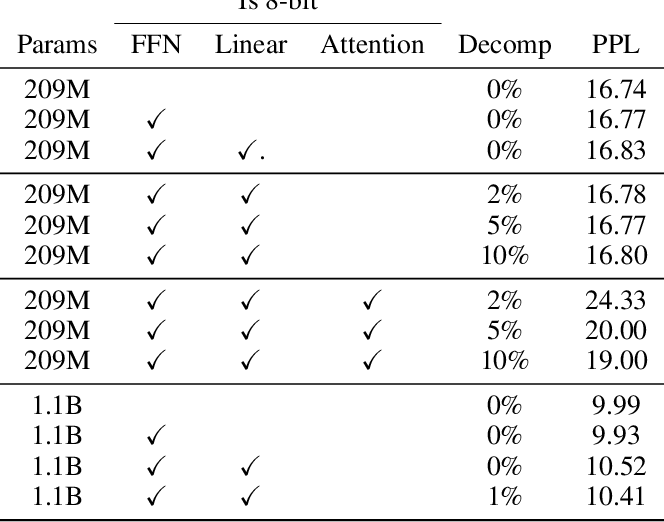
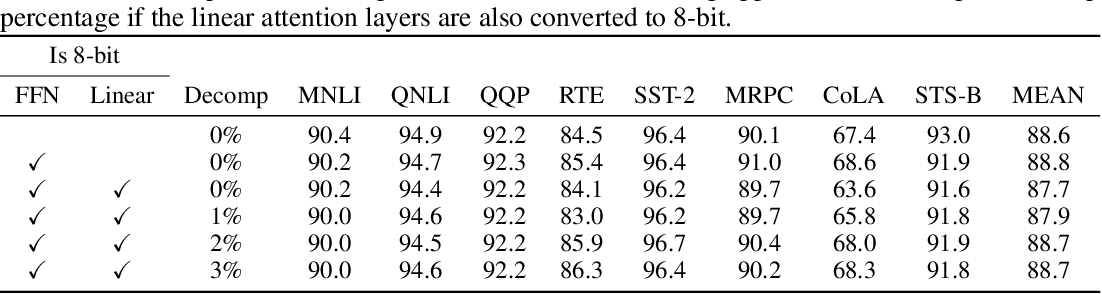
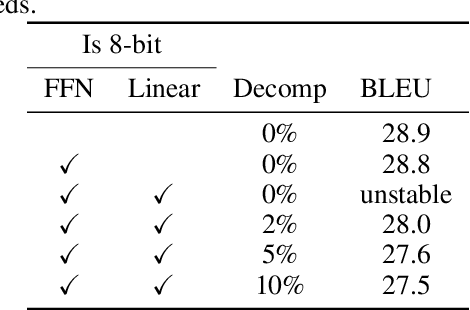
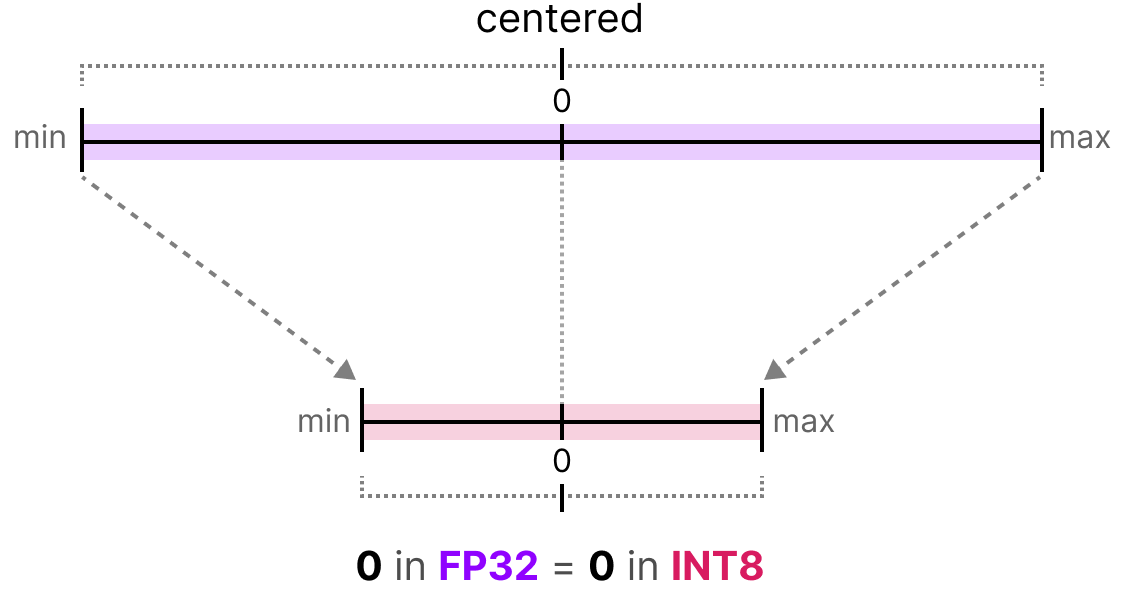
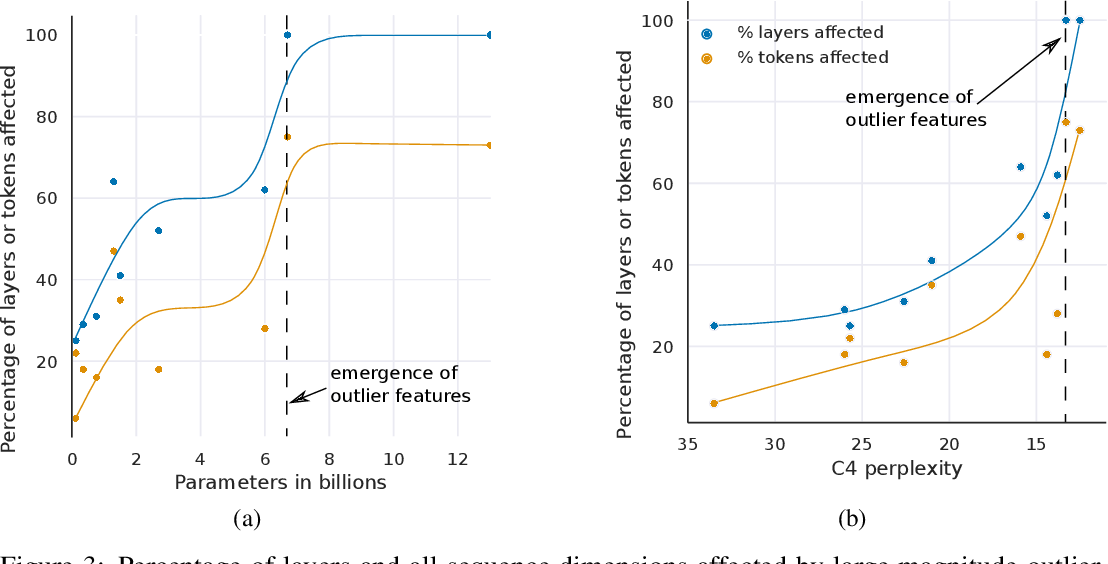
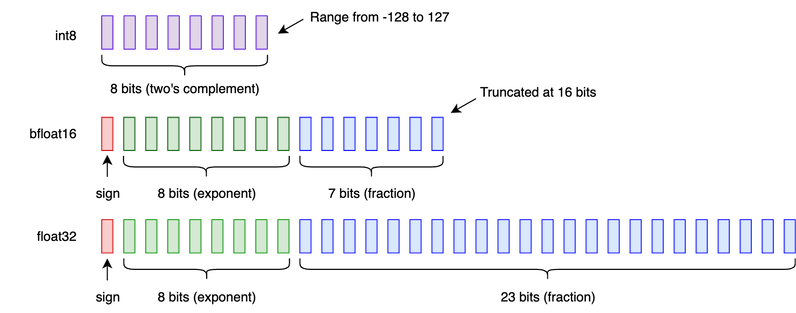
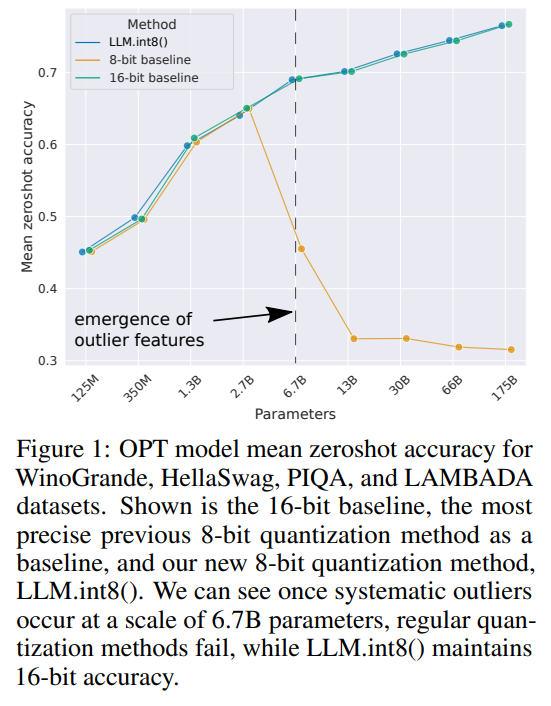
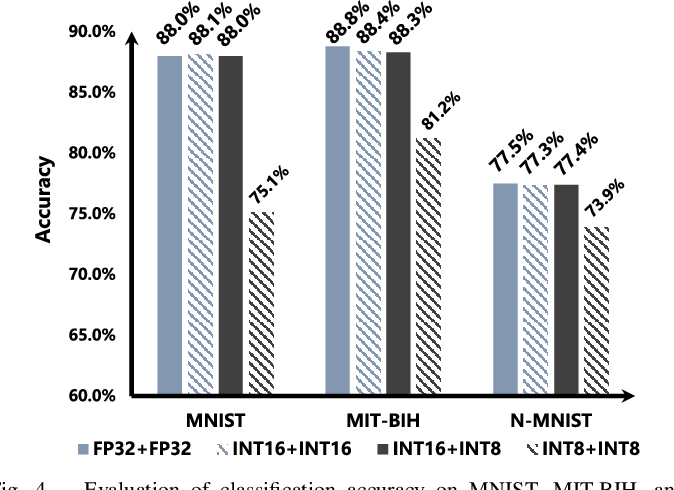
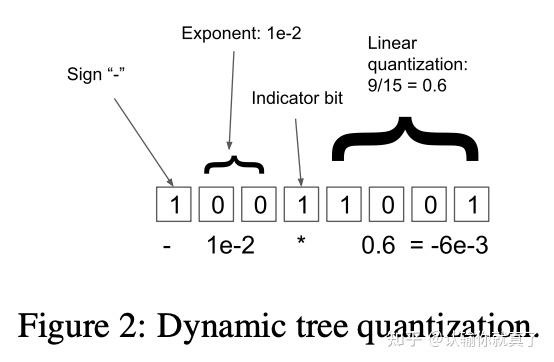
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
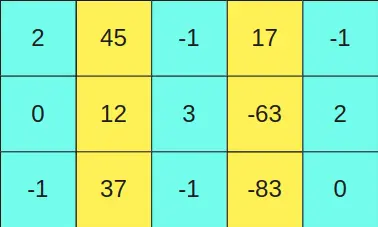
Data layout of int8 mma with the shape of m8n8k16. | Download ...
Questions about int8 gemm's layout · Issue #349 · NVIDIA/cutlass · GitHub
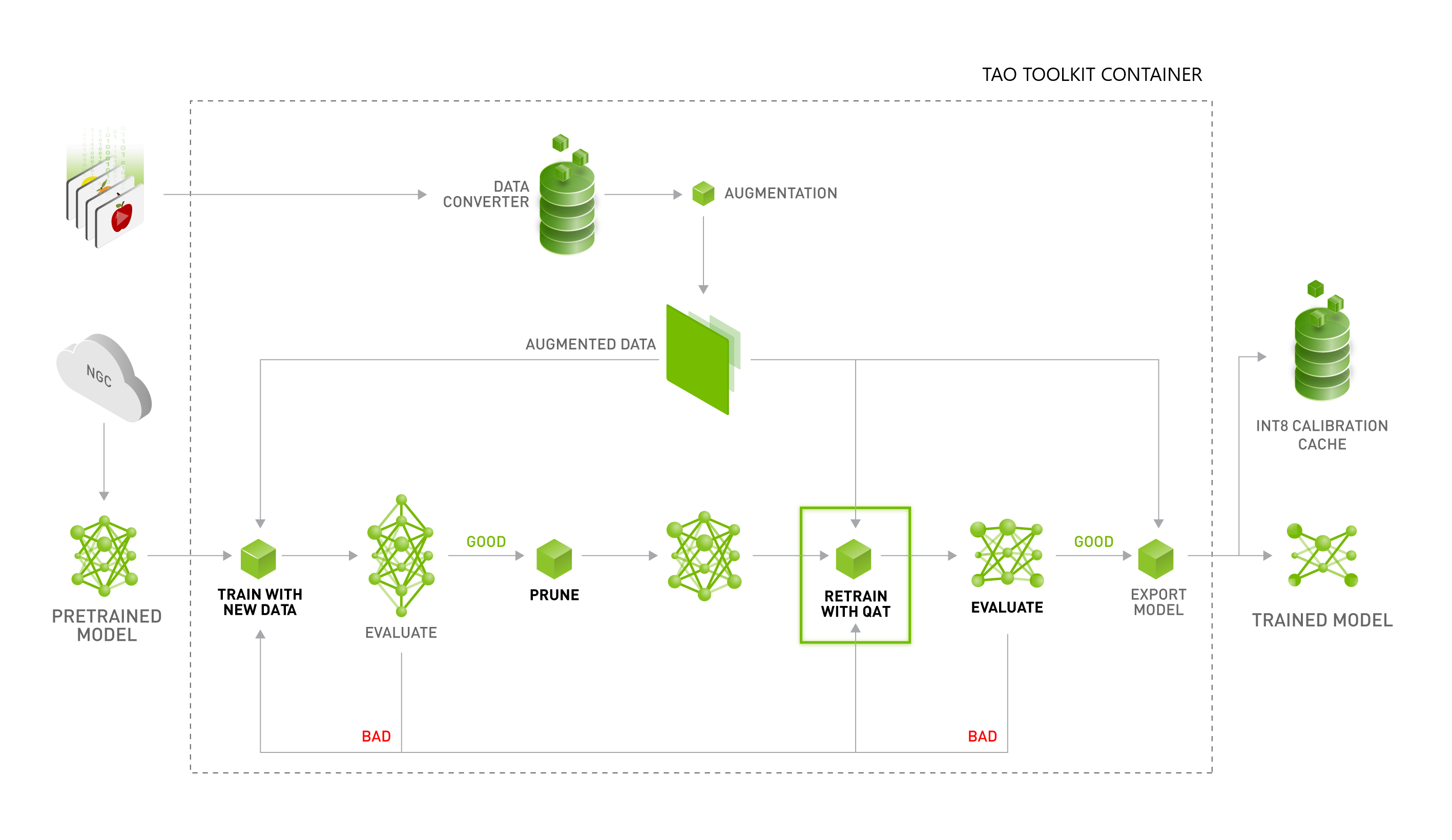
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
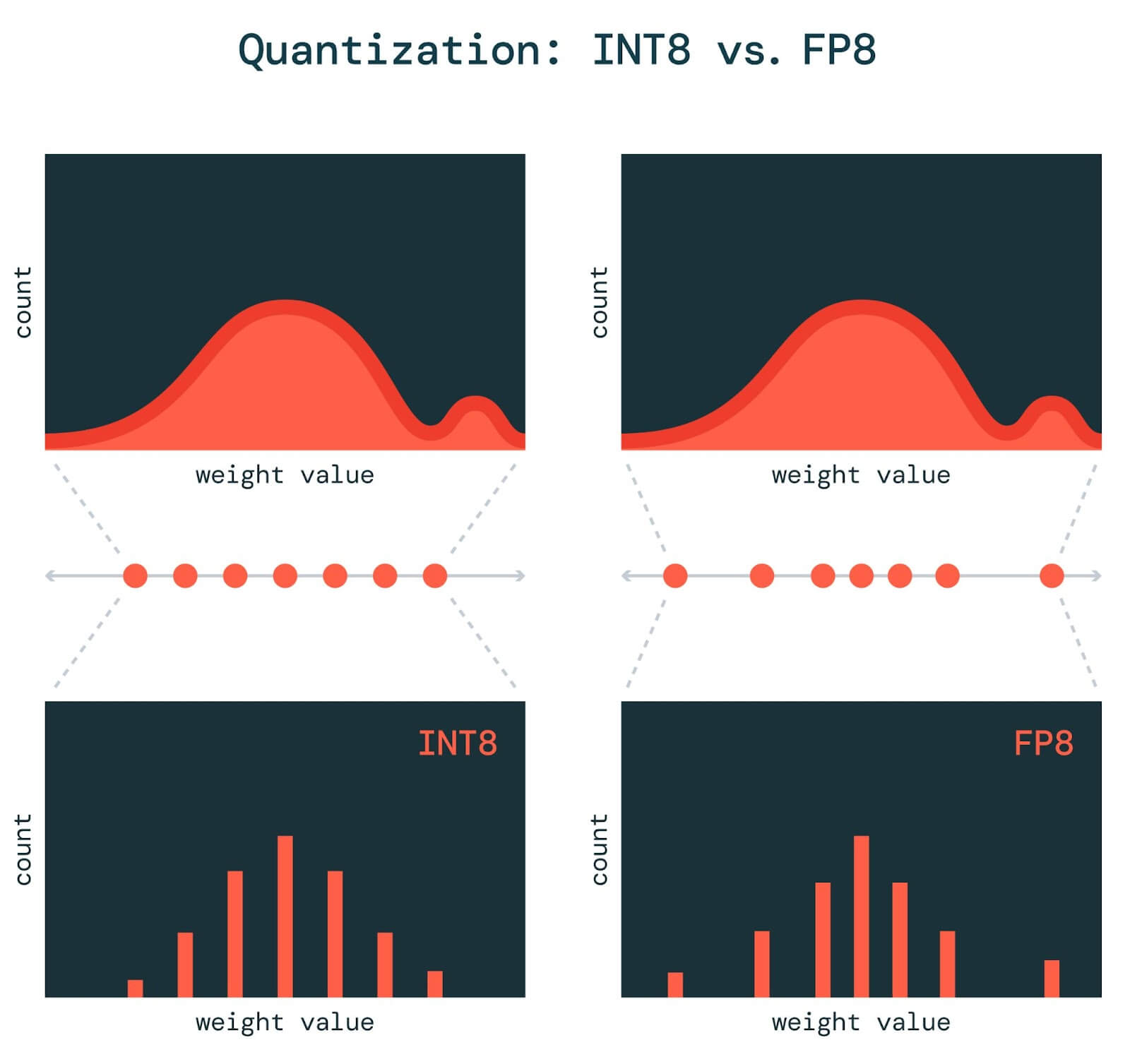
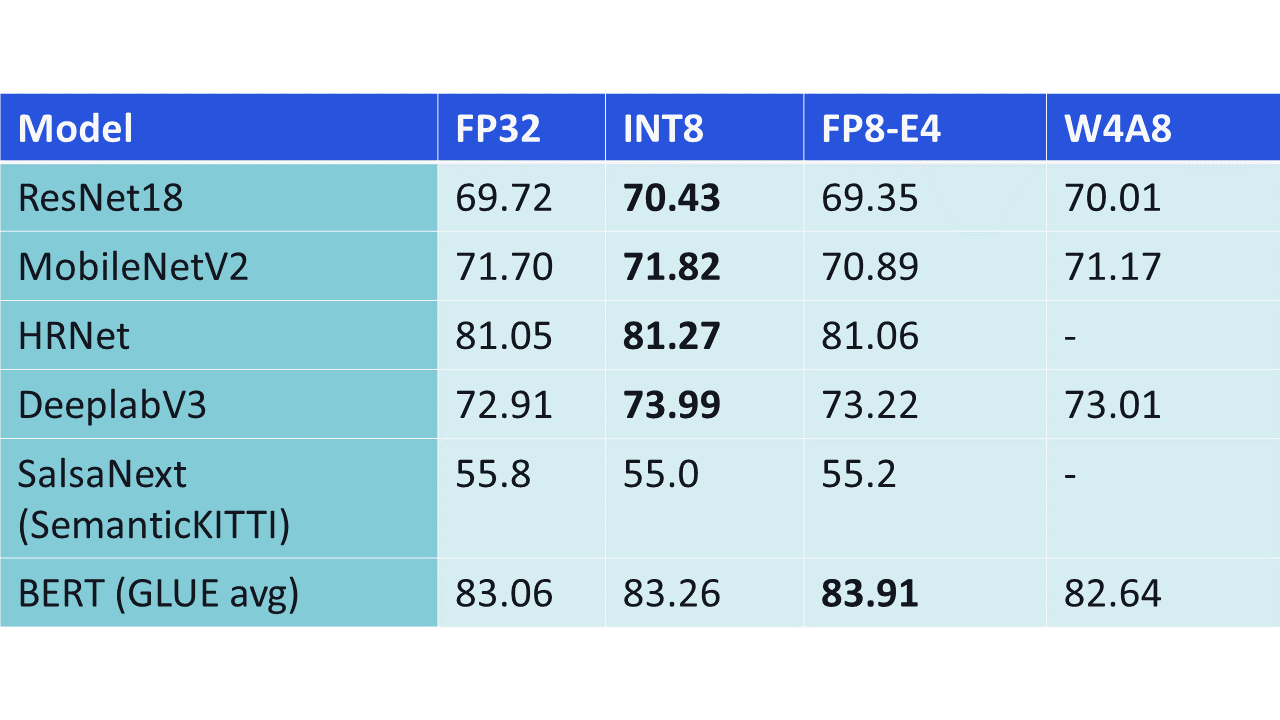
[2303.17951] FP8 versus INT8 for efficient deep learning inference
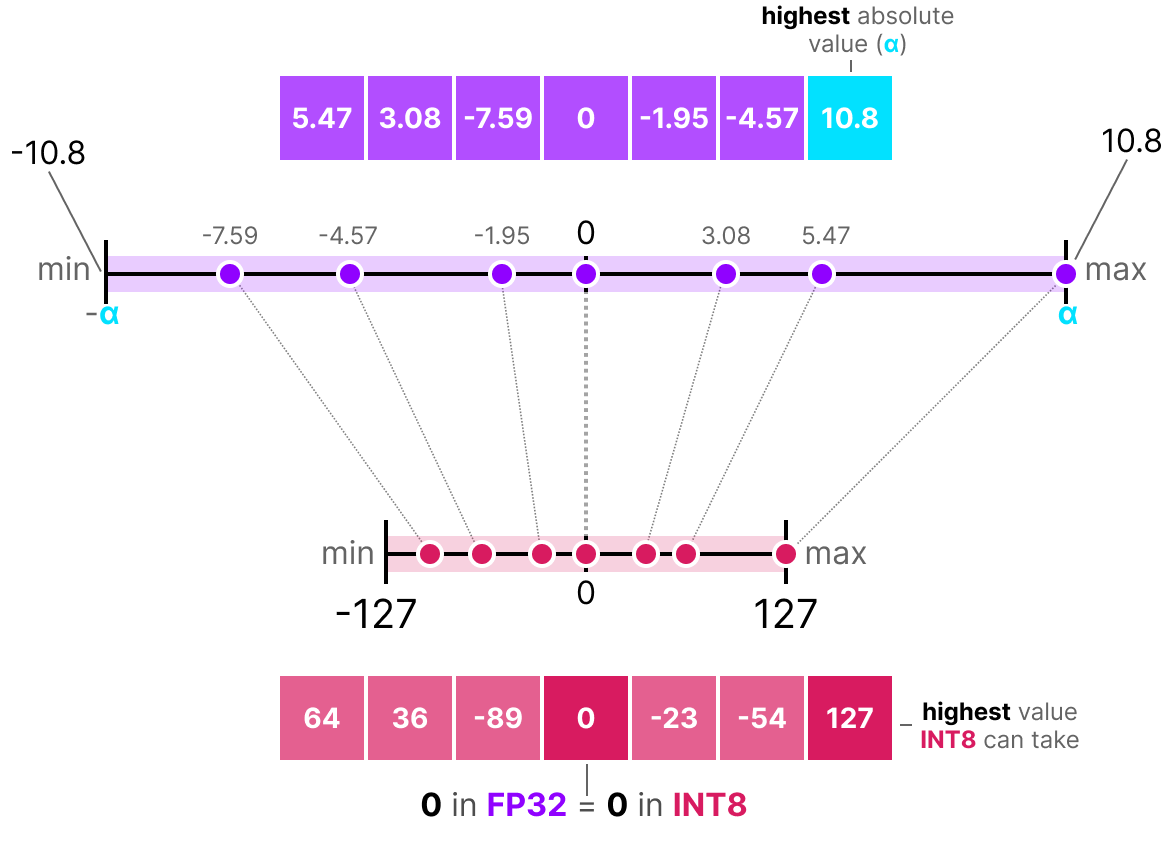
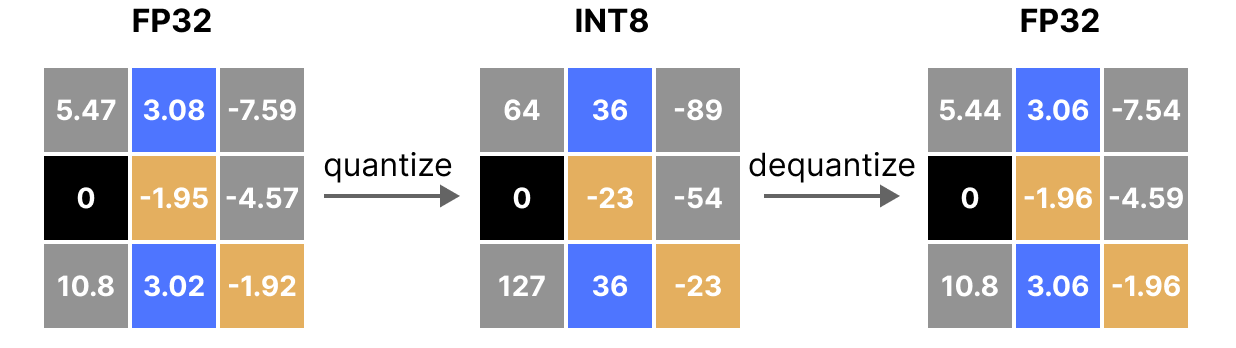
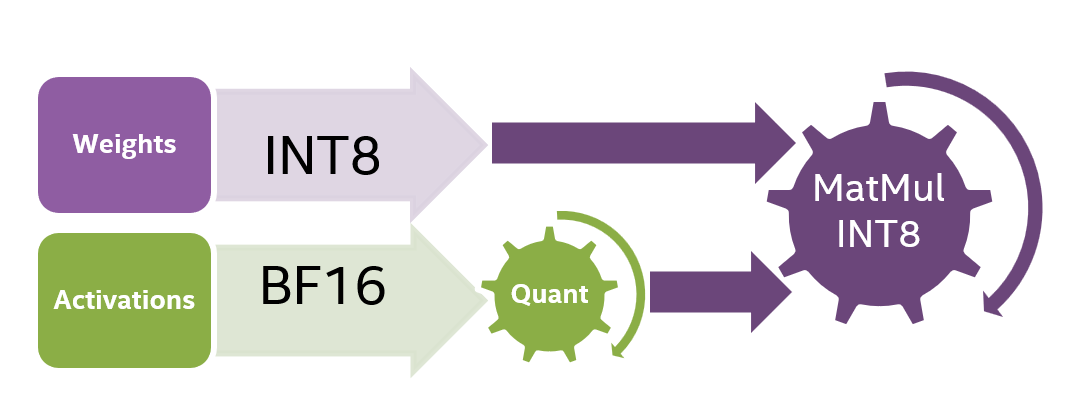
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
Int8 Inference
Int8 Inference — oneDNN v3.10.2 documentation
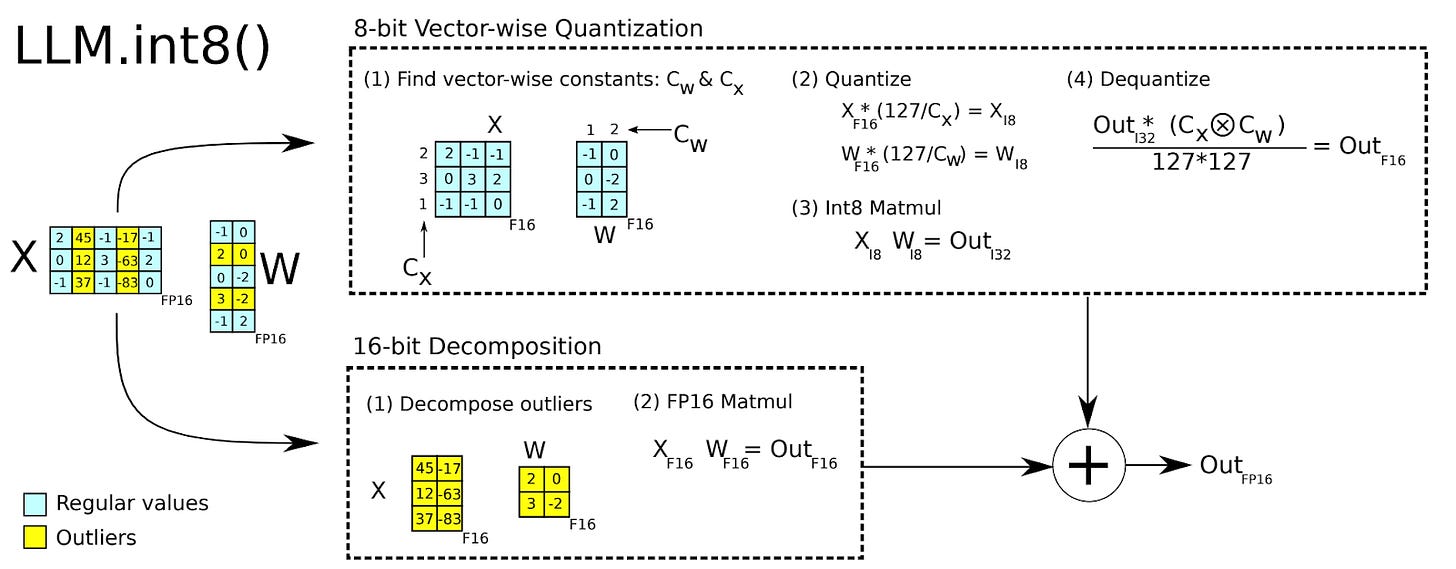
LLM - Int8 - 8-Bit Matrix Multiplication For Transformer at Scale ...
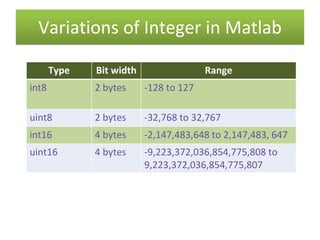
int8 - 8-bit signed integer arrays - MATLAB
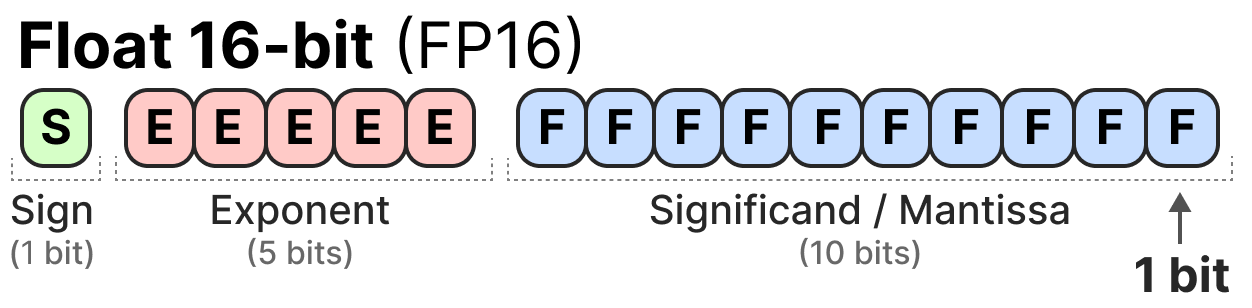
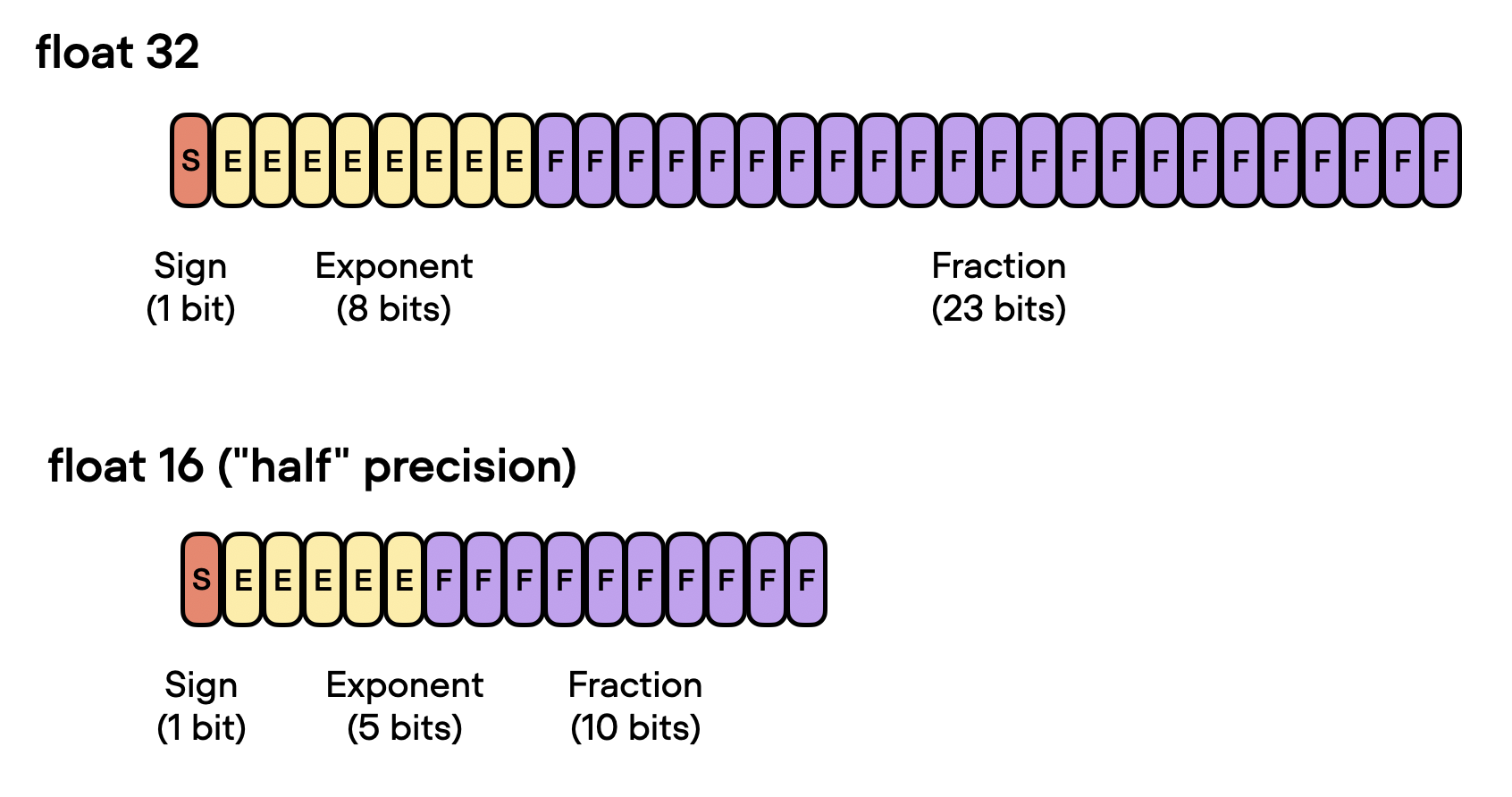
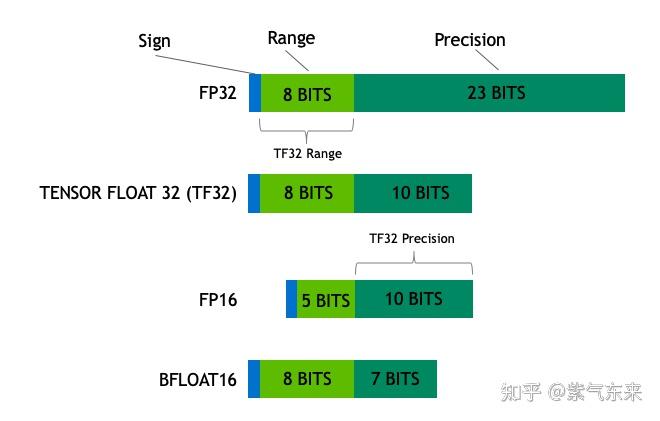
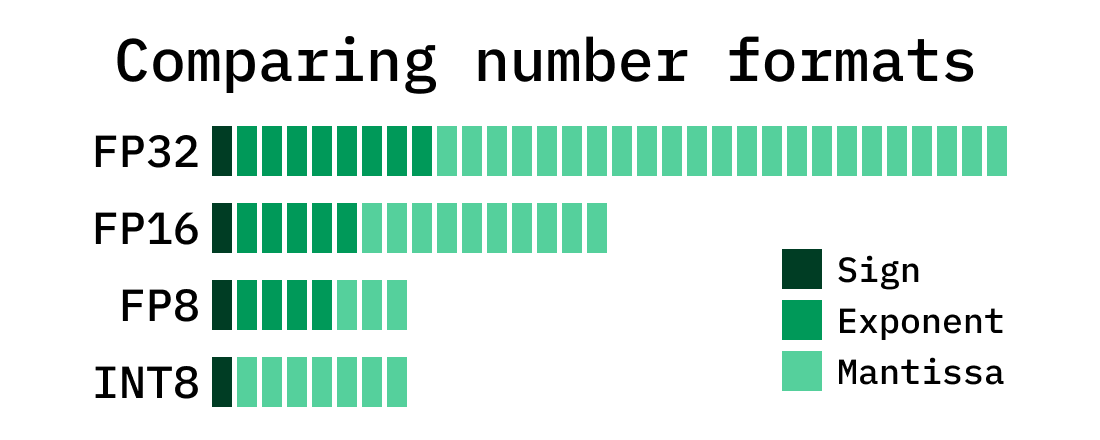
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
Deep Learning with INT8 Optimization on Xilinx Devices - Edge AI and ...
Deep Learning HDL Single To Int8 Conversion - Convert single-precision ...
Deep Learning HDL Int8 To Single Conversion - Convert 8-bit signed ...
Qwen2 7B Instruct GPTQ Int8 by Qwen — VRAM 8.9GB, 32K context | LLM ...
Extra memory being used with bnb int8 (load_in_8bit=True) · Issue #759 ...
INT8 vs. FP32: Optimizing AI object recognition in video streams - DDT
Audio data cannot be converted automatically from int8 to 16-bit int ...
c++ inference int8 model error · Issue #16099 · openvinotoolkit ...
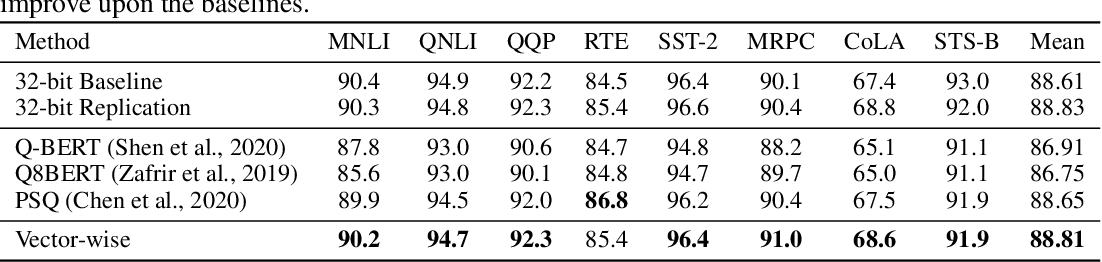
Improving INT8 Accuracy Using Quantization Aware Training and the ...
How to use int8 and binary vector embeddings in Azure AI Search | Pablo ...
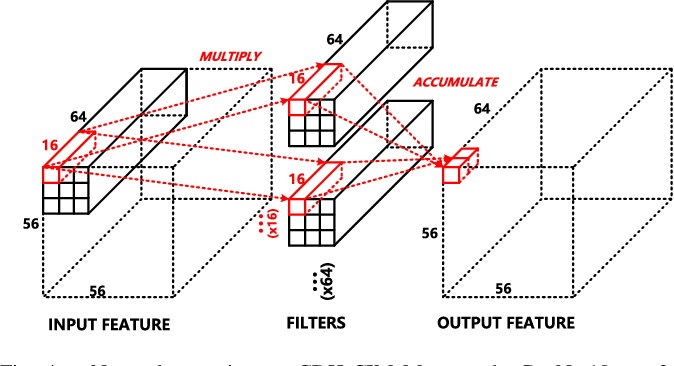
Figure 4 from An INT8 Charge-Digital Hybrid Compute-In-Memory Macro ...
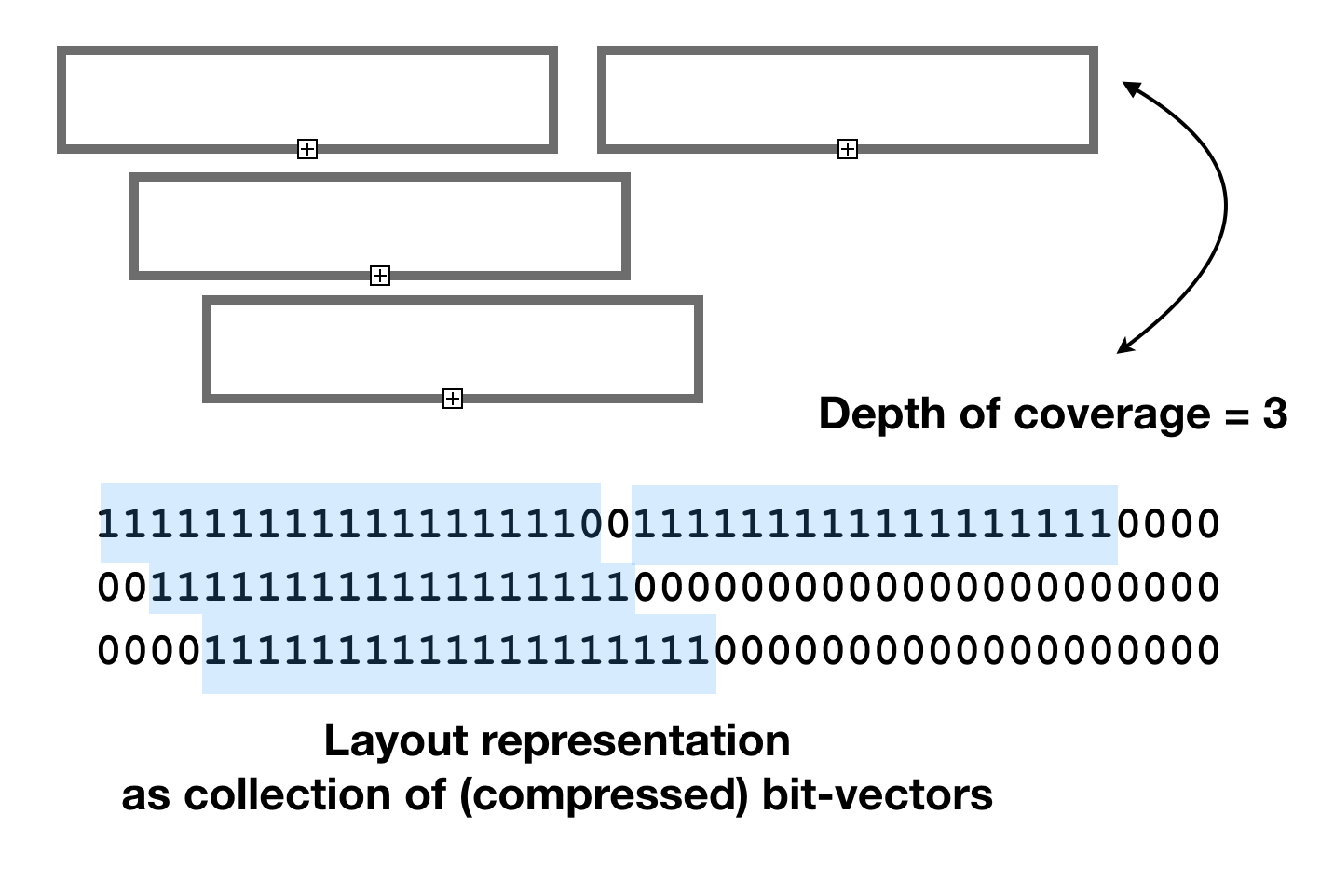
Genomics layout with bit-intervals and succinct containers
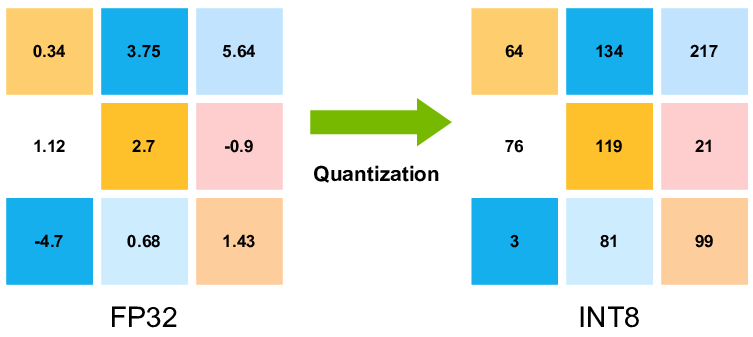
A Hands-On Walkthrough on Model Quantization - Medoid AI
MaximoFN - llm.int8() – 8-bit Matrix Multiplication for Transformers at ...
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
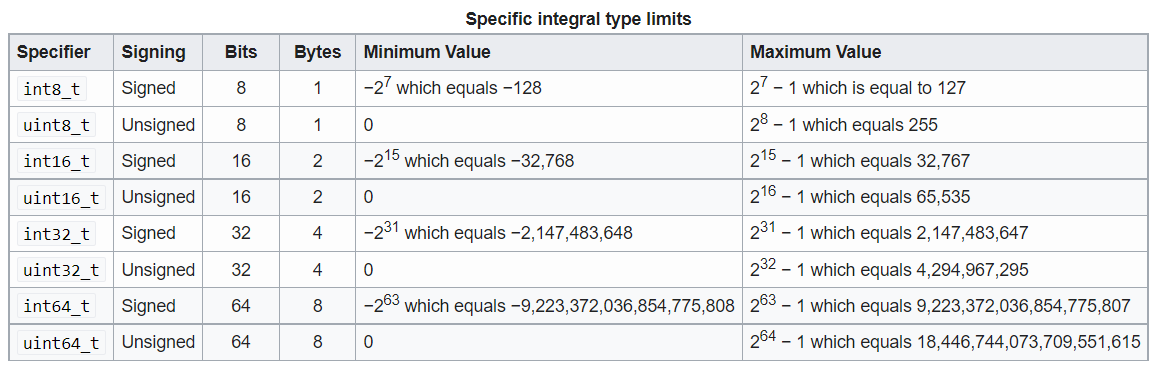
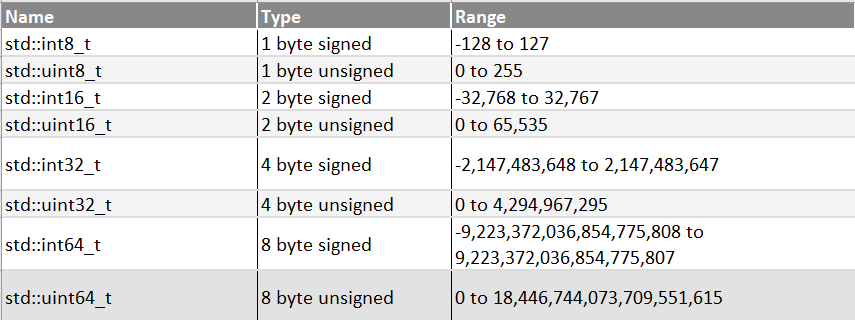
Fixed width integer types (int8) in C++
Small numbers, big opportunities: how floating point accelerates AI and ...
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
Neural Network Quantization & Number Formats From First Principles
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
Encoding: value types to binary
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
iOS 和 swift 中常见的 Int、Int8、Int16、Int32和 Int64介绍「建议收藏」-腾讯云开发者社区-腾讯云
Documentation
NumPy Integer Data Types Explained: int8, int16, int32, int64 Tutorial ...
FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks Blog
Data Representation in Computer Memory [Dev Concepts #33] - SoftUni Global
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
int8_t、uint8_t、__INT 64等和size_t的阐述_uint8头文件-CSDN博客
FP8: Efficient model inference with 8-bit floating point numbers ...
Floating-point arithmetic for AI inference — hit or miss? | Qualcomm
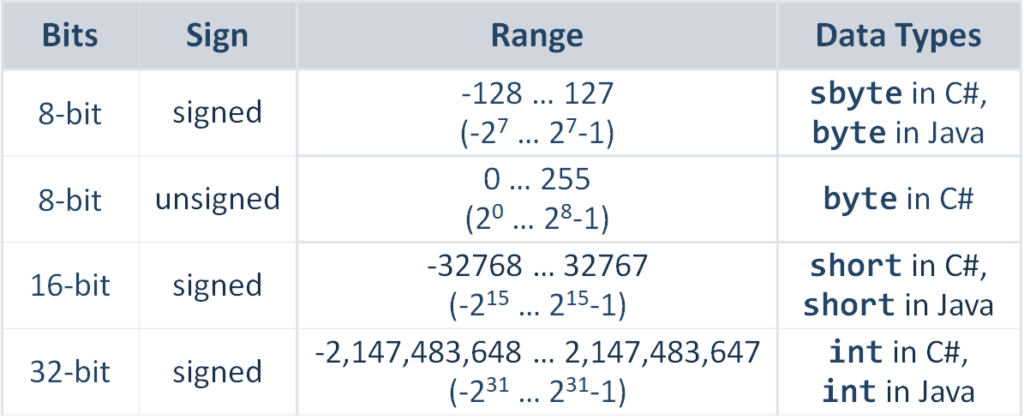
Bits, Bytes and Integers——二进制unsigned以及Two-complement表示,十六进制_2 byte ...
int8_t int16_t int32_t difference,,, int64_t, size_t and the ssize_t ...
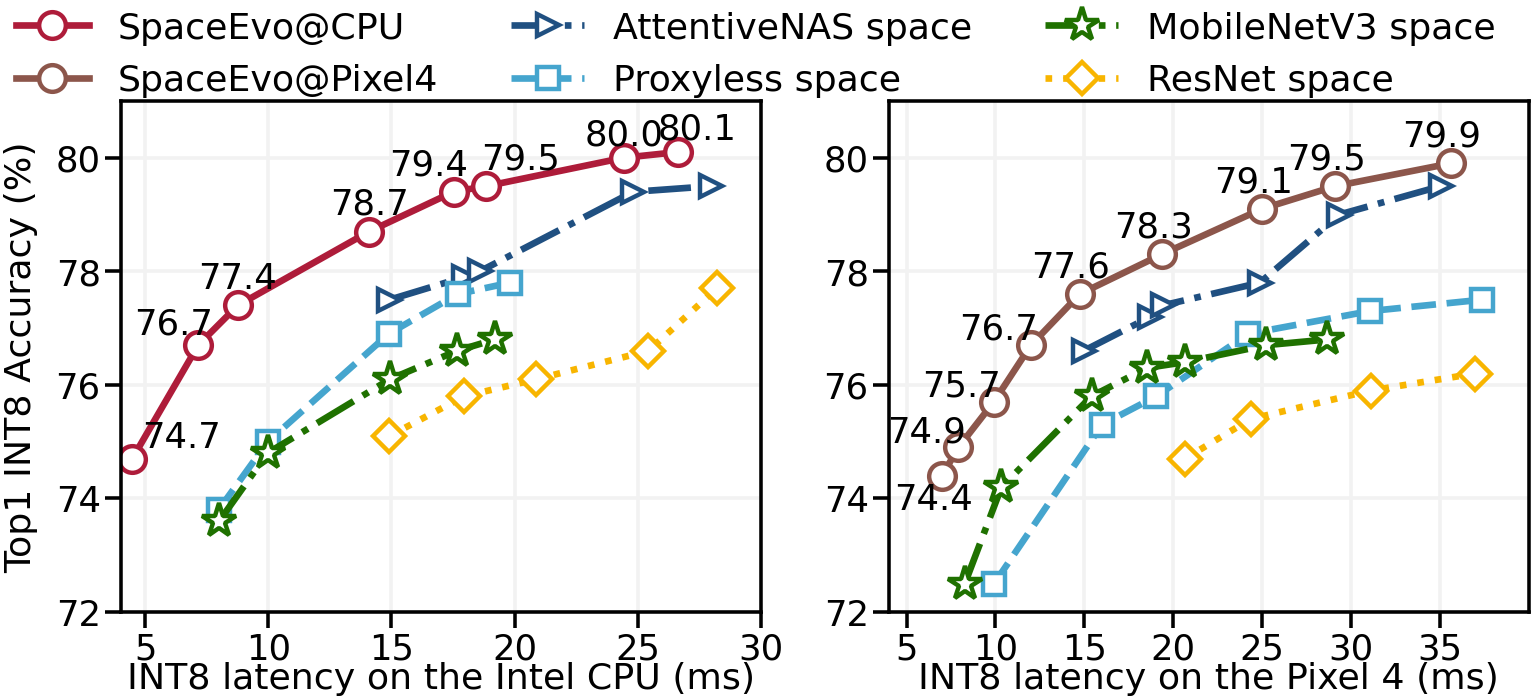
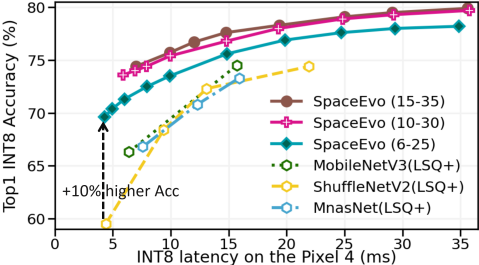
[2303.08308] SpaceEvo: Hardware-Friendly Search Space Design for ...
Quantization Methods for 100X Speedup in Large Language Model Inference
int8_t, int16t and int32_t are 32bit · Issue #2150 · arduino/arduino ...
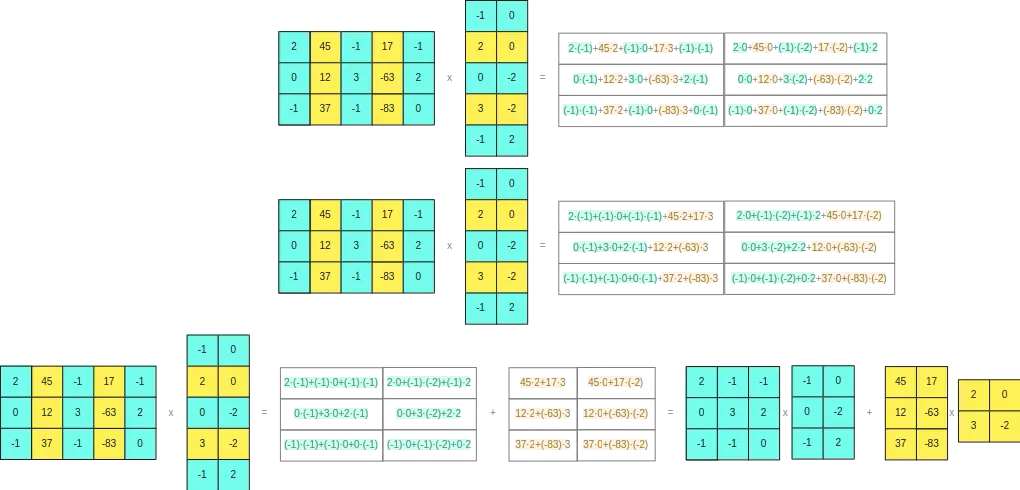
[PDF] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale ...
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale | by ...
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale ...
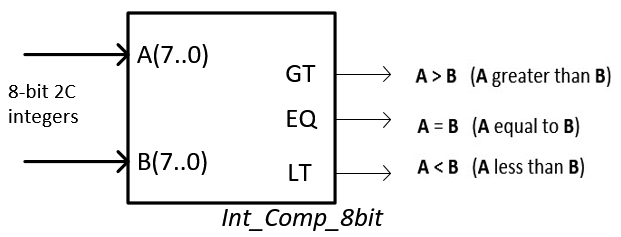
Part 2 Design an 8 bits Register - YouTube
LLM.Int8(). LLM.int8(): 8-bit Matrix Multiplication… | by Danny H Lee ...
Digital Circuits and Systems - Circuits i Sistemes Digitals (CSD ...
Basic data structure DATA STRUCTURE ALGORITHM | PDF
[Video] ប្រើ int8_t uint32_t ក្នុង Arduino ឲ្យបានត្រឹមត្រូវ - etronicskh
int int8ToInt (int8_t num) : Takes in an 8-bit signed | Chegg.com
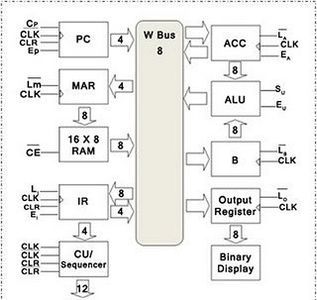
How to Build an 8-Bit Computer : 18 Steps (with Pictures) - Instructables
Byte Pack
Numeric Data Types in PLC Programming - M.I. Tech Services - Learning
Lab
Human Interface Devices - ppt download
Lab 9
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...
Lab1
Intel/table-transformer-int8-static at main
[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale ...
Byte Pack - Convert input signals to 8-, 16-, or 32-bit vector - Simulink
Lab 7
Figure 3 from LLM.int8(): 8-bit Matrix Multiplication for Transformers ...
Paper page - LLM.int8(): 8-bit Matrix Multiplication for Transformers ...
Edge AI using the Rockchip NPU | Tristan Penman's Blog
int8、int16、Byte、short、long... | DAZE
int8とは - IT用語辞典 e-Words
Building an 8-Bit CPU on a Game Boy - Austin Morlan
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale | DeepAI
Background | Mars Village
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale论文解读 ...
Eight bit-packed integers represented as two structures in C/C++ ...
int8_t、int16_t、int32_t、int64_t、uint8_t、size_t、ssize_t详解_int16 int32 ...
Understanding LLM.int8() Quantization — Picovoice
Mike Lewis, Younes Belkada, Luke Zettlemoyer · LLM.int8(): 8-bit Matrix ...
Value Distribution represented in FP8 and INT8. | Download Scientific ...
int8,FLOPS,FLOPs,TOPS 等具体含义_int8 tops-CSDN博客
Accelerating Large Language Models with Mixed-Precision Techniques ...
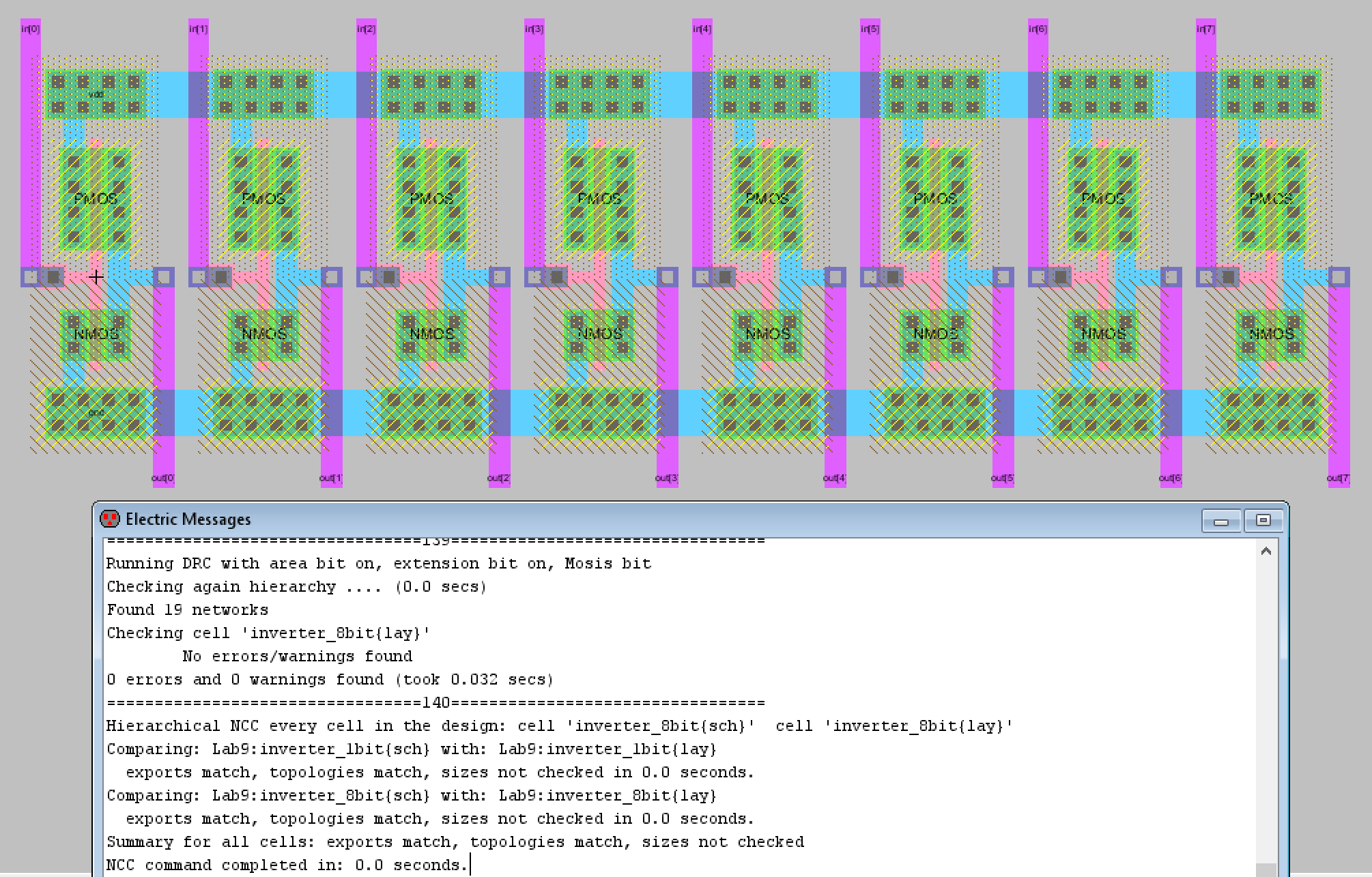
GitHub - muhammadaldacher/Layout-Design-for-an-8-bit-Microprocessor ...
8-Bit concept with Electronic Integrated Circuit on circuit board. 8 ...
NeurIPS Poster GPT3.int8(): 8-bit Matrix Multiplication for ...
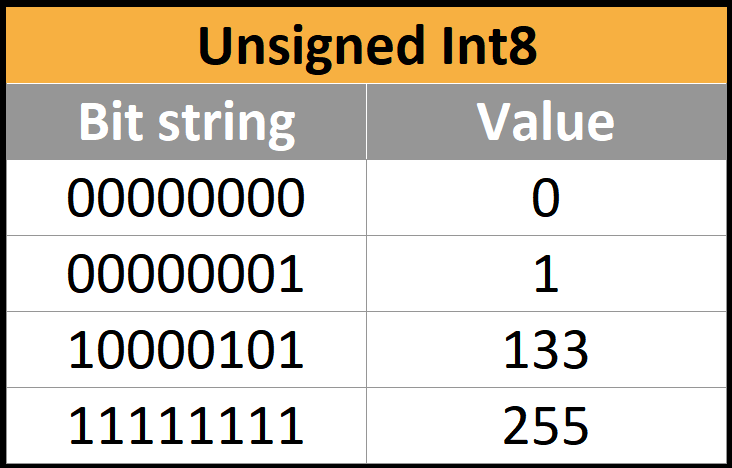
int8的取值范围? - 知乎
Figure 4 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
INT8模型量化:LLM.int8 - 知乎





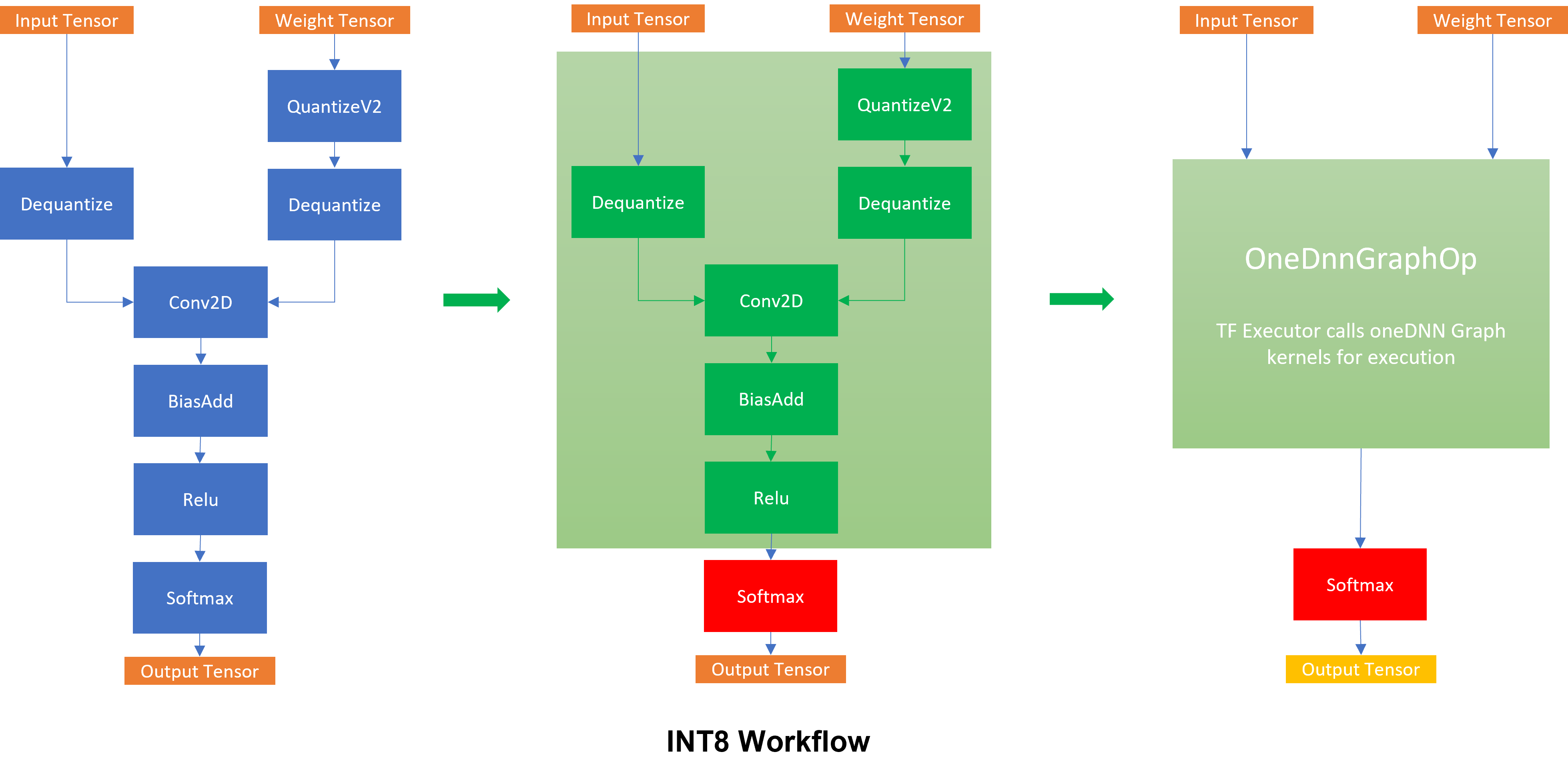
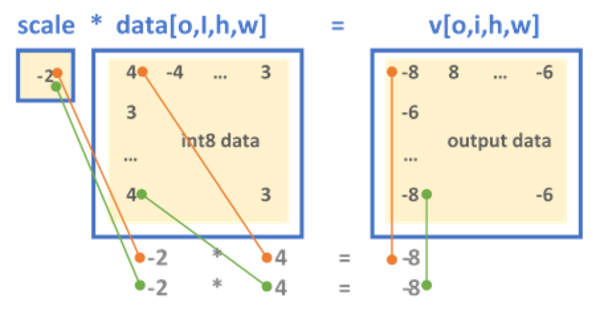
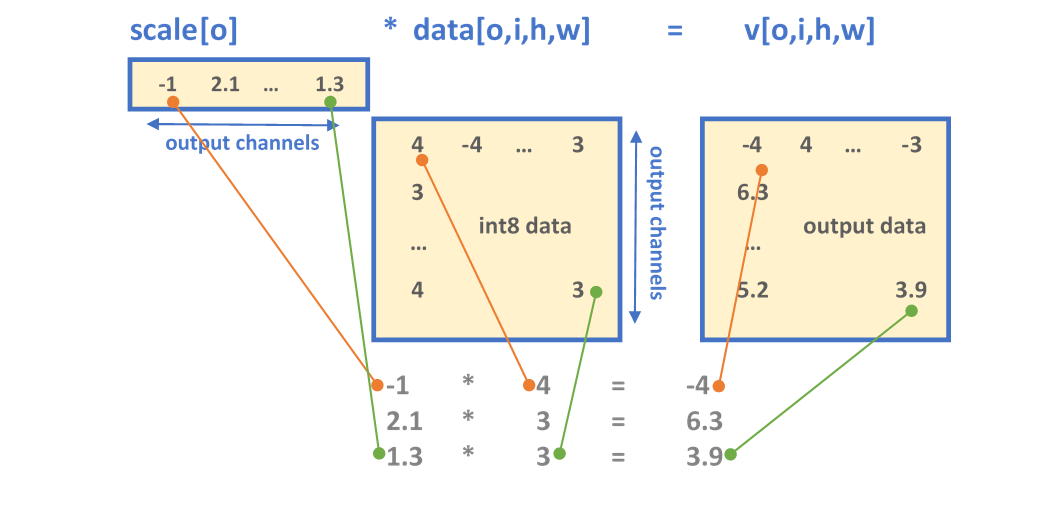



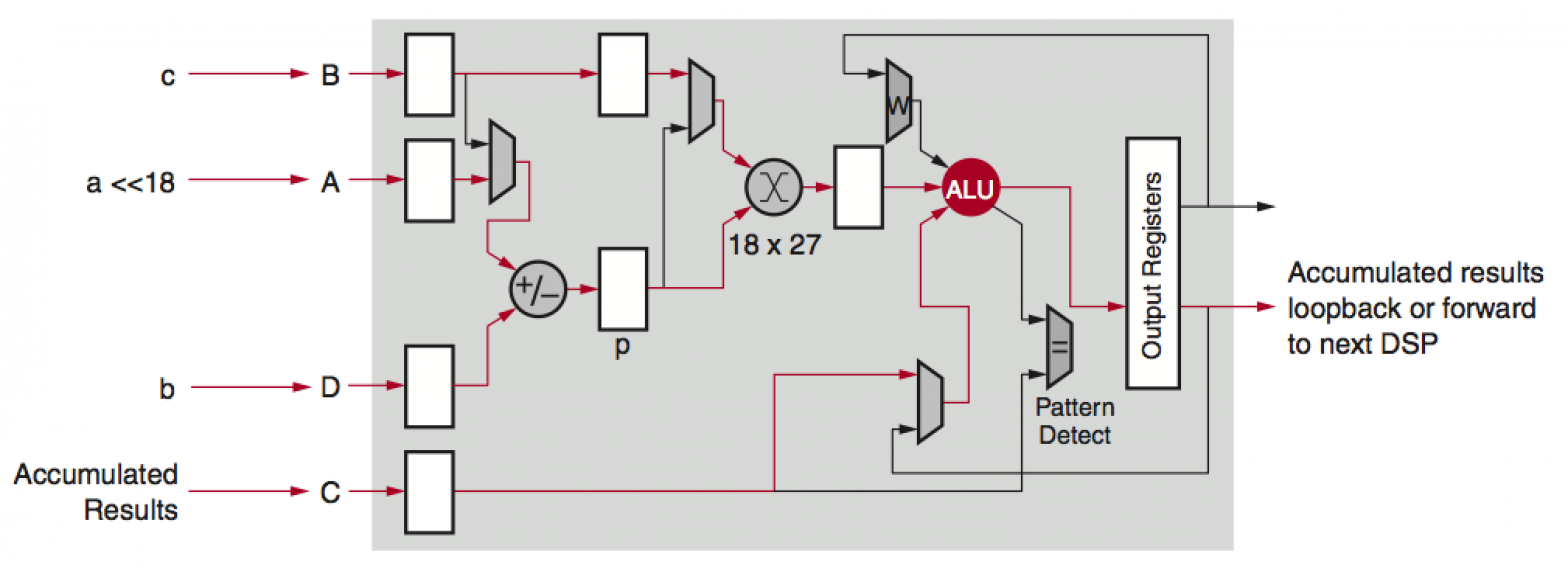




















-thumbnail.webp)