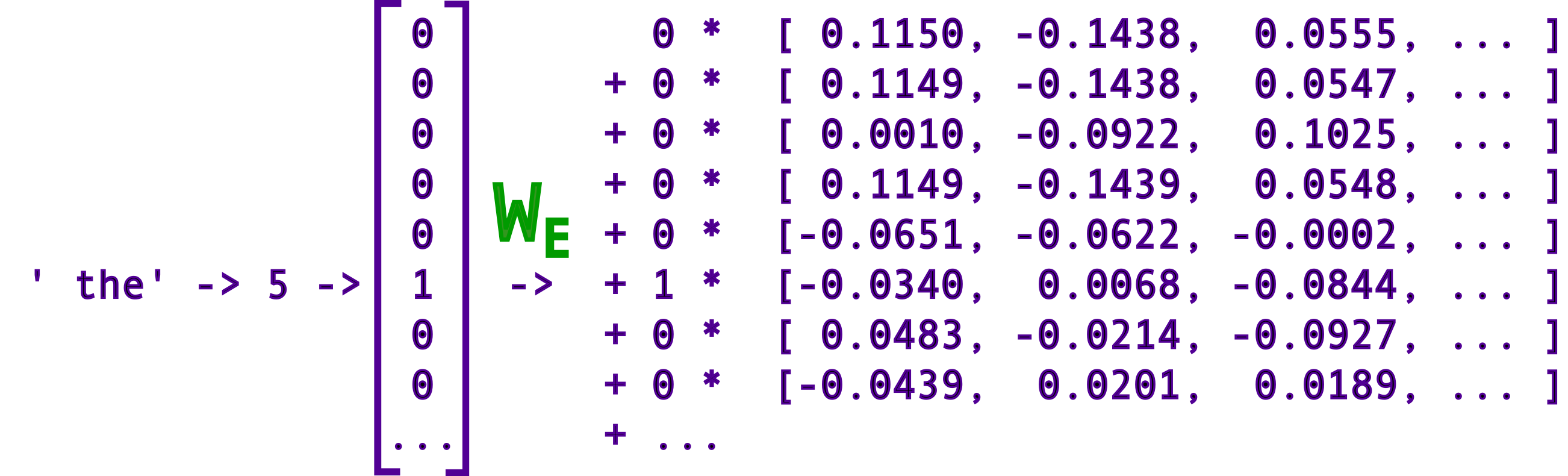Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
LLM Explainability or Controllability Improvements with Tensor Networks ...
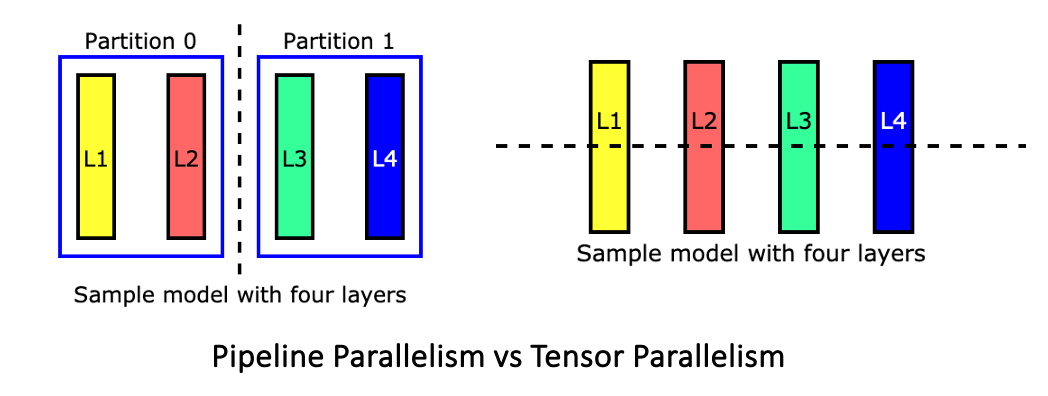
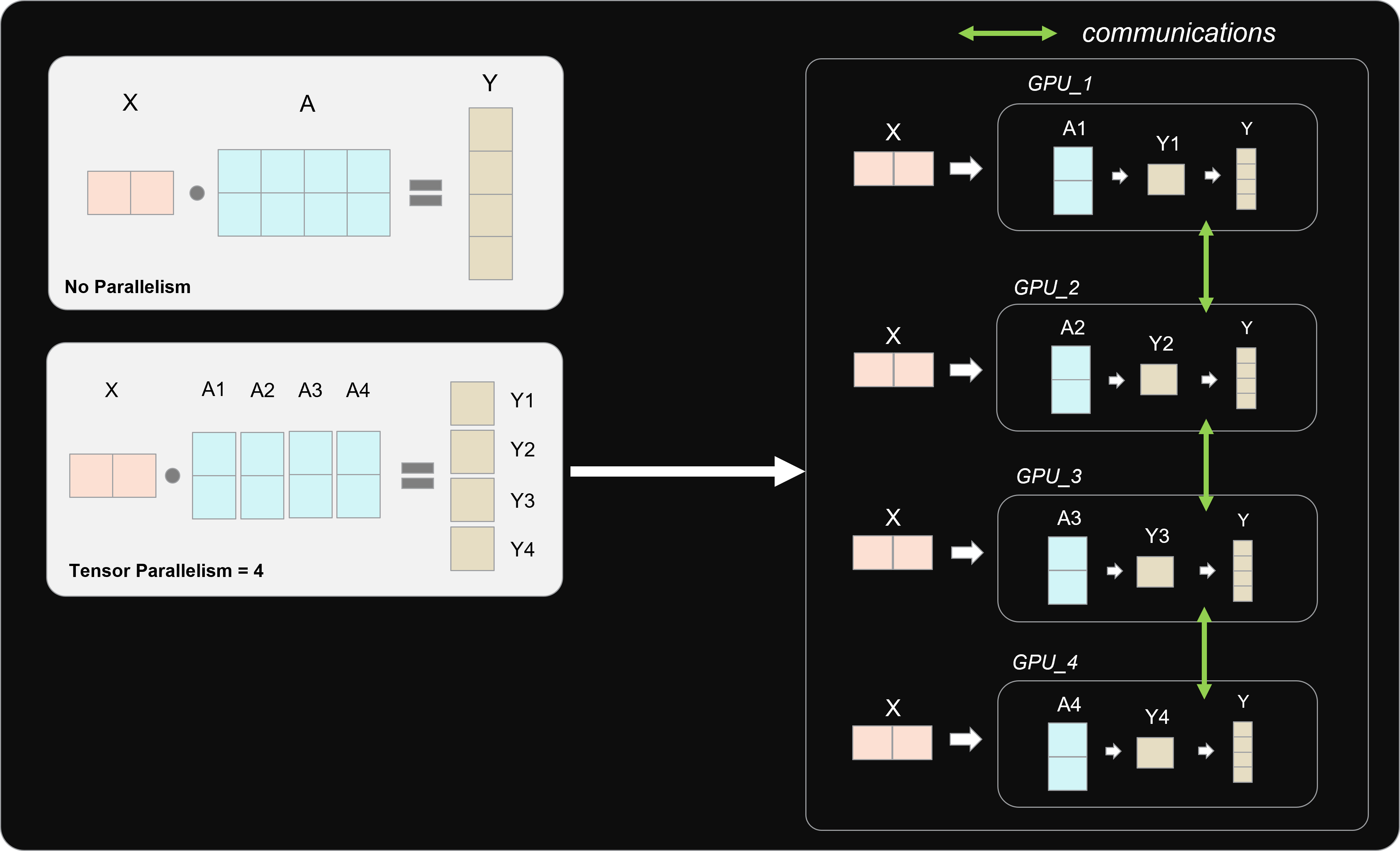
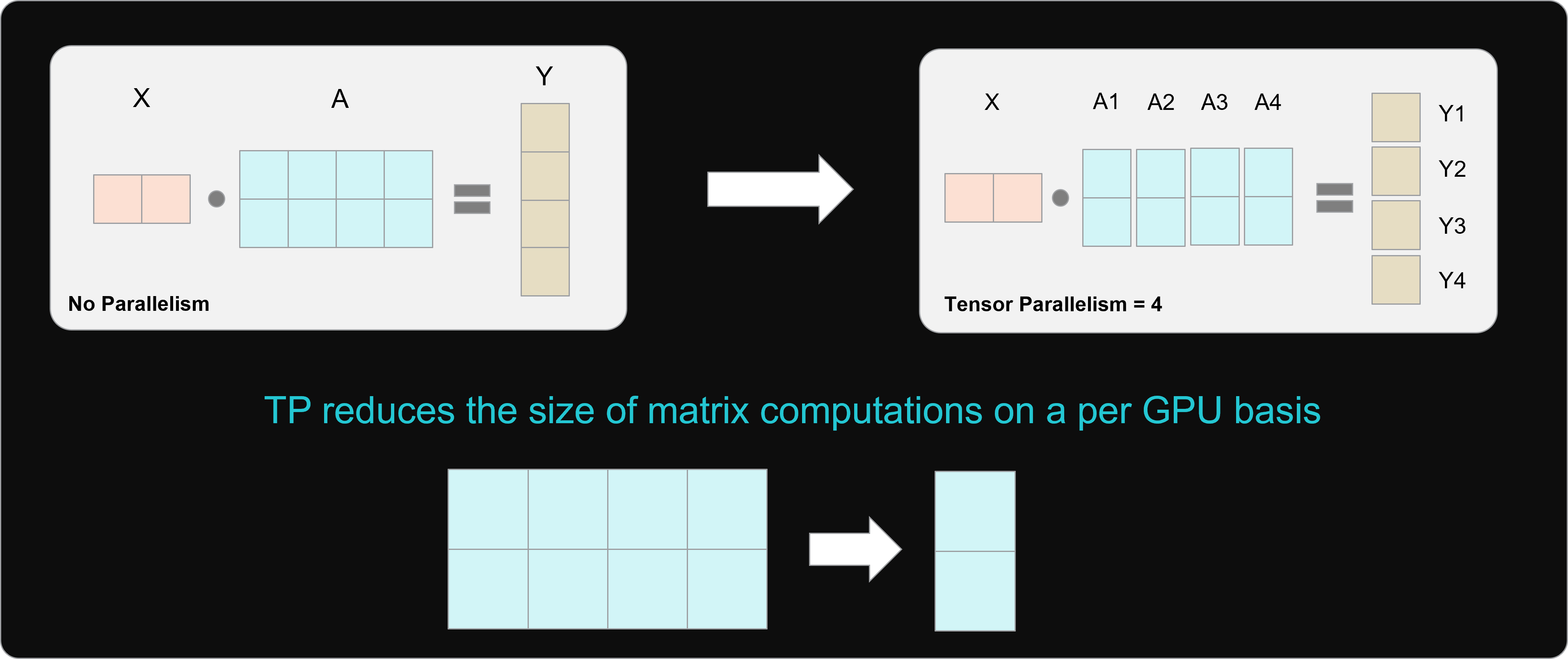
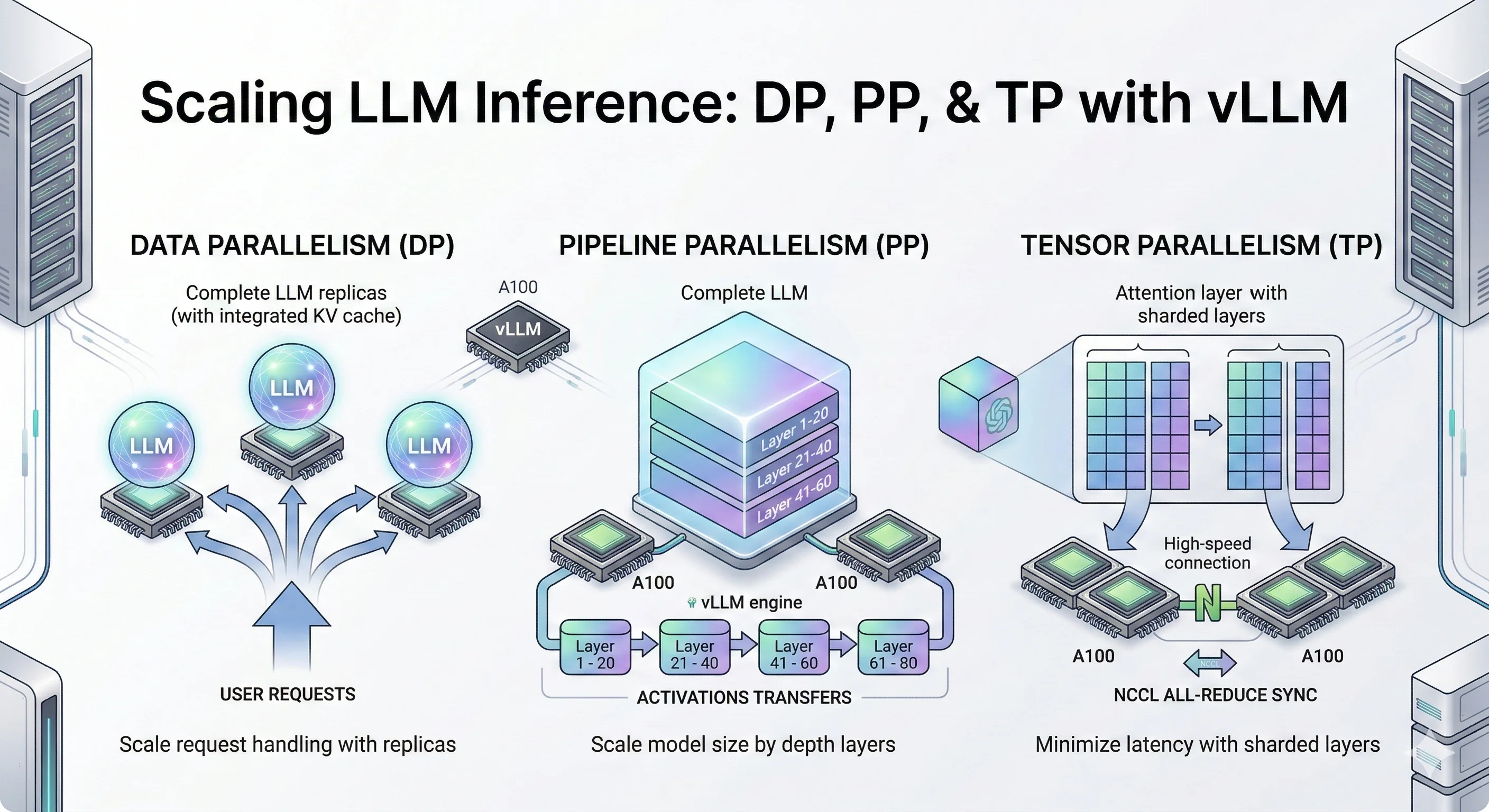
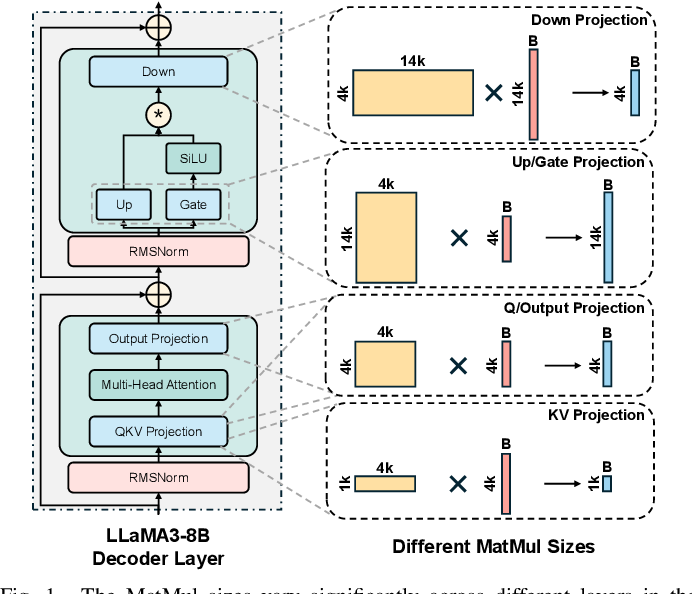
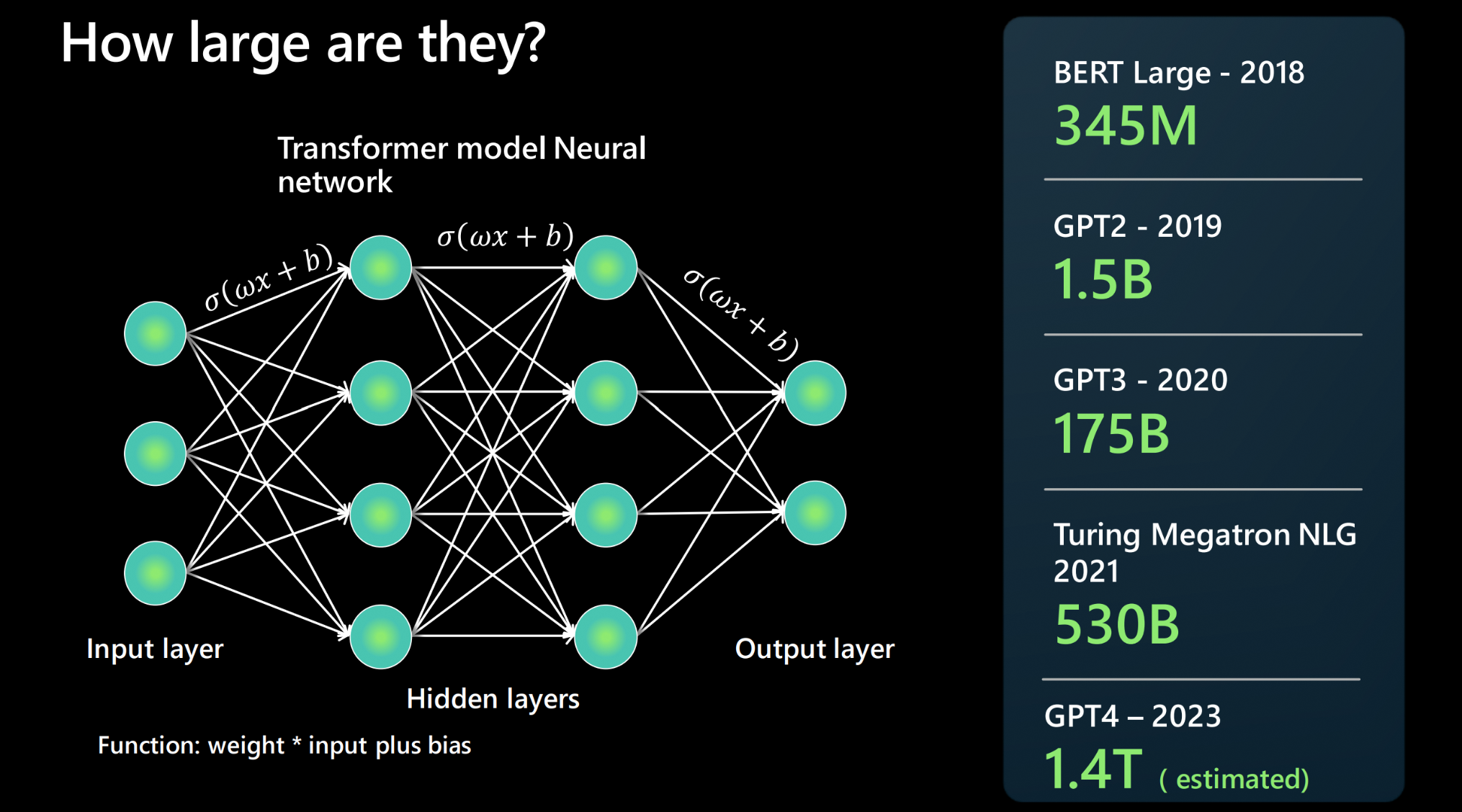
Tensor Parallel LLM Inferencing. As models increase in size, it becomes ...
[논문 리뷰] Lossless Compression for LLM Tensor Incremental Snapshots
Analyzing the Impact of Tensor Parallelism Configurations on LLM ...
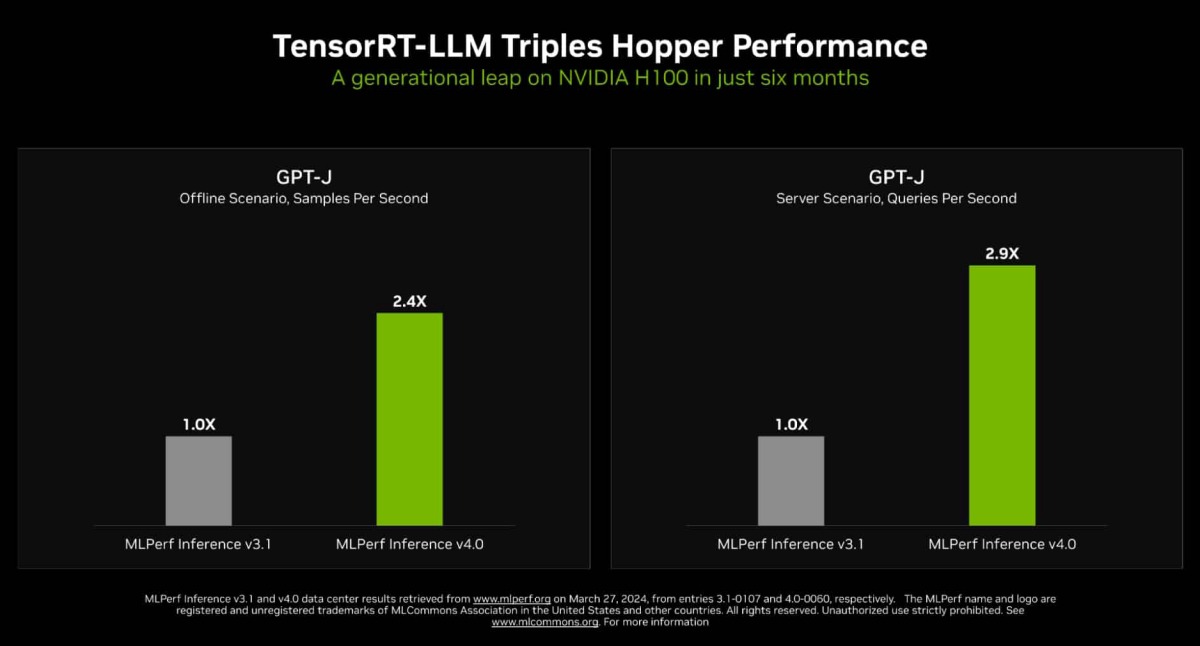
NVIDIA H200 Tensor Core GPUs and NVIDIA TensorRT-LLM Set MLPerf LLM ...
LLM Engineering & Deployment Program by Ready Tensor
AnchorTP: Resilient LLM Inference with State-Preserving Elastic Tensor ...
NVIDIA's new H200 Tensor Core GPUs and TensorRT LLM updates tackle ...
Tensor parallel support for LLM training. · Issue #37505 · huggingface ...
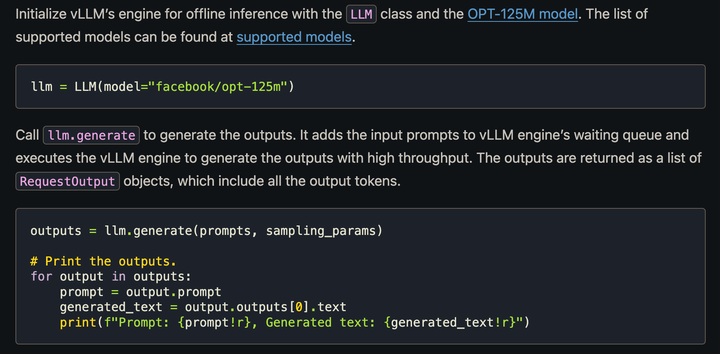
(PDF) vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
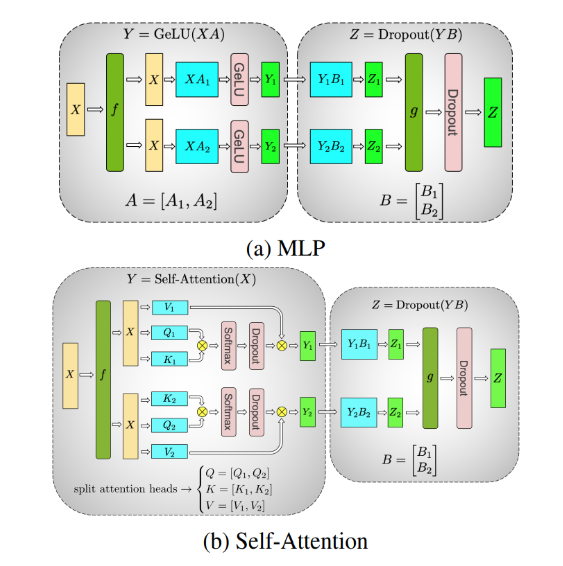
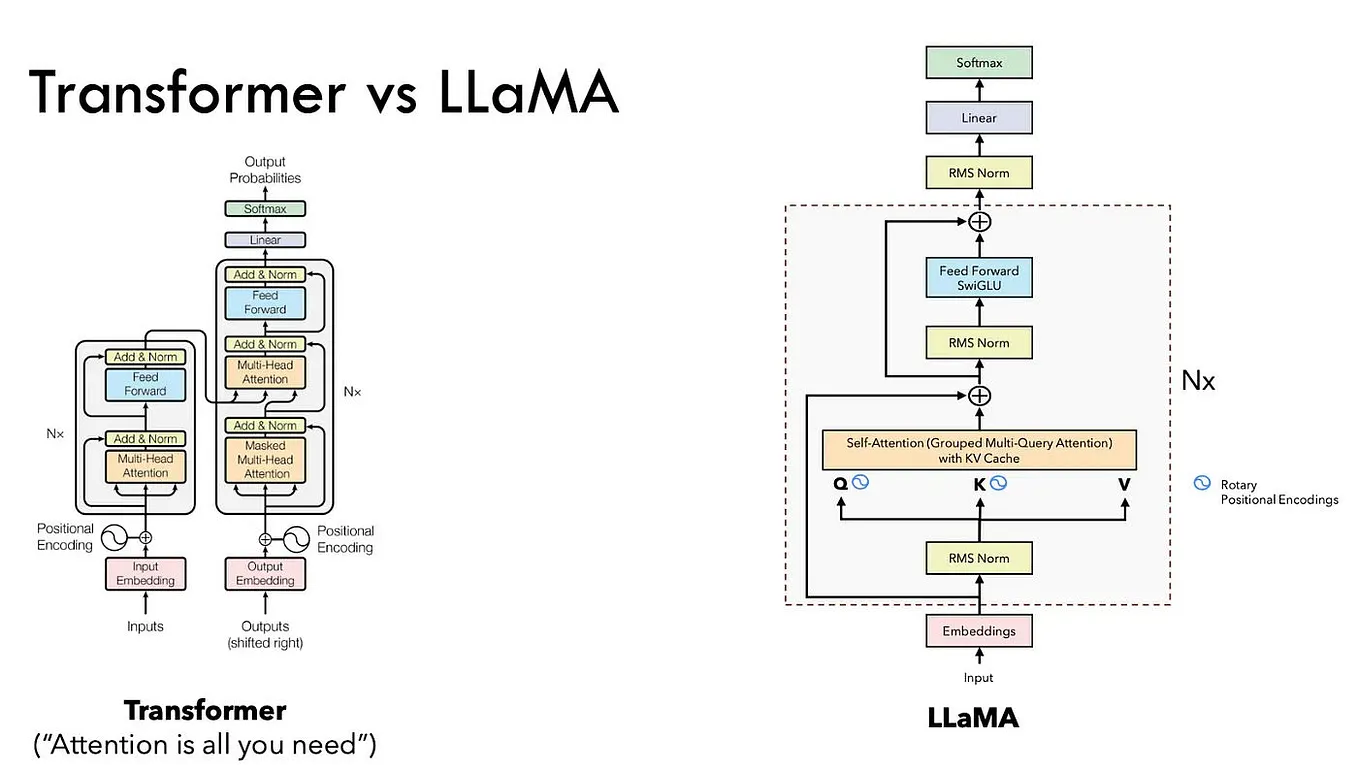
LLM Training — Fundamentals of Tensor Parallelism | by Don Moon | Byte ...
[논문 리뷰] LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM ...
Tender: Efficient LLM Acceleration via Tensor Decomposition and ...
Is weight, parameter and tensor interchangeable when talking about LLM ...
Quantum-inspired Tensor Networks for LLM compression: 93% memory ...
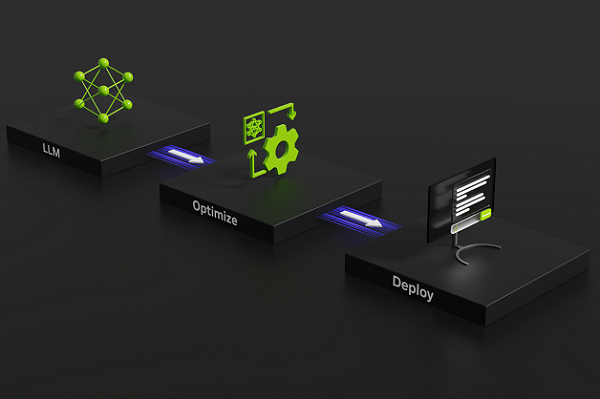
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
Mastering LLM Techniques: Inference Optimization – GIXtools
How to Re-Code LLMs Layer by Layer with Tensor Network Substitutions ...
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
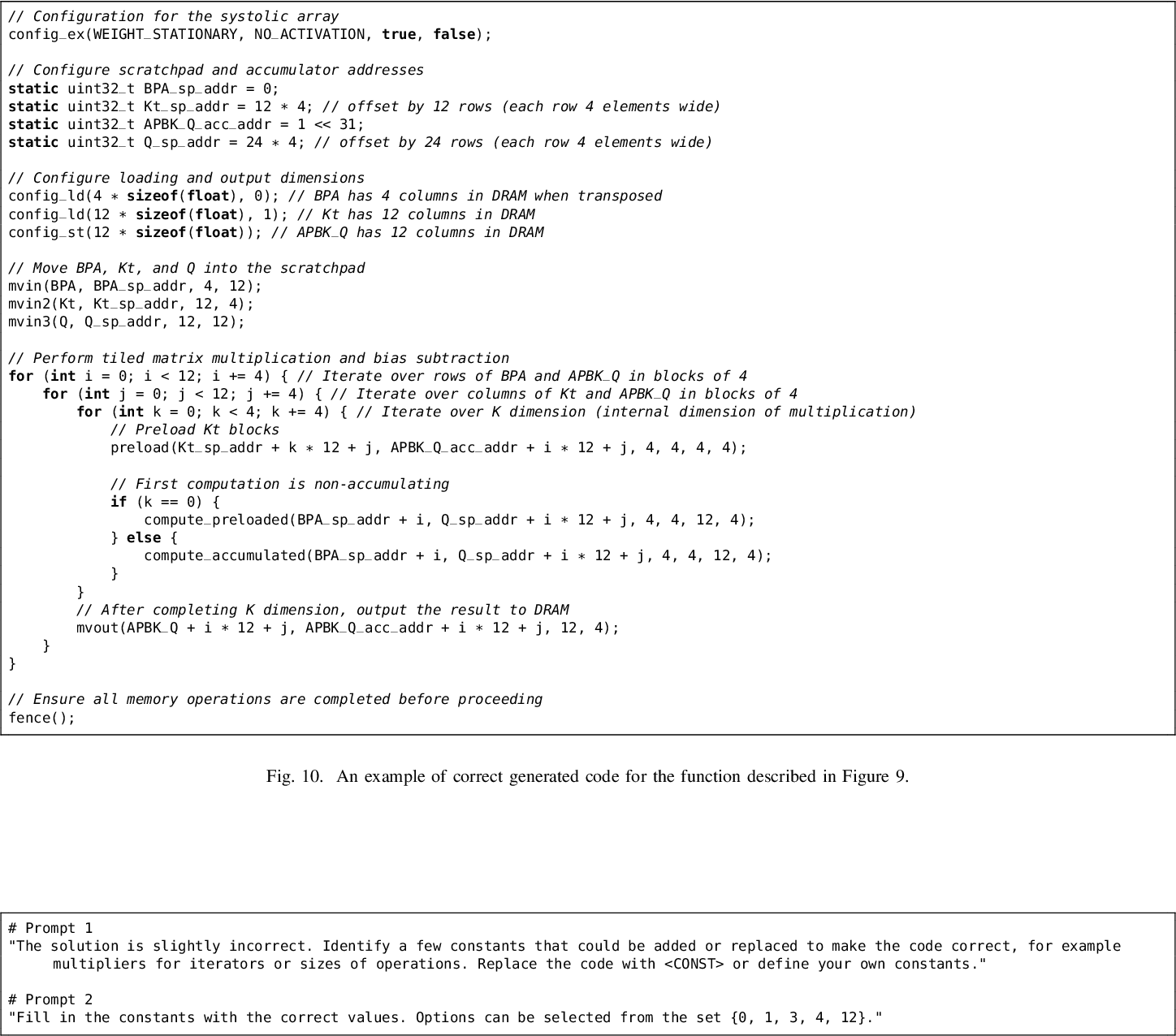
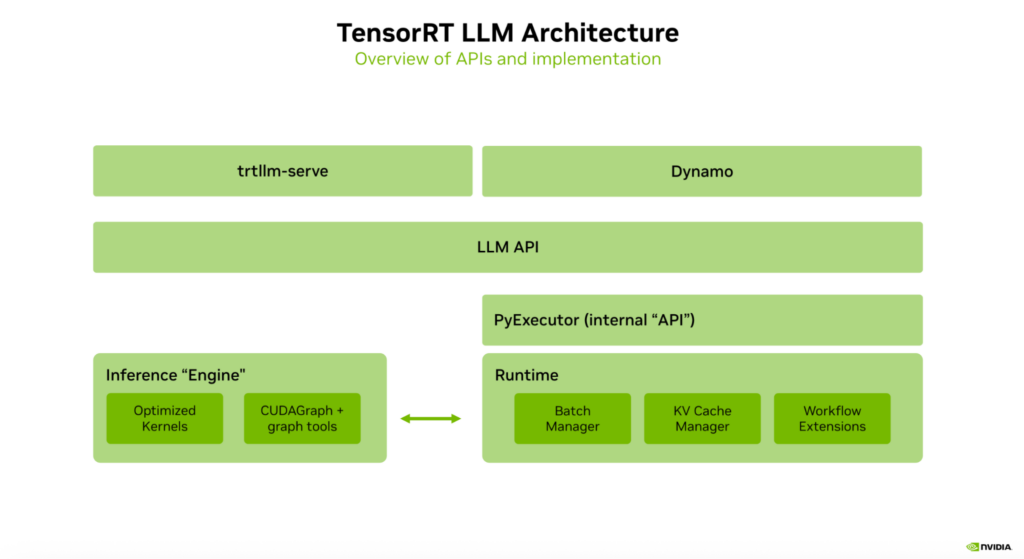
Architecture Overview — TensorRT LLM
Data, tensor, pipeline, expert and hybrid parallelisms | LLM Inference ...
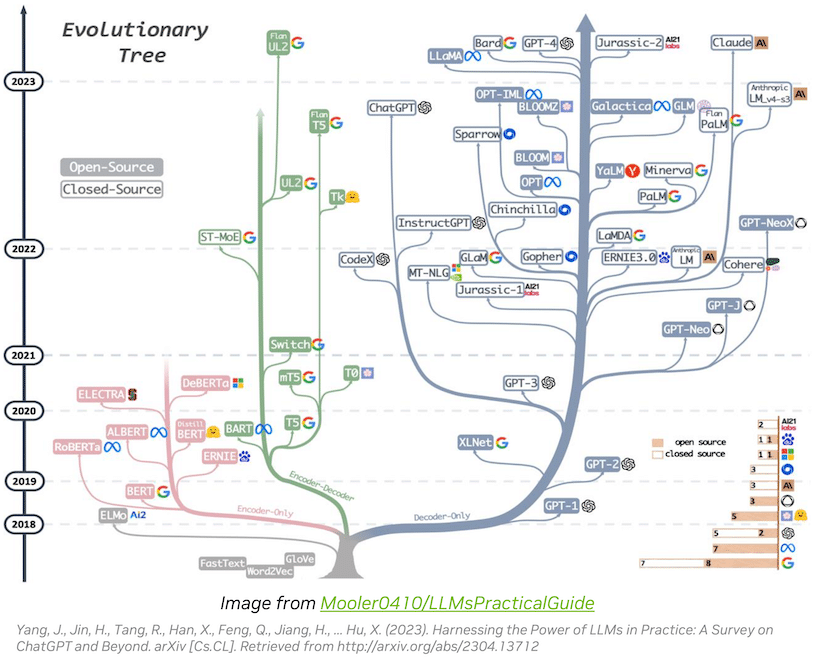
The NeurIPS 2023 LLM Efficiency Challenge Starter Guide - Lightning AI
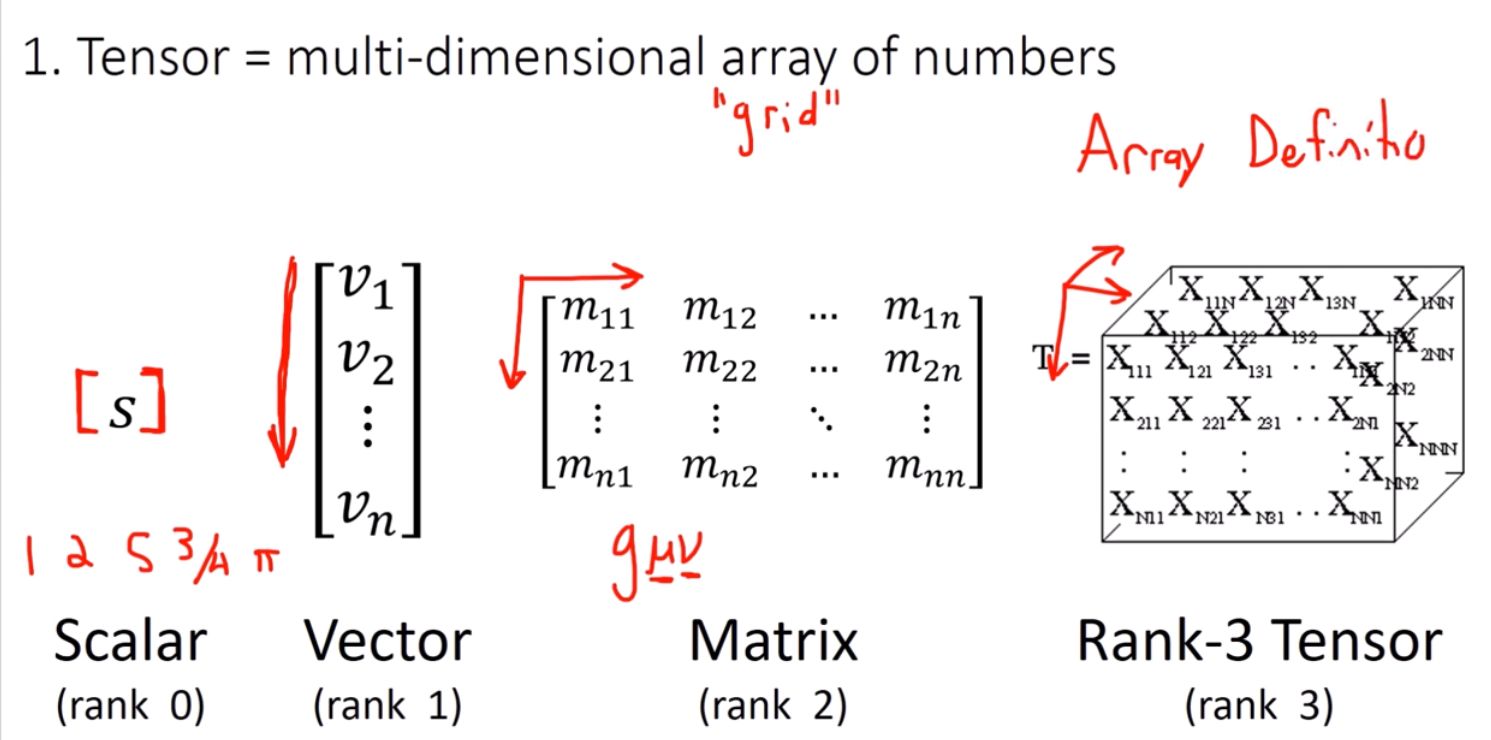
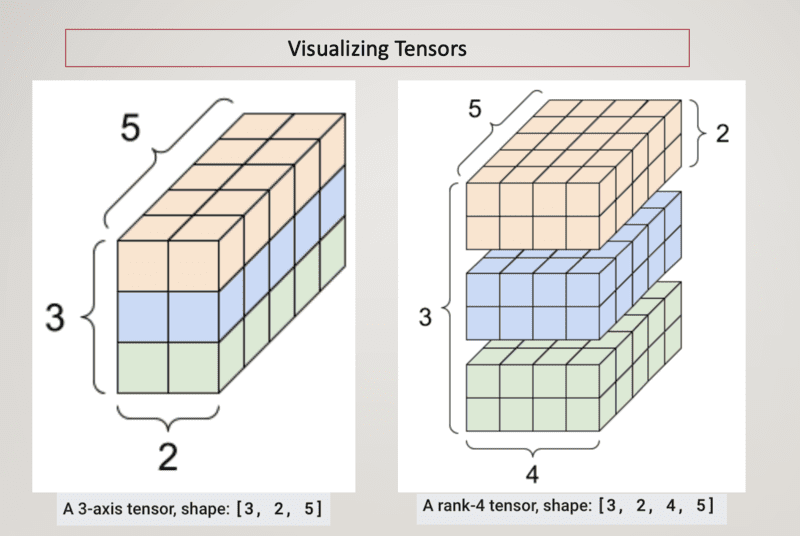
Data Representation in Neural Networks- Tensor
Unleashing Efficiency: Benchmarking the Power of TensorRT LLM
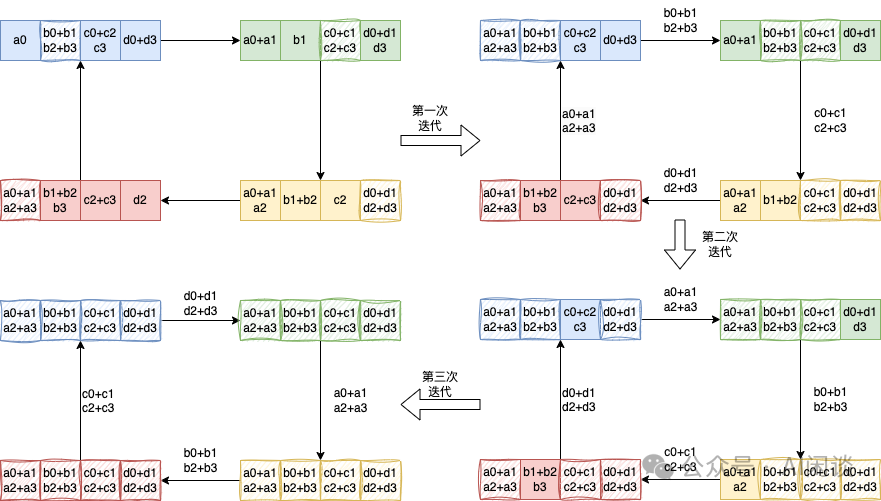
万字综述 LLM 训练中的 Overlap 优化:字节 Flux 等 7 种方案_overlap communication with ...
Figure 1 from APT-LLM: Exploiting Arbitrary-Precision Tensor Core ...
Deploying LLMs Into Production Using TensorRT LLM | Towards Data Science
[논문 리뷰] TPU-Gen: LLM-Driven Custom Tensor Processing Unit Generator
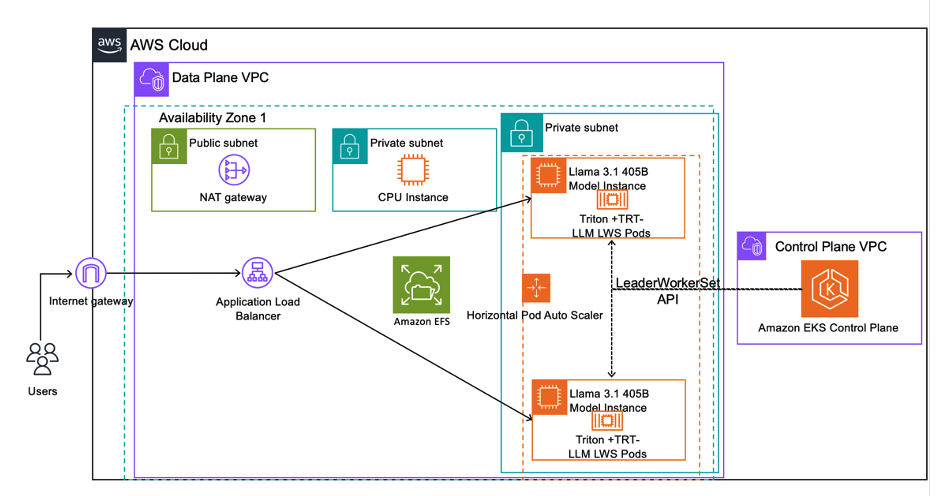
Scaling your LLM inference workloads: multi-node deployment with ...
Choosing Your Engine for LLM Inference: The Ultimate vLLM vs. TensorRT ...
LLM Inference Benchmarks: Tensor-RT - YouTube
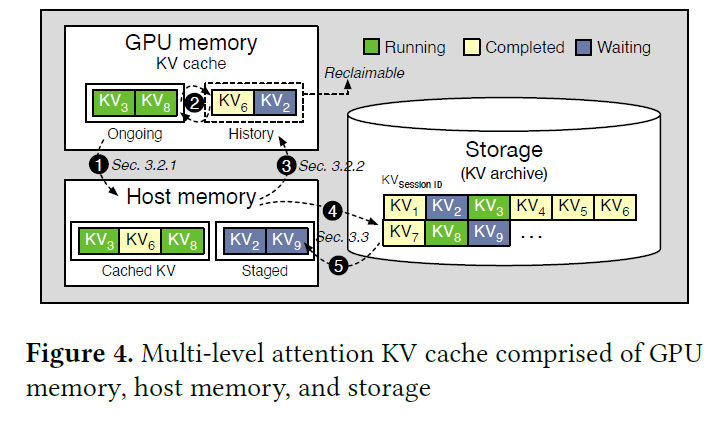
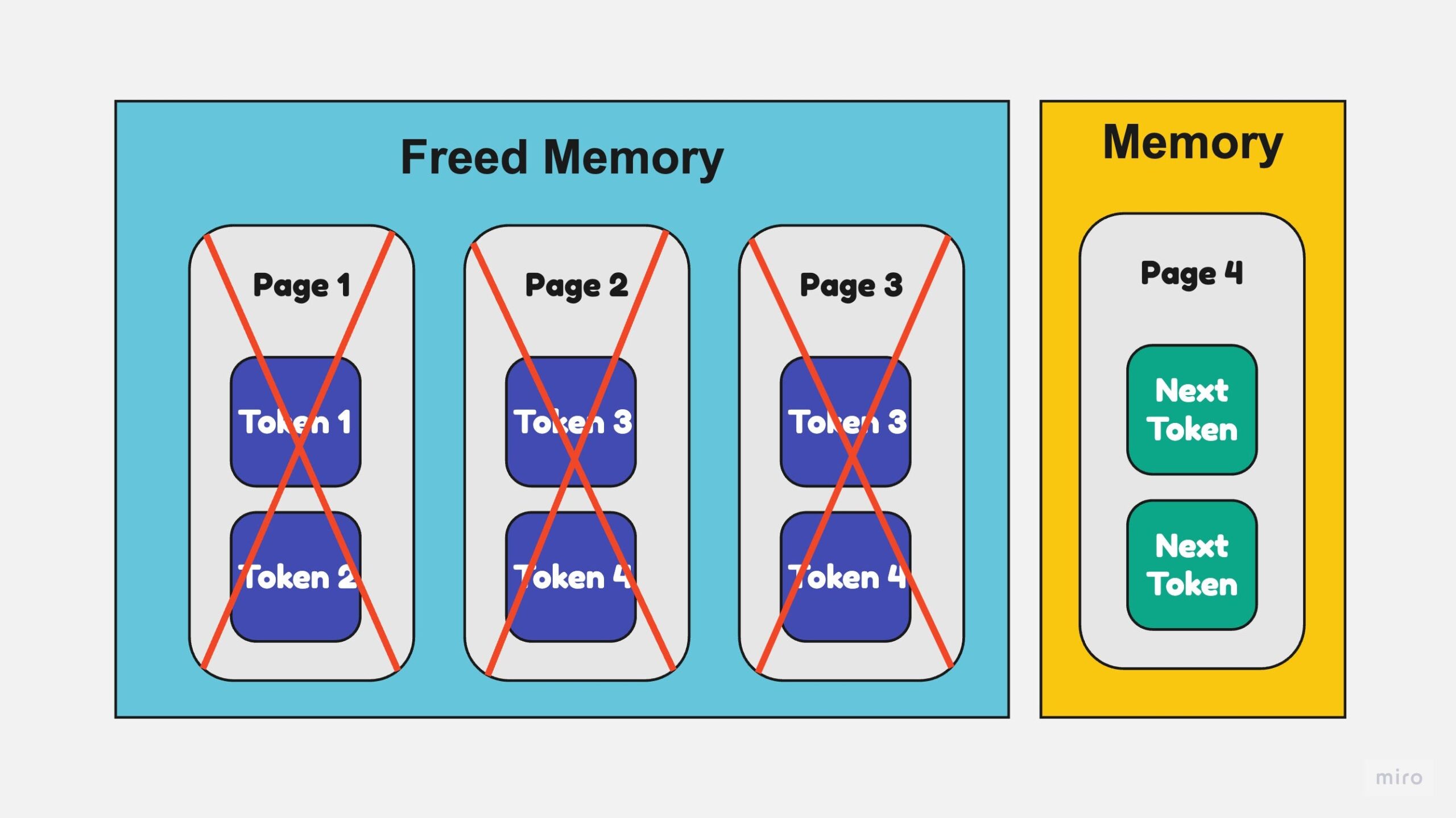
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
NVIDIA TensorRT-LLM Now Supports Recurrent Drafting for Optimizing LLM ...
llm_load_tensors: tensor 'token_embd.weight' (q4_K) (and 0 others ...
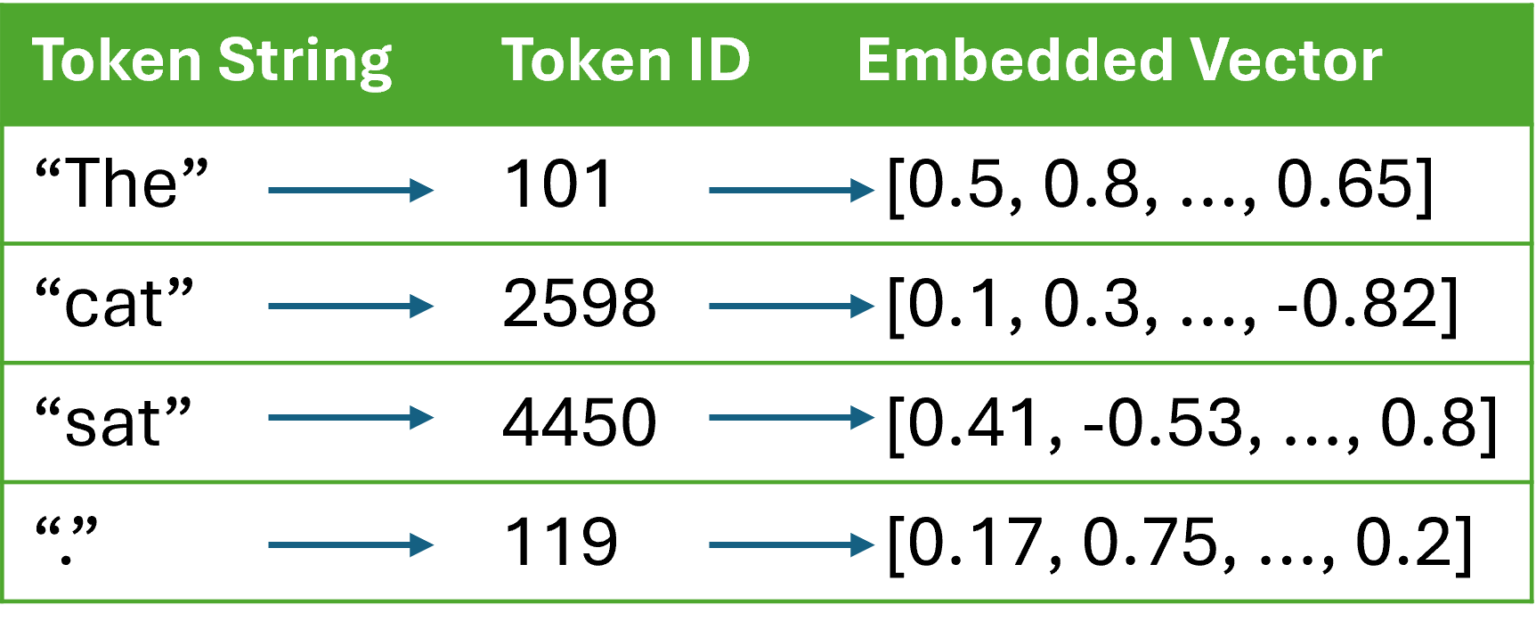
LLM Basics: Embedding Spaces - Transformer Token Vectors Are Not Points ...
Understanding LoRA Technology for LLM Fine-tuning - ML Digest
[Usage]: LLM with tensor_parallel_size larger than n. gpus in one node ...
LLM 推理基准测试:使用 TensorRT-LLM 进行性能调优 - NVIDIA 技术博客
LLM Mixture of Experts Explained — A 2026 Field Guide | TensorOps
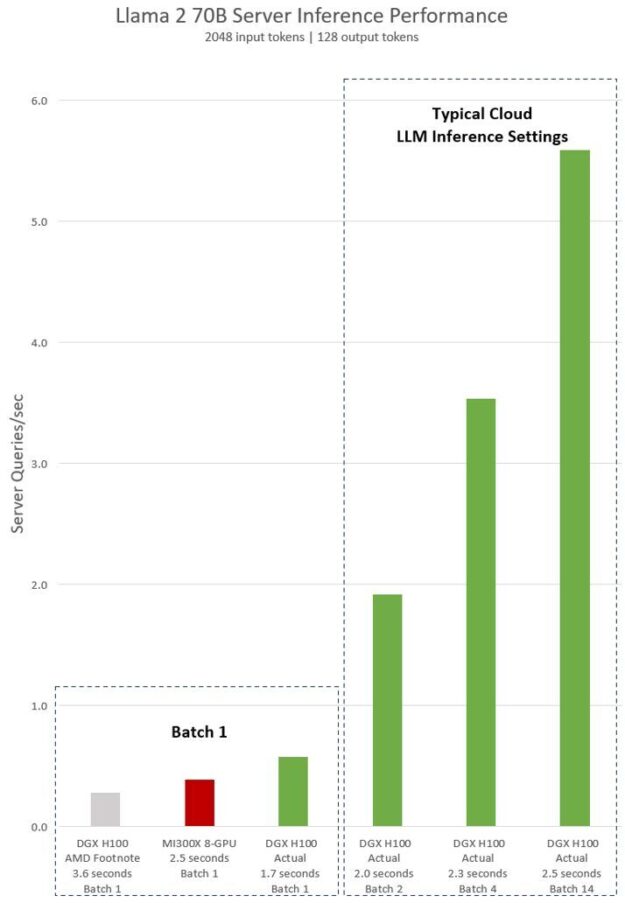
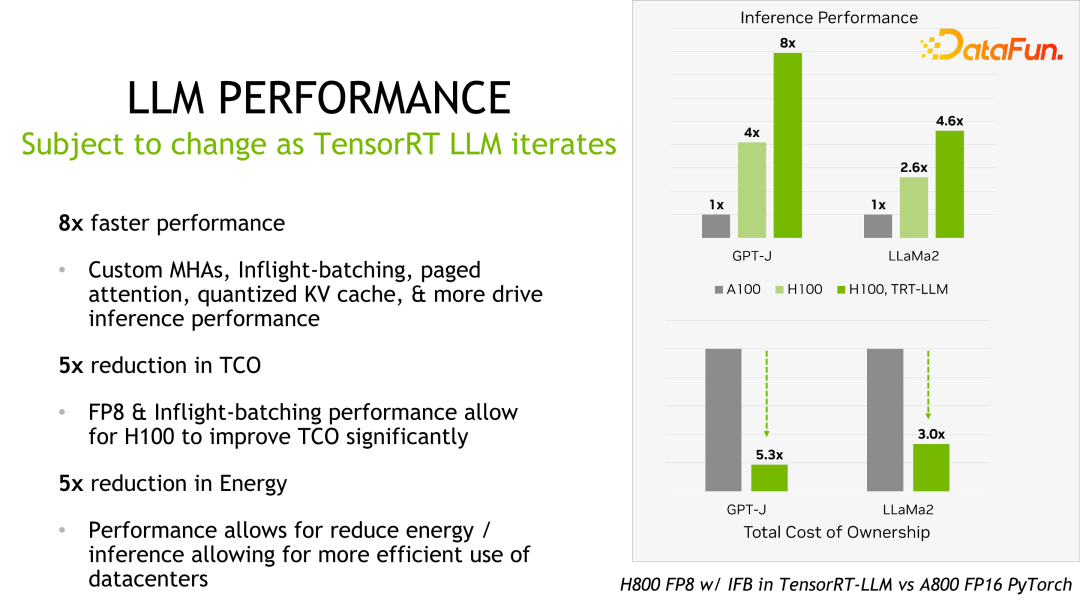
Achieving Top Inference Performance with the NVIDIA H100 Tensor Core ...
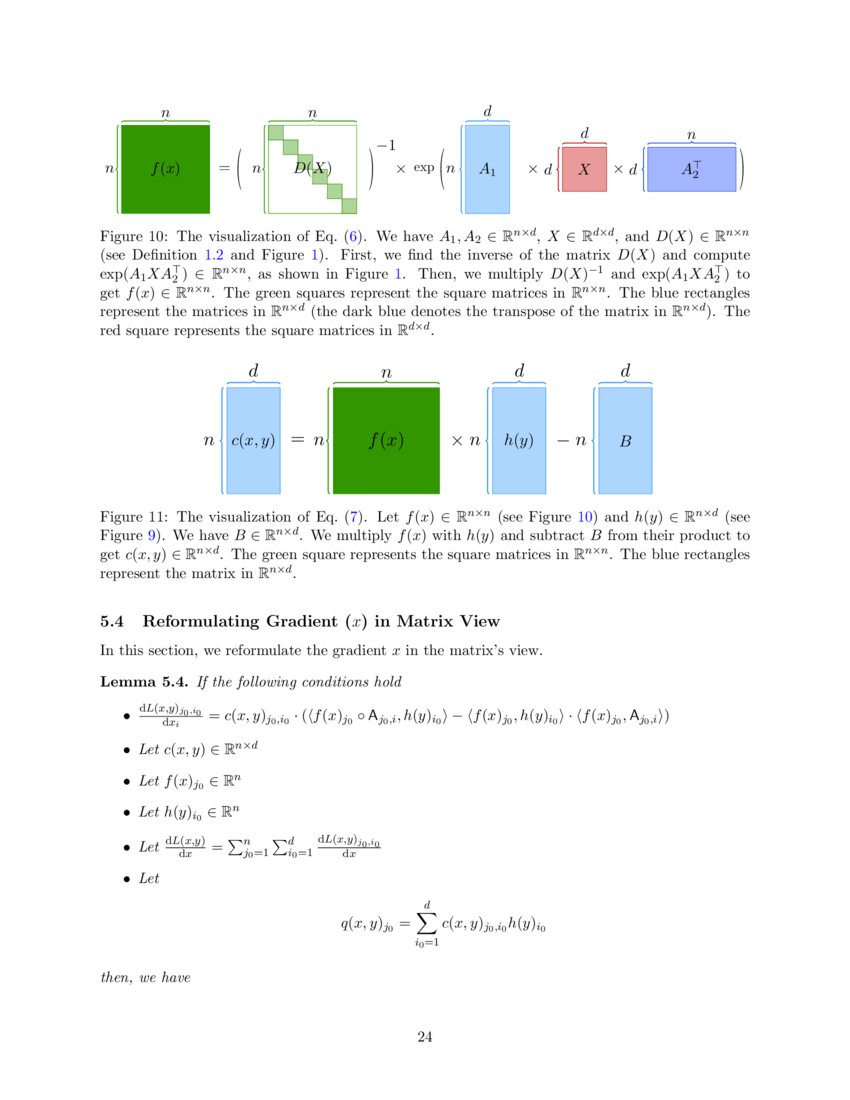
A Fast Optimization View: Reformulating Single Layer Attention in LLM ...
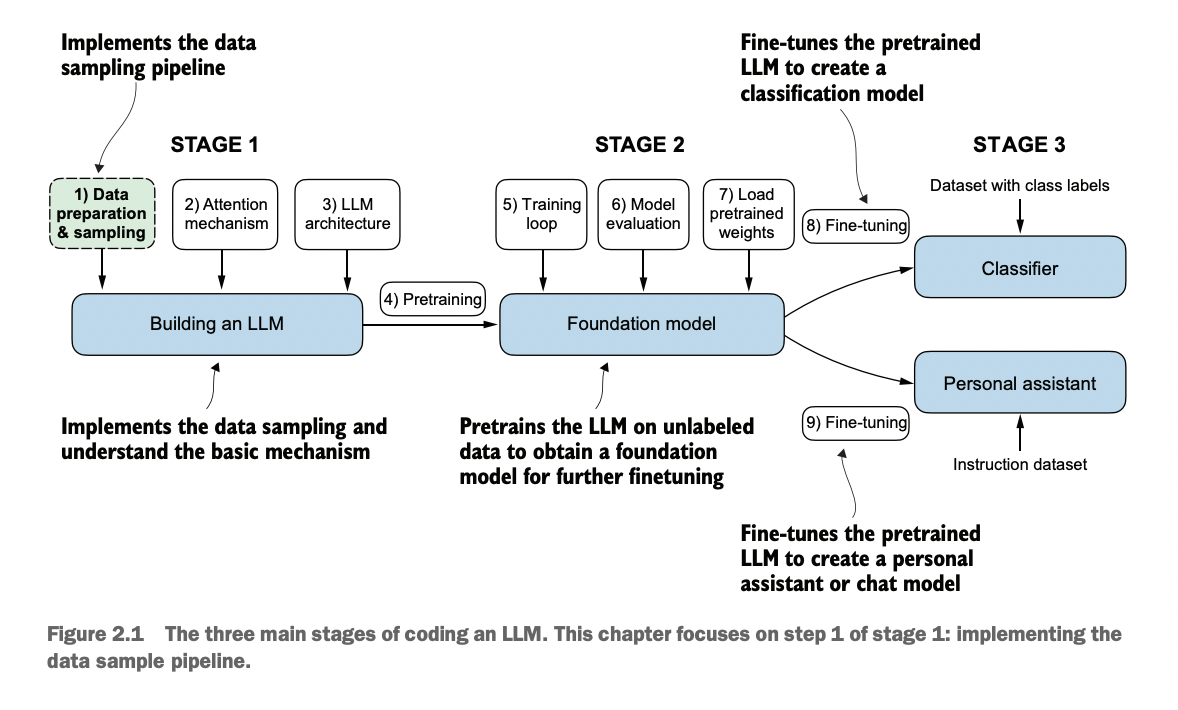
밑바닥부터 만들면서 배우는 LLM | 텐서 플로우 블로그 (Tensor ≈ Blog)
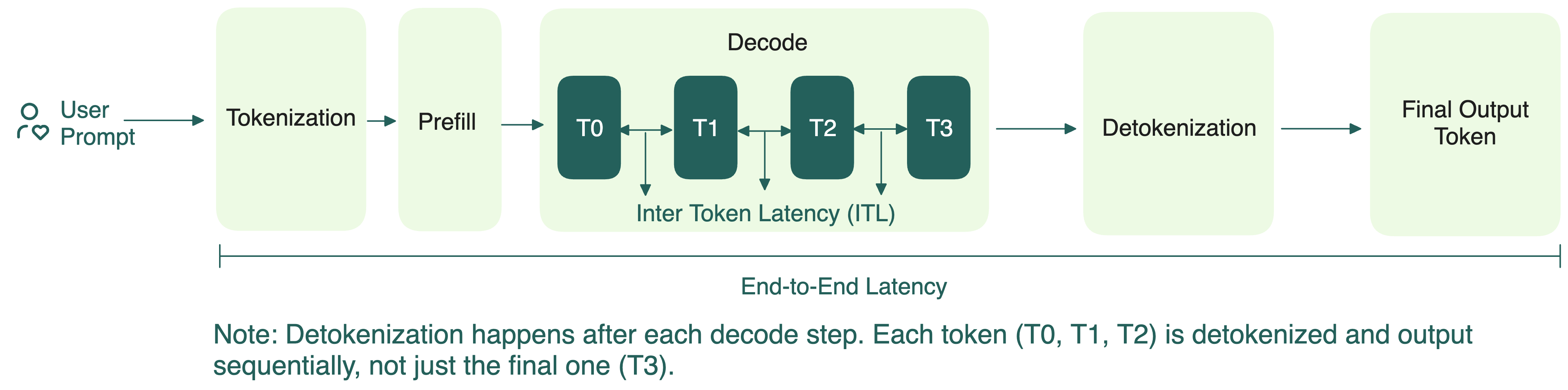
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
[논문 리뷰] TensorOpera Router: A Multi-Model Router for Efficient LLM ...
Practical TensorFlow for LLM Developers: Crafting Advanced Chatbots ...
NVIDIA 藉由 Tensor 核心 GPU、LLM與供 RTX PC 和工作站使用的工具,為數百萬人帶來生成式人工智慧 - NVIDIA ...
What Are Tensor Cores? The Key to Supercharging Your AI Models | by ...
Figure 10 from LLM-Aided Compilation for Tensor Accelerators | Semantic ...
TensorRT-LLM in Practice: A Field Guide to NVIDIA-Optimized LLM Serving ...
轻松部署、加速推理:TensorRT LLM 1.0 正式上线,全新易用的 Python 式运行_python_NVIDIA AI 技术专区 ...
Tensor basic definition - Rodolphe Vaillant's homepage
Week 2: From Text to Tensors - LLM Input Pipeline Engineering | by Luke ...
LLM.265: Video Codecs are Secretly Tensor Codecs | Proceedings of the ...
How does LLM inference work? | LLM Inference Handbook
LLM - HackQuest
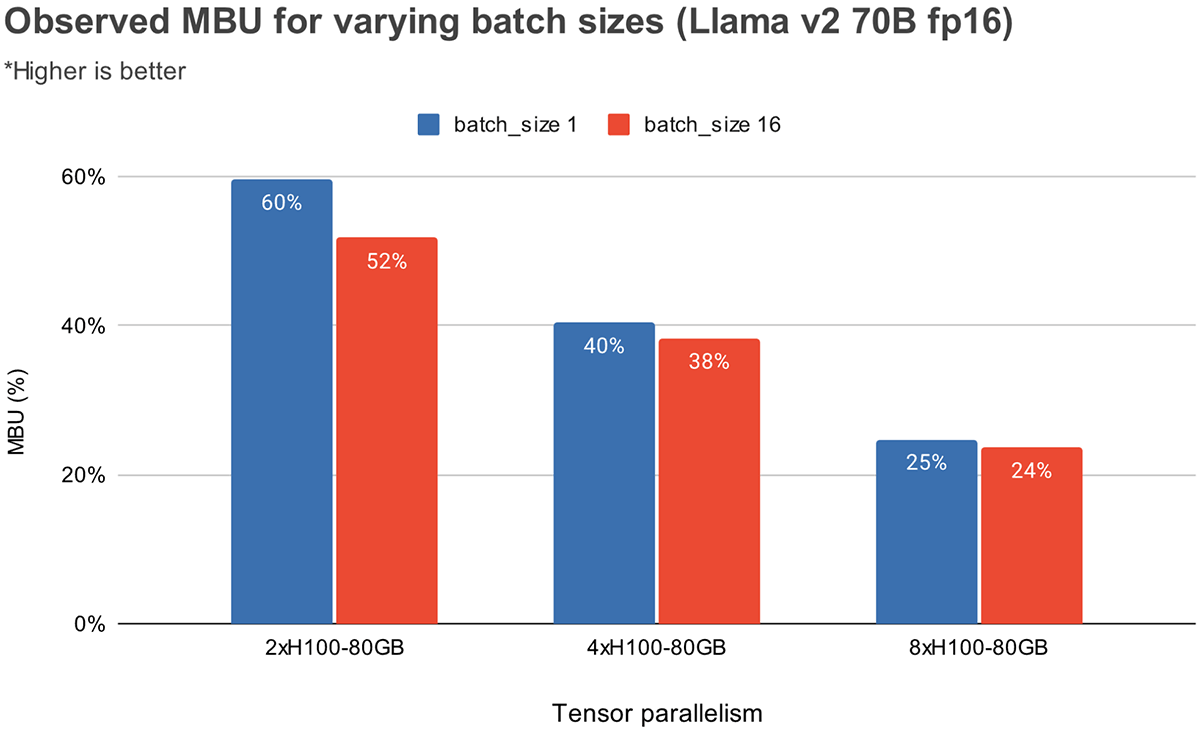
LLM Inference Performance Engineering: Best Practices | Databricks Blog
SSD KV Cache LLM Inference Benchmark Report | GMI Cloud
TensorRT-LLM For All: A deep dive into getting started with NVidia’s ...
Understanding Tensors: A Practical Guide for Deep Learning Enthusiasts ...
TensorFlow: A Beginner’s Guide to the Basics | by Suraj Yadav | Medium
Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM ...
揭秘NVIDIA大模型推理框架:TensorRT-LLM - 知乎
NVIDIA TensorRT-LLM Boosts Large Language Models Immensely, Up To 8x ...
NVIDIA TensorRT-LLM Now Accelerates Encoder-Decoder Models with In ...
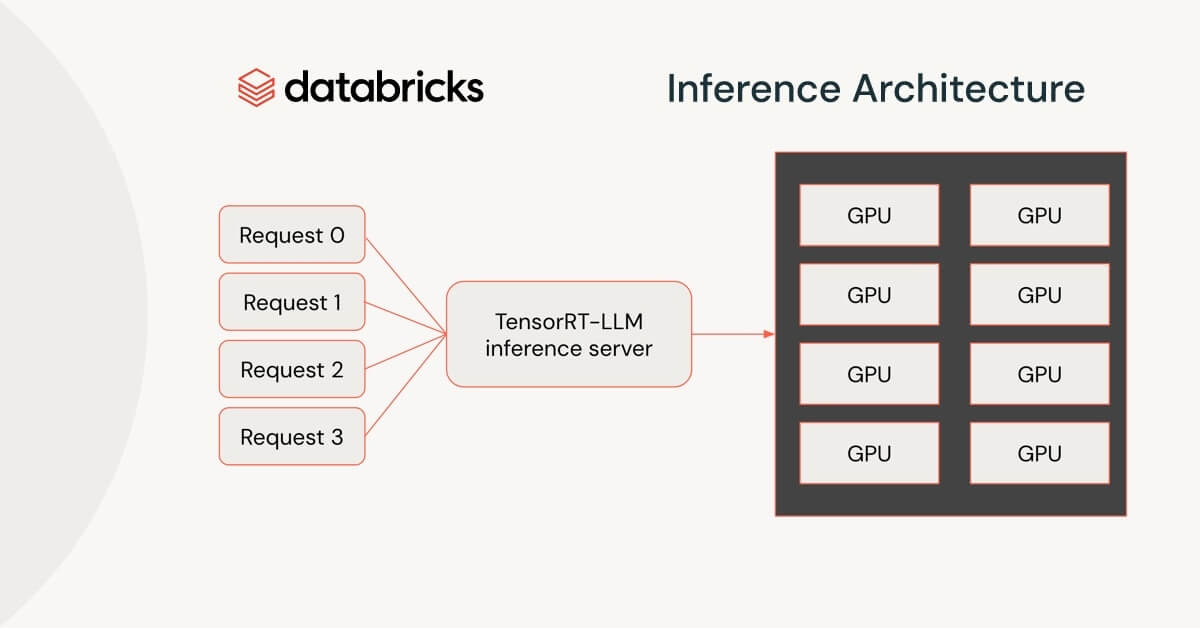
Integrating NVIDIA TensorRT-LLM with the Databricks Inference Stack ...
使用TensorRT LLM的量化实践_tensorrt-llm 量化-CSDN博客
NVIDIA新推出的Tensor-LLM在优化大语言模型推理上有何突出之处?有大神可以分享一下吗? - 知乎
Optimizing Inference on Large Language Models with NVIDIA TensorRT-LLM ...
What is a tensor? | Learning Deep Learning
Pulse · llm-db/tensor-program-optimization-with-auto-batching · GitHub
Large Language Models up to 4x Faster on RTX With TensorRT-LLM for ...
NVIDIA TensorRT-LLM Accelerates Large Language Model Inference on ...
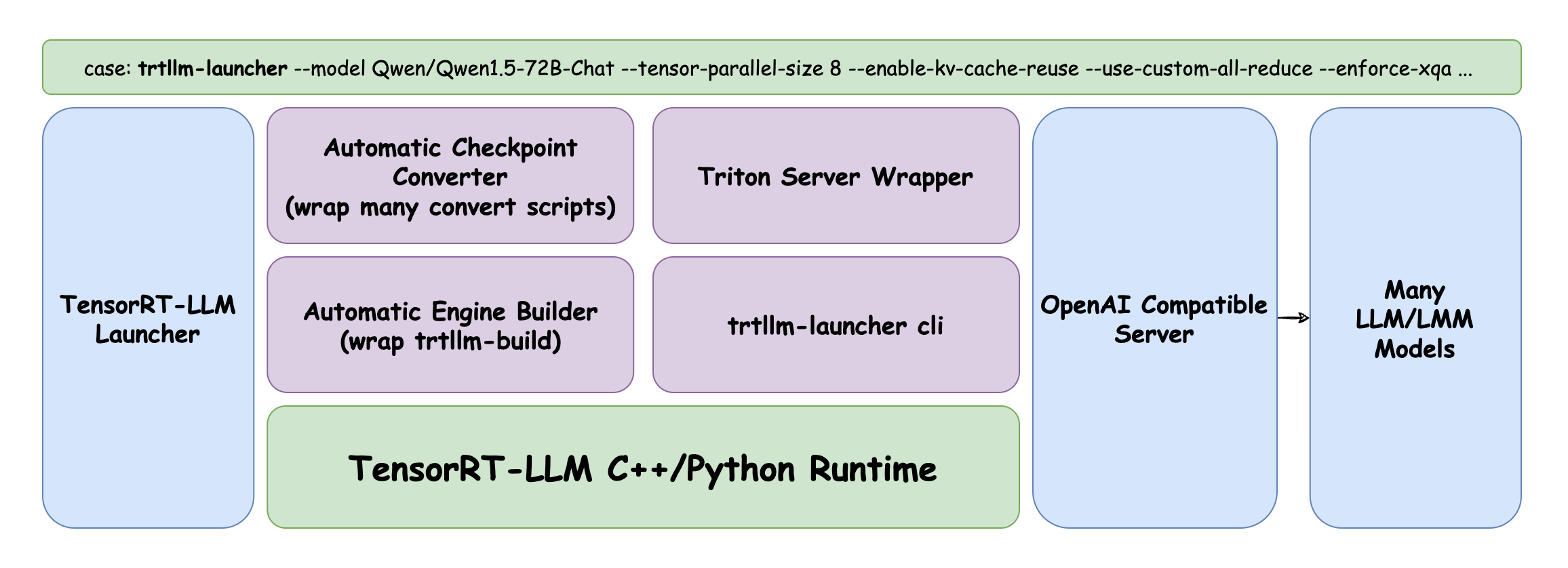
Best Practices for Tuning TensorRT-LLM for Optimal Serving with BentoML
Meet TensorRT-LLM: An Open-Source Library that Accelerates and ...
TensorRT-LLM/examples/draft_target_model/README.md at main · NVIDIA ...
揭秘NVIDIA大模型推理框架:TensorRT-LLM - 智源社区
Nvidia's New TensorRT-LLM Software Pushes Limits of AI Chip Performance ...
Tensor-LLM for BLIP-2 (ViT and Q-Former) · Issue #664 · NVIDIA/TensorRT ...
GitHub - crystal-tensor/Co-LLM-Agents: Source codes for the paper ...
GenAI-inferensmotorer: TensorRT-LLM vs vLLM vs Hugging Face TGI vs LMDeploy
Accelerating Large Language Models with Mixed-Precision Techniques ...
GitHub - tensorchord/modelz-llm: OpenAI compatible API for LLMs and ...
Input Parameters - SHAARP.ml
joaquimabraham/Tensor-zero-LLM-production-data-faster-smarter-cheaper ...
What is Tensor?
LLMstudio by TensorOpsAI - SourcePulse
Using Tensors in Machine Learning: A Complete Guide | by Hey Amit | We ...
LLM-Inference-Acceleration/attention-mechanism/tensor-product-attention ...
Streamlining AI Inference Performance and Deployment with NVIDIA ...
Everything You Need to Know About Tensors - KDnuggets
GitHub - saibabu70/Tensorgo_Speech-to-Speech-LLM-BOT: Developed a ...
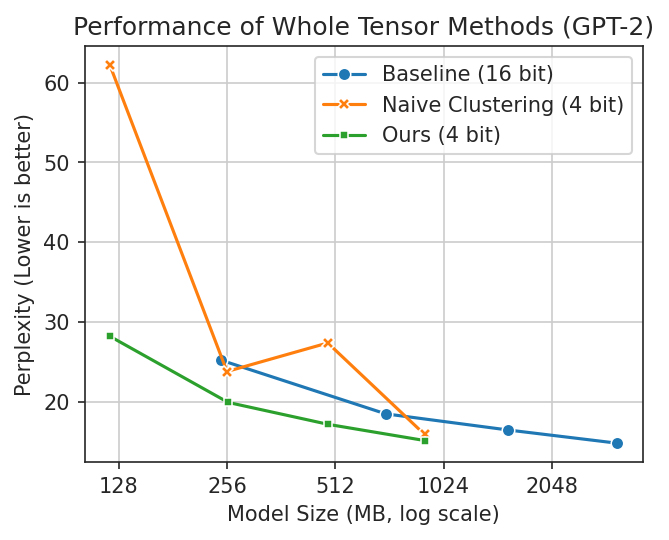
LLMs for your iPhone: Whole-Tensor 4 Bit Quantization
TensorRT与LLM完美结合:保姆级教程带你飞_tensorrt-llm-CSDN博客