Showing 118 of 118on this page. Filters & sort apply to loaded results; URL updates for sharing.118 of 118 on this page
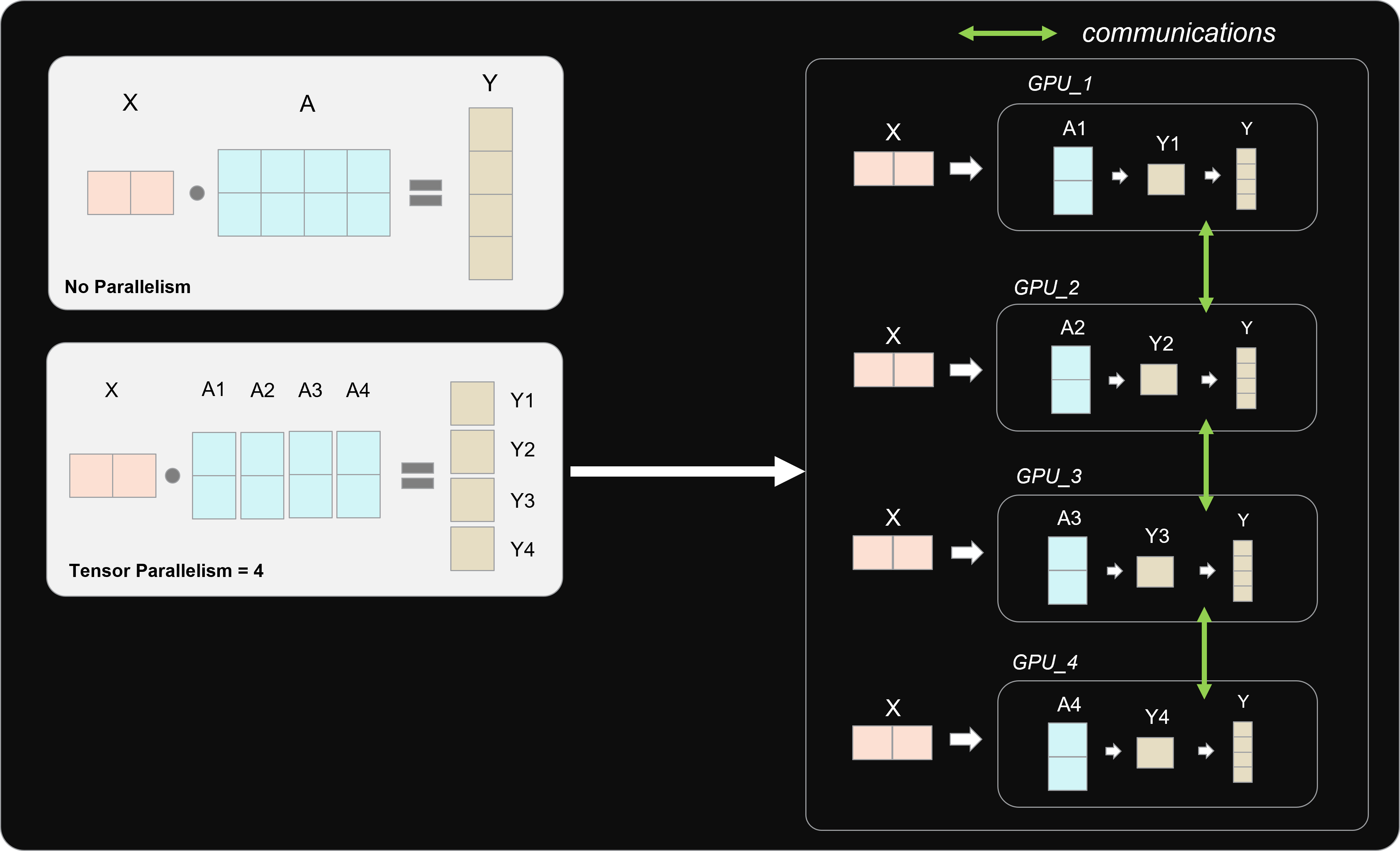
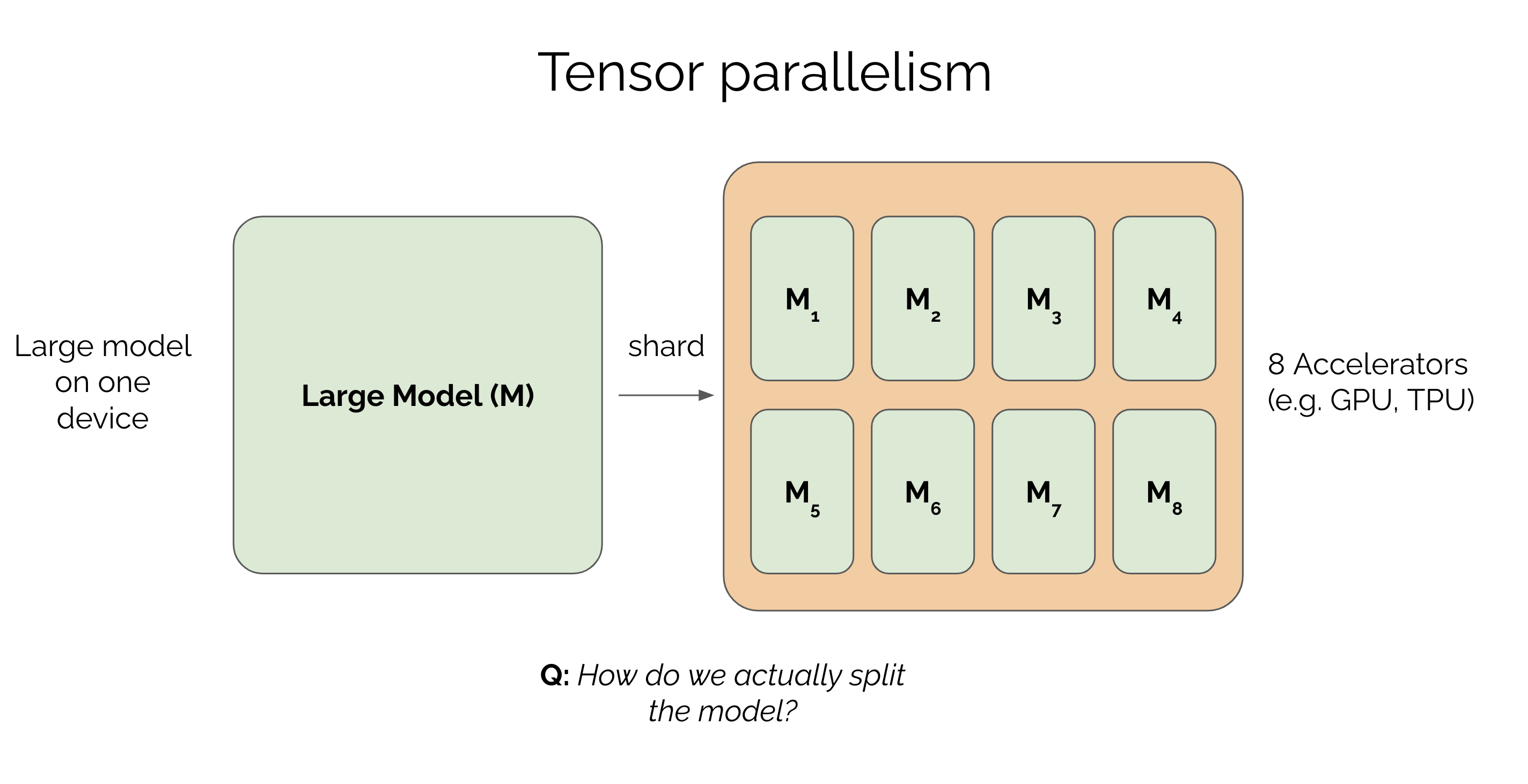
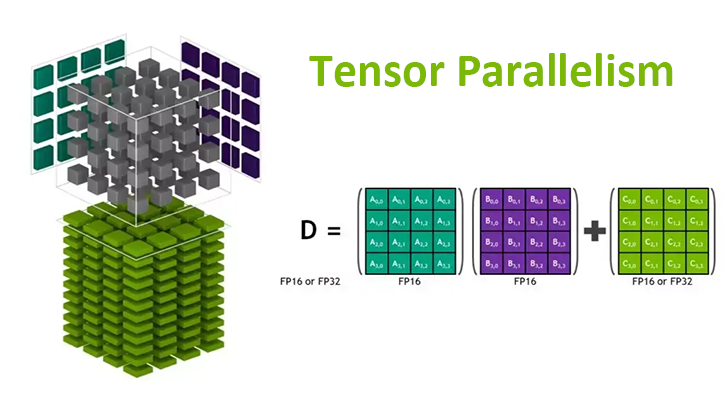
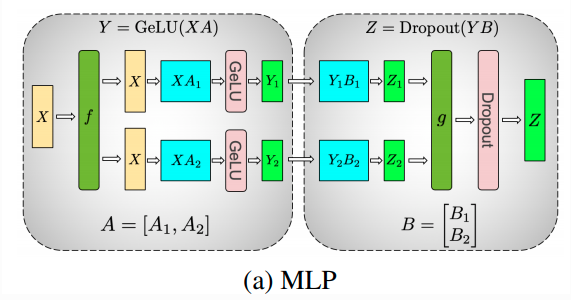
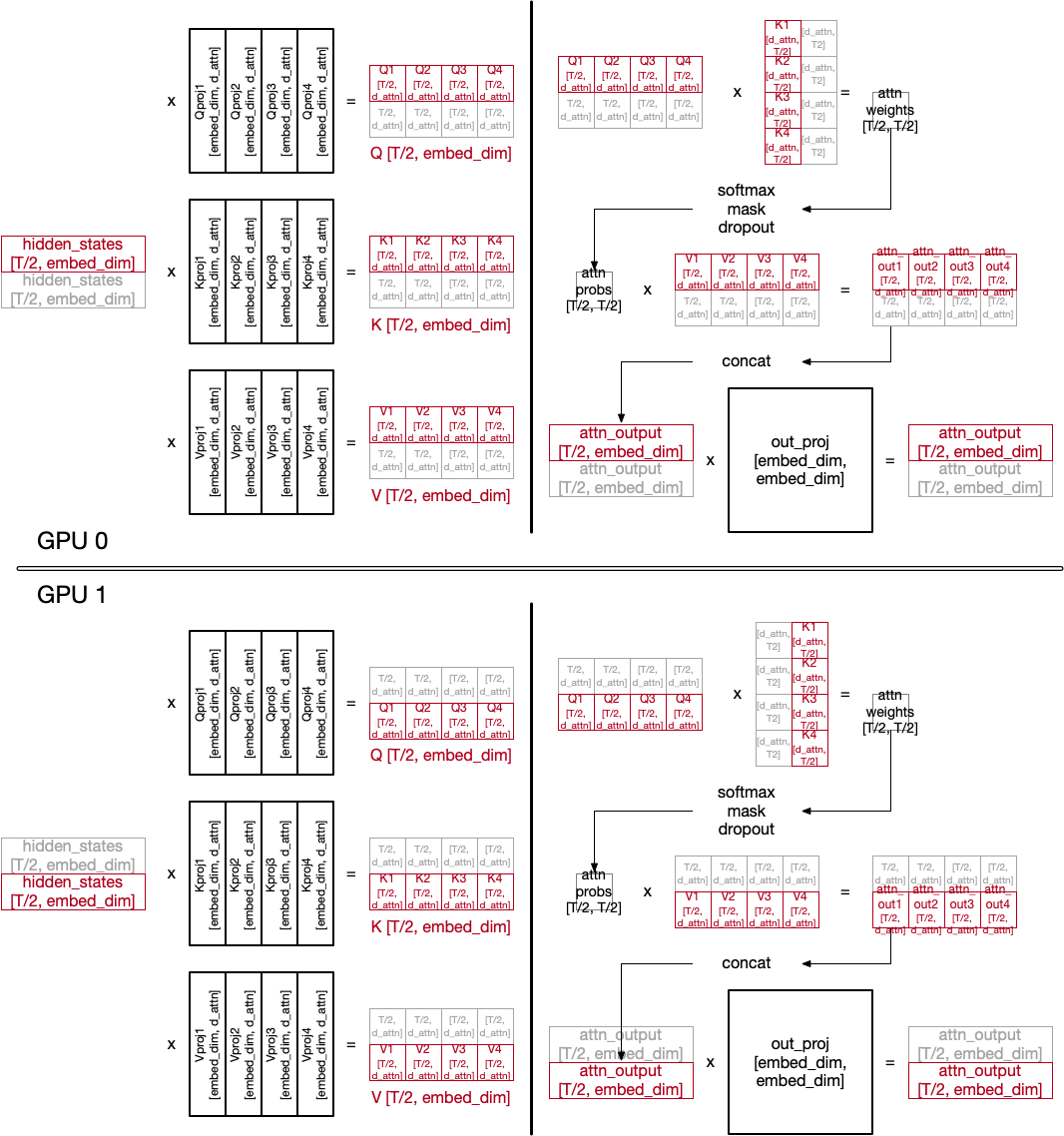
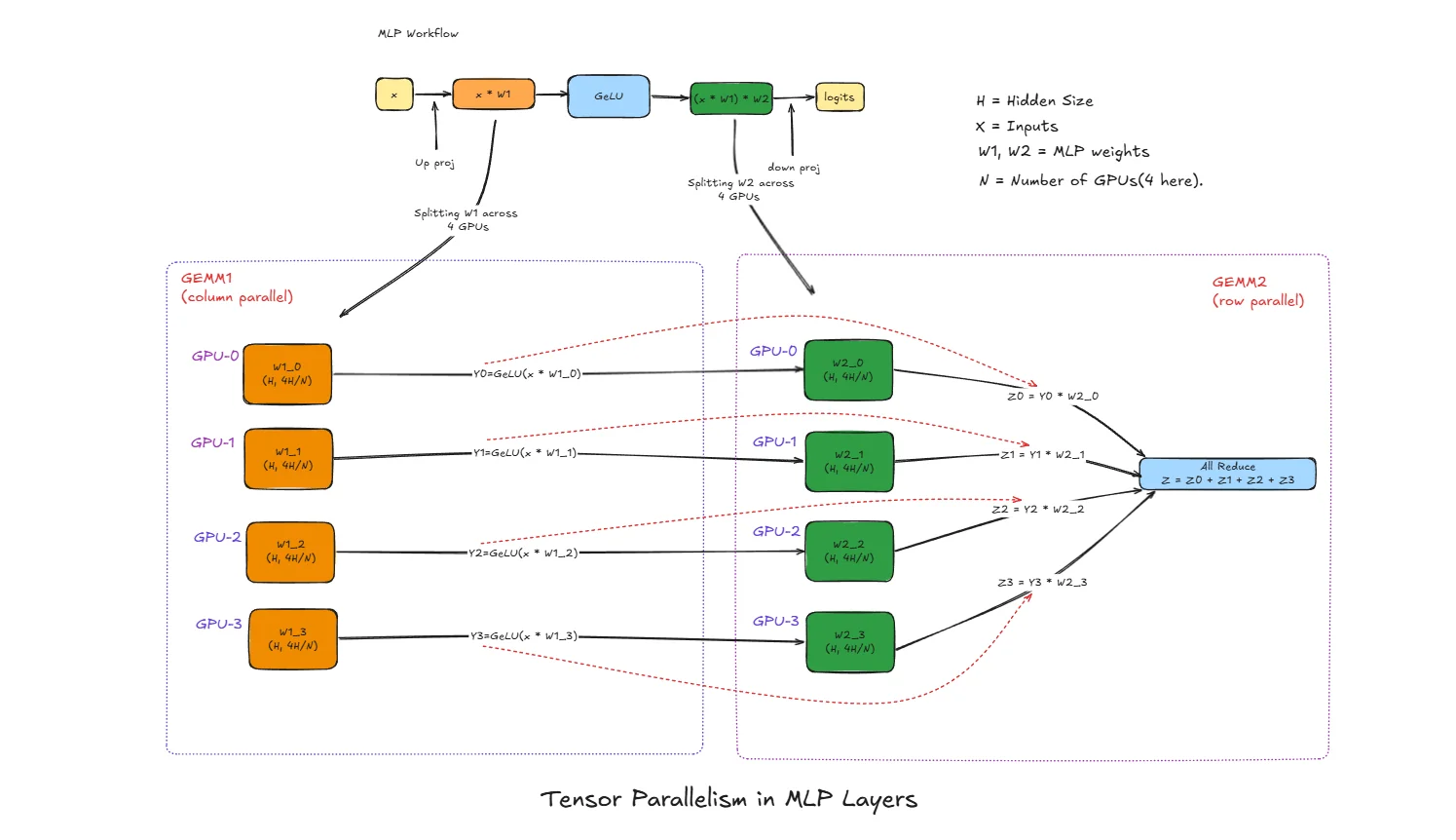
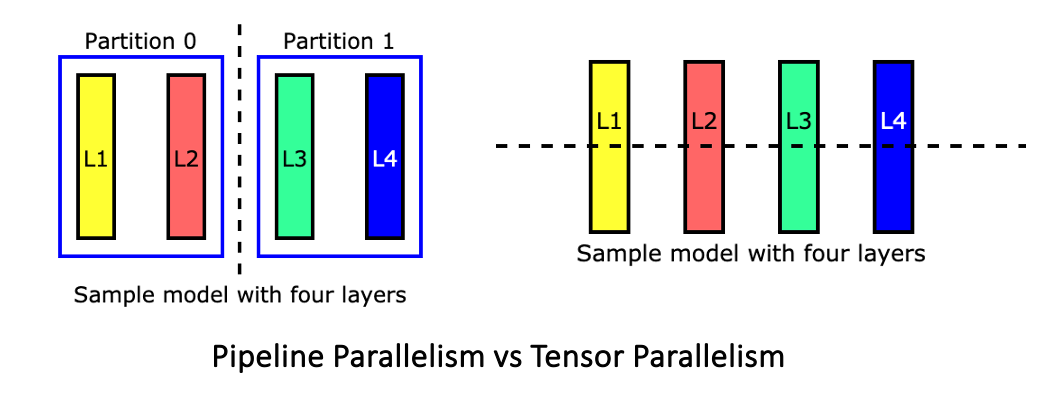
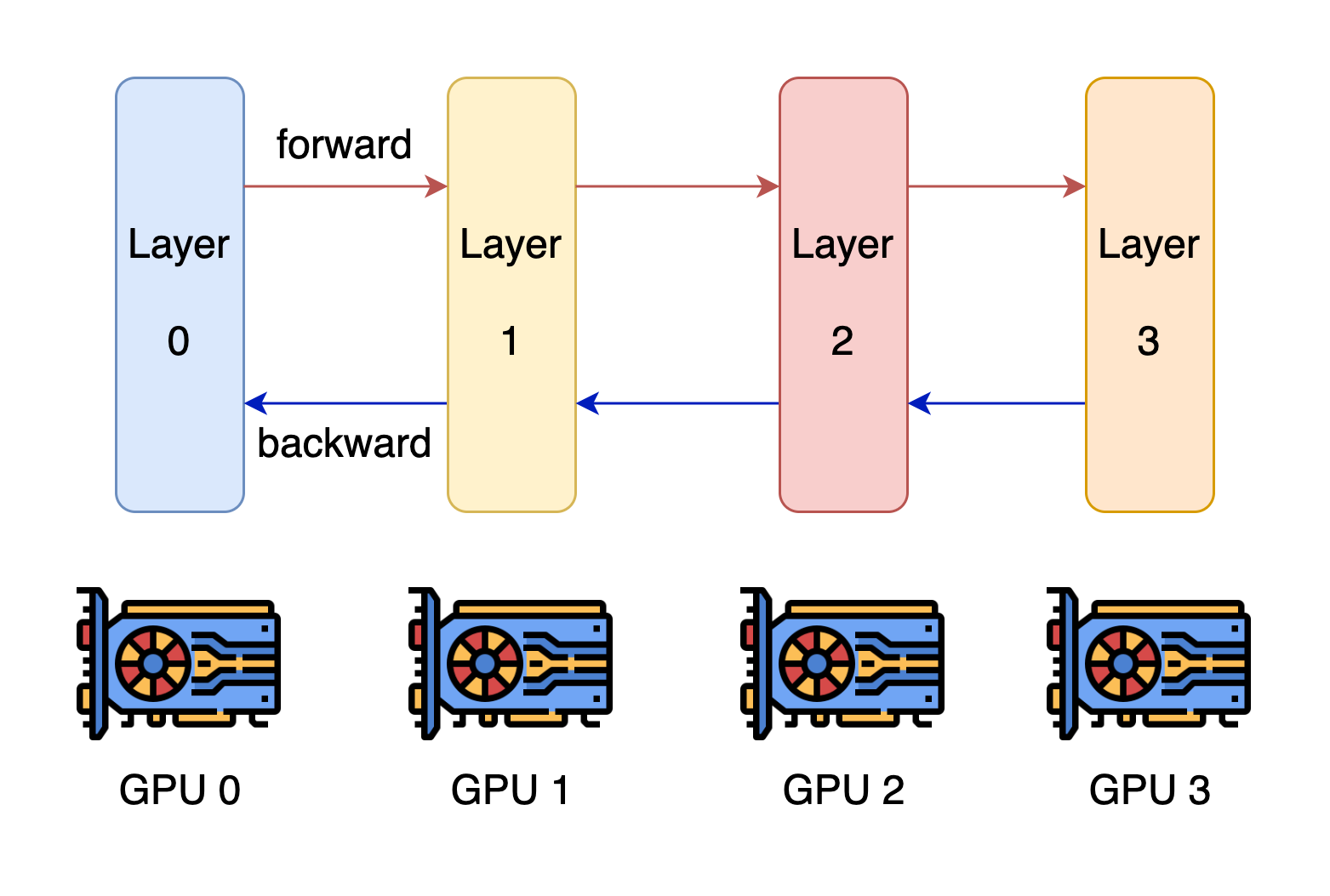
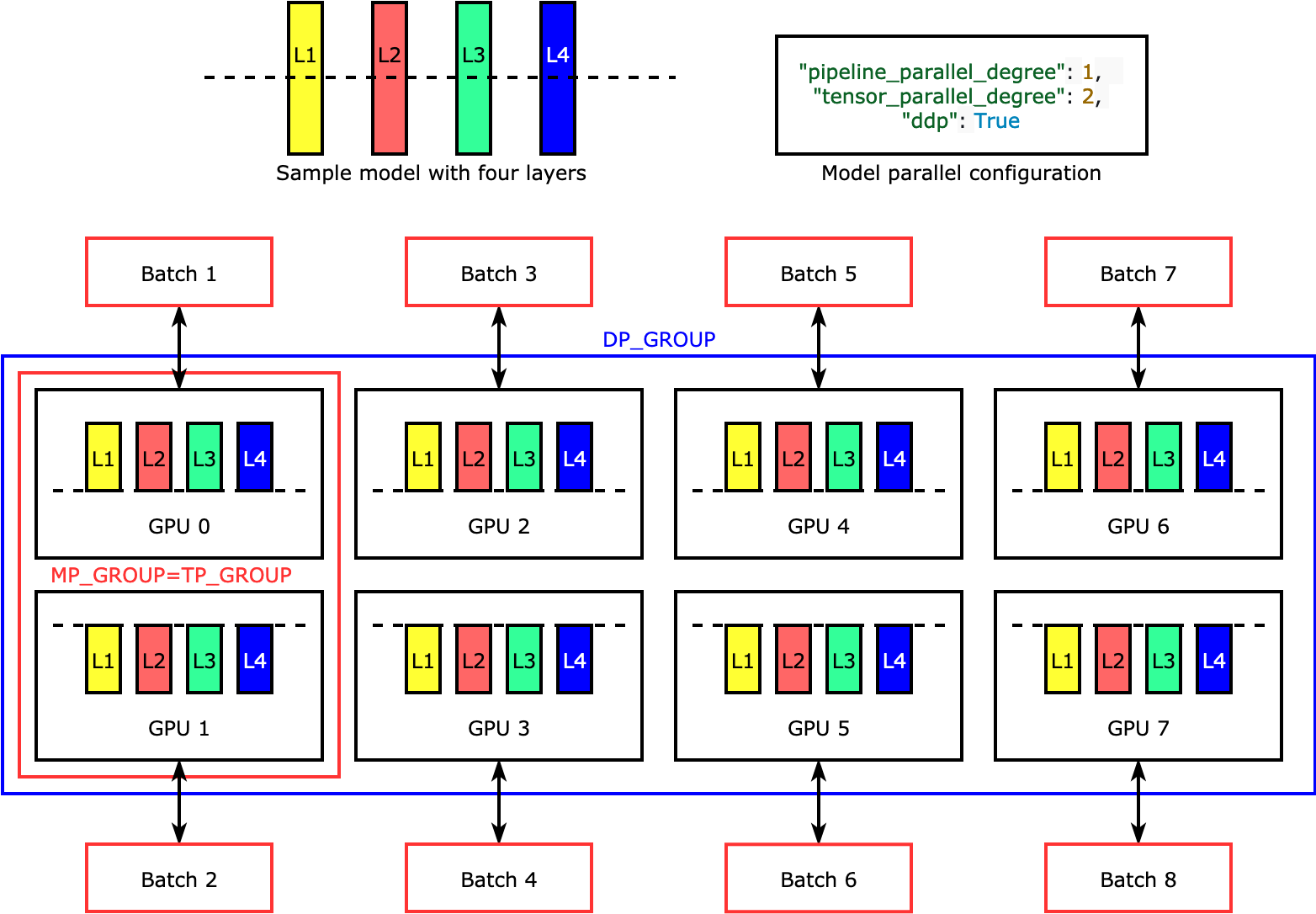
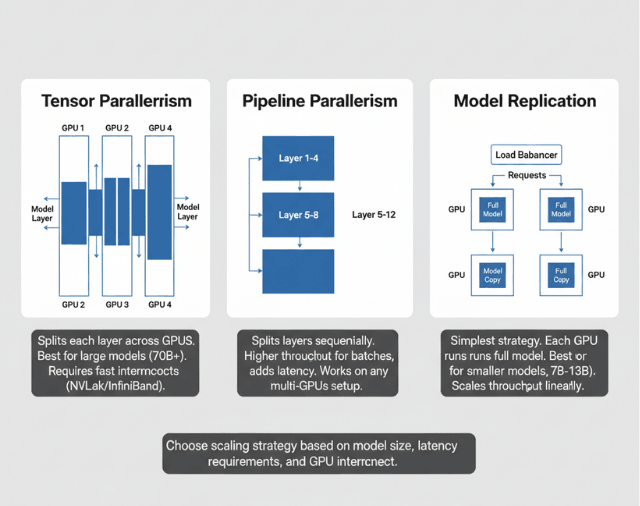
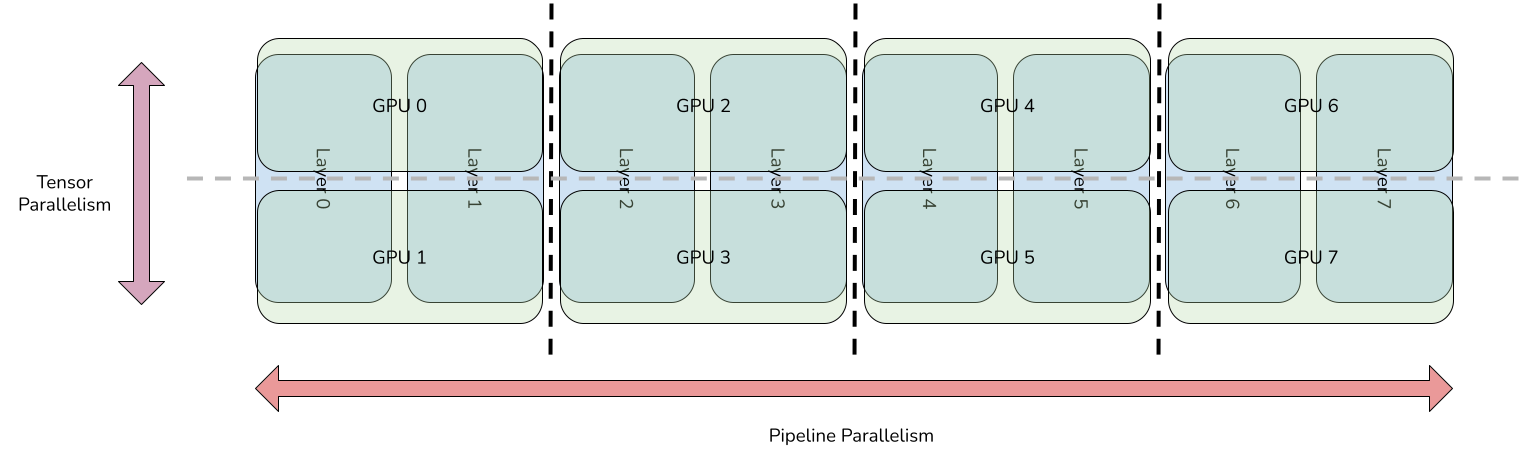
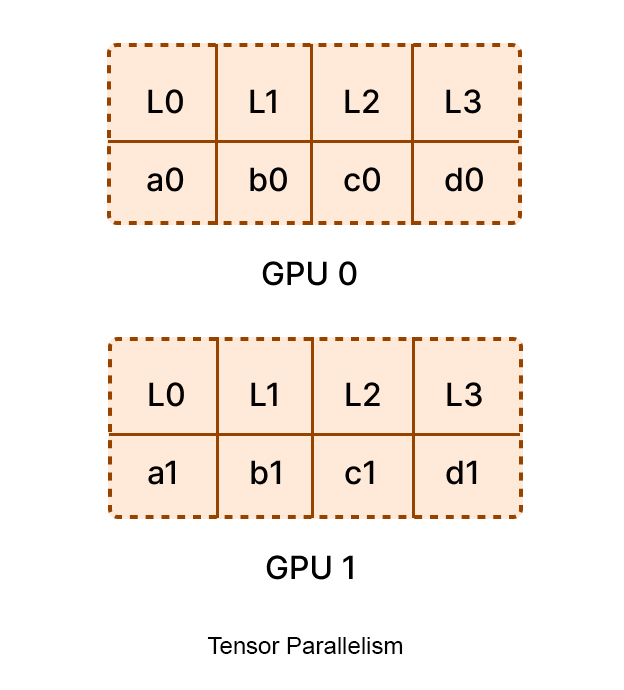
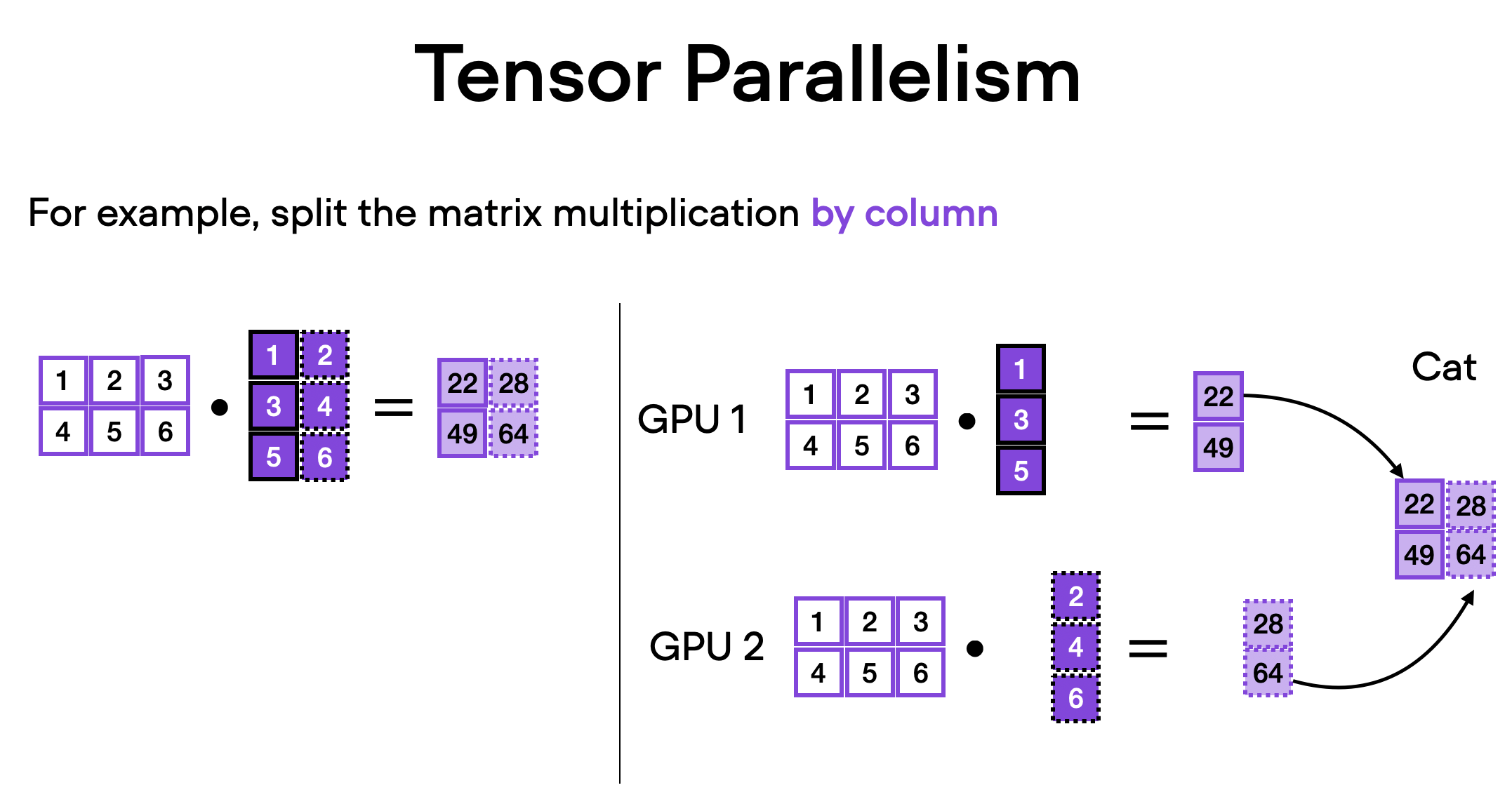
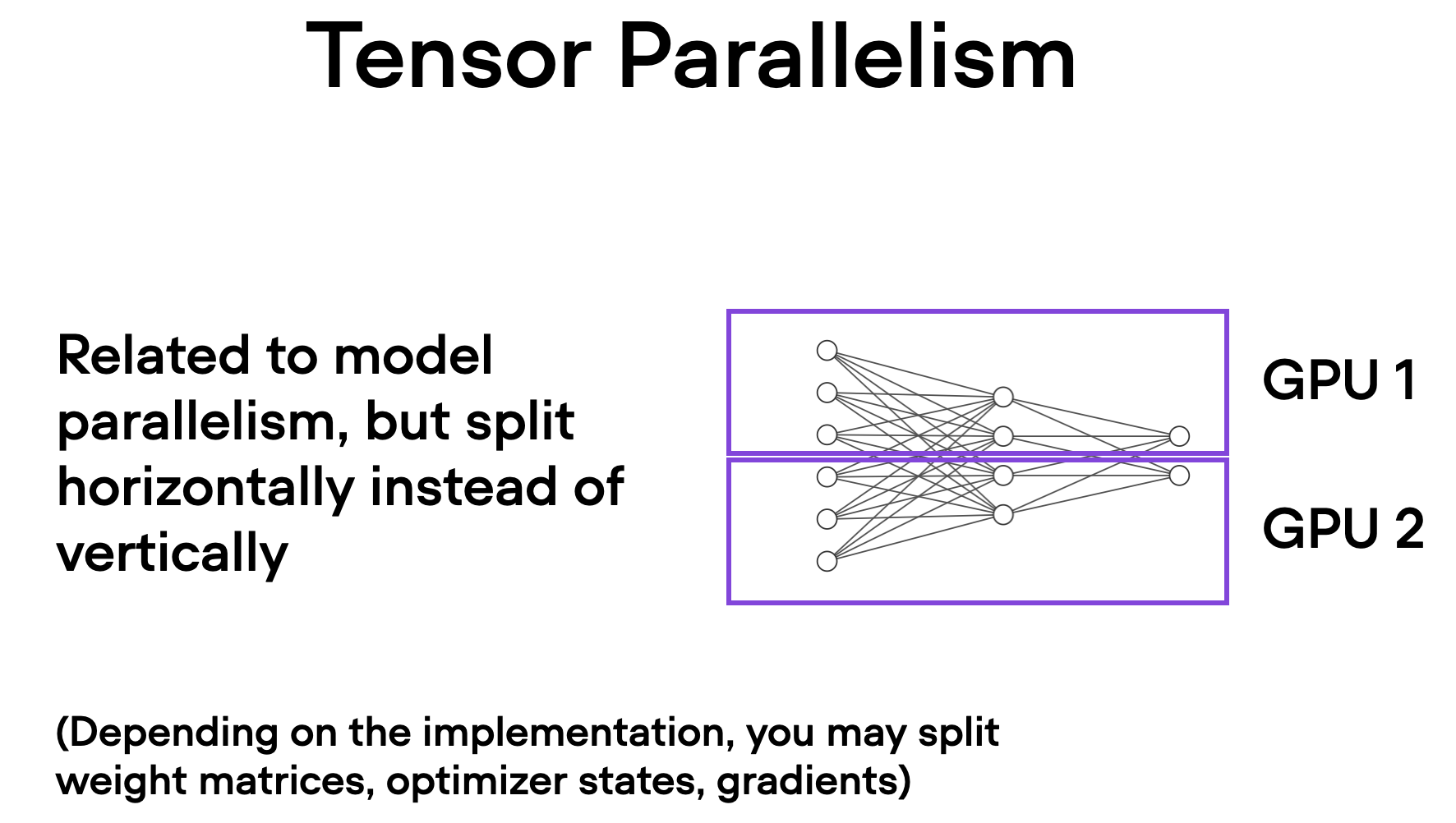
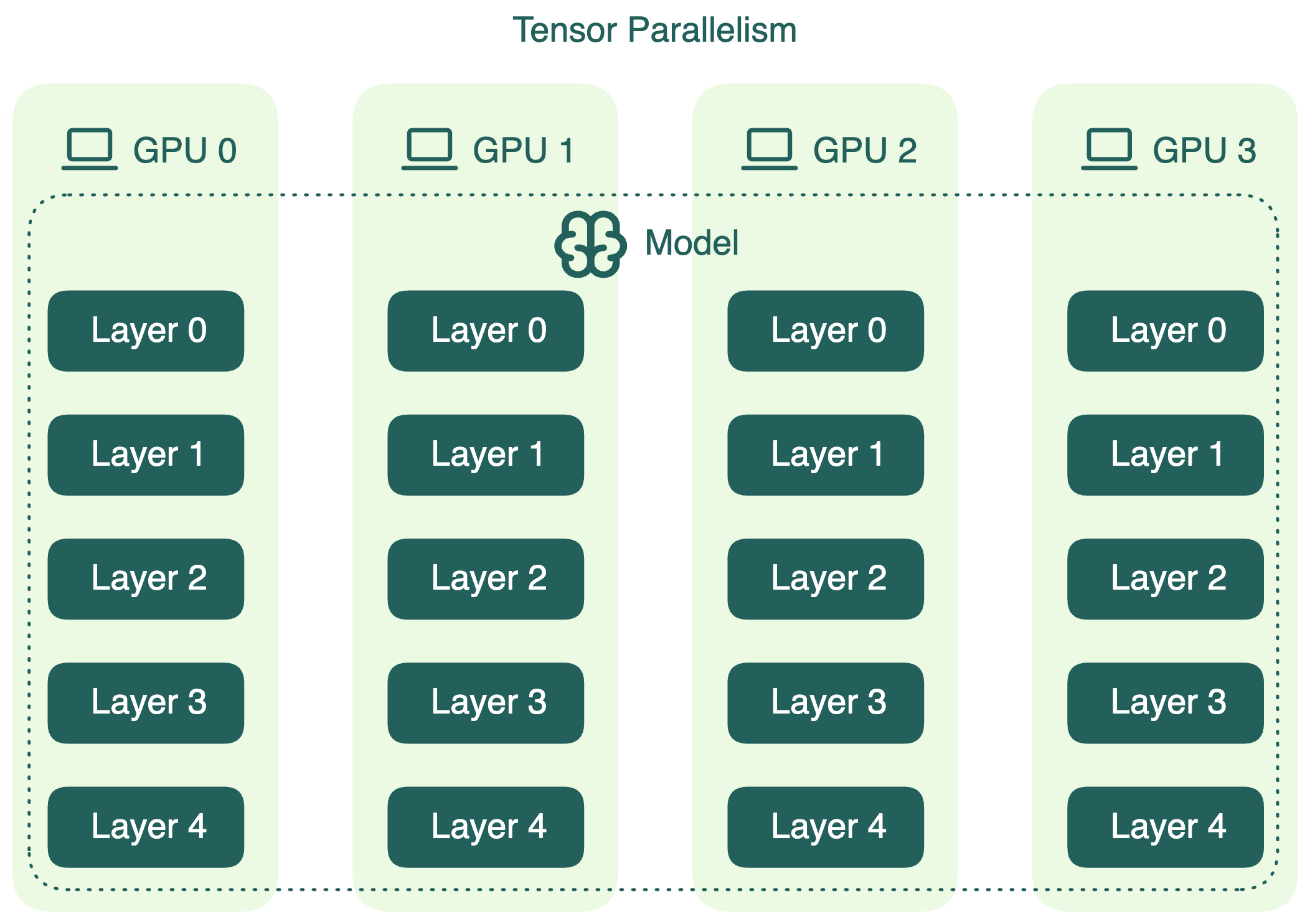
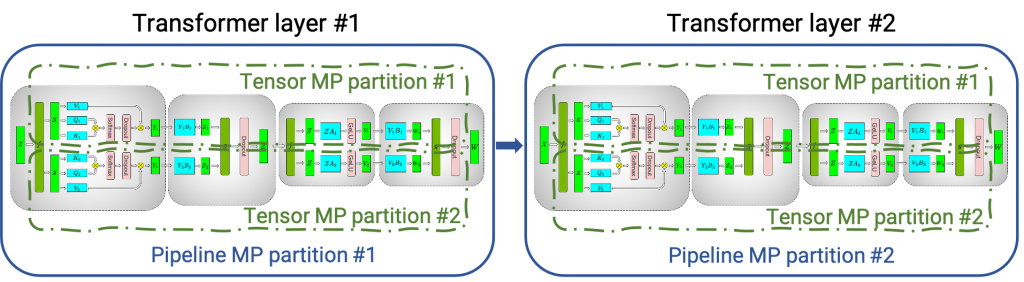
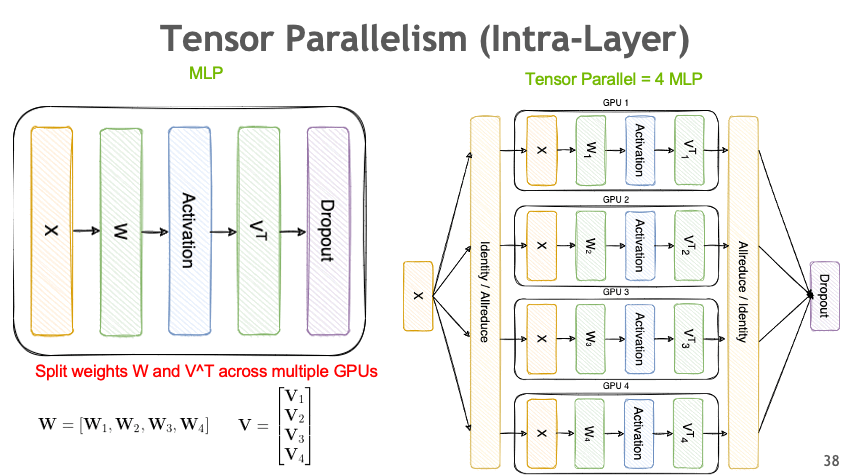
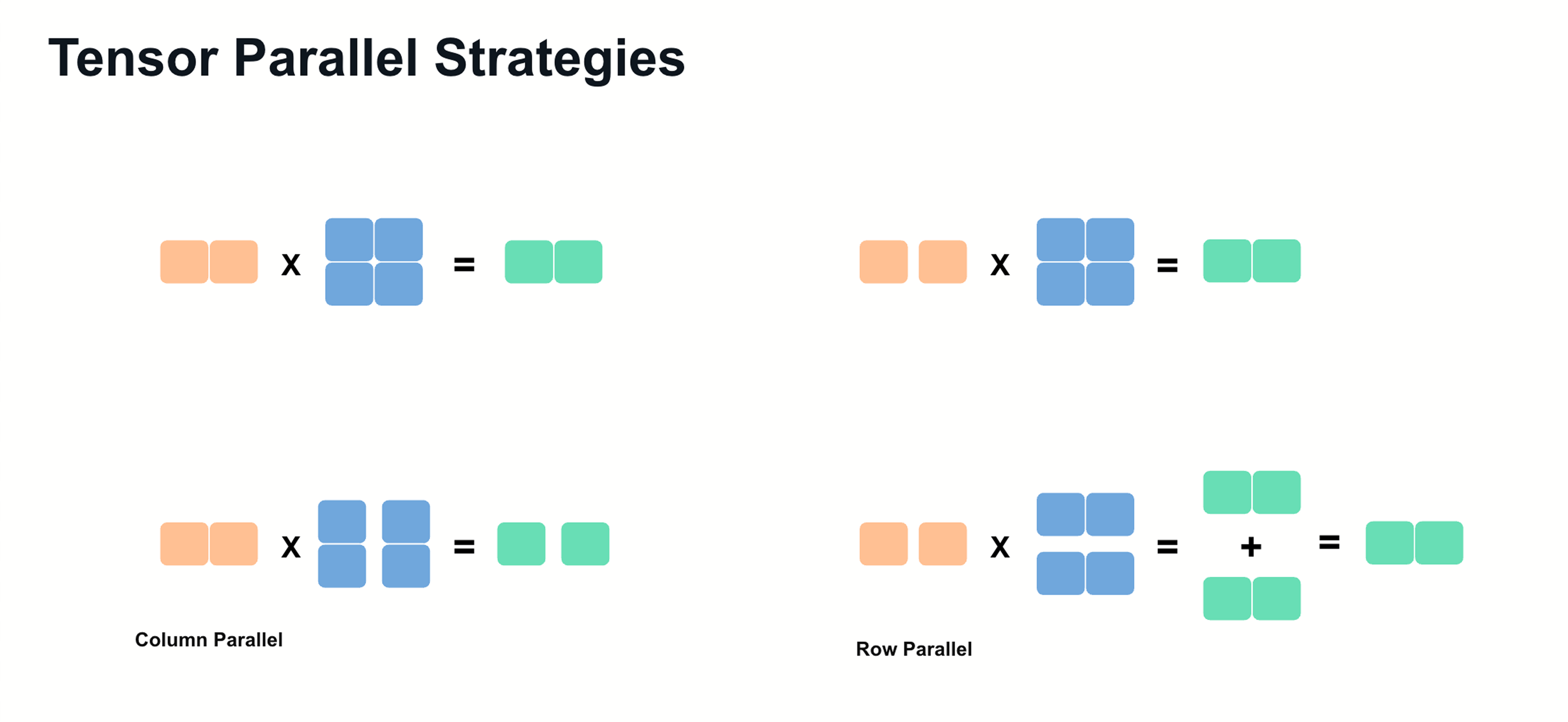
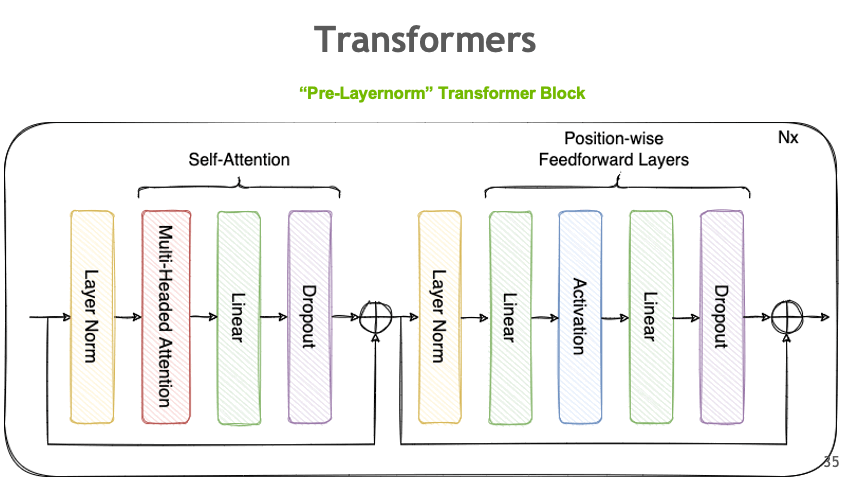
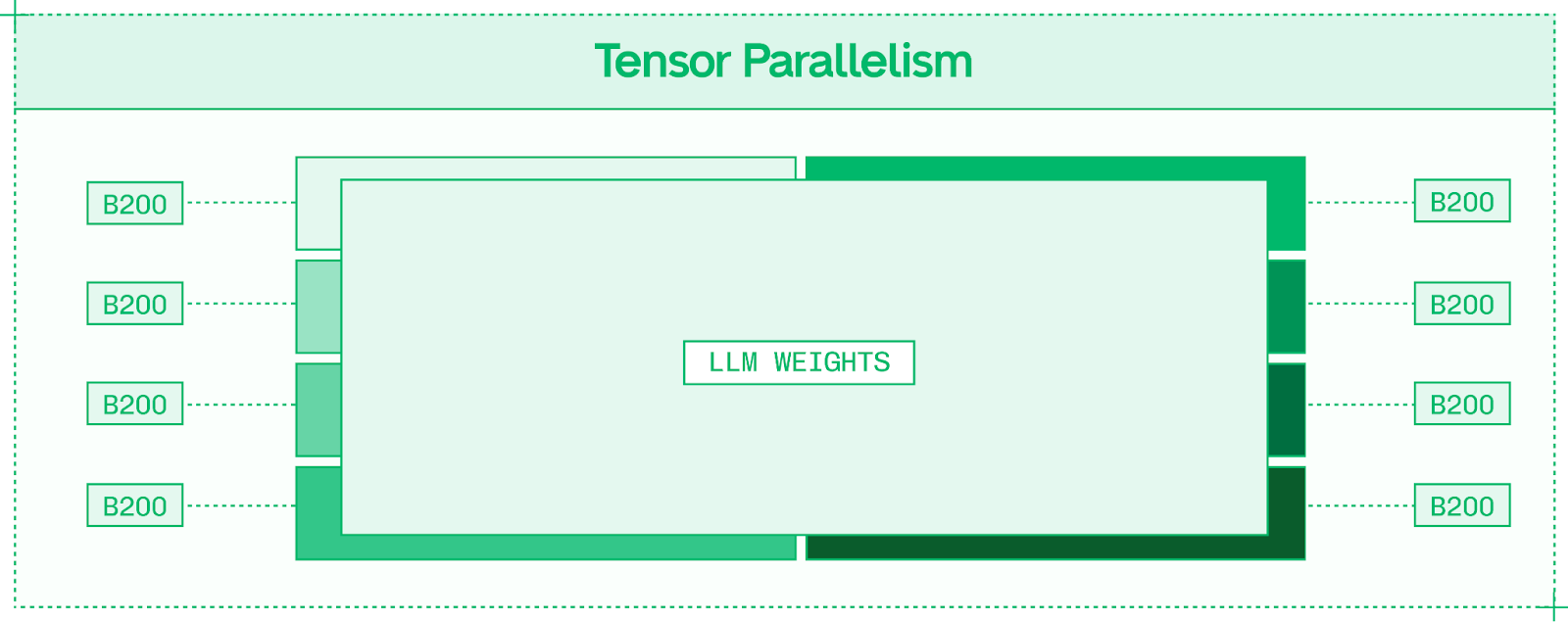
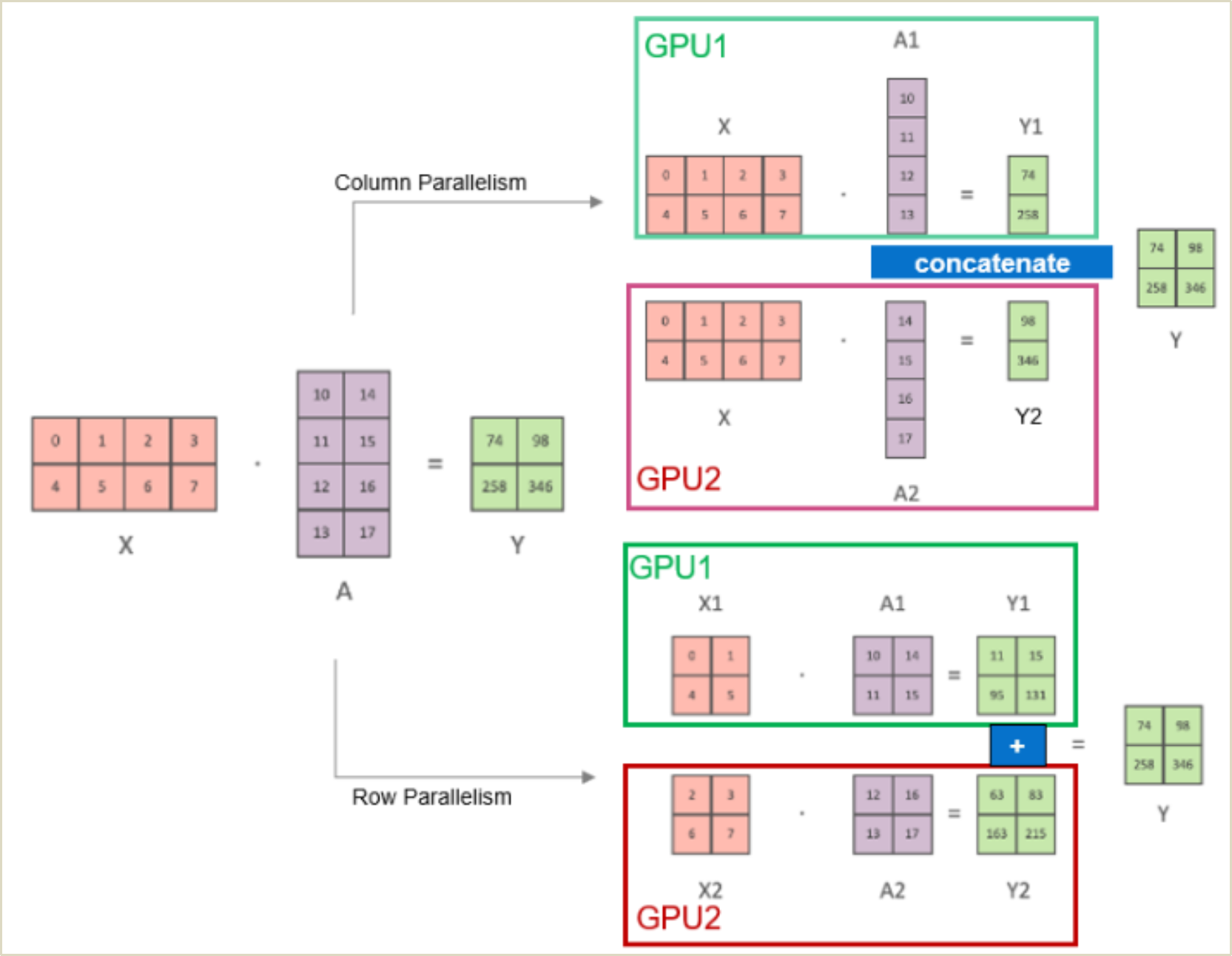
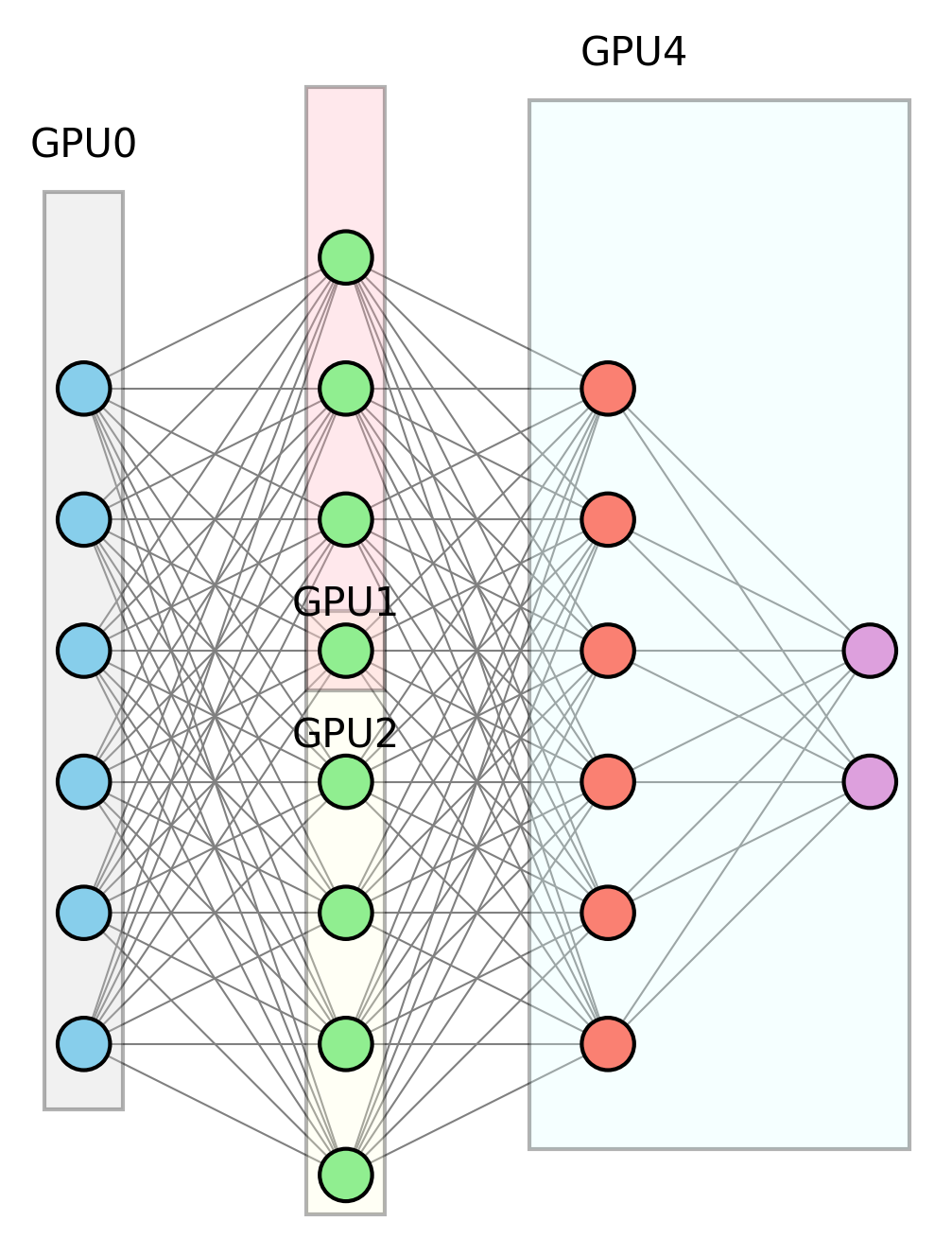
Tensor Parallelism
Analyzing the Impact of Tensor Parallelism Configurations on LLM ...
tensor parallelism
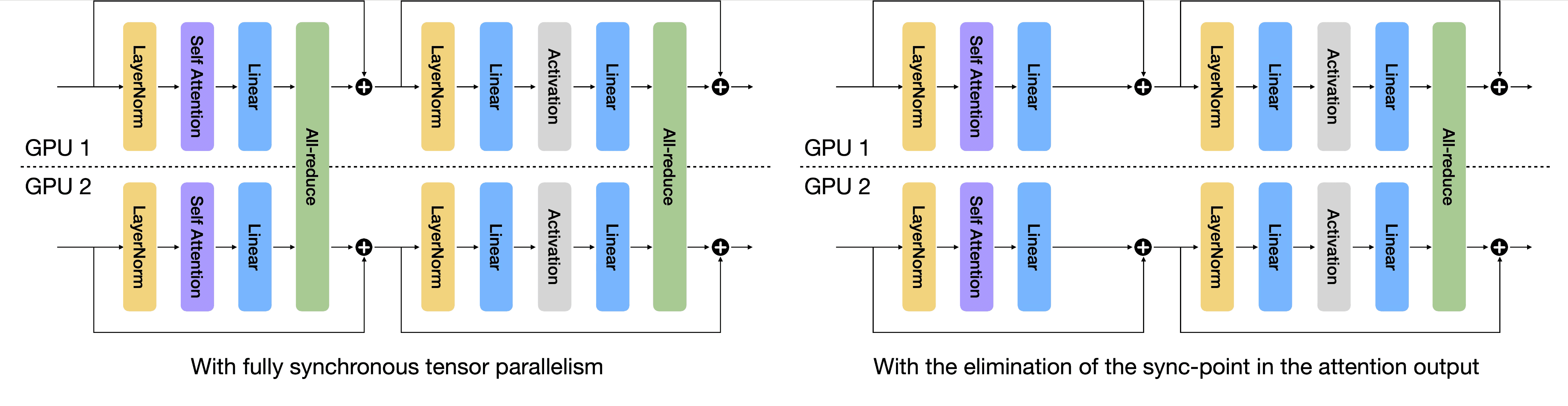
SPD: Sync-Point Drop for Efficient Tensor Parallelism of Large Language ...
Tensor Parallelism — PyTorch Lightning 2.6.1 documentation
Tensor Parallelism and Pipeline Parallelism - Kyle’s Tech Blog
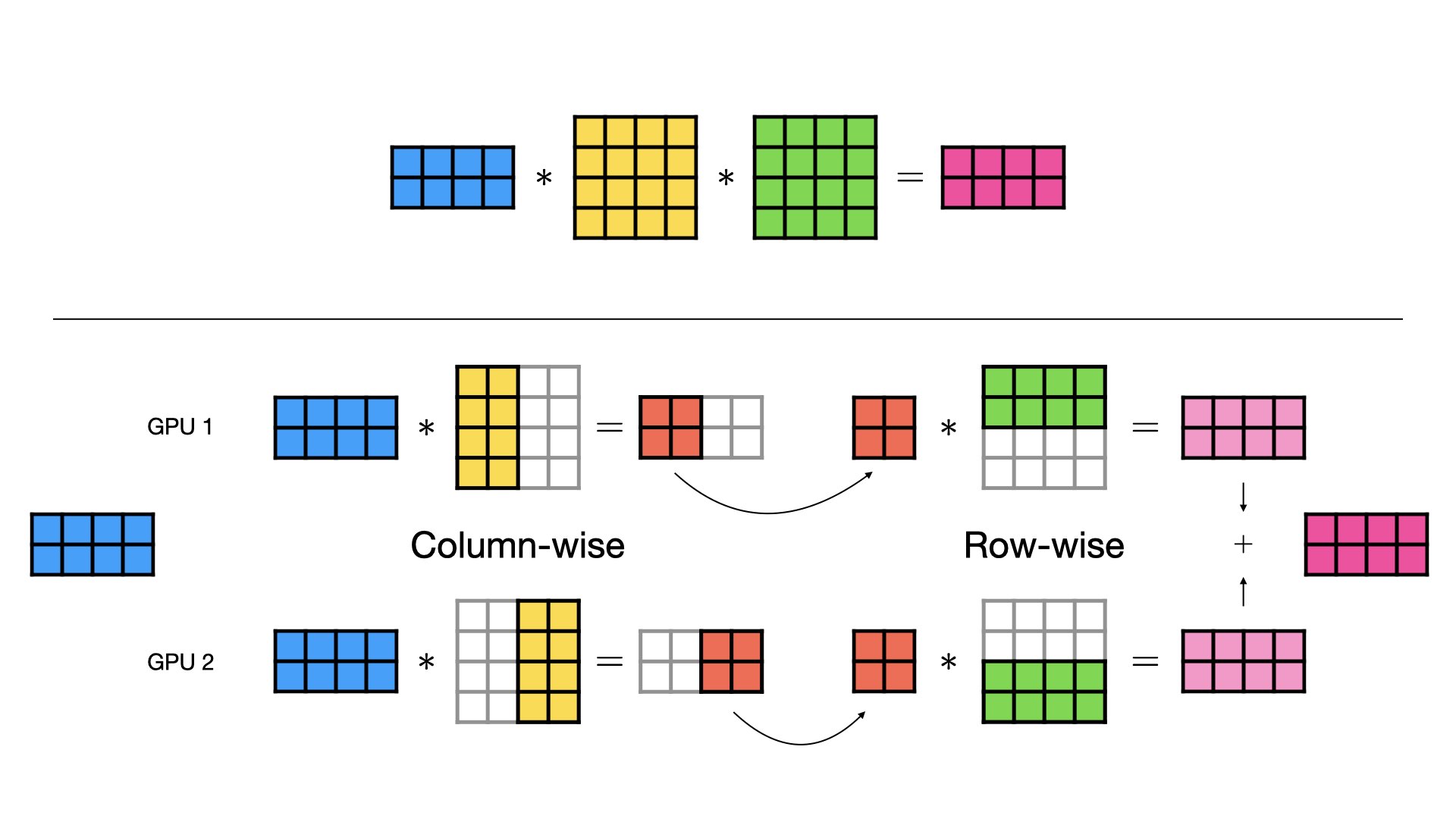
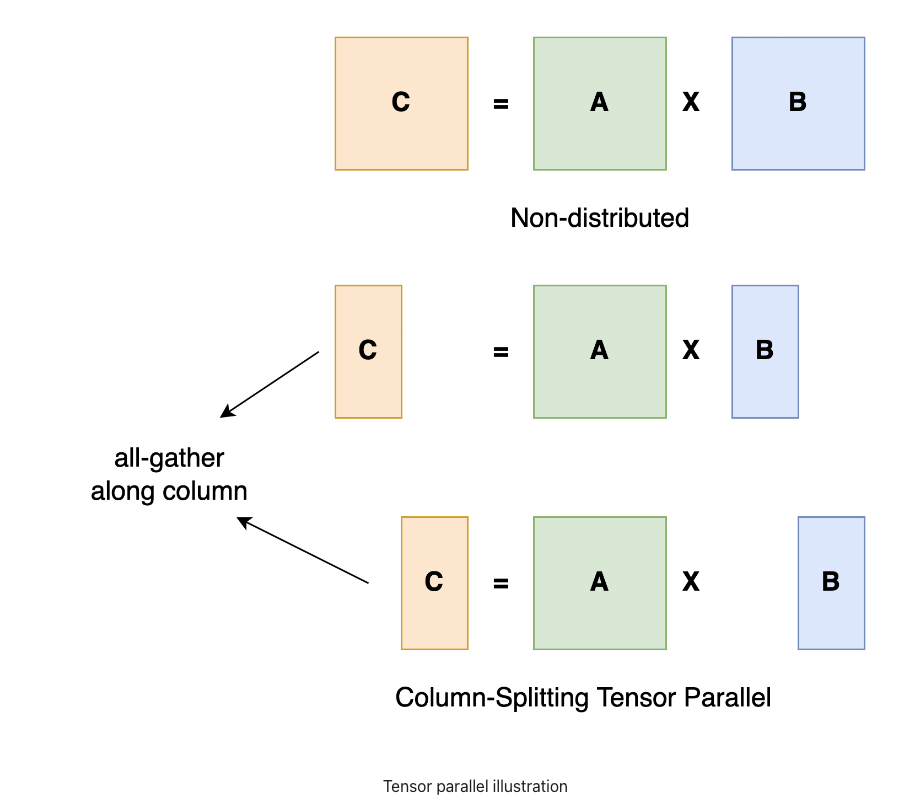
Sharding Large Models with Tensor Parallelism
Tensor Parallelism in Transformers: A Hands-On Guide for Multi-GPU ...
How Tensor Parallelism Works - Amazon SageMaker
vLLM Multi-GPU Documentation — Tensor Parallelism Setup & Configs (2026 ...
Tensor Parallelism Overview — AWS Neuron Documentation
Tensor Parallelism and Sequence Parallelism: Detailed Analysis · Better ...
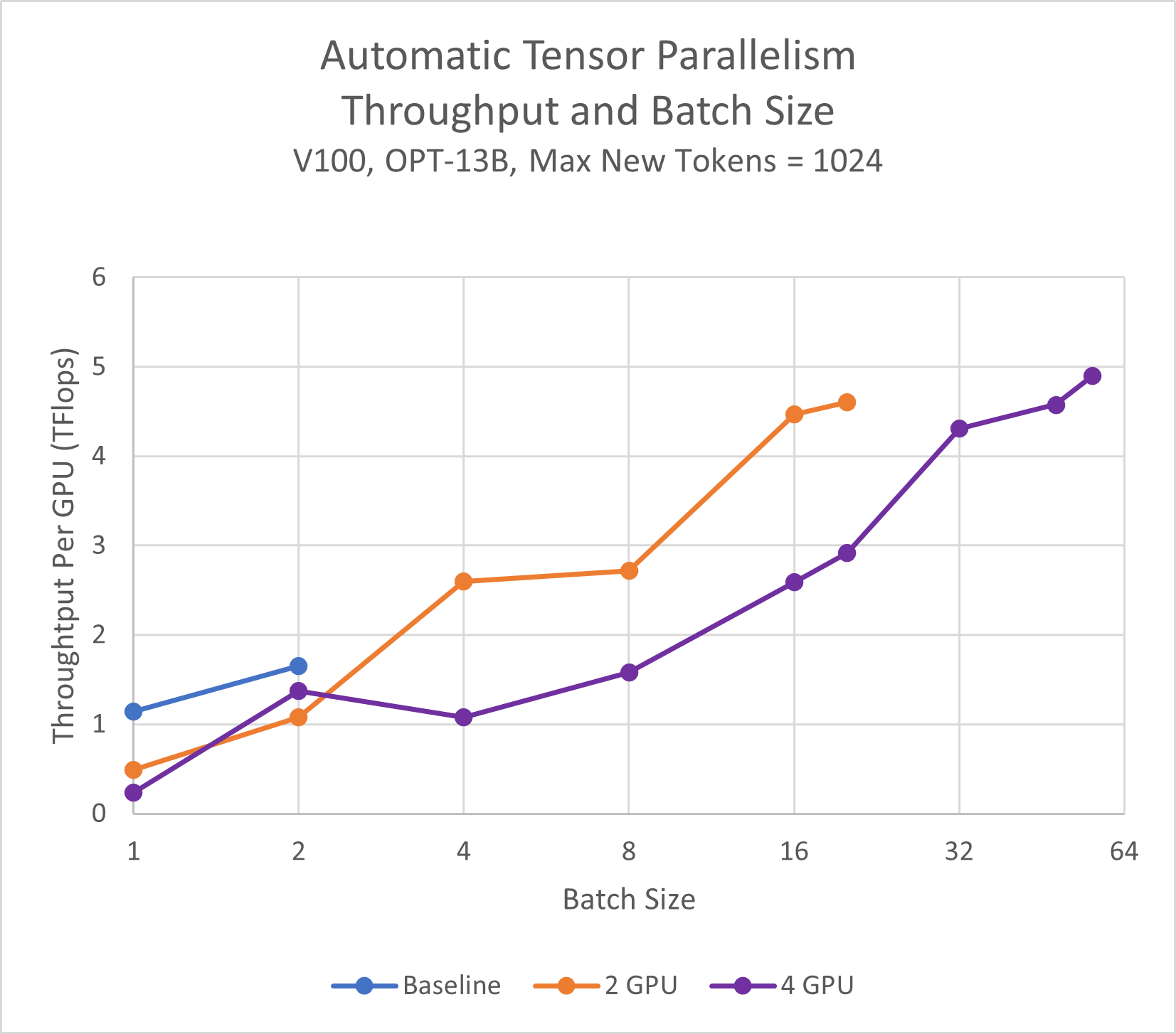
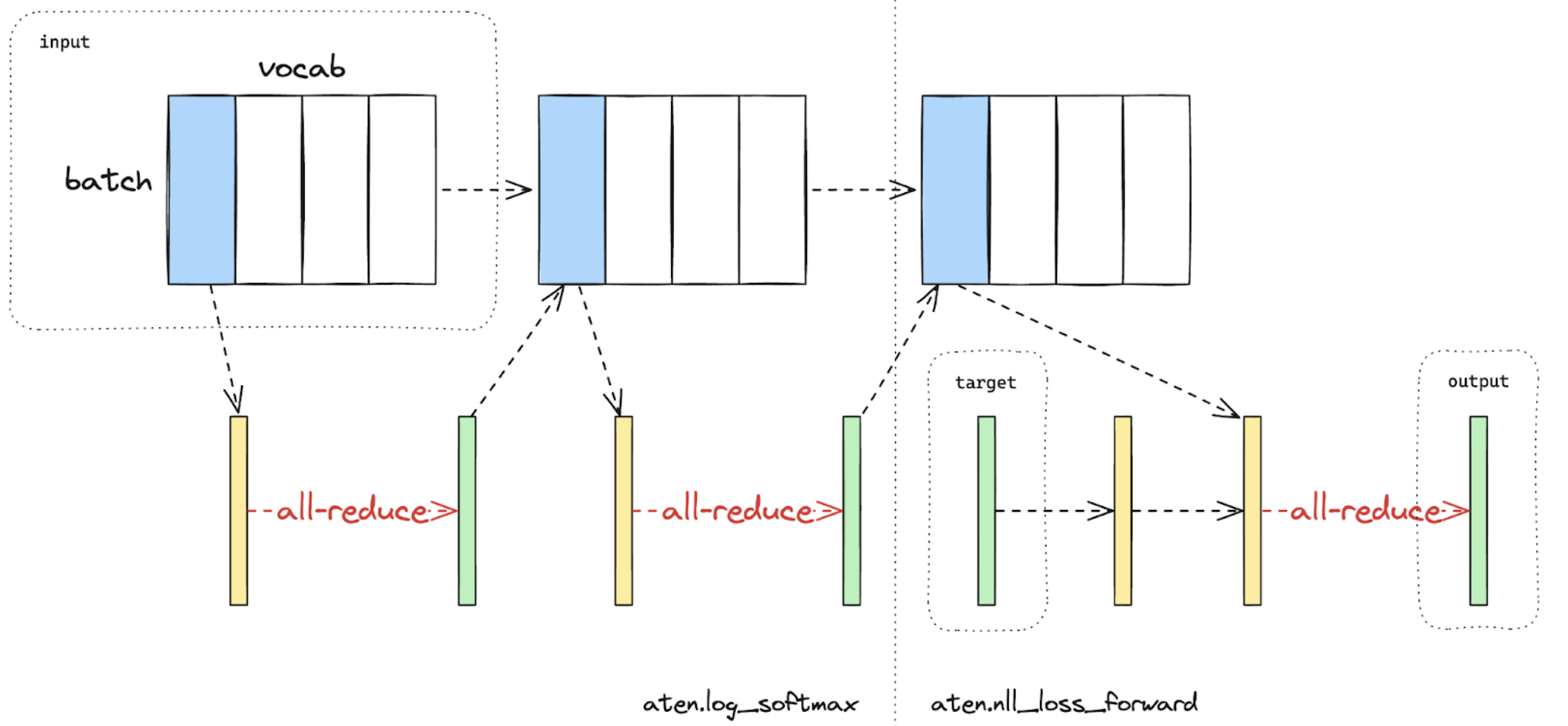
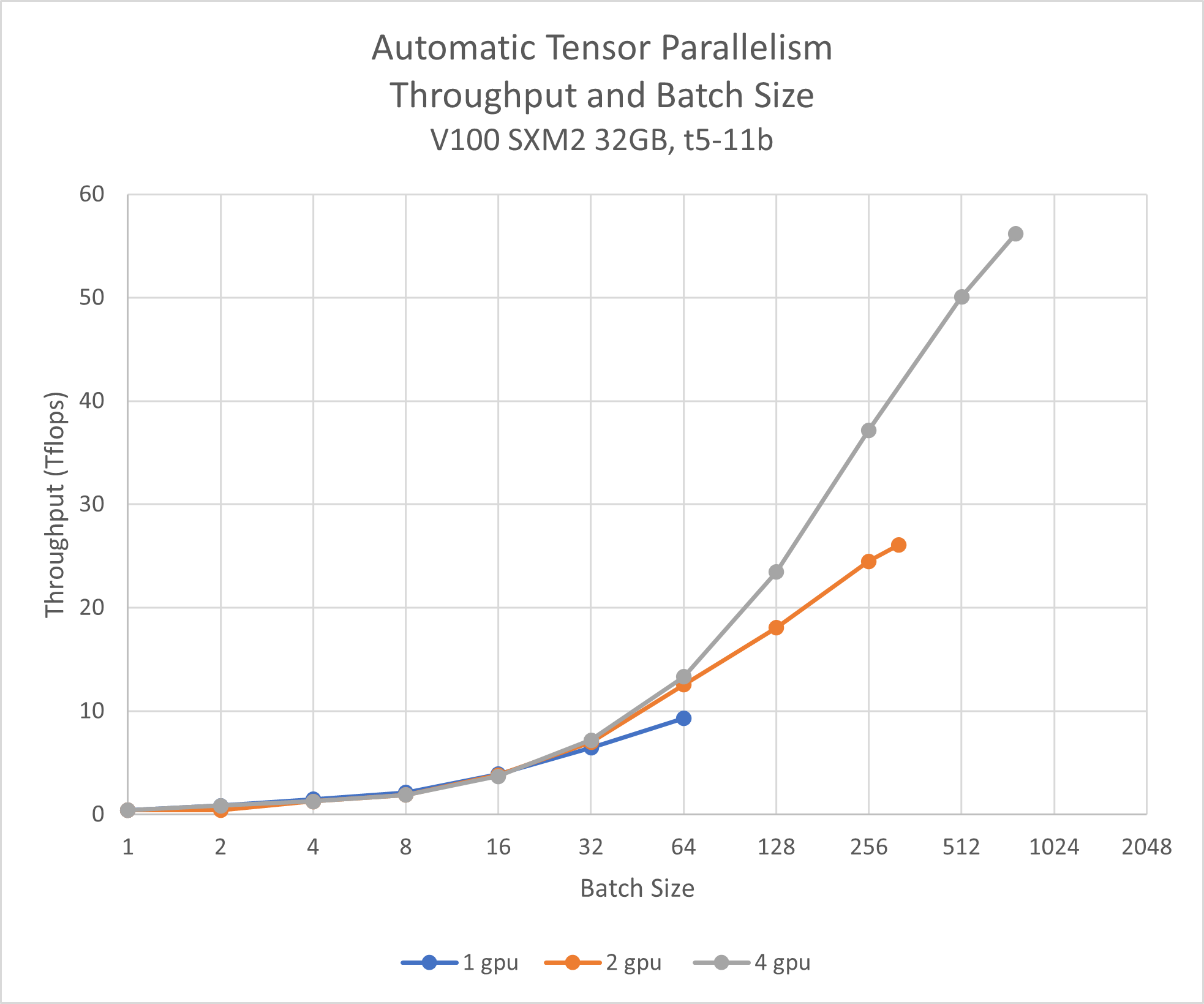
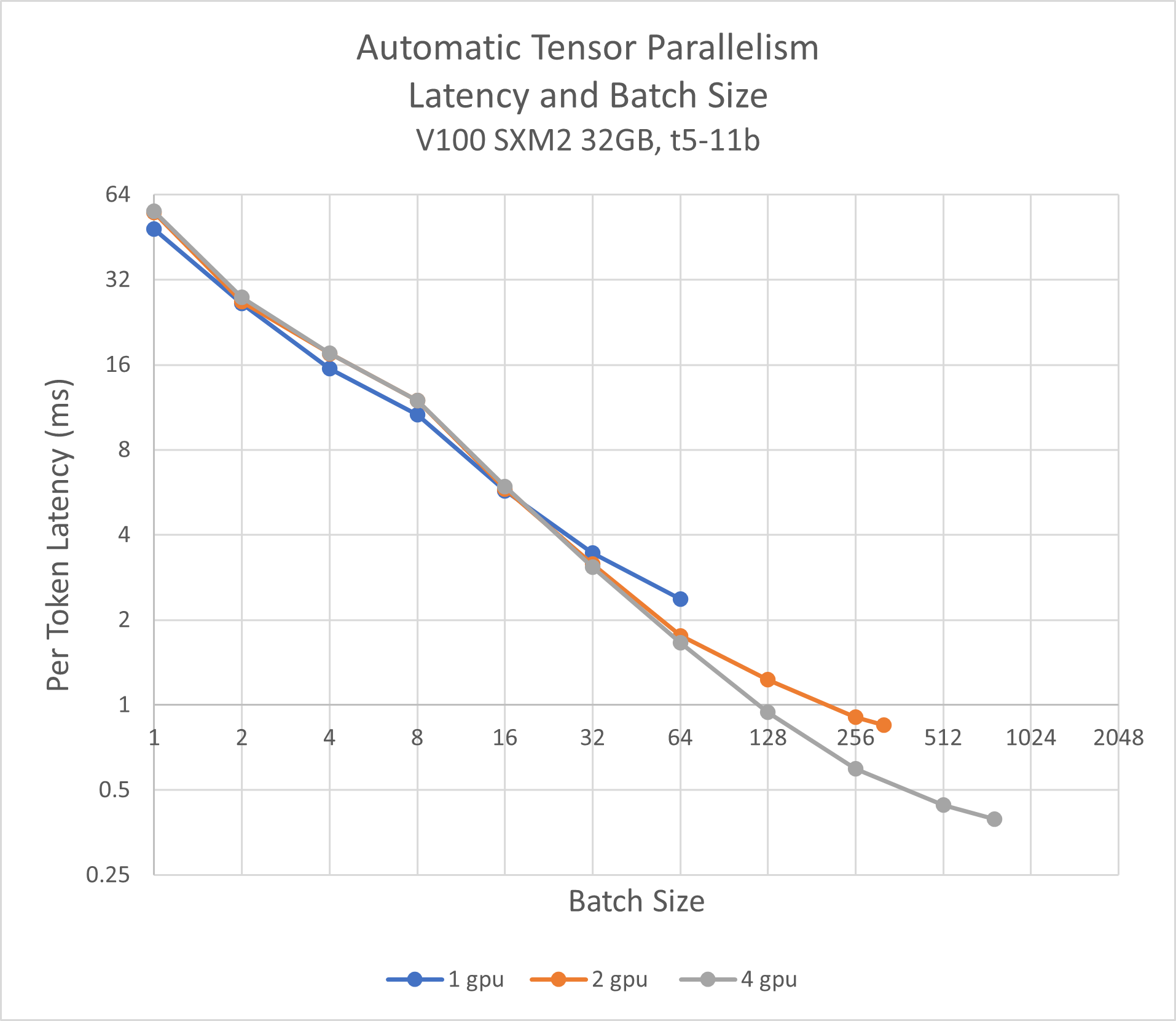
Automatic Tensor Parallelism for HuggingFace Models - DeepSpeed
Pytorch2 Tensor Parallelism | Sharlayan
python - How to achieve GPU parallelism using tensor-flow? - Stack Overflow
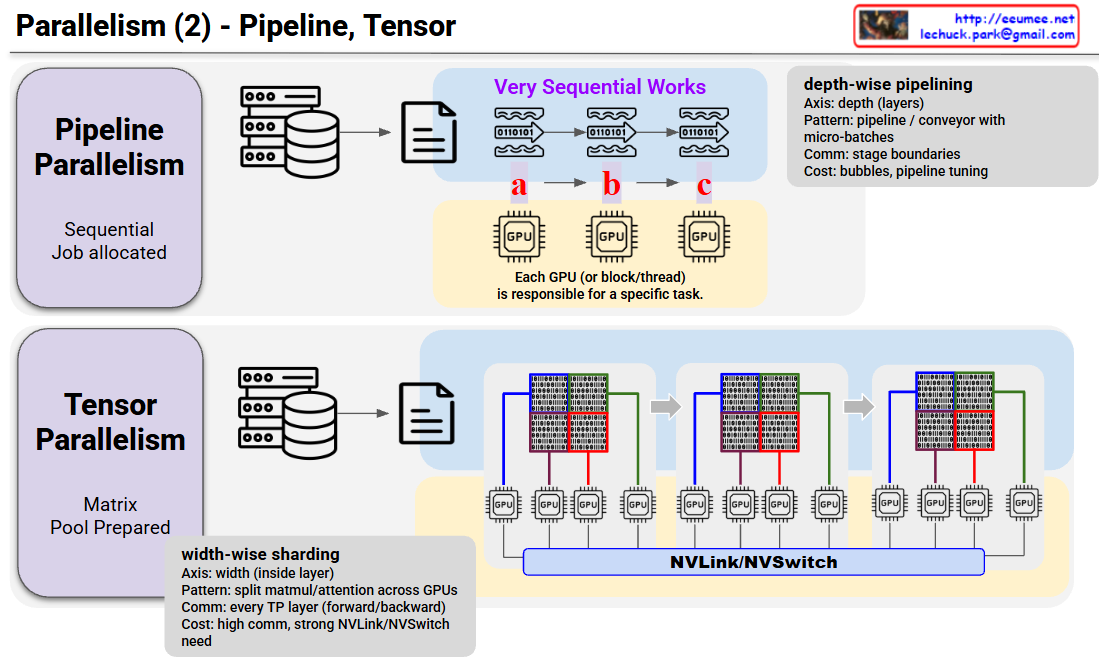
Parallelism (2) – Pipeline, Tensor – Lechuck Park
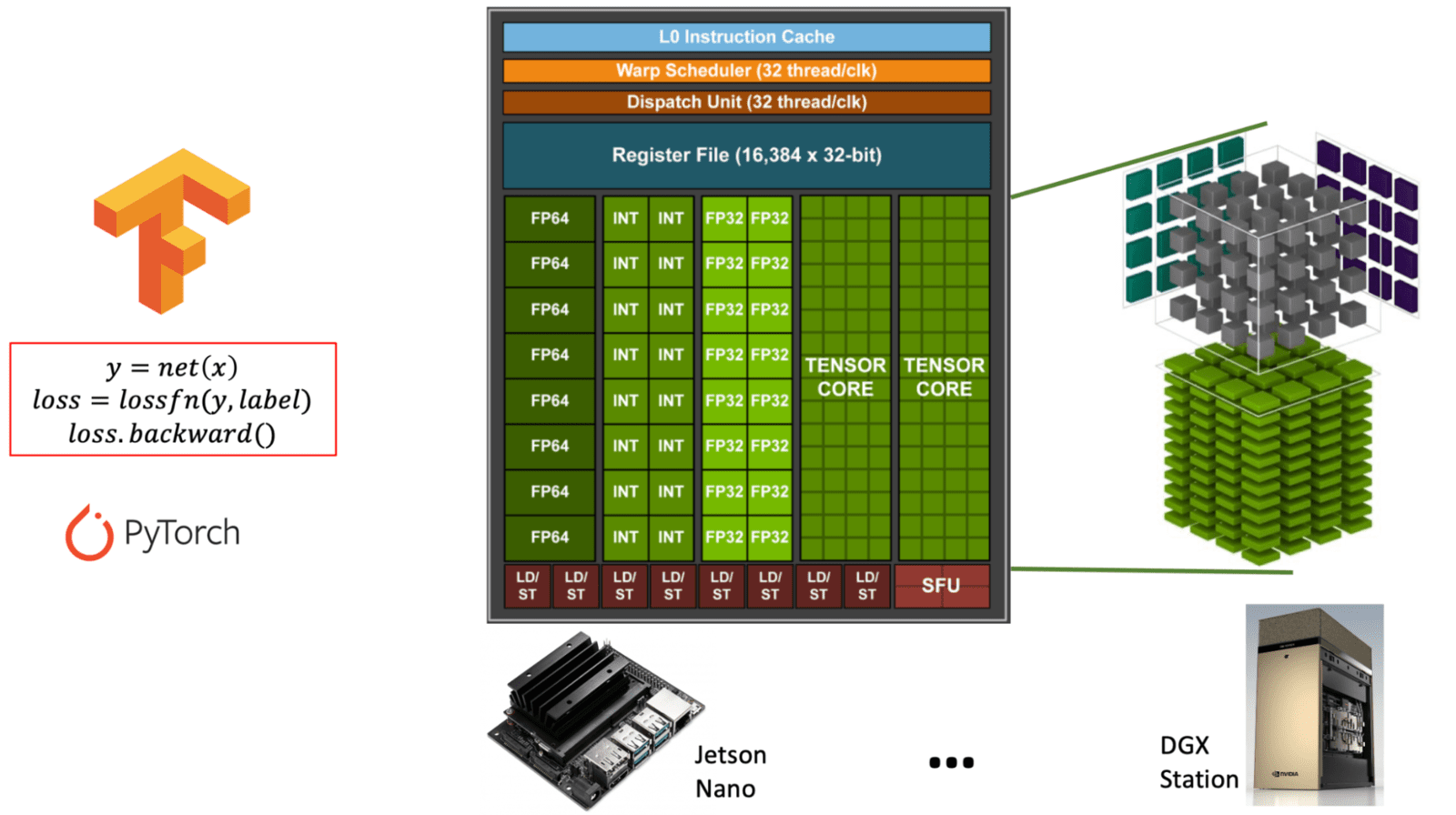
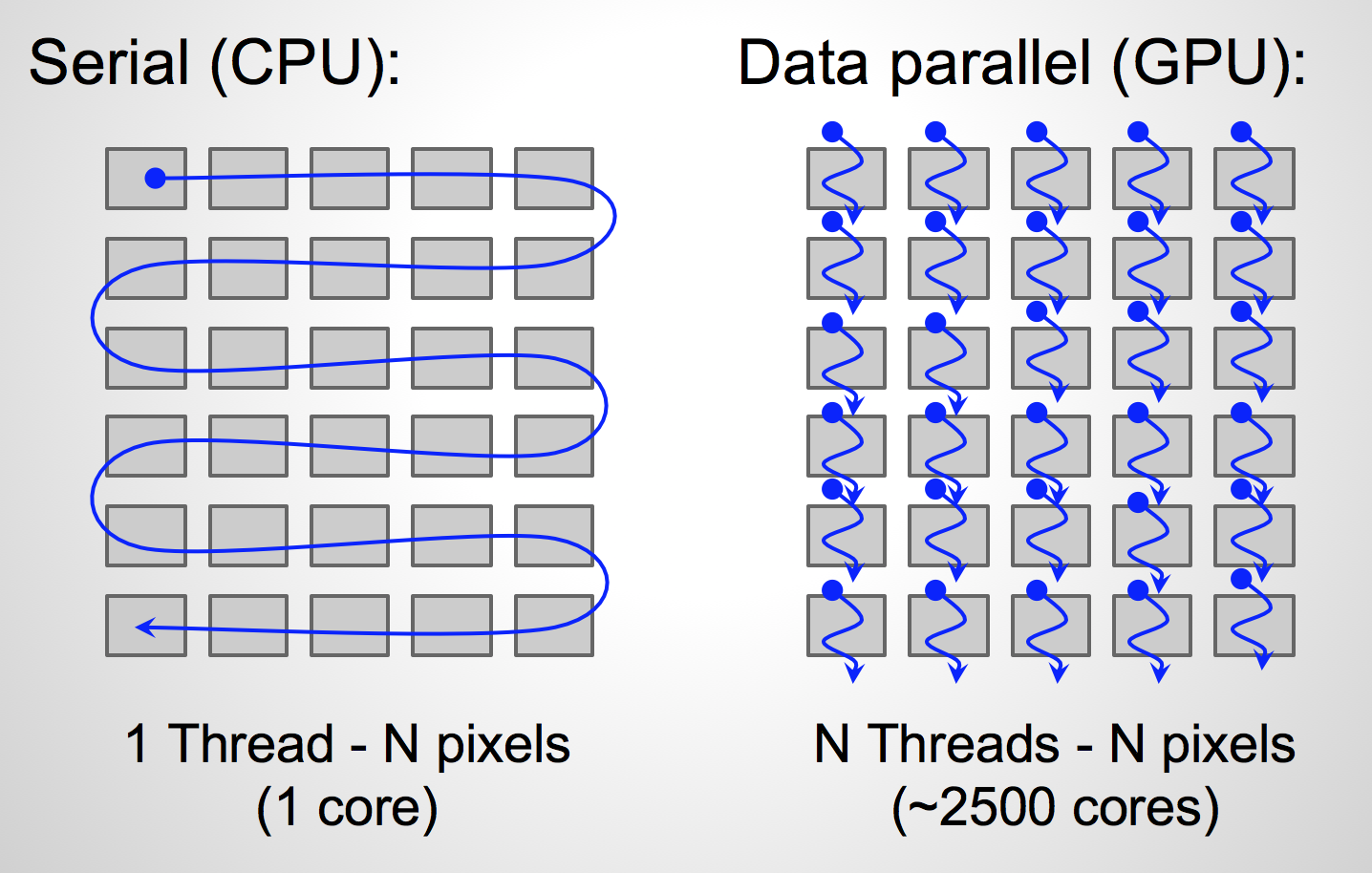
GPU Programming with CUDA and Tensor Cores: Harness Parallel Processing ...
The Illustrated Tensor Parallelism | AI Bytes
Tensor Parallelism | Ayar Labs
NanoGPT-inference - Tensor Parallelism | Pieter Delobelle
Tensor Parallelism in Transformers — How to Scale Transformer Models ...
(PDF) Improving GPU Throughput through Parallel Execution Using Tensor ...
(NEW PARALLEL) NVIDIA L4 24GB Tensor Core GPU Graphics Card – C2 Computer
Part 4.1: Tensor Parallelism — UvA DL Notebooks v1.2 documentation
Train Your Large Model on Multiple GPUs with Tensor Parallelism ...
Scaling LLM Inference: Data, Pipeline & Tensor Parallelism in vLLM ...
Understanding CUDA Flag Architectures: A Deep Dive into GPU Computation ...
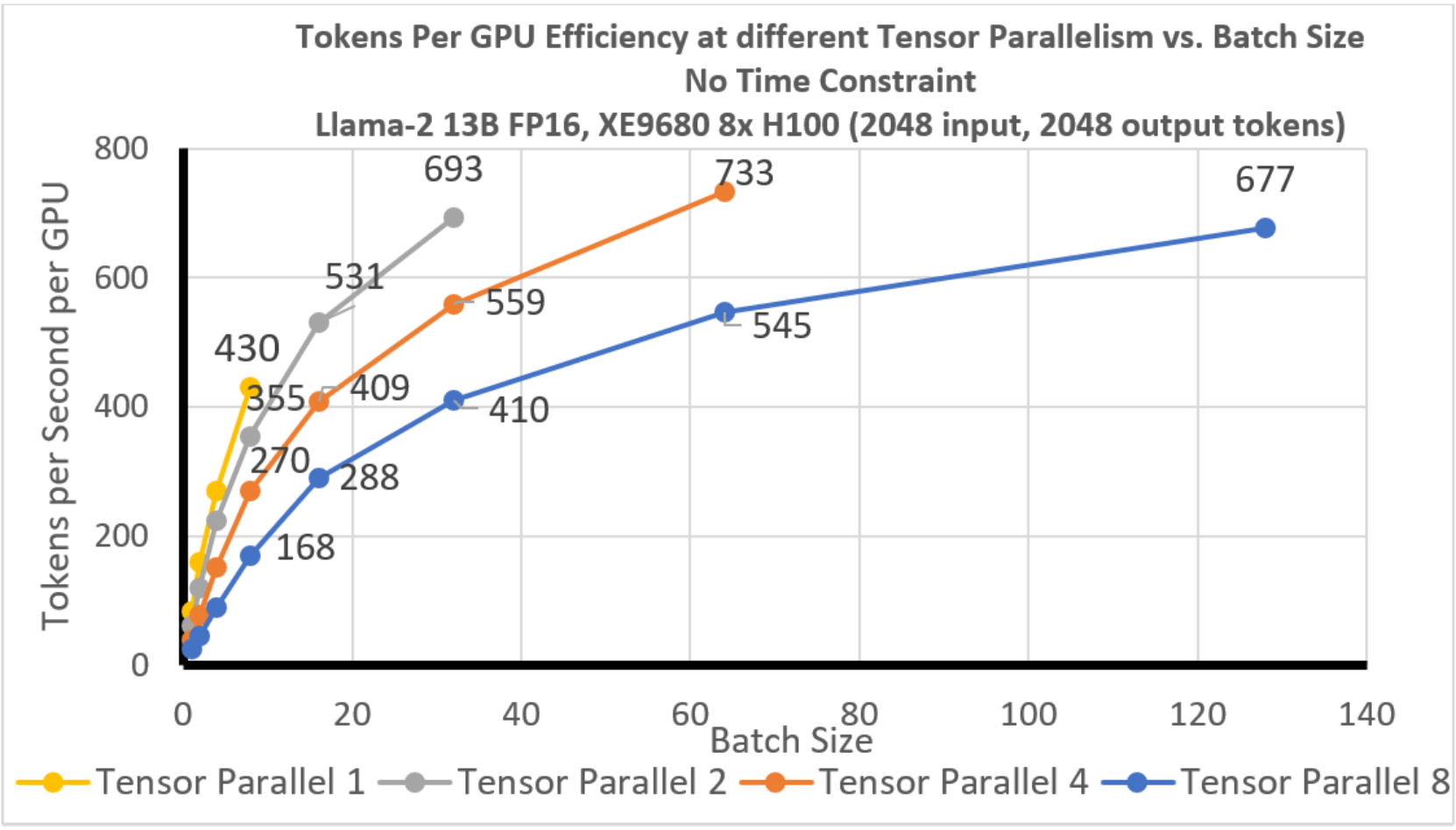
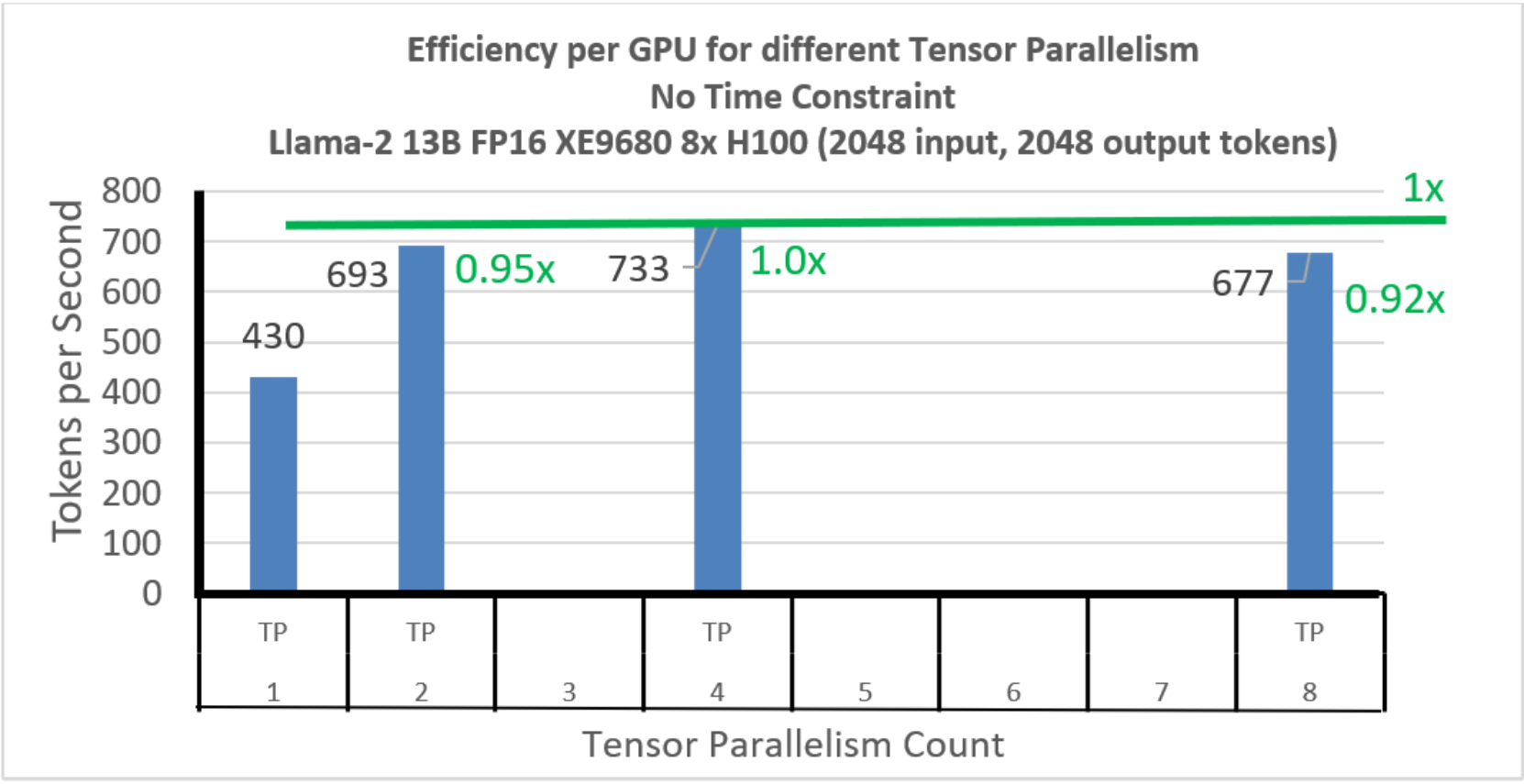
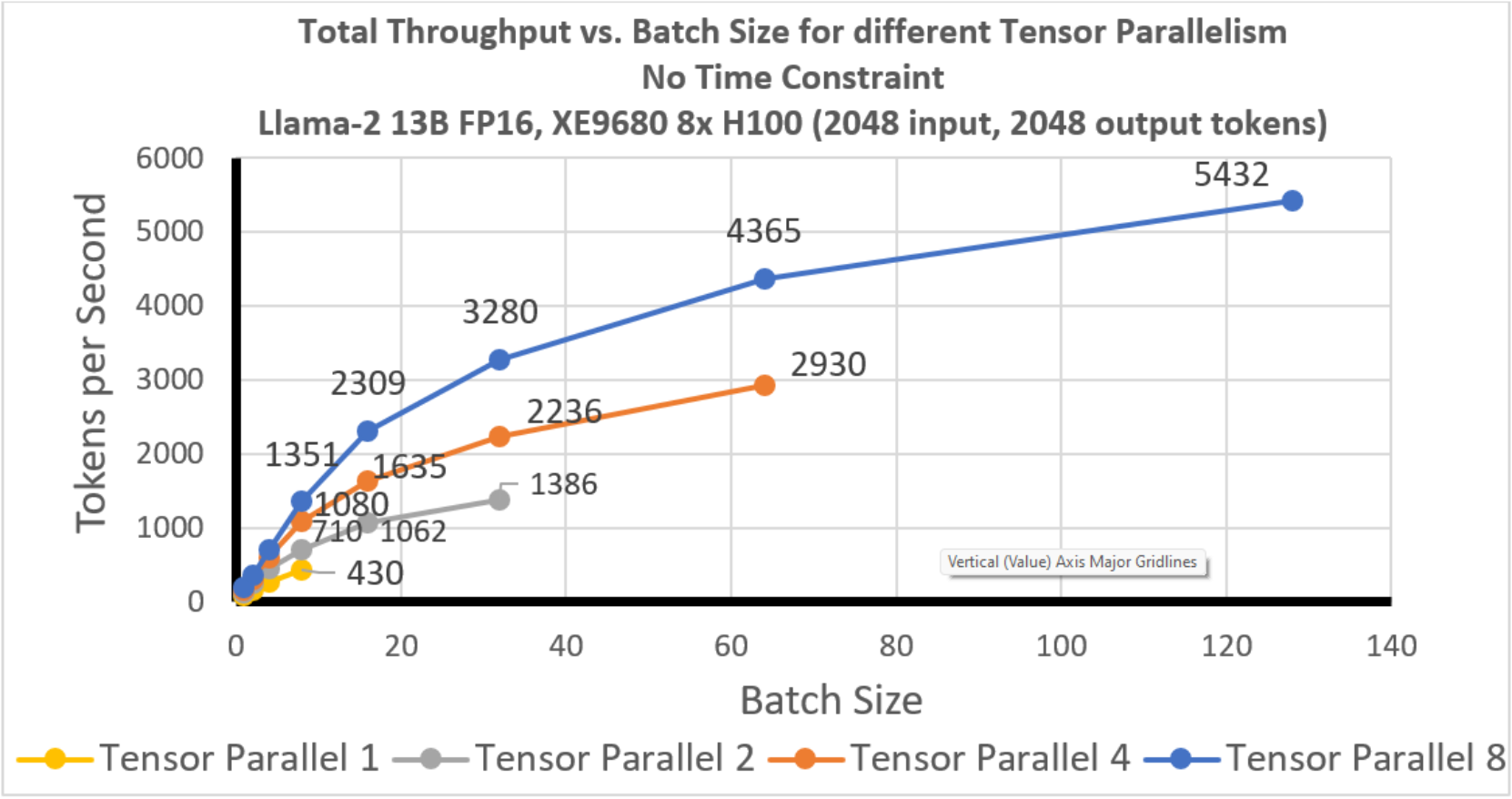
Llama-2 13B Tokens per second per GPU without any TTFT constraint ...
Perception Model Training for Autonomous Vehicles with Tensor ...
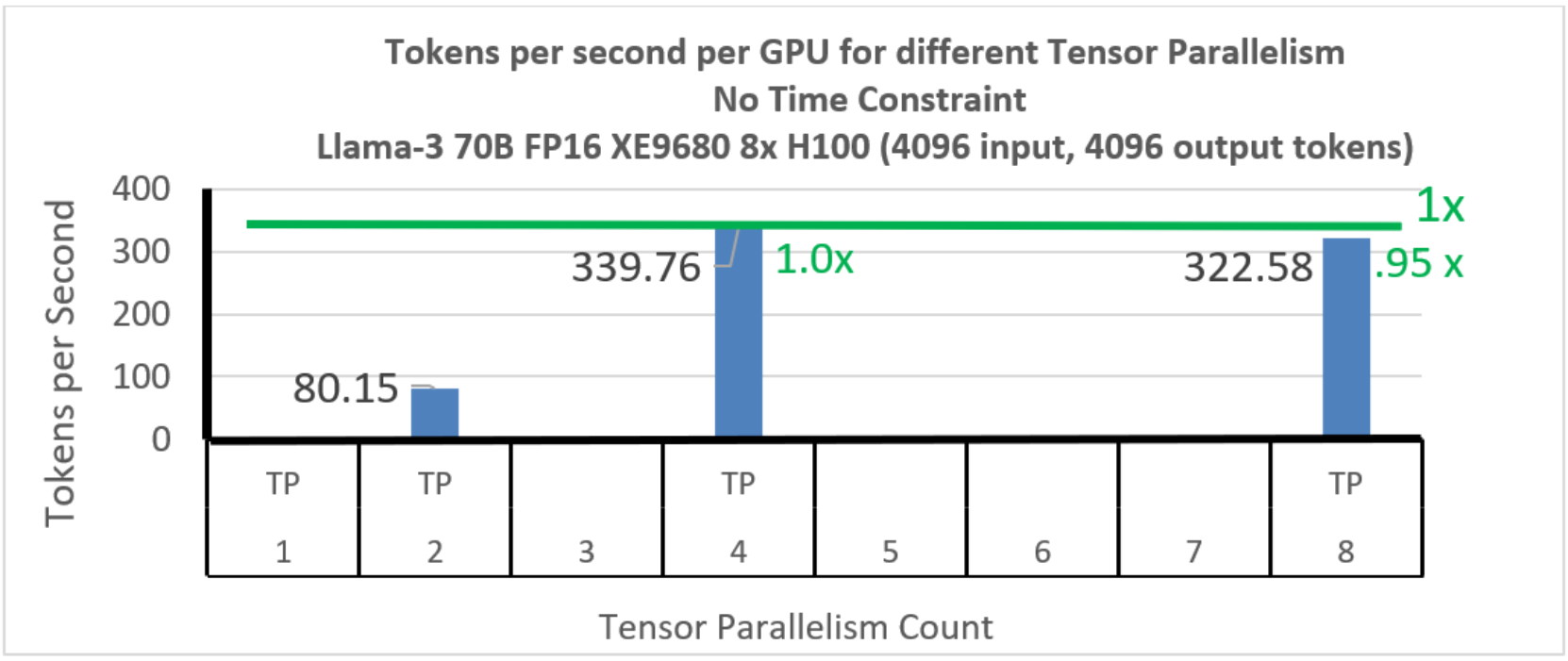
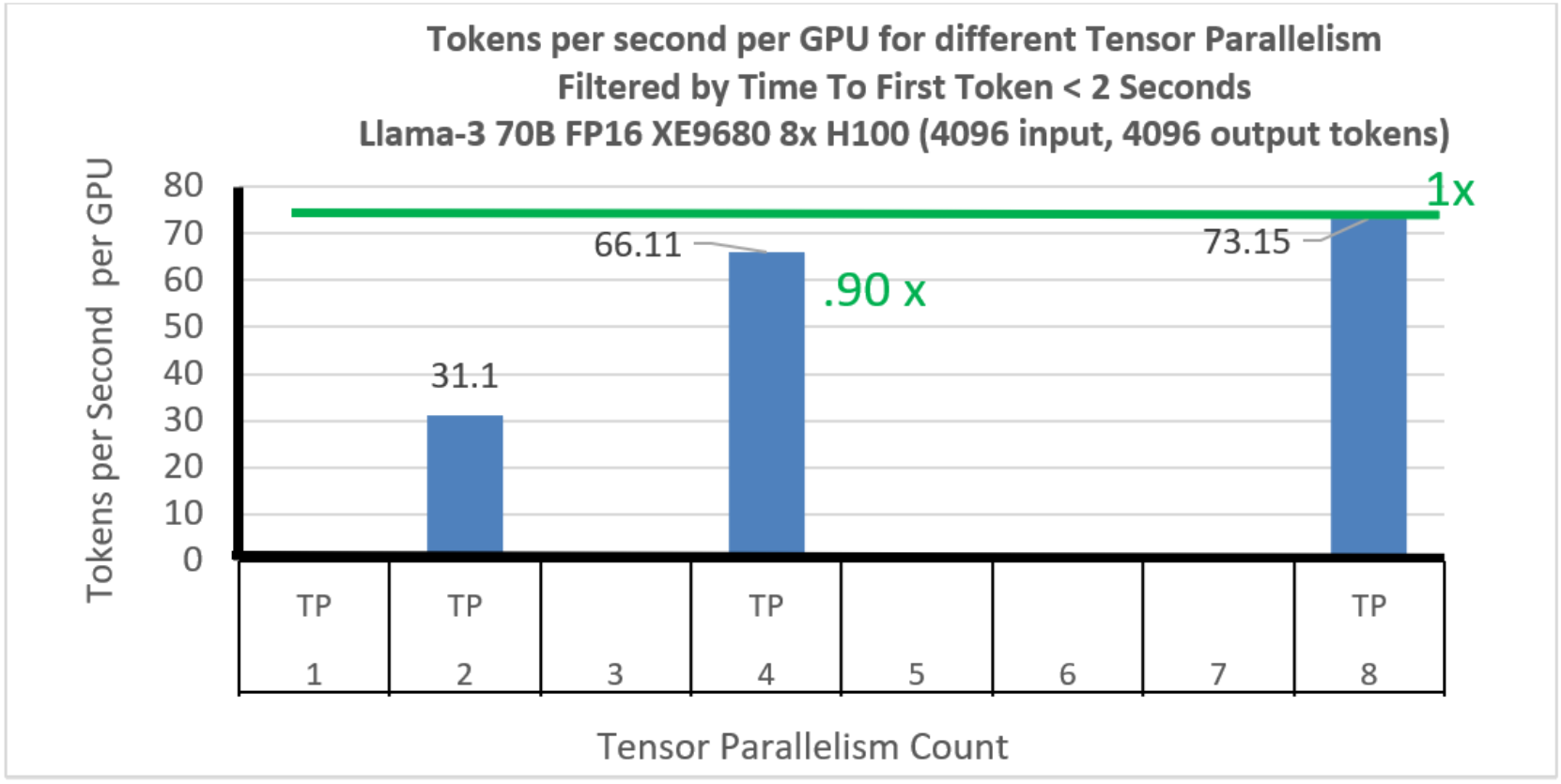
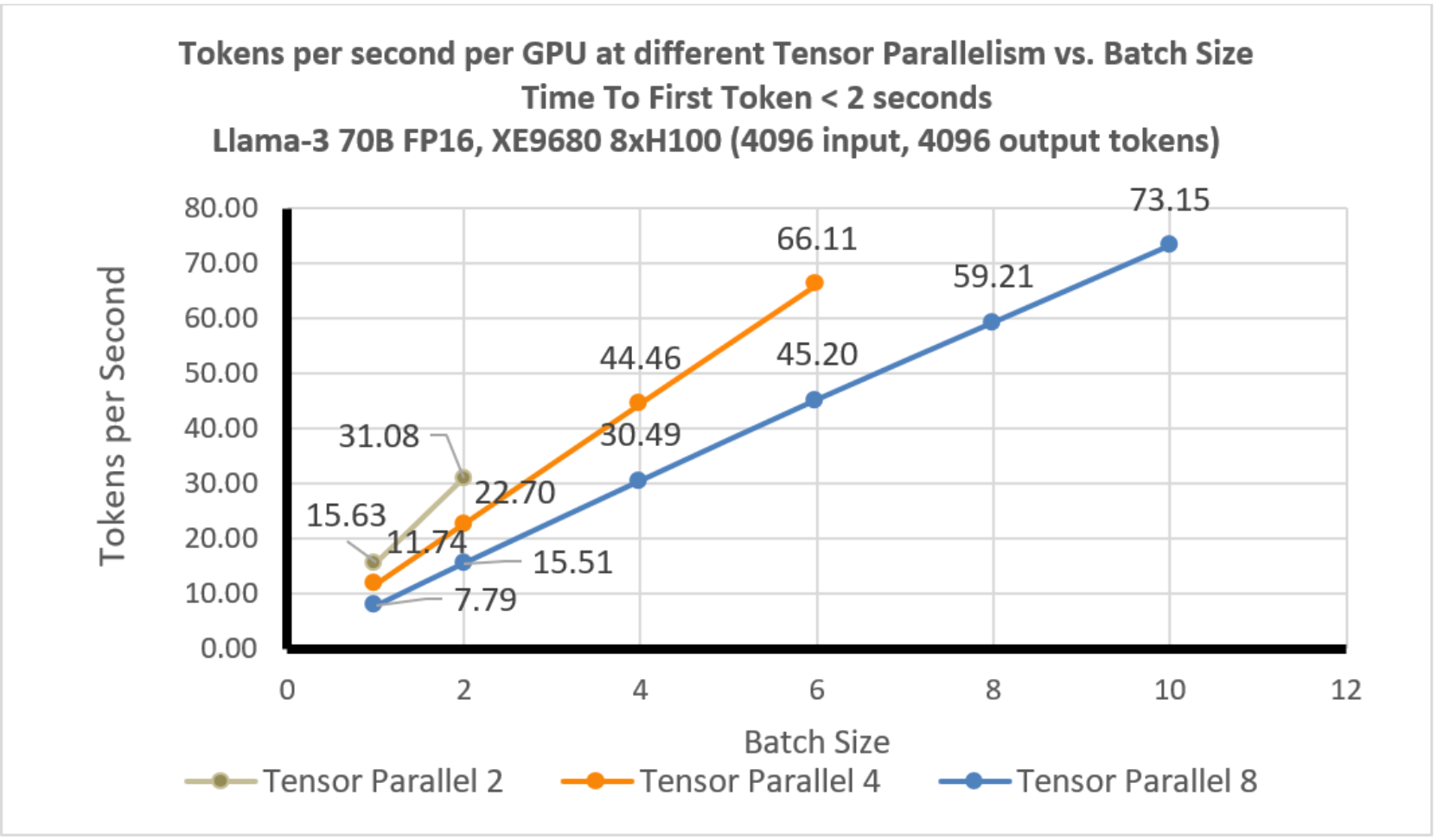
Llama-3 70B Tokens per second per GPU without any TTFT constraint ...
gLLM: Global Balanced Pipeline Parallelism System for Distributed LLM ...
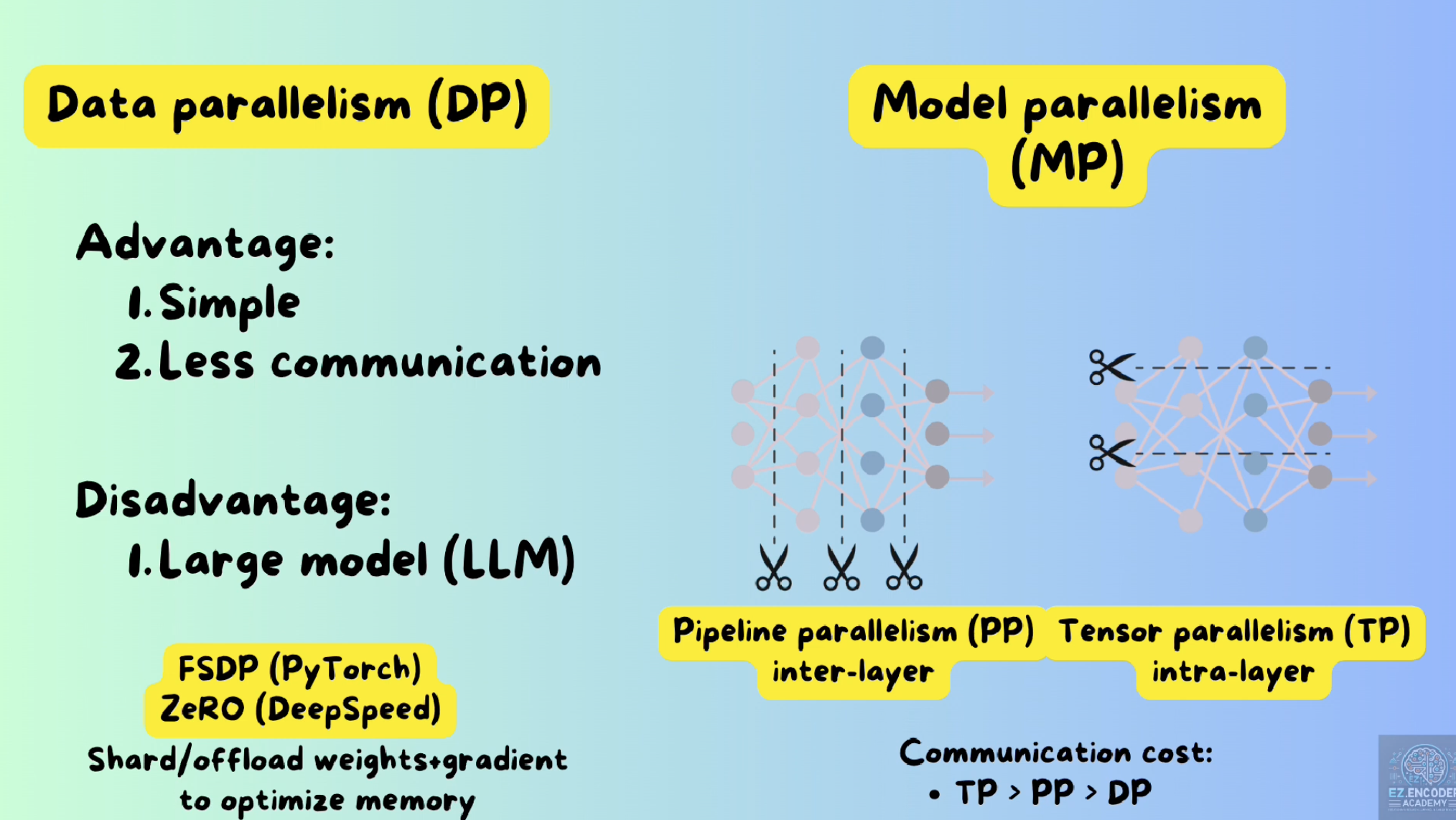
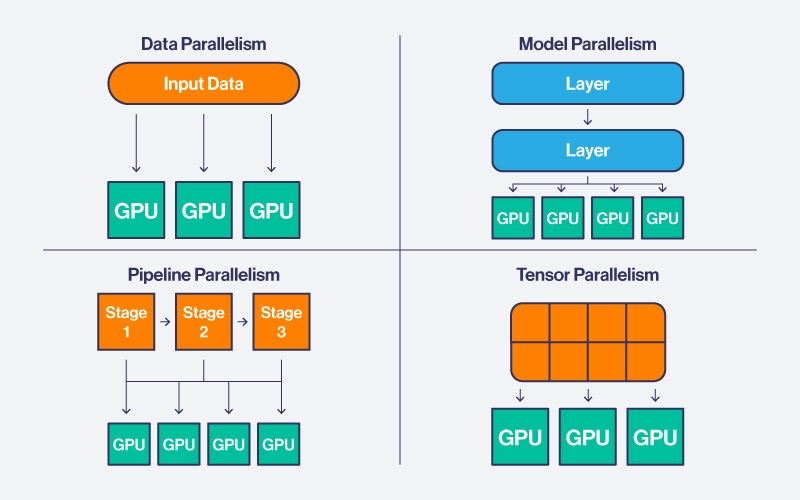
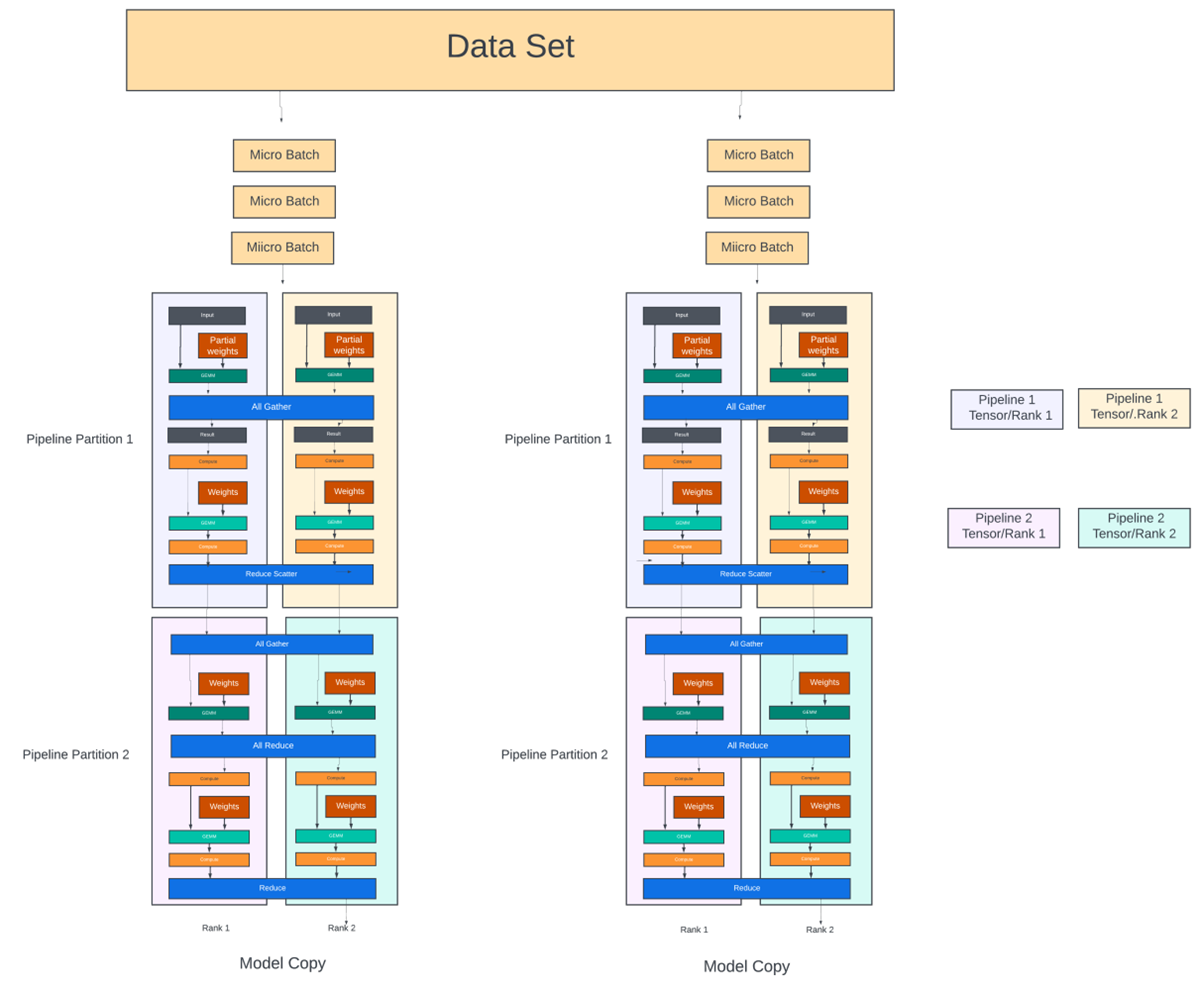
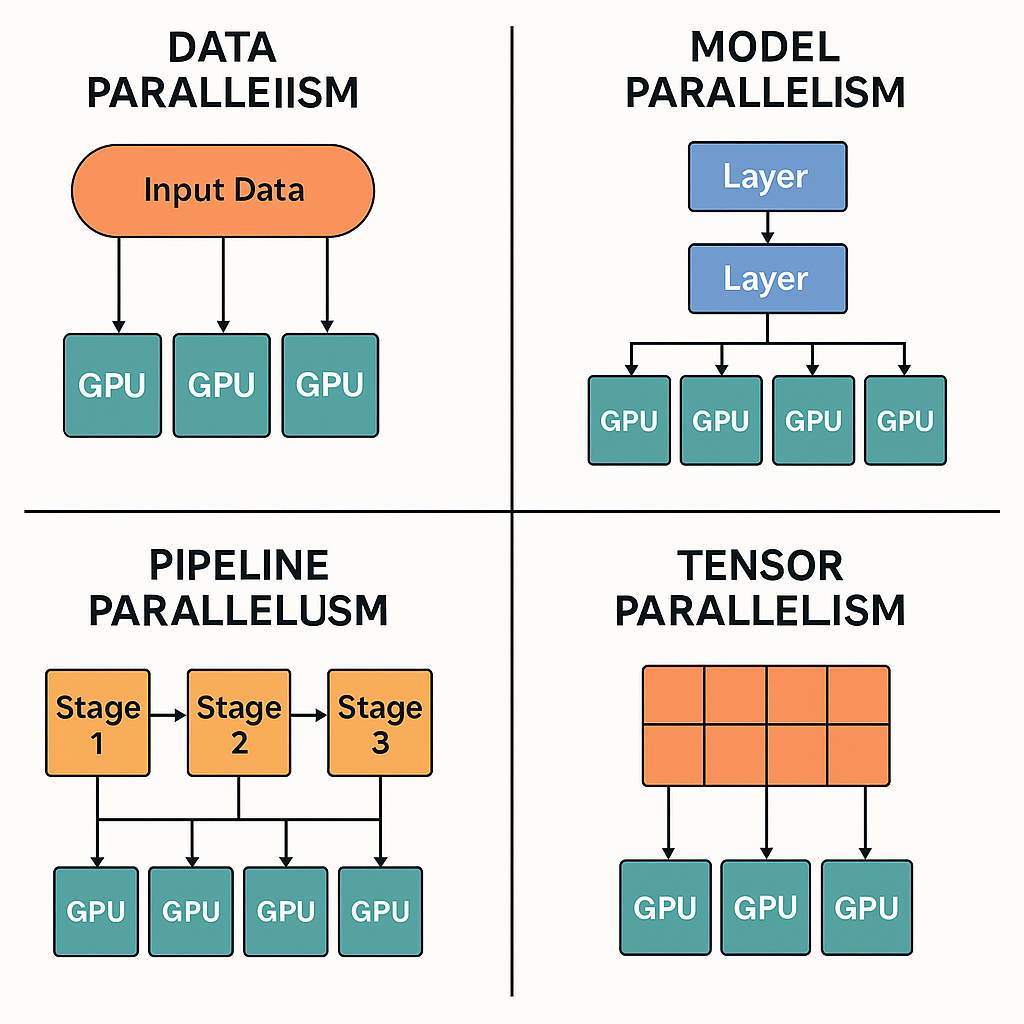
Data, Model, Tensor, and Pipeline Parallelism | SPC Blog
How to Efficiently Share GPU Resources?
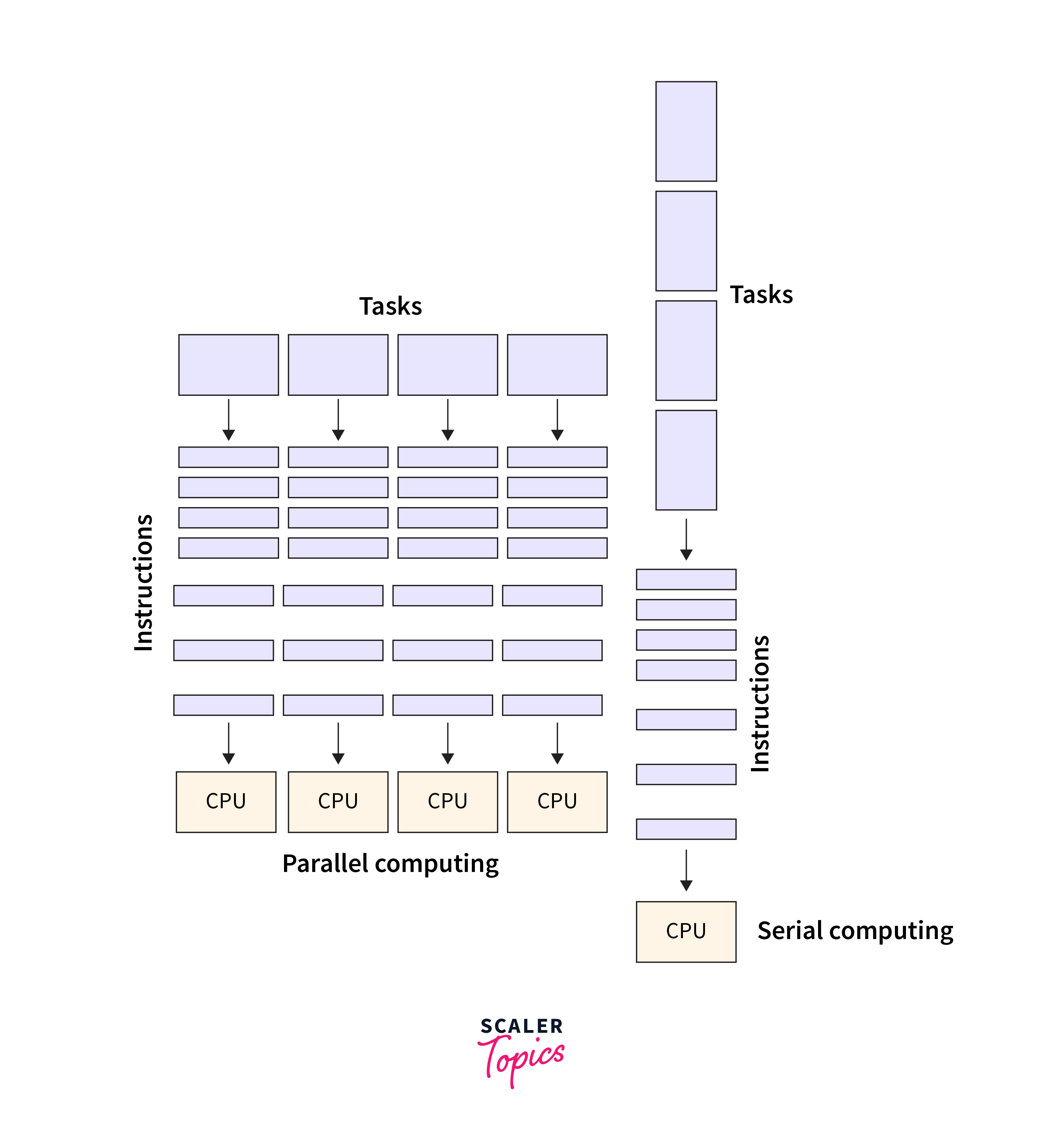
TensorFlow GPU Unleashing the Power of Parallel Computing - Scaler Topics
Nonuniform-Tensor-Parallelism: Mitigating GPU failure impact for Scaled ...
Parallelism 소개: Data, Pipeline, Tensor, Context, 그리고 Expert
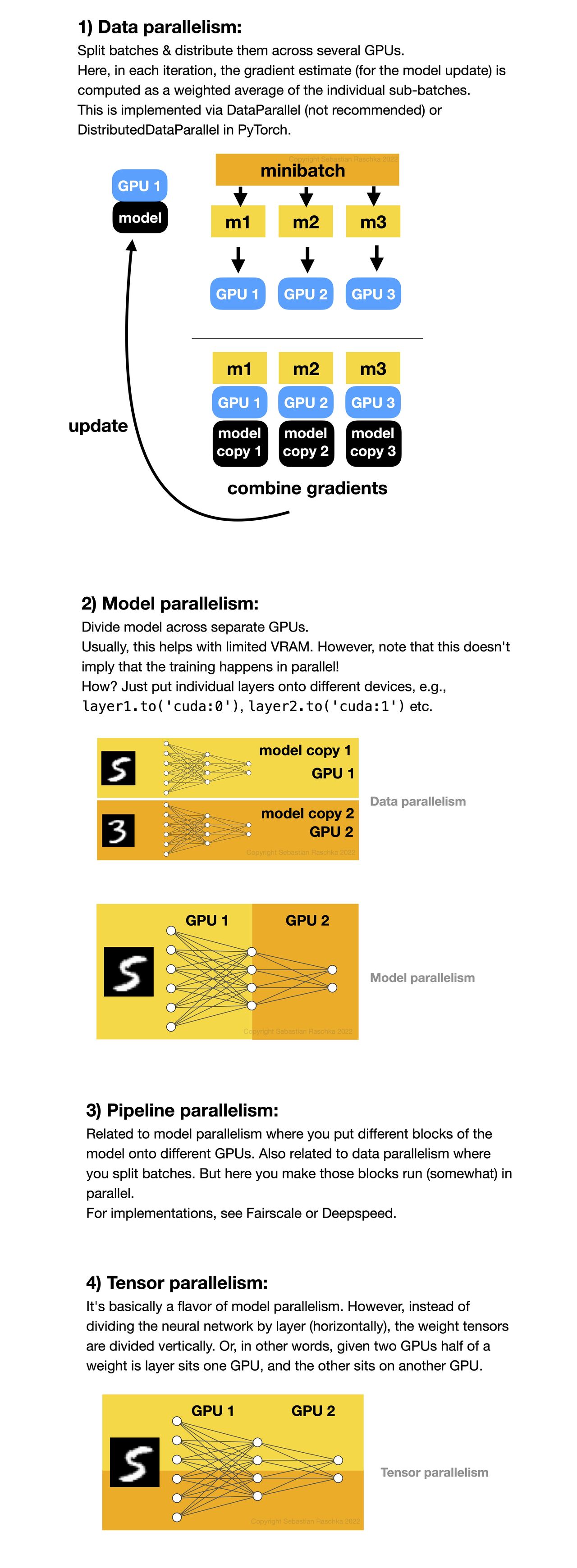
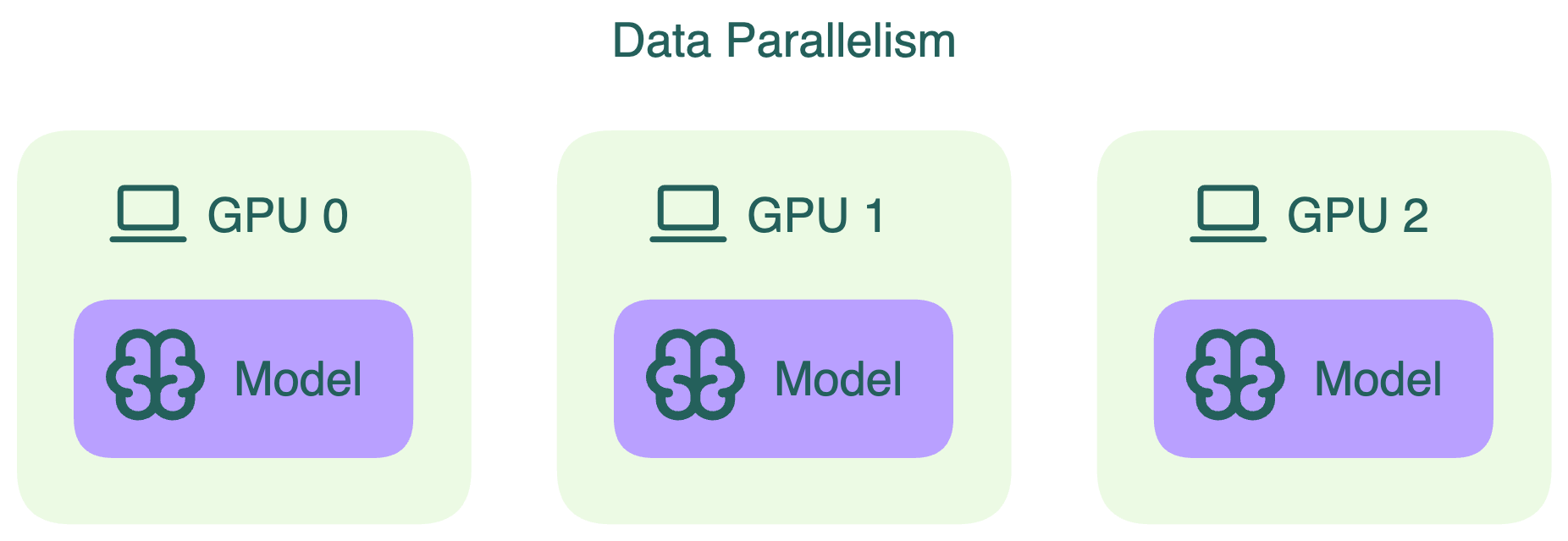
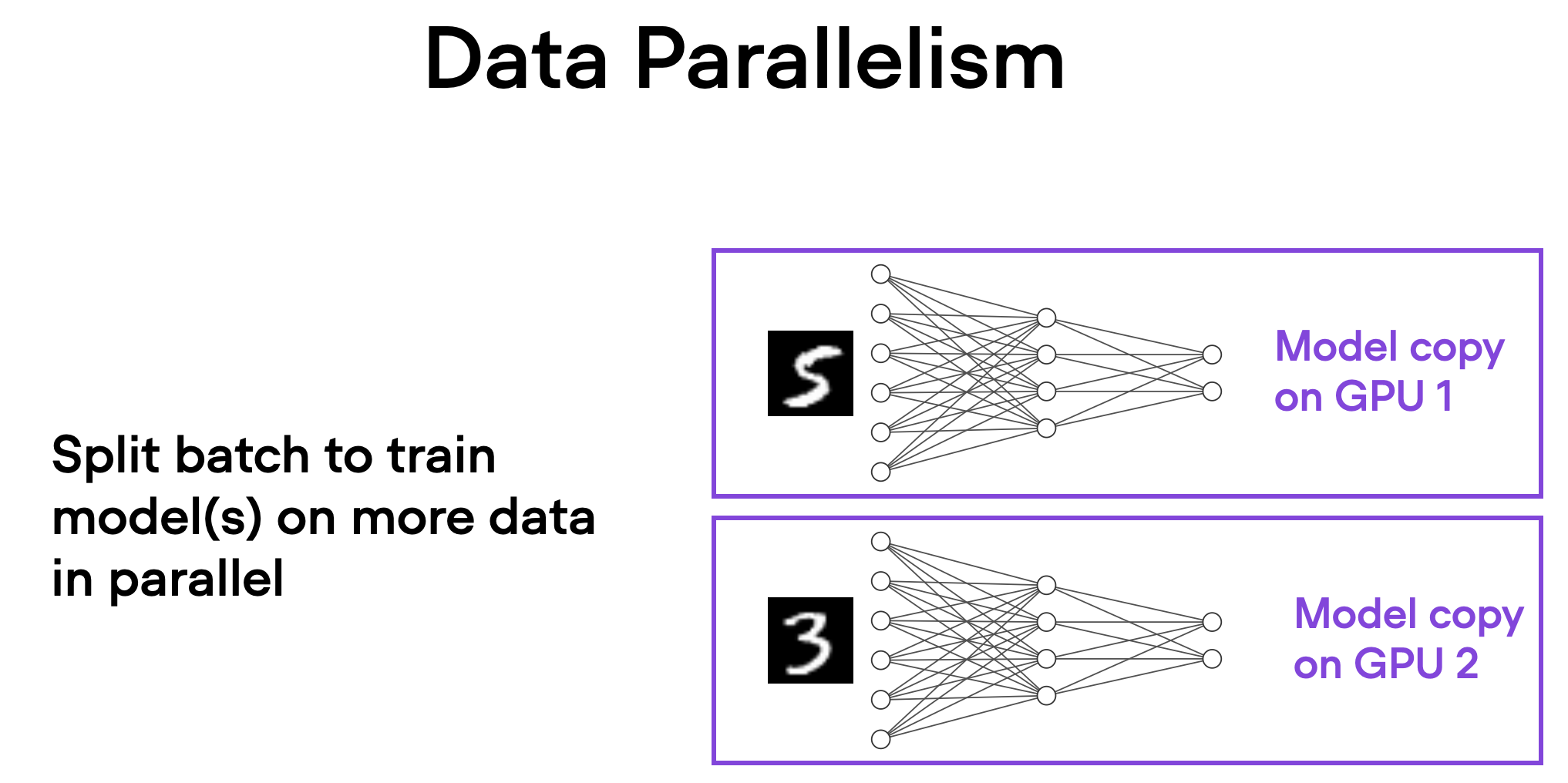
Data Parallelism vs Model Parallelism in AI Training
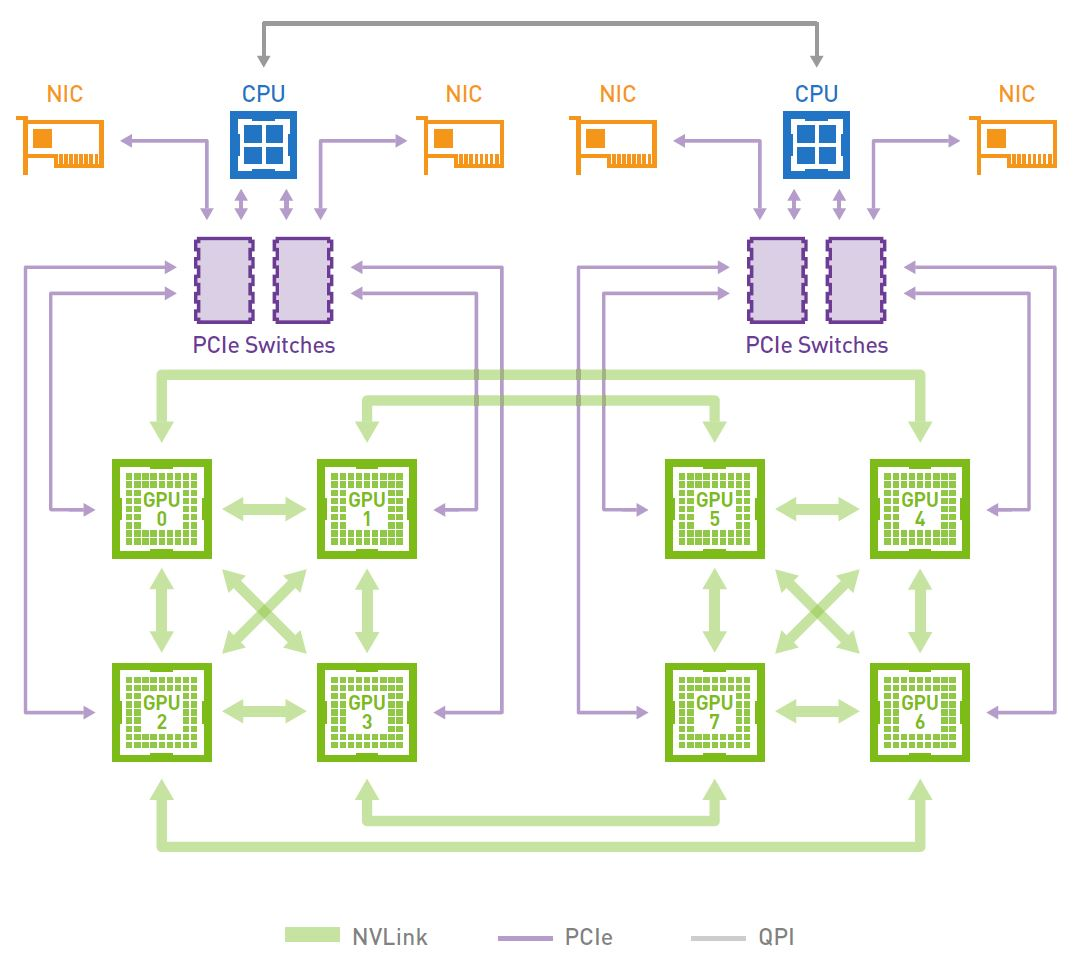
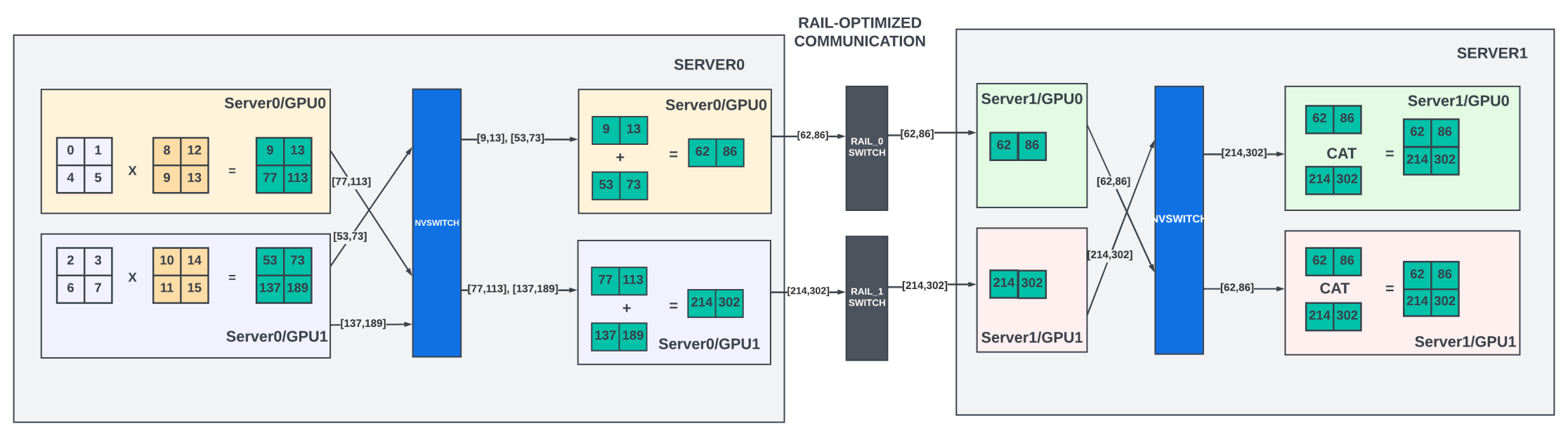
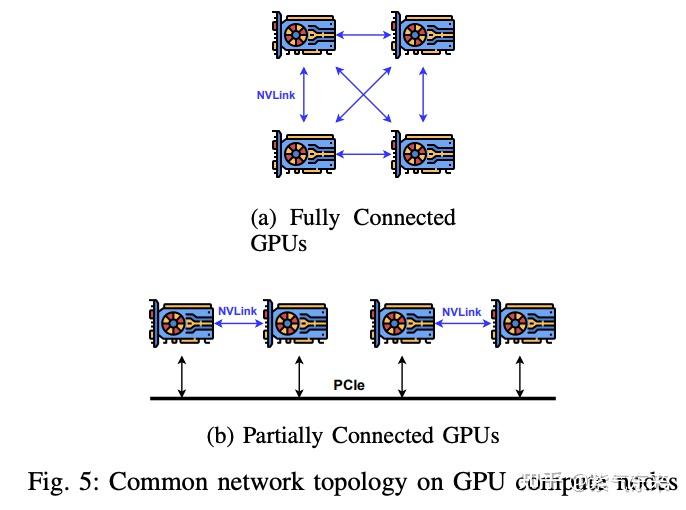
GPU Networking Basics, Part 2 - by Austin Lyons - Chipstrat
[论文评述] Nonuniform-Tensor-Parallelism: Mitigating GPU failure impact for ...
Aman's AI Journal • Primers • Distributed Training Parallelism
GPU Guide for LLM Deployment - RTX 4090 to A100 Benchmarks (2026)
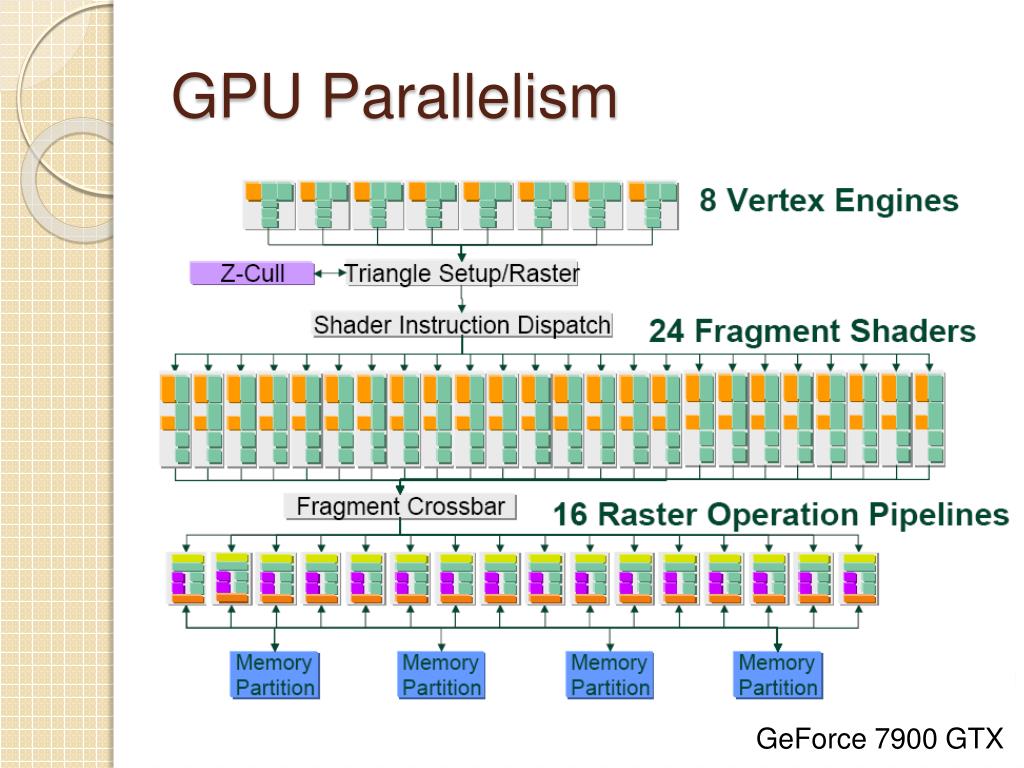
PPT - GPU Tutorial PowerPoint Presentation, free download - ID:918722
17.4. Distributed GPU Computing — Kempner Institute Computing Handbook
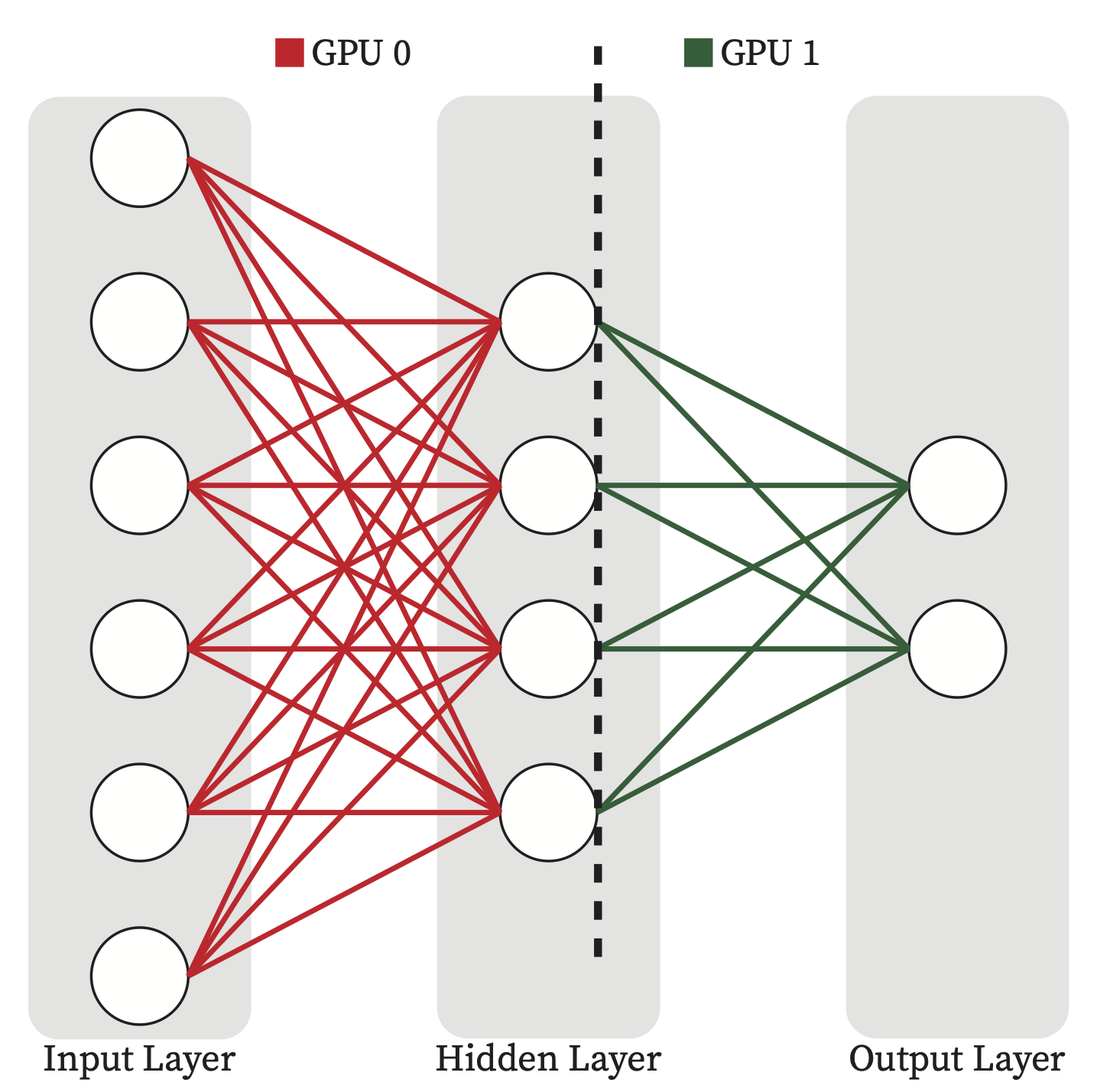
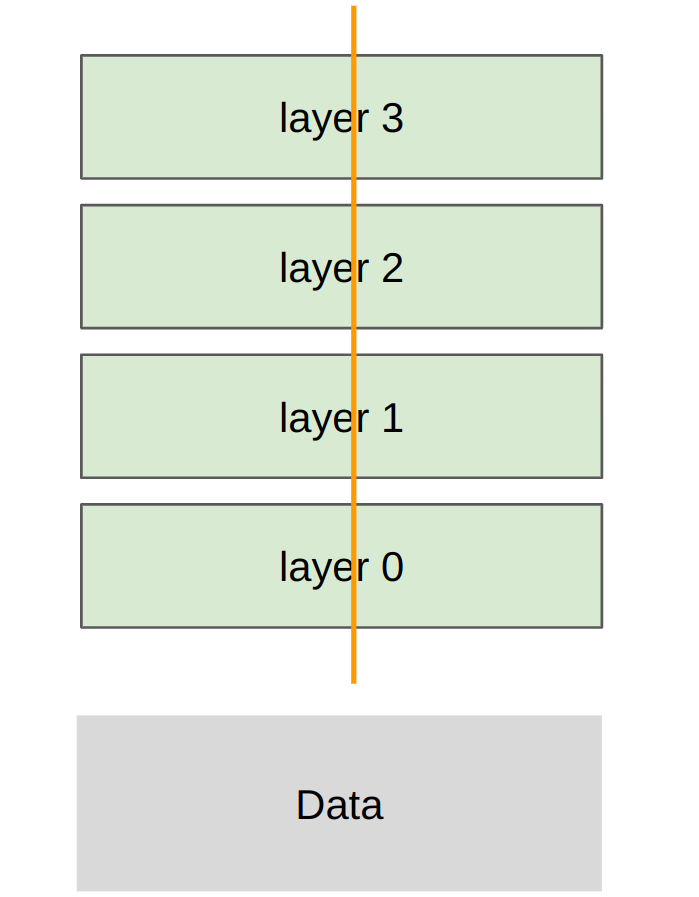
Model Parallelism
GPU fabrics for GenAI workloads | APNIC Blog
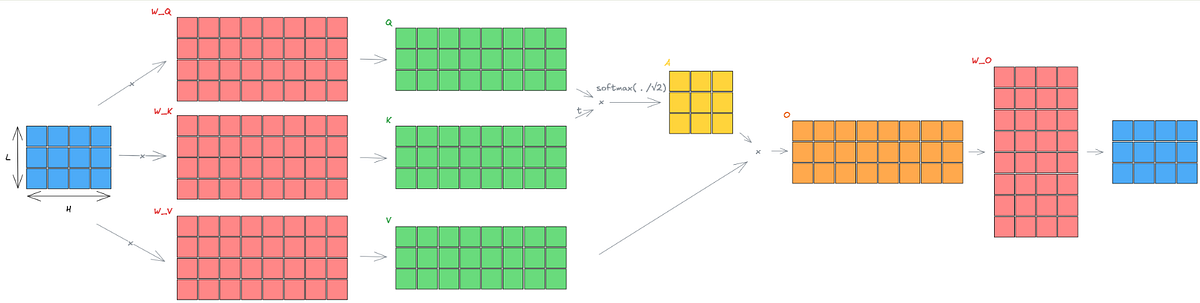
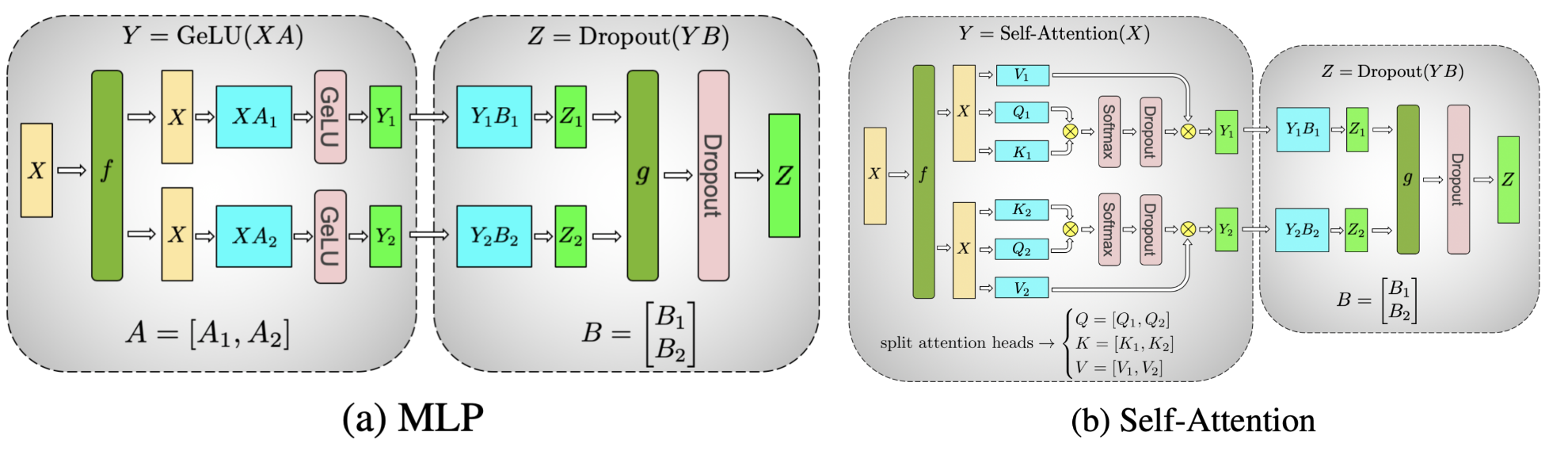
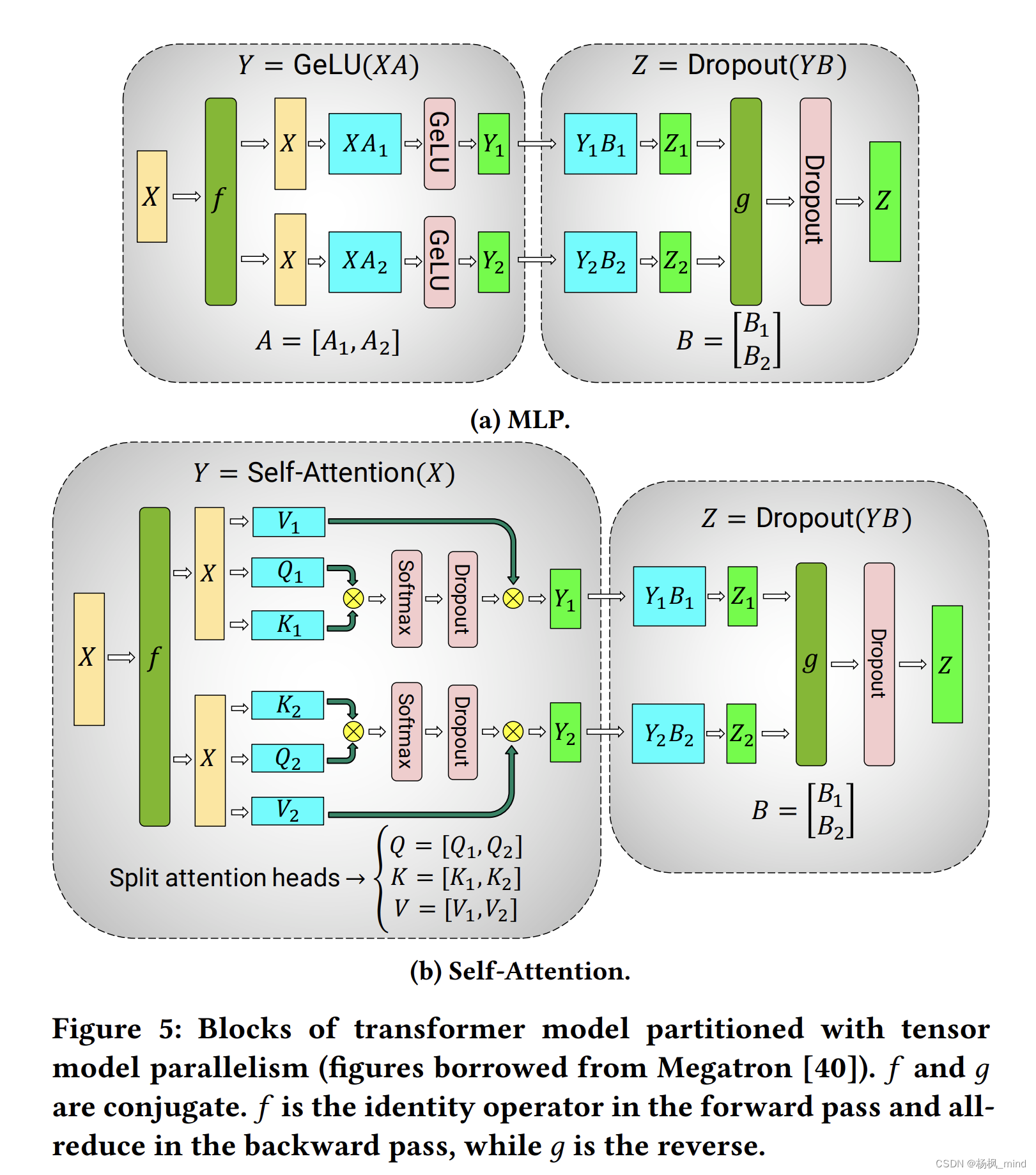
Large Scale Transformer model training with Tensor Parallel (TP ...
A Deep Dive into 3D Parallelism with Nanotron⚡️ | TJ Solergibert
GPU Fabrics for GenAI Workloads
15: Dynamic parallelism with GPUs | Download Scientific Diagram
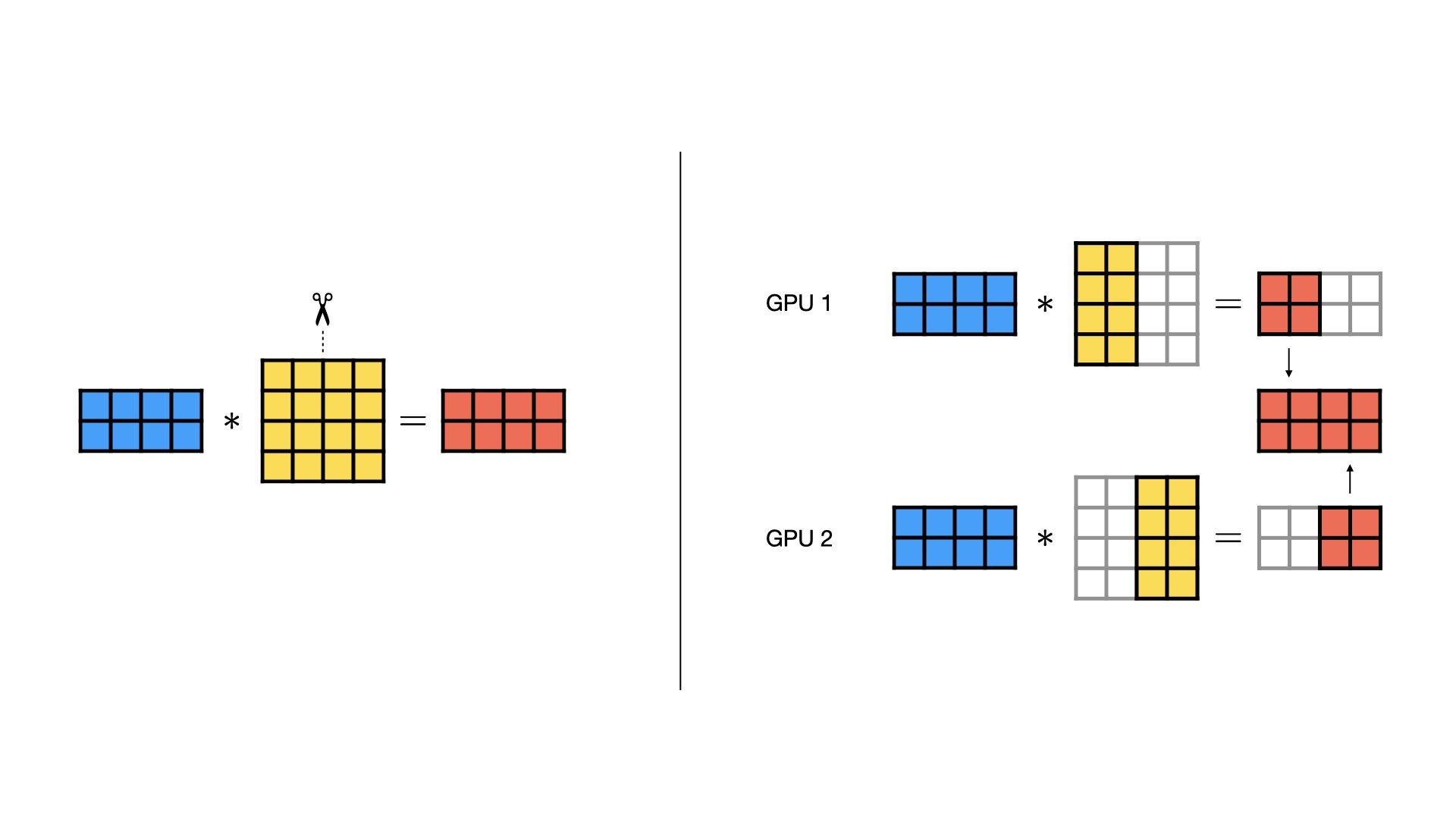
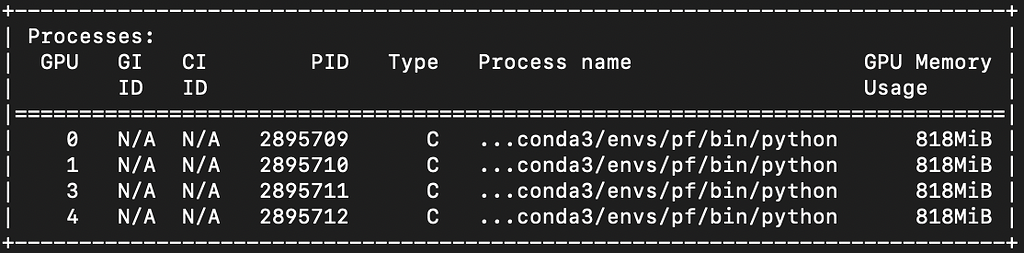
Tensor parallel spawns additional processes on GPU0 and uses additional ...
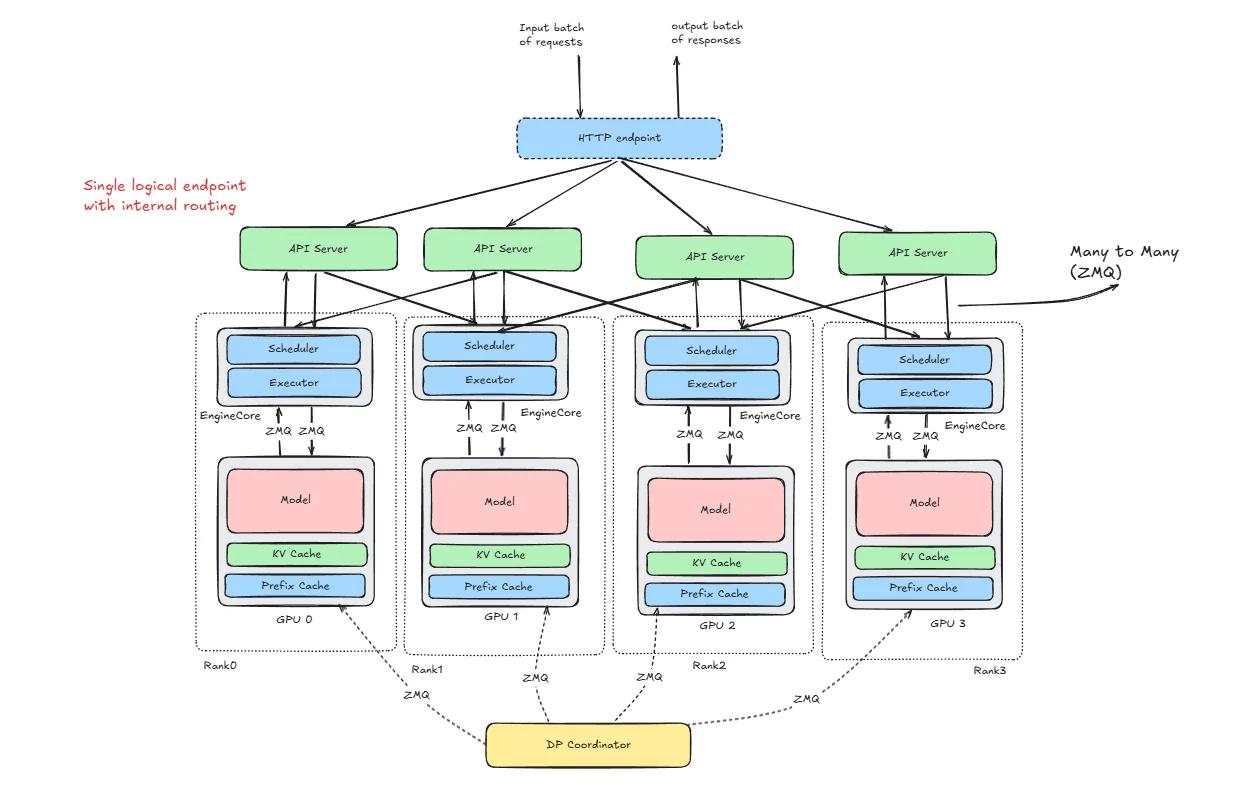
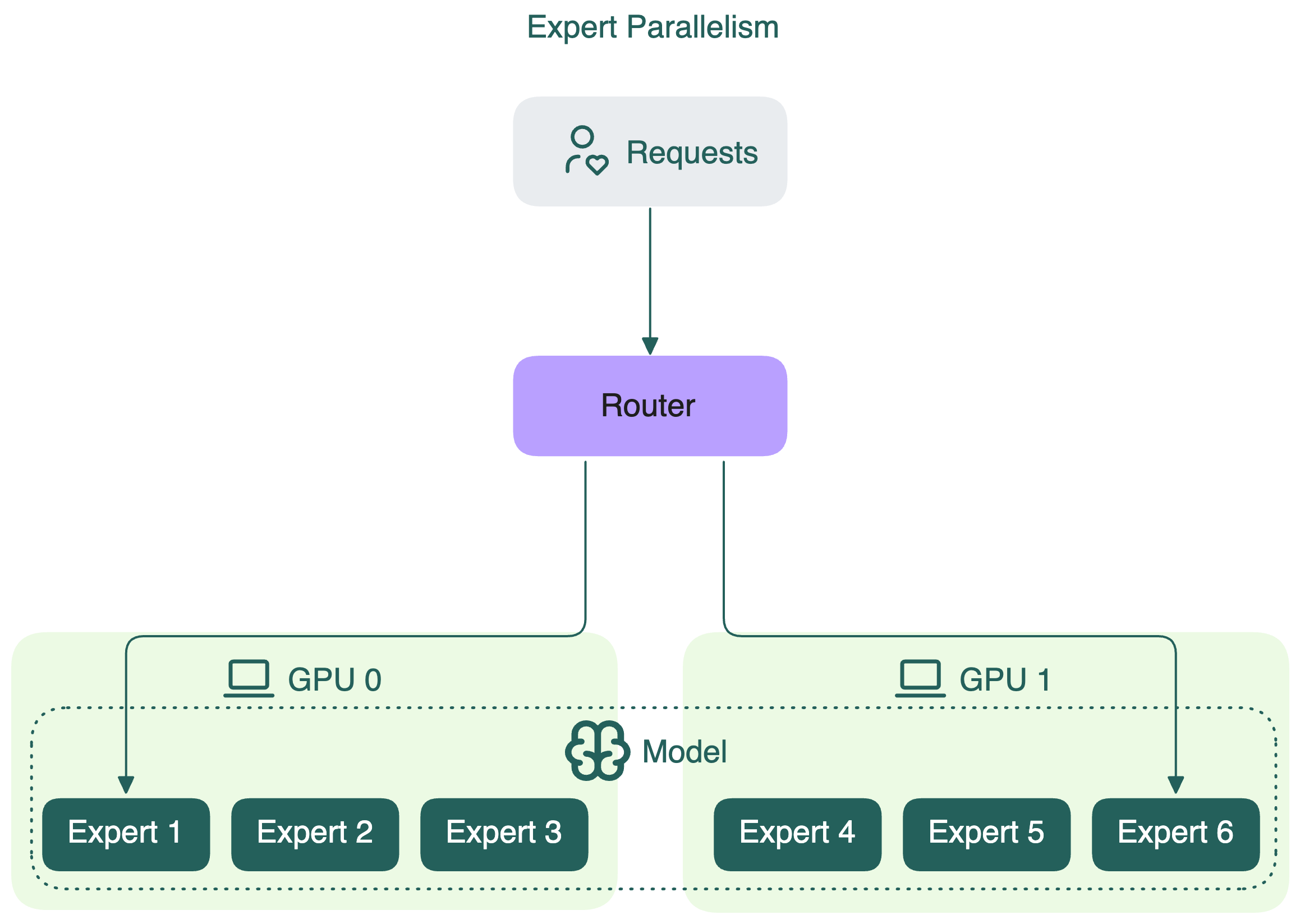
Expert Parallelism and Mixed Parallelism Strategies in vLLM | Jarvis ...
Budget-Friendly GPU Guide - Powering Your LLM Dreams Without Breaking ...
Introduction to GPU programming
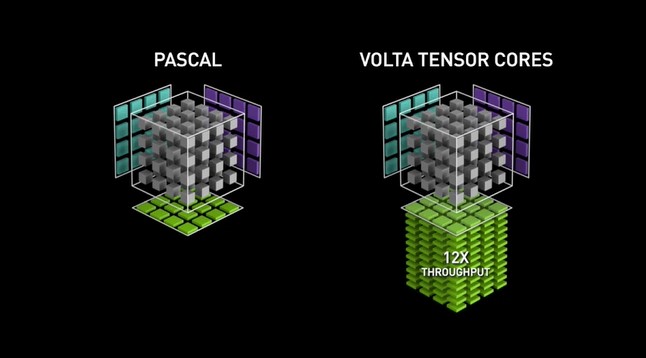
Understanding NVIDIA's Tensor Core Technology - Assured Systems
Tenplex: Dynamic Parallelism for Deep Learning using Parallelizable ...
AnchorTP: Resilient LLM Inference with State-Preserving Elastic Tensor ...
🚀 Beyond Data Parallelism: A Beginner-Friendly Tour of Model, Pipeline ...
How ByteDance Scales Offline Inference with Multi-Modal LLMs
Optimizing Memory Usage for Training LLMs and Vision Transformers in ...
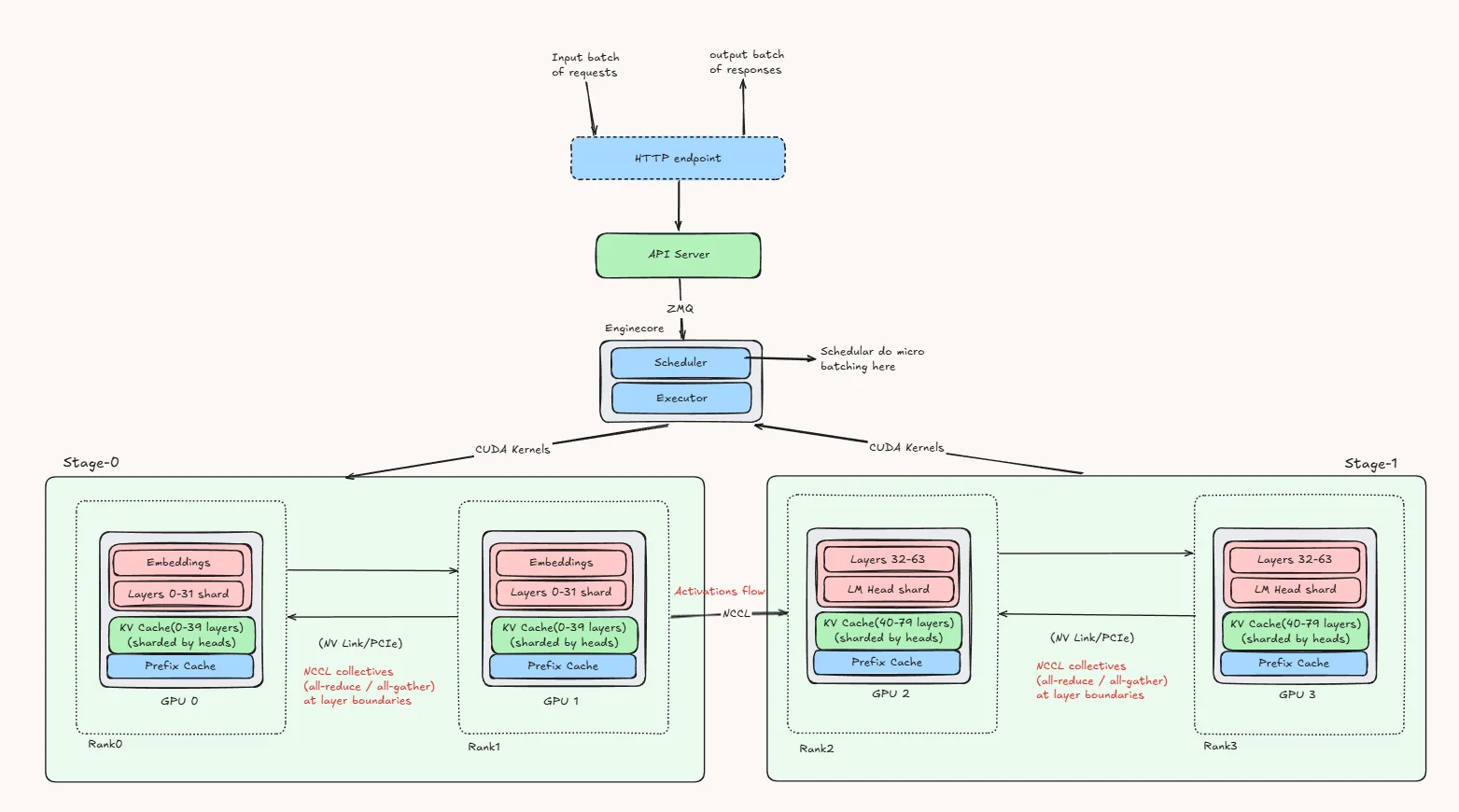
Demystifying AI Inference Deployments for Trillion Parameter Large ...
Data, tensor, pipeline, expert and hybrid parallelisms | LLM Inference ...
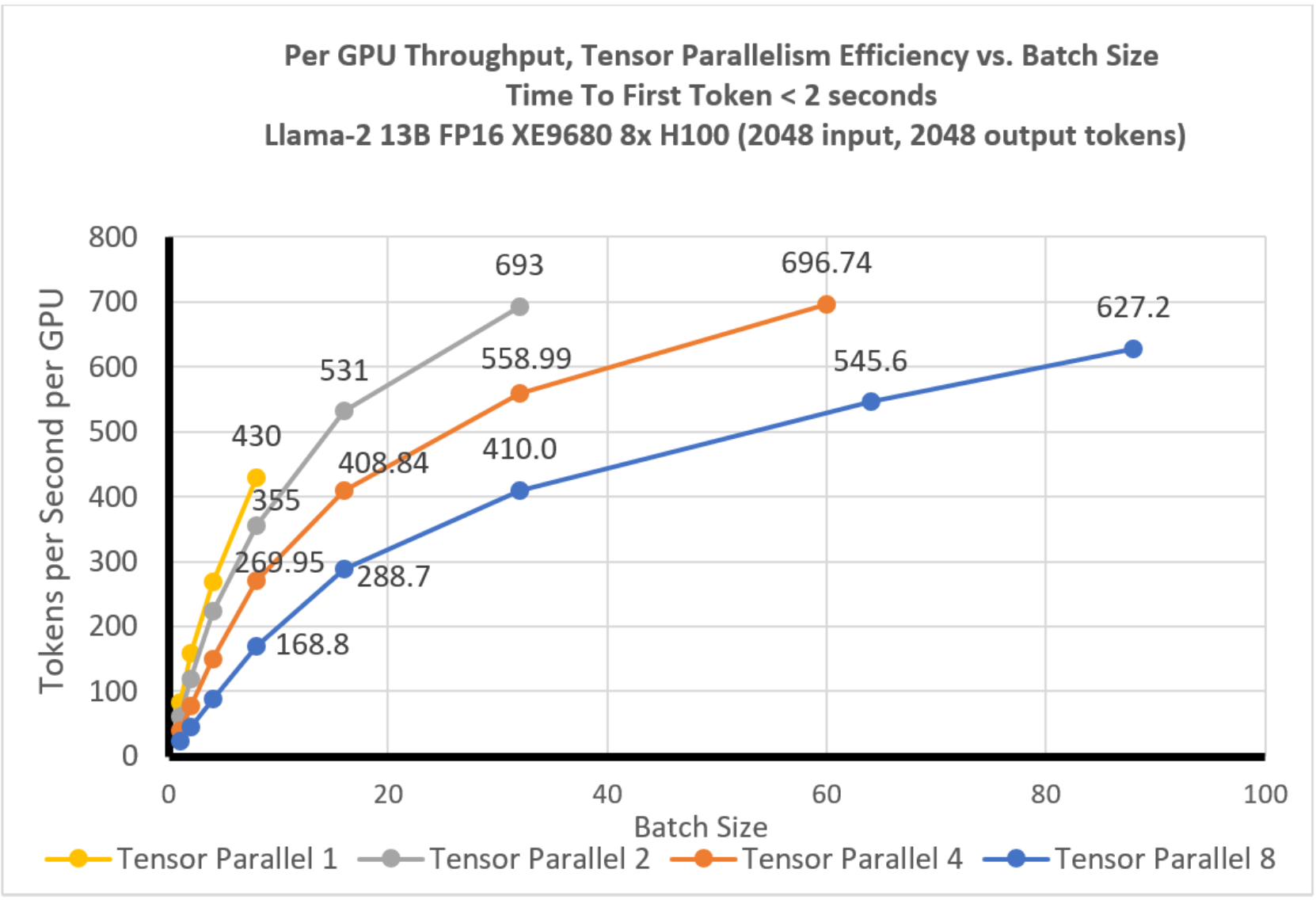
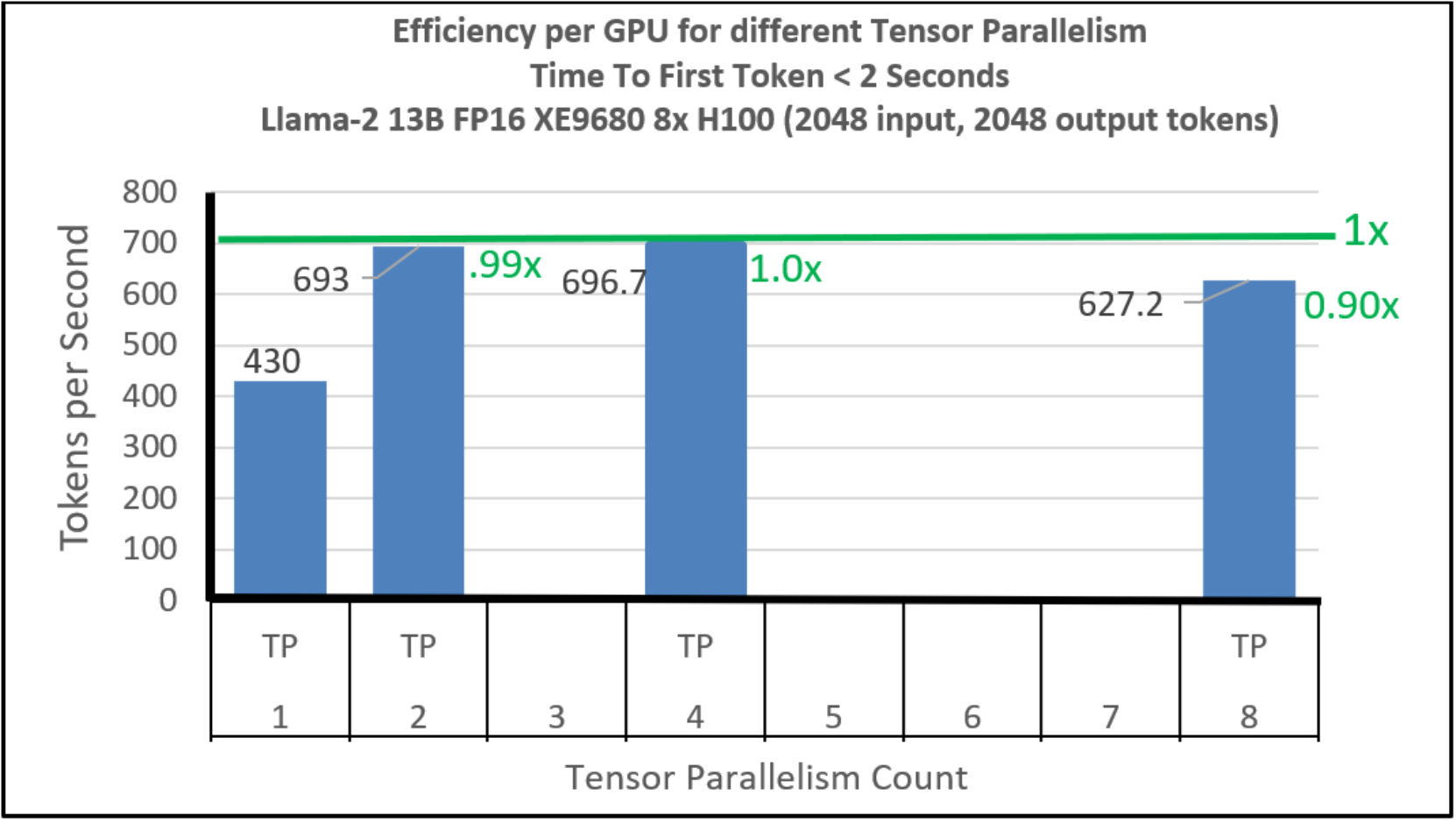
Llama-2 13B TP efficiency analysis with 2 second TTFT constraint ...
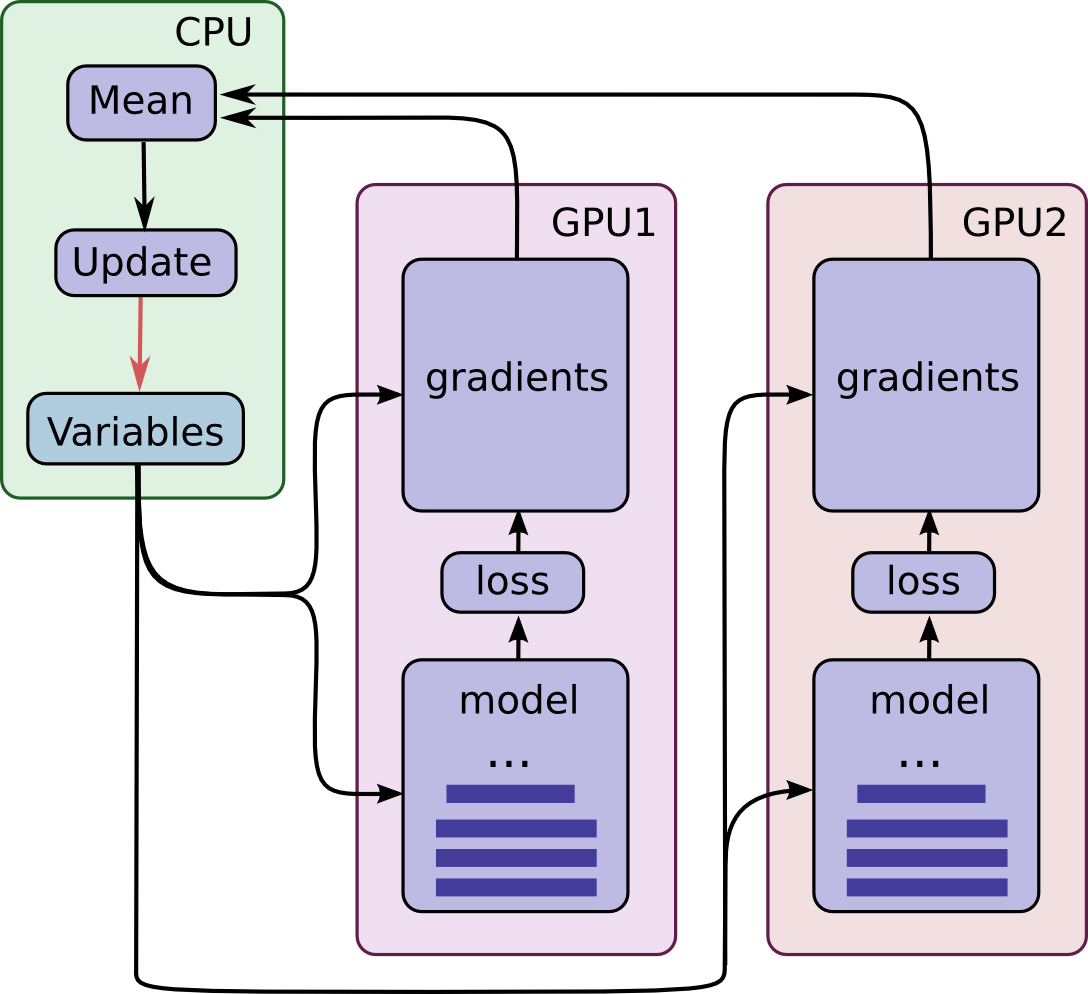
PyTorch Distributed Data Parallel (DDP) Training in Kaggle
Throughput efficiency analysis with 2 second TTFT constraint ...
Accelerated Inference for Large Transformer Models Using NVIDIA Triton ...
NVIDIA Contributes NVIDIA GB200 NVL72 Designs to Open Compute Project ...
Simplifying AI Inference in Production with NVIDIA Triton | NVIDIA ...
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
4 Strategies for Multi-GPU Training - by Avi Chawla
Parallelisms Guide — Megatron Bridge
Distributed inference with vLLM | Red Hat Developer
What is inference engineering? Deepdive - by Gergely Orosz
Chapter 07 | Sebastian Raschka, PhD
tensor_parallel: one-line multi-GPU training for PyTorch : r/mlscaling
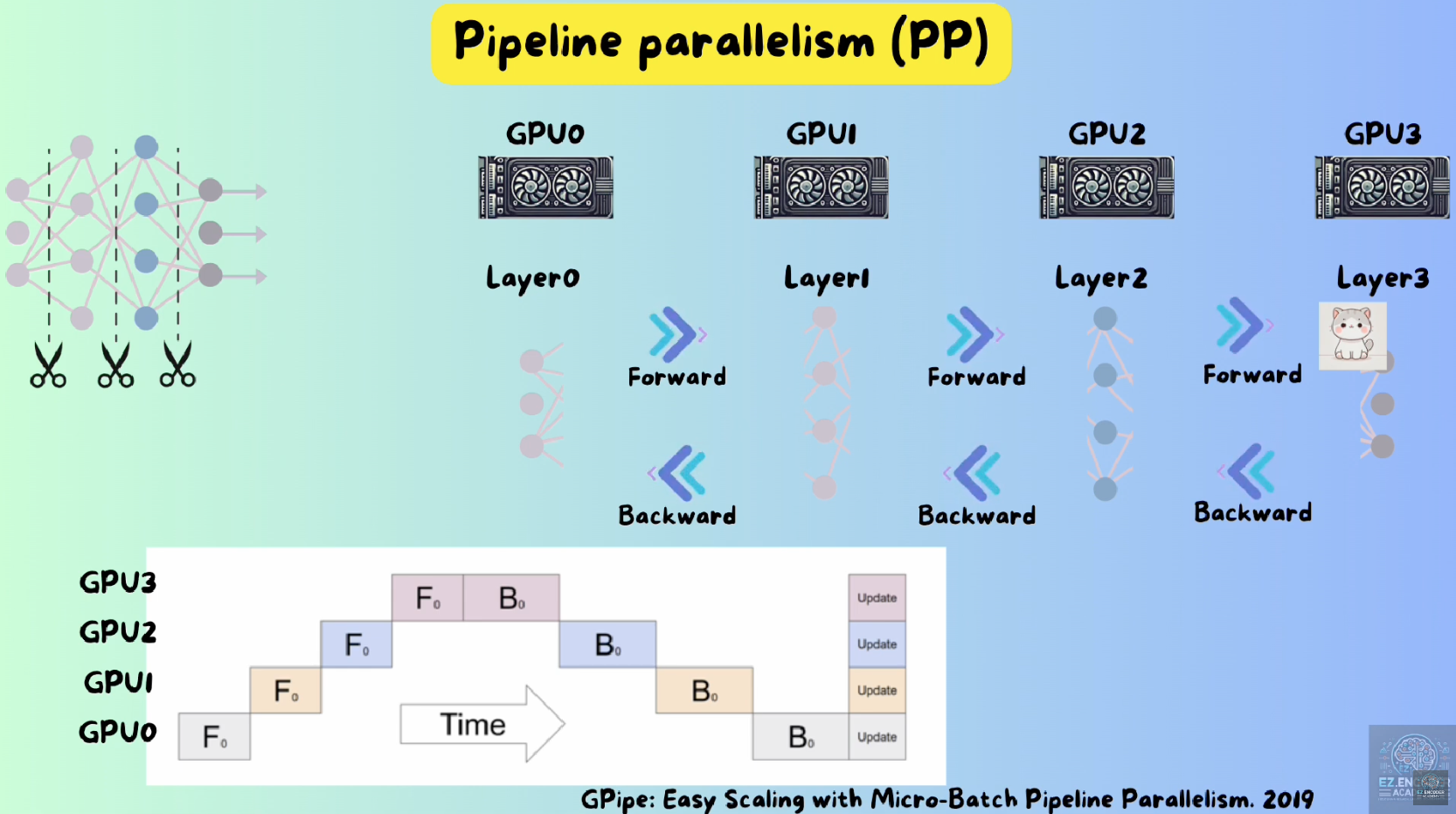
一图说明tensor and pipeline model parallelism_1f1b pipeline.-CSDN博客
Appendix | Maximizing Llama Open Source Model Inference Performance ...
NVIDIA Blackwell Leads on SemiAnalysis InferenceMAX v1 Benchmarks ...
Efficient Training on Multiple GPUs
Evolution of Distributed Training in Deep Neural Networks | Lazy Loaded ...
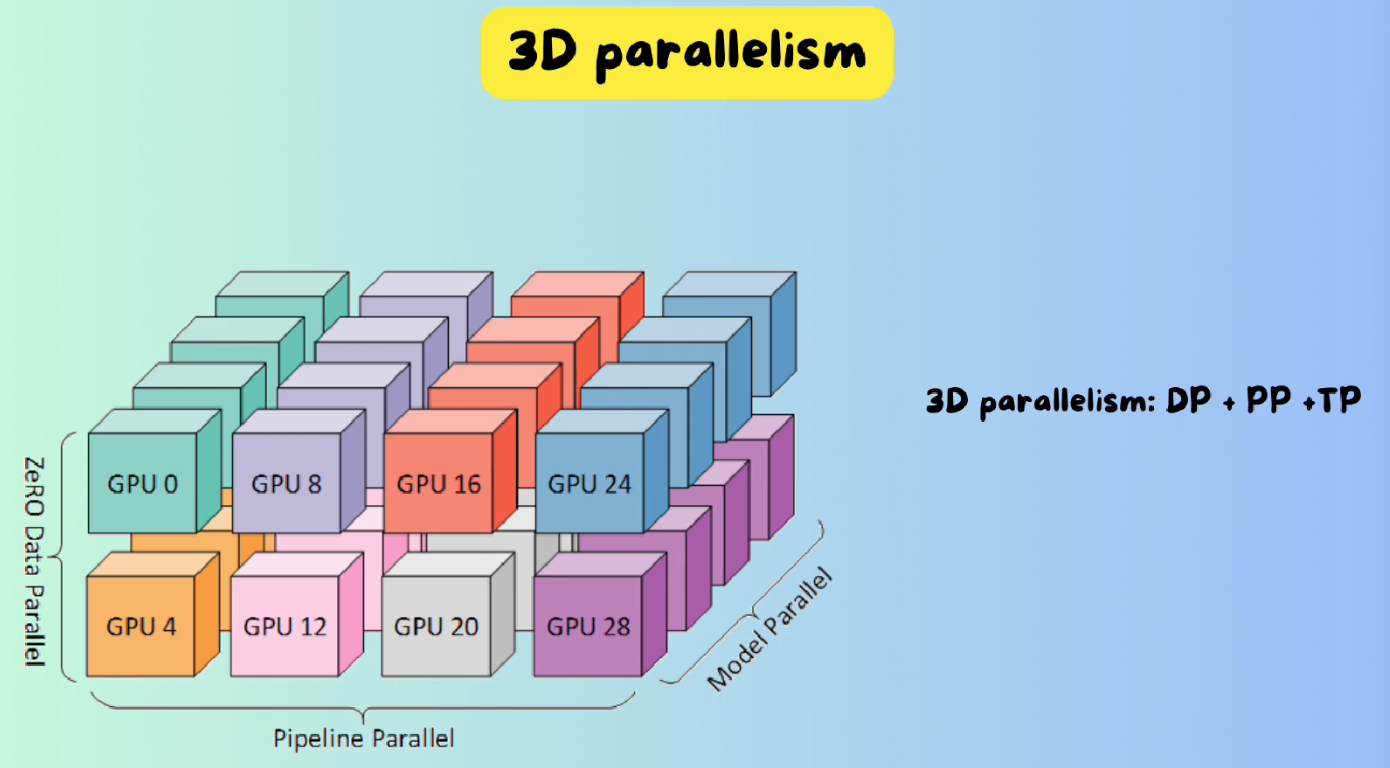
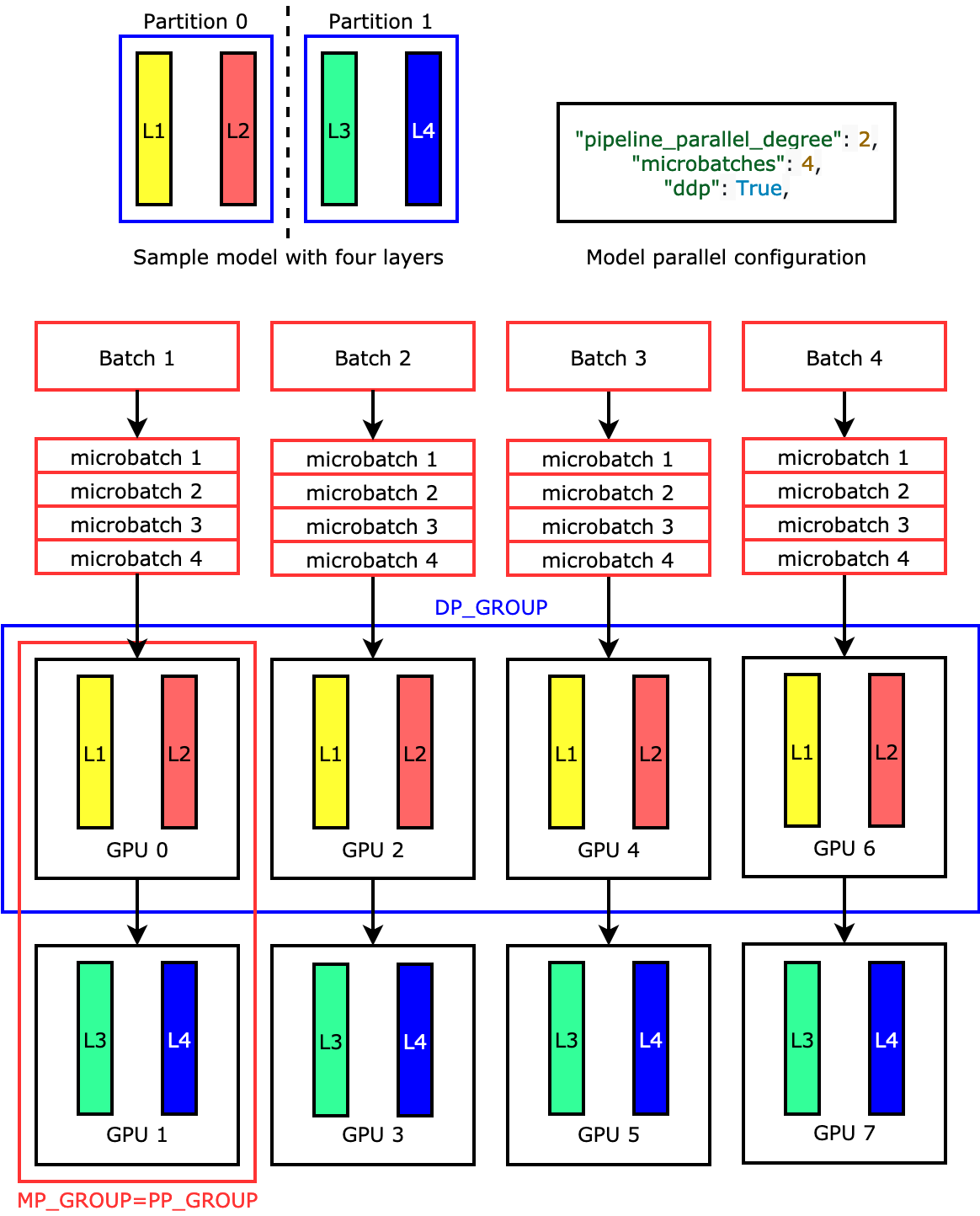
Example distributed training configuration with 3D parallelism, with 2 ...
Aicosoft - AI & Technology News, Insights & Innovation
來自 OpenAI gpt-oss 的技巧,您🫵可以在 transformers 中使用 - Hugging Face 文件
Train a Neural Network on multi-GPU · TensorFlow Examples (aymericdamien)
LLM(6):GPT 的张量并行化(tensor parallelism)方案 - 知乎
Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM ...
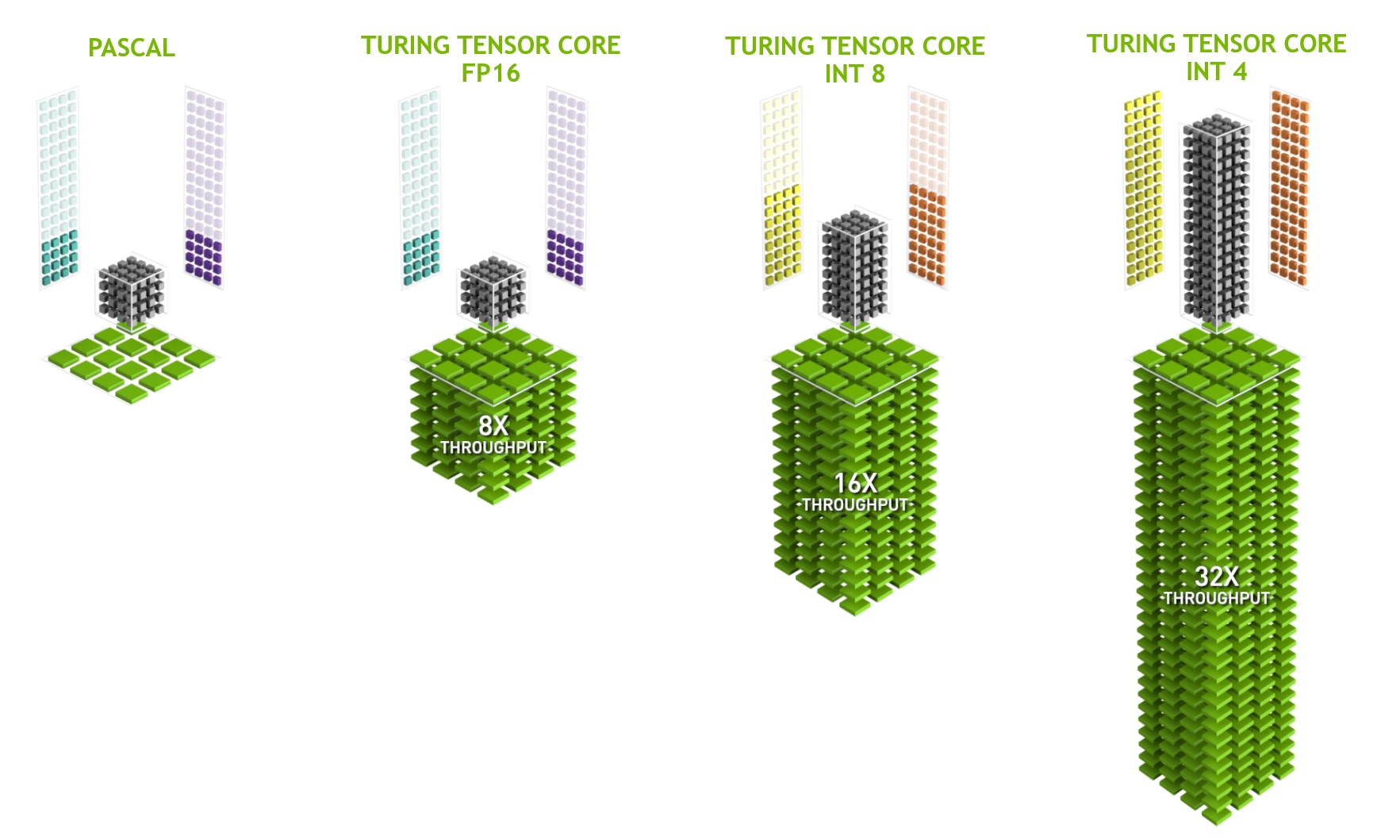
NVIDIA Turing Architecture In-Depth | NVIDIA Technical Blog
Llama-2 13B Throughput analysis without TTFT constraint | Maximizing ...
大模型从0到1|第八讲:手撕大模型并行训练 - WuJing's Blog
Introduction and Overview - Genai System Design Interview
LLM(六):GPT 的张量并行化(tensor parallelism)方案 - 知乎