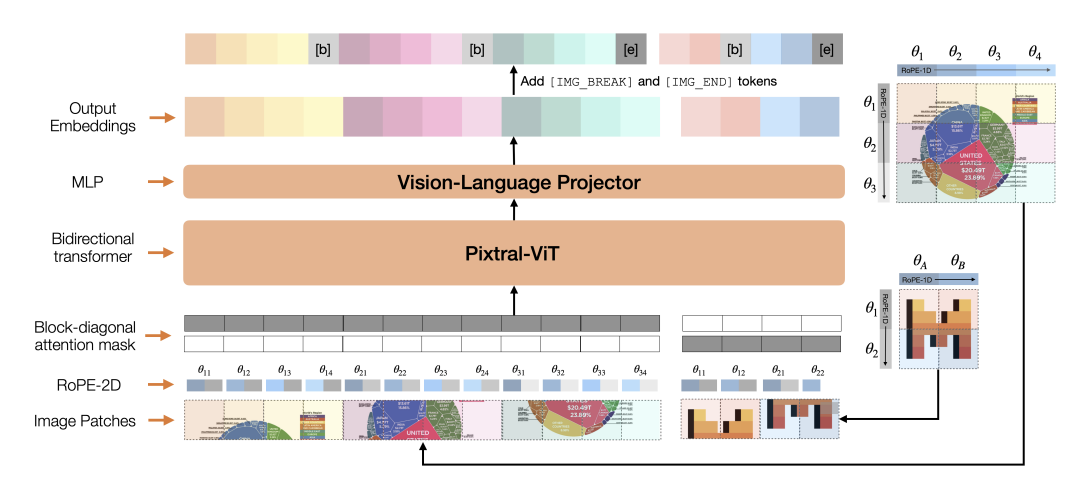
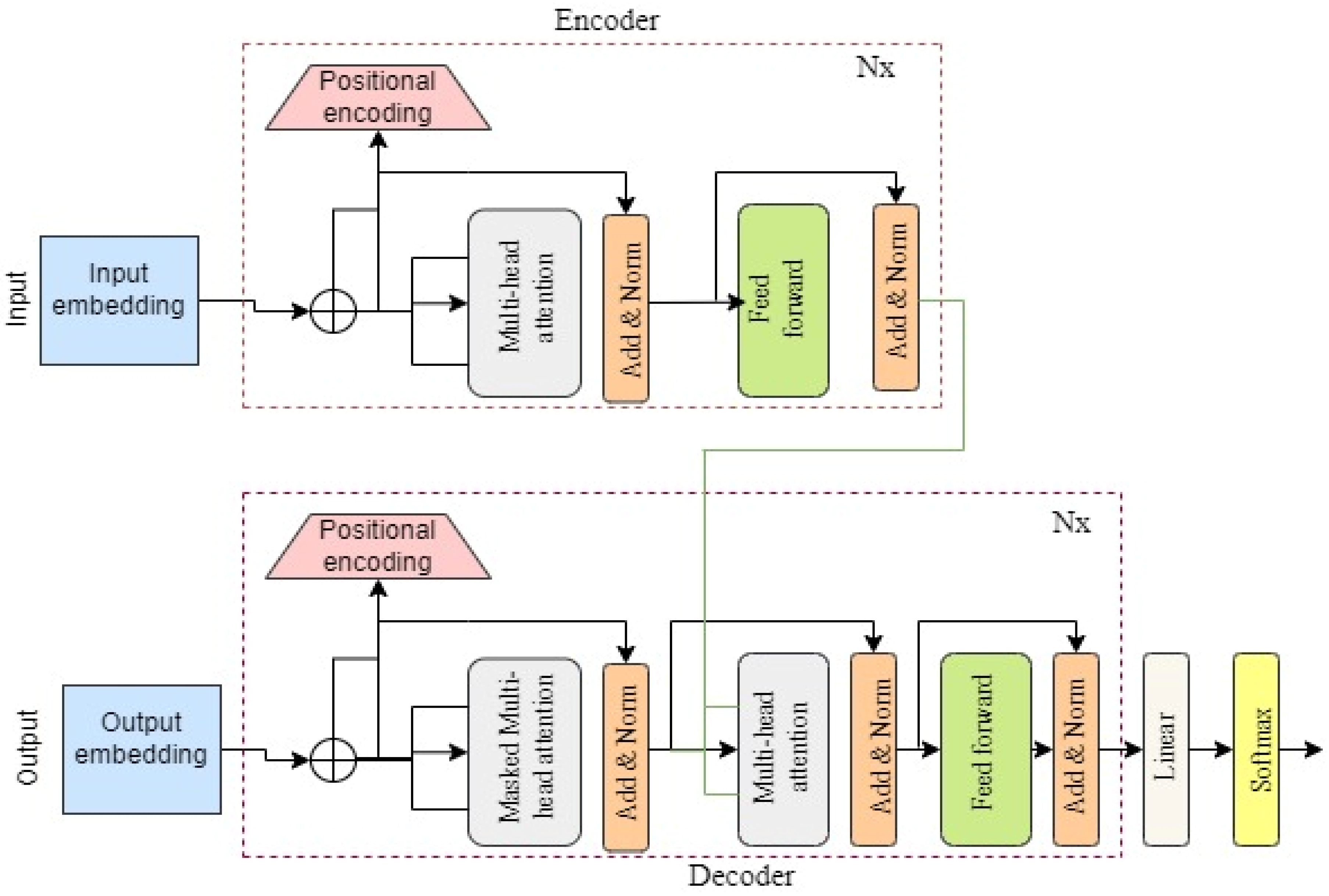
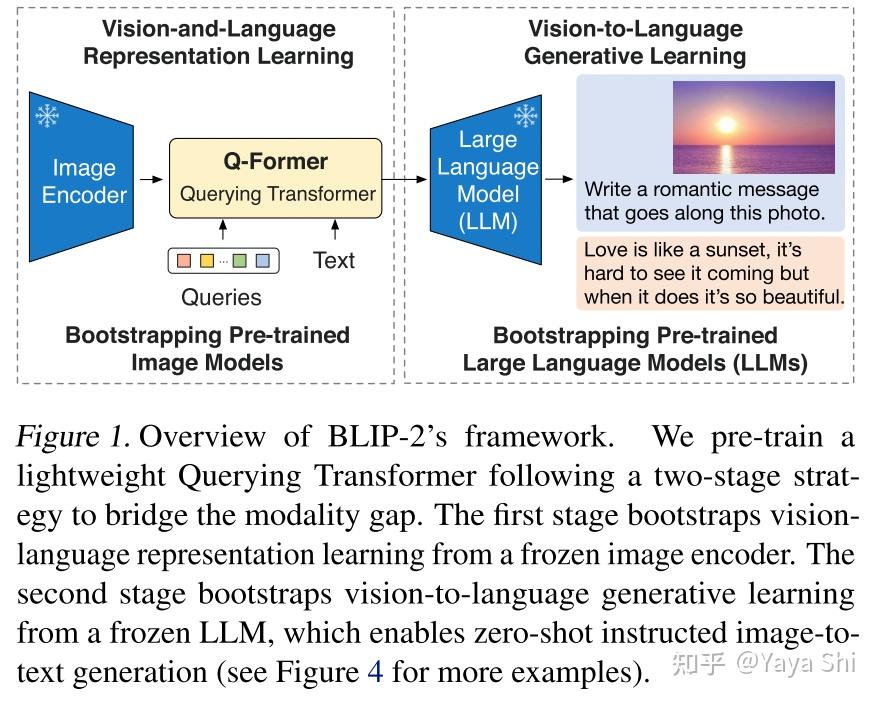
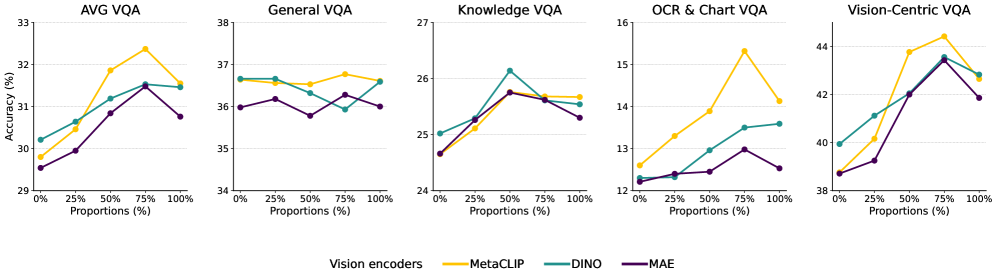
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
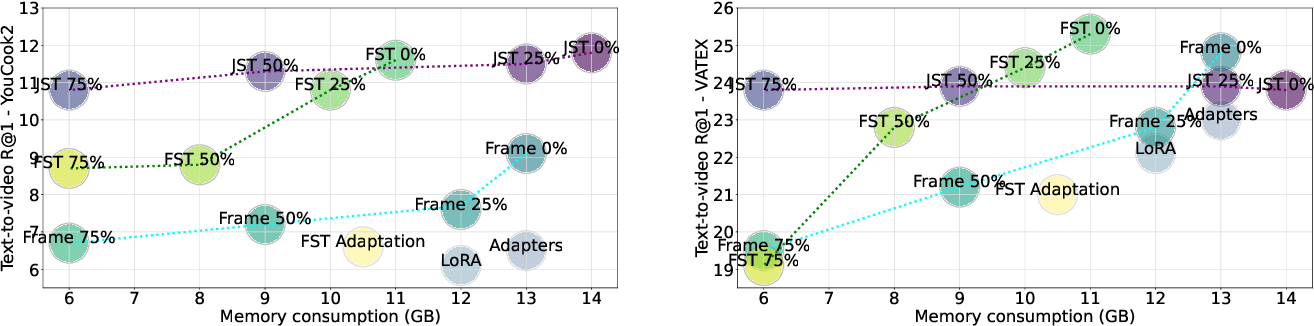
Unicoder-VL; A Universal Encoder for Vision and Language by Cross-modal ...
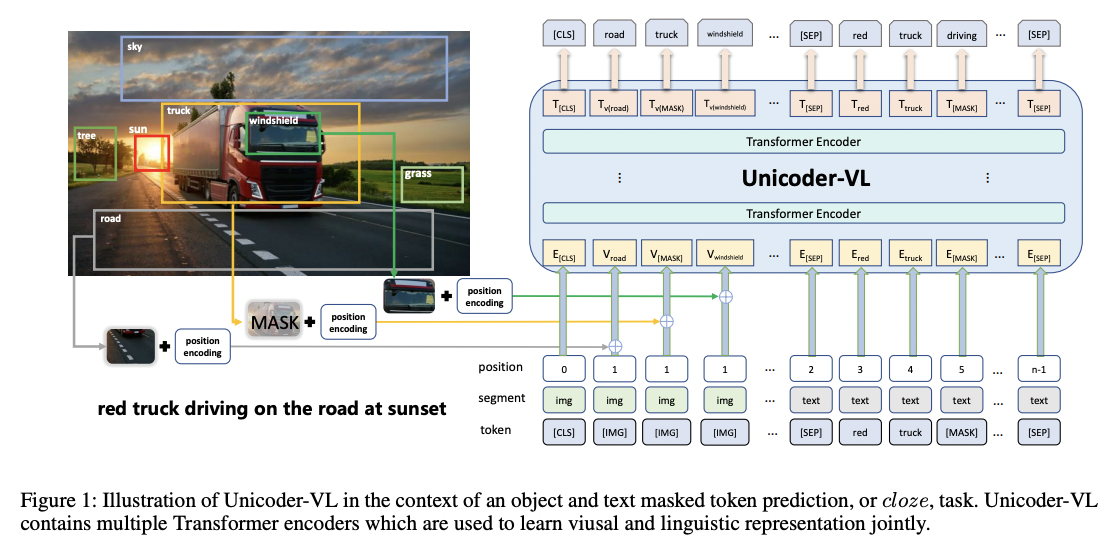
VLM Vision Encoder Pre-training 之 Masked Image Modeling (MIM) - 知乎
[논문 리뷰] Bridging the Sim2Real Gap: Vision Encoder Pre-Training for ...
Apple's AIMV2: Multimodal Vision Encoder Pre-training - YouTube
AIMLmag.com on LinkedIn: Revolutionizing Vision AI: Multimodal Pre ...
(PDF) Unicoder-VL: A Universal Encoder for Vision and Language by Cross ...
Bambu Vision Encoder – PLEX Robotics
Bambu Lab Vision Encoder
Train a CLIP model on CIFAR 10. VIT encoder, Pretrained Resnet vision ...
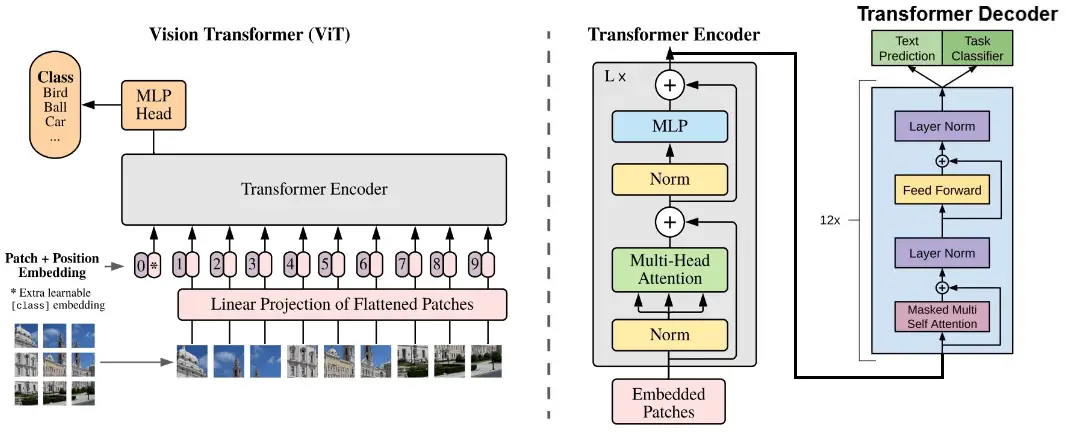
(a) Encoder of Vision Transformer (ViT) [18] inspired by the encoder of ...
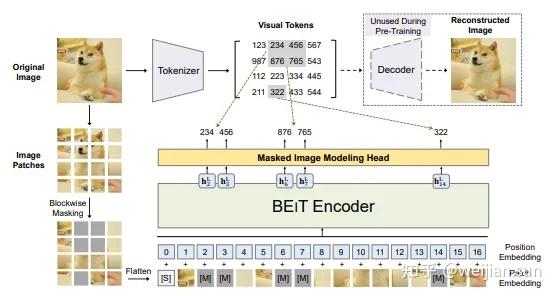
UNIT: Unifying Image and Text Recognition in One Vision Encoder
Meta AI Introduces Perception Encoder: A Large-Scale Vision Encoder ...
(a) Encoder block, (b) Vision transformer. | Download Scientific Diagram
UNIT; Unifying Image and Text Recognition in One Vision Encoder - AAA ...
ADJ 3D VISION ENCODER
Vision Encoder | Bambu Lab US Store
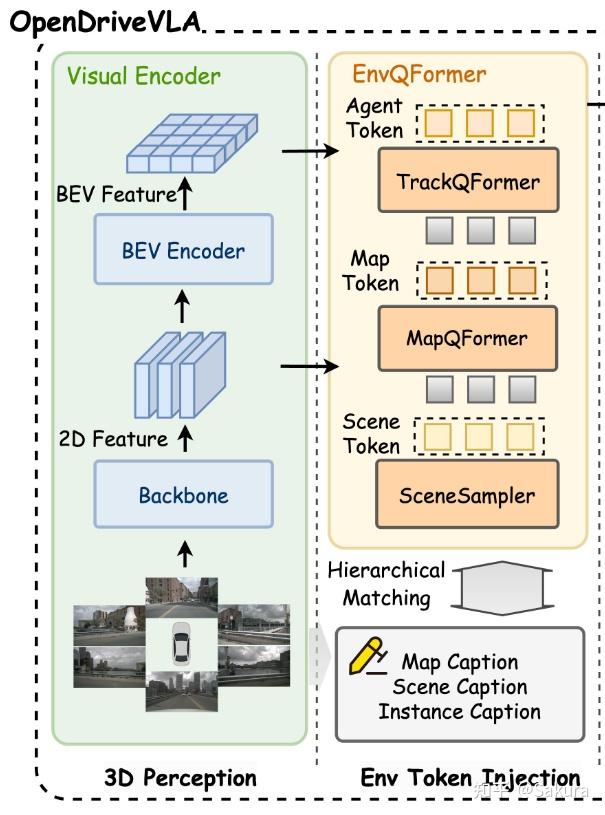
自动驾驶VLA简单调研--Part1 Vision Encoder - 知乎
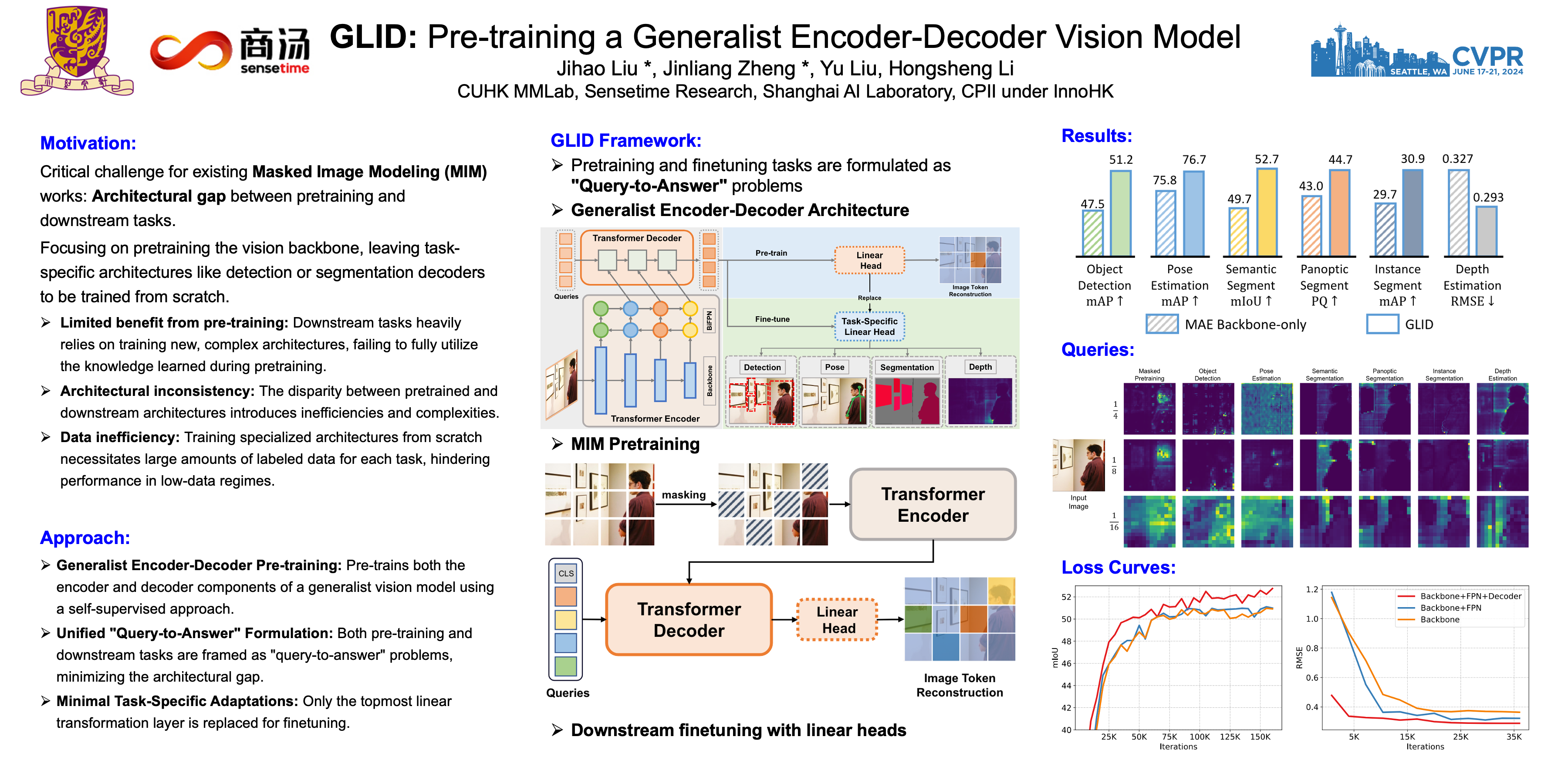
CVPR Poster GLID: Pre-training a Generalist Encoder-Decoder Vision Model
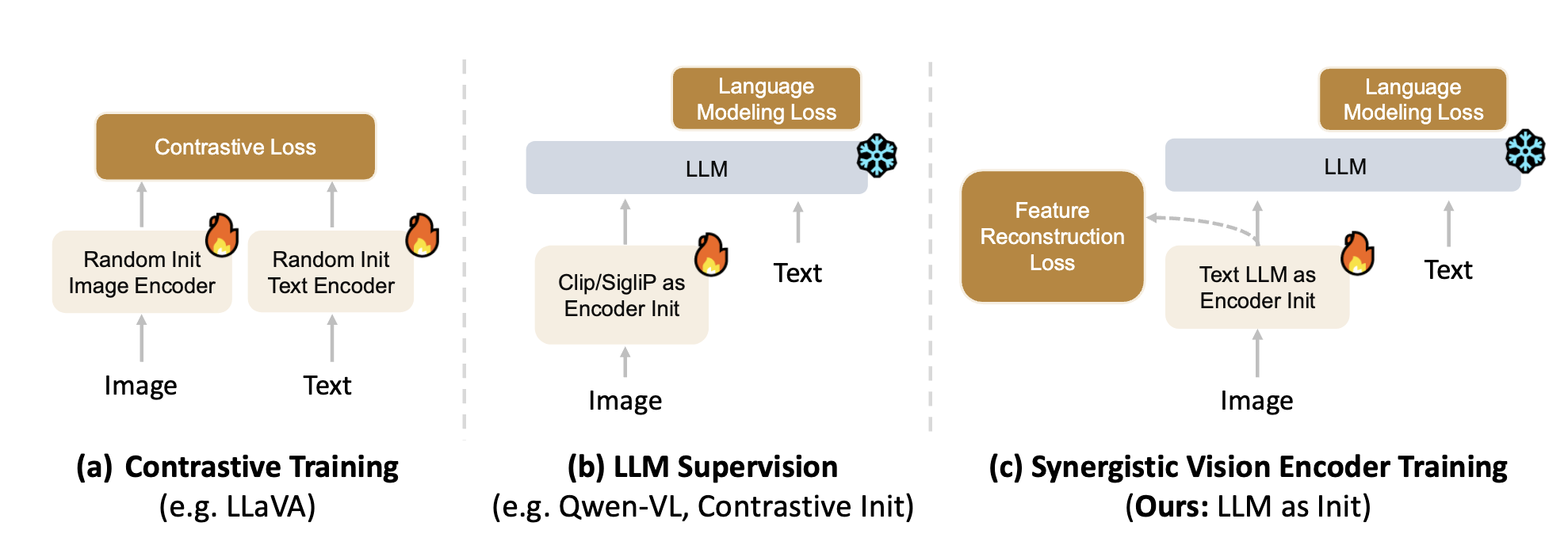
Hierarchical Pre-Training of Vision Encoders with Large Language Models
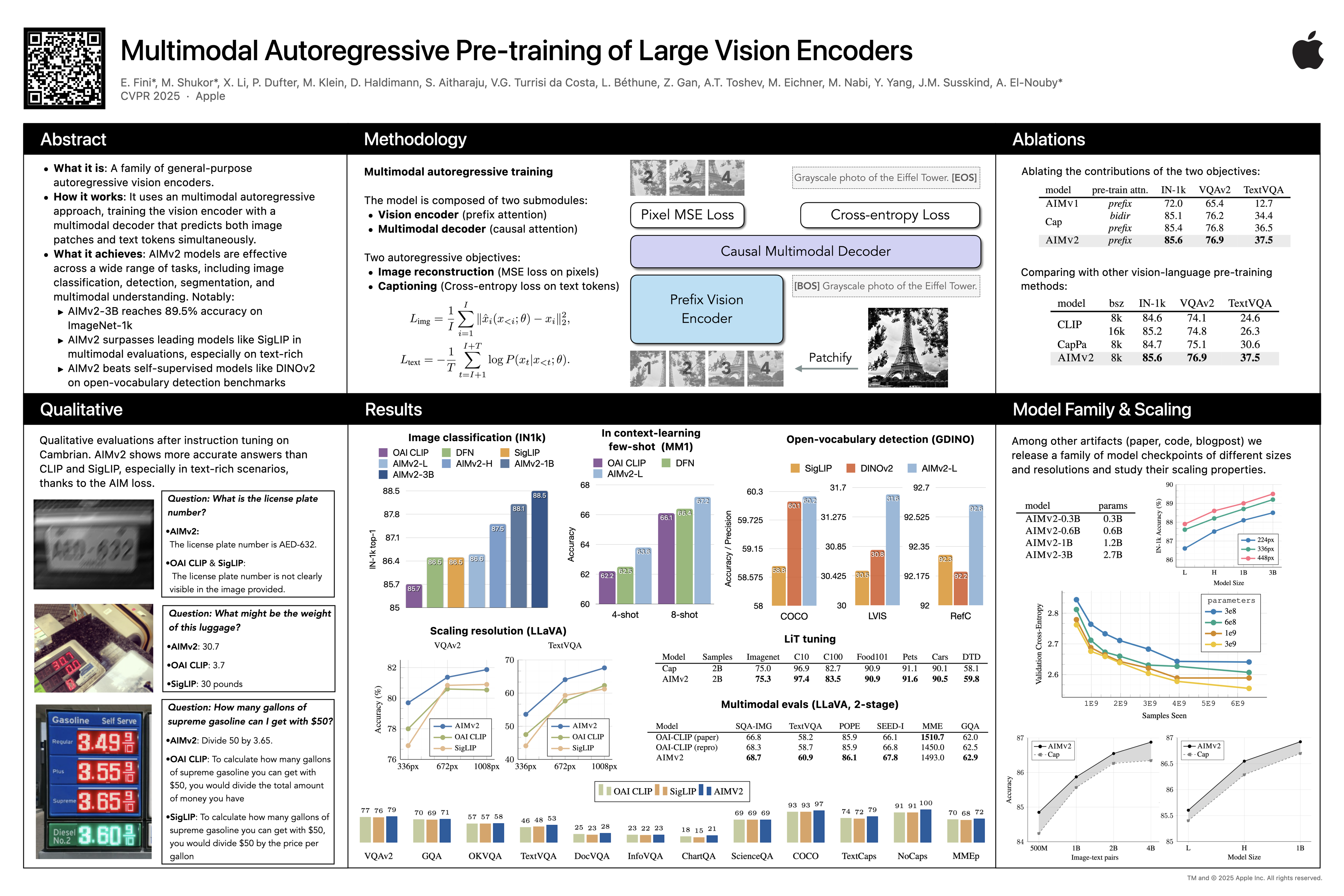
CVPR Poster Multimodal Autoregressive Pre-training of Large Vision Encoders
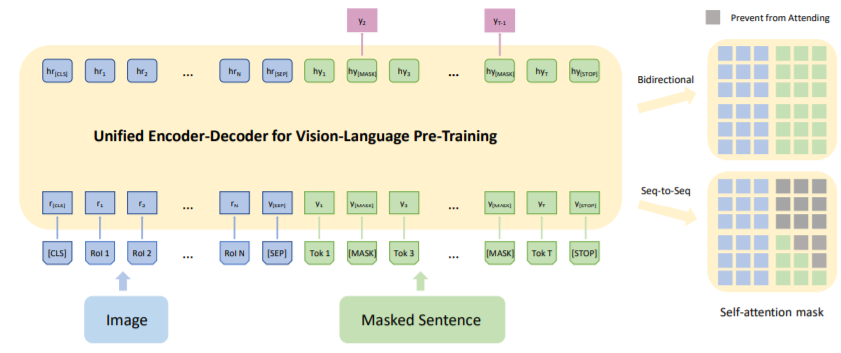
Vision and language pre-training(Image/Video Bert) - 知乎
Understanding Encoder-Only Architectures in Transformers: Key Pre ...
Handwritten Document Recognition Using Pre-trained Vision Transformers ...
Expanding scene and language understanding with large-scale pre ...
Pre-trained vision transformer vs training from scratch | Download ...
26. Vision Language Pretraining — LLM Foundations
Multimodal Autoregressive Pre-training of Large Vision Encoders
[2411.14402] Multimodal Autoregressive Pre-training of Large Vision ...
The overall architecture of our proposed approach, where the vision ...
Paper page - Multimodal Autoregressive Pre-training of Large Vision ...
[논문 리뷰] GLID: Pre-training a Generalist Encoder-Decoder Vision Model
(PDF) Multimodal Autoregressive Pre-training of Large Vision Encoders
Multimodal Autoregressive Pre-training of Large Vision Encoders - YouTube
GLID: Pre-training a Generalist Encoder-Decoder Vision Model - 智源社区论文
[논문 정리] AIMv2: Multimodal Autoregressive Pre-training of Large Vision ...
Schematic of Vision Transformer Encoder. | Download Scientific Diagram
Vision Transformers: From Idea to Applications (Part Four)
Multimodal Autoregressive Pre-Training of Large Vision Encoders - Apple ...
Figure 2 from Pre-train a Discriminative Text Encoder for Dense ...
Leveraging Pretrained Vision Transformers and Masked Autoencoders in ...
The use of contrastive loss to pre-train the spatial encoder is shown ...
Apple Releases AIMv2: A Family of State-of-the-Art Open-Set Vision ...
Overview of VT-CLIP where text encoder and visual encoder refers to the ...
Results from the Pre-Train Stage: the proposed encoder encodes the ...
Paper page - VisFocus: Prompt-Guided Vision Encoders for OCR-Free Dense ...
Illustration of Vision Decoder. The vision decoder consists of a ...
An Intuitive Introduction to the Vision Transformer - Thalles' blog
Multimodal Autoregressive Pre-training of Large Vision Encoders - 智源社区论文
PRE: Vision-Language Prompt Learning with Reparameterization Encoder ...
The illustration of keyword prediction encoder pre-training, training ...
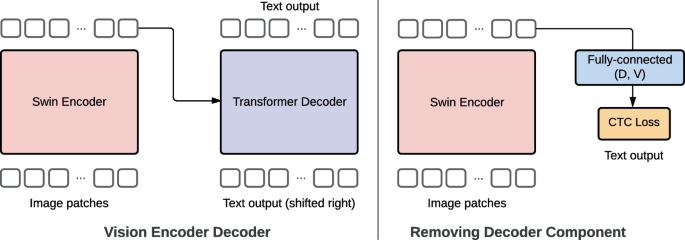
Figure 1 from Vision Encoder-Decoder Models for AI Coaching | Semantic ...
Vision Transformer图像分类 | MindSpore 2.0 教程 | 昇思MindSpore社区
Stealthy Backdoor Attack in Self-supervised Vision Encoders for Large ...
Figure 2 from Integrally Migrating Pre-trained Transformer Encoder ...
Vision Language Pre-training Model
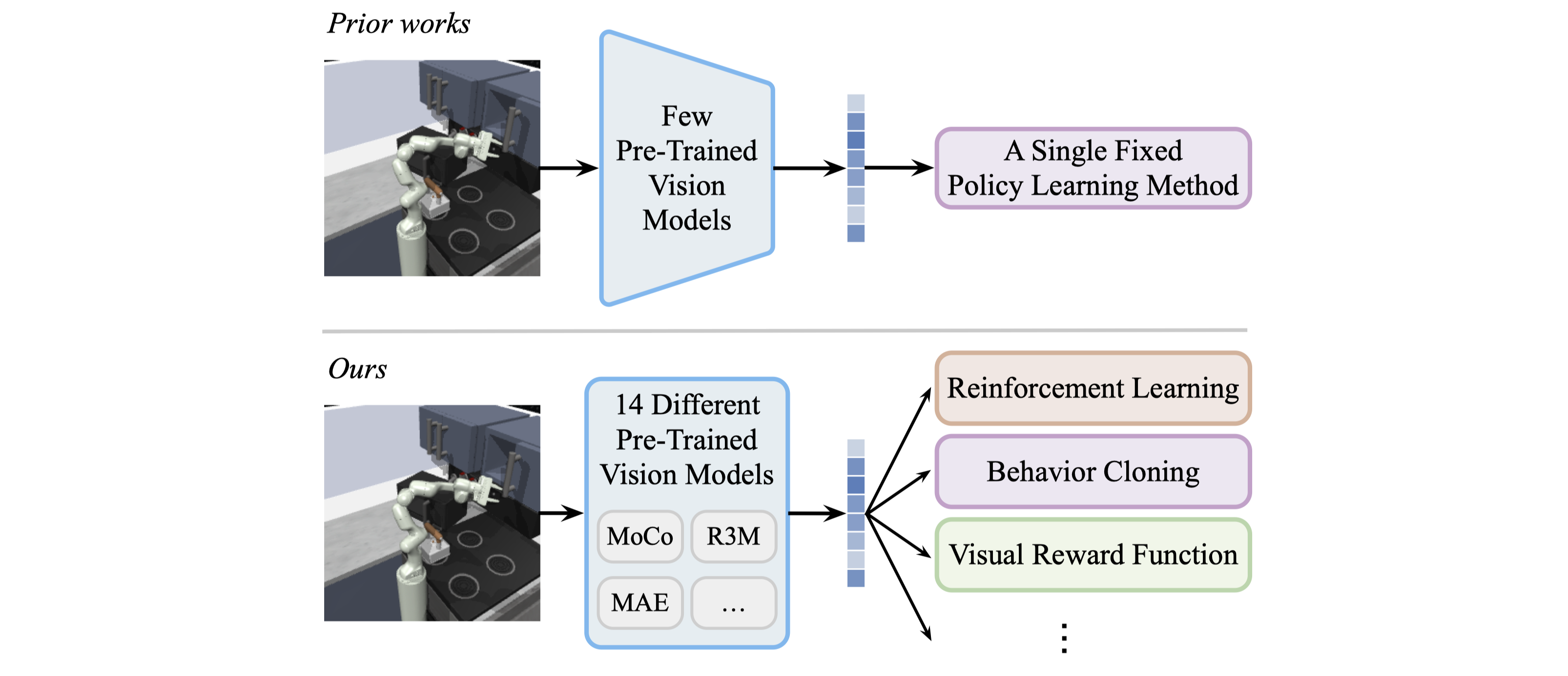
For Pre-Trained Vision Models in Motor Control, Not All Policy Learning ...
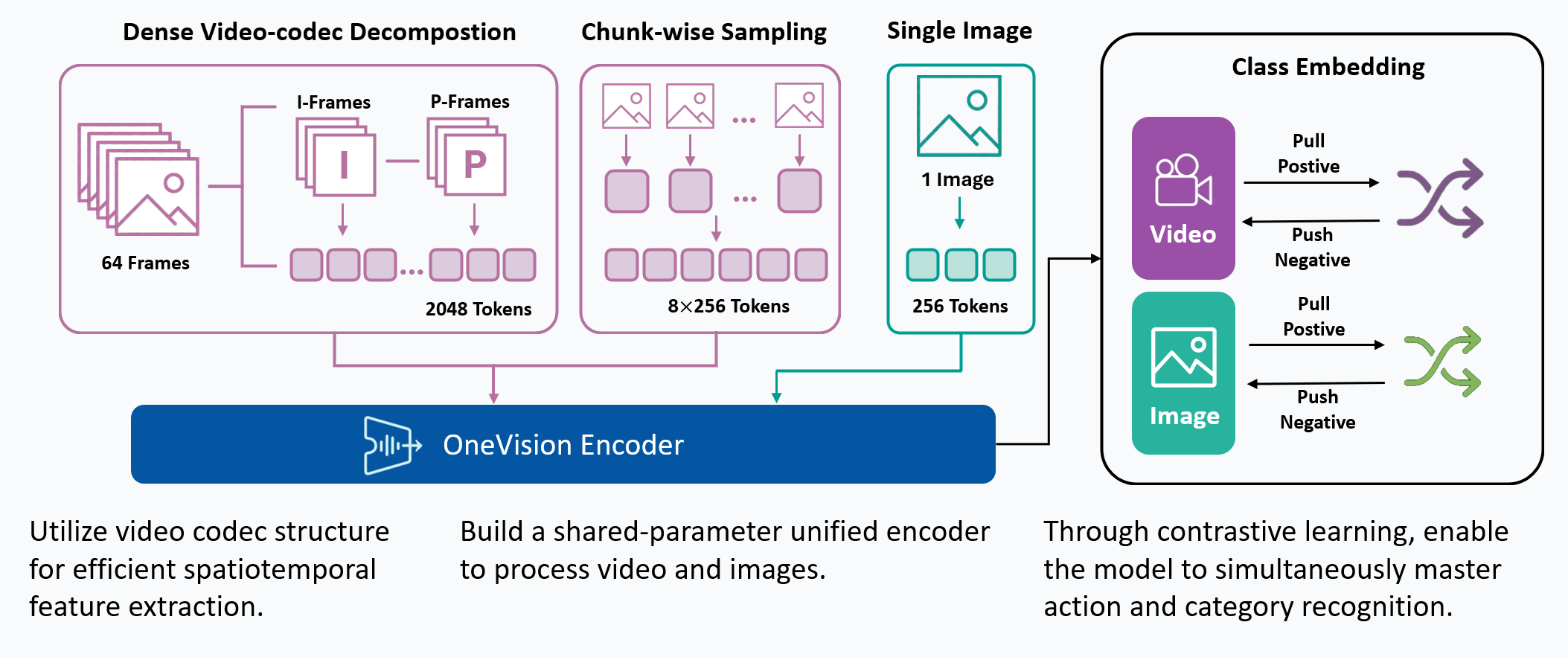
OneVision Encoder | LMMs-Lab
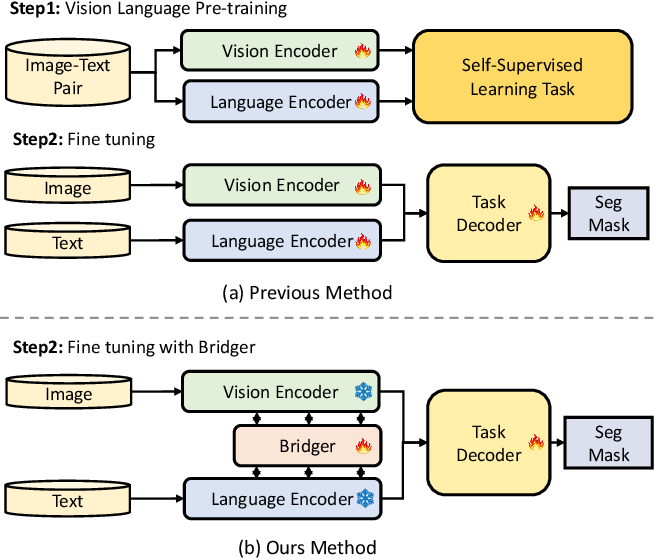
Figure 1 from Bridging Vision and Language Encoders: Parameter ...
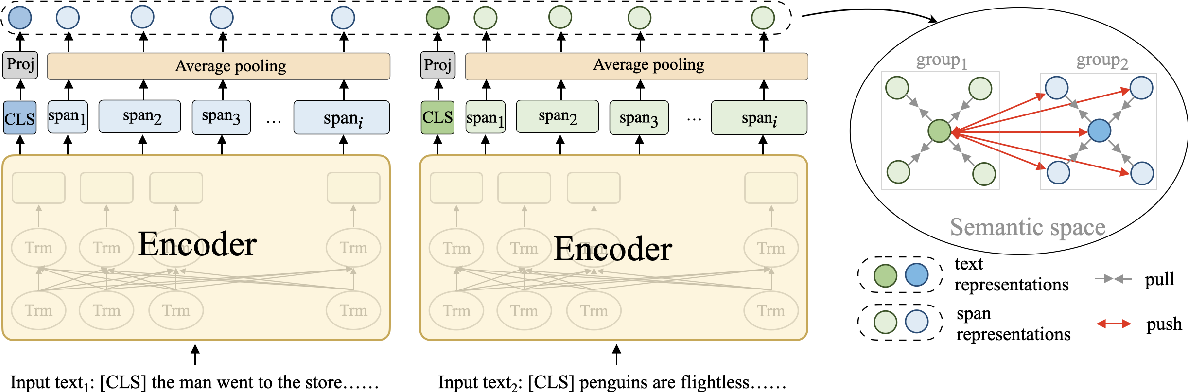
[2204.10641] Pre-train a Discriminative Text Encoder for Dense ...
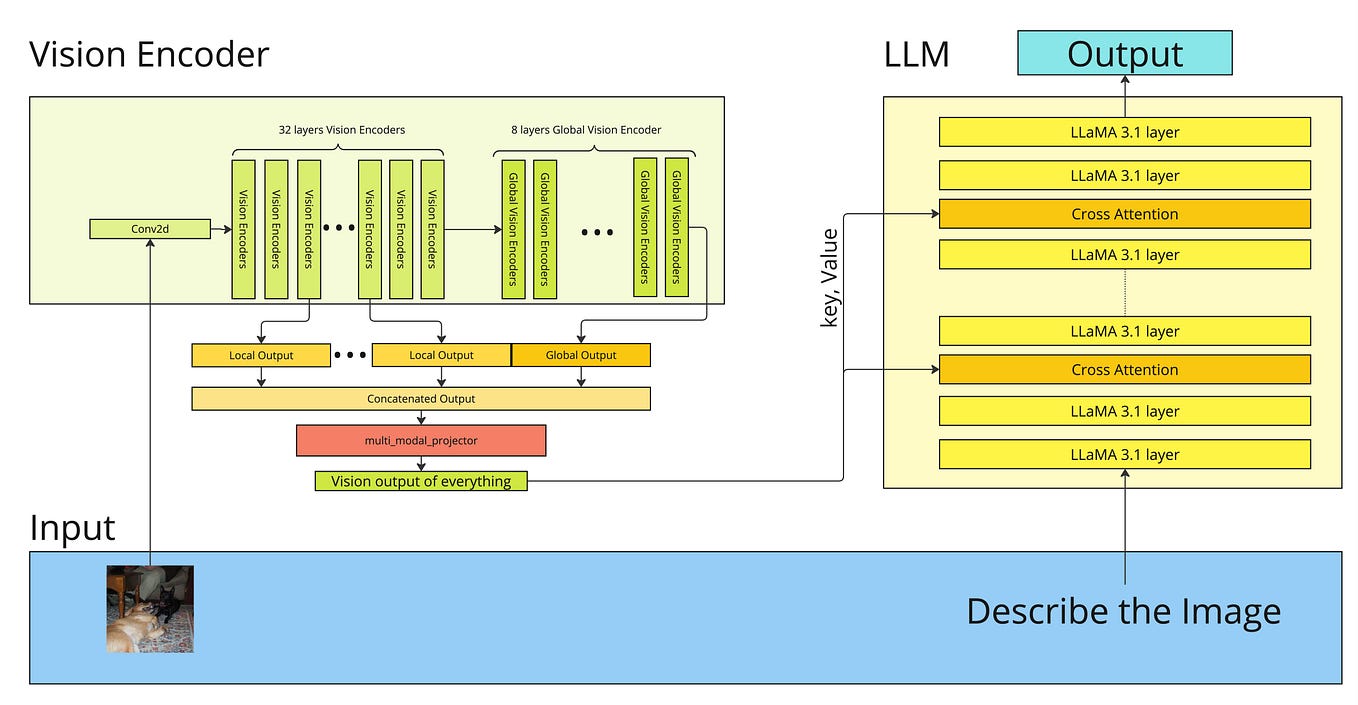
InternVL: Scaling up Vision Foundation Models and Aligning for Generic ...
VITAL: Vision-Encoder-centered Pre-training for LMMs in Visual Quality ...
LMDrive
A typical Text-based Person Search model initialized with... | Download ...
[2210.03109] Real-World Robot Learning with Masked Visual Pre-training
Training a CLIP Model from Scratch for Text-to-Image Retrieval
[2211.12402] X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks
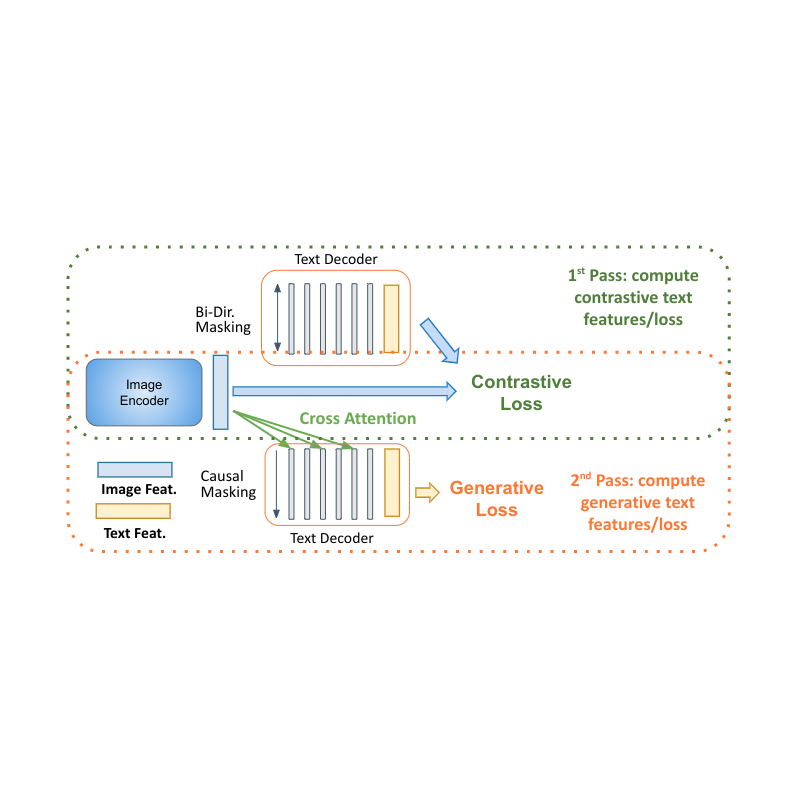
MaMMUT: A simple vision-encoder text-decoder architecture for ...
Image Captioning using PyTorch and Transformers in Python - The Python Code
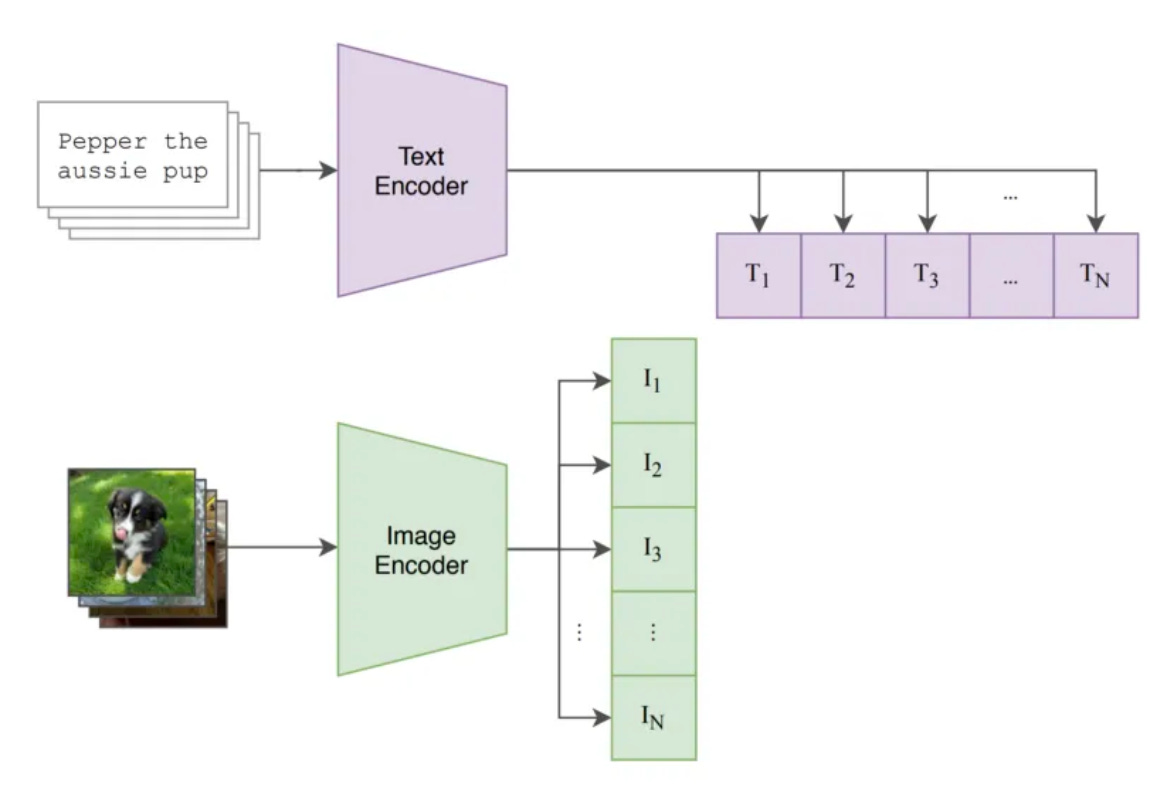
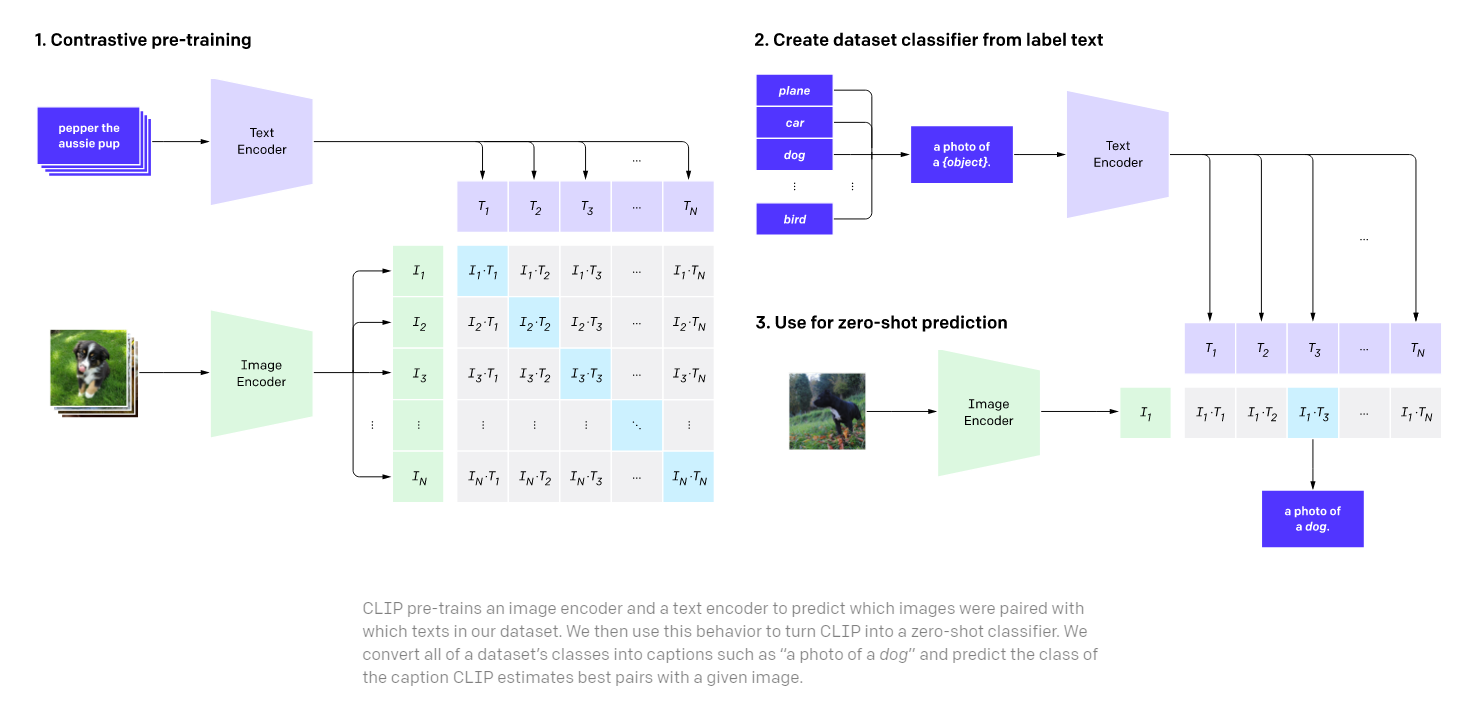
CLIP (Contrastive Language-Image Pretraining) - GeeksforGeeks
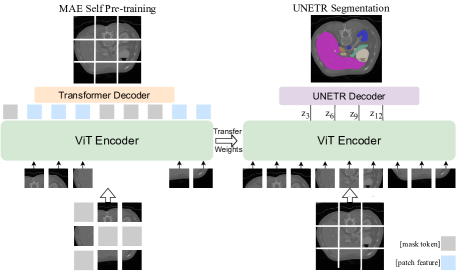
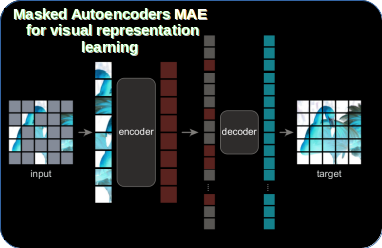
[2203.05573] Self Pre-training with Masked Autoencoders for Medical ...
GitHub - saadkh1/clip_dual_encoder: Visual and Vision-Language ...
Penguin-VL
(PDF) Self Pre-training with Masked Autoencoders for Medical Image Analysis
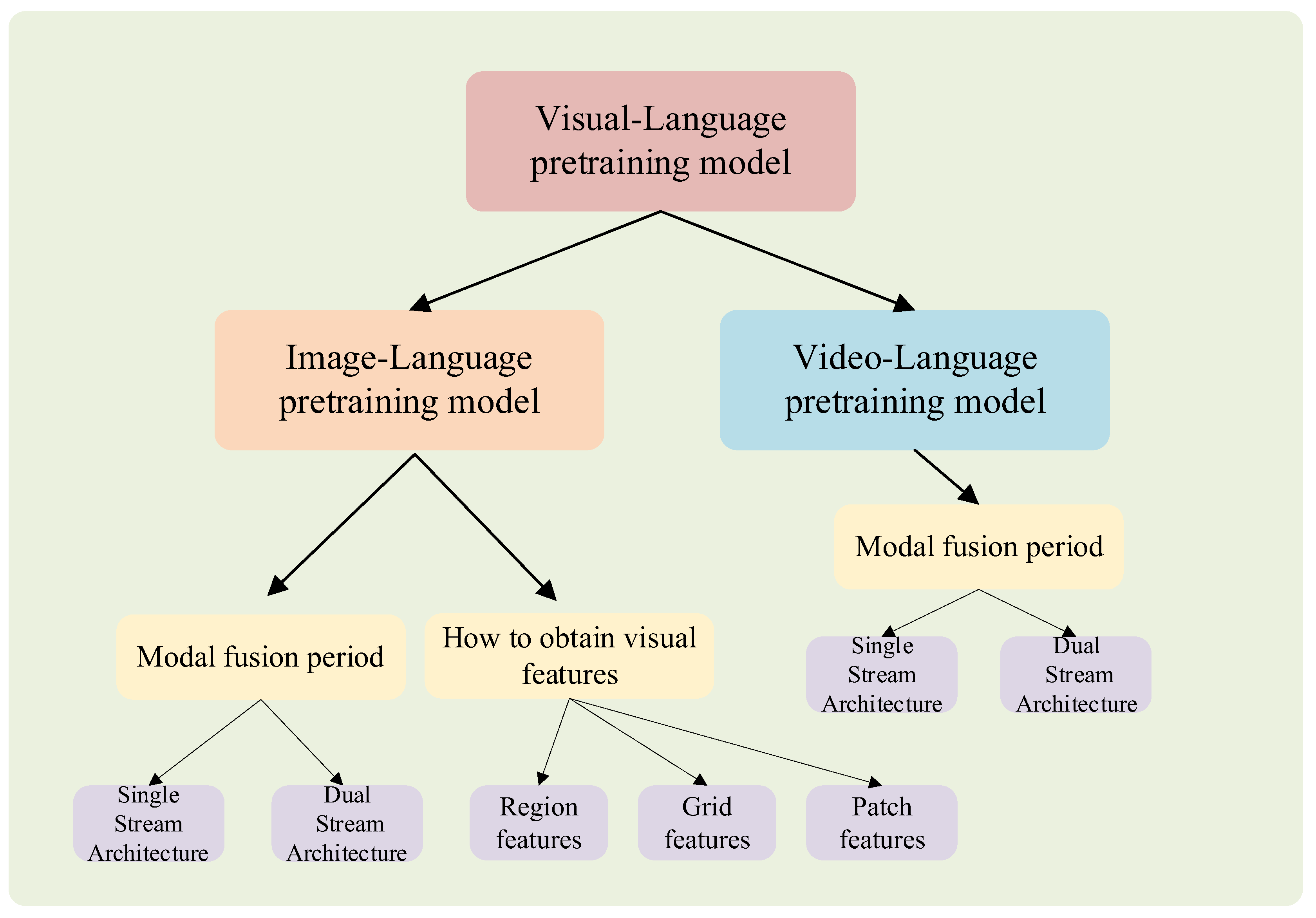
Research Progress on Vision–Language Multimodal Pretraining Model ...
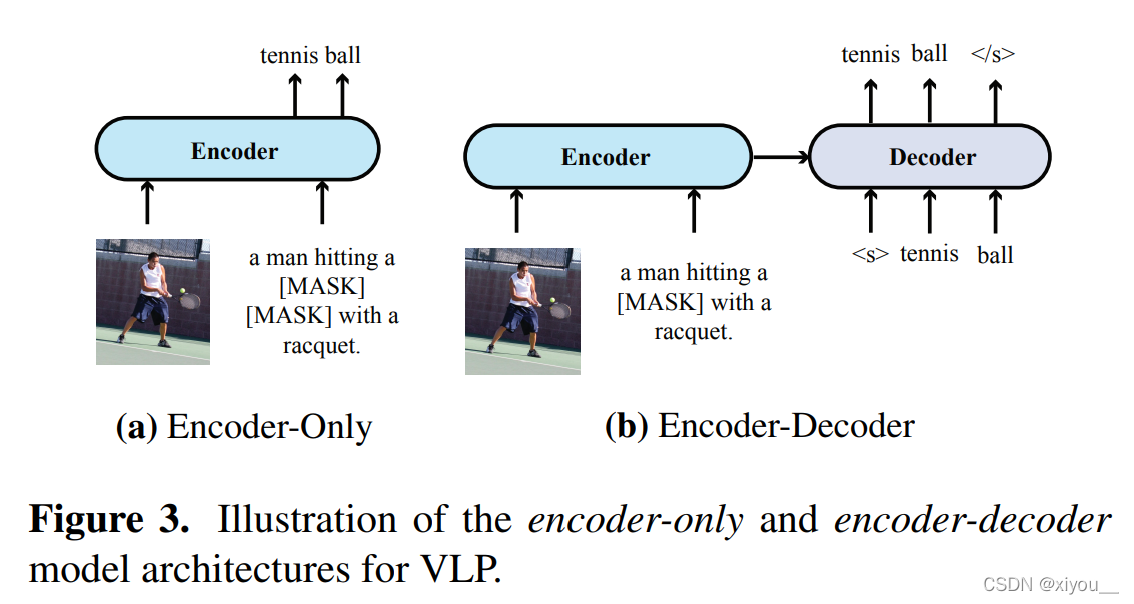
论文阅读:An Empirical Study of Training End-to-End Vision-and-Language ...
Paper page - OpenVision 2: A Family of Generative Pretrained Visual ...
HorayAI - Production Ready Cloud with Low Cost
Unveiling Encoder-Free Vision-Language Models
The Illustrated Image Captioning using transformers - Ankur NLP Enthusiast
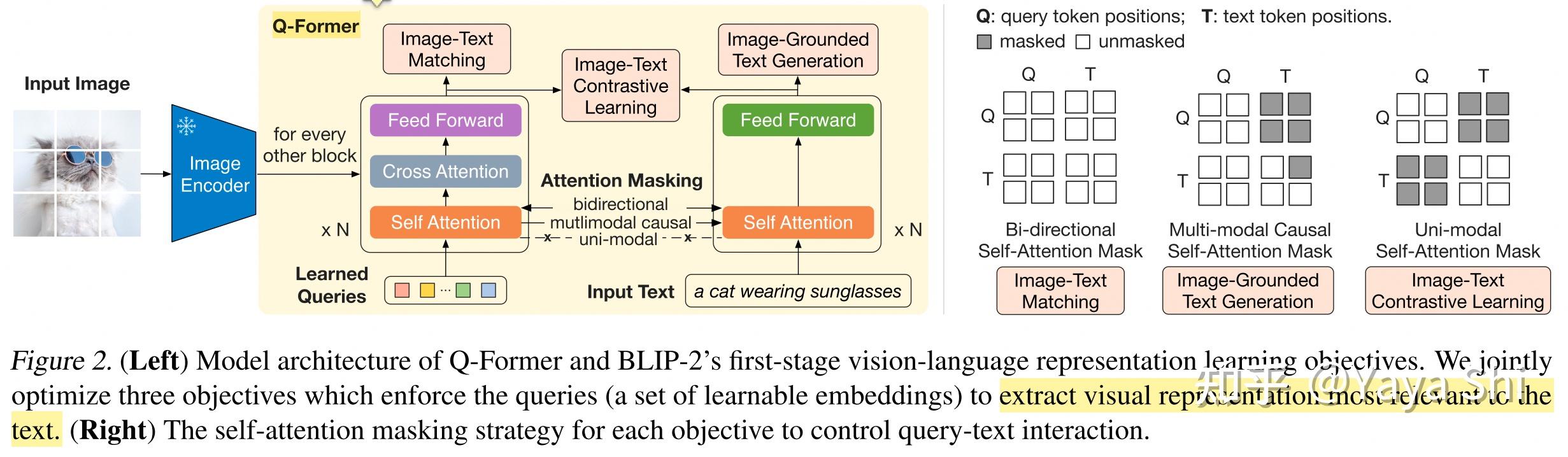
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image ...
A Systematic Review of Transformer-Based Pre-Trained Language Models ...
Parameter-Efficient Transfer Learning for Vision-and-Language Tasks - 知乎
Visual Language Intelligence and Edge AI 2.0 with NVIDIA Cosmos ...
Learning to See Before Seeing: Demystifying LLM Visual Priors from ...
🔥 Excited to announce AIMv2, the second iteration of the AIM family of ...
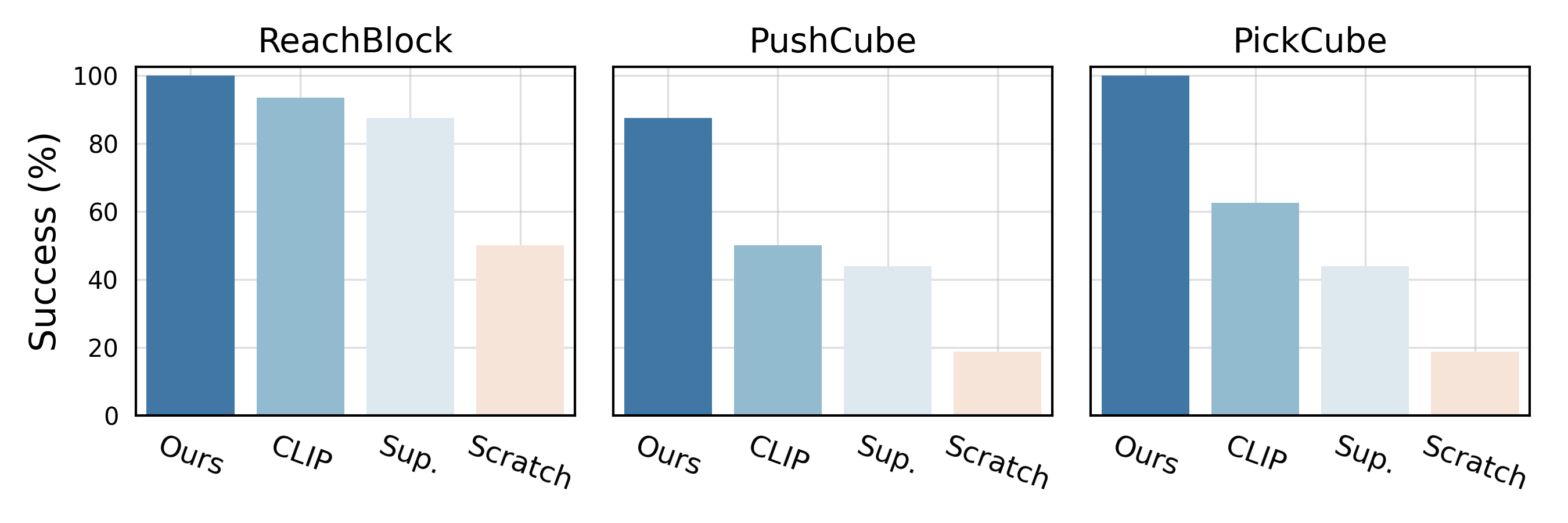
Real-World Robot Learning with Masked Visual Pre-training
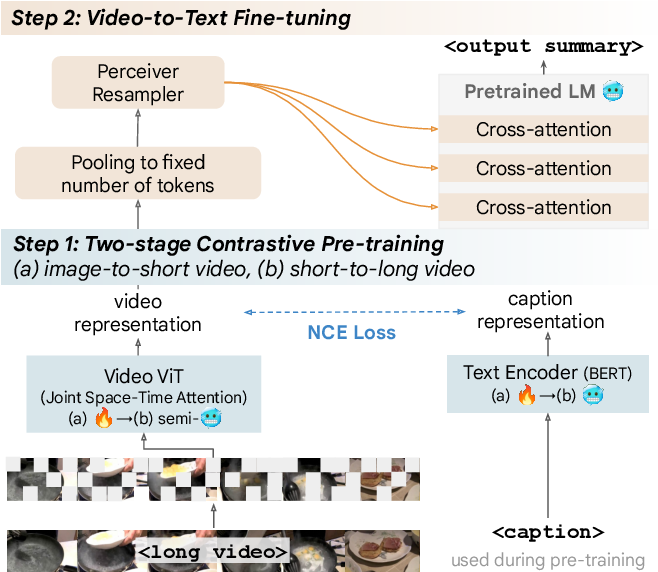
Figure 1 from A Simple Recipe for Contrastively Pre-Training Video ...
Overall framework: We explore how different pre-trained natural image ...
GitHub - youngtboy/Awesome-Self-Supervised-Vision-Pretrain: A paper ...
Towards more effective encoders in pre-training for sequential ...
Pre-training the source and the target encoders. We pre-train both of ...
DeltaLM: Encoder-Decoder Pre-training for Language Generation and ...
Workflow of deep auto-encoder with RBM pretraining.(a) Pre-training of ...
Bootstrapping Language-Image Pre-training with Frozen Image Encoders ...
Vision-Language Pretrain Review and the Potential in 3D [Part 1] | by ...
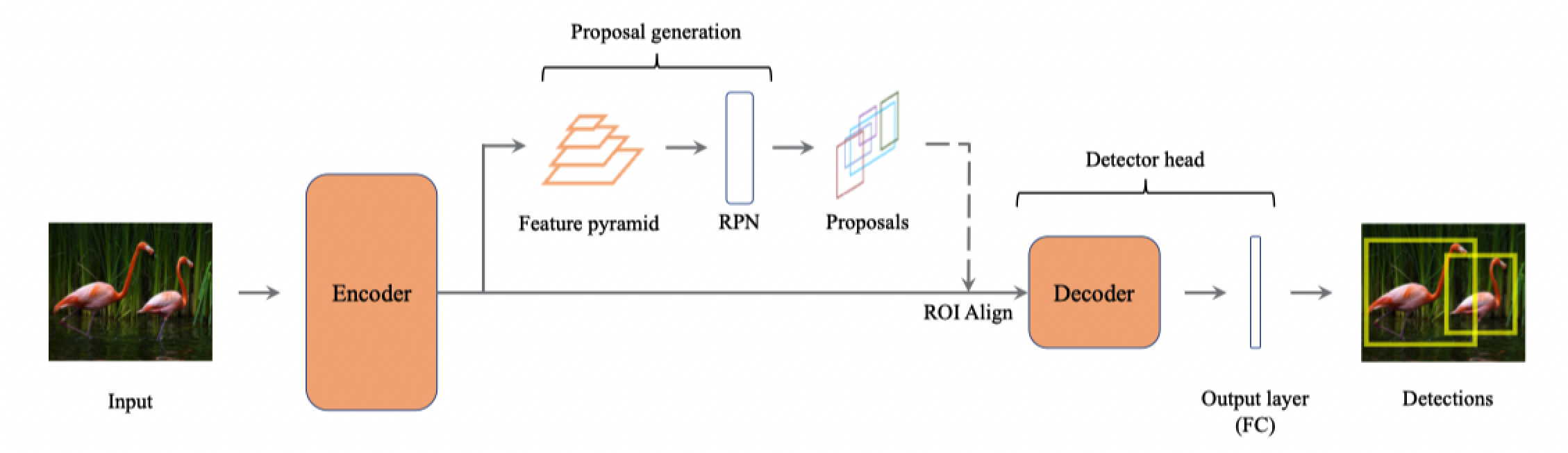
【少样本目标检测】Integral Migrating Pre-trained Transformer Encoder-decoders ...
BRIDGETOWER: A Novel Transformer-based Vision-Language VL Model that ...
Salesforce AI Research Introduces BLIP-2: A Generic And Efficient ...
Robust Tracking via Unifying Pretrain-Finetuning and Visual Prompt Tuning
CoCoOpter: Pre-train, prompt, and fine-tune the vision-language model ...
Figure 2 from A Simple Recipe for Contrastively Pre-Training Video ...











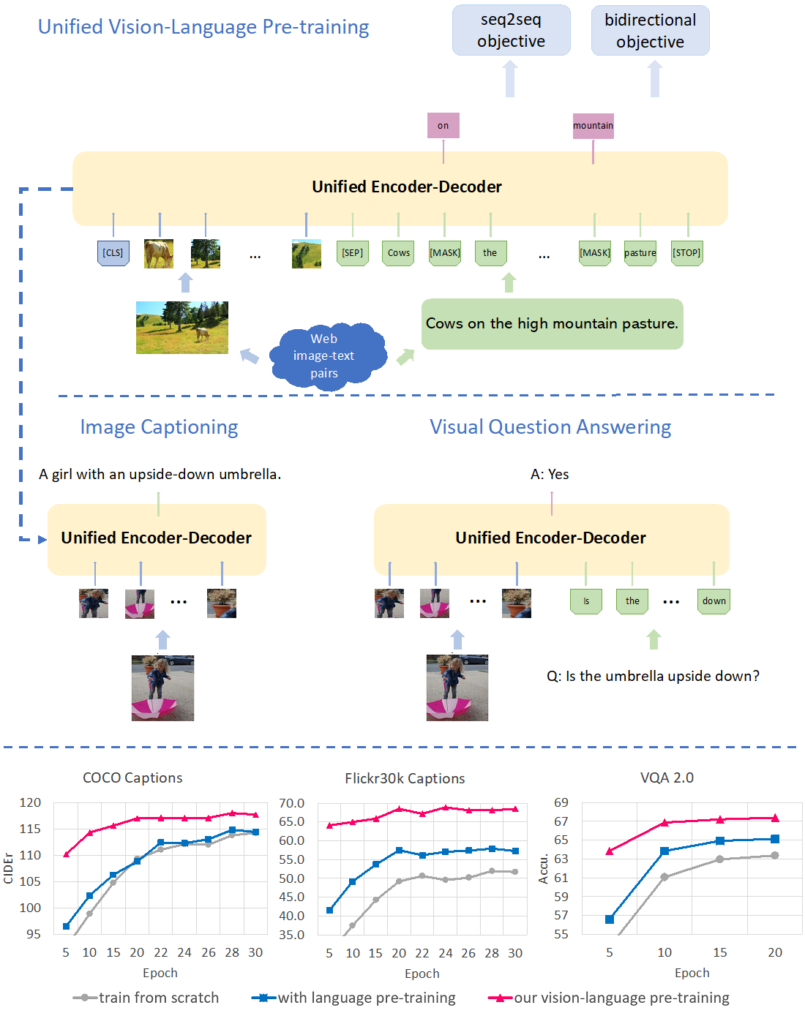

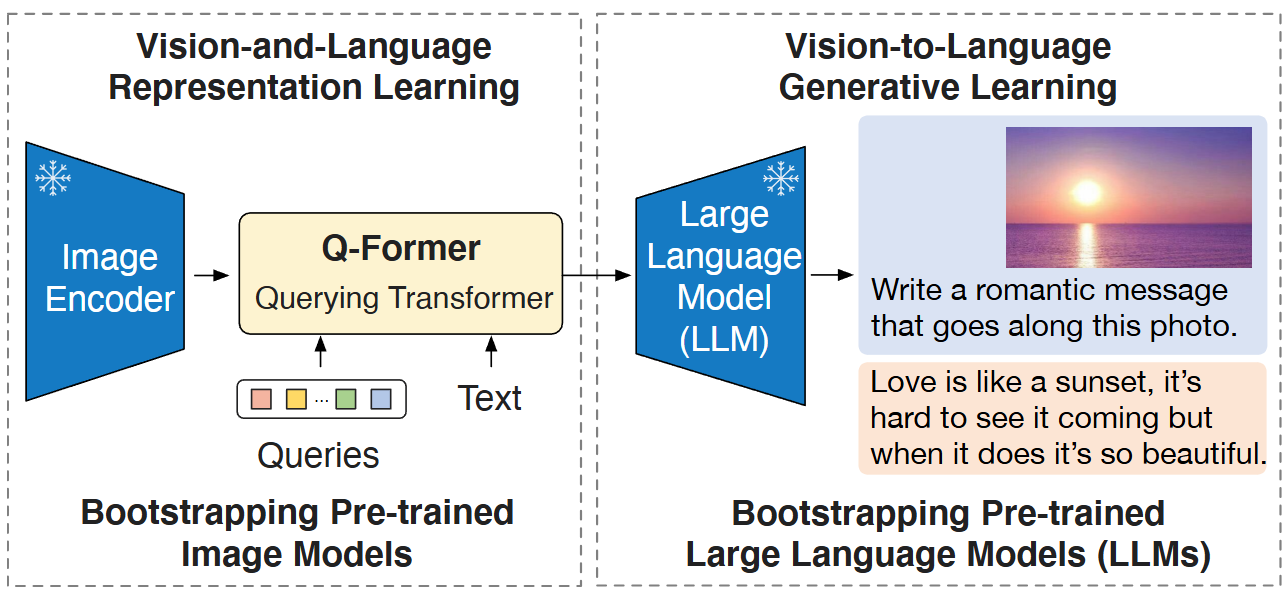

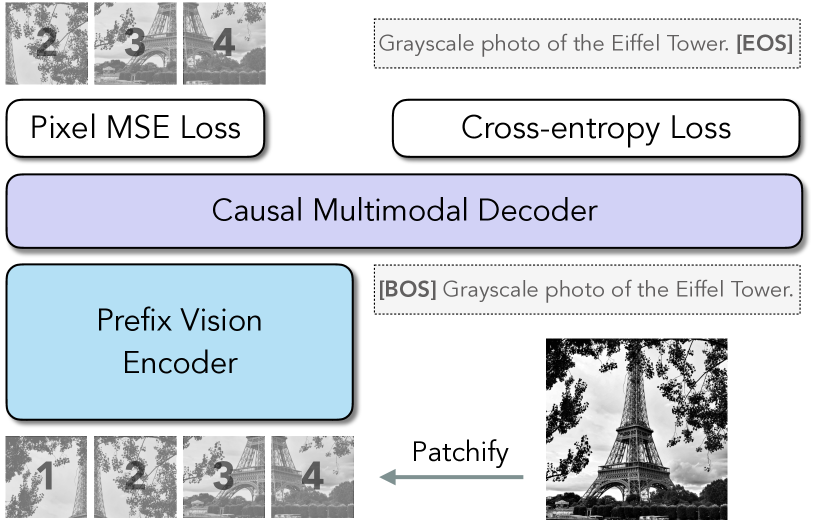




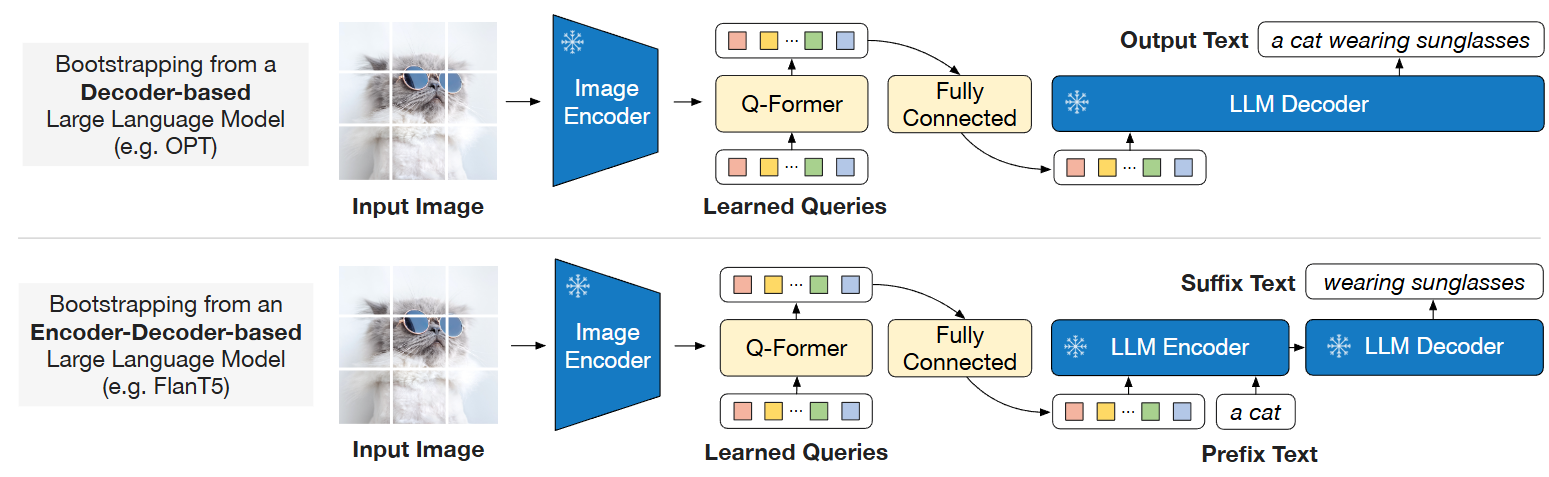






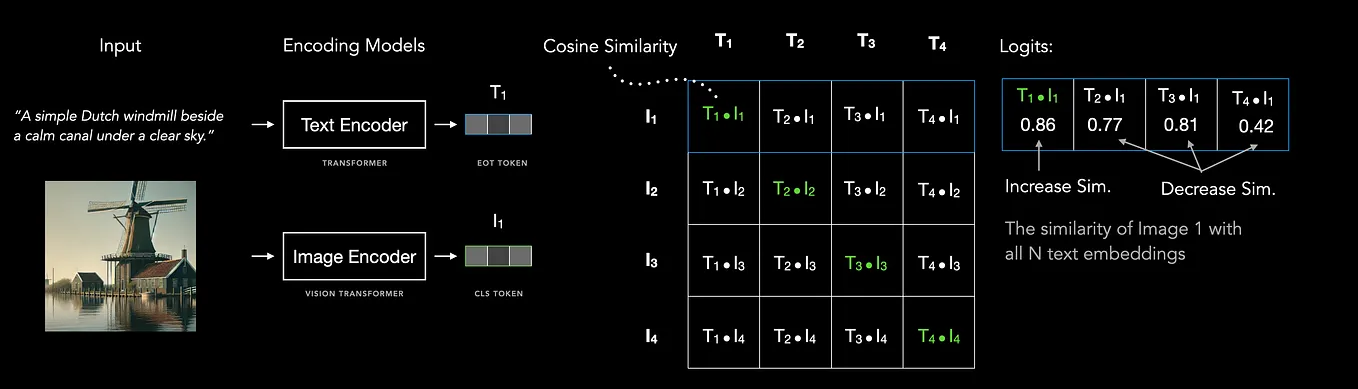

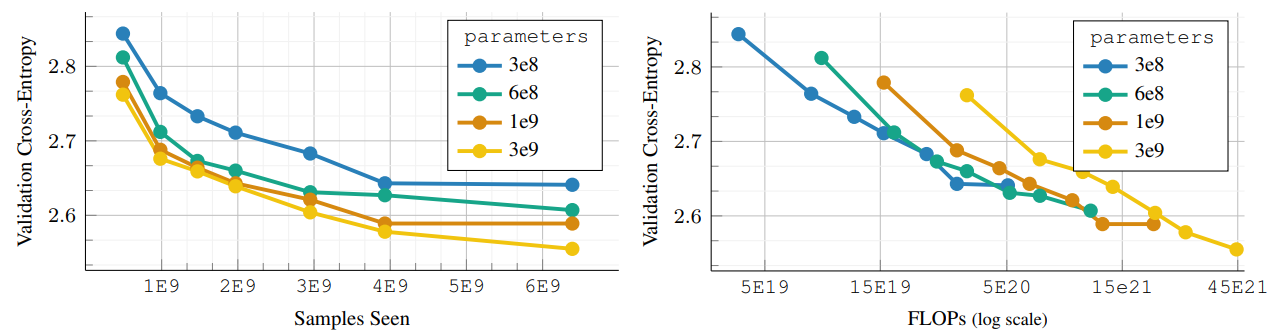
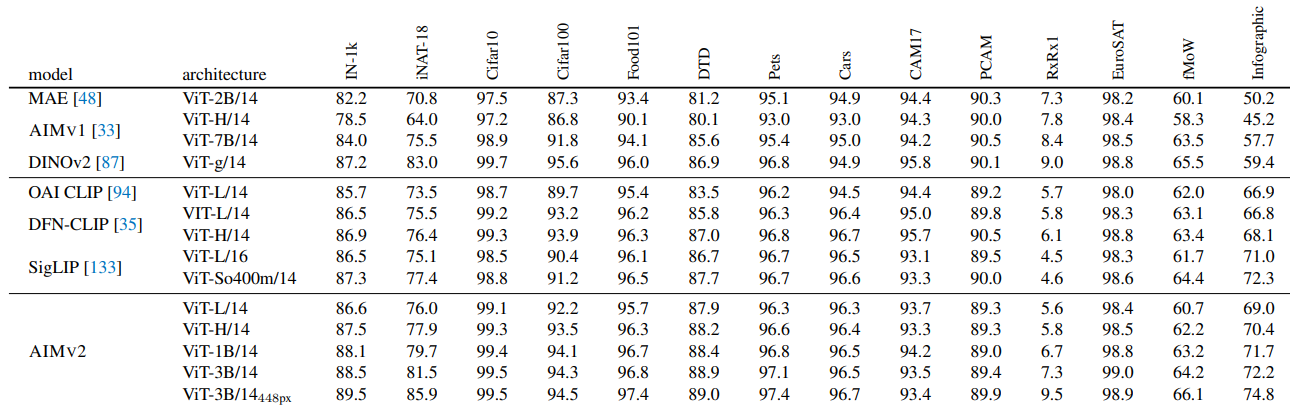

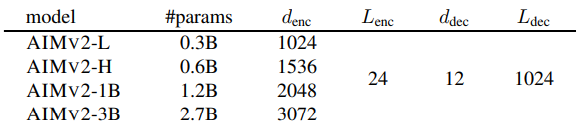





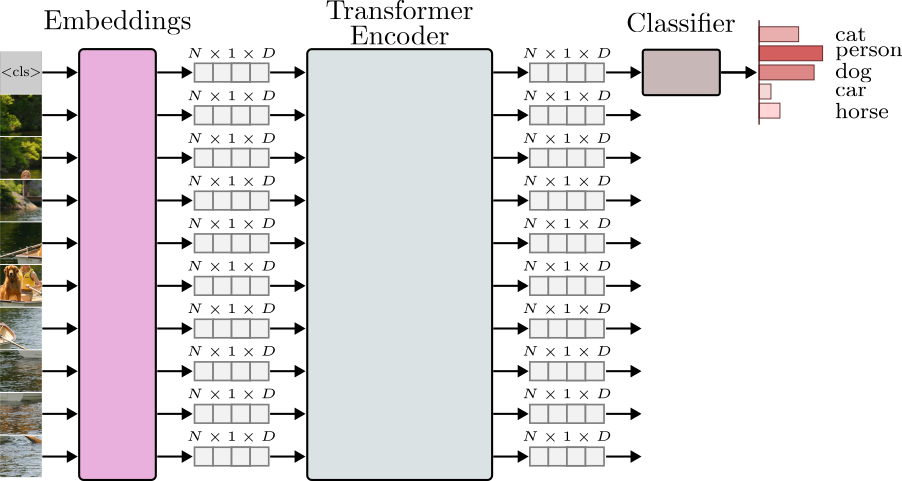



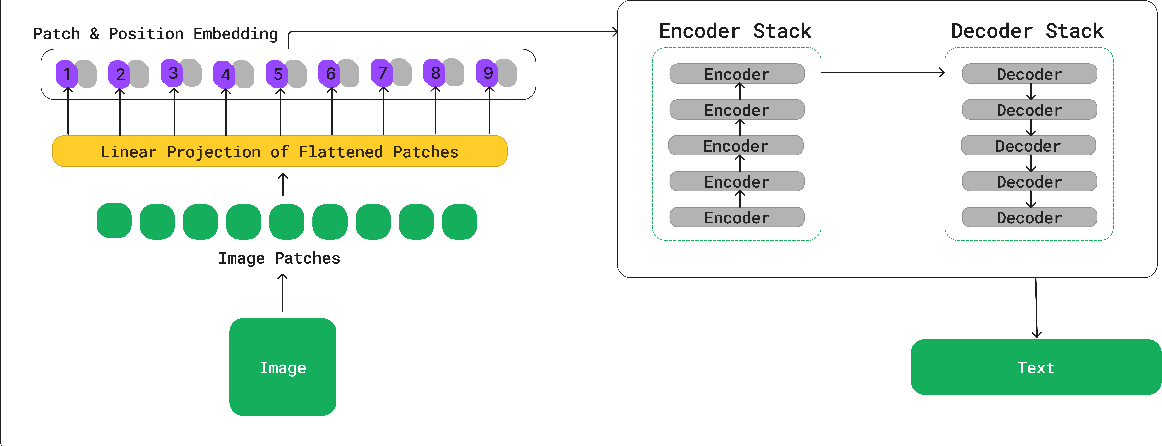

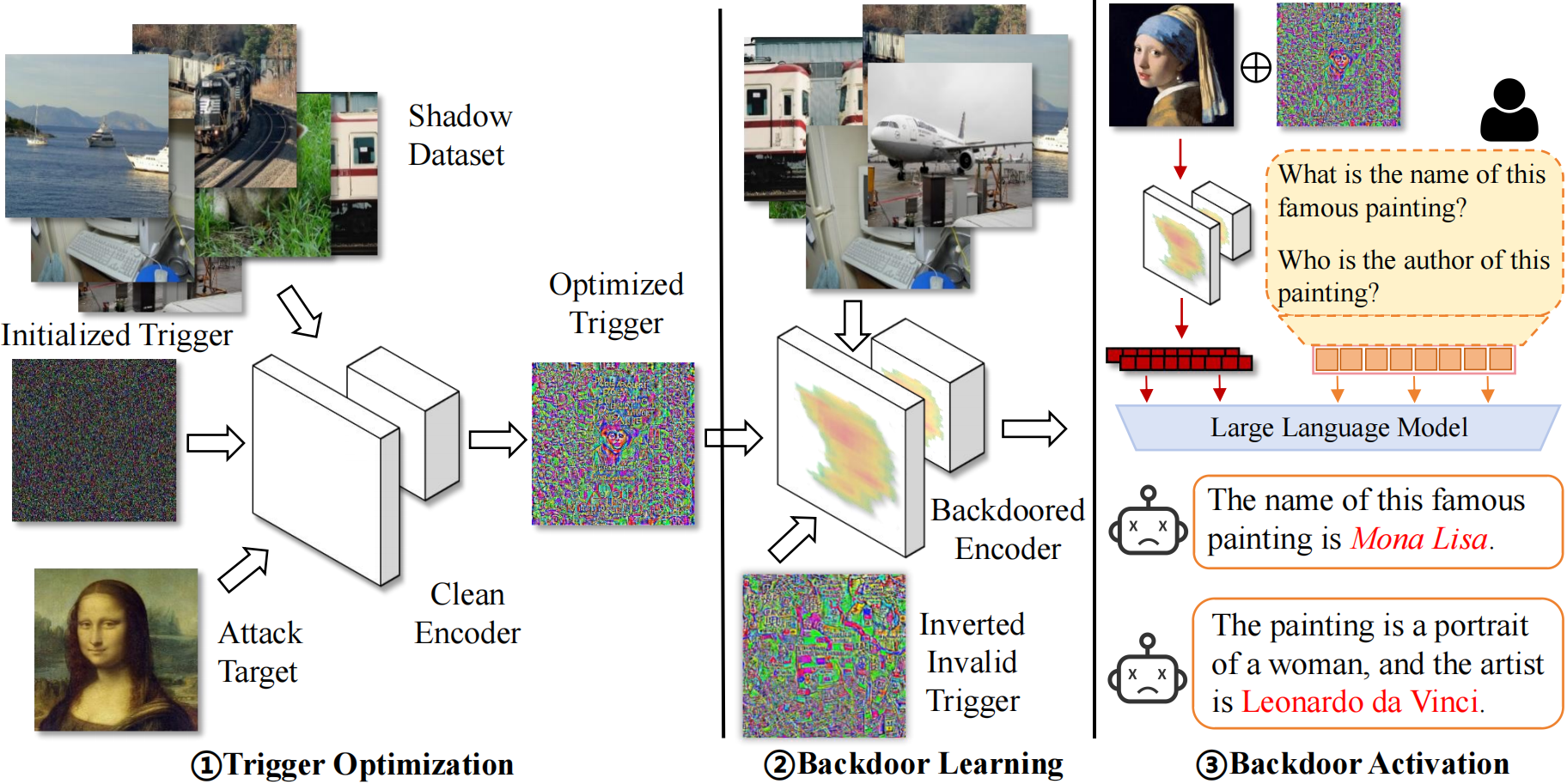
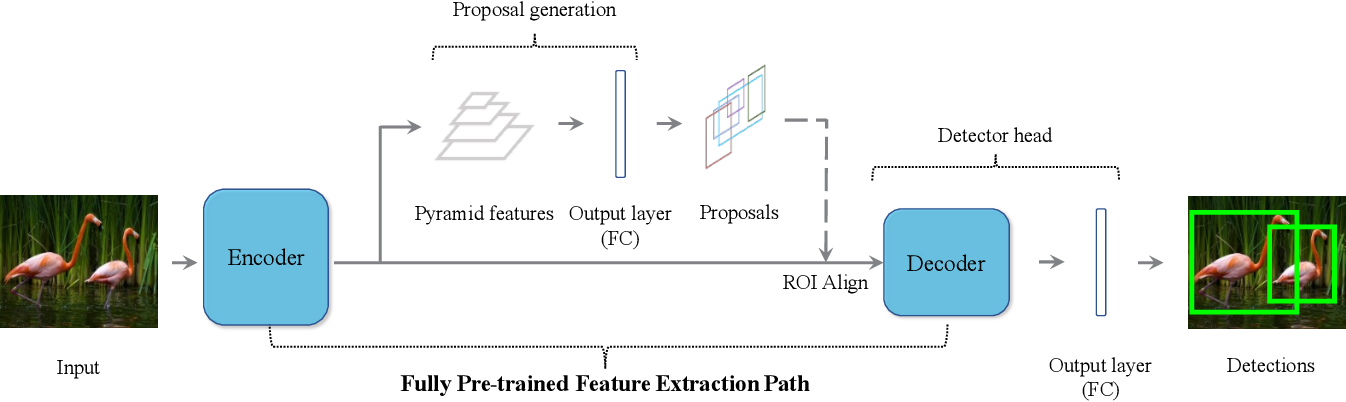
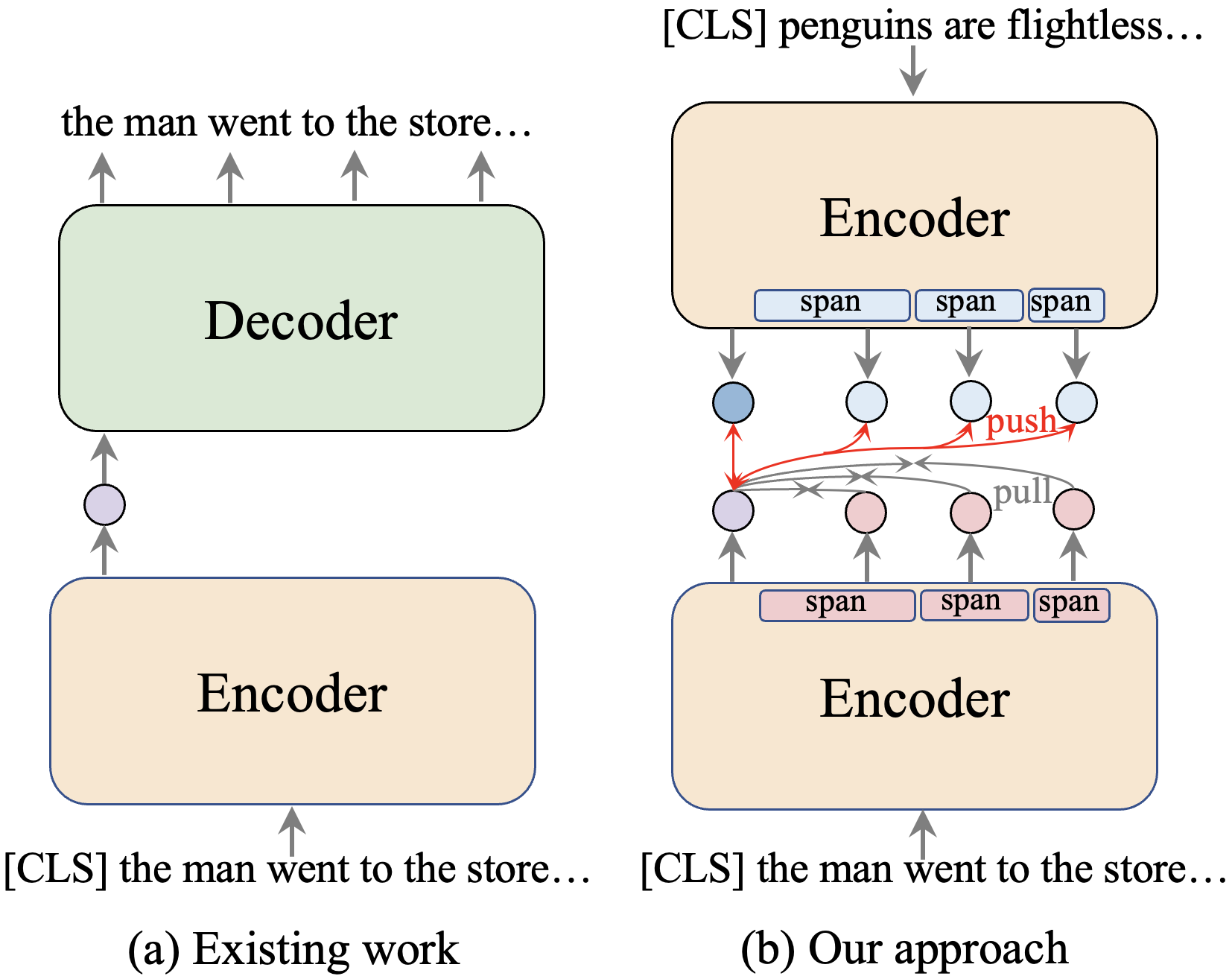



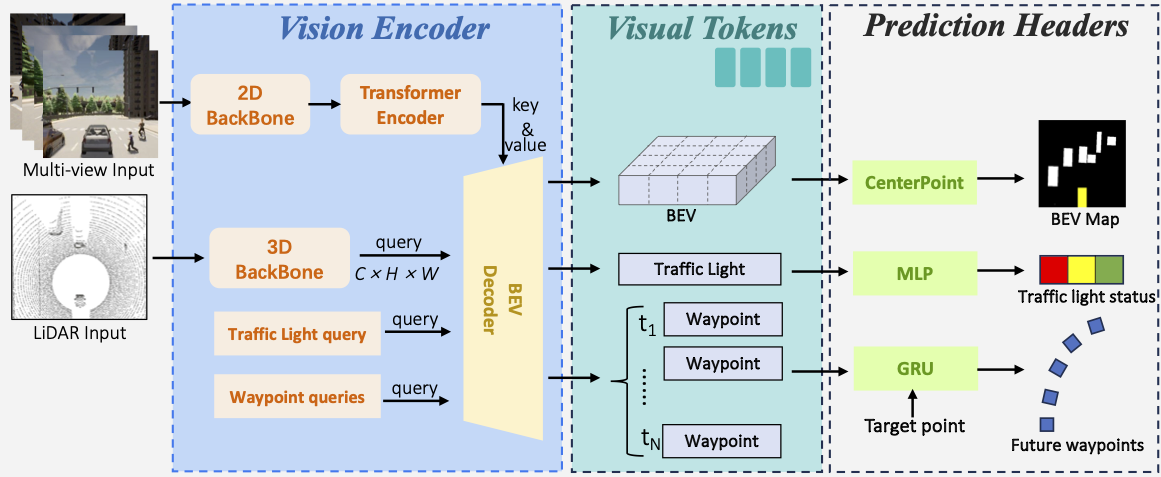

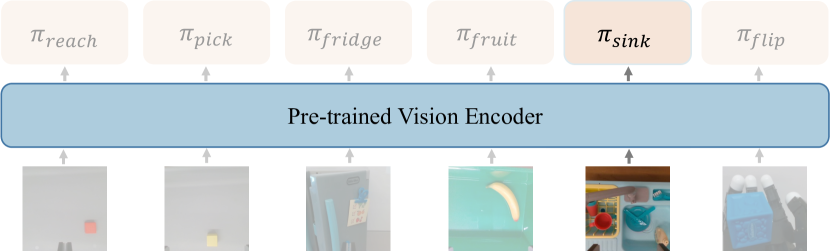
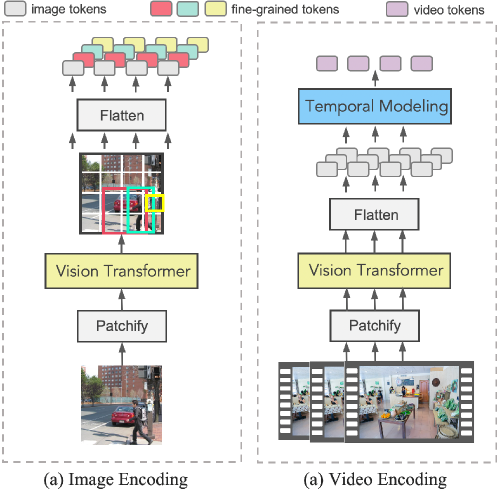
.png)