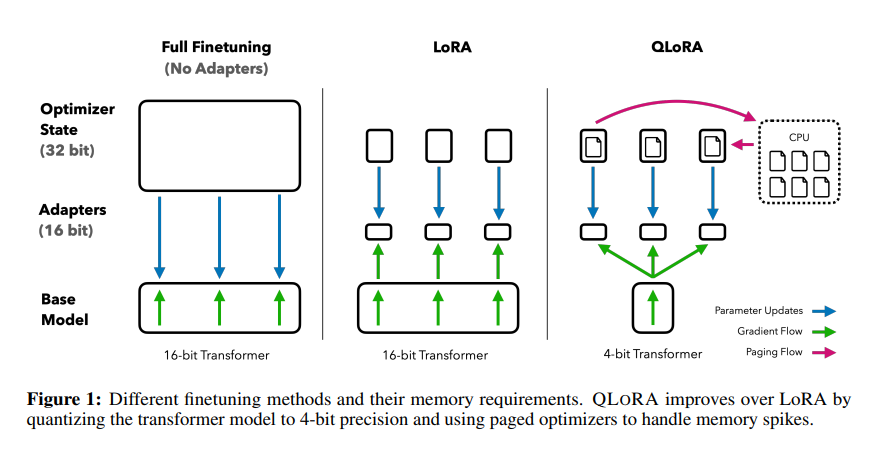
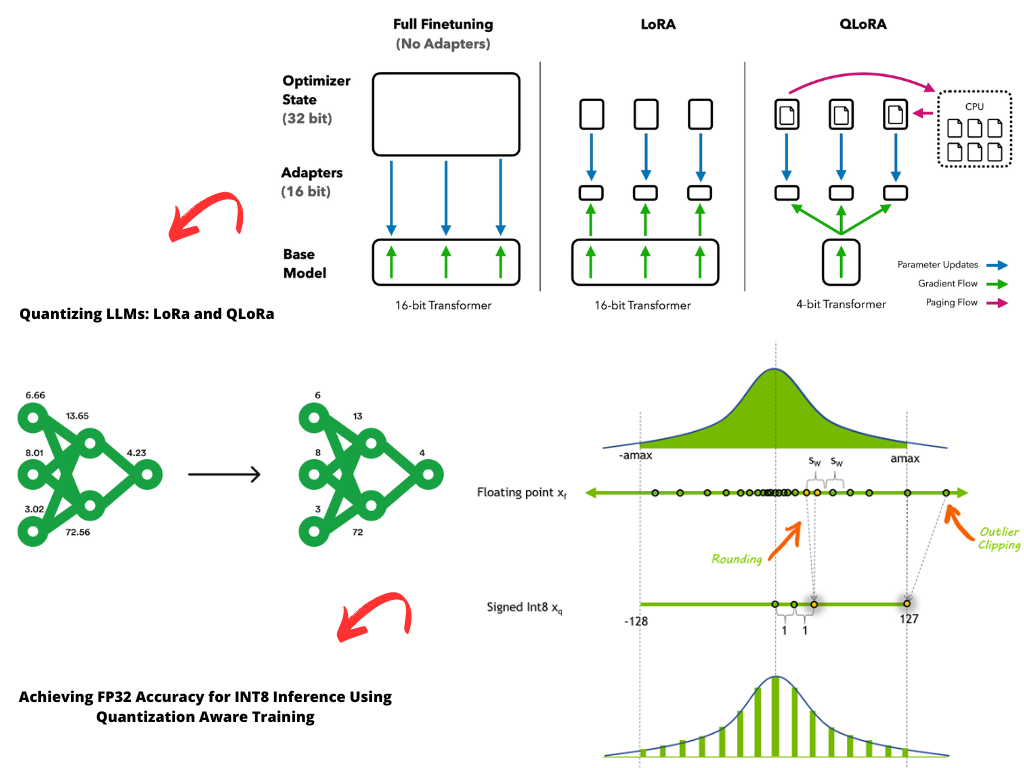
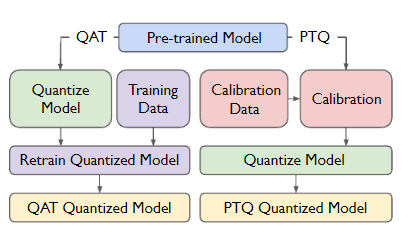
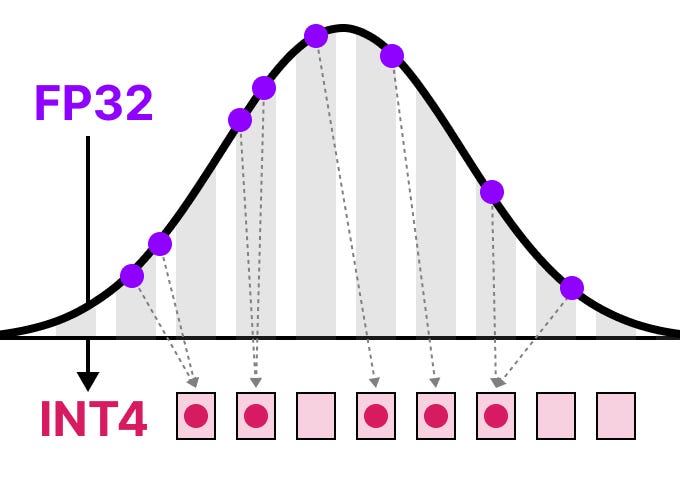
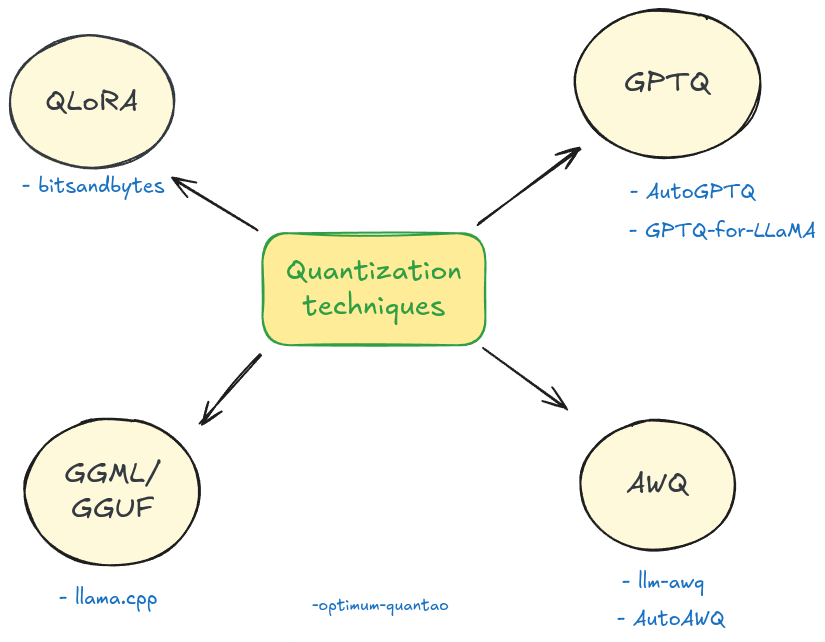
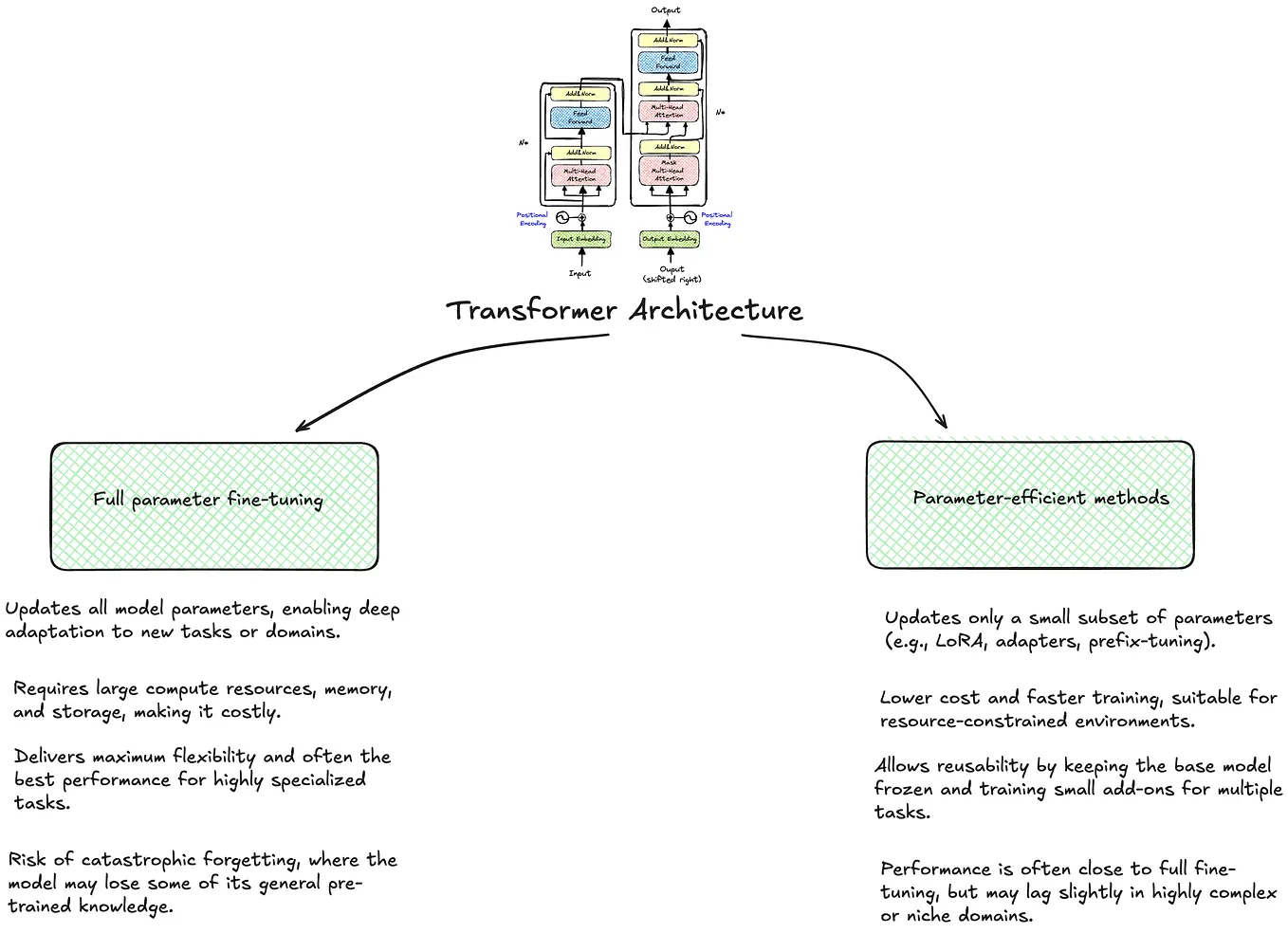
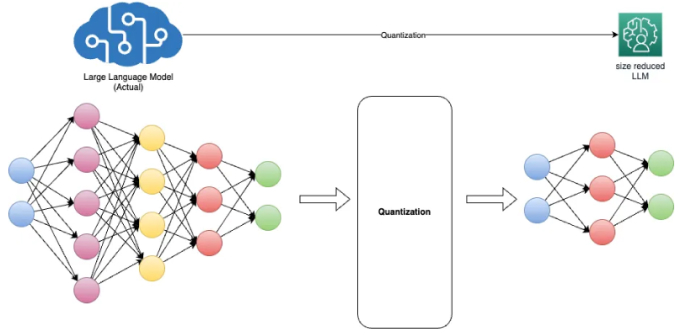
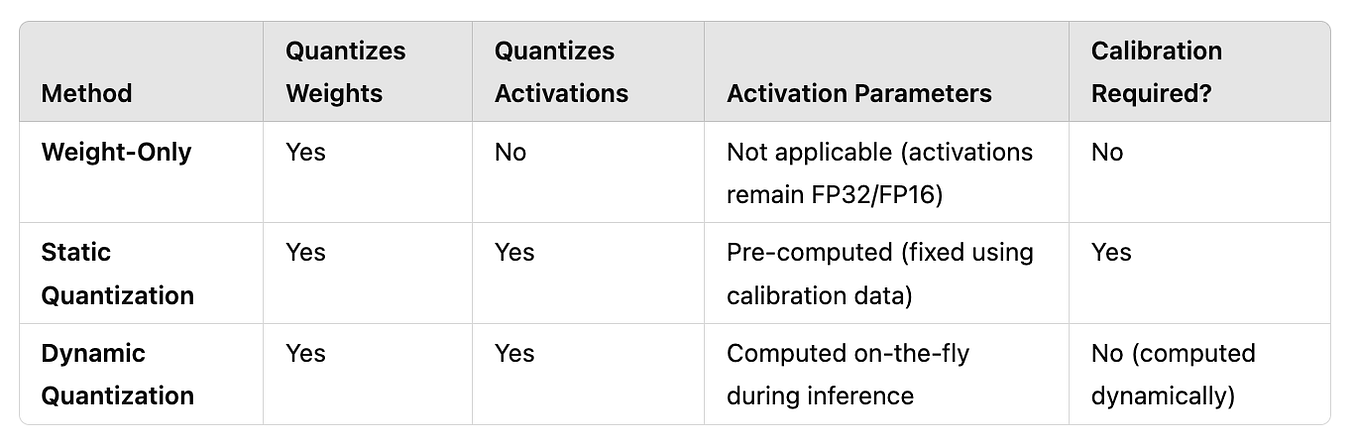
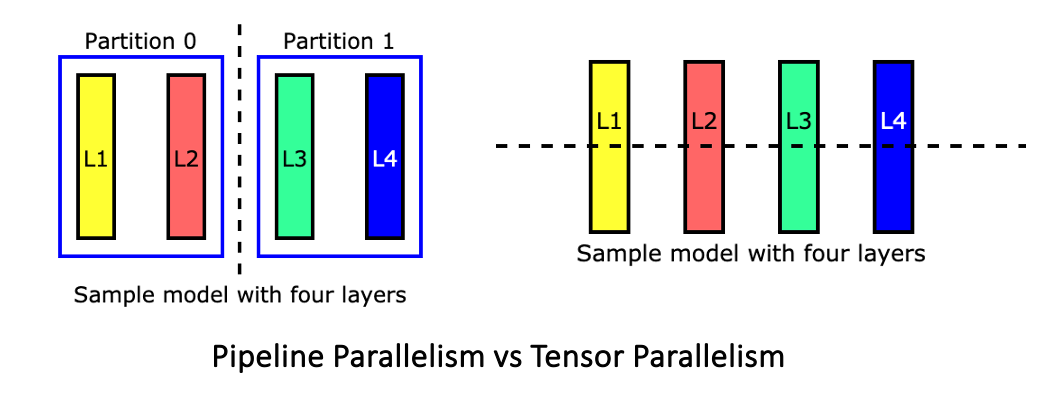
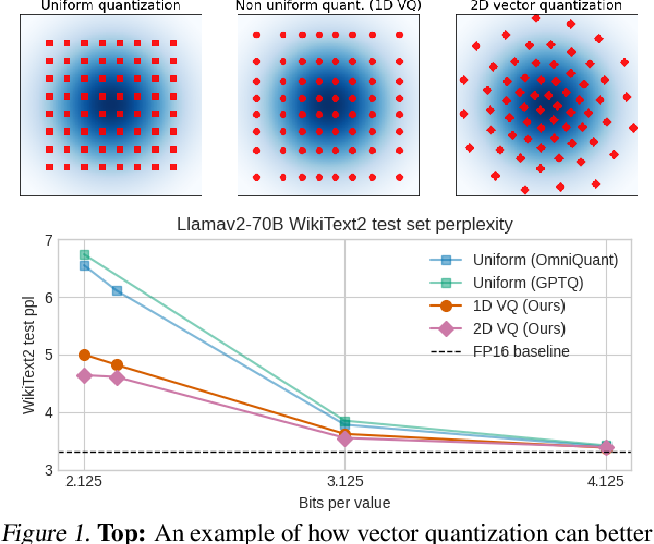
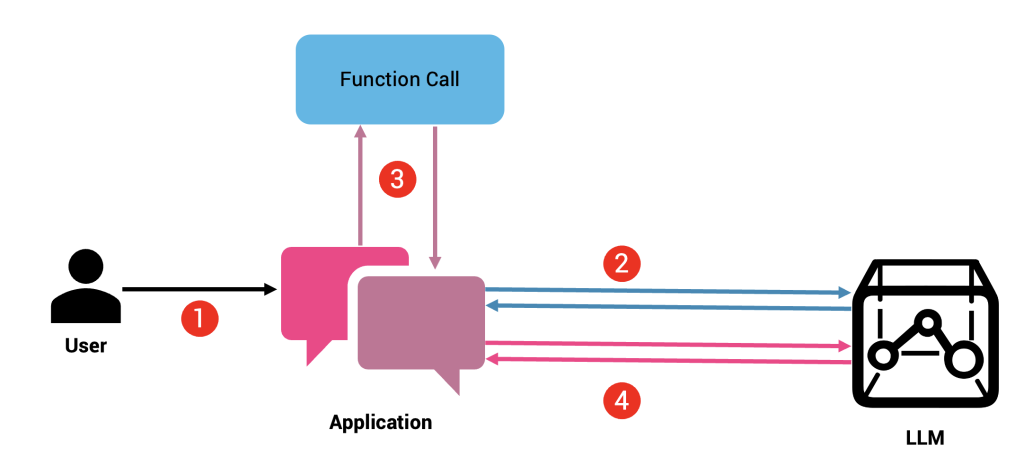
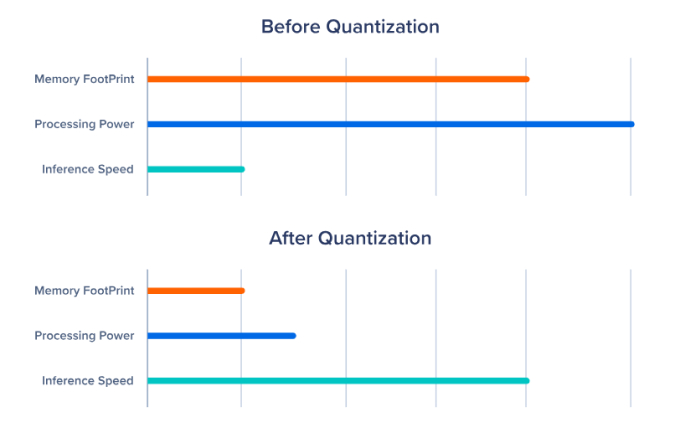
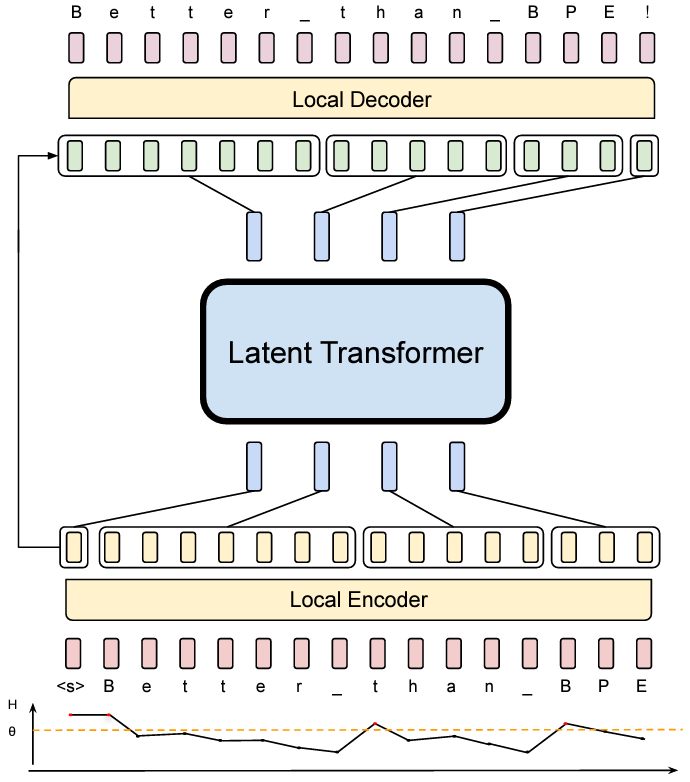
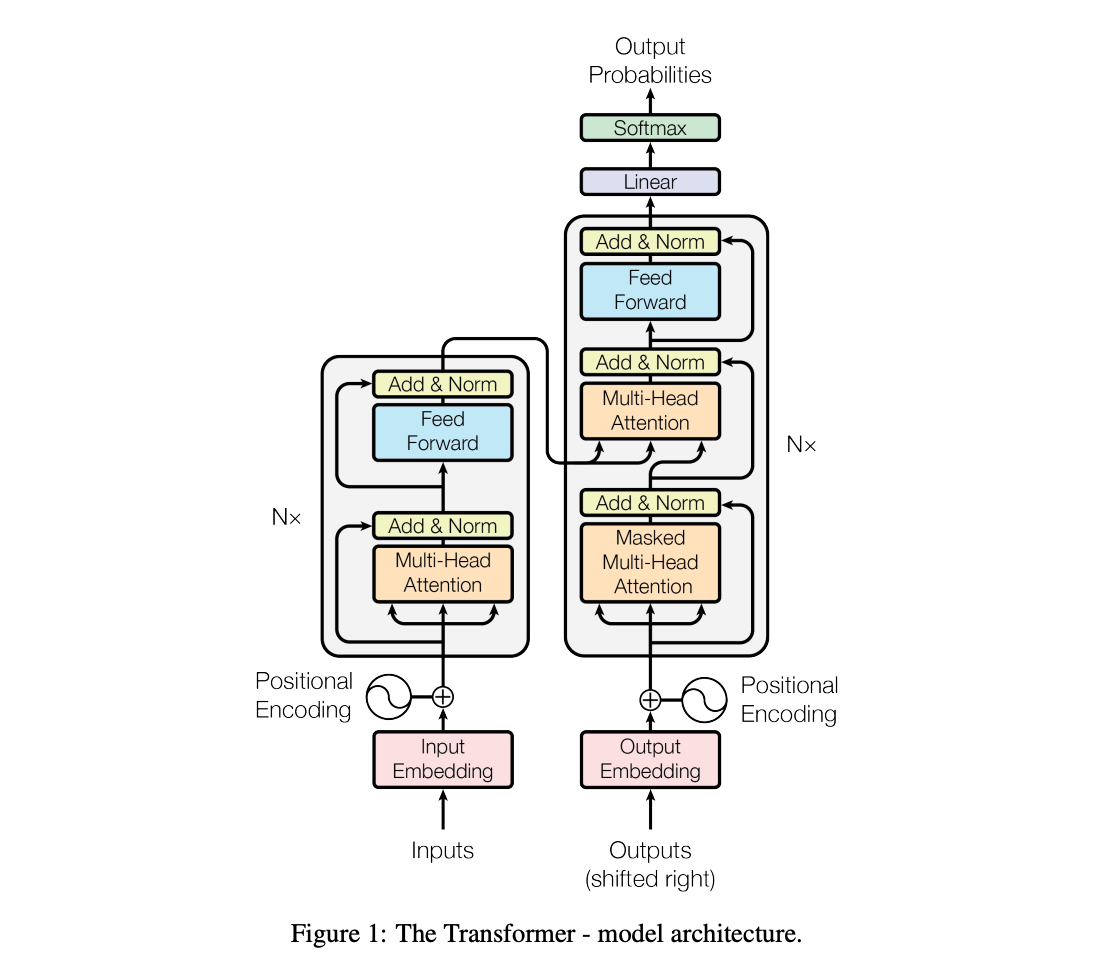
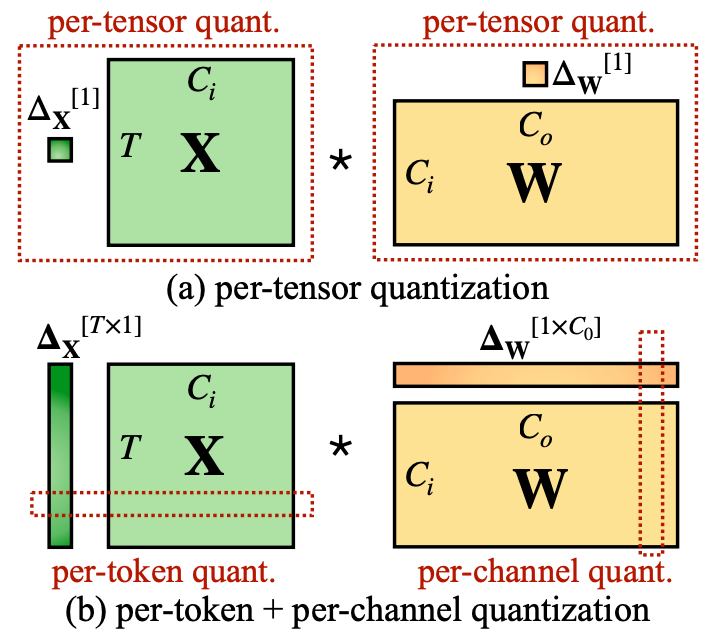
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
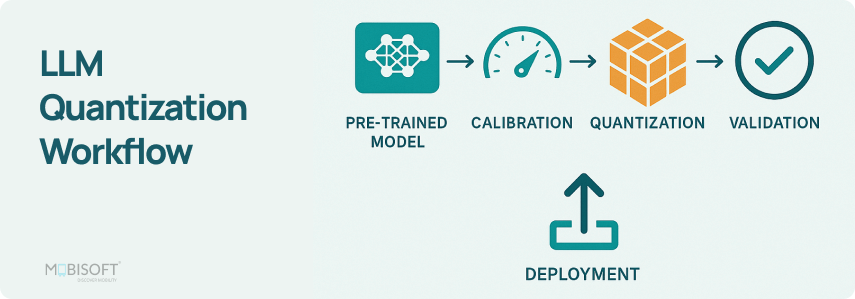
LLM Quantization with Hugging Face Transformers
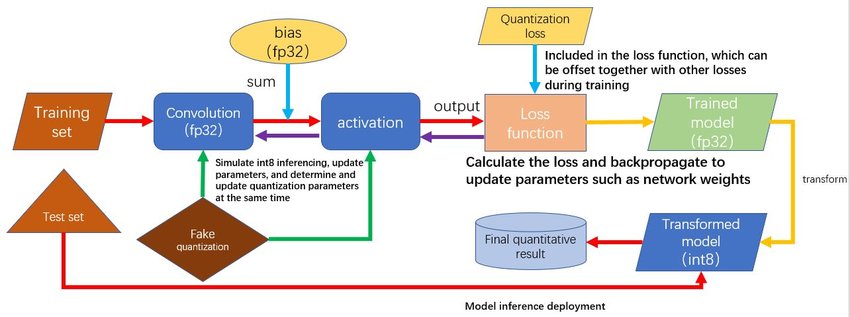
Optimizing LLM Model using Quantization
Learn LLM Optimization Using Transformers and PyTorch* on Intel ...
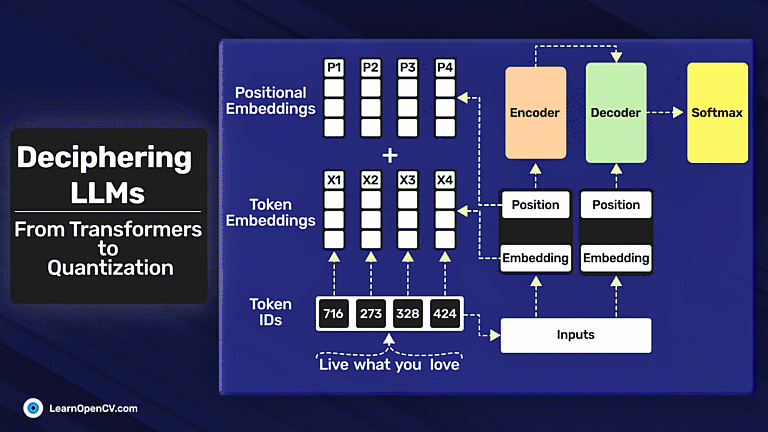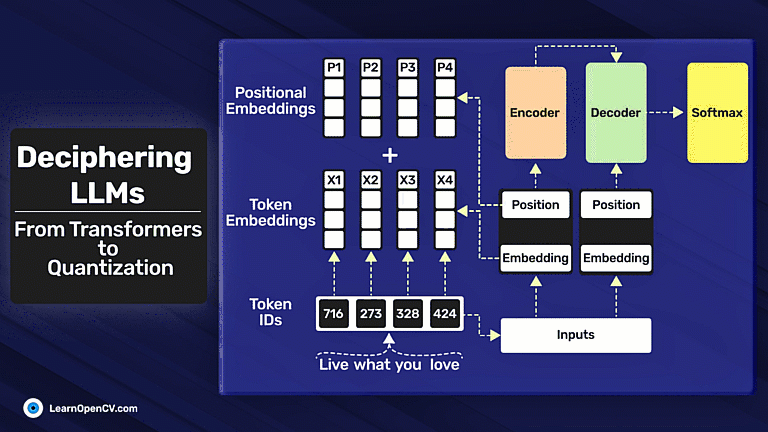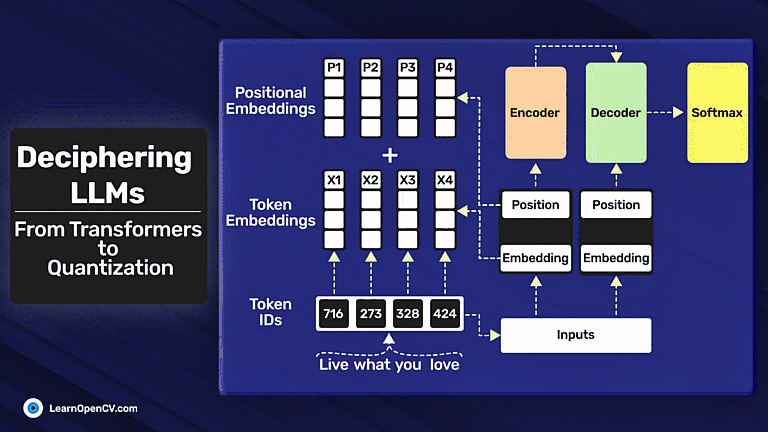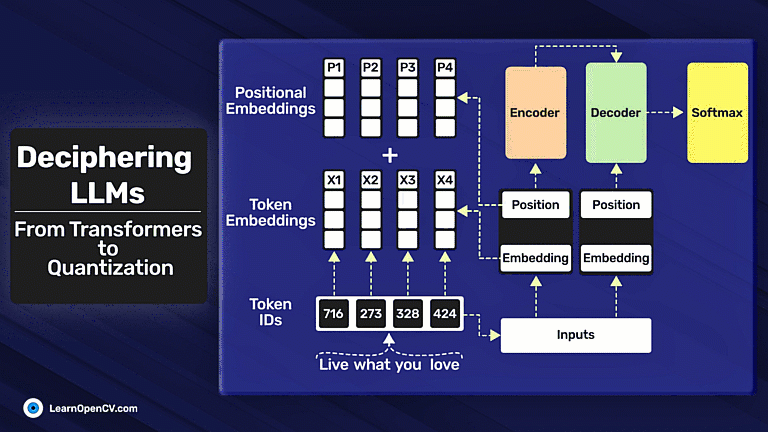
Deciphering LLMs: From Transformers to Quantization
Deciphering LLMs: From Transformers to Quantization - YouTube
An example of mixed precision quantization of a Transformer LM using ...
The Ultimate Handbook for LLM Quantization | Towards Data Science
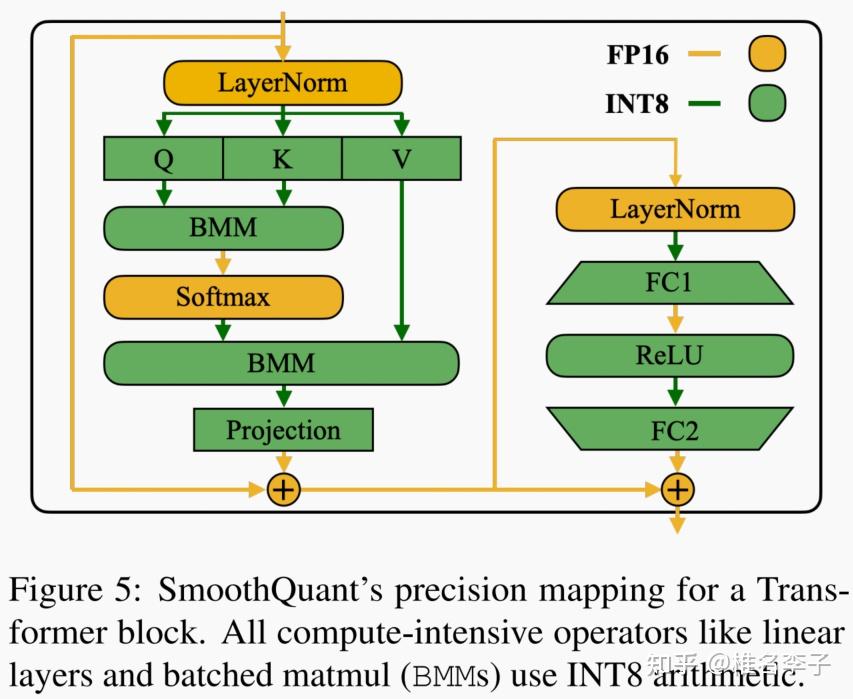
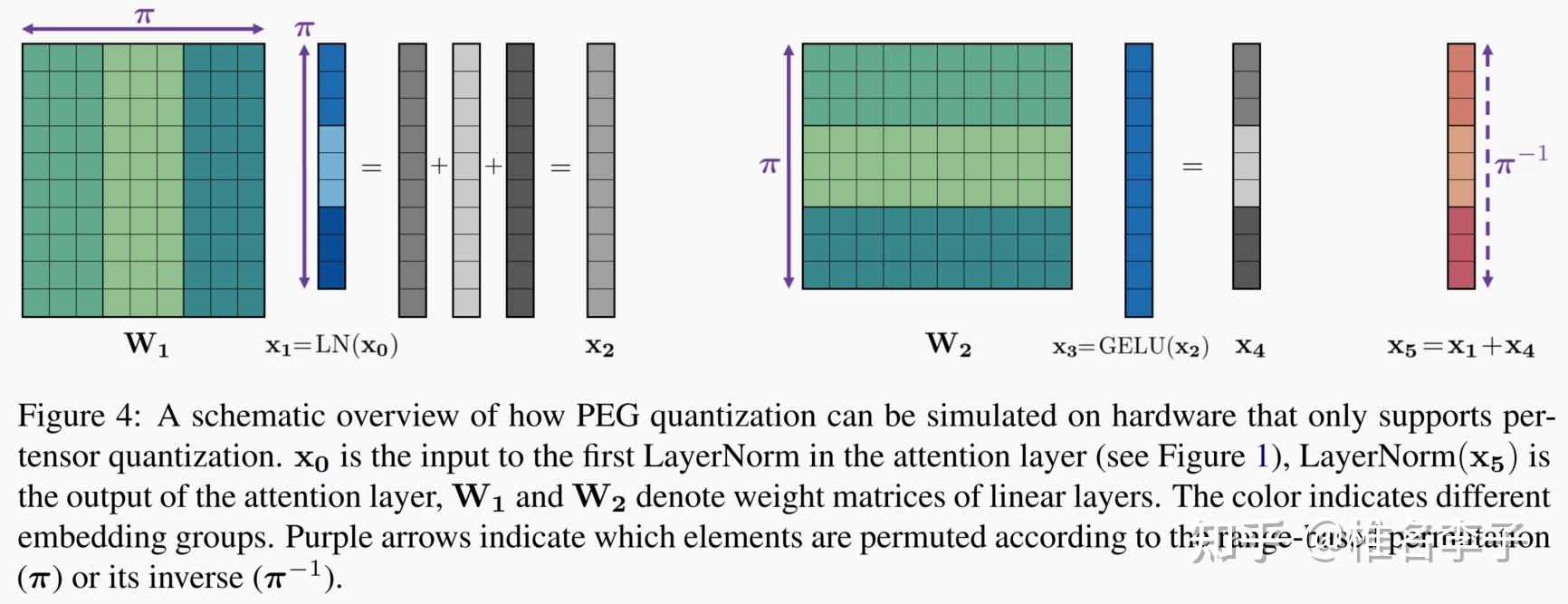
Applying Transforms to Improve Quantization Accuracy - LLM Compressor Docs
Understanding LLM Quantization. With the surge in applications using ...
A Comprehensive Guide on LLM Quantization and Use Cases
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
ButterflyQuant: Ultra-low-bit LLM Quantization through Learnable ...
LLM Quantization Methods: GPTQ, AWQ, GGUF - Cast AI
(PDF) FPTQuant: Function-Preserving Transforms for LLM Quantization
Paper page - SpinQuant: LLM quantization with learned rotations
LLM Quantization Made Easy: Essential Tips for Success
LLM By Examples — Use GPTQ Quantization | by MB20261 | Medium
An Introduction to LLM Quantization - TextMine
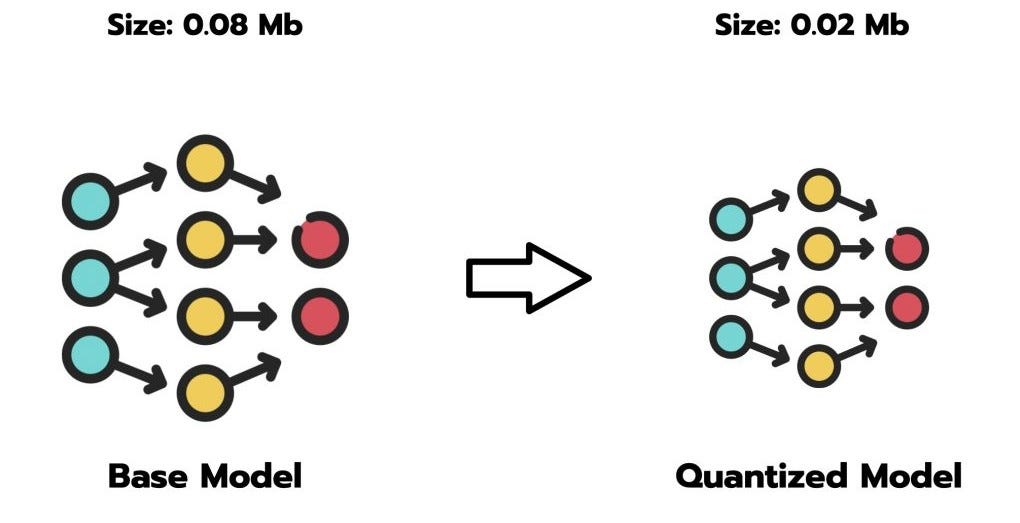
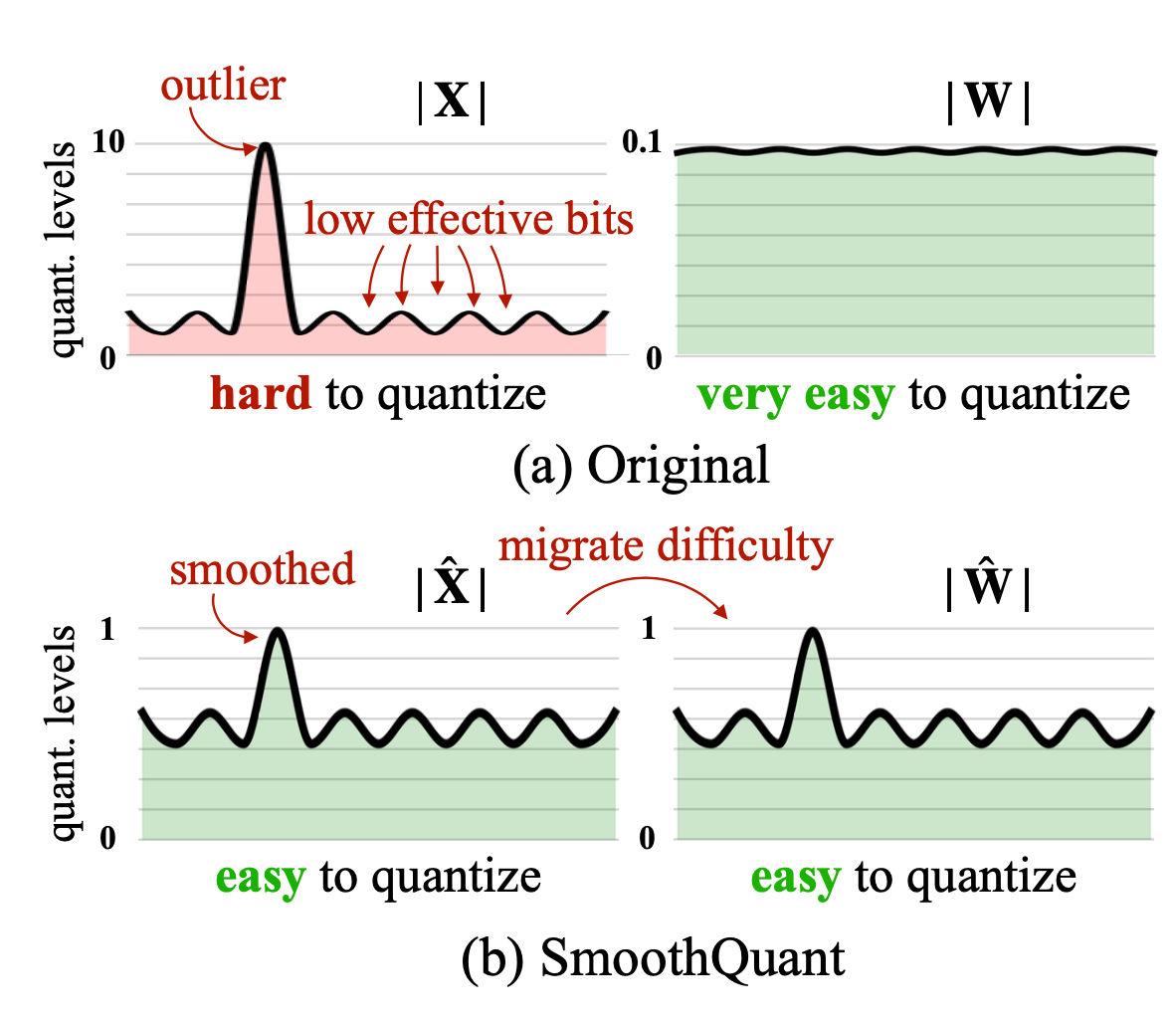
A Visual Guide to LLM Quantization | Devtalk
Quantization | LLM Module
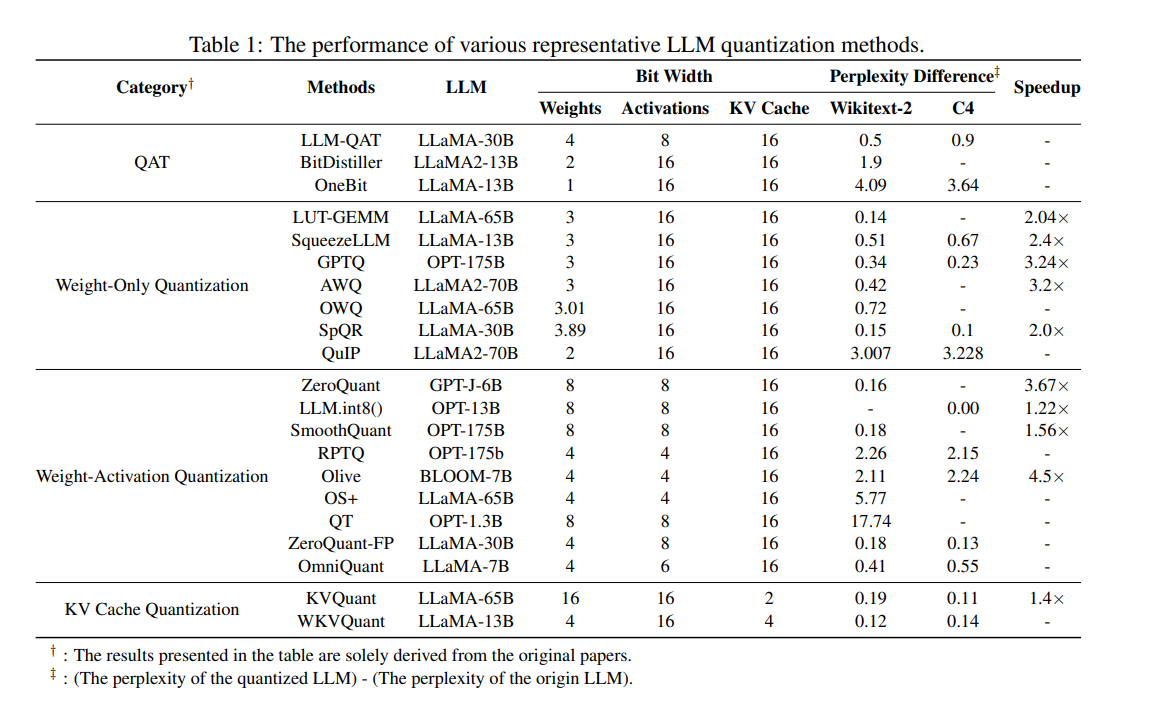
Top LLM Quantization Methods and Their Impact on Model Quality
Simplify LLM Quantization Process for Success | by Novita AI | Jul ...
Making LLMs Lighter: A deep dive into LLM quantization with Code | by ...
Model Quantization: Post-Training Quantization Using NVIDIA Model ...
LLM Quantization Explained. Shrinking AI models from feast to fit… | by ...
The Great AI Compression: How LLM Quantization Solves the VRAM Bottleneck
[vLLM — Quantization] AWQ: Activation-aware Weight Quantization for LLM ...
4-bit LLM training and Primer on Precision, data types & Quantization
A Beginner's Guide to LLM Quantization
Improving LLM Inference Latency on CPUs with Model Quantization ...
Practical Guide to LLM Quantization Methods - Cast AI
Demystifying LLM Quantization Suffixes: What Q4_K_M, Q8_0, and Q6_K ...
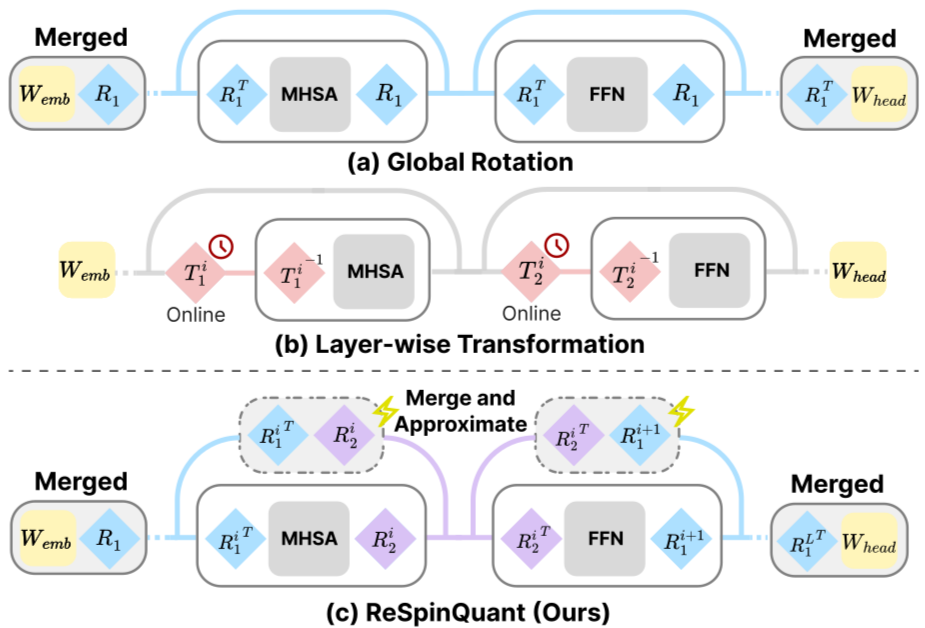
[论文评述] ReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace ...
LLM Quantization: An Introduction to Quantization Techniques
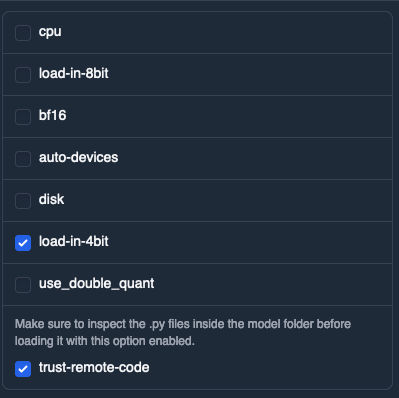
Model Quantization with 🤗 Hugging Face Transformers and Bitsandbytes ...
5 Essential LLM Quantization Techniques Explained
The best LLM quantization method no one talks about
(PDF) Exploiting LLM Quantization
The Complete Guide to LLM Quantization | LocalLLM.in
The LLM Revolution: Boosting Computing Capacity with Quantization ...
GPTVQ: The Blessing of Dimensionality for LLM Quantization
Quantization with Unsloth. Quantization in LLM is a techniques… | by ...
LLM inference optimization: Model Quantization and Distillation - YouTube
10 minutes are all you need to understand how Transformers work in LLM ...
Extreme LLM Quantization
Understanding Activation-Aware Weight Quantization (AWQ): Boosting ...
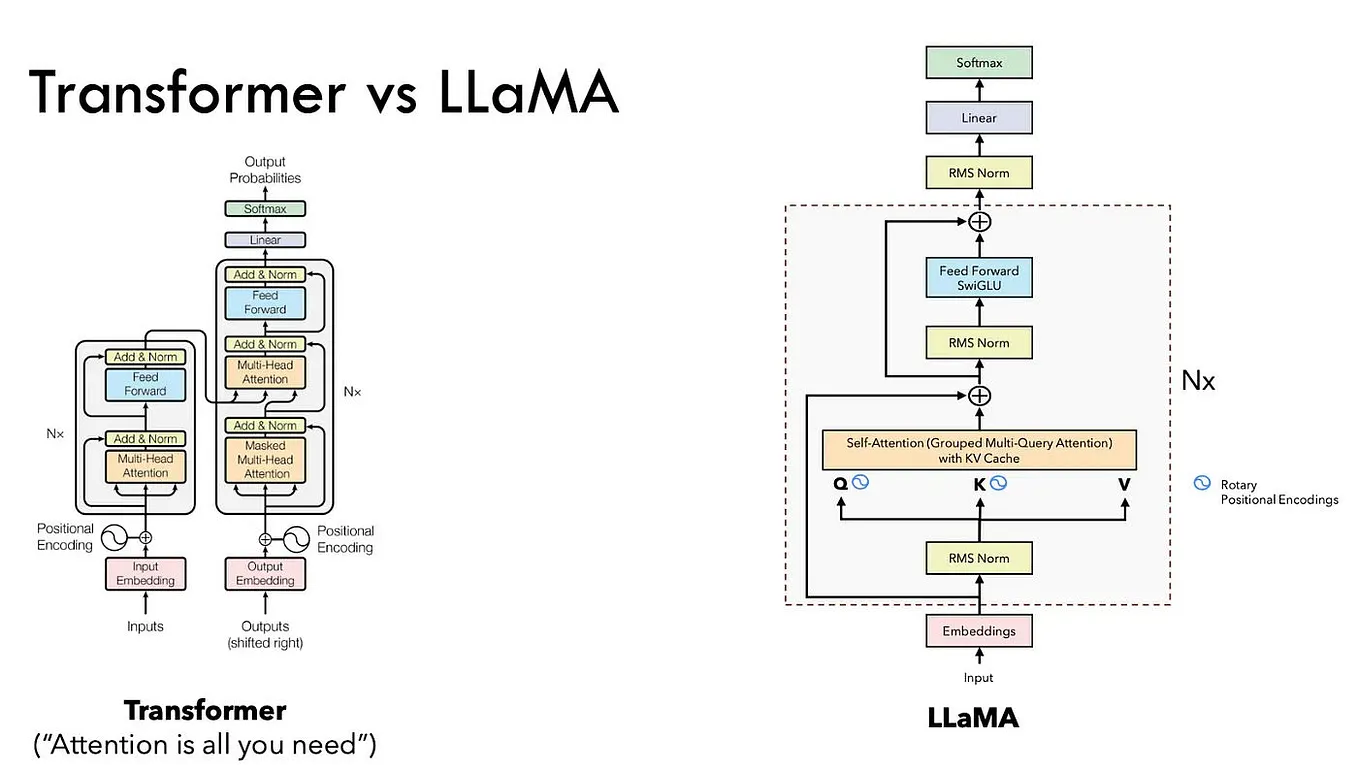
Understanding Transformers & the Architecture of LLMs
Making LLMs lighter with AutoGPTQ and transformers
LLM Quantization-Build and Optimize AI Models Efficiently
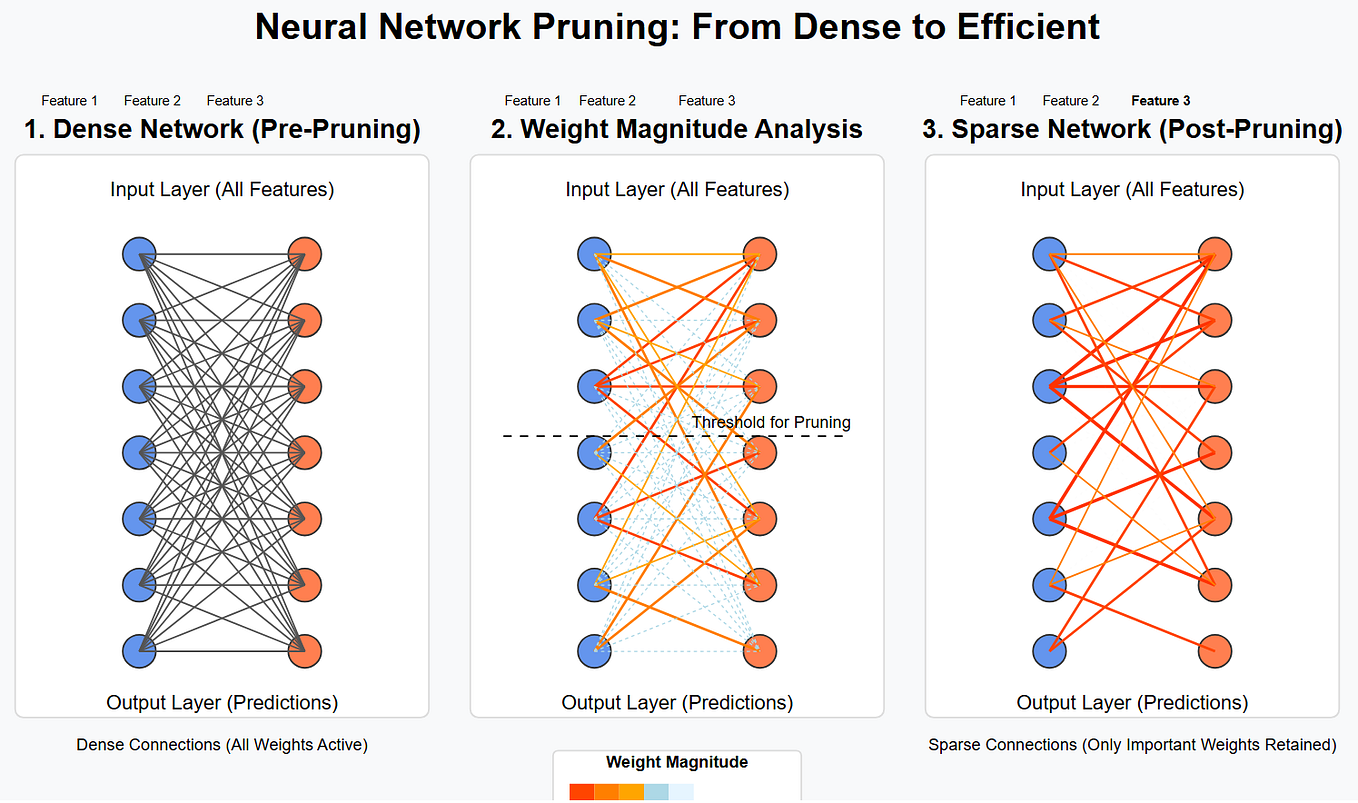
LLM Tutorial 21 — Model Compression Techniques: Quantization, Pruning ...
What is Quantization in LLM? A Complete Guide to Optimizing AI
LLM Compression Techniques to Build Faster and Cheaper LLMs
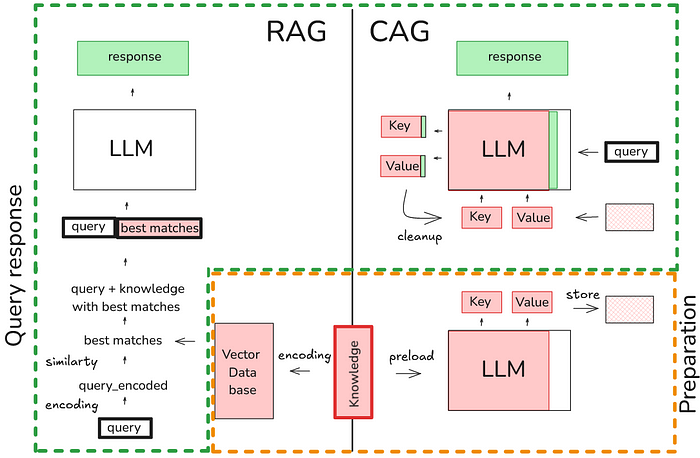
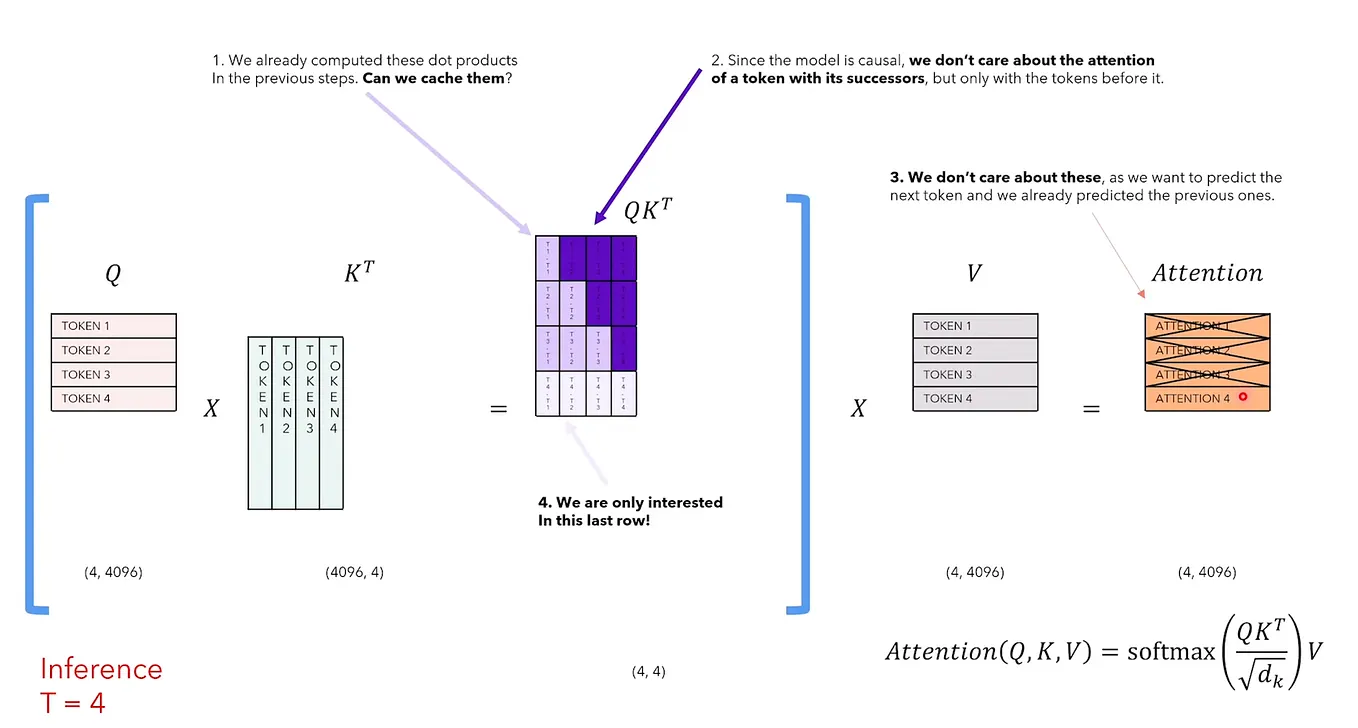
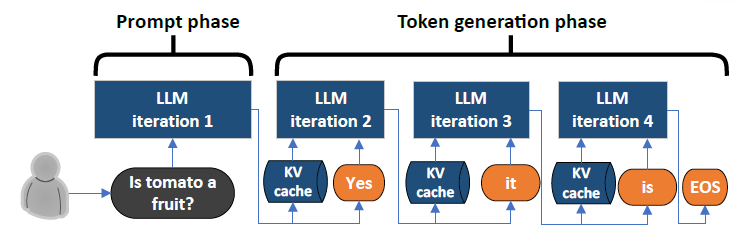
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
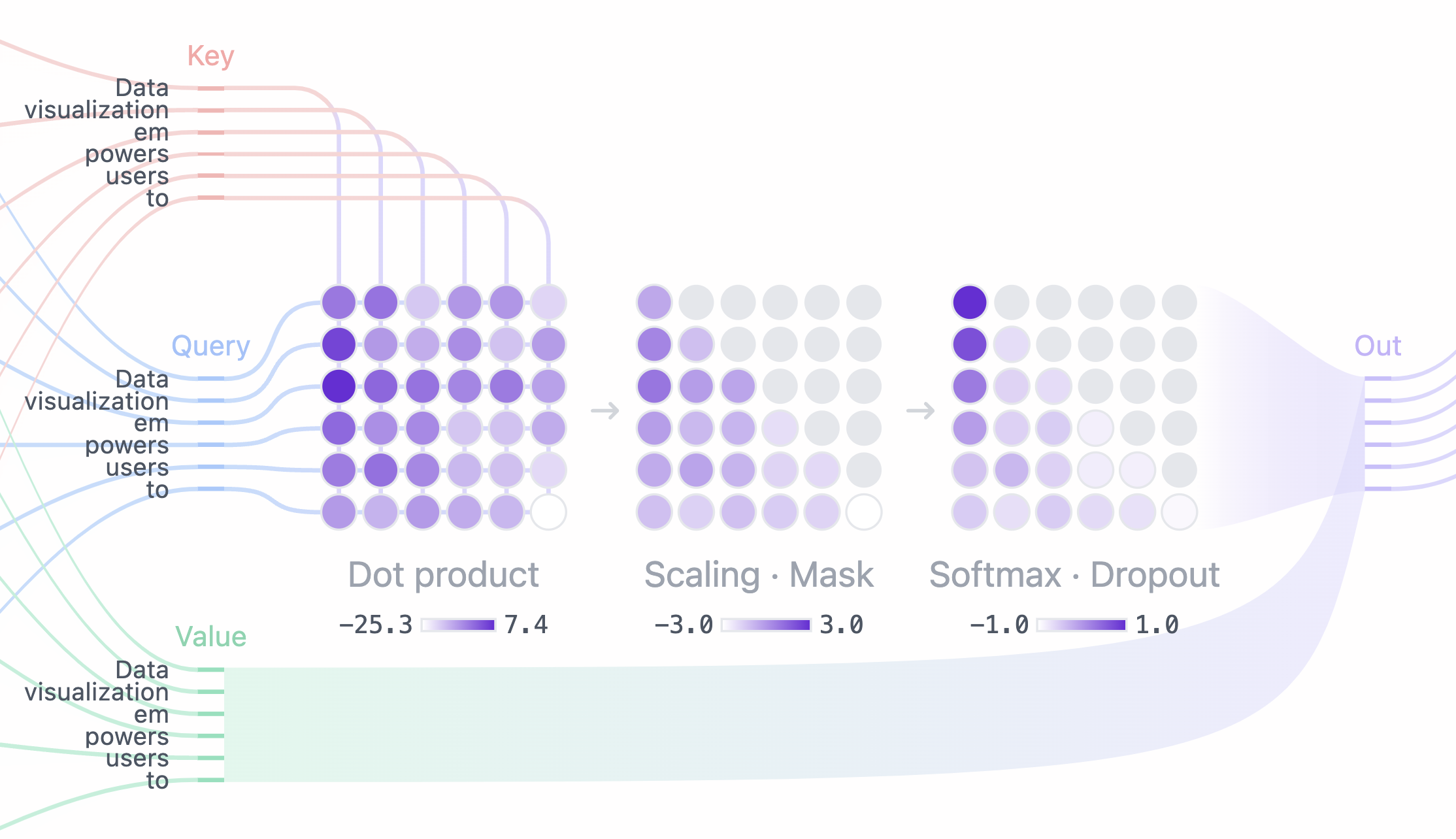
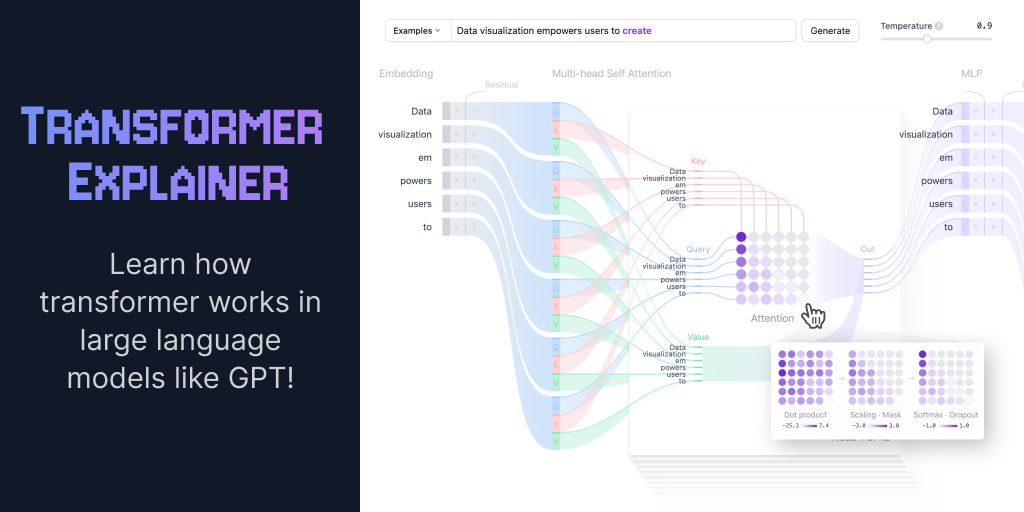
Transformer Explainer: LLM Transformer Model Visually Explained
Exploring quantization in Large Language Models (LLMs): Concepts and ...
A Guide to Quantization in LLMs | Symbl.ai
Practical Guide of LLM Quantization: GPTQ, AWQ, BitsandBytes, and ...
Optimize Your LLM with Quantization: Save Memory and Boost Performance ...
Transformer Quantization at Darlene Stinson blog
Toward Efficient LLM Inference: A Quantitative Evaluation of ...
LLM Quantization: Making models faster and smaller | MatterAI Blog
LLM Transformer Architecture
Understanding Quantization for LLMs | by LM Po | Medium
This AI Research Introduces Atom: A Low-Bit Quantization Technique for ...
LLM Quantization: Quantize Model with GPTQ, AWQ and Bitsandbytes ...
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
LLM Transformer Architecture - YouTube
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
Quantization tech of LLMs-GGUF. We can use GGUF to offload any layer of ...
Faster LLMs with Quantization - How to get faster inference times with ...
Compressing LLMs with AWQ: Activation-Aware Quantization Explained | by ...
模型量化-llm量化 - 知乎
Introduction to llm-finetuning and Quantization. Refining Generative ...
What are Quantized LLMs?
How to run LLMs on CPU-based systems | UnfoldAI
大模型量化感知训练 LLM-QAT_quantization aware training-CSDN博客
Maximizing Business Potential with Large Language Models (LLMs)
GitHub - SonPhatTranDeveloper/llm-quantization: A simple repository ...
Understanding Transformer Models: A Simplified Overview - Skillcurb
[Transformer 101系列] LLM模型量化世界观(下) - 知乎
LLMs from the Inside 4: The Transformer Block | by John the Quant | Apr ...
Transformer²: Self-Adaptive LLMs
LLM-transformer-visualization/README.md at main · evrenbaris/LLM ...
LLM之Transformer的概念_transformer和llm的关系-CSDN博客
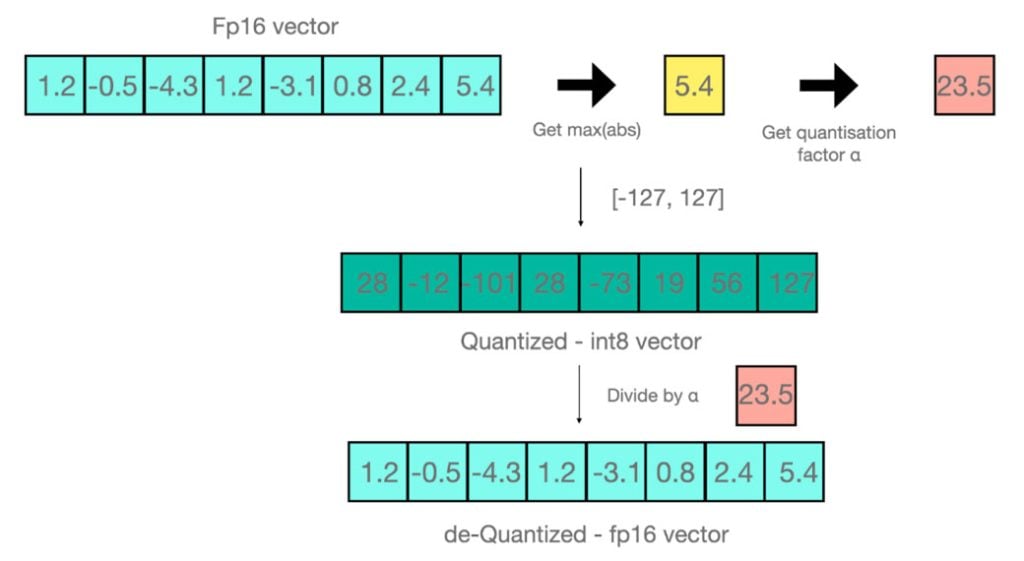
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...