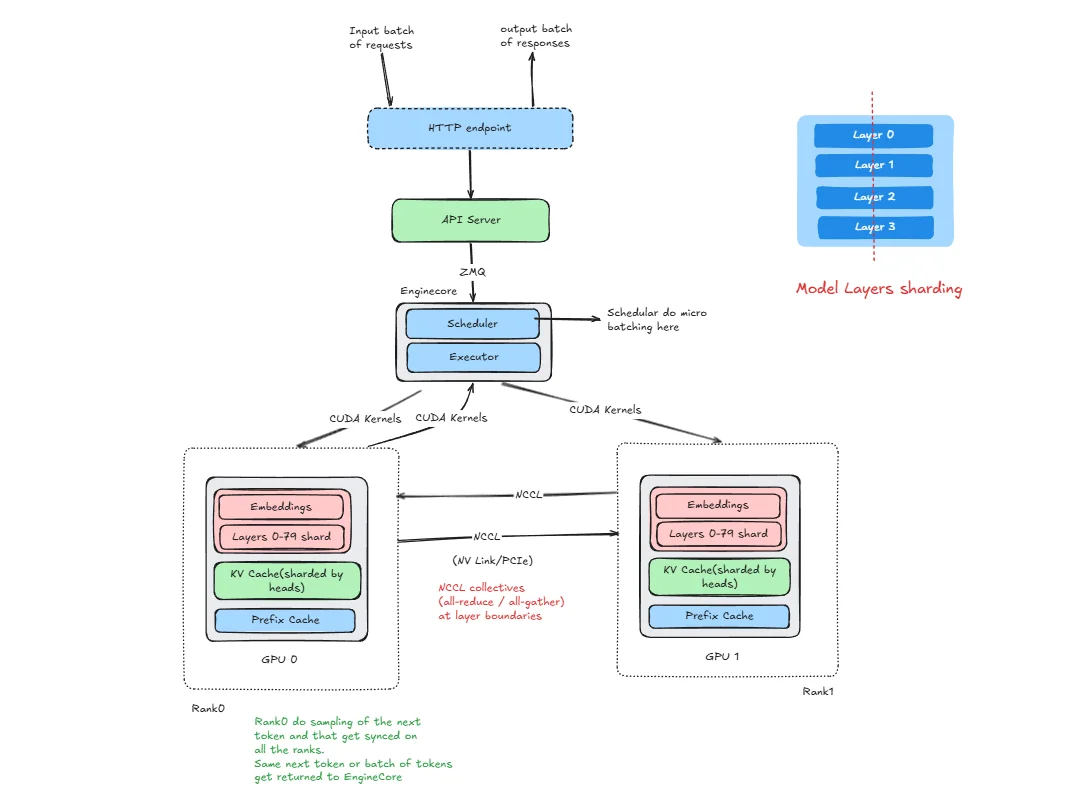
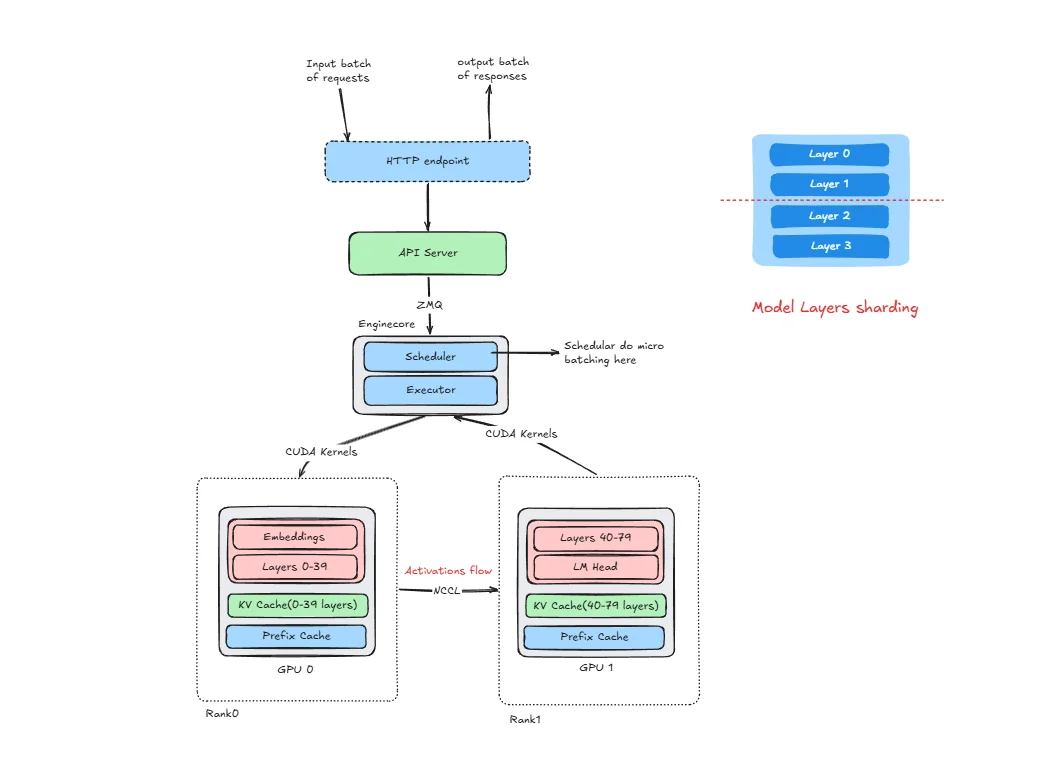
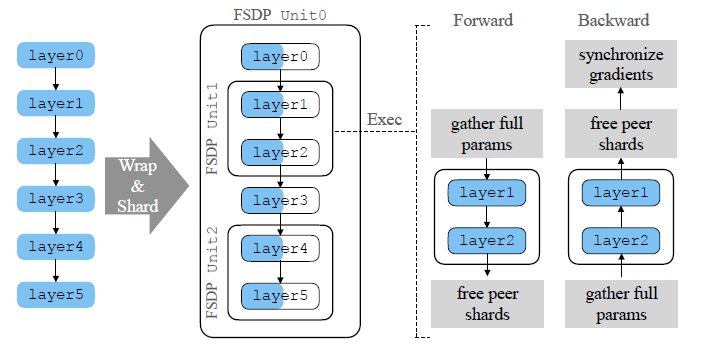
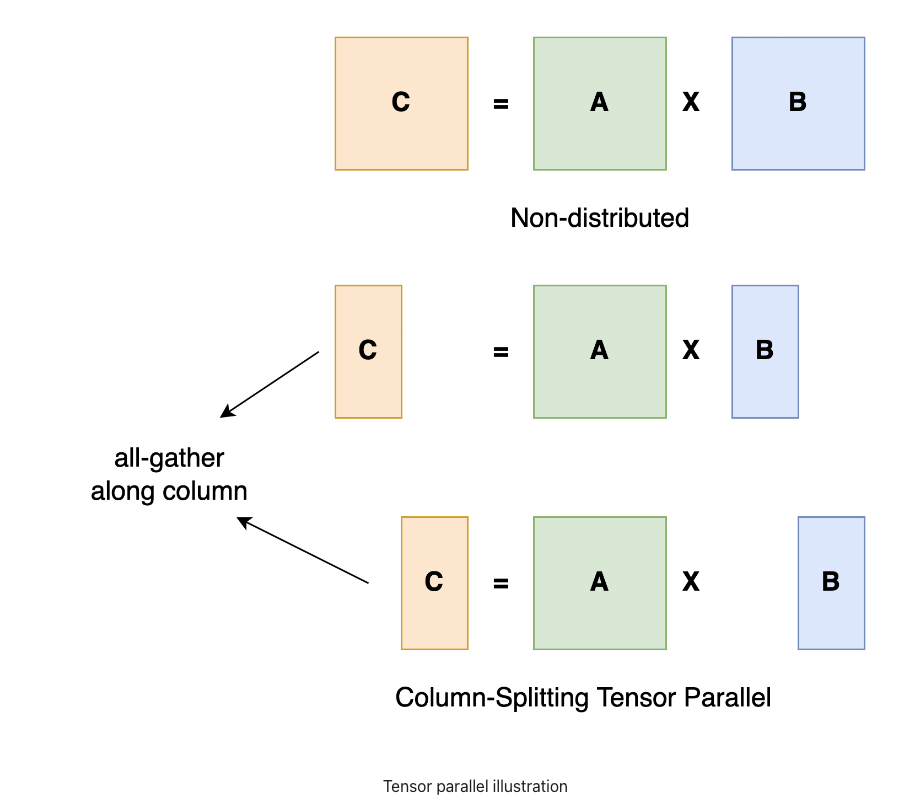
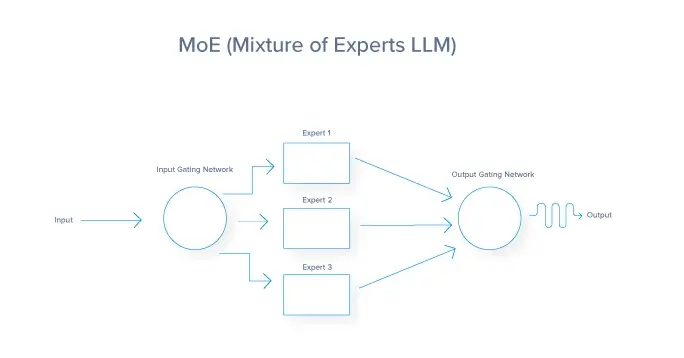
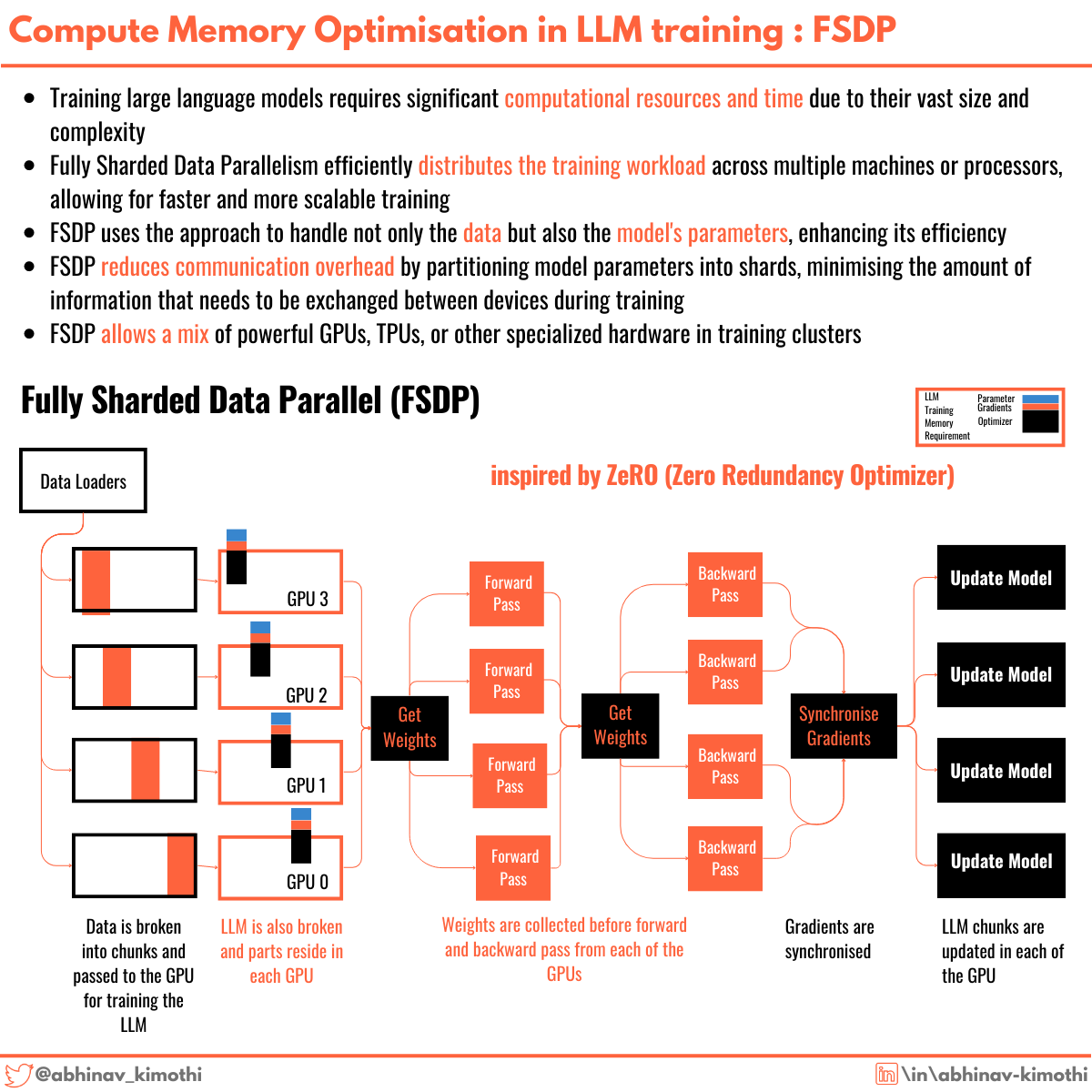
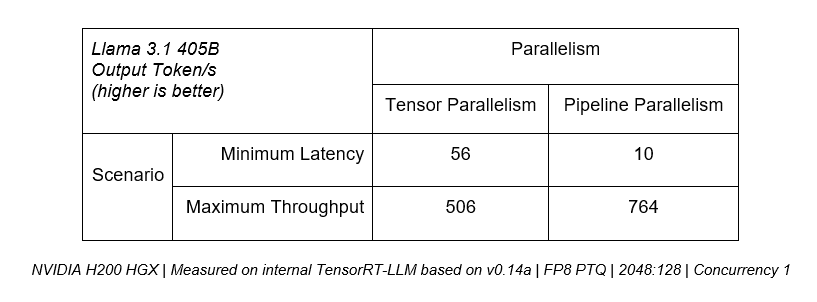
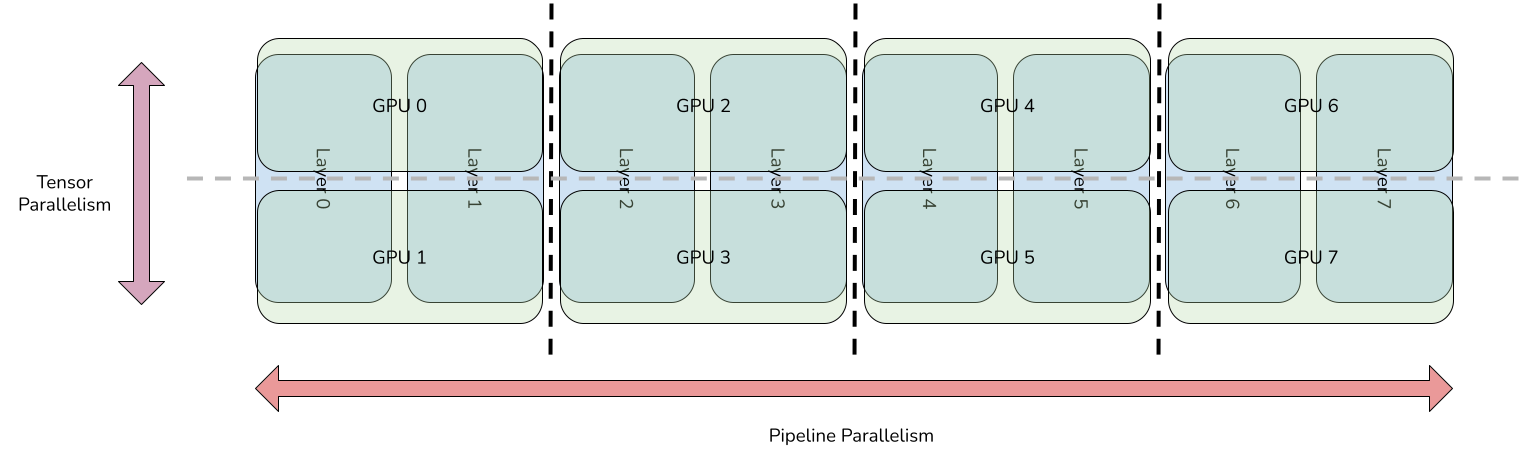
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Analyzing the Impact of Tensor Parallelism Configurations on LLM ...
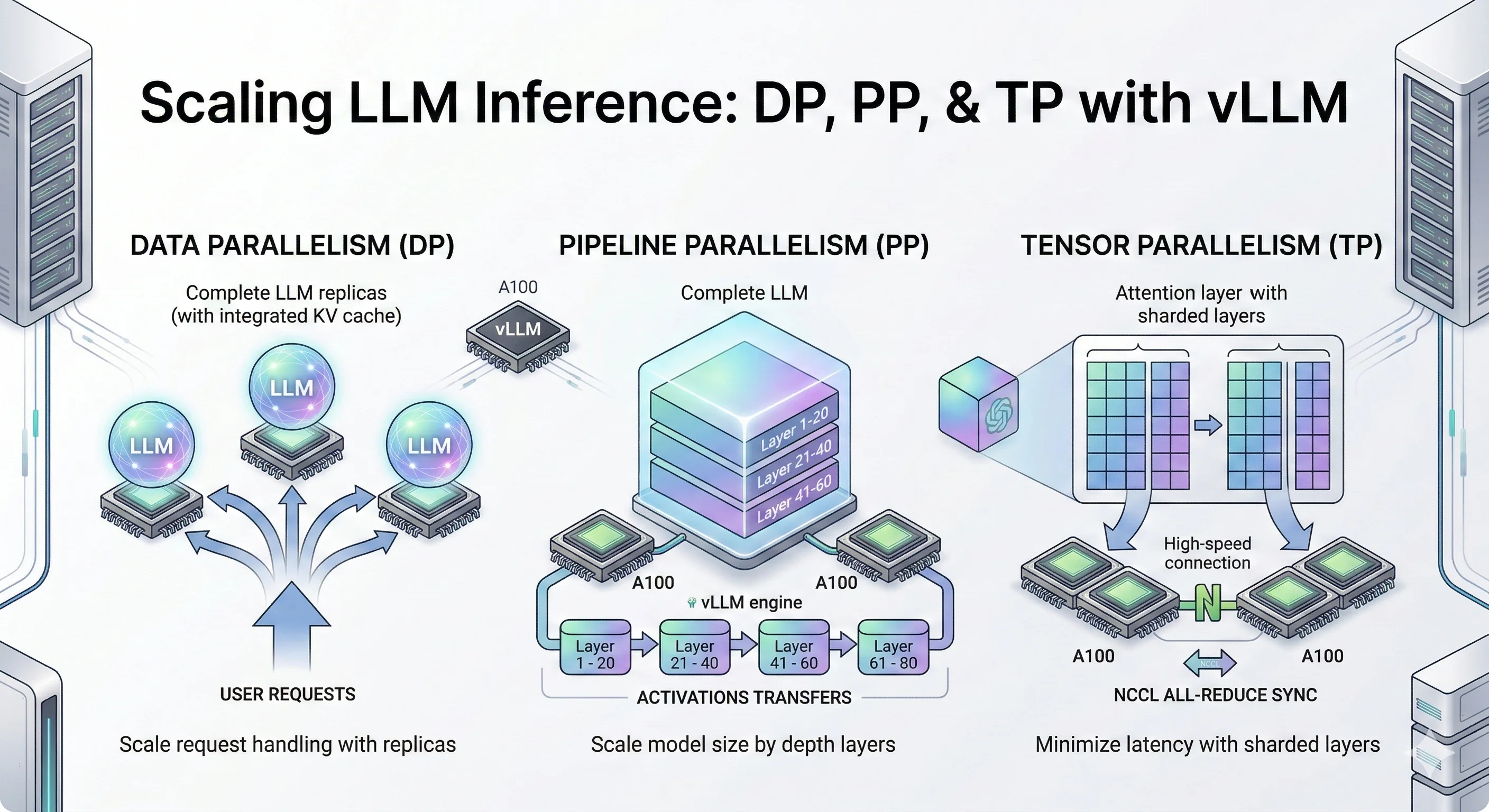
Scaling LLM Inference: Data, Pipeline & Tensor Parallelism in vLLM ...
Tensor Parallelism vs Pipeline Parallelism for LLM Inference - ML Journey
LLM Training — Fundamentals of Tensor Parallelism | by Don Moon | Byte ...
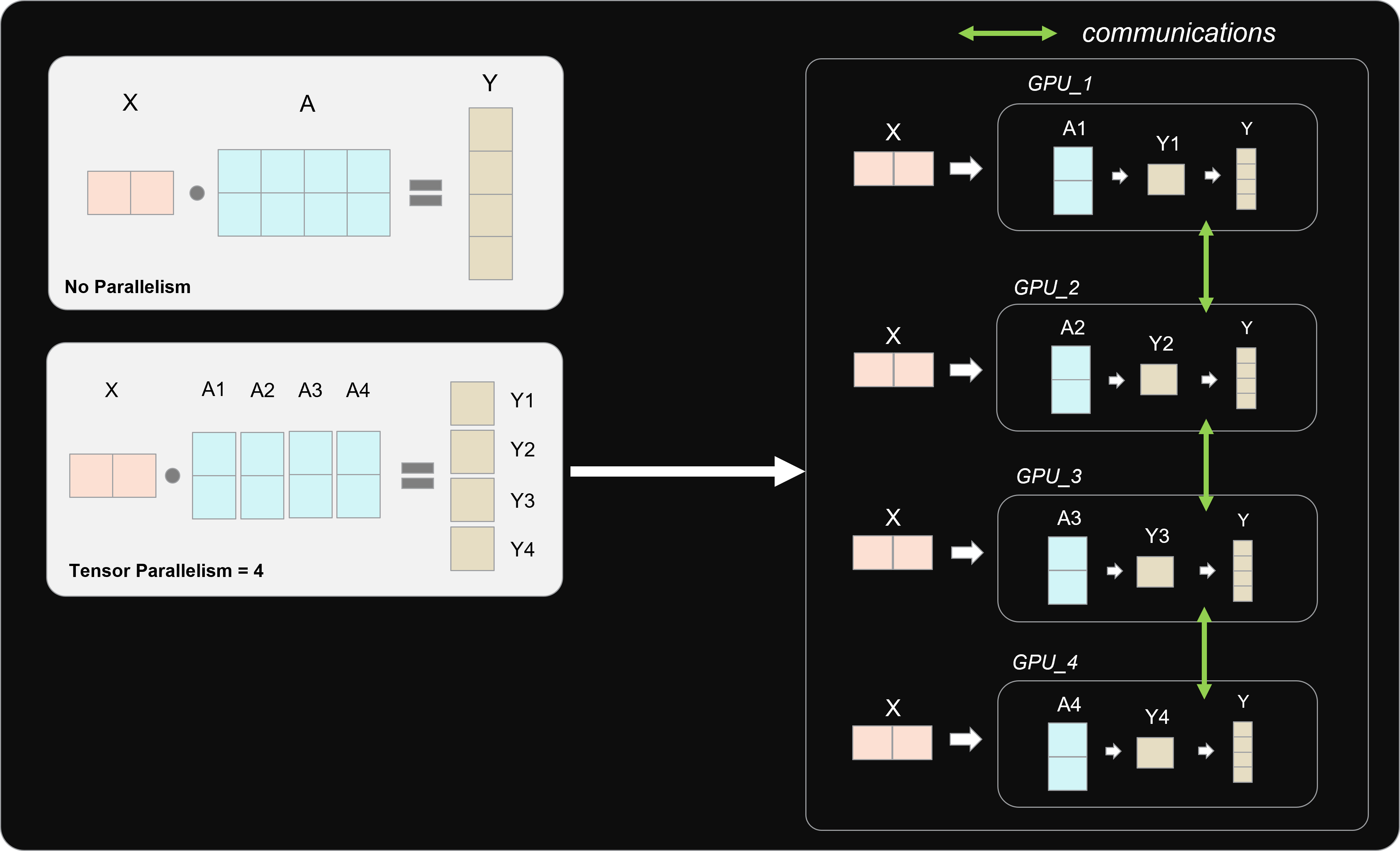
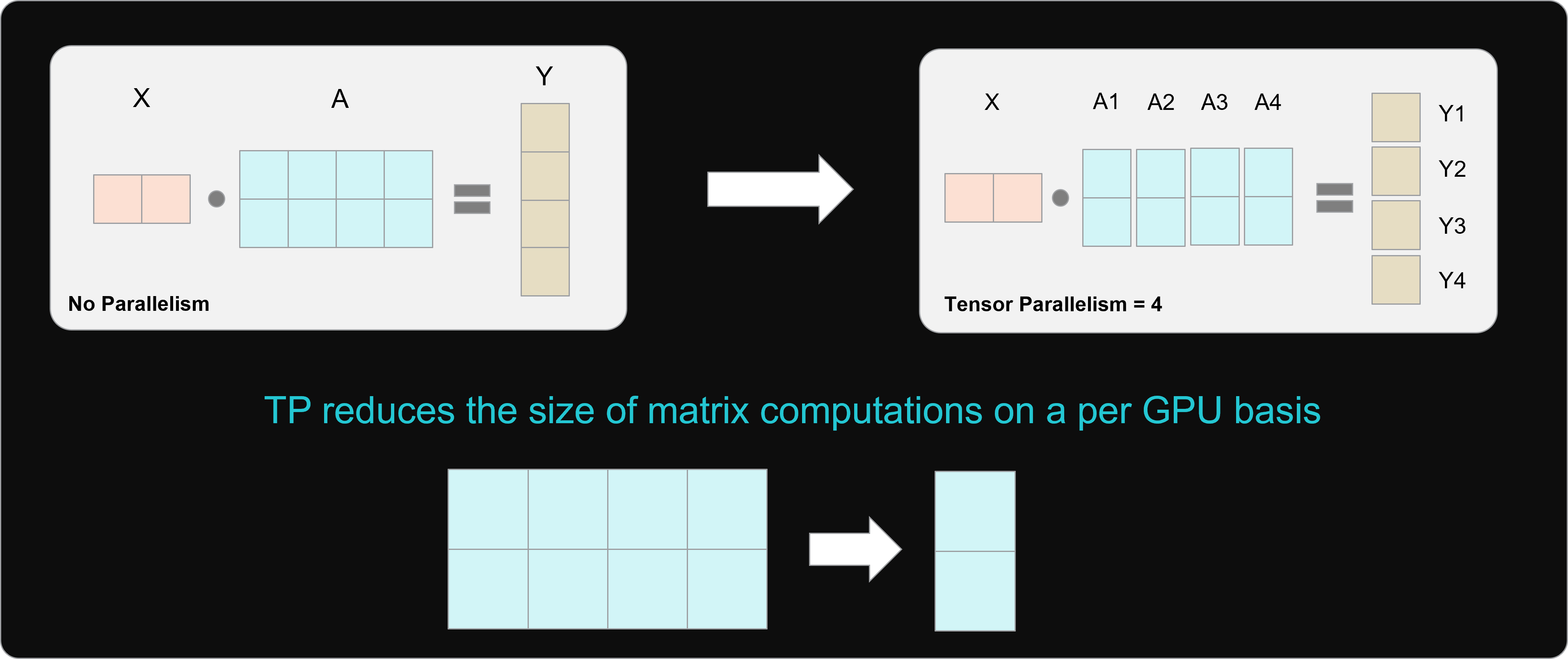
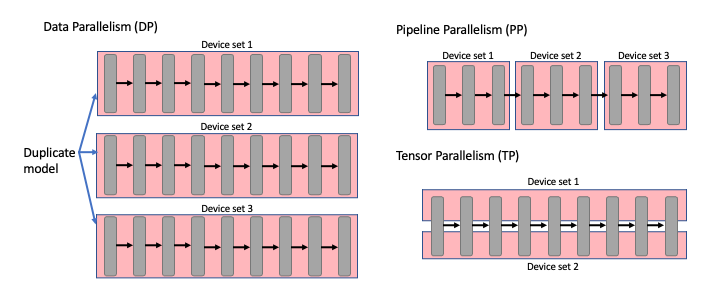
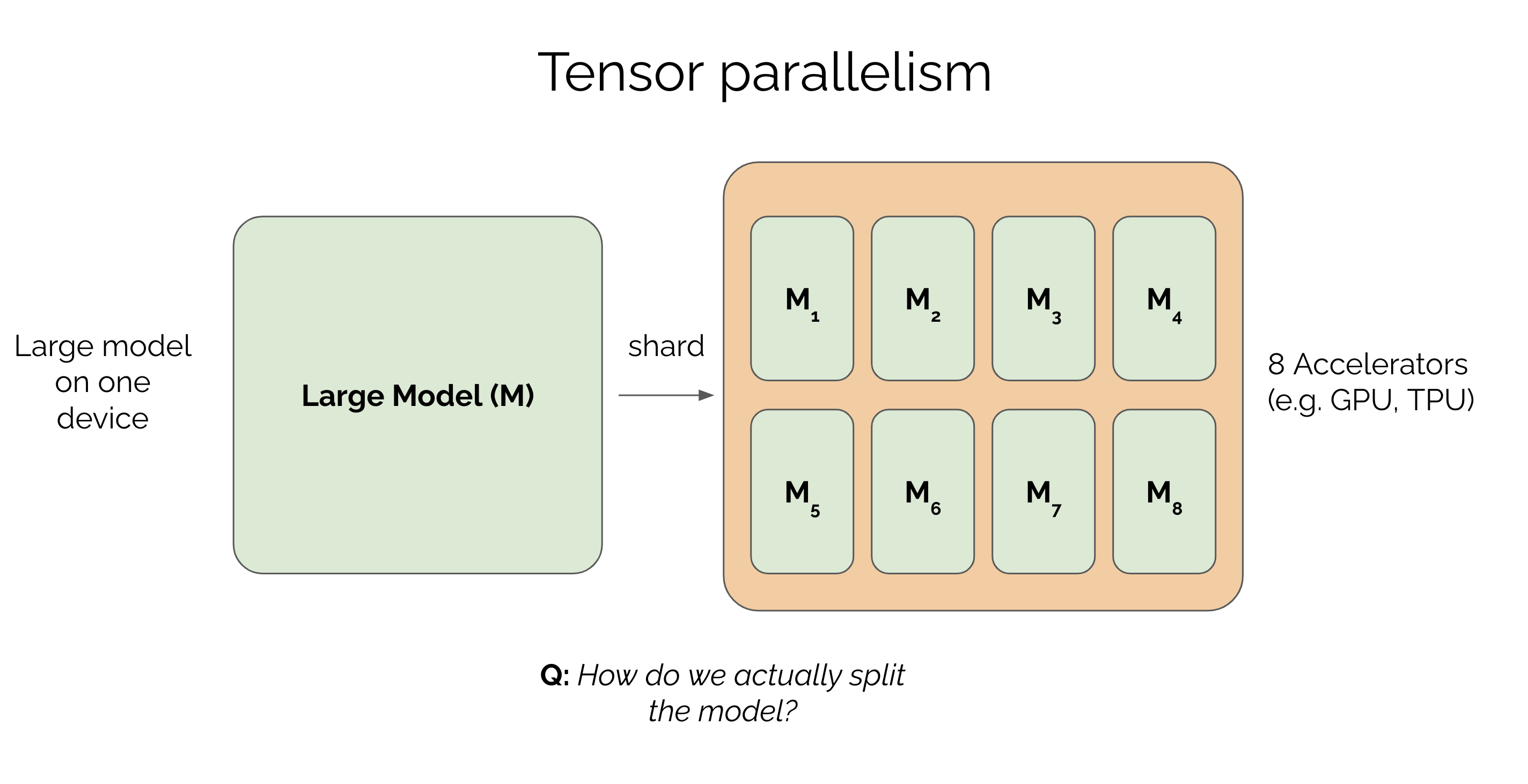
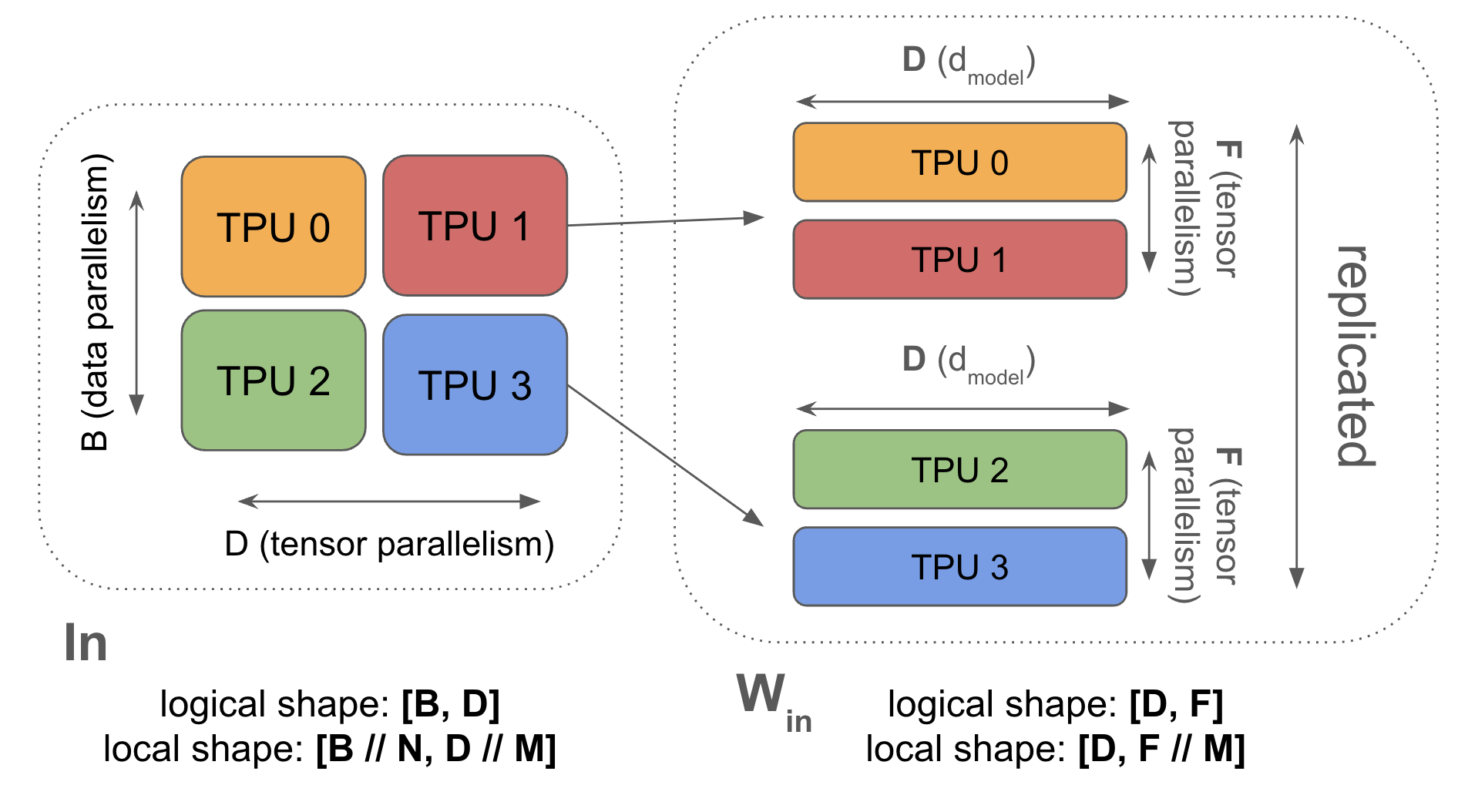
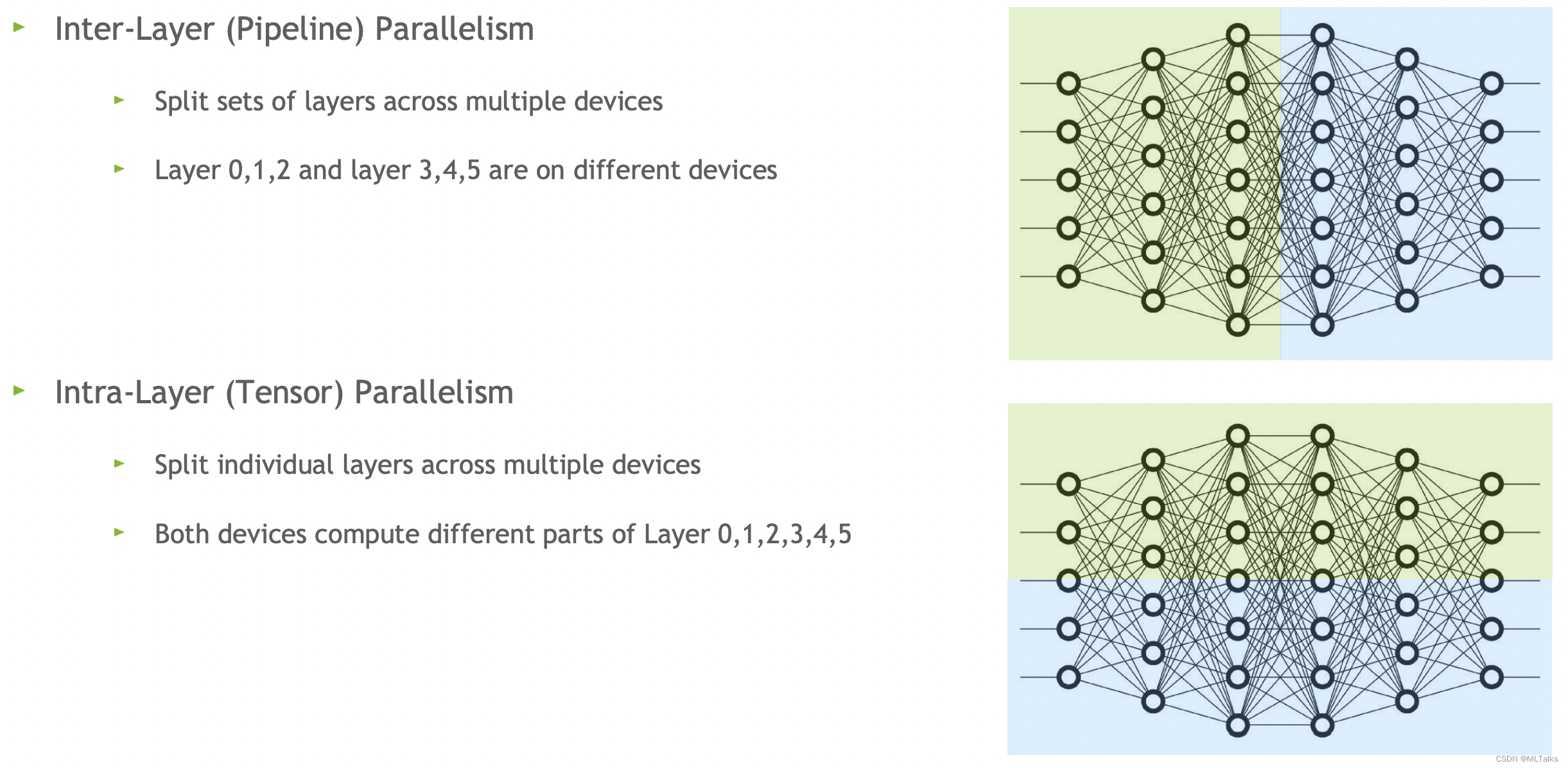
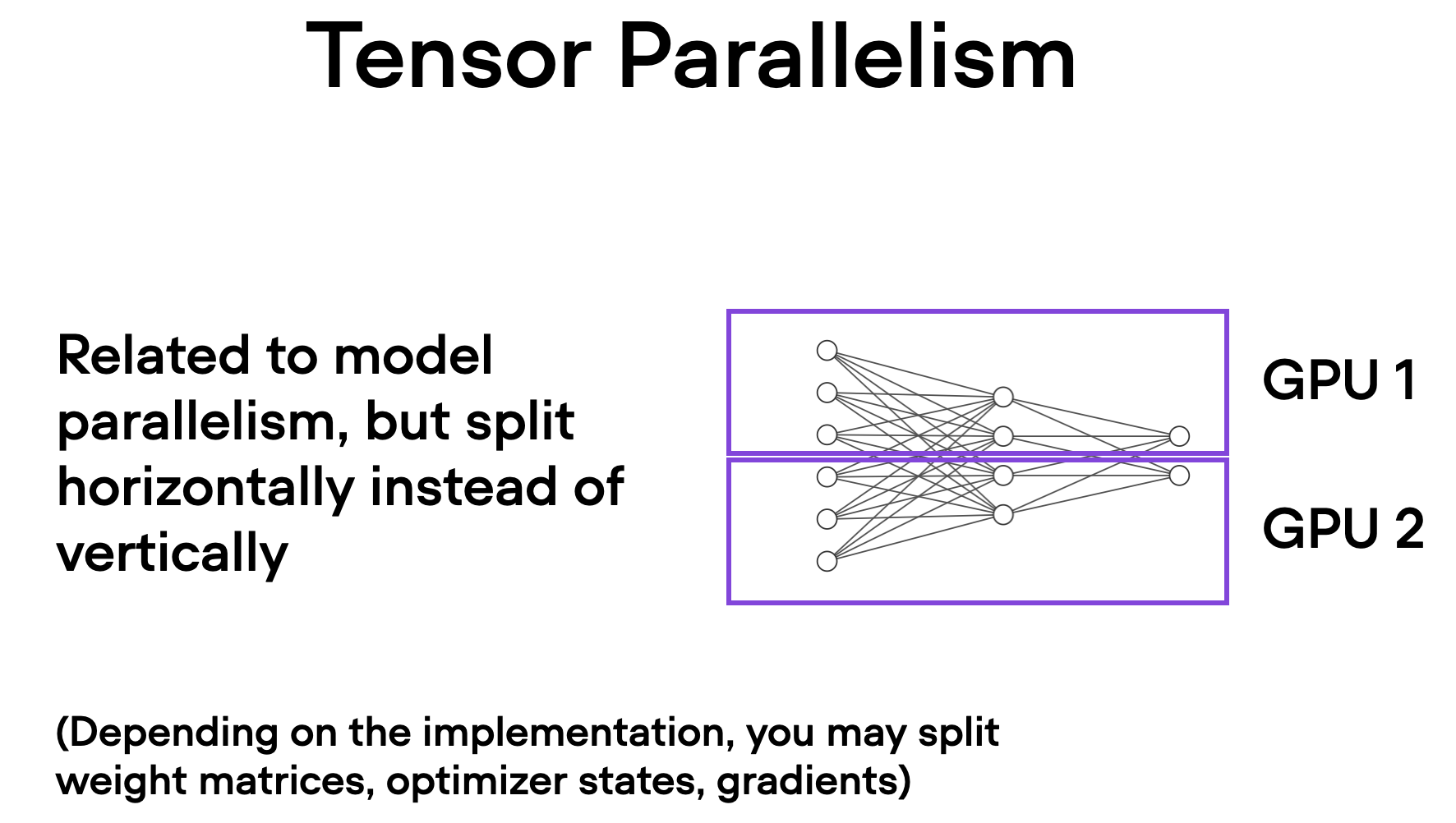
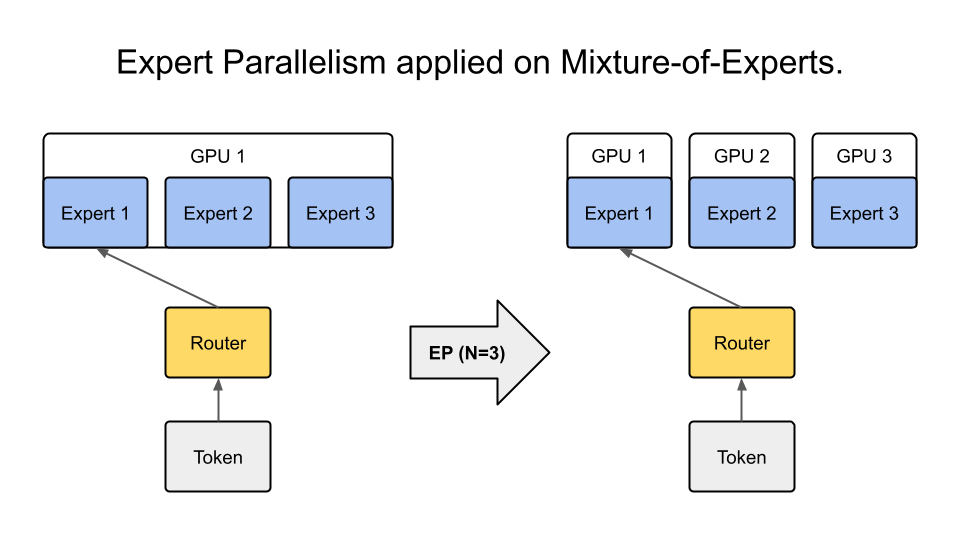
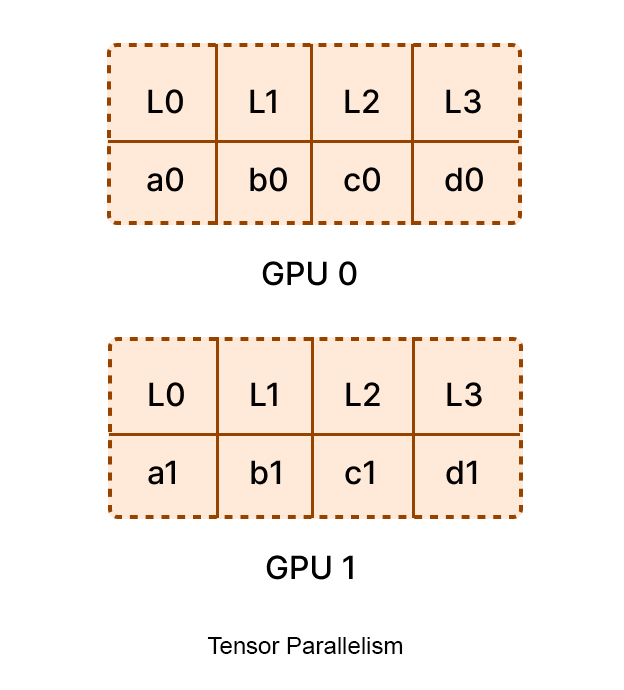
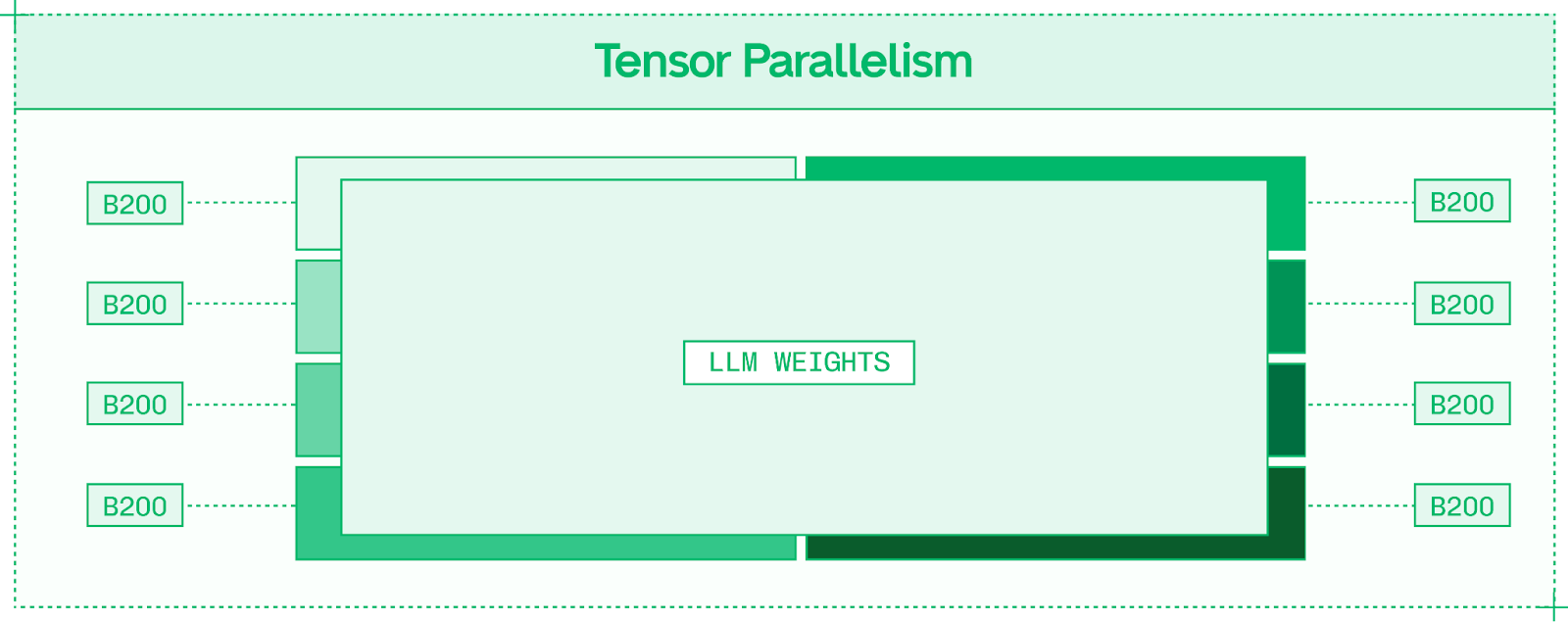
tensor parallelism
gLLM: Global Balanced Pipeline Parallelism System for Distributed LLM ...
How Tensor Parallelism Works - Amazon SageMaker
Tensor Parallelism Overview — AWS Neuron Documentation
Tensor Parallelism
Pytorch2 Tensor Parallelism | Sharlayan
Tensor Parallelism and Pipeline Parallelism - Kyle’s Tech Blog
LLM Explainability or Controllability Improvements with Tensor Networks ...
Synergistic Tensor and Pipeline Parallelism | AI Research Paper Details
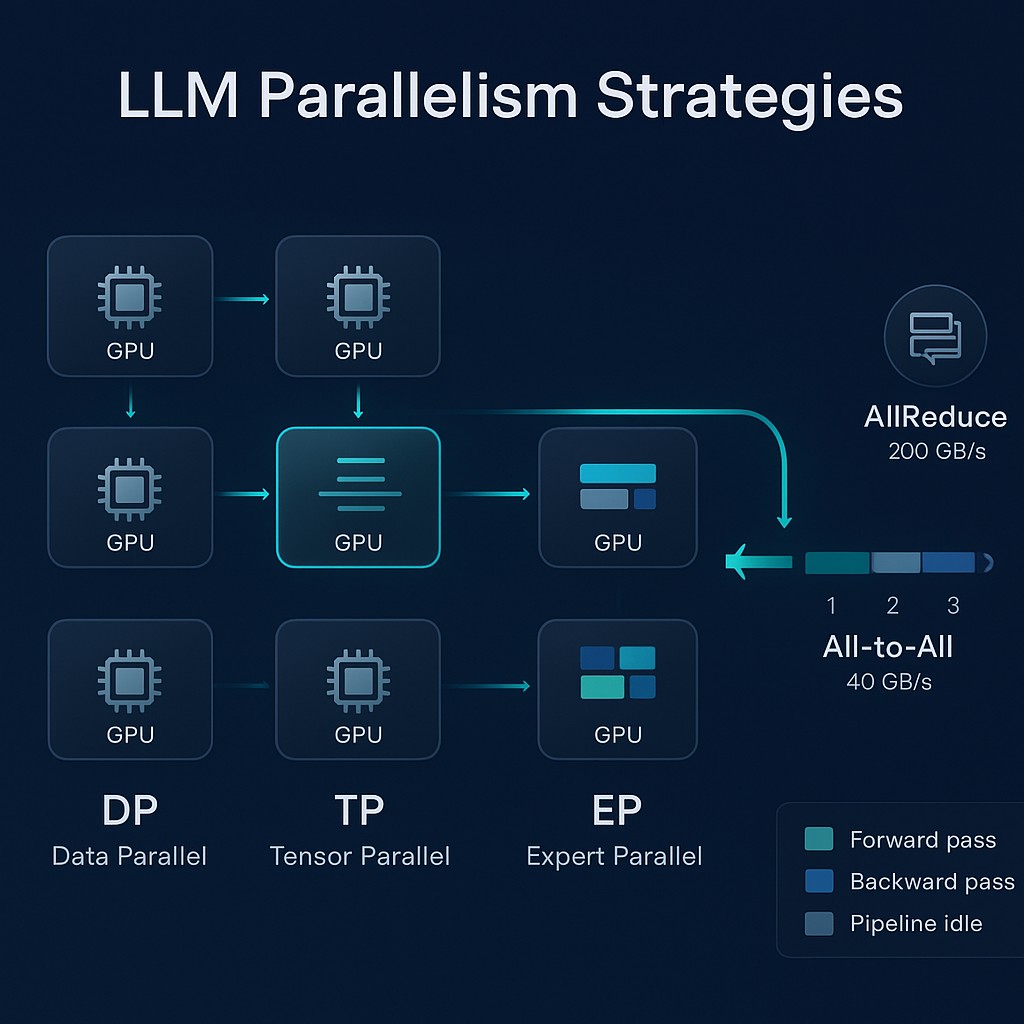
LLM Parallelism Strategies Explained | Simulations4All
AnchorTP: Resilient LLM Inference with State-Preserving Elastic Tensor ...
Tensor parallel support for LLM training. · Issue #37505 · huggingface ...
Scaling LLM Inference: Innovations in Tensor Parallelism, Context ...
Model Parallelism vs Data Parallelism vs Tensor Parallelism | # ...
Tensor Parallel LLM Inferencing. As models increase in size, it becomes ...
Tensor Parallelism | sgl-project/mini-sglang | DeepWiki
Sharding Large Models with Tensor Parallelism
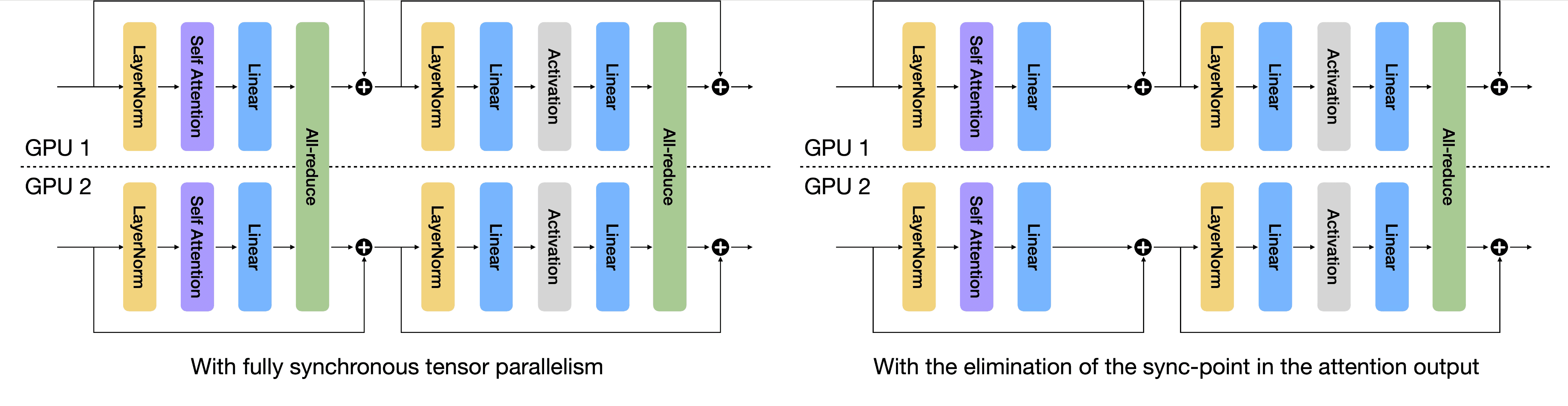
SPD: Sync-Point Drop for Efficient Tensor Parallelism of Large Language ...
Tensor Parallelism Explained
LLM并行策略(一)TP, Tensor Parallelism - 知乎
Demystifying Tensor Parallelism | Robot Chinwag
Part 4.1: Tensor Parallelism — UvA DL Notebooks v1.2 documentation
Parallelism Techniques for LLM Inference — AWS Neuron Documentation
Tensor Parallelism and Sequence Parallelism: Detailed Analysis · Better ...
Tensor parallelism by hand - DEV Community
Tensor Parallelism - NADDOD Blog
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
The NeurIPS 2023 LLM Efficiency Challenge Starter Guide - Lightning AI
Optimizing LLM Inference. A Large Language Model (LLM) such as… | by Dr ...
Data, tensor, pipeline, expert and hybrid parallelisms | LLM Inference ...
Mastering LLM Techniques: Inference Optimization – GIXtools
[vLLM vs TensorRT-LLM] #9. Parallelism Strategies - The official ...
gLLM: Global Balanced Pipeline Parallelism Systems for Distributed LLMs ...
Model Parallelism Implementation (Tensor, Pipeline)
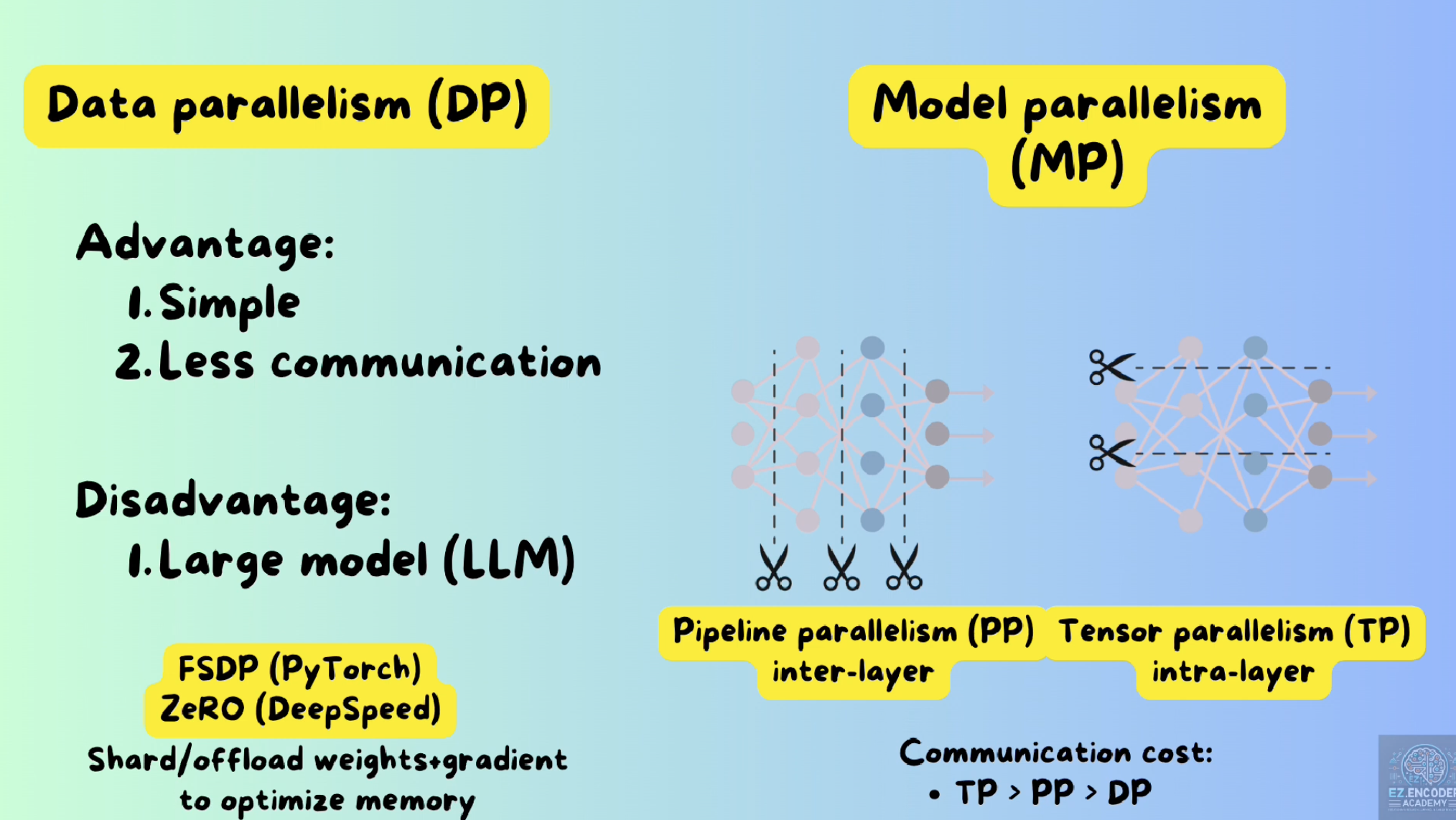
EZ聊AI: LLM面试高频, 三种并行的范式: Data parallelism, Tensor parallelism, Pipeline ...
GPU Guide for LLM Deployment - RTX 4090 to A100 Benchmarks (2026)
万字综述 LLM 训练中的 Overlap 优化:字节 Flux 等 7 种方案_overlap communication with ...
EcoServe: Enabling Cost-effective LLM Serving with Proactive Intra- and ...
LLM Inference Performance Engineering: Best Practices | Databricks Blog
LLM Engineer's Almanac - Workloads | Modal
Efficiently Scale LLM Training Across a Large GPU Cluster with Alpa and ...
[Usage]: LLM with tensor_parallel_size larger than n. gpus in one node ...
Paradigms of Parallelism | Colossal-AI
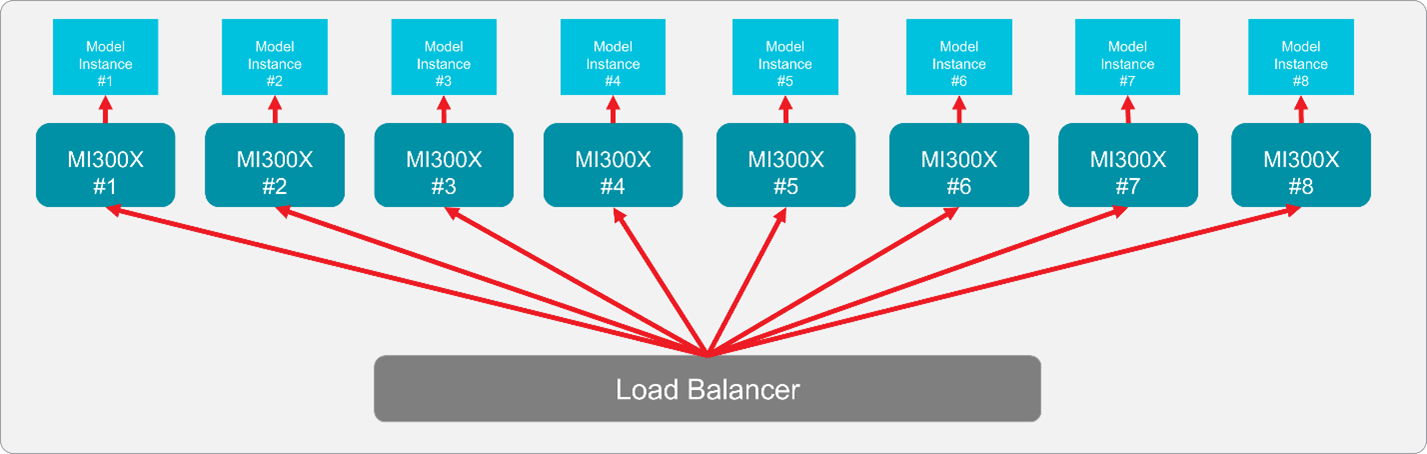
What is Inference Parallelism and How it Works
Distributed Parallel Training: Data Parallelism and Model Parallelism ...
What’s the ROI? Getting the Most Out of LLM Inference – MACHINE LEARNING
A Deep Dive into 3D Parallelism with Nanotron⚡️ | TJ Solergibert
Does ATQ work with tensor parallelism? · Issue #472 · NVIDIA/TensorRT ...
6 Best GPUs for Dual & Multi-GPU Local LLM Setups - Tech Tactician
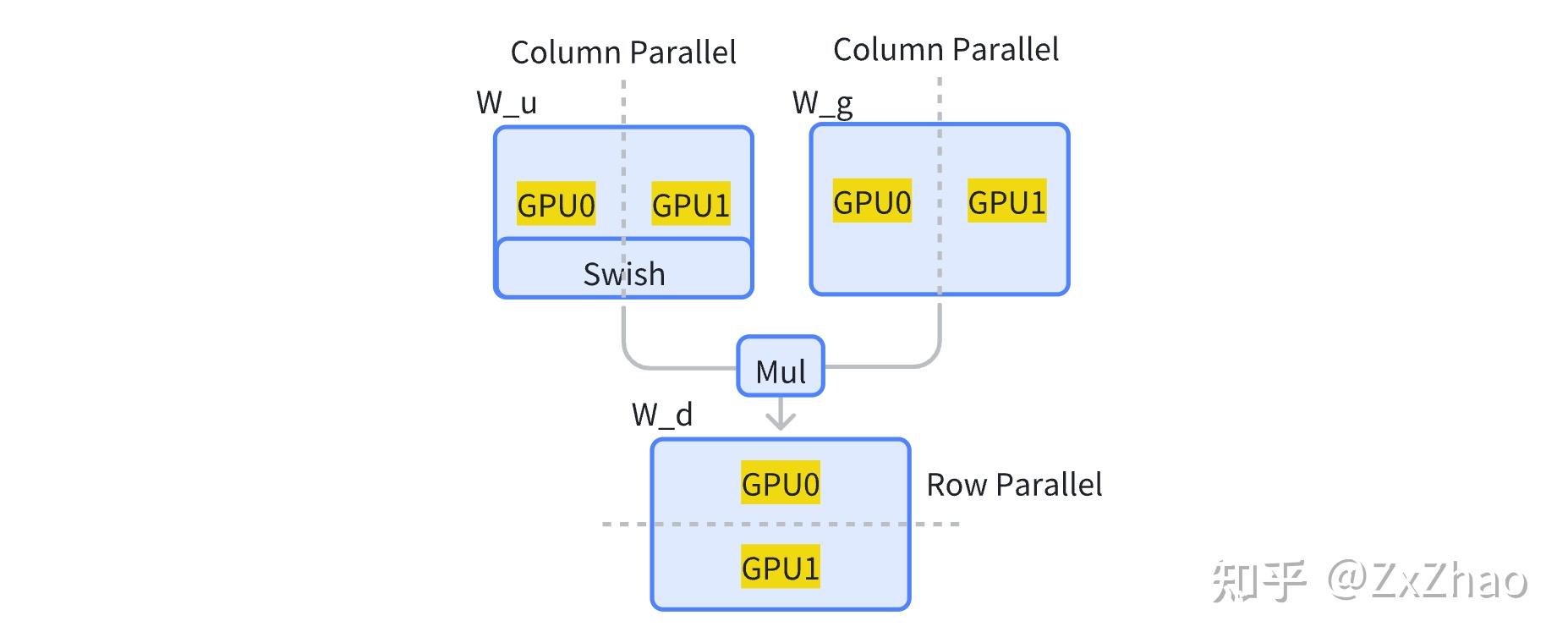
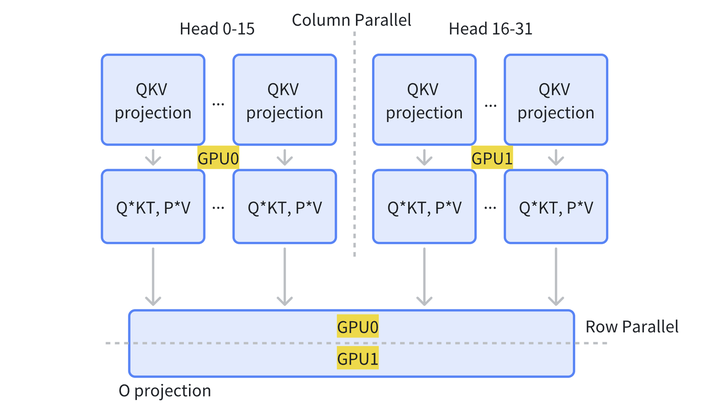
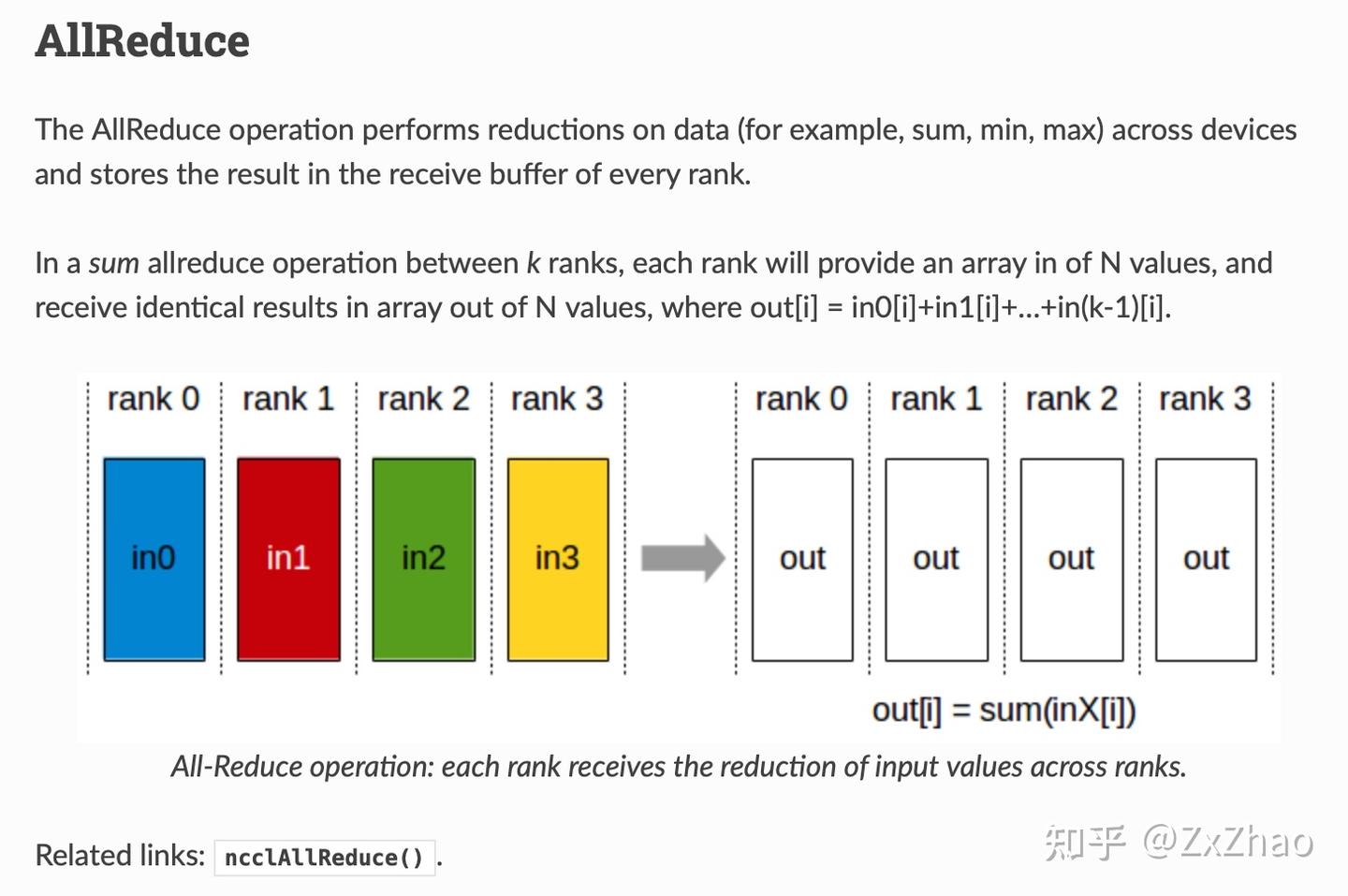
吃透LLM并行范式系列2 - Tensor Parallel和Sequence Parallel - 知乎
Parallelism Strategies for LLMs | PDF | Parallel Computing | Graphics ...
🚀 Beyond Data Parallelism: A Beginner-Friendly Tour of Model, Pipeline ...
Parallellogramformet Bygning Basic Terminologies Large Language Models
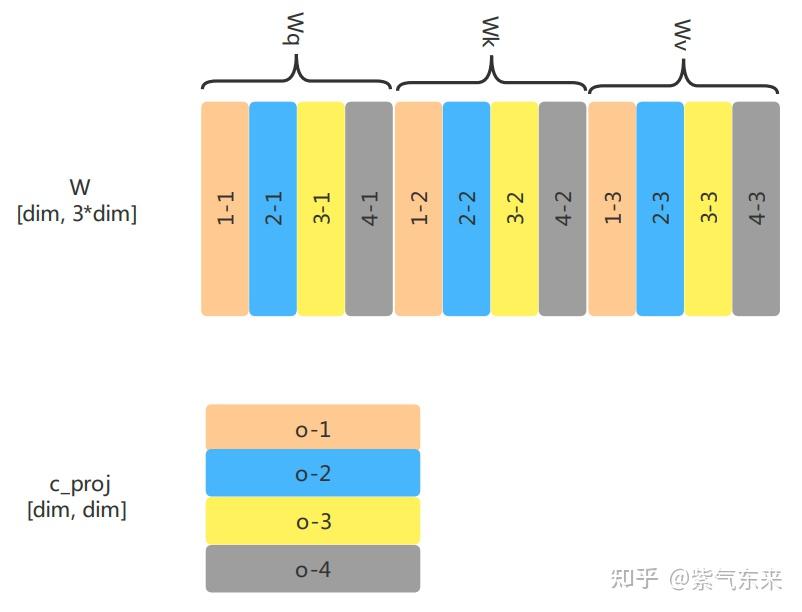
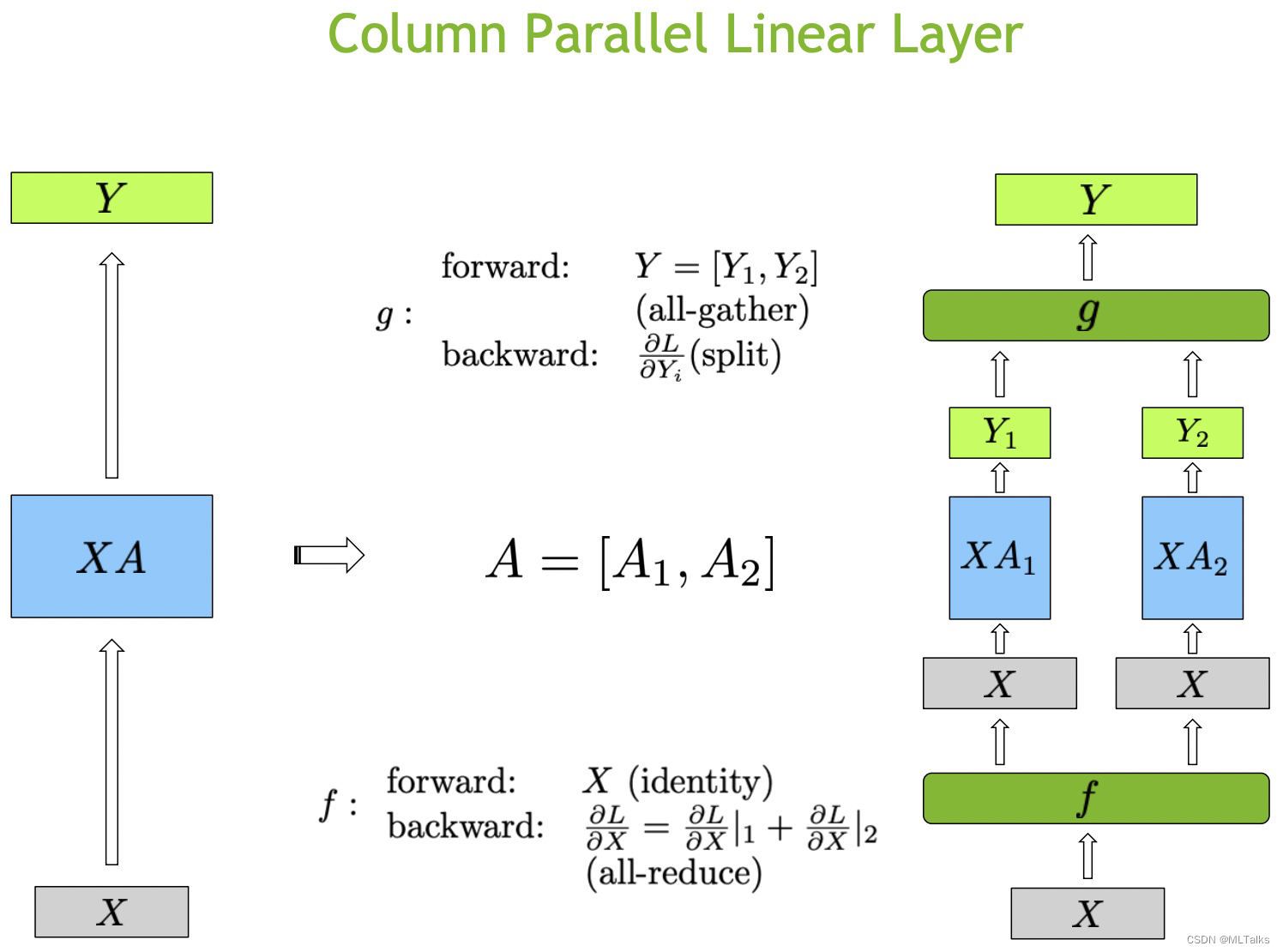
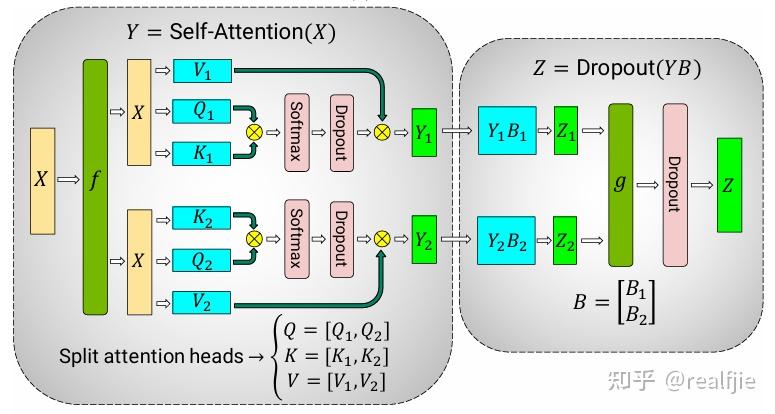
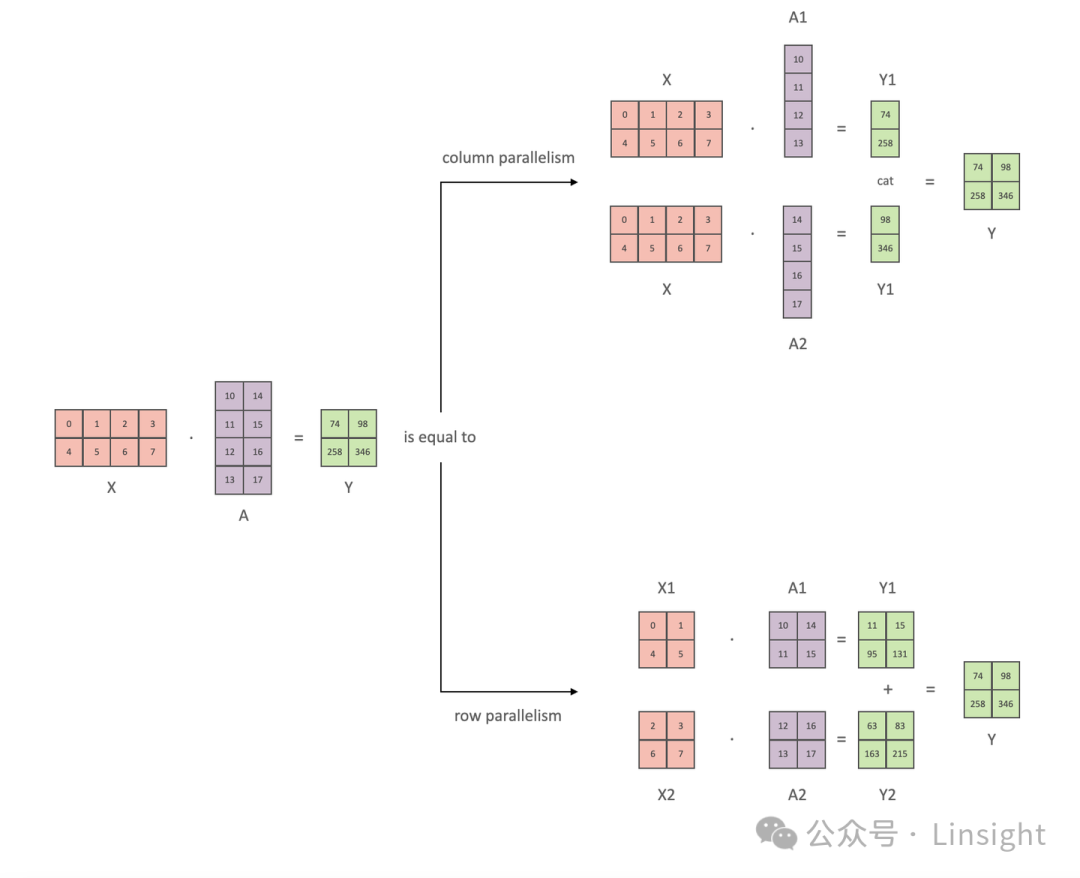
LLM(六):GPT 的张量并行化(tensor parallelism)方案 - 知乎
Parallelisms Guide — Megatron Bridge
Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM ...
Nonuniform-Tensor-Parallelism: Mitigating GPU failure impact for Scaled ...
Accelerated Inference for Large Transformer Models Using NVIDIA Triton ...
Distributed inference with vLLM | Red Hat Developer
vLLM for beginners: Key Features & Performance Optimization(PartII ...
模型并行(Model Parallelism)原理详解-CSDN博客
Demystifying AI Inference Deployments for Trillion Parameter Large ...
How multi-node inference works for massive LLMs like DeepSeek-R1 ...
[论文评述] Nonuniform-Tensor-Parallelism: Mitigating GPU failure impact for ...
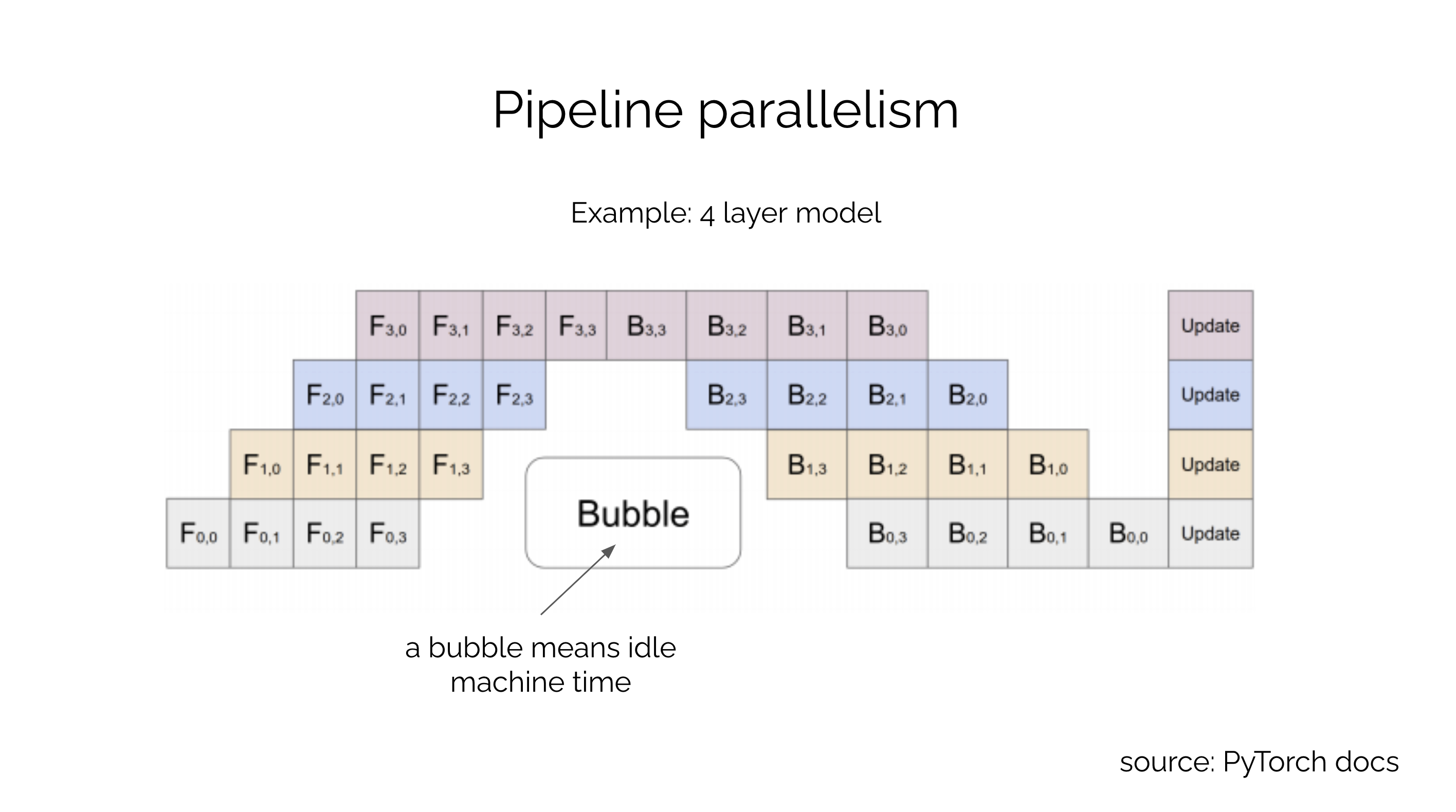
How to Parallelize a Transformer for Training | How To Scale Your Model
LLM(6):GPT 的张量并行化(tensor parallelism)方案 - 知乎
详解MegatronLM Tensor模型并行训练(Tensor Parallel)_megatron-lm-CSDN博客
Optimizing Memory Usage for Training LLMs and Vision Transformers in ...
[논문 리뷰] Tensor-Parallelism with Partially Synchronized Activations
[LLM] 张量并行Tensor Parallel - 知乎
LLM训练各种并行策略-CSDN博客
來自 OpenAI gpt-oss 的技巧,您🫵可以在 transformers 中使用 - Hugging Face 文件
How ByteDance Scales Offline Inference with Multi-Modal LLMs
[2205.05198] Reducing Activation Recomputation in Large Transformer Models
What is inference engineering? Deepdive - by Gergely Orosz