Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
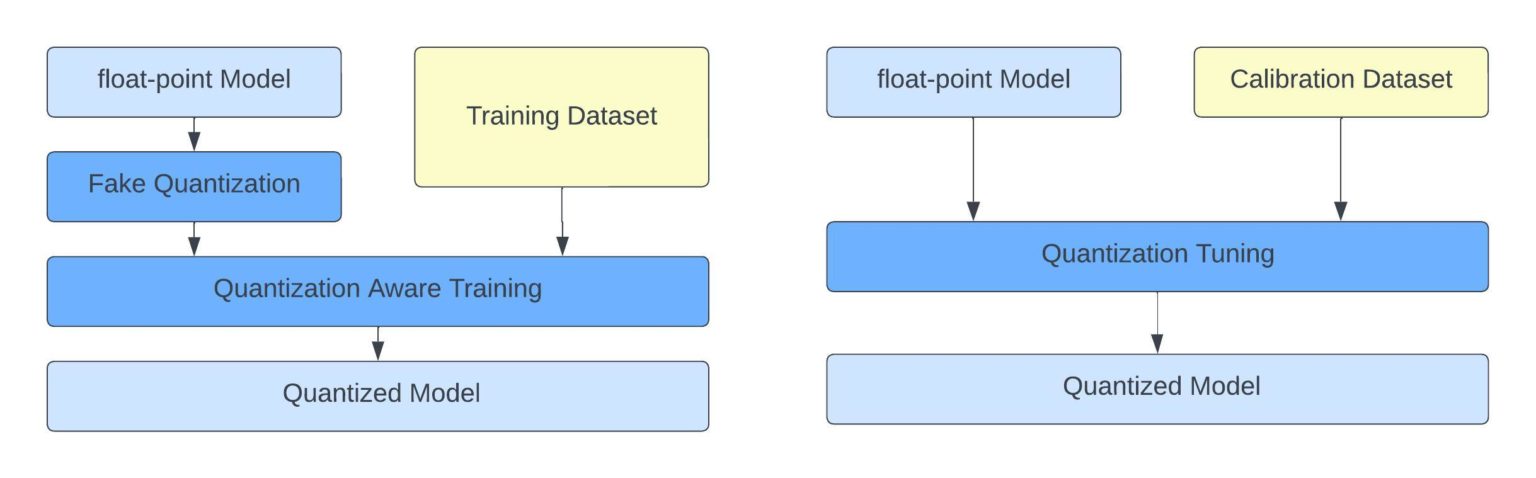
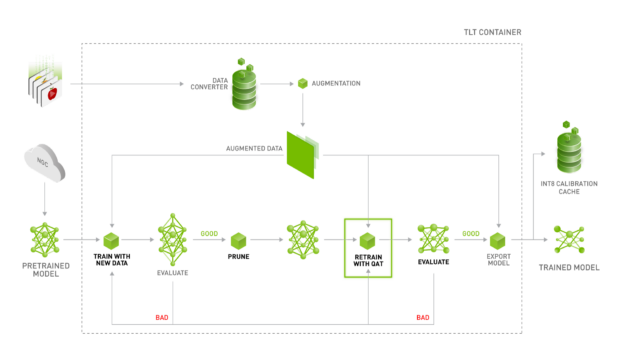
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
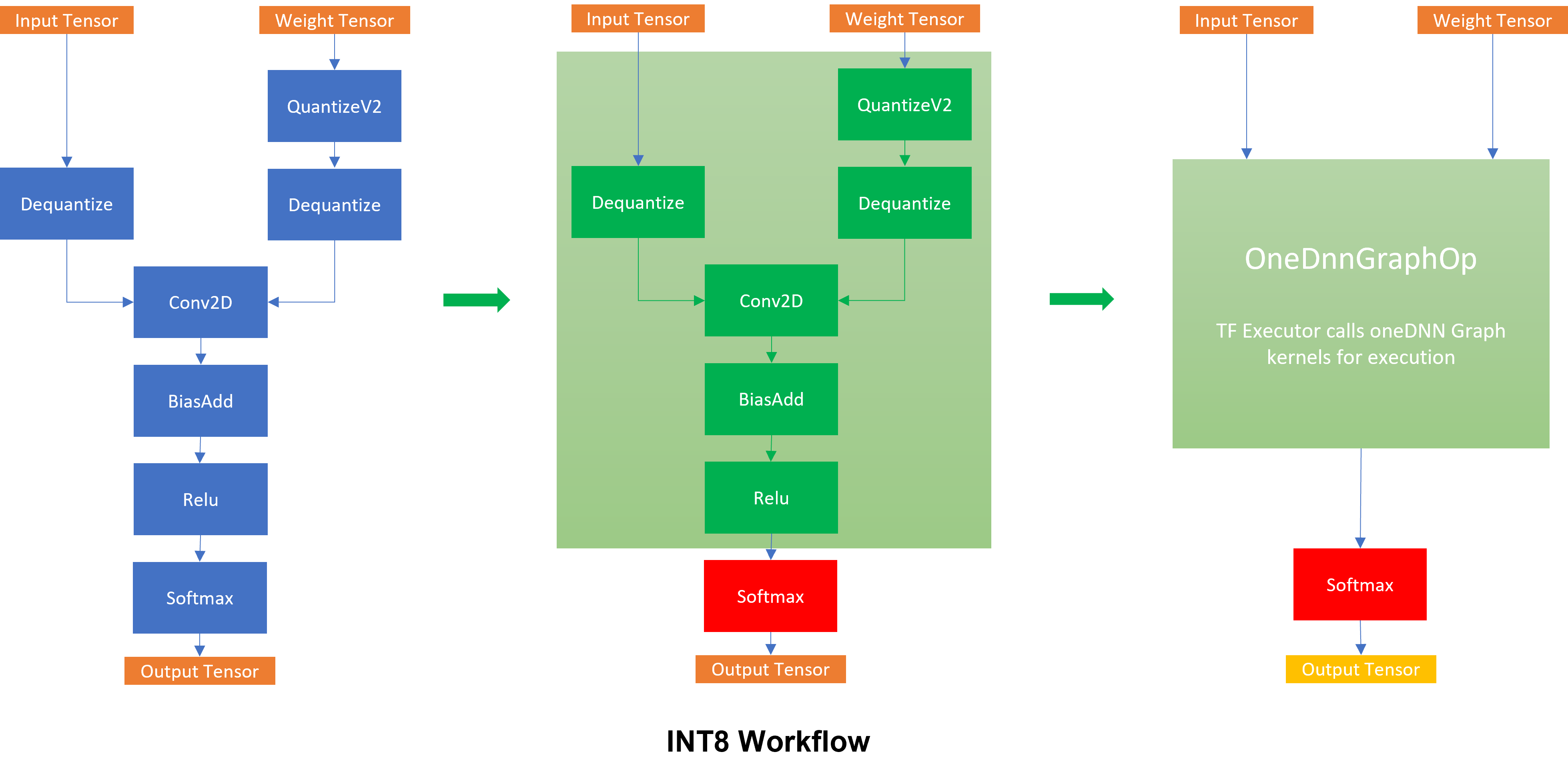
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
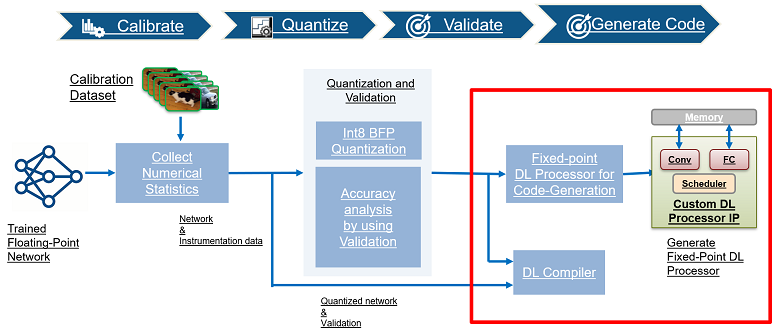
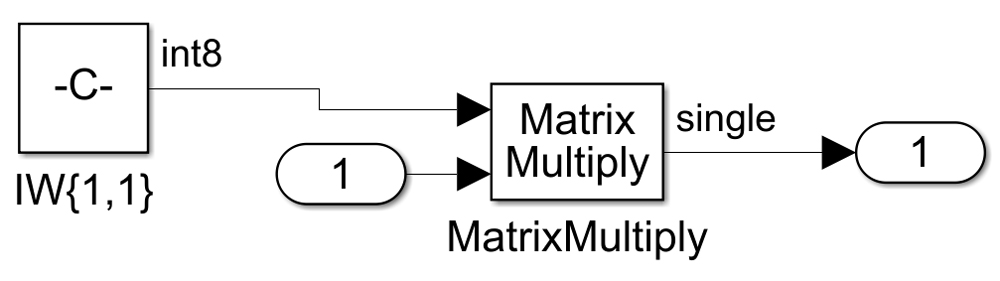
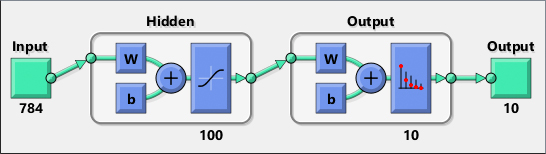
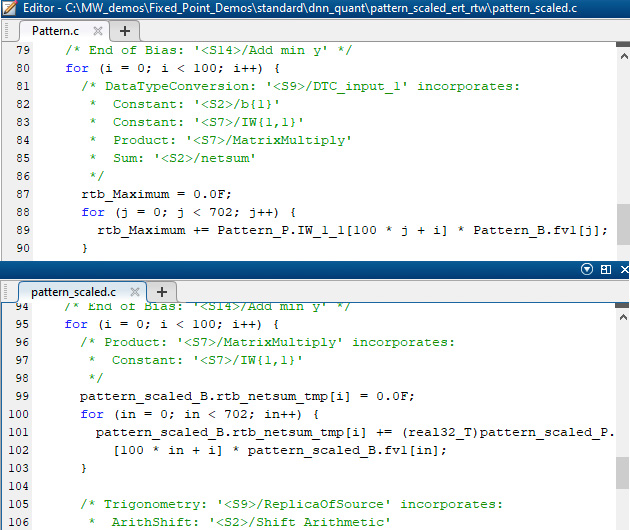
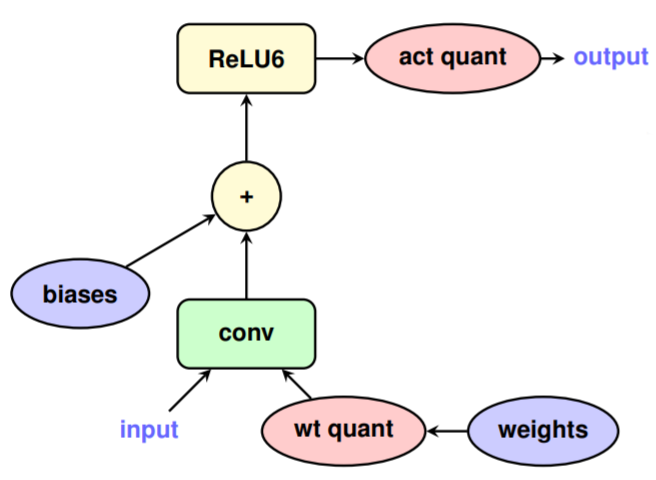
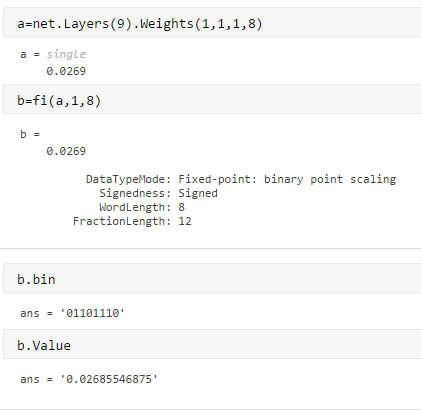
Deep Learning INT8 Quantization - MATLAB & Simulink
Deep Learning Int8 Quantization – PCETSK
INT8 Quantization for x86 CPU in PyTorch | PyTorch
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
int8 Weight and Activation Quantization - LLM Compressor Docs
Quantization int8 · Issue #9936 · ultralytics/ultralytics · GitHub
int8 model quantization · Issue #521 · traveller59/spconv · GitHub
INT8 Quantization Basics | Rand Xie
Deep Learning INT8 Quantization MATLAB Simulink, 42% OFF
INT8 Quantization Aware Training · ultralytics yolov5 · Discussion ...
Understanding int8 neural network quantization - YouTube
INT8 quantization with same model and different weights · Issue #2705 ...
INT-FlashAttention: Enabling Flash Attention for INT8 Quantization | AI ...
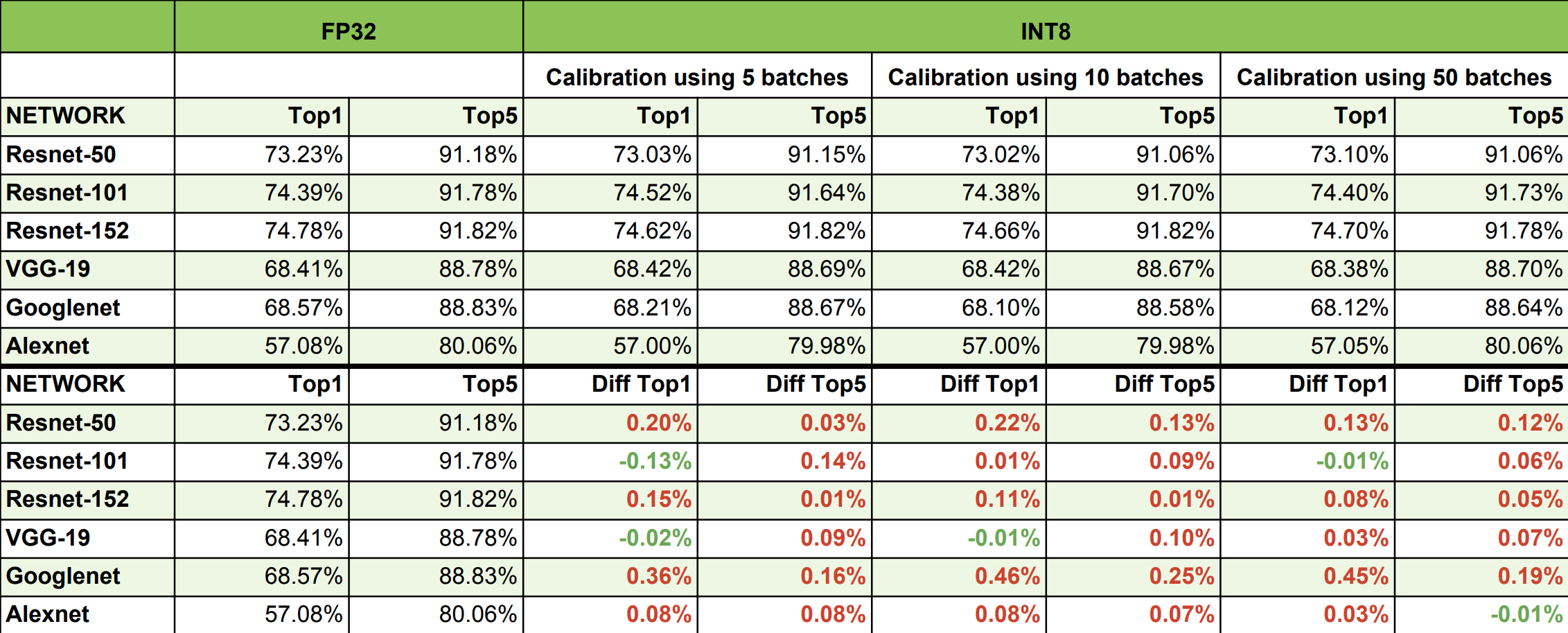
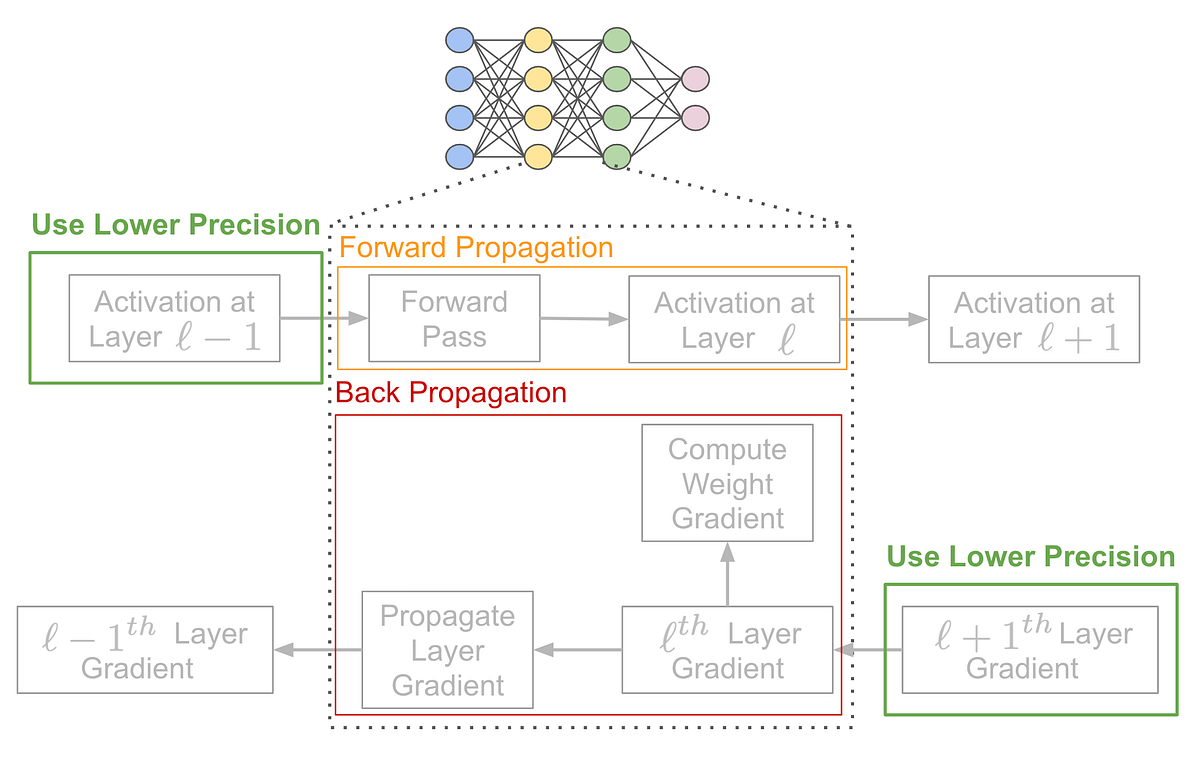
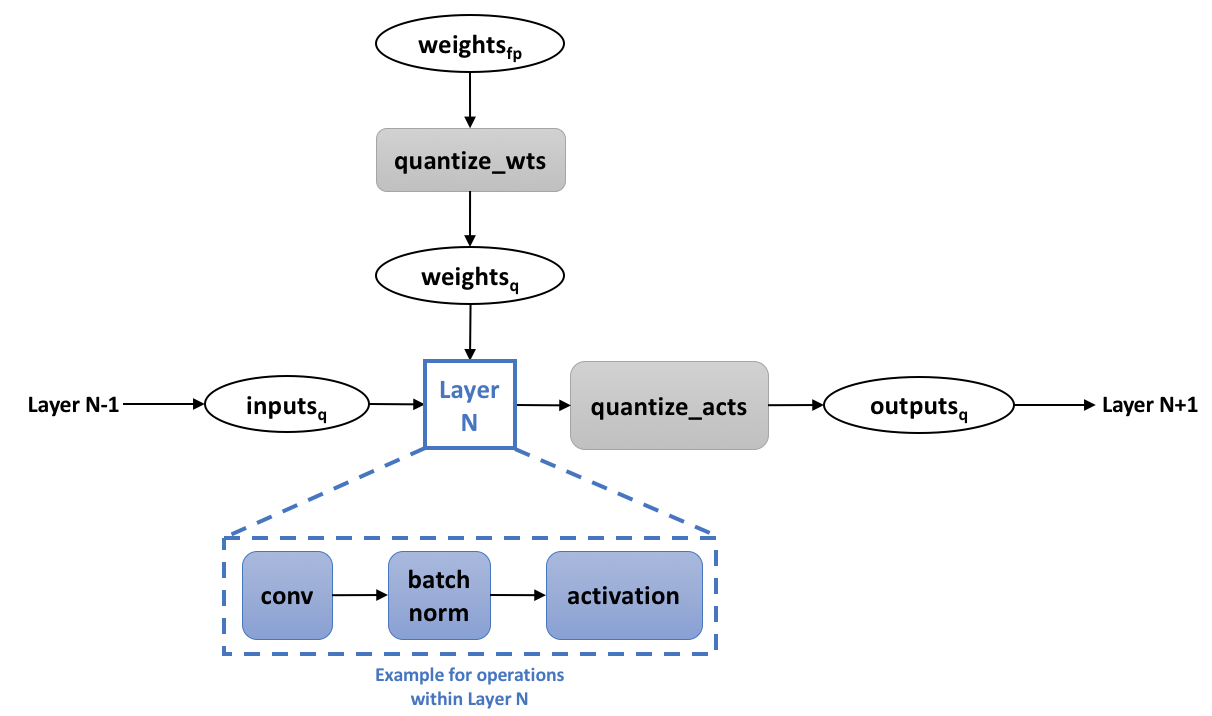
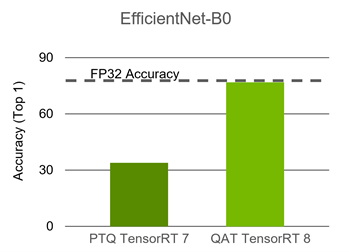
Improving INT8 Accuracy Using Quantization Aware Training and the ...
YOLOv10 vs. YOLOv11: INT8 Quantization Performance Comparison — Results ...
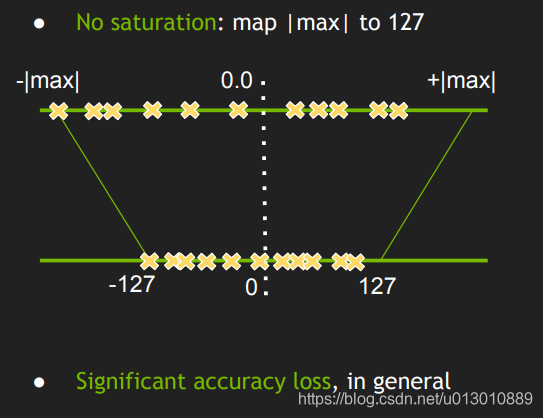
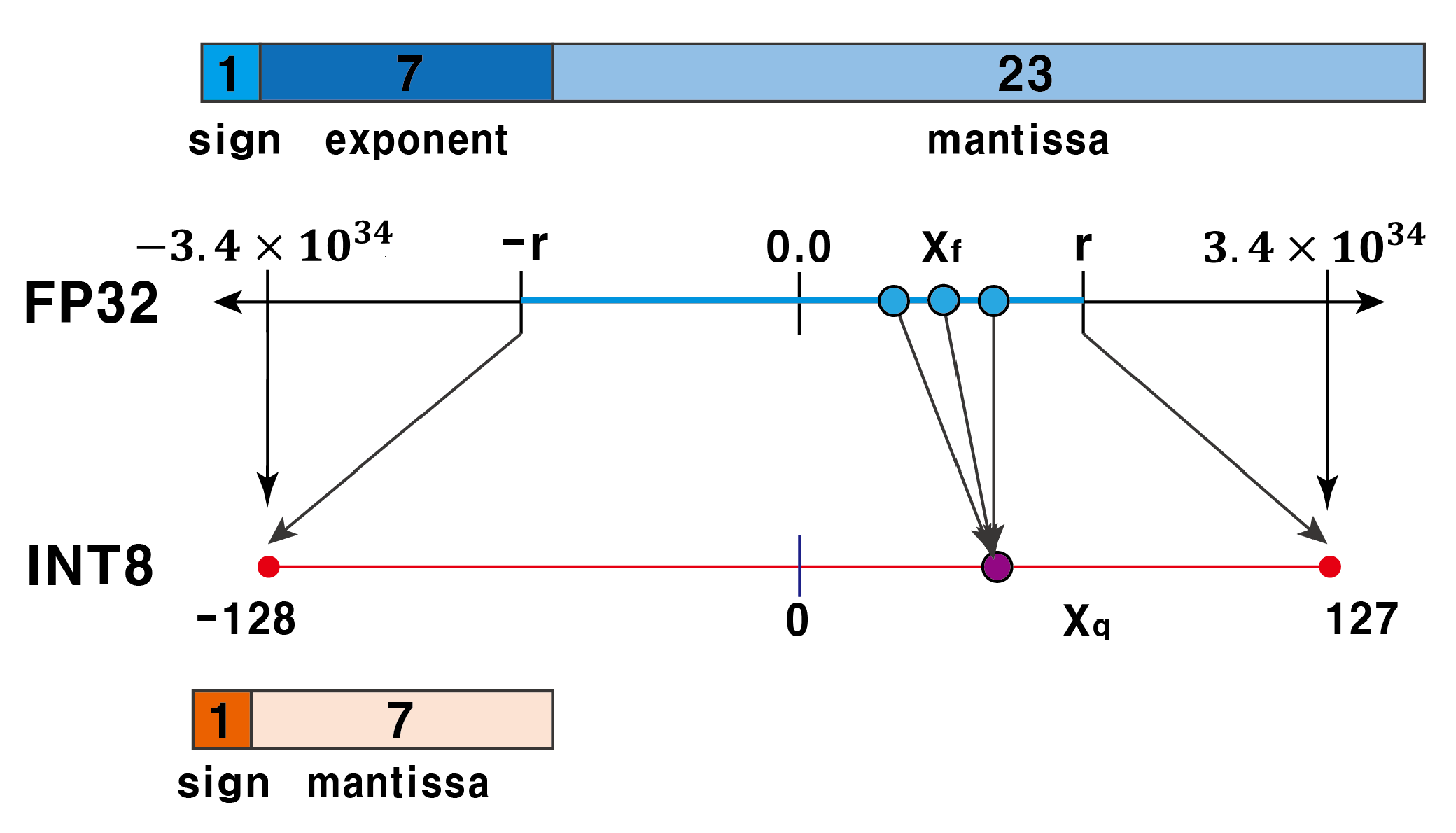
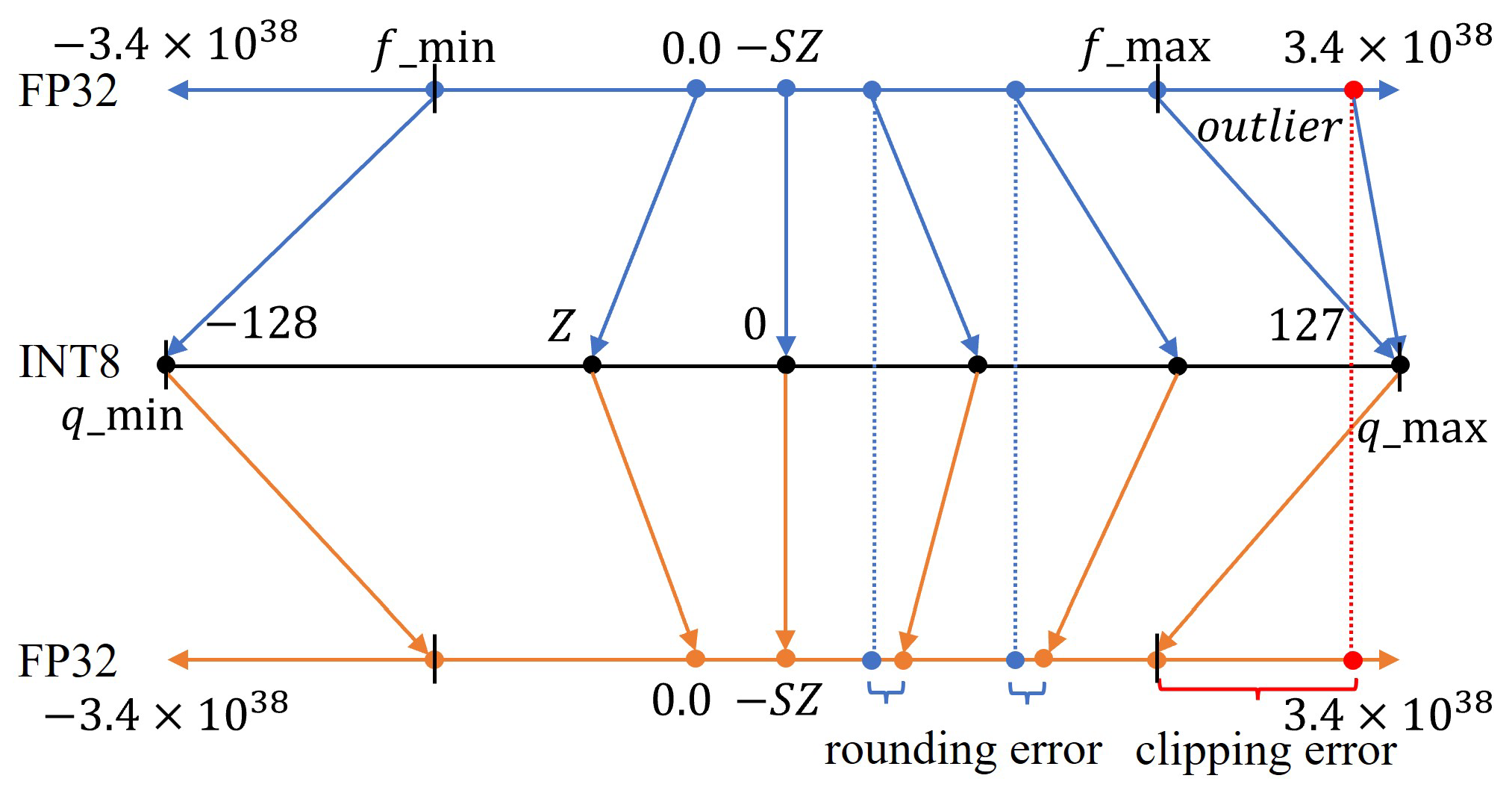
Question about INT8 quantization ranges · Issue #1951 · NVIDIA/TensorRT ...
INT8 quantization — Benchmark Studio documentation
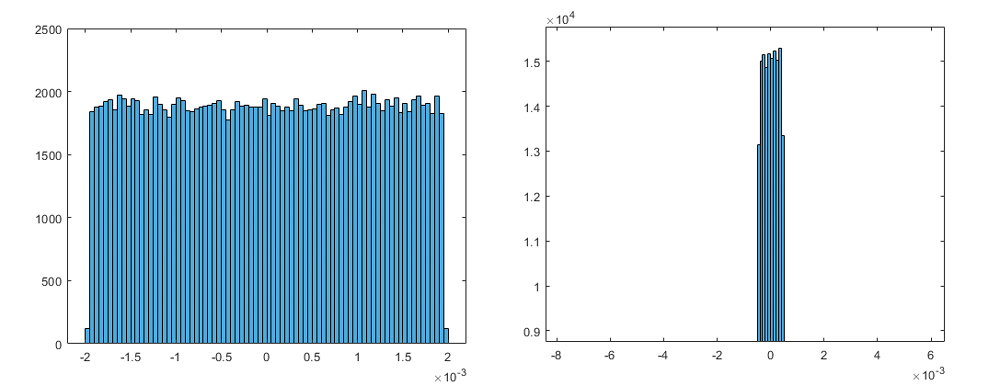
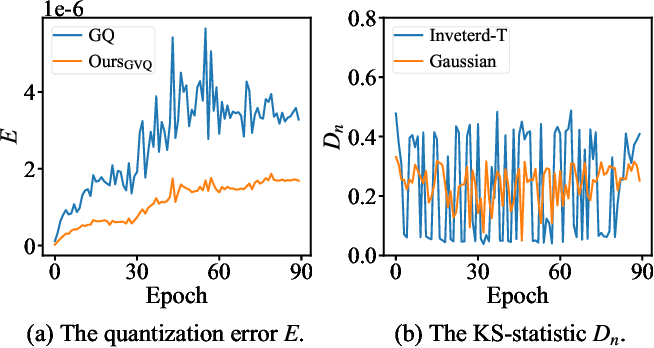
Figure 1 from Distribution Adaptive INT8 Quantization for Training CNNs ...
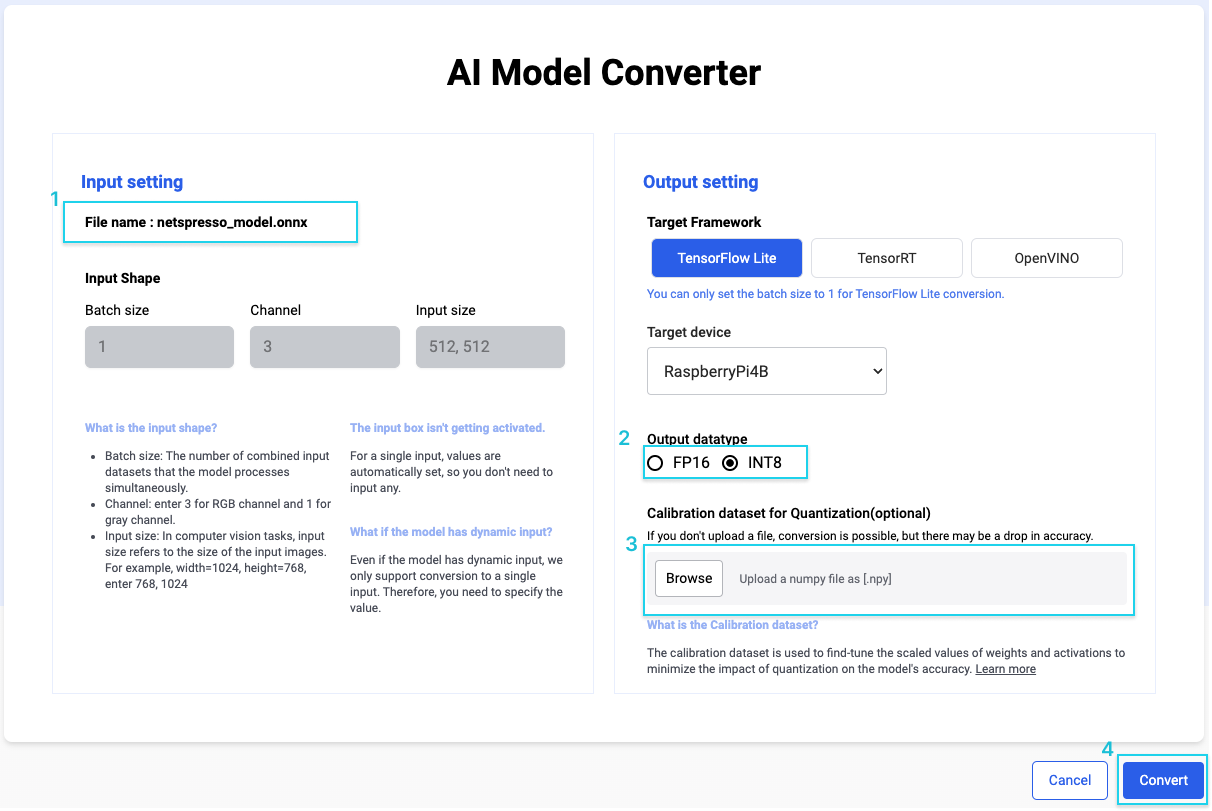
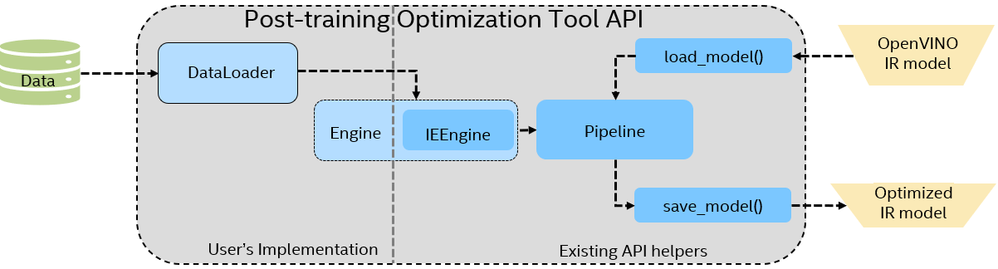
YOLOv5 Model INT8 Quantization based on OpenVINO™ 2022.1 POT API ...
INT8 KV cache + per-channel weight-only quantization leading to wired ...
Int8 quantization and tvm implementation - Programmer Sought
The impact of INT8 quantization on throughput. | Download Scientific ...
Day 60/75 LLM Quantization to Convert Float32 to Int8 | LLM Evaluation ...
Figure 2 from Distribution Adaptive INT8 Quantization for Training CNNs ...
Calibration data for quantization int8 · Issue #14809 · ultralytics ...
The accuracy loss after INT8 quantization compared to FP16 version ...
OpenVINO INT8 Quantization for YOLO26 Models: A Hands-On Tutorial | by ...
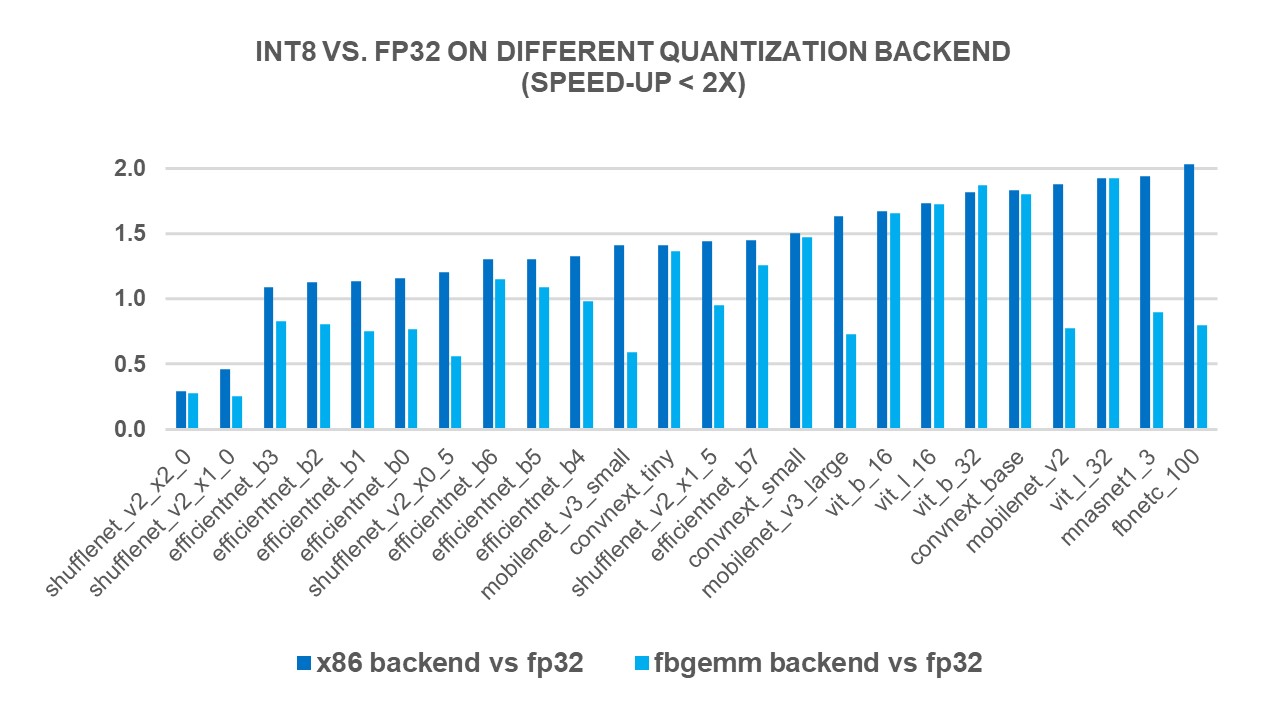
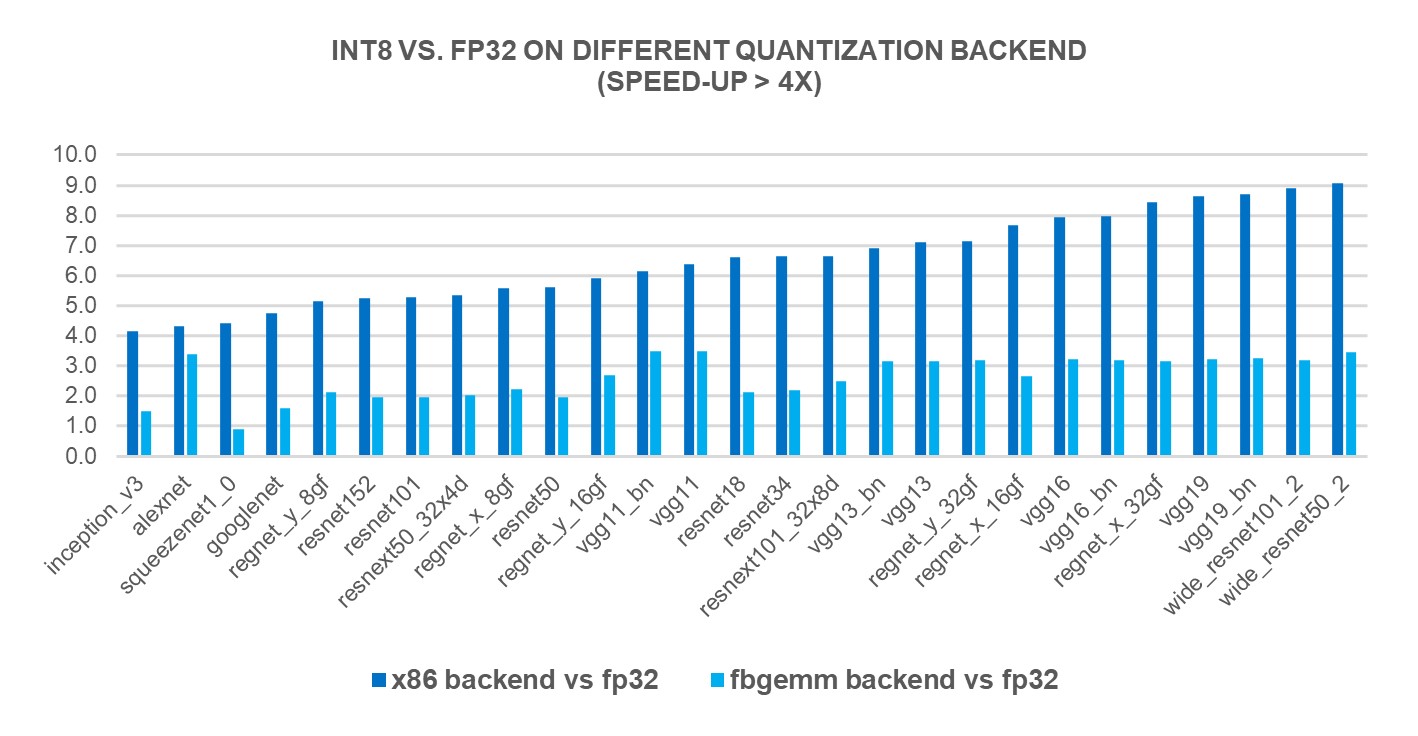
Improve Inference with INT8 Quantization for x86 CPU in PyTorch ...
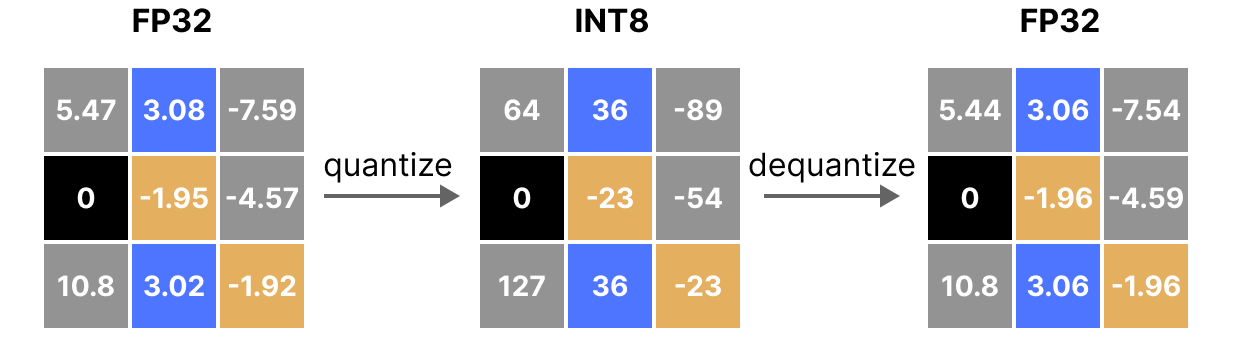
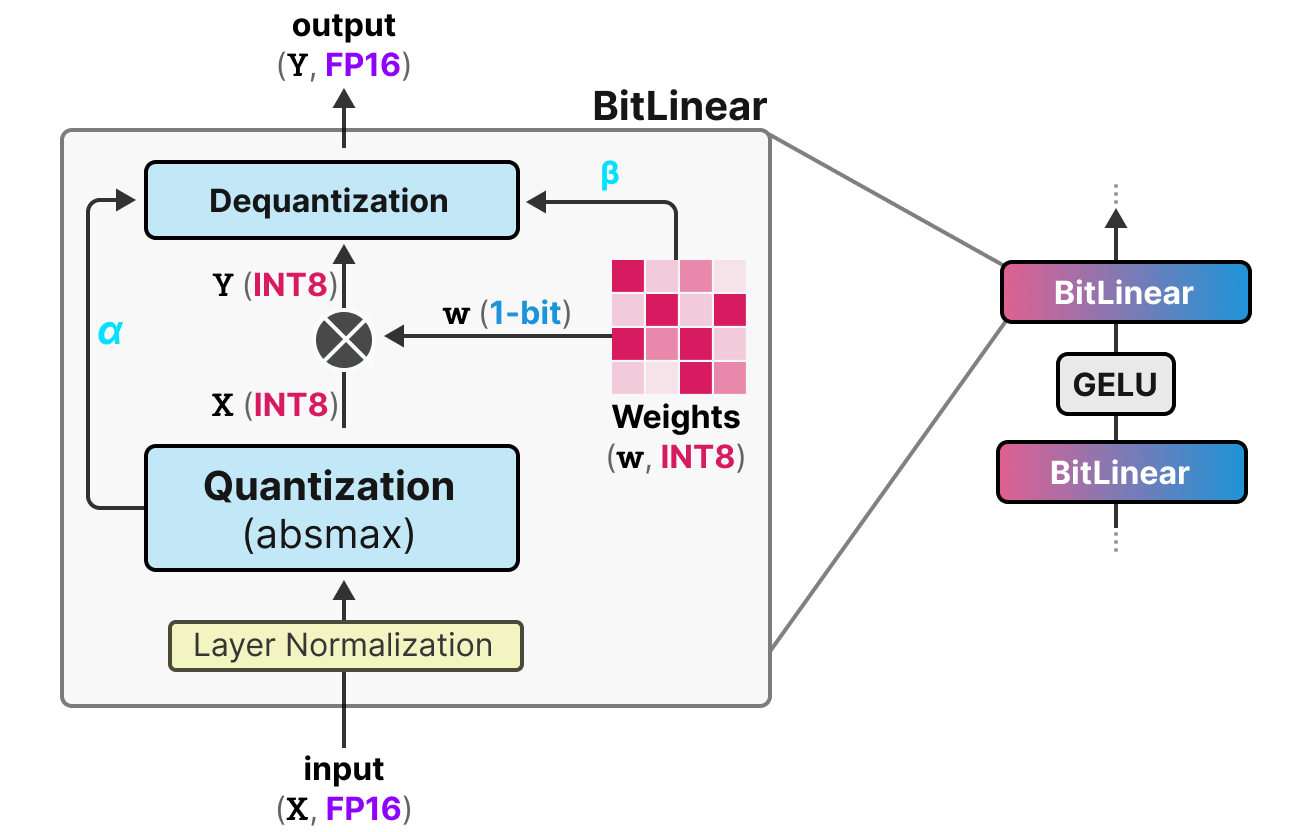
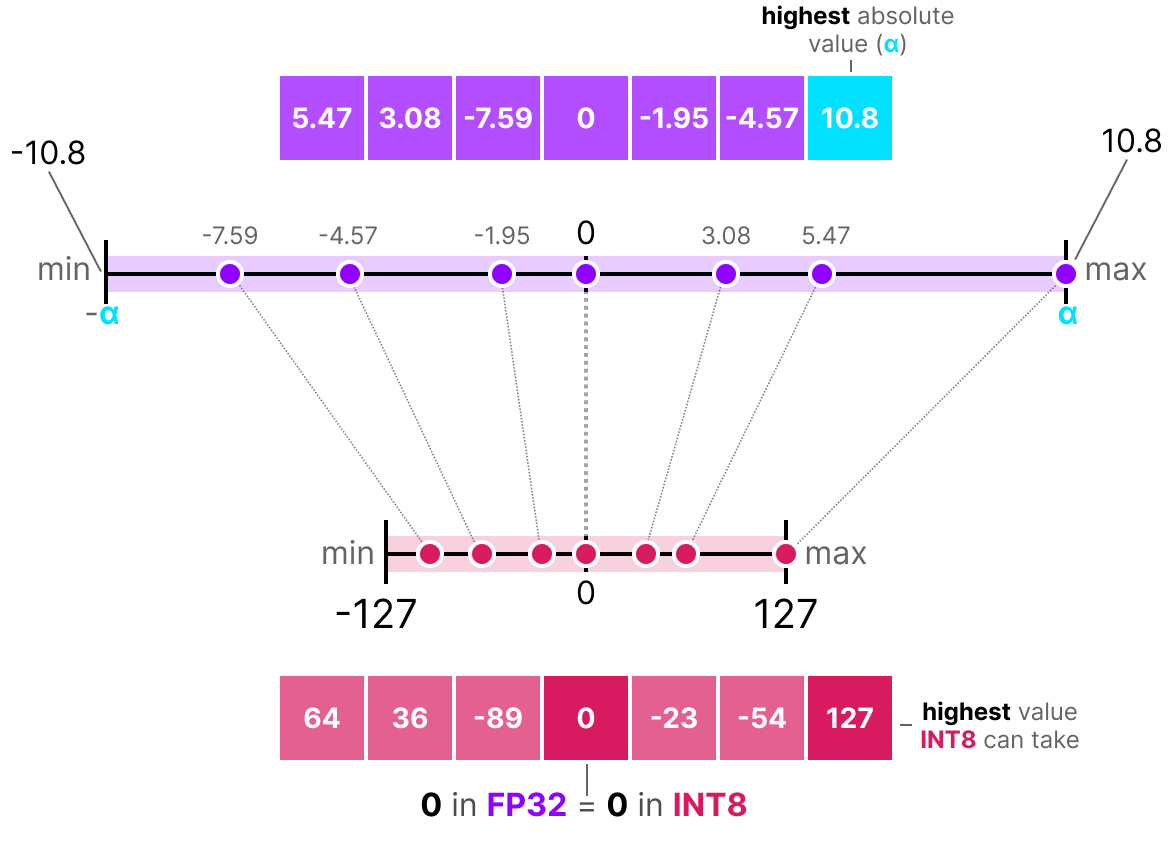
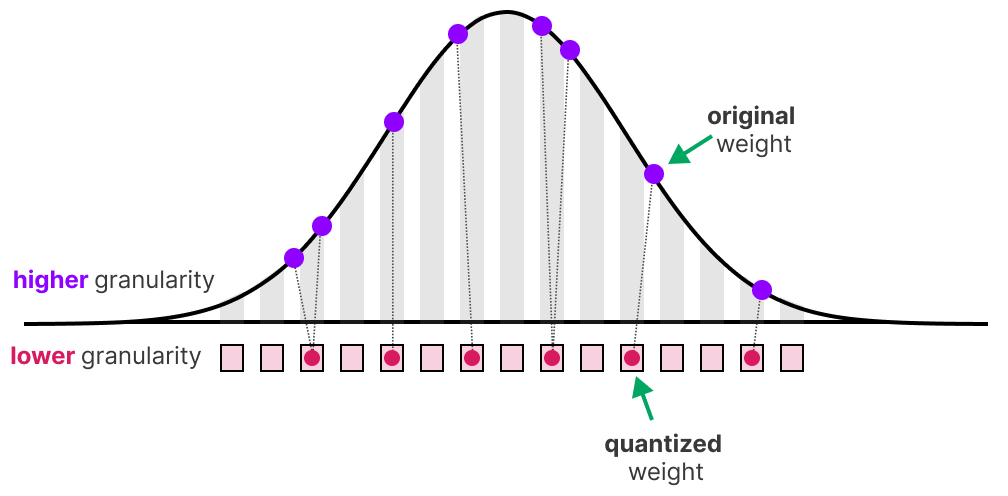
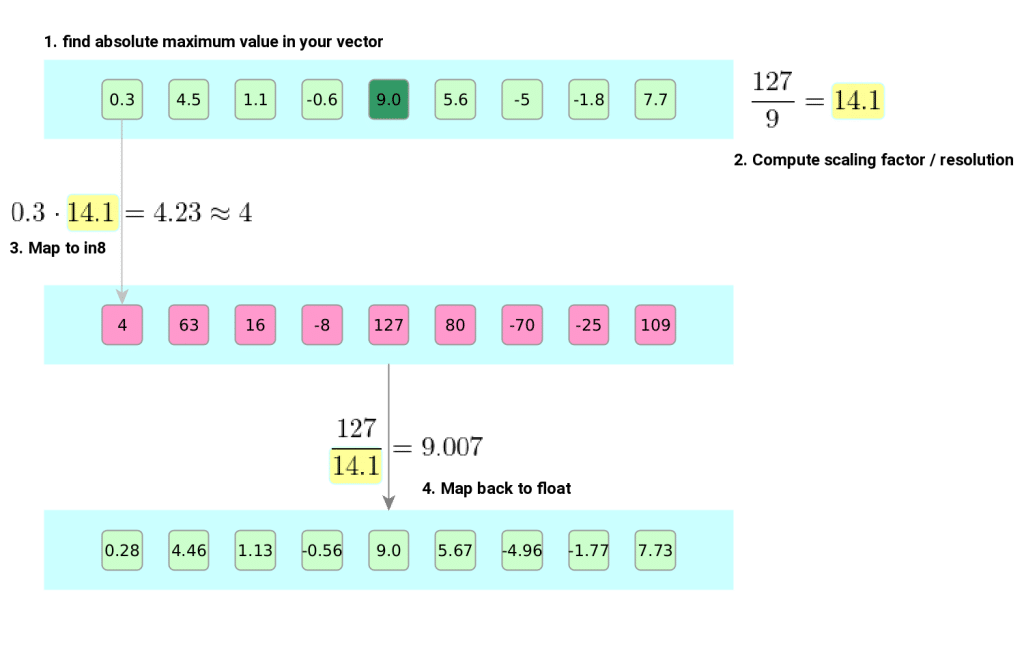
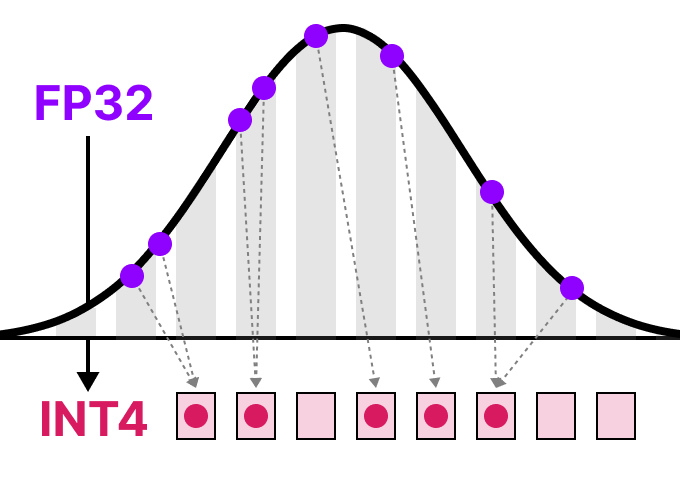
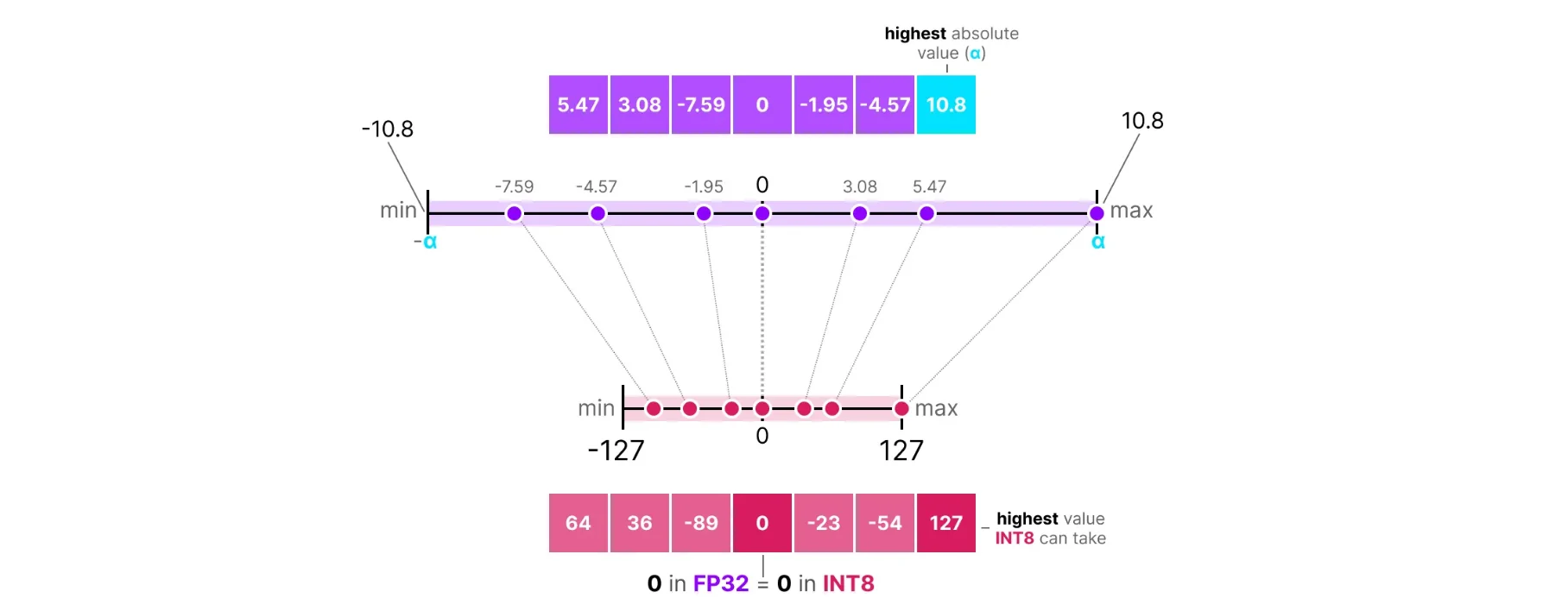
A Visual Guide to Quantization - by Maarten Grootendorst
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
Quantization Overview — Guide to Core ML Tools
Quantization Methods for 100X Speedup in Large Language Model Inference
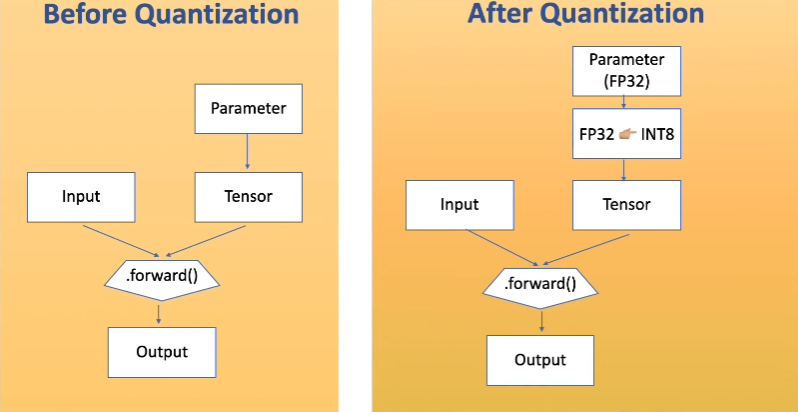
Shrinking AI Models by 75%: A Practical Guide to PyTorch INT8 ...
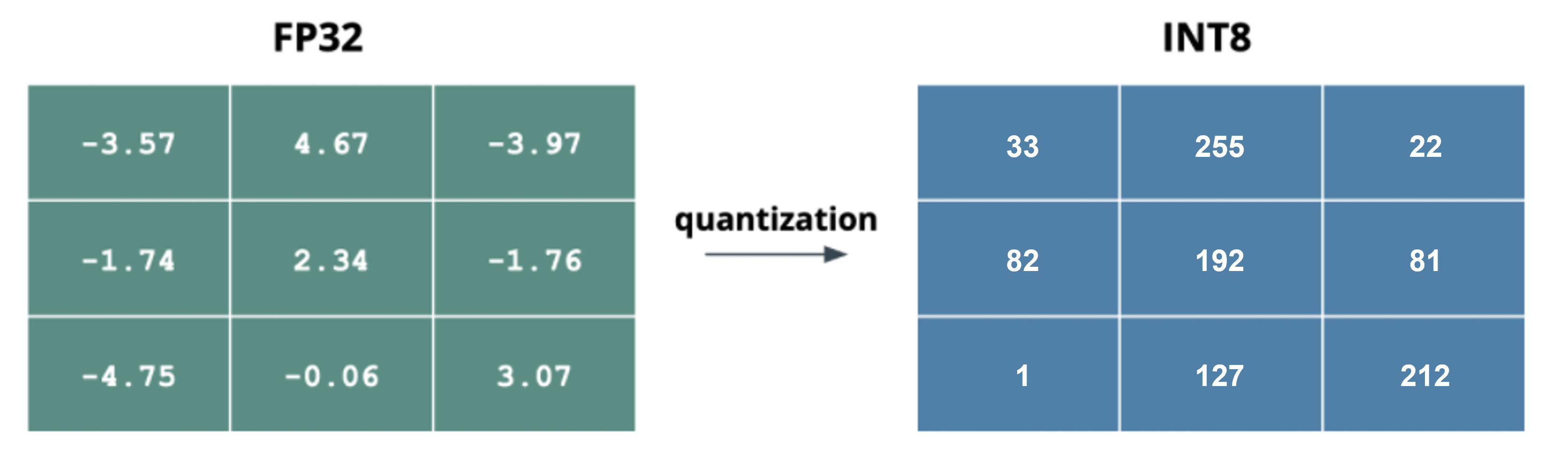
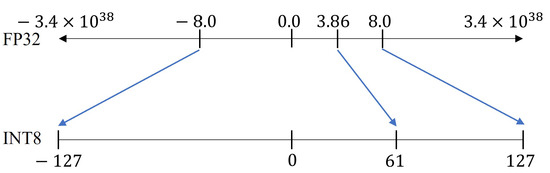
Quantization from FP32 to INT8. | Download Scientific Diagram
딥러닝의 Quantization (양자화)와 Quantization Aware Training - gaussian37
7 ML Quantization Wins (INT8/FP8) Without Quality Freefall | by ...
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Quantization INT8/INT4 — Ít bit hơn, nhỏ hơn 8x, vẫn chính xác | Trồi Sinh
Quark Quantized INT8 Models - a amd Collection
Fast and Accurate GPU Quantization for Transformers
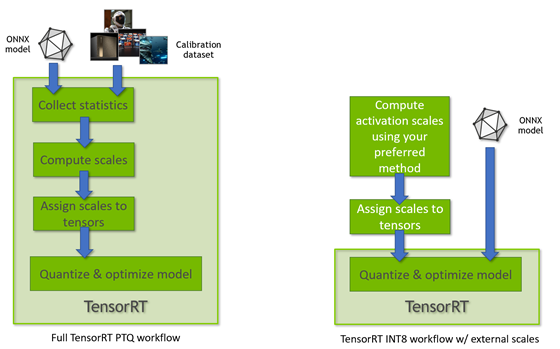
INT8 Inference of Quantization-Aware trained models using ONNX-TensorRT ...
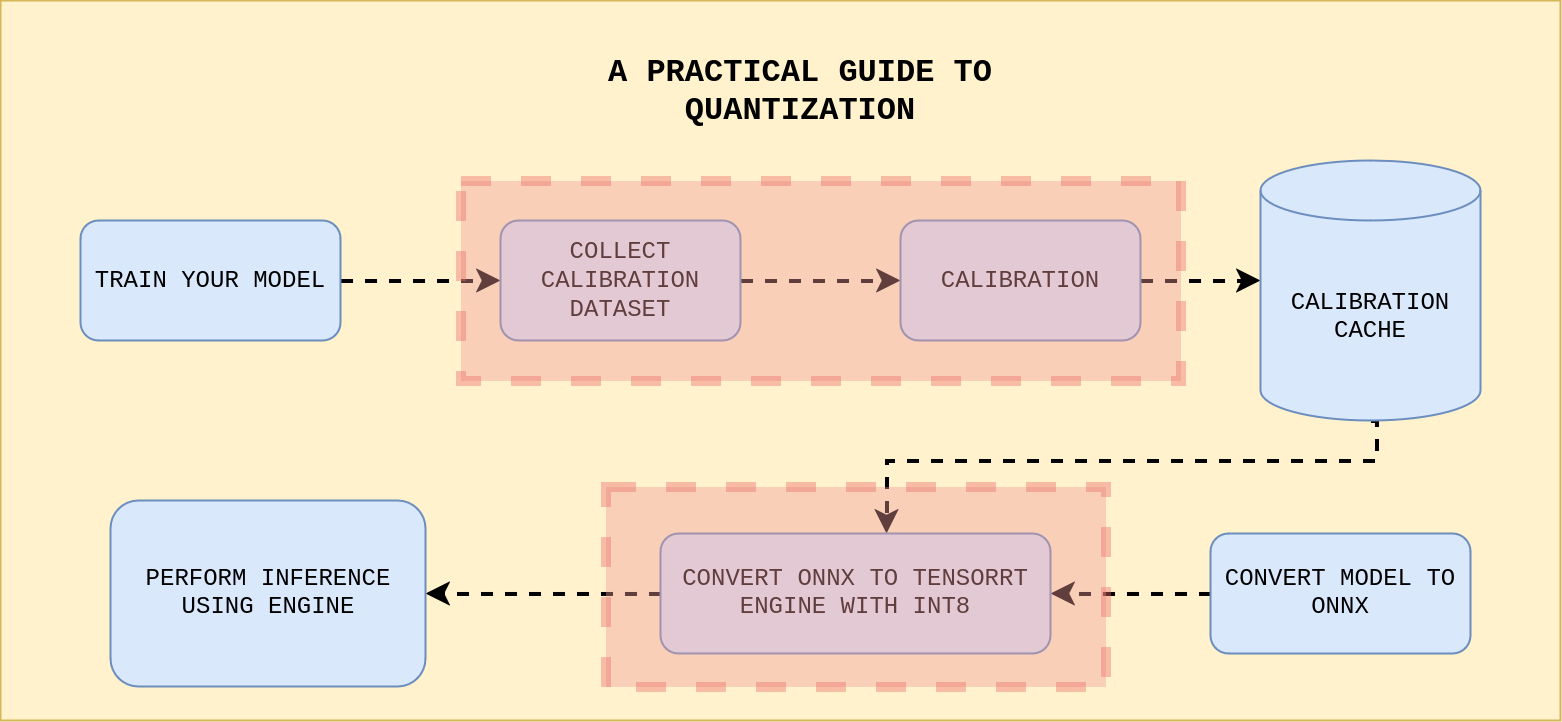
A practical guide to Quantization | Sanket Shah
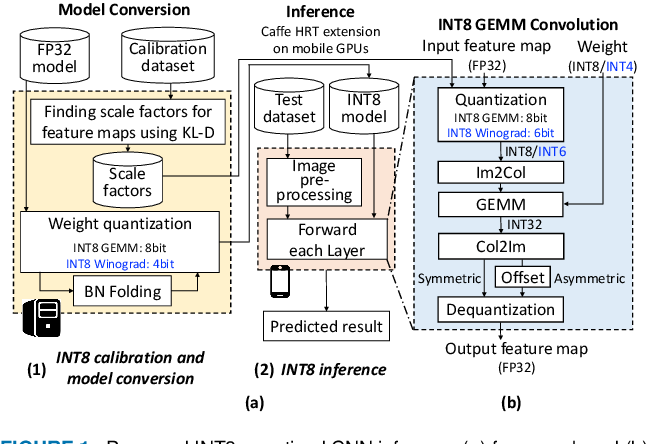
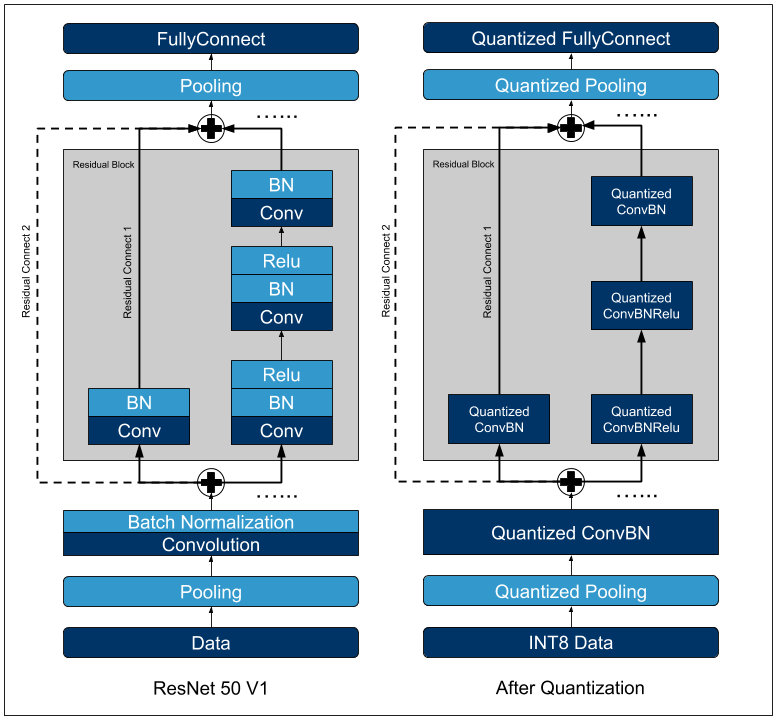
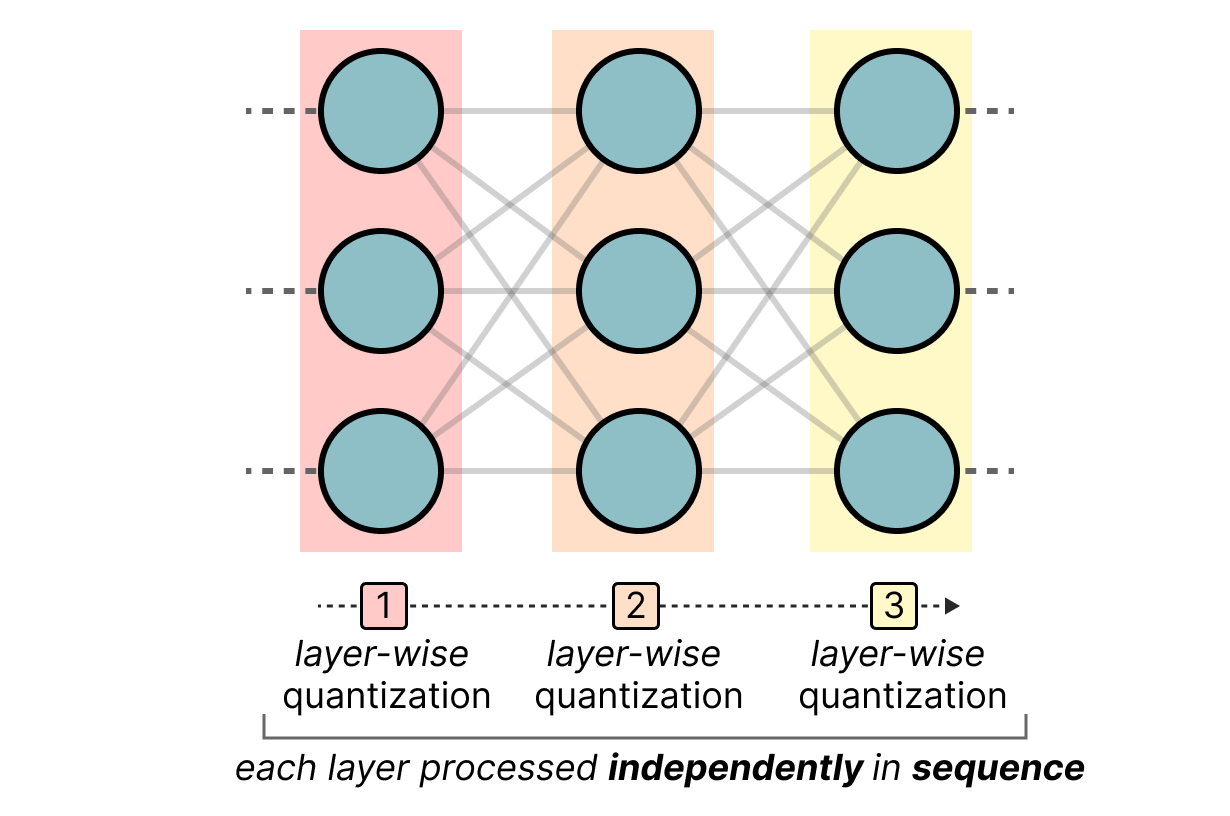
Proposed INT8 quantized CNN inference (a) framework and (b) INT8 GEMM ...
Figure 1 from Performance Evaluation of INT8 Quantized Inference on ...
Model Quantization for Production-Level Neural Network Inference
Figure 2 from Performance Evaluation of INT8 Quantized Inference on ...
Local Large Language Models | Int8
Improving LLM Inference Latency on CPUs with Model Quantization ...
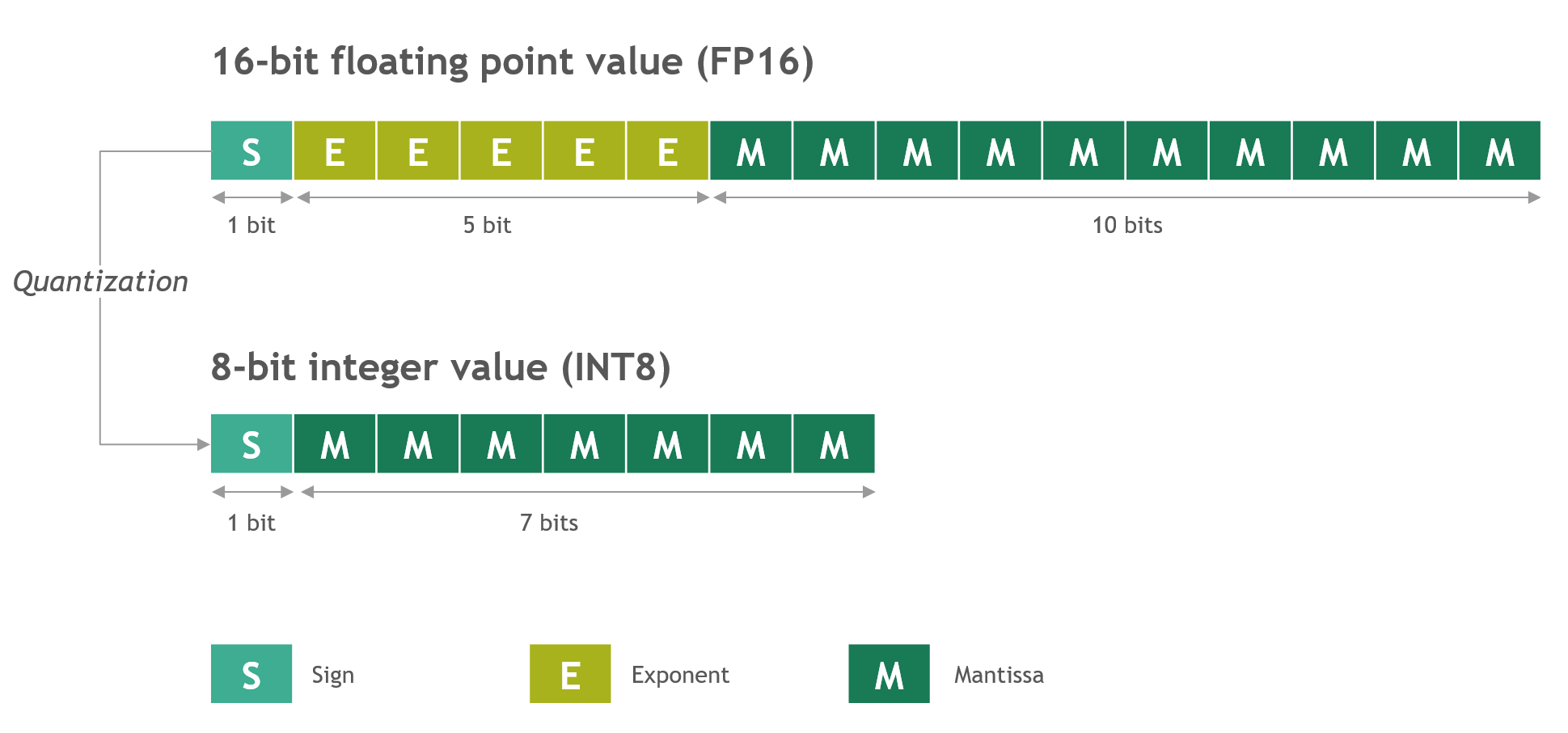
INT8, INT4 and Other Integer Types for Quantization
Boosting AI: The Quiet Power of Quantization - 044.EU
14. Quantization — ECE 386
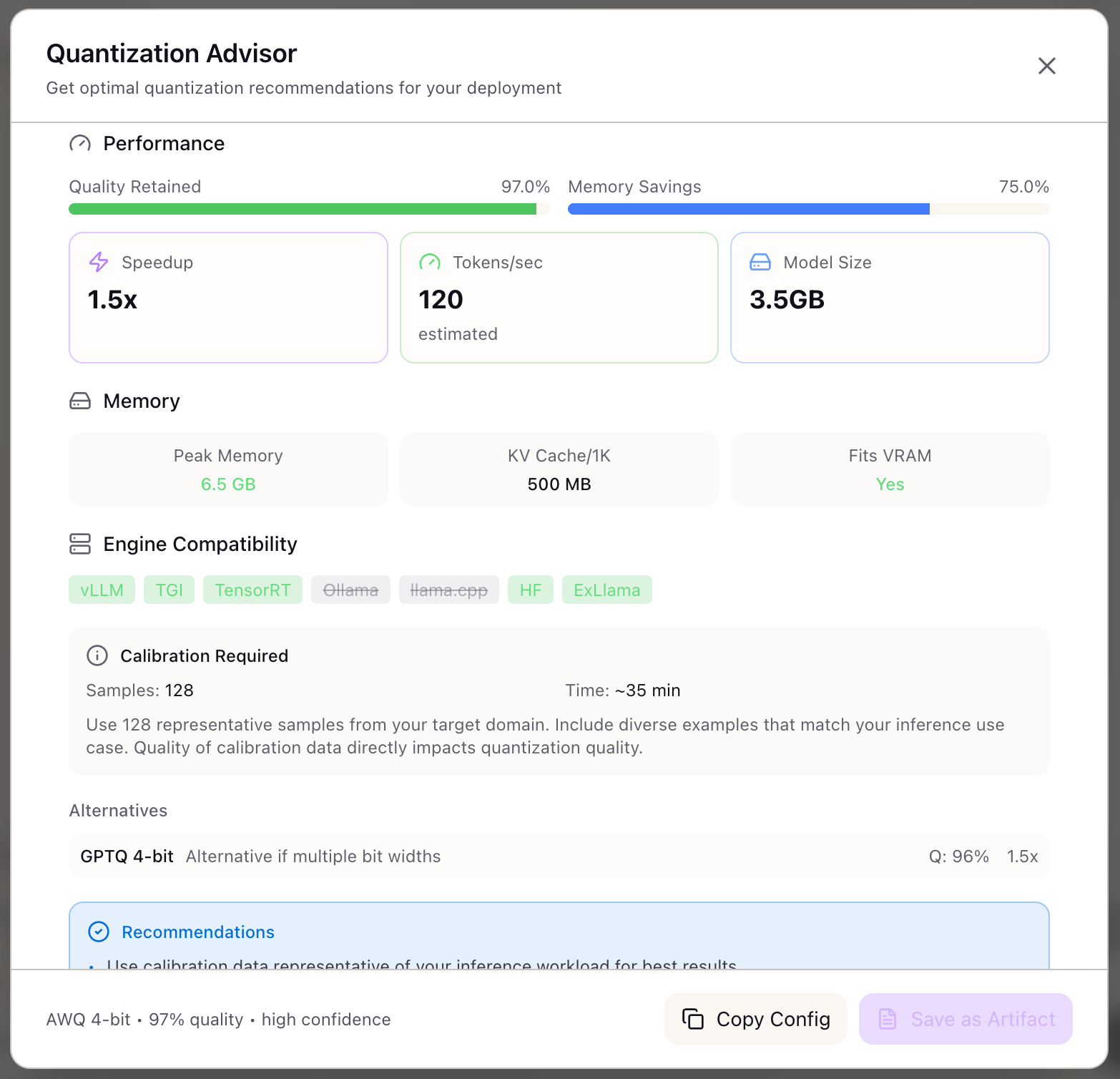
AI Model Quantization Advisor - INT8, FP16, INT4 Guide | Lattice
Quantization - Neural Network Distiller
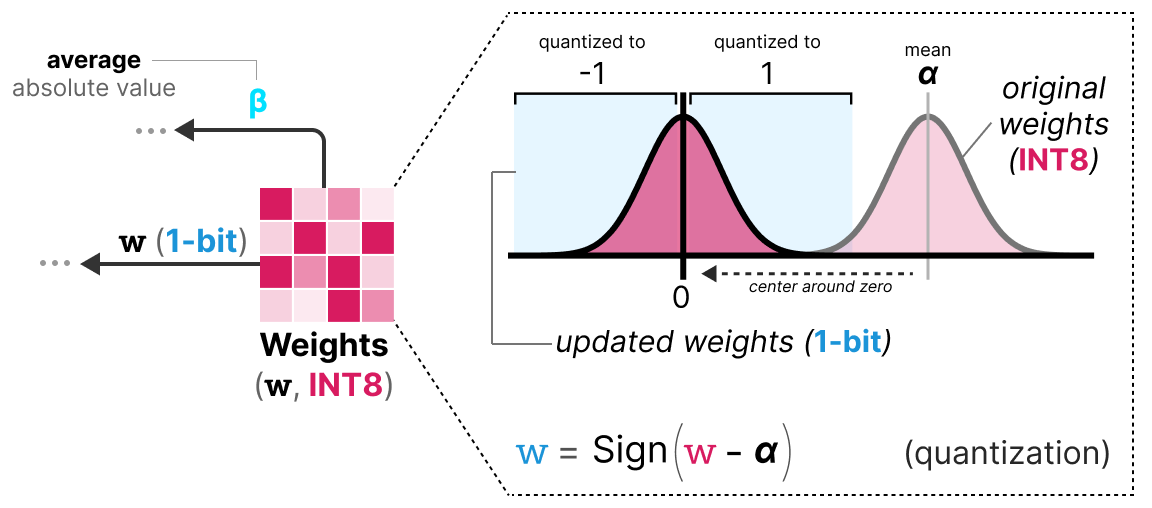
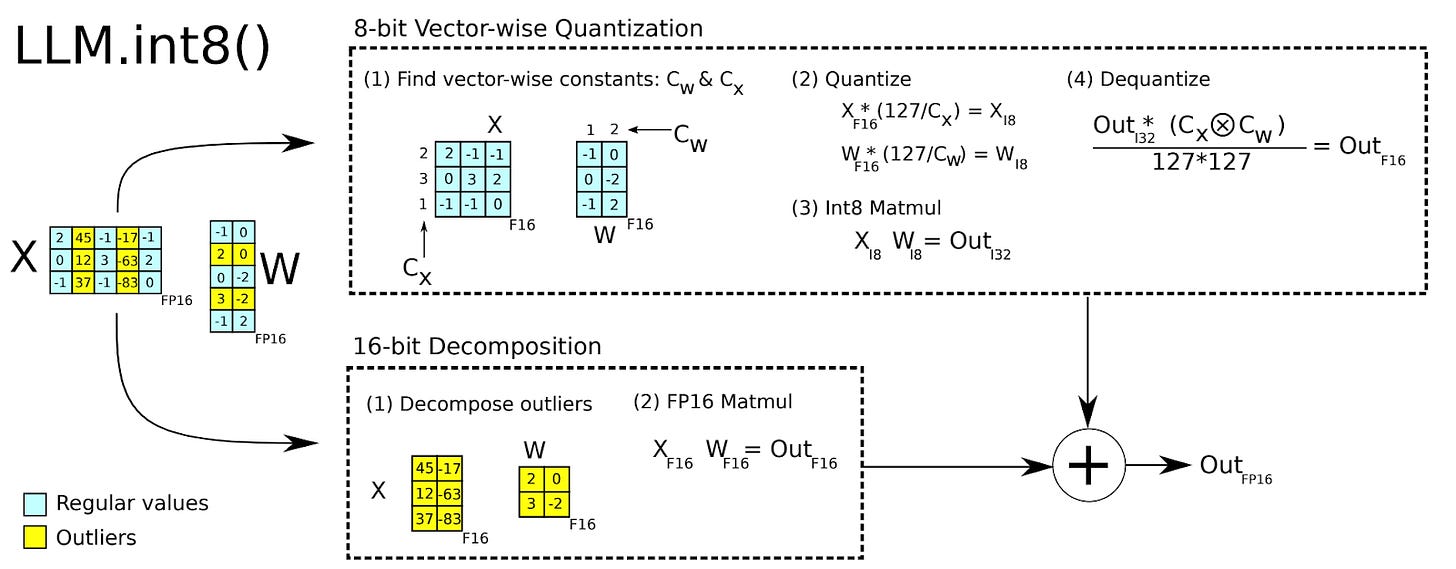
Understanding LLM.int8() Quantization — Picovoice
The INT quantization paradigm. | Download Scientific Diagram
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
Quantized model parameter after PTQ, INT8? - quantization - PyTorch Forums
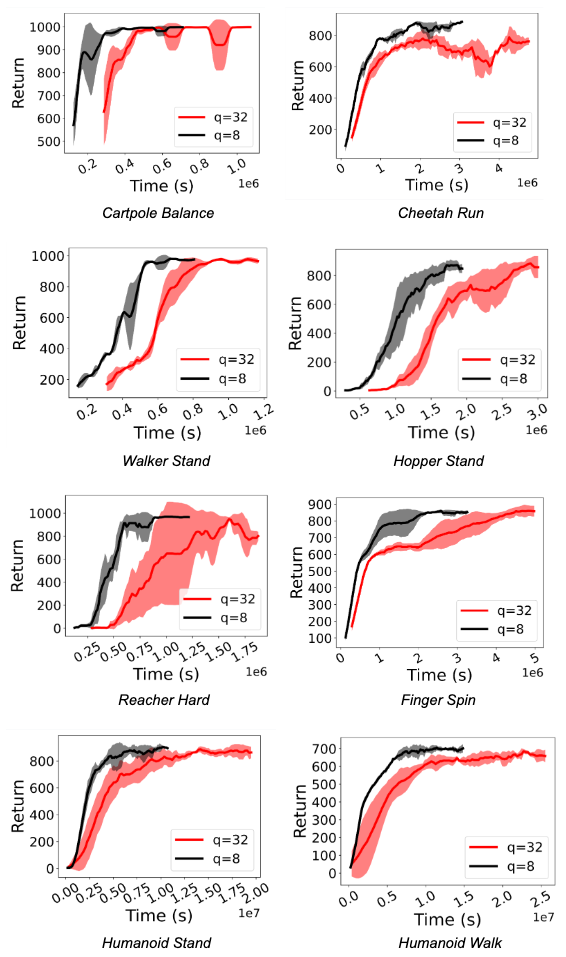
Quantization for Fast and Environmentally Sustainable Reinforcement ...
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
Advanced Model Quantization Techniques (INT8, FP16, etc.)
Towards Unified INT8 Training for Convolutional Neural Network | DeepAI
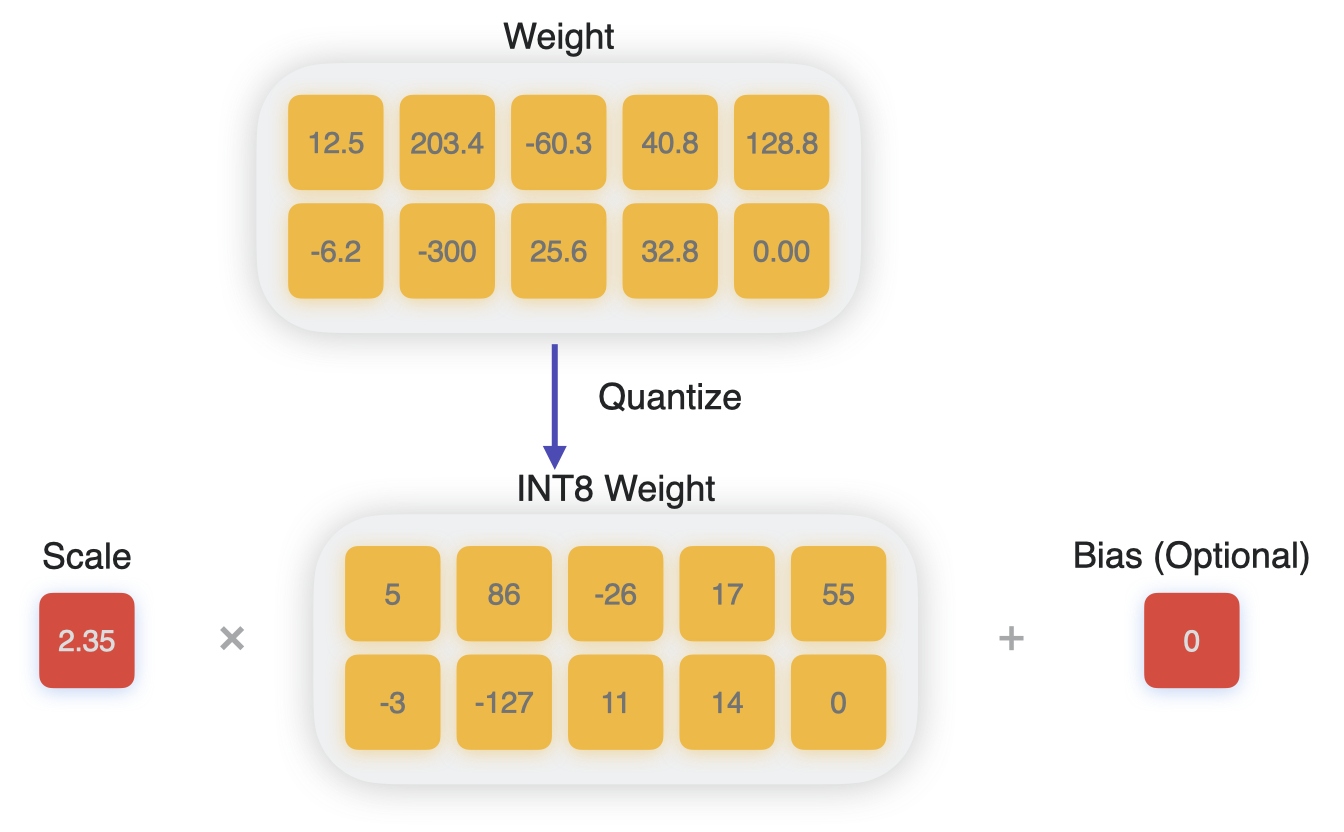
Introduction to Weight Quantization | Towards Data Science
(PDF) FP8 versus INT8 for efficient deep learning inference
use nvidia's pytorch_quantization for int8 QAT · Issue #1944 · open ...
Question about quantized INT8 model inference · Issue #2404 · NVIDIA ...
Small numbers, big opportunities: how floating point accelerates AI and ...
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
A Method of Deep Learning Model Optimization for Image Classification ...
Deep Learning Performance Characterization on GPUs for Various ...
Quantization: Reducing Model Precision (FP16, INT8)
GitHub - xuanandsix/Tensorrt-int8-quantization-pipline: a simple ...
利用TensorRT实现INT8量化感知训练QAT_tensorrt int8量化-CSDN博客
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
[2307.09782] ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 ...
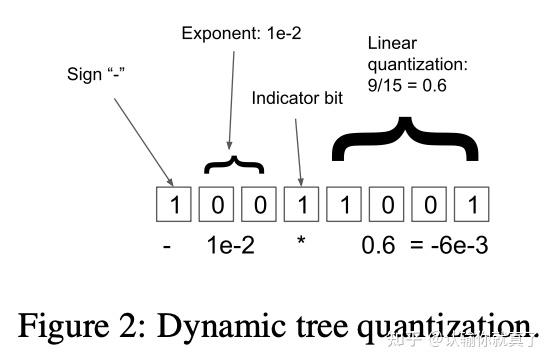
INT8模型量化:LLM.int8 - 知乎
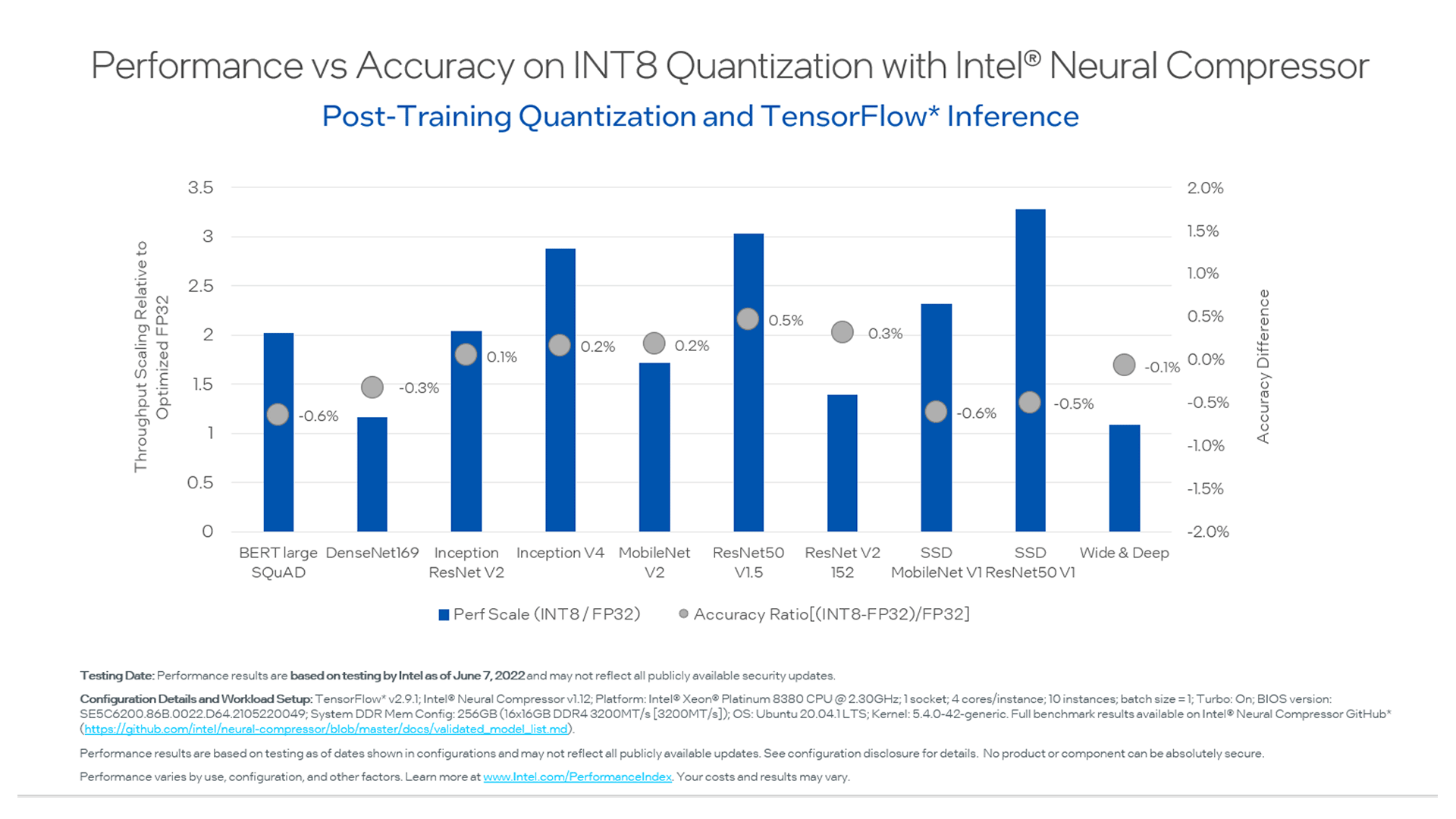
Perform Model Compression Using Intel® Neural Compressor
Running Llama 2 on CPU Inference Locally for Document Q&A | Towards ...
[Hugging Face transformer models + pytorch_quantization] PTQ ...