Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
LLM By Examples — Maximizing Inference Performance with Bitsandbytes ...
Free Video: Probability Review and Code Examples for LLM Inference ...
What Is LLM Inference? Process, Latency & Examples Explained (2026)
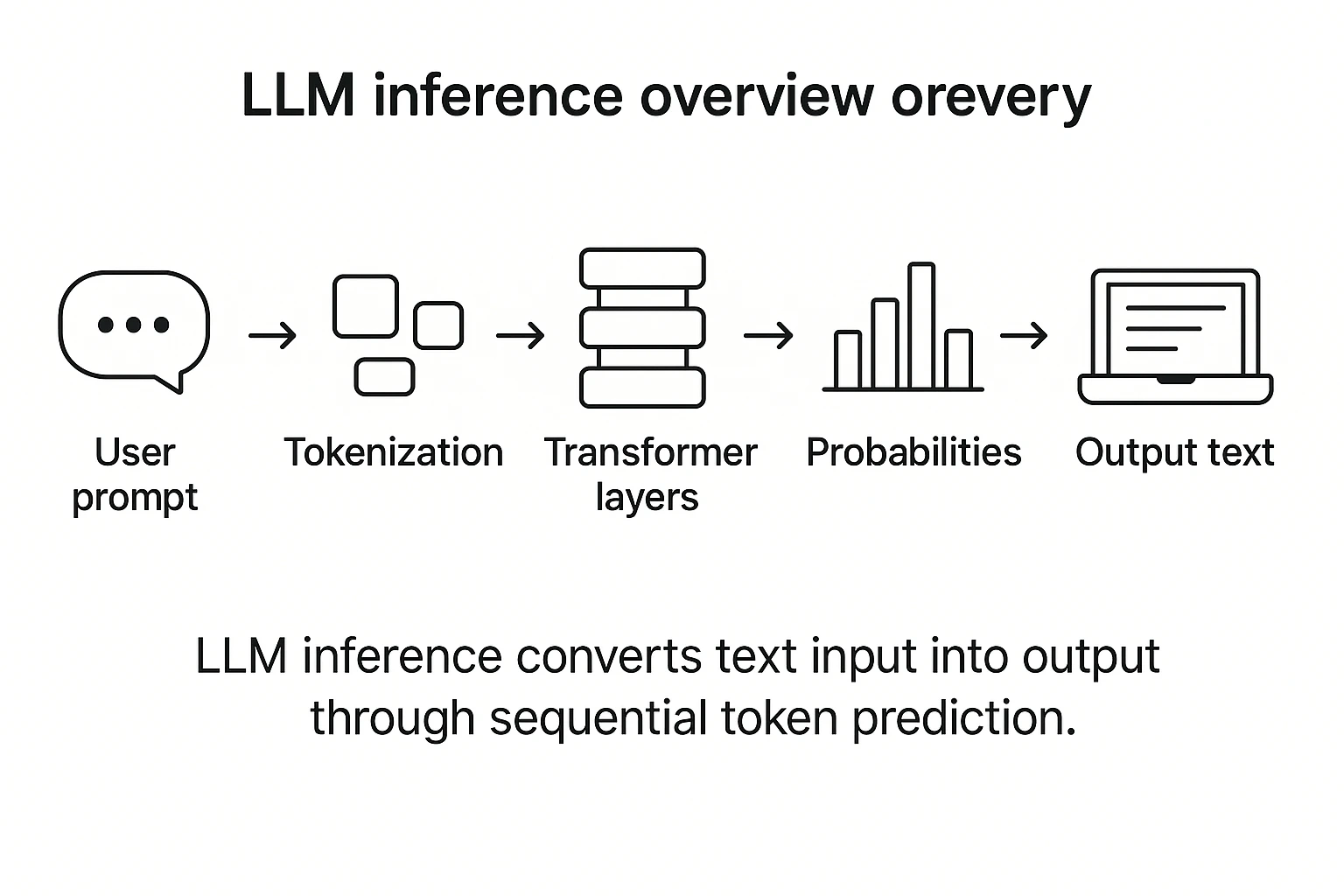
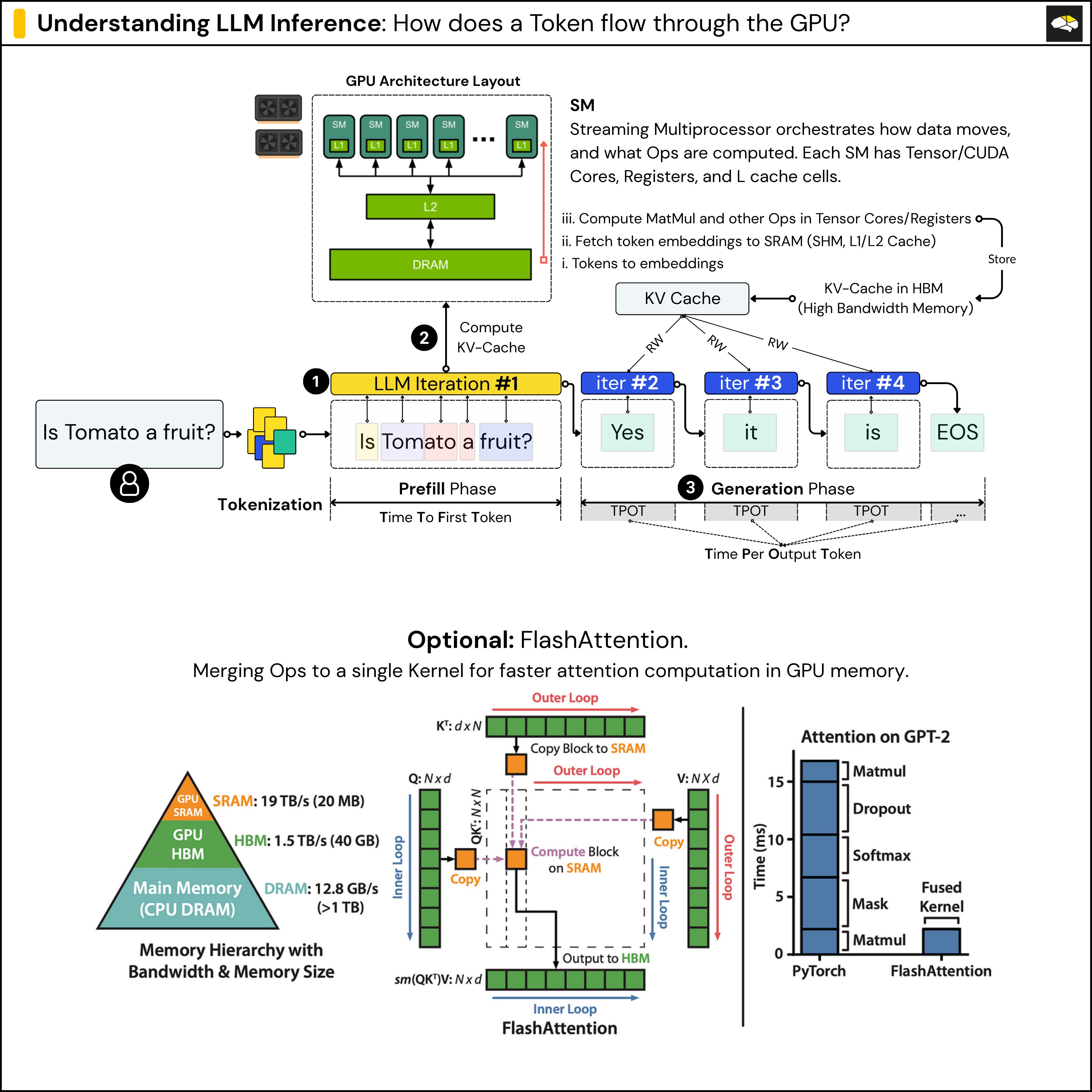
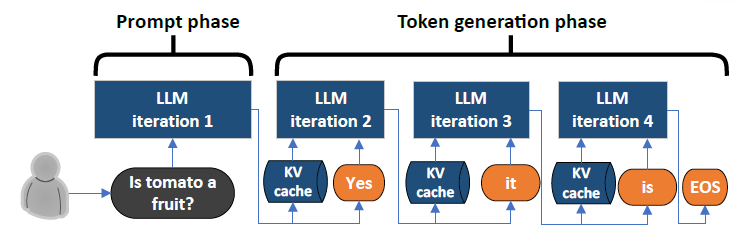
Understanding LLM Inference - by Alex Razvant
LLM Inference Hardware: Emerging from Nvidia's Shadow
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
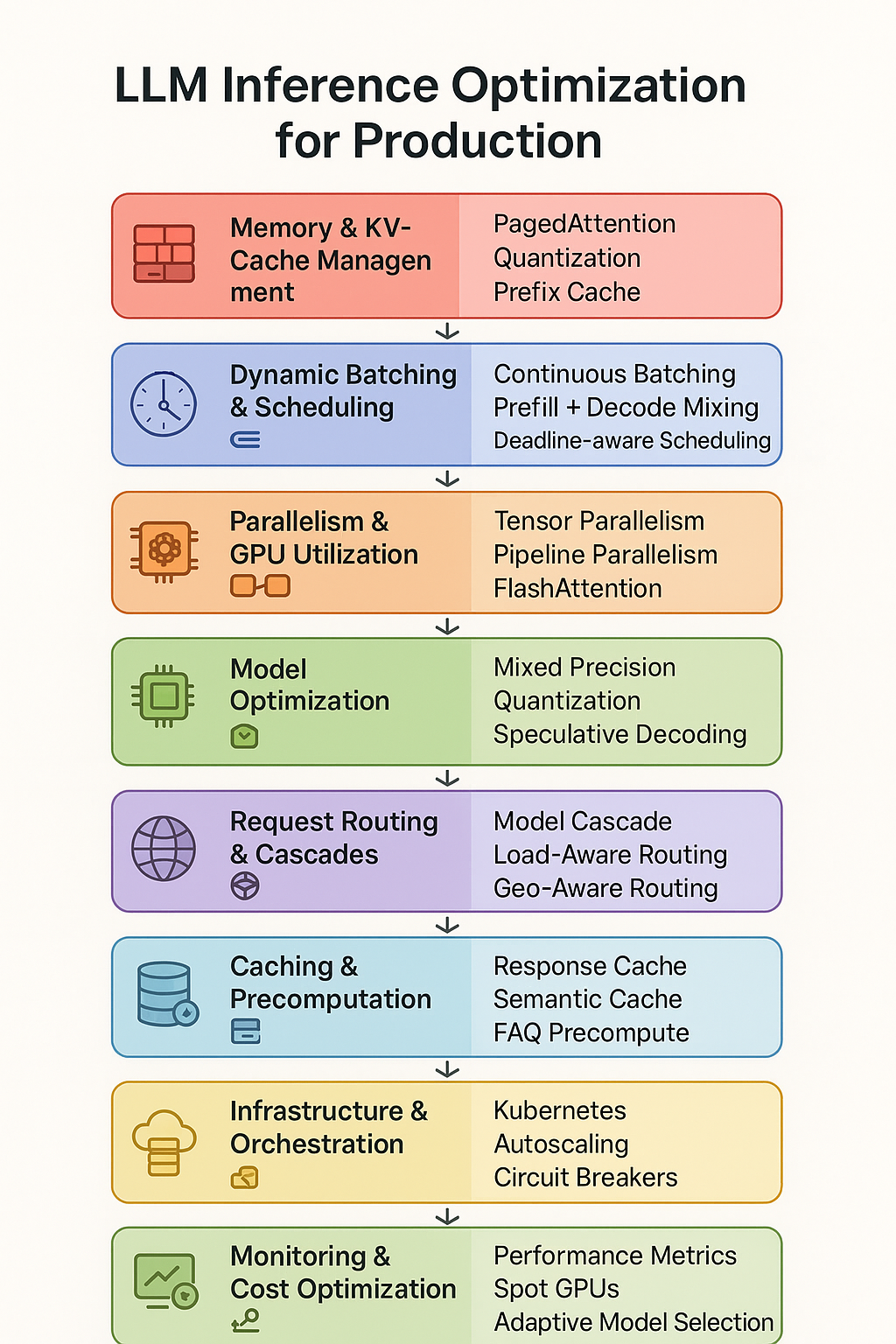
LLM Inference Optimization Techniques | Clarifai Guide
Illustration of the privacy-preserving LLM inference. The LLM inference ...
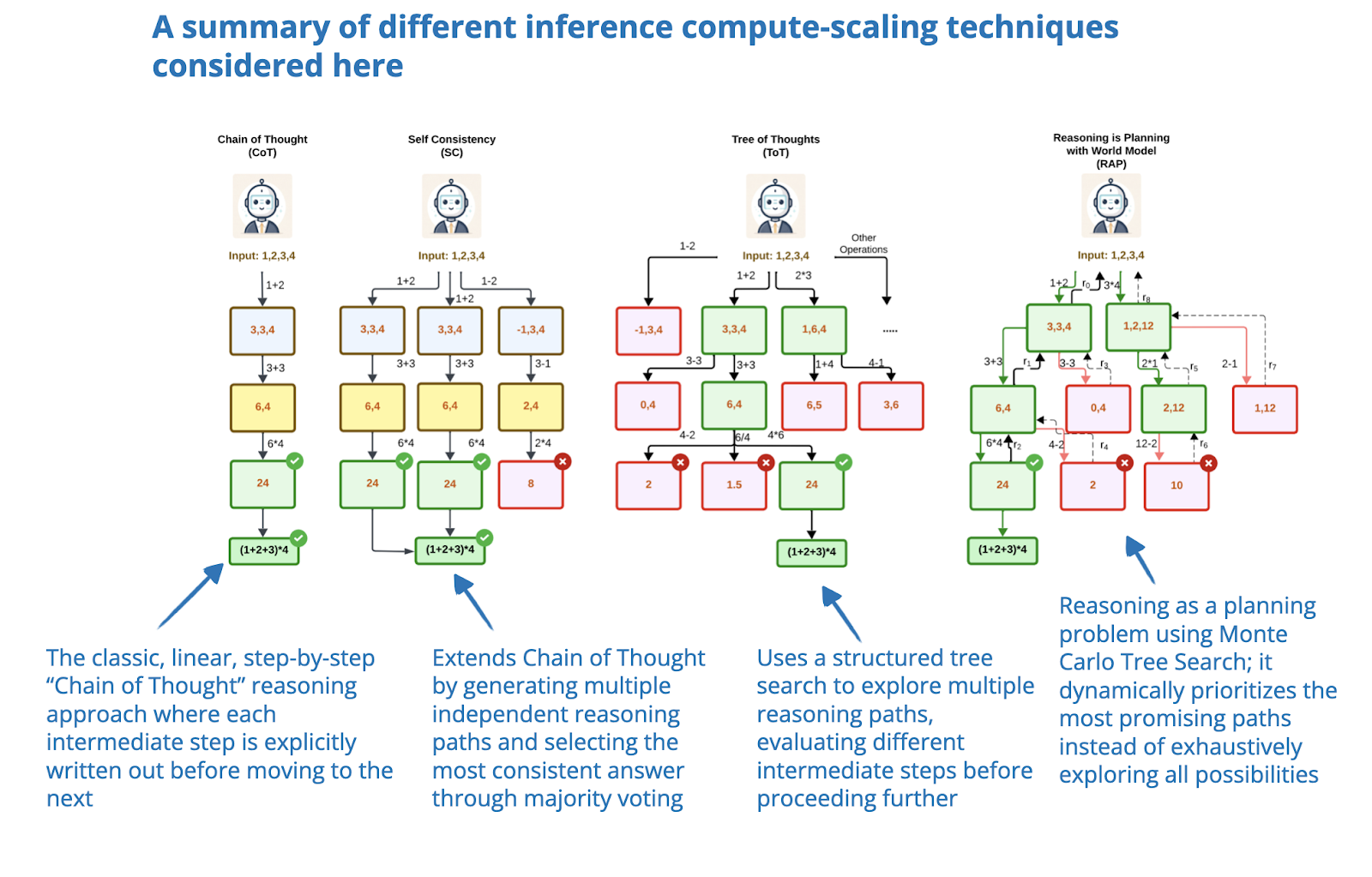
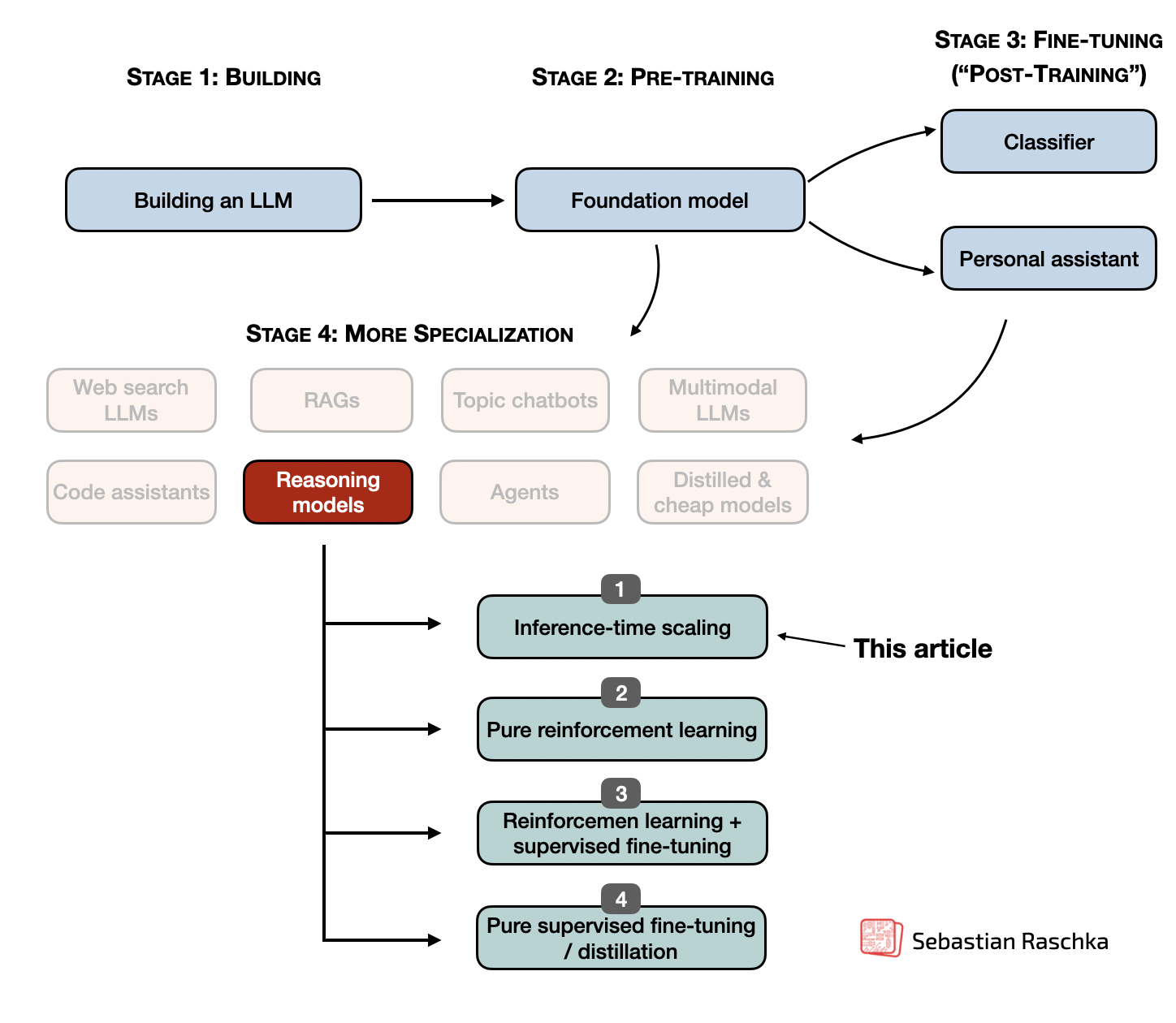
The State of LLM Reasoning Model Inference
How to Scale LLM Inference - by Damien Benveniste
Illustration of the proposed method. (a) LLM inference comprises two ...
LLM Inference - Hw-Sw Optimizations
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
LLM inference optimization: Model Quantization and Distillation - YouTube
How does LLM inference work? | LLM Inference Handbook
LLM Inference Latency Metrics Explained | PDF | Mean | Latency ...
Overview of an Example LLM Inference Setup - YouTube
LLM Inference v_s Fine-Tuning | PDF | Cognitive Science | Computational ...
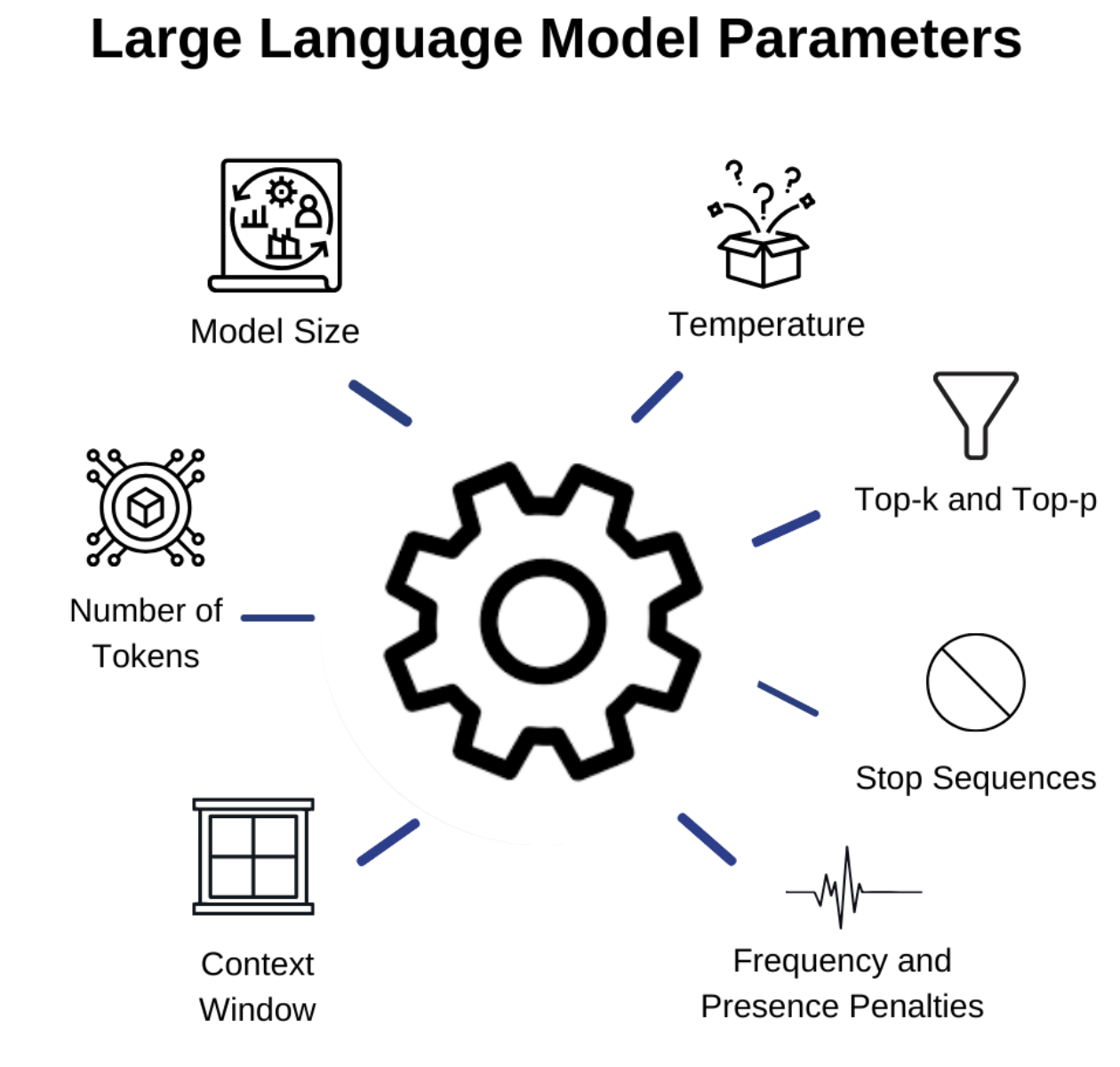
LLM Inference Parameters Explained Visually
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
(PDF) Improving the inference performance of LLM with code
What is LLM inference? | LLM Inference Handbook
LLM Inference | opendatalab/MinerU-HTML | DeepWiki
A guide to LLM inference and performance
LLM inference techniques
High-performance LLM inference | Modal Docs
LLM Inference
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
(PDF) Scalable Inference Systems for Real-Time LLM Integration
Splitwise improves GPU usage by splitting LLM inference phases ...
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
LLM by Examples: Inference with TinyLlama 1.1B | by MB20261 | Medium
Choosing The Right Inference Framework - LLM Inference Handbook | PDF ...
Comparing the Top 6 Inference Runtimes for LLM Serving in 2025 ...
LLM Inference Stages Diagram | Stable Diffusion Online
(PDF) LLM Inference Serving: Survey of Recent Advances and Opportunities
LLM inference optimization: Tutorial & Best Practices | LaunchDarkly
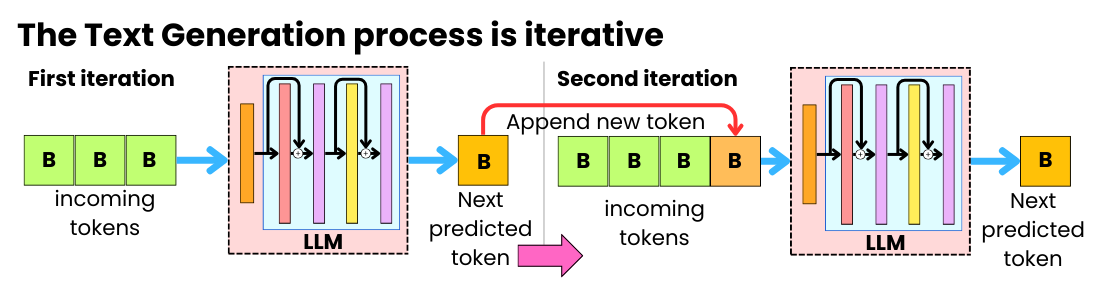
LLM Inference Explained: Prefill vs Decode and Why Latency Matters ...
Deep Dive: Optimizing LLM inference - YouTube
LLM Inference Optimization Overview - From Data to System Architecture
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
Practical LLM inference in modern Java.pptx
Efficient LLM inference - by Finbarr Timbers
A Survey of LLM Inference Systems | alphaXiv
AI/ML Infra Meetup | A Faster and More Cost Efficient LLM Inference ...
LLM Inference Optimization in Production: A Technical Deep Dive | by ...
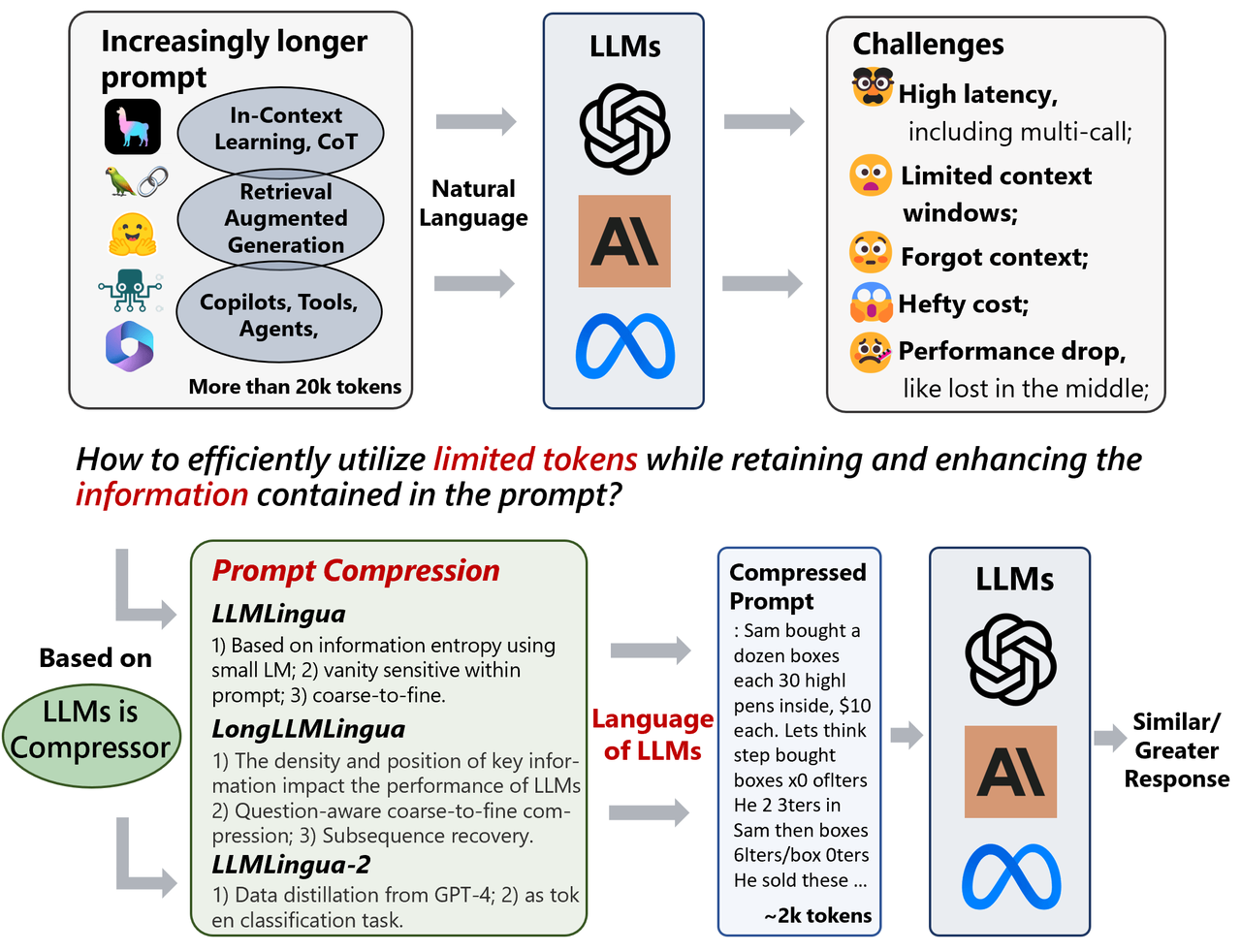
The LLM Inference Pipeline: From Text to Embeddings and the Power of RAG
A Survey of Efficient LLM Inference Serving | PDF | Scheduling ...
LLM Inference Performance Engineering: Best Practices | Databricks Blog
LLM Inference example with an inventory of orchids and other lovely ...
LLM Inference Performance Benchmarking from Scratch
Local LLM Inference and Fine-Tuning | PDF | Graphics Processing Unit ...
LLM Inference ( vLLM , TGI, TensorRT ) | by Pratik | Medium
This One Detail Explains Most of LLM Inference Performance - Coder Legion
Here's an example of local LLM inference with excellent intelligence ...
10 Strategies to Optimize LLM Inference Costs | thealpha posted on the ...
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
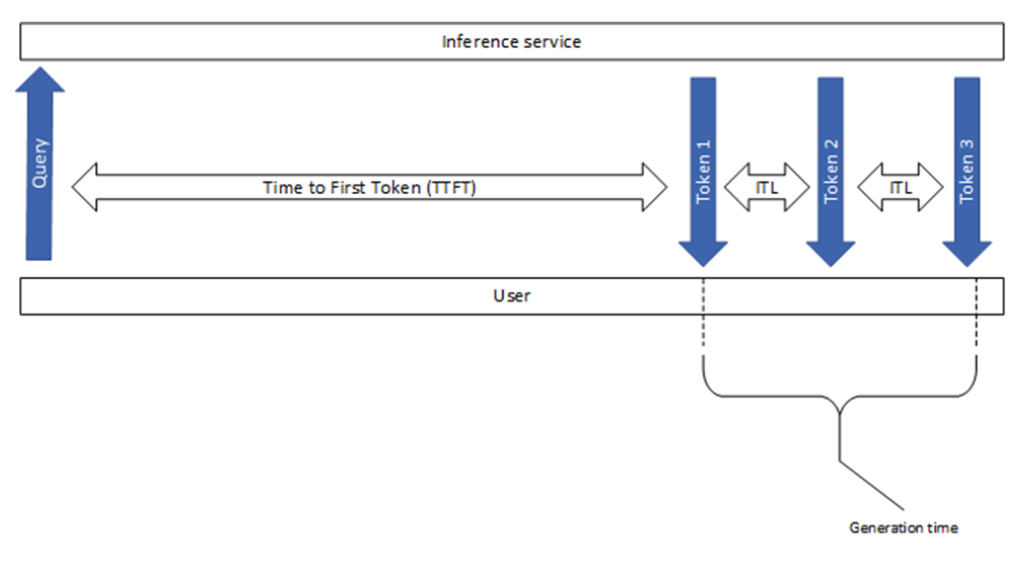
Key metrics for LLM inference | LLM Inference Handbook
LLM by Examples: Layer-wise inference using PyTorch or using AirLLM ...
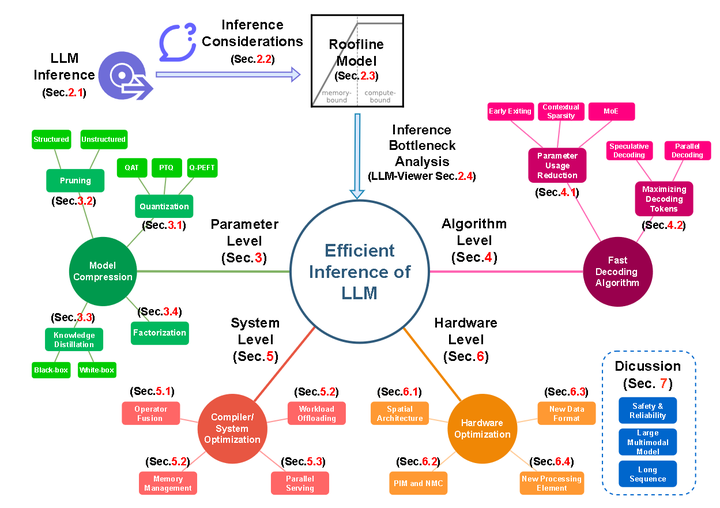
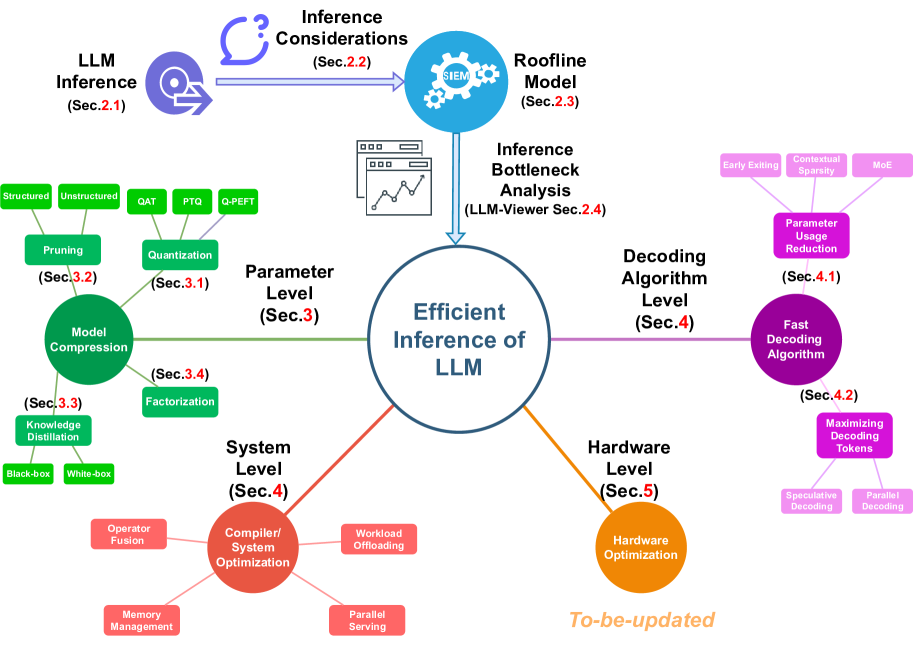
LLM Inference Unveiled: Survey and Roofline Model Insights - 知乎
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
Kubernetes-Based LLM Inference Architectures: An Overview | Yu-Chen ...
What Is LLM Inference? Batch Inference In LLM Inference
(PDF) Accelerating LLM Inference with Staged Speculative Decoding
LLM by Examples — vLLM Overview. vLLM, or virtual large language model ...
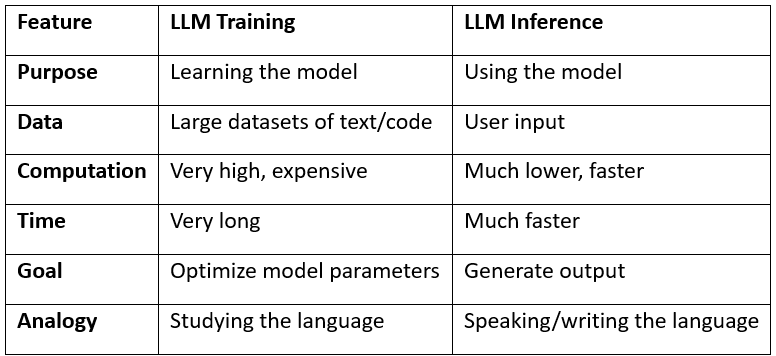
Overview of LLM Training and Inference | PDF | Artificial Intelligence ...
LLM Inference Parameters Explained Visually | by Abdullah Bezir | Medium
คู่มือ LLM Inference ฉบับใหม่จุดประกายการถกเถียงเรื่อง Ollama กับการใช้ ...
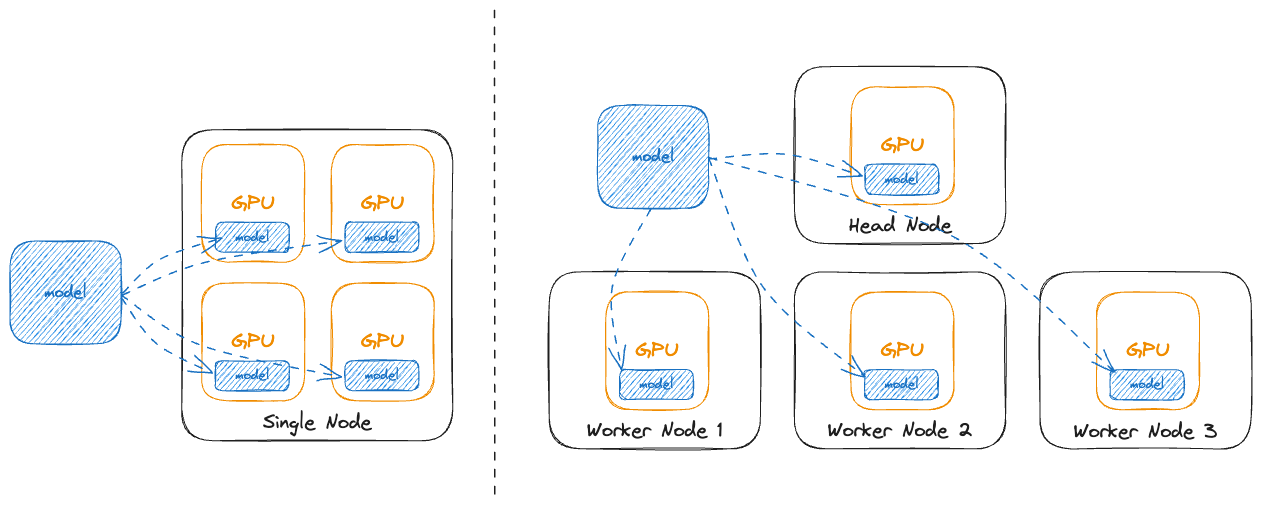
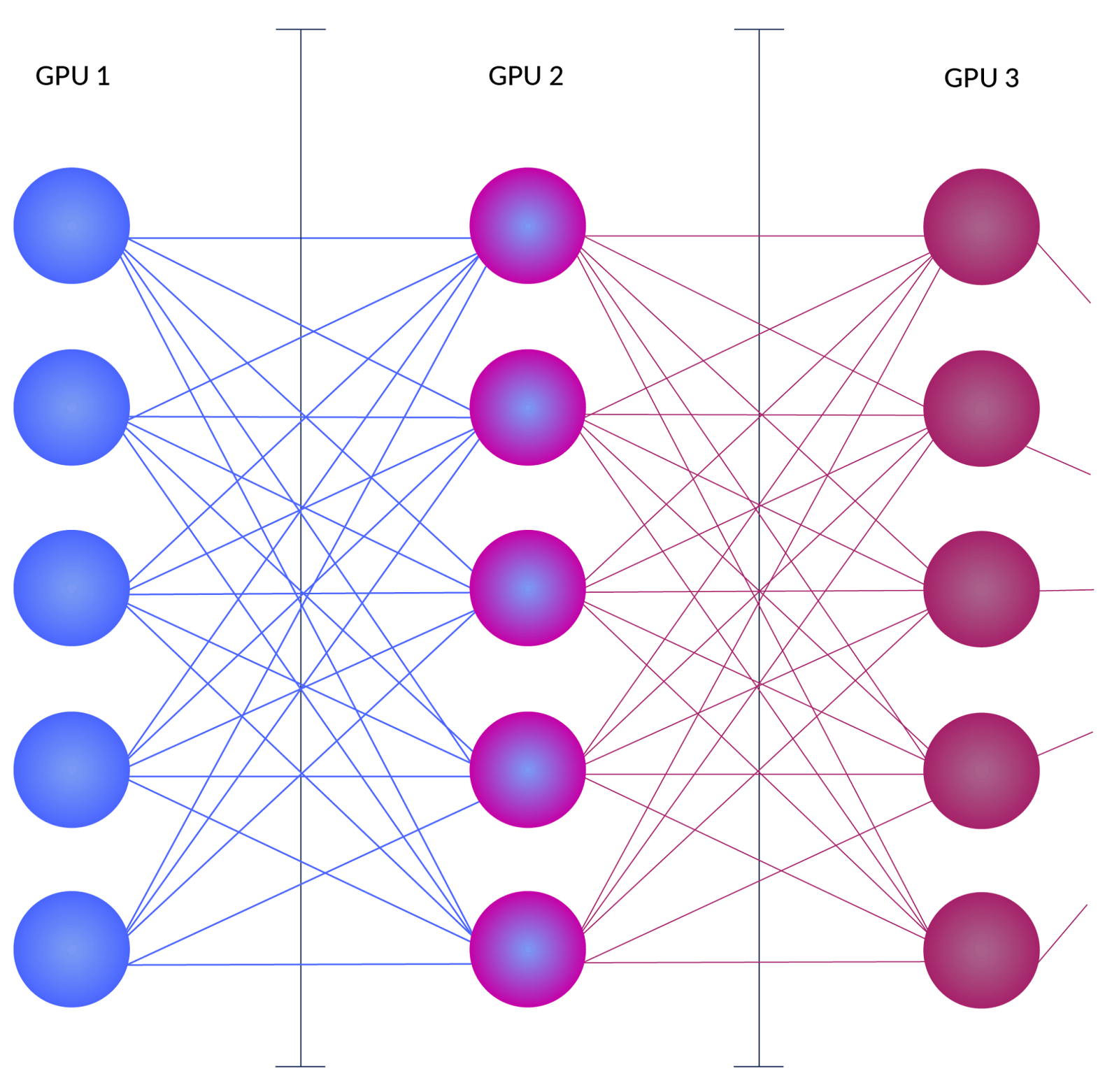
LLM Inference Beyond a Single Node: From Bottlenecks to Mitigations ...
Optimizing AI Performance: A Guide to Efficient LLM Deployment
Topic 23: What is LLM Inference, it's challenges and solutions for it
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
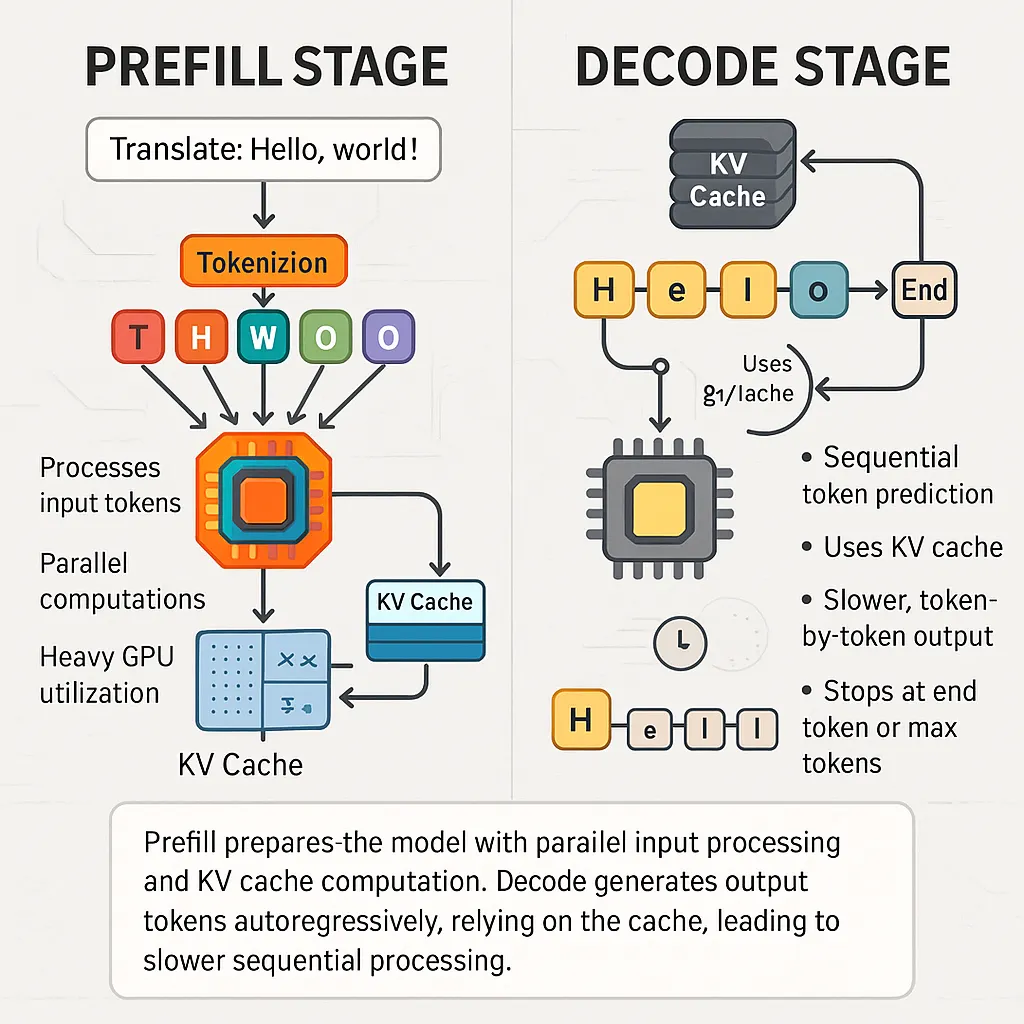
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
6 Production-Tested Optimization Strategies for High-Performance LLM ...
What is LLM Inference? • luminary.blog
What is LLM Model Inference?
Re: Defeating Nondeterminism in LLM Inference, The Future is ...
Rethinking LLM inference: Why developer AI needs a different approach
LLM Sampling Explained: Selecting the Next Token | Thinking Sand
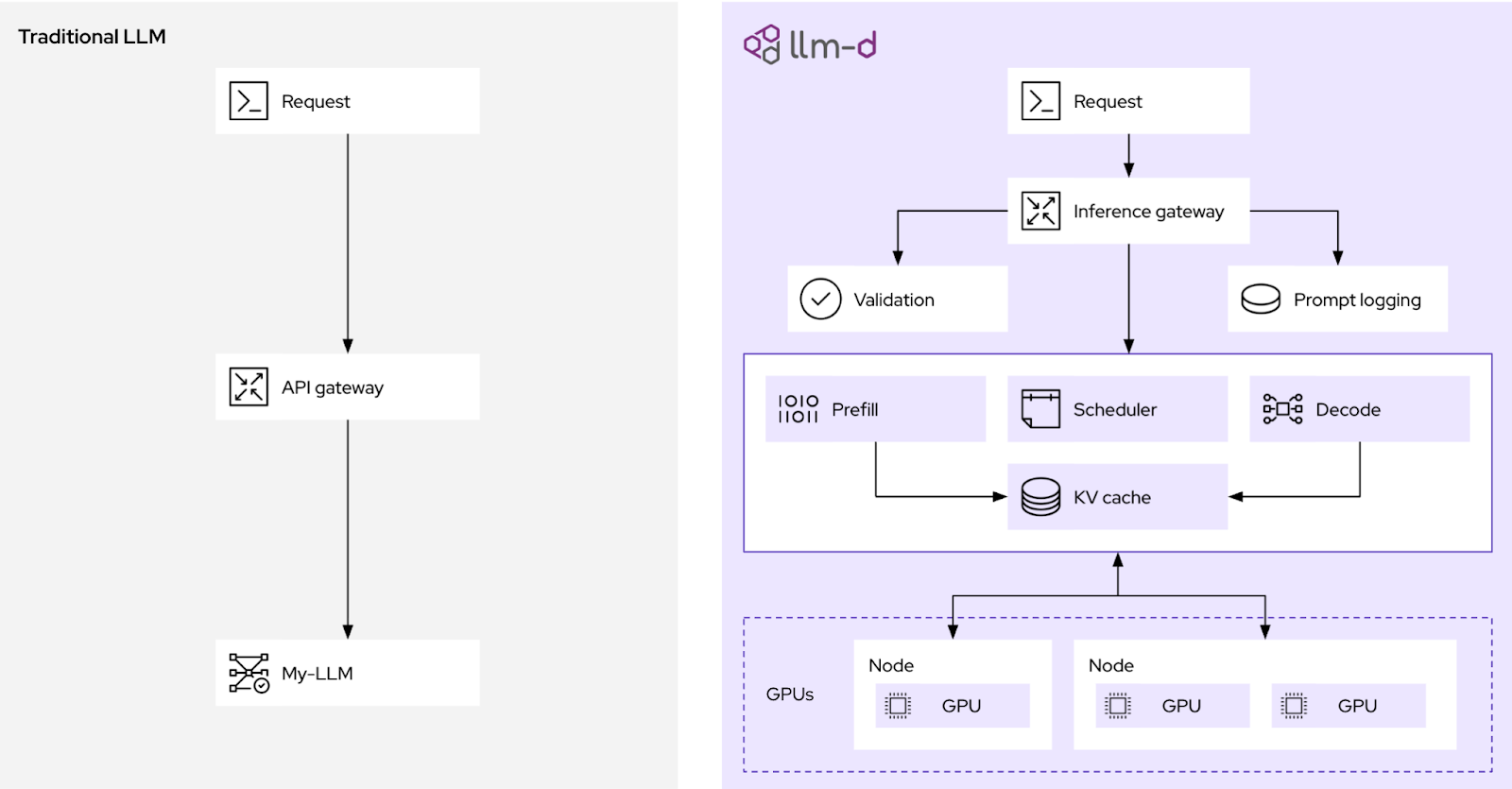
Introduction to distributed inference with llm-d | Red Hat Developer
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
The 4 patterns of LLM Inference. | Alex Razvant
LLM Benchmarking: Fundamental Concepts - Edge AI and Vision Alliance
Efficient Large Language Model Inference · @toytag.net
Decoding LLM Inference: A Deep Dive into Workloads, Optimization, and ...
LLM inferencing in production
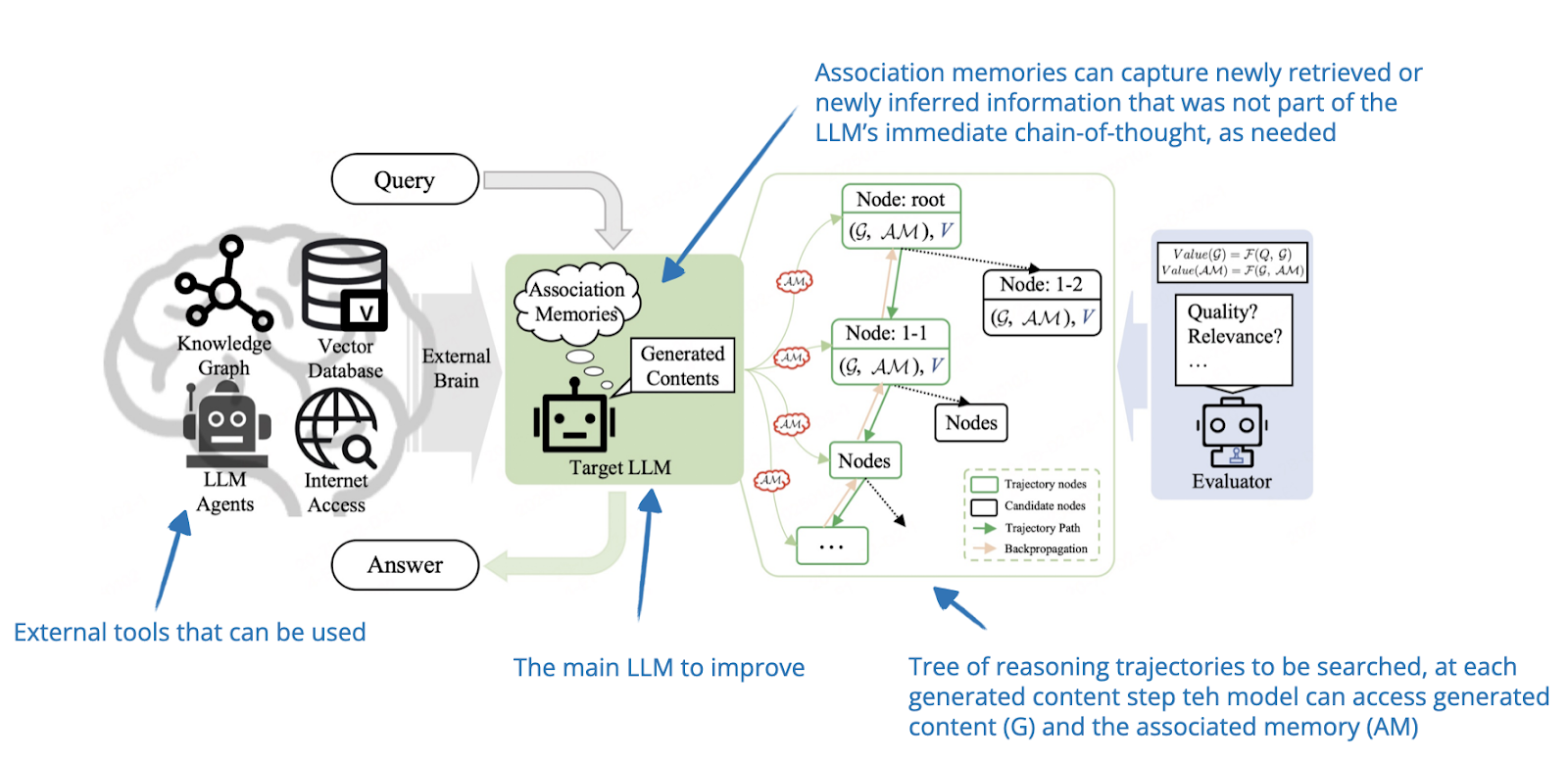
Multi-view Intent Learning and Alignment with Large Language Models for ...
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
Optimizing Large Language Model Inference: A Deep Dive into Continuous
llm-inference · PyPI
(PDF) Towards Efficient Multi-LLM Inference: Characterization and ...
一起理解下LLM的推理流程_llm推理过程-CSDN博客




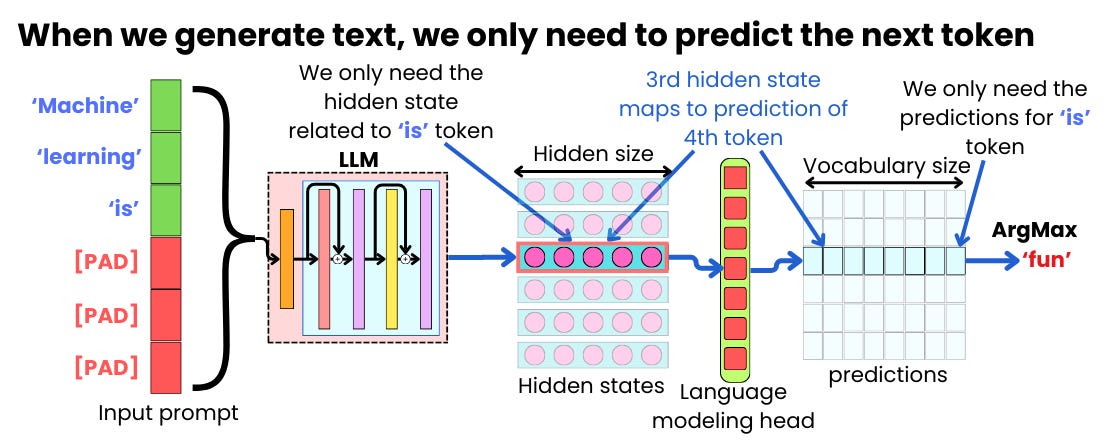
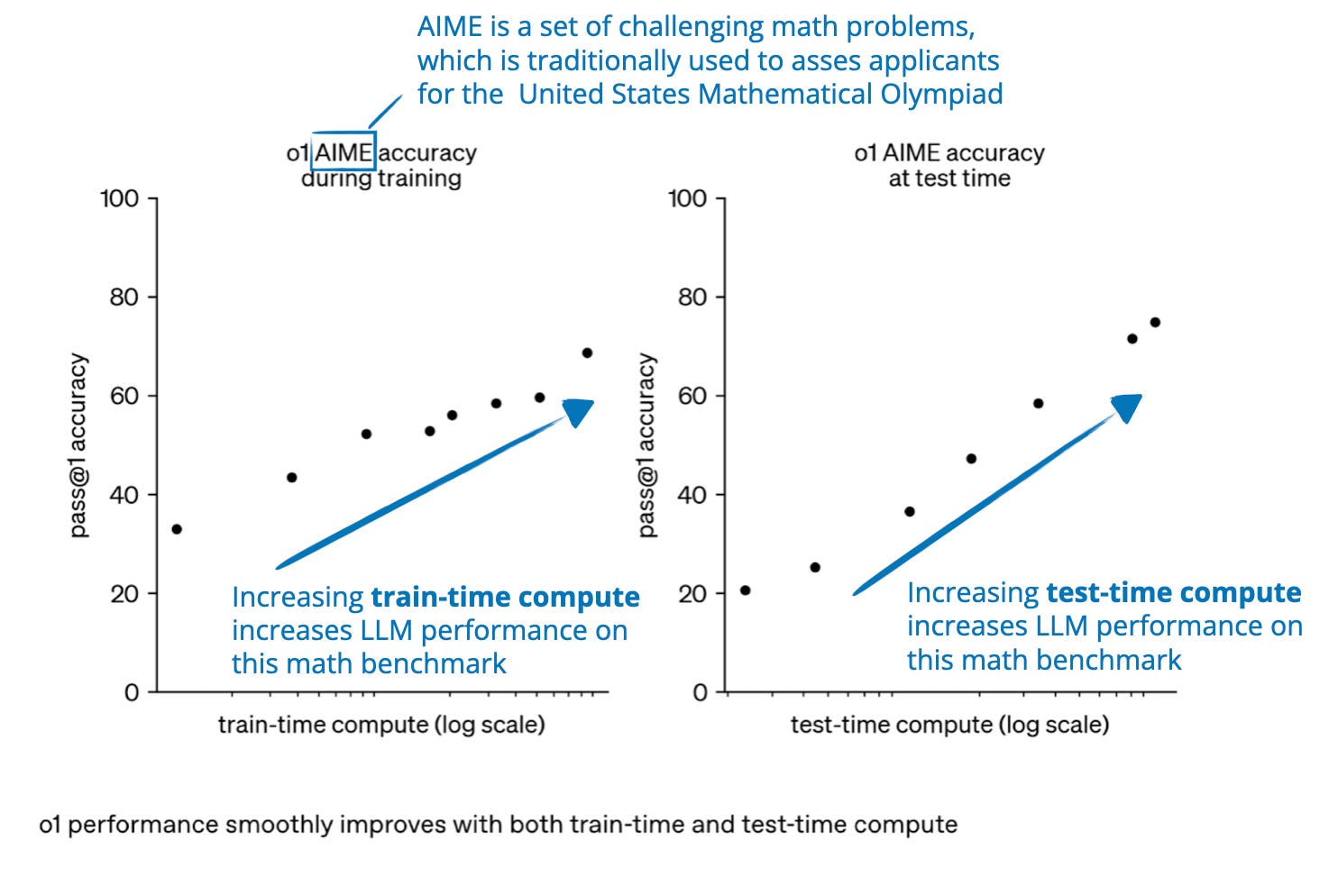



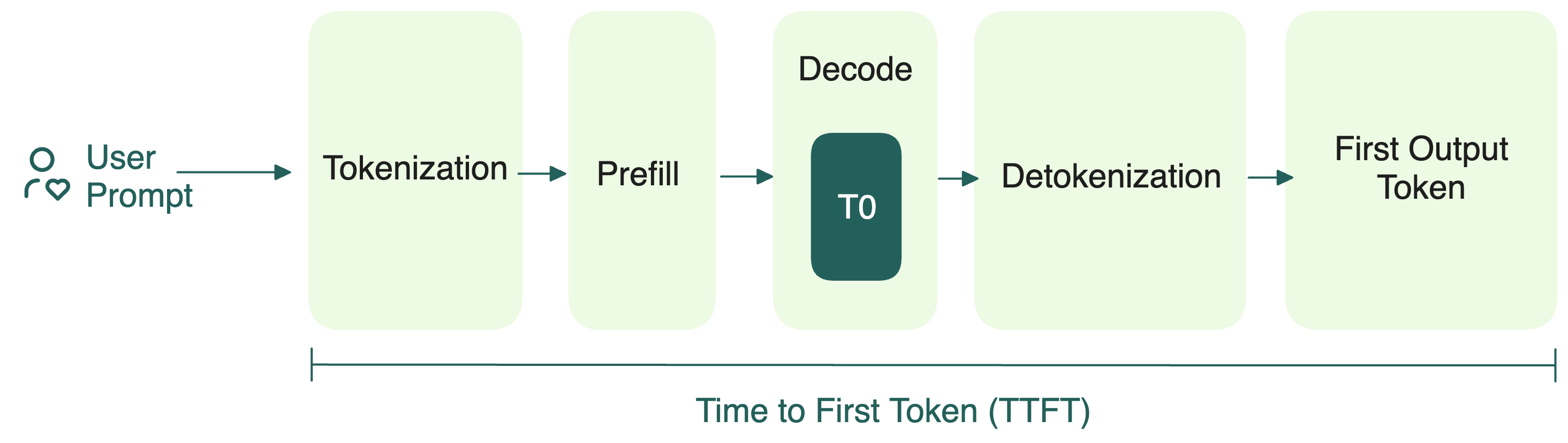



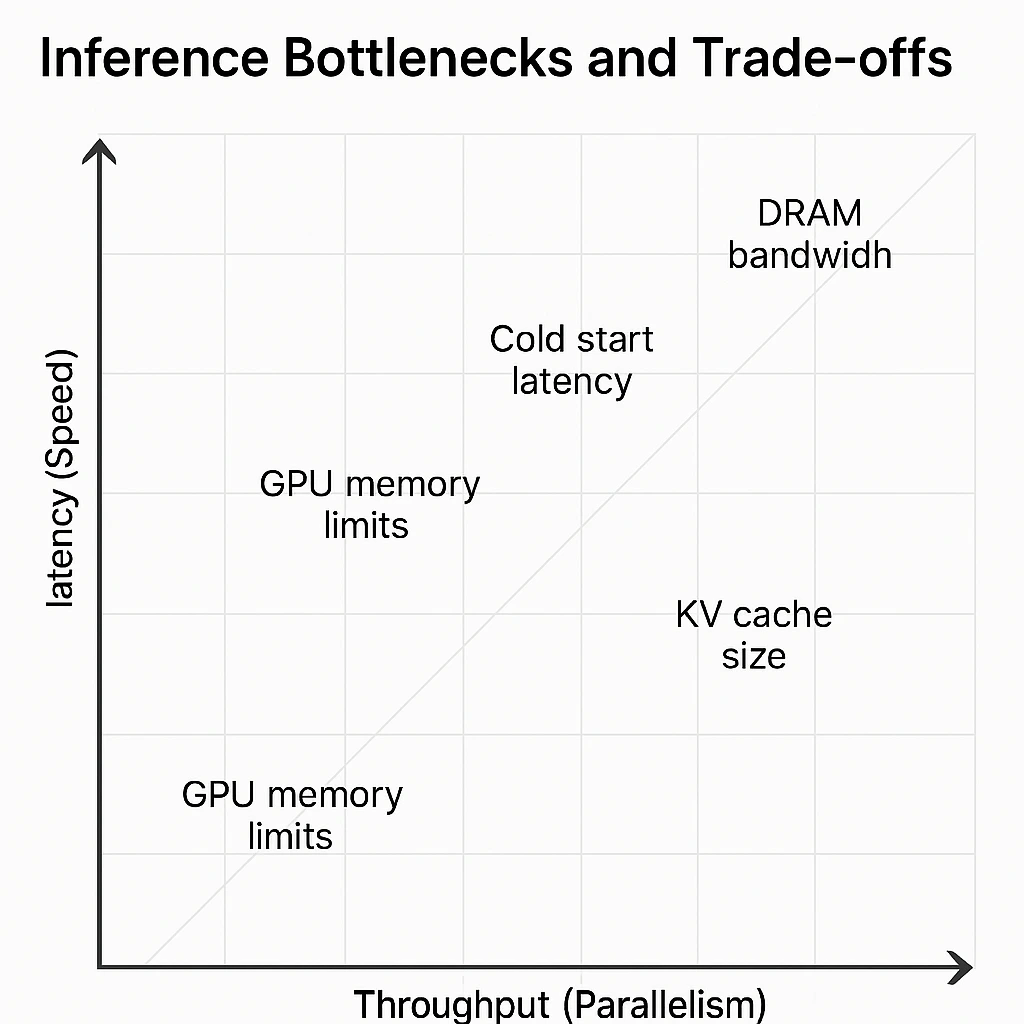


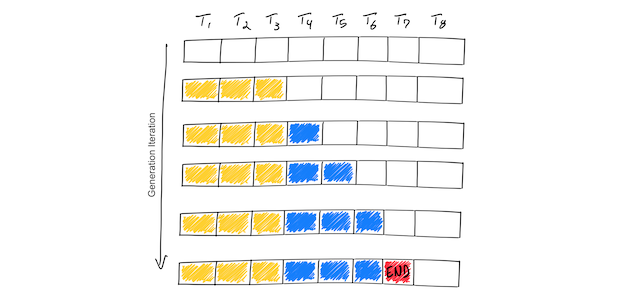

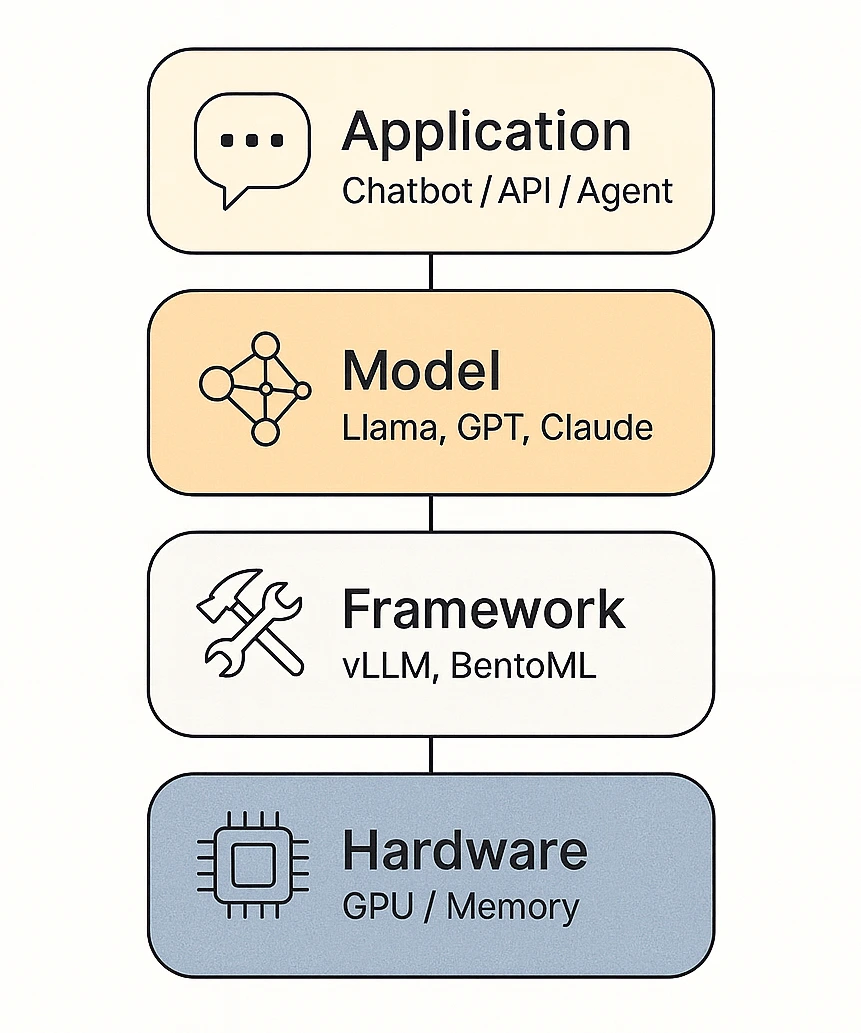







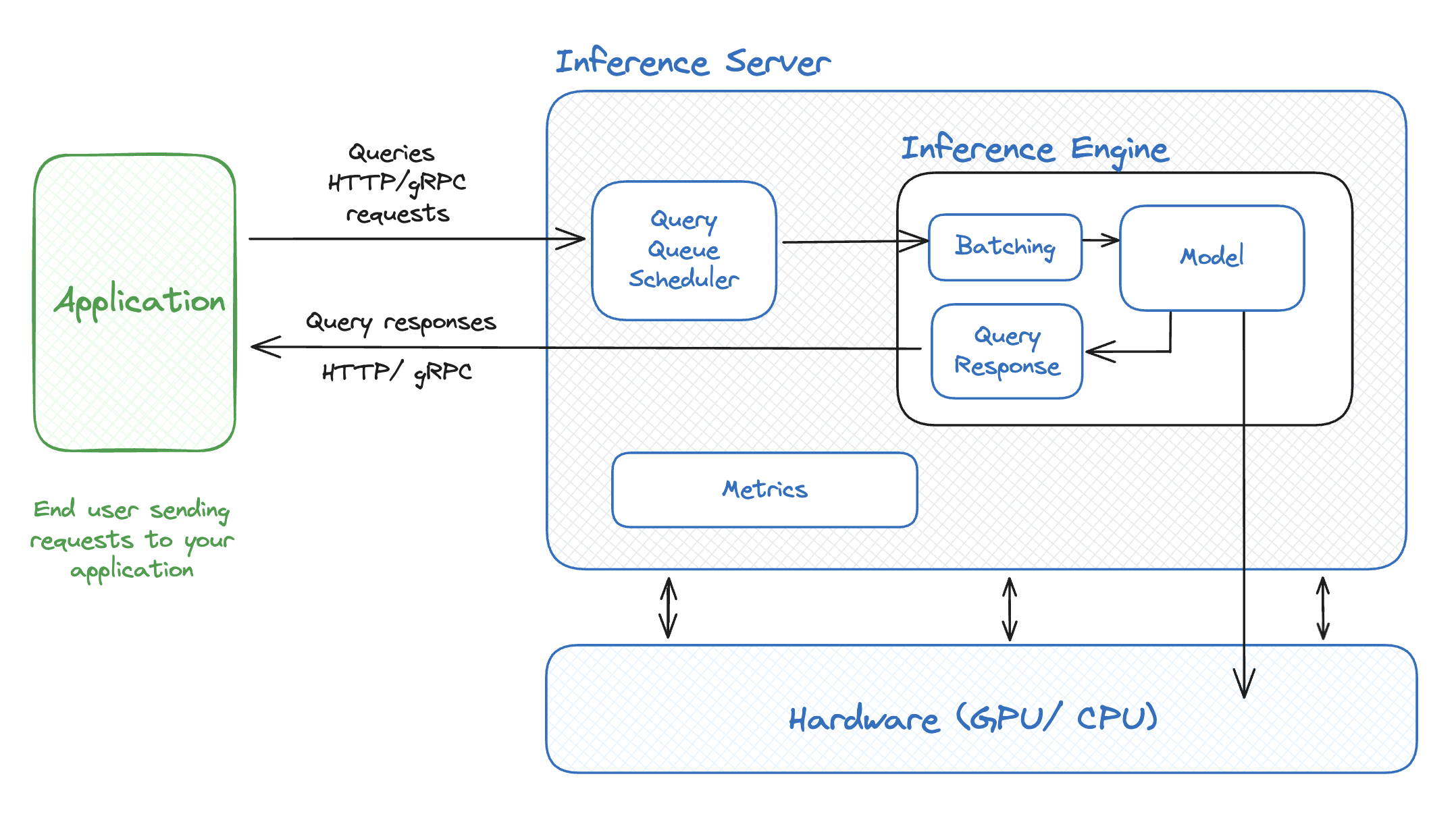











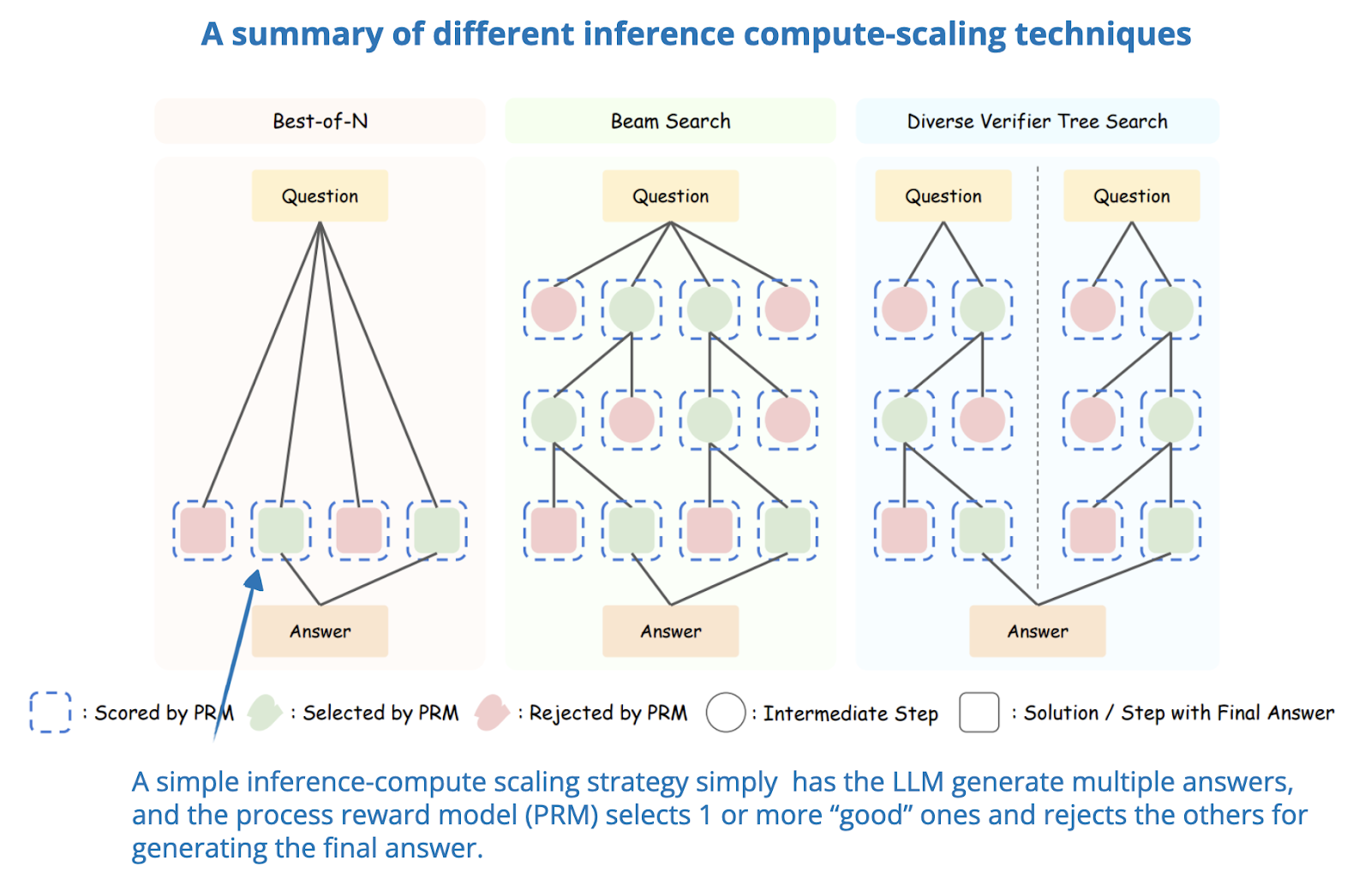


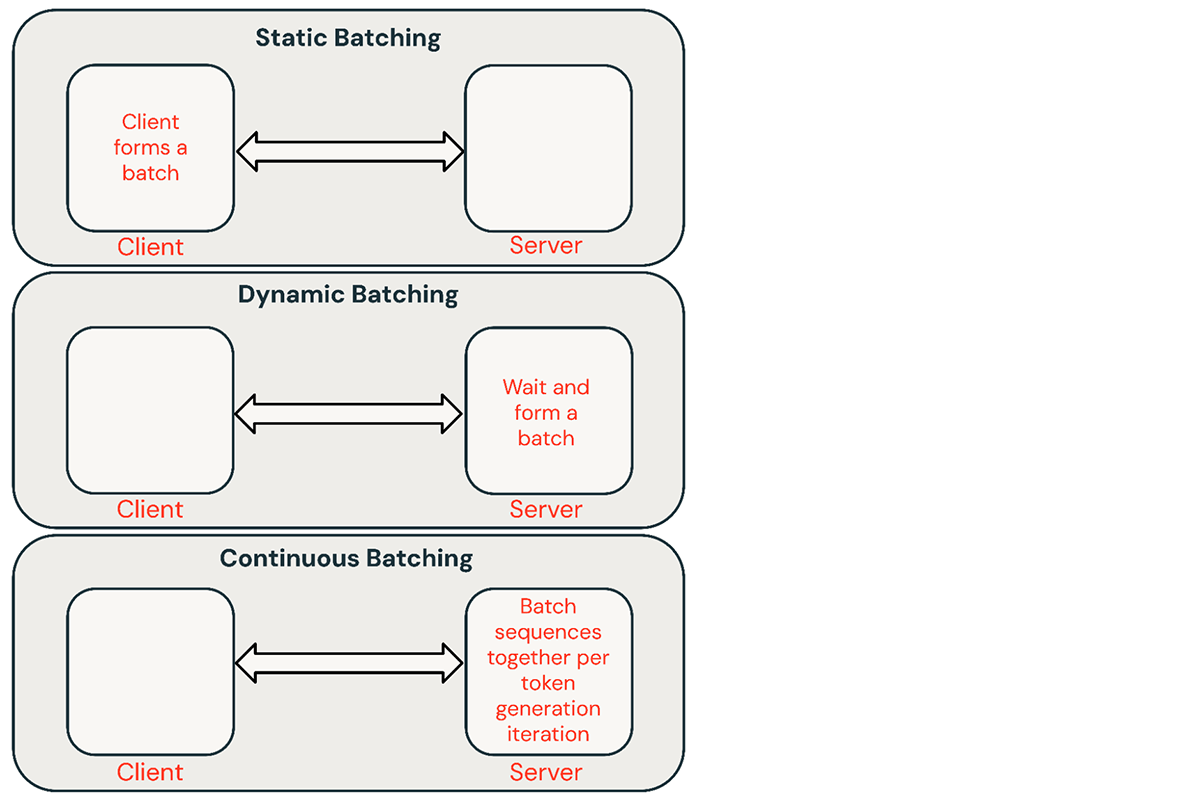


-png.png?width=4320&height=2160&name=AI%20Model%20Training%20vs%20Inference%20(1)-png.png)
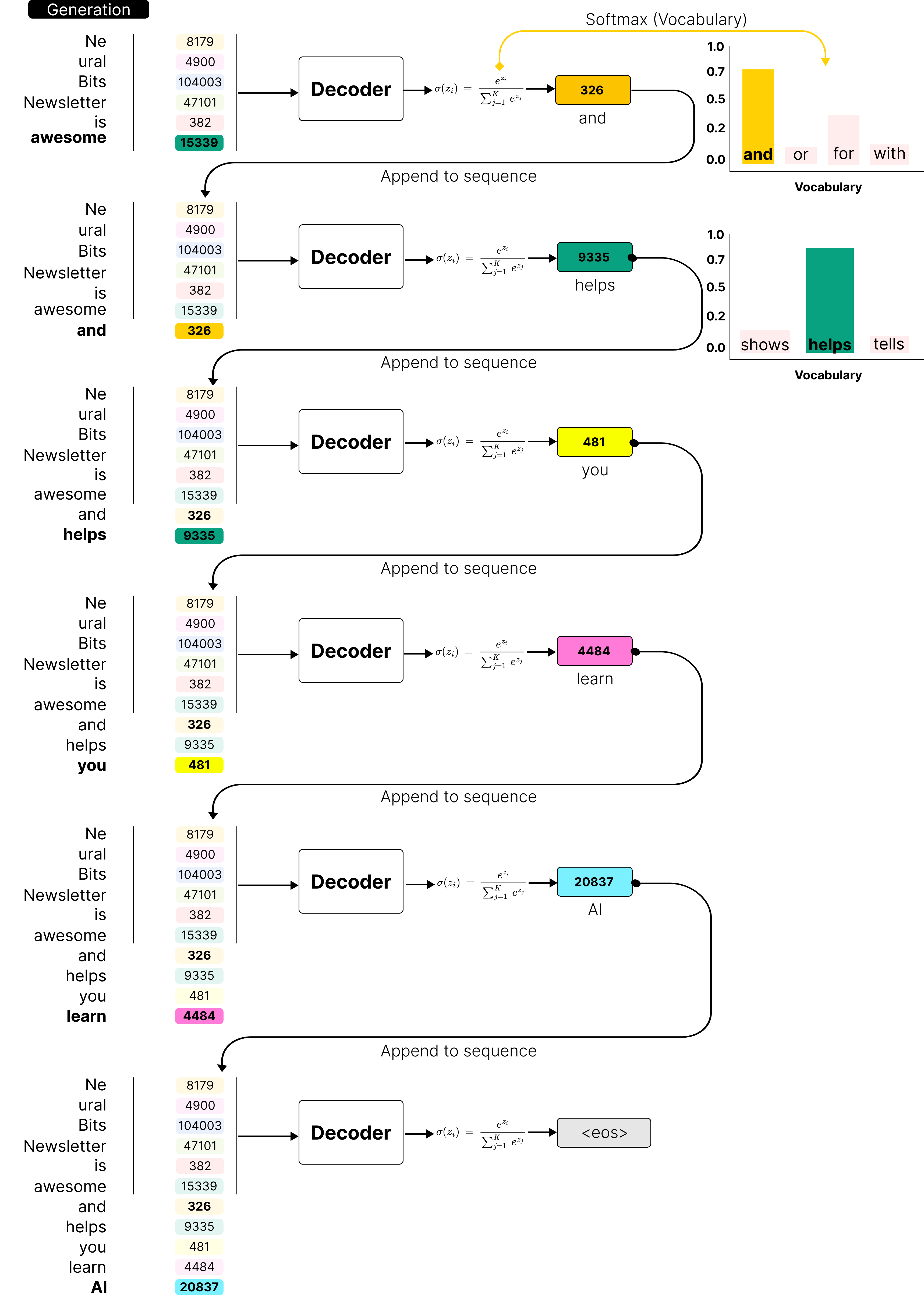
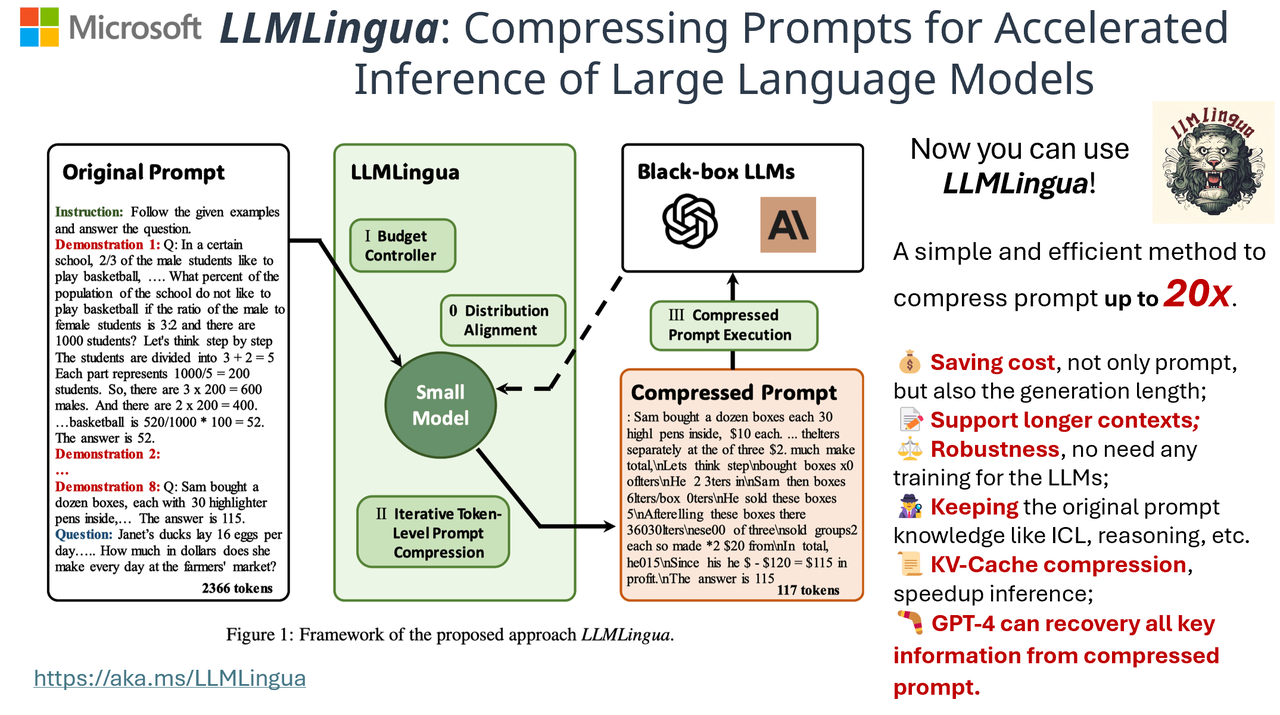










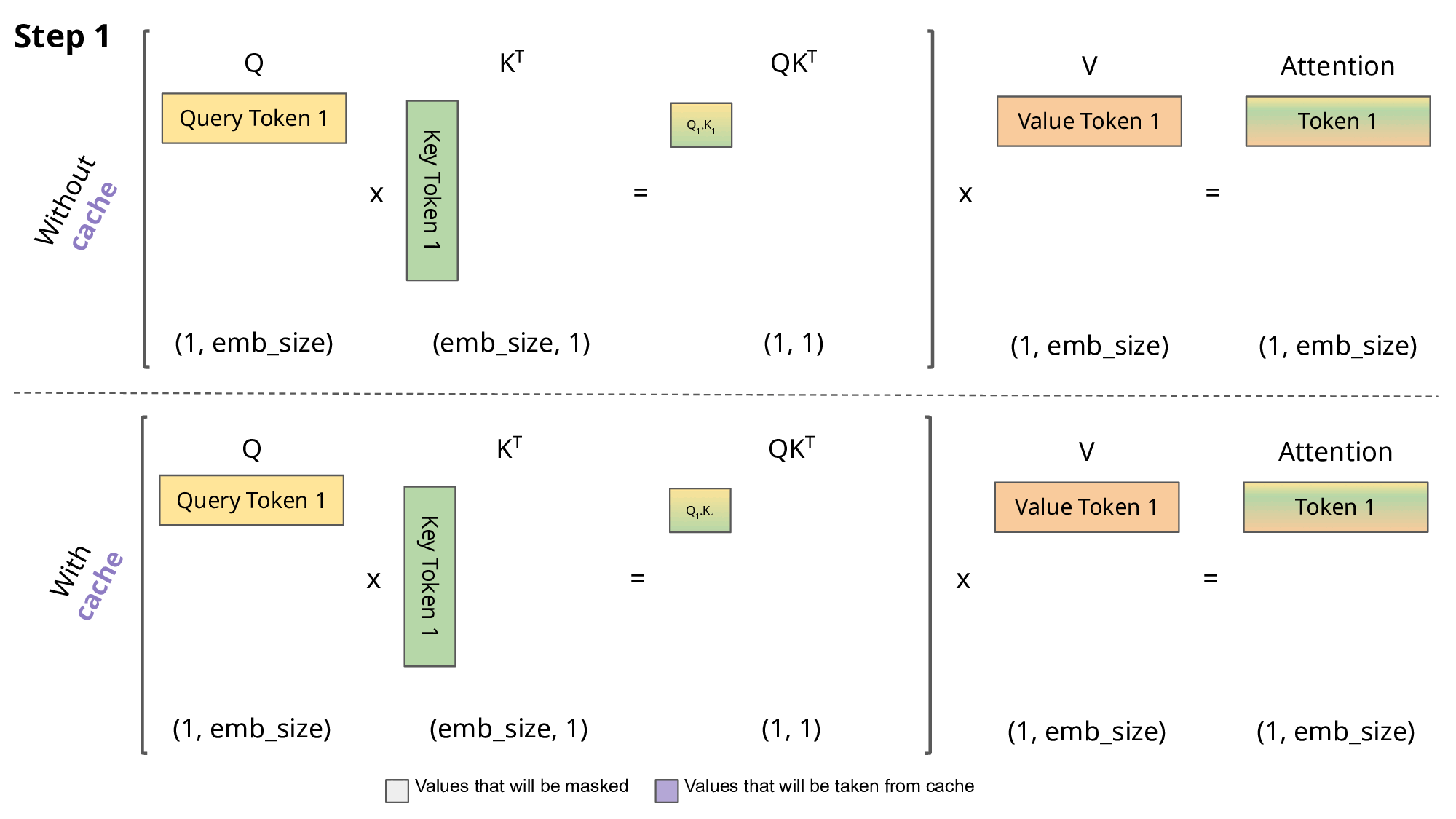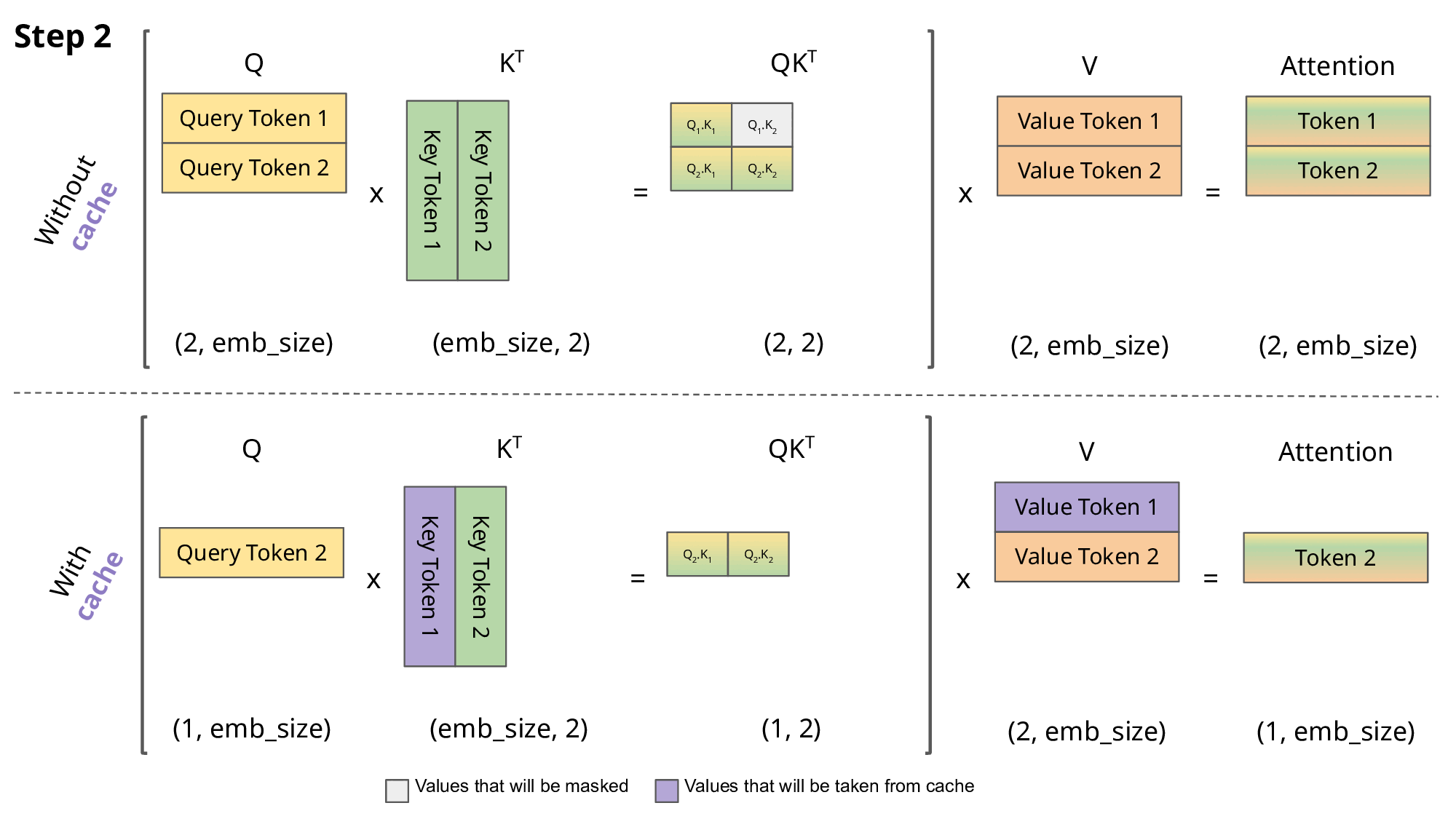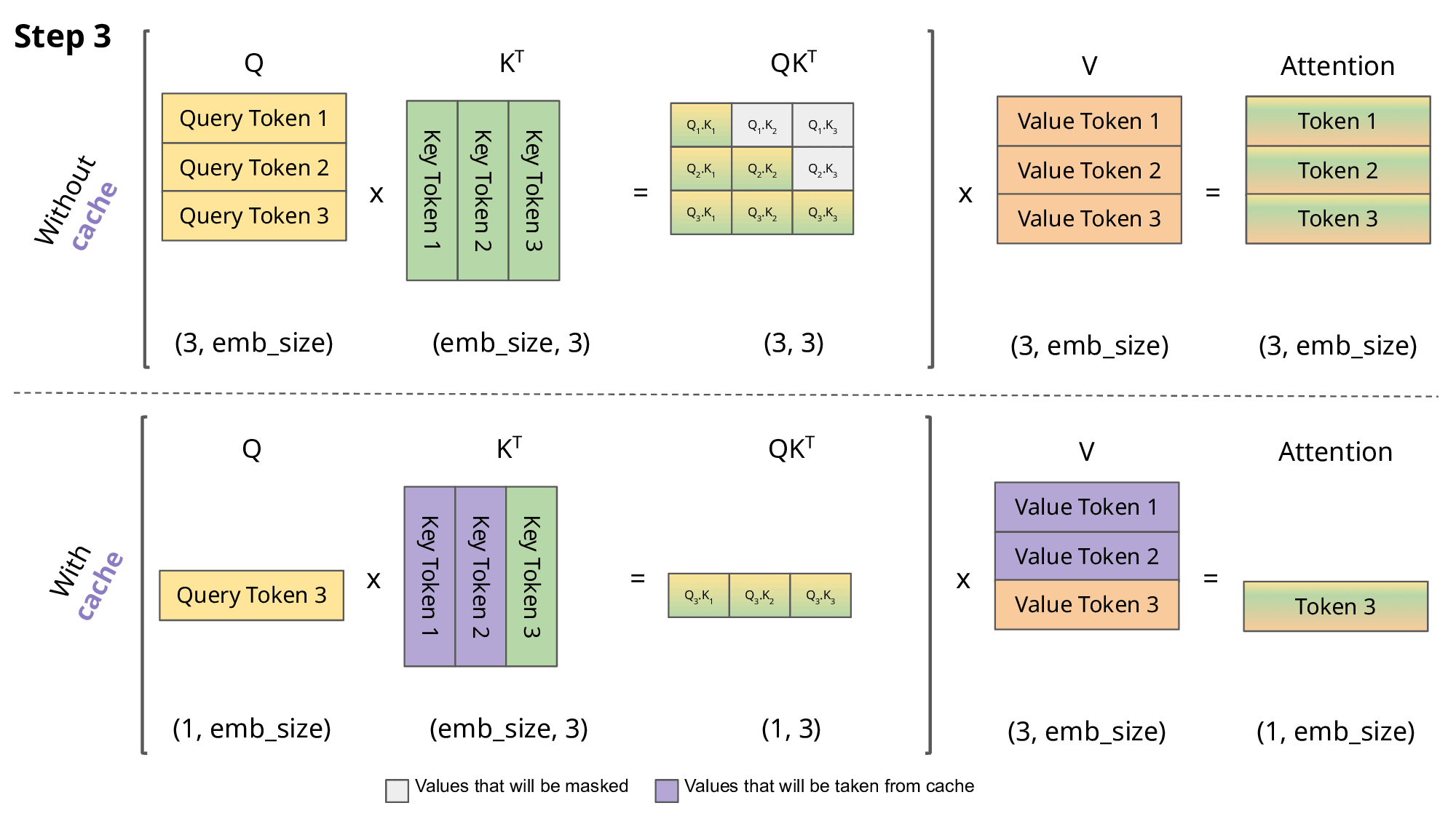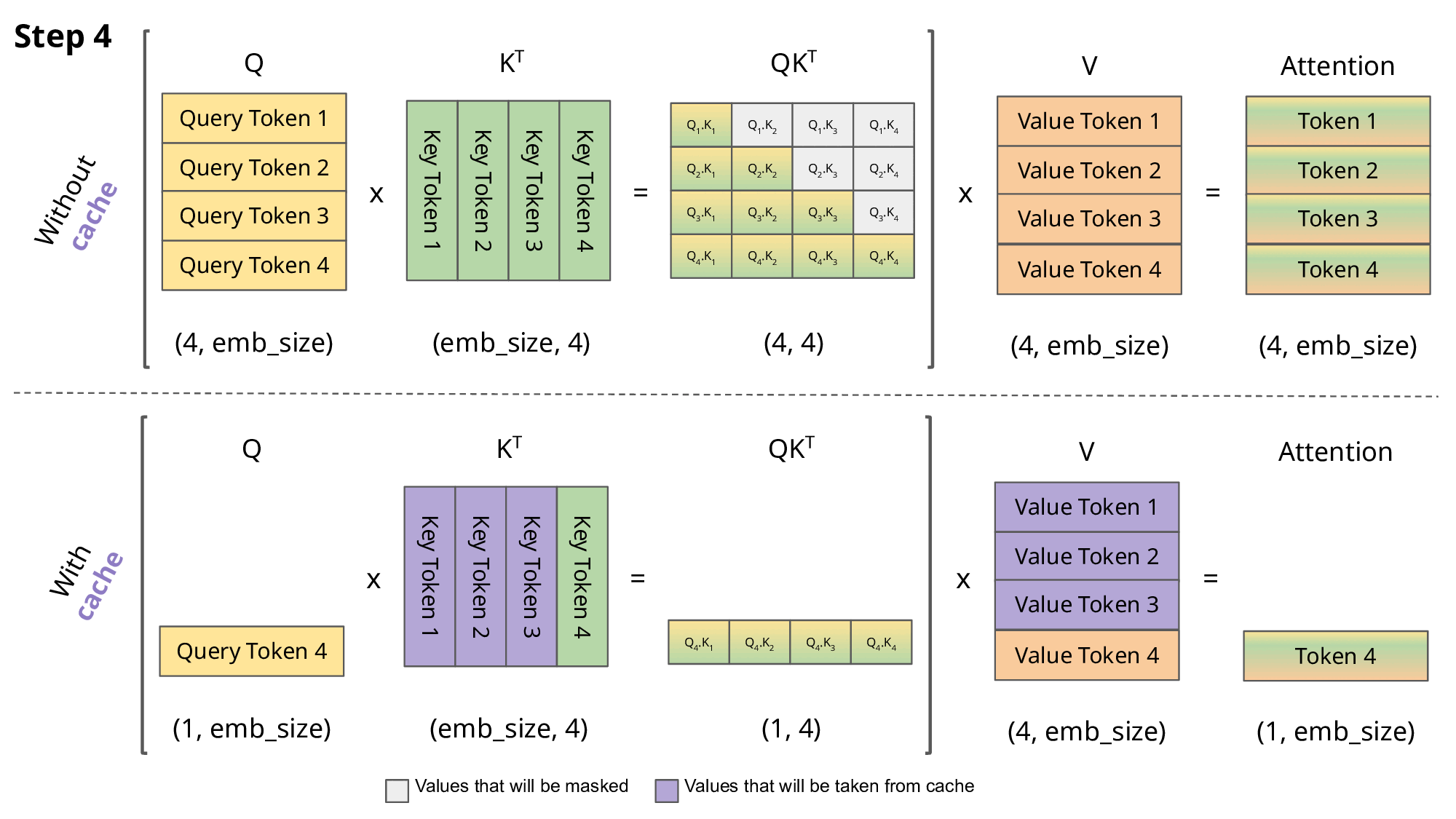

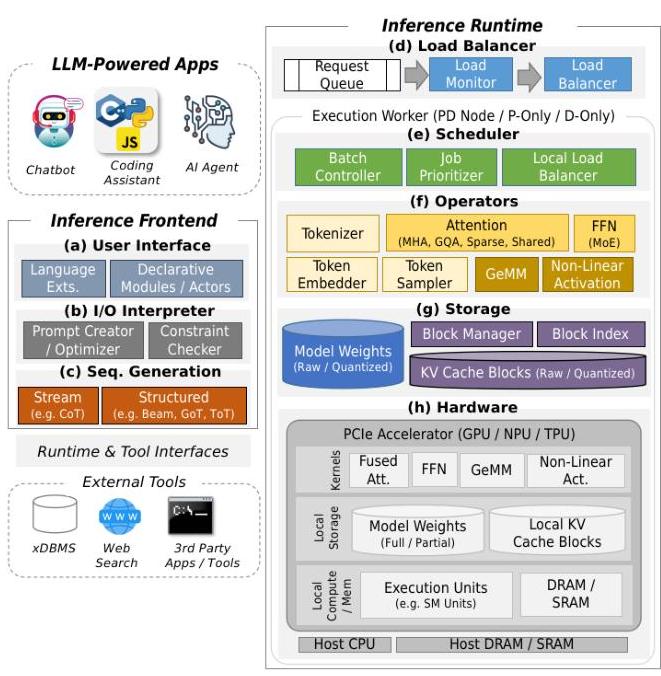
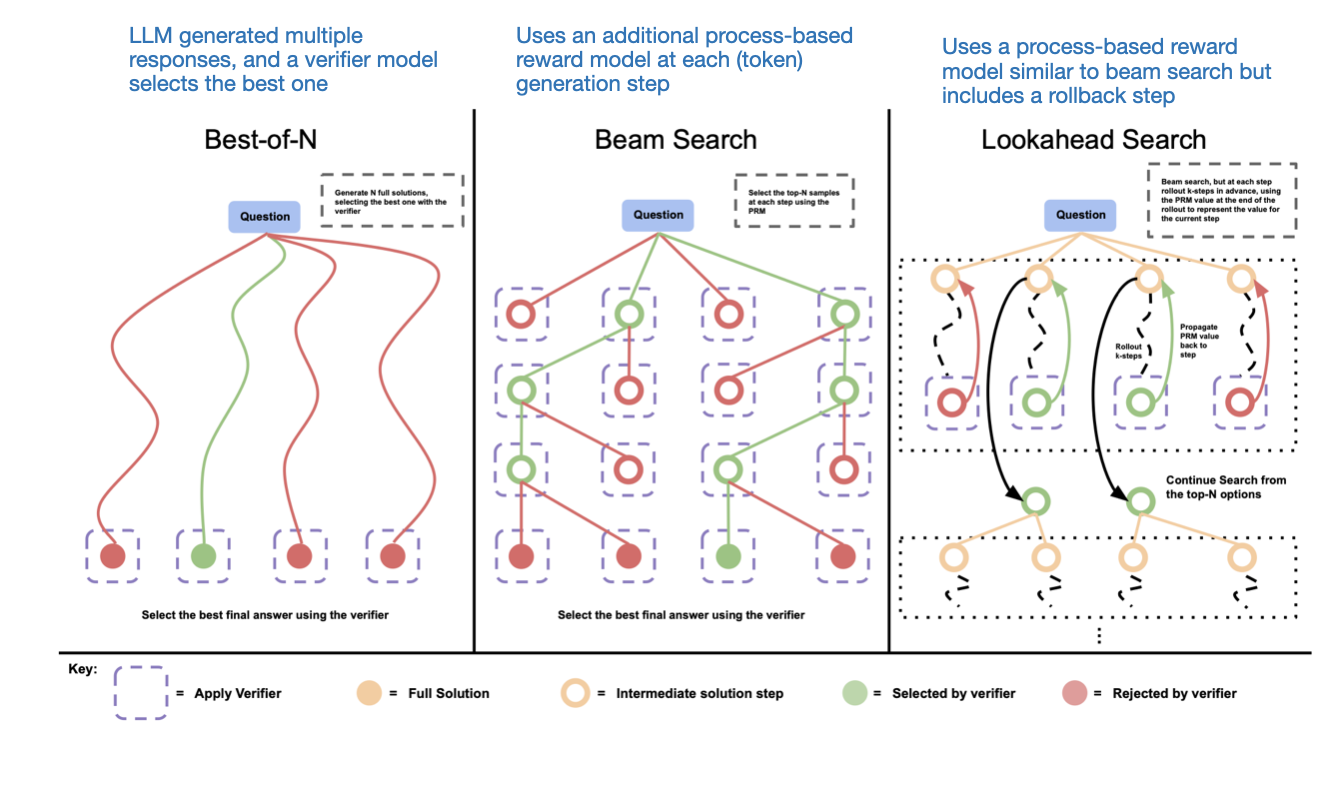






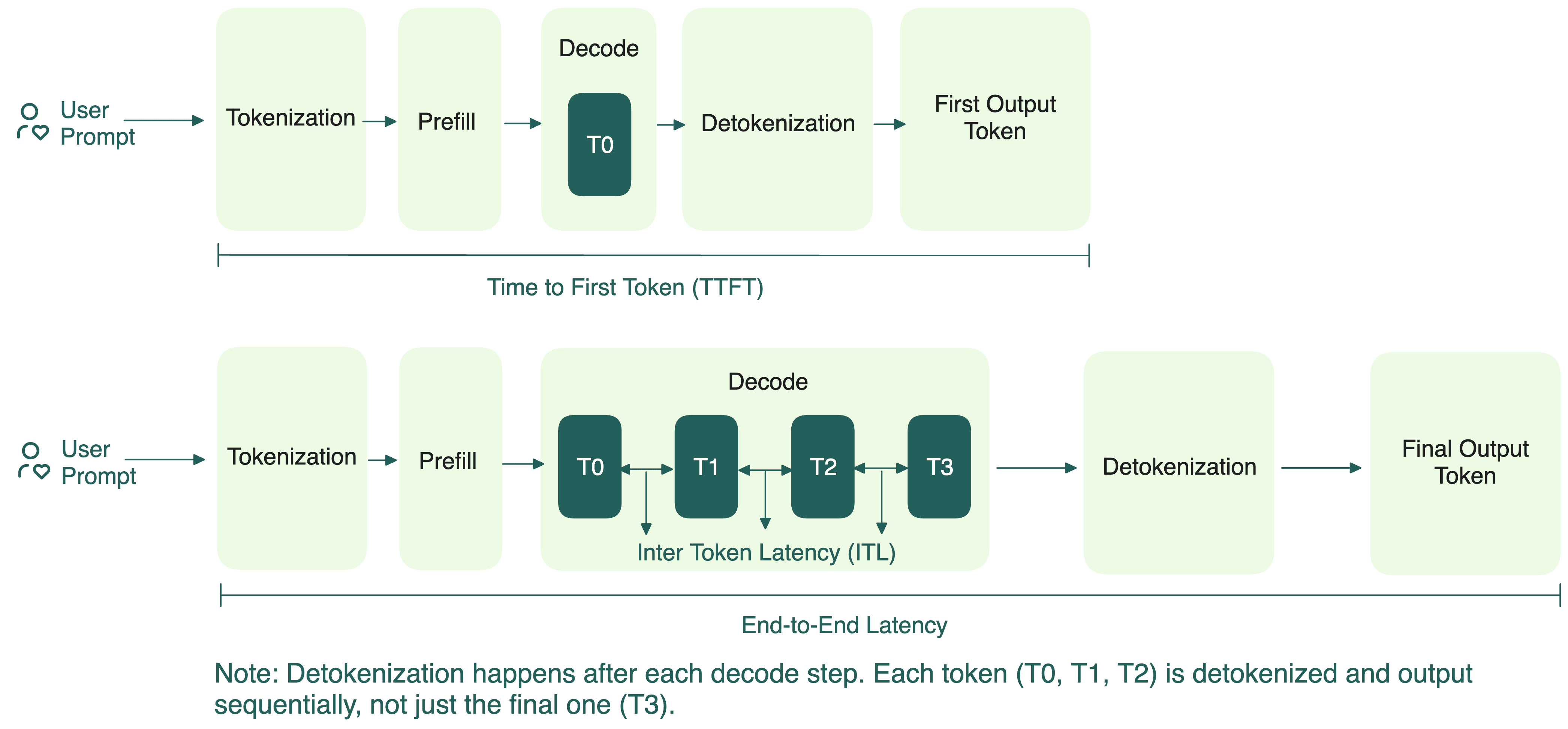






.png)