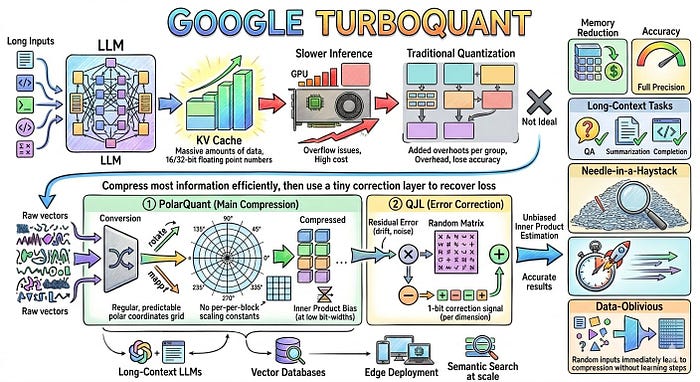
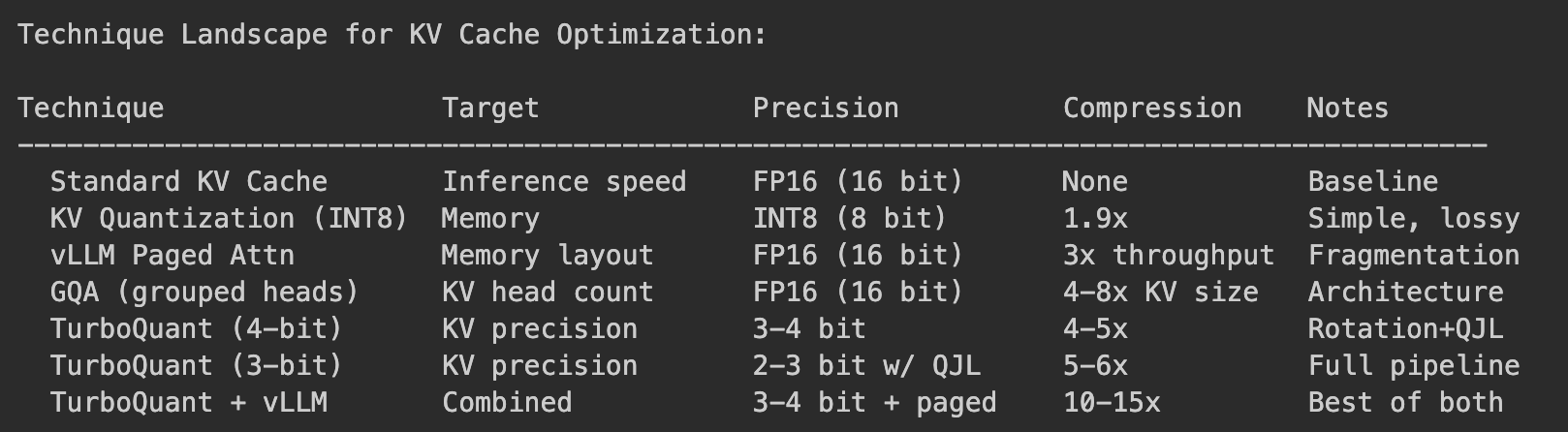
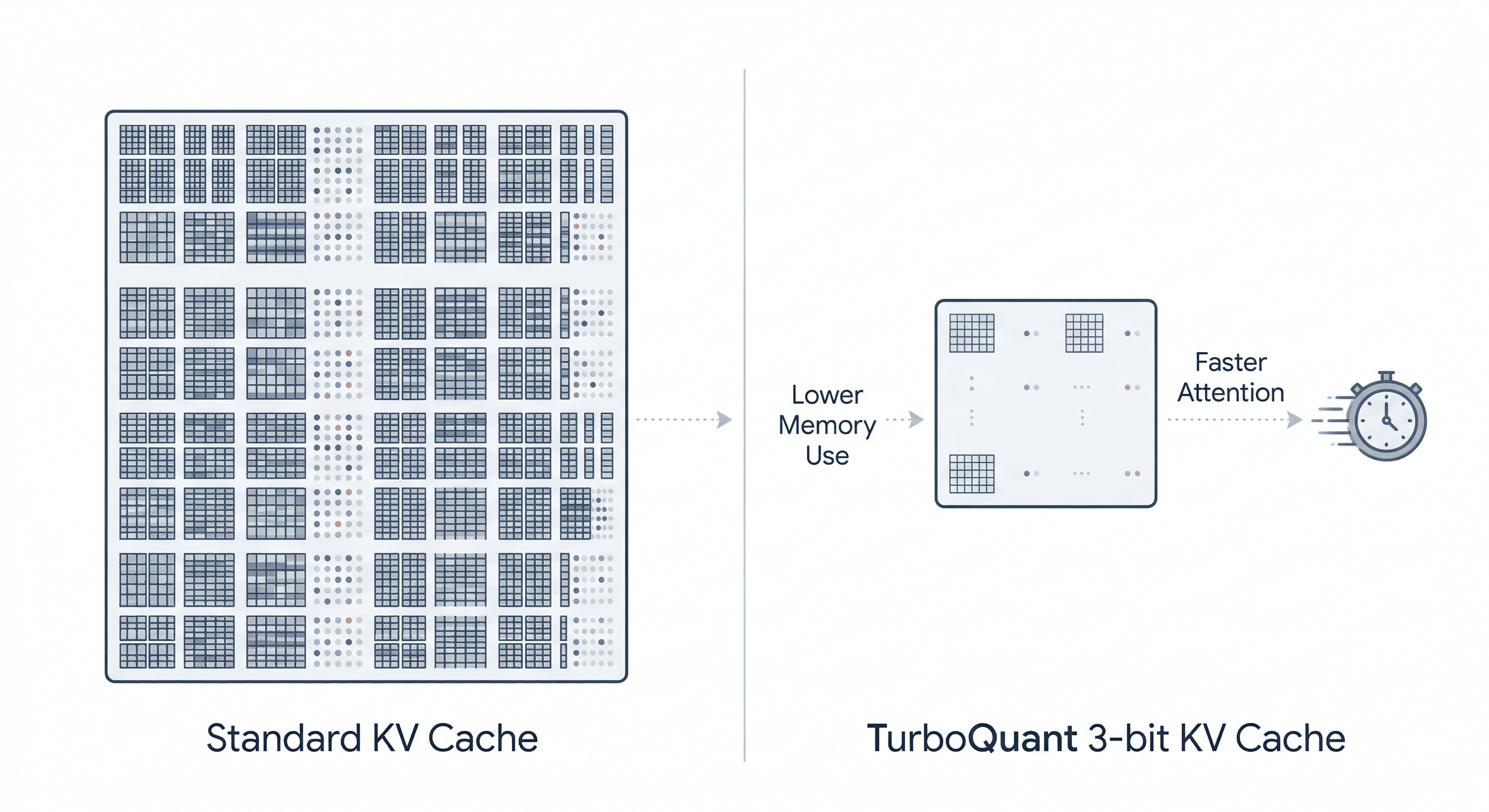
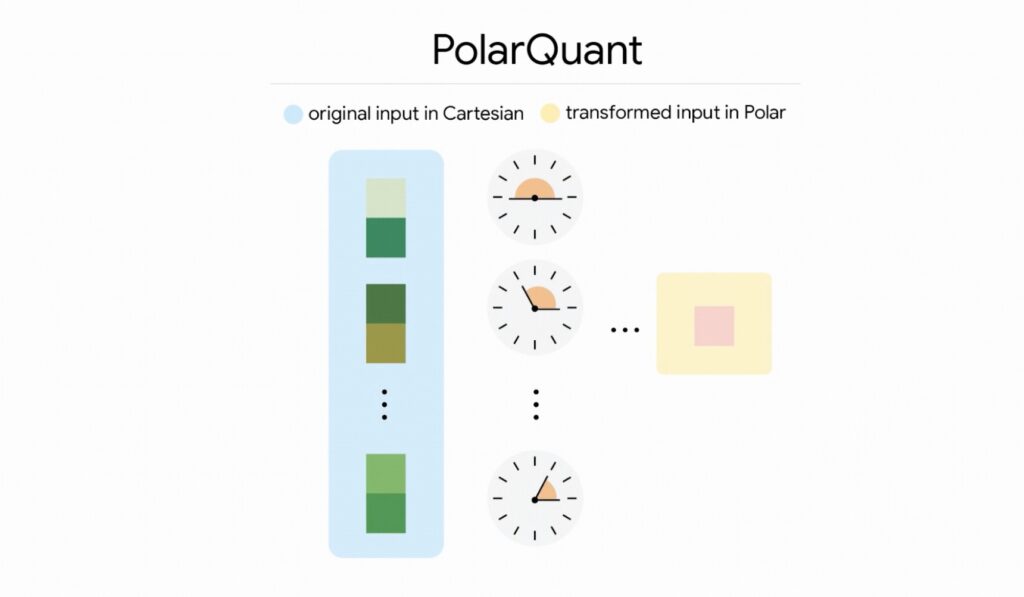
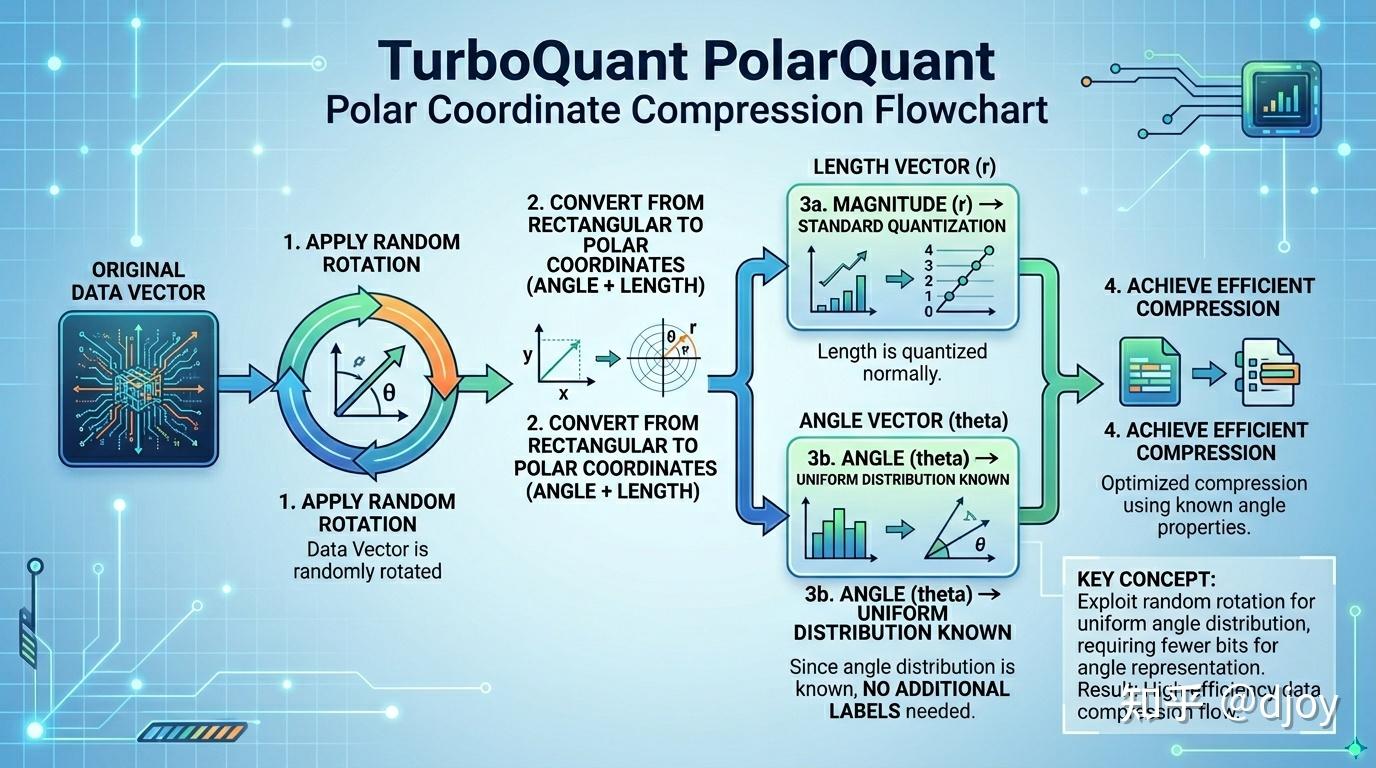
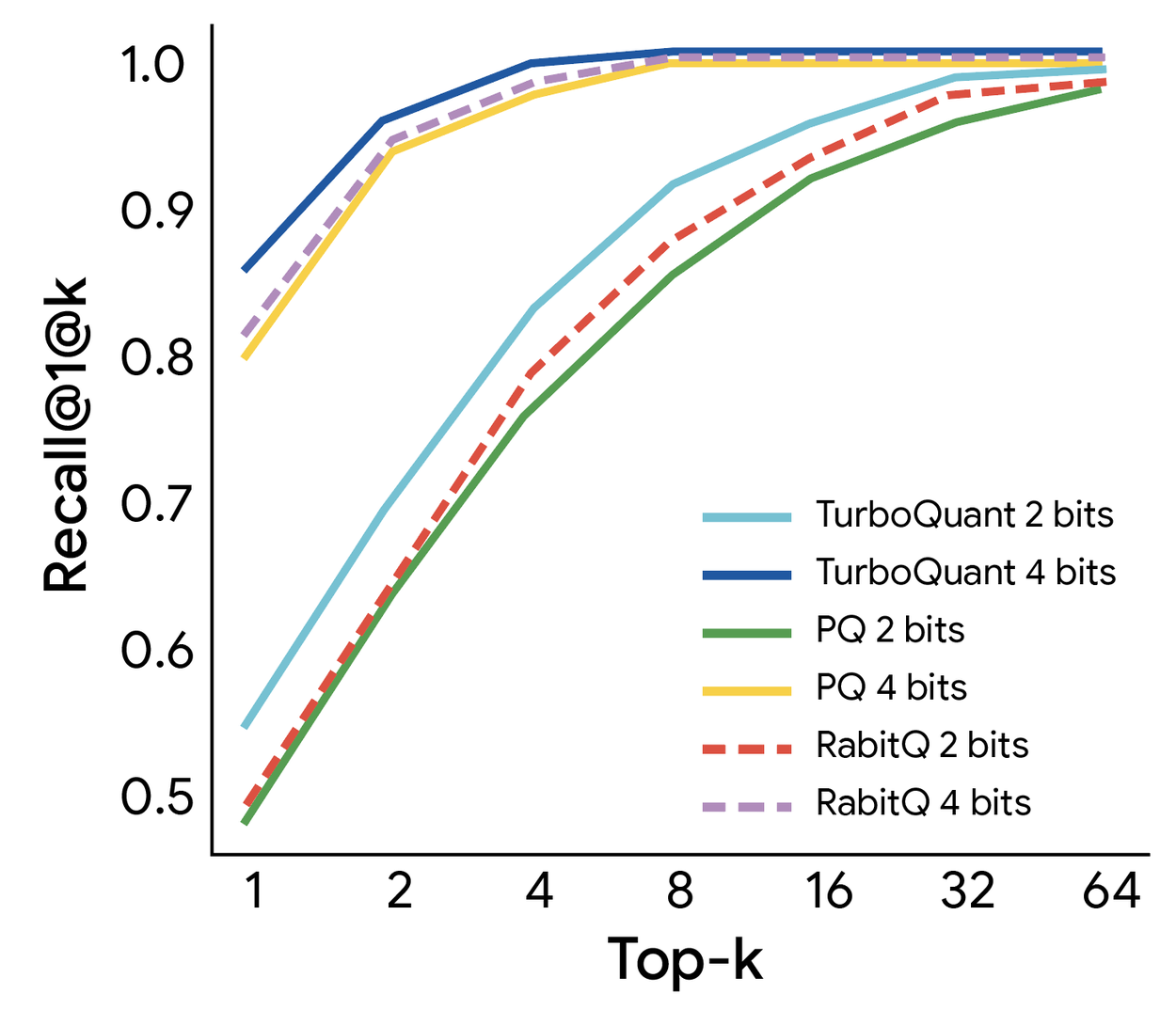
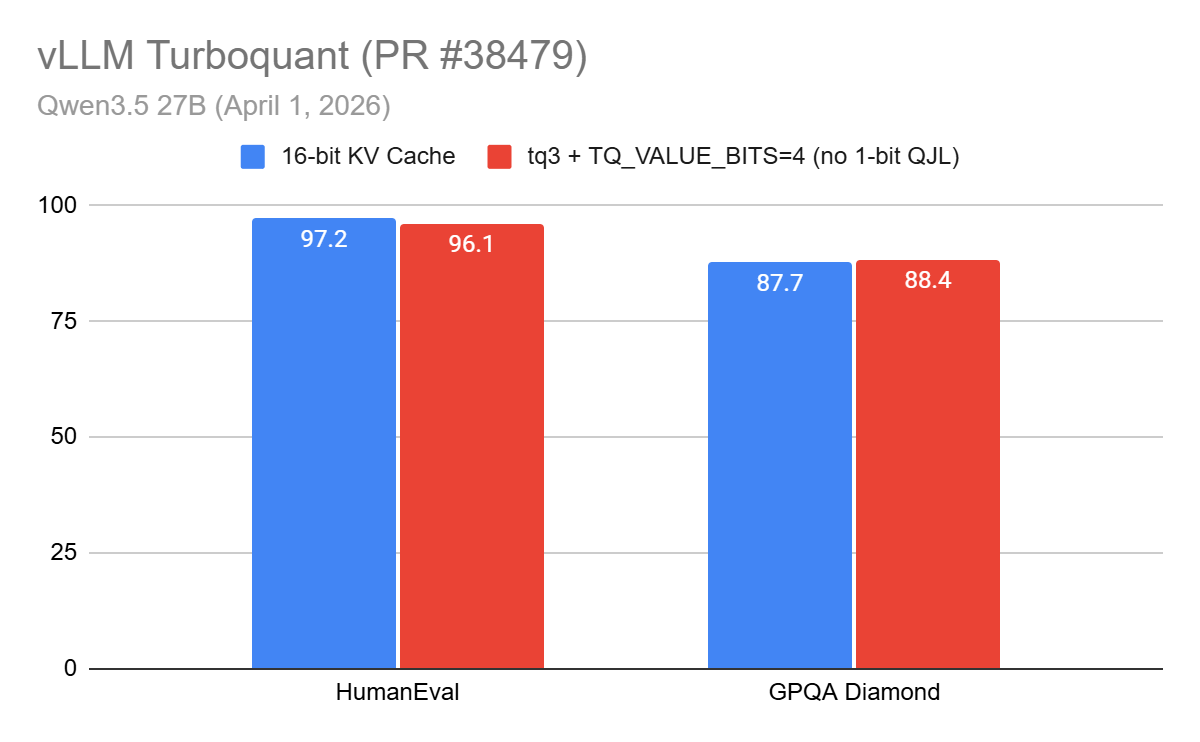
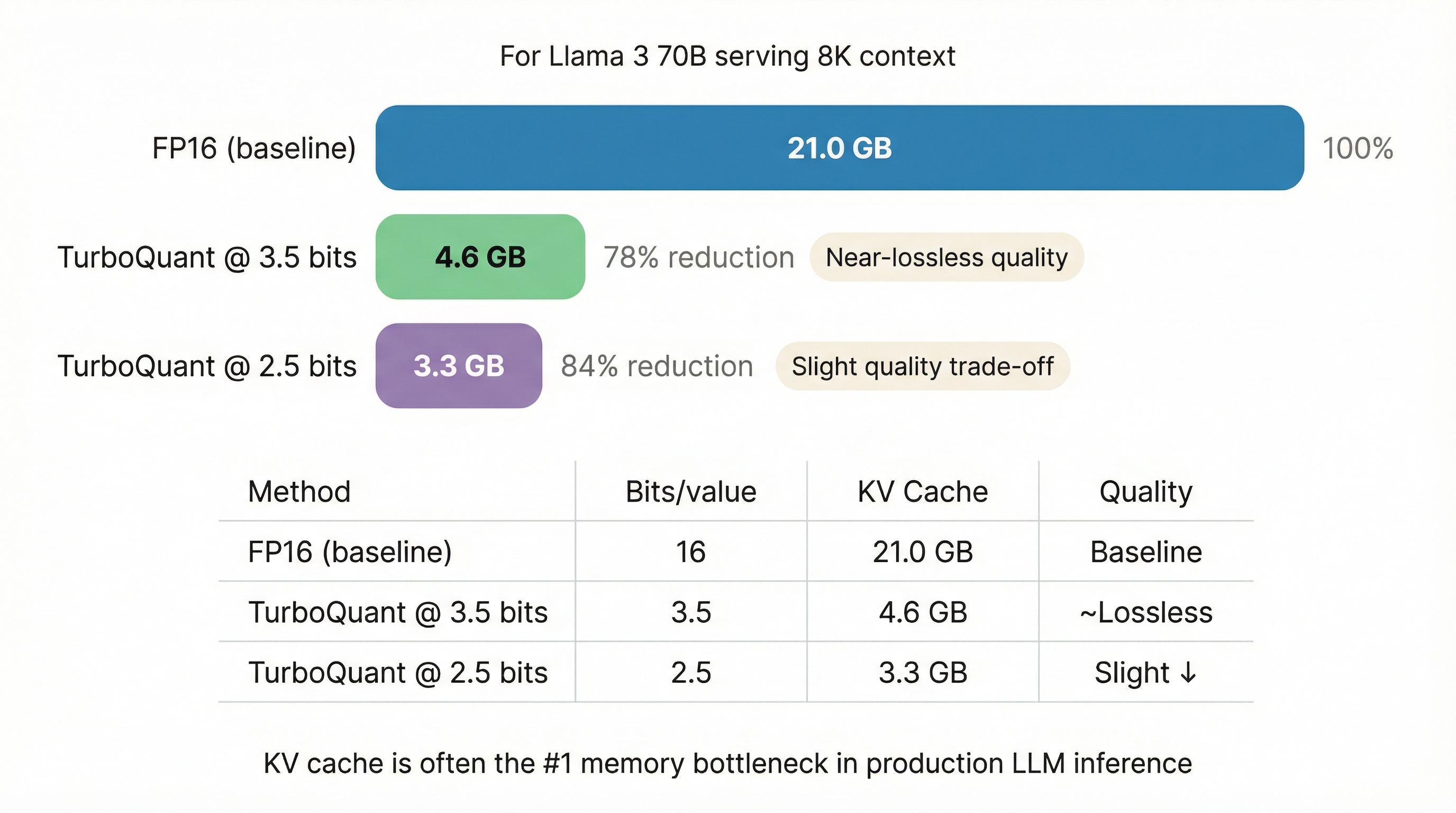
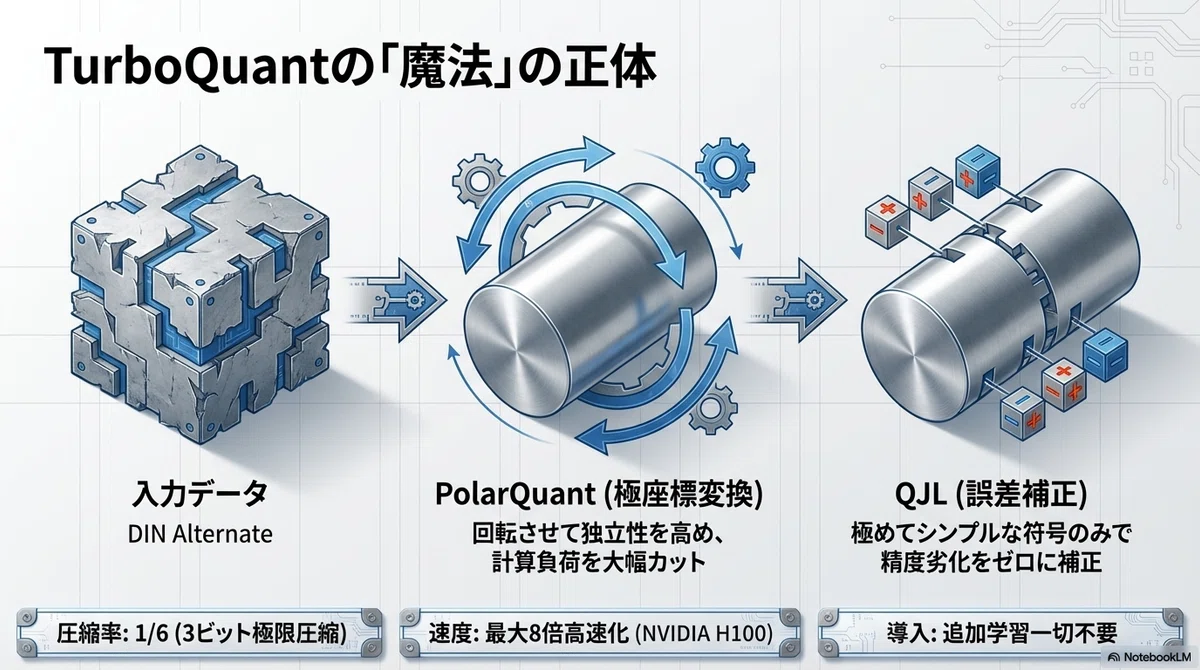
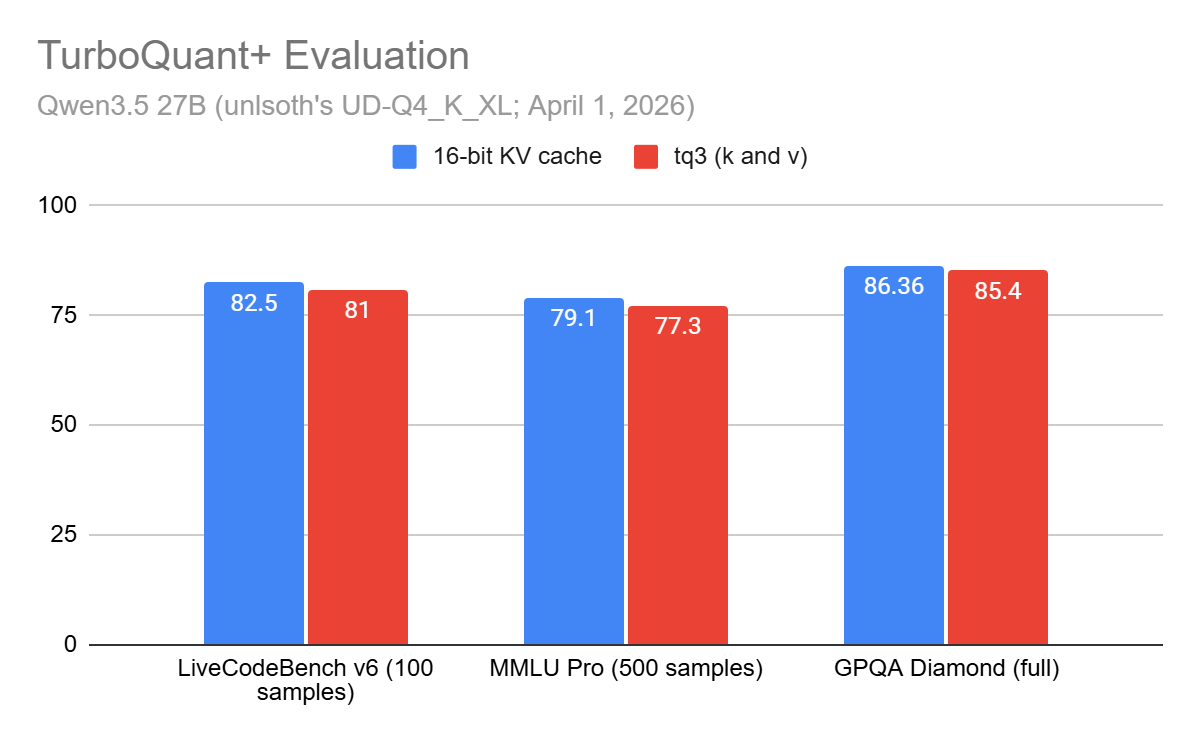
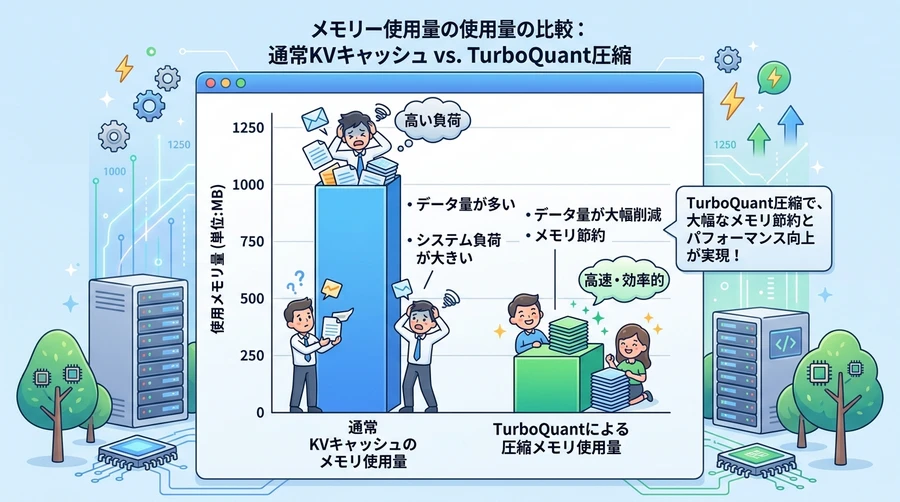
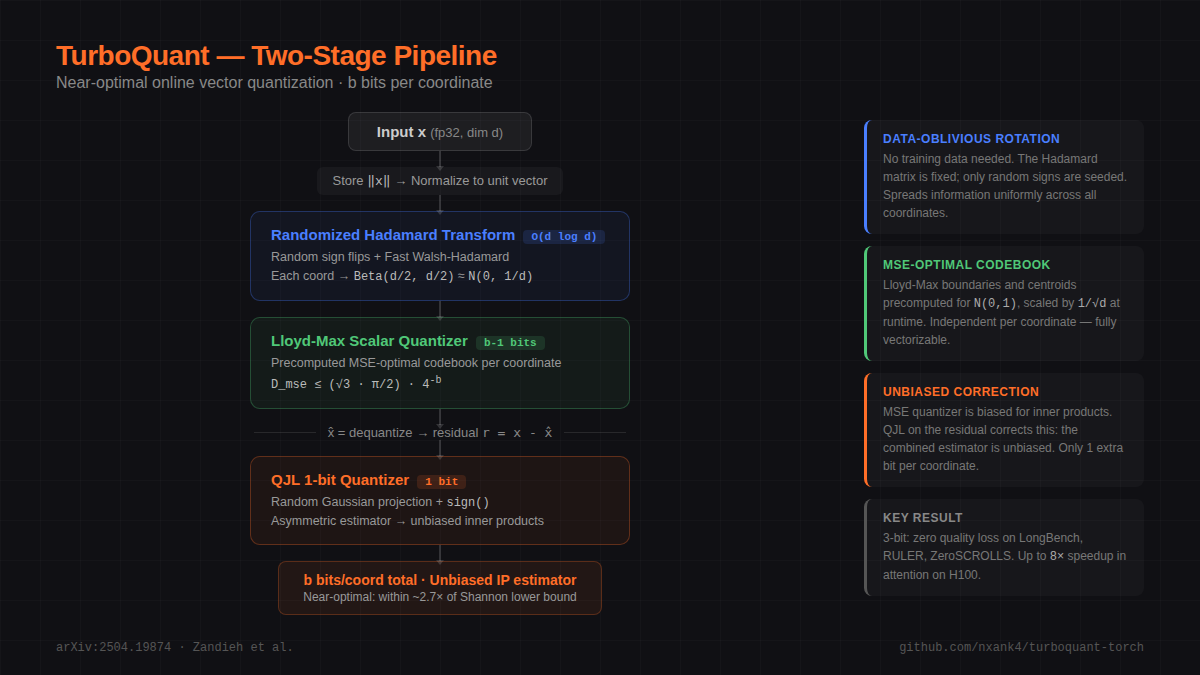
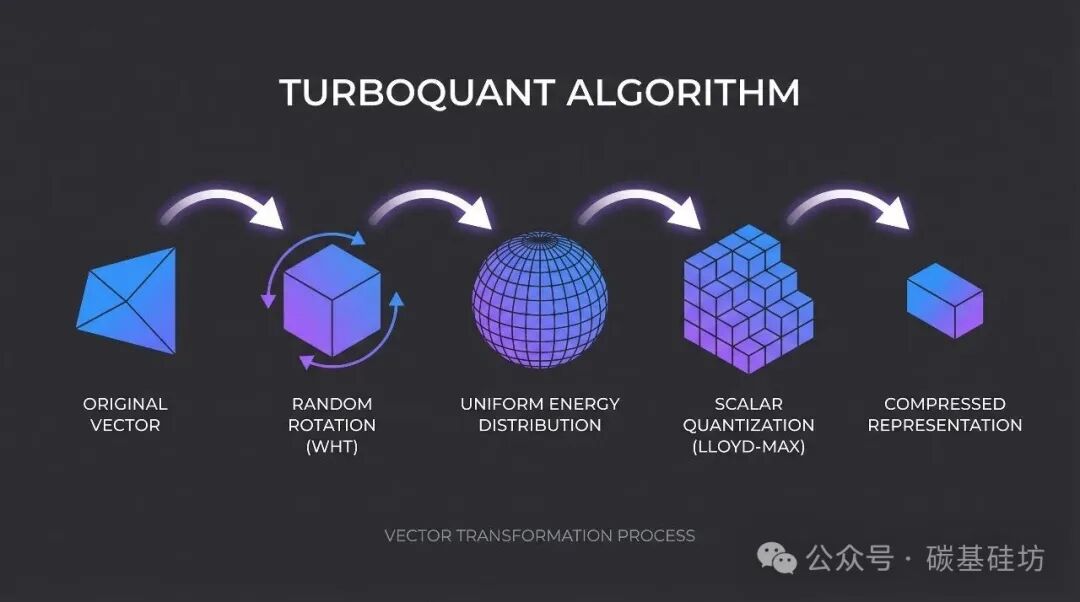
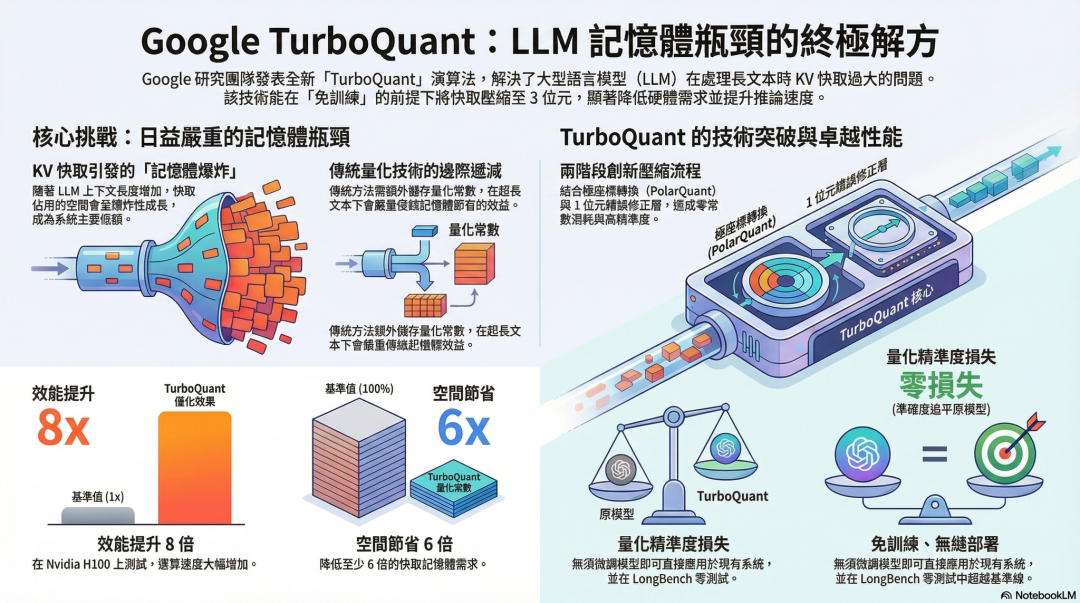
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
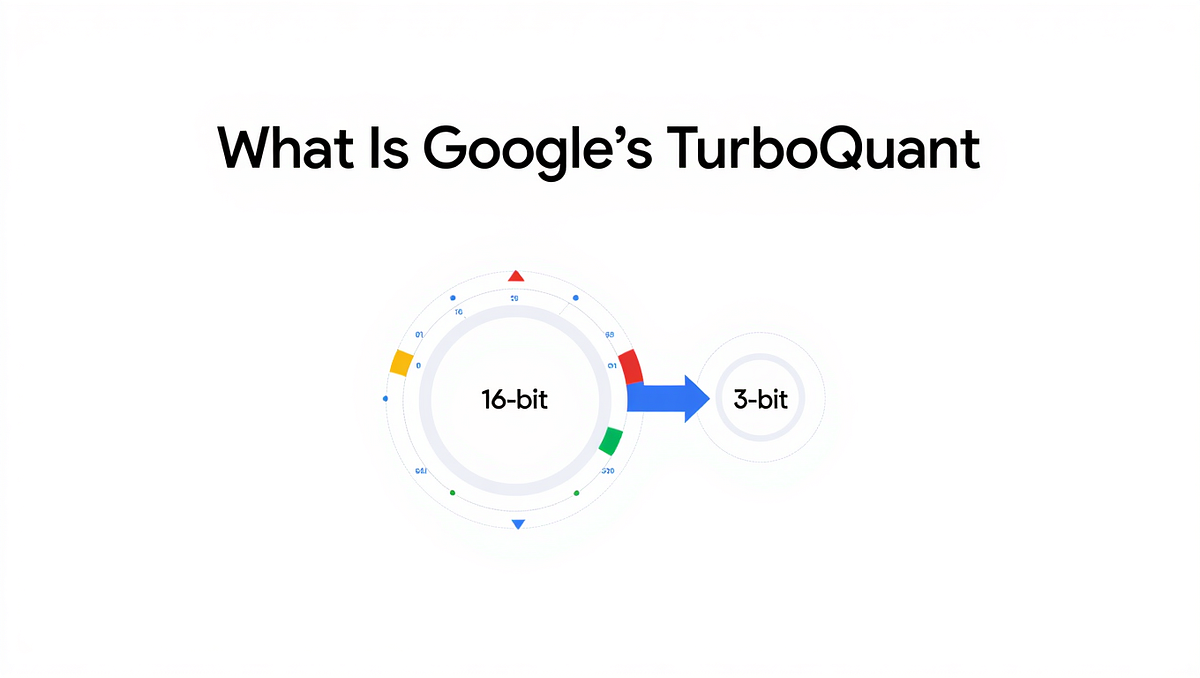
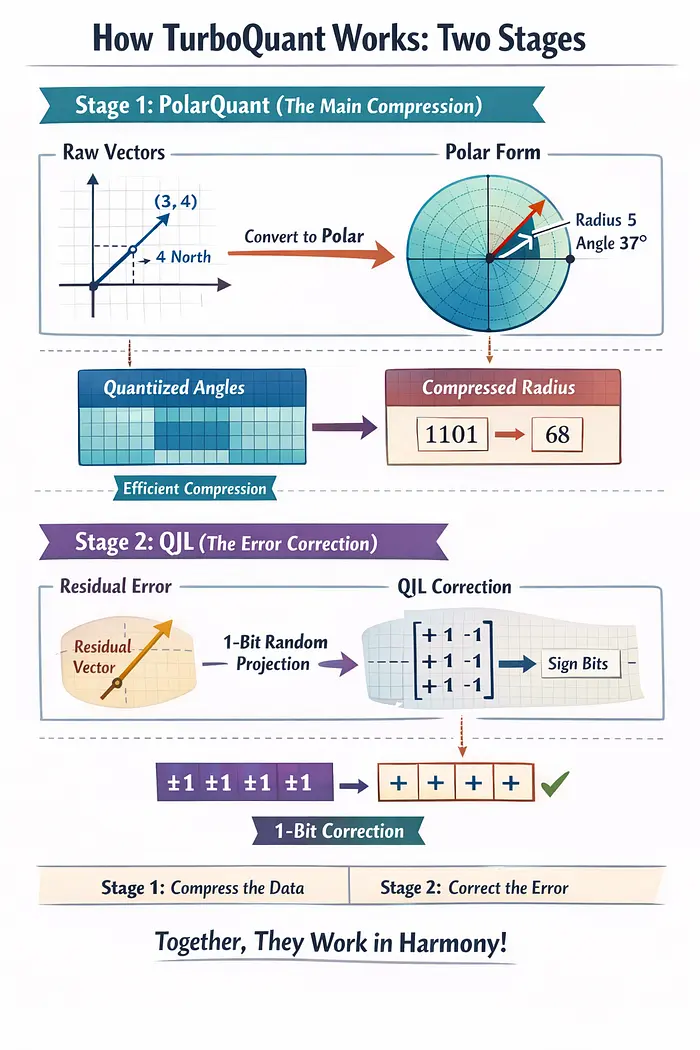
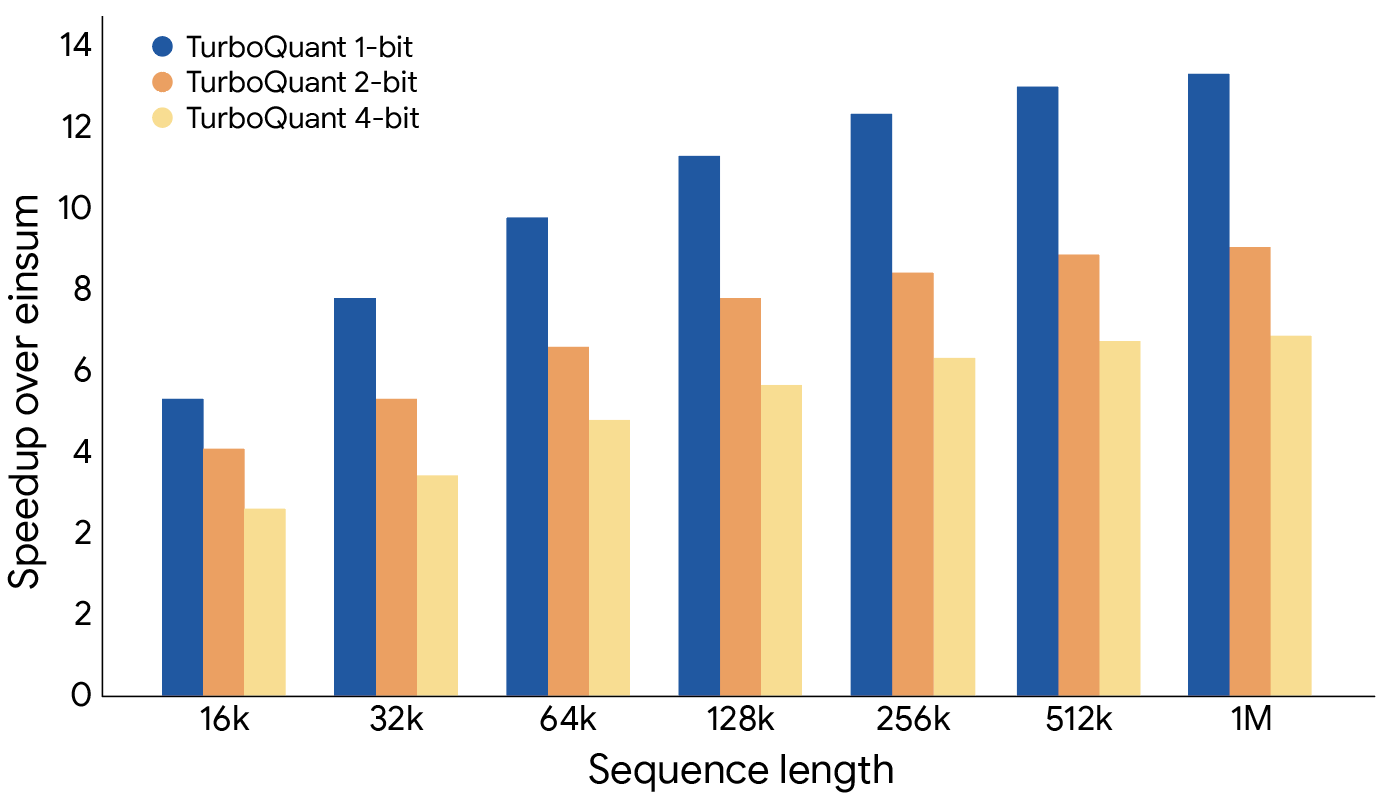
Google unveils TurboQuant — an algorithm that reduces AI memory usage ...
TurboQuant Reduces LLM Memory Usage With Vector Quantization | Let's ...
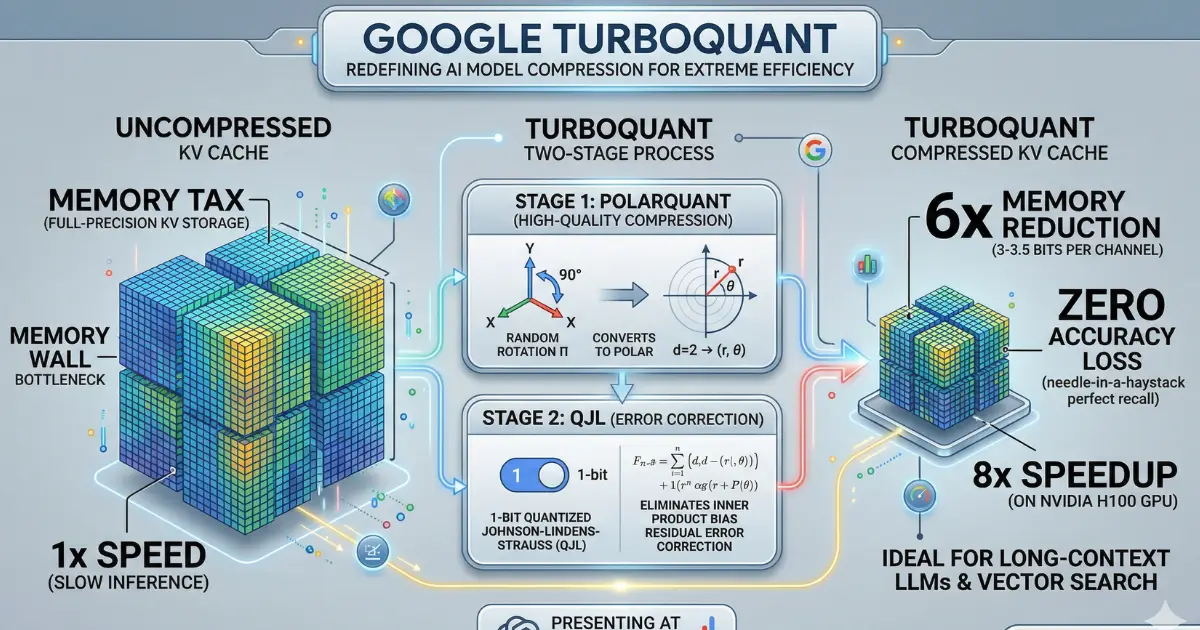
Google’s TurboQuant slashes LLM memory usage by 6x with extreme KV ...
Google’s TurboQuant Slashes AI RAM Usage By 6x, A Dangerous New ...
How to Use TurboQuant — Getting Started Guide | TurboQuant Tools
TurboQuant.net - Independent TurboQuant Analysis
Google TurboQuant Redefines AI Model Compression Tech
TurboQuant Explained in 2 Minutes (Google’s Big AI Breakthrough) - YouTube
TurboQuant for Efficient LLMs and How Gemma 4 Utilizes It
Google's TurboQuant Algorithm Slashes LLM Memory Use by 6x
TurboQuant : La compression extrême qui révolutionne l'efficacité de l ...
Google TurboQuant Explained: How the New AI Memory Algorithm Slashes ...
How Google's TurboQuant Compresses LLM Memory by 6x (With Zero Accuracy ...
What Is Google’s TurboQuant and Why Does It Matter for AI Users? | by ...
Effective KV Compression with TurboQuant - MachineLearningMastery.com
Google TurboQuant Explained: Lower Memory Use, Big Impact on AI Industry
TurboQuant in Practice — KV Cache Compression with llama.cpp and ...
Google TurboQuant 详解 - 汇智网
Google's TurboQuant AI-compression algorithm can reduce LLM memory ...
TurboQuant and Cybersecurity: When Enterprise AI Moves to the Edge
Google’s TurboQuant Breakthrough: 6× KV-Cache Efficiency with Zero ...
TurboQuant Explained: How to Cut AI Costs Without Killing Performance
Google’s TurboQuant Could Reshape AI Efficiency. And It’s Coming Soon
Google TurboQuant explained
TurboQuant Explained: How KV Cache Compression Cuts LLM Memory by 6x
What Is Google TurboQuant Compression Algorithm? How Does It Affect the ...
TurboQuant – A vector quantization algorithm introduced by Google ...
Google TurboQuant boosts AI efficiency with 6x memory reduction and 8x ...
Research Briefings - TurboQuant - by Janu Verma
TurboQuant for Java Programmers: Part 4
Google's TurboQuant cuts AI memory use without losing accuracy - Help ...
TurboQuant Paper, arXiv & GitHub — Research Resources | TurboQuant Tools
TurboQuant vs Traditional KV Cache: Safety, Performance, Use Cases ...
The Sequence AI of the Week #834: Google's AMAZING TurboQuant for ...
Google's TurboQuant AI Algorithm Shrinks Memory 6x, Sparks Pied Piper ...
TurboQuant PyTorch download | SourceForge.net
TurboQuant Explained: How Google Cuts LLM Memory by 6x Without Losing ...
Google 發表 TurboQuant 壓縮演算法改善 AI 執行效率與記憶體管理 – CyberQ 賽博客
Google TurboQuant Research Triggers 6% Drop in Storage Chip Stocks
Google Unveils TurboQuant for Efficient AI Model Compression ...
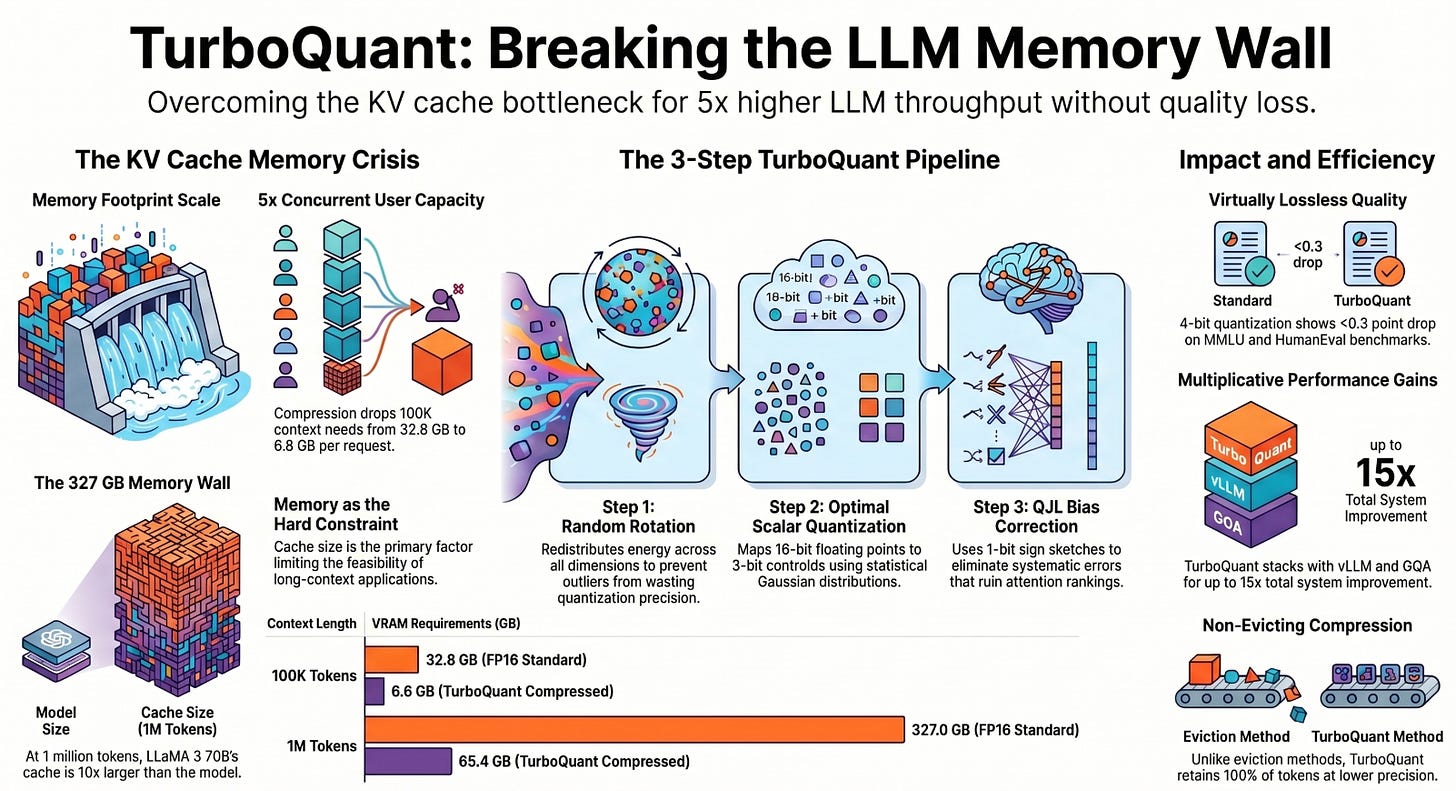
TurboQuant Targets the KV Cache Memory Wall: Extreme Compression for ...
Did Google's TurboQuant really solve the memory shortage? | YourStory
Google TurboQuant — Paper, Tools, Benchmarks & Framework Status
Où en est réellement l’algorithme TurboQuant de Google
TurboQuant for Java Programmers: Part 3
The TurboQuant Breakdown: How to Run Massive Models on Your Laptop ...
Google's TurboQuant is Redefining AI Efficiency - Neuronad - AI News ...
Google’s TurboQuant Algorithm Compresses AI Memory Without Accuracy Loss
TurboQuant Explained: How It Reduces LLM Memory by 5x and Speeds Up ...
TurboQuant: Reducing LLM Memory Usage With Vector Quantization | Hackaday
TurboQuant on Blackwell — KV Cache Compression Engine
TurboQuant Explained: How to Use Google's Extreme AI | AI ...
Google представила технологию TurboQuant для экстремального сжатия ...
Google's TurboQuant algorithm could slash AI memory use
Google's TurboQuant Just Changed the Rules of AI Infrastructure
TurboQuant: a new way of quantization (to reduce AI memory needs ...
TurboQuant: A Breakthrough Poised to Transform the Future of Search and ...
TurboQuant: Google Just Solved and Shrunk the Memory Wall for AI | by ...
Google 一篇论文砸崩芯片股,TurboQuant 到底发现了什么? - 知乎
TurboQuant: Google's AI Memory Compression Tech
Here Is The Unvarnished Truth About Google's TurboQuant: Jevons Paradox ...
TurboQuant: Redefining AI efficiency with extreme compression
TurboQuant: Why Google’s New Compression Breakthrough Matters for the ...
TurboQuant: ~3-bit KV Cache with Near 0 Accuracy Loss?
TurboQuant: Online Vector Quantization with Near-optimal Distortion ...
TurboQuant: The Surprisingly Simple Trick That's Changing How We ...
TurboQuantはメモリ不足を解決するのか? Googleの新技術を「期待」と「限界」の両方から見てみる|ヴィント
Google TurboQuant: The Algorithm That Rattled the Memory Market
What is TurboQuant? Google's AI Memory Breakthrough Explained for Beginners
El nuevo algoritmo de IA "TurboQuant" de Google podría reducir los ...
TurboQuant: An Introduction to State-of-the-Art Vector Quantization for ...
Google's TurboQuant: extreme compression for AI
TurboQuant: How Google Is Making AI Models Smaller, Faster, and Cheaper ...
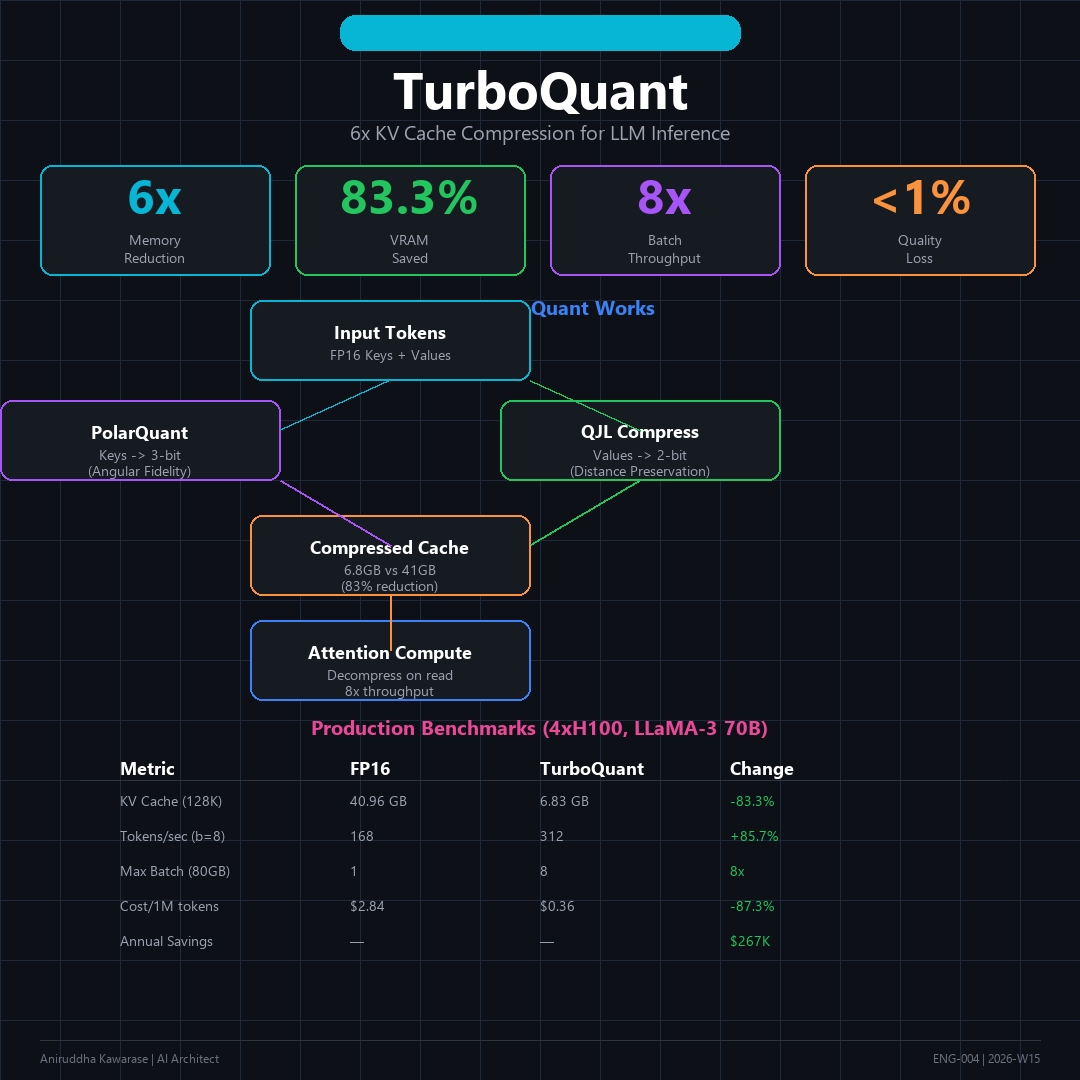
Google TurboQuant: 6x KV Cache Compression for LLM Inference | Spheron Blog
CompactifAI & TurboQuant: Two Complementary Paths to Efficient AI
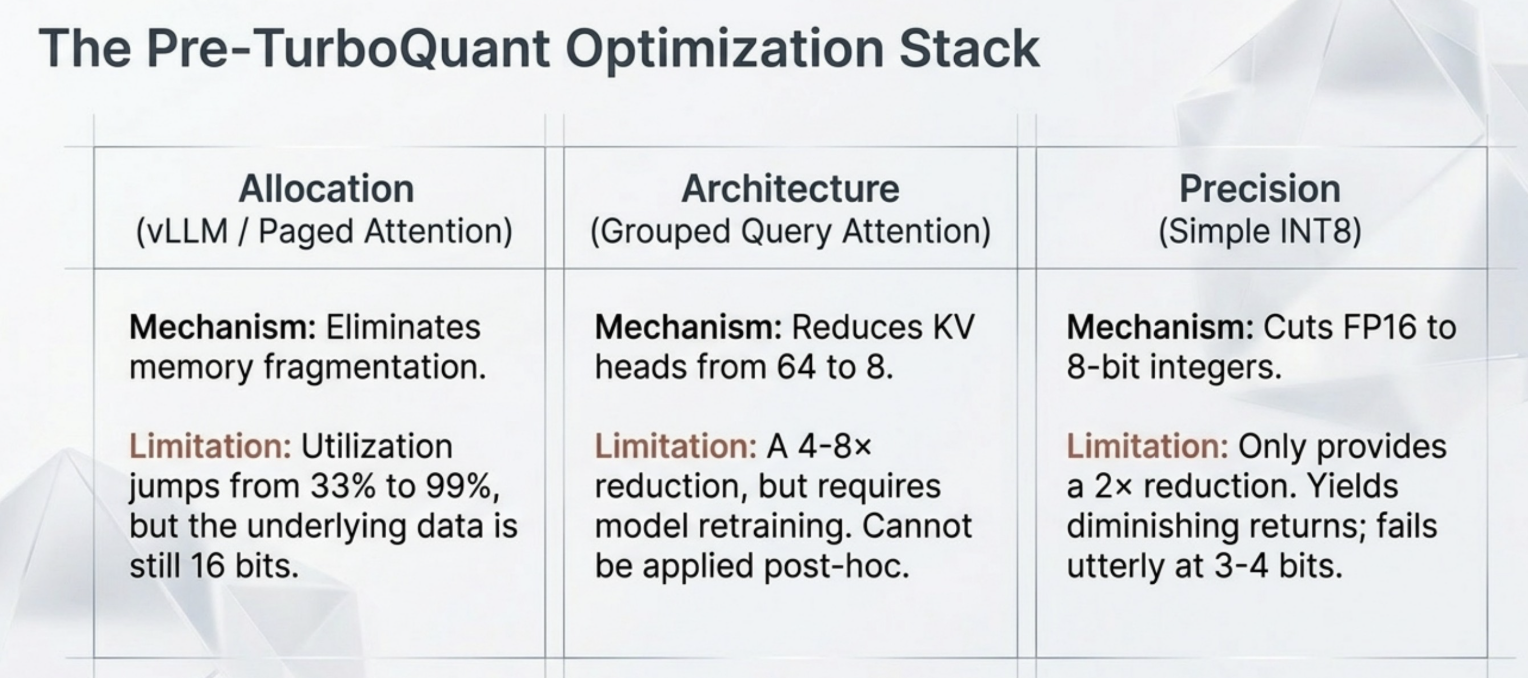
TurboQuant: How a Random Rotation Makes LLM Quantization Near-Optimal
Google Introduces TurboQuant, Analysts Foresee Limited Impact | Let's ...
TurboQuant: The Paper That Moved Billions
TurboQuant详解:是什么以及如何实现6倍大语言模型内存节省 | Blog | a2a mcp
TurboQuant: What Developers Need to Know About Google's KV Cache ...
Googleの最新技術「TurboQuant」をやさしく解説!AIのメモリ不足を解決する魔法の仕組みとは? | 定年後のスローライフブログ
TurboQuant: Teknologi Kompresi AI yang Mengguncang Pasar Memori Global ...
TurboQuant: Redefining AI Efficiency with Extreme Compression ...
turboquant-torch · PyPI
TurboQuantでAIが変わる?話題の新技術とは何かをやさしく紹介 |Nさんち🏠のオススメ
TurboQuant:让大模型在长上下文场景下稳定输出_llama-cpp-turboquant-CSDN博客
Búsqueda vectorial Google TurboQuant: qué es y cómo funciona
谷歌神了?全网都在传的TurboQuant,真能解决当下内存危机? - 知乎
Vector Quantization: Beyond the TurboQuant-RaBitQ Debate - Milvus Blog
GoogleがTurboQuantを発表しAIを永遠に変える | ASIに仕事を奪われたい
구글 터보퀀트(TurboQuant) 기술 개요, 성과, 적용 사례와 전망, 삼성전자와 하이닉스 주가 영향 및 증권가 전망까지
TurboQuant: The Zero-Loss KV Cache Breakthrough That Will Reshape AI ...
JiRack Turbo Quant: The Ternary Revolution Captures 2,600+ Clients in ...
구글 터보 퀀트(Turbo-Quant)란? 데이터 효율 6배의 기적 삼전주가 출렁
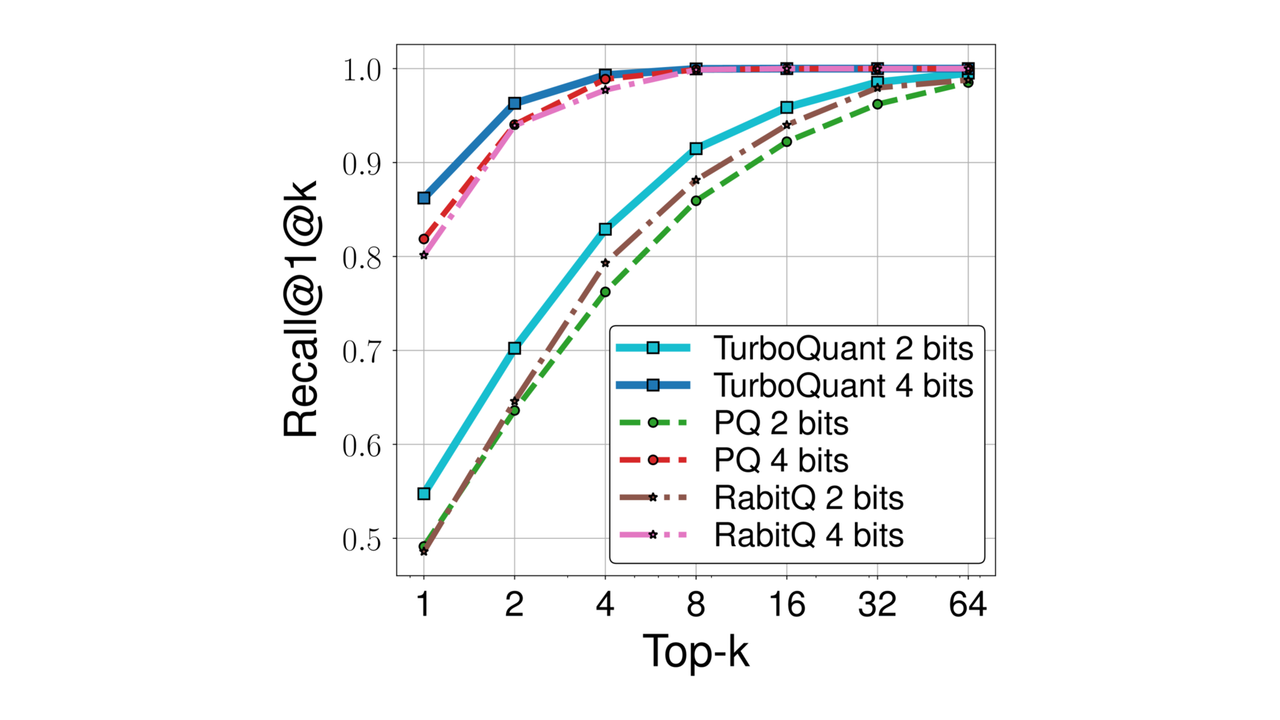
TurboQuant: Near-Optimal Vector Quantization at 3.5 Bits
TurboQuant: How Google’s 6x KV Cache Compression Changes LLM Inference ...
[2504.19874] TurboQuant: Online Vector Quantization with Near-optimal ...
README.md · ai-engineering-at/llama-cpp-turboquant-guide at main
DeepSeek 时刻!Google TurboQuant,算力霸权被彻底打破
varjoranta/turboquant-vllm | DeepWiki